Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations


 and
and 
Abstract
:1. Introduction
2. Materials and Methods
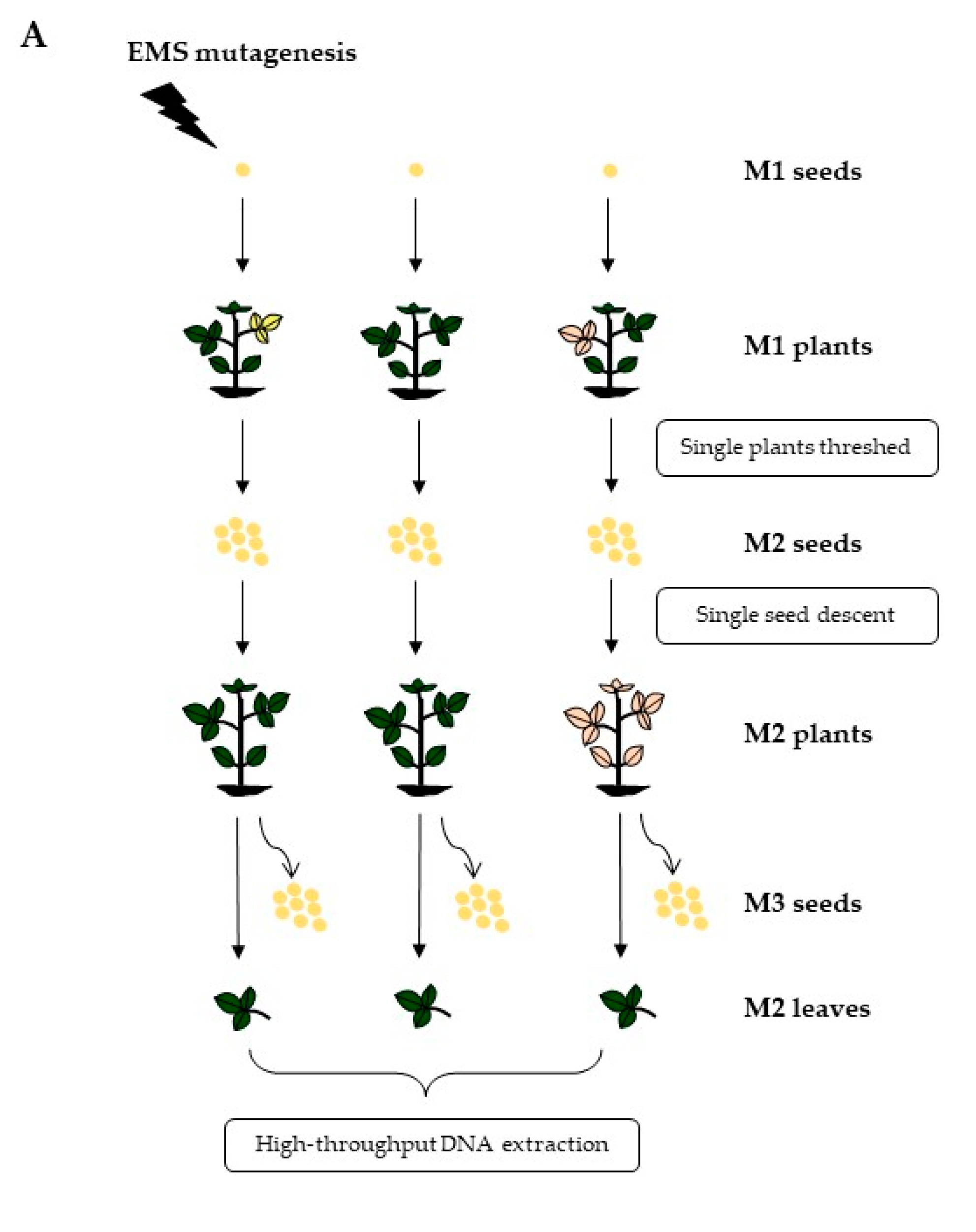
2.1. EMS Mutagenesis and Mutant Population Development
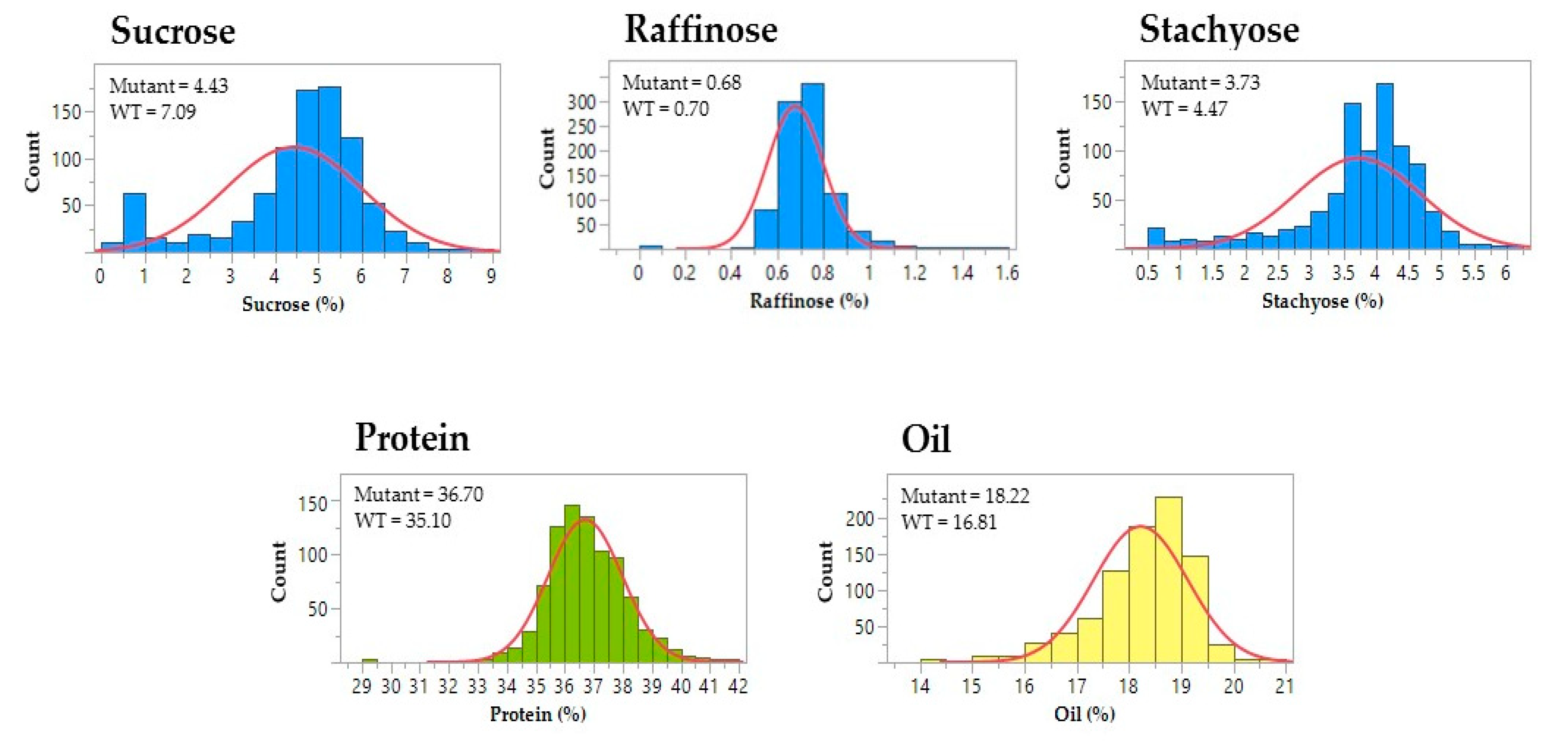
2.2. Seed Protein, Oil, and Carbohydrates Phenotyping
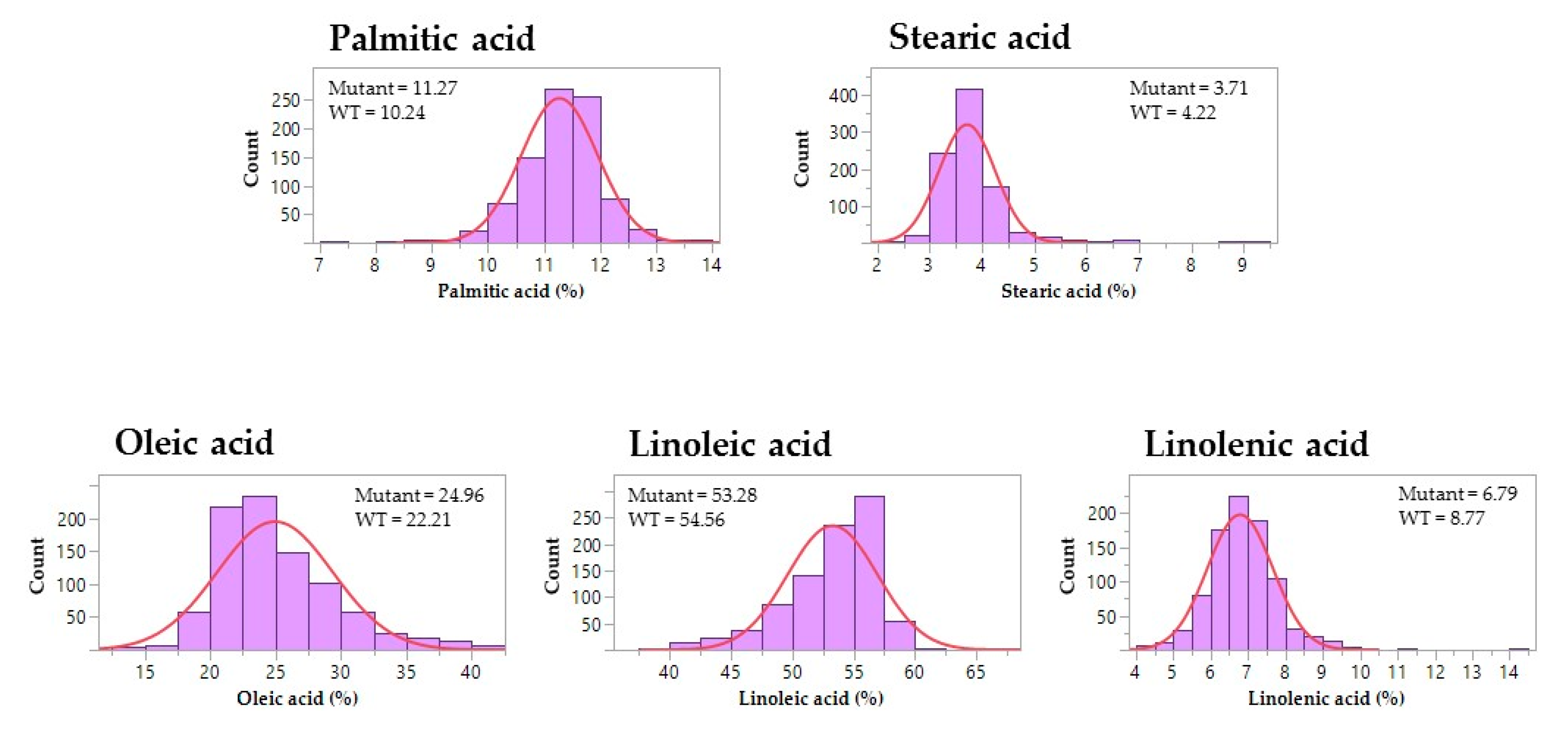
2.3. Seed Fatty Acids Phenotyping
2.4. Statistical Analysis
3. Results
3.1. Development of Chemically Mutagenized Soybean Populations
3.2. Seed Composition Phenotypes of Mutagenized Soybean Populations
3.3. New Sources of Soybean Seed Composition Traits Identified by Forward Genetic Screening
3.4. Correlation Analyses of Soybean Seed Composition Traits of TILLING Population
3.5. Correlation Analyses of Soybean Seed Composition Traits of Soybean Germplasm Lines
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- American Soybean Association. A Reference Guide to Soybean Facts and Figures. Available online: http://soystats.com/2018-soystats/ (accessed on 5 January 2019).
- Openshaw, S.J.; Hadley, H.H. Maternal Effects on Sugar Content in Soybean Seeds 1. Crop Sci. 1978, 18, 581–584. [Google Scholar] [CrossRef]
- Shi, A.; Chen, P.; Zhang, B.; Hou, A. Genetic diversity and association analysis of protein and oil content in food-grade soybeans from Asia and the United States. Plant Breed. 2010, 129, 250–256. [Google Scholar] [CrossRef]
- Hymowitz, T.; Collins, F.; Panczner, J.; Walker, W. Relationship between the content of oil, protein, and sugar in soybean seed 1. Agron. J. 1972, 64, 613–616. [Google Scholar] [CrossRef]
- Rachis, J.J. Oligosaccharides of food legumes: Alphagalactosidase activity and the flatulence problem. In Physiological Effects of Food Carbohydrates; American Chemical Society: Washington, DC, USA, 1975; pp. 207–222. [Google Scholar]
- Wilson, R.F. Seed composition. In Soybeans: Improvement, Production, and Uses; American Society of Agronomy, Crop Science Society of America, and Soil Science Society of America: Madison, WI, USA, 2004; pp. 621–677. [Google Scholar]
- Hu, F.B.; Stampfer, M.J.; Manson, J.E.; Rimm, E.; Colditz, G.A.; Rosner, B.A.; Hennekens, C.H.; Willett, W.C. Dietary fat intake and the risk of coronary heart disease in women. N. Eng. J. Med. 1997, 337, 1491–1499. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Derr, J.; Etherton, T.D.; Kris-Etherton, P.M. Plasma cholesterol-predictive equations demonstrate that stearic acid is neutral and monounsaturated fatty acids are hypocholesterolemic. Am. J. Clin. Nutr. 1995, 61, 1129–1139. [Google Scholar] [CrossRef]
- Lee, J.D.; Bilyeu, K.D.; Shannon, J.G. Genetics and breeding for modified fatty acid profile in soybean seed oil. J. Crop Sci. Biotech. 2007, 10, 201–210. [Google Scholar]
- Rao, S.; Abdel-Reheem, M.; Bhella, R.; McCracken, C.; Hildebrand, D. Characteristics of High α-Linolenic Acid Accumulation in Seed Oils. Lipids 2008, 43, 749–755. [Google Scholar] [CrossRef]
- Aghoram, K.; Wilson, R.F.; Burton, J.W.; Dewey, R.E. A mutation in a 3-keto-acyl-ACP synthase II gene is associated with elevated palmitic acid levels in soybean seeds. Crop Sci. 2006, 46, 2453–2459. [Google Scholar] [CrossRef]
- Bilyeu, K.; Gillman, J.D.; LeRoy, A.R. Novel FAD3 mutant allele combinations produce soybeans containing 1% linolenic acid in the seed oil. Crop Sci. 2011, 51, 259–264. [Google Scholar] [CrossRef]
- Pham, A.T.; Lee, J.D.; Shannon, J.G.; Bilyeu, K.D. A novel FAD2-1 A allele in a soybean plant introduction offers an alternate means to produce soybean seed oil with 85% oleic acid content. Theor. Appl. Genet. 2011, 123, 793–802. [Google Scholar] [CrossRef]
- Thapa, R.; Carrero-Colón, M.; Hudson, K.A. New alleles of FATB1A to reduce palmitic acid levels in soybean. Crop Sci. 2016, 56, 1076–1080. [Google Scholar] [CrossRef]
- Taiz, L. Respiration and lipid metabolism. In Plant Physiology, 3rd ed.; Taiz, L., Zeiger, E., Eds.; Sinauer Associates: Sunderland, MA, USA, 2002; pp. 223–258. [Google Scholar]
- Burton, J.W. Quantitative genetics: Results relevant to soybean breeding. In Soybeans: Improvement, Production, and Uses; American Society of Agronomy, Crop Science Society of America, and Soil Science Society of America: Madison, WI, USA, 1987. [Google Scholar]
- Cober, E.; D Voldeng, H. Developing high-protein, high-yield soybean populations and lines. Crop Sci. 2000, 40, 39–42. [Google Scholar] [CrossRef]
- Shannon, J.; Wilcox, J.; Probst, A. Estimated Gains from Selection for Protein and Yield in the F4 Generation of Six Soybean Populations 1. Crop Sci. 1972, 12, 824–826. [Google Scholar] [CrossRef]
- Hartwig, E.E.; Kuo, T.M.; Kenty, M.M. Seed protein and its relationship to soluble sugars in soybean. Crop Sci. 1997, 37, 770–773. [Google Scholar] [CrossRef]
- Hawkins, S.; Fehr, W.; Hammond, E. Resource Allocation in Breeding for Fatty Acid Composition of Soybean Oil 1. Crop Sci. 1983, 23, 900–904. [Google Scholar] [CrossRef]
- Liu, K.; Orthoefer, F.; Brown, E.A. Association of seed size with genotypic variation in the chemical constituents of soybeans. J. Am. Oil Chem. Soc. 1995, 72, 189–192. [Google Scholar] [CrossRef]
- Parry, M.A.J.; Madgwick, P.J.; Bayon, C.; Tearall, K.; Hernandez-Lopez, A.; Baudo, M.; Rakszegi, M.; Hamada, W.; Al-Yassin, A.; Ouabbou, H. Mutation discovery for crop improvement. J. Exp. Bot. 2009, 60, 2817–2825. [Google Scholar] [CrossRef]
- Joint FAO/IAEA Programme. Plant Breeding and Genetics. Available online: http://www-naweb.iaea.org/nafa/pbg/ (accessed on 4 October 2019).
- Till, B.J.; Reynolds, S.H.; Greene, E.A.; Codomo, C.A.; Enns, L.C.; Johnson, J.E.; Burtner, C.; Odden, A.R.; Young, K.; Taylor, N.E. Large-scale discovery of induced point mutations with high-throughput TILLING. Genome Res. 2003, 13, 524–530. [Google Scholar] [CrossRef]
- Nida, H.; Blum, S.; Zielinski, D.; Srivastava, D.A.; Elbaum, R.; Xin, Z.; Erlich, Y.; Fridman, E.; Shental, N. Highly efficient de novo mutant identification in a Sorghum bicolor TILLING population using the ComSeq approach. Plant J. 2016, 86, 349–359. [Google Scholar] [CrossRef]
- Boualem, A.; Fleurier, S.; Troadec, C.; Audigier, P.; Kumar, A.P.; Chatterjee, M.; Alsadon, A.A.; Sadder, M.T.; Wahb-Allah, M.A.; Al-Doss, A.A. Development of a Cucumis sativus TILLinG platform for forward and reverse genetics. PLoS ONE 2014, 9, e97963. [Google Scholar] [CrossRef]
- Vicente-Dolera, N.; Troadec, C.; Moya, M.; del Rio-Celestino, M.; Pomares-Viciana, T.; Bendahmane, A.; Pico, B.; Román, B.; Gómez, P. First TILLING platform in Cucurbita pepo: A new mutant resource for gene function and crop improvement. PLoS ONE 2014, 9, e112743. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Abernathy, B.; Zeng, Y.; Ozias-Akins, P. TILLING by sequencing to identify induced mutations in stress resistance genes of peanut (Arachis hypogaea). BMC Genom. 2015, 16, 157. [Google Scholar] [CrossRef] [PubMed]
- McCallum, C.M.; Comai, L.; Greene, E.A.; Henikoff, S. Targeted screening for induced mutations. Nat. Biotechnol. 2000, 18, 455. [Google Scholar] [CrossRef] [PubMed]
- Cooper, J.L.; Till, B.J.; Laport, R.G.; Darlow, M.C.; Kleffner, J.M.; Jamai, A.; El-Mellouki, T.; Liu, S.; Ritchie, R.; Nielsen, N. TILLING to detect induced mutations in soybean. BMC Plant Biol. 2008, 8, 9. [Google Scholar] [CrossRef] [PubMed]
- Tsuda, M.; Kaga, A.; Anai, T.; Shimizu, T.; Sayama, T.; Takagi, K.; Machita, K.; Watanabe, S.; Nishimura, M.; Yamada, N. Construction of a high-density mutant library in soybean and development of a mutant retrieval method using amplicon sequencing. BMC Genom. 2015, 16, 1014. [Google Scholar] [CrossRef] [PubMed]
- Lakhssassi, N.; Zhou, Z.; Liu, S.; Colantonio, V.; AbuGhazaleh, A.; Meksem, K. Characterization of the FAD2 gene family in soybean reveals the limitations of gel-based TILLING in genes with high copy number. Front. Plant Sci. 2017, 8, 324. [Google Scholar] [CrossRef]
- Li, Z.; Jiang, L.; Ma, Y.; Wei, Z.; Hong, H.; Liu, Z.; Lei, J.; Liu, Y.; Guan, R.; Guo, Y. Development and utilization of a new chemically-induced soybean library with a high mutation density. J. Integr. Plant Biol. 2017, 59, 60–74. [Google Scholar] [CrossRef]
- Espina, M.J.; Ahmed, C.; Bernardini, A.; Adeleke, E.; Yadegari, Z.; Arelli, P.; Pantalone, V.; Taheri, A. Development and phenotypic screening of an ethyl methane sulfonate mutant population in soybean. Front. Plant Sci. 2018, 9, 394. [Google Scholar] [CrossRef]
- Meksem, K.; Liu, S.; Liu, X.H.; Jamai, A.; Mitchum, M.G.; Bendahmane, A.; El-Mellouki, T. TILLING: A reverse genetics and a functional genomics tool in soybean. In The Handbook of Plant Functional Genomics: Concepts and Protocols; Wiley Online Library: Hoboken, NJ, USA, 2008; pp. 251–265. [Google Scholar]
- Workma, J., Jr.; Springsteen, A. Applied Spectroscopy: A Compact Reference for Practitioners; Academic Press: Cambridge, MA, USA, 1998. [Google Scholar]
- La, T.C.; Pathan, S.M.; Tri, V.; Lee, J.-D.; Scaboo, A.M.; Smith, J.R.; Gillen, A.M.; Gillman, J.; Ellersieck, M.R.; Nguyen, H.T.; et al. Effect of High-Oleic Acid Soybean on Seed Oil, Protein Concentration, and Yield. Crop Sci. 2014, 54, 2054–2062. [Google Scholar] [CrossRef]
- Valliyodan, B.; Shi, H.; Nguyen, H.T. A simple analytical method for high-throughput screening of major sugars from soybean by normal-phase HPLC with evaporative light scattering detection. Chromatogr. Res. Int. 2015, 2015, 757649. [Google Scholar] [CrossRef]
- Kramer, J.K.; Fellner, V.; Dugan, M.E.; Sauer, F.D.; Mossoba, M.M.; Yurawecz, M.P. Evaluating acid and base catalysts in the methylation of milk and rumen fatty acids with special emphasis on conjugated dienes and total trans fatty acids. Lipids 1997, 32, 1219–1228. [Google Scholar] [CrossRef]
- The International Service for the Acquisition of Agri-biotech Applications (ISAAA). Executive Summary: Global Status of Commercialized Biotech/GM Crops. Available online: http://www.isaaa.org/resources/publications/briefs/54/executivesummary/default.asp (accessed on 4 October 2019).
- Kandoth, P.K.; Liu, S.; Prenger, E.; Ludwig, A.; Lakhssassi, N.; Heinz, R.; Zhou, Z.; Howland, A.; Gunther, J.; Eidson, S. Systematic mutagenesis of serine hydroxymethyltransferase reveals an essential role in nematode resistance. Plant Physiol. 2017, 175, 1370–1380. [Google Scholar] [CrossRef] [Green Version]
- Lakhssassi, N.; Colantonio, V.; Flowers, N.D.; Zhou, Z.; Henry, J.; Liu, S.; Meksem, K. Stearoyl-acyl carrier protein desaturase mutations uncover an impact of stearic acid in leaf and nodule structure. Plant Physiol. 2017, 174, 1531–1543. [Google Scholar] [CrossRef] [Green Version]
- Hoshino, T.; Takagi, Y.; Anai, T. Novel GmFAD2-1b mutant alleles created by reverse genetics induce marked elevation of oleic acid content in soybean seeds in combination with GmFAD2-1a mutant alleles. Breed. Sci. 2010, 60, 419–425. [Google Scholar] [CrossRef] [Green Version]
- Pham, A.T.; Lee, J.D.; Shannon, J.G.; Bilyeu, K.D. Mutant alleles of FAD2-1A and FAD2-1B combine to produce soybeans with the high oleic acid seed oil trait. BMC Plant Biol. 2010, 10, 195. [Google Scholar] [CrossRef] [Green Version]
- Wilcox, J.R.; Shibles, R.M. Interrelationships among Seed Quality Attributes in Soybean. Crop Sci. 2001, 41, 11–14. [Google Scholar] [CrossRef]
- Prenger, E.M.; Ostezan, A.; Mian, M.A.R.; Stupar, R.M.; Glenn, T.; Li, Z. Identification and characterization of a fast-neutron-induced mutant with elevated seed protein content in soybean. Theor. Appl. Genet. 2019. [Google Scholar] [CrossRef]
- Alt, J.L.; Fehr, W.R.; Welke, G.A.; Sandhu, D. Phenotypic and Molecular Analysis of Oleate Content in the Mutant Soybean Line M23. Crop Sci. 2005, 45, 1997–2000. [Google Scholar] [CrossRef]
- Ohlrogge, J.; Browse, J. Lipid biosynthesis. Plant Cell 1995, 7, 957–970. [Google Scholar] [CrossRef] [Green Version]
- Cicek, M.S.; Chen, P.; Maroof, S.; Buss, G.R. Interrelationships among agronomic and seed quality traits in an interspecific soybean recombinant inbred population. Crop Sci. 2006, 46, 1253–1259. [Google Scholar] [CrossRef]
- Bachlava, E.; Burton, J.W.; Brownie, C.; Wang, S.; Auclair, J.; Cardinal, A.J. Heritability of oleic acid content in soybean seed oil and its genetic correlation with fatty acid and agronomic traits. Crop Sci. 2008, 48, 1764–1772. [Google Scholar] [CrossRef] [Green Version]
- Dhungana, S.K.; Kulkarni, K.P.; Kim, M.; Ha, B.-K.; Kang, S.; Song, J.T.; Shin, D.-H.; Lee, J.-D. Environmental stability and correlation of soybean seed starch with protein and oil contents. Plant Breed. Biotechnol. 2017, 5, 293–303. [Google Scholar] [CrossRef] [Green Version]
- Marcin, K.; Wojtek, K.; MaŁgorzata, T. Use of the correlation coefficient in agricultural sciences: Problems, pitfalls and how to deal with them. An. Acad. Bras. Ciênc. 2012, 1147–1156. [Google Scholar] [CrossRef]
- Mukaka, M.M. Statistics Corner: A guide to appropriate use of Correlation coefficient in medical research. Malawi Med. J. 2012, 24, 69–71. [Google Scholar]
- Taylor, R. Interpretation of the correlation-coefficient a basic review. J. Diagn. Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- Van Harten, A.M. Mutation Breeding: Theory and Practical Applications; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plant ID | Sucrose (%) | Raffinose (%) | Stachyose (%) | Protein (%) | Oil (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| M3 | M4 | M3 | M4 | M3 | M4 | M3 | M4 | M3 | M4 | |
| F690 | 0.56 | 2.42 | 0.59 | 0.78 | 2.03 | 3.45 | 36.87 | - | 17.79 | - |
| F788 | 0.67 | 4.52 | 0.67 | 0.81 | 2.05 | 3.15 | 37.13 | - | 17.20 | - |
| F80 | 0.56 | 4.59 | 0.48 | 0.93 | 2.02 | 3.55 | 37.81 | - | 18.39 | - |
| F103 | 0.71 | 5.58 | 0.49 | 1.00 | 1.62 | 3.79 | 36.82 | - | 18.30 | - |
| F264 | 5.33 | - | 0.91 | - | 3.72 | - | 41.56 | 39.88 | 16.42 | - |
| Forrest | 7.09 | 5.88 | 0.70 | 0.81 | 4.47 | 5.10 | 35.10 | 35.95 | 16.81 | - |
| Sucrose | Raffinose | Stachyose | Protein | Oil | 16:0 | 18:0 | 18:1 | 18:2 | 18:3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Sucrose | ||||||||||
| Raffinose | 0.265 *** | |||||||||
| Stachyose | 0.551 *** | 0.228 *** | ||||||||
| Protein | −0.117 *** | −0.011 ns | −0.067 ns | |||||||
| Oil | 0.011ns | −0.122 *** | 0.020 ns | −0.575 *** | ||||||
| 16:0 | 0.028 ns | −0.028 ns | 0.051 ns | −0.106 ** | 0.106 ** | |||||
| 18:0 | 0.033 ns | −0.079 * | 0.045 ns | 0.031 ns | −0.151 *** | −0.153 *** | ||||
| 18:1 | −0.021 ns | −0.014 ns | −0.052 ns | 0.186 *** | −0.129 ** | −0.527 *** | 0.119 *** | |||
| 18:2 | −0.004 ns | −0.008 ns | 0.039 ns | −0.187 *** | 0.161 *** | 0.420 *** | −0.204 *** | −0.962 *** | ||
| 18:3 | 0.066 ns | 0.069 * | 0.038 ns | −0.111 ** | 0.003 ns | 0.325 *** | −0.134 *** | −0.704 *** | 0.595 *** |
| Sucrose | Raffinose | Stachyose | Protein | Oil | 16:0 | 18:0 | 18:1 | 18:2 | 18:3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Sucrose | ||||||||||
| Raffinose | 0.450 *** | |||||||||
| Stachyose | 0.105 ns | −0.106 ns | ||||||||
| Protein | −0.278 ** | 0.082 ns | −0.275 ** | |||||||
| Oil | 0.537 *** | 0.243 ns | −0.126 ns | −0.198 * | ||||||
| 16:0 | −0.373 *** | −0.020 ns | 0.067 ns | 0.181 ns | −0.357 *** | |||||
| 18:0 | 0.227 * | −0.178 ns | 0.058 ns | 0.024 ns | 0.240 * | −0.147 ns | ||||
| 18:1 | 0.378 *** | 0.177 ns | −0.071 ns | −0.004 ns | 0.420 *** | −0.388 *** | 0.058 ns | |||
| 18:2 | −0.014 ns | 0.018 ns | −0.180 ns | −0.068 ns | 0.151 ns | −0.076 ns | 0.128 ns | −0.644 *** | ||
| 18:3 | −0.272 ** | −0.249 * | 0.187 ns | −0.117 ns | −0.579 *** | 0.336 *** | −0.172 * | −0.788 *** | 0.213 * |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Lakhssassi, N.; Cullen, M.A.; El Baz, A.; Vuong, T.D.; Nguyen, H.T.; Meksem, K. Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations. Genes 2019, 10, 975. https://doi.org/10.3390/genes10120975
Zhou Z, Lakhssassi N, Cullen MA, El Baz A, Vuong TD, Nguyen HT, Meksem K. Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations. Genes. 2019; 10(12):975. https://doi.org/10.3390/genes10120975
Chicago/Turabian StyleZhou, Zhou, Naoufal Lakhssassi, Mallory A. Cullen, Abdelhalim El Baz, Tri D. Vuong, Henry T. Nguyen, and Khalid Meksem. 2019. "Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations" Genes 10, no. 12: 975. https://doi.org/10.3390/genes10120975
APA StyleZhou, Z., Lakhssassi, N., Cullen, M. A., El Baz, A., Vuong, T. D., Nguyen, H. T., & Meksem, K. (2019). Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations. Genes, 10(12), 975. https://doi.org/10.3390/genes10120975