Genome-Wide Identification and Expression Analysis of the HD-Zip Gene Family in Wheat (Triticum aestivum L.)



Abstract
:1. Introduction
2. Materials and Methods
2.1. Genome-Wide Identification of HD-Zip Gene Family in Wheat
2.2. Phylogenetic Analysis and Gene Duplication
2.3. Gene Structure and Protein Conserved Motifs Analysis
2.4. Expression Profile Analysis of TaHDZ Genes
2.5. Interaction Network of TaHDZ Genes
2.6. Plant Materials, Growth Conditions and Abiotic Stress Treatments
2.7. Quantitative Real-Time Polymerase Chain Reaction Analysis
3. Results and Discussion
3.1. Identification of TaHDZ Genes in Wheat
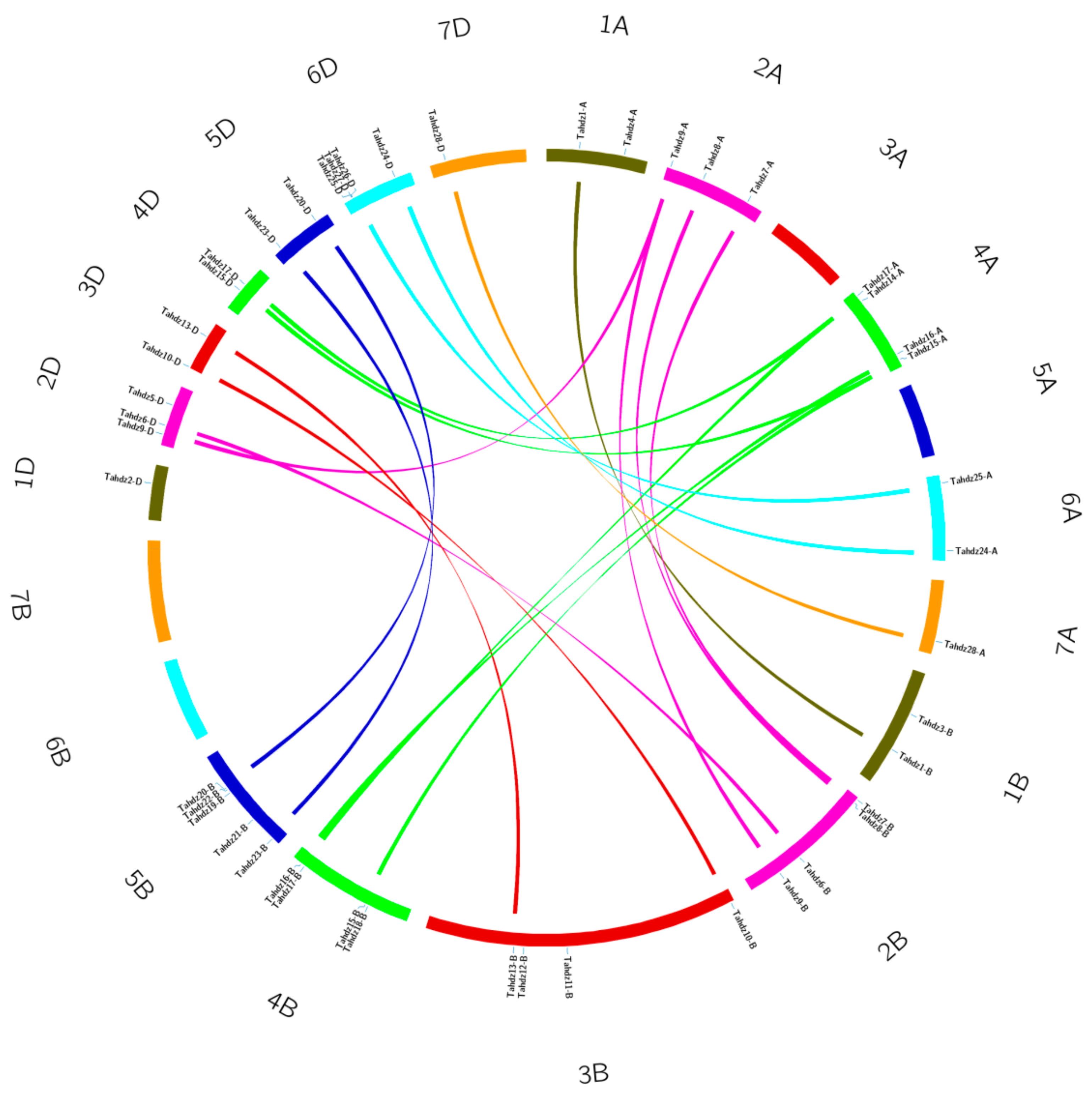
3.2. Chromosome Localization Analysis of TaHDZs
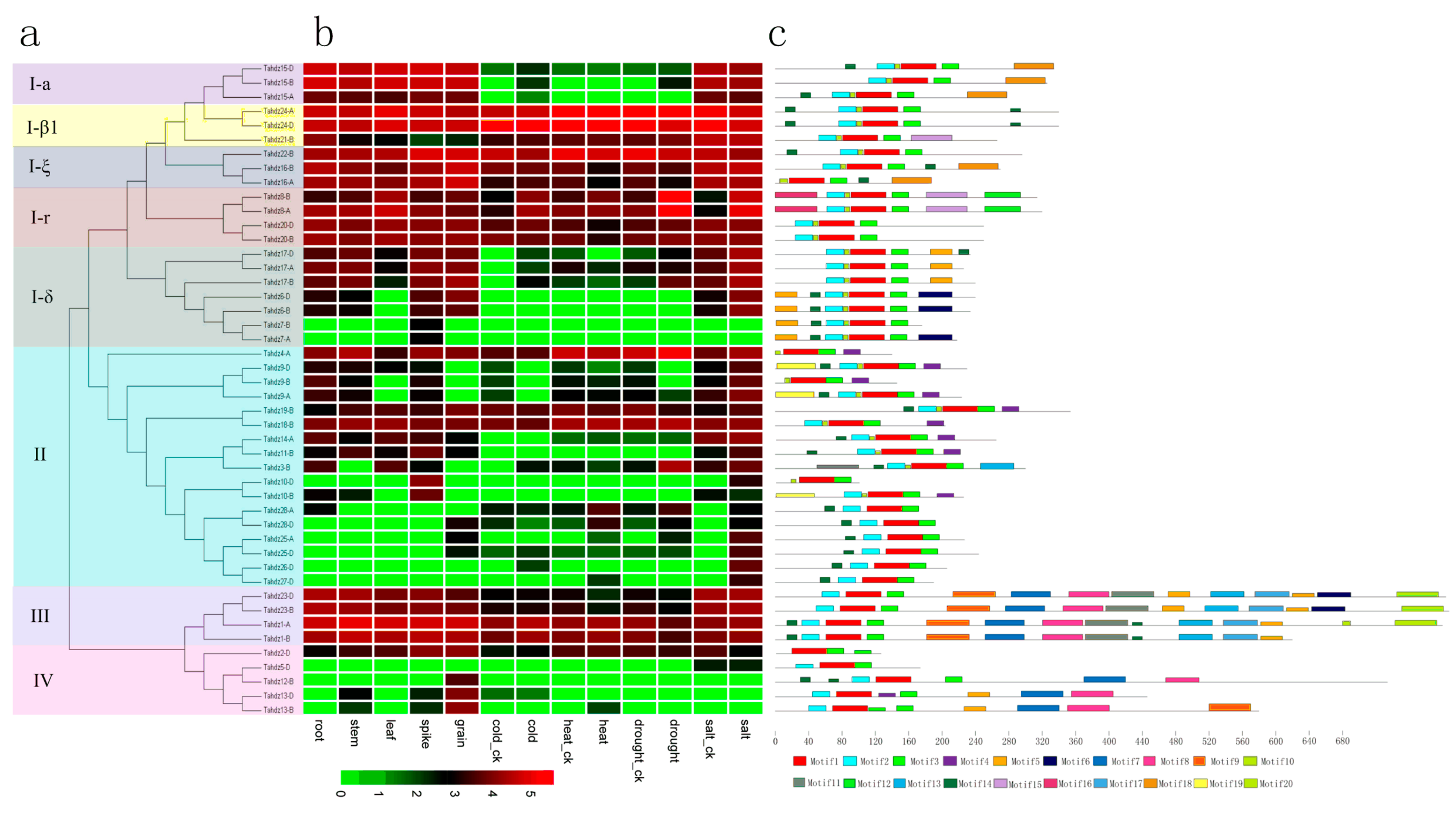
3.3. Phylogenetic Analysis of TaHDZ Genes
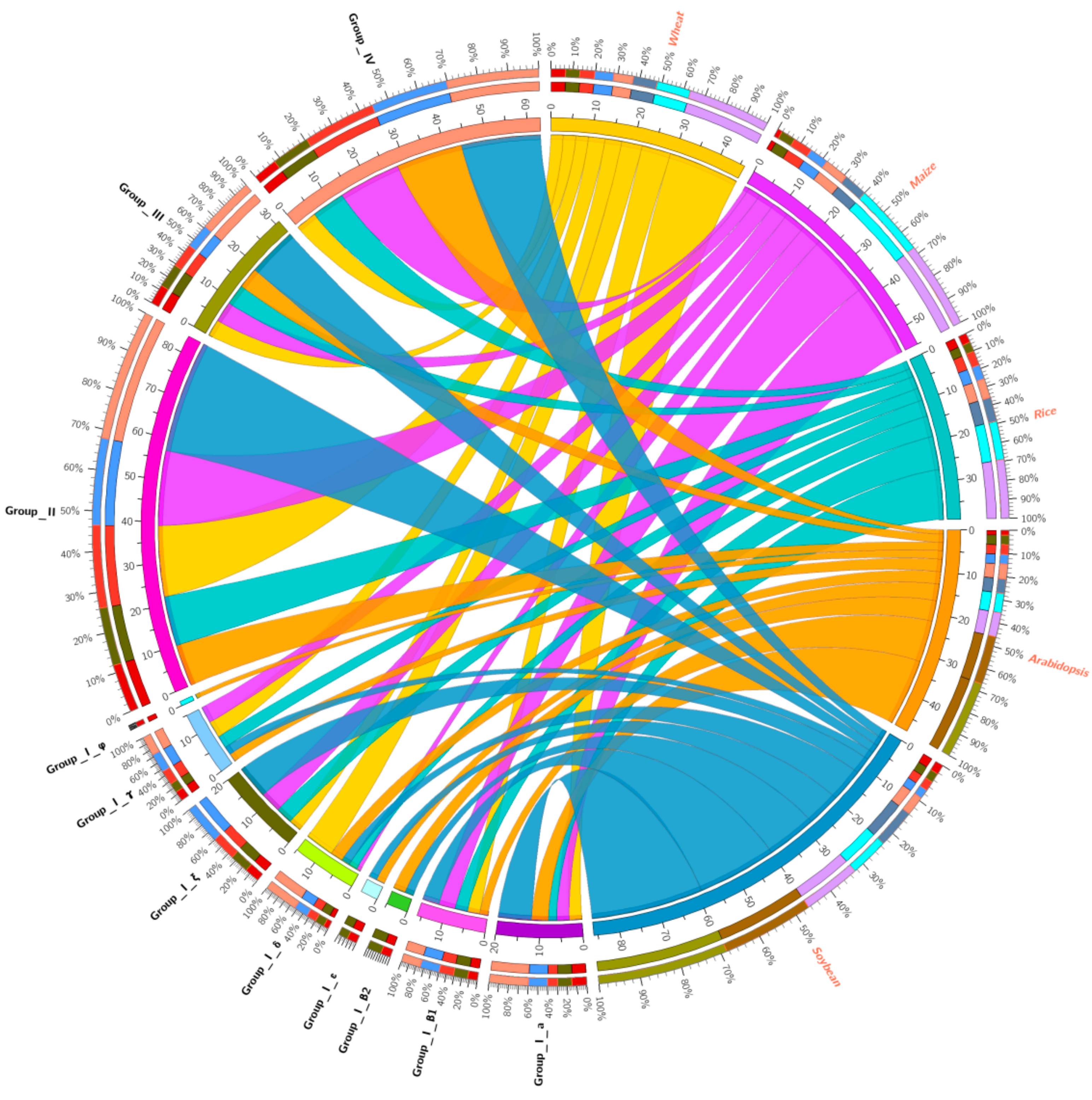
3.4. Co-Expression Network between TaHDZ Genes and Other Genes in Wheat
3.5. Conserved Motifs and Expression Profile Analysis of TaHDZ Genes
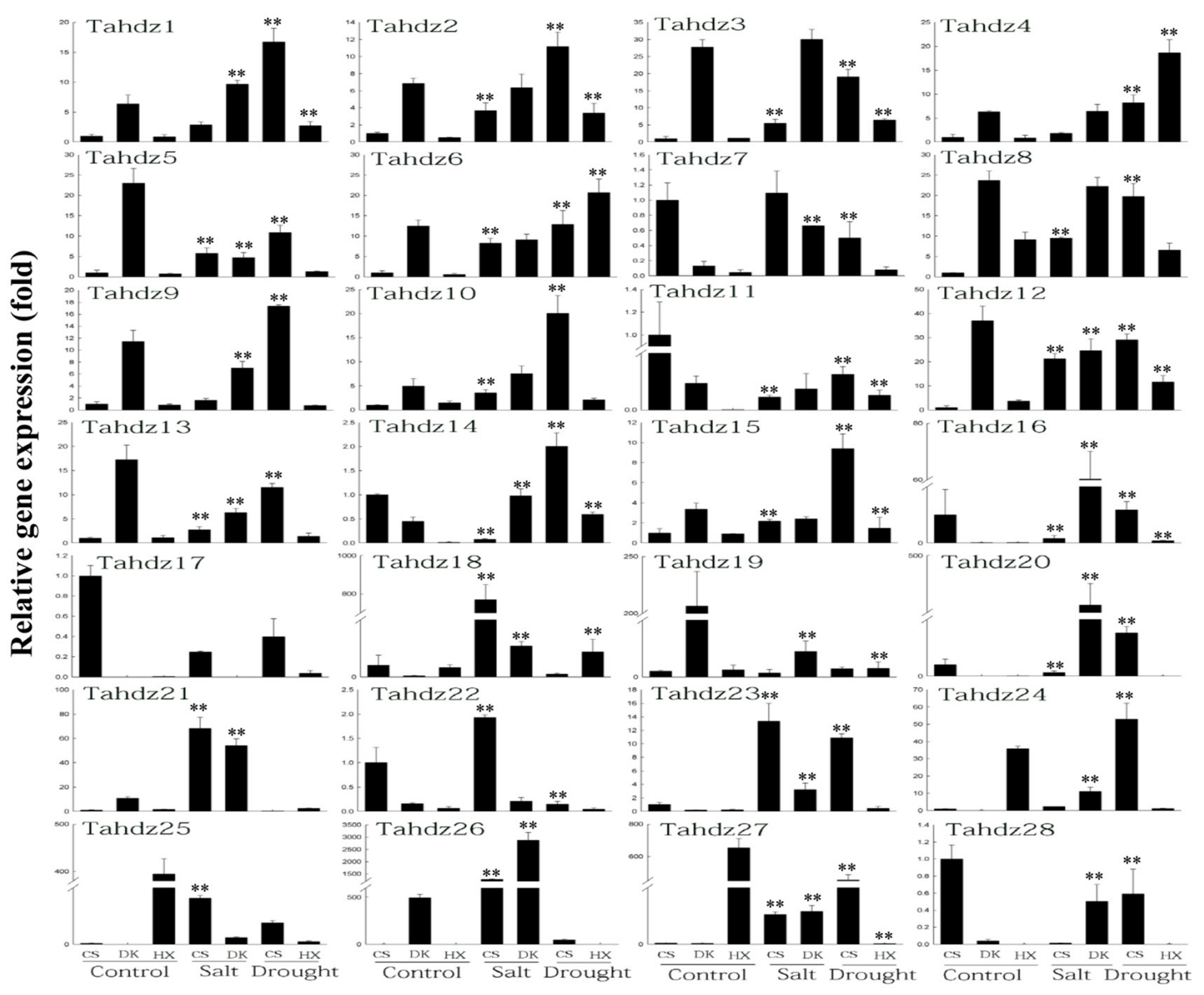
3.6. Expression Profiles of TaHDZ Genes under Abiotic Stress in Wheat by qRT-PCR Analysis
4. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hu, W.; Wang, L.Z.; Tie, W.W.; Yan, Y.; Ding, Z.H.; Liu, J.H.; Li, M.Y.; Ming, P.; Xu, B.Y.; Jin, Z.Q. Genome-wide analyses of the bZip family reveal their involvement in the development, ripening and abiotic stress response in banana. Sci. Rep. 2016, 6, 30203. [Google Scholar] [CrossRef] [PubMed]
- Chan, R.L.; Gago, G.M.; Palena, C.M.; Gonzalez, D.H. Homeoboxes in plant development. Biochim. Biophys. Acta 1998, 1442, 1–19. [Google Scholar] [CrossRef]
- Mcginnis, W.; Garber, R.L.; Wirz, J.; Kuroiwa, A.; Gehring, W.J. A homologous protein-coding sequence in Drosophila homeotic genes and its conservation in other metazoans. Cell 1984, 37, 403–408. [Google Scholar] [CrossRef]
- Ruberti, I.; Giovanna, S.; Lucchetti, S.; Morelli, G. A novel class of plant proteins containing a homeodomain with a closely linked leucine zipper motif. EMBO J. 1991, 10, 1787–1791. [Google Scholar] [PubMed]
- Wolfgang, F.; Phillips, J.; Salamini, F.; Bartels, D. Two dehydration-inducible transcripts from the resurrection plant Craterostigma plantagineumencode interacting homeodomain-leucine zipper proteins. Plant J. 1998, 15, 413–421. [Google Scholar]
- Ariel, F.D.; Manavella, P.A.; Dezar, C.A.; Chan, R.L. The true story of the HD-Zip family. Trends Plant Sci. 2007, 12, 419–426. [Google Scholar] [CrossRef] [PubMed]
- Meijer, A.H.; Scarpella, E.; van Dijk, E.L.; Qin, L.; Taal, A.J.; Rueb, S.; Harrington, S.E.; McCouch, S.R.; Schilperoort, R.A.; Hoge, J.H. Transcriptional repression by Oshox1, a novel homeodomain leucine zipper protein from rice. Plant J. 1997, 11, 263–276. [Google Scholar] [CrossRef] [PubMed]
- Tron, A.E.; Bertoncini, C.W.; Chan, R.L.; Gonzalez, D.H. Redox regulation of plant homeodomain transcription factors. J. Biol. Chem. 2002, 277, 34800–34807. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Chi, X.; Chai, G.; Kong, Y.; He, G.; Wang, X.; Shi, D.; Zhang, D.; Zhou, G. Genome-wide identification, evolutionary expansion and expression profile of homeodomain-leucine zipper gene family in poplar (Populus trichocarpa). PLoS ONE 2012, 7, e31149. [Google Scholar] [CrossRef] [PubMed]
- Ponting, C.P.; Aravind, L. START: A lipid-binding domain in StAR, HD-ZIP and signalling proteins. Trends Biochem. Sci. 1999, 24, 130–132. [Google Scholar] [CrossRef]
- Schrick, K.; Nguyen, D.; Karlowski, W.M.; Mayer, K.F. START lipid/sterol-binding domains are amplified in plants and are predominantly associated with homeodomain transcription factors. Genome Biol. 2004, 5, R41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.; Zhu, C.; Zhao, H.L.; Zhao, Y.; Cheng, B.J.; Xiang, Y. Genome-wide analysis of soybean HD-ZIP gene family and expression profiling under salinity and drought treatments. PLoS ONE 2014, 9, e87156. [Google Scholar] [CrossRef] [PubMed]
- Mukherjee, K.; Bürglin, T.R. MEKHLA, a novel domain with similarity to PAS domains, is fused to plant homeodomain-leucine zipper III proteins. Plant Physiol. 2006, 140, 1142–1150. [Google Scholar] [CrossRef] [PubMed]
- Sessa, G.; Steindler, C.; Morelli, G.; Ruberti, I. The Arabidopsis Athb-8,-9 and genes are members of a small gene family coding for highly related HD-ZIP proteins. Plant Mol. Biol. 1998, 38, 609–622. [Google Scholar] [CrossRef] [PubMed]
- Abe, M.; Katsumata, H.; Komeda, Y.; Takahashi, T. regulation of shoot epidermal cell differentiation by a pair of homeodomain proteins in Arabidopsis. Development 2003, 130, 635–643. [Google Scholar] [CrossRef] [PubMed]
- Di Cristina, M.; Sessa, G.; Dolan, L.; Linstead, P.; Baima, S.; Ruberti, I.; Morelli, G. The Arabidopsis Athb-10 (GLABRA2) is an HD-Zip protein required for regulation of root hair development. Plant J. 1996, 10, 393–402. [Google Scholar] [CrossRef] [PubMed]
- Kubo, H.; Peeters, A.J.; Aarts, M.G.; Pereira, A.; Koornneef, M. ANTHOCYANINLESS2, a homeobox gene affecting anthocyanin distribution and root development in Arabidopsis. Plant Cell. 1999, 11, 1217–1226. [Google Scholar] [CrossRef] [PubMed]
- Yuan, D.; Tang, Z.; Wang, M.; Gao, W.; Tu, L.; Jin, X.; Chen, L.; He, Y.; Zhang, L.; Zhu, L.; et al. the genome sequence of Sea-Island cotton (Gossypium barbadense) provides insights into the allopolyploidization and development of superior spinnablefibres. Sci. Rep. 2015, 5. [Google Scholar] [CrossRef]
- Mao, H.; Yu, L.; Li, Z.; Liu, H.; Han, R. Molecular evolution and gene expression differences within the HD-Zip Transcription Factor Family of Zea mays L. Genetica 2016, 144, 243–257. [Google Scholar] [CrossRef] [PubMed]
- Kovalchuk, N.; Chew, W.; Sornaraj, P.; Borisjuk, N.; Yang, N.; Singh, R.; Bazanova, N.; Shavrukov, Y.; Guendel, A.; Munz, E.; et al. The Homeodomain Transcription Factor TaHD-Zipl-2 from wheat regulates frost tolerance, flowering time and spike development in transgenic barley. New Phytol. 2016, 211, 671–687. [Google Scholar] [CrossRef] [PubMed]
- Capella, M.; Ribone, P.A.; Arce, A.L.; Chan, R.L. Arabidopsis thaliana HomeoBox 1 (AtHB1), a homedomain-leucine zipper I (HD-Zip I) transcription factor, is regulated by PHYTOCHROME-INTERACTING FACTOR 1 to promote hypocotyl elongation. New Phytol. 2015, 207, 669–682. [Google Scholar] [CrossRef] [PubMed]
- Aoyama, T.; Dong, C.H.; Wu, Y.; Carabelli, M.; Sessa, G.; Ruberti, I.; Morelli, G.; Chua, N.H. Ectopic expression of the Arabidopsis transcriptional activator Athb-1 alters leaf cell fate in tobacco. Plant Cell. 1995, 7, 1773–1785. [Google Scholar] [CrossRef] [PubMed]
- Ni, Y.; Wang, X.; Li, D.; Wu, Y.; Xu, W.; Li, X. novel cotton homeobox gene and its expression profiling in root development and in response to stresses and phytohormones. Acta Biochim. Biophys. Sin. 2008, 40, 78–84. [Google Scholar] [CrossRef]
- Harris, J.C.; Sornaraj, P.; Taylor, M.; Bazanova, N.; Baumann, U.; Lovell, B.; Langridge, P.; Lopato, S.; Hrmova, M. Molecular interactions of the γ-clade homeodomain-leucine zipper class I transcription factors during the wheat response to water deficit. Plant Mol. Biol. 2016, 90, 435–452. [Google Scholar] [CrossRef] [PubMed]
- Ge, X.X.; Liu, Z.; Wu, X.M.; Chai, L.J.; Guo, W.W. Genome-wide identification, classification and analysis of HD-Zip gene family in citrus and its potential roles in somatic embryogenesis regulation. Gene 2015, 574, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Chen, Y.; Zhao, M.; Zhang, W.H. A novel Medicagotruncatula HD-Zip gene, MtHB2, is involved in abiotic stress responses. Environ. Exp. Bot. 2012, 80, 1–9. [Google Scholar] [CrossRef]
- Turchi, L.; Carabelli, M.; Ruzza, V.; Possenti, M.; Sassi, M.; Peñalosa, A.; Sessa, G.; Salvi, S.; Forte, V.; Morelli, G.; et al. Arabidopsis HD-Zip II transcription factors control apical embryo development and meristem function. Development 2013, 140, 2118–2129. [Google Scholar] [CrossRef] [PubMed]
- Dezar, C.A.; Giacomelli, J.I.; Manavella, P.A.; Ré, D.A.; Alves-Ferreira, M.; Baldwin, I.T.; Bonaventure, G.; Chan, R.L. HAHB10, a Sunflower HD-ZIP II transcription factor, participates in the induction of flowering and in the control of phytohormone-mediated responses to biotic stress. J. Exp. Bot. 2011, 62, 1061–1076. [Google Scholar] [CrossRef] [PubMed]
- Ooi, S.E.; Ramli, Z.; Kulaveerasingam, H.; Ong-Abdullah, M. EgHOX1, a HD-Zip II gene, is highly expressed during early oil palm (Elaeis guineensis Jacq.) somatic embryogenesis. Plant Gene 2016, 8, 16–25. [Google Scholar] [CrossRef]
- Franco, D.M.; Silva, E.M.; Saldanha, L.L.; Adachi, S.A.; Schley, T.R.; Rodrigues, T.M.; Dokkedal, A.L.; Nogueira, F.T.; Rolim de Almeida, L.F. Flavonoids modify root growth and modulate expression of SHORT-ROOT and HD-ZIP III. J. Plant Physiol. 2015, 188, 89–95. [Google Scholar] [CrossRef] [PubMed]
- Landau, U.; Lior, A.; Leor, E.W. The ERECTA, CLAVATA and Class III HD-ZIP pathways display synergistic interactions in regulating floral meristem activities. PLoS ONE 2015, 10, e0125408. [Google Scholar] [CrossRef] [PubMed]
- Hawker, N.P.; Bowman, J.L. Roles for class III HD-Zip and KANADI genes in Arabidopsis root development. Plant Physiol. 2004, 4, 2261–2270. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Song, D.; Sun, J.; Wang, X.; Li, L. PtrHB7, a class III HD-Zip gene, plays a critical role in regulation of vascular cambium differentiation in Populus. Mol. Plant. 2013, 6, 1331–1343. [Google Scholar] [CrossRef] [PubMed]
- Carlsbecker, A.; Lee, J.Y.; Roberts, C.J.; Dettmer, J.; Lehesranta, S.; Zhou, J.; Lindgren, O.; Moreno-Risueno, M.A.; Vatén, A.; Thitamadee, S.; et al. Cell signalling by microRNA165/6 directs gene dose-dependent root cell fate. Nature 2010, 465, 316–321. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zhang, C.; Guo, Y.; Niu, W.; Wang, Y.; Xu, Y. Genome-wide analysis of HD-Zip genes in grape (Vitis vinifera). Tree Genet. Genomes. 2014, 1, 1–11. [Google Scholar]
- Kamata, N.; Okada, H.; Komeda, Y.; Takahashi, T. Mutations in epidermis-specific HD-Zip IV genes affect floral organ identity in Arabidopsis thaliana. Plant J. 2013, 75, 430–440. [Google Scholar] [CrossRef] [PubMed]
- Kamata, N.; Okada, H.; Komeda, Y.; Takahashi, T. The HD-Zip IV Transcription Factor OCL4 is necessary for trichome patterning and anther development in maize. Plant J. 2009, 59, 883–894. [Google Scholar]
- Pan, Y.; Bo, K.; Cheng, Z.; Weng, Y. The loss-of-function GLABROUS 3 Mutation in Cucumber Is Due to LTR-retrotransposon Insertion in a class IV HD-ZIP transcription factor gene CsGL3 that is epistatic over CsGL1. BMC Plant Biol. 2015, 15, 302. [Google Scholar] [CrossRef] [PubMed]
- Gill, B.S.; Appels, R.; Botha-Oberholster, A.M.; Buell, C.R.; Bennetzen, J.L.; Chalhoub, B.; Chumley, F.; Dvorák, J.; Iwanaga, M.; Keller, B.; et al. A workshop report on wheat genome sequencing. Genetics 2004, 168, 1087–1096. [Google Scholar] [CrossRef] [PubMed]
- International Wheat Genome Sequencing Consortium. A chromosome-based draft sequence of the hexaploid bread wheat (Triticum aestivum) genome. Science 2014, 345, 1251788. [Google Scholar]
- Kovalchuk, N.; Wu, W.; Eini, O.; Bazanova, N.; Pallotta, M.; Shirley, N.; Singh, R.; Ismagul, A.; Eliby, S.; Johnson, A.; et al. The scutellar vascular bundle–specific promoter of the wheat HD-Zip IV transcription factor shows similar spatial and temporal activity in transgenic wheat, barley and rice. Plant Biotechnol. J. 2012, 10, 43–53. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Luang, S.; Harris, J.; Riboni, M.; Li, Y.; Bazanova, N.; Hrmova, M.; Haefele, S.; Kovalchuk, N.; Lopato, S. Overexpression of the class I homeodomain transcription factor TaHD-ZipI-5 increases drought and frost tolerance in transgenic wheat. Plant Biotechnol. J. 2017. [Google Scholar] [CrossRef] [PubMed]
- Kersey, P.J.; Allen, J.E.; Armean, I.; Boddu, S.; Bolt, B.J.; Carvalho-Silva, D.; Christensen, M.; Davis, P.; Falin, L.J.; Grabmueller, C.; et al. Ensembl Genomes 2016: More genomes, more complexity. Nucleic Acids Res. 2015, 44, D574–D580. [Google Scholar]
- Finn, R.D.; Mistry, J.; Schuster-Böckler, B.; Griffiths-Jones, S.; Hollich, V.; Lassmann, T.; Moxon, S.; Marshall, M.; Khanna, A.; Durbin, R.; et al. PFAM: Clans, web tools and services. Nucleic Acids Res. 2006, 34, D247–D251. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, T.J.; Eddy, S.R. NHMMER: DNA homology search with profile HMMs. Bioinformatics 2013, 29, 2487–2489. [Google Scholar] [CrossRef] [PubMed]
- The Conserved Domain Database. Available online: https://www.ncbi.nlm.nih.gov/cdd (accessed on 15 November 2017).
- Compute pI/mw Tool. Available online: https://web.expasy.org/compute_pi/ (accessed on 20 November 2017).
- Chou, K.C.; Shen, H.B. Cell-PLoc: A package of web-servers for predicting subcellular localization of proteins in various organisms. Nat. Protoc. 2008, 3, 153–162. [Google Scholar] [CrossRef] [PubMed]
- Larkin, M.; Blackshields, G.; Brown, N.; Chenna, R.; McGettigan, P.; McWilliam, H.; Valentin, F.; Wallace, I.M.; Wilm, A.; Lopez, R.; et al. Clustal W and Clustal X version 2.0. Bioinformatics 2007, 23, 2947–2948. [Google Scholar] [CrossRef] [PubMed]
- Tamura, K.; Stecher, G.; Peterson, D.; Filipski, A.; Kumar, S. MEGA6: Molecular evolutionary genetics analysis version 6.0. Mol. Boil. Evol. 2013, 30, 2725–2729. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Yue, H.; Feng, K.; Deng, P.; Song, W.; Nie, X. Genome-wide identification, phylogeny and expressional profiles of mitogen activated protein kinase kinasekinase (MAPKKK) gene family in bread wheat (Triticum aestivum L.). BMC Genom. 2016, 17, 668. [Google Scholar] [CrossRef] [PubMed]
- Krzywinski, M.; Schein, J.; Birol1, İ.; Connors, J.; Gascoyne, R.; Horsman, D.; Jones, S.J.; Marra, M.A. Circos: An information aesthetic for comparative genomics. Genome Res. 2009, 19, 1639–1645. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Jin, J.; Guo, A.Y.; Zhang, H.; Luo, J.; Gao, Ge. GSDS 2.0: An upgraded gene feature visualization server. Bioinformatics 2015, 31, 1296–1297. [Google Scholar] [CrossRef] [PubMed]
- Bailey, T.L.; Boden, M.; Buske, F.A.; Frith, M.; Grant, C.E.; Clementi, L.; Ren, J.; Li, W.W.; Noble, W.S. MEME SUITE: Tools for motif discovery and searching. Nucleic Acids Res. 2009, 37, W202–W208. [Google Scholar] [CrossRef] [PubMed]
- Seq Repository in URGI Wheat Database. Available online: https://urgi.versailles.inra.fr/files/RNASeqWheat/ (accessed on 30 November 2017).
- FastQC. Available online: http://www.bioinformatics.babraham.ac.uk/projects/fastqc/ (accessed on 30 November 2017).
- Trapnell, C.; Pachter, L.; Salzberg, S.L. TopHat: Discovering splice junctions with RNA-Seq. Bioinformatics 2009, 25, 1105–1111. [Google Scholar] [CrossRef] [PubMed]
- Cufflinks 2.2.1. Available online: http://cole-trapnell-lab.github.io/cufflinks/releases/v2.2.1/ (accessed on 10 November 2017).
- Lee, T.; Yang, S.; Kim, E.; Ko, Y.; Hwang, S.; Shin, J.; Shim, J.E.; Shim, H.; Kim, H.; Kim, C.; et al. AraNet v2: An improved database of co-functional gene networks for the study of Arabidopsis thaliana and 27 other nonmodel plant species. Nucleic Acids Res. 2015, 43, D996–D1002. [Google Scholar] [CrossRef] [PubMed]
- Maere, S.; Heymans, K.; Kuiper, M. BiNGO: A Cytoscape plugin to assess overrepresentation of gene ontology categories in biological networks. Bioinformatics 2005, 21, 3448–3449. [Google Scholar] [CrossRef] [PubMed]
- Primer Premier: A Comprehensive PCR Primer Design Software. Available online: http://www.premierbiosoft.com/primerdesign/ (accessed on 1 December 2017).
- Xu, L.; Tang, Y.; Gao, S.; Su, S.; Hong, L.; Wang, W.; Fang, Z.; Li, X.; Ma, J.; Quan, W.; et al. Comprehensive analyses of the annexin gene family in wheat. BMC Genom. 2016, 17, 415. [Google Scholar] [CrossRef] [PubMed]
- Qiao, L.; Zhang, X.; Han, X.; Zhang, L.; Li, X.; Zhan, H.; Ma, J.; Luo, P.; Zhang, W.; Cui, L.; et al. A genome-wide analysis of the auxin/indole-3-acetic acid gene family in hexaploid bread wheat (Triticum aestivum L.). Front. Plant Sci. 2015, 6, 770. [Google Scholar] [CrossRef] [PubMed]
- Belamkar, V.; Weeks, N.T.; Bharti, A.K.; Farmer, A.D.; Graham, M.A.; Cannon, S.B. Comprehensive characterization and RNA-Seq Profiling of the HD-Zip transcription factor family in soybean (Glycine max) during dehydration and salt stress. BMC Genom. 2014, 15, 950. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Zhou, Y.; Jiang, H.; Li, X.; Gan, D.; Peng, X.; Zhu, S.; Cheng, B. Systematic analysis of sequences and expression patterns of drought-responsive members of the HD-Zip gene family in maize. PLoS ONE 2011, 12, e28488. [Google Scholar] [CrossRef] [PubMed]
- Song, A.; Li, P.; Xin, J.; Chen, S.; Zhao, K.; Wu, D.; Fan, Q.; Gao, T.; Chen, F.; Guan, Z. Transcriptome-wide survey and expression profile analysis of putative chrysanthemum HD-Zip I and II genes. Genes 2016, 7, 19. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.Y.; Jing, J.; Huan, L.; Qing, D.; Hanwei, Y.; Defang, G.; Wei, Z.; Suwen, Z. Genome-wide analysis of HD-Zip genes in grape (Vitis vinifera). Tree Genet. Genom. 2015, 11, 827. [Google Scholar] [CrossRef]
- Zhang, J.Z. Evolution by gene duplication: An update. Trends Ecol. Evol. 2003, 18, 292–298. [Google Scholar] [CrossRef]
- Feldman, M.; Levy, A.A. Allopolyploidy—A shaping force in the evolution of wheat genomes. Cytogenet. Genome Res. 2005, 109, 250–258. [Google Scholar] [CrossRef] [PubMed]
- Lynch, M.; Force, A. The probability of duplicate gene preservation by subfunctionalization. Genetics 2000, 154, 459–473. [Google Scholar] [PubMed]
- Ré, D.A.; Capella, M.; Bonaventure, G.; Chan, R.L. Arabidopsis AtHB7 and AtHB12 evolved divergently to fine tune processes associated with growth and responses to water stress. BMC Plant Biol. 2014, 14, 150. [Google Scholar] [CrossRef] [PubMed]
- Yue, H.; Wang, M.; Liu, S.; Du, X.; Song, W.; Nie, X. Transcriptome-wide identification and expression profiles of the WRKY transcription factor family in Broomcorn millet (Panicum miliaceum L.). BMC Genom. 2016, 17, 343. [Google Scholar] [CrossRef] [PubMed]
- Schena, M.; Davis, R.W. structure of homeobox-leucine zipper genes suggests a model for the evolution of gene families. Proc. Natl. Acad. Sci. USA 1994, 91, 8393–8397. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Haider, I.; Kohlen, W.; Jiang, L.; Bouwmeester, H.; Meijer, A.H.; Schluepmann, H.; Liu, C.M.; Ouwerkerk, P.B. Function of the HD-Zip I gene Oshox22 in ABA-mediated drought and salt tolerances in rice. Plant Mol. Biol. 2012, 80, 571–585. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene | Sequence ID | Location | AA Length | PI | MW | Subcellular Location |
|---|---|---|---|---|---|---|
| TaHDZ1-A | Traes_1AL_0BE456AC0.1 | 1A:80794504-80805037 | 840 | 5.65 | 92,041.09 | Chloroplast |
| TaHDZ1-B | Traes_1BL_43408C9B0.2 | 1B:202405337-202411629 | 620 | 5.80 | 68,027.69 | Chloroplast |
| TaHDZ2-D | Traes_1DL_9FB53E48A.1 | 1DL:scaff527273:1-682 | 128 | 9.00 | 14,621.61 | Nucleus |
| TaHDZ3-B | Traes_1BL_BCA60D8B6.2 | 1BL:scaff3858366:4943-6233 | 302 | 6.68 | 33,291.33 | Nucleus |
| TaHDZ4-A | Traes_1AL_1444D461A.1 | 1A:192016994-192017547 | 326 | 8.50 | 34,647.92 | Nucleus |
| TaHDZ5-D | Traes_2DL_036F2A3FC.1 | 2DL:scaff9746565:6-712 | 251 | 8.31 | 26,889.50 | Chloroplast |
| TaHDZ6-B | Traes_2BS_BD0ED621D.2 | 2B:203096624-203098080 | 238 | 7.12 | 25,888.92 | Chloroplast |
| TaHDZ6-D | Traes_2DS_20F748657.2 | 2D:47948060-47949499 | 238 | 6.76 | 25,755.72 | Chloroplast |
| TaHDZ7-A | Traes_2AL_CC3E5591E.1 | 2A:214032194-214033814 | 218 | 8.84 | 24,308.27 | Peroxisome |
| TaHDZ7-B | Traes_2BL_419CEED79.1 | 2BL:scaff8047670:2819-3802 | 196 | 9.54 | 21,615.02 | Nucleus |
| TaHDZ8-A | Traes_2AL_BFB0C6D4C.1 | 2A:92585473-92586697 | 183 | 5.15 | 20,209.38 | Chloroplast |
| TaHDZ8-B | Traes_2BL_B69300543.1 | 2BL:scaff8082479:11478-12572 | 259 | 5.20 | 29,003.43 | Nucleus |
| TaHDZ9-A | Traes_2AL_EF9549D16.1 | 2AL:scaff6334009:1565-3326 | 227 | 8.84 | 25,675.08 | Nucleus |
| TaHDZ9-B | Traes_2BL_02479C76A.1 | 2B:265061413-265062697 | 159 | 9.78 | 18,432.80 | Nucleus |
| TaHDZ9-D | Traes_2DL_67F1183B2.1 | 2D:25397187-25398979 | 230 | 8.84 | 25,914.27 | Nucleus |
| TaHDZ10-B | TRAES3BF043500070CFD_t1 | 3B:8112566-8113594 | 228 | 8.64 | 25,282.62 | Nucleus |
| TaHDZ10-D | Traes_3DS_7CCB5ECD2.1 | 3D:813820-814506 | 183 | 9.12 | 20,819.69 | Nucleus |
| TaHDZ11-B | TRAES3BF026400090CFD_t1 | 3B:424323223-424326762 | 222 | 9.42 | 24,704.13 | Nucleus |
| TaHDZ12-B | TRAES3BF023000040CFD_t1 | 3B:530484425-530487959 | 755 | 7.80 | 81,462.58 | Chloroplast |
| TaHDZ13-B | TRAES3BF075200070CFD_t1 | 3B:554475326-554479704 | 674 | 8.48 | 73,671.85 | Chloroplast |
| TaHDZ13-D | Traes_3DL_8AAFB7B06.1 | 3D:86091404-86095021 | 446 | 8.33 | 49,134.62 | Nucleus |
| TaHDZ14-A | Traes_4AL_822582A19.1 | 4AL:scaff7079911:4919-6438 | 266 | 9.26 | 28,237.92 | Chloroplast |
| TaHDZ15-A | Traes_4AS_F04DD4409.1 | 4AS:scaff5975837:1-1802 | 278 | 6.76 | 28,363.81 | Chloroplast |
| TaHDZ15-B | Traes_4BL_BE3E058A6.1 | 4BL:scaff7026111:366-3006 | 325 | 9.24 | 33,237.48 | Nucleus |
| TaHDZ15-D | Traes_4DL_88ABAD6C0.1 | 4DL:scaff14448085:2765-5409 | 330 | 6.17 | 36,411.50 | Nucleus |
| TaHDZ16-A | Traes_4AL_99A941299.1 | 4A:184972869-184975111 | 318 | 4.94 | 34,975.56 | Mitochondrion |
| TaHDZ16-B | Traes_4BL_ECD20BE67.1 | 4B:292827483-292829670 | 316 | 4.99 | 35,099.79 | Nucleus |
| TaHDZ17-A | Traes_4AS_1EA23DE08.1 | 4AS:scaff3077305:961-2471 | 231 | 6.24 | 25,530.54 | Peroxisome |
| TaHDZ17-B | Traes_4BL_BE10705D5.2 | 4B:282781983-282783490 | 233 | 6.04 | 25,576.61 | Peroxisome |
| TaHDZ17-D | Traes_4DL_4798D0BBD.1 | 4D:68945470-68946969 | 234 | 6.24 | 25,708.82 | Chloroplast |
| TaHDZ18-B | Traes_4BL_78DD63002.1 | 4BL:scaff6966681:8297-10341 | 205 | 8.94 | 22,631.64 | Chloroplast |
| TaHDZ19-B | Traes_5BL_4A3874701.1 | 5B:170563162-170564690 | 355 | 6.27 | 37,049.33 | Nucleus |
| TaHDZ20-B | Traes_5BL_9C32B27E2.1 | 5BL:scaff10897212:246-2341 | 249 | 5.02 | 27,502.62 | Nucleus |
| TaHDZ20-D | Traes_5DL_96F9EED93.2 | 5DL:scaff4539911:3583-5740 | 249 | 5.02 | 27,488.59 | Nucleus |
| TaHDZ21-B | Traes_5BL_028D02DF6.1 | 5B:84457851-84460016 | 299 | 4.86 | 32,566.01 | Chloroplast |
| TaHDZ22-B | Traes_5BL_5DE02D63E.1 | 5BL:scaff10833801:1080-2780 | 269 | 4.70 | 28,884.88 | Chloroplast |
| TaHDZ23-B | Traes_5BS_360DD5644.1 | 5B:18562939-18569007 | 879 | 6.61 | 95,339.96 | Chloroplast |
| TaHDZ23-D | Traes_5DS_50846FD0C.1 | 5D:21777479-21783627 | 883 | 6.73 | 95,733.49 | Chloroplast |
| TaHDZ24-A | Traes_6AL_36AB0312C.1 | 6A:185224197-185226370 | 340 | 4.61 | 37,072.67 | Chloroplast |
| TaHDZ24-D | Traes_6DL_FF4C8C4AB.1 | 6D:138591996-138594281 | 340 | 4.67 | 37,147.85 | Chloroplast |
| TaHDZ25-A | Traes_6AS_3E534A2C1.1 | 6AS:scaff4406943:3994-5166 | 226 | 8.72 | 24,538.57 | Chloroplast |
| TaHDZ25-D | Traes_6DS_17B737547.1 | 6D:24274468-24275712 | 225 | 8.38 | 24,759.74 | Nucleus |
| TaHDZ26-D | Traes_6DS_D281B7D32.1 | 6D:23048583-23049661 | 205 | 9.87 | 22,606.56 | Nucleus |
| TaHDZ27-D | Traes_6DS_F00EB2E01.1 | 6D:21598812-21599534 | 192 | 9.79 | 20,888.56 | Chloroplast |
| TaHDZ28-A | Traes_7AL_44206BE21.1 | 7A:149156319-149157237 | 169 | 10.68 | 19,423.03 | Mitochondrion |
| TaHDZ28-D | Traes_7DL_2FE5181AF.1 | 7DL:scaff1534355:1875-3077 | 185 | 9.50 | 20,757.18 | Nucleus |
| Species | Group I-a | Group I-β1 | Group I-β2 | Group I-ε | Group I-б | Group I-ξ | Group I-r | Group I-φ | Group II | Group III | Group IV | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| wheat | 3 | 3 | 0 | 0 | 7 | 3 | 4 | 0 | 17 | 4 | 5 | 46 |
| Maize | 3 | 4 | 0 | 0 | 1 | 5 | 4 | 0 | 18 | 5 | 15 | 55 |
| Rice | 2 | 3 | 0 | 0 | 2 | 4 | 3 | 0 | 12 | 5 | 8 | 39 |
| Arabidopsis | 4 | 2 | 3 | 2 | 3 | 0 | 2 | 1 | 10 | 5 | 16 | 48 |
| Soybean | 8 | 4 | 2 | 2 | 2 | 8 | 2 | 0 | 27 | 12 | 19 | 86 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, H.; Shu, D.; Wang, M.; Xing, G.; Zhan, H.; Du, X.; Song, W.; Nie, X. Genome-Wide Identification and Expression Analysis of the HD-Zip Gene Family in Wheat (Triticum aestivum L.). Genes 2018, 9, 70. https://doi.org/10.3390/genes9020070
Yue H, Shu D, Wang M, Xing G, Zhan H, Du X, Song W, Nie X. Genome-Wide Identification and Expression Analysis of the HD-Zip Gene Family in Wheat (Triticum aestivum L.). Genes. 2018; 9(2):70. https://doi.org/10.3390/genes9020070
Chicago/Turabian StyleYue, Hong, Duntao Shu, Meng Wang, Guangwei Xing, Haoshuang Zhan, Xianghong Du, Weining Song, and Xiaojun Nie. 2018. "Genome-Wide Identification and Expression Analysis of the HD-Zip Gene Family in Wheat (Triticum aestivum L.)" Genes 9, no. 2: 70. https://doi.org/10.3390/genes9020070
APA StyleYue, H., Shu, D., Wang, M., Xing, G., Zhan, H., Du, X., Song, W., & Nie, X. (2018). Genome-Wide Identification and Expression Analysis of the HD-Zip Gene Family in Wheat (Triticum aestivum L.). Genes, 9(2), 70. https://doi.org/10.3390/genes9020070