
A Short-Term Wind Speed Forecasting Model Based on a Multi-Variable Long Short-Term Memory Network


Abstract
:1. Introduction
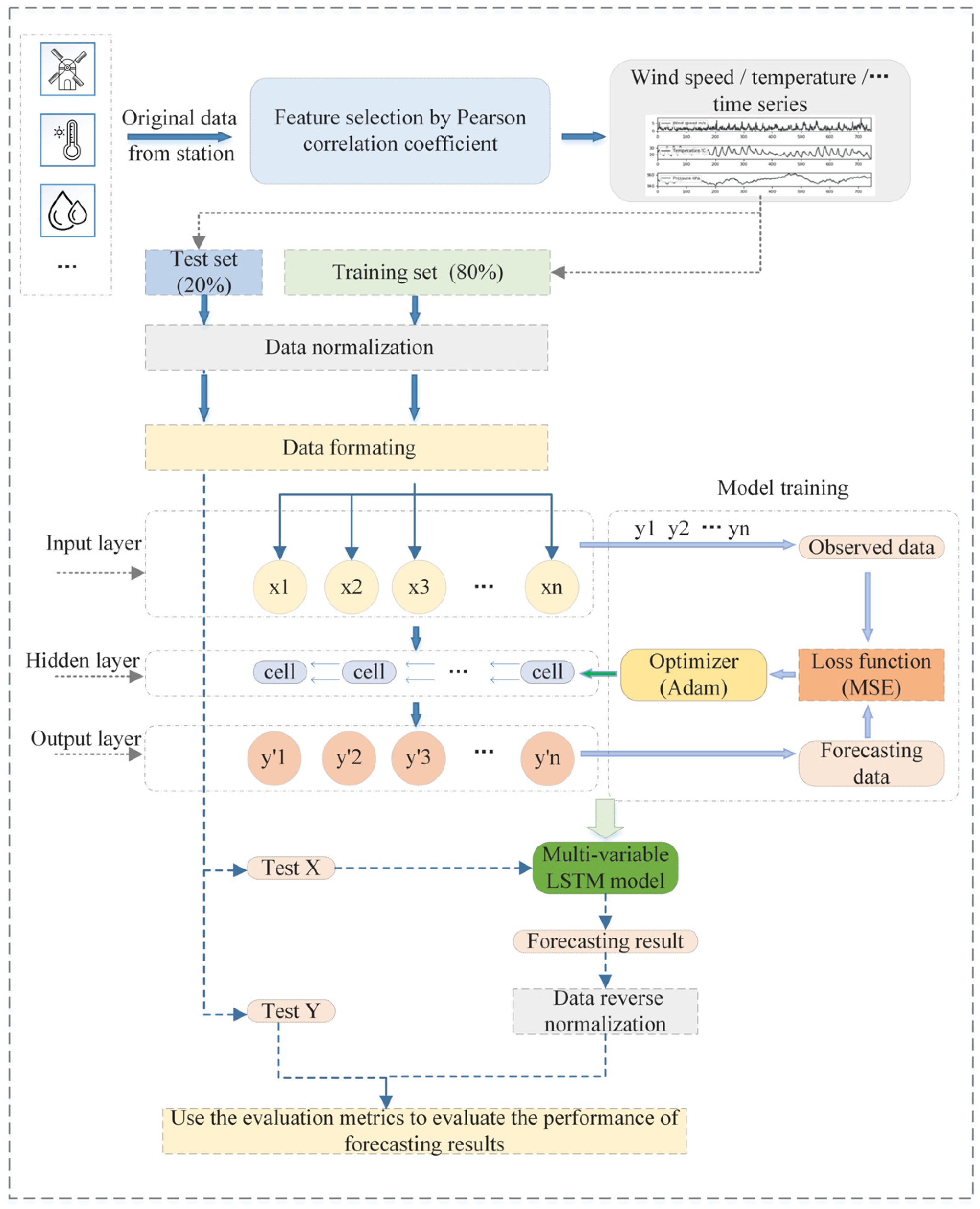
2. Data and Methods
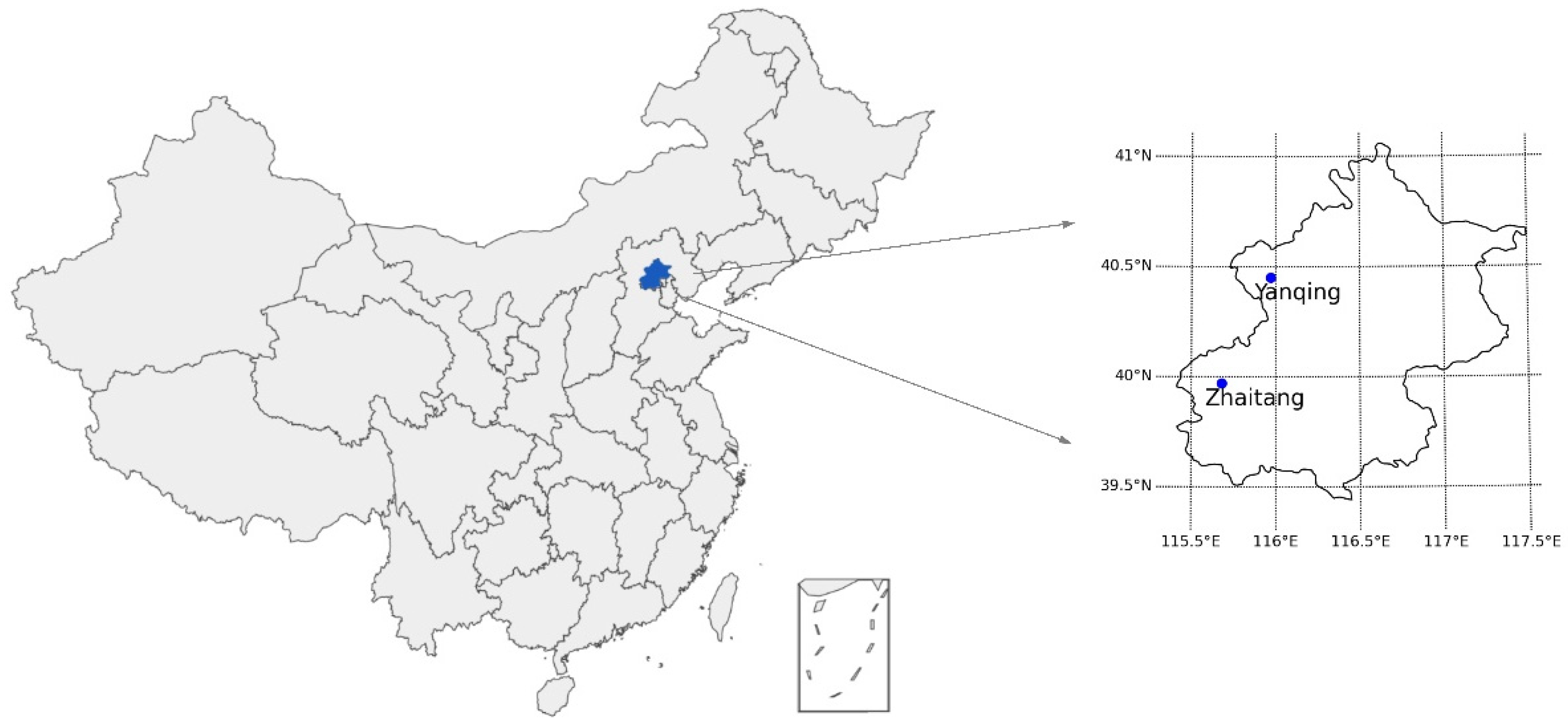
2.1. Site Description
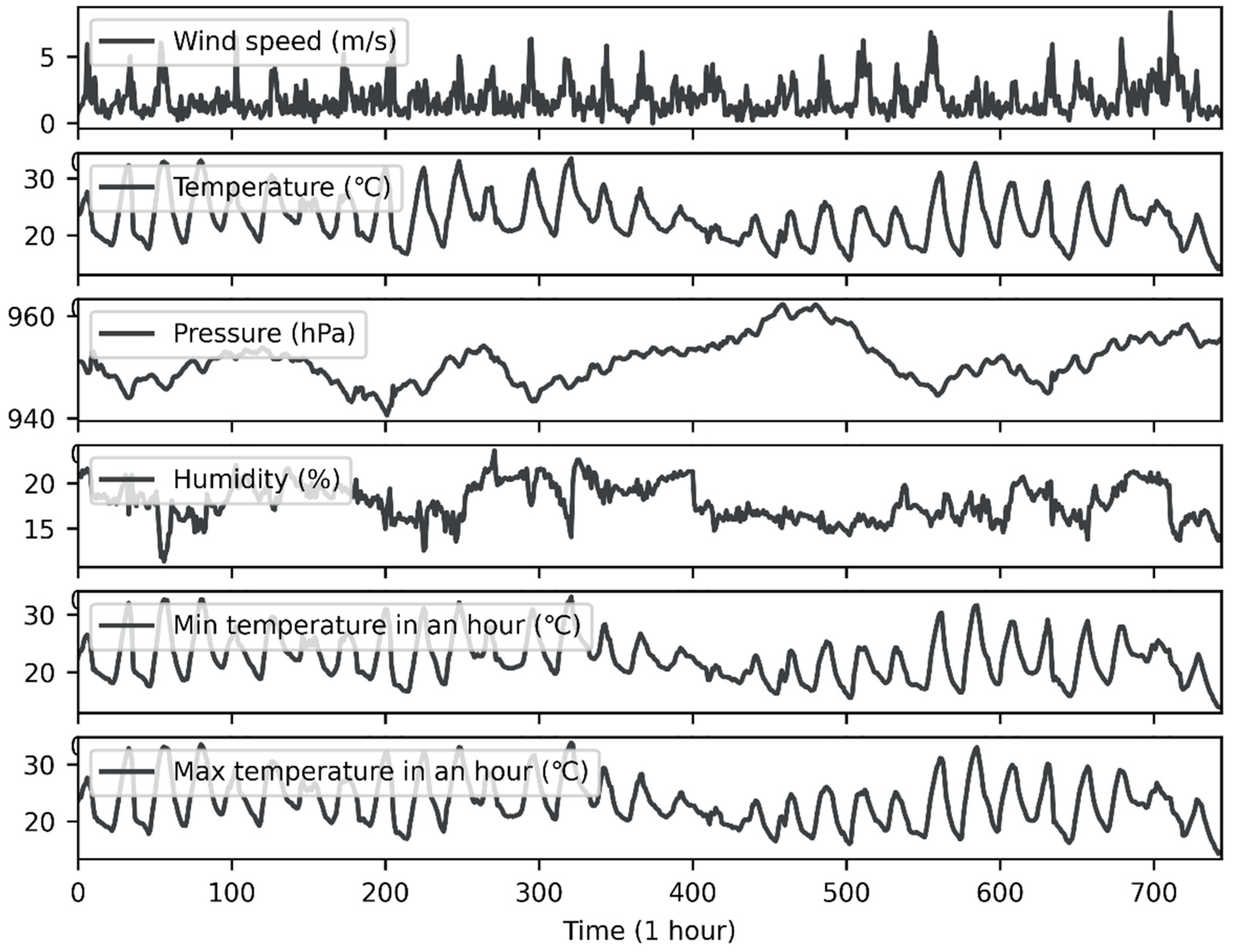
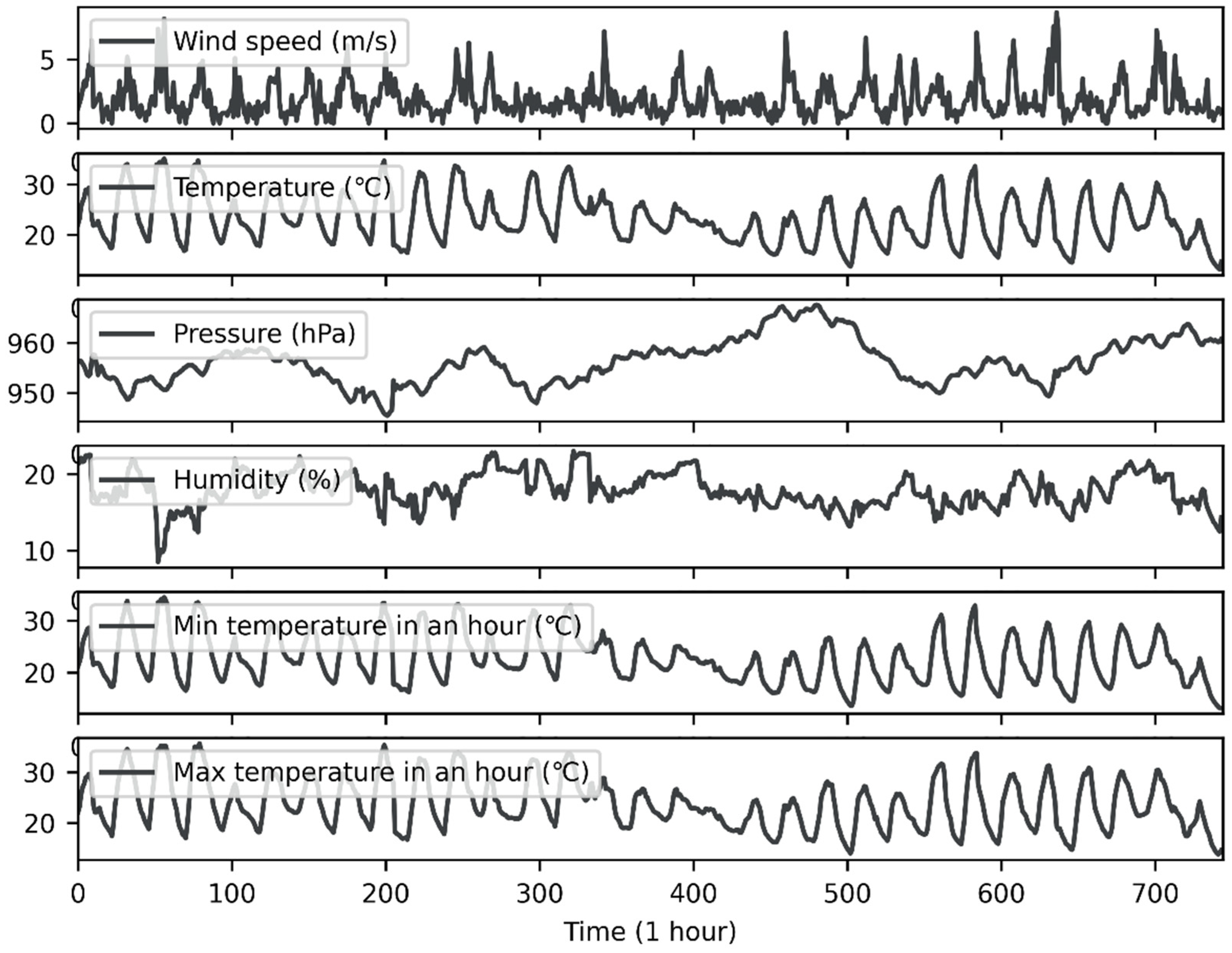
2.2. Data Description
2.3. Prediction Methods
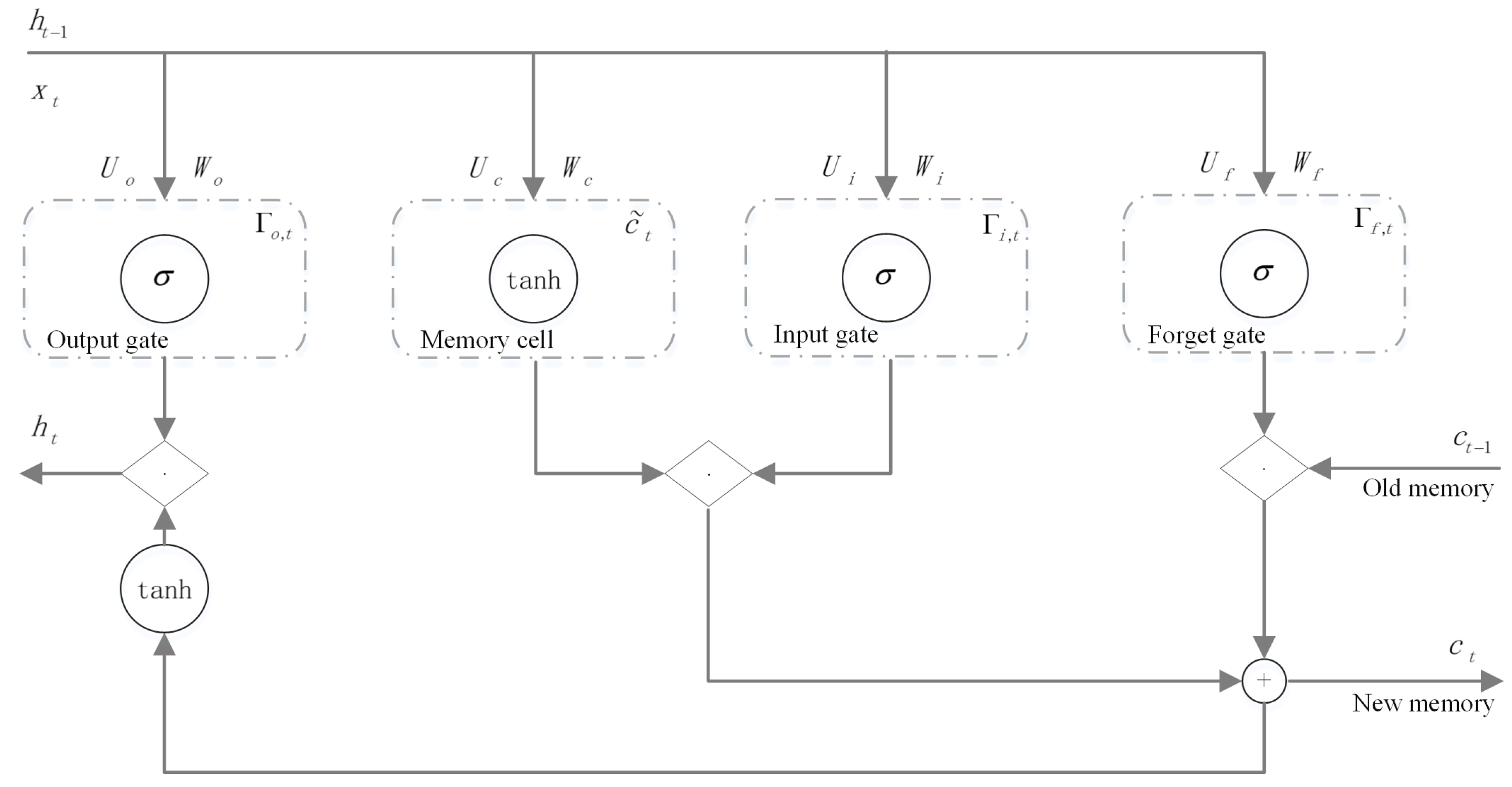
2.3.1. Long Short-Term Memory (LSTM) Networks
- 1.
- The forgetting gate determines what information in needs to be discarded or retained. By obtaining and , the output [0, 1] is assigned to , where 1 means completely retained and 0 means completely discarded. The output of the forgetting gate is as follows (where is the bias vector of the hidden layer element, is the bias vector, and the subscript is the corresponding element):
- 2.
- The input gate determines how much information to add to the cell and generates the information of the sigmoid and tanh by combining with the forgetting gate to update the state of the cell. The input gate steps are:
- 3.
- The output gate determines which part of the information of the current cell state is used as the output, and is still completed by the sigmoid and tanh. The output gate steps are:
2.3.2. Multi-Variable Long Short-Term Memory (MV-LSTM) Network
- (1)
- We first propose the null hypothesis and the alternative hypothesis:The null hypothesis: which means that the two variables (X and Y) are linearly independent;The alternative hypothesis: , which means that the two variables are linearly dependent.
- (2)
- We calculate the probability value (p-value) of the null hypothesis being true (when the two variables are linearly independent).
- (3)
- We set the significance level: .
- (4)
- We compare the p-value to . If the p-value is less than , the null hypothesis is considered as the extreme case, thus rejecting the null hypothesis and accepting the alternative hypothesis, which means that the linear correlation between X and Y is statistically significant.
2.4. Evaluation Metrics
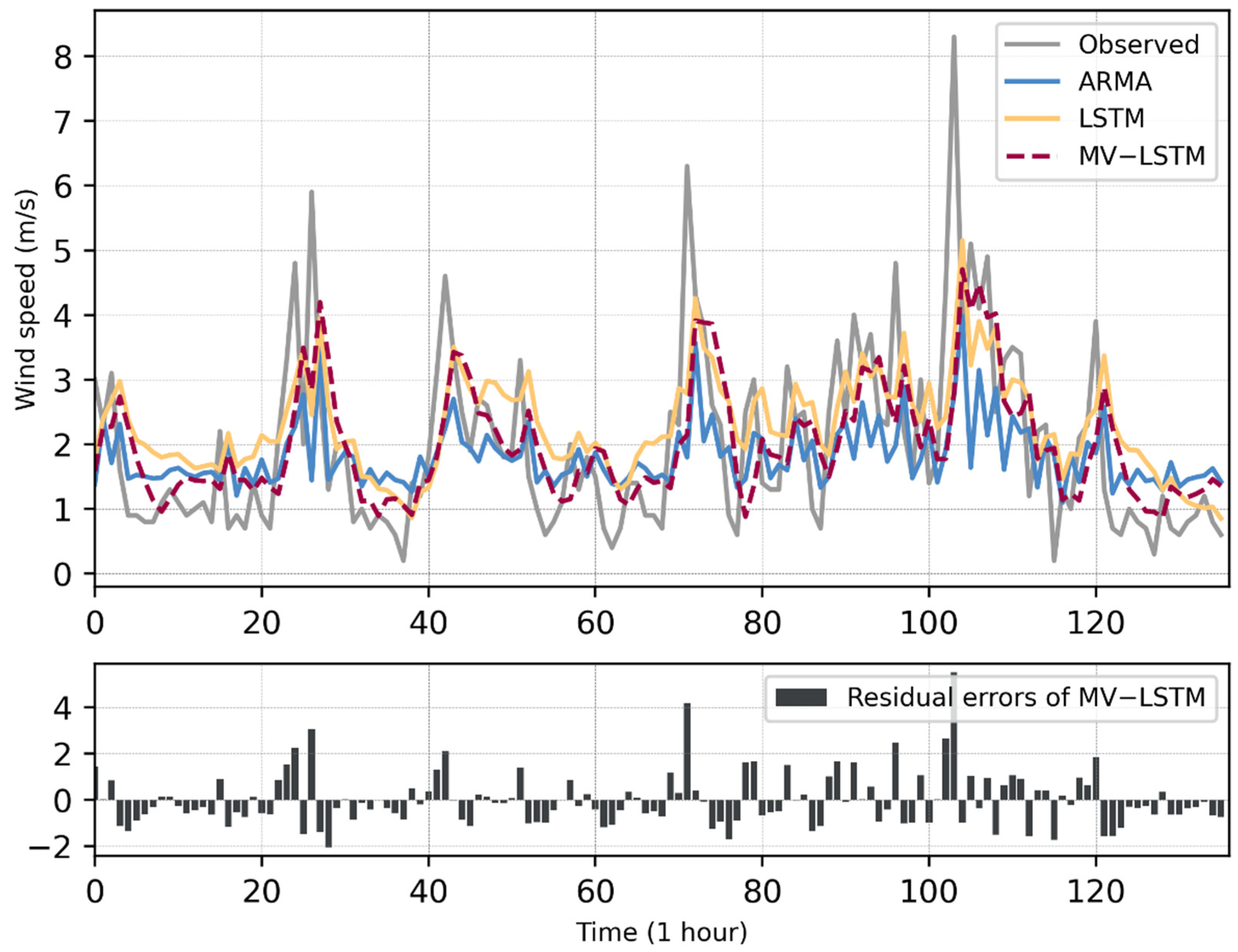
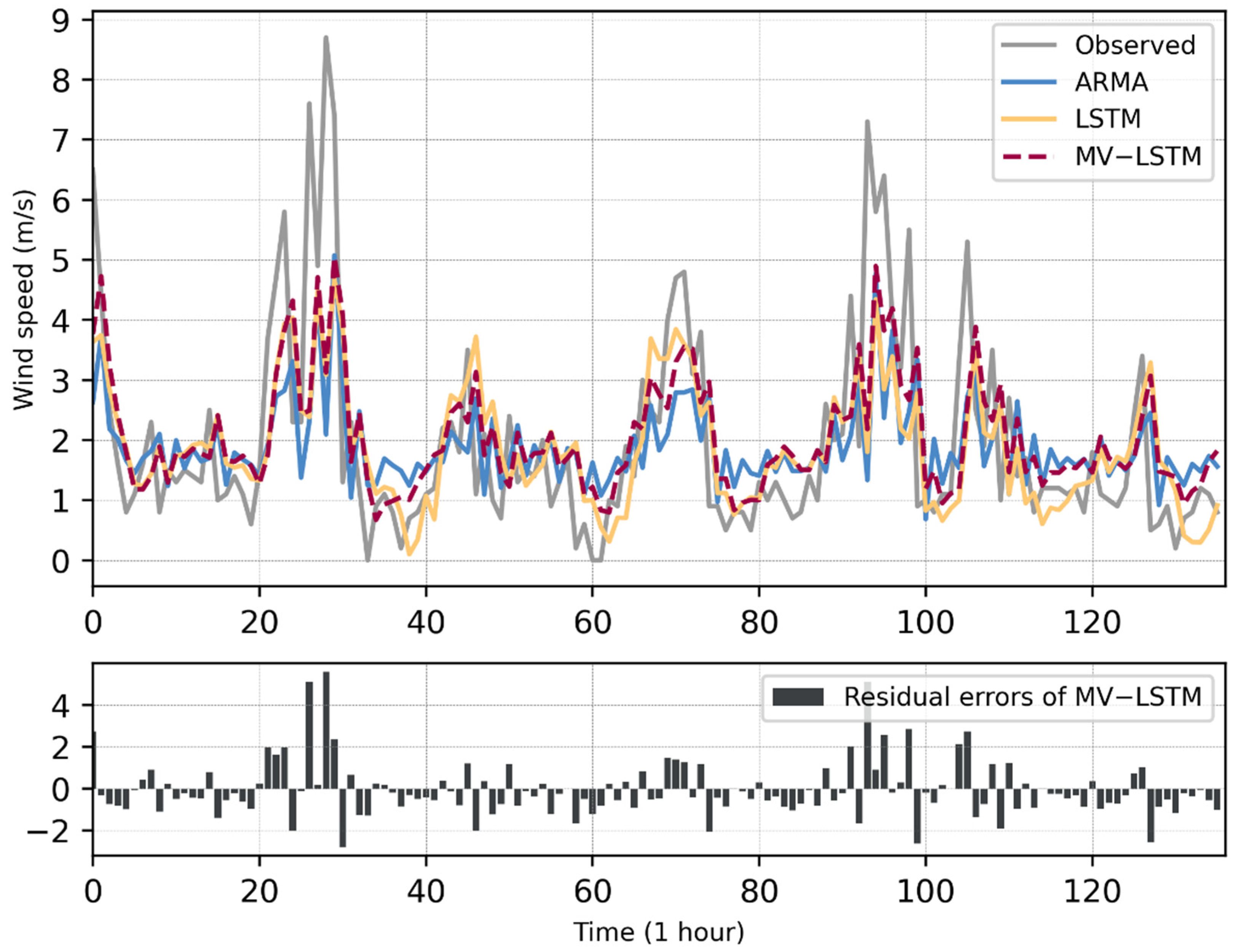
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Burton, T. Wind Energy Handbook; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Hu, Y.L.; Liang, C. A nonlinear hybrid wind speed forecasting model using LSTM network, hysteretic ELM and Differential Evolution algorithm. Energy Conv. Manag. 2018, 173, 123–142. [Google Scholar] [CrossRef]
- Würth, I.; Valldecabres, L.; Simon, E.; Möhrlen, C.; Uzunoğlu, B.; Gilbert, C.; Giebel, G.; Schlipf, D.; Kaifel, A. Minute-Scale Forecasting of Wind Power—Results from the Collaborative Workshop of IEA Wind Task 32 and 36. Energies 2019, 12, 712. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, W.; Wang, J.; Han, T.; Kong, L. A novel hybrid approach for wind speed prediction. Inf. Sci. 2014, 273, 304–318. [Google Scholar] [CrossRef]
- Giebel, G.; Brownsword, R.; Kariniotakis, G.; Denhard, M.; Draxl, C. The State of the Art in Short-Term Prediction of Wind Power A Literature Overview; Technical Report; Technical University of Denmark (DTU): Roskilde, Denmark, 2011. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, W.; Li, Y.; Wang, J.; Dang, Z. Forecasting wind speed using empirical mode decomposition and Elman neural network. Appl. Soft Comput. 2014, 23, 452–459. [Google Scholar] [CrossRef]
- Chen, D.H.; Xue, J.S. Present situation and prospect of numerical weather forecast business model. Acta Meteorol. Sin. 2004, 623–633. [Google Scholar] [CrossRef]
- Liao, D.X. Design of Atmospheric Numerical Models; China Meteorological Press: Beijing, China, 1999. [Google Scholar]
- Han, X.; Chen, F.; Cao, H.; Li, X.; Zhang, X. Short-term wind speed prediction based on LS-SVM. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 3200–3204. [Google Scholar]
- Poggi, P.; Muselli, M.; Notton, G.; Cristofari, C.; Louche, A. Forecasting and simulating wind speed in Corsica by using an autoregressive model. Energy Convers. Manag. 2003, 44, 3177–3196. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-ARIMA models. Renew Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Lydia, M.; Kumar, S.S.; Selvakumar, A.I.; Kumar, G.E.P. Linear and non-linear autoregressive models for short-term wind speed forecasting. Energy Convers. Manag. 2016, 112, 115–124. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Guo, Z.; Yang, W. Research and application of a novel hybrid forecasting system based on multi-objective optimization for wind speed forecasting. Energy Convers. Manag. 2017, 150, 90–107. [Google Scholar] [CrossRef]
- Würth, I.; Ellinghaus, S.; Wigger, M.; Niemeier, M.J.; Clifton, A.; Cheng, P.W. Forecasting wind ramps: Can long-range lidar increase accuracy? J. Physics Conf. Ser. 2018, 1102, 012013. [Google Scholar] [CrossRef] [Green Version]
- Valldecabres, L.; Peña, A.; Courtney, M.; Von Bremen, L.; Kuhn, M. Very short-term forecast of near-coastal flow using scanning lidars. Wind. Energy Sci. 2018, 3, 313–327. [Google Scholar] [CrossRef] [Green Version]
- Ren, C.; An, N.; Wang, J.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowledge-Based Syst. 2014, 56, 226–239. [Google Scholar] [CrossRef]
- Baran, S. Probabilistic wind speed forecasting using Bayesian model averaging with truncated normal components. Comput. Stat. Data Anal. 2014, 75, 227–238. [Google Scholar] [CrossRef] [Green Version]
- Santhosh, M.; Venkaiah, C.; Kumar, D.V. Ensemble empirical mode decomposition based adaptive wavelet neural network method for wind speed prediction. Energy Convers. Manag. 2018, 168, 482–493. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Li, C.; Fu, W.; Peng, T. A compound structure of ELM based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 143, 360–376. [Google Scholar] [CrossRef]
- Cao, Q.; Ewing, B.T.; Thompson, M.A. Forecasting wind speed with recurrent neural networks. Eur. J. Oper. Res. 2012, 221, 148–154. [Google Scholar] [CrossRef]
- Chen, N.; Xialihaer, N.; Kong, W.; Ren, J. Research on Prediction Methods of Energy Consumption Data. J. New Media 2020, 2, 99–109. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, Y.; Zhang, S. Ship Trajectory Prediction Based on BP Neural Network. J. Artif. Intell. 2019, 1, 29–36. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Hu, X.; Chen, H. Wind Speed Prediction Modeling Based on the Wavelet Neural Network. Intell. Autom. Soft Comput. 2020, 26, 625–630. [Google Scholar] [CrossRef]
- Chen, M.-R.; Zeng, G.-Q.; Lu, K.-D.; Weng, J. A Two-Layer Nonlinear Combination Method for Short-Term Wind Speed Prediction Based on ELM, ENN, and LSTM. IEEE Internet Things J. 2019, 6, 6997–7010. [Google Scholar] [CrossRef]
- Fang, W.; Zhang, F.; Ding, Y.; Sheng, J. A new Sequential Image Prediction Method Based on LSTM and DCGAN. Comput. Mater. Contin. 2020, 64, 217–231. [Google Scholar] [CrossRef]
- Yan, B.; Tang, X.; Wang, J.; Zhou, Y.; Zheng, G.; Zou, Q.; Lu, Y.; Liu, B.; Tu, W.; Xiong, N. An Improved Method for the Fitting and Prediction of the Number of COVID-19 Confirmed Cases Based on LSTM. Comput. Mater. Contin. 2020, 64, 1473–1490. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar] [CrossRef]
- Chen, J.; Zeng, G.-Q.; Zhou, W.; Du, W.; Lu, K. Wind speed forecasting using nonlinear-learning ensemble of deep learning time series prediction and extremal optimization. Energy Convers. Manag. 2018, 165, 681–695. [Google Scholar] [CrossRef]
- Nerlove, M.; Diebold, F.X. Autoregressive and Moving-average Time-series Processes. In Time Series and Statistics; Eatwell, J., Milgate, M., Newman, P., Eds.; Palgrave Macmillan UK: London, UK, 1990; pp. 25–35. [Google Scholar]
- Yan, B.Z.; Sun, J.; Wang, X.Z.; Han, N.; Liu, B. Groundwater level prediction based on multivariable LSTM neural network. J. Jilin Univ. 2020, 50, 1. [Google Scholar]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part. C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Liang, S.; Nguyen, L.; Jin, F. A Multi-variable Stacked Long-Short Term Memory Network for Wind Speed Forecasting. IEEE Int. Conf. Big Data 2018, 4561–4564. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.H. Machine Learning; Tsinghua University Press: Beijing, China, 2016. [Google Scholar]
- Lange, M.; Waldl, H.P. Assessing the uncertainty of wind power predictions with regard to specific weather situations. In Proceedings of the European Wind Energy Conference, Copenhagen, Denmark, 2–6 July 2001; pp. 695–698. [Google Scholar]
- Pearson, K. Notes on the History of Correlation. Biometrika 1920, 13, 25. [Google Scholar] [CrossRef]
- Stigler, S.M. Francis Galton’s Account of the Invention of Correlation. Stat. Sci. 1989, 4, 73–79. [Google Scholar] [CrossRef]
- Song, Z.; Jiang, Y.; Zhang, Z. Short-term wind speed forecasting with Markov-switching model. Appl. Energy 2014, 130, 103–112. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Station ID | Longitude (°E) | Latitude (°N) | Altitude(m) |
|---|---|---|---|---|
| Yanqing | 54406 | 115.97 | 40.45 | 487.9 |
| Zhaitang | 54501 | 115.68 | 39.97 | 440.3 |
| Station | Dataset | Max | Median | Min | Mean | Standard Deviation |
|---|---|---|---|---|---|---|
| Yanqing | Entire dataset | 8.30 | 1.35 | 0.00 | 1.75 | 1.24 |
| Training dataset | 7.00 | 1.30 | 0.00 | 1.72 | 1.20 | |
| Test dataset | 8.30 | 1.40 | 0.20 | 1.92 | 1.36 | |
| Zhaitang | Entire dataset | 8.70 | 1.50 | 0.00 | 1.87 | 1.42 |
| Training dataset | 8.20 | 1.50 | 0.00 | 1.83 | 1.33 | |
| Test dataset | 8.70 | 1.30 | 0.00 | 2.02 | 1.71 |
| Parameter | Value |
|---|---|
| epoch size | 30 |
| batch size | 4 |
| neuron size | 6 |
| loss function | mean squared error (MSE) |
| optimizer | adaptive moment estimation (ADAM) |
| Yanqing Station | Zhaitang Station | |||
|---|---|---|---|---|
| Correlation | p-Value | Correlation | p-Value | |
| Temperature | 0.37 * | 0.00 | 0.50 * | 0.00 |
| Pressure | −0.08 * | 0.03 | −0.14 * | 0.00 |
| Humidity | −0.09 * | 0.02 | 0.01 | 0.78 |
| Min T | 0.37 * | 0.00 | 0.51 * | 0.00 |
| Max T | 0.39 * | 0.00 | 0.52 * | 0.00 |
| Precipitation in One Hour | 0.01 | 0.70 | −0.00 | 0.99 |
| Method | RMSE (m/s) | MAE (m/s) | MBE (m/s) | MAPE (%) |
|---|---|---|---|---|
| ARMA | 1.2287 | 0.8853 | −0.1548 | 0.6615 |
| LSTM | 1.1477 | 0.9132 | 0.3170 | 0.7910 |
| MV-LSTM | 1.1460 | 0.8468 | 0.0276 | 0.6412 |
| Method | RMSE (m/s) | MAE (m/s) | MBE (m/s) | MAPE (%) |
|---|---|---|---|---|
| ARMA | 1.4638 | 1.0277 | −0.0764 | 0.73611 |
| LSTM | 1.3622 | 0.9343 | −0.1040 | 0.65081 |
| MV-LSTM | 1.3270 | 0.9375 | 0.0602 | 0.68880 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, A.; Yang, H.; Chen, J.; Sheng, L.; Zhang, Q. A Short-Term Wind Speed Forecasting Model Based on a Multi-Variable Long Short-Term Memory Network. Atmosphere 2021, 12, 651. https://doi.org/10.3390/atmos12050651
Xie A, Yang H, Chen J, Sheng L, Zhang Q. A Short-Term Wind Speed Forecasting Model Based on a Multi-Variable Long Short-Term Memory Network. Atmosphere. 2021; 12(5):651. https://doi.org/10.3390/atmos12050651
Chicago/Turabian StyleXie, Anqi, Hao Yang, Jing Chen, Li Sheng, and Qian Zhang. 2021. "A Short-Term Wind Speed Forecasting Model Based on a Multi-Variable Long Short-Term Memory Network" Atmosphere 12, no. 5: 651. https://doi.org/10.3390/atmos12050651
APA StyleXie, A., Yang, H., Chen, J., Sheng, L., & Zhang, Q. (2021). A Short-Term Wind Speed Forecasting Model Based on a Multi-Variable Long Short-Term Memory Network. Atmosphere, 12(5), 651. https://doi.org/10.3390/atmos12050651