1. Introduction
High-quality observational time series have a double role in climate research, supporting the analysis of the past climate and the validation and correction of climate information obtained from the climate models, or other proxy data (tree rings, pollens, etc.) [
1,
2,
3]. Analyzing climate variability based on instrumental data is strongly dependent on the length and the spatial density of the available time series, the number of usable climate elements, and data quality. Most of the existing historical datasets have certain shortcomings regarding one or more of these basic requirements. Among the global datasets, the Integrated Surface Database (ISD) has the best spatial coverage in Europe [
4]. The database includes over 35,000 stations worldwide, with some of them in function since 1901. The most popular dataset in Europe is the European Climate Assessment & Dataset [
5], which covers daily observational datasets for the period from 1900 to the present; however, very few ECA&D stations include useful data before 1961 [
6]. Datasets such as NCEP/NCAR [
7] and ERA5 [
8] are collections of synoptic data combined with model outputs. They are three-dimensional in space, offer a high level of “real-time quality”, provide a high spatial and temporal resolution, and contain the full range of meteorological elements, they cover the most recent 60 years, but their quality in terms of long-term homogeneity is questionable. Other regional gridded databases are the CARPATCLIM [
9], containing data for the Carpathian Region for the period of 1961–2010, and ROCADA [
10] for Romania, covering the interval 1961–2013.
We can conclude that the above-mentioned datasets are useful to obtain climate information from observations or reanalysis, but they are available only after the 1950s, whereas fewer measurements, but with comparable quality (e.g., measurements using similar instruments), exist for earlier periods as well. Very few databases, such as HISTALP for the Alpine Region [
11], contain 18–19th century measurements, despite the high accuracy, quality, and thorough documentation of these measurements [
12]. A similar supranational activity was the NACD project [
13], which focused on Northern Europe.
In 1848, the Austrian Academy of Sciences officially approved the first meteorological observation network for the entire territory of the Habsburg Monarchy. The Central Institute for Meteorology and Geodynamics (Zentralanstalt für Meteorologie und Geodynamik, ZAMG) was founded in Vienna in 1851 [
14]. After the Austro-Hungarian Monarchy was established in 1867, The Royal Hungarian Central Institute of Meteorology and Earth Magnetism (RHCIMEM) was founded in 1870. Starting in 1871, the institute published its yearbooks [
15], which included the meteorological, geomagnetic, and plant phenology measurements carried out in the territory of the historical Kingdom of Hungary, which included most of the Carpathian Region. Despite the significant utility of this climate information, only very few studies processed these data [
16,
17,
18].
To construct long-term data series beyond the present databases, usually available in a digital format, the issue of merging or comparing historic instrumental measurements with newer ones has to be addressed. This operation requires special prudency because of the differences in instrumentation, measuring methods, observation time, and calculations. Historical instrumental measurements inevitably contain inhomogeneities and outliers due to changes in locations, instruments, or methodology. For this reason, special attention should be paid to data quality control (QC) as well. Taking this into consideration, Izsák et al. [
16] computed the longest ever homogenized, gridded daily dataset for Hungary, covering the period of 1870–2020. The authors used the MASH (Multiple Analysis of Series for Homogenization) [
19,
20] homogenization method to correct errors and fill data gaps, followed by the MISH (Meteorological Interpolation based on Surface Homogenized Data Basis; [
21]) method to interpolate data to a regular grid.
Despite several shortcomings, records from paper-based meteorological yearbooks are unique sources of past information about atmospheric parameters, and they could become references for climate variability and climate change assessments. They can also be of great help in other environmental and social science research. To highlight the importance of long-term meteorological observations, the WMO has a mechanism to recognize centennial observing stations [
22]. It promotes sustainable observational standards and best practices facilitating the generation of high-quality time series. In 2017, the WMO recognized a first set of the WMO centennial observing stations, and further calls are planned to be released every two years. In the Carpathian Region, eight stations are recognized (HU: Budapest, Debrecen, Pécs, Szeged, and Szombathely; HR: Zagreb; RO: Drobeta-Turnu Severin; and SK: Hurbanovo).
This study aims to capture the main features of climate variability and analyze climate changes in the Carpathian Region using a long-term meteorological dataset. To explore the characteristics of the climatic conditions, we investigated 13 stations from the Carpathian Region having the most complete monthly mean, minimum, and maximum temperature and precipitation time series for the period of 1871–1918. The selected stations are (with historical Hungarian and German station names as provided in the yearbooks): Arad (RO), Bistrița (Beszterce, Bistritz) (RO), Miercurea Ciuc (Csíkszereda, Szeklerburg) (RO), Cluj-Napoca (Kolozsvár, Klausenburg) (RO), Baia Mare (Nagybánya, Frauenbach) (RO), Sibiu (Nagyszeben, Hemannstadt) (RO), Budapest (Ofen-Pesth) (HU), Debrecen (Debrețin, Debrezin) (HU), Pécs (Fünfkirchen) (HU), Szeged (Seghedin, Segedin) (HU), Uzhhorod (Ungvár, Ungwar) (UA), Košice (Kassa, Kaschau) (SK), and Zagreb (Zágráb, Agram) (HR) (
Figure 1). First, statistical tests were conducted to compare the main statistical parameters (mean, distributions) of the historical datasets (1871–1918) with the current data (1971–2020). Furthermore, trend analysis was performed to detect possible changes in climate over the past 150 years. In addition, daily fog observations for eight stations were analyzed (
Figure 1). It should be mentioned that the fog data were available for different time periods in the cases of these stations, as follows: Budapest (HU) 1886–1919, Pécs (HU) 1890–1916, Cluj-Napoca (RO) 1901–1916, Jimbolia (Zsombolya, Hatzfeld) (RO) 1889–1906, Sfântu Gheorghe (Sepsiszentgyörgy, Sankt Georgen) (RO) 1901–1915, Sibiu (RO) 1886–1916, Uzhhorod (UA) 1890–1916, and Zagreb (HR) 1886–1914.
In
Section 2 of the paper, the source of the historical data as well as the homogenization process used are presented.
Section 3 contains the results regarding long-term changes in temperature, precipitation, and fog events for the stations considered in the Carpathian Region. In
Section 4, we conclude our results and provide a discussion of our research state and an outlook.
2. Materials and Methods
2.1. Historical Records
In order to carry out our research, we utilized the historical instrumental climatological surface time series available in the yearbooks of RHCIMEM for the Carpathian Region [
15] for the period of 1871–1918. As the institute continuously developed the observational network—the number of stations increased from 47 stations in 1871 to 204 stations in 1911 (+1222 rain gauge)—the contents of the yearbooks therefore also extended year by year. This development decelerated because of World War I, and measurements stopped in 1919. Data after 1919 are stored in yearbooks belonging to different institutes in the Carpathian Basin countries.
In the first stage, the structure and content of the meteorological yearbooks were analyzed (
Figure S1 of Supplementary Material). Each meteorological yearbook for the period of 1871–1918 begins with a preface including very valuable metadata summarizing changes in the observation network and structure of the yearbook, instruments and calculations, and editors and other staff contributing to the yearbook. This is followed by the list of stations (name, country, county, geographical coordinates, altitude, observing hours, and name and the profession of the observer) and special notes for the stations. Monthly averages of meteorological observations are presented in the first chapter of the yearbooks (mean, maximum, and minimum air temperature (°C), atmospheric pressure (mmHg), water vapor pressure (mmHg), relative humidity (%), precipitation amount (mm), cloudiness, and windspeed (Beaufort no.) and wind direction (cardinal and intercardinal directions), supplemented with several specific observations such as soil temperature (°C), fog observations, and lightning detections. Starting from 1886, daily observations (one or three times of the days) of atmospheric pressure, air temperature, relative humidity, cloudiness, fog, wind direction and speed, and amount and type of precipitation are also presented for a number of selected stations (in total 24 stations, but different time periods from 1886 to 1918). Next, observations of geomagnetism (magnetic declination) are included, and the last chapter contains agrometeorological observations including the phenology (canopy development, blooming, and ripening) of different plants and crops.
The metadata section of the yearbooks presents a detailed description of instruments and calculations of meteorological parameters. For measurements, all the stations used 0.2 °C-scaled thermometers in shaded conditions. The instrument used for precipitation was also similar to the ones used for recent measurements (rain gauge), giving the precipitation amount in mm. The temperature was measured three times per day, usually at 7 a.m., 2 p.m., and 9 p.m. local time at that time (in few cases, the observation hours were changed e.g., 8 a.m. instead of 7 a.m.). The monthly average temperature is calculated as the arithmetic mean of these data. The monthly minimum and maximum temperature present the absolute minimum and absolute maximum values among these observations; no additional minimum and maximum temperature observations were performed. However, in addition to the daytime observations (7 a.m., 2 p.m., and 9 p.m.) the real (24 h) daily mean values are also derived. These values were calculated based on the method described by Károly Jelinek and summarized in the preface of the 1871 yearbook. First, several reference stations were denoted as having more frequent/24 h measurements (e.g., Prague, Wien, Milano, and Dej). In the case of these reference stations, from the diurnal cycle of the temperature, a C correction factor was determined as the difference between the mean of the three observations (at 7 a.m., 2 p.m., and 9 p.m.) and the 24 h mean (different for each month and time combination). At the same time, for these stations, a D correction factor was also determined representing the sum of differences between the observations of 7 a.m.–2 p.m. and 2 p.m.–9 p.m. In the case of the regional stations (having only three observations a day), a D’ correction factor could also be determined in the same way as the D correction factor in the case of the reference stations. The hourly data for regional stations were derived using Equations (1) and (2).
where C’—hourly correction factor for regional stations having only three observations a day.
Based on the data of the nearest reference stations, the ratio of C/D was given for each regional station. In order to calculate the C’ correction factor, and thus to calculate the hourly data, only the D’ correction factor (the sum of differences between the observations of 7 a.m. and 2 p.m. and 2 p.m. and 9 p.m.) should be calculated and multiplied by C/D at each regional station. Original observations (daytime) based on three measurements and derived 24 h values were both analyzed in this study.
The definition of fog in the case of historical observations is the same as that of today, i.e., it means fog is detected if the maximum horizontal visibility is less than 1 km. Fog observations were performed three times per day, generally at 7 a.m., 2 p.m., and 9 p.m. If fog was detected at least once during the day, the day was considered foggy. In this way, the number of foggy days per month was calculated and compared with recent observations. However, the different frequency of observations must be kept in mind during interpretation of the results.
In this study, 13 stations with the best temporal coverage were chosen to represent the Carpathian Region: Arad, Bistrița, Miercurea Ciuc, Cluj-Napoca, Baia Mare, Sibiu (RO); Budapest, Debrecen, Pécs, Szeged (HU); Uzhhorod (UA), Kosice (SK), and Zagreb (HR). Monthly mean (daily/24 hourly and daytime/from 3 observations), minimum and maximum temperature, and precipitation data series of these stations were digitalized manually from the yearbooks and double checked. In some cases, it was necessary to combine adjacent time series with interruptions to have a complete series: Cluj-Napoca (Cluj-Napoca City, University, and Manastur), Miercurea Ciuc (Miercurea Ciuc and Șumuleu Ciuc), and Arad (Arad City, Ceala). From the above-mentioned stations, Budapest, Cluj-Napoca, Pécs, Sibiu, Uzhhorod, and Zagreb stations had fog observations as well. Taking into account stations with available recent fog observations in Romania, historic data from two more stations (Jimbolia and Sf. Gheorghe) were also introduced. These two stations did not have a relatively long temperature and precipitation series, but their fog data series were very useful.
2.2. Data Quality Control
Data quality control of the historical time series consisted of homogeneity testing and homogenization, outlier checks, removal of respective errors, and data gap filling. For homogenization, the MASH v3.03 (Multiple Analysis of Series for Homogenization) software was used, which was formulated and developed by Szentimrey [
19,
20].
MASH is a relative and iterative homogeneity test procedure based on hypothesis testing and uses a multiple-breakpoint approach in the sense that it detects and corrects multiple break structures. Venema et al. [
23] showed that multiple-break methods generally perform better than hierarchic methods.
The MASH procedure was developed originally for homogenization of monthly series. In case of having monthly series for all the 12 months, the monthly, seasonal, and annual series can be homogenized together. In the newer versions, the daily inhomogeneities can also be derived from the monthly ones. For monthly series, the following procedure is elaborated: series comparison, breakpoint and outlier detection, correction of series, missing data complementing, automatic usage of meta data, and a verification procedure to evaluate the homogenization results.
For time series comparison, it applies multiple reference series without assuming homogeneity of the reference series. A candidate series is chosen from the set of available series, and the remaining ones are treated as potential reference series. Then, the candidate time series is compared with multiple surrounding stations in a step-by-step way, where the role of series (candidate or reference series) changes step by step. During one iterative step, several difference series are constructed from the candidate and various weighted reference series. The optimal weights are determined according to the kriging interpolation formula that minimizes the variance of the difference series. Provided that the candidate series is the only one with a break in common with all the difference series, these break points can be attributed to the candidate series. Each series is considered the candidate series, and difference series between this candidate and the weighted reference series are used to identify inhomogeneity location, confidence intervals, and magnitudes. The difference between the average in the reference series and the candidate series gives the inhomogeneity magnitude. These series are then compared and adjusted in an iterative process until no more inhomogeneities are found. Depending on the distribution of examined meteorological elements, additive (e.g., temperature) or multiplicative (e.g., precipitation) models can be applied. Meta data (probable dates of break points) can be used automatically but are optional. The outlier detection and missing value completion based on kriging interpolation are also part of the procedure. In general, the fewer the gaps, the easier to find breakpoints, determine inhomogeneities, fill the gaps, and perform quality control. In MASH, it is recommended to start with missing data of less than 33%. On the other hand, it is not recommended to have missing data from a large area at the same time period. After the automated process, raw datasets are manually compared with the homogenized ones, analyzing break points and checking gap filling.
The MASH algorithm has been applied to several regional datasets [
9,
10,
16,
24,
25]. The method seems to be one of the most comprehensive procedures for homogenization [
26,
27]. A comprehensive assessment of the homogenization techniques for climate series was included in the scientific program of the COST Action HOME ES 0601 Advances in Homogenization Methods of Climate series: An integrated approach. Relying on the HOME blind test experiments, MASH is considered one out of the best three methods [
23]. MASH is also recommended by the World Meteorological Organization, which considers it an excellent statistical homogenization package [
28].
In general, homogenization greatly improved the quality of time series by reducing the regional variability and improving both the temporal and spatial coherence. Izsak et al. [
29] show a great improvement of timeseries after the MASH homogenization process for 25 stations over Hungary. In the case of temperature, homogenized data series show a significant increase for each series, while in the case of a quarter of the raw data series no change can be detected. The average difference between the homogenized and raw trend is generally 0.3 C (1901–2018). The greatest differences can be seen in the cities, where homogenization with MASH gave the highest value of inhomogeneities. Thanks to the mathematical model, using the MASH software, it is possible to detect climate change in the homogenized dataset [
20,
23,
26,
30].
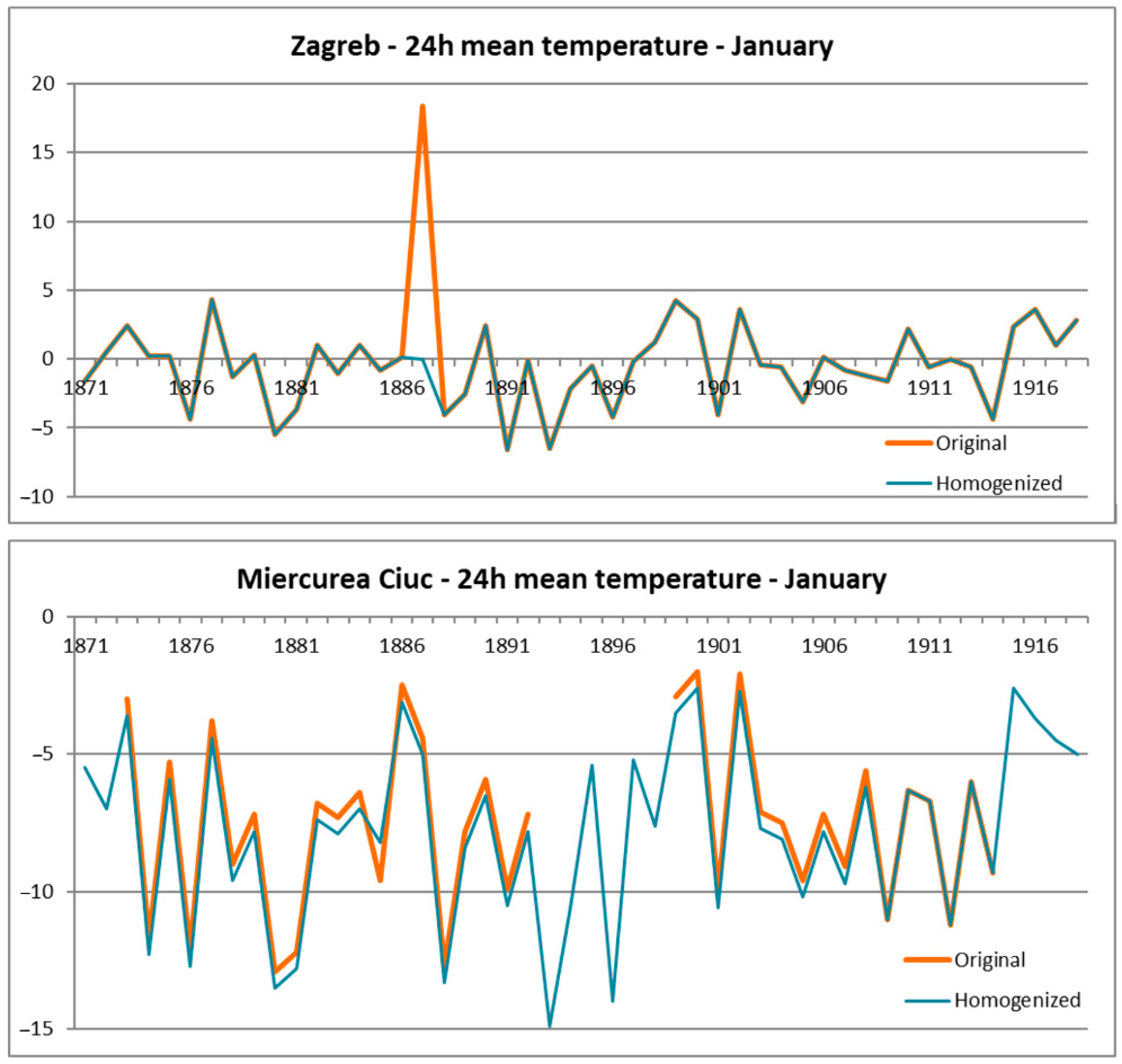
Figure 2 presents the monthly data series for January before and after homogenization for Zagreb (upper) and Miercurea Ciuc (bottom). Zagreb presents one of the most complete historical datasets (completeness 99.1%), while the dataset from Miercurea Ciuc has the most gaps (completeness 70.7%). In the case of Zagreb, we had an outlier in 1887 (a typo during the digitalization process) removed by the MASH homogenization process. In the case of the time series from Miercurea Ciuc, the MASH process filled the data gaps and detected two break points (1885 and 1908). The second break point could be connected to the relocation of the station from Șumuleu (Csíksomlyó) to Miercurea Ciuc (Csíkszereda) in 1910. The distance between the two stations was approximately 2.5 km. After this year. no systematic difference (about 0.6 °C) between raw and homogenized is present.
The most important verification statistics (homogeneity test statistics before and after the homogenization, relative modification of series, and representativity of stations network) are presented in
Table S1. The spatial means show an improvement after the MASH homogenization process (e.g., excepting May, all the test statistics become less then the critical value). To analyze the spatial coherence, temperature and precipitation anomalies (reference period 1871–1901) of the historical series are also calculated before and after the homogenization process (
Figure S2). In the case of temperature, no significant improvement is detected; however, in the case of precipitation, the spatial coherence obviously increased after homogenization in all seasons.
2.3. Recent Data
High-quality hourly temperature and seasonal precipitation datasets for the period 1970–2020 were provided by the Romanian National Meteorological Administration (ANM—Administrația Națională de Meteorologie) for the six stations in Romania (Arad, Bistrița, Miercurea Ciuc, Cluj-Napoca, Baia Mare, and Sibiu). Current fog datasets (number of foggy days per month) were also provided by the ANM for the period 1990–2020 for four Romanian stations (Cluj-Napoca, Jimbolia, Sfântu Gheorghe, and Sibiu). For the stations of Budapest, Debrecen, Pécs, Szeged, Uzhhorod, Kosice, and Zagreb, daily mean temperature and precipitation series were downloaded from the European Climate Assessment & Dataset (ECA&D) [
5].
4. Conclusions and Discussion
In order to achieve a better understanding of regional climate and deliver relevant climate data, this study aimed to create the longest climate dataset ever in the Carpathian Region. It combines climate records back to 1871 with current data till 2020 (spanning a period of 150 years).
The first part of the investigation consisted of systematizing and digitalizing the records available for the region from the meteorological yearbooks of RHCIMEM. Since the content of the yearbooks was not fully investigated, several unexpected questions popped up during the working process. Several general concepts were predefined in terms of station selection, as follows: the best possible extension back to the early instrumental period (longest data series); the best possible spatial coverage (including stations having gaps in the time series); and the best possible treatment of data quality (homogeneity breaks, outliers, and gaps). In this way, we selected 13 stations over the Carpathian Region to assess the characteristics of temperature and precipitation and 8 stations for analyzing changes in foggy events. Based on our work on historical instrumental datasets, we found that the quality and homogeneity of the data were major problems that required unique solutions and lots of work.
Next, a comprehensive comparison between the periods of 1871–1918 and 1971–2020 based on statistical tests and trend analysis was performed utilizing the temperature and precipitation time series. It was conducted to elaborate the main features of the region in terms of climate change. In the case of the observed 24 h temperature, the last five decades (1971–2020) were 0.77 °C warmer than the 1871–1918 period. The strongest warming was detected during wintertime (1.29 °C). However, this rate of warming was exceeded by daytime warming, showing a 1.1 °C change in the annual mean temperature between the historical and recent periods. Along with that, shifts in distributions towards high values were also detected in a majority of the cases. Looking at the significant warming trends, in the few cases of the fastest-growing cities in the historical period (Cluj-Napoca, Budapest, and Pécs), the general warming during the cold season could be considered an urban effect. On the contrary, the period of 1970–2020 shows significant warming trends in the case of all stations in the Carpathian Region. Furthermore, the period of 1971–2020 presents significant increasing trends in summertime minimum temperature and significant increasing trends for all seasons in the case of maximum temperature.
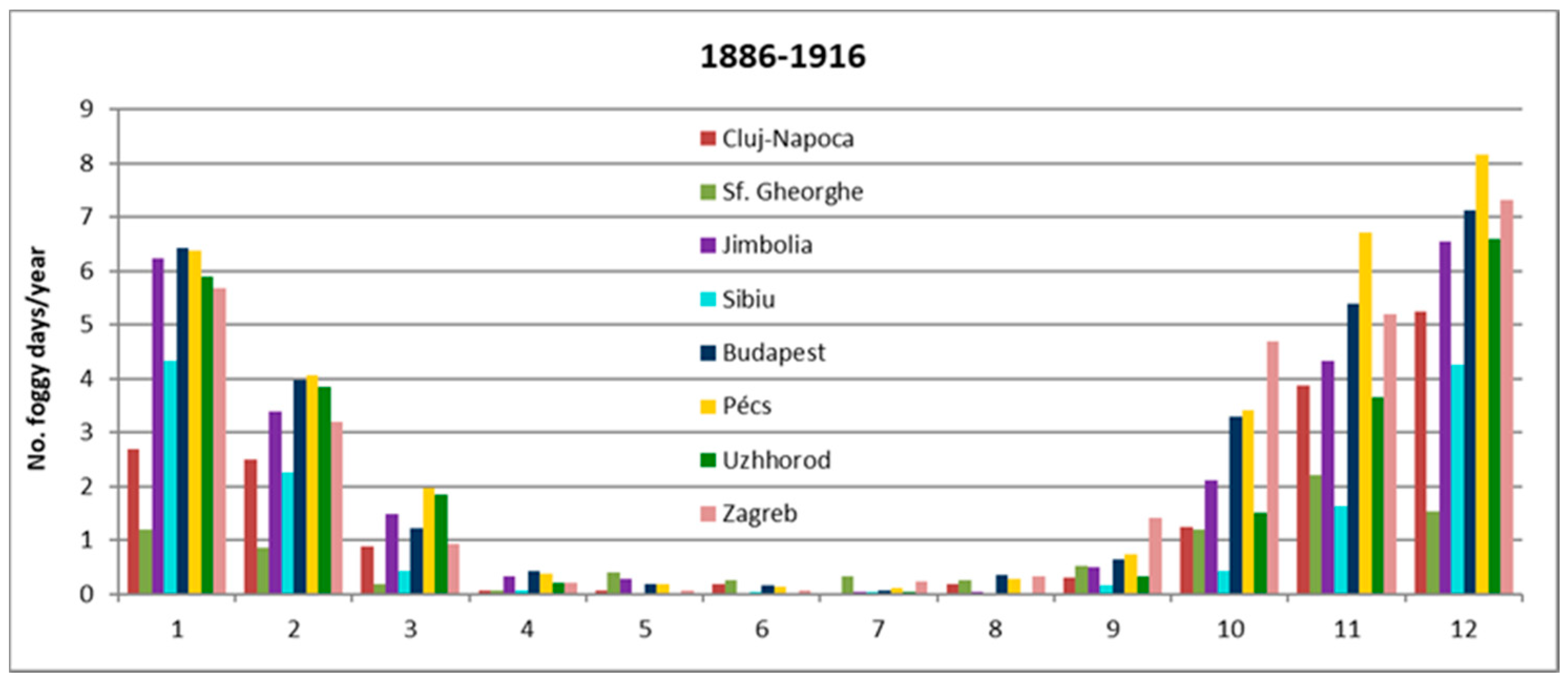
The seasonal changes in the amount of precipitation (%) in the last 150 years were also investigated. We detected significant differences in spring and autumn (less precipitation in the recent period). At three stations, the trends indicate an increase in precipitation during wintertime in the recent period. Based on long-term fog observations, higher frequency in foggy events is detected in the recent period for the Transylvania Region. On an annual scale, in the last three decades (1990–2020), the number of foggy days increased by 16.2 as compared with the 1886–1916 period.
In this study, we aimed at comparing the main climate features of historical (1871–1918) and present (1970–2020) periods and found significant differences between the two time periods. Even if some local trends were detected in the historical period (e.g., Cluj-Napoca), significant changes are much more characteristic in the recent period for all stations in the region, which indicates a large-scale climate change in the last few decades. It should be mentioned that the homogenization technique was applied to the historical data (1871–1918). Since no continuous data series starting from 1871 till the recent period are available for all the stations considered in the study, the historical period was compared with the sub-period of 1971–2020.
However, using the same MASH method, Izsak. et al. [
16] homogenized daily mean temperature and precipitation time series of 11 Hungarian stations for the whole period 1871–2020. As a result, the longest continuous homogenized daily datasets became available for Hungary (available at
https://www.met.hu/omsz/tevekenysegek/adattar/, accessed on 26 July 2022). There are two stations in common with our study (Budapest and Szeged). In order to justify our results, a comparison of the temperature trends calculated from Izsak et al.`s series and our series is presented in
Table 7. The results are very similar: the RMSE between the trends obtained from the series obtained by the different MASH homogenization processes is 0.09; furthermore, in more than 90% of the cases, the differences are situated inside the confidence interval of the Sen’s slope.
Even if several historical datasets are available for the region [
17,
32,
33], since they used different sources and timeframes, direct comparison with our results is not applicable.
The novelty of this study consists in processing the historical data from the yearbooks of RHCIMEM spanning the 48-year period of 1871–1918. We presented the initial steps of the database construction, as well as the first results of analyzing the temperature, precipitation, and fog measurements in the Carpathian Region. Digitization of the yearbooks with a uniform structure, quality assessments, and the creation and processing of historical climate data series are the tasks for the future.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}