
Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method



Abstract
:1. Introduction
2. Materials and Methods
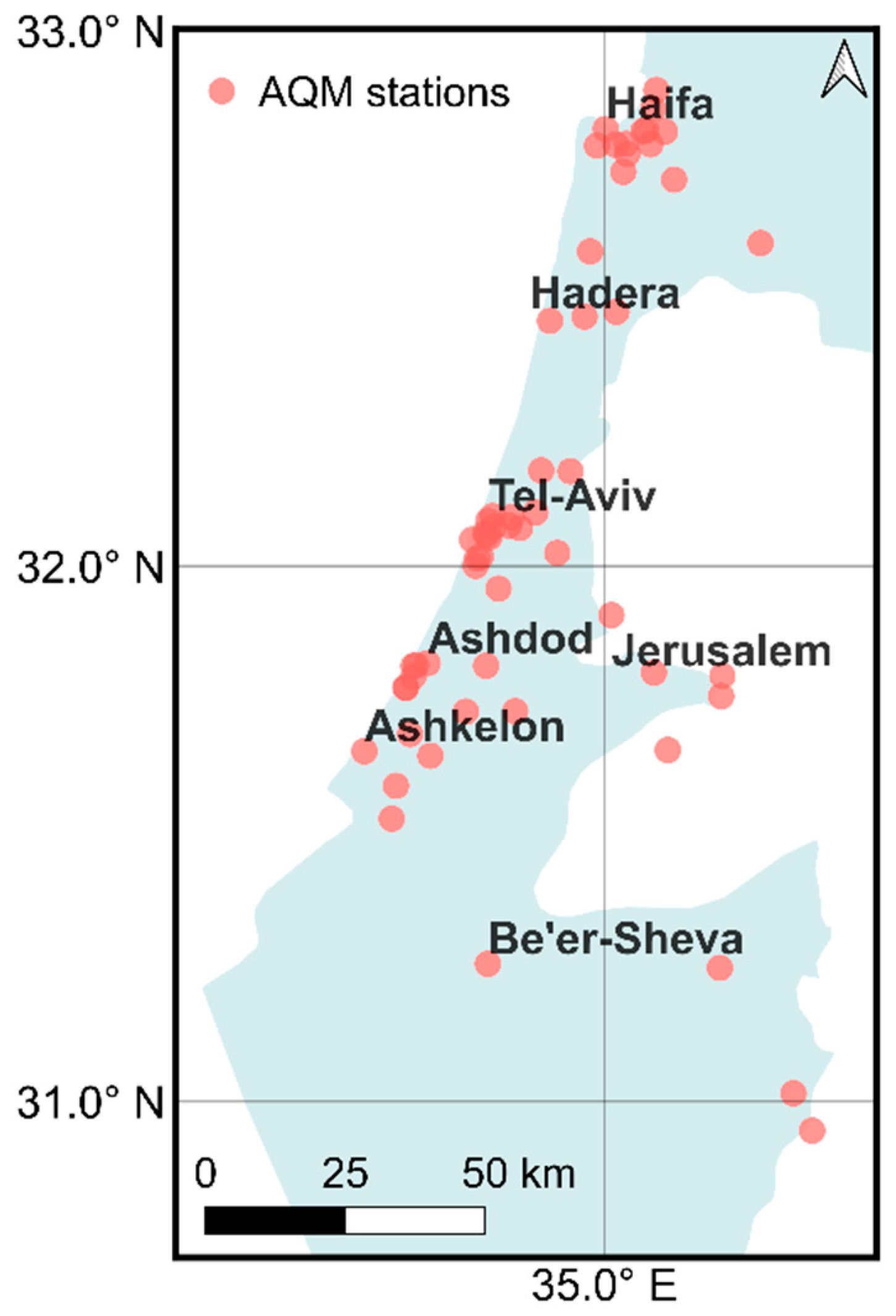
2.1. Study Area and Data
2.2. Missing-Data Characteristics
2.3. Workflow
- (i)
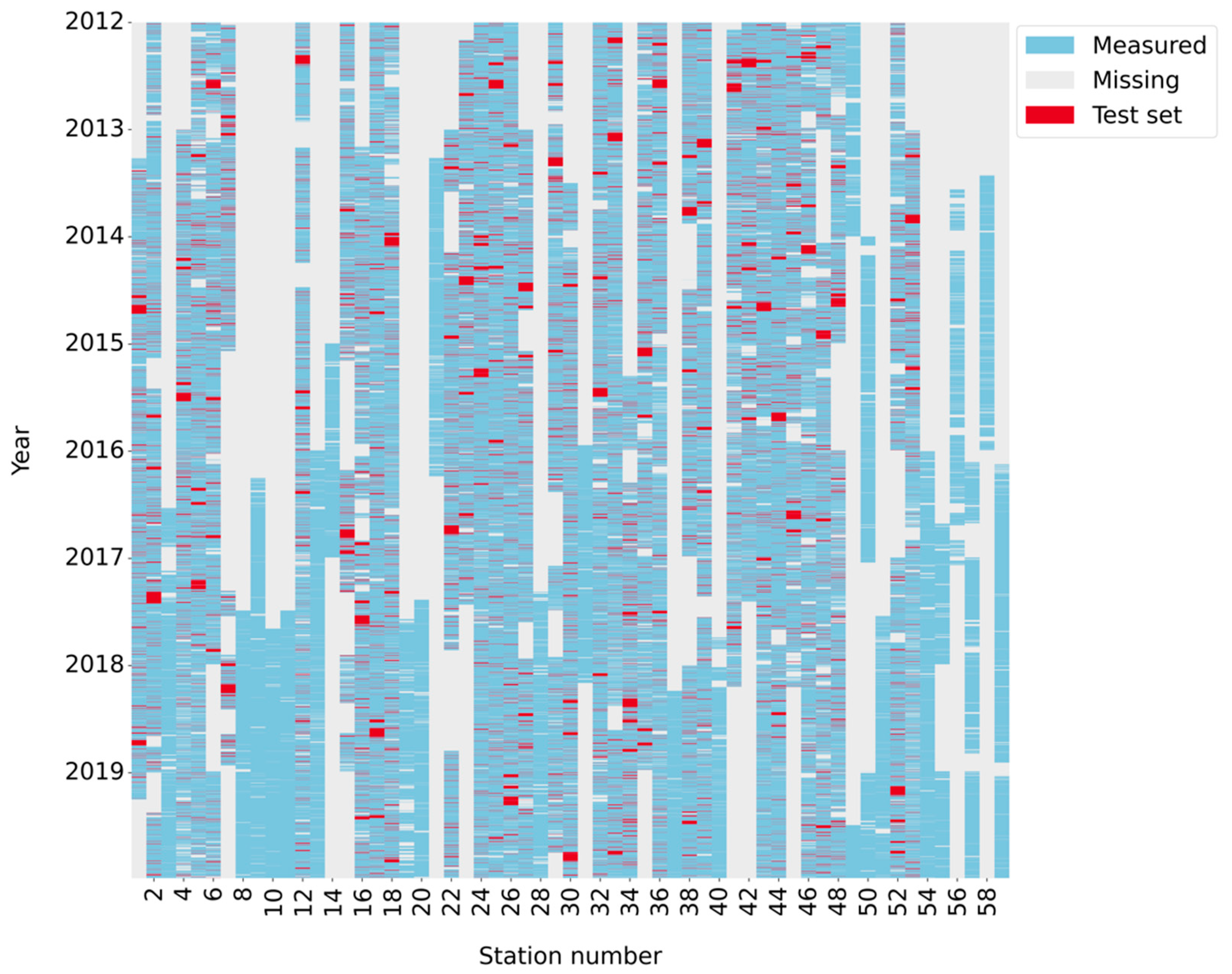
- Setting aside a test set for the imputation models’ performance evaluation. For each AQM station, this set included N randomly sampled chunks of observations of length L, denoted hereafter “time-windows” (N L: 720 0.5 h, 360 1 h, 180 2 h, 120 3 h, 120 6 h, 30 24 h (1 d), 20 36 h, 10 72 h, 3 240 h (10 d), and 1 720 h (30 d, i.e., 1 m)), that were artificially designated as missing (marked in red in Figure 2). The artificially removed data intervals were categorized into four categories: very short (0.5 h, 1 h, 2 h, 3 h), short (6 h, 24 h), medium-length (36 h, 72 h), and long (10 d, 30 d). Overall, in each of the 36 AQM stations with accumulated missing observations ≤4 years (marked in bold in Table S1 in the Supplementary Materials), 11,520 time points (half hours) served as the test set, corresponding on average to 11% (9–17%) of the non-missing observations.
- (ii)
- Tuning the models’ hyperparameters using a cross-validation (CV) procedure with repeated random sub-sampling of the training set (marked in blue in Figure 2). In each iteration, a sub-sample of the training set was designated as missing and served as a validation set against which the model performance was examined for different hyperparameters. The tuning of the hyperparameters was conducted separately for the very short, short, medium-length, and long time-window categories of the artificial missing data. Each of these category-based sub-samples accounted for 12% (9–20%) of the training set.

- (iii)
- Building the imputation models using the training set and the models’ optimal hyperparameters.
- (iv)
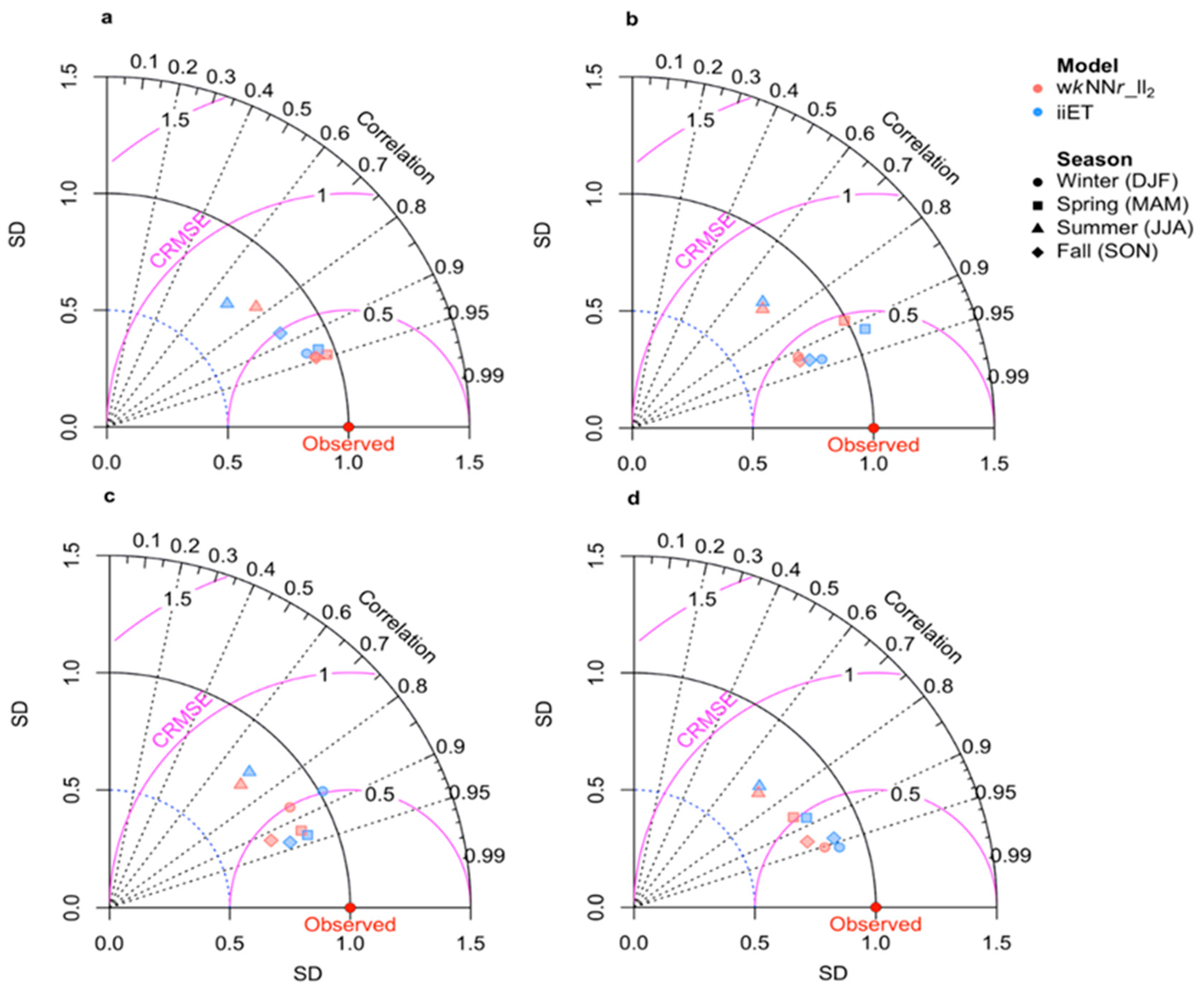
- Evaluation of the performance of the imputation models on the test sets for each of the 36 AQM stations and for the four categories of missing-data interval length (very short, short, medium-length, and long). The following metrics were used for evaluating the models’ performance (see Table S2 in the Supplementary Materials): normalized root mean squared error (NRMSE), coefficient of determination (R2), and normalized mean absolute error (NMAE). The normalization of the metrics was required to enable comparison across missing-data interval lengths, seasons, and geographic regions (i.e., different AQM stations). We compared the imputation performance of the different models using the non-parametric Kruskal-Wallis one-way analysis of variance, followed by the Conover-Iman post-hoc test [42]. Furthermore, we examined how the model performance varied among seasons by means of Taylor diagrams [43].
- (v)
- Finally, a test-case of a very long (2 years) missing-data interval was examined, to inspect the ability of the models to handle large missing-data intervals. For this, we randomly removed two years of records (i.e., a sequence of 35,040 time points) from 25 AQM stations (one at a time) that had less than two years of accumulated missing observations. For each of these AQM stations, we ran the imputation models with the optimal hyperparameters found for the long (7 d< L ≤ 30 d) missing-data time-window (Tables S3 and S4 in the Supplementary Materials).
2.4. Model Description
2.4.1. Multivariate Weighted-kNN Imputation Using Correlations (wkNNr)
2.4.2. Multivariate Iterative Imputation with Extra Trees (iiET)
2.5. Accounting for Adjacent Lagging and Leading Observations
3. Results
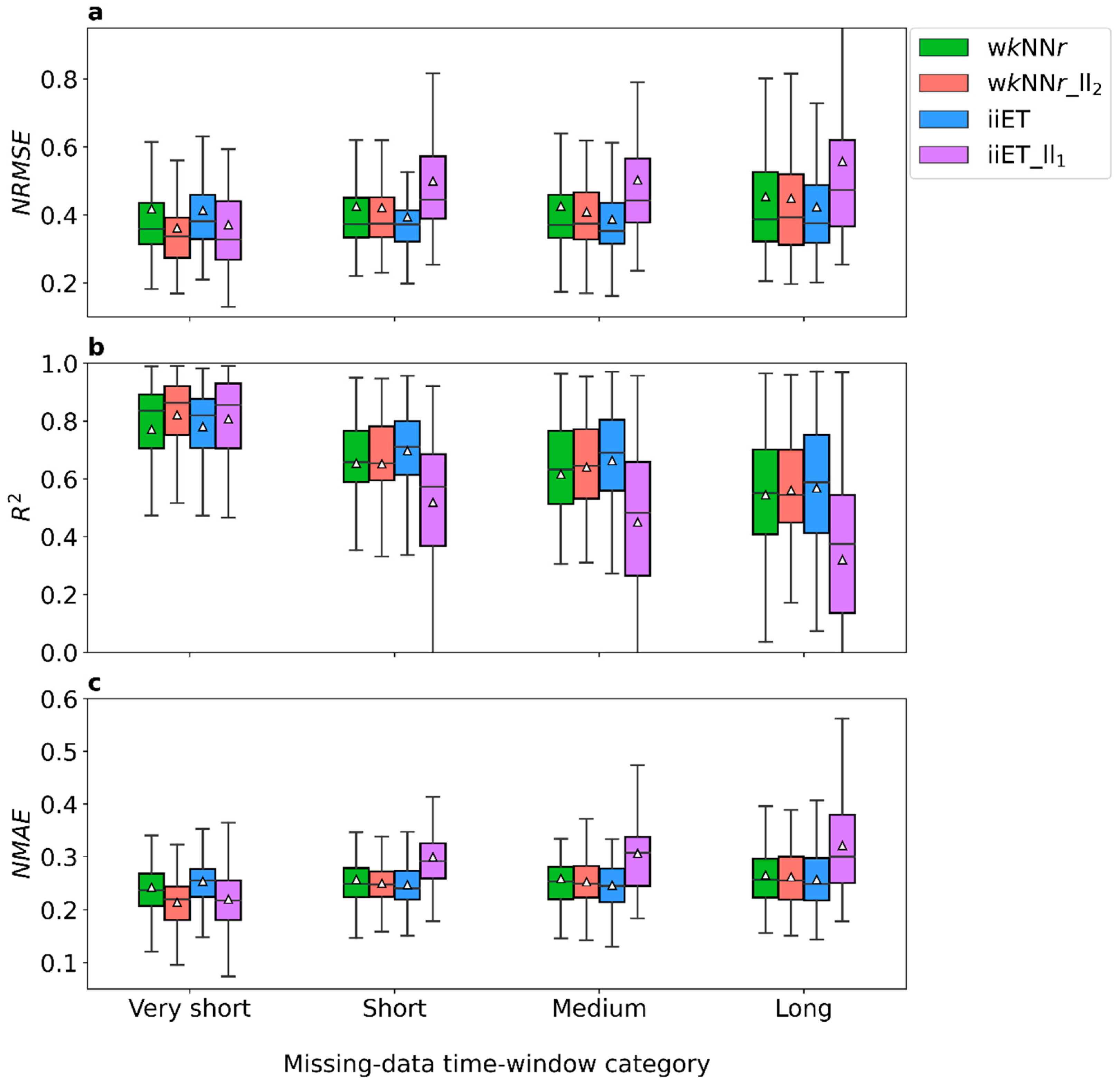
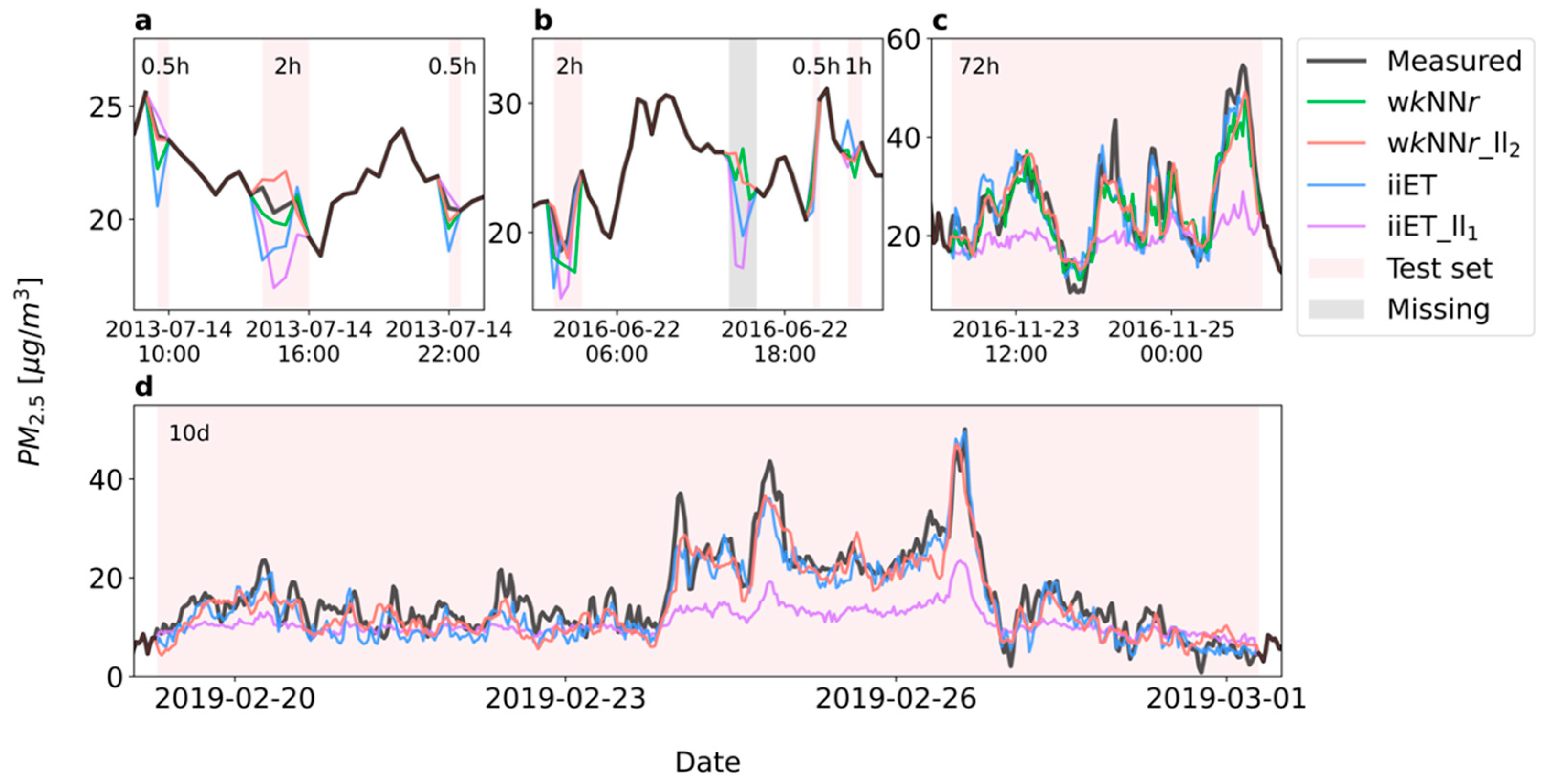
3.1. Model Performance for Different Missing-Data Time-Window Lengths


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Model | NRMSE | R2 | NMAE |
|---|---|---|---|---|
| Very short | wkNNr | 0.42 (0.22) | 0.77 (0.19) | 0.24 (0.06) |
| wkNNr_ll2 | 0.36 (0.16) | 0.82 (0.13) | 0.21 (0.05) | |
| iiET | 0.41 (0.17) | 0.78 (0.14) | 0.25 (0.05) | |
| iiET_ll1 | 0.37 (0.21) | 0.81 (0.16) | 0.22 (0.07) | |
| p value a | <0.001 | 0.004 | <0.001 | |
| Significant differences b | 1, 4, 5, 6 | 1, 4, 5, 6 | 1, 3, 4, 5, 6 | |
| Short | wkNNr | 0.43 (0.17) | 0.65 (0.18) | 0.26 (0.06) |
| wkNNr_ll2 | 0.42 (0.16) | 0.65 (0.24) | 0.25 (0.04) | |
| iiET | 0.39 (0.13) | 0.70 (0.15) | 0.25 (0.04) | |
| iiET_ll1 | 0.50 (0.16) | 0.52 (0.25) | 0.30 (0.06) | |
| p value a | <0.001 | <0.001 | <0.001 | |
| Significant differences b | 2, 4, 5 | 2, 4, 5 | 2, 4, 5 | |
| Medium length | wkNNr | 0.43 (0.20) | 0.62 (0.21) | 0.26 (0.07) |
| wkNNr_ll2 | 0.41 (0.15) | 0.64 (0.18) | 0.25 (0.05) | |
| iiET | 0.39 (0.15) | 0.66 (0.21) | 0.25 (0.06) | |
| iiET_ll1 | 0.50 (0.20) | 0.45 (0.28) | 0.31 (0.07) | |
| p value a | <0.001 | <0.001 | <0.001 | |
| Significant differences b | 2, 4, 5 | 2, 4, 5 | 2, 4, 5 | |
| Long | wkNNr | 0.45 (0.21) | 0.55 (0.22) | 0.27 (0.07) |
| wkNNr_ll2 | 0.45 (0.20) | 0.56 (0.21) | 0.26 (0.06) | |
| iiET | 0.42 (0.17) | 0.57 (0.23) | 0.26 (0.06) | |
| iiET_ll1 | 0.56 (0.29) | 0.32 (0.37) | 0.32 (0.09) | |
| p value a | <0.001 | <0.001 | <0.001 | |
| Significant differences b | 2, 4, 5 | 2, 4, 5 | 2, 4, 5 | |


3.2. A Test-Case of a Very Long Missing-Data Time-Window
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bräuner, E.V.; Forchhammer, L.; Møller, P.; Simonsen, J.; Glasius, M.; Wåhlin, P.; Raaschou-nielsen, O.; Loft, S. Exposure to ultrafine particles from ambient air and oxidative stress–induced DNA damage. Environ. Health Perspect. 2007, 115, 1177–1182. [Google Scholar] [CrossRef]
- Grahame, T.J.; Klemm, R.; Schlesinger, R.B. Public health and components of particulate matter: The changing assessment of black carbon. J. Air Waste Manag. Assoc. 2014, 64, 620–660. [Google Scholar] [CrossRef] [PubMed]
- Janssen, N.A.H.; Hoek, G.; Simic-Lawson, M.; Fischer, P.; van Bree, L.; Brink, H.; Keuken, M.; Atkinson, R.W.; Anderson, R.; Brunekreef, B.; et al. Black carbon as an additional indicator of the adverse health effects of airborne particles compared with PM10 and PM2.5. Environ. Health Perspect. 2011, 119, 1691–1699. [Google Scholar] [CrossRef] [Green Version]
- Krall, J.R.; Strickland, M.J. Recent approaches to estimate associations between source-specific air pollution and health. Curr. Environ. Health Rep. 2017, 4, 68–78. [Google Scholar] [CrossRef]
- de Prado Bert, P.; Mercader, E.M.H.; Pujol, J.; Sunyer, J.; Mortamais, M. The effects of air pollution on the brain: A review of studies interfacing environmental epidemiology and neuroimaging. Curr. Environ. Health Rep. 2018, 5, 351–364. [Google Scholar] [CrossRef] [Green Version]
- Sarnat, S.E.; Winquist, A.; Schauer, J.J.; Turner, J.R.; Sarnat, J.A. Fine particulate matter components and emergency department visits for cardiovascular and respiratory diseases in the St. Louis, Missouri–Illinois, metropolitan area. Environ. Health Perspect. 2015, 123, 437–444. [Google Scholar] [CrossRef] [Green Version]
- WHO. Ambient Air Pollution: Health Impacts. 2018. Available online: https://www.who.int/airpollution/ambient/health-impacts/en/ (accessed on 10 May 2020).
- Moritz, S.; Sardá, A.; Bartz-Beielstein, T.; Zaefferer, M.; Stork, J. Comparison of different methods for univariate time series imputation in R. arXiv 2015, arXiv:1510.03924. [Google Scholar]
- Ottosen, T.B.; Kumar, P. Outlier detection and gap filling methodologies for low-cost air quality measurements. Environ. Sci. Process. Impacts 2019, 21, 701–713. [Google Scholar] [CrossRef]
- Moshenberg, S.; Lerner, U.; Fishbain, B. Spectral methods for imputation of missing air quality data. Environ. Syst. Res. 2015, 4, 26. [Google Scholar] [CrossRef] [Green Version]
- Williams, D.A.; Nelsen, B.; Berrett, C.; Williams, G.P.; Moon, T.K. A comparison of data imputation methods using Bayesian compressive sensing and Empirical Mode Decomposition for environmental temperature data. Environ. Model. Softw. 2018, 102, 172–184. [Google Scholar] [CrossRef]
- Dabrowski, J.J.; Rahman, A. Sequence-to-sequence imputation of missing sensor data. In Proceedings of the Australasian Joint Conference on Artificial Intelligence—AI 2019: Advances in Artificial Intelligence, Adelaide, Australia, 2–5 December 2019; pp. 265–276. [Google Scholar] [CrossRef]
- Hamami, F.; Dahlan, I.A. Univariate time series data forecasting of air pollution using LSTM neural network. In Proceedings of the International Conference on Advancement in Data Science, E-Learning and Information Systems, ICADEIS, Lombok, Indonesia, 20–21 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Evans, S.W.; Jones, N.L.; Williams, G.P.; Ames, D.P.; Nelson, E.J. Groundwater level mapping tool: An open source web application for assessing groundwater sustainability. Environ. Model. Softw. 2020, 131, 104782. [Google Scholar] [CrossRef]
- Plaia, A.; Bondì, A. Regression imputation for space-time datasets with missing values. In Data Analysis and Classification; Springer: Berlin/Heidelberg, Germany, 2010; pp. 465–472. [Google Scholar] [CrossRef]
- Shahbazi, H.; Karimi, S.; Hosseini, V.; Yazgi, D.; Torbatian, S. A novel regression imputation framework for Tehran air pollution monitoring network using outputs from WRF and CAMx models. Atmos. Environ. 2018, 187, 24–33. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory analysis, nonparametric discrimination: Consistency properties. Int. Stat. Rev. 1951, 57, 238–247. [Google Scholar] [CrossRef]
- Hudak, A.T.; Crookston, N.L.; Evans, J.S.; Hall, D.E.; Falkowski, M.J. Nearest neighbor imputation of species-level, plot-scale forest structure attributes from LiDAR data. Remote Sens. Environ. 2008, 112, 2232–2245. [Google Scholar] [CrossRef] [Green Version]
- Poyatos, R.; Sus, O.; Badiella, L.; Mencuccini, M.; Martínez-Vilalta, J. Gap-filling a spatially explicit plant trait database: Comparing imputation methods and different levels of environmental information. Biogeosciences 2018, 15, 2601–2617. [Google Scholar] [CrossRef] [Green Version]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [Green Version]
- Pan, L.; Li, J. k-Nearest Neighbor based missing data estimation algorithm in wireless sensor networks. Wirel. Sens. Netw. 2010, 2, 115–122. [Google Scholar] [CrossRef]
- Feng, L.; Nowak, G.; Neill, T.J.O.; Welsh, A.H. CUTOFF: A spatio-temporal imputation method. J. Hydrol. 2014, 519, 3591–3605. [Google Scholar] [CrossRef]
- Brás, L.P.; Menezes, J.C. Improving cluster-based missing value estimation of DNA microarray data. Biomol. Eng. 2007, 24, 273–282. [Google Scholar] [CrossRef]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Requia, W.J.; Jhun, I.; Coull, B.A.; Koutrakis, P. Climate impact on ambient PM2.5 elemental concentration in the United States: A trend analysis over the last 30 years. Environ. Int. 2019, 131, 104888. [Google Scholar] [CrossRef] [PubMed]
- Salvador, P.; Pandolfi, M.; Tobías, A.; Gómez-Moreno, F.J.; Molero, F.; Barreiro, M.; Pérez, N.; Revuelta, M.A.; Marco, I.M.; Querol, X.; et al. Impact of mixing layer height variations on air pollutant concentrations and health in a European urban area: Madrid (Spain), a case study. Environ. Sci. Pollut. Res. 2020, 27, 41702–41716. [Google Scholar] [CrossRef] [PubMed]
- Sofowote, U.M.; Healy, R.M.; Su, Y.; Debosz, J.; Noble, M.; Munoz, A.; Jeong, C.H.; Wang, J.M.; Hilker, N.; Evans, G.J.; et al. Sources, variability and parameterizations of intra-city factors obtained from dispersion-normalized multi-time resolution factor analyses of PM2.5 in an urban environment. Sci. Total Environ. 2021, 761, 143225. [Google Scholar] [CrossRef]
- Yuval Tritscher, T.; Raz, R.; Levi, Y.; Levy, I.; Broday, D.M. Emissions vs. turbulence and atmospheric stability: A study of their relative importance in determining air pollutant concentrations. Sci. Total Environ. 2020, 733, 139300. [Google Scholar] [CrossRef]
- Arroyo, Á.; Herrero, Á.; Tricio, V.; Corchado, E.; Wo, M.B. Neural models for imputation of missing ozone data in air-quality datasets. Complexity 2018, 2018, 7238015. [Google Scholar] [CrossRef] [Green Version]
- Brown, R.J.C.; Brown, A.S.; Kim, K.H. A temperature-based approach to predicting lost data from highly seasonal pollutant data sets. Environ. Sci. Process. Impacts 2013, 15, 1256–1263. [Google Scholar] [CrossRef]
- Chen, M.; Zhu, H.; Chen, Y.; Wang, Y. A Novel Missing Data Imputation Approach for Time Series Air Quality Data Based on Logistic Regression. Atmosphere 2022, 13, 1044. [Google Scholar] [CrossRef]
- Şahin, Ü.A.; Bayat, C.; Uçan, O.N. Application of cellular neural network (CNN) to the prediction of missing air pollutant data. Atmos. Res. 2011, 101, 314–326. [Google Scholar] [CrossRef]
- Dayan, U.; Ricaud, P.; Zbinden, R.; Dulac, F. Atmospheric pollution over the eastern Mediterranean during summer—A review. Atmos. Chem. Phys. 2017, 17, 13233–13263. [Google Scholar] [CrossRef] [Green Version]
- Dayan, U.; Levy, I. The influence of meteorological conditions and atmospheric circulation types on PM10 and visibility in Tel Aviv. J. Appl. Meteorol. 2005, 44, 606–619. [Google Scholar] [CrossRef]
- Erel, Y.; Kalderon-Asael, B.; Dayan, U.; Sandler, A. European atmospheric pollution imported by cooler air masses to the Eastern Mediterranean during the summer. Environ. Sci. Technol. 2007, 41, 5198–5203. [Google Scholar] [CrossRef] [PubMed]
- Yuval; Sorek-Hamer, M.; Stupp, A.; Alpert, P.; Broday, D.M. Characteristics of the east Mediterranean dust variability on small spatial and temporal scales. Atmos. Environ. 2015, 120, 51–60. [Google Scholar] [CrossRef]
- Yuval; Levi, Y.; Dayan, U.; Levy, I.; Broday, D.M. On the association between characteristics of the atmospheric boundary layer and air pollution concentrations. Atmos. Res. 2020, 231, 104675. [Google Scholar] [CrossRef]
- Greenland, S.; Finkle, W.D. A critical look at methods for handling missing covariates in epidemiologic regression analyses. Am. J. Epidemiol. 1995, 142, 1255–1264. [Google Scholar] [CrossRef] [PubMed]
- Junger, W.L.; Leon, A.P. Imputation of missing data in time series for air pollutants. Atmos. Environ. 2015, 102, 96–104. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Conover, W.; Iman, R. On Multiple-comparisons procedures. In Technical Report LA-7677-MS; Los Alamos Scientific Laboratory: Los Alamos, NM, USA, 1979. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Weiss, R.; Brucher, M. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Alkabbani, H.; Ramadan, A.; Zhu, Q.; Elkamel, A. An Improved Air Quality Index Machine Learning-Based Forecasting with Multivariate Data Imputation Approach. Atmosphere 2022, 13, 1144. [Google Scholar] [CrossRef]
- Alsaber, A.R.; Pan, J.; Al-Hurban, A. Handling complex missing data using random forest approach for an air quality monitoring dataset: A case study of kuwait environmental data (2012 to 2018). Int. J. Environ. Res. Public Health 2021, 18, 1333. [Google Scholar] [CrossRef] [PubMed]
- Ghorbani, S.; Desmarais, M.C. Performance comparison of recent imputation methods for classification tasks over binary data. Appl. Artif. Intell. 2017, 31, 1–22. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- van Buuren, S.; Groothuis-Oudshoorn, K. MICE: Multivariate imputation by chained equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Ko, W.; Kim, J. Analysis and impact evaluation of missing data imputation in day-ahead PV generation forecasting. Appl. Sci. 2019, 9, 204. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 24th International Conference on Neural Information Processing Systems (Advances in Neural Information Processing Systems), Vancouver, BC, Canada, 6–9 December 2010; pp. 2546–2554. [Google Scholar]


| Length of Missing Data Interval (L) | Length Category | Fraction of Missing Data Intervals out of the Total Number of Missing Intervals (%) | Fraction of Missing Observations out of the Total Number of Missing Observations (%) |
|---|---|---|---|
| L ≤ 3 h | very short | 92.88 | 7.44 |
| 3 h < L ≤ 24 h | short | 5.32 | 4.33 |
| 24 h < L ≤ 7 d | medium length | 1.45 | 9.01 |
| 7 d < L ≤ 30 d | long | 0.22 | 7.20 |
| 30 d < L ≤ 2 y | very long | 0.12 | 53.91 |
| 2 y < L ≤ 4 y | extremely long | 0.01 | 18.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belachsen, I.; Broday, D.M. Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method. Atmosphere 2022, 13, 1934. https://doi.org/10.3390/atmos13111934
Belachsen I, Broday DM. Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method. Atmosphere. 2022; 13(11):1934. https://doi.org/10.3390/atmos13111934
Chicago/Turabian StyleBelachsen, Idit, and David M. Broday. 2022. "Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method" Atmosphere 13, no. 11: 1934. https://doi.org/10.3390/atmos13111934
APA StyleBelachsen, I., & Broday, D. M. (2022). Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method. Atmosphere, 13(11), 1934. https://doi.org/10.3390/atmos13111934