



Application of New Modified Genetic Algorithm in Inverse Calculation of Strong Source Location


Abstract
:1. Introduction
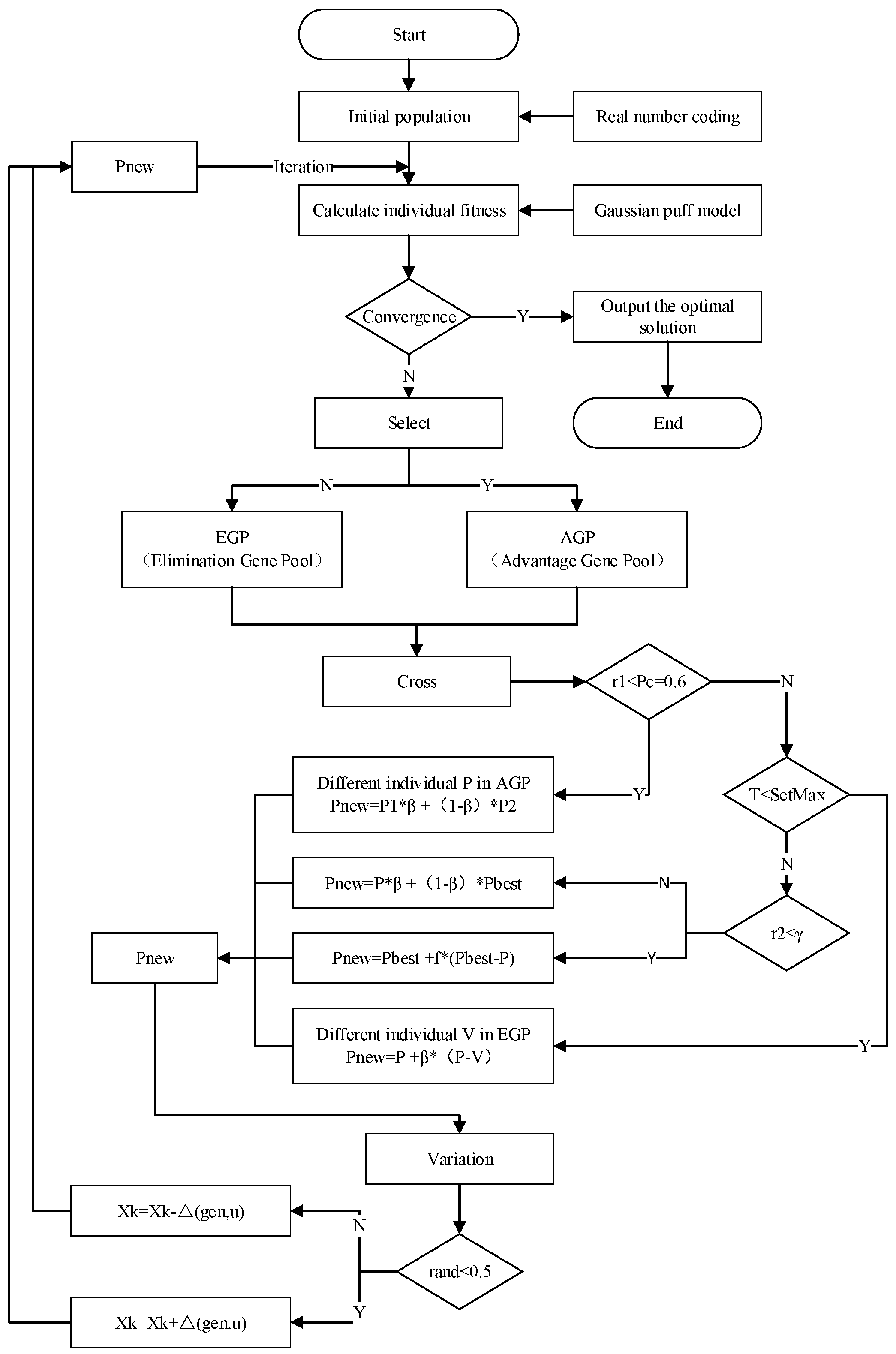
2. Improved Design of the Genetic Algorithm
2.1. Initial Population Generation
2.2. Selection Operation
2.3. Improvement of Crossover Operator
2.4. Mutation Operator
2.5. Improvement of Crossover Rate and Mutation Rate
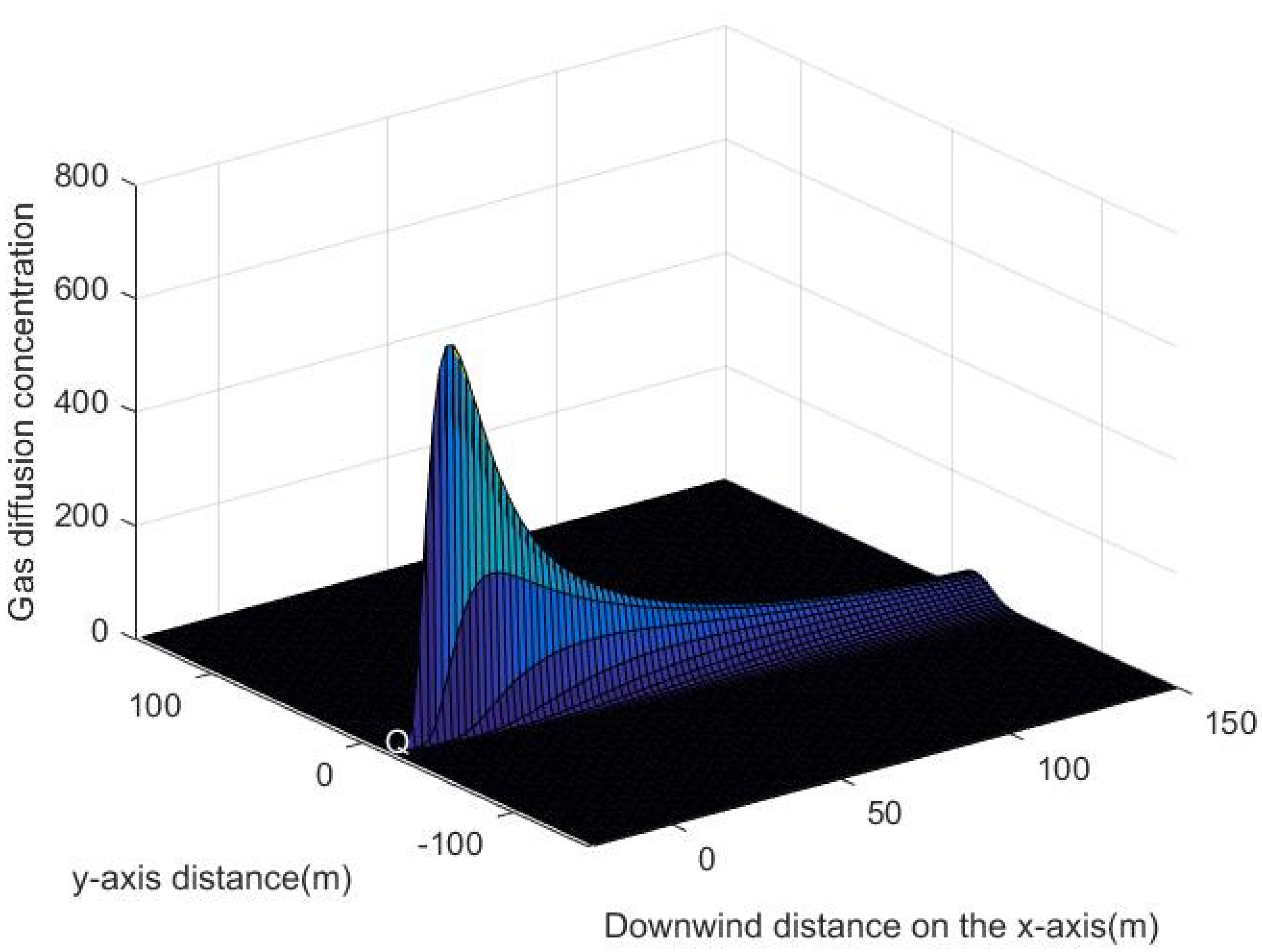
3. Simulation of Continuous Leakage of Single-Point Gas Source in 3D Space
4. Case Application and Analysis
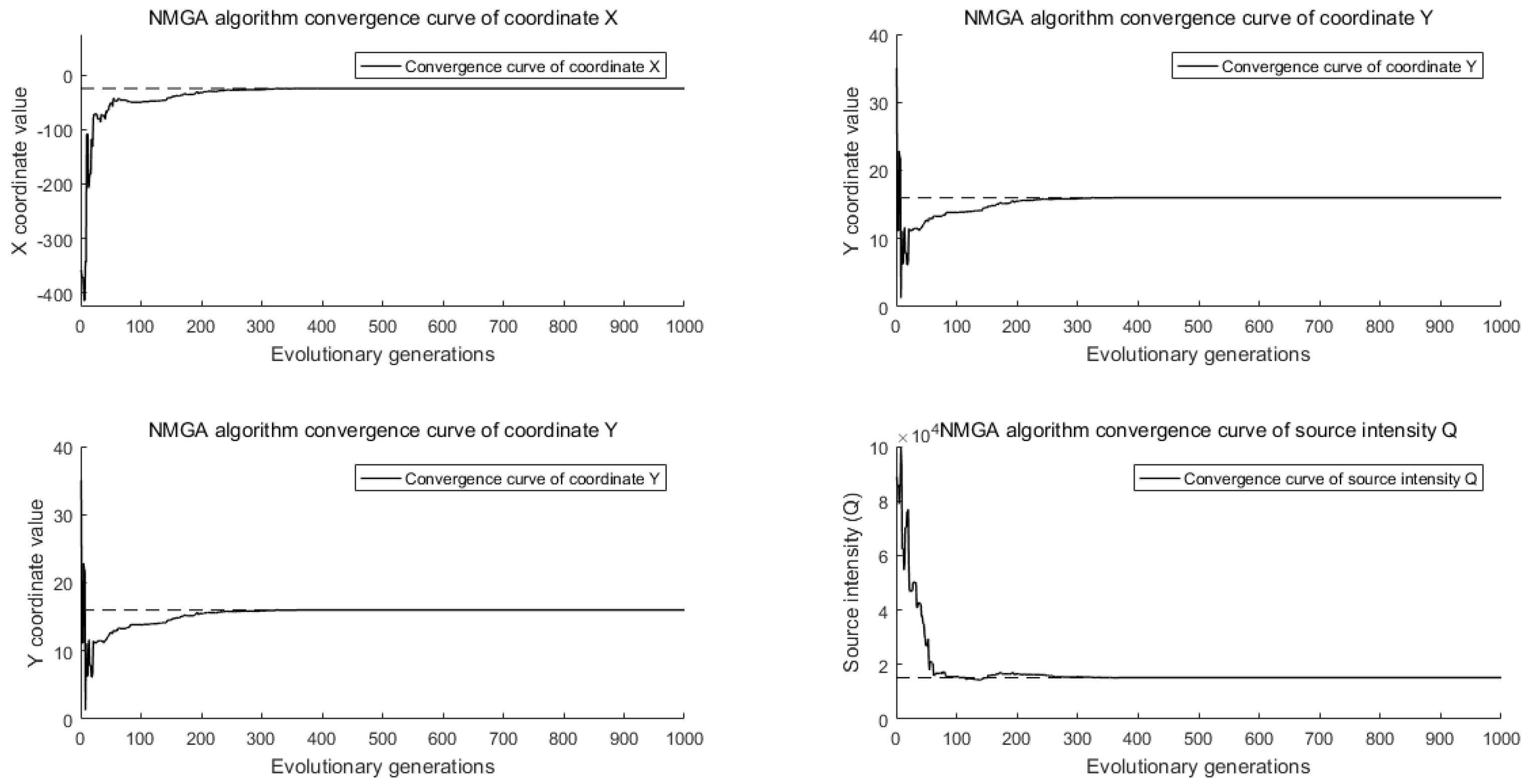
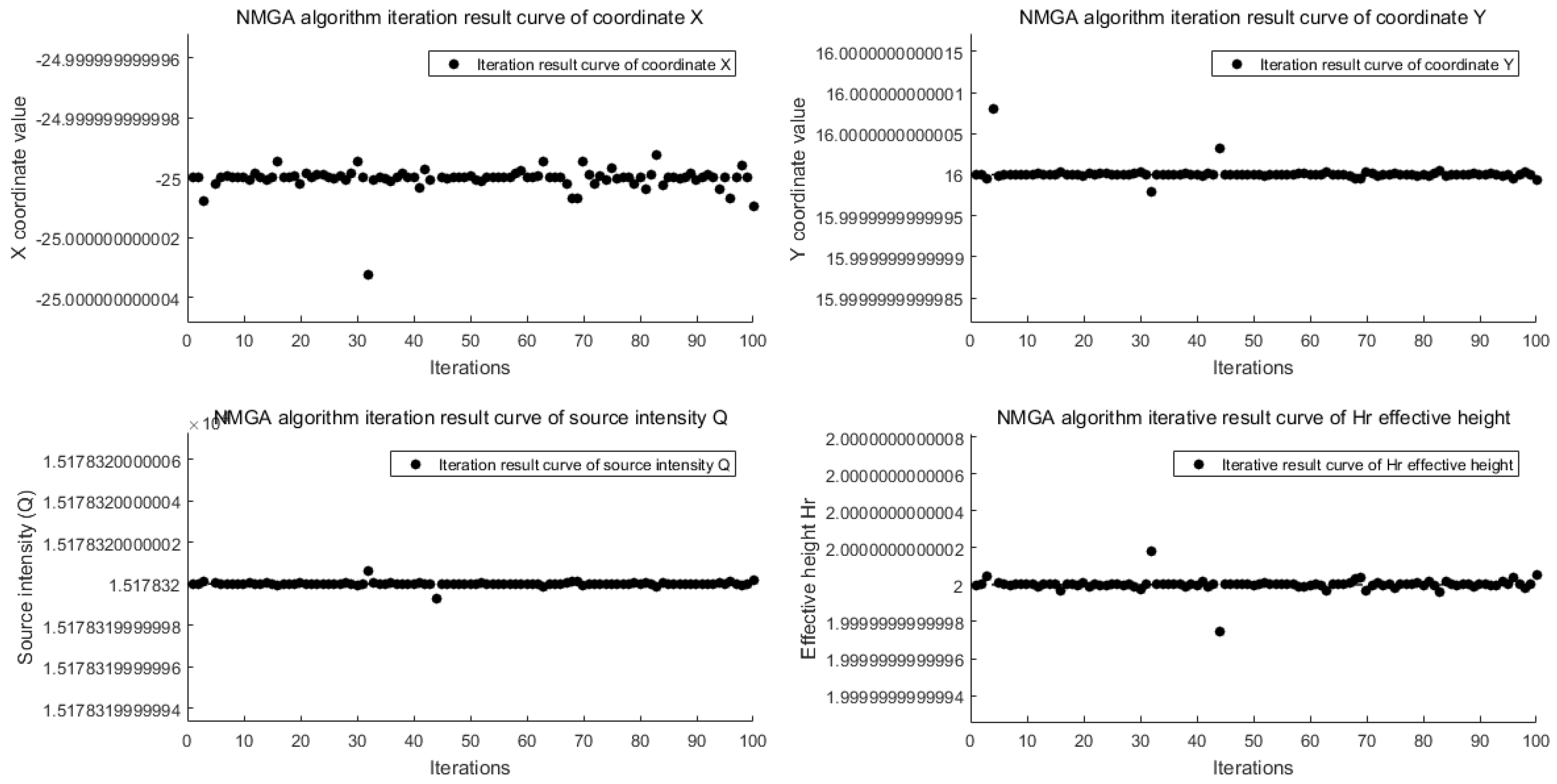
4.1. Implementation of Modified Genetic Algorithm
4.2. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Liu, X.; Wei, L. Comparative study on the method of strong inverse calculation of leakage source of hazardous chemicals. China Saf. Sci. J. 2009, 19, 165–171. [Google Scholar] [CrossRef]
- Thomson, L.C.; Hirst, B.; Gibson, G.; Gillespie, S.; Jonathan, P.; Skeldon, K.D.; Padgett, M.J. An modified algorithm for locating a gas source using inverse methods. Atmos. Environ. 2007, 41, 1128–1134. [Google Scholar] [CrossRef]
- Zheng, X.; Xing, H. The source strength inverse calculation of pattern search algorithm in gas leakage. China Saf. Sci. J. 2010, 20, 29–34. [Google Scholar]
- Zhang, J. Research and Application of Source Strong Inverse Calculation Algorithm BASED on Monitoring Data; China Petroleum University: Beijing, China, 2011. [Google Scholar]
- Wang, Y. Source Strength and Position Inverse calculation Based on Hybrid Genetic-Nelder Mead Simplex Algorithm; Beijing University of Chemical Engineering: Beijing, China, 2011. [Google Scholar]
- Zhang, J.; Wang, Y.; Zheng, X.; Wang, Z. Source strength and position inverse calculation based on mixed genetic-Nelder Mead simplex algorithm. Theory Pract. Syst. Eng. 2011, 31, 1581–1587. [Google Scholar]
- Reich, S.L.; Gomez, D.R.; Dawidowski, L.E. Artificial neural network for the identification of unknown air pollution sources. Atmos. Environ. 1999, 33, 3045–3052. [Google Scholar] [CrossRef]
- Fan, Q.; Wang, P.; Gao, X.J. Improved genetic algorithm based on oriented crossover. Control Decis. 2009, 24, 542–546. [Google Scholar]
- Cui, S.S. Some Improvements of the Genetic Algorithm and their Applications; University of Science and Technology of China: Hefei, China, 2010. [Google Scholar]
- Haupt, S.E.; Beyer-Lout, A.; Long, K.J.; Young, G.S. Assimilating concentration observations for transport and dispersion modeling in a meandering wind field. Atmos. Environ. 2009, 43, 1329–1338. [Google Scholar] [CrossRef]
- Zhang, R.; Li, J. Source strength inverse calculation based on an improved genetic algorithm. China Saf. Sci. J. 2016, 26, 57–62. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Boston, MA, USA, 1992; pp. 203–205. [Google Scholar]
- Yu, Y.; Liu, Y.; Wei, G. Encoding theory and application of genetic algorithm. Comput. Eng. Appl. 2006, 3, 86–89. [Google Scholar]
- Zhang, C.; Zheng, J.; Qian, J. Comparison of genetic algorithm coding schemes. Comput. Appl. Res. 2011, 28, 819–822. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Wang, X.; Xue, L.; Zhang, B.; Zhang, S. Improvement and parallelism of real-coded genetic algorithm. J. Hebei Univ. 2019, 39, 86–92. [Google Scholar]
- Zhou, Y.; Hu, Z. Application of improved fast genetic algorithm in function optimization. Mod. Electron. Tech. 2018, 41, 153–157. [Google Scholar]
- Ge, J.; Qiu, Y.; Wu, C.; Pu, G. Review of genetic algorithm research. Comput. Appl. Res. 2008, 2911–2916. [Google Scholar]
- Sourabh, K.; Singh, C.S.; Vijay, K. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar]
- Shen, C.S. Implementation of common selection operators in MATLAB in genetic algorithm. J. Shanghai Inst. Appl. Technol. 2003, 199–202. [Google Scholar]
- Pan, J.; Qian, Q.; Fu, Y.; Feng, Y. Multi-group genetic algorithm for optimal weight dynamic control learning mechanism. Comput. Sci. Explor. 2021, 15, 2421–2437. [Google Scholar]
- Bian, X.; Mi, L. Research Progress on Genetic Algorithm Theory and Its Application. Appl. Res. Comput. 2010, 27, 2425–2429+2434. [Google Scholar]
- Huang, W.; Xu, X.; Fan, J. Matlab implementation and application of common variation operators in real number coding genetic algorithm. Guangxi Light Ind. 2007, 77–78. [Google Scholar]
- Lim, S.M.; Sultan, A.B.; Sulaiman, M.N.; Mustapha, A.; Leong, K.Y. Crossover and Mutation Operators of Genetic Algorithms. Int. J. Mach. Learn. Comput. 2017, 7, 9–12. [Google Scholar] [CrossRef] [Green Version]
- Yan, C.; Li, M.; Zhou, X. Application of improved genetic algorithm in function optimization. Appl. Res. Computers. 2019, 39, 2982–2985. [Google Scholar]
- Schrider, D.R.; Shanku Alexander, G.; Kern Andrew, D. Effects of Linked Selective Sweeps on Demographic Inference and Model Selection. Genetics 2016, 204, 1207–1223. [Google Scholar] [CrossRef]
- Yang, C.; Qian, Q.; Wang, F.; Sun, M. Application of improved adaptive genetic algorithm in function optimization. Comput. Appl. Res. 2018, 35, 1042–1045. [Google Scholar]
- Flew, A. Darwinian Evolution; Taylor and Francis: London, UK, 2018. [Google Scholar]
- Liu, C.; Su, T.; Zhou, R.; Jiang, J. Research on inversion of gas leakage source information under modified Gaussian model. China Saf. Sci. J. 2022, 32, 98–104. [Google Scholar]
- Li, S.; Wang, J.; Zeng, J. An improved Gaussian prediction model algorithm for radioactive gas diffusion. Appl. Res. Comput. 2012, 29, 123–126. [Google Scholar]
- Sun, Q.; Dong, X.; Ren, Z. GIS Visualization of Atmospheric point source diffusion model. Surv. Mapp. Sci. 2011, 36, 24–25+142. [Google Scholar]
- Gifford, J.F.A. Use of routine meteorological observations for estimating atmospheric dispersion. Nucl. Saf. 1961, 2, 47–51. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Type | ||
|---|---|---|---|
| MGA | NMGA | NMGA | |
| Population × generation (N × M) | 100 × 2000 | 100 × 1000 | 100 × 500 |
| Mean of x/m | 49.86 | −25 | −24.9719 |
| Mean of y/m | 25.02 | 16 | 16.0081 |
| Mean of Q/(g·s−1) | 10,442.96 | 15,178.00 | 15,173 |
| Mean of Hr/(g·s−1) | — | 2.00 | 1.9981 |
| x standard deviation/m and relative error | 1.04 and 2.08% | 7.96 × 10−12 and 5.46 × 10−14 | 0.25 and 0.11% |
| y standard deviation/m and relative error | 0.08 and 0.32% | 5.32 × 10−13 and 5.71 × 10−15 | 0.02 and 0.011% |
| Q distribution standard deviation/(g·s−1) and relative error | 55.40 and 0.53% | 1.46 × 10−9 and 1.43 × 10−14 | 42.24 and 0.038% |
| Hr standard deviation/m and relative error | — | 4.4 × 10−13 and 3.7 × 10−14 | 0.02 and 0.094% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, J.; Liu, Y.; Feng, Z.; Liu, T.; Zhou, S.; Liu, H. Application of New Modified Genetic Algorithm in Inverse Calculation of Strong Source Location. Atmosphere 2023, 14, 89. https://doi.org/10.3390/atmos14010089
Yao J, Liu Y, Feng Z, Liu T, Zhou S, Liu H. Application of New Modified Genetic Algorithm in Inverse Calculation of Strong Source Location. Atmosphere. 2023; 14(1):89. https://doi.org/10.3390/atmos14010089
Chicago/Turabian StyleYao, Jiming, Yajing Liu, Zhengwen Feng, Tong Liu, Shuai Zhou, and Hongjian Liu. 2023. "Application of New Modified Genetic Algorithm in Inverse Calculation of Strong Source Location" Atmosphere 14, no. 1: 89. https://doi.org/10.3390/atmos14010089
APA StyleYao, J., Liu, Y., Feng, Z., Liu, T., Zhou, S., & Liu, H. (2023). Application of New Modified Genetic Algorithm in Inverse Calculation of Strong Source Location. Atmosphere, 14(1), 89. https://doi.org/10.3390/atmos14010089