



Probabilistic Hotspot Prediction Model Based on Bayesian Inference Using Precipitation, Relative Dry Spells, ENSO and IOD

 ,
, 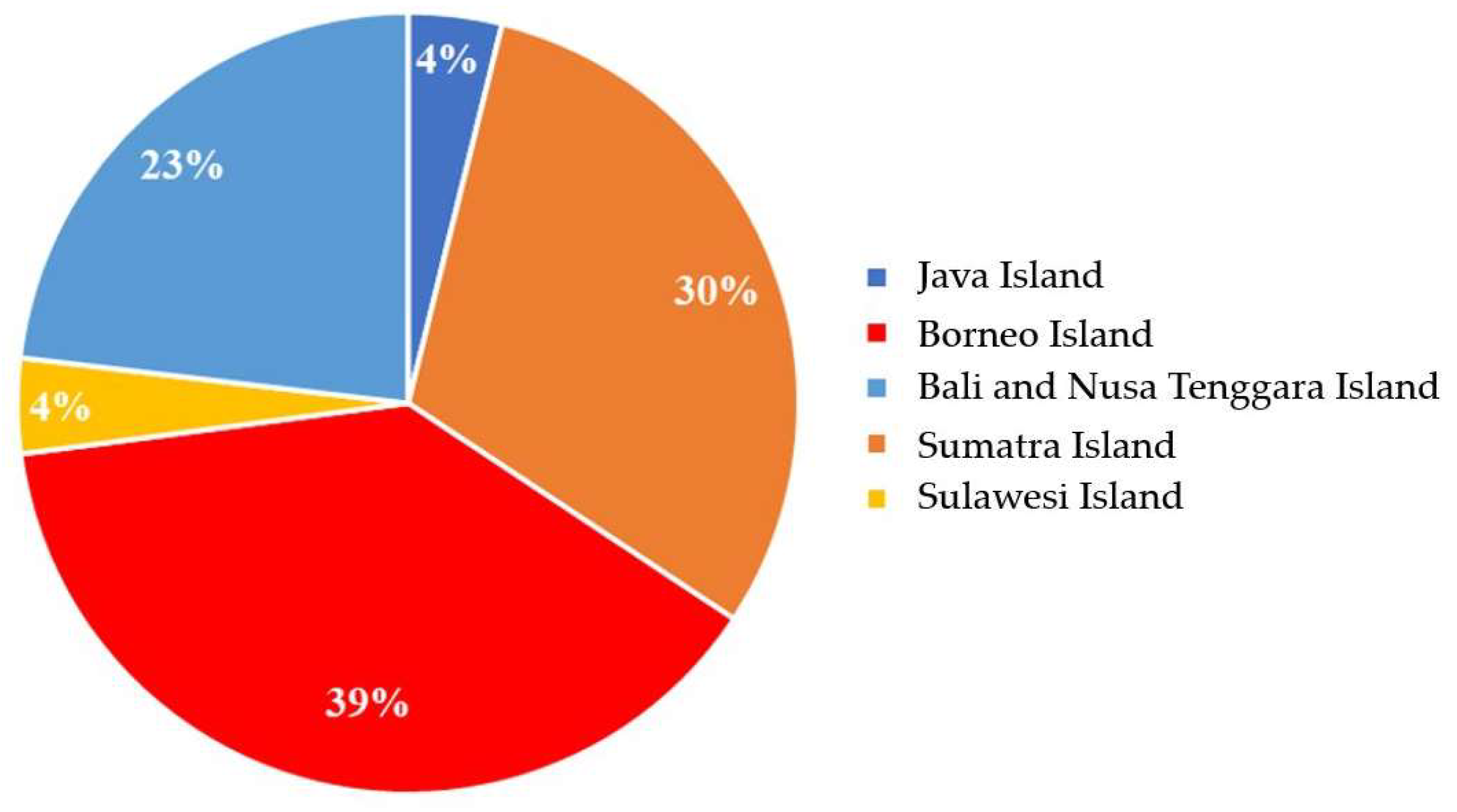{kind=link}
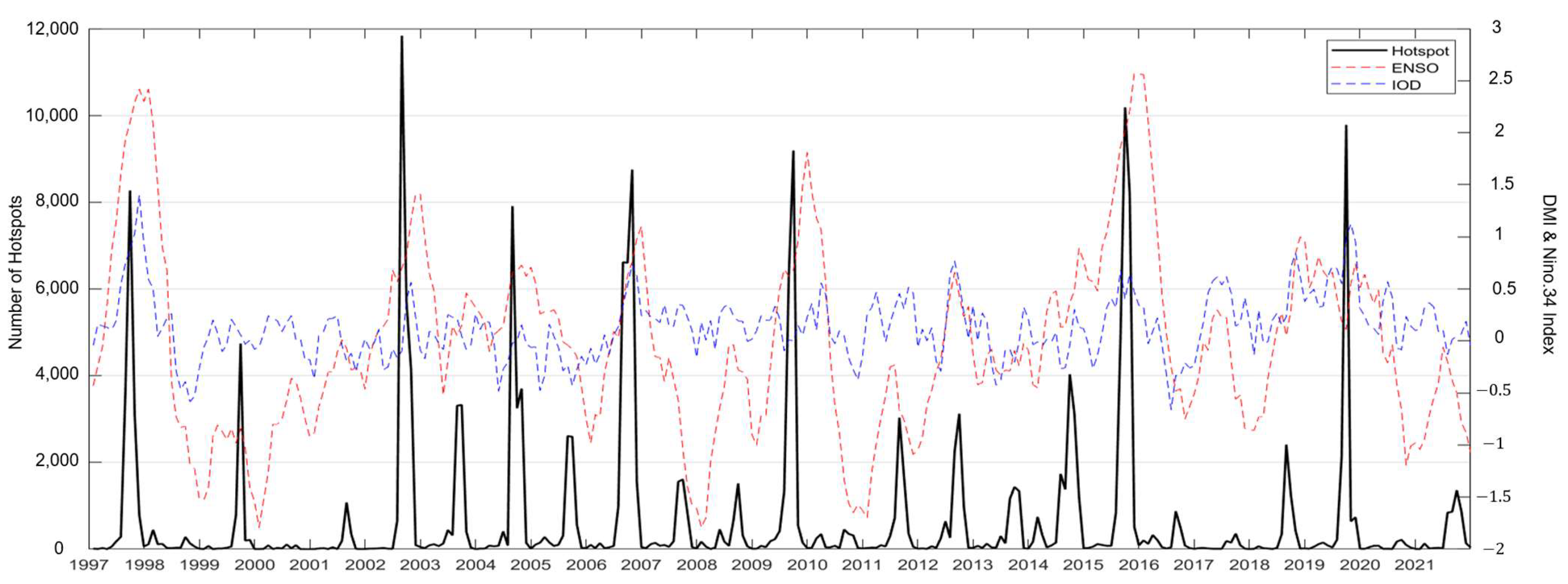{kind=link}
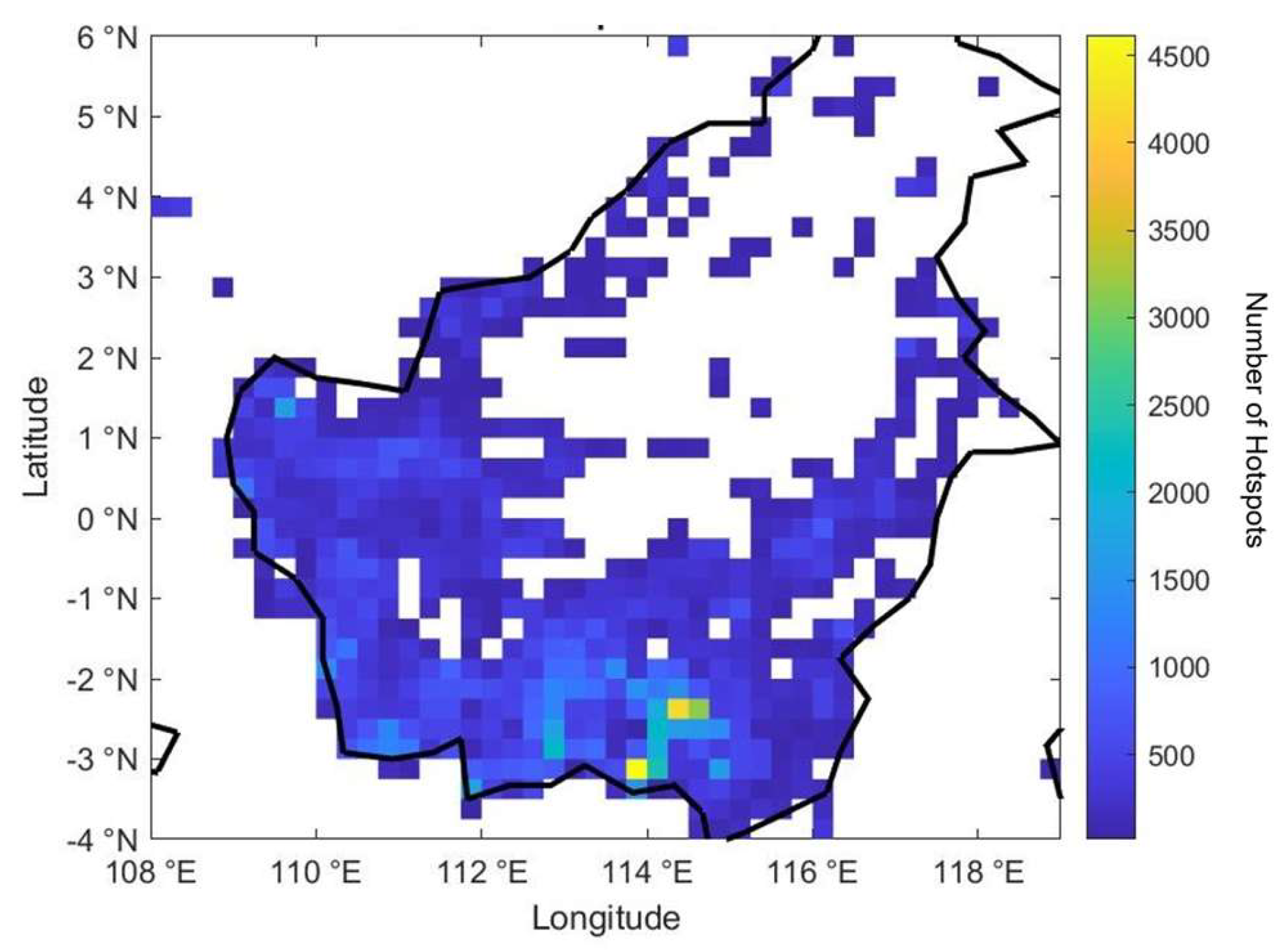{kind=link}
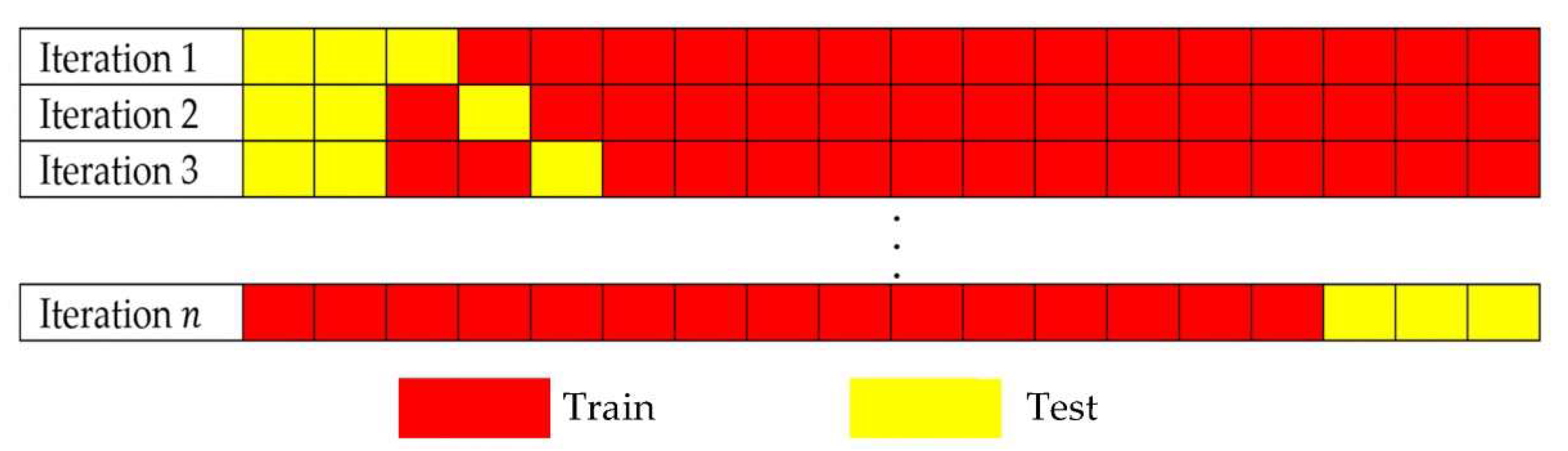{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data and Study Area
2.2. Principal Model Analysis
2.3. Bayesian Linear Regression
Prior and Posterior
2.4. Cross Validation
3. Results
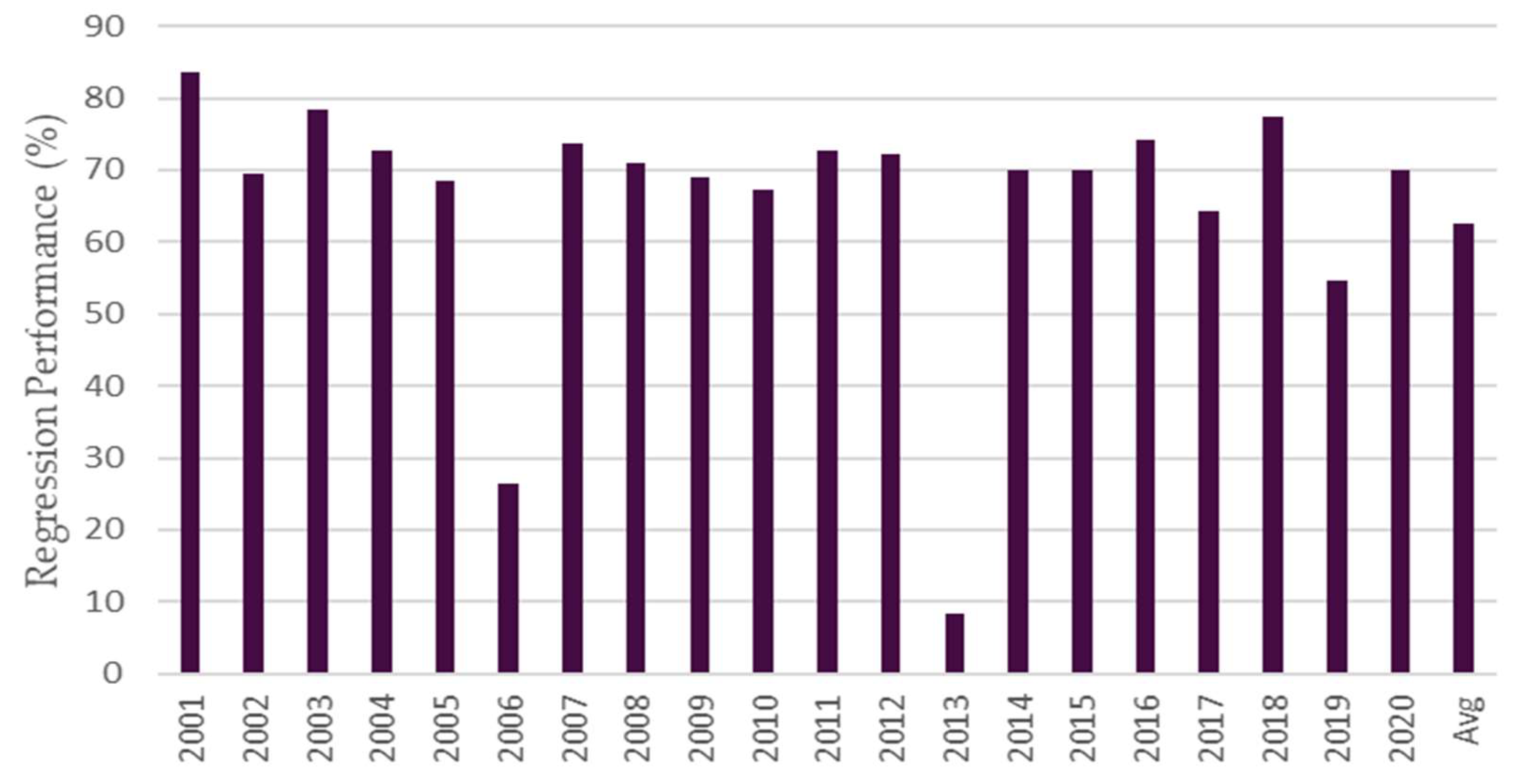
3.1. Evaluation of Year’s Characteristic When Used in Prior and Posterior Process
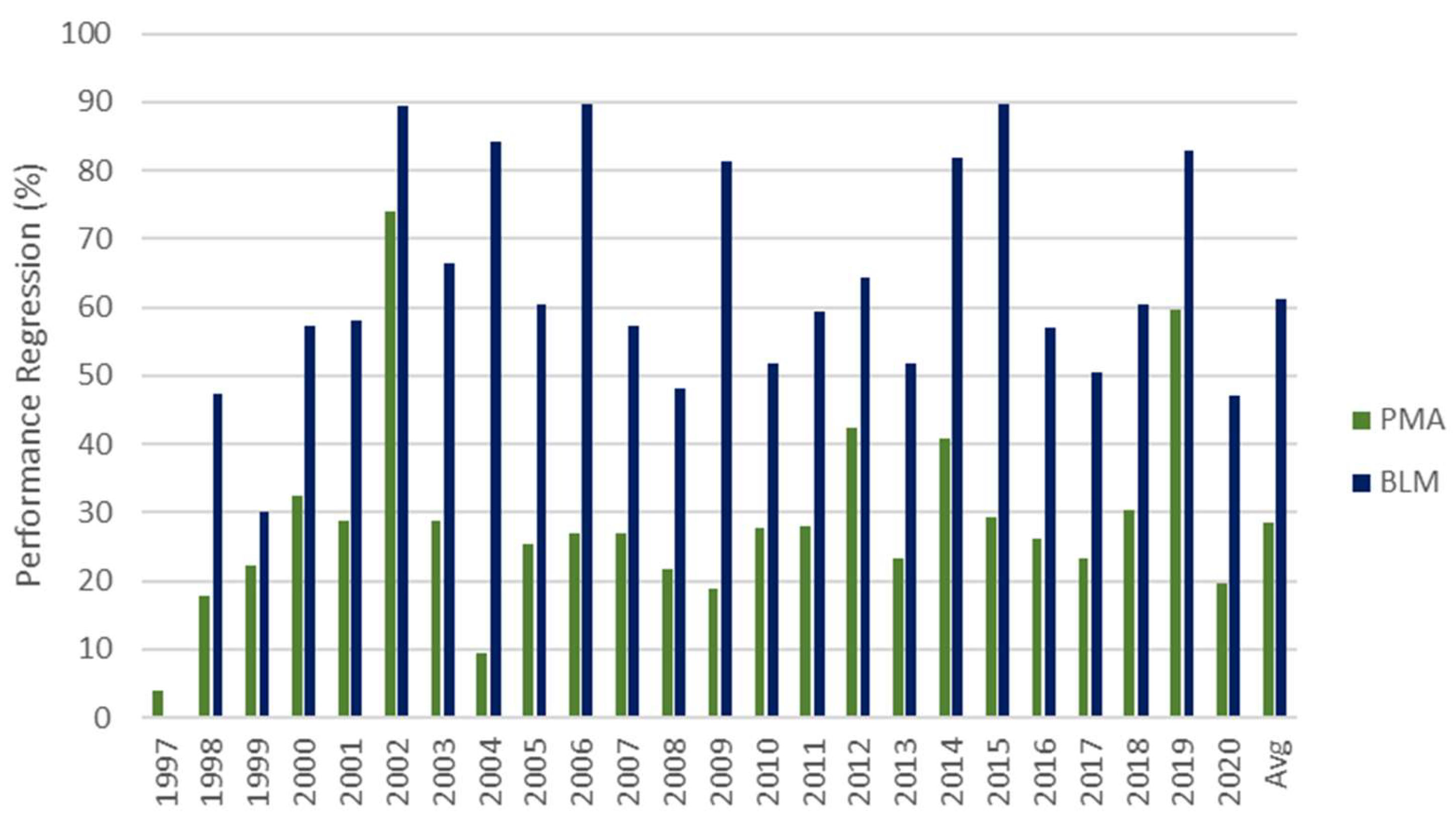
3.2. Evaluation of Bayesian Concept When Used as Robust Model
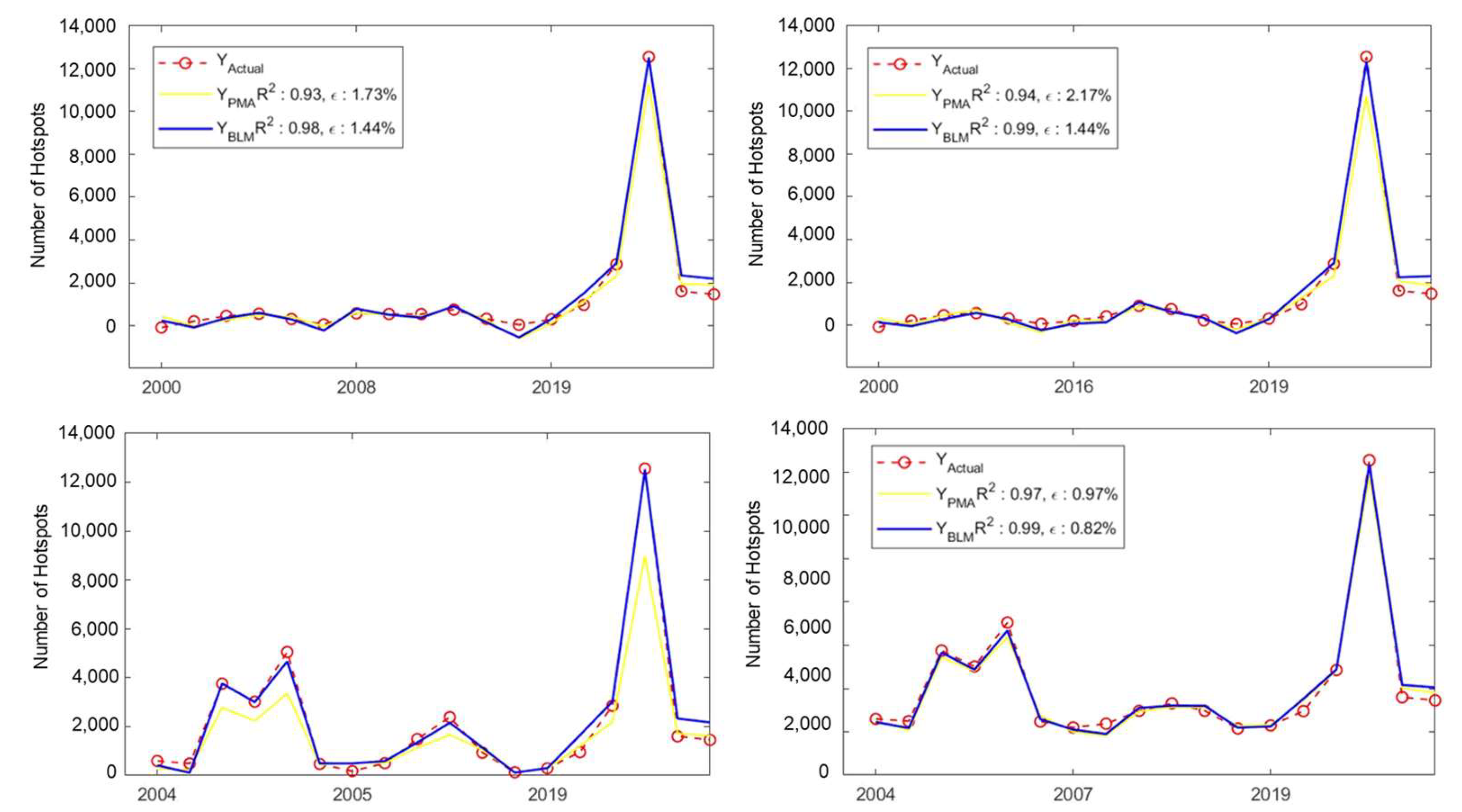
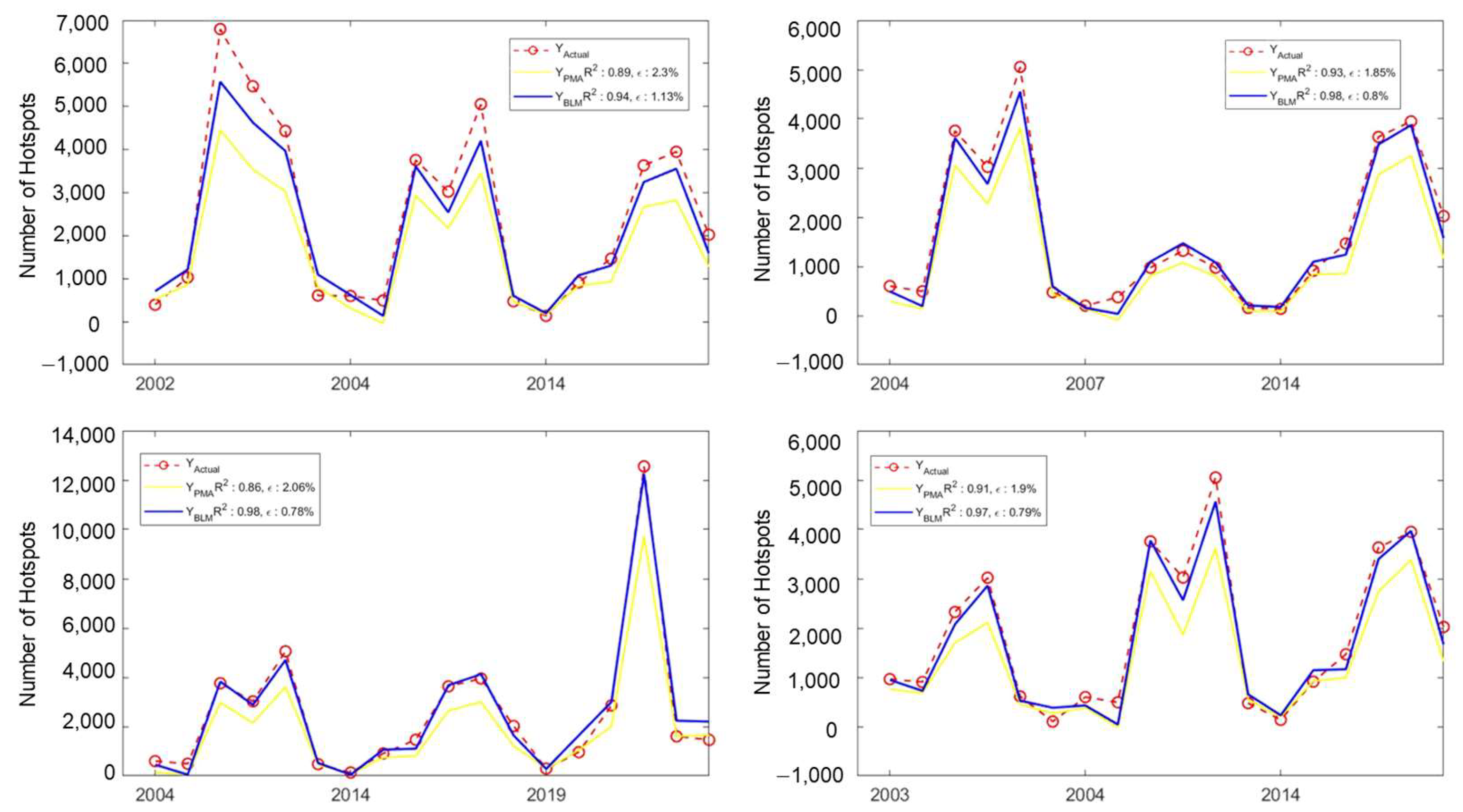
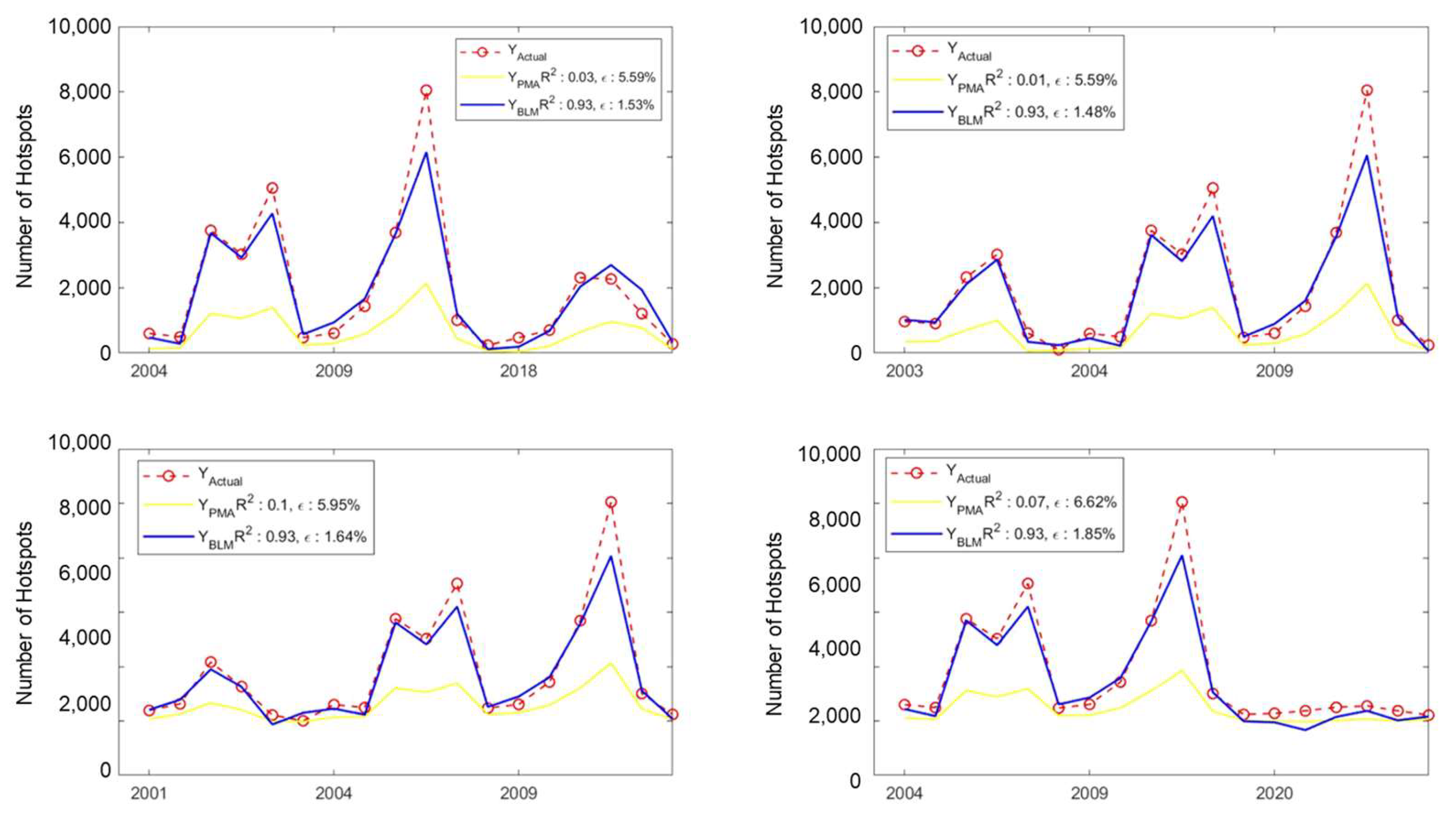
3.2.1. Case Study: Four Models with Highest Values of Coefficient Determination ()
3.2.2. Case Study: Four Models with Lowest Values of Root Mean Square Error ()
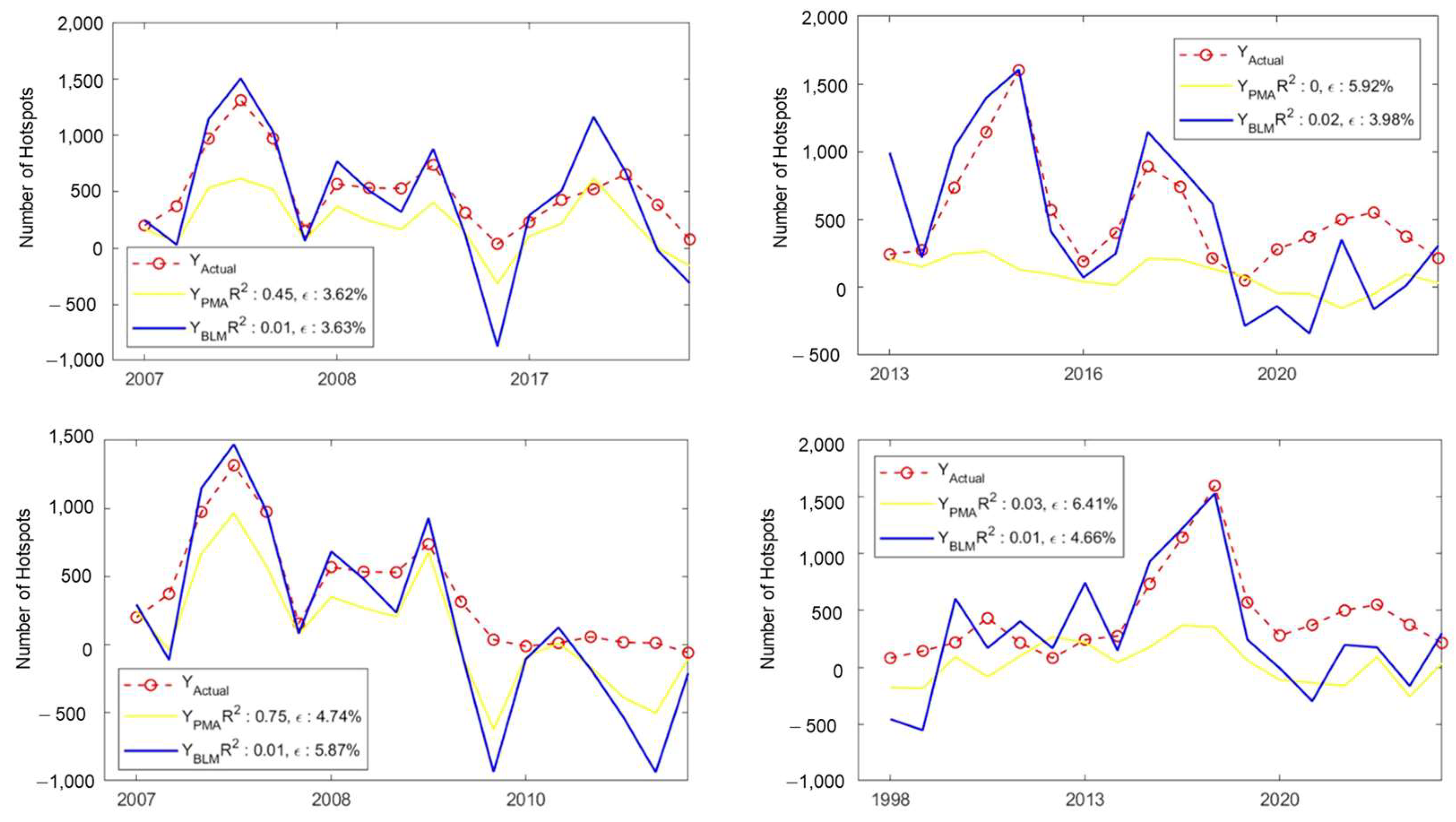
3.2.3. Case Study: Four Models with Lowest Value of Coefficient Determination ()
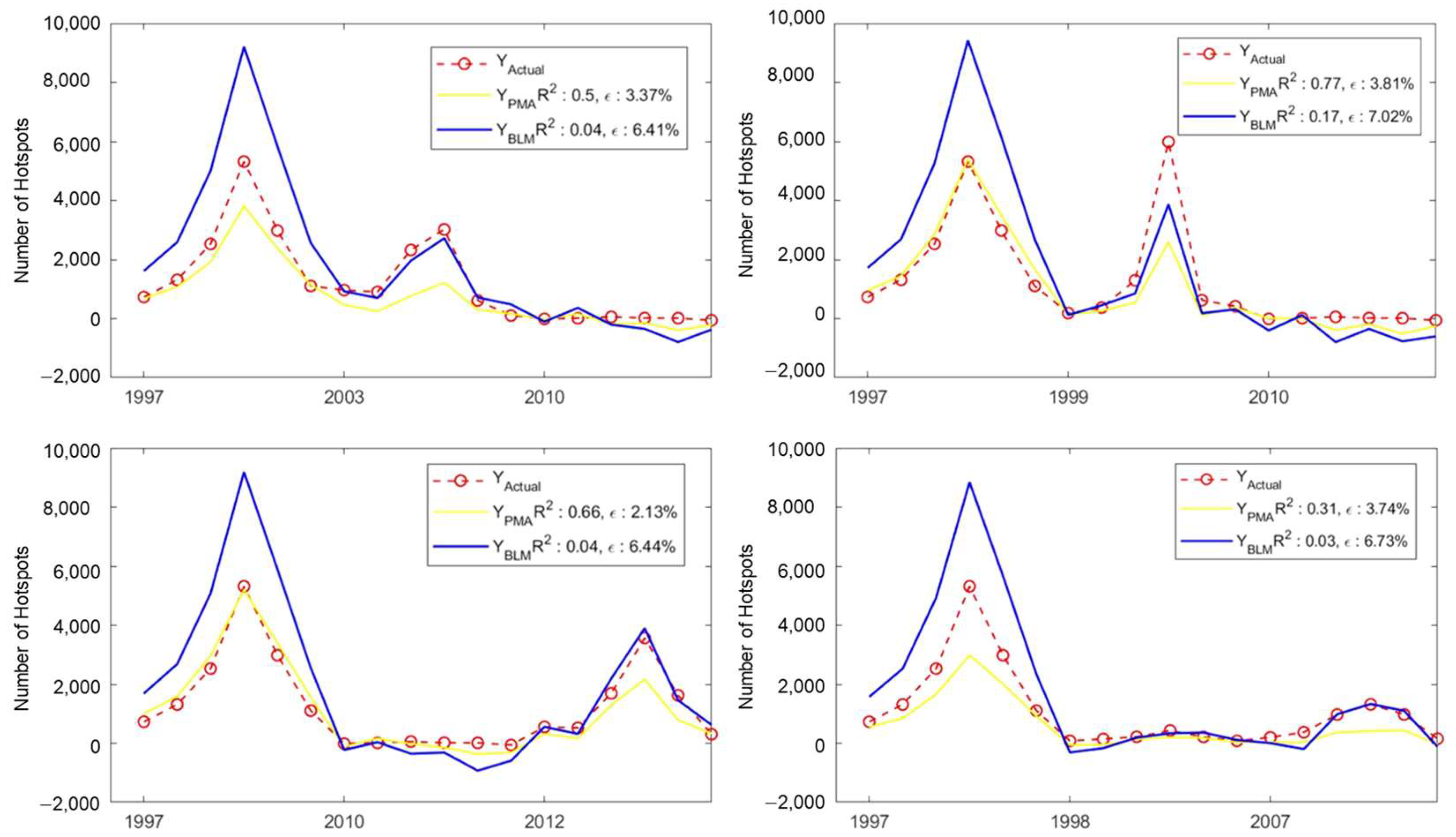
3.2.4. Case study: Four Models with Highest Values of Root Mean Square Error ()
3.2.5. Case Study: Four Models That BLM Failed to Improve
3.2.6. Case Study: Four Models That Necessitate Use of BLM
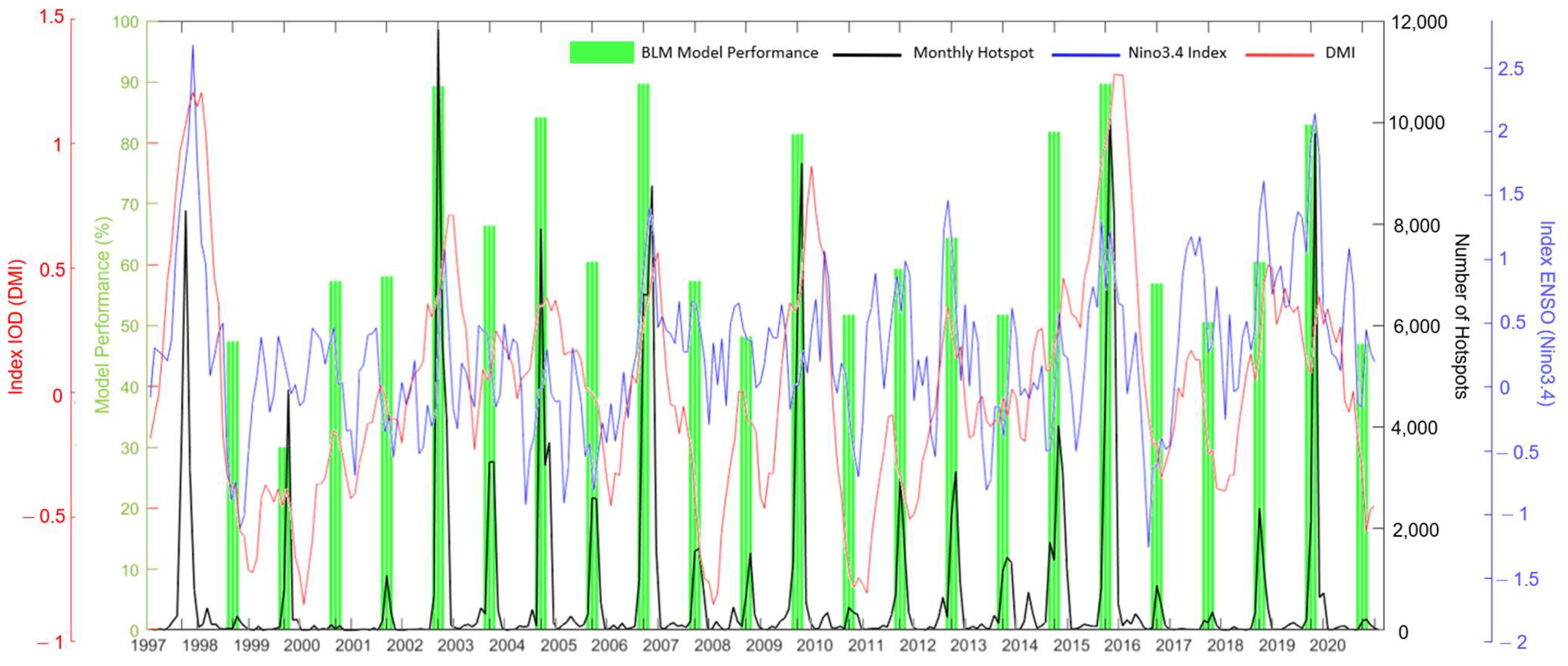
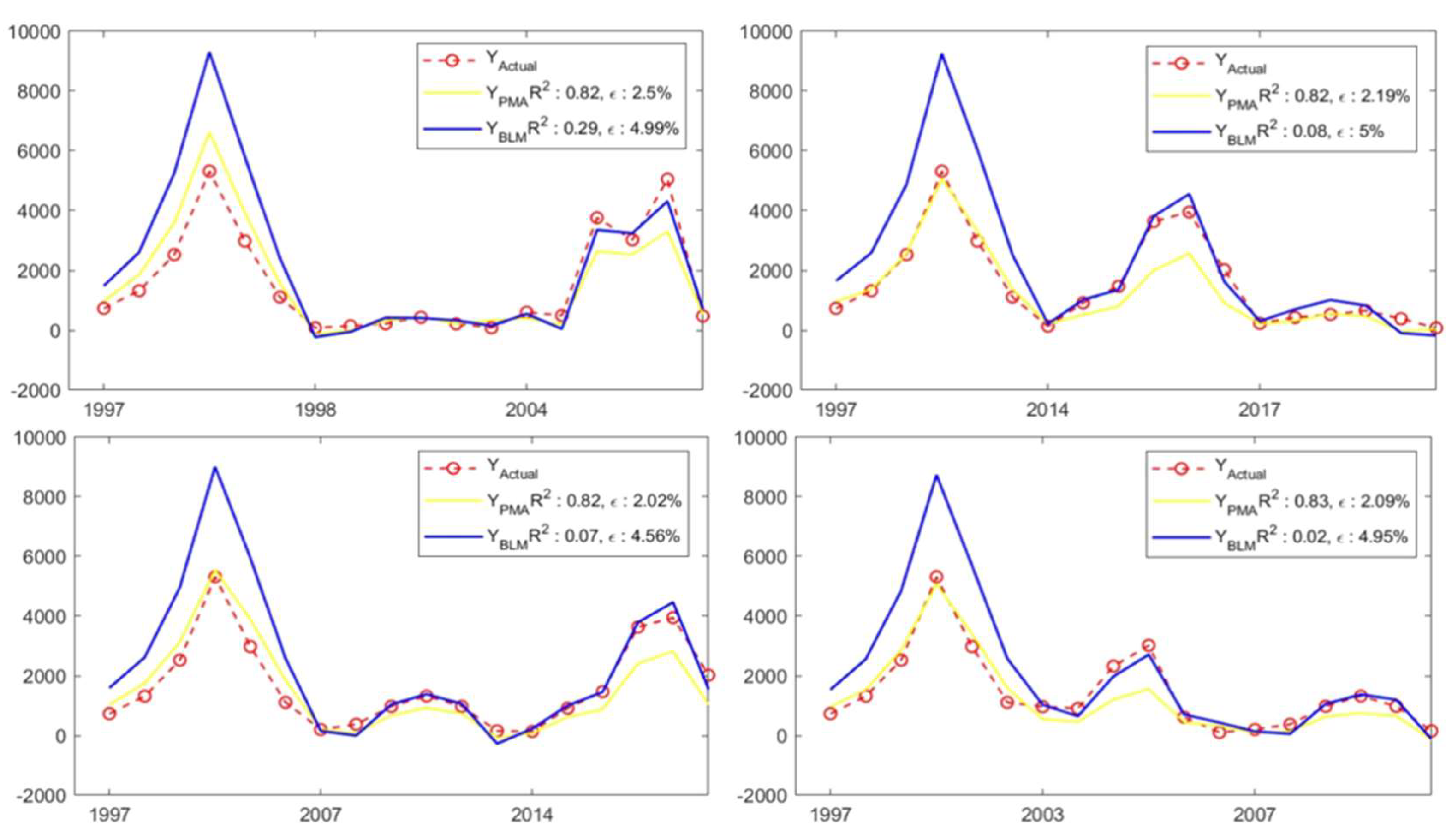
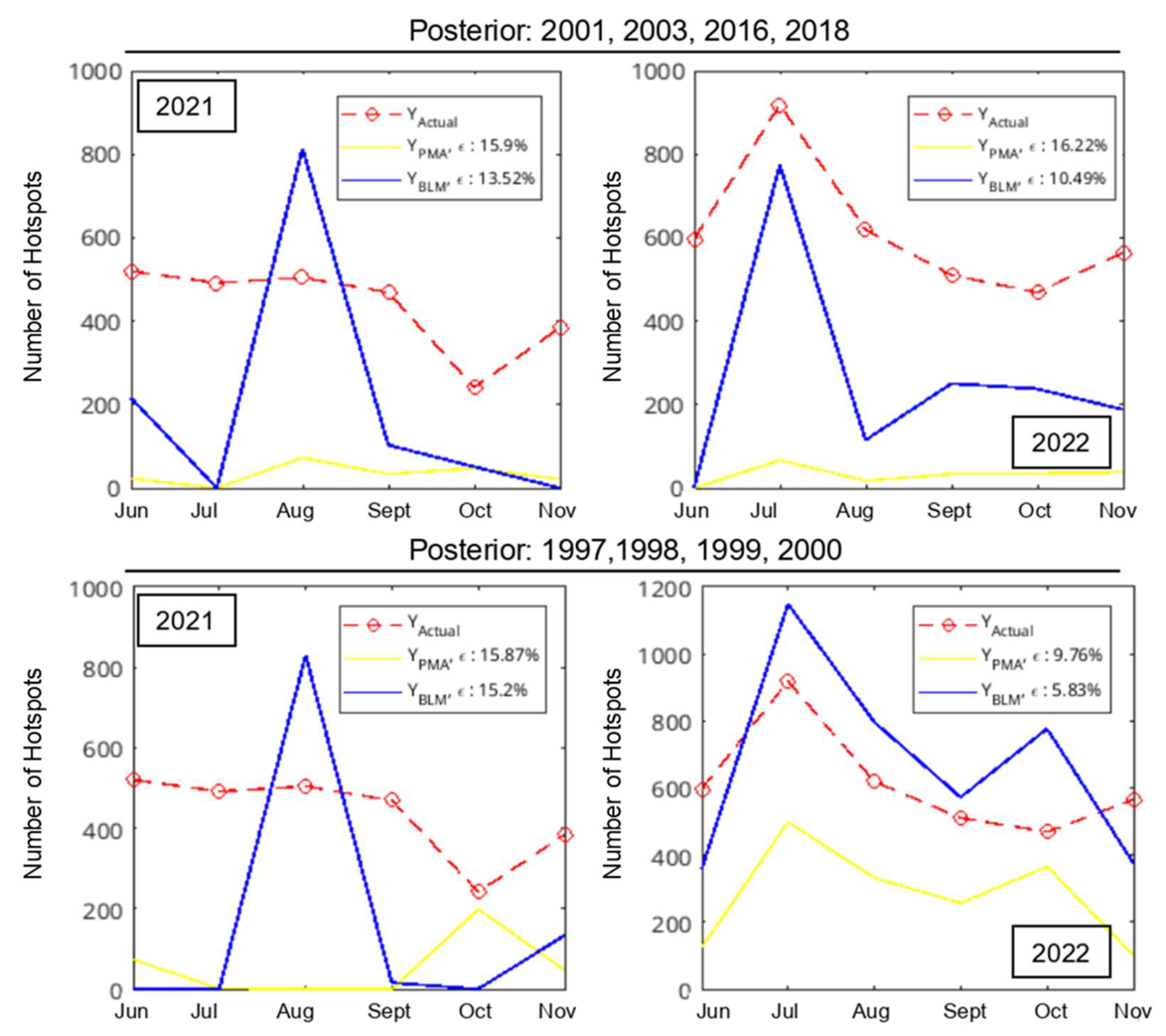
3.3. Estimation of Monthly Hotspots in 2021 and 2022
4. Discussion
Wildfire Characteristics in 2006, 2013, and 2019
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nurdiati, S.; Bukhari, F.; Julianto, M.T.; Najib, M.K.; Nazria, N. Heterogeneous Correlation Map Between Estimated ENSO And IOD From ERA5 And Hotspot In Indonesia. Jambura Geosci. Rev. 2021, 3, 65–72. [Google Scholar] [CrossRef]
- Shafitri, L.D.; Prestyo, Y.; Hani’ah. Analysis of Forest Deforestation in Riau Province Using Polarimetric Method in Remote Sensing. J. Geod. Undip. 2018, 7, 212–222. (In Indonesian) [Google Scholar]
- Dafri, M.; Nurdiati, S.; Sopaheluwakan, A. Quantifying ENSO and IOD Impact to Hotspot in Indonesia Based on Heterogeneous Correlation Map (HCM). J. Phys. Conf. Ser. 2021, 1869, 012150. [Google Scholar] [CrossRef]
- Atmadja, S.; Indriatmoko, Y.; Utomo, N.A.; Komalasari, M.; Ekaputri, A.D. Kalimantan Forests and Climate Partnership, Central Kalimantan, Indonesia. In REDD+ on the Ground: A Case Book of Subnational Initiatives across the Globe; Sills, E.O., Ed.; Center for International Forestry Research (CIFOR): Bogor, Indonesia, 2015; pp. 290–308. [Google Scholar]
- Ministry of Environment and Forestry of The Republic of Indonesia Sipongi.menhlk.go.id. Available online: Sipongi.menhlk.go.id (accessed on 30 November 2022).
- Santriwati, S.; Halide, H.; Hasanuddin, H. Oceanic-Atmospheric Factors to Predict Hostspots in the Southern Southeast Asia Region. J. Geocelebes 2021, 5, 116–130. (In Indonesian) [Google Scholar] [CrossRef]
- Candra, A.; Thamrin, M. Analysis of the Influence of Climate Factors and Forest/Land Fires on Pm10 Concentrations in Pekanbaru City During the Period of 2011–2015. Ilmu Lingkung. 2017, 11, 209–227. (In Indonesian) [Google Scholar] [CrossRef]
- Najib, M.K.; Nurdiati, S.; Sopaheluwakan, A. Copula-Based Joint Distribution Analysis of the ENSO Effect on the Drought Indicators over Borneo Fire-Prone Areas. Model. Earth Syst. Environ. 2022, 8, 2817–2826. [Google Scholar] [CrossRef]
- Endrawati, E. Identification of Forest and Land Fire Scars Using Semi-Automated Analysis of Landsat Satellite Imagery. Semin. Nas. Geomatika 2018, 2, 273. (In Indonesian) [Google Scholar] [CrossRef] [Green Version]
- Samsuri, A.; Zaitunah, O.R. Green Open Space Needs Analysis: Oxygen Demand Approach. J. Silva Trop. 2021, 5, 305–320. (In Indonesian) [Google Scholar]
- Fanin, T.; Van Der Werf, G.R. Precipitation-Fire Linkages in Indonesia (1997–2015). Biogeosciences 2017, 14, 3995–4008. [Google Scholar] [CrossRef] [Green Version]
- Gutierrez, A.A.; Hantson, S.; Langenbrunner, B.; Chen, B.; Jin, Y.; Goulden, M.L.; Randerson, J.T. Wildfire response to changing daily temperature extremes in California’s Sierra Nevada. Sci. Adv. 2021, 7, eabe6417. [Google Scholar] [CrossRef]
- Supari; Tangang, F.; Juneng, L.; Aldrian, E. Observed changes in extreme temperature and precipitation over Indonesia. Int. J. Climatol. 2017, 37, 1979–1997. [Google Scholar] [CrossRef]
- Wahyuni, H.; Suranto, S. The Impact of Large-Scale Deforestation on Global Warming in Indonesia. JIIP J. Ilm. Ilmu Pemerintah. 2021, 6, 148–162. (In Indonesian) [Google Scholar] [CrossRef]
- Handoko, E.Y.; Filaili, R.B.; Yuwono. Analysis of the Enso Phenomenon in Indonesian Waters Using Topex/Poseidon and Jason Series Altimetry Data 1993–2018. Geoid 2019, 14, 43. (In Indonesian) [Google Scholar] [CrossRef] [Green Version]
- Hidayat, A.M.; Efendi, U.; Agustina, L.; Winarso, P.A. Correlation of Niño 3.4 Index and Southern Oscillation Index (Soi) with Rainfall Variation in Semarang. J. Sains Teknol. Modif. Cuaca 2018, 19, 75. (In Indonesian) [Google Scholar] [CrossRef]
- Abram, N.J.; Wright, N.M.; Ellis, B.; Dixon, B.C.; Wurtzel, J.B.; England, M.H.; Ummenhofer, C.C.; Philibosian, B.; Cahyarini, S.Y.; Yu, T.L.; et al. Coupling of Indo-Pacific Climate Variability over the Last Millennium. Nature 2020, 579, 385–392. [Google Scholar] [CrossRef]
- Saji, N.H.; Goswami, B.N.; Vinayachandran, P.N.; Yamagata, T. A Dipole Mode in the Tropical Indian Ocean. Nature 1999, 401, 360–363. [Google Scholar] [CrossRef]
- Kertayasa, I.M.; Sukarasa, I.K.; Widagda, I.G.A.; Hendrawan, I.G. Effect of Indian Ocean Dipole Mode (Iodm) on Rain Intensity in the Western Indonesian Maritime Continent (Bmi). Buletin Fisika 2013, 14, 25–30. (In Indonesian) [Google Scholar]
- Nur’utami, M.N.; Hidayat, R. Influences of IOD and ENSO to Indonesian Rainfall Variability: Role of Atmosphere-Ocean Interaction in the Indo-Pacific Sector. Procedia Environ. Sci. 2016, 33, 196–203. [Google Scholar] [CrossRef] [Green Version]
- Najib, M.K.; Nurdiati, S.; Sopaheluwakan, A. Multivariate Fire Risk Models Using Copula Regression in Kalimantan, Indonesia. Nat. Hazards 2022, 113, 1263–1283. [Google Scholar] [CrossRef]
- Nurdiati, S.; Sopaheluwakan, A.; Septiawan, P. Spatial and Temporal Analysis of El Niño Impact on Land and Forest Fire in Kalimantan and Sumatra. Agromet 2021, 35, 1–10. [Google Scholar] [CrossRef]
- Nurdiati, S.; Sopaheluwakan, A.; Julianto, M.T.; Septiawan, P.; Rohimahastuti, F. Modelling and Analysis Impact of El Niño and IOD to Land and Forest Fire Using Polynomial and Generalized Logistic Function: Cases Study in South Sumatra and Kalimantan, Indonesia. Model. Earth Syst. Environ. 2022, 8, 3341–3356. [Google Scholar] [CrossRef]
- Sang, Y.F.; Singh, V.P.; Xu, K. Evolution of IOD-ENSO Relationship at Multiple Time Scales. Theor. Appl. Climatol. 2019, 136, 1303–1309. [Google Scholar] [CrossRef]
- Cane, M.A. The Evolution of El Niño, Past and Future. Earth Planet. Sci. Lett. 2005, 230, 227–240. [Google Scholar] [CrossRef]
- Suhermat, M.; Dimyati, M.; Supriatna, S.; Martono, M. Impact of Climate Change on Sea Surface Temperature and Chlorophyll-a Concentration in South Sukabumi Waters. J. Ilmu Lingkung. 2021, 19, 393–398. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, Y. Extreme IOD Induced Tropical Indian Ocean Warming in 2020. Geosci. Lett. 2021, 8, 37. [Google Scholar] [CrossRef]
- Muttalib, A.M.A.; Ameen, S.M.M.; Mahmood, A.B. The Impacts of ENSO and IOD on the MSL of the Arabian Gulf and the Arabian Sea by Using Satellite Altimetry Data. Ilmu Kelaut. Indones. J. Mar. Sci. 2021, 26, 143–147. [Google Scholar] [CrossRef]
- Cai, W.; Santoso, A.; Collins, M.; Dewitte, B.; Karamperidou, C.; Kug, J.S.; Lengaigne, M.; McPhaden, M.J.; Stuecker, M.F.; Taschetto, A.S.; et al. Changing El Niño–Southern Oscillation in a Warming Climate. Nat. Rev. Earth Environ. 2021, 2, 628–644. [Google Scholar] [CrossRef]
- Nikonovas, T.; Spessa, A.; Doerr, S.H.; Clay, G.D.; Mezbahuddin, S. ProbFire: A probabilistic fire early warning system for Indonesia, Nat. Hazards Earth Syst. Sci. 2022, 22, 303–322. [Google Scholar] [CrossRef]
- Ardiansyah, M.; Boer, R.; Situmorang, A.P. Typology of Land and Forest Fire in South Sumatra, Indonesia Based on Assessment of MODIS Data. IOP Conf. Ser. Earth Environ. Sci. 2017, 54, 012058. [Google Scholar] [CrossRef]
- Sabani, W.; Rahmadewi, D.P.; Rahmi, K.I.N.; Priyatna, M.; Kurniawan, E. Utilization of MODIS Data to Analyze the Forest/Land Fires Frequency and Distribution (Case Study: Central Kalimantan Province). IOP Conf. Ser. Earth Environ. Sci. 2019, 243, 012032. [Google Scholar] [CrossRef]
- Aisyah, S.; Simaremare, A.A.; Adytia, D.; Aditya, I.A.; Alamsyah, A. Exploratory Weather Data Analysis for Electricity Load Forecasting Using SVM and GRNN, Case Study in Bali, Indonesia. Energies 2022, 15, 3566. [Google Scholar] [CrossRef]
- Nurdiati, S.; Sopaheluwakan, A.; Najib, M.K. Statistical Bias Correction for Predictions of Indian Ocean Dipole Index with Quantile Mapping Approach. In Proceedings of the 1st Int’ Conference on Sccience and Mathemtics (IMC-SciMath), Parapat, Indonesia, 9–11 October 2019. [Google Scholar]
- Najib, M.K.; Nurdiati, S. Statistical Bias Correction on Predicted Sea Surface Temperature Data in the Western and Eastern Indian Ocean Dipole Regions. Jambura Geosci. Rev. 2021, 3, 9–17. (In Indonesian) [Google Scholar] [CrossRef]
- Morales-Velázquez, M.I.; Herrera, G.D.S.; Aparicio, J.; Rafieeinasab, A.; Lobato-Sánchez, R. Evaluating Reanalysis and Satellite-Based Precipitation at Regional Scale: A Case Study in Southern Mexico. Atmósfera 2021, 34, 189–206. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, Y.; Lu, F.; Yu, Y.; Yan, D.; Hu, Y.; Xue, W. Evaluating satellite- and reanalysis-based precipitation products over the Qinghai-Tibetan Plateau in the perspective of a new error-index system. Int. J. Climatol. 2022, 2022, 1–20. [Google Scholar] [CrossRef]
- Hassan, J.O.; Amer, S.M. Evaluation of satellite-based and reanalysis precipitation datasets by hydrologic simulation in the Chenab river basin. J. Water Clim. Chang. 2022, 13, 1563–1582. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Horányi, A.; Muñoz, J.; Sabater.; Nicolas, J.; Radu, R.; Schepers, D.; Simmons, A.; et al. Global Reanalysis: Goodbye ERA-Interim, Hello ERA5. ECMWF Newsl. 2019, 159, 17–24. [Google Scholar]
- Rizani, M.; Fathurrahmani, F. Web-based Day Without Rain (HTH) Monitoring Application at Banjarbaru Class 1 Climatology Station. J. Sains Dan Inform. 2018, 4, 63–72. (In Indonesian) [Google Scholar] [CrossRef] [Green Version]
- He, B.; Zhong, Z.; Chen, D.; Liu, J.; Chen, Y.; Miao, C.; Ding, R.; Yuan, W.; Guo, L.; Huang, L.; et al. Lengthening dry spells intensify summer heatwaves. Geophys. Res. Lett. 2022, 49, e2022GL099647. [Google Scholar] [CrossRef]
- Groisman, P.Y.; Knight, R.W. Prolonged dry episodes over the conterminous United States: New tendencies emerging during the last 40 years. J. Clim. 2008, 21, 1850–1862. [Google Scholar] [CrossRef]
- Brunetti, M.; Maugeri, M.; Monti, F.; Nanni, T. Changes in daily precipitation frequency and distribution in Italy over the last 120 years. J. Geophys. Res. 2004, 109, D05102. [Google Scholar] [CrossRef]
- Palmer, P.B.; O’Connell, D.G. Research Corner: Regression Analysis for Prediction: Understanding the Process. Cardiopulm. Phys. Ther. J. 2009, 20, 23–26. [Google Scholar] [CrossRef] [PubMed]
- Dimitriadou, S.; Nikolakopoulos, K.G. Multiple Linear Regression Models with Limited Data for the Prediction of Reference Evapotranspiration of the Peloponnese, Greece. Hydrology 2022, 9, 124. [Google Scholar] [CrossRef]
- Manoj, S.; Valliyammai, C.; Kalyani, V. Multivariate Regression Analysis of Climate Indices for Forecasting the Indian Rainfall. Lect. Notes Netw. Syst. 2020, 107, 713–720. [Google Scholar] [CrossRef]
- Kalyani, V.; Valliyammai, C.; Manoj, S. Multivariate Regression Analysis on Climate Variables for Weather Forecasting in Indian Subcontinent. Adv. Intell. Syst. Comput. 2020, 1118, 621–628. [Google Scholar] [CrossRef]
- Xie, Q.; Tang, L.; Li, W.; John, V.; Hu, Y. Principal Model Analysis Based on Partial Least Squares. arXiv 2019, arXiv:1902.02422. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Partial Least Squares Methods: Partial Least Squares Correlation and Partial Least Square Regression. Methods Mol. Biol. NeuroImage 2013, 930, 549–579. [Google Scholar]
- Chen, C.; Cao, X.; Tian, L. Partial Least Squares Regression Performs Well in MRI-Based Individualized Estimations. Front. Neurosci. 2019, 13, 1282. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.P.; Tiao, G.C. Bayesian Inference in Statistical Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1992; ISBN 9781118033197. [Google Scholar]
- Hulu, S.; Sihombing, P.; Sutarman. Analysis of Performance Cross Validation Method and K-Nearest Neighbor in Classification Data. Int. J. Res. Rev. 2020, 7, 69–73. [Google Scholar]
- Wright, S. Correlation and causation. J. Agric. Res. 1921, 20, 7. [Google Scholar]
- Nurdiati, S.; Bukhari, F.; Julianto, M.T.; Sopaheluwakan, A.; Aprilia, M.; Fajar, I.; Najib, M.K.; Septiawan, P. The Impact of El Niño Southern Oscillation and Indian Ocean Dipole on the Burned Area in Indonesia. Terr. Atmos. Ocean. Sci. 2022, 33, 16. [Google Scholar] [CrossRef]
- Nurdiati, S.; Sopaheluwakan, A.; Septiawan, P.; Ardhana, M.R. Joint Spatio-Temporal Analysis of Various Wildfire and Drought Indicators in Indonesia. Atmosphere 2022, 13, 1591. [Google Scholar] [CrossRef]
- Safril, A. Rainfall Variability Study in Kalimantan as an Impact of Climate Change and El Niño. AIP Conf. Proc. 2021, 2320, 040002. [Google Scholar] [CrossRef]
- Lee, H.S. General Rainfall Patterns in Indonesia and the Potential Impacts of Local Seas on Rainfall Intensity. Water 2015, 7, 1751–1768. [Google Scholar] [CrossRef]
- Mcbride, J.L.; Sahany, S.; Hassim, M.E.E.; Nguyen, C.M.; Lim, S.-Y.; Rahmat, R.; Cheong, W.-K. The 2014 Record Dry Spell at Singapore: An Intertropical Convergence Zone (ITCZ) Drought. Bull. Am. Meteorol. Soc. 2015, 96, S126–S130. [Google Scholar] [CrossRef]
- Hendrawan, I.G.; Asai, K.; Triwahyuni, A.; Valentina Lestari, D. The Interanual Rainfall Variability in Indonesia Corresponding to El Niño Southern Oscillation and Indian Ocean Dipole. Acta Oceanol. Sin. 2019, 38, 57–66. [Google Scholar] [CrossRef]
- Yun, K.-S.; Lee, J.-Y.; Timmermann, A.; Stein, K.; Stuecker, M.F.; Fyfe, J.C.; Chung, E.-S. Increasing ENSO–Rainfall Variability Due to Changes in Future Tropical Temperature–Rainfall Relationship. Commun. Earth Environ. 2021, 2, 43. [Google Scholar] [CrossRef]
- Cai, W.; Zheng, X.-T.; Weller, E.; Collins, M.; Cowan, T.; Lengaigne, M.; Yu, W.; Yamagata, T. Projected Response of the Indian Ocean Dipole to Greenhouse Warming. Nat. Geosci. 2013, 6, 999–1007. [Google Scholar] [CrossRef]
- Nurdiati, S.; Sopaheluwakan, A.; Septiawan, P. Joint Distribution Analysis of Forest Fires and Precipitation in Response to ENSO, IOD, and MJO (Study Case: Sumatra, Indonesia). Atmosphere 2022, 13, 537. [Google Scholar] [CrossRef]
- Kusumaningtyas, S.D.A.; Aldrian, E. Impact of the June 2013 Riau Province Sumatera Smoke Haze Event on Regional Air Pollution. Environ. Res. Lett. 2016, 11, 075007. [Google Scholar] [CrossRef]
- Zhang, C. Madden–Julian Oscillation: Bridging Weather and Climate. Bull. Am. Meteorol. Soc. 2013, 94, 1849–1870. [Google Scholar] [CrossRef]
- Reid, J.S.; Xian, P.; Hyer, E.J.; Flatau, M.K.; Ramirez, E.M.; Turk, F.J.; Sampson, C.R.; Zhang, C.; Fukada, E.M.; Maloney, E.D. Multi-Scale Meteorological Conceptual Analysis of Observed Active Fire Hotspot Activity and Smoke Optical Depth in the Maritime Continent. Atmos. Chem. Phys. 2012, 12, 2117–2147. [Google Scholar] [CrossRef] [Green Version]
- Kurniadi, A.; Weller, E.; Min, S.-K.; Seong, M.-G. Independent ENSO and IOD Impacts on Rainfall Extremes over Indonesia. Int. J. Climatol. 2021, 41, 3540–3656. [Google Scholar] [CrossRef]
- As-Syakur, A.R.; Adnyana, I.W.S.; Mahendra, M.S.; Wayan, I.A.; Merit, I.N.; Kasa, I.W.; Ekayanti, N.W.; Nuarsa, I.W.; Sunarta, I.N. Observation of Spatial Patterns on the Rainfall Response to ENSO and IOD over Indonesia Using TRMM Multisatellite Precipitation Analysis (TMPA). Int. J. Climatol. 2014, 34, 3825–3839. [Google Scholar] [CrossRef]
- Iskandar, I.; Lestrai, D.O.; Nur, M. Impact of El Niño and El Niño Modoki Events on Indonesian Rainfall. Makara J. Sci. 2019, 23, 7. [Google Scholar] [CrossRef] [Green Version]
- Lestari, D.O.; Sutriyono, E.; Sabaruddin; Iskandar, I. Respective Influences of Indian Ocean Dipole and El NiñoSouthern Oscillation on Indonesian Precipitation. J. Math. Fundam. Sci. 2018, 50, 257–272. [Google Scholar] [CrossRef] [Green Version]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ardiyani, E.; Nurdiati, S.; Sopaheluwakan, A.; Septiawan, P.; Najib, M.K. Probabilistic Hotspot Prediction Model Based on Bayesian Inference Using Precipitation, Relative Dry Spells, ENSO and IOD. Atmosphere 2023, 14, 286. https://doi.org/10.3390/atmos14020286
Ardiyani E, Nurdiati S, Sopaheluwakan A, Septiawan P, Najib MK. Probabilistic Hotspot Prediction Model Based on Bayesian Inference Using Precipitation, Relative Dry Spells, ENSO and IOD. Atmosphere. 2023; 14(2):286. https://doi.org/10.3390/atmos14020286
Chicago/Turabian StyleArdiyani, Evi, Sri Nurdiati, Ardhasena Sopaheluwakan, Pandu Septiawan, and Mohamad Khoirun Najib. 2023. "Probabilistic Hotspot Prediction Model Based on Bayesian Inference Using Precipitation, Relative Dry Spells, ENSO and IOD" Atmosphere 14, no. 2: 286. https://doi.org/10.3390/atmos14020286
APA StyleArdiyani, E., Nurdiati, S., Sopaheluwakan, A., Septiawan, P., & Najib, M. K. (2023). Probabilistic Hotspot Prediction Model Based on Bayesian Inference Using Precipitation, Relative Dry Spells, ENSO and IOD. Atmosphere, 14(2), 286. https://doi.org/10.3390/atmos14020286