


A Hybrid Deep Learning Model for Air Quality Prediction Based on the Time–Frequency Domain Relationship

Abstract
:1. Introduction
2. Problem Scenario
2.1. Wavelet Transform Used for Time-Series Decomposition
2.2. Encoder
2.3. Decoder
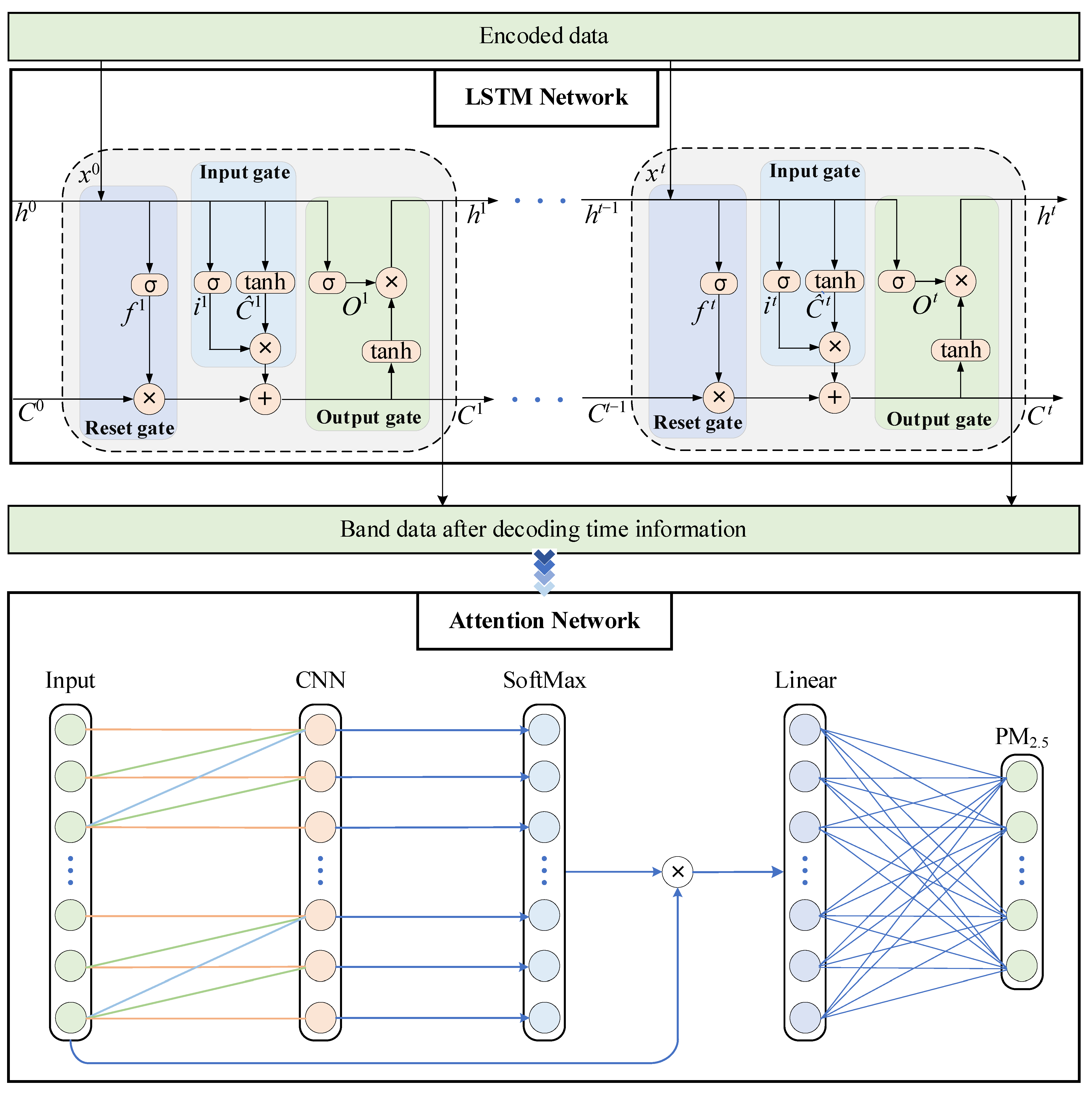
2.3.1. LSTM
2.3.2. Attention
2.4. Data Sources
3. Methods
3.1. Framework
3.2. Data Processing
3.3. Construction of Frequency Separator
3.4. Construction of Encoder
3.5. Construction of the Decoder
3.6. Evaluation Criterion
4. Experimental Results and Analysis
4.1. Network Parameters
4.2. Prediction Performance
4.3. Ablation Experiment
4.4. Correlation Analysis between PM2.5 and Other Variables
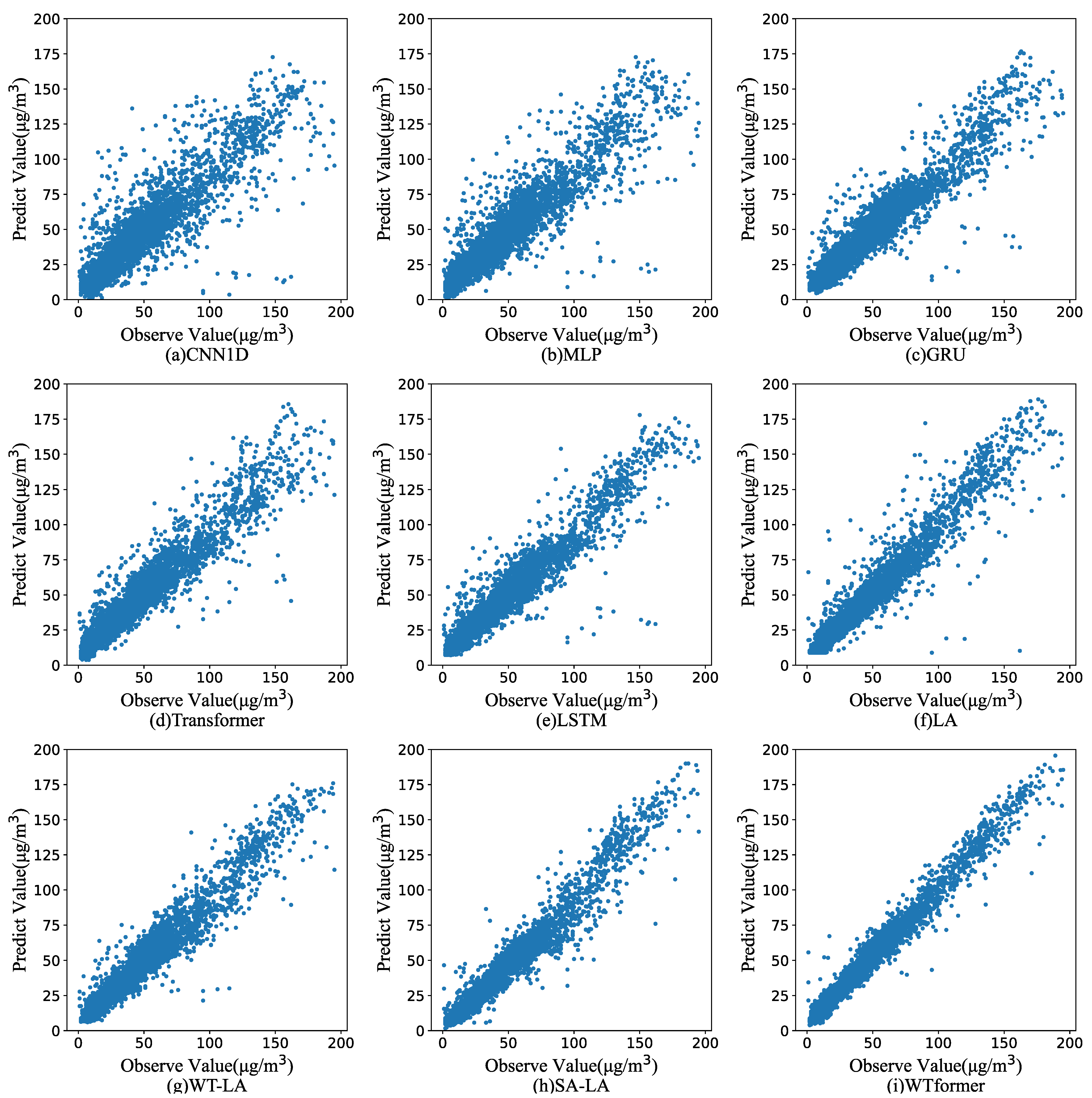
4.5. Comparison of WTformer with Other Methods
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, H.; Deng, G.; Liu, Y. Monitoring the Influence of Industrialization and Urbanization on Spatiotemporal Variations of AQI and PM2.5 in Three Provinces, China. Atmosphere 2022, 13, 1377. [Google Scholar] [CrossRef]
- Li, G.; Fang, C.; Wang, S.; Sun, S. The Effect of Economic Growth, Urbanization, and Industrialization on Fine Particulate Matter (PM2.5) Concentrations in China. Environ. Sci. Technol. 2016, 50, 11452–11459. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Dong, T.; Zhang, X. Research on the Impact of Industrialization and Urbanization on Carbon Emission Intensity of Energy Consumption: Evidence from China. Pol. J. Environ. Stud. 2022, 31, 4413–4425. [Google Scholar] [CrossRef]
- Kim, D.; Chen, Z.; Zhou, L.-F.; Huang, S.-X. Air pollutants and early origins of respiratory diseases. Chronic Dis. Transl. Med. 2018, 4, 75–94. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Omaye, S.T. Air pollutants, oxidative stress and human health. Mutat. Res.-Genet. Toxicol. Environ. Mutagen. 2009, 674, 45–54. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Liu, X.; Wan, H.; Pan, X.; Li, J. A Feature Extraction and Classification Method to Forecast the PM2.5 Variation Trend Using Candlestick and Visual Geometry Group Model. Atmosphere 2021, 12, 570. [Google Scholar] [CrossRef]
- Xu, R.; Deng, X.; Wan, H.; Cai, Y.; Pan, X. A deep learning method to repair atmospheric environmental quality data based on Gaussian diffusion. Journal of Cleaner Production 2021, 308. [Google Scholar] [CrossRef]
- Masood, A.; Ahmad, K. A review on emerging artificial intelligence (AI) techniques for air pollution forecasting: Fundamentals, application and performance. J. Clean. Prod. 2021, 322, 129072. [Google Scholar] [CrossRef]
- Cheng, S.; Li, J.; Feng, B.; Jin, Y.; Hao, R. A Gaussian-box modeling approach for urban air quality management in a northern Chinese city: I. Model development. Water Air Soil Pollut. 2007, 178, 37–57. [Google Scholar] [CrossRef]
- Overcamp, T.J. Diffusion-Models for Transient Releases. J. Appl. Meteorol. 1990, 29, 1307–1312. [Google Scholar] [CrossRef]
- Alizadeh, Z.; Yazdi, J.; Najafi, M.S. Improving the outputs of regional heavy rainfall forecasting models using an adaptive real-time approach. Hydrol. Sci. J. 2022, 67, 550–563. [Google Scholar] [CrossRef]
- Calvetti, L.; Pereira Filho, A.J. Ensemble Hydrometeorological Forecasts Using WRF Hourly QPF and TopModel for a Middle Watershed. Adv. Meteorol. 2014, 2014, 484120. [Google Scholar] [CrossRef] [Green Version]
- Iriza, A.; Dumitrache, R.C.; Lupascu, A.; Stefan, S. Studies regarding the quality of numerical weather forecasts of the WRF model integrated at high-resolutions for the Romanian territory. Atmosfera 2016, 29, 11–21. [Google Scholar] [CrossRef] [Green Version]
- Byun, D.W. One-atmosphere dynamics description in the Models-3 Community Multi-scale Air Quality (CMAQ) modeling system. In Proceedings of the 7th International Air Pollution Conference, Stanford University, Stanford, CA, USA, 26–28 July 1999; pp. 883–892. [Google Scholar]
- Byun, D.W.; Ching, J.K.S.; Novak, J.; Young, J. Development and implementation of the EPA’s models-3 initial operating version: Community multi-scale air quality (CMAQ) model. In Proceedings of the 22nd NATO/CCMS International Technical Meeting on Air Pollution Modeling and its Application, Clermont Ferra, France, 2–6 June 1997; pp. 357–368. [Google Scholar]
- Cheng, Y.; Li, X.C.; Li, Z.J.; Jiang, S.X.; Jiang, X.F. Fine-Grained Air Quality Monitoring Based on Gaussian Process Regression. In Proceedings of the 21st International Conference on Neural Information Processing (ICONIP), Kuching, Malaysia, 3–6 November 2014; pp. 126–134. [Google Scholar]
- Rogers, R.E.; Deng, A.; Stauffer, D.R.; Gaudet, B.J.; Jia, Y.; Soong, S.-T.; Tanrikulu, S. Application of the Weather Research and Forecasting Model for Air Quality Modeling in the San Francisco Bay Area. J. Appl. Meteorol. Climatol. 2013, 52, 1953–1973. [Google Scholar] [CrossRef] [Green Version]
- Lee, P.C.; Pleim, J.E.; Mathur, R.; McQueen, J.T.; Tsidulko, M.; DiMego, G.; Iredell, M.; Otte, T.L.; Pouliot, G.; Young, J.O.; et al. Linking the ETA model with the Community Multiscale Air Quality (CMAQ) modeling system: Ozone boundary conditions. In Proceedings of the 27th NATO/CCMS International Technical Meeting on Air Pollution Modeling and Its Application, Banff, AB, Canada, 24–29 October 2004; p. 379. [Google Scholar]
- Martin, F.; Palomino, I.; Vivanco, M.G. Combination of measured and modelling data in air quality assessment in Spain. Int. J. Environ. Pollut. 2012, 49, 36–44. [Google Scholar] [CrossRef]
- Westerlund, J.; Urbain, J.-P.; Bonilla, J. Application of air quality combination forecasting to Bogota. Atmos. Environ. 2014, 89, 22–28. [Google Scholar] [CrossRef]
- Feng, R.; Gao, H.; Luo, K.; Fan, J.-r. Analysis and accurate prediction of ambient PM2.5 in China using Multi-layer Perceptron. Atmos. Environ. 2020, 232, 117534. [Google Scholar] [CrossRef]
- Lu, W.Z.; Fan, H.Y.; Lo, S.M. Application of evolutionary neural network method in predicting pollutant levels in downtown area of Hong Kong. Neurocomputing 2003, 51, 387–400. [Google Scholar] [CrossRef]
- Suarez Sanchez, A.; Garcia Nieto, P.J.; Riesgo Fernandez, P.; del Coz Diaz, J.J.; Iglesias-Rodriguez, F.J. Application of an SVM-based regression model to the air quality study at local scale in the Aviles urban area (Spain). Math. Comput. Model. 2011, 54, 1453–1466. [Google Scholar] [CrossRef]
- Wang, W.; Men, C.; Lu, W. Online prediction model based on support vector machine. Neurocomputing 2008, 71, 550–558. [Google Scholar] [CrossRef]
- Pan, B.; Iop. Application of XGBoost algorithm in hourly PM2.5 concentration prediction. In Proceedings of the 3rd International Conference on Advances in Energy Resources and Environment Engineering (ICAESEE), Harbin, China, 8–10 December 2017. [Google Scholar]
- Putra, F.M.; Sitanggang, I.S. Classification model of air quality in Jakarta using decision tree algorithm based on air pollutant standard index. In Proceedings of the 2nd International Conference on Environment and Forest Conservation (ICEFC), Mindanao State University, Bogor, Indonesia, 1–3 October 2019. [Google Scholar]
- Shaziayani, W.N.; Ul-Saufie, A.Z.; Mutalib, S.; Noor, N.M.; Zainordin, N.S. Classification Prediction of PM10 Concentration Using a Tree-Based Machine Learning Approach. Atmosphere 2022, 13, 538. [Google Scholar] [CrossRef]
- Amuthadevi, C.; Vijayan, D.S.; Ramachandran, V. Development of air quality monitoring (AQM) models using different machine learning approaches. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 33. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Prediction of Air Pollutant Concentration Based on One-Dimensional Multi-Scale CNN-LSTM Considering Spatial-Temporal Characteristics: A Case Study of Xi’an, China. Atmosphere 2021, 12, 1626. [Google Scholar] [CrossRef]
- Verma, I.; Ahuja, R.; Meisheri, H.; Dey, L.; Ieee. Air pollutant severity prediction using Bi-directional LSTM Network. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; pp. 651–654. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. Ieee Transactions on Neural Networks 2009, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J.; Ieee. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liao, Q.; Zhu, M.; Wu, L.; Pan, X.; Tang, X.; Wang, Z. Deep Learning for Air Quality Forecasts: A Review. Curr. Pollut. Rep. 2020, 6, 399–409. [Google Scholar] [CrossRef]
- Yi, X.; Zhang, J.; Wang, Z.; Li, T.; Zheng, Y.; Acm. Deep Distributed Fusion Network for Air Quality Prediction. In Proceedings of the 24th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), London, UK, 19–23 August 2018; pp. 965–973. [Google Scholar]
- Sayeed, A.; Lops, Y.; Choi, Y.; Jung, J.; Salman, A.K. Bias correcting and extending the PM forecast by CMAQ up to 7 days using deep convolutional neural networks. Atmos. Environ. 2021, 253, 118376. [Google Scholar] [CrossRef]
- Huang, C.-J.; Kuo, P.-H. A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [Green Version]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM(2.5) based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef]
- Perrone, M.G.; Gualtieri, M.; Consonni, V.; Ferrero, L.; Sangiorgi, G.; Longhin, E.; Ballabio, D.; Bolzacchini, E.; Camatini, M. Particle size, chemical composition, seasons of the year and urban, rural or remote site origins as determinants of biological effects of particulate matter on pulmonary cells. Environ. Pollut. 2013, 176, 215–227. [Google Scholar] [CrossRef] [PubMed]
- Guido, R.C. Wavelets behind the scenes: Practical aspects, insights, and perspectives. Phys. Rep. 2022, 985, 1–23. [Google Scholar] [CrossRef]
- Qiao, W.; Tian, W.; Tian, Y.; Yang, Q.; Wang, Y.; Zhang, J. The Forecasting of PM2.5 Using a Hybrid Model Based on Wavelet Transform and an Improved Deep Learning Algorithm. IEEE Access 2019, 7, 142814–142825. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Siwek, K.; Osowski, S. Improving the accuracy of prediction of PM10 pollution by the wavelet transformation and an ensemble of neural predictors. Eng. Appl. Artif. Intell. 2012, 25, 1246–1258. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, G.; Chen, F.; He, Y. A hybrid-wavelet model applied for forecasting PM2.5 concentrations in Taiyuan city, China. Atmos. Pollut. Res. 2019, 10, 1884–1894. [Google Scholar] [CrossRef]
- Wang, J.; Lu, X.; Yan, Y.; Zhou, L.; Ma, W. Spatiotemporal characteristics of PM(2.5) concentration in the Yangtze River Delta urban agglomeration, China on the application of big data and wavelet analysis. Sci. Total Environ. 2020, 724, 138134. [Google Scholar] [CrossRef]
- Gao, C.; Zhang, N.; Li, Y.; Bian, F.; Wan, H. Self-attention-based time-variant neural networks for multi-step time series forecasting. Neural Comput. Appl. 2022, 34, 8737–8754. [Google Scholar] [CrossRef]
- Huang, S.; Wang, D.; Wu, X.; Tang, A. DSANet. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2129–2132. [Google Scholar]
- Shi, L.; Liang, N.; Xu, X.; Li, T.; Zhang, Z. SA-JSTN: Self-Attention Joint Spatiotemporal Network for Temperature Forecasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9475–9485. [Google Scholar] [CrossRef]
- Choudhury, A.; Middya, A.I.; Roy, S. Attention enhanced hybrid model for spatiotemporal short-term forecasting of particulate matter concentrations. Sustain. Cities Soc. 2022, 86, 104112. [Google Scholar] [CrossRef]
- Lin, Y.; Chen, K.; Zhang, X.; Tan, B.; Lu, Q. Forecasting crude oil futures prices using BiLSTM-Attention-CNN model with Wavelet transform. Appl. Soft Comput. 2022, 130, 109723. [Google Scholar] [CrossRef]
- Nandi, A.; De, A.; Mallick, A.; Middya, A.I.; Roy, S. Attention based long-term air temperature forecasting network: ALTF Net. Knowl. Based Syst. 2022, 252, 109442. [Google Scholar] [CrossRef]
- Long, T.; Peng, B.; Yang, Z.; Tang, C.; Ye, Z.; Zhao, N.; Chen, C. Spatial Distribution and Source of Inorganic Elements in PM(2.5) During a Typical Winter Haze Episode in Guilin, China. Arch Environ Contam Toxicol 2020, 79, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Janarthanan, R.; Partheeban, P.; Somasundaram, K.; Elamparithi, P.N. A deep learning approach for prediction of air quality index in a metropolitan city. Sustain. Cities Soc. 2021, 67, 102720. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Variables | Unit |
|---|---|---|
| Pollutant | PM2.5 | ug/m3 |
| PM10 | ug/m3 | |
| CO | ug/m3 | |
| NO2 | ug/m3 | |
| SO2 | ug/m3 | |
| O3 | ug/m3 | |
| Climate variables | Wind speed | m/s |
| Temperature | °C | |
| Humidity | % | |
| Rain | mm | |
| Pressure | hpa |
| MLP | CNN1D | GRU | Transformer | LSTM | LA | WT-LA | SA-LA | WTformer | ||
|---|---|---|---|---|---|---|---|---|---|---|
| +1 h | RMSE | 7.475 | 7.349 | 6.799 | 8.083 | 6.840 | 6.614 | 6.475 | 6.404 | 6.334 |
| MAE | 4.406 | 3.815 | 3.567 | 4.117 | 3.270 | 3.146 | 3.061 | 3.034 | 3.002 | |
| SMAPE | 0.119 | 0.106 | 0.086 | 0.117 | 0.084 | 0.081 | 0.080 | 0.077 | 0.076 | |
| +4 h | RMSE | 15.554 | 16.364 | 13.099 | 12.607 | 12.172 | 10.703 | 10.287 | 9.681 | 8.162 |
| MAE | 10.151 | 10.233 | 8.725 | 8.830 | 8.091 | 6.655 | 6.582 | 6.509 | 5.679 | |
| SMAPE | 0.261 | 0.266 | 0.228 | 0.233 | 0.222 | 0.184 | 0.183 | 0.176 | 0.171 | |
| +8 h | RMSE | 19.372 | 20.008 | 19.044 | 16.806 | 18.459 | 16.465 | 15.741 | 15.410 | 13.096 |
| MAE | 12.695 | 13.647 | 12.665 | 11.492 | 12.451 | 11.069 | 10.814 | 10.468 | 8.604 | |
| SMAPE | 0.306 | 0.348 | 0.304 | 0.291 | 0.303 | 0.270 | 0.263 | 0.258 | 0.215 | |
| +24 h | RMSE | 27.650 | 29.452 | 27.077 | 24.478 | 26.321 | 22.820 | 21.086 | 20.938 | 17.140 |
| MAE | 19.209 | 20.949 | 19.103 | 17.604 | 18.868 | 16.208 | 15.008 | 14.723 | 12.213 | |
| SMAPE | 0.445 | 0.491 | 0.439 | 0.401 | 0.432 | 0.361 | 0.336 | 0.332 | 0.271 | |
| +48 h | RMSE | 32.492 | 33.115 | 36.878 | 30.027 | 33.649 | 28.905 | 26.794 | 26.419 | 21.379 |
| MAE | 23.569 | 23.581 | 25.987 | 21.295 | 24.135 | 20.442 | 18.991 | 18.630 | 14.943 | |
| SMAPE | 0.538 | 0.524 | 0.567 | 0.487 | 0.539 | 0.455 | 0.417 | 0.409 | 0.331 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, R.; Wang, D.; Li, J.; Wan, H.; Shen, S.; Guo, X. A Hybrid Deep Learning Model for Air Quality Prediction Based on the Time–Frequency Domain Relationship. Atmosphere 2023, 14, 405. https://doi.org/10.3390/atmos14020405
Xu R, Wang D, Li J, Wan H, Shen S, Guo X. A Hybrid Deep Learning Model for Air Quality Prediction Based on the Time–Frequency Domain Relationship. Atmosphere. 2023; 14(2):405. https://doi.org/10.3390/atmos14020405
Chicago/Turabian StyleXu, Rui, Deke Wang, Jian Li, Hang Wan, Shiming Shen, and Xin Guo. 2023. "A Hybrid Deep Learning Model for Air Quality Prediction Based on the Time–Frequency Domain Relationship" Atmosphere 14, no. 2: 405. https://doi.org/10.3390/atmos14020405
APA StyleXu, R., Wang, D., Li, J., Wan, H., Shen, S., & Guo, X. (2023). A Hybrid Deep Learning Model for Air Quality Prediction Based on the Time–Frequency Domain Relationship. Atmosphere, 14(2), 405. https://doi.org/10.3390/atmos14020405