1. Introduction
Rainfall-Runoff (RR) modeling is one of the classical applications of hydrology. It has the purpose of simulating a river flow hydrograph in a given cross river section induced by an observed or a hypothetical rainfall forcing [
1]. Depending on their complexity, rainfall-runoff models can also simulate the dynamics of water quality, ecosystems, and other dynamical systems related to water, therefore embedding laws of chemistry, ecology, social sciences, and other fields into the model. These models can be used for flood simulation, forecasting, and prevention [
2,
3,
4,
5,
6], management of water resources [
7,
8], and water supply simulation and forecasting [
9,
10]. Moreover, the applications also include land use and land cover (LULC) impact assessment [
11] and management practices and water quality evaluation [
12].
The hydrology and water resources domains have witnessed growing interest in using data-driven models to improve the simulation of RR processes whether by directly replacing or being used in conjunction with classical hydrological models (HMs) [
13].
The physics-based modeling methods, for example the Soil and Water Assessment Tool (SWAT), solve hydrological problems through computing the conservation equations of momentum, mass, and energy and mathematically quantifying real-world physics [
14]. Meanwhile, data-driven modeling approaches, for example machine learning, depend primarily on numerical data to solve hydrological problems. The last decade has seen rapid developments and a trend shift toward data-driven hydrological modeling, primarily in order to overcome the uncertainty and high parametric requirement of physically-based models [
15].
Among the many different methods of soft computing, Artificial Neural Networks (ANN) have been shown to be the method of preference when it comes to modeling the complicated rainfall-runoff phenomena. Neural networks were used by Tokar and Johnson [
16] to estimate daily runoff as a product of daily precipitation, temperature, and snowmelt. According to the findings of the research, the ANN model had a higher degree of accurate prediction when compared with both regression and conceptual models. Wilby et al. [
17] developed a conceptual and neural network rainfall-runoff model using the data they obtained from precipitation, evaporation, and discharge. To assess the degree to which neural networks can reliably ingest the hydrological processes, three separate experiments were carried out, each with a gradually diminishing quantity of information. According to the findings of the research, a neural network consisting of seven inputs and three hidden nodes could comprehend the behavior of the conceptual model.
Most recently, there has been a significant shift toward the use of hybrid soft computing strategies for the purpose of resolving difficulties faced in real life. The symbiotic relationship that exists between the various soft computing methodologies is seen to be the driving force for this expansion. The combination of methods helps to overcome the shortcomings of each of the separate approaches and ultimately results in the creation of reliable computational strategies [
18]. For example, Okkan et al. [
19] developed a novel nested hybrid rainfall-runoff modelling framework based on the confluence of machine learning (ANN and support vector machine (SVM)) and a conceptual rainfall-runoff model (dynamic water balance model (dynwbm)). The findings reflect that the nested hybrid model bested the standalone machine learning, and the conceptual models, and the coupled models. Likewise, Poonia and Tiwari [
20] used two variants of ANN, radial basis function (RBF) and feed-forward back propagation (FFBP), to link rainfall events with runoff generation in the Hoshangabad basin of the Narmada River. The outcomes supported RBF as a highly accurate rainfall-runoff modeling technique (i.e., R
2 = 0.9964) in the basin. Similarly, Gomes and Blanco [
21] coupled conventional ANN models with MODWT to estimate daily rainfall in the Tocantins-Araguaia Hydrographic Region, Brazil. The results indicate an enhancement in the performance of hybrid MODWT-ANN models (i.e., NSE = 0.81–0.95) when compared to stand-alone ANN models. A similar study by Nourani et al. [
22] formulated a wavelet-based M5 tree model (Wavelet-M5 model) and employed the model in a rainfall-runoff simulation of the Sardrud catchment in Iran. The authors also compared the novel hybrid model with a simple M5 tree model and a hybrid wavelet-ANN (WANN) model. The study revealed that wavelet coupling enhanced modeling performance of the M5 model by approximately 31%. In another study, Nourani et al. [
23] systematically reviewed the application of wavelet-based hybrid Artificial Intelligence (AI) modelling in hydro-climatology. The authors primarily explored the wavelet-hybrid applications of AI models, including ANN, decision tree, and random forest models, in different contexts such as sediment modelling, flow forecasting, precipitation modelling, and rainfall-runoff modelling. Ouma et al. [
24] compared the performance of a hybrid machine learning model (WNN) with a deep learning model long short-term memory (LSTM) in rainfall and runoff time-series trend analysis in the Nzoia basin. The results reflected the higher prediction accuracy of LSTM (i.e., R
2 = 0.861) when compared to WNN models (0.782). Saifullah et al. [
25] explored the rainfall-runoff linkage of the Jhelum River in Pakistan by using gene expression programming (GEP), a support vector machine coupled with radial biases function (RBF-SVM), and an M5-Model tree. The authors concluded that GEP performed better in light of observations made from flow duration curves. Similarly, Kavoosi and Khozeymehnnhad [
26] also employed GEP to simulate rainfall-runoff process in the Halil River in Iran. The authors compared the performance with neural network and fuzzy logic models. The outcomes indicated that GEP was outperformed by a particle swarm optimized-adaptive neural fuzzy inference system (ANFIZ-PSO). Asadi et al. [
27] used a genetic algorithm (GA) for the purpose of evolving the weights of the neural network that was utilized for modeling the rainfall-runoff process. To improve the accuracy of the model’s predictions, the data were pre-processed using several techniques, including data transformation, input variable selection, and data clustering. According to the findings of the research, using this technique results in a more expedient learning process, a high degree of accuracy, and good adaptability to the nonlinear functional connections that exist between rainfall and runoff. Similarly, Okkan and Serbes [
28] employed three machine learning techniques–feed forward neural networks (FFNN), multiple linear regression (MLP), and least square support vector machine (LSSVM)–with discrete wavelet transformation (DWT) to model reservoir inflow of the Demirkopru Dam in Turkey. The authors observed that the DWT-FFNN hybrid model outperformed the other models used in the study. In another study, Okkan [
29] proposed wavelet-based WNN and wavelet-multi linear regression (WREG) hybrid models to predict the monthly reservoir inflow of the Kemer Dam in Turkey. The outcomes indicated that integration of DWT with FFNN and REG models enhanced the prediction accuracy of hybrid models when compared to the standalone models.
Researchers have also used more advanced and sophisticated structures of artificial intelligence in hydrology and climatology problems. For instance, a deep learning (DL) model, the convolutional neural network (CNN), has been implemented to increase precipitation forecasting accuracy [
30], rainfall-runoff modelling [
31], and non-periodic flow prediction [
32]. Similarly, basic and improved structures of long short-term memory (LSTM) models have been employed in solving hydro-climatological problems including precipitation forecasting [
33], rainfall-runoff modelling [
34], and wave height prediction [
35]. The above cited works emphasize the importance of rainfall-runoff modeling and the application of machine learning techniques in developing high accuracy models for understanding this latent hydrological relationship. In this context, in a previous study [
18], the authors applied five machine learning techniques and wavelet pre-processing to understand rainfall-runoff dynamics of the Soan River basin. However, the RR process of the other five basins, which play an equally important role in the hydrology of the Pothohar region, has not been analyzed. Indeed, the literature review highlights a significant research gap in terms of an unclear quantification of rainfall-runoff phenomenon in this region. Moreover, a comprehensive study on performance comparison of relevant machine learning techniques used for RR modeling on diverse and/or interrelated river basins is also required to demonstrate the applications of machine learning in hydrology. Lastly, the influence of using advanced wavelet transformation-based pre-processed input data on diverse machine learning techniques performance is still unclear.
This research work applies five of the major and most used machine learning techniques as stand-alone models and as hybrid models coupled with maximal overlap discrete wavelet transformation (MODWT) to evaluate the upshot of input data transformation on the modeling accuracy. The machine learning techniques can consist of logistic and linear regression models, naïve bayes, support vector machine, k-Nearest neighbor, and gradient boosting models but we have selected single decision tree (SDT), decision tree forest (DTF), tree boost (TB), multilayer perceptron (MLP), and gene expression modeling (GEP) owing to their contemporary modeling variants and inordinate and incessant applications in environmental and hydrological contexts. The above-mentioned machine learning methods have been discreetly explored in hydrological settings in previous studies [
36,
37,
38,
39,
40]. However, this study will provide thorough research work on the application of machine learning in rainfall-runoff modeling along with employment of wavelet pre-processing for enhancing modeling accuracy. Moreover, the present study aims to contribute to the existing research gaps by studying the linkage between rainfall and runoff in the Pothohar region of Pakistan. The multi-basin study covering ML techniques and wavelet transformation in the Pothohar region is the original effort by the authors.
Hence, the main objectives of this study are (i) the clear determination of linkages between rainfall events and runoff generation in the Pothohar region of Pakistan, (ii) the stand-alone application and assessment of the selected ML approaches (DTF, SDT, MLP, TB, and GEP), (iii) coupling each of the above-mentioned technique with MODWT to quantify the influence of input pre-processing on model results, and (iv) the comparison of the performance of each machine learning technique in the basins of the Pothohar region.
4. Discussion
The performance of five widely used machine learning approaches is comprehensively compared in this work alongside the impact of MODWT pre-processing on rainfall-runoff modeling in the Pothohar region of Pakistan. This research work is a follow up to our previous work [
18], in which the above-mentioned techniques were applied to model rainfall-runoff relationship in the Soan River basin only. Here, the authors have studied the links between rainfall and runoff in the entire Pothohar region.
In particular, the study revealed that the MODWT-DTF model performed best with an NSE equal to 0.88 and R
2 equal to 0.91 at Lo4 in the Soan-Haro River basin. In contrast to our study, Hussain et al. [
58] modeled the rainfall-runoff relation of this region with a maximum R
2 value of only 0.66. Ghani et al. [
59] used HEC-HMS and HEC-GeoHMS software to map the rainfall-runoff connection of the Pothohar region and the Soan River basin with 92% accuracy. The results of our study offer quantitative evidence for the conclusions regarding machine learning model efficiency increases when combined with wavelet pre-processing.
Additionally, the Soan-Haro River basin’s optimal lag order was found to be four, meaning that the models worked effectively when rainfall data was delayed up to four days with input variables R
t−1, R
t−2, R
t−3, and R
t−4. The time it takes for runoff generated due to rainfall in the farthest part of the basin to reach the basin outlet is related to this optimum lag number. Examination of the rainfall and runoff dataset revealed that the highest runoff (1407.69 m
3/s) occurred four days after the highest rainfall event (68.70 mm). This was in contrast to the testing period, when the highest runoff was discovered to occur after three days and lasted up to four days after the maximum rainfall event. Previous investigations [
36,
37,
60] have also noted this relationship between the theoretical idea of lag order, sometimes known as time lag or lag number, and the physical concept of time of concentration (Tc).
The single decision tree models are largely prone to lose information in tasks requiring multiple categorizations. This makes SDT less accurate in learning and predicting the relationship between continuous variables [
61]. Moreover, the decision tree-based models, including SDT and TB, are highly unstable and overly sensitive to minor changes in time series data. As such, modelling performance is significantly impacted by the range of time series data. In contrast, DTF combines the outcomes from several decision trees and the outcome is based on an ensembled result of variable categorization in all the trees. Moreover, the decision tree forest also creates more diverse sets of decision trees that capture different features in the data [
62]. This makes DTF less likely to be sensitive to a minor variation and overfitting problem and therefore more accurate in prediction tasks when compared to SDT and TB. Similar trends have been observed in the findings of our study, as DTF and MODWT models clearly outperformed stand-alone and MODWT-based SDT and TB models in both scenarios. Similarly, gene expression programming (GEP) and multi-layer perceptron (MLP) models can sometimes lack generalization and interpretability of data features in prediction tasks [
63,
64]. Moreover, both GEP and MLP are prone to overfitting in cases of diverse hyperparameter settings. Lower NSE values of stand-alone and hybrid MLP and GEP models are consistent with these caveats of the techniques.
This work contributed to the body of knowledge by demonstrating the usefulness of DTF and MODWT-based DTF in the hydrological modeling of the Pothohar region, while other earlier studies [
28,
38,
40,
51,
65] support the conclusions of our study regarding improving modeling accuracy using wavelet transformation.
Nevertheless, it may be noted that, although the Pothohar region is one of the main basins in the Indus River basin, it does not entirely represent the hydrology of the Indus River plane, since there exist other portions of the Indus basin.
A combination of evapotranspiration, rainfall, and infiltration data can also be used in any future research work to better comprehend the association between these hydrological processes. Moreover, the hydrological response of catchment basins is expected to become more complicated under the influence of changing climate trends. Therefore, multivariate quantification of runoff would be helpful in solving prospective hydrological problems. Furthermore, this experiment only utilizes rainfall and pre-processed rainfall data to retrieve obscured details and additional information from the time series. Long short-term memory (LSTM), a deep learning approach, may be useful in examining the novel aspects of the hydrological parameters of the basin since deep learning applications in hydrology have progressed significantly.
These recommendations for further study effort are highly likely to be implemented by the authors in subsequent studies.
5. Conclusions
This study employed five machine learning techniques (SDT, TB, DTF, MLP, and GEP) as stand-alone models and hybrid models coupled with maximal overlap discrete wavelet transformation (MODWT) to garner the relationship between rainfall and runoff in the Pothohar region of Pakistan. The study area consisted of six sub-basins, from which four major sub-basins were selected as the focused study area. The analysis was run in two different homogeneous areas including the combined Bunha-Kahan River basin and the Soan-Haro River basin. The rainfall data of each combined river basin were aggregated against the water level data (converted from m to mm) from each gauging station, located in the downstream river basin.
In each case, the analysis was initially run using standalone ML technique (SDT, TB, DTF, MLP, and GEP) settings and then coupled with MODWT. The findings reflected that the MODWT-based DTF model at lag order 3 (Lo3) performed best in the Bunha-Kahan River basin and at Lo4 in the Soan-Haro River basin. The modeling accuracy ranged from 0.85 to 0.90, in terms of NSE, and from 0.90 to 0.92, in terms of R2. Additionally, it was proven that wavelet pre-processing improved the modeling accuracy of stand-alone machine learning models.
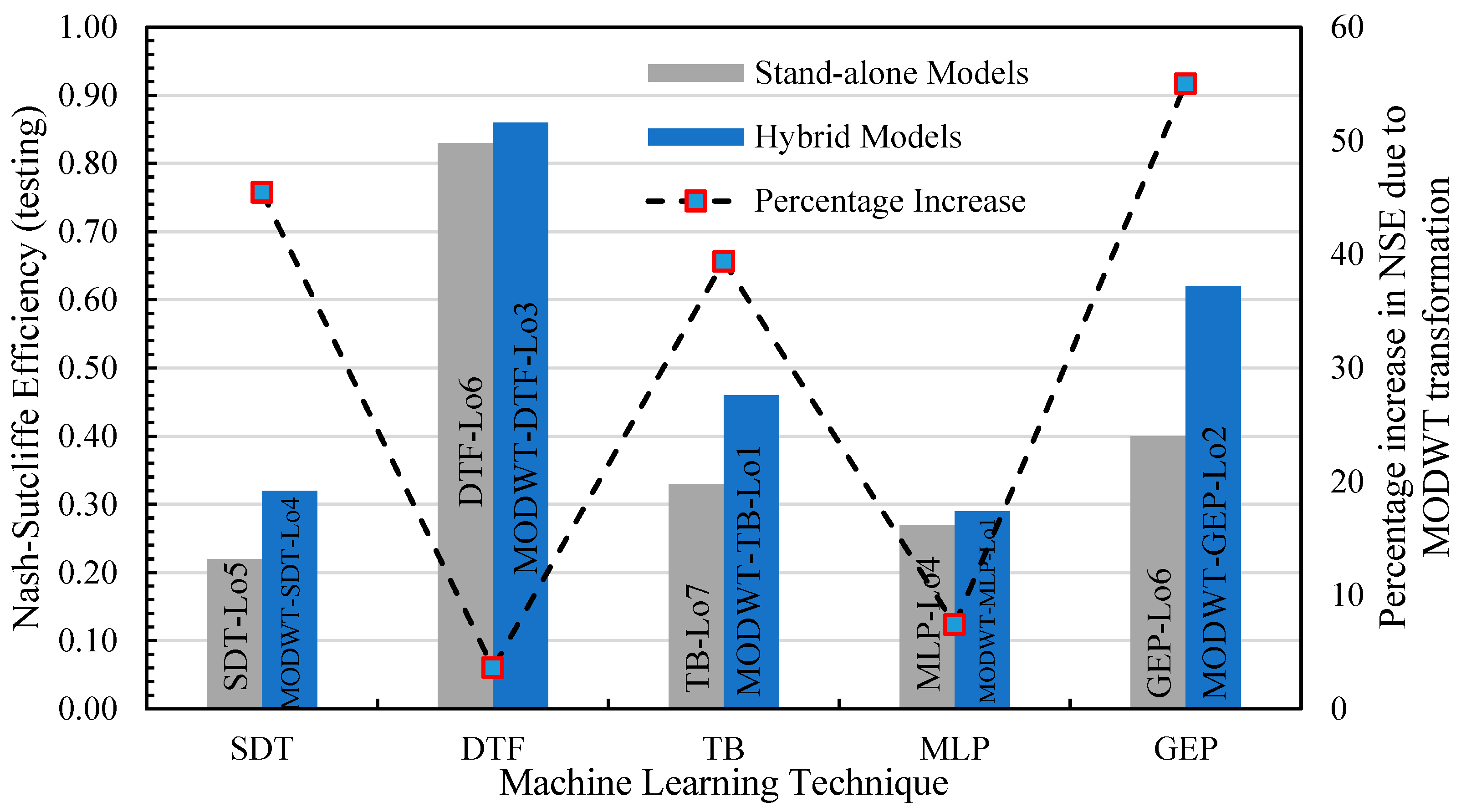
In the Bunha-Kahan River basin, the DTF mode, in combination with MODWT, performed best at Lo3 with an NSE value of 0.86. RMSE and R2-values were 220.45 and 0.92, respectively. The MODWT-GEP model showed the second-best performance, with an NSE value of 0.62 at Lo2, followed by an NSE value of 0.46 for the MODWT-TB model at Lo1. In the Soan-Haro River basin, the MODWT-based DTF model again performed best, with an 88% accuracy at Lo4. The MODWT-TB model recreated runoff data with 54% accuracy at lag order 2 (Lo2). The Decision Tree Forest (DTF) model performed well in each of the sub-basins when compared to standalone counter-models. When coupled with MODWT, the performance of all ML models was enhanced. However, other than the MODWT-DTF model, the modeling accuracy of SDT, TB, MLP, and GEP was generally unsatisfactory, except MODWT-GEP-Lo2 in the Bunha-Kahan River basin (NSE = 0.62).
This performance improvement is a result of the wavelet transformation’s propensity to recover latent details from the univariate time series during input signal pre-processing. Therefore, MODWT may be applied with confidence to issues requiring many variables to provide better results while using less parametric information and sparse modeling. The type, geography, and characteristics of the basin might affect the wavelet technique’s findings. Thus, it is important to choose the right wavelet family and type as well as decomposition level in order to obtain the best results.





 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















