
A Visualization Approach to Air Pollution Data Exploration—A Case Study of Air Quality Index (PM2.5) in Beijing, China



Abstract
:1. Introduction
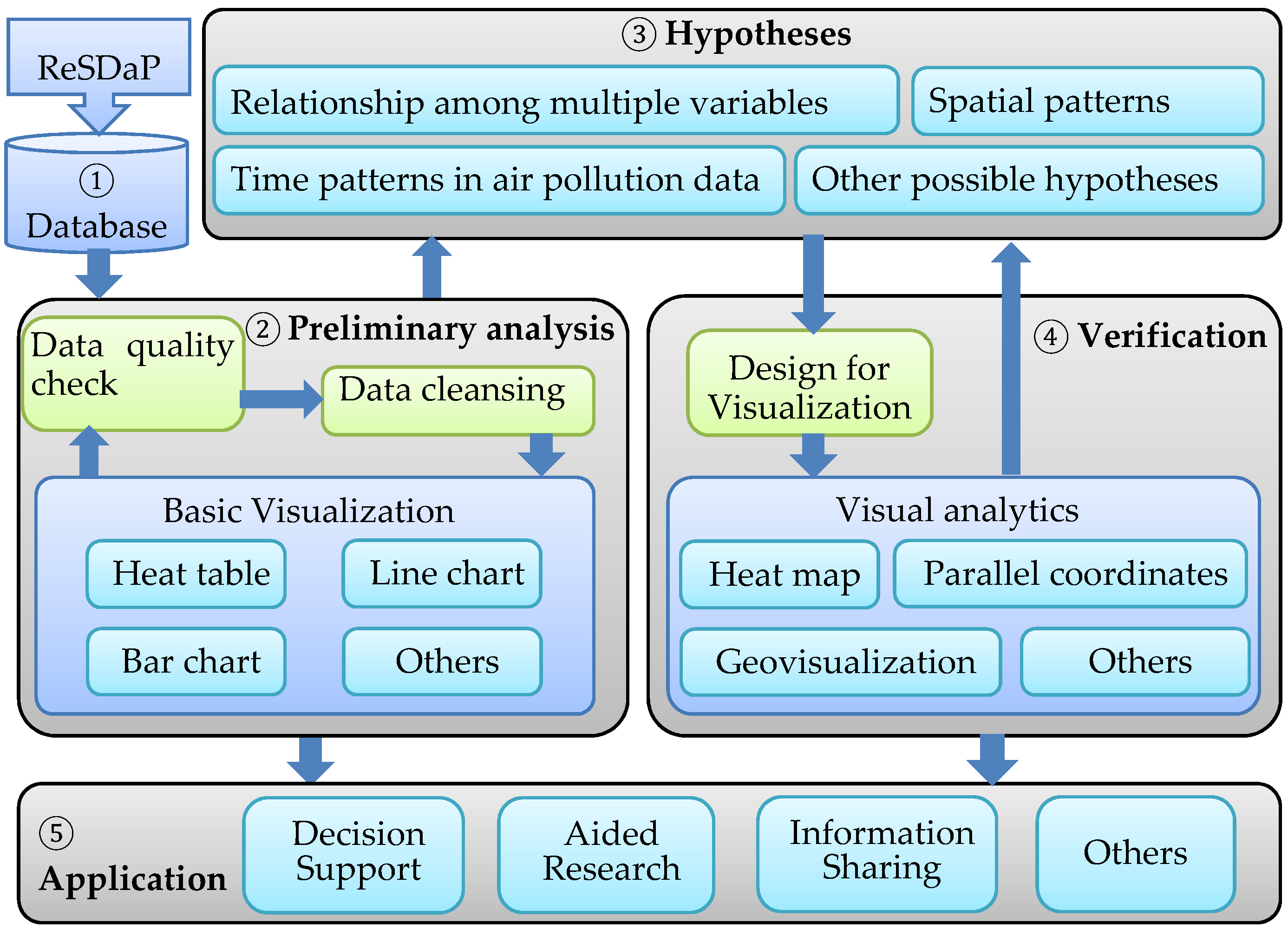
2. Method and Data
2.1. Preliminary Analysis
2.2. Hypotheses
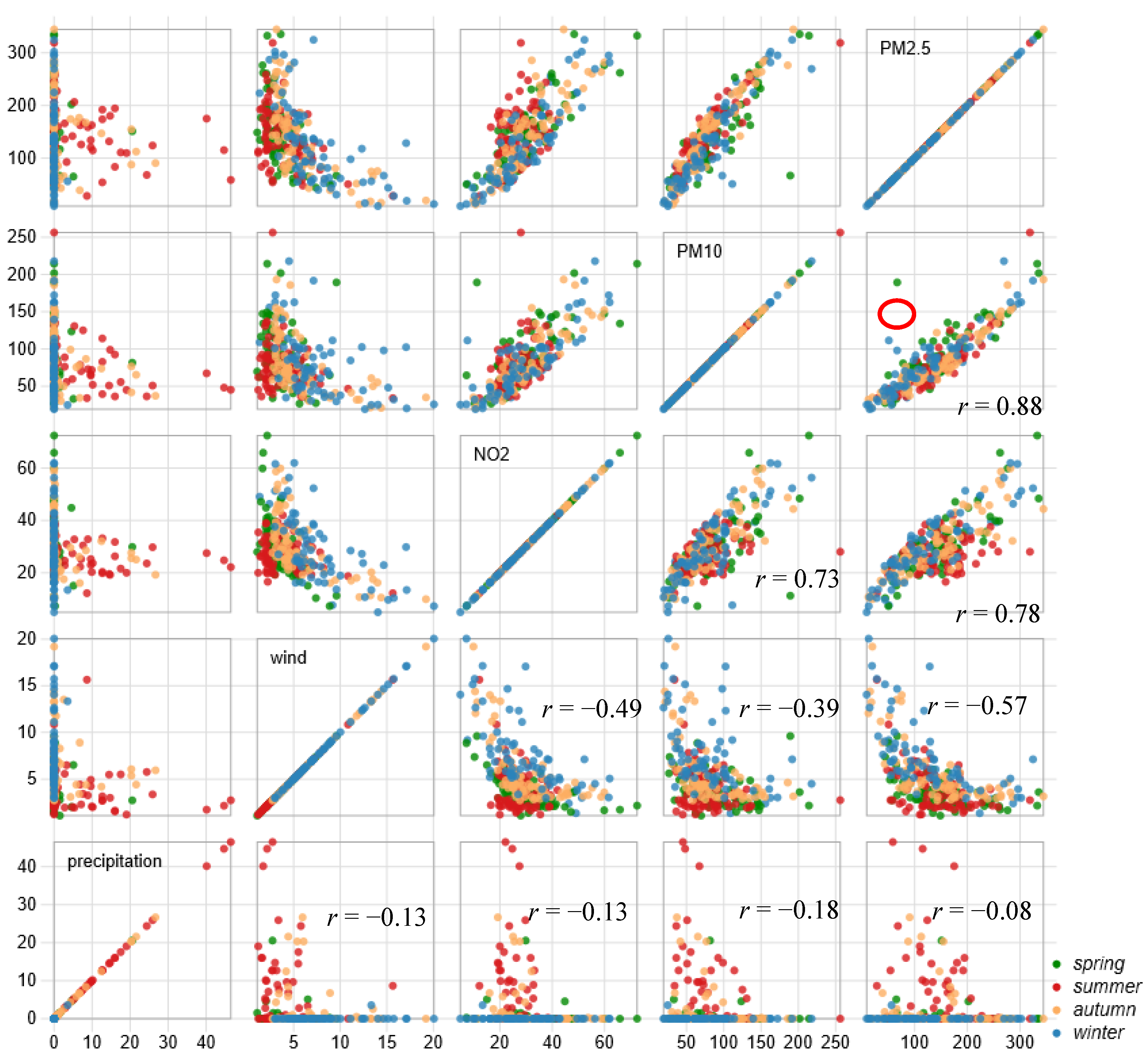
2.3. Verification of the Hypotheses
2.4. Application Layer
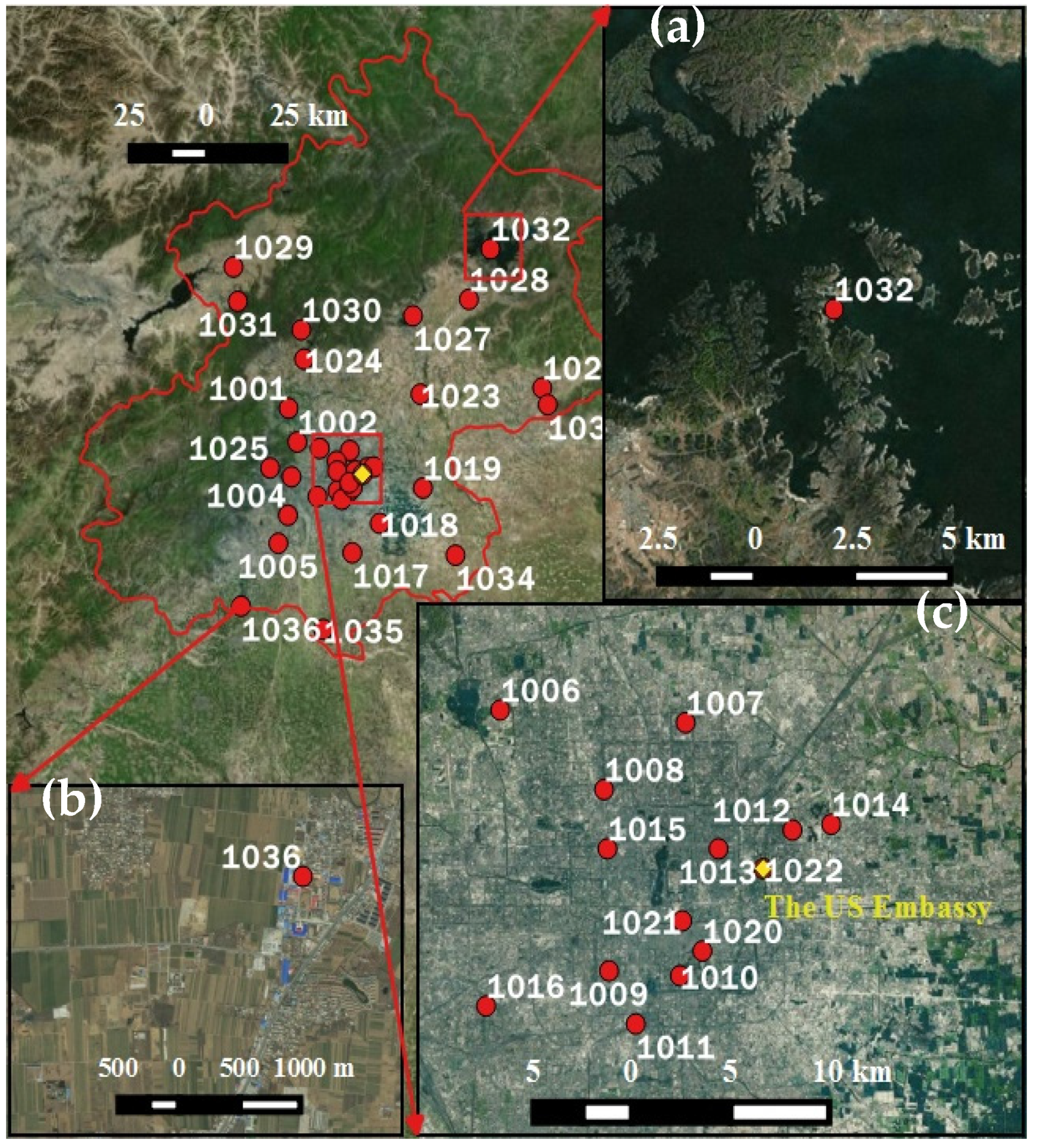
2.5. Experimental Data
3. Results and Discussion
3.1. General Analysis and Hypotheses
3.2. Multi-Perspective and Various Visual Analysis
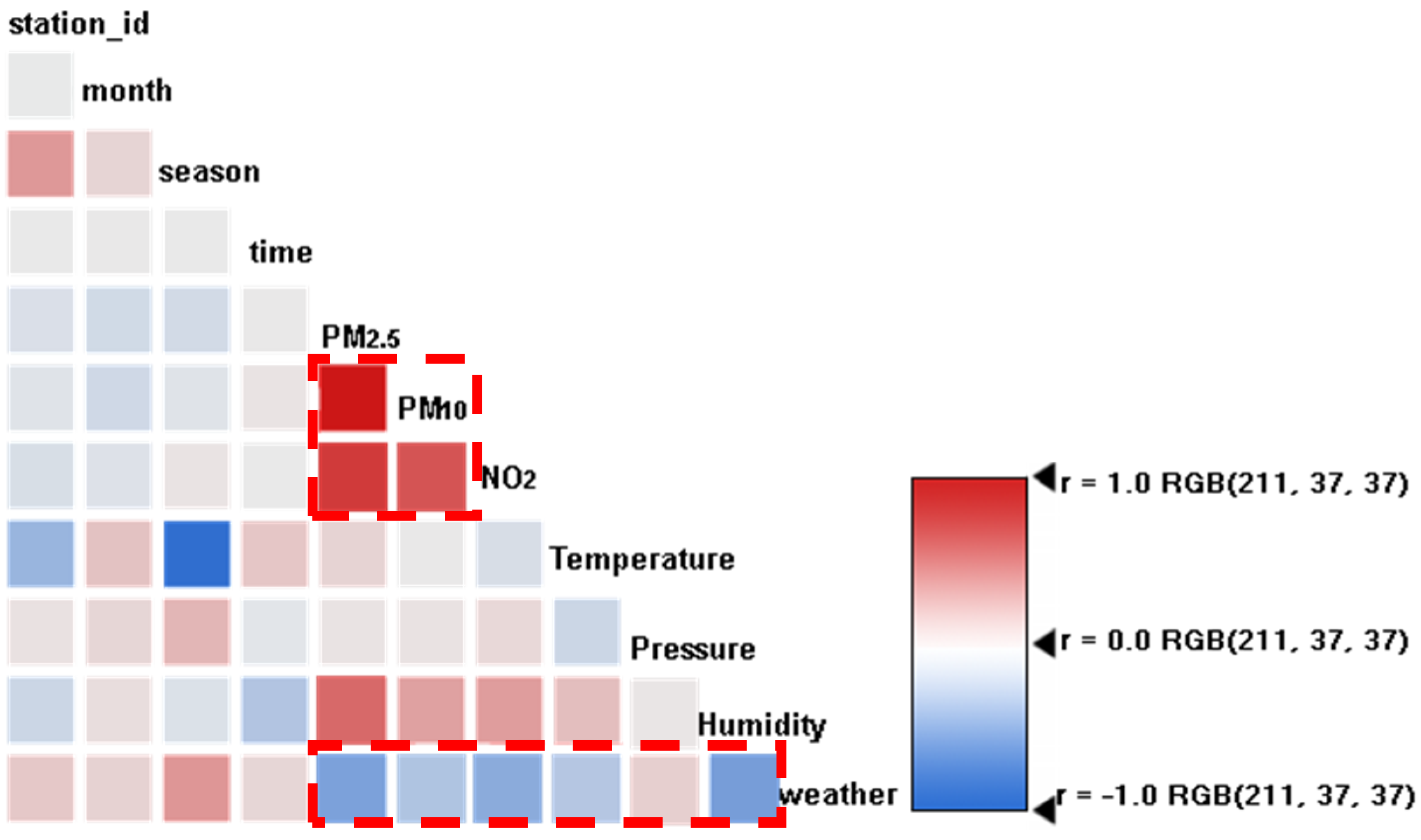
3.2.1. Relationship between Multiple Factors
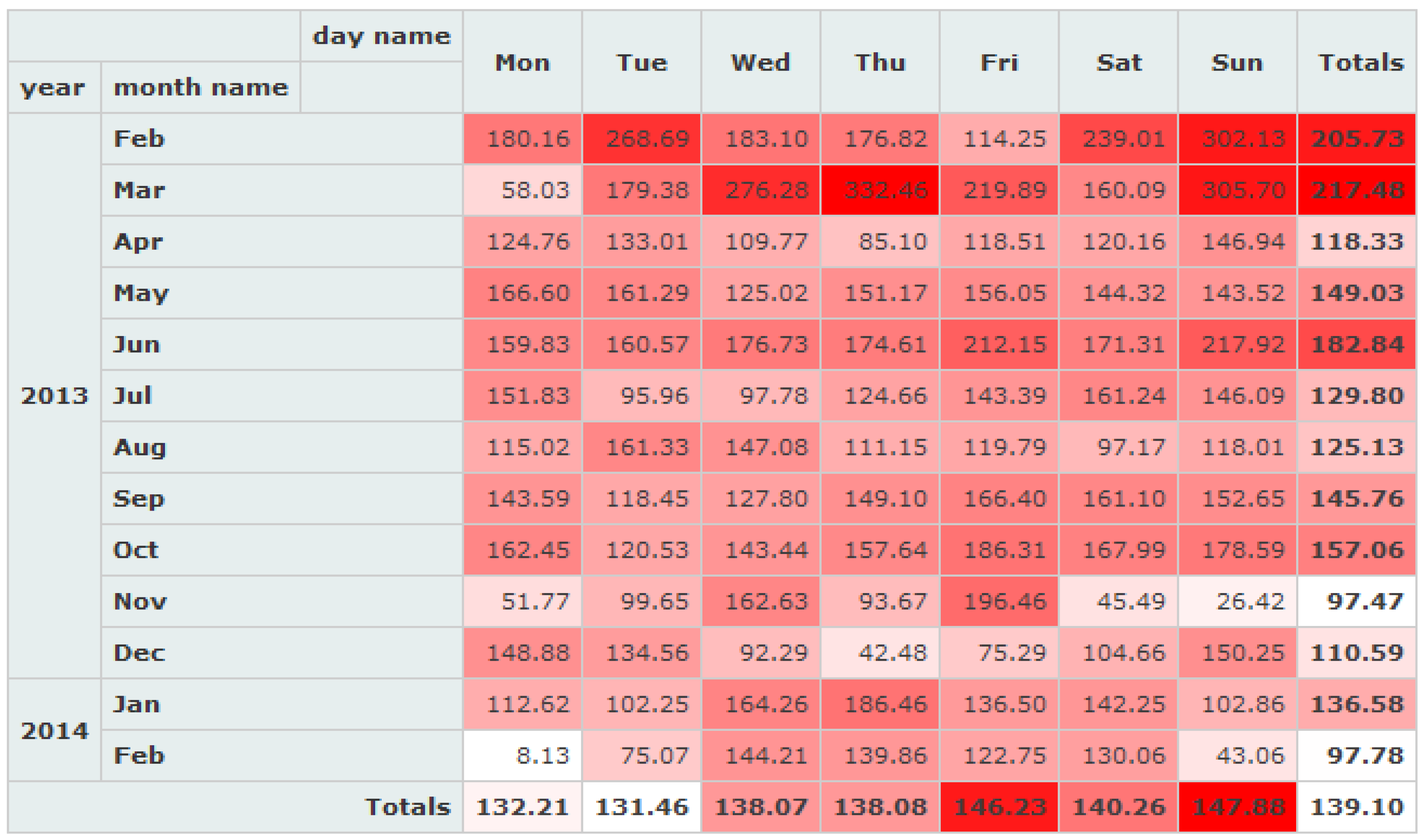
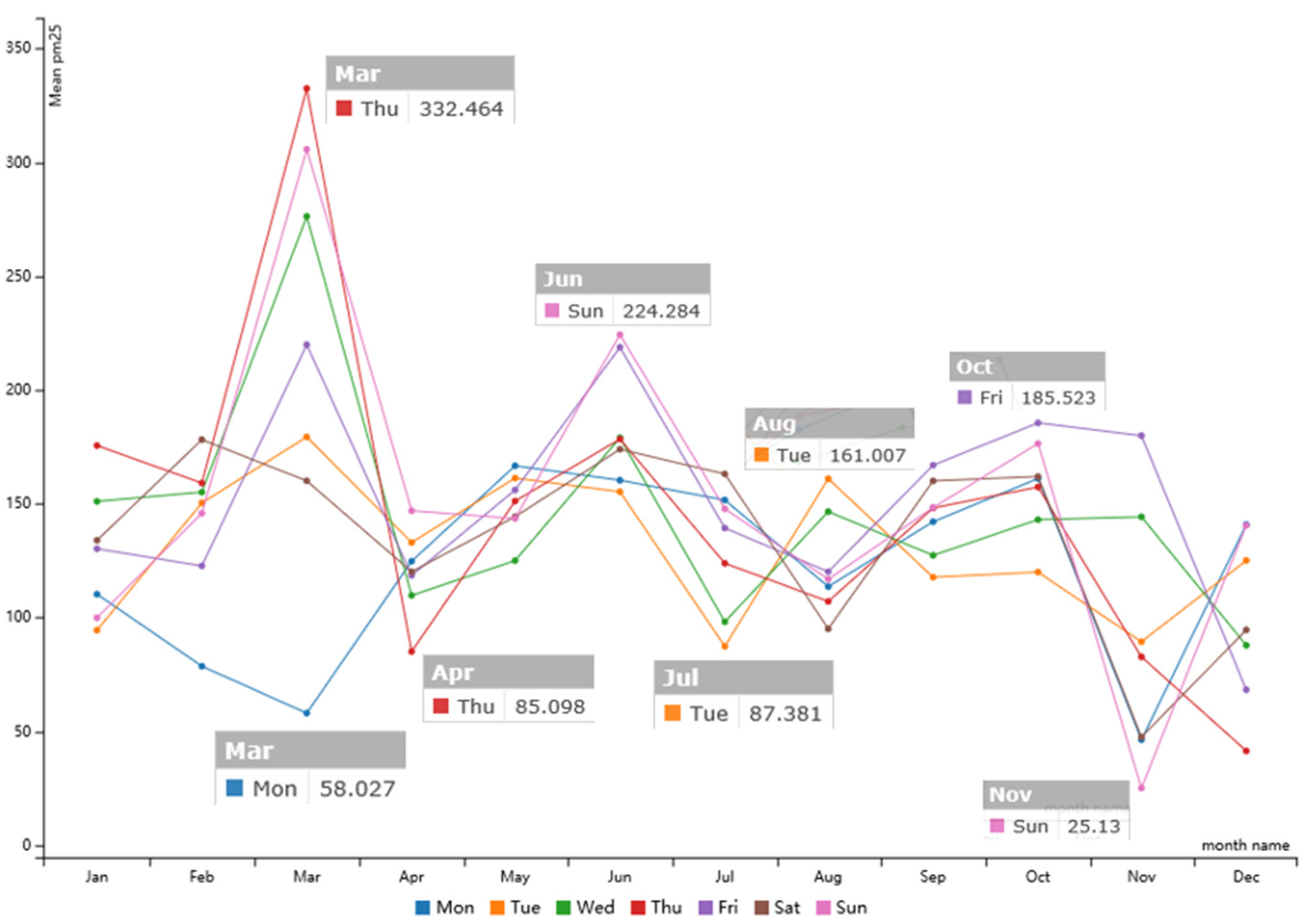
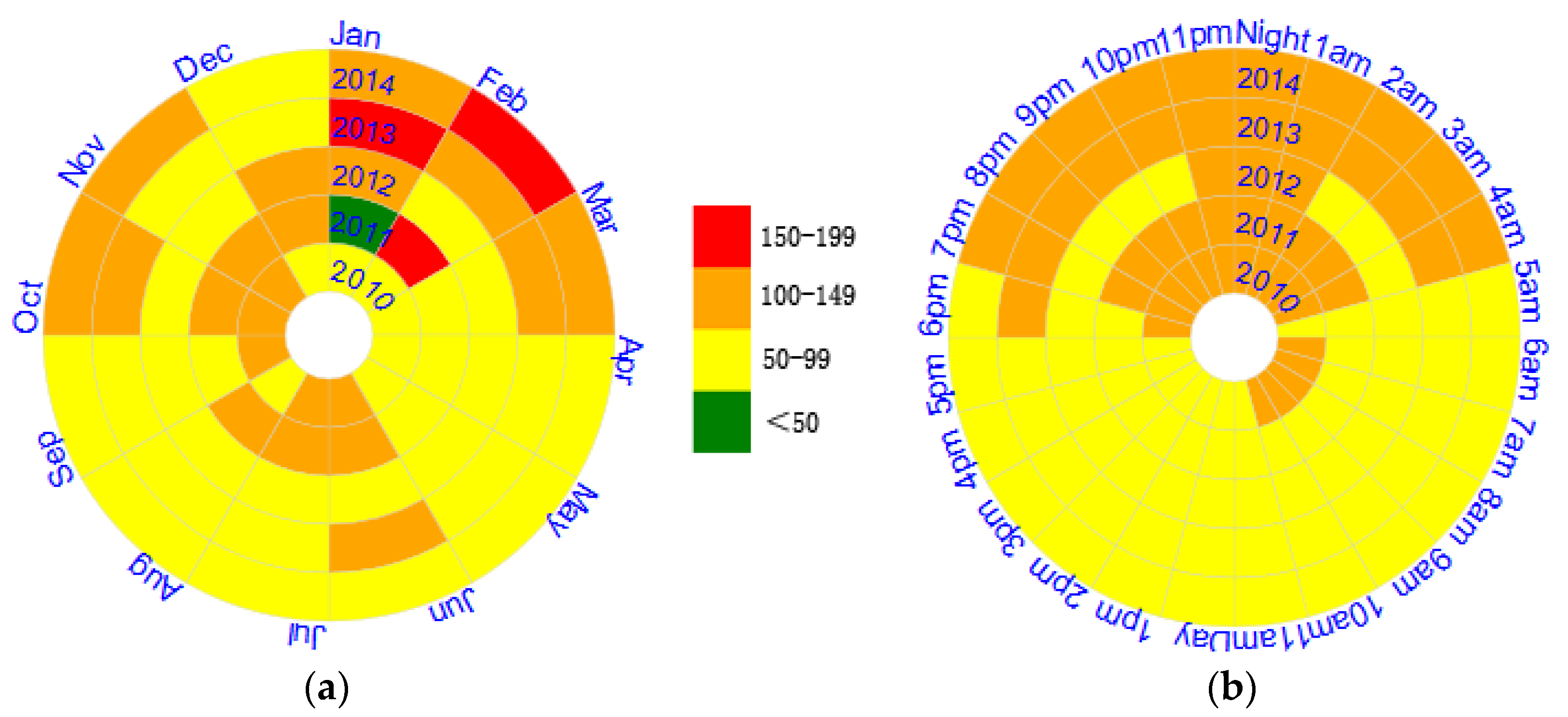
3.2.2. Temporal Characteristics
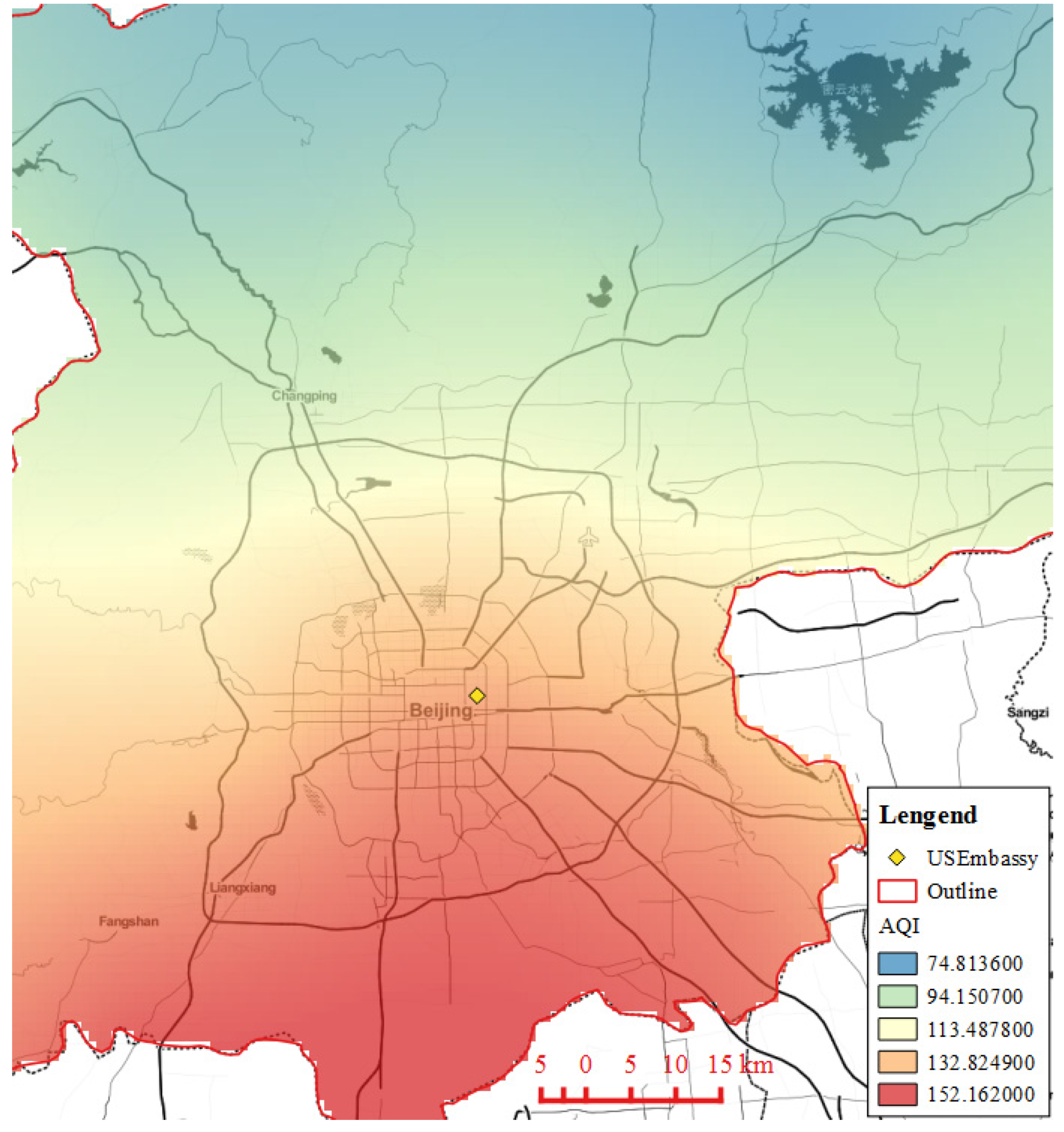
3.2.3. Spatial Characteristics
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
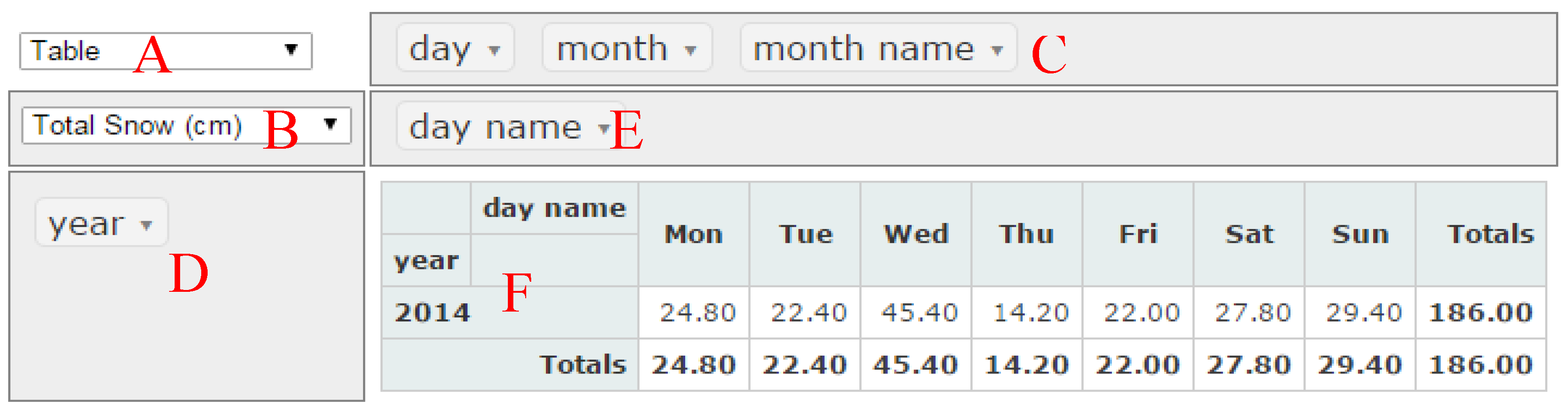
Appendix A. Open source visualization tools
PivotTable.js

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Interpolation | Return Value |
|---|---|
| %y: date.getFullYear () | 2013 |
| %m: zeroPad (date.getMonth () +1) | 2 |
| %n: mthNames (date.getMonth ()) | Feb |
| %d: zeroPad (date.getDate ()) | 8 |
| %w: dayNames (date.getDay ()) | Fri |
| %x: date.getDay () | 5 (Sunday is Zero) |
| %H: zeroPad (date.getHours ()) | 21 ("PM" is auto-computed) |
| %M: zeroPad (date.getMinutes ()) | 10 |
| %S: zeroPad (date.getSeconds ()) | 30 |

D3.js
Appendix B. Data quality check of the U-Air data


Appendix C. Data processing
| Hypotheses | Plots type | Visualization tools | Data Preprocessing |
|---|---|---|---|
| Relationship exists among pollutants and wind speed | Scatter plots | D3.js | By PivotTable.js |
| There are some regular patterns in time | Heat maps (Circular heat chart, Calendar view) | D3.js | |
| Concentration distributionof pollutants in space | Geovisualization | Openlayers |
References
- Mao, F.; Duan, M.; Min, Q.; Gong, W.; Pan, Z.; Liu, G. Investigating the impact of haze on modis cloud detection. J. Geophys. Res. Atmos. 2015, 120, 12237–12247. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Cao, F. Fine particulate matter (PM2.5) in China at a city level. Sci. Rep. 2015, 5, 14884. [Google Scholar] [CrossRef] [PubMed]
- Matejicek, L.; Engst, P.; Jaňour, Z. A GIS-based approach to spatio-temporal analysis of environmental pollution in urban areas: A case study of Prague’s environment extended by LiDAR data. Ecol. Model. 2006, 199, 261–277. [Google Scholar] [CrossRef]
- Retalis, A.; Sifakis, N. Urban aerosol mapping over Athens using the differential textural analysis (dta) algorithm on meris-envisat data. ISPRS J. Photogramm. Remote Sens. 2010, 65, 17–25. [Google Scholar] [CrossRef]
- Chen, W.; Tang, H.; Zhao, H. Diurnal, weekly and monthly spatial variations of air pollutants and air quality of beijing. Atmos. Environ. 2015, 119, 21–34. [Google Scholar] [CrossRef]
- Carslaw, D.C.; Ropkins, K. Openair—An R package for air quality data analysis. Environ. Model. Softw. 2012, 27–28, 52–61. [Google Scholar] [CrossRef]
- Janssen, N.A.H.; Fischer, P.; Marra, M.; Ameling, C.; Cassee, F.R. Short-term effects of PM2.5, PM10 and PM2.5–10 on daily mortality in the Netherlands. Sci. Total Environ. 2013, 463, 20–26. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Wong, M.S.; Wang, J.; Zhao, Y. Analysis of airborne particulate matter (PM2.5) over Hong Kong using remote sensing and GIS. Sensors 2012, 12, 6825–6836. [Google Scholar] [CrossRef] [PubMed]
- Van Wijk, J.J. The value of visualization. Proc. IEEE 2005. [Google Scholar] [CrossRef]
- Cai, Z.; Wang, Q.; Weng, M.; Jiang, S.; Du, Q. Information organization and visualization mechanism of electronic map. Geo-Spat. Inf. Sci. 2008, 11, 262–268. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Demsar, U.; Dransch, D.; Dykes, J.; Fabrikant, S.I.; Jern, M.; Kraak, M.J.; Schumann, H.; Tominski, C. Space, time and visual analytics. Int. J. Geogr. Inf. Sci. 2010, 24, 1577–1600. [Google Scholar] [CrossRef]
- Kraak, M.J. Geovisualization illustrated. ISPRS J. Photogramm. Remote Sens. 2003, 57, 390–399. [Google Scholar] [CrossRef]
- Keim, D.; Andrienko, G.; Fekete, J.-D.; Görg, C.; Kohlhammer, J.; Melançon, G. Visual analytics: Definition, process, and challenges. In Information Visualization; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Li, X.; Coltekin, A.; Kraak, M.-J. Visual exploration of eye movement data using the space-time-cube. In Geographic Information Science; Fabrikant, S.I., Reichenbacher, T., van Kreveld, M., Schlieder, C., Eds.; Springer: Heidelberg, Germany, 2010; Volume 6292, pp. 295–309. [Google Scholar]
- Zirui, L.; Bo, H.; Dongsheng, J.; Yonghong, W.; Mingxing, W.; Yuesi, W. Diurnal and seasonal variation of the PM2.5 apparent particle density in Beijing, China. Atmos. Environ. 2015, 120, 328–338. [Google Scholar]
- Pope, C.A.; Burnett, R.T.; Thun, M.J.; Calle, E.E.; Krewski, D.; Ito, K.; Thurston, G.D. Lung cancer, cardiopulmonary mortality, and long-term exposure to fine particulate air pollution. Jama-J. Am. Med. Assoc. 2002, 287, 1132–1141. [Google Scholar] [CrossRef]
- Revised Air Quality Standards for Particle Pollution and Updates to the Air Quality Index (AQI). Available online: http://www.epa.gov/airquality/particlepollution/2012/decfsstandards.pdf (accessed on 25 February 2016).
- Technical Regulation on Ambient Air Quality Index (on Trial). Available online: http://kjs.mep.gov.cn/hjbhbz/bzwb/dqhjbh/jcgfffbz/201203/W020120410332725219541.pdf (accessed on 25 February 2016).
- Jeon, S.J.; Meuzelaar, H.L.C.; Sheya, S.A.N.; Lighty, J.S.; Jarman, W.M.; Kasteler, C.; Sarofim, A.F.; Simoneit, B.R.T. Exploratory studies of PM10 receptor and source profiling by GC/MS and principal component analysis of temporally and spatially resolved ambient samples. J. Air Waste Manag. Assoc. 2001, 51, 766–784. [Google Scholar] [CrossRef] [PubMed]
- Chu, D.A.; Kaufman, Y.J.; Zibordi, G.; Chern, J.D.; Mao, J.; Li, C.C.; Holben, B.N. Global monitoring of air pollution over land from the earth observing system-terra moderate resolution imaging spectroradiometer (MODIS). J. Geophys. Res.-Atmos. 2003, 108. [Google Scholar] [CrossRef]
- Wang, J.; Christopher, S.A. Intercomparison between satellite-derived aerosol optical thickness and PM2.5 mass: Implications for air quality studies. Geophys. Res. Lett. 2003, 30. [Google Scholar] [CrossRef]
- Othman, N.; MatJafri, M.Z.; Lim, H.S.; Abdullah, K. Retrieval of aerosol optical thickness (AOT) and its relationship to air pollution particulate matter (PM10). In Proceedings of the Sixth International Conference on Computer Graphics, Imaging and Visualization, 2009 CGIV ‘09, Tianjin, China, 11–14 August 2009; pp. 516–519.
- Zheng, Y.; Liu, F.; Hsieh, H.-P. U-air: When urban air quality inference meets big data. In 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: Chicago, IL, USA,, 2013; pp. 1436–1444. [Google Scholar]
- Bostock, M.; Ogievetsky, V.; Heer, J. D-3: Data-driven documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef] [PubMed]
- Matejicek, L. Spatio-temporal analysis of environmental pollution in urban areas: A case study of the environment in the city of Prague. In Proceedings of the 19th International Congress on Modelling and Simulation (Modsim2011), Perth, Australia, 12–16 December 2011; pp. 1909–1915.
- Guo, D.S.; Chen, J.; MacEachren, A.M.; Liao, K. A visualization system for space-time and multivariate patterns (Vis-Stamp). IEEE Trans. Vis. Comput. Graphics 2006, 12, 1461–1474. [Google Scholar]
- Andrienko, G.; Andrienko, N. A general framework for using aggregation in visual exploration of movement data. Cartogr. J. 2010, 47, 22–40. [Google Scholar] [CrossRef]
- Kveladze, I.; Kraak, M.J.; van Elzakker, C.P.J.M. A methodological framework for researching the usability of the space-time cube. Cartogr. J. 2013, 50, 201–210. [Google Scholar] [CrossRef]
- Li, H.; Fan, H.; Wu, H.; Feng, H.; Li, P. Resdap: A real-time data provision system architecture for sensor webs. In Web and Wireless Geographical Information Systems; Springer: Heidelberg, Germany; pp. 85–99.
- Fan, H.; Li, H. An on-Demand provision model for geospatial multisource information with active self-adaption services. Proc. SPIE 2015, 9815. [Google Scholar] [CrossRef]
- Fan, M.; Fan, H.; Chen, N.; Chen, Z.; Du, W. Active on-demand service method based on event-driven architecture for geospatial data retrieval. Comput. Geosci. 2013, 56, 1–11. [Google Scholar] [CrossRef]
- Li, L.; Losser, T.; Yorke, C.; Piltner, R. Fast inverse distance weighting-based spatiotemporal interpolation: A web-based application of interpolating daily fine particulate matter PM2.5 in the contiguous U.S. Using parallel programming and k-d tree. Int. J. Environ. Res. Public Health 2014, 11, 9101–9141. [Google Scholar] [CrossRef] [PubMed]
- Van Wijk, J.J.; Van Selow, E.R. Cluster and calendar based visualization of time series data. IEEE Symp. Inf. Vis. 1999, 140. [Google Scholar] [CrossRef]
- Department of State Air Quality Monitoring Program. Available online: http://www.stateair.net/web/mission/1/ (accessed on 10 December 2015).
- Zheng, Y. Urban Air. Microsoft. Available online: http://research.microsoft.com/en-us/projects/urbanair/default.aspx (accessed on 15 October 2015).
- World Weather. Available online: http://en.tutiempo.net/ (accessed on 20 January 2016).
- Qiao, Z.; Tian, G.; Xiao, L. Diurnal and seasonal impacts of urbanization on the urban thermal environment: A case study of Beijing using MODIS data. ISPRS J. Photogramm. Remote Sens. 2013, 85, 93–101. [Google Scholar] [CrossRef]
- Gong, W.; Zhang, T.; Zhu, Z.; Ma, Y.; Ma, X.; Wang, W. Characteristics of PM1.0, PM2.5, and PM10, and their relation to black carbon in Wuhan, central China. Atmosphere 2015, 6, 1377–1387. [Google Scholar] [CrossRef]
- Logan, T.; Xi, B.; Dong, X. A comparison of the mineral dust absorptive properties between two Asian dust events. Atmosphere 2013, 4, 1–16. [Google Scholar] [CrossRef]
- Cressie, N. The origins of kriging. Math. Geol. 1990, 22, 239–252. [Google Scholar] [CrossRef]
- Sanabria, L.; Qin, X.; Li, J.; Cechet, R.; Lucas, C. Spatial interpolation of McArthur’s forest fire danger index across Australia: Observational study. Environ. Model. Softw. 2013, 50, 37–50. [Google Scholar] [CrossRef]
- Clark, I. Practical Geostatistics; Applied Science Publishers: London, UK, 1979; Volume 3. [Google Scholar]
- Huang, Y.; Nian, P.; Zhang, W. The prediction of interregional land use differences in Beijing: A markov model. Environ. Earth Sci. 2015, 73, 4077–4090. [Google Scholar] [CrossRef]
- Wang, W.; Gong, W.; Mao, F.; Zhang, J. Long-term measurement for low-tropospheric water vapor and aerosol by Raman LiDAR in Wuhan. Atmosphere 2015, 6, 521–533. [Google Scholar] [CrossRef]
- PivotTable.js. Available online: https://github.com/nicolaskruchten/pivottable (accessed on 24 October 2015).
- D3.js. Available online: http://d3js.org/ (accessed on 14 November 2015).












| Stations (ID) | Months | Mean AQI of PM2.5 |
|---|---|---|
| Part (01–22) | All months | Relationship with Month, Day, Hour |
| All (01–36) | Part (1, 2, 11, 12) | Relationship with Geo-location |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Fan, H.; Mao, F. A Visualization Approach to Air Pollution Data Exploration—A Case Study of Air Quality Index (PM2.5) in Beijing, China. Atmosphere 2016, 7, 35. https://doi.org/10.3390/atmos7030035
Li H, Fan H, Mao F. A Visualization Approach to Air Pollution Data Exploration—A Case Study of Air Quality Index (PM2.5) in Beijing, China. Atmosphere. 2016; 7(3):35. https://doi.org/10.3390/atmos7030035
Chicago/Turabian StyleLi, Huan, Hong Fan, and Feiyue Mao. 2016. "A Visualization Approach to Air Pollution Data Exploration—A Case Study of Air Quality Index (PM2.5) in Beijing, China" Atmosphere 7, no. 3: 35. https://doi.org/10.3390/atmos7030035
APA StyleLi, H., Fan, H., & Mao, F. (2016). A Visualization Approach to Air Pollution Data Exploration—A Case Study of Air Quality Index (PM2.5) in Beijing, China. Atmosphere, 7(3), 35. https://doi.org/10.3390/atmos7030035