
Predicting PM2.5 Concentrations at a Regional Background Station Using Second Order Self-Organizing Fuzzy Neural Network


Abstract
:1. Introduction
2. Study Site and Data
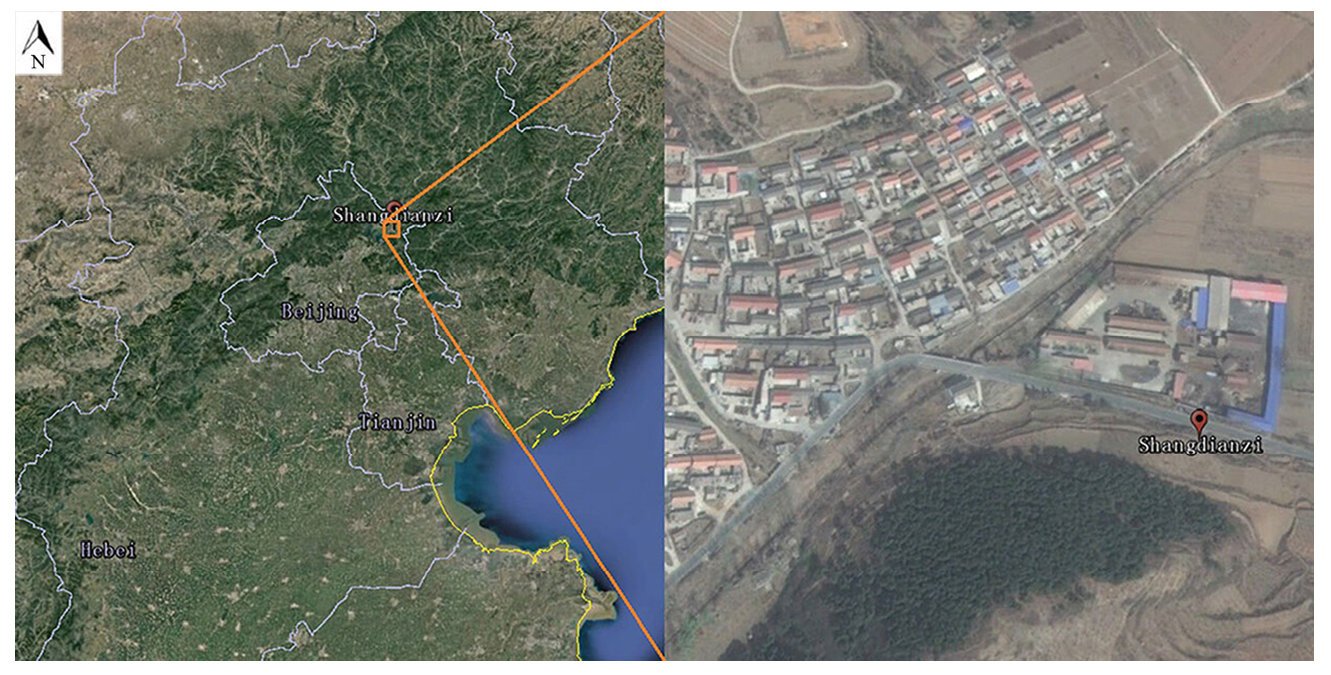
2.1. Study Site
2.2. Data Preparation
3. Theory and Methodology
3.1. Principal Component Analysis
- Let 182 × 11 data matrix denotes the 182 h of measurements of predictors and are 182 × 1 data vectors of T, RH, WS, WD, Pre, Vis, AOD, CO, NO2, O3 and SO2, respectively. The data matrix should be transformed into a standardized form:where is the standardized data matrix generated from ; and are the values of predictor j in sample i before and after the standardization; and and are the arithmetic mean value and the standard deviation for predictor j, respectively.
- Calculate the correlation coefficient matrix using Equation (2):
- Compute the eigenvalues and the corresponding eigenvectors of 11 × 11 correlation matrix .
- Reorder the eigenvalues in descending order to bring and readjust the eigenvectors as accordingly.
- Obtain the unit orthogonal eigenvectors using the Schmidt orthogonal method on .
- Calculate the cumulative contribution rate of the eigenvalues and variables will be extracted if where is the preset extraction efficiency.
- The data of the dominating variables is acquired by computing the projection of on the extracted unit orthogonal eigenvectors using Equation (3):where .
3.2. Sensitivity Analysis Based Self-Organizing Fuzzy Neural Network with Second Order Gradient Algorithm
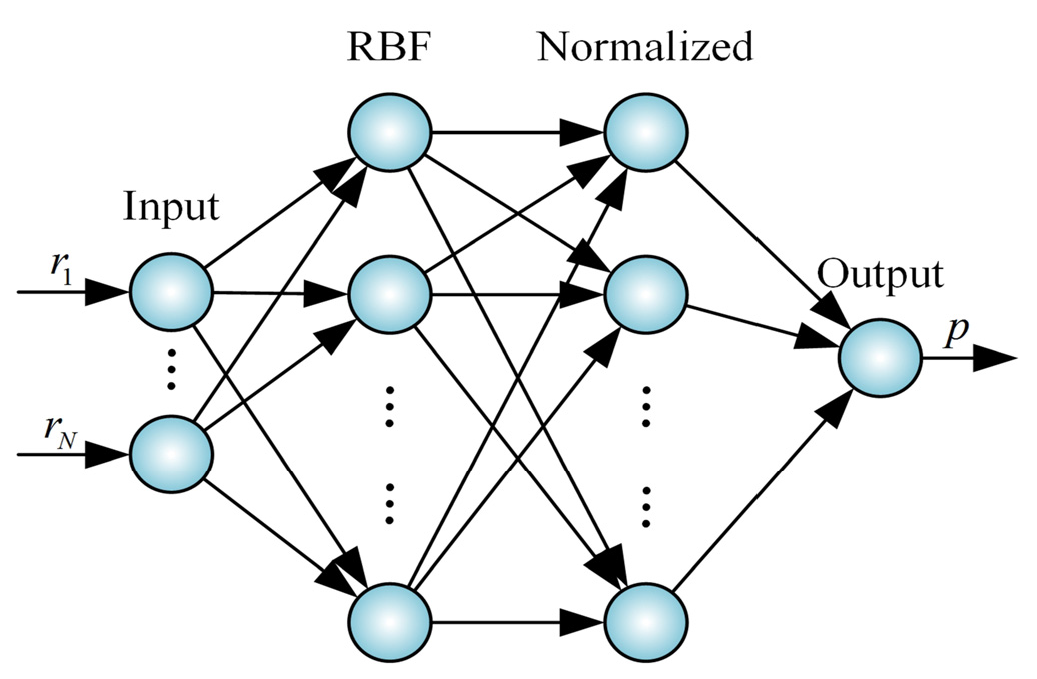
3.2.1. Architecture of the Proposed Model
- Input layer: There are N neurons in this layer and the output value of the ith neuron can be expressed as follows:where represents the dominating variables extracted from the predictors through PCA method.
- RBF layer: The Gaussian membership functions (MFs) of every of RBF neurons in this layer is selected to deal with the input variables. Each RBF neuron represents an if-part of a fuzzy rule, and the outputs of RBF neurons are calculated in the following manner:where is the output of the jth RBF neuron; and are the center and width of the ith membership function (MF) in the jth neuron, respectively; and M is the total number of neurons in this layer.
- Normalized layer: The number of the neurons in the normalized layer is the same as that in the RBF layer. The output values of nodes in this layer are given as follows:where is the lth output value in the normalized layer.
- Output layer: There is only one neuron in this layer, in which of the output represents the PM2.5 concentration that can be clarified through the gravity method given as follows:where is the weight connecting the lth neuron in the normalized layer and the neuron in the output layer.
3.2.2. Sensitivity Analysis Method
3.2.3. Second Order Gradient Algorithm
3.2.4. Design of the Second Order Sensitivity Analysis Based Self-Organizing Fuzzy Neural Network
- Initialization of the SOG-SASOFNN: The initial SOG-SASOFNN is with random number of neurons in the normalized layer and the inputs of the SOG-SASOFNN are dominating variables selected through PCA method. There is one neuron in the output layer in which of the output represents the PM2.5 concentration. The parameters such as centers, widths, and weights of the SOG-SASOFNN are initially distributed on the random range of [0, 1].
- Parameter learning: Adjust the parameters of the SOG-SASOFNN using Equation (22) with all training set for several training steps.
- Growing phase: After some time () steps, calculate the standardized total sensitivity index of output of each normalized neuron to the network output using Equation (20). The hth normalized neuron is overactive and will be spilt into two new normalized neurons if is larger than . In order to guarantee the convergence, the outputs of the SOG-SASOFNN before and after the structure has been adjusted must be identical and the initial parameters of the two new normalized neurons are set as follows:where new1 and new2 denote the two new normalized neurons. , and are the center vector, width vector and weight of neuron new1, respectively. , and are the center vector, width vector and weight of neuron new2, respectively. , and are the center vector, width vector and weight of the hth normalized neuron before the structure has been adjusted at step t, respectively. is a random number which is distributed in the range of [0, 1].
- Pruning phase: The hth normalized neuron is useless and will be pruned if is less than . To reduce the fluctuation of the output of the network, the parameters of the nearest neuron are compensated as:where nea is the normalized neuron with the minimum Euclidean distance to the hth normalized neuron and . , and are the center vector, width vector and weight of neuron nea after pruning at step t, respectively. , and are the center vector, width vector and weight of neuron nea before pruning at step t, respectively. is the weight of the hth normalized neuron before pruning when training to step t. and are the output of the hth normalized neuron and neuron nea before pruning when training to step t, respectively.
- Relearning of parameters: Turn the algorithm to procedure 2 to make the parameters under relearning applying Equation (22). The training process terminates when the process achieves the expected training RMSE Ed or reaches the pre-set running step Rmax.
- Test stage: Once the SOG-SASOFNN is optimized by the training set, this optimized nonlinear function is used to make prediction on the test data.
4. Results and Discussion
4.1. Variation of PM2.5 Concentrations with Meteorological Conditions and Aerosol Optical Depth at SDZ
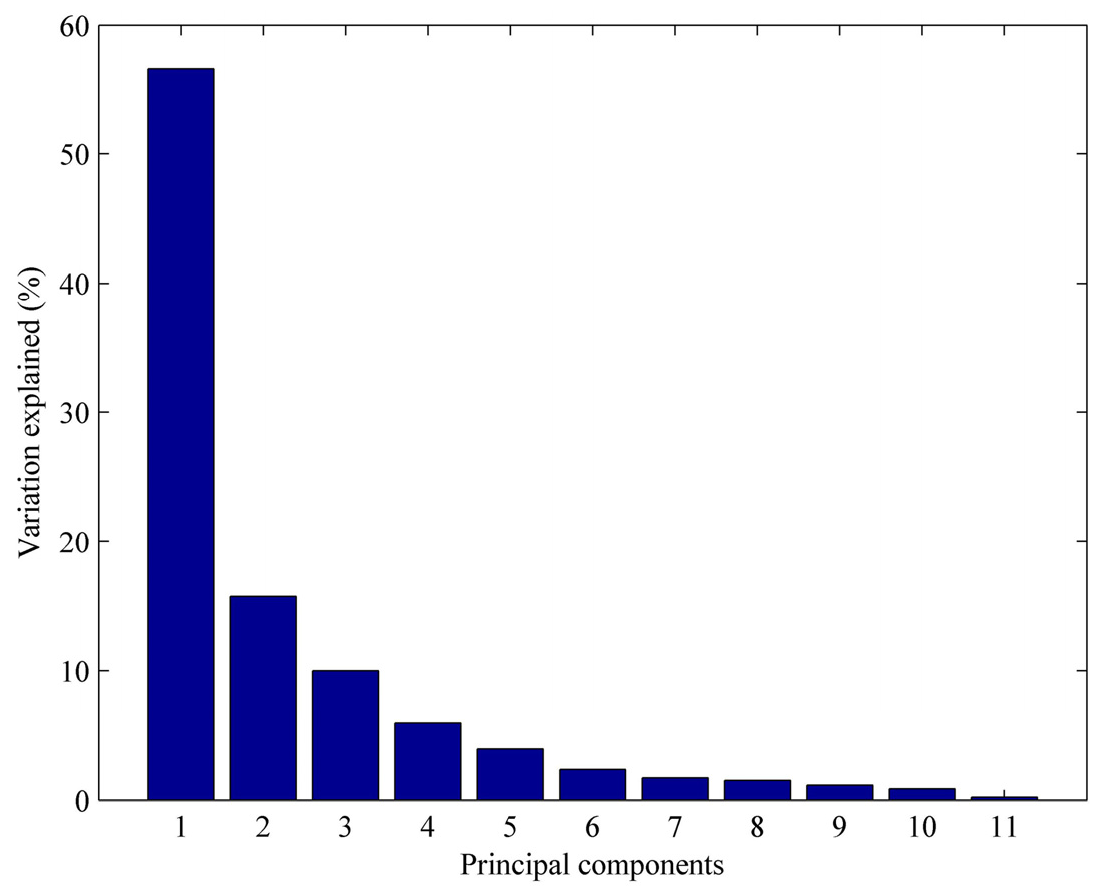
4.2. Dominating Variables Selected by Principal Component Analysis
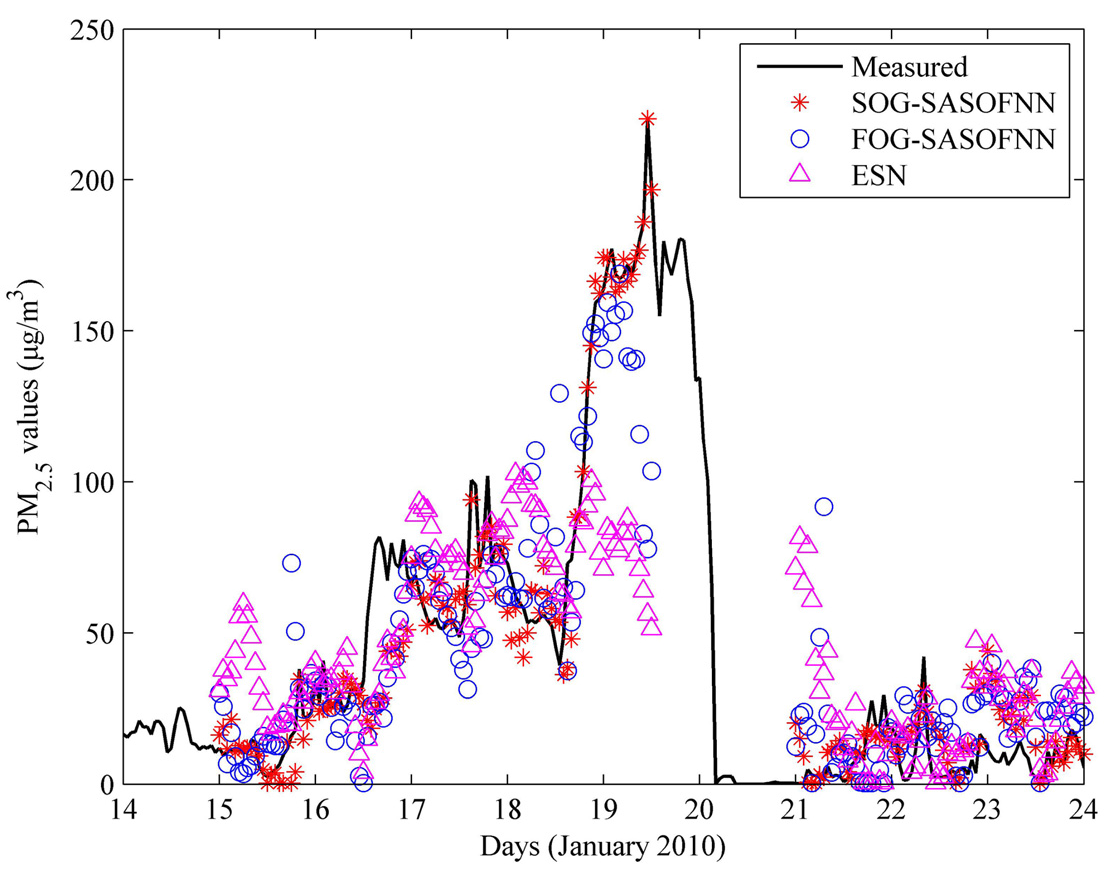
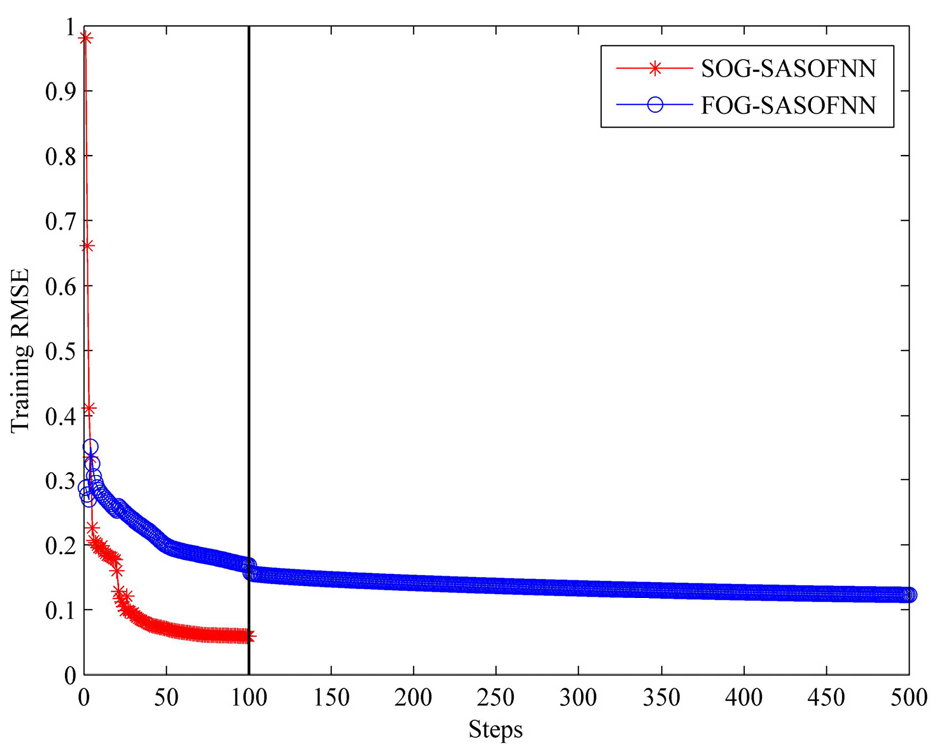
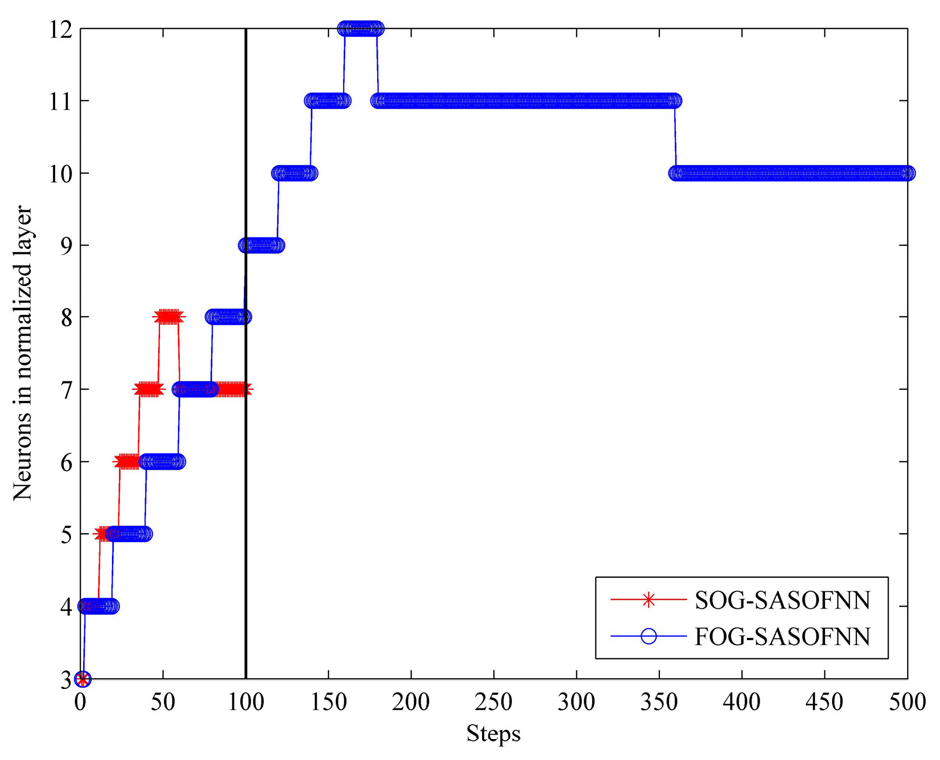
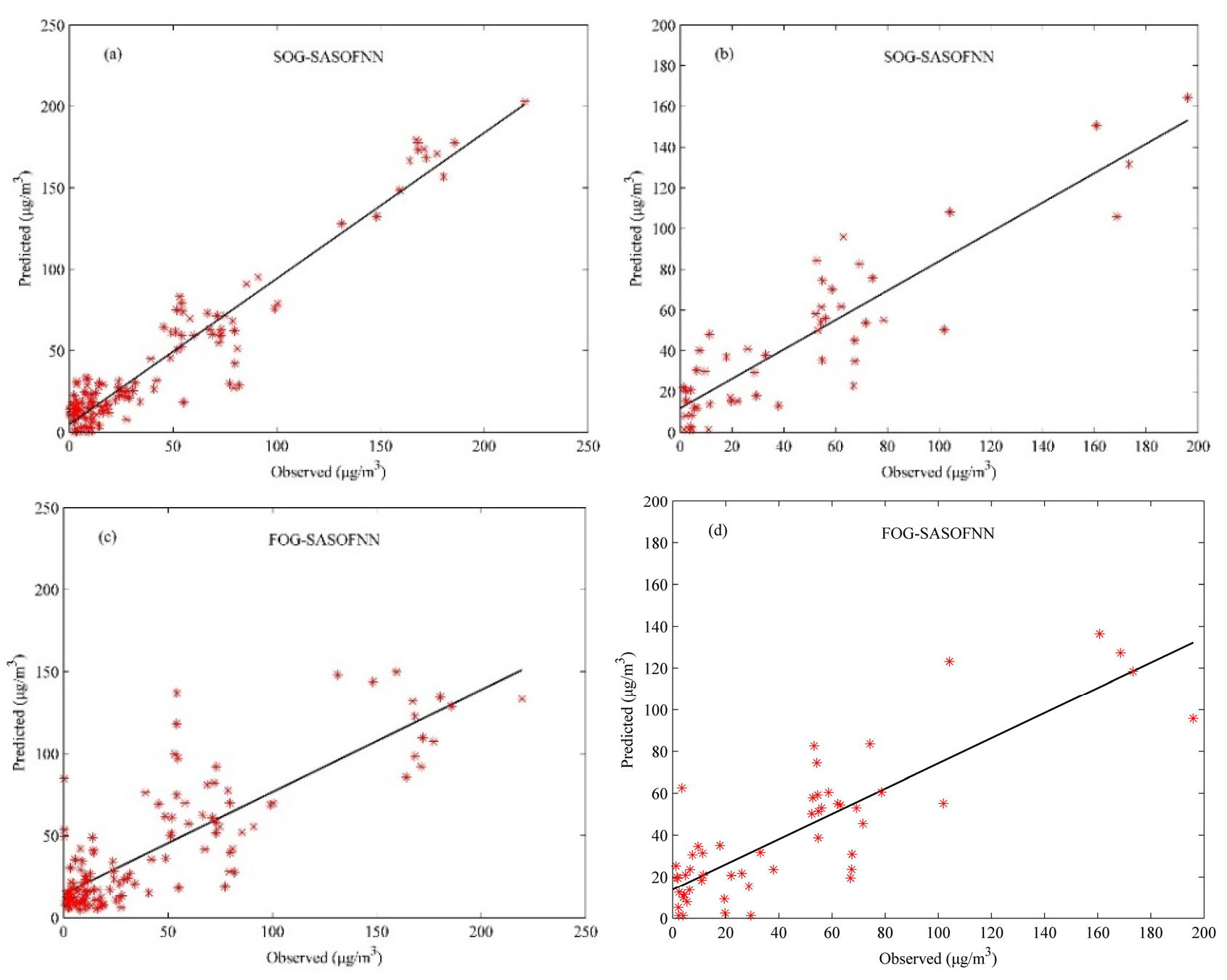
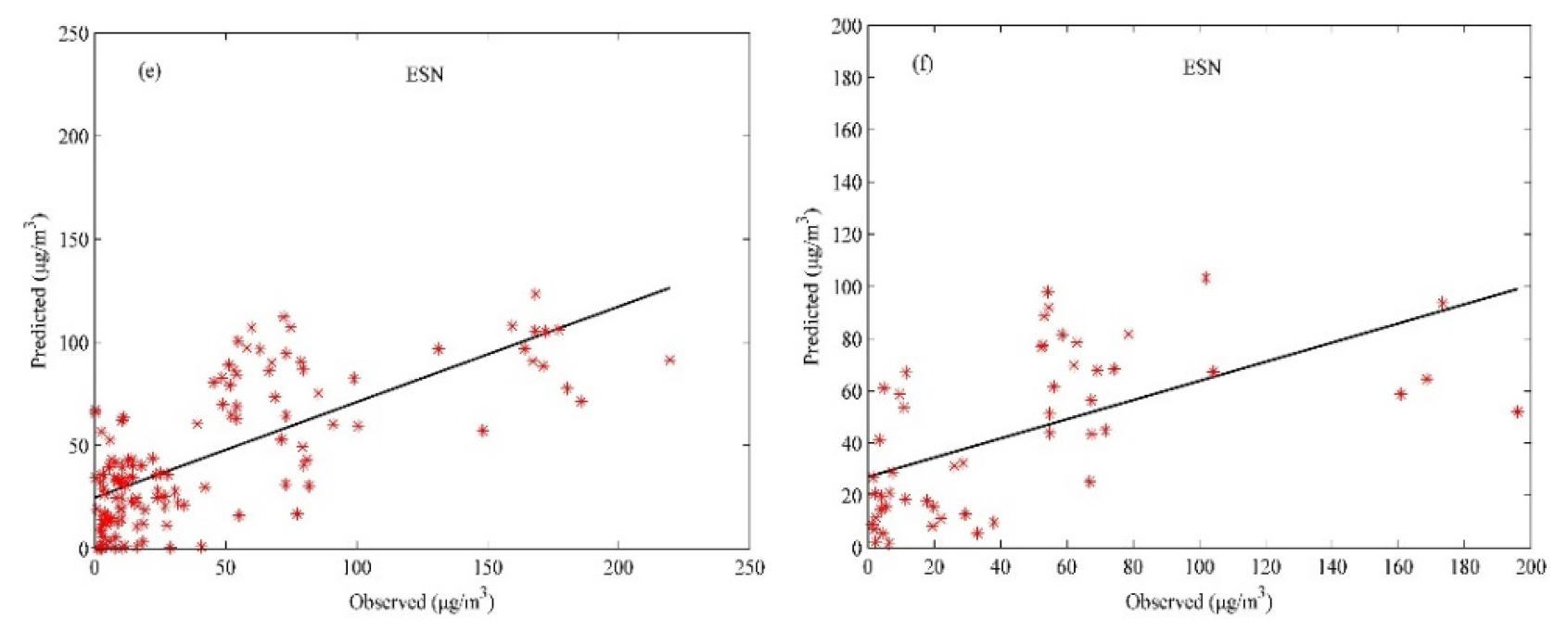
4.3. Modeling: Training and Validation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Song, Y.; Zhang, Y.H.; Xie, S.D.; Zeng, L.M.; Zheng, M.; Salmon, L.G.; Shao, M.; Slanina, S. Source apportionment of PM2.5 in Beijing by positive matrix factorization. Atmos. Environ. 2006, 40, 1526–1537. [Google Scholar] [CrossRef]
- Lv, B.L.; Hu, Y.T.; Chang, H.H.; Russell, A.G.; Bai, Y.Q. Improving the accuracy of daily PM2.5 distributions derived from the fusion of ground-level measurements with aerosol optical depth observations, a case study in north China. Environ. Sci. Technol. 2016, 50, 4752–4759. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A., III; Dockery, D.W. Health effects of fine particulate air pollution: Lines that connect. J. Air Waste Manag. 2006, 56, 709–742. [Google Scholar] [CrossRef]
- Lepeule, J.; Laden, F.; Dockery, D.; Schwartz, J. Chronic exposure to fine particles and mortality: An extended follow-up of the Harvard Six Cities study from 1974 to 2009. Environ. Health Perspect. 2012, 120, 965–970. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metzger, K.B.; Tolbert, P.E.; Klein, M.; Peel, J.L.; Flanders, W.D.; Todd, K.; Mulholland, J.A.; Ryan, P.B.; Frumkin, H. Ambient air pollution and cardiovascular emergency department visits. Epidemiology 2004, 15, 46–56. [Google Scholar] [CrossRef] [PubMed]
- Peel, J.L.; Tolbert, P.E.; Klein, M.; Metzger, K.B.; Flanders, W.D.; Todd, K.; Mulholland, J.A.; Ryan, P.B.; Frumkin, H. Ambient air pollution and respiratory emergency department visits. Epidemiology 2005, 16, 164–174. [Google Scholar] [CrossRef] [PubMed]
- Levy, H., II; Horowitz, L.W.; Schwarzkopf, M.D.; Ming, Y.; Golaz, J.C.; Naik, V.; Ramaswarmy, V. The roles of aerosol direct and indirect effects in past and future climate change. J. Geophys. Res. 2013, 118, 4521–4532. [Google Scholar]
- Zhao, P.S.; Zhang, X.L.; Xu, X.F.; Zhao, X.J. Long-term visibility trends and characteristics in the region of Beijing, Tianjin, and Hebei, China. Atmos. Res. 2011, 101, 711–718. [Google Scholar] [CrossRef]
- Valverde, V.; Pay, M.T.; Baldasano, J.M. Circulation-type classification derived on a climatic basis to study air quality dynamics over the Iberian Peninsula. Int. J. Climatol. 2015, 35, 2877–2897. [Google Scholar] [CrossRef] [Green Version]
- Raga, G.B.; Moyne, L.L. On the nature of air pollution dynamics in Mexico City—I. Nonlinear analysis. Atmos. Environ. 1996, 30, 3987–3993. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, X.P.; Liu, X.N.; Qian, Z.G. Combining DMSP/OLS nighttime light with echo state network for prediction of daily PM2.5 average concentrations in Shanghai, China. Atmosphere 2015, 6, 1507–1520. [Google Scholar] [CrossRef]
- Chemel, C.; Fisher, B.E.A.; Kong, X.; Francis, X.V.; Sokhi, R.S.; Good, N.; Collins, W.J.; Folberth, G.A. Application of chemical transport model CMAQ to policy decisions regarding PM2.5 in the UK. Atmos. Environ. 2014, 82, 410–417. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.C.; Mathur, R.; Schere, K.; Kang, D.W.; Pleim, J.; Young, J.; Tong, D.; Pouliot, G.; McKeen, S.A.; Rao, S.T. Evaluation of real-time PM2.5 forecasts and process analysis for PM2.5 formation over the eastern United States using the Eta-CMAQ forecast model during the 2004 ICARTT study. J. Geophys. Res. 2008, 113, D06204. [Google Scholar] [CrossRef]
- Fernando, H.J.S.; Mammarella, M.C.; Grandoni, C.; Fedele, P.; Marco, R.D.; Dimitrova, R.; Hyde, P. Forecasting PM10 in metropolitan areas: Efficacy of neural networks. Environ. Pollut. 2012, 163, 62–67. [Google Scholar] [CrossRef] [PubMed]
- Elbayoumi, M.; Ramli, N.A.; Yusof, N.F.F.M.; Yahaya, A.S.B.; Madhoun, W.A.; UI-Saufie, A.Z. Multivariate methods for indoor PM10 and PM2.5 modeling in naturally ventilated schools buildings. Atmos. Environ. 2014, 94, 11–21. [Google Scholar] [CrossRef]
- Niska, H.; Hiltunen, T.; Karppinen, A.; Ruuskanen, J.; Kolehmainen, M. Evolving the neural network model for forecasting air pollution time series. Eng. Appl. Artif. Intell. 2004, 17, 159–167. [Google Scholar] [CrossRef]
- Nagendra, S.M.S.; Khare, M. Artificial neural network approach for modelling nitrogen dioxide dispersion from vehicular exhaust emissions. Ecol. Model. 2006, 190, 99–115. [Google Scholar] [CrossRef]
- Corani, G. Air quality prediction in Milan: Feed-forward neural networks, pruned neural networks and lazy learning. Ecol. Model. 2005, 185, 513–529. [Google Scholar] [CrossRef]
- Chaloulakou, A.; Grivas, G.; Spyrellis, N. Neural network and multiple regression models for PM10 prediction in Athens: A comparative assessment. J. Air Waste Manage. 2003, 53, 1183–1190. [Google Scholar] [CrossRef]
- Ordieres, J.B.; Vergara, E.P.; Capuz, R.S.; Salazar, R.E. Neural network prediction model for fine particulate matter (PM2.5) on the US-Mexico border in El Paso (Texas) and Ciudad Juaŕez (Chihuahua). Environ. Model. Softw. 2005, 20, 547–559. [Google Scholar] [CrossRef]
- Lin, C.J. An efficient immune-based symbiotic particle swarm optimization learning algorithm for TSK-type neuro-fuzzy networks design. Fuzzy Sets Syst. 2008, 159, 2890–2909. [Google Scholar] [CrossRef]
- Assimakopoulos, M.N.; Dounis, A.; Spanou, A.; Santamouris, M. Indoor air quality in a metropolitan area metro using fuzzy logic assessment system. Sci. Total Environ. 2013, 449, 461–469. [Google Scholar] [CrossRef] [PubMed]
- Mishra, D.; Goyal, P. Neuro-fuzzy approach to forecast NO2 pollutants addressed to air quality dispersion model over Delhi, India. Aerosol Air Qual. Res. 2016, 16, 166–174. [Google Scholar] [CrossRef]
- Mishra, D.; Goyal, P.; Upadhyay, A. Artificial intelligence based approach to forecast PM2.5 during haze episodes: A case study of Delhi, India. Atmos. Environ. 2015, 102, 239–248. [Google Scholar] [CrossRef]
- Wu, S.Q.; Er, M.J.; Gao, Y. A fast approach for automatic generation of fuzzy rules by generalized dynamic fuzzy neural networks. IEEE Trans. Fuzzy Syst. 2001, 9, 578–594. [Google Scholar] [CrossRef]
- Wu, S.Q.; Er, M.J. Dynamic fuzzy neural networks-a novel approach to function approximation. IEEE Trans. Syst. Man. Cybern. B. Cybern. 2000, 30, 358–364. [Google Scholar] [PubMed]
- Kupongsak, S.; Tan, J. Application of fuzzy set and neural network techniques in determining food process control set points. Fuzzy Sets Syst. 2006, 157, 1169–1178. [Google Scholar] [CrossRef]
- Leng, G.; McGinnity, T.M.; Prasad, G. Design for self-organizing fuzzy neural networks based on genetic algorithms. IEEE Trans. Fuzzy Syst. 2006, 14, 755–766. [Google Scholar] [CrossRef]
- Habbi, H.; Boudouaoui, Y.; Karaboga, D.; Ozturk, C. Self-generated fuzzy systems design using artificial bee colony optimization. Inf. Sci. 2015, 295, 145–159. [Google Scholar] [CrossRef]
- Han, H.G.; Qiao, J.F. A self-organizing fuzzy neural network based on a growing-and-pruning algorithm. IEEE Trans. Fuzzy Syst. 2010, 18, 1129–1143. [Google Scholar] [CrossRef]
- Wilamowski, B.M.; Yu, H. Improved computation for Levenberg-Marquardt training. IEEE Trans. Neural Netw. 2010, 21, 930–937. [Google Scholar] [CrossRef] [PubMed]
- Xie, T.T.; Yu, H.; Hewlett, J.; Rozycki, P.; Wilamowski, B. Fast and efficient second-order method for training radial basis function networks. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 609–619. [Google Scholar] [PubMed]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.; Xu, X.; Zhang, X.; Tang, J. Contributions of pollutants from North China Plain to surface ozone at the Shangdianzi GAW Station. Atmos. Chem. Phys. 2008, 8, 5889–5898. [Google Scholar] [CrossRef]
- Zhao, X.J.; Zhang, X.L.; Xu, X.F.; Xu, J.; Meng, W.; Pu, W.W. Seasonal and diurnal variations of ambient PM2.5 concentration in urban and rural environments in Beijing. Atmos. Environ. 2009, 43, 2893–2900. [Google Scholar] [CrossRef]
- Zhao, X.J.; Zhao, P.S.; Xu, J.; Meng, W.; Pu, W.W.; Dong, F.; He, D.; Shi, Q.F. Analysis of a winter regional haze event and its formation mechanism in the North China Plain. Atmos. Chem. Phys. 2013, 13, 5685–5696. [Google Scholar] [CrossRef]
- Chavent, M.; Guegan, H.; Kuentz, V.; Patouille, B.; Saracco, J. PCA- and PMF-based methodology for air pollution sources identification and apportionment. Environmetrics 2009, 20, 928–942. [Google Scholar] [CrossRef]
- Viana, M.; Querol, X.; Alastuey, A.; Gil, J.I.; Menendez, M. Identification of PM sources by principal component analysis (PCA) coupled with wind direction data. Chemosphere 2006, 65, 2411–2418. [Google Scholar] [CrossRef] [PubMed]
- Carslaw, D.C.; Ropkins, K. Openair-an R package for air quality data analysis. Environ. Model. Softw. 2012, 27, 52–61. [Google Scholar] [CrossRef]
- Elangasinghe, M.A.; Singhal, N.; Dirks, K.N.; Salmond, J.A.; Samarasinghe, S. Complex time series analysis of PM10 and PM2.5 for a coastal site using artificial neural network modeling and k-means clustering. Atmos. Environ. 2014, 94, 106–116. [Google Scholar] [CrossRef]
- Lauret, P.; Fock, E.; Mara, T.A. A node pruning algorithm based on a Fourier amplitude sensitivity test method. IEEE Trans. Neural Netw. 2006, 17, 273–293. [Google Scholar] [CrossRef] [PubMed]
- Han, H.G.; Qiao, J.F. A structure optimisation algorithm for feedforward neural network construction. Neurocomput 2013, 99, 347–357. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | T | RH | WS | WD | Pre | Vis | CO | NO2 | O3 | SO2 | PM2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Units | °C | % | m/s | ° | hPa | km | ppm | ppb | ppb | ppb | μg/m3 |
| Statistical Parameter | Description | Mathematical Function |
|---|---|---|
| IA | Expresses the difference between predicted and observed values | |
| R2 | A measure of linear relationship between predicted and observed values | |
| NMB | Indicates over or under estimation of the model | |
| NMGE | Indicates mean error regardless of it is over or under estimation | |
| RMSE | Provides an overall measure of how close predicted values and observed values are | |
| MB | Measure of model bias |
| PCs | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Percent (%) | 56.55 | 15.71 | 10.00 | 5.98 | 4.01 | 2.34 | 1.71 | 1.50 | 1.13 | 0.86 | 0.21 |
| Additive percent (%) | 56.55 | 72.26 | 82.26 | 88.24 | 92.25 | 94.59 | 96.30 | 97.80 | 98.93 | 99.79 | 100 |
| Statistical Parameter | Ideal Value | SOG-SASOFNN | FOG-SASOFNN | ESN | Eta-CMAQ | |||
|---|---|---|---|---|---|---|---|---|
| Training | Test | Training | Test | Training | Test | |||
| IA | 1 | 0.97 | 0.95 | 0.91 | 0.86 | 0.80 | 0.70 | ~ |
| R2 | 1 | 0.89 | 0.84 | 0.72 | 0.70 | 0.51 | 0.30 | 0.22 * |
| NMB | 0 | −0.01 | −0.05 | −0.17 | −0.23 | −0.26 | 0.31 | −0.32 * |
| NMGE | 0 | 0.25 | 0.37 | 0.42 | 0.43 | 0.52 | 0.57 | 0.51* |
| RMSE (μg/m3) | 0 | 13.56 | 17.90 | 26,84 | 29.31 | 35.35 | 39.79 | 11.6 * |
| MB (μg/m3) | 0 | −0.16 | −1.86 | −2.01 | −3.6 | −5.61 | 6.33 | −5.2 * |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, J.; Cai, J.; Han, H.; Cai, J. Predicting PM2.5 Concentrations at a Regional Background Station Using Second Order Self-Organizing Fuzzy Neural Network. Atmosphere 2017, 8, 10. https://doi.org/10.3390/atmos8010010
Qiao J, Cai J, Han H, Cai J. Predicting PM2.5 Concentrations at a Regional Background Station Using Second Order Self-Organizing Fuzzy Neural Network. Atmosphere. 2017; 8(1):10. https://doi.org/10.3390/atmos8010010
Chicago/Turabian StyleQiao, Junfei, Jie Cai, Honggui Han, and Jianxian Cai. 2017. "Predicting PM2.5 Concentrations at a Regional Background Station Using Second Order Self-Organizing Fuzzy Neural Network" Atmosphere 8, no. 1: 10. https://doi.org/10.3390/atmos8010010
APA StyleQiao, J., Cai, J., Han, H., & Cai, J. (2017). Predicting PM2.5 Concentrations at a Regional Background Station Using Second Order Self-Organizing Fuzzy Neural Network. Atmosphere, 8(1), 10. https://doi.org/10.3390/atmos8010010