1. Introduction
The reanalysis and interpretation of products of numerical weather prediction (NWP) is essential in an NWP system, which is of great importance for the improvement in accuracy of prediction systems [
1,
2,
3,
4,
5]. However, limited by the resolution of numerical models, computing power, and storage capacity, the resolution of such products are not adequate for more accurate inferences [
6,
7], such as extreme weather processes analyses. A well-defined interpolation algorithm can increase the resolution of these products more accurately.
Conventional surface fitting methods, such as bilinear and spline methods, are only applicable to specific cases [
8]. They are deterministic without taking the randomness of natural weather events into account. Interpolations only rely on local information without taking the anisotropy, physical characteristics, spatial dependences, etc. into consideration [
9].
To overcome these problems, several interpolation methods based on different models have been proposed: fuzzy inference [
10], hybrid models such as artificial neural networks (ANNs) combined with Kalman filters (KFs) [
11], ANNs conjuncted with Markov chains [
12], kernel machines such as weighted least square support vector machines (WLS-SVMs) [
13], Gaussian process regression (GPR) [
14,
15,
16,
17], and so forth. Hybrid models and kernel machines are the mainstay of these new approaches.
With appropriate hybrid components, hybrid models are capable of handling both stationary and nonstationary series. The model that is composed of an autoregressive integrated moving average (ARIMA) model and an ANN is more efficient than either an ANN or an ARIMA alone when forecasting wind speed [
18]. Moreover, the KF-ANN model [
11], the ARIMA-ANN model [
19], and the ARIMA-Kalman model [
19] all perform well in forecasting nonlinear wind speed. The increasing number of imported algorithms makes the hybrid models become more effective but more difficult to operate, especially in choosing hybrid components and fine tuning.
Compared with hybrid models, kernel machines (such as SVM and GPR) are easier to operate and can give rise to acceptable results. The proper kernel functions play an important role in kernel machines while predicting winds speed [
20,
21]. Excluding the choice of kernels, tuning skills required by kernel machines are not as difficult as that by hybrid models because of the single model framework. Hence, kernel machines are the more versatile and simpler models compared with hybrid models.
GPR is one of the most popular methods among various kernel machines. Firstly, the Gaussian process (GP) defines a particular distribution for any finite number of samples. The distribution functions, which are called the family of finite dimensional distributions, reasonably describe the randomness of each sample. For localized and instantaneous weather processes, the sampling environment of each sample cannot be identical. Sampling in the same position at different moments or at the same moment in different positions will result in different distributions for each sample. Secondly, owing to the instantaneity of weather processes [
22,
23], the influence radius and influence intensity of the wind genesis factors are different. By composing kernel functions, GPR is applied to multi-scale inference, which can extract different radii and intensities [
24]. Thirdly, most weather processes with cyclones are non-stationary, whereas the kernel trick in GPR, which means mapping the features in low-dimensional space into high-dimensional space, can handle them. In addition, as a nonparametric algorithm with no demand of the professional tuning skills, it guarantees universality and portability.
Most GPR applications are proposed for time series [
14,
15,
16,
17] that handle the wind data sampled in one position at multiple moments. They confirm the efficiency of GPR, but they are not appropriate for interpolating the space series of wind fields sampled from different regions at the same time or sampled from the same time but from different regions. The reasons can be listed as follows. First, most methods for time series take time, or the series itself as the explanatory feature [
11,
18,
19], which is one-dimensional. However, the spatial distributions of the wind fields are two-dimensional at least. Substantially, air temperature, atmospheric pressure, and spatial inhomogeneity influence wind genesis [
25,
26,
27]. Furthermore, for each factor, the influencing radius is not the same [
22,
23]. A single kernel cannot capture this multi-scale information [
28]. In addition, the non-stationary of the spatial series of the weather processes with cyclones is more obvious. However, the kernel for interpolating time series is mostly designed for stationary series [
24]. Therefore, considering only a one-dimensional interpreting variable and a single scale without handling the anisotropy, and designing interpolation algorithms only for stationary series, models are blind to spatial series of weather processes. This is a challenge when accurately improving the resolution of products released by NWP.
Considering the relationship of the factors of wind genesis [
29,
30,
31], introducing more information may be one way to meet this challenge. The SVM model, which takes wind speed and temperature or wind speed and wind direction as the input features, generates ideal predictions [
32,
33]. Grover et al. adopted wind direction, space distance, pressure, and temperature to infer long-range spatial dependencies by GPR [
34]. All models work but are not applicable for determining weather processes with cyclones, such as typhoons, which are multi-range dependent and instantaneous. SVM could not capture the different distribution of each sample, which is natural in weather processes. Although GPR can fix this problem by importing random processes, Grover’s proposal can only be used to figure out long-range dependencies. Additionally, the single squared exponential kernel in their method is too smooth for weather processes. To handle multi-range dependencies of the weather processes with cyclones, a multi-scale kernel is required, and more features are needed to correct the underfitting parameters trained by the unilateral spatial information.
Taking all of the above into account, a two-dimensional multi-scale anisotropic kernel function based on GPR is proposed. Taking space coordinates (longitude and latitude) as explanatory variables, the kernel is designed to capture detailed features. Despite the one-sided spatial information, the first principle feature is also introduced as the correction feature to help correct the hyperparameters of the multi-scale anisotropic kernel function. It is generated from air temperature, air pressure and wind direction by principle component analysis (PCA). Different models are specified for weather processes without cyclones and weather processes with cyclones.
The rest of the paper is organized as follows. The basis of the GPR model and the kernel functions associated with weather processes are described in
Section 2.
Section 3 provides details about the multi-scale anisotropic kernel function for weather processes and the multivariate correction models for spatial interpolation based on GPR. The numerical experiment in
Section 4 shows the efficiency of the new models. The dataset used here is ERA Interim [
35], a 10 m wind field dataset released by the European Centre for Medium-Range Weather Forecasts (ECMWF). The last section provides conclusions.
2. GPR and Kernel Functions Associated with Weather Processes
2.1. GPR with the Kernel Trick
GPR is a nonparametric algorithm based on a Bayesian framework. The predictions of any finite number have a joint Gaussian distribution [
24], which is implied by Equation (3).
Assume there is a training set of n observations, , where denotes the D-dimensional input vector, and y denotes the scalar observed label of . , represent the collection of , y, respectively. The test set of m test input is denoted as . represent the collection of .
Given the training input
and the corresponding scalar labels
, the optimal interpolation value
at any test input
in
is
The prediction
follows a Gaussian distribution
and the joint distribution of
and
is
where
K,
, and
denote the covariance matrix generated by the kernel function
, in which
are the input vectors either in the test set or in the training set. Specifically,
K denotes the covariance matrix of the training set,
denotes the covariance matrix between the training set and the test set, and
denotes the covariance matrix of the test set.
Projecting the input vectors in the D-dimensional space into an N-dimensional feature space, GPR is capable of handling nonlinear problem, which is a common characteristic for weather processes. The idea of projecting is also known as kernel trick.
2.2. The Characteristics of Kernel Functions for Weather Processes
A kernel trick is employed in several kernel machines. An abundance of kernels can be chosen.
Different kernels suit different problems. Some are suitable for linear problems, e.g., the linear covariance function; some focus on periodic variation, e.g., the periodic covariance function; some are sensitive to the diversity in different directions, e.g., the Gabor kernel function; and some perform well while describing rough physical process, e.g., the Matérn kernel function.
The most popular kernel is the squared exponential (SE) covariance function, but it is overly smooth for depicting weather processes [
24]. The function is expressed as follows:
where
, and
l is the length-scale hyperparameter.
Fixing the over-smoothness of the SE, the Matérn kernel is suitable for approaching weather processes, especially when
, or
. The general expression of Matérn kernel is
where
and
l are the hyperparameters,
is a modified Bessel function, and
denotes the Gamma function. When
, it is simplified as
The Gabor kernel is preferred in image processing for its capability of edge and texture extraction. It is a short-time Fourier transform (STFT) with a Gaussian window function. The variation in wind direction and wind speed between each wind belt is exactly what the Gabor kernel can capture. It is written as
where
,
denotes the matrix of periodical length-scale hyperparamters, and
l denotes the length-scale hyperparamter.
It has been proven that the summation, the product, and the scale of existing kernels are still kernels [
24]. Namely,
where
denotes a real number. Mapping a kernel to
periodic space also gives rise to a kernel that extracts periodic information.
A significant advantage of combining kernel functions is the capability of extracting multi-scale information. By combining the kernels mentioned above according to Equation (8), the new kernel will be capable of extracting multiple pieces of information: periodical information, the diversity in different directions, or rough and localized features. The length-scale hyperparameters of kernels imply the influencing radius of each specific feature.
4. A Case Study of Wind Fields 10 m in Height
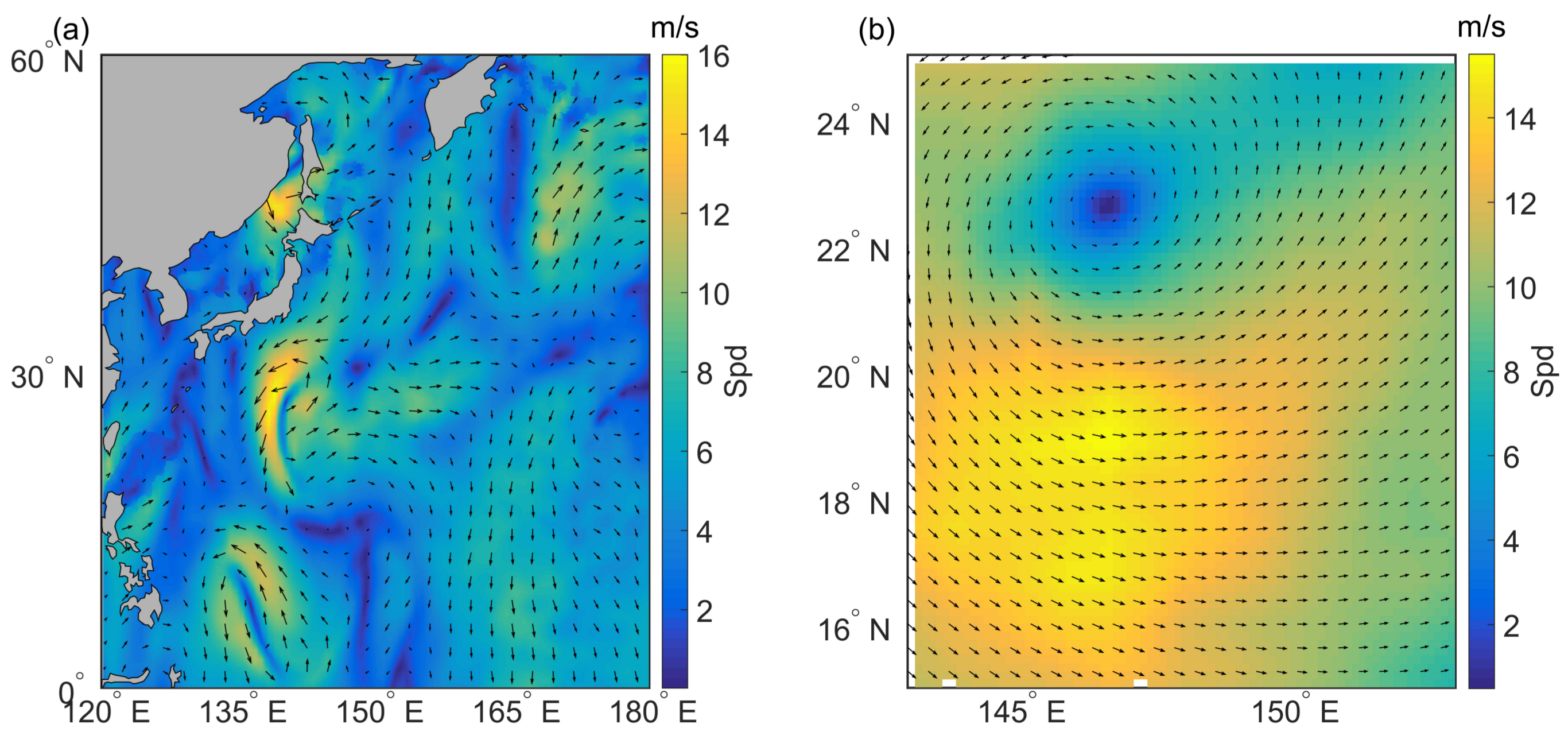
The dataset of 10 m wind fields used in this study is from the ERA Interim dataset published by the ECMWF. It is subject to global atmospheric reanalysis and has been continuously updated in real time since 1979. The region of the data used in this study ranges from N to N and from E to E. The original resolution of the wind field dataset is . Here, the resolution of the training set is , which is sampled from the original dataset, and the rest are imposed for testing. Concretely, the secondary features are sea surface temperature (SST), mean sea level pressure (MSLP), and wind direction computed from the u wind component and the v wind component.
The efficiency of interpolation is evaluated by the root mean square error (RMSE), which is expressed as
where
denotes the
i-th predicted
u or
v wind component,
denotes the
i-th
u or
v wind component in the original data, and
n denotes the number of the interpolated points. The wind speed of the
i-th interpolated point is deduced by
where
and
denote the
u and
v wind component either in predictions or in the original data, respectively. The wind speed error of the
i-th interpolated point is
where
are the
i-th
u,
v wind component from the original data, respectively; and
and
are the
i-th predicted
u and
v wind components, respectively.
4.1. Weather Processes without Cyclones
The first experiment compares the efficiency of the and models. Because a large region results in a huge covariance matrix that is computationally expensive to invert, the region is divided into subregions firstly and interpolations are then made on each of them. The grid size of each subregion is , which is the number of interpolated points.
To obtain a steady estimation of the unknown hyperparameters mentioned in
Section 3.1, each training series is processed 100 times. Two kinds of series are used, one is sampled from different regions at the same time, and the other is sampled from the same region at 20 different moments. After training, the hyperparameters of the series from different regions at the same time are used to interpolate the series at the same moment but from different regions. The hyperparameters of the series at different times in the same region are used to interpolate the series of the same region sampled at other times.
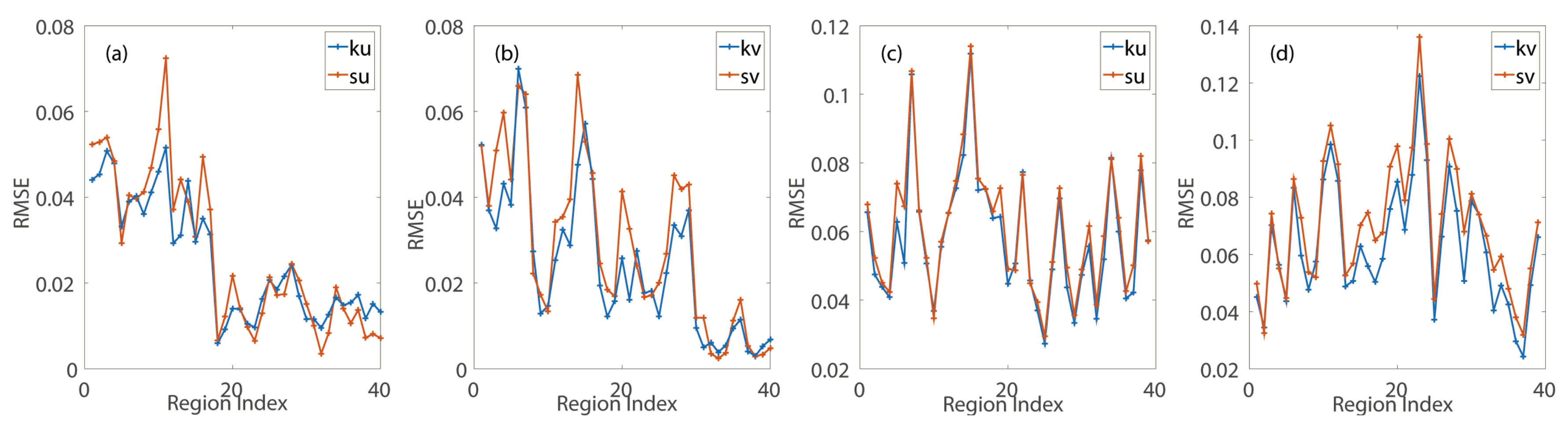
The mean RMSE after interpolating the series sampled from different regions with
outperforms the result of the spline method, while the RMSE does not, which is shown in
Figure 2a,b. Single multi-scale anisotropic kernel
is underfitting while interpolating the space series.
Weather processes without cyclones change seasonally. Interpolating the regions sampled from forty different times (within 10 days of the sampling time in the training set) confirms that what
extracts is not contradictory. As shown in
Figure 2c,d, in most regions, the RMSE, after interpolating the series sampled from the same region but at different times with
, is always smaller than that after interpolation with the spline method.
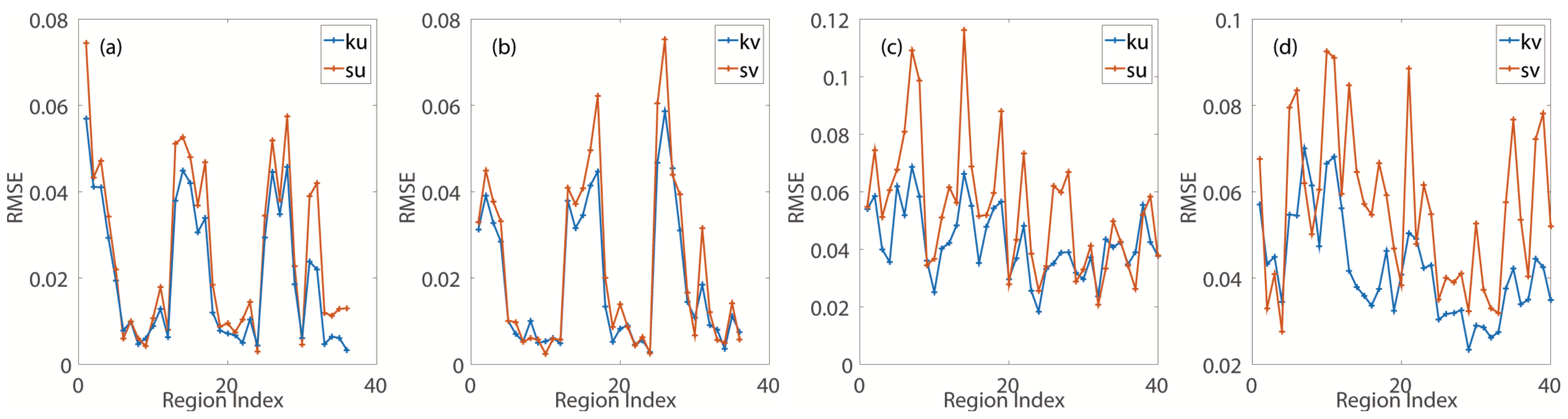
When interpolating the space series sampled from the same time, the mean RMSE of all the interpolated regions with
is reduced by
at least compared with that of the spline method, which is shown in
Figure 3a,b. Additionally, the number of regions increases; the RMSE of these regions is smaller than that after using the spline method. This indicates that
has captured the multi-scale local spacial feature.
Figure 3c,d shows the results after interpolating the space series sampled from the same region at different times. The mean RMSE of
Figure 3c,d declines by
for the
u wind component and by
for the
v wind component compared with that of the spline method.
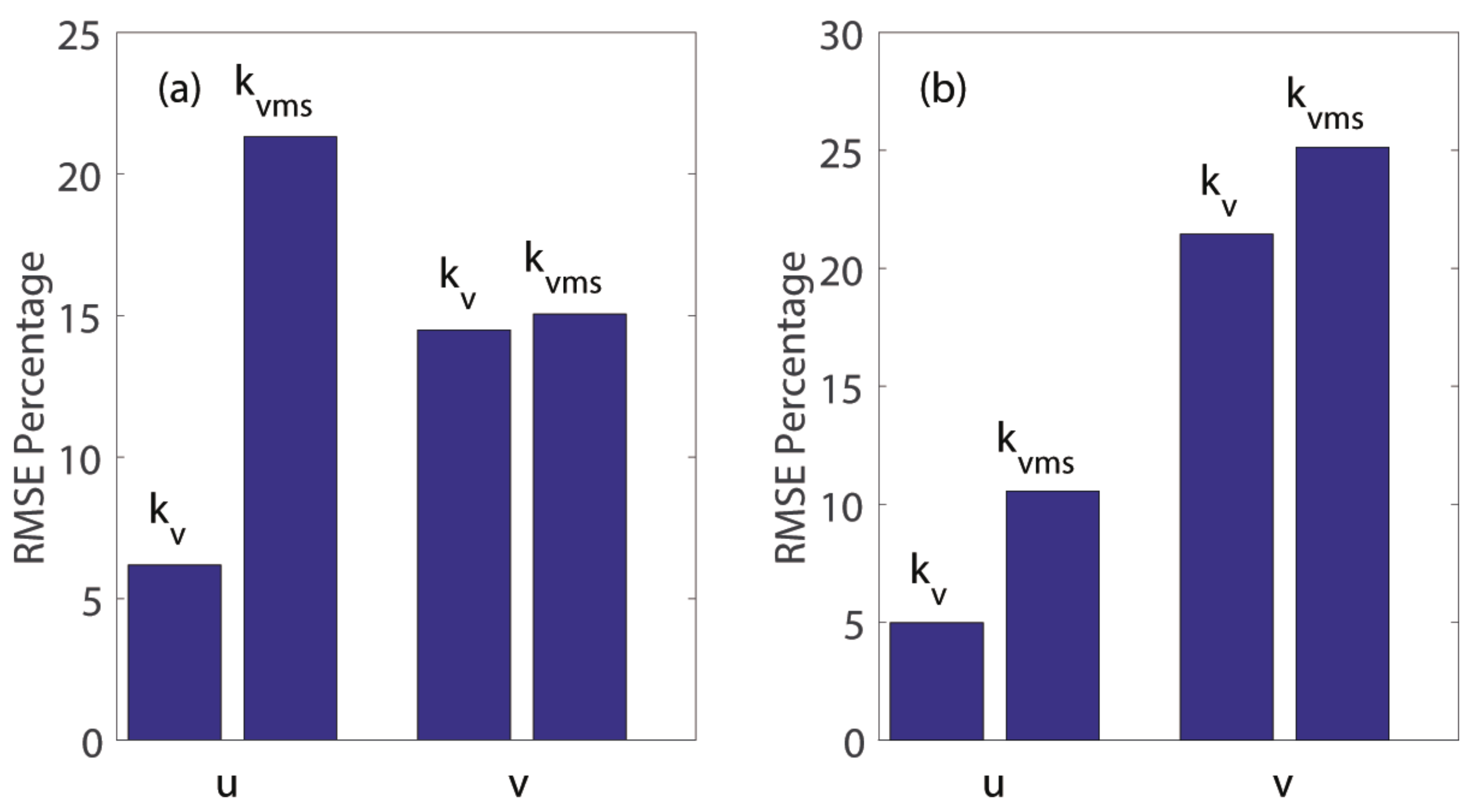
In
Figure 4, the promotion of the
method, compared with the spline method, outperforms that of the
method, which implies that the correction model
fixes the one-sided feature trained by single space information.
4.2. Weather Processes with Cylcones
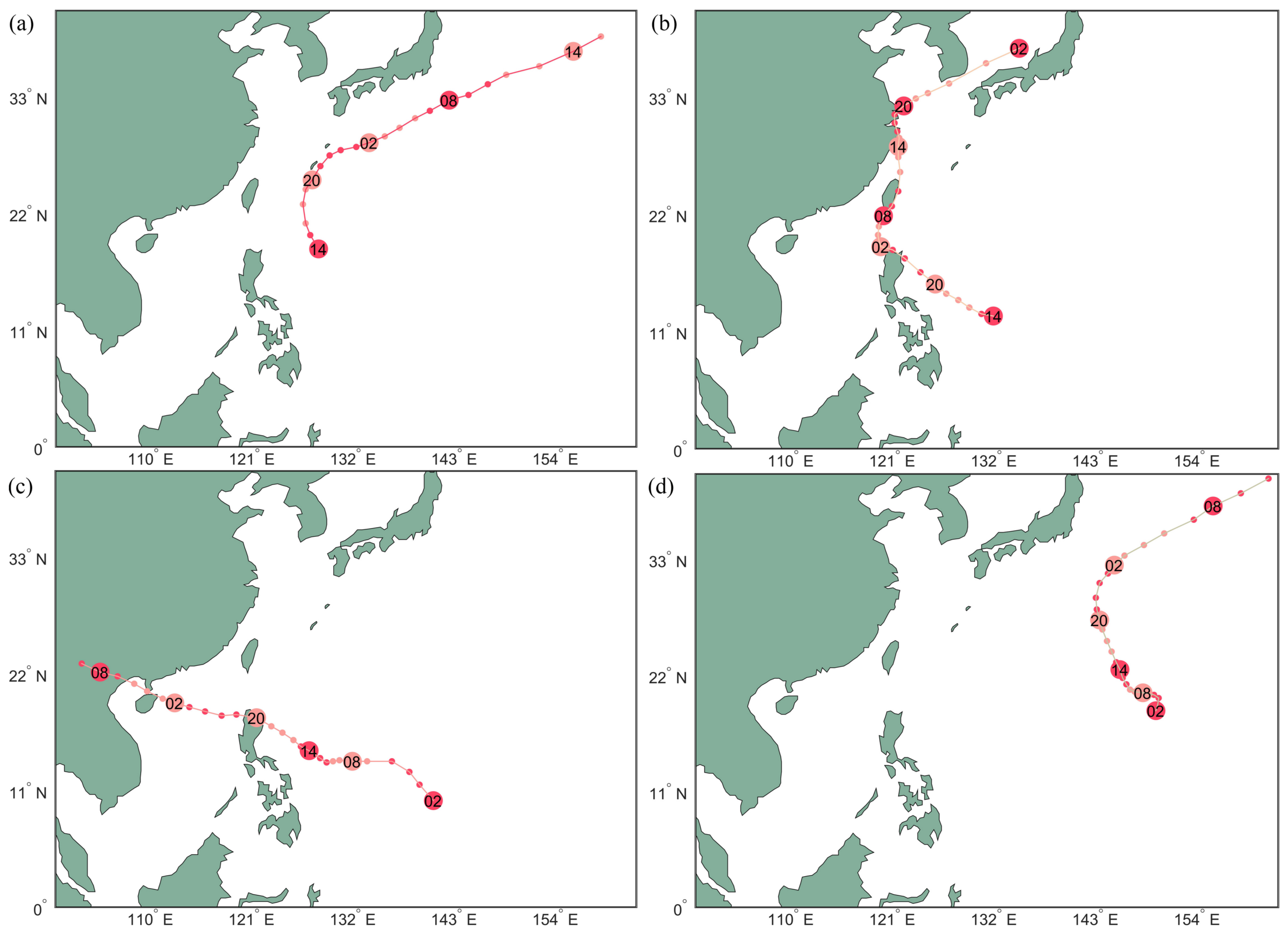
Typhoons Fengshen, Kalmaegi, Fung-wong and Kammuri in 2014 are selected as examples of weather processes with cyclones. Their tracks are shown in
Figure 5. Using kernel
, 26 regions of Fung-wong that are sampled from 26 different times are trained. The grid size of each region is
, which is the number of interpolated points. After training, the hyperparameters are used to interpolate the other typhoon regions sampled from Fengshen, Kalmaegi, and Kammuri.
Except for the baseline spline, the other baseline for comparison is a back propagation (BP) neural networks, which is composited of several fully connected layers. In this study, the entire work can be regarded as a nonlinear regression function. The BP framework used here is shown in
Figure 6. All layers, except the output layers, are activated by ReLu activation functions. The output layer is activated by linear activation functions.
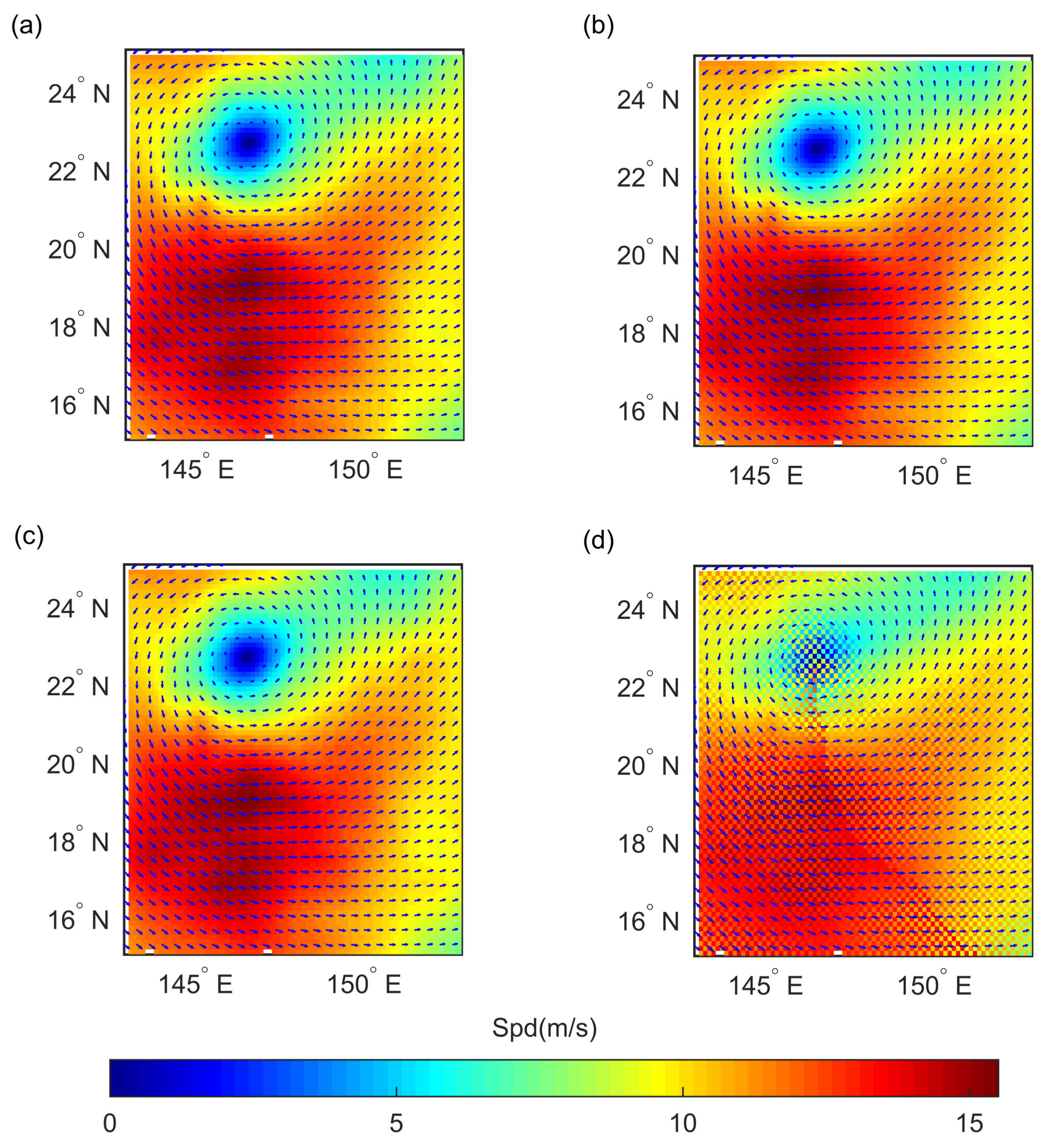
Figure 7 shows the interpolated wind speed and the wind vector field of typhoon Kamurri at 0000 UTC on 26 September 2014. Compared with the reference field shown in
Figure 7a, the structural information and scale information are preserved. The field interpolated by BP exhibits an obvious sawtooth phenomenon at the interpolation position. BP adopts wind direction, SST, longitude, and latitude to fit wind fields. It is natural that the result is worse than
. There are no scale parameters in BP. What is generated by BP is only a picewise linear function that cannot approach the nonlinear features well. The same features employed in BP are also used to train GPR with a simple multi-scale anisotropic kernel
, the result is still under-performing compared with the
model. This implies that the major interpreting variables (longitude and latitude) make more sense than the other features, while interpolating wind fields. Spline behaves well owing to the fact that it takes a small number of points around the target point to approach. Although the spline method does not take longer-dependencies into consideration, the result is still acceptable because the weather processes with cyclones dramatically change mainly due to the local environment. However, as shown in
Figure 8,
Figure 9 and
Figure 10, the result of the spline method is still over-smooth in some positions.
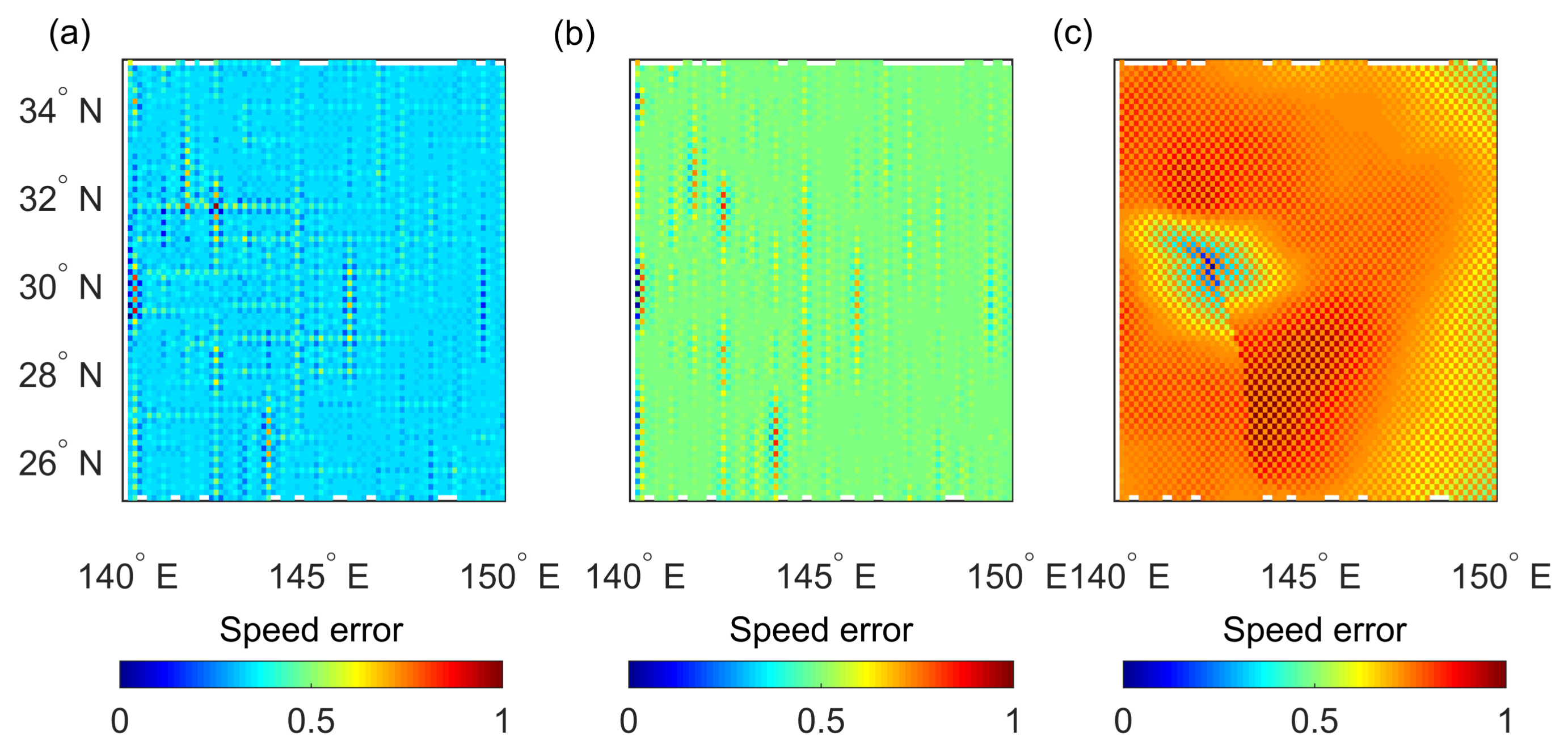
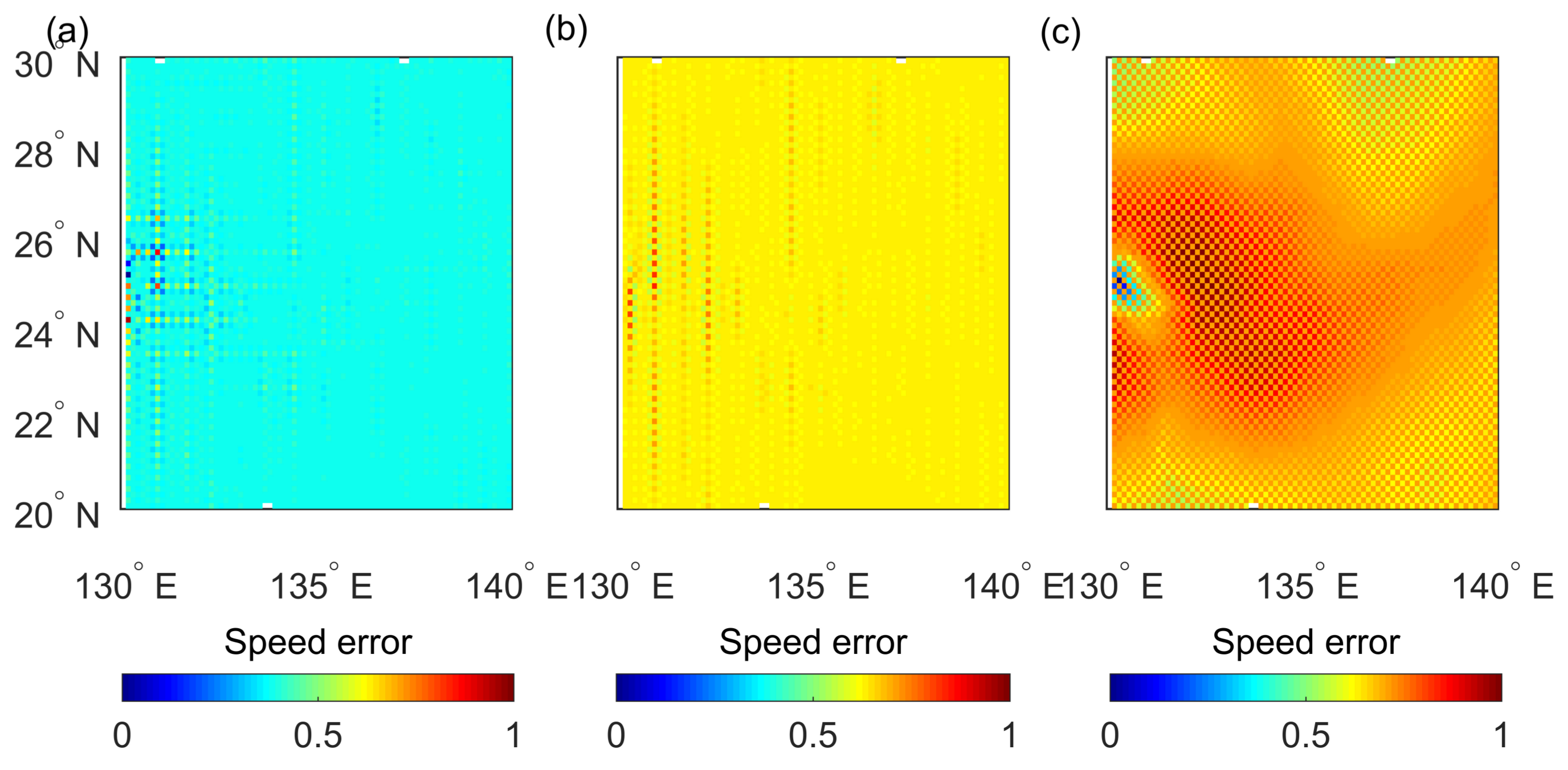
Figure 8,
Figure 9 and
Figure 10 show the speed error after interpolating.
Figure 8 shows the region of Kamurri at 1800 UTC on 28 September,
Figure 9 gives the region of Fengshen at 0000 UTC on 8 September, and
Figure 10 shows the region of Kalmaegi at 1800 UTC on 13 September. The error bar of the result of
in
Figure 8 centers around 0.4, which indicates that the mean RMSE of
is smaller than that of the spline and BP methods. The speed error of
shown in
Figure 9 and
Figure 10 also validates the improvement. Considering the instantaneous variation of wind speed and wind direction in the vortex, the approach function cannot be too smooth. However, the spline method is over-smooth because it involves two times continuous derivatives. For the Matérn kernel function in the
model, the process is mean square continuous (if a sequence of points
and a fixed point
are assumed, then a process
is mean square continuous at
if
as
), but not mean square differential (if a covariance function
is assumed, the mean square derivative in the
i-th direction of a process
is defined as
, where
denotes two different input vectors, and
denote the vector in the
i direction) [
24]. This leads to the reasonable roughness that the weather processes require because the smooth function is infinitely derivable in the domain of definition.
The improvement of the mean RMSE in all interpolated regions sampled from Fengshen, Kalmaegi, and Kammuri, after using the hyperparameters trained by Fung-wong, is shown in
Table 1.
There is always a tradeoff between accuracy and cost. Although the result of multivariate correction models (either
or
) outperforms that of the spline method, the interpolation time of these methods does not. The computing demand of the naive implementation in this experiment is nearly 100 times greater than that of the spline method. The complexity of the spline method is
[
40], while the main cost of GPR increases as
[
24]. The inverse of the covariance matrix requires more computing resources. Works focusing on reducing the computing cost of the inverse of the covariance matrix have been published. Fine and Scheinberg proposed the low-rank incomplete Cholesky factorization, which take
if the number of decomposition pivots that are greater than the threshold is
k [
41]. Bae D.H. et al. optimize the memory distribution in a cloud computing system for a massive matrix and made excellent progress [
42]. After optimization and parallelization, this method is expected to be operationalized in quickly processing global data generated by NWP systems.
5. Conclusions
In this study, to improve the resolution of products released by the NWP system, a two-dimensional multi-scale anisotropic kernel for the spatial interpolation of wind fields is proposed. To fix the partial information trained by space information, multivariate correction models, namely the model for weather processes without cyclones and the model for weather processes with cyclones, were designed by importing a correction feature (the first principle component of temperature, pressure, and wind direction generated by PCA). The numerical examples of 10 m wind fields in ERA Interim reanalysis demonstrate improvement. Given correction feature, outperforms the spline and simple models. For weather processes with cyclones, interpolating typhoon regions with generates the best result. The model works well compared with the spline and BP methods.
The interpolation time of the models remains undetermined. To construct models that can quickly improve the resolution of global data released by the NWP system, research will focus on reductions in the computation of this naive experiment. Possible approaches include optimizing the inverse algorithm of the massive matrix, GPR sparse inferences or paralleling. After optimization, these new models can be used in variational data assimilation to improve interpolation operators, and this will lead to more accurate forecasting.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}