1. Introduction
There is growing interest in the extent to which productivity is reduced in workers exposed to high ambient temperatures and high humidity, and the related impacts of climate change [
1,
2,
3]. A recent survey of the economic costs of extreme weather noted that “labour productivity loss [is] expected to make a substantial contribution to the overall economic impacts associated with a warmer climate” [
4]. In the latest climate change impact assessment related to human health concerns [
5], the heat effects on human performance and work capacity were given high visibility. The importance of considering humidity, as well as temperature, was stressed in a projection of labour capacity out to the year 2200, which suggested a global reduction to a 40% capacity in the peak months under unmitigated climate change [
6].
Besides the likely economic implications [
7,
8,
9], there are also important health considerations. In poor communities, individual workers may be faced with the dilemma of [
10] whether to reduce their work output and suffer a loss of family income or to continue to work in conditions of unsafe heat stress, risking personal injury or even death [
11,
12]. When the heat stress is temporary, physiological heat acclimatization plays a limited protective role [
12], but in more continuous heat exposure situations, behavioural or technological acclimatization will be of great importance, including applying air-cooling systems. However, for many jobs, air-cooling is difficult or impossible to apply, and the limitation of climate change impacts will depend on reducing the extent of the global climate change [
5]. The many ways in which climate change will impact worker safety and health are surveyed in Schulte et al. (2016) [
13].
Absolute productivity, that is, the hourly output of some industrial or agricultural product, is peculiar to each work environment, so we are concerned rather with the relative productivity. Nevertheless, data will most often be available in terms of the actual output, so here we provide a class of models suitable for modelling such data and capturing the relative output as a discrete component of the model. Despite the importance, both economic and epidemiological, in how worker productivity is reduced through heat stress, few published reports of heat-related productivity loss from actual field observations of workplaces are so far available, and the very few datasets can be used for quantitative analysis [
14,
15,
16]. It is therefore important to make the best possible use of the meagre data that are available, and the method presented here provides a method for analysing such data and comparing the results between disparate settings.
In this paper, I propose a new model for the output of an individual worker in a particular work environment. The model has two components, each with its own assumptions. First, we suppose that each worker has a maximum potential output under ideal conditions, and model this theoretical maximum as being normally distributed across the population of workers in that industry. Secondly, we suppose that in any work environment, an individual’s actual output will be reduced by environmental stress to something less than their potential maximum. This proportional reduction will itself vary between workers, and we model it using beta distributions that vary with the environment. A worker’s actual output under given conditions is then the product of their potential maximum output and the proportion that they can maintain, or choose to maintain, in those conditions.
An important feature of this model is that it captures the inter-individual variation in the reduction of output. It is workers in the tails of this distribution that are at the greatest risk to their health and/or income. We turn next to the details of this aspect of the model.
2. Experiments
In a given work environment, including an ideal environment, workers will vary in their relative output, so a probabilistic model is required to capture the mean relative productivity and the variation around the mean. We define ideal conditions as those that maximise the probability of achieving a 100% relative output. Less ideal conditions will reduce this probability, perhaps to zero if no workers can maintain full output, and will increase the probability of lower levels of productivity, potentially to no output at all, if work becomes impossible for at least some workers.
A suitable family of distributions to express variation in a proportion or percentage is the two-parameter beta family, usually parameterised as
This distribution has a mean μ = α/(α + β ) and variance
A convenient reparameterisation for modelling purposes is directly in terms of μ and a scale parameter θ = , from which the usual parameters can be recovered as α = θϕ, β = θ/ϕ where ϕ 2 = μ/(1 – μ).
Usually, we will model μ to express how it varies with the work conditions. Here we model μ as a logistic function of heat stress T, and estimate θ as a constant. If a particular parametric model implies a mean output of μ, maximising the log-likelihood of the data with respect to the parameters that determine μ in each environment, and also with respect to θ, provides the maximum likelihood estimates of those parameters.
We let the potential maximum output for individual i under ideal conditions following a normal distribution, Zi ~ N(ψ, τ2), and express the proportional reduction in the work environment j as Pij ~ B(μ (Tj), θ). Here, Tj represents the heat stress of that environment on some scale such as ordinary ambient temperature, or a more specialised heat stress measure such as effective temperature ET or wet bulb globe temperature, WBGT.
The observed output is Y = Z × P. Since the mean of Z is ψ and that of P is μ, the mean of Y is approximately E[Y] ≈ ψμ. A given level of output might represent a small proportion P of a large potential Z, or vice-versa, so the model, as so far described, will be poorly conditioned in terms of ψ and μ, and a further model constraint is required. Published reports often describe an optimal environment under which heat stress is essentially absent. For example, Wyndham (1969) [
14] assumed no loss of productivity until the ambient heat (expressed as natural wet bulb temperature, Tnw) exceeded 27.7 °C. It seems reasonable, then, to assume that the beta distribution representing reduced productivity in such an environment has its mode at P = 1, approaching a degenerate distribution in which all workers deliver 100% output. Under the conventional Beta(α, β) parameterisation, such distributions are the subfamily in which β = 1. This sub-family can be specified through a logistic model in the form:
Then μ(T0) = θ2/(1 + θ2), α(T0) = θ2, and β(T0) = 1 as required. The overall model now has four parameters: the mean ψ and variance τ2 of the maximum potential output; the (negative) regression parameter b that relates the mean relative output μ to the environmental stress measure T; and the beta-distribution scale parameter θ, which also determines the intercept of the regression. Sometimes, T0 can also be estimated from the data, but this may be unstable in small datasets, and then better results are achieved by setting T0 from external considerations such as local knowledge or expert opinion. Both approaches are applied in the examples below.
As well as modelling the mean output through a logistic regression equation, which may include many covariates, the model also flexibly captures between-worker variance in output, through two parameters τ
2 and θ. The first measures the inter-worker variation of output in ideal, comfortable conditions, while θ determines how the variance changes with temperature. A large θ implies that the variance reduces in proportion with the mean output, as assumed by the original author in the first example below [
14]. A small θ, on the other hand, implies that the variance is maintained, or even increased, as adverse conditions cause the output to fall, which is the case in which any given setting will in itself be a research question of interest, to be answered through the analysis of relevant field data.
3. Results
Little research has been published reporting either experimental or observational data on occupational productivity loss. We present analyses of three papers, dating from 1969, 1992 and 2013, which report various types of data as discussed below.
3.1. Example 1: Wyndham 1969 [14], Gold-Mining in South Africa
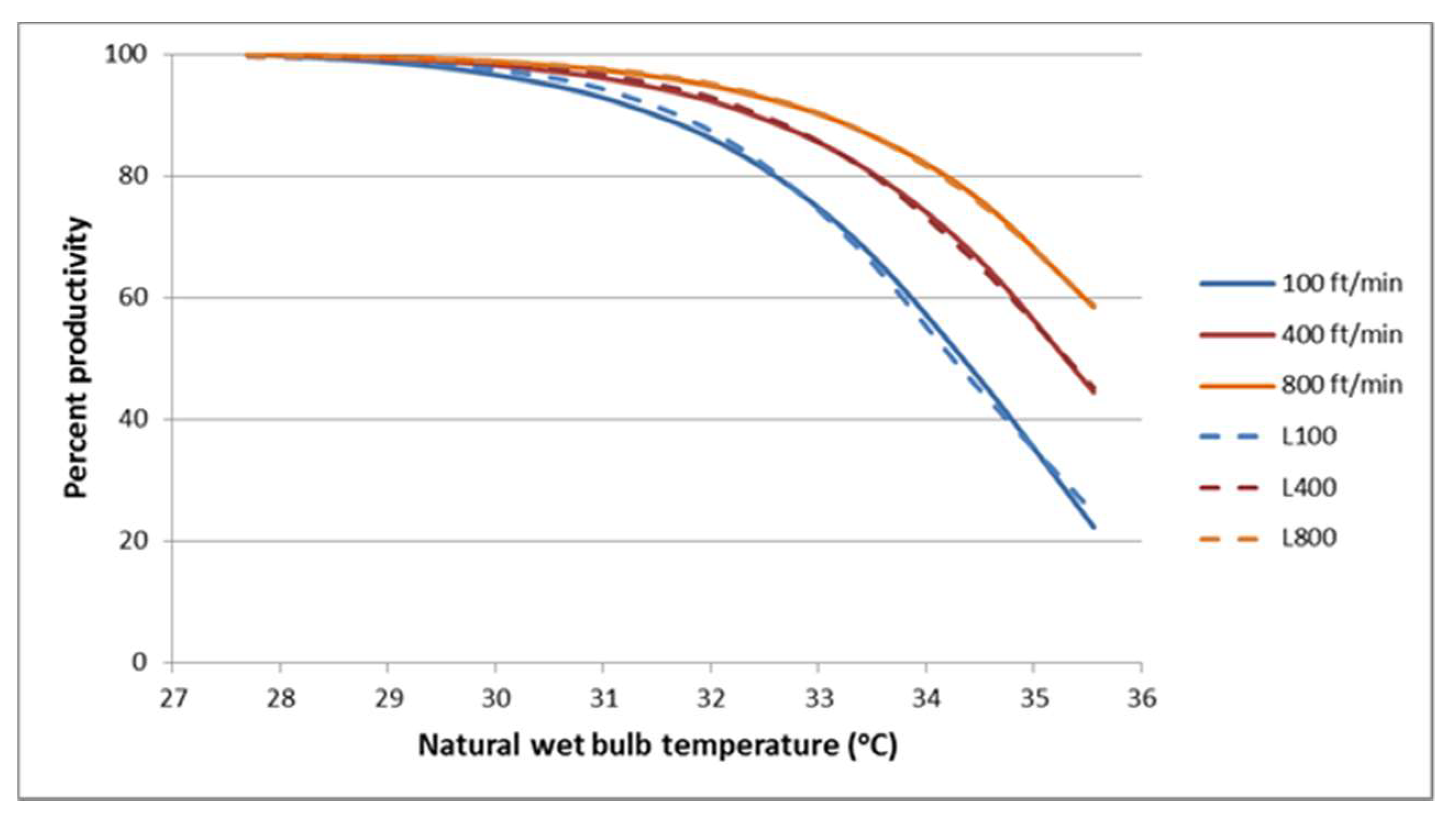
Wyndham [
14] presents fitted curves, but no data, of percentage performance (P) against natural wet bulb temperature (Tnw) for three wind speeds: 100, 400, and 800 ft/min (approximately 0.5, 2 and 4 ms
−1). This temperature metric will typically (except in extremely humid conditions) take lower values than other scales such as Effective Temperature (ET), or WBGT. Wyndham’s curves can be expressed as
This ensures P = 100% when Tnw = 27.7 °C, which is the complement of how Wyndham defined the vertical axis of his graphs (“percentage falloff in productivity from the level at 27.7 °C wet bulb temperature”). We recovered Wyndham’s fit by digitising values from the published figures and fitting this equation to them by least squares (on the P scale). We found that a common value of r = 1.880 provides an essentially perfect fit (data not shown), with b = 0.00460, 0.00245, and 0.00165, respectively, for wind speeds of 100, 400, and 800 ft/min. The exponential model chosen by Wyndham can be closely approximated by our preferred logistic model.
Figure 1 shows logistic equations fitted by least squares to the same digitised values, with Wyndham’s exponential curves for comparison.
The estimated logistic curves, shown as dashed lines in
Figure 1, are
(100 ft/min) logit(μ) = 29.4 − 0.858 × Tnw,
(400 ft/min) logit(μ) = 27.4 − 0.775 × Tnw,
(800 ft/min) logit(μ) = 26.4 − 0.734 × Tnw.
In terms of the model proposed here, these represent logistic curves for the mean μ of the beta distribution, with slope b that reduces with increasing wind speed. Wyndham gave no actual output data, so we have no direct information about the mean ψ and variance τ2 of the maximum output.
However, we can infer something about θ. Wyndham adds 78% confidence intervals (±1.23 SE) to these graphs, stating that “where they do not overlap, there is a 95% chance that there is a real difference between the two curves”, presumably on the basis that (1 − 0.78)2 ≈ 0.05. Regardless of the statistical logic, when combined with the reported design points, and the sample size of 10 individuals tested in each environment, these intervals furnish information on the between-subject standard deviation, which simulations using nonlinear least squares modelling suggest was about 0.05 on the log10 scale or roughly ±12%. Constant variance of log-transformed data, as Wyndham assumed, implies that on the original productivity scale, the SD would be proportional to the mean; that is, the variance of Y falls at high temperatures in proportion to μ, and so has no contribution from the variation in P but only the original between-subject variation in Z. Under our model, this implies a degenerate beta distribution for P with zero variance, represented by an unbounded θ. Unfortunately, Wyndham did not present his original data, from which we might have tested this and estimated θ. Nevertheless, these data provide some support for the general applicability of our logistic model.
The estimated relative output (%) is shown in
Table 1 for the range of temperatures in the Wyndham data, assuming a wind speed of 200 ft/min (approximately 1 m·s
−1). As noted above, standard deviations for the between-worker variation around these means cannot be estimated from the data published.
3.2. Example 2: Nag 1992 [15], Light Manual Workers in India
Reports of productivity in relation to heat stress do not always provide individual-level data, but may only give summary statistics such as the mean production in each environment and some measure of variation or uncertainty such as the standard error of each reported mean (SE) or the between-worker standard deviation (SD). The model parameters can be estimated from these summary statistics by maximising the sum of the two log-likelihood terms, one for the mean and one for the standard deviation SD, where , and V = ψ2σ2 + μ2τ2. Τhere are υ = n − 1 degrees of freedom for standard deviations estimated from groups of n workers. The likelihood contribution from each experimental environment is then
This function is maximised over our model parameters T0, ψ, τ, b and θ, which jointly determine the mean and standard deviation of production in each environment.
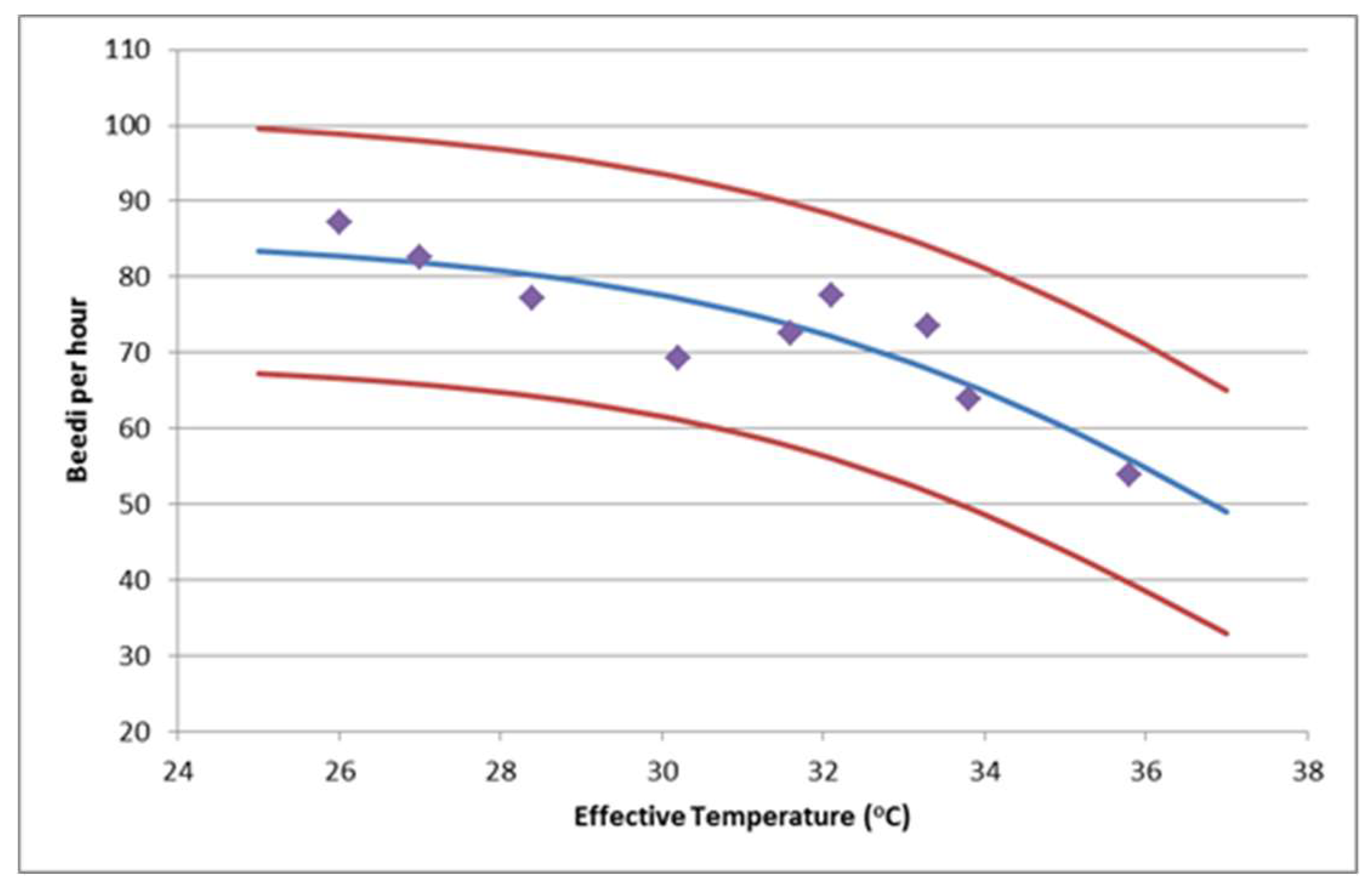
Figure 2 of Nag and Nag (1992) [
15] shows the means with error bars of actual production in the first, second, and third hour of 3-hour observation periods, at nine controlled heat stress levels from 26.0 °C to 35.8 °C effective temperature (ET), which is similar to WBGT. Each of the six workers was observed in each environment over nine days, experiencing one environment per day in a different order for each worker. Here, we ignore the first hour as representing a “run-in” period and average the output of the second and third hours. The data used here, digitised and summarised from the published graph, are shown in
Table 2. The units are beedi/h.
To estimate the between-worker variation, we can measure the width of the published error bars, averaged where distinguishable on the original graph, which is approximately 8 beedi/h. Assuming these are standard-error bars, the standard error of the means is about 4, which implies (since n = 6) a between-subject standard deviation in each hour of ≈ 9.8 beedi/h. The within-subject correlation between hours is unknown, but a correlation close to 1 seems likely in the workers’ output in two consecutive hours, in which case the standard deviation of the individual output averaged across two hours remains 9.8 beedi/h.
We next use a logistic model for μ, and here we are able to estimate the optimal-conditions parameter T0 from the data using the maximum likelihood. Thus, we write logit(μ) = 2ln(θ) + b(T − T0), where θ, b and T0 are all parameters to be estimated. We also estimate the two parameters of the N(ψ, τ2) distribution of maximum potential output. The parameter estimates are T0 = 19.7 °C, ψ = 85.4, τ = 9.97, b = −0.285, and θ = 13.626. Thus, the optimal temperature is about 20 degrees Celsius, under which conditions workers produce about 85 ± 10 beedi/h. Production falls to about 65% when the temperature rises to 36 degrees, but relative production at that temperature varies between workers from about 50% to 80%. At T = 20 °C effective temperature, the relative production follows a Beta(178, 1.04) distribution, with a mean of 0.994 and a 90% probability interval (0.983, 0.9997), so that all workers are then, in effect, fully productive.
3.3. Example 3: Sahu 2013 [16], Rice Harvesters in India
Sahu et al. (2013) [
16] report the number of bundles of rice gathered over several days, by groups of 18 workers in the first and fifth hours of each day.
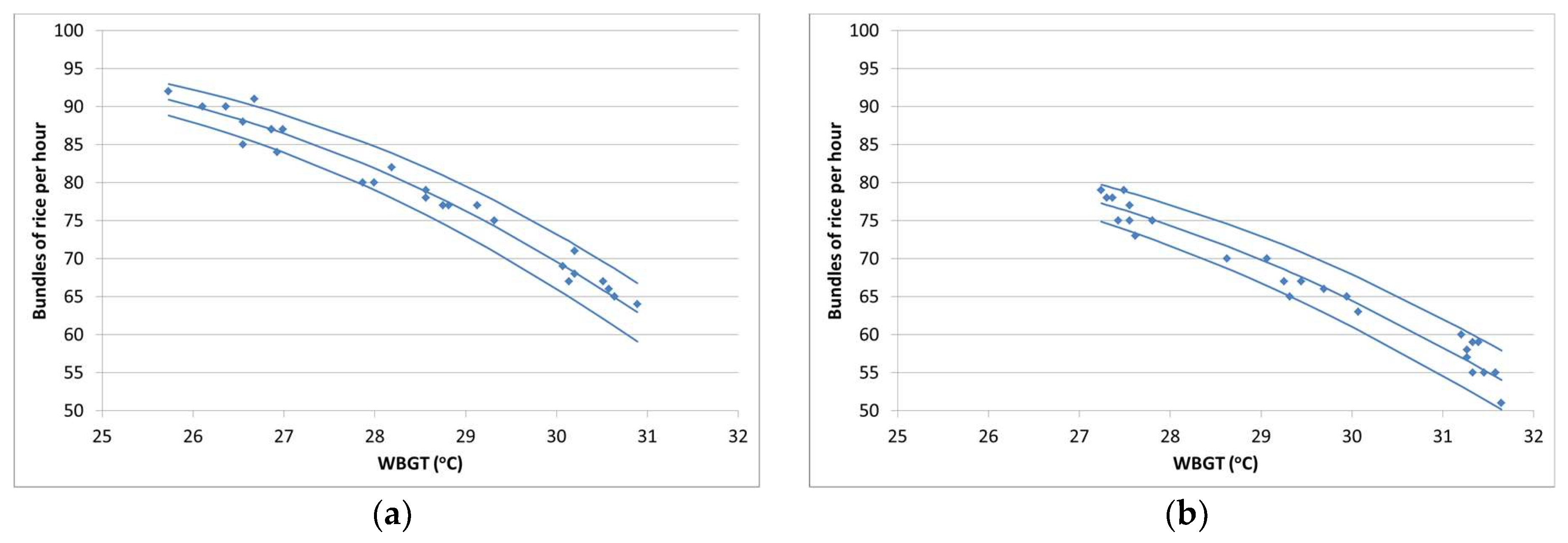
Figure 3 shows the data: productivity strongly declines with temperature, and is lower for any given temperature towards the end of the working day, presumably due to tiredness and perhaps dehydration. By the end of a hot day, work proceeds at only about 60% of the rate at the start of a cool day.
Individual data are not available, so we model the output of a group as the dependent variable. There is no evidence of a threshold temperature even at the “coolest” conditions observed (which were nevertheless very hot), so we can reasonably set T
0 to any sufficiently low value, well below the observed range.
Figure 3a shows the fitted model for hour 1 and
Figure 3b, for hour 5, using T
0 = 0 °C on the WBGT scale.
These results agree well with those reported in Sahu et al. (2013) [
16] as regards to the reduction in the mean output per degree increase in WBGT. Their linear model showed a mean reduction of 5.42 beed
i/h per degree in the first hour, 5.14 in the fifth, where our model, illustrated in
Figure 3, shows an average reduction of about 5.4 in the first hour, 5.3 in the fifth, but falling more steeply at higher temperatures. To these results, we can now add information about the between-worker variation in this reduction, finding that the variation itself strongly increases with the temperature, as shown in the last column of
Table 1.
Estimating the parameters by maximum likelihood requires the marginal probability distribution of the product of the two random variables Z and P, which is not analytically tractable. The estimation may be done through approximate numerical quadrature, integrating over the distribution of Z using Simpson’s rule. The calculations were done using the “solver” utility of Microsoft Excel. An approximate variance for the product is available as Var(Y) ≈ ψ
2σ
2 + μ
2τ
2, and this can be used to generate probability intervals for individual output at a given temperature, as shown in
Figure 3.
4. Discussion
Assessing how worker productivity is impacted by hot working environments is important and urgent. There is as yet very little data, and none of it is individual data, but given the importance of the topic, more data should and doubtless will be generated. A class of models is needed for investigating such data.
There is interest in two aspects—health and economics—and models should ideally allow exploration of both. From a health perspective, individual risk matters. The model can also be of value as input to the four-stage SOBANE strategy (Screening, OBservation, ANalysis, Expertise) for the prevention and control of thermal problems in the workplace, specifically at the third analysis stage [
17,
18]: if the data show a great variation in the output under heat stress, there is more of a cause for concern about the health of the workers. This does indeed appear to be the case for those two of our three examples in which we are able to assess it. Both the Nag data and the Sahu data suggest that under heat stress the degree to which workers maintain their individual output becomes increasingly variable. This, in turn, suggests that a proportion of the workforce may high experience levels of stress, not fully apparent from looking only at the mean output of groups of workers.
Economically, we are interested in the overall output of an industry, so the mean is the key aspect. Assessing the cost-effectiveness of preventive measures to protect health clearly involves knowing the productivity cost of inaction [
19].
We have presented here a class of models, the logistic-beta models, that have the following features: (a) they can be fitted to individual or groups data; (b) they capture well the patterns seen so far, in three very diverse settings; (c) they yield estimates of both mean output and variation about the mean, and how these vary with ambient heat, however measured.
The model can be applied to any measure of environmental stress that impacts worker productivity. Our three examples used three different measures: Tnw, ET and WBGT, respectively. While all three attempt to capture mainly heat and humidity, they are not directly comparable, and many other measures might be used [
12,
20].
Our work has some limitations. There appears to be very little available, published data. One of our sources [
14] provided only a fitted model, with little indication of how the data varied around it. The other two provided work output from groups of workers, not from individuals. In one case [
15], the threshold, i.e., the temperature below which full productivity is obtained, was estimable from the data. On the other [
16], the temperature range represented in the data was too narrow for the threshold to be identified and the output appeared still to be rising strongly at the lower limit of the temperature range (
Figure 3). The threshold was therefore set to zero degrees, at which value the shape of the fitted curve subjectively fitted the data well, though values as high as 10 degrees were also consistent.
The model is appropriate for workplaces where the measurable output is generated, such as factories and fields. Heat stress may limit worker efficiency and threaten worker health in other settings also, such as in the boiler rooms of ships [
21].
The logistic-beta model is somewhat complicated, and care is needed in using general-purpose software. There is, therefore, a need for the method to be implemented in special-purpose software, such as a Stata program, SAS macro or R function. This work is in progress.
5. Conclusions
I have proposed a new model for individual or grouped worker productivity and illustrated it using three sets of data from very different settings. The model is widely applicable to such data and can be fitted to datasets with different properties and levels of completeness using readily available software (Microsoft Excel). This is the first time a model has been proposed that is capable of quantitatively capturing, estimating and displaying not just how average worker productive declines in hot conditions, but also how between-worker variation is affected, a consideration of great epidemiologic importance.
The model might be used as input to assessing (a) health risk to workers and (b) economic risk to industries under climate change, as extreme work environments arise and become increasingly frequent and severe.






{kind=link}
{kind=link}
{kind=link}