1. Introduction
The behavior of crops under environmental conditions and cultivation practices can be analyzed with the useful tool and technique of crop growth models. Depending on their purpose, the models differ in their approaches and complexity, with consequences for the required type and amount of input data. Consisting of one or more mathematical equations, descriptive or empirical models define the behavior of a system or part of a system in a simple manner [
1], such as agrometeorological indices. These can be an efficient tool to relate various crop responses to environmental observations if the extent of the measurements or of data availability is limited. Explanatory (or process-oriented) crop models comprise quantitative descriptions of the mechanisms and processes that cause the behavior of a system [
1]. These are based on bio-physical plant processes, simulating the diurnal effects of changes in the environment on plant growth as well as development. The core processes of such crop models are all methods which aim to assess potential changes in plant production, e.g., phenology, photosynthesis, dry matter production. Environments with limited water and nutrition are included by using soil water balance modules including transpiration and nutrient (e.g., nitrogen, phosphor, and potassium) transformations in the soil as well as remobilization within the plants [
2].
The main aim of a crop simulation model is to assess the consequences of climatic conditions and individual management behavior on plant production at the field scale. In a further step the results can be implemented in a distributed model at the regional scale. Limitations usually occur on the availability and quality of used data. Weak quality input data is often the main source of uncertainty in simulated outputs; e.g., caused by spatial representative problems or measurement errors. In addition, challenges arise at the regional scale in which model input parameters must be collected at dispersed point features such as weather stations [
3] and produce outputs for local spots (for example, soil pits). Spatial data analysis and modelling in combination with geographical information systems (GIS) can help to integrate information from crop model outputs into a larger area [
4,
5]. For example, soil, climate, and topographical data provide the interface of these two technologies and are at the same time the basis for spatial and temporal analysis. An increasingly promising approach for monitoring crop growth or grain yield over large regions more accurately is the additional use of remote sensing data for spatial crop growth model applications. The linkage between crop simulation models with remote sensing and modelling techniques has been already applied in various examples, such as regional crop forecasting [
6,
7,
8], agro-ecological zoning [
9,
10,
11], crop suitability assessments [
12,
13,
14], yield gap analysis [
15,
16], and in precision agriculture applications [
17,
18].
Data assimilation methods that incorporate remote sensing data into existing crop growth modelling frameworks might help to reduce uncertainty of the model simulations and to increase the evidence of the predicted models [
19,
20]. In such frameworks, one needs to distinguish between (i) driving variables (which constrain the system); (ii) state variables (which characterize the system behavior); (iii) model parameters (which establish the relation between driving and state variables); and (iv) output variables (observable functions of the state variables) [
4]. Several methods have been developed and used to combine remote sensing data into agroecosystem models, mainly [
4,
20]: (i) the direct use of remote sensing inputs as a forcing variable, where at least one state variable must be replaced by measured data. A key challenge is the precondition of model calibration [
4,
21]; (ii) crop simulation models must re-initialize or re-calibrate using simulated and observed state variables [
19,
20,
21]. This approach has gained attention in the scientific community by using optimize algorithms. Nevertheless, this method increases the amount of computation resources [
20,
22,
23,
24,
25,
26]; (iii) the continuous updating of a state variable of the model (for example, leaf area index) is only possible if data observation is ongoing. This method shows a higher flexibility in comparison to the others. However, this methodological approach requires a higher accuracy of data quality from remote sensing [
27,
28,
29,
30].
A key advantage of using remotely sensed information is to provide quantitative information on actual state of crop conditions over a large scale [
2]; whereabouts crop models can assess the temporal dynamics of the plants. Even in the early use of crop model applications, Wiegand et al. [
31] and Richardson et al. [
32] recommended the use of remotely sensed information to enhance crop model outputs. Satellite rainfall as a model input was studied by Reynolds et al. [
33], who used rainfall estimation images for regional yield prediction with a resolution of 7.6 km obtained from the geostationary Meteosar-5 satellite for Africa; Ovando et al. [
34] evaluated soybean yield estimations using satellite precipitation input data in a crop growth model.
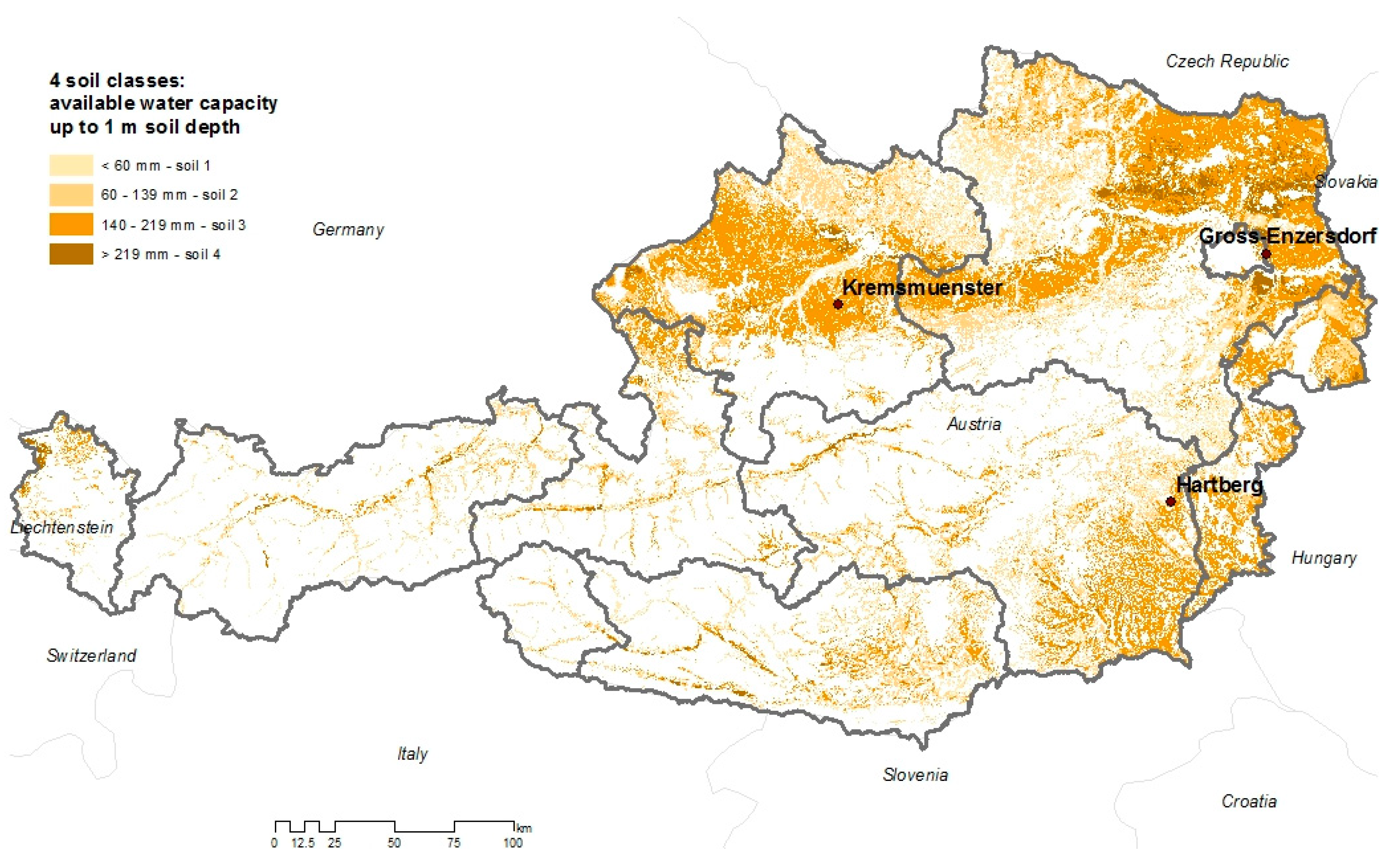
This paper analyses how different types of spatial precipitation data, taken as the input, influence a crop model application. Finding site-representative precipitation estimates is of importance, as rainfall patterns during the growing season play a key role in crop growth and development conditions. Similar importance is reported for other applications, such as the assessment of drought events, adaptive behavior and response to a warmer climate, weather forecasting, agriculture, and disease prevention [
35,
36]. In the current study, the dynamic crop growth and yield model Decision Support System for Agrotechnology Transfer (DSSAT v.4.0.2.0) [
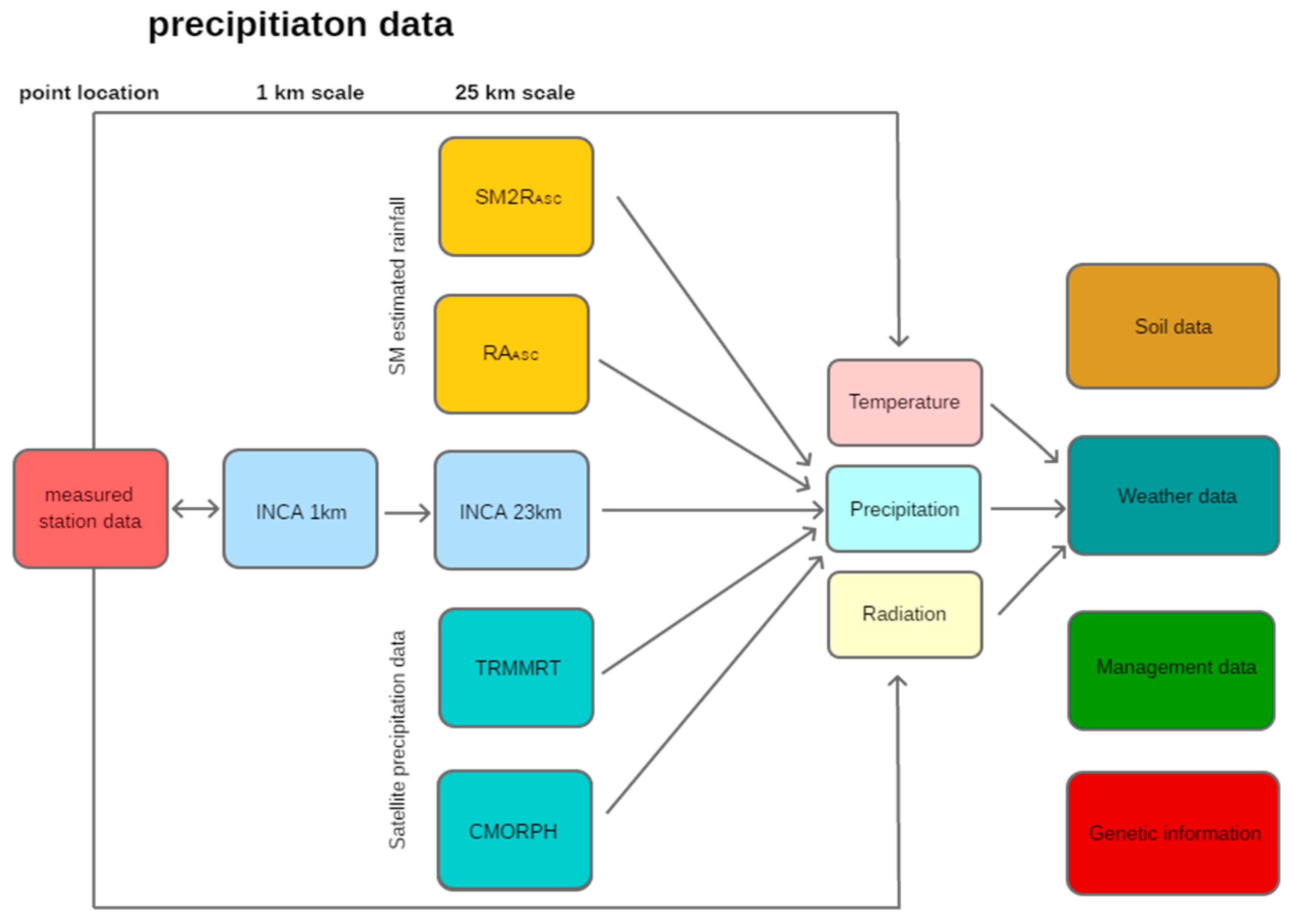
37] for wheat and barley was applied at three case study sites in Austria, characterized by different climate and soil conditions. Precipitation input data were used on the one hand as a reference from weather station-based measurements (point location) and on the other hand were compared to different types of spatial precipitation data: the data from the INtegrated Calibration and Application Tool (INCA) from the Meteorological Service Austria (1 km grid spatial resolution as well as a 25 km raster mean value), two satellite precipitation data sources—Multisatellite Precipitation Analysis (TMPA) and Climate Prediction Center MORPHing (CMORPH) with a 0.25 × 0.25° spatial resolution—a new soil moisture (SM)-derived rainfall dataset obtained through the application of the SM2RAIN algorithm [
38,
39] to the Metop-A/B Advanced SCATtermonter (ASCAT) soil moisture product (25 km spatial resolution) and a simple regression analysis of satellite SM data from Metop ASCAT (25 km spatial resolution). First, the performance of the different precipitation data was assessed for the three reference locations (weather station sites at each case study area). The second purpose of this study was to evaluate the consequences of the different types of precipitation data as crop model inputs, considering simulated spring barley and winter wheat yield at different soil types in the three study areas. The main aim was to test and compare whether the satellite-based precipitation data are suitable sources as input data for crop models and to identify their limitations in comparison to INCA. INCA data sets, with their high spatial resolution of 1 km, are already used as crop model inputs in Austria (for example, for the operational drought monitoring system in Austria and in research studies); however, INCA data are relatively expensive, so a survey of acceptable alternatives is of interest for several applications. Further, it is also of interest to determine under which circumstances and to which degree errors in precipitation data are propagated into final crop model results (simulated crop yield). Precipitation is the main uncertain limiting crop growth parameter over the area of interest; thus, information regarding under which conditions this important weather input parameter could be replaced by alternative spatial sources is essential.
4. Discussion
Crop growth simulation models are increasingly being utilized as tools to assess the regional impact on crop production under different environmental conditions, such as changing climate and management options. These models need spatially and temporally detailed input data of weather, soil, crop management, and cultivar, which are usually difficult to get reliably for larger areas [
58]. As observation data are merely available at a limited number of meteorological stations within a region, it is essential to estimate the required weather inputs for the related simulation-scale [
59]. The focus of this study was set on daily precipitation data, as they are the main uncertain limiting crop growth parameter over the area of interest. Crop models are highly sensitive to soil water, as soil moisture is a limiting factor for different processes for crop growth and yield. A valued alternative to ground-based measurements can be satellite-rainfall estimate systems, which produce global coverage data and supply information in areas where data from other sources are unavailable [
60]. The spatial and temporal resolution increased lately; e.g., the current NASA–JAXA joint Global Precipitation Measurement (GPM) mission makes available rainfall products in near-real time with a spatial sampling of 0.1° each 30 min, by utilizing different satellite sensors [
61]. Satellite rainfall products which have been previously developed include the near-real-time TMPA 3B42RT [
48]; the Precipitation Estimation from Remotely Sensed Information using Artificial Neural Networks (PERSIANN) [
62]; CMORPH [
49]; and the Climate Hazards Group InfraRed Precipitation with Station (CHIRPS) products [
63]. Nevertheless, satellite rainfall estimations are not free of error [
64,
65]. One main reason is the inconsistent scan of rainfall patterns, which makes the reconstruction of the accumulated rainfall in longer temporal scales (e.g., daily accumulated rainfall) challenging [
66]. Further, the estimation of light rainfall is generally underestimated especially over land by remote sensing analyses as a result of land surface emissivity [
36,
60,
67].
Approaches to enhance the quality of satellite rainfall estimates, the use of satellite surface soil moisture (SSM) data has been utilized recently [
38,
39,
68,
69,
70,
71]. These methods analyze the intense correlation between SSM and rainfall to improve and/or estimate rainfall by using satellite surface SM data. Here, SM2RAIN [
38] is the first method, which directly makes available rainfall estimates from SSM observations, whereas the other approaches are correction-based techniques [
36,
38,
39,
60,
72,
73,
74,
75]. In our study, we also added a new approach to estimate rainfall directly using the statistical relationship between measured precipitation and the SM of the ASCAT.
Meteorological station data are normally spatially irregular and can be interpolated to a regular grid. At this point, especially high-resolution gridded data sets can be used for impact studies. Examples are the EURO4M-APGD dataset for the Alps [
76], the European E-OBS [
77], and JRC’s Agri4cast dataset (
http://agri4cast.jrc.ec.europa.eu). These data were not analyzed in the current study. Here (e.g., for Austria), INCA data exists with a very high-resolution gridded data set; unfortunately, they are not freely available.
An important aspect of crop models is that they are sensitive to perturbations in precipitation. In Eitzinger et al. [
78], the sensitivity of seven different crop models for winter wheat and maize to extreme heat and drought over a short but critical period of two weeks after the start of flowering in two locations in Austria was studied. It showed, that the models respond differently to climate stresses (according to references [
79,
80]), even though they mainly present similar trends in grain yields between different climatic situations. In Fronzek et al. [
81], process-based wheat models were applied, and no single model property was found, which describe the combined yield response to temperature and precipitation perturbations.
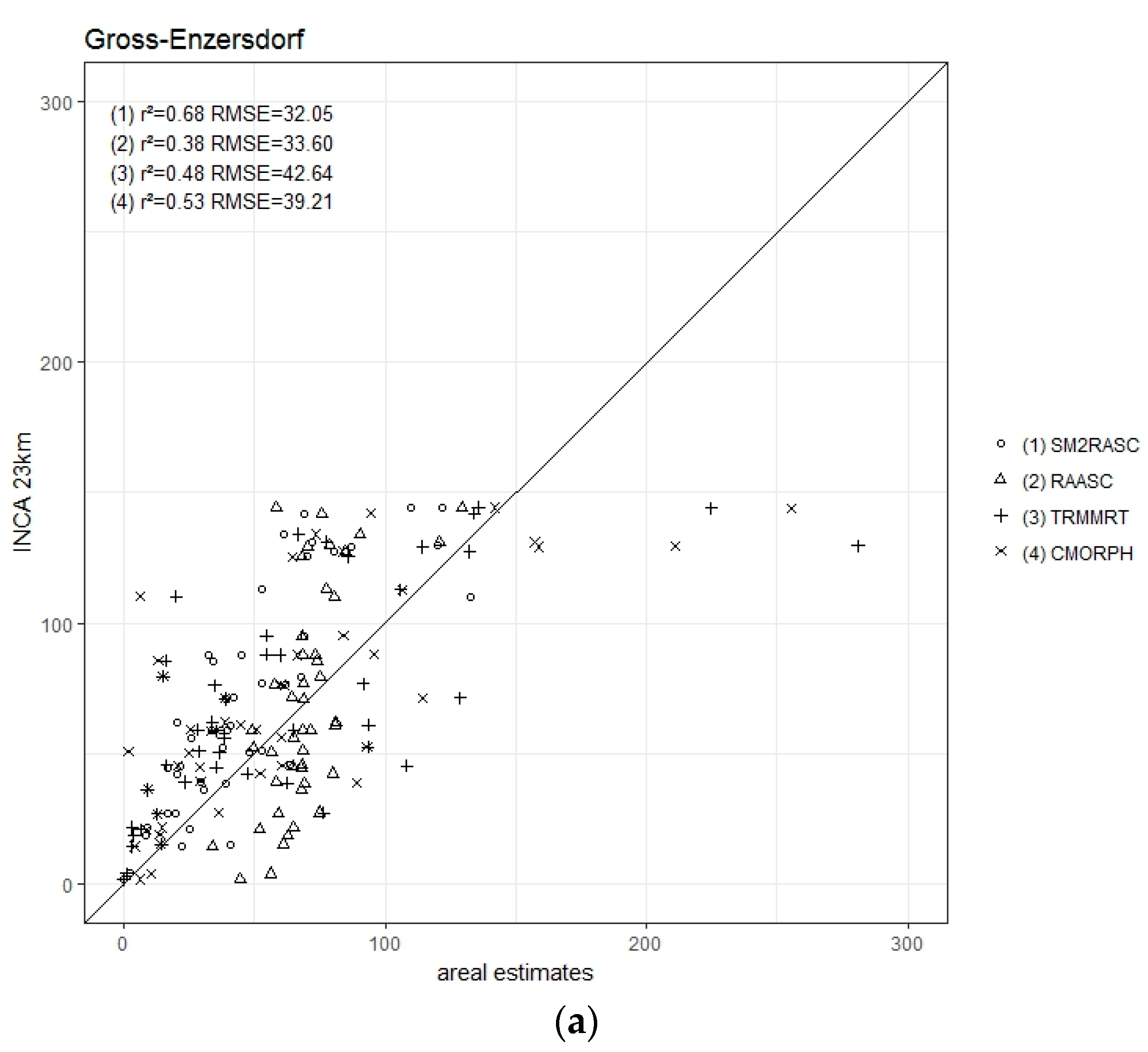
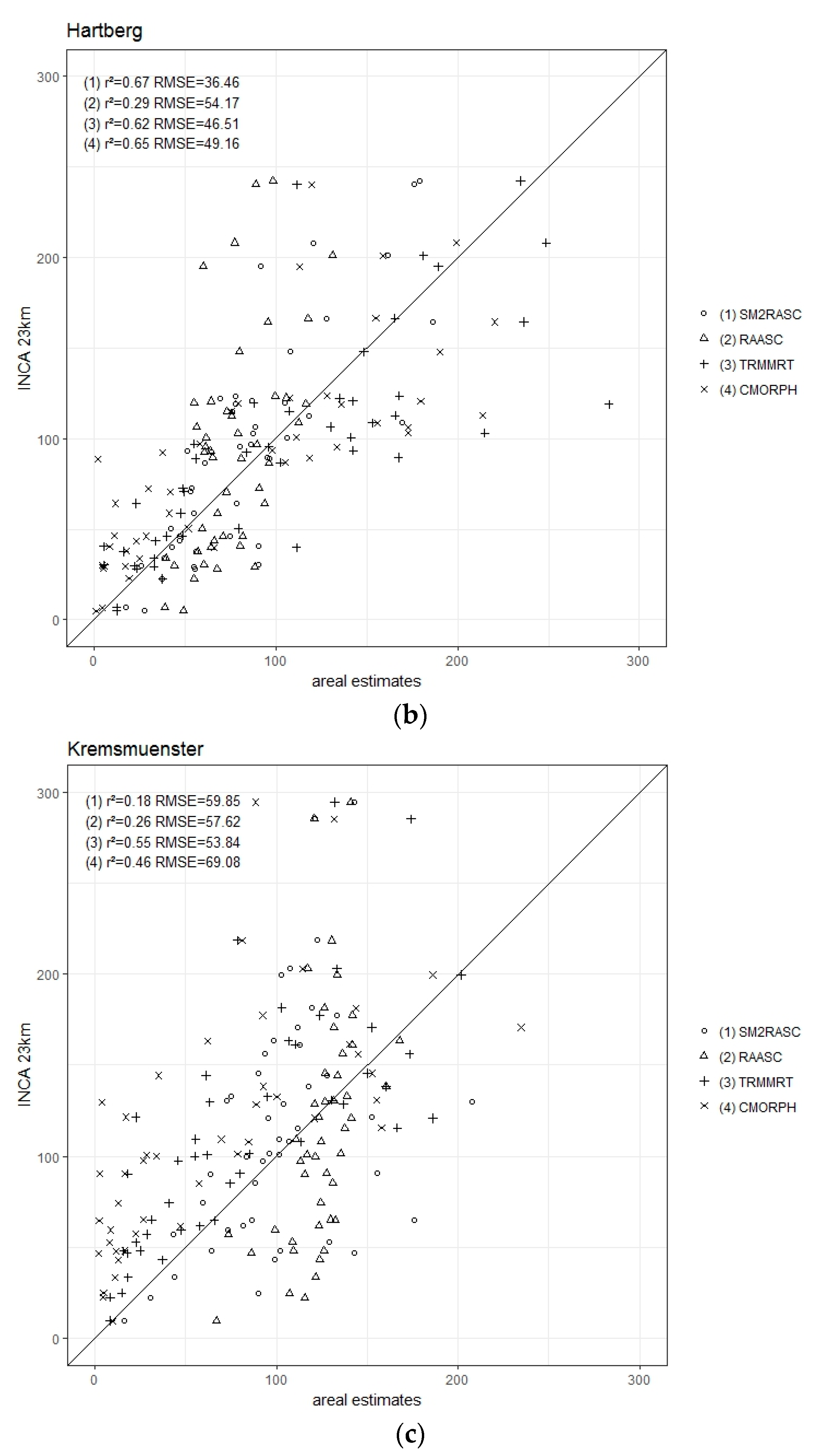
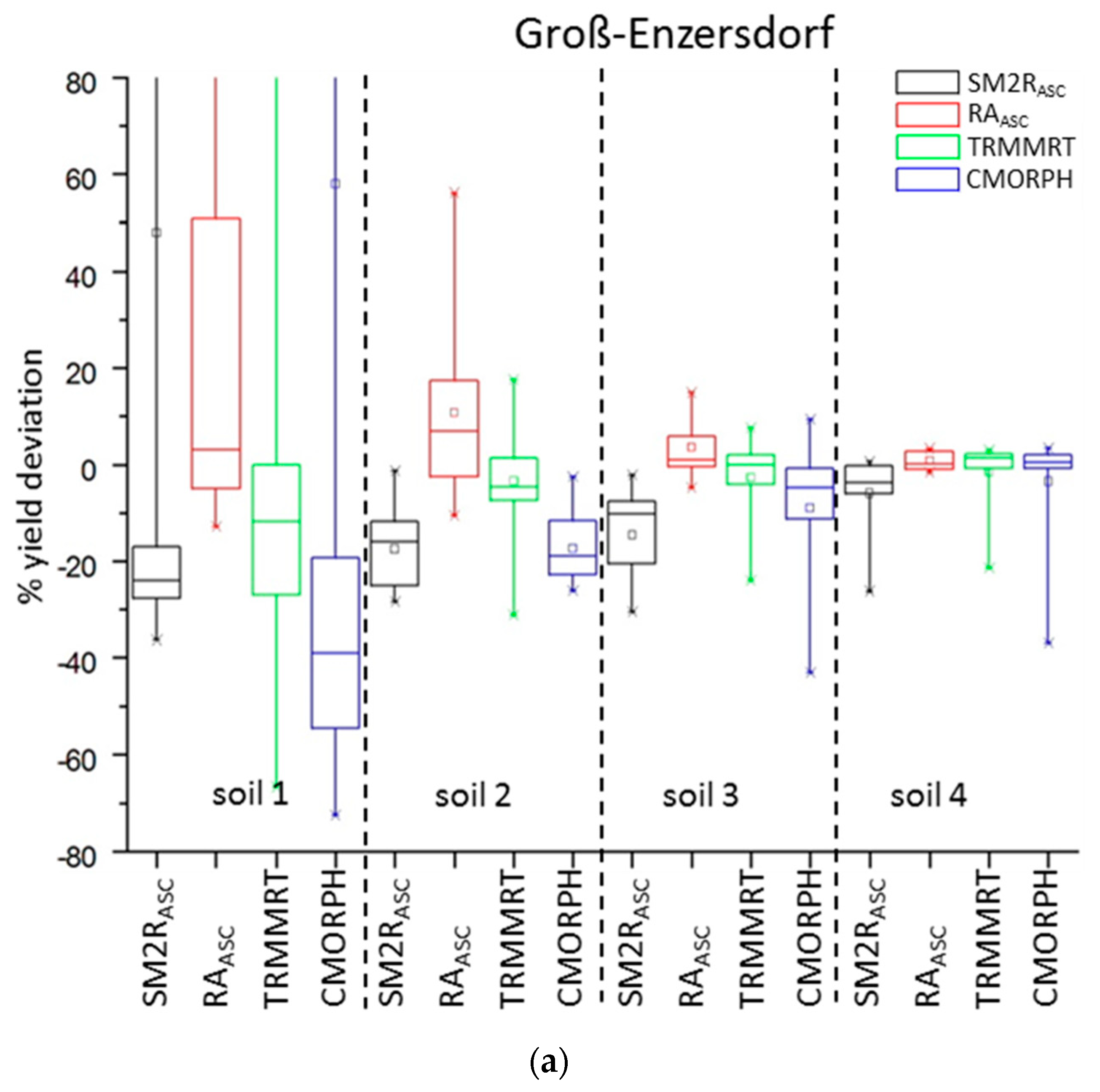
The main objective of the current study was to test different types of spatial precipitation data as inputs for a crop model application in three locations in Austria with different soil types and climates. As INCA data are not freely available, a study of acceptable spatial alternatives is of interest for serval applications. Also, under which circumstances and to which degree errors in precipitation data are propagated into final crop model results are of interest. Therefore, the aggregated INCA23km presented in all three locations already a higher precipitation sum as INCA1km and were thus not free of errors.
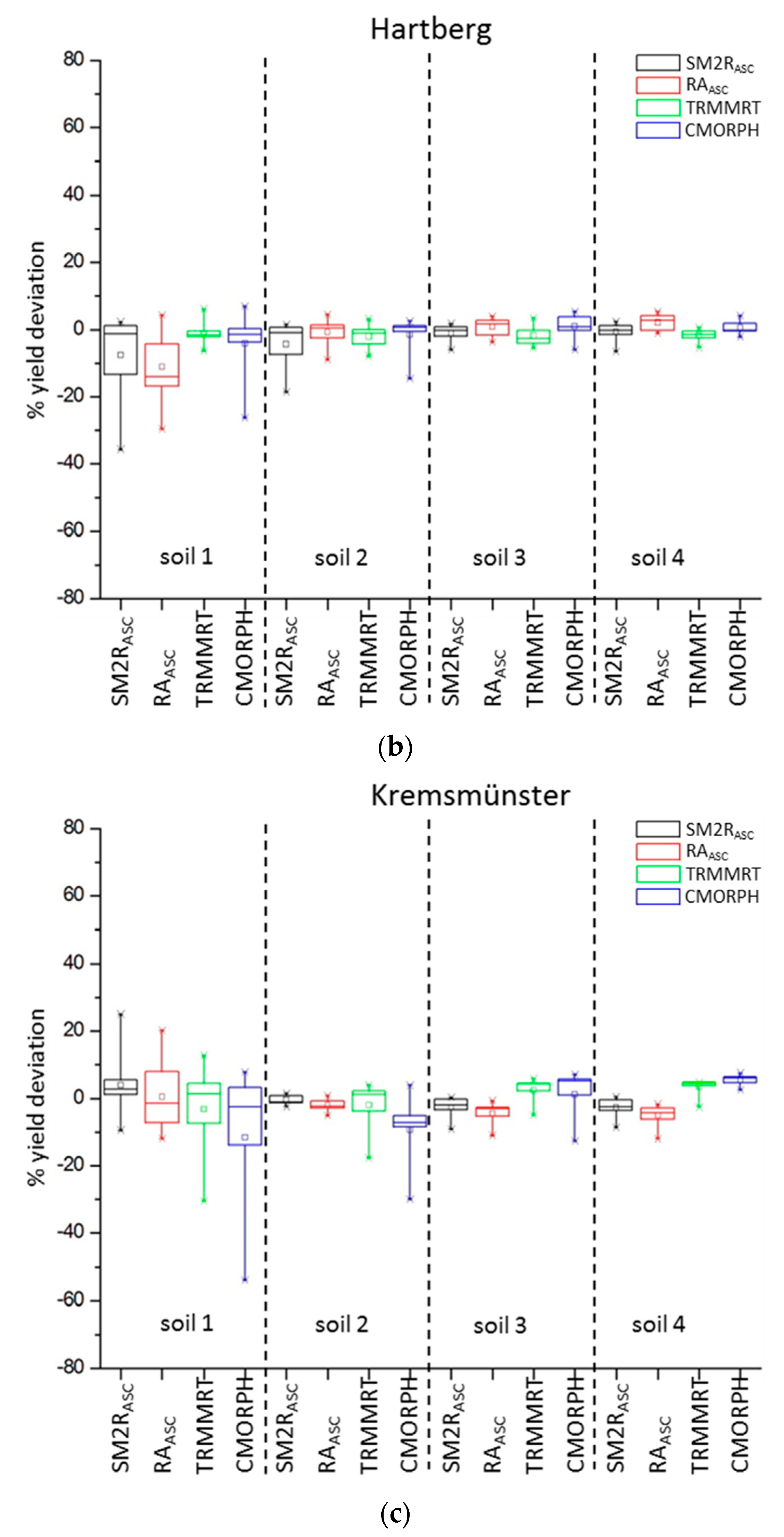
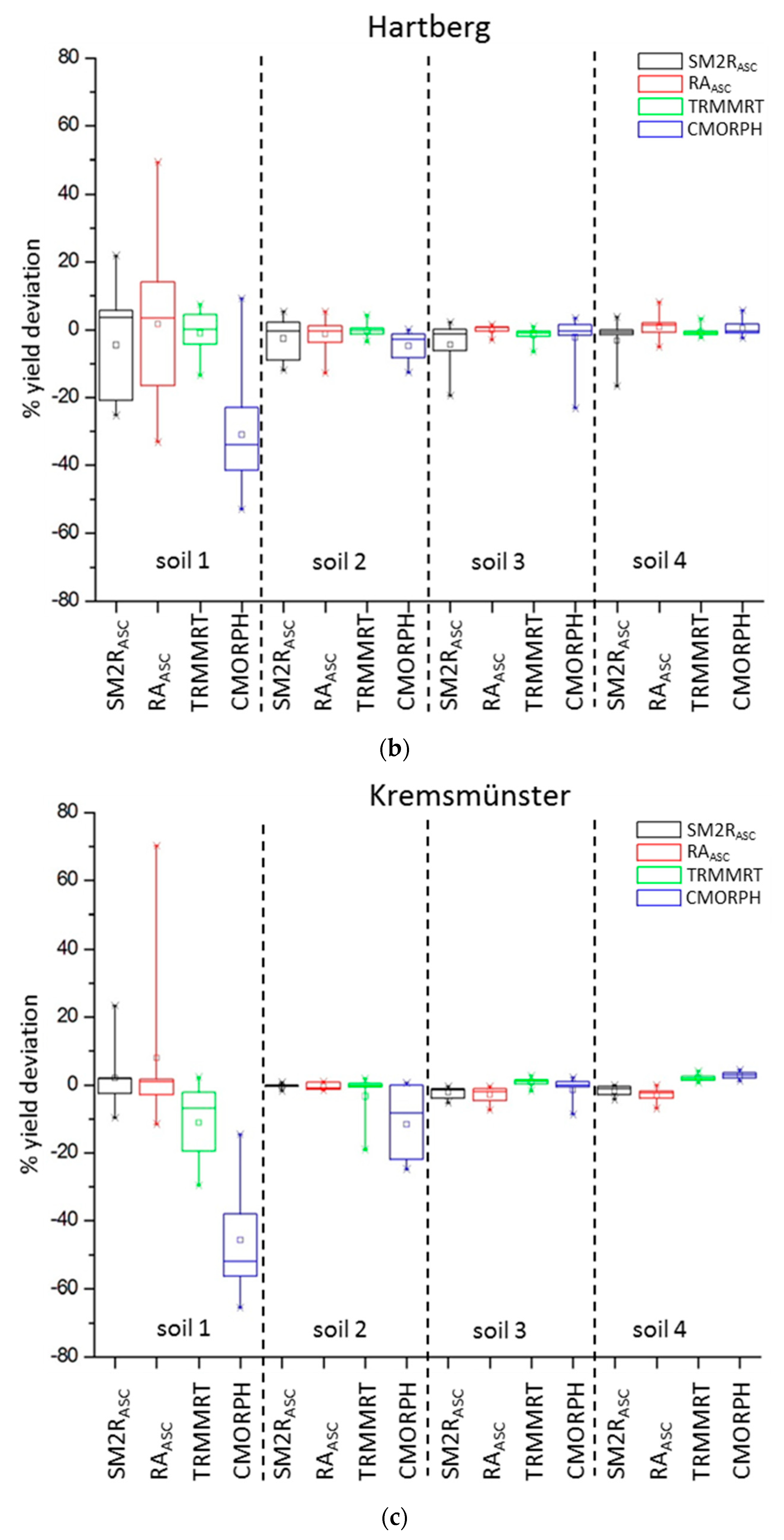
All investigated grid-based types of precipitation data perform at their best as crop yield model inputs on moderately fine-textured soils and under humid conditions (Hartberg and Kremsmünster).
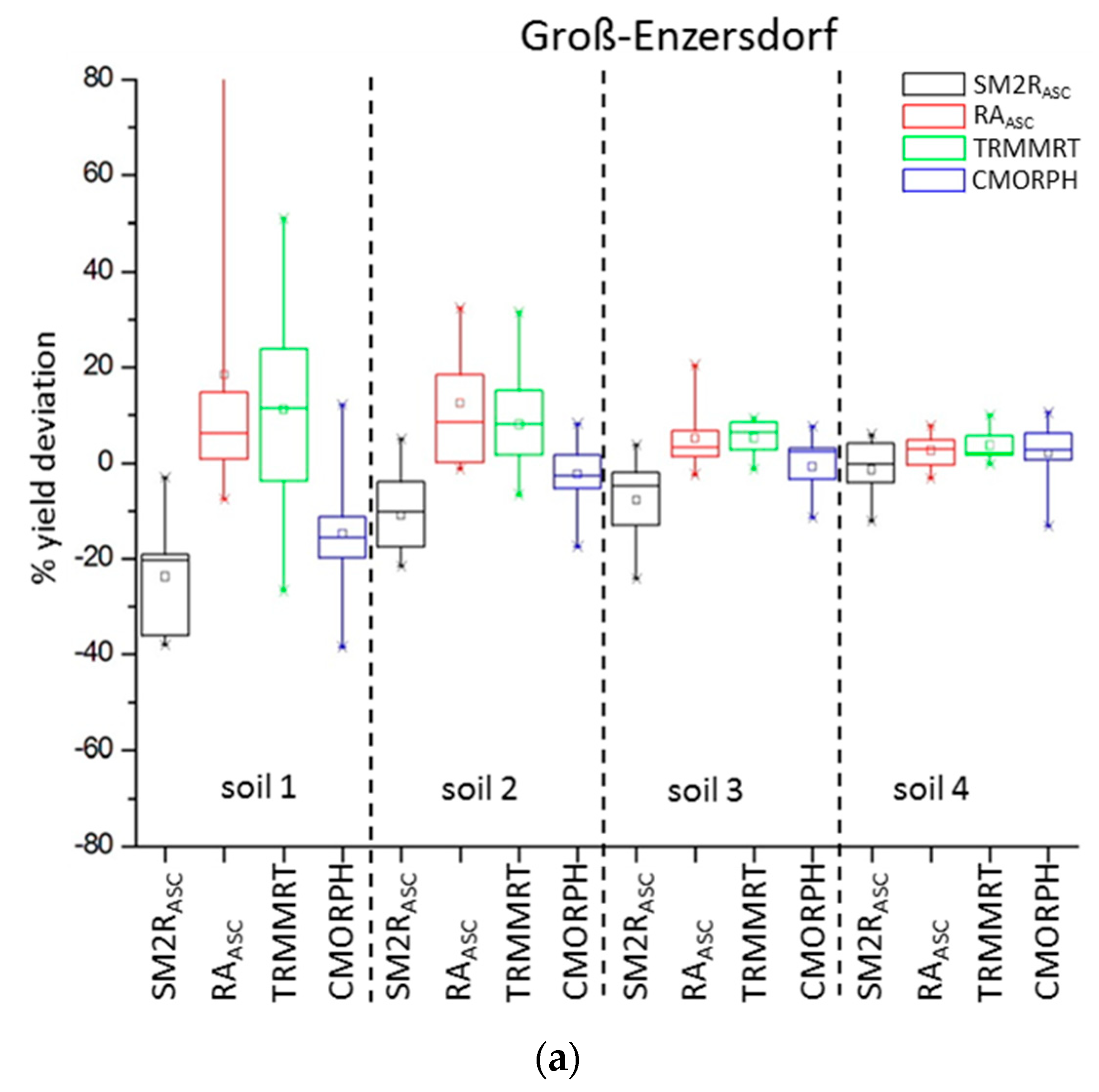
In the semi-arid region of Groß-Enzersdorf, winter wheat and spring barley simulations are very sensitive to different precipitation model inputs; especially in light-textured soils. This is due to the fact that soil water availability is a more dominant limiting growth factor under drought-prone conditions. Therefore, little differences in precipitation input can affect greatly the simulated yield (high RMSE, low d and r2 values). Also, even one missing precipitation event in a critical development stage can cause a crop failure. In this region, the model reacts more sensitively for winter wheat than for spring barley. RAASC (winter wheat) and TRMMRT (winter wheat and spring barley) seem to be the best predictors for this location.
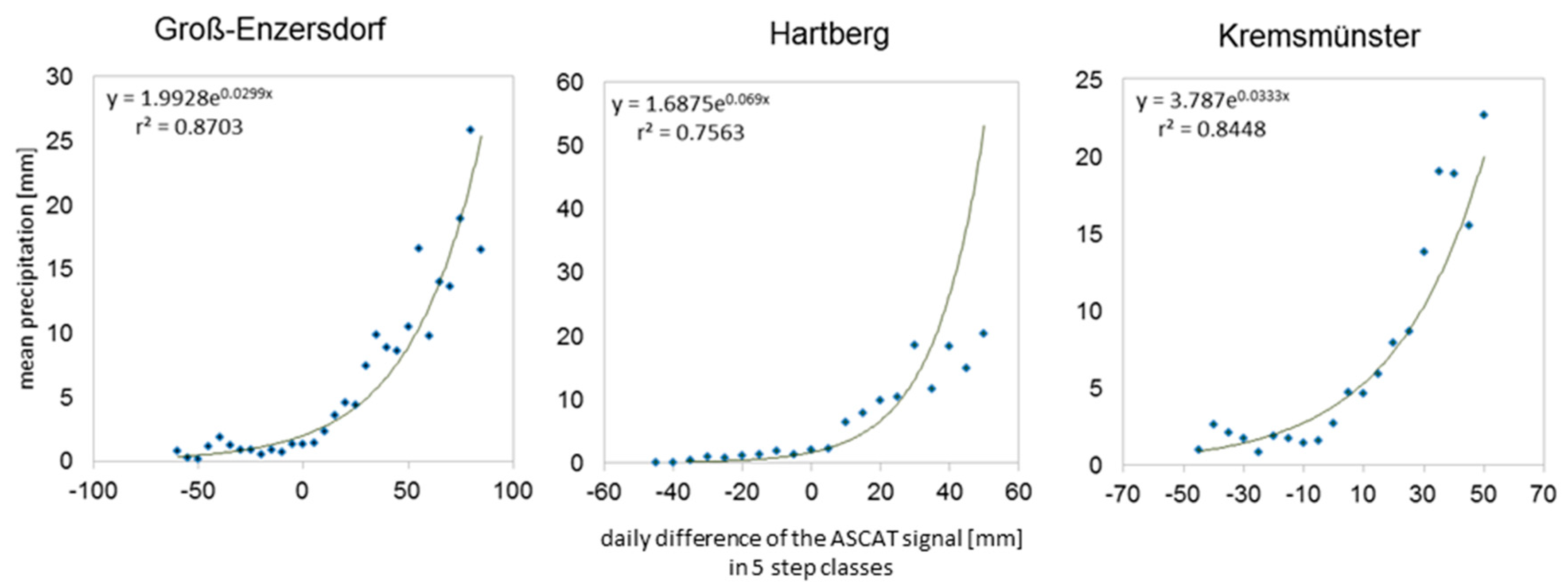
In the more humid places of Hartberg and Kremsmünster, all four precipitation inputs produced good agreements. Plant water stress does not occur often and can be observed mainly in light-textured soils. A bias in the precipitation sum is not such a crucial factor here; much more important is a prediction of the event. In Hartberg, crop yields with RA
ASC and TRMMRT input data correspond best with INCA
23km input data (except RA
ASC soil 1). In Kremsmünster, both SM-based products present good yield results for soils 1 and 2; even if high monthly precipitation differences to INCA
23km were calculated (
Figure 3). Winter wheat and spring barley show similar yield predictions in both locations.
The poorest performances in all three locations and for both crops were found with CMORPH input data. The general underestimation of rainfall provided by CMORPH is in line with the finding of Stampoulis and Anagnostou [
82], who assess the quality of this product over Europe.
Looking at SM estimated rainfall in more detail, SM2R
ASC and RA
ASC perform well in this study, especially on light-textured soils in Kremsmünster and Hartberg compared to the two satellite precipitation data. Here, for example, the use of information regarding the spatial–temporal variability of top soil moisture could improve spatial crop yield simulations against the use of single point information for single weather stations for a given area. Therefore, the SM estimations (SM2R
ASC, RA
ASC) could be an alternative for potential agriculture applications in regions where other products are not available once calibrated to the specific climatic conditions. In addition, a remote sensing product does not necessarily have to be “better” than the model. It should be considered whether the data add value or new information. Hence, even when
r2 values are lower than for models, clever data assimilation approaches may take advantage of the data (see e.g., [
28]).


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}