The proposed approach is tested by four cases. Case I is based on several test functions that have a true Pareto front. Several performance metrics from the standard literature are also shown, such as generational distance, error ratio and spacing. Case II adds noise of different strengths in test functions to test our approach’s ability to reduce the influence of noise. The applicability of our approach is further tested in Case III, which is the O’Connor model, and Case IV, which is the Crops Engineers Integrated Compartment Water Quality Model (CE-QUAL-ICM) in Chaohu Lake.
3.1. Case I
Multi-objective optimization test problems are crucial in determining the effectiveness of the detection algorithm in solving the multi-objective optimization problems. Currently, some well-known test functions have been widely used in the testing of various multi-objective algorithms, such as ZDT [
66], DTLZ [
67] and so on. ZDT was proposed by Zitzler et al. and contains six problems (ZDT1–ZDT6). These problems have different characteristics of the Pareto front. ZDT1–ZDT6 are based on two objective functions to reflect essential aspects of multi-objective optimization. DTLZ1–DTLZ7were proposed by Deb et al., which can have more than two objective functions to test the ability of algorithms to optimize objective functions.
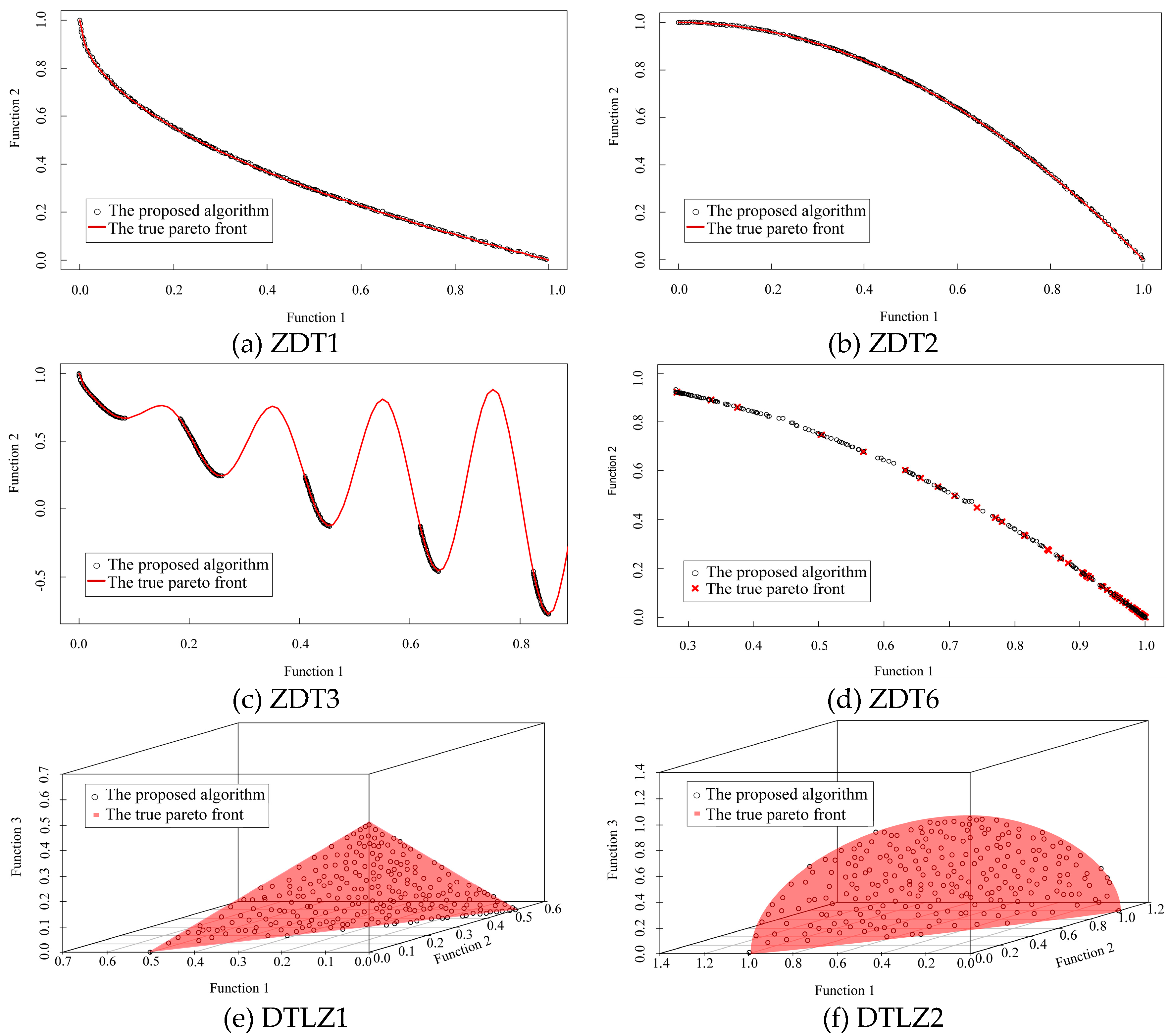
Several test functions, such as ZDT1–ZDT3, ZDT6, DTLZ1 and DTLZ2, were adopted to test the performance of algorithms in this present paper. ZDT1 has a convex Pareto front, while ZDT2 has a non-convex Pareto front. The Pareto front of ZDT3 is characterized by five discontinuous convex regions. ZDT6 has a complex Pareto front, which is a discontinuous non-convex region with a non-uniform distribution of the solution. Therefore, the test problem for ZDT6 is more difficult than that for ZDT1–ZDT3. DTLZ1 has a linear Pareto front with more than two objective functions. Furthermore, the search space contains multiple local Pareto fronts, which makes it difficult for the multi-objective optimization algorithm to achieve the global optimization. DTLZ2 has a spherical non-linear Pareto front. These test functions have different characteristics of Pareto fronts, which examine the capability of multi-objective algorithms to find and produce a quality distribution of the Pareto front.
There are three performance metrics (generational distance, spacing and error ratio) for multi-objective optimization, which are selected to compare the performance of the proposed algorithm to other popular multi-objective algorithms, such as MOPSO [
28], NSGA-II [
23] and MOPSO-CD [
39]. The parameter setting for each algorithm is shown in
Table 1. The parameter dimensions for ZDT1–ZDT3, ZDT6 were set to 30 and the number of objective functions was 2. For the DTLZ1 and DTLZ2, the parameter dimensions and the number of objective functions were 10 and 3, respectively.
The following are the results of 30 independent runs of each algorithm. The true Pareto front and median results with respect to the generational distance metric produced by the proposed algorithm for the six test functions are shown in
Figure 3. The comparison of results of the different performance metrics of four algorithms are shown in
Table 2.
The generational distance (
GD) [
68] is used to estimate how far the members in the non-dominated set are from their nearest members in the Pareto optimal set. It is measured in objective space and is defined as:
where
s is the number of members in the non-dominated set found thus far; and
is the Euclidean distance between the members in the non-dominated set and their nearest members in the Pareto optimal set. If
GD is 0, all non-dominated solutions obtained are in the Pareto optimal set. In
Table 2, the average performance of the MOPSO-CD and our approach with respect to
GD is far better than that of NSGA-II and MOPSO for the six test functions. For ZDT1 and ZDT2, the average performance of our approach is equivalent to that of MOPSO-CD with respect to
GD. For ZDT3 and ZDT6, our approach has the best average performance of the four algorithms, with
GDs of 0.0011 and 0.0181, respectively. The results of our approach are also best for all test functions with three objects, especially DTLZ1. Furthermore,
Table 2 and
Figure 3 shows that our approach is able to find good solutions that are accurate estimates of the true Pareto optimal set. The
GD can be applied to estimate the convergence of the optimal iterations [
28,
68]. When there is a small difference of
GD values between the front and back generation, the results can be considered as having converged. The threshold of this difference is set to be 5% times the
GD of this generation. Overall, the convergence of proposed algorithms is about the same as MOPSO-CD, while it is slightly better than MOPSO and NSGA-II. This is especially the case in complexity test functions, such as ZDT6, DTLZ1 and DTLZ2.
The error ratio (
ER) [
28] indicates the percentage of solutions (from the non-dominated set obtained so far) that are not members of the Pareto optimal set and is defined as:
where
s is the numbers of members in the non-dominated set found thus far. If
, it indicates that the solution
i is the member of the Pareto optimal set, while
otherwise. A value of 0 for
ER indicates that all non-dominated solutions obtained by an algorithm belong to the Pareto optimal set.
Table 2 shows that all the non-dominated solutions obtained by the proposed approach so far are almost in the Pareto optimal set within a certain precision (<0.01) for most of the test functions. The average performance of NSGA-II and MOPSO with respect to
ER is equal to 1 for the six test functions. Essentially, these two algorithms may fail to find the true Pareto optimal set for the six test functions. For ZDT1–ZDT3 and DTLZ2 the
ER evaluation of our approach is 0. In addition, for ZDT6, the
ER evaluation of our approach is 0.0094, while MOPSO-CD has a value of 0.0124. These results indicate that MOPSO-CD is better than NSGA-II and MOPSO for evaluating
ER, but is slightly inferior to our proposed approach. This is also seen in the
ER results of DTLZ1. These results indicate that our approach has better performance than the other three algorithms because they have relatively larger
ER values than our approach inmost test functions.
Spacing (
SP) [
69] is used to measure the distribution of solutions throughout the set of non-dominated solutions and is defined as:
where
;
s is the number of members in the non-dominated set found so far; m is the numbers of objectives; and
is the mean of
. If
SP is 0, it indicates that all of the currently available members of the Pareto front are equidistantly spaced. In
Table 2, although the average performance of the proposed algorithm for
SP is better than those of NSGA-II and MOPSO in some of the test functions, including DTLZ1 and DTLZ2, the results of our approach for the ranking of
SP are lower than the results of MOPSO-CD. The reason for this difference may be because our approach is based on the Mahalanobis distance for measuring the degree of similarity between the solutions. Therefore, there is a natural inconsistency with
SP, which is based on the Euclidean distance for measuring the equidistance of the solutions. In addition, if the non-dominated solutions produced by the algorithm are not part of the true Pareto front, the
SP metric is irrelevant [
28]. For an example, the
SP for the MOPSO is 0.0016, which is better than the
SP value of our algorithm (0.0083) in ZDT2. However, the
ER for the MOPSO is 1, which indicates that the non-dominated solutions obtained by MOPSO are far from the true Pareto front.
Based on the above discussion, it is shown that the proposed approach can generate a better set of non-dominated solutions for the six test functions.
3.2. Case II
For testing the ability of the proposed approach in minimizing the influence of noise, different noise strengths from Gaussian distributions N(0, 0.05) and N(0, 0.15) were added to the test functions in Case II. The setting of the algorithm-related parameters is the same as in Case I. The comparison of the algorithm results is shown in
Table 3 and
Table 4.
Table 3 shows that the average performance of the two algorithms in all of the test functions with noise N(0, 0.05) is inferior to that without noise, which is shown in
Table 2. However, the proposed algorithm has an overwhelming advantage compared to MOPSO-CD in all of the performance tests. The average performance of our approach with respect to
GD and
ER for ZDT1 is 0.0079 and 0.0127, respectively, which is 5.4–5.8 times better than that of MOPSO-CD. For ZDT2, the average performance of MOPSO-CD with respect to
GD and
ER is 0.0571 and 0.1302, which is approximately 158% and 350% more than the
GD (0.0221) and
ER (0.0290) of our approach, respectively. The
GD and
ER of the MOPSO-CD for ZDT3 are approximately 6 and 7 times that of our approach, respectively. Compared to other ZDT series test functions, the superior performance of our approach is not as significant in ZDT6, but its corresponding
GD,
SP and
ER are also approximately 1/3–7/8 of those of MOPSO-CD. In addition, the average performance of our approach with respect to
SP for all of the test functions are better than those of MOPSO-CD. The
SP is 0.0521 in our approach and 0.1571 in MOPSO-CD for ZDT3, which is 70% higher than ours. For DTLZ1 and DTLZ2 test functions, the performance of our algorithm is far better than MOPSO-CD with the results of the MOPSO-CD approach being 2–5 times our results.
Table 3 shows that our approach has better stability compared to MOPSO-CD in all test functions. The standard deviation of the
GD values from the MOPSO-CD for ZDT1 and ZDT3 is approximately 6 times that of our approach, while this difference is around 2–9 times for DTLZ1 and DTLZ2. The above results show that when noise N(0, 0.05) is added to the test functions, our approach has better results than MOPSO-CD in terms of the average performance metrics and standard deviation, which means that proposed algorithm can effectively reduce the influence of noise on the optimization results.
To test the performance of the algorithm under stronger noise, noise according to N(0, 0.15) was added to the test functions. The test results of the performance of the two algorithms can be seen in
Table 4. The advantages of our approach are not as obvious as in
Table 3, but are 1.5–6 times better than the results of MOPSO-CD. This may be because the signal-to-noise ratio decreases with the increase in the disturbance intensity, causing the value to become submerged by noise. Nevertheless, our approach is still superior to MOPSO-CD in almost all of the test functions in
Table 4. For instance, the
ER of MOPSO-CD for DTLZ2 is 1, while the
ER of our algorithm is only about 0.5. This indicates that the MOPSO-CD algorithm is hardly to obtain the true Pareto optimal set, while our algorithm was able to obtain this set even under the stronger noise.
The convergence of the proposed algorithm under noise is better than MOPSO-CD. There are 1500–2000 fewer function evaluations from our algorithm compared to MOPSO-CD for ZDT1, ZDT2, ZDT3 and ZDT6 under N(0, 0.05) noise. For DTLZ1 and DTLZ2, this difference is 1200. The lead of the proposed algorithm is slightly larger under the stronger noise.
Our approach has a good performance compared to MOPSO-CD with respect to GD, SP and ER almost in all of the test functions with different noise strengths. This result indicates that our approach can produce a well-distributed non-dominated solution set even under different strengths of noise. The stability of our approach, which has a smaller standard deviation with respect to GD, SP and ER, is also better than that of MOPSO-CD. Under different noise strengths, our approach has a good performance for convergence, distribution and anti-noise.
3.3. Case III
The O’Connor model is a one-dimensional steady-state river model based on the Streeter-Phelps model, which takes into account the degradation, sedimentation, oxygen consumption of organic matter decomposition oxygen demand (CBOD) and nitrification oxygen demand (NBOD), as well as the role of dissolved oxygen (DO) re-oxygenation [
70]. It contains four parameters: the CBOD degradation coefficient
K1, re-oxygenation coefficient
K2, CBOD settlement coefficient
K3 and NBOD degradation coefficient
KN. The four parameters are a good measure of the performance of the algorithm in model applications, in which these values vary widely. These values have a range of 0.9–4. According to the measured results of a river section on the Taihu Plain in China, the value of the initial conditions and parameters are shown in
Table 5.
In the following section, the two algorithms are used for parameter estimation of the O’Connor model. The three objection functions, which are the relative errors of CBOD, NBOD and OD, are optimized by MOPSO-CD and the proposed algorithm. The population size, number of iterations and size of the external repository are set to 40, 50 and 100, respectively. The calibration initially occurs in regard to the variables CBOD, NBOD, and OD without noise, with the results shown in
Table 6.
In
Table 6, although the range and standard deviation of the parameters obtained by MOPSO-CD are small, which shows more stability than ours, the
K1,
K3 and
KN obtained do not cover the true parameter values. This means that the parameters from MOPSO-CD are unreliable and cannot be used in modeling. Compared with the MOPSO-CD results, the parameters generated by the proposed algorithm cover these true values and the means of the parameters obtained by our algorithm are close to the true values. For example, the mean of
KN obtained by our algorithm is 0.127, while it is 0.072 for MOPSO-CD. The relative error for the true values (0.125) are 1.6% and 42.4%, respectively. Since the means of the parameters are often used for calculating the model in practice, the above results indicate the advantage of our algorithm.
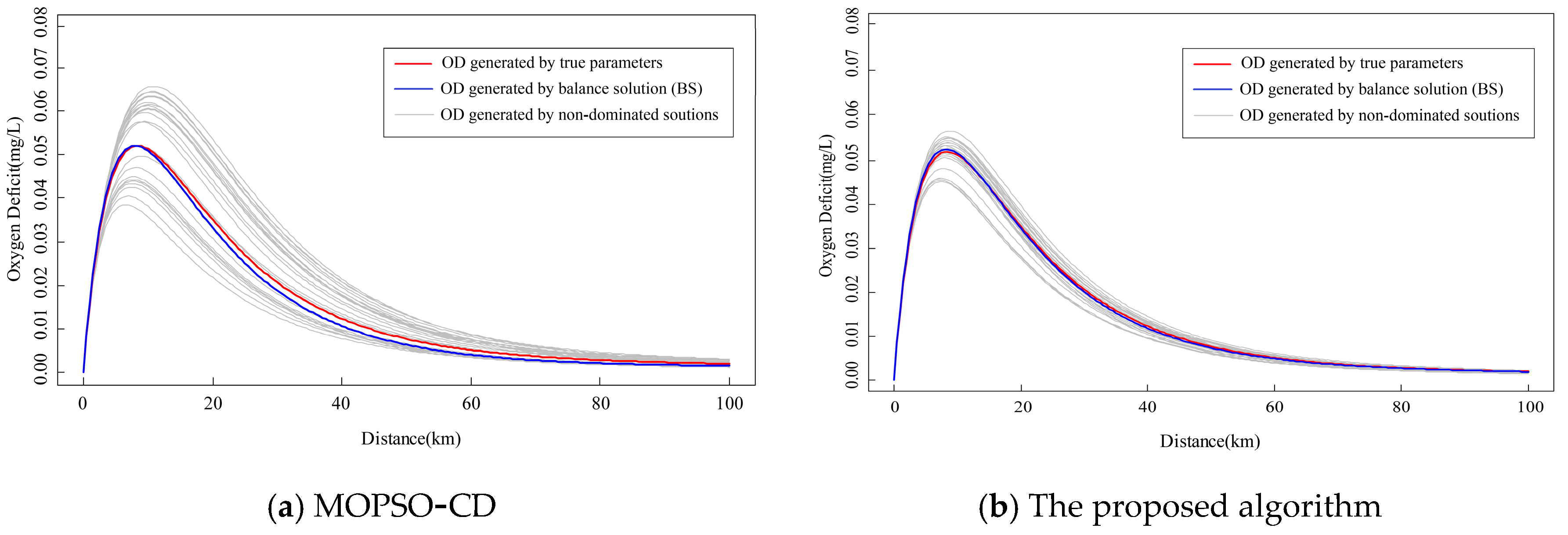
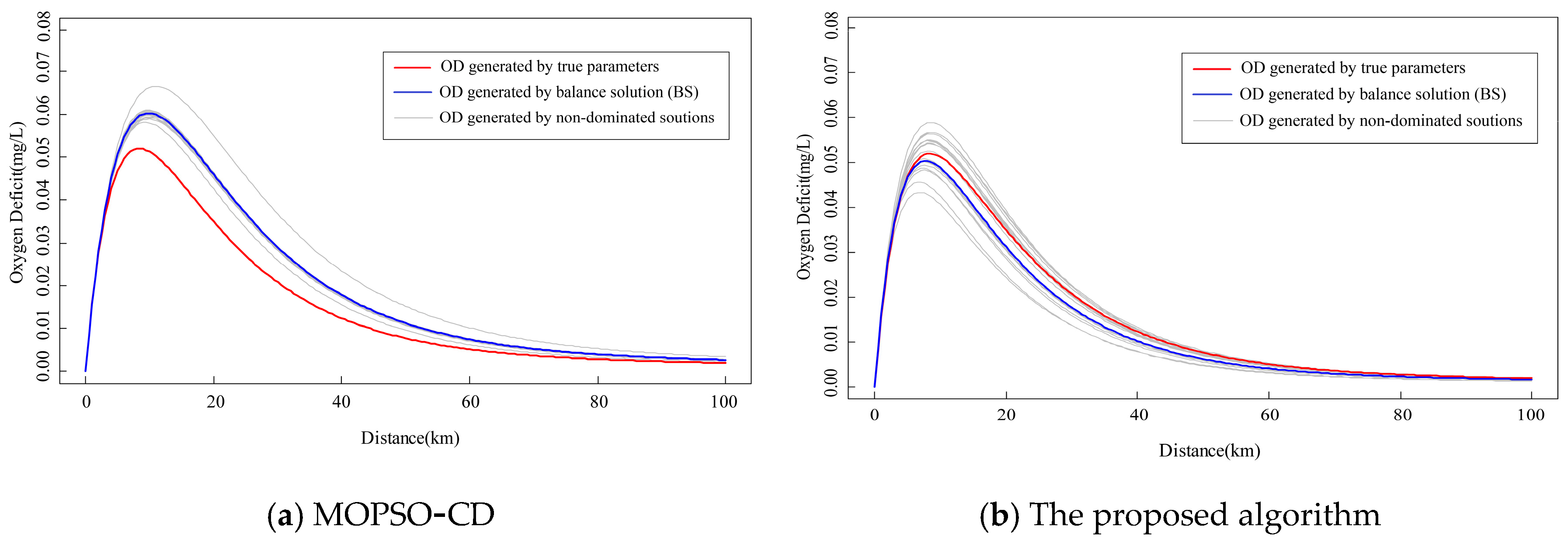
Taking OD as an example, the changes in OD (0–100 km) are shown in
Figure 4, which correspond to different non-dominated solutions obtained. The line generated by the balance solution (BS) is also shown, which has the smallest sum of the distance to the true parameters.
Since the relationship between the variables and parameters is non-linear and they have complex correlations with each other, the range of OD values obtained by our approach is narrower than that of MOPSO-CD even if the parameter range of our approach is larger than that of MOPSO-CD. This result indicates that there is less uncertainty in the results worked by our approach. Although the result of the true parameters is covered by the results of two algorithms, the OD curve generated by the BS of our approach is closer to the true value curve. The maximum error of the curve from the BS of our approach is 1.2%, while the maximum error is approximately 15.6% in MOPSO-CD. The maximum OD position calculated by MOPSO-CD is different from the true position. These results showed that there would be a large ecological risk if the MOPSO-CD results were applied to water quality predictions. Our results are almost identical with the true position at the same time.
The noise according to the N(0, 0.05) and N(0, 0.15) are added to the observed values and the optimum objection functions are the same as the condition without noise. The estimation of the parameters is conducted according to the relative errors of CBOD, NBOD and OD. The calibration results of the two algorithms are shown in
Table 7 and
Table 8. The OD curves with different noise levels are shown in
Figure 5 and
Figure 6.
The range of
K1,
K2 and
K3 obtained by MOPSO-CD still does not cover the true value, while the range of parameters obtained by our method covered the true values. In the case of adding noise according to N(0, 0.05) being used to multiply the calculated values, there are only 8 non-dominated solutions generated by MOPSO-CD. The range of OD values obtained by MOPSO-CD does not cover the true value curve and has large errors (
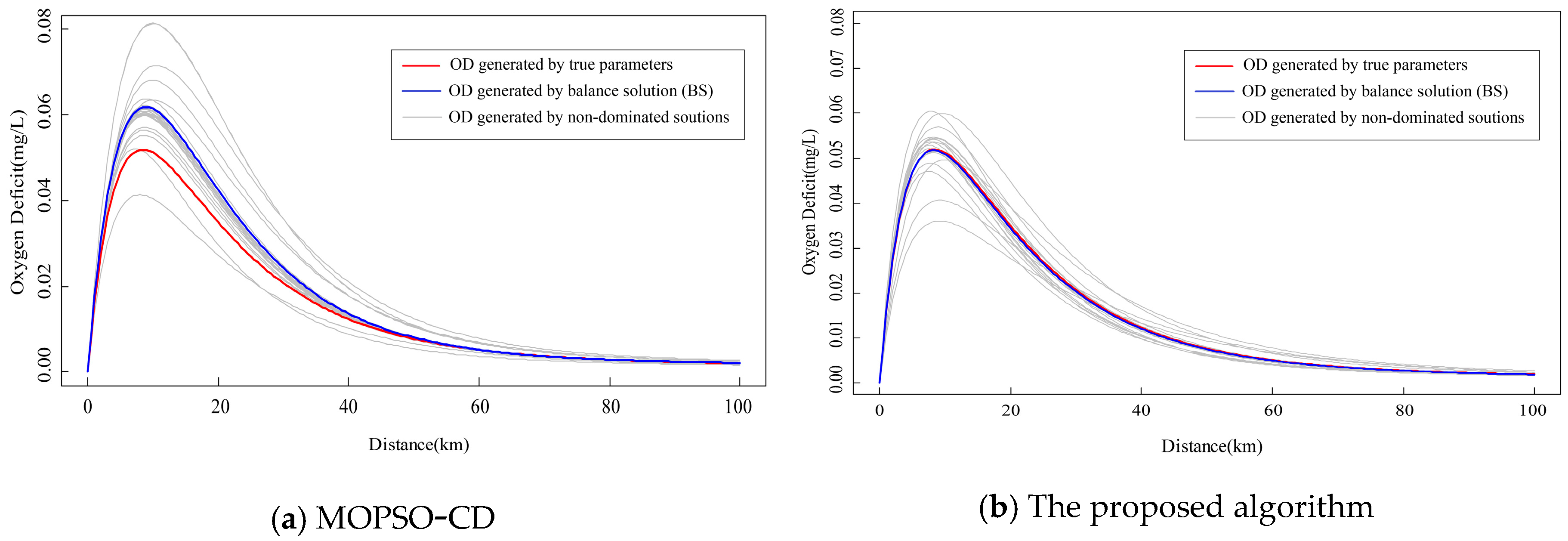
Figure 5). The position and value of the maximum OD for the BS curve are very different from the true value curve with an error of 23%. The shape of the curve determined by BS also diverges from the true value curve. These parameters can hardly be used for model prediction due to the large risk. By contrast, our approach generates more non-dominated solutions and the OD curves completely cover the true value. The BS curve is not as good as that without noise, but the errors of the value and phase are much smaller than those of the MOPSO-CD. Therefore, our approach can be applied in a practical environment with noise.
Due to the increase in noise strength, the range of parameters obtained by MOPSO-CD and our approach expanded, while the range of
K3 by MOPSO-CD failed to cover the true value. The range of the maximum OD calculated by MOPSO-CD is 0.038–0.082, which is significantly larger than that from our approach (0.035–0.059;
Figure 6). This result indicates that the uncertainty of the maximum OD generated by MOPSO-CD is higher. The OD curves obtained by the two algorithms cover the true value curve. However, the true value curve is at the lower edge of the OD curve area of MOPSO-CD (
Figure 6a). The shape of the OD curves and position of the maximum OD of the MOPSO-CD results have large discrepancies from the true values. By contrast, the true value curve is located in the central region of the OD curves produced by our approach (
Figure 6b). For both the shape and position of the maximum OD, the OD curves of our approach are very close to the true value curve. In addition, the curve of BS obtained by MOPSO-CD is very different from the true value curve at the position of the maximum OD. This shows that the results from our approach are better. This also shows that our approach has more advantages in the case of noise.
In general, the O’Connor model calibration results from our approach are consistent with the true parameter values in a water ecosystem with noise, even if the range of parameters is quite different. Its performance and calibration results are superior to those of the classic MOPSO-CD.
3.4. Case IV
CE-QUAL-ICM is used in the fourth case. It was developed by the U.S. Army Corps of Engineers Engineer Research Development Center [
71]. The model computes physical properties, multiple forms of algae, nitrogen, phosphorus, carbon, silica, chemical oxygen demand, salinity, temperature, metal and dissolved oxygen cycles. It involves interactions between various algae and various nutrients, which takes into account the process of algal growth, metabolism, predation and settling. At present, CE-QUAL-ICM has been successfully applied to the study of eutrophication processes of various water bodies [
72,
73]. However, it is considered to be difficult to calibrate due to inevitable data noise and the high dimensionality of the parameter space.
A lake is an open system for material and energy exchange with the environment. We used Chaohu Lake in eastern China as an example to study the parameter optimization problem of the CE-QUAL-ICM model. Chaohu Lake is approximately 780 km
2, with a depth of 1–7 m. As it has been seriously polluted, it is one of the most eutrophic lakes in China and has suffered from frequent outbreaks of algae in recent decades. Therefore, the eutrophication of Chaohu Lake is a significant concern [
74,
75,
76]. Nine major rivers around Chaohu Lake were considered in the model calibration. Although the lake is large, a proper water quality model can capture the main characteristics of the water quality changes over time in Chaohu Lake, even when ignoring spatial heterogeneity and hydrodynamic influences [
77,
78].
The cyanobacteria and DO are two important water quality indicators and were selected for use in the model parameter estimation in the Chaohu Lake water quality model. All data for the modeling were collected from 25 sites that were monitored about weekly in July–September in 2009. It is necessary to select the parameters for the model calibration. The 15 parameters with the greatest influence on the model variables were identified, with their names and ranges provided in
Table 9. The other parameters used the default values [
71].
The CE-QUAL-ICM model in Chaohu Lake is calibrated with a daily time resolution to estimate the cyanobacteria and DO over three months. The two objection functions,
OF1 and
OF2, which are the root mean square error (RMSE) of DO and cyanobacteria, respectively, are optimized by the proposed algorithm.
where
O are the observations;
P are the predictions; and
D is the total number of observations. The ranges of the parameters for the Pareto set is shown in
Table 9. The population size, number of iterations and size of the external repository are set to 20, 30 and 50 here, respectively.
Table 9 shows that the range 2 obtained for most of the parameters by calibration is significantly less than the original range 1. Hence, the uncertainty in most of the parameters can be reduced by our approach.
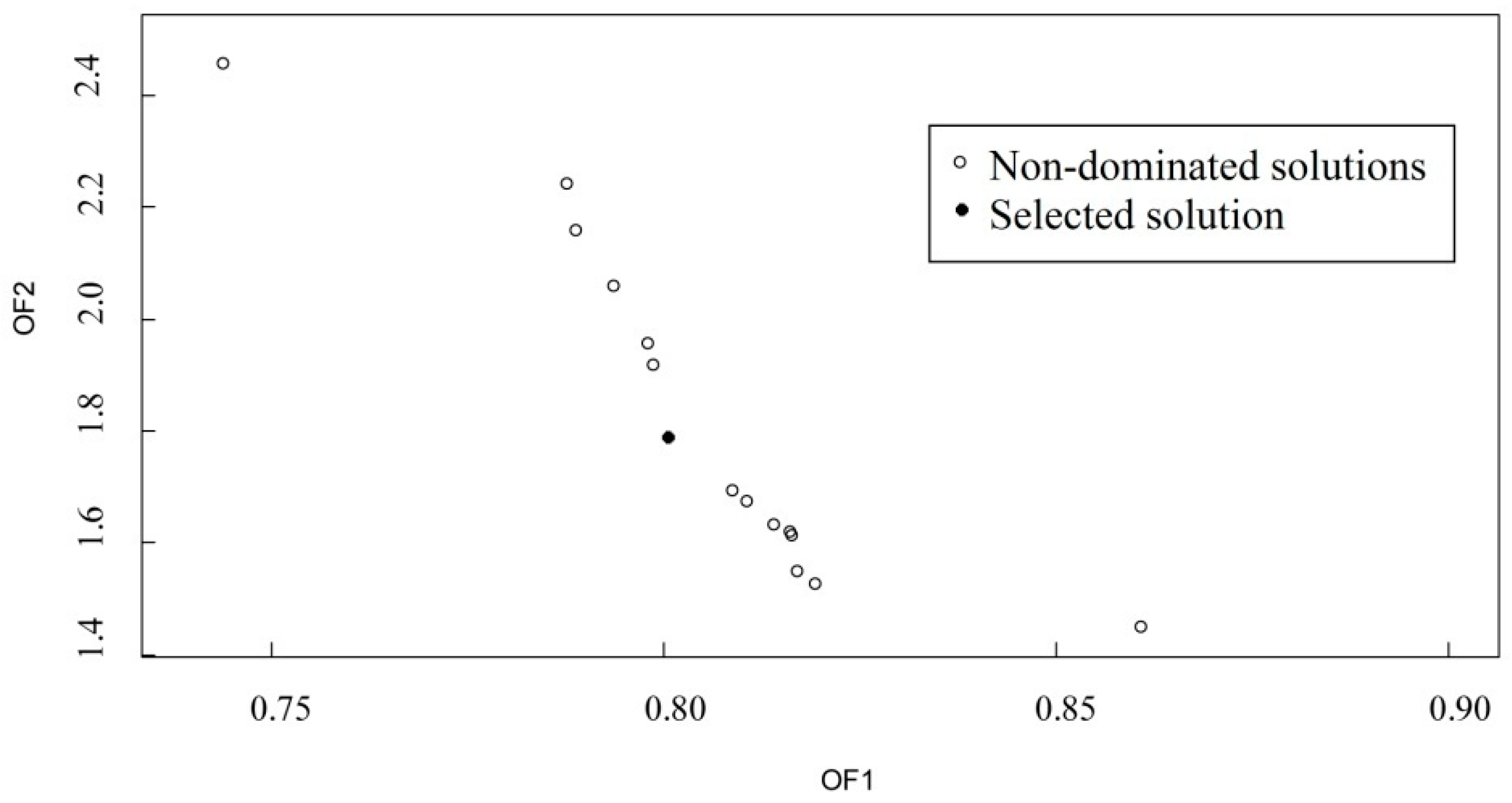
The Pareto front in the objective space is shown in
Figure 7. There are 15 non-dominated solutions that are obtained by our approach. From the definition of the non-dominated solution set, none of the corresponding tradeoffs can be considered to be better than the others if there is a lack of information by which to judge. However, a decision-maker can choose an appropriate solution based on the importance of the objectives for their own interests. The leftmost point of the Pareto front corresponding to the parameter vector assigns the highest fit to the cyanobacteria calibration at the expense of the weakest DO calibration fit. The rightmost point indicates that the highest importance is assigned to DO. The solution with the solid circle in
Figure 7 is a better tradeoff of the calibration of the cyanobacteria and DO. The objection functions
OF1 and
OF2 for the selected solution are equal to 0.80 mg/L and 1.79 μg/L, respectively.
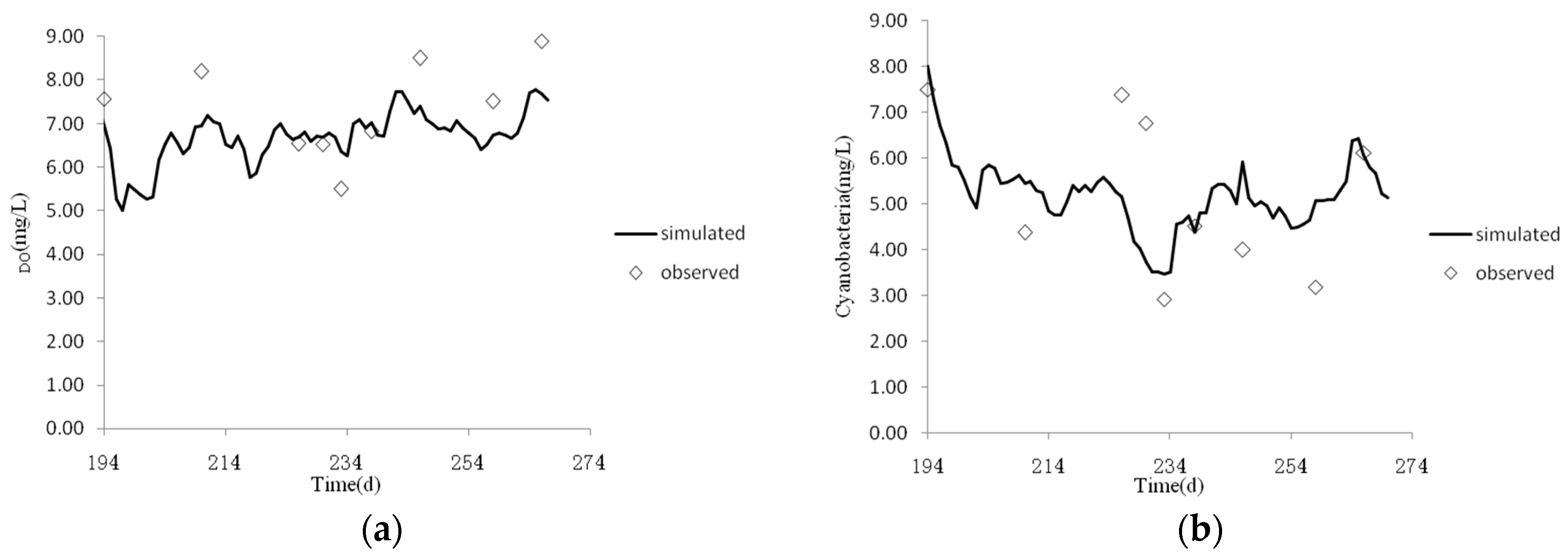
The selected solution is used to simulate the DO and cyanobacteria in summer in Chaohu Lake (
Figure 8). Comparing the simulated results of the model with the observed values, the average relative errors of cyanobacteria and DO were approximately 29% and 28%. The Pearson correlation coefficients between the simulated and observed values of cyanobacteria and DO are 0.59 and 0.64, respectively. The simulation results are consistent with the observed values and trends in Chaohu Lake. These correlation coefficients were not very large, suggesting the trade-off between RMSE of DO and cyanobacteria and the possibility of a non-linear relationship between simulated and observed values.
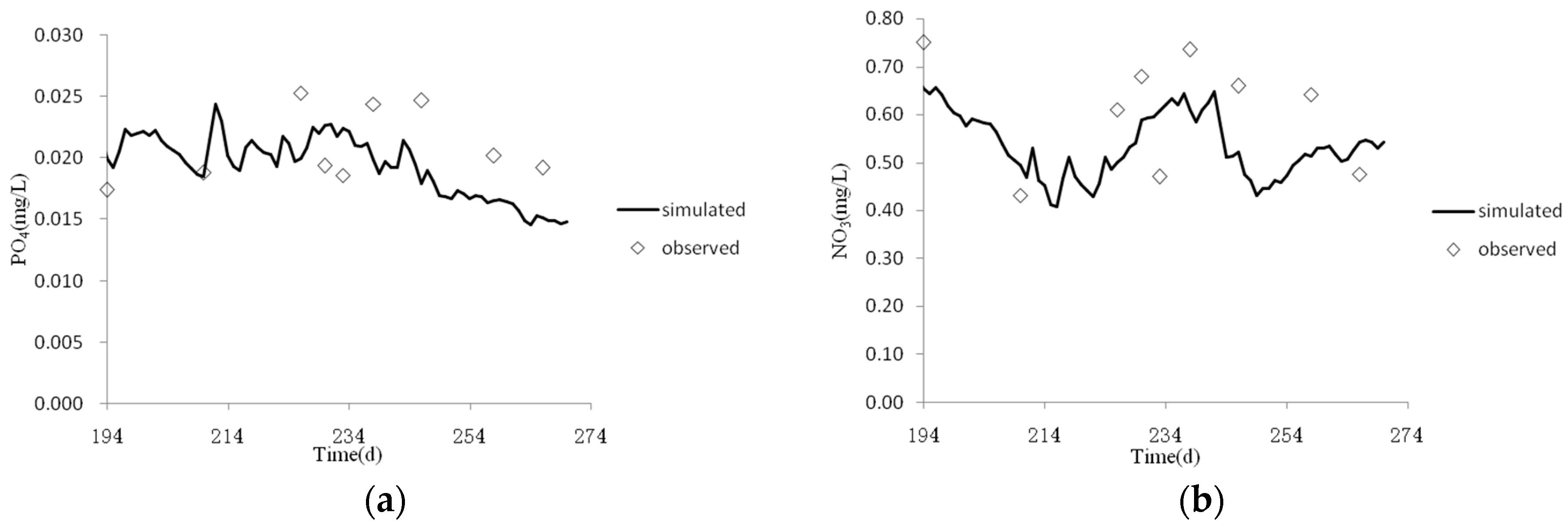
Figure 9 presents the simulation results of phosphate (PO
4) and nitrate (NO
3), which are the parameters of the selected solution. Their average relative errors and Pearson correlation coefficients for PO
4 and NO
3 were approximately 24% and 0.62 as well as 27% and 0.66, respectively. The simulation trends of PO
4 and NO
3 are also consistent with the observed values. This result shows that the parameters obtained by the calibration of the cyanobacteria and DO can also be used to simulate other environmental variables, such as PO
4 and NO
3. This result indicates that there are correlations among variables in the water quality model.
The above results show that our approach has the ability to obtain good results in the multi-objective calibration of a complex water quality model, even though there is unavoidable observation noise in the ecosystem model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}