1. Introduction
Studies addressing water problems have a long tradition. During the past decades, people across the world have been threatened by various ecological disasters, causing heavy economic losses and widespread fatalities. For example, Pall et al. [
1] thought widespread floods in the United Kingdom such as those during the spring of 1998, autumn of 2000, winter of 2003, and summer of 2007 were related to extreme precipitation. From 6 May at 7:00 p.m. to 7 May at 4:00 a.m., 2010, 128 precipitation stations in Guangzhou recorded rainfall of more than 100 mm. Moreover, rainfall in the urban area was near 130 mm on average. Rapid socio-economic and urban developments have led to climate change and frequent extreme rainstorm events. The increase in urban impervious area has made sustainable development problems in cities increasingly prominent. The increase has resulted in an increase in the runoff coefficient and peak flow, and the peak flow time has advanced, differing from river basin flooding. In response to the increasing water problems, different strategies based on the situations of different countries are indispensable. However, as developed countries in Europe, North America, and other continents have already rapidly industrialized and urbanized, they faced and addressed water-related problems earlier than China [
2,
3,
4]. Because of the frequent occurrence of hazards in China and precedents of other countries, it is of great significance for China to put forward new policies suitable to its own realities, known as integrated urban water management [
2]. This is the very reason the concept of sponge city in China was proposed. As some projects of sponge city have been launched, low impact development (LID) measures such as green roofs, permeable pavements, and sunken lawns have caught the designer’s eye.
Because LID measures can feasibly purify water and reduce water contaminant concentrations, several researchers have studied their hydrologic performance. For instance, Stovin et al. [
5] analyzed the performance characteristics of green roofs and employed the green roof moisture flux model to explain runoff behaviors on the foundation of prolonged monitoring data. In another study, Jia et al. [
6] evaluated the benefits of low impact development-best management practices (LID-BMPs) in terms of water quantity and quality based on the storm water management model (SWMM) via a case study conducted in Suzhou, China. Ahiablame et al. [
7] developed the long-term hydrologic impact assessment (L-THIA)-LID model and found that LID implementation was effective in minimizing the impact of urbanization on the hydrologic process. Chui et al. [
8] analyzed the hydrological performance and cost-effectiveness of various LID designs, aiming to identify the optimal design among them. Xing et al. [
9] showed that control efficiencies of water quality and quantity were concerned with LID layouts via weighting analysis and SWMM, appealing that further studies on the efficiency and the management of rainfall runoff control are imperative.
Responding to the problem of combining the optimal proportions of each LID facility may not be the optimal solution to the combination of all facilities, studies on LID layouts and optimization have been conducted. By developing different models, Hu et al. [
10] tentatively explored the general thinking of LID layouts and optimization methods in a LID demonstration area. Wang et al. [
11] attempted to identify the optimal proportion of each LID appliance in an old city area by simulating various proportions of LID appliances in the SWMM. They also explored the optimal LID combination layout. In addition, Young et al. [
12] applied the analytic hierarchy process (AHP) to select a single BMP when simultaneously considering several influential criteria.
Nevertheless, given all the previously mentioned studies, further research is still needed. Because some evaluation approaches such as the AHP and the entropy weight method (EWM) have the disadvantages of considering weights and contain subjective factors, it is still of great significance to put forward a novel approach to evaluate combined LID appliances under different rainstorm intensities. In this study, an innovative approach, namely random forest, was applied to this difficult problem.
Random forest is an integrated non-parametric learning machine based on decision trees. It is compatible for classification and regression of variables. With the advantages of simple principles, precise predictions, relative flexibility, and rapid training speed, it has become a new favorite in substantial academic fields. However, its results are not easily interpreted, that is to say, the meaning of the classification model is hard to describe [
13].
In this study, we tentatively explored the hydrologic effects of LID measures via a case study in LiWan district, Guangzhou city. Five LID measure layout scenarios were designed, and six categories of contaminants were tested to investigate the influence of the five scenarios on water quality. A model was developed to quantitatively assess the hydrologic effects of LID appliances under six rainstorm design recurrence periods with the help of the LID controls module in the SWMM. Eight indices were selected as assessment criteria for each scenario. Apart from these measures, random forest algorithm based on Python was applied to evaluate the comprehensive performance of each scenario. Finally, some recommendations for sponge city construction are given at the end of this paper based on the simulation results.
2. Materials and Methods
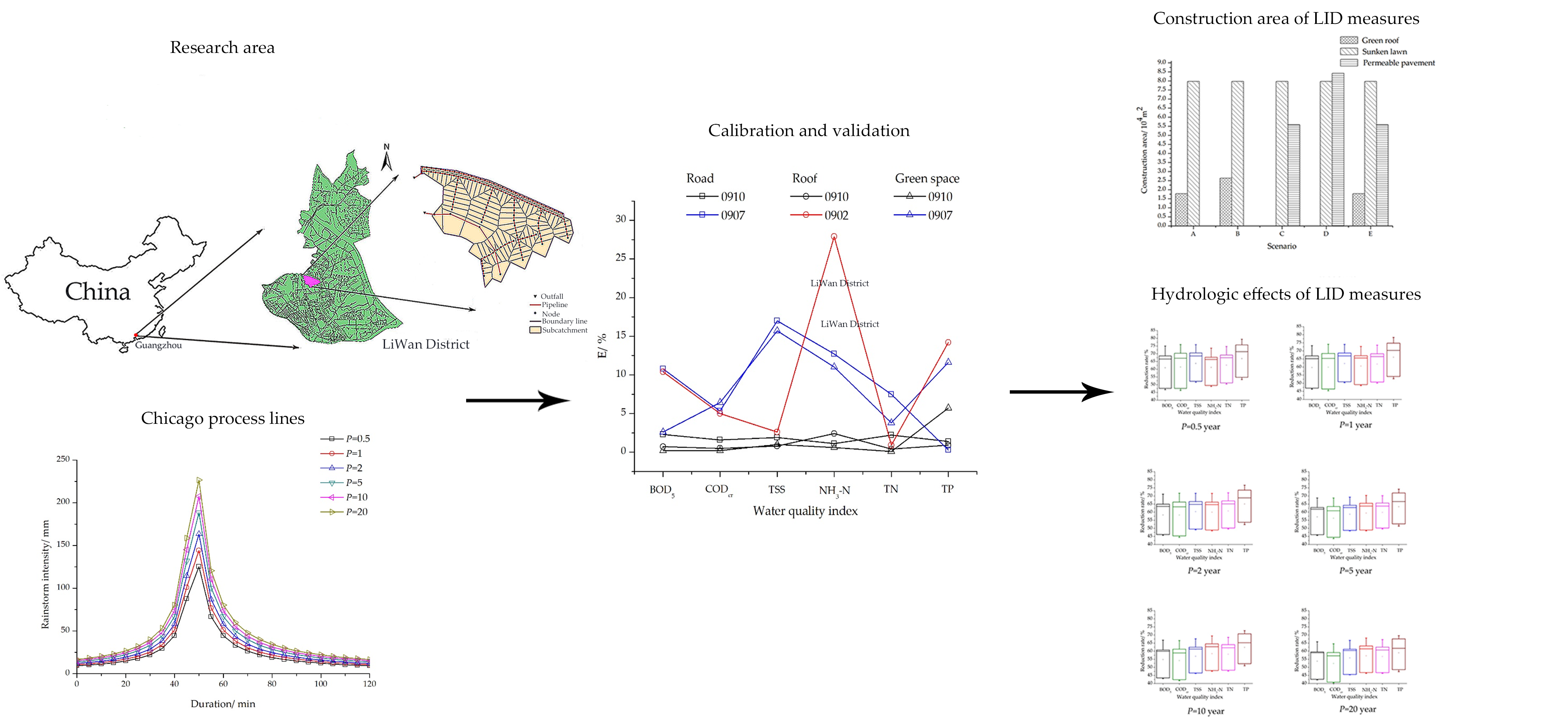
A simple flow chart of the experiment is shown in
Figure 1.
2.1. Research Area
Located in the LiWan district of Guangzhou city and surrounded by rivers on three sides, the research area is residential and covers a total area of 0.4329 km2. It has an isolated and closed drainage system with rain and sewage diversion. In this study, roofs, roads, green spaces, and bare lands were chosen to be the underlying surfaces.
Considering the rainwater pipe network, terrain conditions and principles of the SWMM, the model of the area was divided into 128 subcatchments, consisting of 128 nodes, 129 pipes, and 2 outlets (
Figure 2).
2.2. SWMM
The SWMM, a dynamic rainfall–runoff simulation model, is available for a single event or long-term simulation of runoff quantity and quality from primarily urban areas [
14,
15]. First developed by the US Environmental Protection Agency (EPA) in 1971, it is a watershed-scale distributed hydrologic model based on water diffusion. Given the availability of the source code and library functions, it is thought to be the most widely used urban stormwater model throughout the world [
16]. Considering the spatial variability and principles of the SWMM, the model of a research area is often simplified into several subcatchments, each of which is generalized as a nonlinear reservoir when completing surface runoff calculations. Since version 5.1.007, the LID controls module has been implemented to simulate the hydrologic effect of rain gardens, permeable pavements, infiltration trenches, etc. Aiming to define the corresponding areal coverage, LID measures can be assigned within the selected subcatchments [
17]. According to Ahiablame et al. [
18], various combinations of structural layers ought to correspond to various LID practices in the light of permeation theory. In this study, we selected green roofs, permeable pavements, and sunken lawns as LID implementations in each subcatchment and the Horton model was applied to simulate the infiltration of unsaturated soil area under precipitation.
2.3. Random Forest
Put forward by Leo Breiman and Adele Culter, random forest, an integrated non-parametric learning machine, is an ensemble of numerous tree predictors. With the purpose of sample training, considerable classification and regression trees (CART) are often constructed. All trees in the forest are identically distributed and the generation of each tree relies on the values of random vectors [
19]. Random forest can fit multiple classification trees to a dataset [
20]. In this technique, a small random sample that can interpret variables is chosen and these limited variables are competent to make the best split [
21]. Ascribed to this characteristic, this algorithm performs much better than other classifiers based on standard trees [
22]. Regarding classification, each tree in random forest votes for the most popular class, which is described as Equation (1). The final result depends on the majority vote of these tree predictors as follows [
23]:
where H(
x) is the classification result of random forest,
hi(
x) is the classification result of a single decision tree,
Y is the classification object, and
I(·) is the indicator function.
The generalization error is given by Equation (2) as follows:
where
P is the probability,
E* is the mathematical expectation, and
mg(
X, Y) is the margin function.
The convergence of the generalization error is given by Equation (3) as follows:
The results show that random forest will not overfit as more decision trees are added.
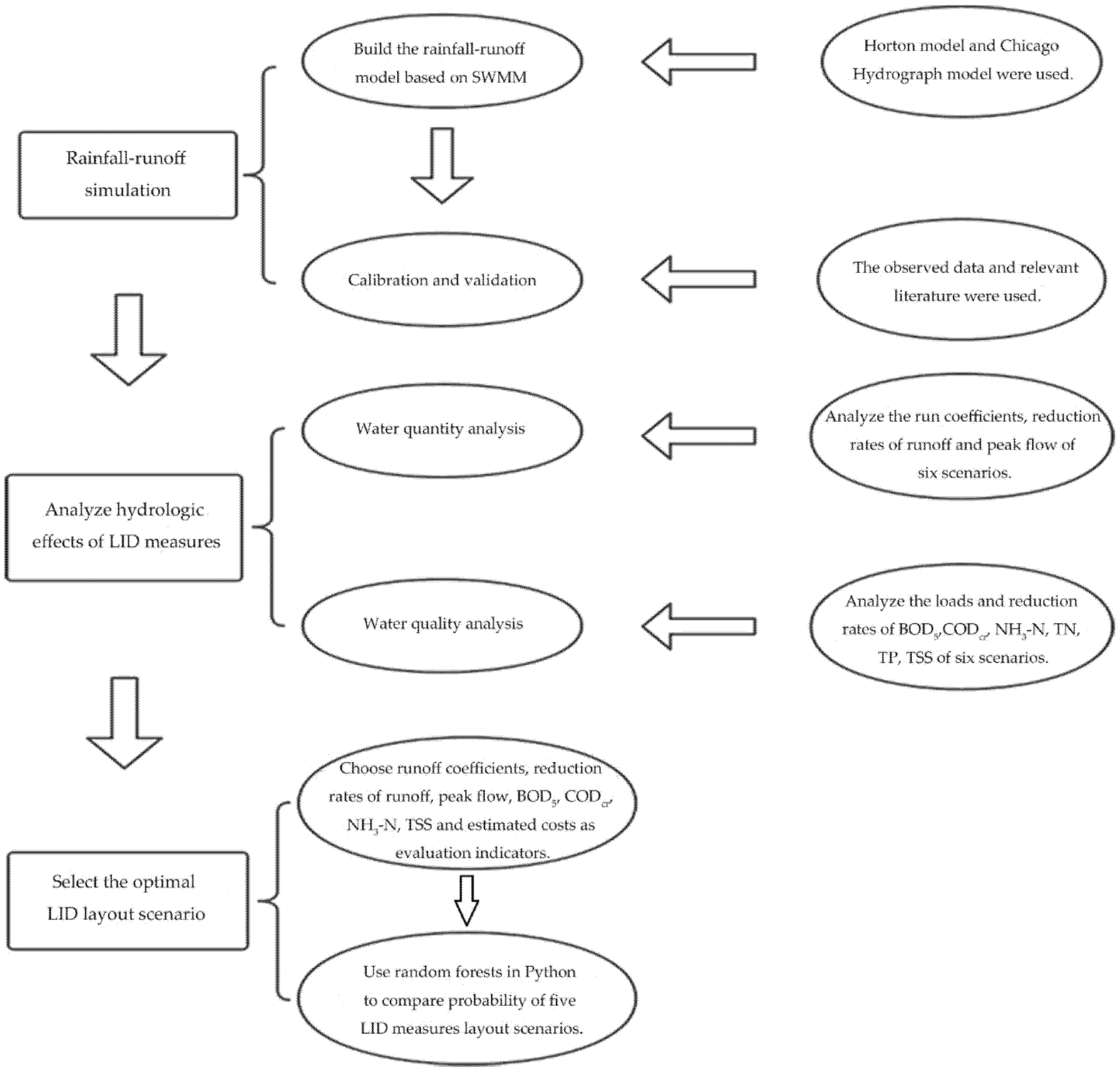
To clarify, the implementation process of this eminent algorithm can be summarized as follows.
Step I: Create an original training set termed N, and then, apply the bootstrap method to randomly extract some self-help sample sets in the number of k. Samples that are not extracted each time will be a component of data out of the bag.
Step II: Assume a total of m variables and x variables are randomly selected at each node of each tree, and then a variable with the most classification ability is selected in the x variable. The threshold of the variable classification is determined by checking each classification point.
Step III: Each tree is fully grown without any pruning.
Step IV: A random forest is finally composed of multiple trees, and the new data are classified by a random forest classifier. The classification results are determined according to the vote of the tree classifier.
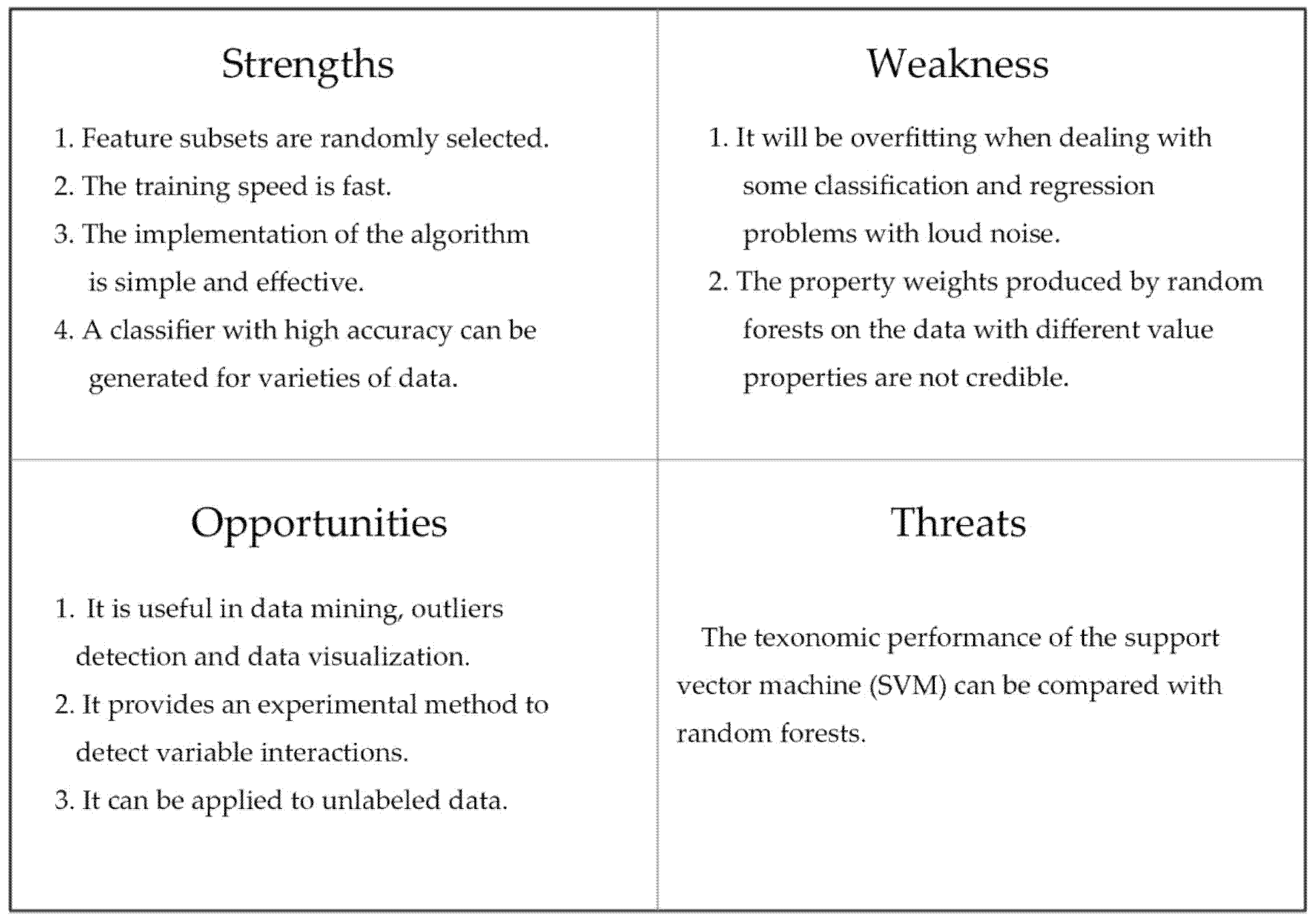
A strengths, weaknesses, opportunities, and threats (SWOT) analysis of random forest is shown in
Figure 3.
2.4. Methodology
2.4.1. Model Building
Aiming to simplify the research area, the equal angle line method was applied to define the boundary lines of the catchment. Subsequently, the Tyson polygon rule was used to divide the catchment into several subcatchments. According to the principle of water nearby discharge, the research area was finally simplified into 128 subcatchments. In the research conducted by Zhu et al. [
24] in the adjacent area, they used rainfall–runoff events during 2013 and 2014 to calibrate the parameters and applied ten other events to validate the model, which promised sufficient precision. Thus, the water quantity parameters in this study, as shown in
Table 1, were determined by referring to both the model manual [
14] and relevant research mentioned previously. Water quality simulation in SWMM is related to different underlying surfaces. The street sweeping parameters shown in
Table 2 were used for water quality simulation in the SWMM.
To calibrate parameters and validate the built model, data of three rainfall events during September 2016 were collected. Five-day biological oxygen demand (BOD
5), chemical oxygen demand (COD
cr), ammoniacal nitrogen (NH
3-N), total nitrogen (TN), total phosphorous (TP), and total suspended solids (TSS) are water quality indices typically used to analyze water pollution of various underlying surfaces. Specifically, data of the rainfall event that occurred on 7 September were used to validate the water quality and quantity parameters of green spaces and roads. Data collected on 2 September were used to validate the same parameters for roofs. The relative errors (
E) between the simulation results and the observed data of the six contaminants were determined to ensure the precision of the model. The calculation formula is shown as Equation (4):
where E is the relative error, %;
is the maximum simulation value;
is the maximum observed value;
is the average value of simulation;
is the average value of observations;
is an instantaneous value of simulation;
is an instantaneous value of observations at the same time of the simulation; and
is the average value of
,
, and
.
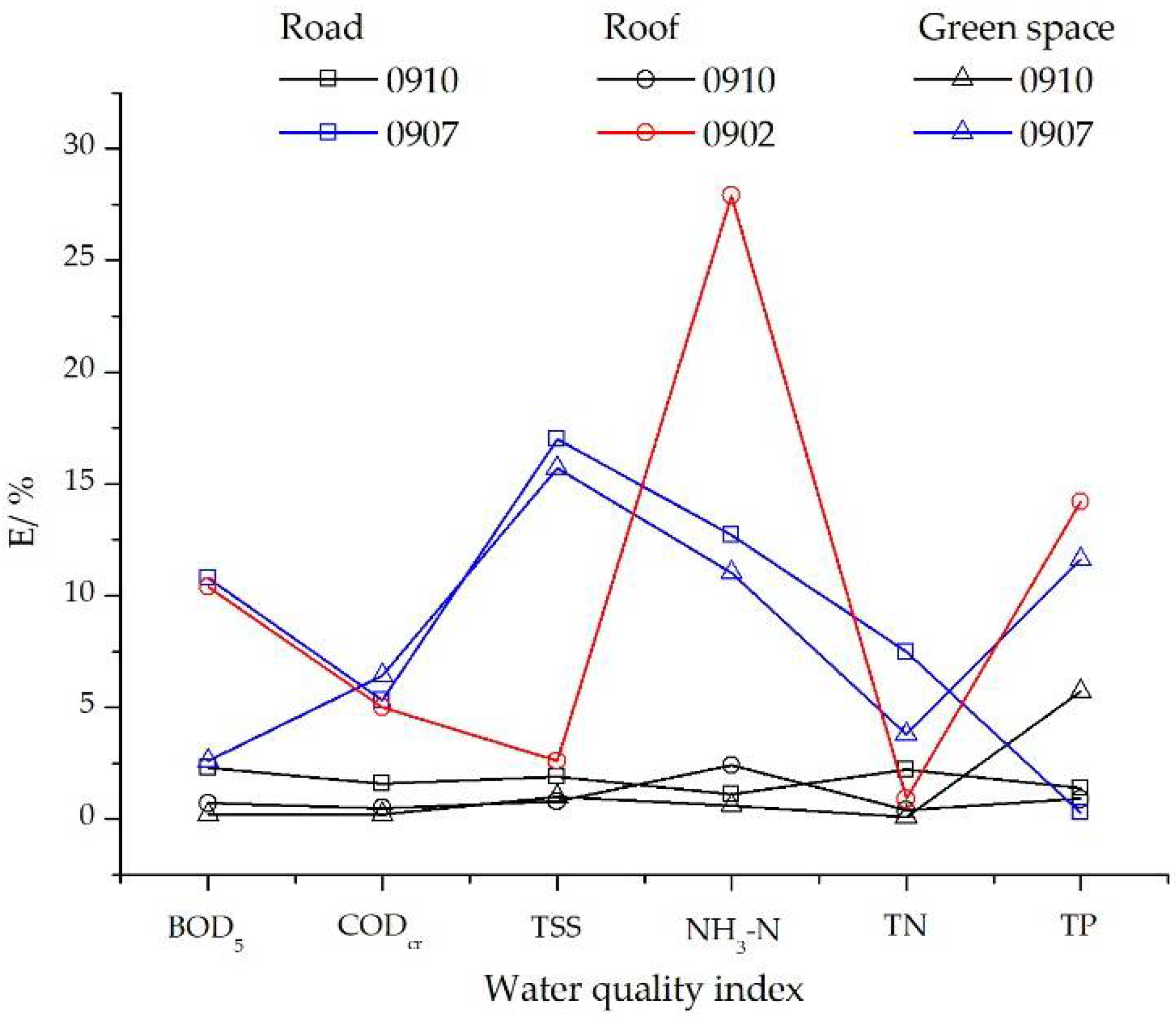
The relative errors (
E) of the three previously mentioned rainfall events were analyzed. Based on the results shown in
Figure 4, the relative errors (
E) were overwhelmingly less than 15%, which illustrates that the simulation results conform to the precision requirements.
2.4.2. Rainfall Simulation
In this study, the formula for storm intensity (Equation (5)) was applied to calculate rainfall in Guangzhou. On the foundation of storm rainfall data over the last 30 years, this formula was derived using the multi sample method and is as follows [
25,
26]:
where
q is the design storm intensity (L/s·ha),
t is the duration of a rainfall event (min), and
P is the rainstorm design recurrence period (year).
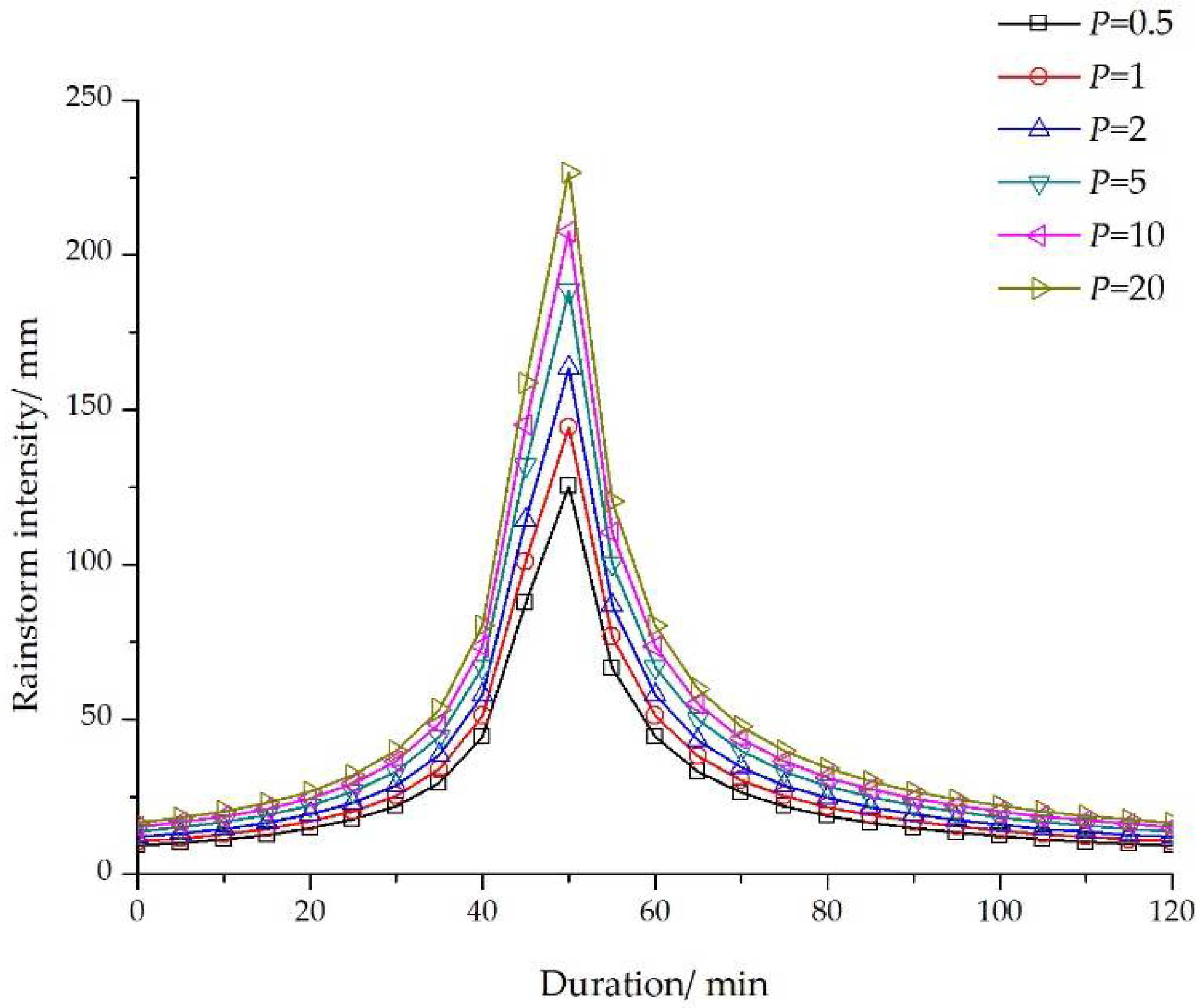
Additionally, a rainfall pattern that is near the reality of the research area using the Chicago Hydrograph Model [
27] was selected to describe the procedures of rainfall events under six rainstorm design recurrence periods (i.e.,
P = 0.5, 1, 2, 5, 10, and 20 years). The duration of each rainstorm design recurrence period in this manuscript was determined to be 120 min. The Chicago rainfall process lines of different rainstorm design recurrence periods are shown in
Figure 5.
2.4.3. Computational Principles of LID Measures
LID rainwater utilization technology mainly utilizes different functions of different facilities to decrease total runoff volume and peak flow, purify and utilize rainwater, and improve the eco-environment. A single LID measure such as a sunken lawn may have multiple functions.
LID measures are formed using different layers. For example, a permeable pavement is composed of pavers, sub-base, and a reservoir course; a green roof is composed of a vegetation layer, growing medium, drainage filter, and drainage layer; and sunken lawns and bio-retention cells are composed of storage layers, cultivated soils, and local soils. Based on the principles of various LID measures, the SWMM has incorporated seven LID control measures: bio-retention cell, infiltration trench, permeable pavement, rain barrel, vegetative swale, rain garden, and green roof. In this model, these measures are also represented by combinations of different vertical layers, including the surface and a soil, pavement, storage, and drain layer. The specific layers that each LID measure contains are shown in
Table 3.
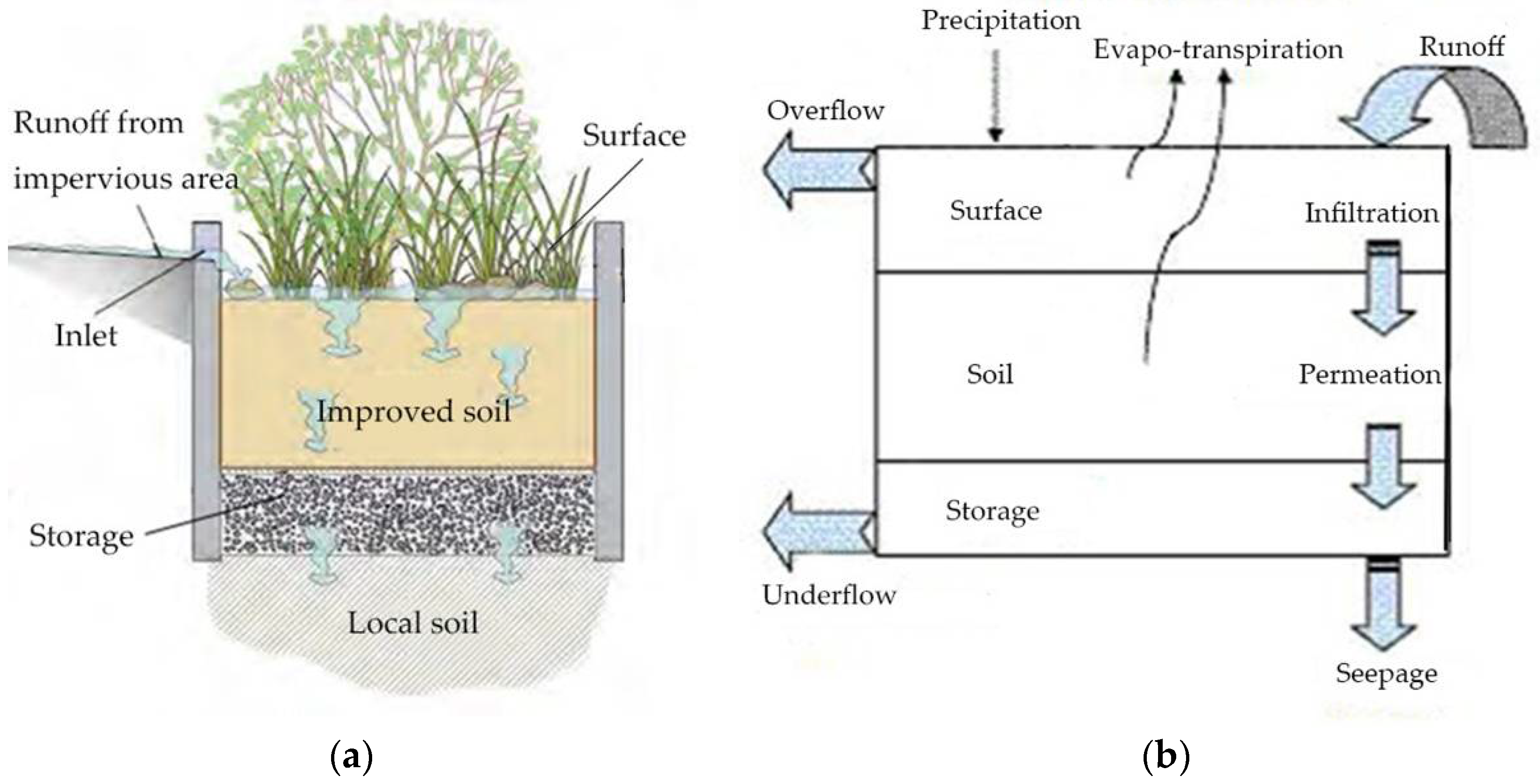
Among these seven LID measures, the bio-retention cell is introduced as an example for LID computational principles. The SWMM has generalized each LID measure as a reservoir that contains fillers with pores (
Figure 6). Direct rainwater and rainwater from other impervious areas flows into the surface of the reservoir, in which vegetation has been planted. Different parameters are also set for the surface, including berm height, vegetation volume fraction, Manning coefficient, and slope. When the surface capacity is saturated, runoff discharges from the top. The soil layer needs to consist of coefficients of thickness, porosity, field capacity, wilting point, conductivity, conductivity slope, and suction head. Specifically, porosity determines the volume of the pores, which is the volume of the water that can be stored; wilting point measures the water content of the soil when it is the driest; and field capacity indicates the maximal water content when there is no exchange of water between the soil layer and other layers such that it must be greater than the wilting point, otherwise the model would report errors. The storage layer is similar to a reservoir, and needs a thickness, porosity, and seepage rate. Rainwater can seep via the storage layer to the local soil, and if the drainage layer is set, the water would discharge through it. The drainage layer must contain a flow coefficient, flow exponent, and offset height.
2.4.4. LID Measure Layout Approaches
In the SWMM, LID control measures are established in the subcatchment properties, and either different or identical LID measures can be established in the same subcatchment. There are two means to establish LID measures in the subcatchments: adding a single LID measure or multiple LID measures into a subcatchment with no existing LID measures (
Figure 7a) or adding only one LID measure into one subcatchment (
Figure 7b). The first approach allows mixing of different LID control measures in the same subcatchment and all function simultaneously. Each LID measure addresses the water flow in its corresponding area, and the outflow data from one LID measure cannot be taken as the inflow data for another LID measure.
The second approach allows a LID measure to occupy the entire subcatchment, and it can take the outflow from its upstream subcatchment as its inflow, thus satisfying flow direction settings. However, this approach requires building new subcatchments and establishing the corresponding LID properties.
To utilize either the first or the second LID measure layout approach, the impervious rates of the subcatchments have to be adjusted according to the respective measures. For instance, the impervious rate needs to be re-calculated if an originally impervious area becomes pervious, and for the second approach specifically, the areas for the old and new subcatchments need to be adjusted.
Referring to a prior study in Shenzhen [
10] and considering the actual situation of the research area, five LID measure layout scenarios were designed to determine the hydrologic effects of LID measures on the research area. The content of each scenario can be summarized as follows:
Scenario A: 35% of the roofs are transformed into green roofs, through which rainwater directly discharges into the drainage system. In addition, 50% of the green spaces are transformed into sunken lawns, which are used to collect rain generated from roofs without transformation.
Scenario B: 50% of the roofs are converted into green roofs, through which rainwater directly discharges into the drainage system. In addition, 50% of the green spaces are converted into sunken lawns, which are used to collect the rain generated from the roofs without transformation.
Scenario C: 35% of the roads are transformed into permeable pavements, through which rainwater directly discharges into the drainage system. In addition, 50% of the green spaces are transformed into sunken lawns, which are responsible for the purification of rainwater generated from the roofs.
Scenario D: 50% of the roads are transformed into permeable pavement, through which rainwater directly discharges into the drainage system. In addition, 50% of the green spaces are converted into sunken lawns, which are responsible for the purification of rainwater generated from roofs.
Scenario E: A combination of scenarios A and C; 35% of the roofs are transformed into green roofs and 35% of the roads are converted into permeable pavement. Rainwater generated from both discharges directly into the drainage system. In addition, 50% of the green spaces are retrofitted into sunken lawns, which are used to purify rainwater produced by the roofs without transformation.
Referring to similar studies [
10,
28,
29] and the model manual [
14], the parameters of the LID measures previously mentioned are listed in
Table 4,
Table 5 and
Table 6.
2.4.5. Calculation of Estimated Cost for Each LID Measure Layout Scenario
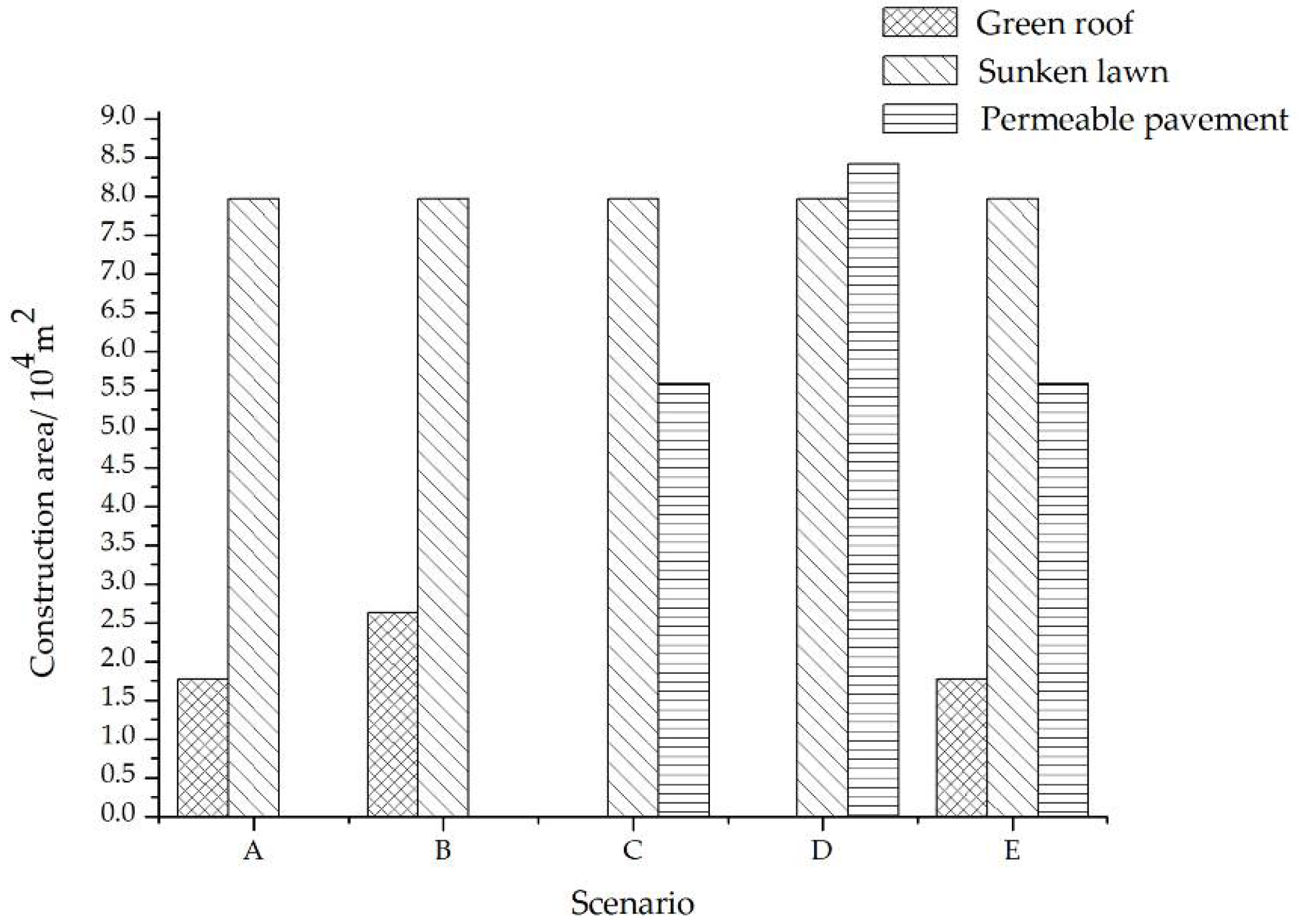
Based on the construction area of each LID measure for the five scenarios (
Figure 8) and the unit price of different types of LID measures based on the investment of more than 40 domestic projects, the estimated cost of each scenario can be calculated as shown in
Table 7.
2.4.6. Selection of the Optimal LID Measure Layout Scenario
Aiming to determine the most reasonable layout among the five scenarios, runoff coefficient, reduction rates of runoff, peak flow, BOD
5, COD
cr, NH
3-N, TSS, and estimated cost of each scenario under three rainstorm design recurrence periods (i.e.,
P = 1, 5, and 10 years) were chosen for comprehensive performance indices. Random forest classification of Scikit-Learn machine learning in Python was applied to analyze the dataset. Values of the partial parameters are shown in
Table 8, while default values were used for parameters not shown.
3. Results and Discussion
The water quantity simulation of the five LID measure layout scenarios under six rainstorm design recurrence periods in the SWMM are shown in
Table 9.
According to the data listed in
Table 9, the following conclusions can be readily drawn. In response to the increase in the rainstorm design recurrence period, the runoff and its coefficient, peak flow, as well as contaminant concentration of all the scenarios increases while the reduction rates decrease. In addition, comparing the five LID measure layout scenarios to the scenario without any LID appliance from multiple indices, LID measures have enormous effects on reducing water quantity and contaminant concentrations. Under three of the rainstorm design recurrence periods (i.e.,
P = 0.5, 1, and 2 years), the five scenarios with runoff coefficients ranking from low to high are D, E, C, A, and B, and the order of the reduction rates of the runoff ranking from low to high is the exact opposite. In terms of the reduction rates of the peak flow under the same rainstorm intensities, the five scenarios ranking from high to low are D, C, E, A, and B. Under the other three rainstorm design recurrence periods (i.e.,
P = 5, 10, and 20 years), the five scenarios with runoff coefficients ranking from low to high are E, D, C, A, and B, whose order is the opposite to the reduction rates of runoff. In terms of the reduction rates of the peak flow under the previously mentioned three rainstorm intensities, the five scenarios ranking from high to low are D, C, E, A, and B.
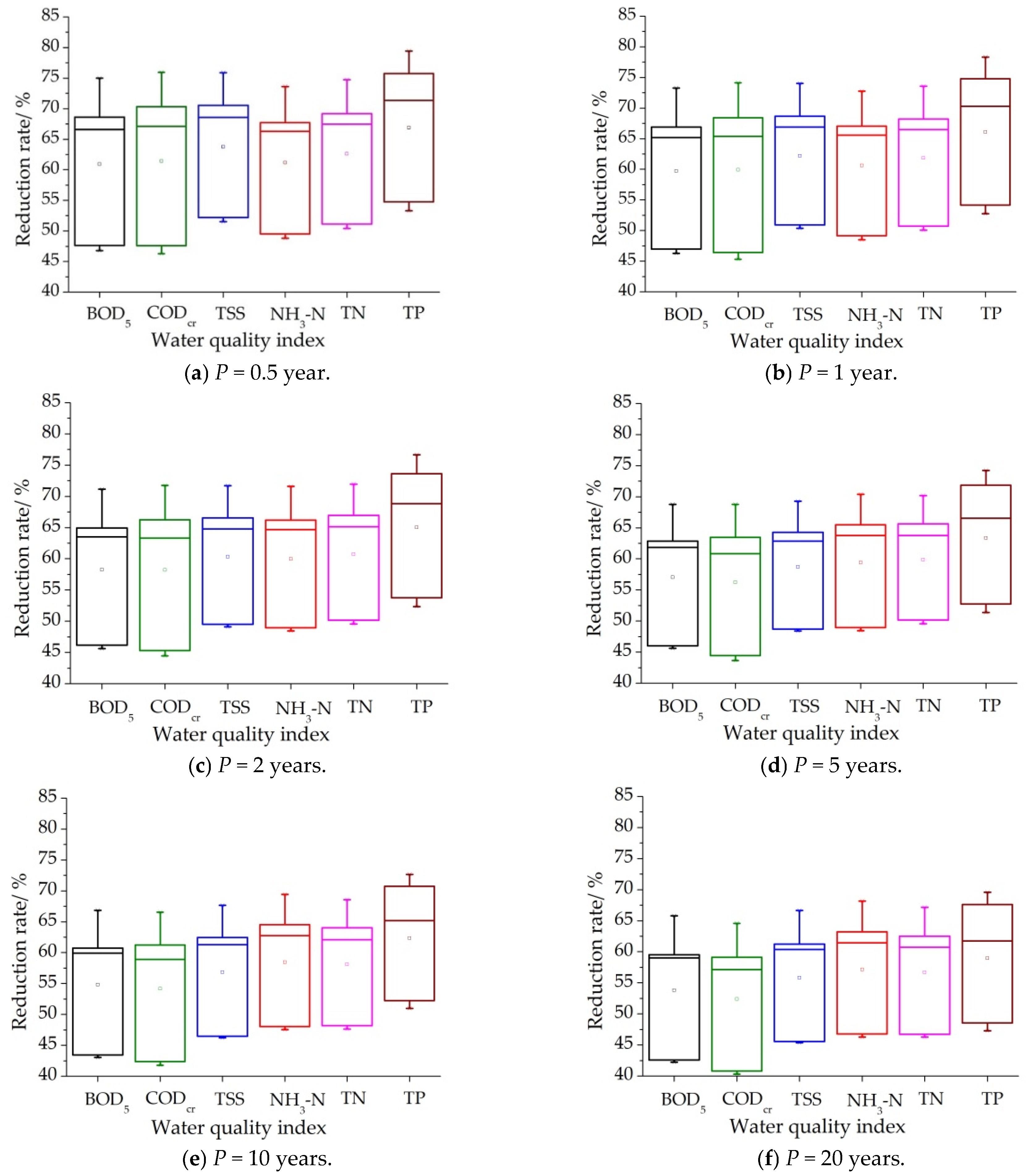
Based on the water quality simulation of the model (
Table 10), reduction rates of the six pollutants under different rainstorm design recurrence periods can be calculated (
Figure 9).
Deducing from the data shown in
Table 10 and the tendencies shown in
Figure 9, the scenarios with reduction rates for the six pollutants ranking from high to low are D, E, C, B, and A under all six rainstorm design recurrence periods. Although all contaminant concentrations increase with the increase in rainstorm intensity, the reduction rates among all the six contaminants decrease.
In virtue of the random forest algorithm in Python, the probabilities of each LID measure layout scenario to be selected as the best scheme are listed in
Table 11.
From a short review of the data shown in
Table 11, the following findings are evident. Comparatively speaking, Scenario D is the optimal scenario when considering runoff coefficient, reduction rates of runoff, peak flow, BOD
5, COD
cr, NH
3-N, TSS, and estimated cost at the same time under rainstorm design recurrence periods of
P = 1, 5, and 10 years. The probability of Scenario D being selected as optimal decreases with an increase in rainstorm intensity.
4. Conclusions
At present, LID utilization is increasingly important for the avoidance of substantial ecological disasters throughout the world. To explore the effects of LID measures on water quality and quantity in a residential area in Guangzhou, a model in the SWMM was developed and five LID measure layout scenarios were analyzed. Focusing on the most reasonable scenario among the five, random forest algorithm in Python was applied simultaneously considering eight indices. Overall, it was demonstrated that there are far-reaching effects resulting from implemented LID measures, which play an important role in purifying water, reducing flood risk, and providing a better environment for citizens. Moreover, via the case study in a residential area in the LiWan district in Guangzhou, the hypothesis that the random forest algorithm can select the most reasonable LID measure layout scenario was tested. Despite the limitations, these conclusions are valuable for sponge city construction, which is an important measure for sustainable urban development and storm water management. For the future research, a systematic study based on this methodology will be carried out in accordance with the actual planning and design scenarios of the sponge city.
Based on the results of this study, several recommendations can be made as follows. First, original roofs can be retrofitted into green roofs and original roads can be retrofitted into permeable pavements to decrease the level of imperviousness in residential areas, and sunken lawns are qualified to directly purify rainwater discharged into them. Second, because the comprehensive reduction effects of LID have a correlation with the combination of different LID measures as well as the proportion of the identical LID measure, selecting the optimal LID layout in a more objective manner is important. Third, because the random forest algorithm can calculate the probability of each LID layout scenario to be the optimal under specific rainstorm design recurrence periods without considering the weight of each selected index, it is a more reasonable and effective method than the AHP and the EWM.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}