Different Approaches to SCADA Data Completion in Water Networks



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
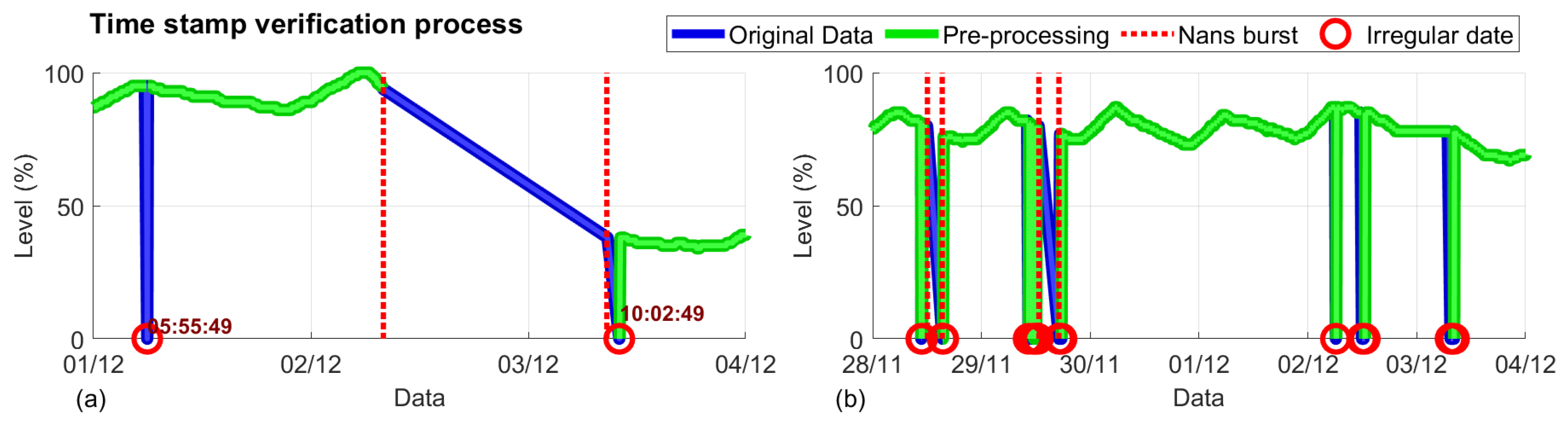
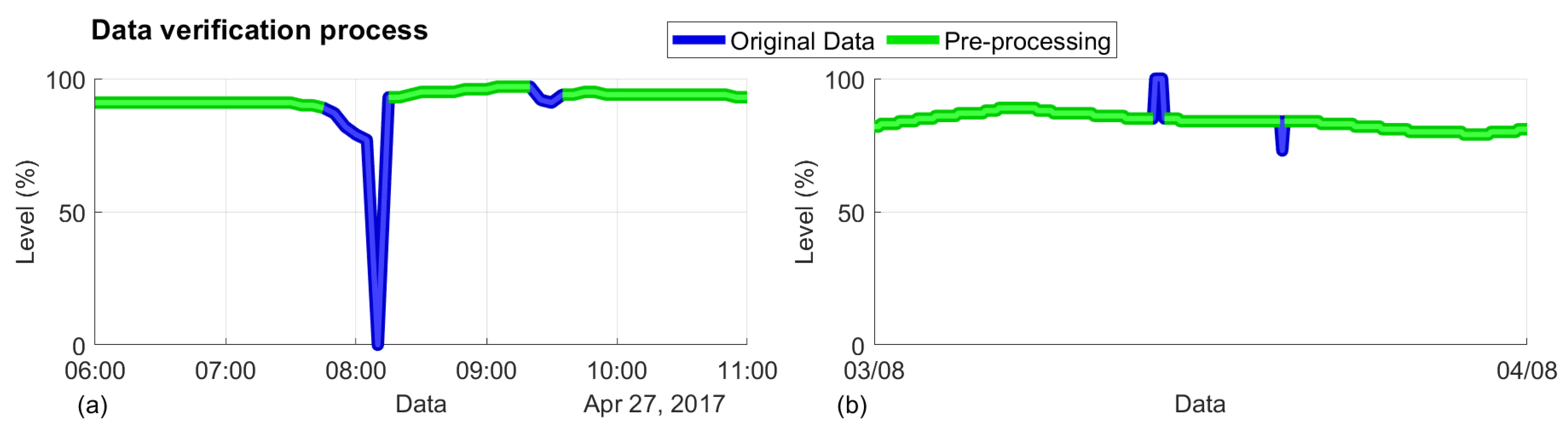
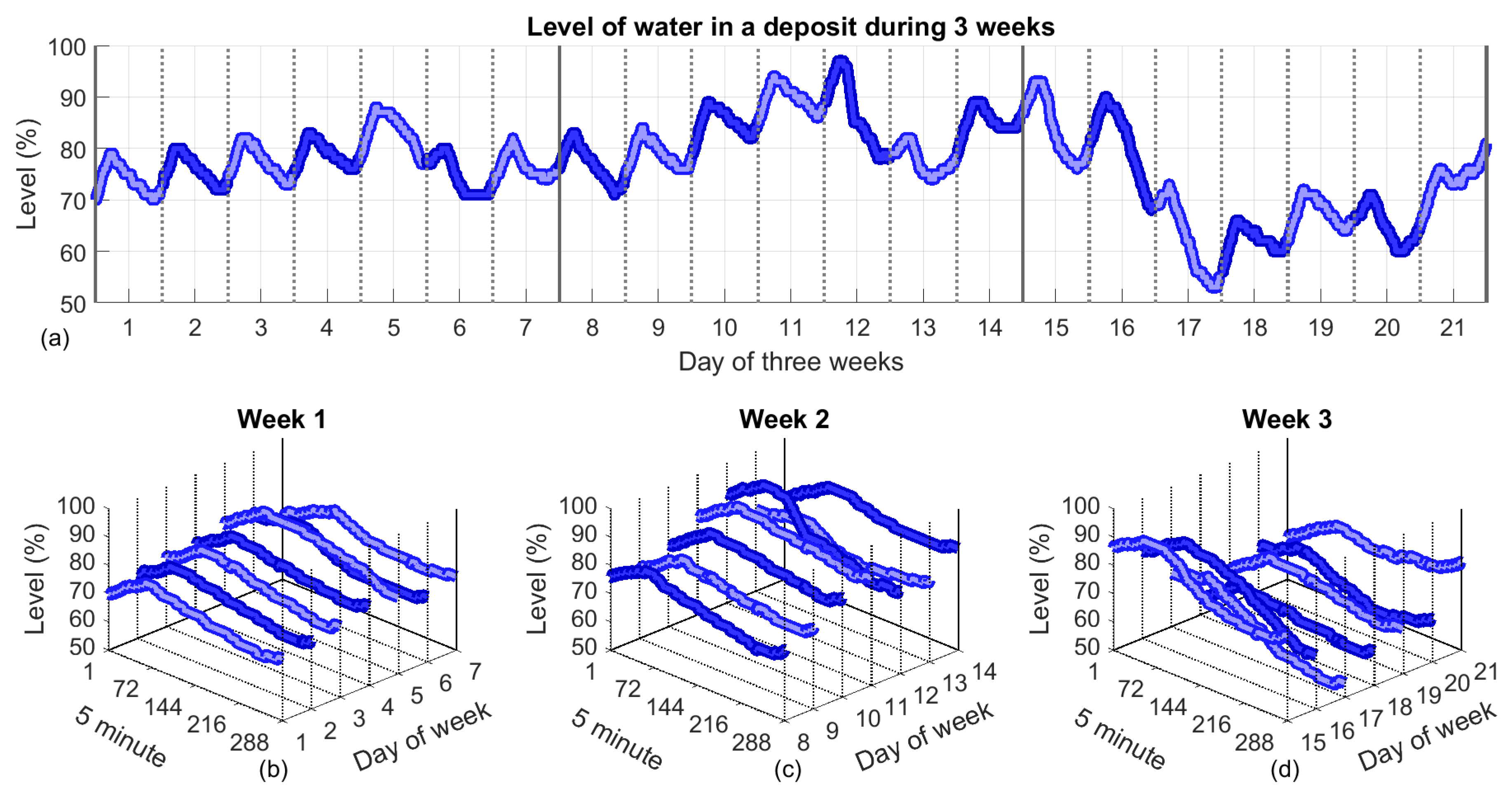
2.1. Data Acquisition
2.2. Data Pre-Processing
2.3. Linear Methods Used for Data Completion
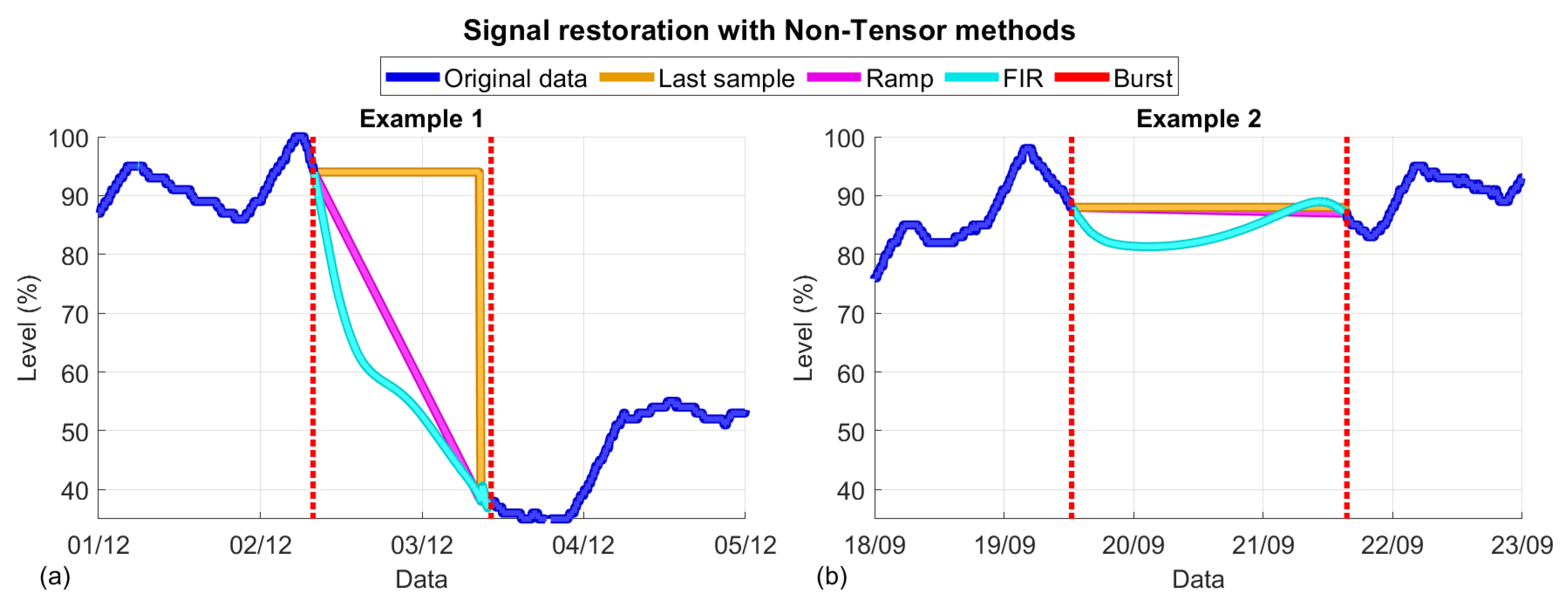
2.3.1. Last Sample Method
2.3.2. Ramp Method
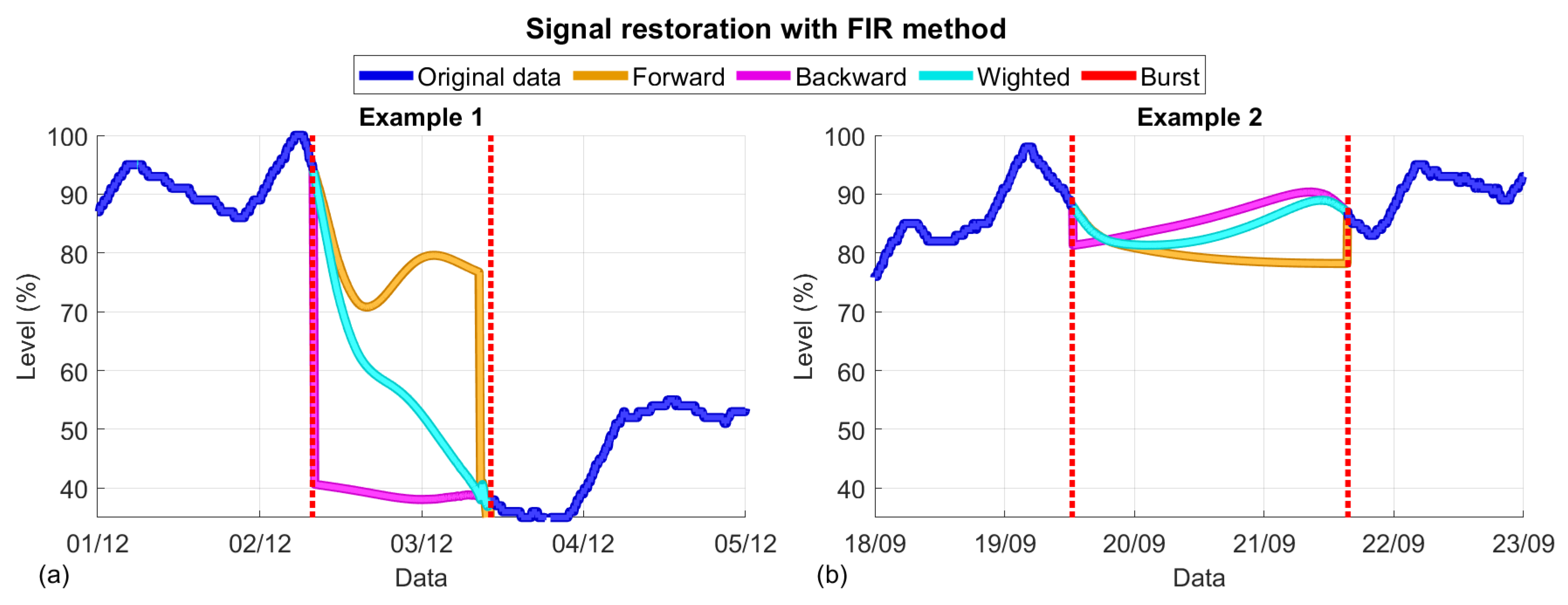
2.3.3. FIR Method. The Wiener Predictor
2.3.4. FIR Method. Forward and Backward Wiener Predictor Combinations
2.4. Tensor-Based Methods for Data Completion
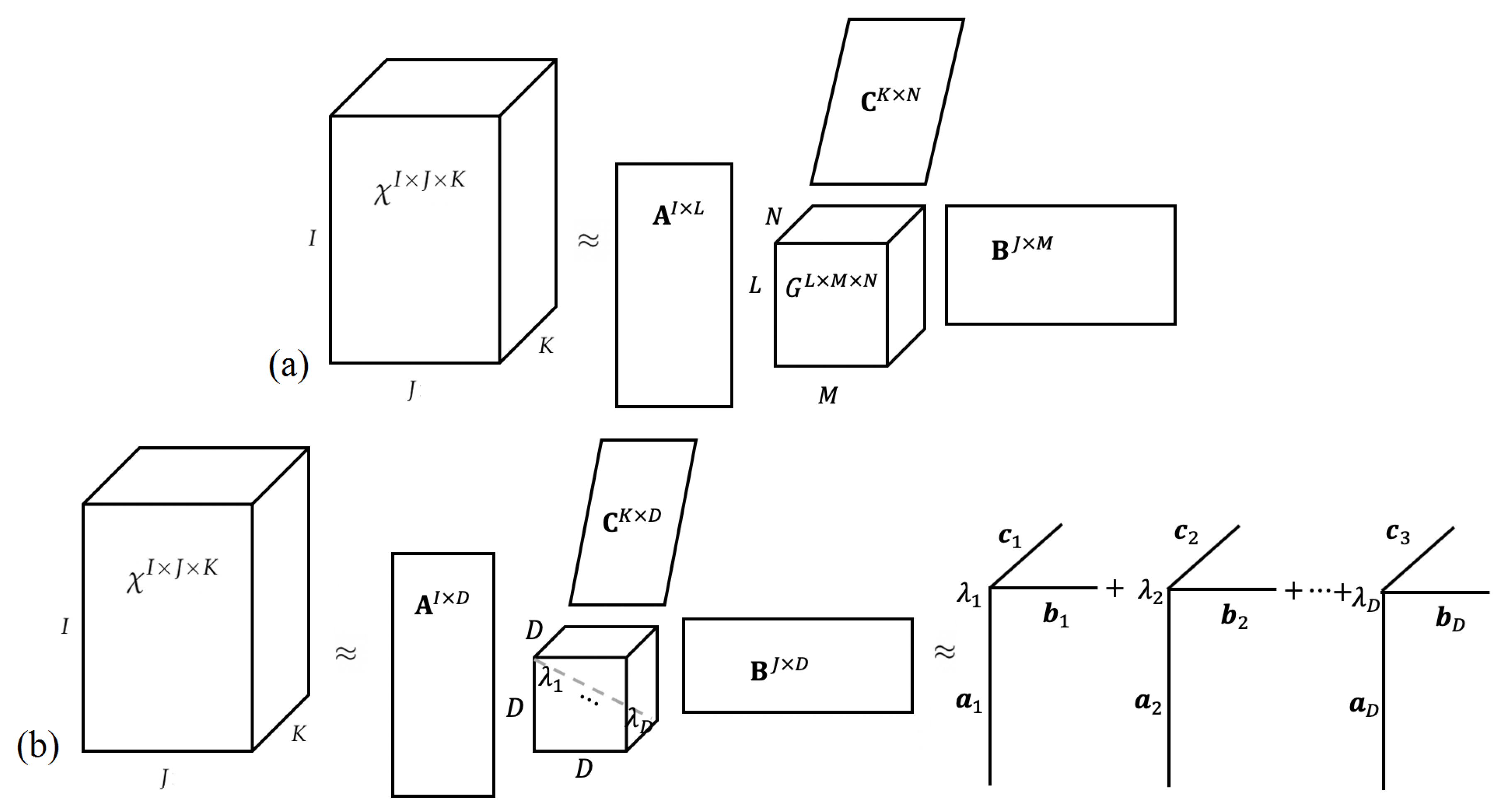
2.4.1. Definition of a Tensor and Some of Its Basic Properties
- By fixing every index but one, the subtensor is a vector, and it is referred to as a fiber. For instance, the fibers , , and are the first column, row, and tube of the three-way tensor , respectively.
- A matrix, also called a slice, is created by fixing all but two tensor indexes. Following the same example, the matrices , , and of the three-way tensor are frontal, vertical, and horizontal slices, respectively.
- Commonly, the notation is used to represent the mode-n matricization of , an operation which reshapes in a matrix .
- Similarly, the reverse operation of mapping a matrix into a tensor is called unmatricization.
- It is denoted and reshapes into a vector .
- The mode-n product of a tensor by a matrix is denoted as , with being the resulting tensor.
- The mode-n product also has the following matrix representation , where and are the mode-n matrization of tensors and , respectively.
2.4.2. Data Tensorization
- Five minute day intervals: indicates 5 min intervals throughout the day. One day is divided into 288 such intervals.
- Day of the week: indicates the day of the week, from Monday to Sunday, which corresponds to a number from 1 to 7.
- Weeks: indicates , the number of weeks included in the tensor.
2.4.3. The Tucker and CANDECOMP/PARAFAC Models
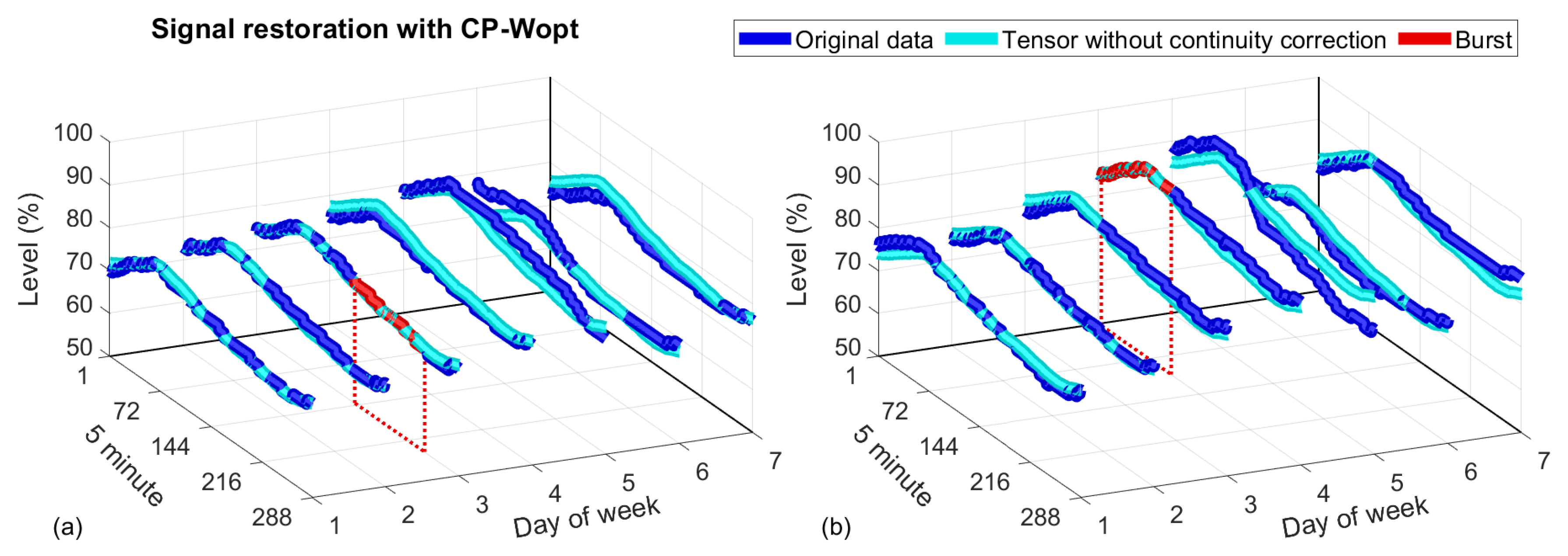
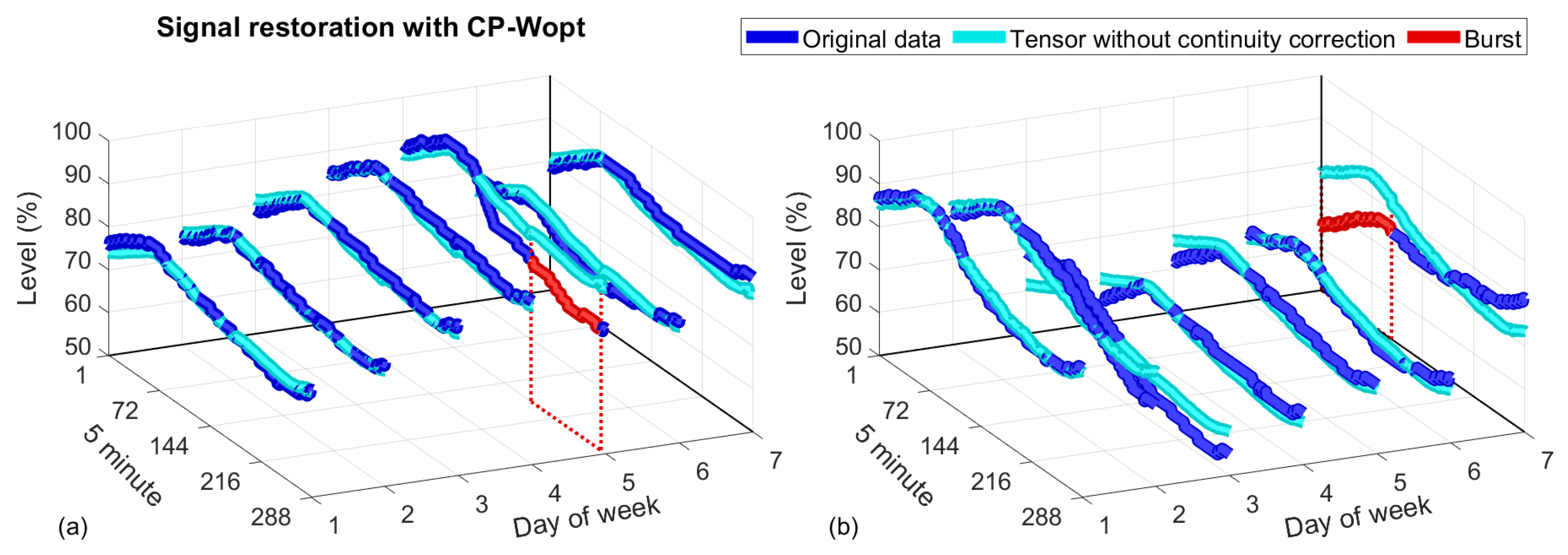
2.4.4. CP Weighted Optimization (CP-Wopt)
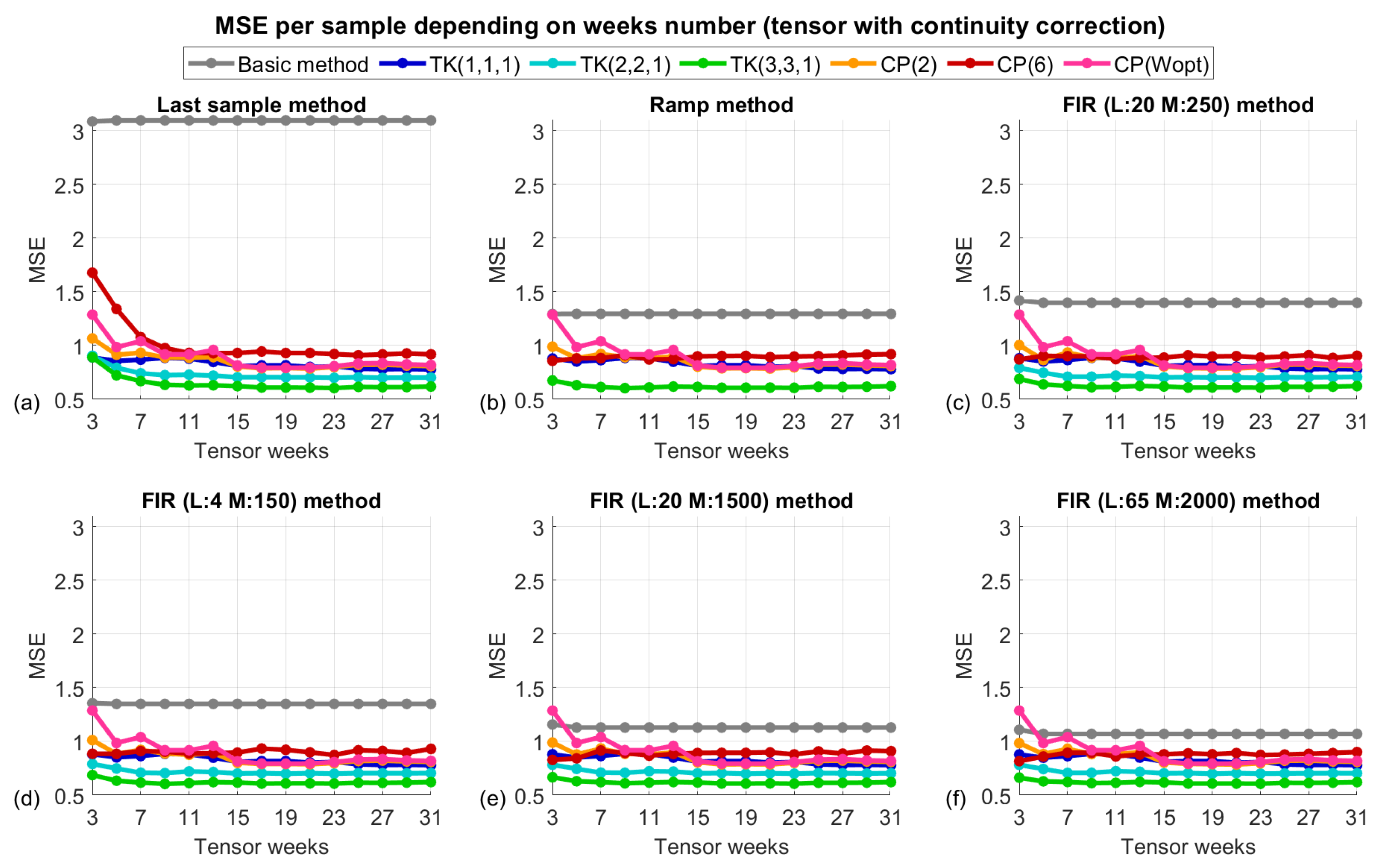
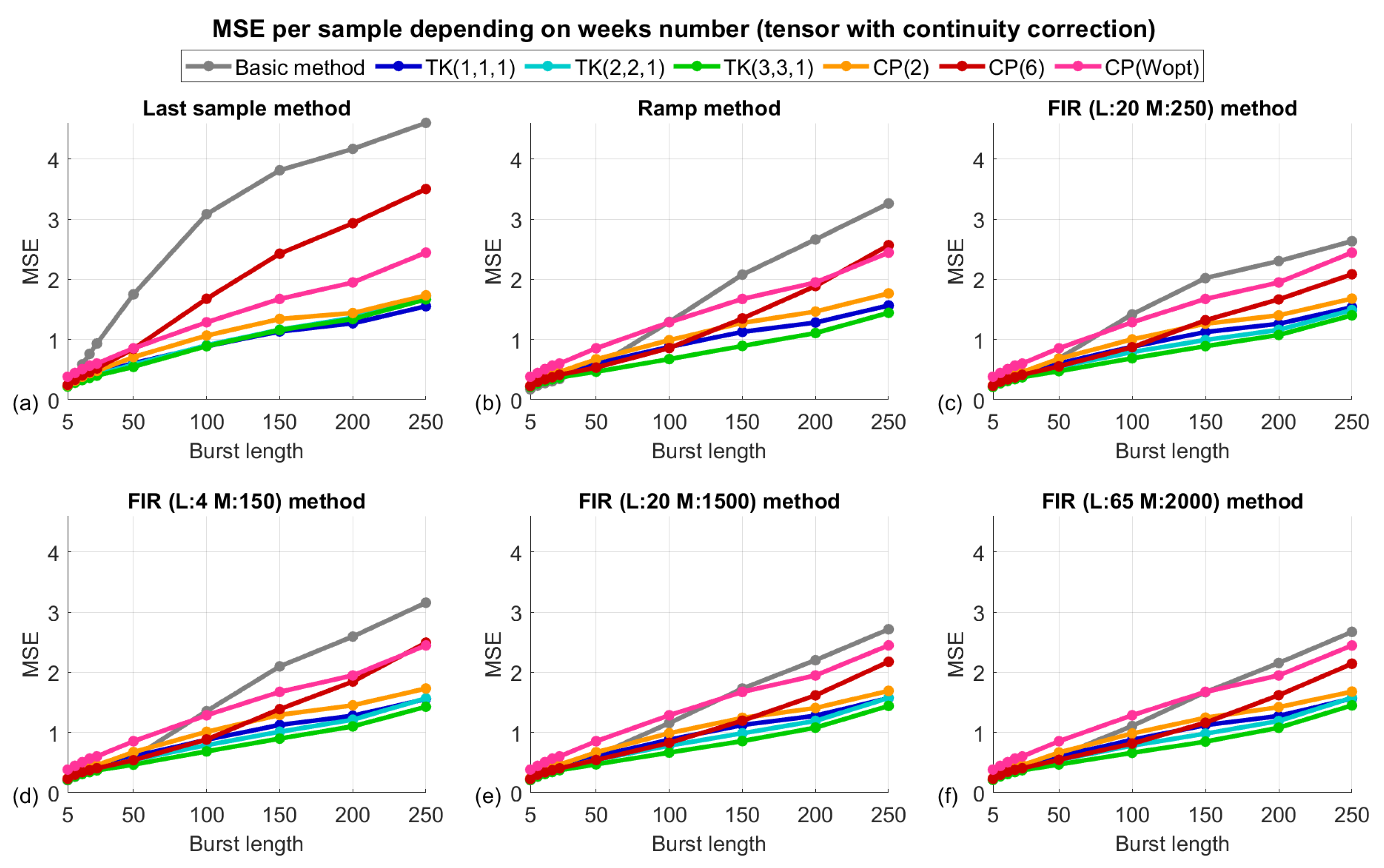
- The algorithm returns a tensor with the missing data filled in but with slightly different values at the continuity points at the ends of the lost burst. When we used the recovered data to fill in the original tensor, this discontinuity usually made the recovery results given by the ramp or FIR methods worse.
- It was observed that the recovered data followed the variations of the original signal in a very reliable way, although with an offset, since the use of tensors can exploit the inter-relationships between dimensions. This behaviour persisted as the size of the lost bursts increased, surpassing the performance of the FIR predictors.
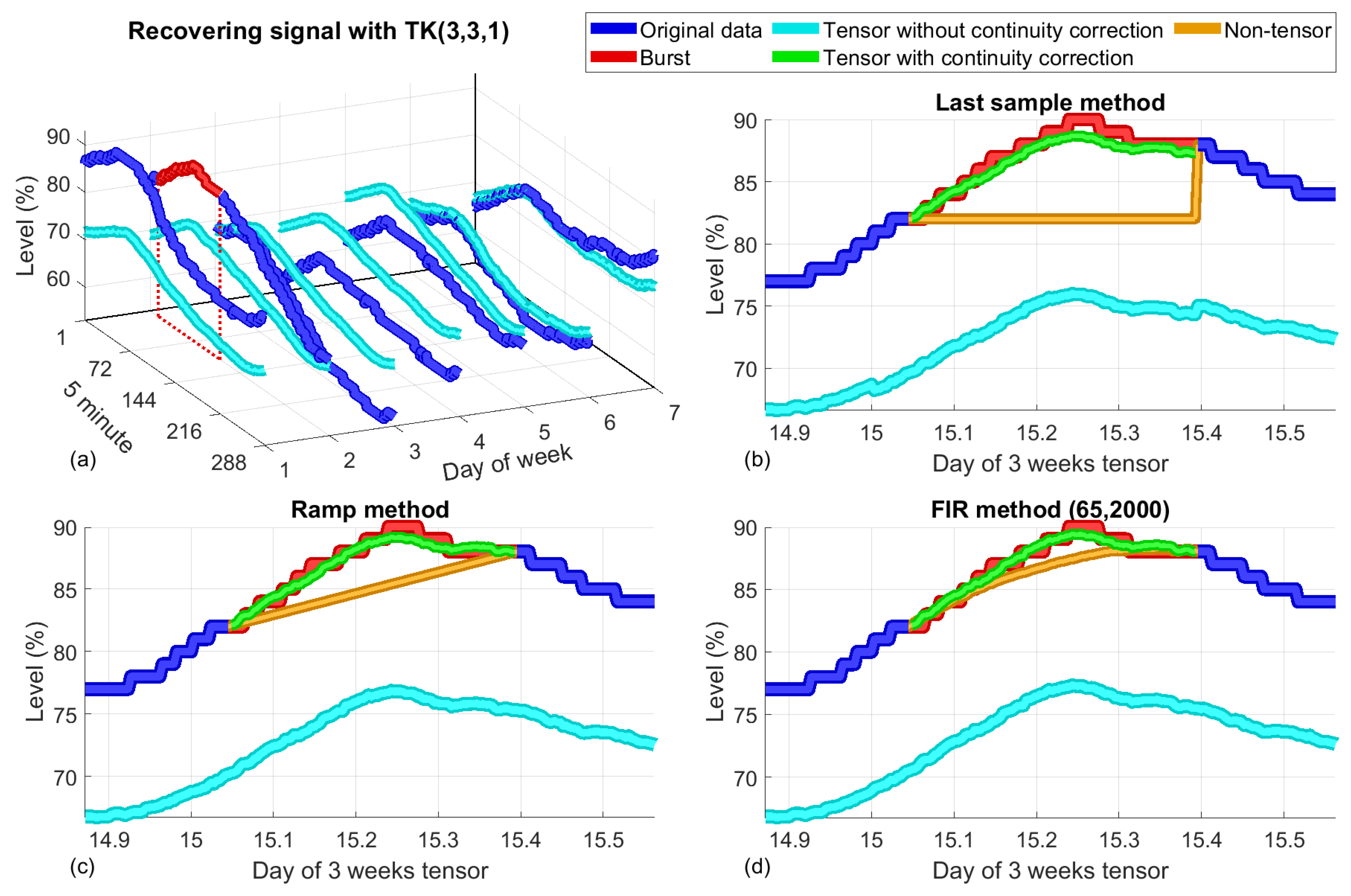
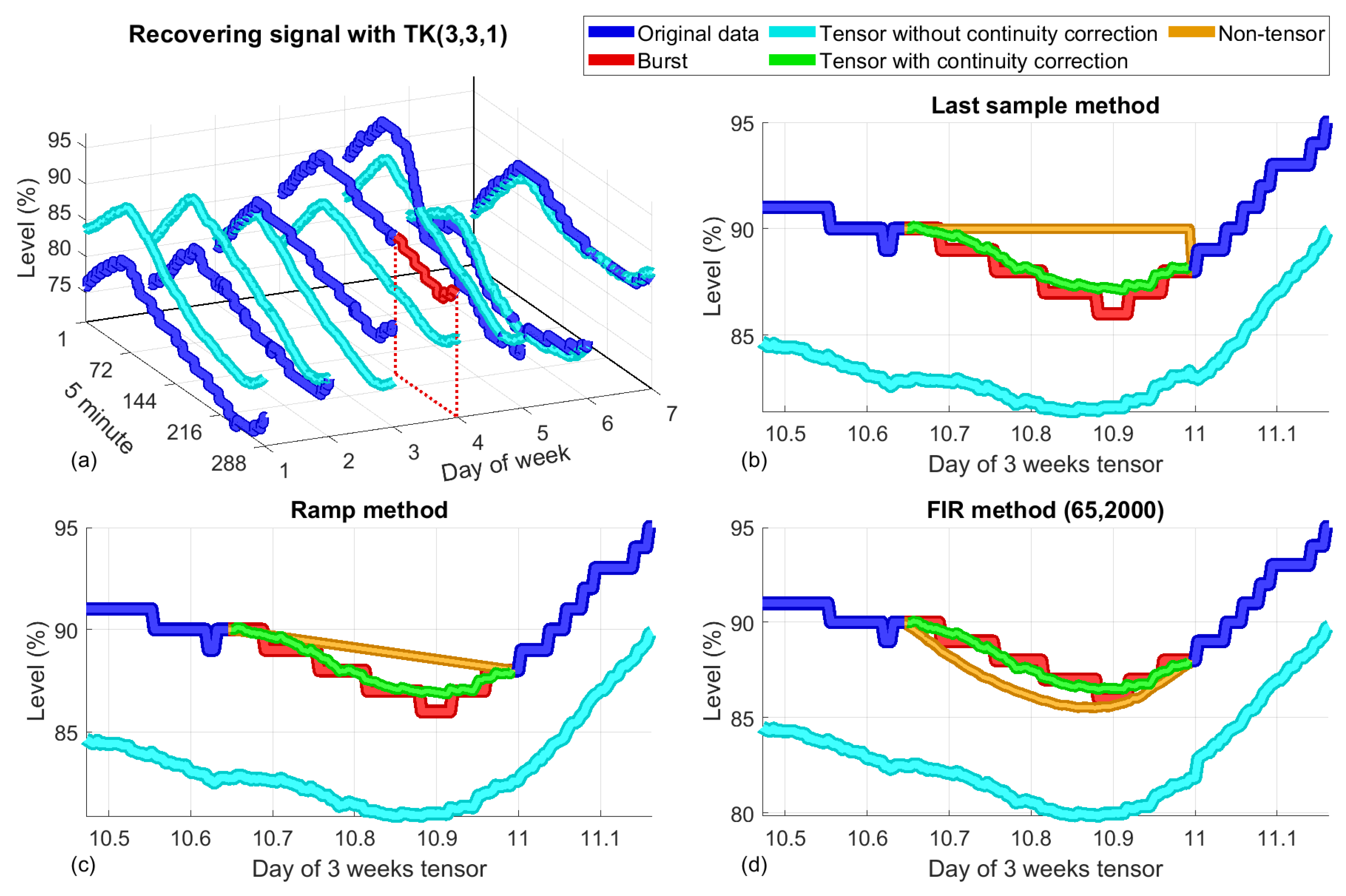
2.4.5. The Proposed Tensor Method with an Offset Correction
- One of the linear methods for data completion described in Section 2.3 is used to fill the empty burst. The positions of the lost data are stored. After this step, there are no empty elements in the tensor.
- A low-range tensor approximation is performed using tensor decomposition. In our case, the popular Tucker and CP algorithms were explored, as explained in Section 2.4.3. This simple approach captures the most important variations of the original tensor, reproducing it with a high level of accuracy. The difference between the low-rank approximation and the original tensor consists of high-frequency components with low amplitudes.
- Samples found in the original lost data positions are retrieved from the low-range tensor and corrected as explained below to maintain continuity when the burst ends. The correction procedure carried out is similar to the one applied to the FIR method. The resulting compensated data are the ones that are subsequently assigned. This last step is referred to as an offset correction.
2.5. Algorithm Performance Evaluation
3. Results
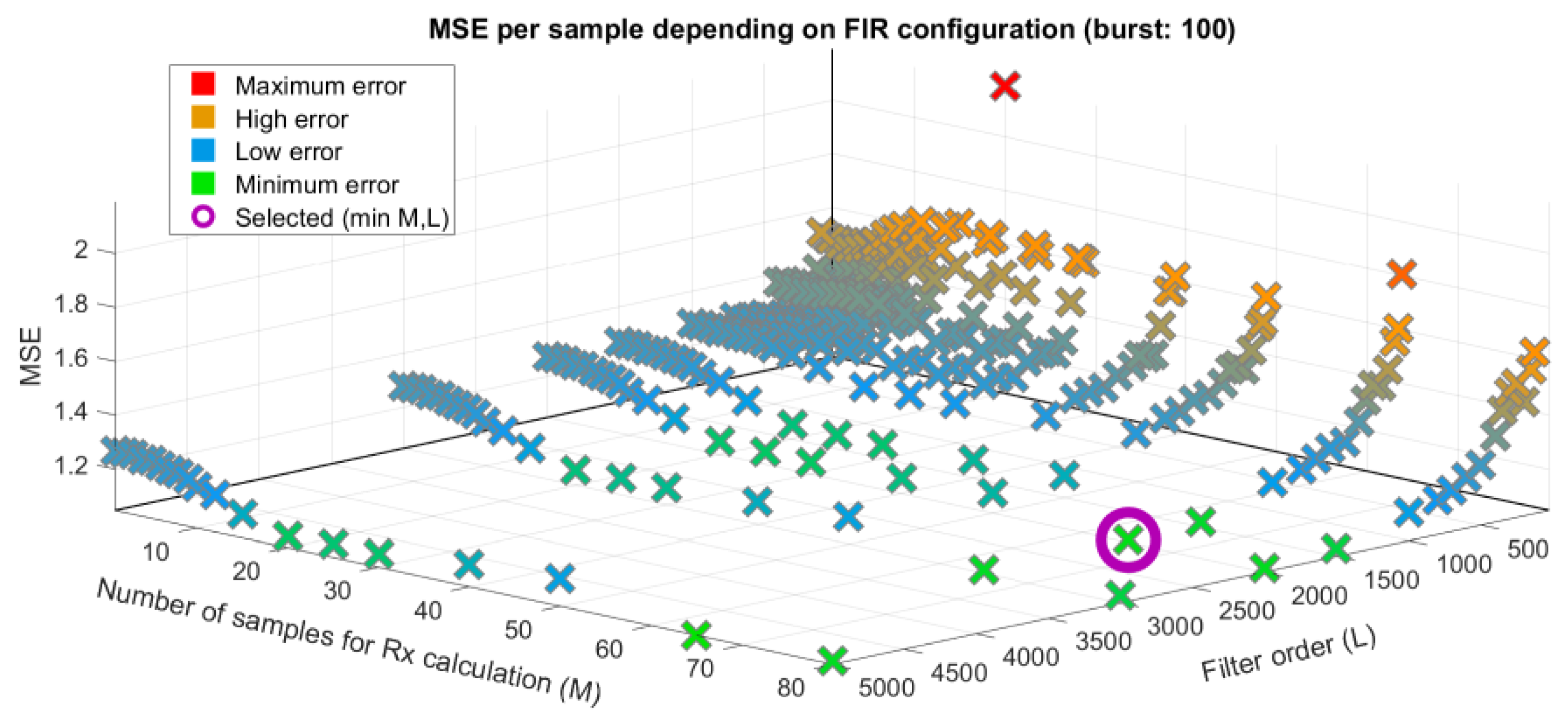
3.1. Tuning the FIR Filters
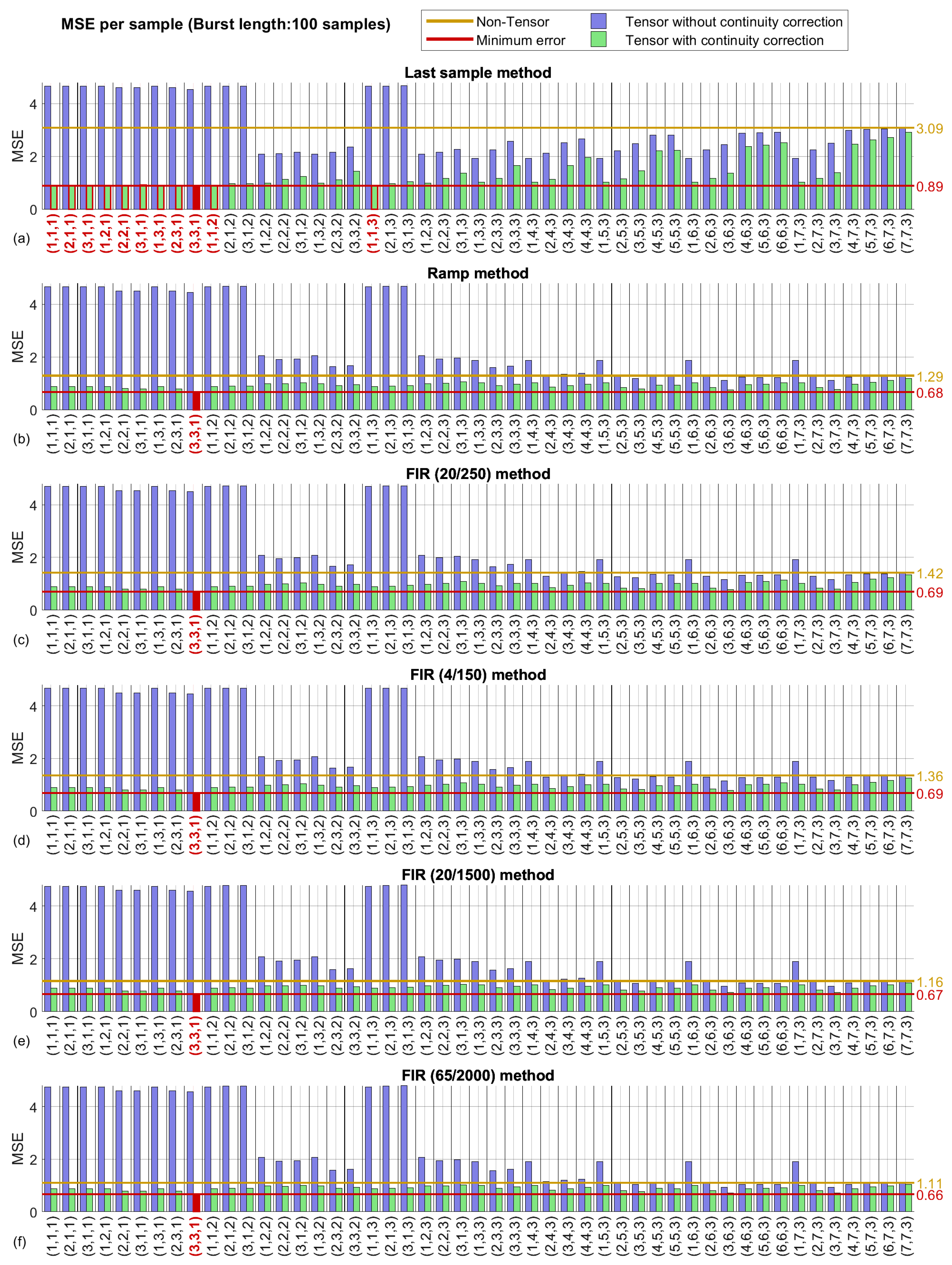
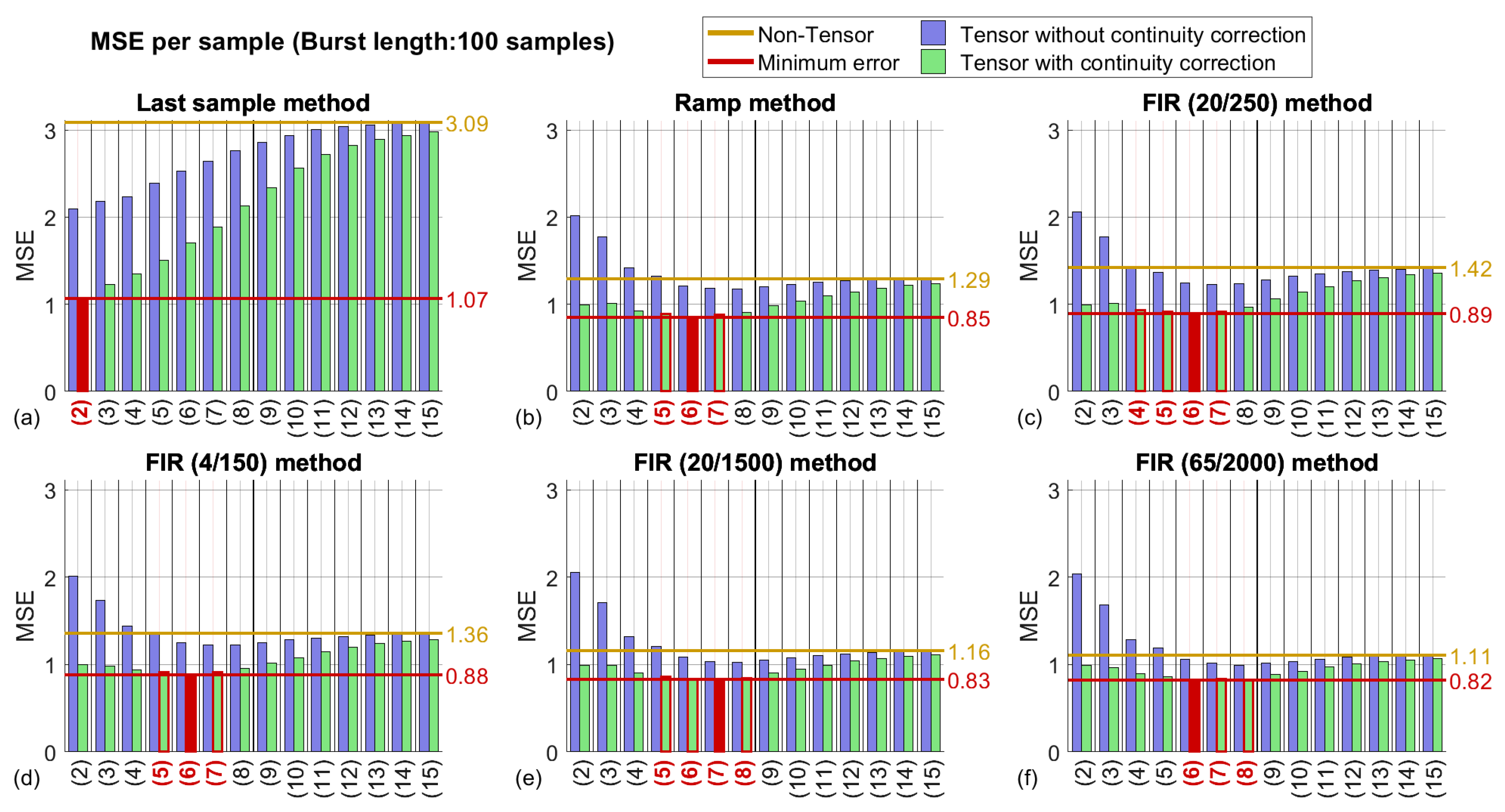
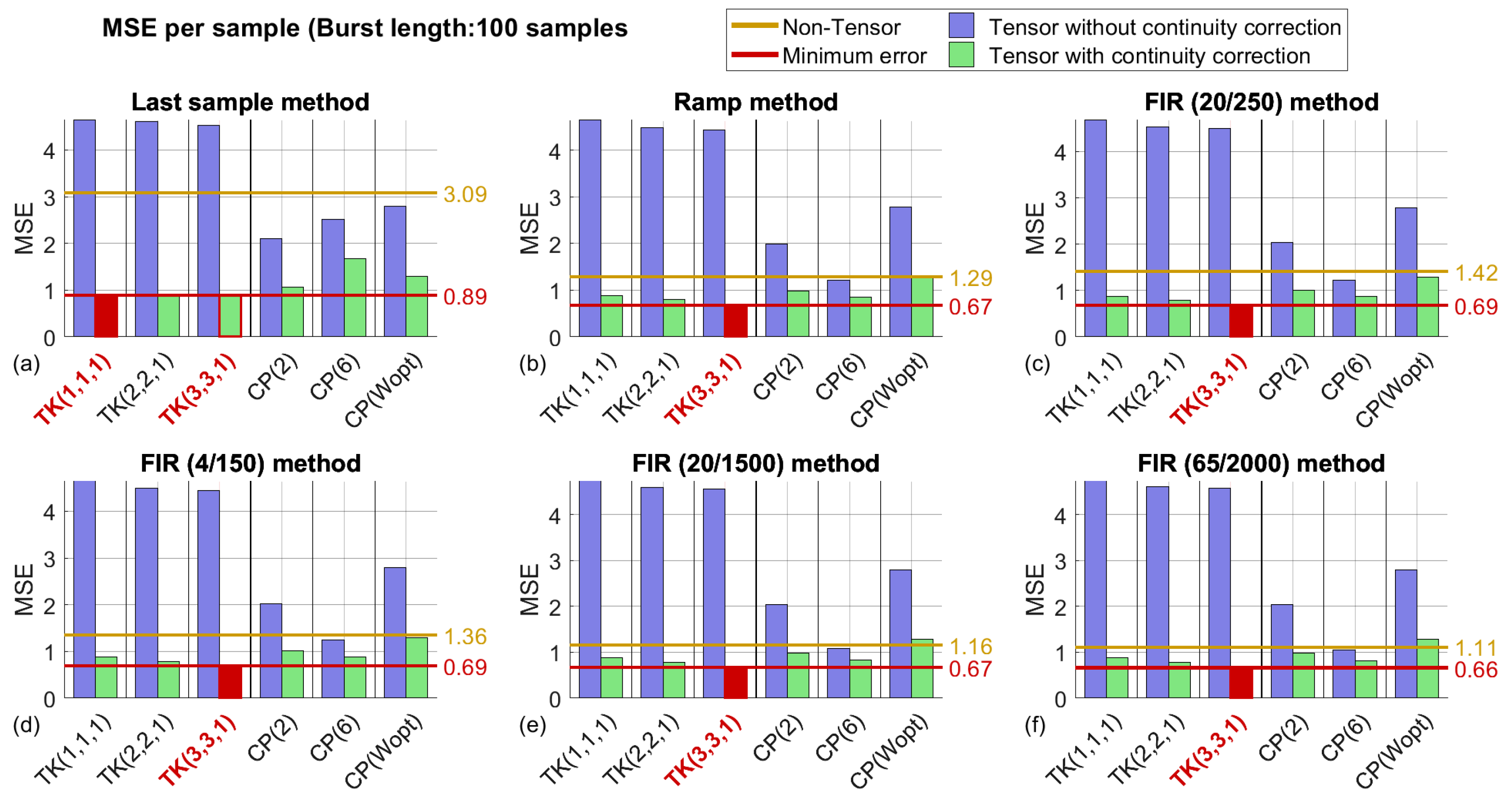
3.2. Tensor Methods—Best Factorization Size
3.2.1. Algorithms employing the Tucker factorization
3.2.2. Algorithms Employing CANDECOMP/PARAFAC or CP Factorization
3.3. The Algorithm’s Performance According to the Tensor Size
3.4. The Algorithm’s Performance According to the Length of the Missing Data Burst
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Langhammer, J.; Česák, J. Applicability of a Nu-Support Vector Regression Model for the Completion of Missing Data in Hydrological Time Series. Water 2016, 8, 560. [Google Scholar] [CrossRef]
- Ahlheim, M.; Frör, O.; Luo, J.; Pelz, S.; Jiang, T. Towards a Comprehensive Valuation of Water Management Projects When Data Availability Is Incomplete—The Use of Benefit Transfer Techniques. Water 2015, 7, 2472–2493. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Q.; Zhu, Y.; Wan, D.; Yu, Y.; Cheng, X. Research on the Data-Driven Quality Control Method of Hydrological Time Series Data. Water 2018, 10, 1712. [Google Scholar] [CrossRef]
- Ekeu-wei, I.T.; Blackburn, G.A.; Pedruco, P. Infilling Missing Data in Hydrology: Solutions Using Satellite Radar Altimetry and Multiple Imputation for Data-Sparse Regions. Water 2018, 10, 1483. [Google Scholar] [CrossRef]
- Lamrini, B.; Lakhal, E.K.; Le Lann, M.V.; Wehenkel, L. Data validation and missing data reconstruction using self-organizing map for water treatment. Neural Comput. Appl. 2011, 20, 575–588. [Google Scholar] [CrossRef] [Green Version]
- Blanch, J.; Puig, V.; Saludes, J.; Quevedo, J. Arima models for data consistency of flowmeters in water distribution networks. IFAC Proc. Vol. 2009, 42, 480–485. [Google Scholar] [CrossRef]
- Puig, V.; Ocampo-Martinez, C.; Pérez, R.; Cembrano, G.; Quevedo, J.; Escobet, T. Real-Time Monitoring and Operational Control of Drinking-Water Systems; Springer: Basel, Switzerland, 2017. [Google Scholar]
- Cugueró-Escofet, M.À.; García, D.; Quevedo, J.; Puig, V.; Espin, S.; Roquet, J. A methodology and a software tool for sensor data validation/reconstruction: Application to the Catalonia regional water network. Control Eng. Pract. 2016, 49, 159–172. [Google Scholar] [CrossRef] [Green Version]
- Acar, E.; Dunlavy, D.M.; Kolda, T.G.; Mørup, M. Scalable tensor factorizations for incomplete data. Chemom. Intell. Lab. Syst. 2011, 106, 41–56. [Google Scholar] [CrossRef] [Green Version]
- Signoretto, M.; Van de Plas, R.; De Moor, B.; Suykens, J.A. Tensor versus matrix completion: A comparison with application to spectral data. IEEE Signal Process. Lett. 2011, 18, 403. [Google Scholar] [CrossRef]
- Mørup, M. Applications of tensor (multiway array) factorizations and decompositions in data mining. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 24–40. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Cichocki, A.; Mandic, D.; De Lathauwer, L.; Zhou, G.; Zhao, Q.; Caiafa, C.; Phan, H.A. Tensor decompositions for signal processing applications: From two-way to multiway component analysis. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef]
- Comon, P. Tensors: A brief introduction. IEEE Signal Process. Mag. 2014, 31, 44–53. [Google Scholar] [CrossRef]
- Vaseghi, S.V. Advanced Digital Signal Processing and Noise Reduction; John Wiley & Sons: Chichester, UK, 2008. [Google Scholar]
- Harshman, R.A. Foundations of the PARAFAC procedure: Models and conditions for an “explanatory” multimodal factor analysis. In Working Papers in Phonetics; UCLA: Los Angeles, CA, USA, 1970; Volume 16, pp. 1–84. [Google Scholar]
- Sørensen, M.; Lathauwer, L.D.; Comon, P.; Icart, S.; Deneire, L. Canonical polyadic decomposition with a columnwise orthonormal factor matrix. SIAM J. Matrix Anal. Appl. 2012, 33, 1190–1213. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef]
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Roughan, M.; Zhang, Y.; Willinger, W.; Qiu, L. Spatio-temporal compressive sensing and internet traffic matrices. IEEE/ACM Trans. Netw. 2012, 20, 662–676. [Google Scholar] [CrossRef]
- Wang, L.; Xie, K.; Semong, T.; Zhou, H. Missing Data Recovery Based on Tensor-CUR Decomposition. IEEE Access 2018, 6, 532–544. [Google Scholar] [CrossRef]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, L.; Cichocki, A. Bayesian CP factorization of incomplete tensors with automatic rank determination. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1751–1763. [Google Scholar] [CrossRef] [PubMed]
- Dunlavy, D.M.; Kolda, T.G.; Acar, E. Poblano v1.0: A Matlab Toolbox for Gradient-Based Optimization; Technical Report SAND2010-1422; Sandia National Laboratories: Albuquerque, NM, USA; Livermore, CA, USA, 2010.
- MATLAB Tensor Toolbox Version 2.6. February 2015. Available online: http://www.sandia.gov/~tgkolda/TensorToolbox/index-2.6.html (accessed on 11 November 2018).
- Vaidyanathan, P. The theory of linear prediction. In Synthesis Lectures on Signal Processing; Morgan & Claypool Publishers: San Rafael, CA, USA, 2007; Volume 2, pp. 1–184. [Google Scholar]
- Kailath, T.; Sayed, A.H.; Hassibi, B. Linear Estimation. In Number Book; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Mitter, S. Linear Estimation-T. Kailath, AH Sayed, and B. Hassibi. IEEE Trans. Autom. Control 2003, 48, 177–182. [Google Scholar]
- Wang, Z.; Yang, F.; Ho, D.W.; Liu, X. Robust finite-horizon filtering for stochastic systems with missing measurements. IEEE Signal Process. Lett. 2005, 12, 437–440. [Google Scholar] [CrossRef] [Green Version]
- Humpherys, J.; Redd, P.; West, J. A fresh look at the Kalman filter. SIAM Rev. 2012, 54, 801–823. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Quinteros, M.E.; Lu, S.; Blazquez, C.; Cárdenas-R, J.P.; Ossa, X.; Delgado-Saborit, J.M.; Harrison, R.M.; Ruiz-Rudolph, P. Use of data imputation tools to reconstruct incomplete air quality datasets: A case-study in Temuco, Chile. Atmos. Environ. 2019, 200, 40–49. [Google Scholar] [CrossRef]
- Yang, Y.; Ma, J.; Osher, S. Seismic data reconstruction via matrix completion. Inverse Probl. Imaging 2013, 7, 1379–1392. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.; Jenkins, G.M. Time Series Analysis: Forecasting and Control, Revised ed.; Holden-Day: San Francisco, CA, USA, 1976. [Google Scholar]
- Zhang, Z.; Ely, G.; Aeron, S.; Hao, N.; Kilmer, M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3842–3849. [Google Scholar]
- Zhang, Z.; Aeron, S. Exact Tensor Completion Using t-SVD. IEEE Trans. Signal Process. 2017, 65, 1511–1526. [Google Scholar] [CrossRef]
- Filipović, M.; Jukić, A. Tucker factorizatio with missig data with applicatio to low-rak tesor completio. Multidimens. Syst. Signal Process. 2015, 26, 677–692. [Google Scholar] [CrossRef]
- Yokota, T.; Zhao, Q.; Cichocki, A. Smooth PARAFAC decomposition for tensor completion. IEEE Trans. Signal Process. 2016, 64, 5423–5436. [Google Scholar] [CrossRef]
- Kressner, D.; Steinlechner, M.; Vandereycken, B. Low-rank tensor completion by Riemannian optimization. BIT Numer. Math. 2014, 54, 447–468. [Google Scholar] [CrossRef]
- Sole-Casals, J.; Caiafa, C.F.; Zhao, Q.; Cichocki, A. Brain-Computer Interface with Corrupted EEG Data: A Tensor Completion Approach. Cognit. Comput. 2018, 10, 1062. [Google Scholar] [CrossRef]
















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marti-Puig, P.; Martí-Sarri, A.; Serra-Serra, M. Different Approaches to SCADA Data Completion in Water Networks. Water 2019, 11, 1023. https://doi.org/10.3390/w11051023
Marti-Puig P, Martí-Sarri A, Serra-Serra M. Different Approaches to SCADA Data Completion in Water Networks. Water. 2019; 11(5):1023. https://doi.org/10.3390/w11051023
Chicago/Turabian StyleMarti-Puig, Pere, Arnau Martí-Sarri, and Moisès Serra-Serra. 2019. "Different Approaches to SCADA Data Completion in Water Networks" Water 11, no. 5: 1023. https://doi.org/10.3390/w11051023
APA StyleMarti-Puig, P., Martí-Sarri, A., & Serra-Serra, M. (2019). Different Approaches to SCADA Data Completion in Water Networks. Water, 11(5), 1023. https://doi.org/10.3390/w11051023