Groundwater Potential Mapping Using an Integrated Ensemble of Three Bivariate Statistical Models with Random Forest and Logistic Model Tree Models


Abstract
:1. Introduction
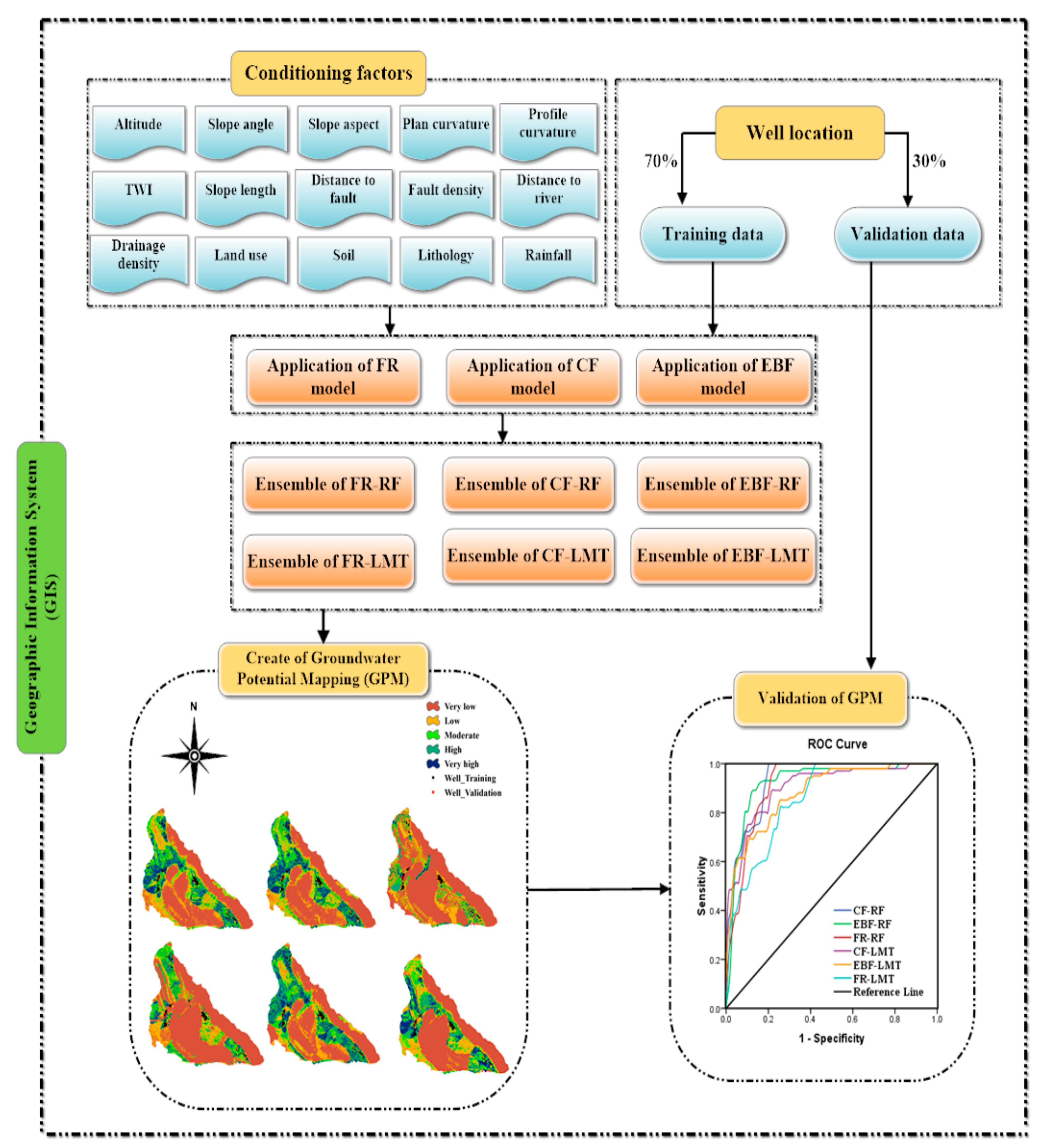
2. Material and Methods
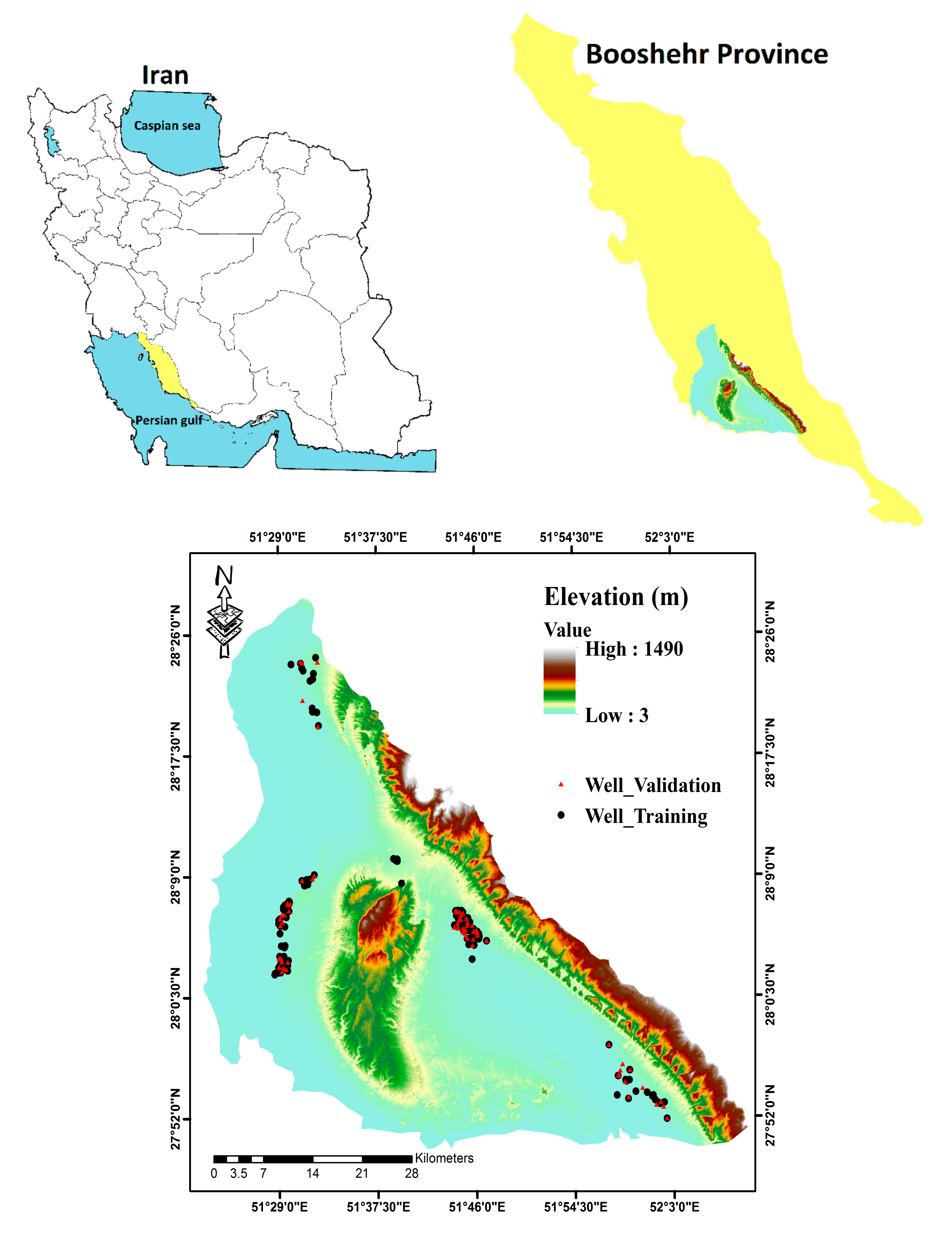
2.1. Study Area
2.2. Well Inventory
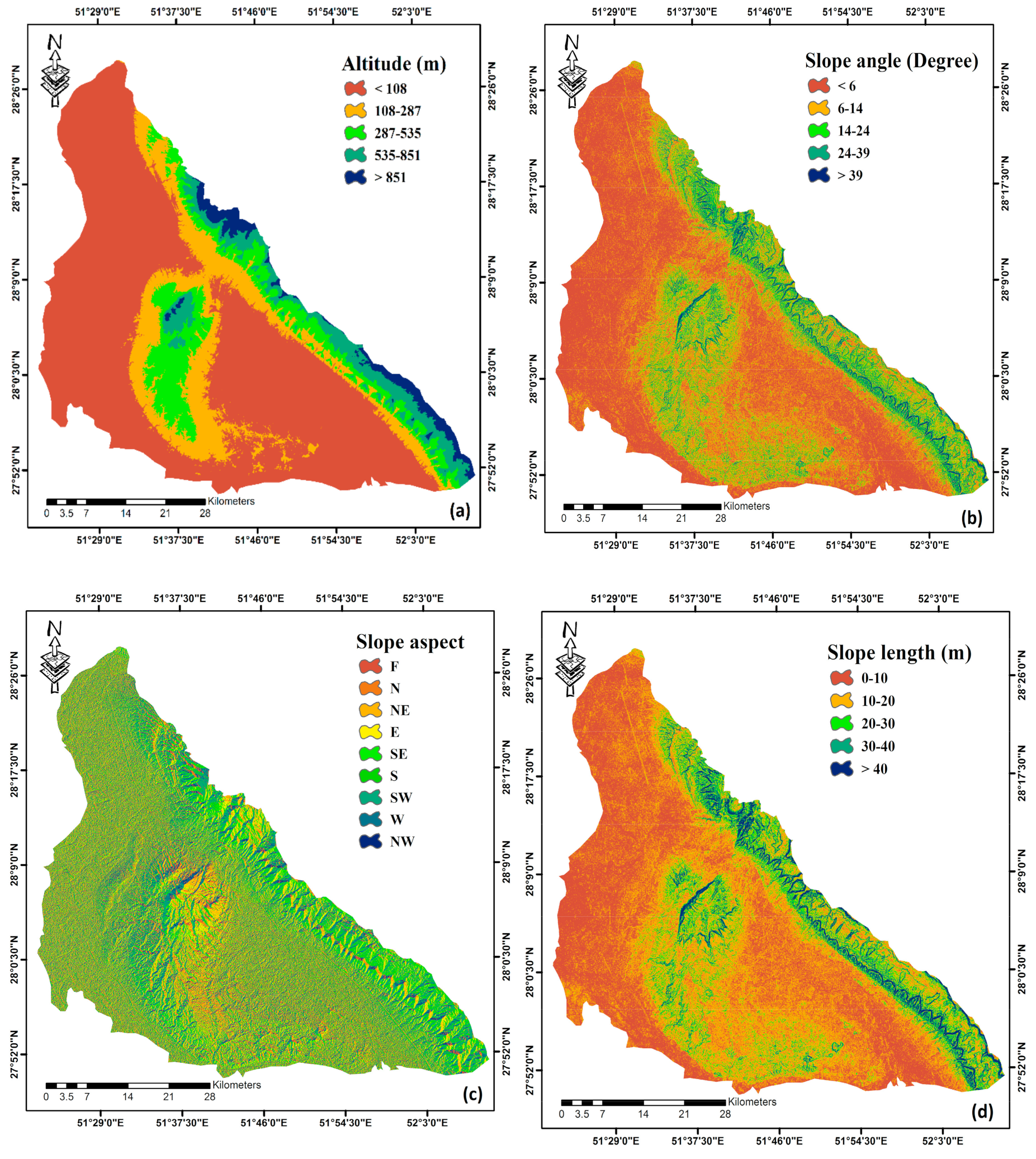
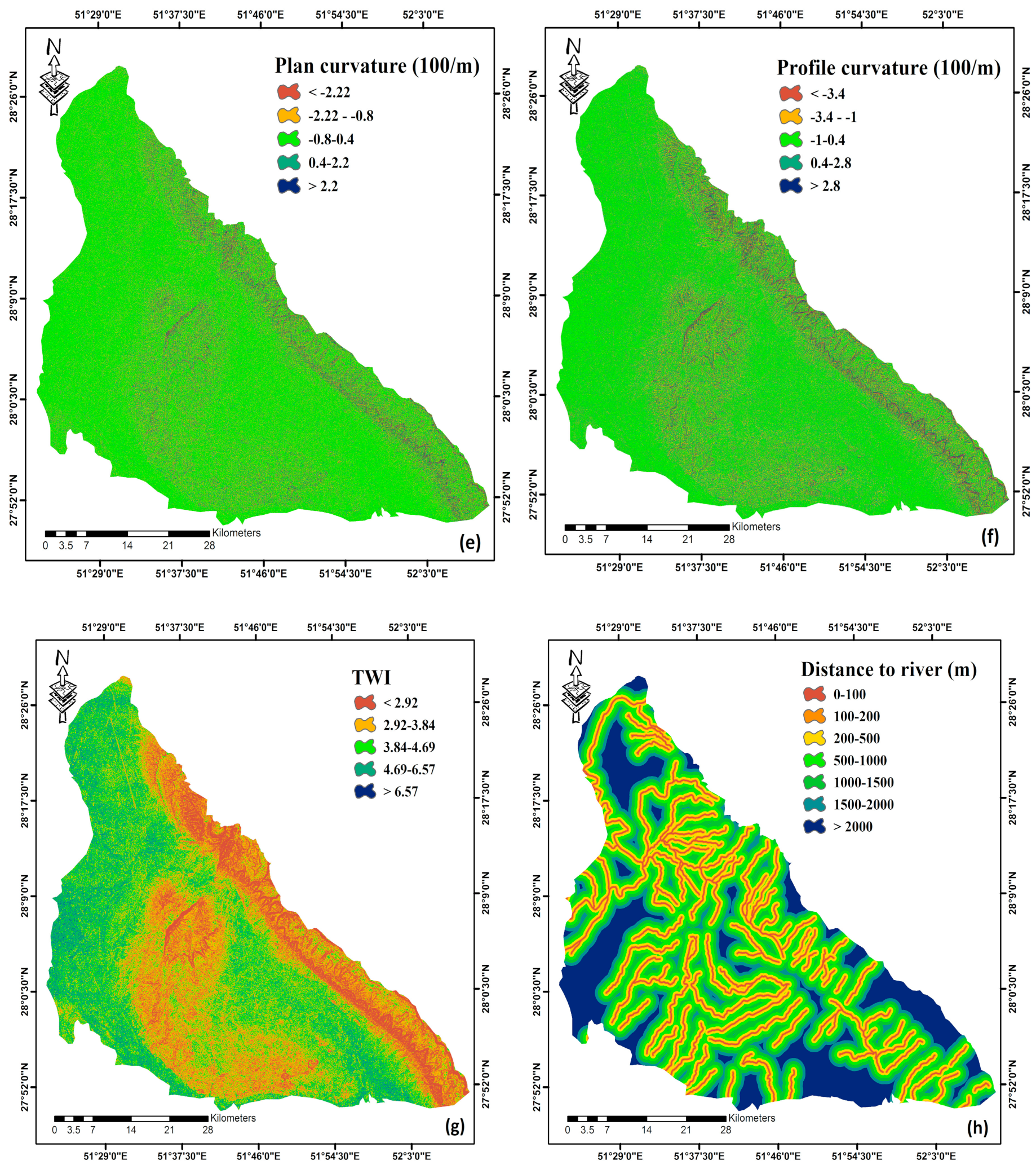
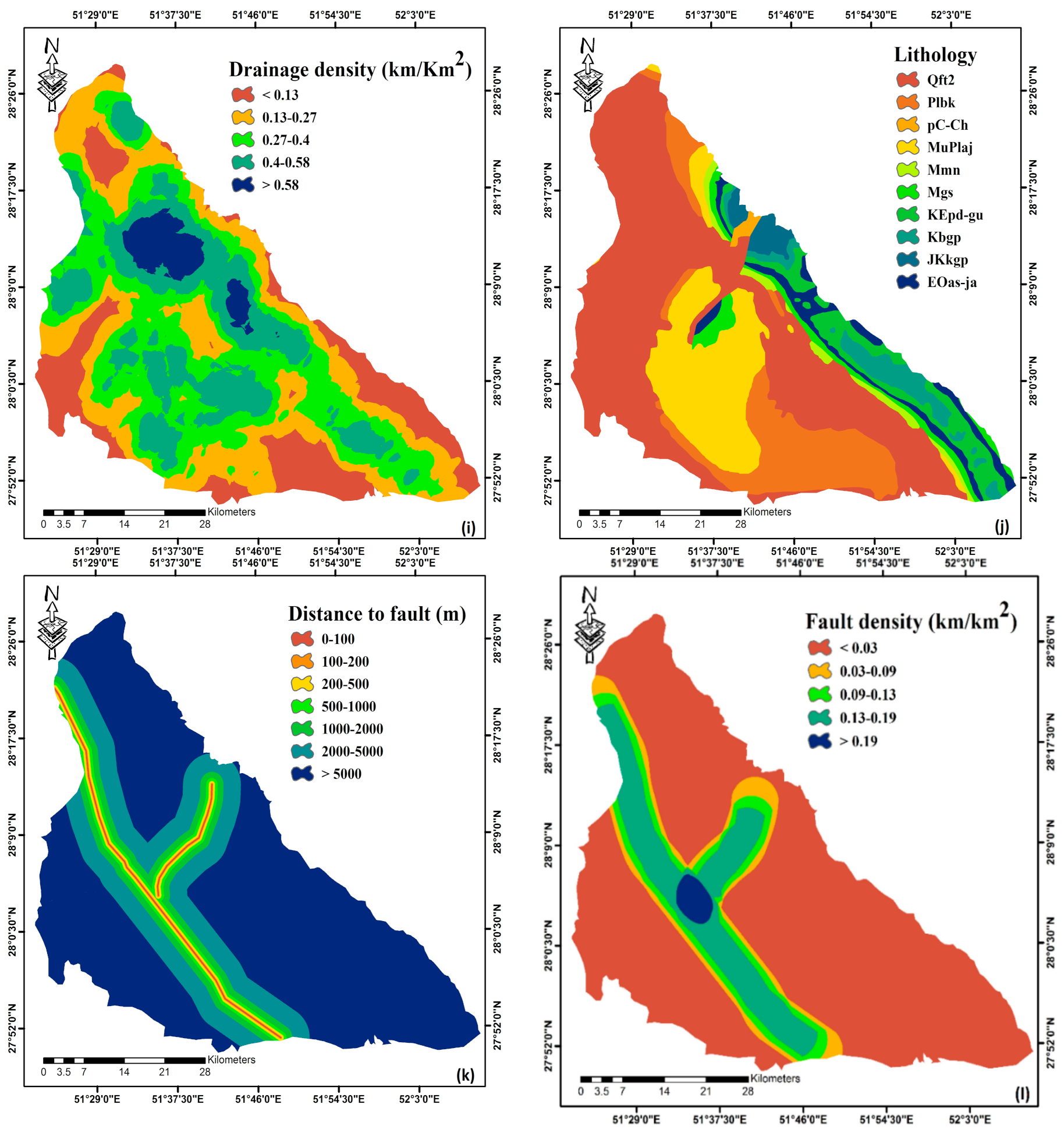
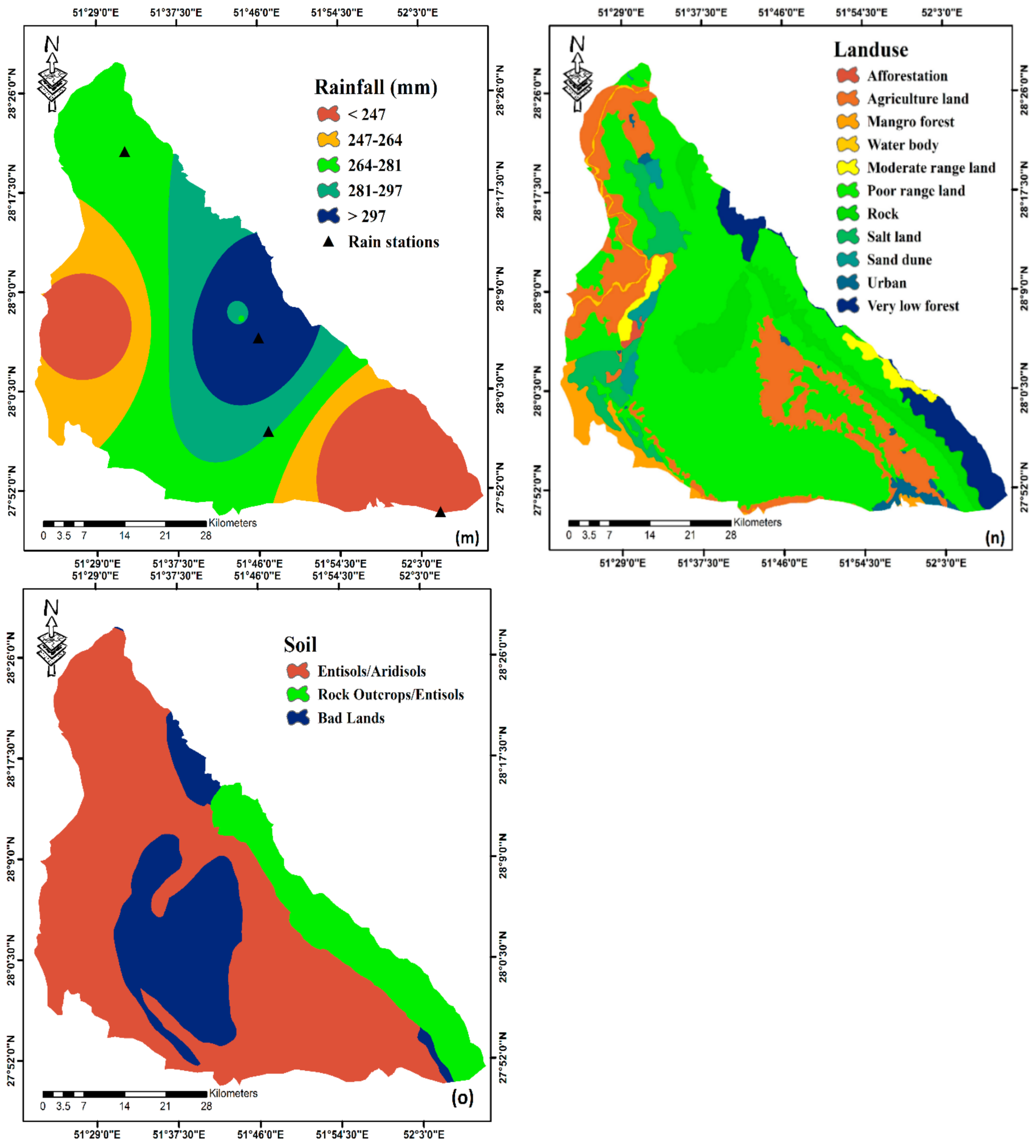
2.3. Conditioning Factors
2.3.1. Topographic Parameters
2.3.2. Hydrological Parameters
2.3.3. Geological Parameters
2.3.4. Climate Parameters
2.3.5. Ecological Parameters
2.4. Models
2.4.1. FR Model
2.4.2. CF Model
2.4.3. EBF Model
2.4.4. RF Model
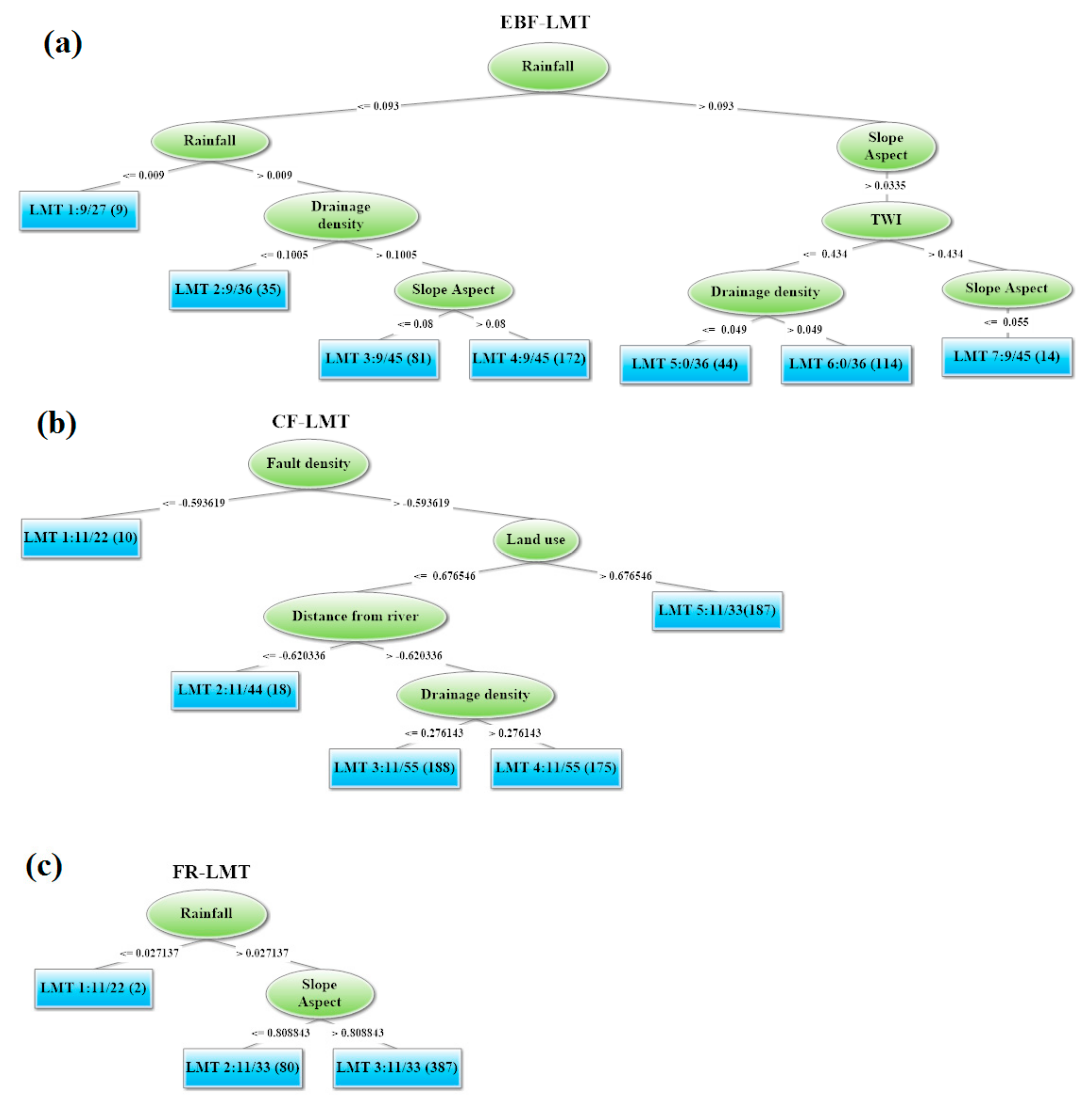
2.4.5. LMT Model
2.5. Validation
3. Results
3.1. Result of Bivariate Statistical Models
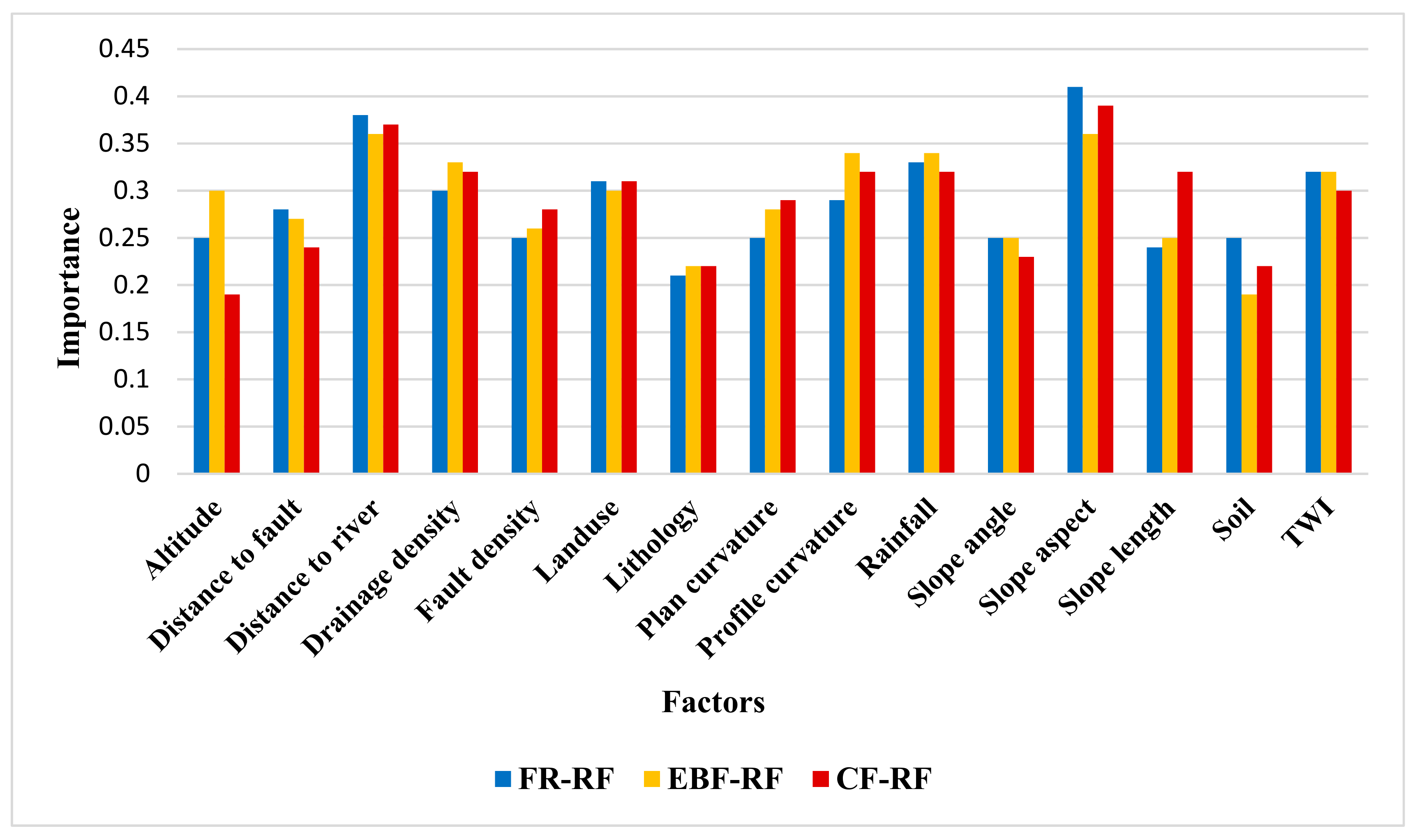
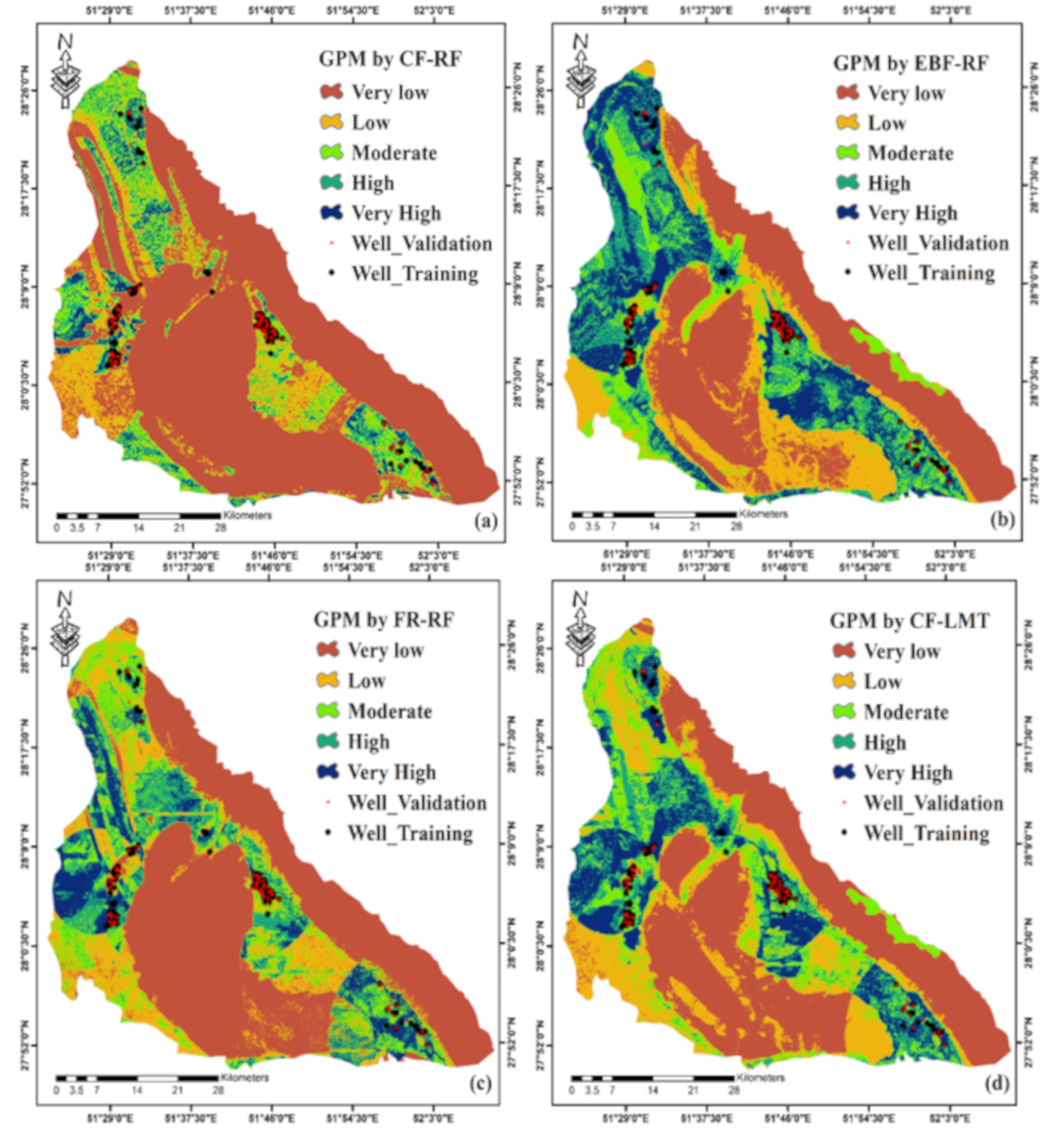
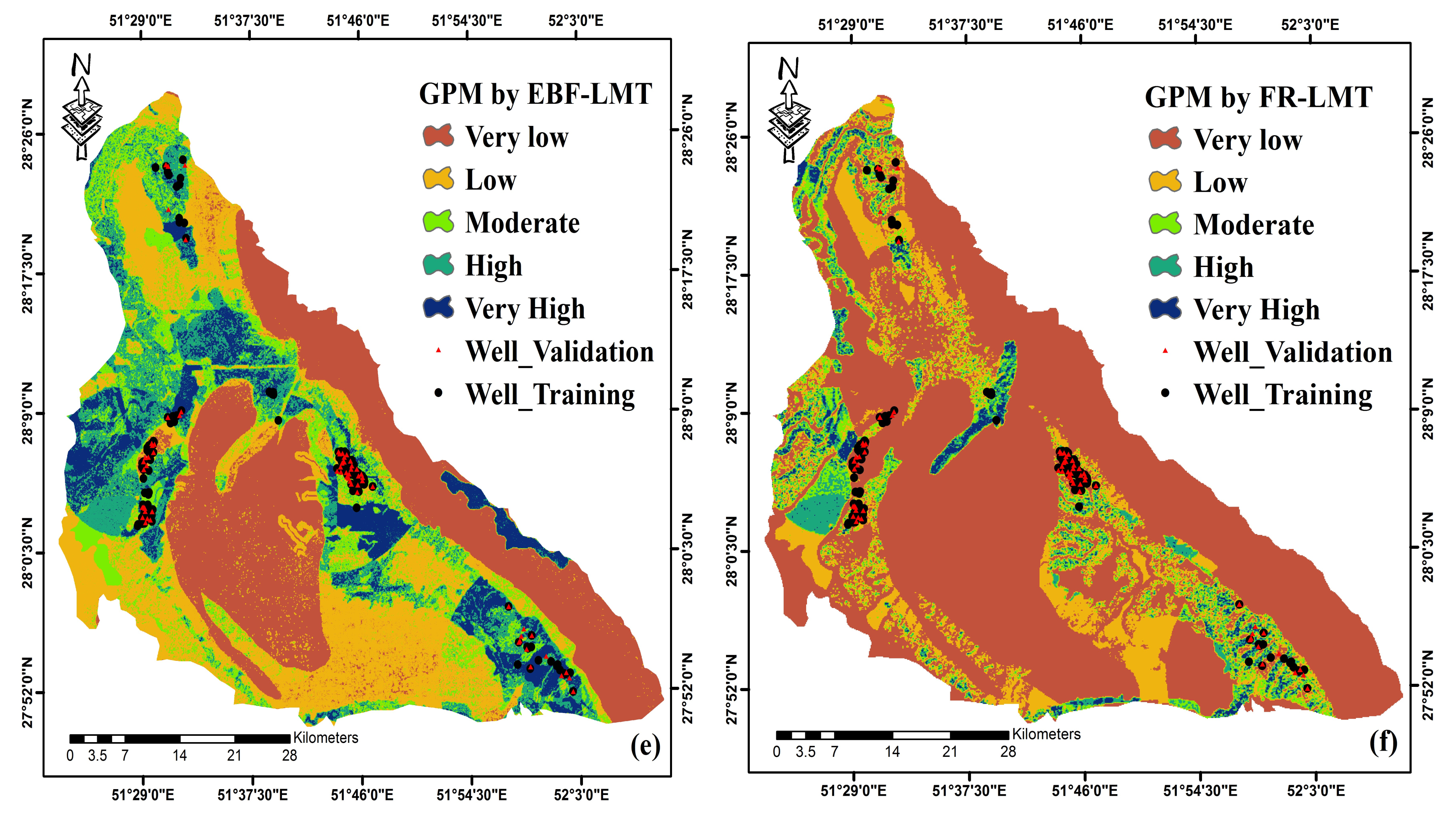
3.2. Application of Ensemble Models
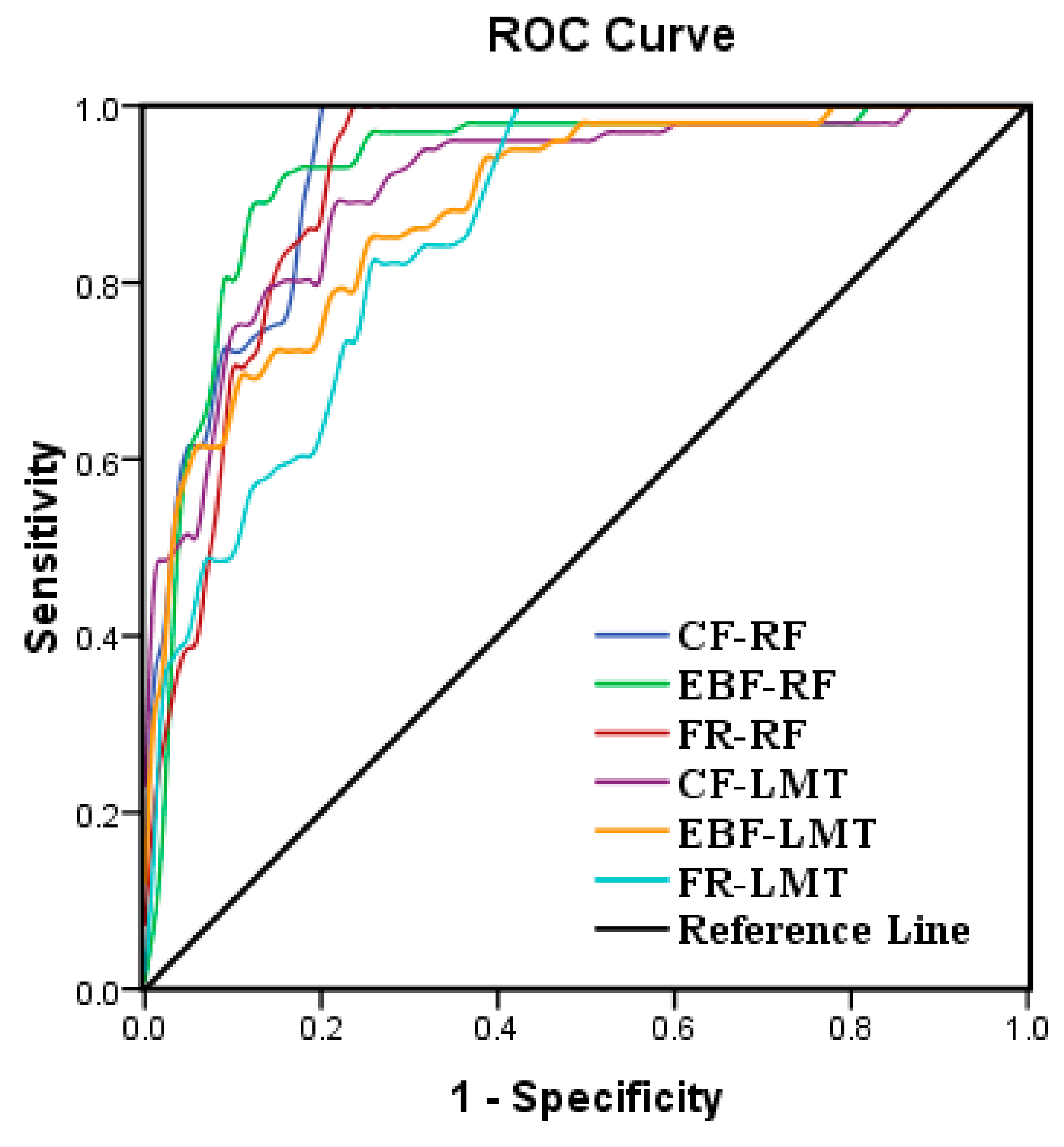
3.3. Validation of Models
4. Discussion
5. Conclusions
- Based on the results from the ROC curve and AUC, the CF-RF model is more accurate in providing GPM, followed by the EBF-RF and FR-RF models.
- The results show that CF and EBF are more accurate than FR in combining with the random forest model via considering the uncertainty in the results.
- In combined models, slope aspect, distance from waterway, rainfall, and topography curve parameters have the most importance, and lithology and soil parameters have the least importance.
- According to the results from FR and CF, the maximum weight is dedicated to an elevation class of less than 108 m, the slope angle class of less than 6°, northwest slope aspect, the topographic curve, the slope length class of less than 10 m, the topographic humidity index between 4.69 and 6.57, the distance from waterway class of less than 100 m, the distance from fault between 1000 and 2000 m, the water density of greater than 0.58, the density of fault between 0.09 and 0.19, rainfall greater than 297 mm, the lithology class of Qft2 unit, the moderate rangeland in land-use class and the Entisols class in the soil parameter. The results of the evidential belief model are largely similar to the other two models, but for some parameters the results are different. According to the results of the evidential belief model, the highest weight is dedicated to the southeast slope aspect, distance from waterway in the 200 to 500 m class, distance from fault in the 2000 to 5000 m class, the water density in the 0.4–0.58 class, the fault density in the class of less than 0.03, rainfall in the class of 0 to 274 mm, and the agricultural class in the land-use parameter.
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | No. Pixels in Domain | No. of Wells | FR | Bel | CF |
|---|---|---|---|---|---|
| Altitude (m) | |||||
| <108 | 427576 | 237 | 1.56 | 0.983 | 0.361 |
| 108–287 | 108357 | 1 | 0.026 | 0.0164 | 0.0164 |
| 287–535 | 736786 | 0 | 0 | 0 | 0 |
| 535–851 | 421447 | 0 | 0 | 0 | 0 |
| >851 | 202301 | 0 | 0 | 0 | |
| Slope Angle (degree) | |||||
| <6 | 340276 | 184 | 1.526 | 0.649 | 0.345 |
| 6–14 | 183016 | 53 | 0.817 | 0.347 | −0.182 |
| 14–24 | 856988 | 0 | 0 | 0 | −1 |
| 24–39 | 475130 | 1 | 0.06 | 0.0025 | −0.94 |
| >39 | 154827 | 0 | 0 | 0 | −1 |
| Slope Aspect | |||||
| F | 470400 | 13 | 0.78 | 0.047 | −0.219 |
| N | 656895 | 8 | 0.343 | 0.02 | −0.656 |
| NE | 730046 | 33 | 1.27 | 0.077 | 0.216 |
| E | 791429 | 25 | 0.891 | 0.053 | −0.108 |
| SE | 101153 | 30 | 0.837 | 0.505 | −0.162 |
| S | 957842 | 47 | 1.385 | 0.083 | 0.278 |
| SW | 941836 | 36 | 1.079 | 0.065 | 0.073 |
| W | 798851 | 27 | 0.954 | 0.057 | −0.045 |
| NW | 361045 | 19 | 1.485 | 0.089 | 0.326 |
| Plan Curvature (100/m) | |||||
| <−2.22 | 146963 | 0 | 0 | 0 | −1 |
| −1.42 | 695619 | 15 | 0.6 | 0.03 | −0.391 |
| −0.8–0.4 | 423317 | 185 | 1.23 | 0.611 | 0.189 |
| 0.4–2.2 | 148465 | 38 | 0.722 | 0.358 | −0.277 |
| >2.2 | 159465 | 0 | 0 | 0 | −1 |
| Soil | |||||
| Entisols/Aridosols | 436865 | 238 | 1.535 | 1 | 0.348 |
| Bad lands | 140085 | 0 | 0 | 0 | −1 |
| Rock outcrops/Entisols | 939041 | 0 | 0 | 0 | −1 |
| Profile Curvature (100/m) | |||||
| <−3.4 | 137472 | 1 | 0.2 | 0.008 | −0.794 |
| −2.4 | 924569 | 3 | 0.091 | 0.004 | −0.908 |
| −1–0.4 | 337923 | 167 | 1.39 | 0.596 | 0.283 |
| 0.4–2.8 | 206784 | 67 | 0.914 | 0.39 | −0.085 |
| >2.8 | 210755 | 0 | 0 | 0 | −1 |
| Slope Length (m) | |||||
| 0–10 | 404924 | 216 | 1.5 | 0.762 | 0.336 |
| 10–20 | 134087 | 21 | 0.442 | 0.223 | −0.557 |
| 20–30 | 740597 | 0 | 0 | 0 | −1 |
| 30–40 | 453420 | 1 | 0.062 | 0.003 | −0.937 |
| >40 | 135739 | 0 | 0 | 0.01 | −1 |
| TWI | |||||
| <2.92 | 115281 | 1 | 0.024 | 0.006 | −0.975 |
| 2.92–3.84 | 187497 | 31 | 0.466 | 0.125 | −0.533 |
| 3.84–4.69 | 212059 | 120 | 1.59 | 0.428 | 0.374 |
| 4.69–6.57 | 147887 | 86 | 1.64 | 0.44 | 0.39 |
| >6.57 | 92617 | 0 | 0 | 0 | −1 |
| Distance to river (m) | |||||
| 0–100 | 418540 | 26 | 1.75 | 0.039 | 0.429 |
| 100–200 | 418903 | 18 | 1.21 | 0.027 | 0.175 |
| 200–500 | 122099 | 60 | 1.38 | 0.309 | 0.279 |
| 500–1000 | 170413 | 44 | 0.72 | 0.162 | −0.271 |
| 1000–1500 | 112869 | 20 | 0.5 | 0.111 | −0.499 |
| 1500–2000 | 563509 | 6 | 0.259 | 0.006 | −0.74 |
| >2000 | 117338 | 64 | 1.539 | 0.343 | 0.35 |
| Distance to fault (m) | |||||
| 0–100 | 52047 | 1 | 0.542 | 0.023 | −0.457 |
| 100–200 | 46406 | 0 | 0 | 0 | −1 |
| 200–500 | 140802 | 0 | 0 | 0 | −1 |
| 500–1000 | 226477 | 0 | 0 | 0 | −1 |
| 1000–2000 | 425525 | 19 | 1.26 | 0.053 | 0.206 |
| 2000–5000 | 124594 | 50 | 1.13 | 0.482 | 0.117 |
| >5000 | 458318 | 168 | 1.03 | 0.44 | 0.033 |
| Drainage Density (km/km2) | |||||
| <0.13 | 118694 | 52 | 1.24 | 0.3067 | 0.195 |
| 0.13–0.27 | 174085 | 27 | 0.44 | 0.108 | −0.559 |
| 0.27–0.4 | 199824 | 28 | 0.39 | 0.098 | −0.602 |
| 0.4–0.58 | 149777 | 82 | 1.55 | 0.383 | 0.356 |
| >0.58 | 331397 | 49 | 4.19 | 0.103 | 0.761 |
| Fault Density (km/km2) | |||||
| <0.03 | 506907 | 190 | 1.058 | 0.808 | 0.054 |
| 0.03–0.09 | 331072 | 0 | 0 | 0 | −1 |
| 0.09–0.13 | 399735 | 24 | 1.69 | 0.129 | 0.409 |
| 0.13–0.19 | 833523 | 24 | 0.812 | 0.062 | −0.187 |
| >0.19 | 84751 | 0 | 0 | 0 | −1 |
| Rainfall (mm) | |||||
| 0–247 | 153067 | 119 | 2.2 | 0.737 | 0.545 |
| 247–264 | 104382 | 2 | 0.054 | 0.018 | 0.00003 |
| 264–281 | 209726 | 21 | 0.283 | 0.095 | 0.000025 |
| 281–297 | 114294 | 7 | 0.173 | 0.058 | 0.000029 |
| >297 | 926820 | 89 | 2.72 | 0.091 | 0.632 |
| Lithology | |||||
| Qft2 | 320270 | 222 | 1.95 | 0.853 | 0.489 |
| MuPlaj | 112135 | 13 | 0.327 | 0.142 | −0.672 |
| Plbk | 959539 | 3 | 0.088 | 0.003 | −0.911 |
| Mmn | 123084 | 0 | 0 | 0 | −1 |
| Mgs | 221836 | 0 | 0 | 0 | −1 |
| Eoas-ja | 288275 | 0 | 0 | 0 | −1 |
| KEpd-gu | 389238 | 0 | 0 | 0 | −1 |
| Kbgp | 258465 | 0 | 0 | 0 | −1 |
| JKkgp | 125464 | 0 | 0 | 0 | −1 |
| Pc-ch | 30462 | 0 | 0 | 0 | −1 |
References
- Jothibasu, A.; Anbazhagan, S. Modeling groundwater probability index in Ponnaiyar river basin of South India using analytic hierarchy process. Model. Earth Syst. Environ. 2016, 2, 109. [Google Scholar] [CrossRef]
- Lee, M.-J.; Park, I.; Lee, S. Forecasting and validation of landslide susceptibility using an integration of frequency ratio and neuro-fuzzy models: A case study of Seorak mountain area in Korea. Environ. Earth Sci. 2015, 74, 413–429. [Google Scholar] [CrossRef]
- Molden, D. Water for Food Water for Life: A Comprehensive Assessment of Water Management in Agriculture; Routledge: London, UK, 2013. [Google Scholar]
- Park, S.; Hamm, S.-Y.; Jeon, H.-T.; Kim, J. Evaluation of logistic regression and multivariate adaptive regression spline models for groundwater potential mapping using R and GIS. Sustainability 2017, 9, 1157. [Google Scholar] [CrossRef]
- Manap, M.A.; Nampak, H.; Pradhan, B.; Lee, S.; Sulaiman, W.N.A.; Ramli, M.F. Application of probabilistic-based frequency ratio model in groundwater potential mapping using remote sensing data and GIS. Arab. J. Geosci. 2014, 7, 711–724. [Google Scholar] [CrossRef]
- Moghaddam, D.D.; Rezaei, M.; Pourghasemi, H.; Pourtaghie, Z.; Pradhan, B. Groundwater spring potential mapping using bivariate statistical model and GIS in the Taleghan watershed, Iran. Arab. J. Geosci. 2015, 8, 913–929. [Google Scholar] [CrossRef]
- Kebede, S. Groundwater potential, recharge, water balance: Vital numbers. In Groundwater in Ethiopia; Springer: Berlin, Germany, 2013; pp. 221–236. [Google Scholar]
- Arabgol, R.; Sartaj, M.; Asghari, K. Predicting nitrate concentration and its spatial distribution in groundwater resources using support vector machines (SVMs) model. Environ. Model. Assess. 2016, 21, 71–82. [Google Scholar] [CrossRef]
- Arabameri, A.; Rezaei, K.; Cerda, A.; Lombardo, L.; Rodrigo-Comino, J. GIS-based groundwater potential mapping in Shahroud plain, Iran. A comparison among statistical (bivariate and multivariate), data mining and MCDM approaches. Sci. Total Environ. 2019, 658, 160–177. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Dashtpagerdi, M.M. Evaluation of four supervised learning methods for groundwater spring potential mapping in Khalkhal region (Iran) using GIS-based features. Hydrogeol. J. 2017, 25, 169–189. [Google Scholar] [CrossRef]
- Razandi, Y.; Pourghasemi, H.R.; Neisani, N.S.; Rahmati, O. Application of analytical hierarchy process, frequency ratio, and certainty factor models for groundwater potential mapping using GIS. Earth Sci. Inform. 2015, 8, 867–883. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Beheshtirad, M. Assessment of a data-driven evidential belief function model and GIS for groundwater potential mapping in the Koohrang watershed, Iran. Geocarto Int. 2015, 30, 662–685. [Google Scholar] [CrossRef]
- Mogaji, K.; Omosuyi, G.; Adelusi, A.; Lim, H. Application of GIS-based evidential belief function model to regional groundwater recharge potential zones mapping in hardrock geologic terrain. Environ. Process. 2016, 3, 93–123. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R. GIS-based groundwater spring potential assessment and mapping in the Birjand Township, southern Khorasan Province, Iran. Hydrogeol. J. 2014, 22, 643–662. [Google Scholar] [CrossRef]
- Chen, W.; Li, H.; Hou, E.; Wang, S.; Wang, G.; Panahi, M.; Li, T.; Peng, T.; Guo, C.; Niu, C. GIS-based groundwater potential analysis using novel ensemble weights-of-evidence with logistic regression and functional tree models. Sci. Total Environ. 2018, 634, 853–867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, S.; Kim, Y.-S.; Oh, H.-J. Application of a weights-of-evidence method and GIS to regional groundwater productivity potential mapping. J. Environ. Manag. 2012, 96, 91–105. [Google Scholar] [CrossRef] [PubMed]
- Naghibi, S.A.; Moghaddam, D.D.; Kalantar, B.; Pradhan, B.; Kisi, O. A comparative assessment of GIS-based data mining models and a novel ensemble model in groundwater well potential mapping. J. Hydrol. 2017, 548, 471–483. [Google Scholar] [CrossRef]
- Zabihi, M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Behzadfar, M. GIS-based multivariate adaptive regression spline and random forest models for groundwater potential mapping in Iran. Environ. Earth Sci. 2016, 75, 665. [Google Scholar] [CrossRef]
- Golkarian, A.; Naghibi, S.A.; Kalantar, B.; Pradhan, B. Groundwater potential mapping using C5. 0, random forest, and multivariate adaptive regression spline models in GIS. Environ. Monit. Assess. 2018, 190, 149. [Google Scholar] [CrossRef] [PubMed]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Lee, S.; Hong, S.-M.; Jung, H.-S. GIS-based groundwater potential mapping using artificial neural network and support vector machine models: The case of Boryeong city in Korea. Geocarto Int. 2018, 33, 847–861. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Ahmadi, K.; Daneshi, A. Application of support vector machine, random forest, and genetic algorithm optimized random forest models in groundwater potential mapping. Water Resour. Manag. 2017, 31, 2761–2775. [Google Scholar] [CrossRef]
- Khosravi, K.; Panahi, M.; Tien Bui, D. Spatial prediction of groundwater spring potential mapping based on an adaptive neuro-fuzzy inference system and metaheuristic optimization. Hydrol. Earth Syst. Sci. 2018, 22, 4771–4792. [Google Scholar] [CrossRef] [Green Version]
- Rahmati, O.; Samani, A.N.; Mahdavi, M.; Pourghasemi, H.R.; Zeinivand, H. Groundwater potential mapping at Kurdistan region of Iran using analytic hierarchy process and GIS. Arab. J. Geosci. 2015, 8, 7059–7071. [Google Scholar] [CrossRef]
- Olden, J.D.; Lawler, J.J.; Poff, N.L. Machine learning methods without tears: A primer for ecologists. Q. Rev. Biol. 2008, 83, 171–193. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, R.B.; Papa, J.P.; Pereira, A.S.; Tavares, J.M.R. Computational methods for pigmented skin lesion classification in images: Review and future trends. Neural Comput. Appl. 2018, 29, 613–636. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, C.; Yang, Q. Data preparation for data mining. Appl. Artif. Intell. 2003, 17, 375–381. [Google Scholar] [CrossRef]
- Kordestani, M.D.; Naghibi, S.A.; Hashemi, H.; Ahmadi, K.; Kalantar, B.; Pradhan, B. Groundwater potential mapping using a novel data-mining ensemble model. Hydrogeol. J. 2019, 27, 211–224. [Google Scholar] [CrossRef]
- Ercanoglu, M.; Gokceoglu, C. Assessment of landslide susceptibility for a landslide-prone area (north of Yenice, NW Turkey) by fuzzy approach. Environ. Geol. 2002, 41, 720–730. [Google Scholar]
- Nampak, H.; Pradhan, B.; Manap, M.A. Application of gis based data driven evidential belief function model to predict groundwater potential zonation. J. Hydrol. 2014, 513, 283–300. [Google Scholar] [CrossRef]
- Moore, I.; Burch, G. Sediment transport capacity of sheet and rill flow: Application of unit stream power theory. Water Resour. Res. 1986, 22, 1350–1360. [Google Scholar] [CrossRef]
- Al-Abadi, A.M.; Al-Temmeme, A.A.; Al-Ghanimy, M.A. A GIS-based combining of frequency ratio and index of entropy approaches for mapping groundwater availability zones at Badra–Al Al-Gharbi–Teeb areas, Iraq. Sustain. Water Resour. Manag. 2016, 2, 265–283. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.; Ladson, A. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Dinesh Kumar, P.; Gopinath, G.; Seralathan, P. Application of remote sensing and GIS for the demarcation of groundwater potential zones of a river basin in Kerala, southwest coast of India. Int. J. Remote Sens. 2007, 28, 5583–5601. [Google Scholar] [CrossRef]
- Ayazi, M.H.; Pirasteh, S.; Arvin, A.; Pradhan, B.; Nikouravan, B.; Mansor, S. Disasters and risk reduction in groundwater: Zagros mountain southwest Iran using geoinformatics techniques. Disaster Adv. 2010, 3, 51–57. [Google Scholar]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2013, 65, 135–165. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Spatial prediction of flood susceptible areas using rule based decision tree (DT) and a novel ensemble bivariate and multivariate statistical models in GIS. J. Hydrol. 2013, 504, 69–79. [Google Scholar] [CrossRef]
- Jamieson, R.; Gordon, R.; Sharples, K.; Stratton, G.; Madani, A. Movement and persistence of fecal bacteria in agricultural soils and subsurface drainage water: A review. Can. Biosyst. Eng. 2002, 44, 1–9. [Google Scholar]
- Abdalla, F. Mapping of groundwater prospective zones using remote sensing and GIS techniques: A case study from the central eastern desert, Egypt. J. Afr. Earth Sci. 2012, 70, 8–17. [Google Scholar] [CrossRef]
- Binaghi, E.; Luzi, L.; Madella, P.; Pergalani, F.; Rampini, A. Slope instability zonation: A comparison between certainty factor and fuzzy Dempster–Shafer approaches. Nat. Hazards 1998, 17, 77–97. [Google Scholar] [CrossRef]
- Komac, B.; Zorn, M. Statistical landslide susceptibility modeling on a national scale: The example of Slovenia. Rev. Roum Géogr. 2009, 53, 179–195. [Google Scholar]
- Sujatha, E.R.; Rajamanickam, G.V.; Kumaravel, P. Landslide susceptibility analysis using Probabilistic Certainty Factor Approach: A case study on Tevankarai stream watershed, India. J. Earth Syst. Sci. 2012, 121, 1337–1350. [Google Scholar] [CrossRef] [Green Version]
- Mohammady, M.; Pourghasemi, H.R.; Pradhan, B. Landslide susceptibility mapping at Golestan Province, Iran: A comparison between frequency ratio, Dempster–Shafer, and weights-of-evidence models. J. Asian Earth Sci. 2012, 61, 221–236. [Google Scholar] [CrossRef]
- Dempster, A.P. A generalization of Bayesian inference. J. R. Stat. Soc. Ser. B (Methodol.) 1968, 30, 205–232. [Google Scholar] [CrossRef]
- Lee, S.; Hwang, J.; Park, I. Application of data-driven evidential belief functions to landslide susceptibility mapping in Jinbu, Korea. Catena 2013, 100, 15–30. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman & Hall: New York, NY, USA, 1984. [Google Scholar]
- Vorpahl, P.; Elsenbeer, H.; Märker, M.; Schröder, B. How can statistical models help to determine driving factors of landslides? Ecol. Model. 2012, 239, 27–39. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Peters, J.; Verhoest, N.; Samson, R.; Boeckx, P.; De Baets, B. Wetland vegetation distribution modelling for the identification of constraining environmental variables. Landsc. Ecol. 2008, 23, 1049–1065. [Google Scholar] [CrossRef]
- Ließ, M.; Glaser, B.; Huwe, B. Uncertainty in the spatial prediction of soil texture: Comparison of regression tree and random forest models. Geoderma 2012, 170, 70–79. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Li, T.; Guo, C.; Hong, H.; Li, W.; Pan, D.; Hui, J.; Ma, M. A novel ensemble approach of bivariate statistical-based logistic model tree classifier for landslide susceptibility assessment. Geocarto Int. 2018, 33, 1398–1420. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Moradi, H.R.; Aghda, S.F.; Gokceoglu, C.; Pradhan, B. GIS-based landslide susceptibility mapping with probabilistic likelihood ratio and spatial multi-criteria evaluation models (north of Tehran, Iran). Arab. J. Geosci. 2014, 7, 1857–1878. [Google Scholar] [CrossRef]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of ANFIS with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef]
- Alatorre, L.C.; Sánchez-Andrés, R.; Cirujano, S.; Beguería, S.; Sánchez-Carrillo, S. Identification of mangrove areas by remote sensing: The ROC curve technique applied to the northwestern Mexico coastal zone using Landsat imagery. Remote Sens. 2011, 3, 1568–1583. [Google Scholar] [CrossRef]
- Termeh, S.V.R.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Aburub, F.; Hadi, W. Predicting groundwater areas using data mining techniques: Groundwater in Jordan as case study. Int. J. Comput. Electr. Autom. Control Inf. Eng. 2016, 10, 1475–1478. [Google Scholar]
- Faridi, M.; Verma, S.; Mukherjee, S. Integration of GIS, Spatial Data Mining, and Fuzzy Logic for Agricultural Intelligence. In Soft computing: Theories and Applications; Springer: Singapore, Singapore, 2018; pp. 171–183. [Google Scholar]
- Clapcott, J.; Goodwin, E.; Snelder, T. Predictive Models of Benthic Macroinvertebrate Metrics; Prepared for Ministry for the Environment; Cawthron Institute: Nelson, New Zealand, 2013. [Google Scholar]
- Tehrany, M.S.; Shabani, F.; Javier, D.N.; Kumar, L. Soil erosion susceptibility mapping for current and 2100 climate conditions using evidential belief function and frequency ratio. Geomat. Nat. Hazards Risk 2017, 8, 1695–1714. [Google Scholar] [CrossRef] [Green Version]











| Unit | Lithology | Unit | Lithology |
|---|---|---|---|
| Qft2 | Low-level piedmont fan | KEpd-gu | Massive fossiliferous limestone |
| MuPlaj | Siltstone, sandstone, red marl (Aghajari formation) | Kbgp | Mostly limestone and shale. |
| Plbk | Conglomerate locally with sandstone (Bakhtyari formation) | pC-Ch | Rock salt, rhyolite basalt, and trachyte |
| Mmn | Gray marls with low weather (Mishan formation) | OMr | Silty red, gray and green marls, little ribs of sandstone (RAZAK FM) |
| Mgs | Red marl, anhydrite, salt locally with argillaceous limestone (Gachsaran formation) | JKkgp | Undivided group of Khami, made up of huge thin limestone bedded |
| EOas-ja | Undivided formation of Asmari and Jahrum |
| Test Result Variable(s) | AUC | Std. Error a | Asymptotic Sig. b | Asymptotic 95% Confidence Interval | |
|---|---|---|---|---|---|
| Lower Bound | Upper Bound | ||||
| CF-RF | 0.927 | 0.018 | 0.000 | 0.892 | 0.963 |
| EBF-RF | 0.924 | 0.021 | 0.000 | 0.884 | 0.965 |
| FR-RF | 0.917 | 0.020 | 0.000 | 0.877 | 0.957 |
| CF-LMT | 0.906 | 0.021 | 0.000 | 0.865 | 0.947 |
| EBF-LMT | 0.885 | 0.023 | 0.000 | 0.841 | 0.929 |
| FR-LMT | 0.830 | 0.029 | 0.000 | 0.773 | 0.886 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Choi, S.-M. Groundwater Potential Mapping Using an Integrated Ensemble of Three Bivariate Statistical Models with Random Forest and Logistic Model Tree Models. Water 2019, 11, 1596. https://doi.org/10.3390/w11081596
Razavi-Termeh SV, Sadeghi-Niaraki A, Choi S-M. Groundwater Potential Mapping Using an Integrated Ensemble of Three Bivariate Statistical Models with Random Forest and Logistic Model Tree Models. Water. 2019; 11(8):1596. https://doi.org/10.3390/w11081596
Chicago/Turabian StyleRazavi-Termeh, S. Vahid, Abolghasem Sadeghi-Niaraki, and Soo-Mi Choi. 2019. "Groundwater Potential Mapping Using an Integrated Ensemble of Three Bivariate Statistical Models with Random Forest and Logistic Model Tree Models" Water 11, no. 8: 1596. https://doi.org/10.3390/w11081596
APA StyleRazavi-Termeh, S. V., Sadeghi-Niaraki, A., & Choi, S. -M. (2019). Groundwater Potential Mapping Using an Integrated Ensemble of Three Bivariate Statistical Models with Random Forest and Logistic Model Tree Models. Water, 11(8), 1596. https://doi.org/10.3390/w11081596