1. Introduction
Management of runoff is one of the most important water quality goals in urbanized watersheds. Accurate estimation of runoff from urban catchments requires hourly or sub-hourly precipitation time series. While historical precipitation time series at this temporal resolution can be used to drive any of the hydrologic and hydraulic models (e.g., USEPA SWMM, SUSTAIN, WinSLAMM, etc.) commonly used for urban simulations, their runoff predictions are directly determined by the particular sequence of precipitation in the historical record that is input. Without uploading additional precipitation time series one by one, none of the existing urban hydrologic models can be used to efficiently investigate the role that alternative patterns of precipitation could have on runoff predictions.
Risk-based hydrologic investigations, for example those focusing on agricultural water use, reservoir/watershed management, and climate change impact assessments, typically use synthetic precipitation series. However, the precipitation sequences used in these kinds of studies typically have a coarser temporal resolution (e.g., daily, monthly) due to the relatively long time scales under consideration in such investigations [
1,
2,
3].
Most synthetic precipitation generators use stochastic methods that assume rainfall is a random process that can be modeled statistically based on the observed characteristics of actual precipitation records. Stochastic precipitation generators have been developed and used extensively for flood risk management [
4], sizing reliable rainwater harvesting systems [
5], and other water resource management tasks [
6].
Stochastic precipitation generators create long continuous Markovian sequences of precipitation through a variety of methods [
7]. Poisson white noise (PWN) method was one of the earliest tools in modelling precipitation by statistically generating storm event arrival time, event duration, and precipitation amount [
8,
9,
10] with independent distributions, usually Poisson for time and duration and Gamma for precipitation. In another method, a precipitation event was conceptualized as an assembly of a number of subcells with aggregation allowed by Neyman-Scott rectangular pulse (NSRP), which is the combination of Poisson rectangular pulse model [
11] and cluster modelling on the spatial distribution of galaxies [
12]. Under this methodology, Poisson or Geometric distributions are typically assumed for arrival time and the precipitation sub-cells are assumed to occur as rectangular pulses. Other similar studies include [
13,
14,
15,
16,
17,
18]. Although extensively studied [
19,
20,
21], parameter estimation is always a big challenge for PWN and NSRP models “even when using physical considerations” [
22] due to the strong assumptions on statistical distributions. Amendment is required for the parameters in the underlying distributions when changing location or temporal aggregation scales. Moreover, since the dynamics and behavior of the precipitation process is too complex and chaotic [
23] to be fully approximated by statistical assumptions on distributions and pulses, the variety of features embedded in the real data, such as a limited record, unusual skew, outliers, and a long tail, etc., may impair the accuracy of the parameter fitting and, in turn, reduce the reliability of the water resource modeling.
To avoid the parameter calibration inherent in stochastic models and improve the portability of precipitation generators, non-parametric methods may be used. Using Kernel density estimation [
24,
25] and K nearest neighbors (KNN) [
25], the probability density function from the historical observation could be represented in a conditional bootstrapping approach [
26]. Lall and Sharma [
27] pioneered this method in modelling hydrological time series data. Successive studies include [
5,
28,
29,
30,
31,
32,
33]. Although non-parametric methods have been tested before, most existing non-parametric weather generators operate at daily time scales or above and are of limited value in simulating Hortonian runoff generated instantaneously whenever precipitation intensity exceeds the landscape’s infiltration capacity. To incorporate historical precipitation uncertainty into probabilistic simulations of Hortonian runoff, synthetic precipitation data is needed at much finer temporal scales. To that end, this paper introduces a new, hourly non-parametric synthetic precipitation generator. The generator is incorporated into the Low Impact Development Rapid Assessment (LIDRA) tool to enable robust simulation and rapid comparison of distributed “green” approaches to urban runoff reduction in different locations. The paper is structured as follows. First the moving window, KNN, stochastic process, and the Markov Chain processes used in the development of the algorithm are presented. Next, the accuracy of the precipitation generation technique is validated through comparison of the synthetic values to observed monthly distributions of average event duration and average event precipitation depth for New York City (NYC). Finally, historical precipitation from New York, NY (1948–2011); Syracuse, NY (1948–2010); and Miami, FL (1996–2010) are used to test the portability of the synthetic generator. It should be noticed that, although non-parametric methods can be used to model extreme events, that is not the purpose of this paper. The study focuses on green infrastructure’s ability to cumulatively reduce stormwater runoff over time, rather than green infrastructure’s impact during extreme flooding events.
2. Methods
To generate synthetic precipitation time series, both the event state (wet or dry) and the precipitation amounts need to be estimated. For precipitation generators involving daily time steps, a multi-state Markov Chain algorithm is typically employed [
30]. For example, the probability of the next day’s state being wet or dry is conditioned by the current day’s state. Once the daily state has been determined, researchers use a variety of methods, including bootstrapping or distributed sampling, to generate precipitation amounts for each wet day derived from historic observations.
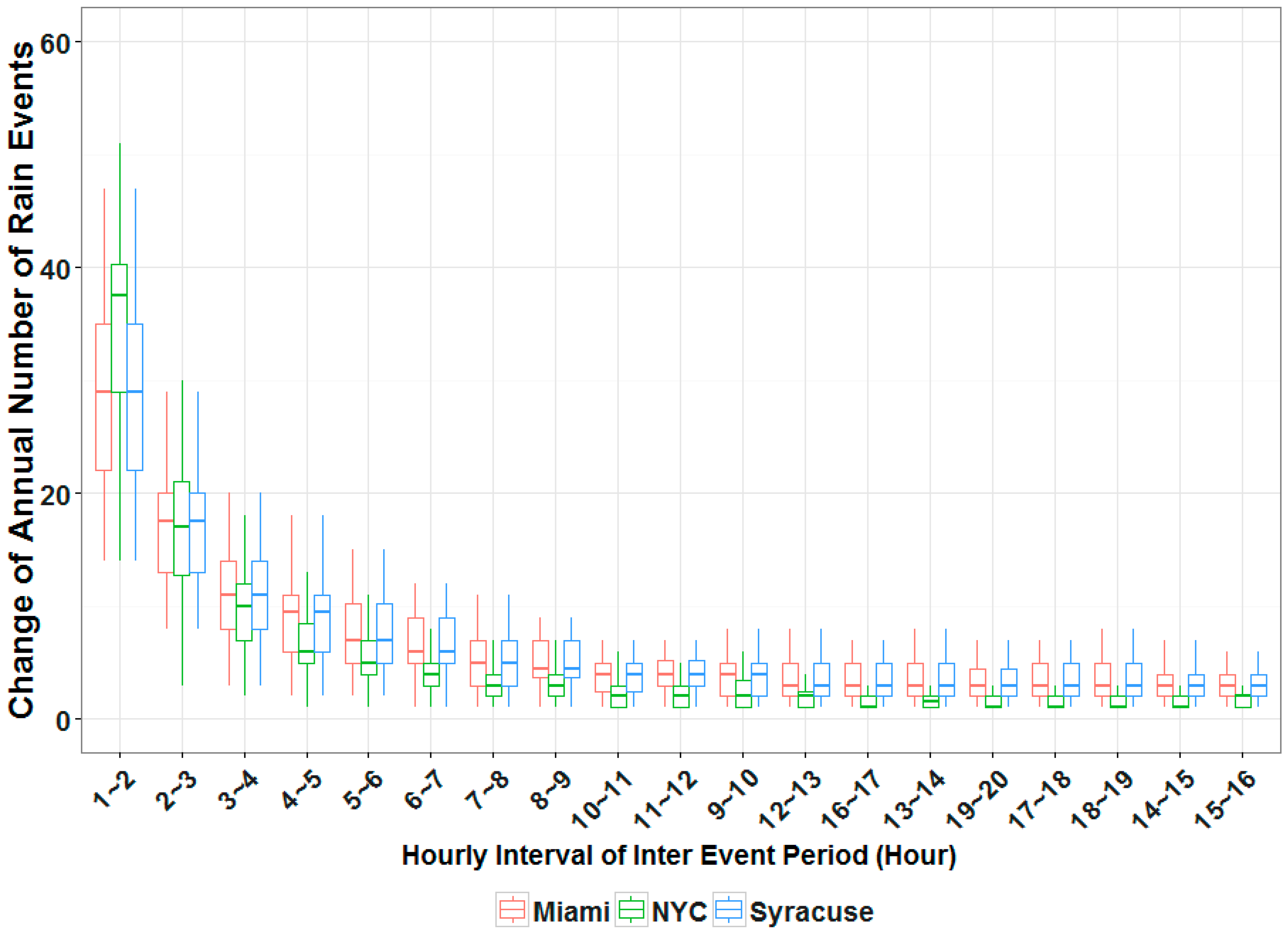
In sub-daily time scales, a similar approach can be employed by considering each rain storm as a separate event. Since individual rain storms typically span multiple hours, and may include brief periods of no rain, a technique for discretizing a continuous precipitation record into alternating wet and dry events is required. In this paper, precipitation data from NYC, Miami, and Syracuse were analyzed specifically to select an Inter Event Dry Period (IntEDP) that is suitable for synthetic precipitation generation in different climatic zones. IntEDP values of 1–20 h were applied to over 50 years of historical precipitation observation from the cities. The corresponding number of events per month based on different IntEDPs are plotted in
Figure 1. While the number of events differs across different cities, shorter InEDP results in more events per month in all three locations. Precipitation in Syracuse is broken down to a mean of more than 50 events per month using a one hour IntEDP, while in NYC and Miami, this same IntEDP yields on average only 14 and 30 events, respectively. These differences are due to different atmospheric causes of precipitation in the flat coastal cities (NYC, Miami) and the higher elevation and more inland city (Syracuse).
In all three cities, the number of enumerated wet events decreases faster until the IntEDP reaches 4 h. When IntEDP > 4 h, the number of wet events obtained is much more stable. Given that the meteorological causes of precipitation in these three locales differ significantly, a four-hour IntEDP is thus considered robust, and appropriate based on the portability goal set for this particular generator.
Using the 4 h IntEDP, synthetic series are assembled non-parametrically as alternating sequences of wet and dry events sampled from the historical record, with the wet event duration and amount both determined by the characteristics of the preceding dry event. In contrast to parametric generators that define the state and amount through separate processes, both wet event duration and amount are defined simultaneously in this approach, since they are sampled directly from the historical record.
Seasonality is considered explicitly in the generator using a “moving window” approach [
32]. A 30-day “window” centered at noon on the day of interest is defined. Seasonal variations are assumed not to exist within the window, regardless of the time of year. Within the moving window, k nearest neighbor (KNN) methods are embedded in the resampling process so that only the most likely events from within the moving window associated with the end of a similar previous event can be appended to the evolving synthetic sequence. The integer, k, is selected using the approach introduced by Lall and Sharma [
27]:
where,
n is the total number of appropriate events (wet if preceding event was dry, and dry if preceding event was wet) within a given moving window, and k is the number of nearest neighbors from which a subsequent event is randomly selected.
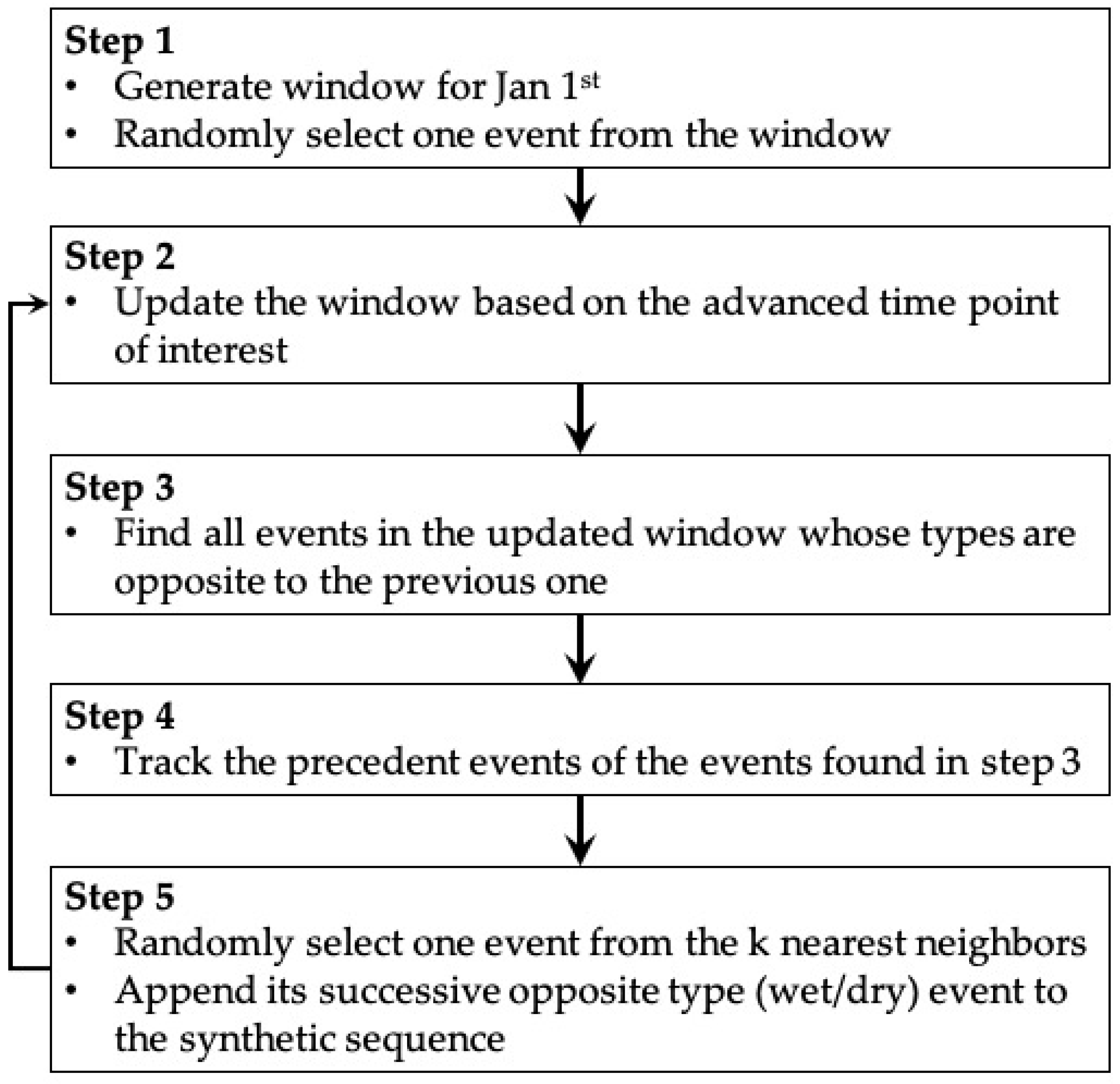
The full generation procedure is diagramed in
Figure 2, as a Markov Chain process. An example is shown in
Figure 3. The historical event sequence can be expressed as, for example, {d
1, w
2, d
3, w
4, …, w
i, d
i+1, w
i+2, …}, where d and w represent dry events and wet events, respectively. The procedure starts by centering a window on 12:00 on January 1st for the year of interest, where J is the indexes set of the events (dry/wet) within this window. In this example, one event w
o, where o ∈ J is selected randomly as the starting point (Step 1). A new window is then created and centered on the time step advanced by w
o (Step 2). Next, all dry events, the opposite type to w
o, in the window determined by Step 2 (121 for this example) are extracted (Step 3); the indexes set is labeled as M. These events, Ed = {d
x|x∈M}, are the pool from which the next event is selected (Step 3). The duration of w
o is compared to the duration of Ew = {w
x−1|x∈M} (circles in
Figure 3), each preceding neighbor of events in Ed = {d
x|x∈M} (Step 4). For this example, the k (11 =
) events Ewk = {w
y|y∈KNN} are chosen with durations most similar to w
o, shown between the dashed lines in
Figure 3. One event is chosen randomly from the Edk = {d
y+1|y∈KNN} as the next event in the synthetic precipitation time series. The Markov Chain processes then loops back to Step 2, with the window pushed forward by the chosen event. The process continues in this way until a complete synthetic series is generated.
Conceptually, this is a first order Markov-chain model using the event duration as the condition to sample synthetic events from historical observations. By alternating event types between wet and dry, the autocorrelations of events, such as wet vs. wet, dry vs. dry, wet vs. dry, on lag 1 is inherently preserved. For coarser scale, the moving window constrains the sampling candidates within a similar period each year, so that the seasonal periodicity can be represented as well [
31]. Many researches treat precipitation amount as a statistically independent variable to event arrival time or event duration [
12,
13,
14,
19,
20]. Yet, duration and amount are two physically associated dimensions for precipitation. Their underlying connection can be an integral with other characteristics [
34]. This model, as a single variable Markov-chain, directly uses the precipitation information associated with each sampled event as the synthetic series.
Historical hourly precipitation records from NYC’s LaGuardia Airport, Syracuse Hancock International Airport, and Miami International Airport were used to generate 100 sets of 30 years of synthetic hourly precipitation series for all three cities. Because the synthetic series from each city were created by resampling historical observations, the synthetic series are stationary, and represent the historical variability in the data about the mean. Statistical characteristics of the synthetic series are expected to be similar to those of the respective historical records.
4. Discussion
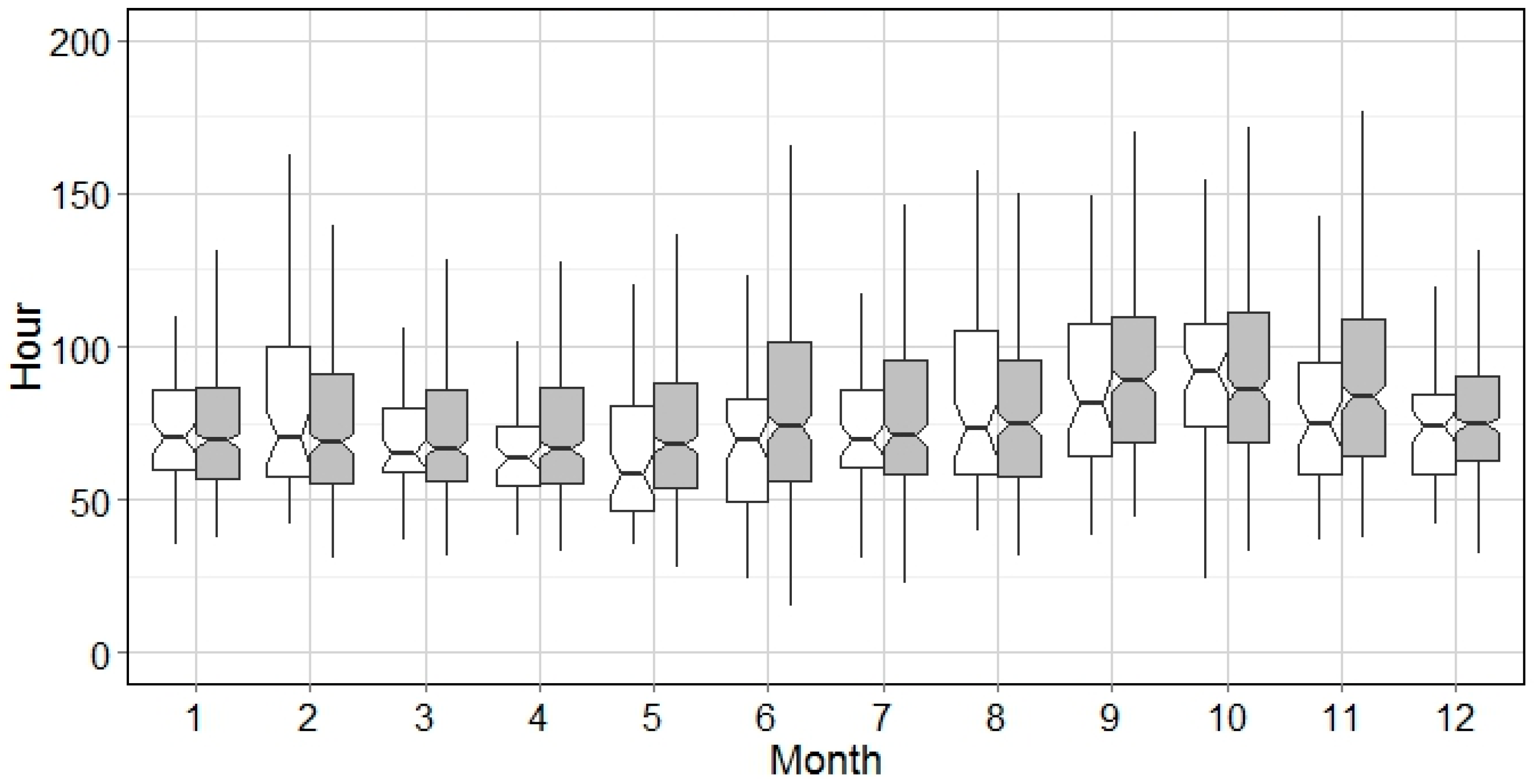
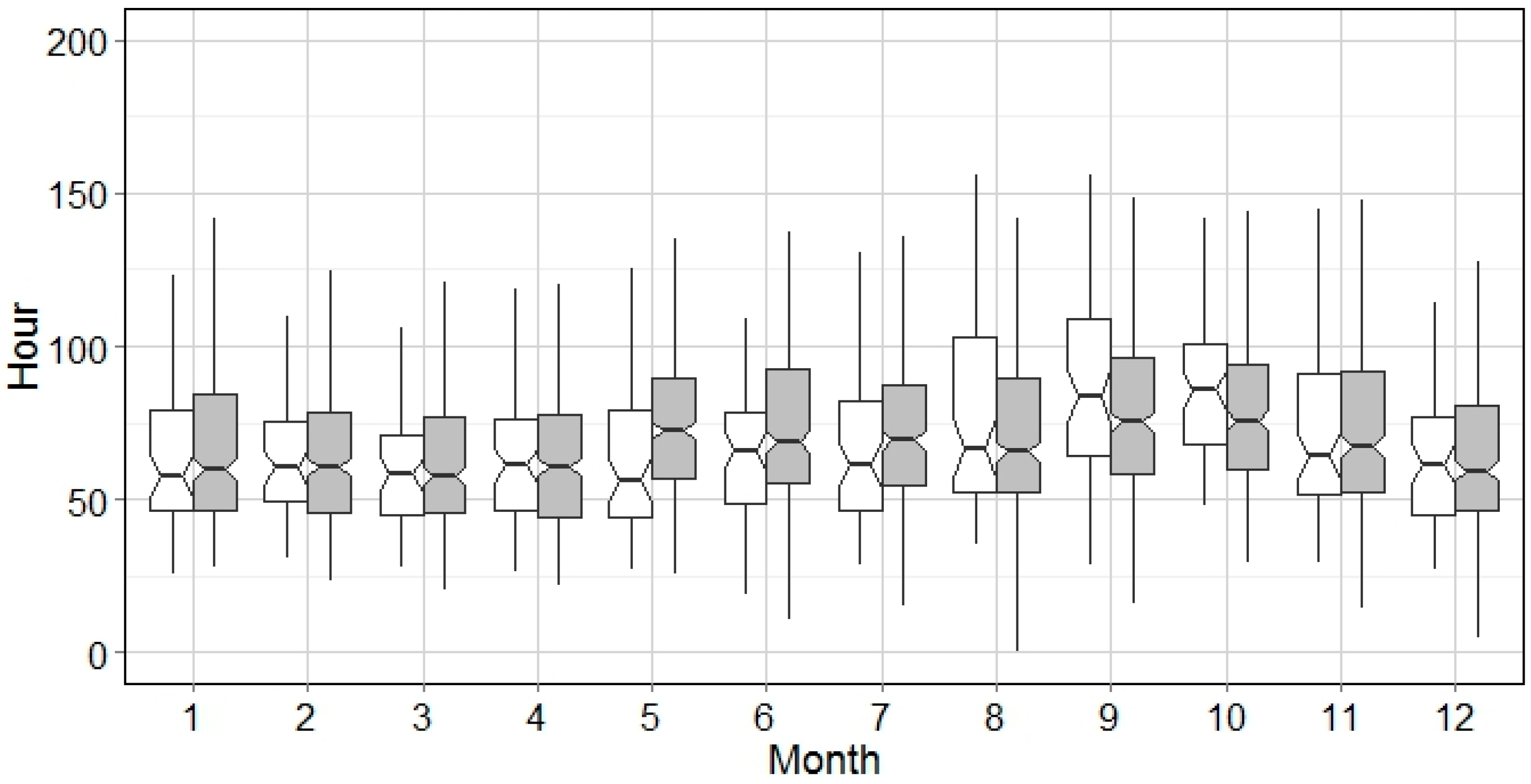
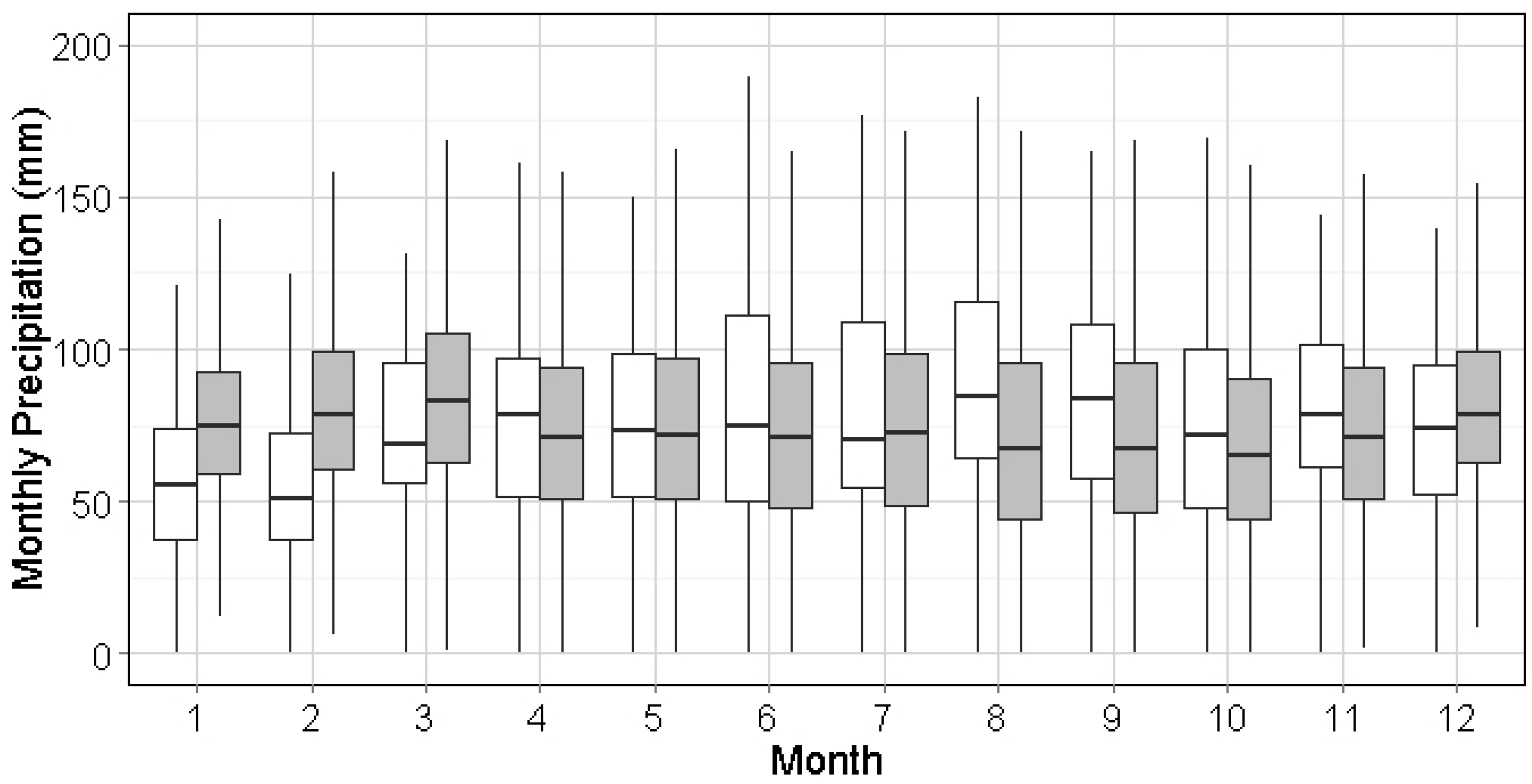
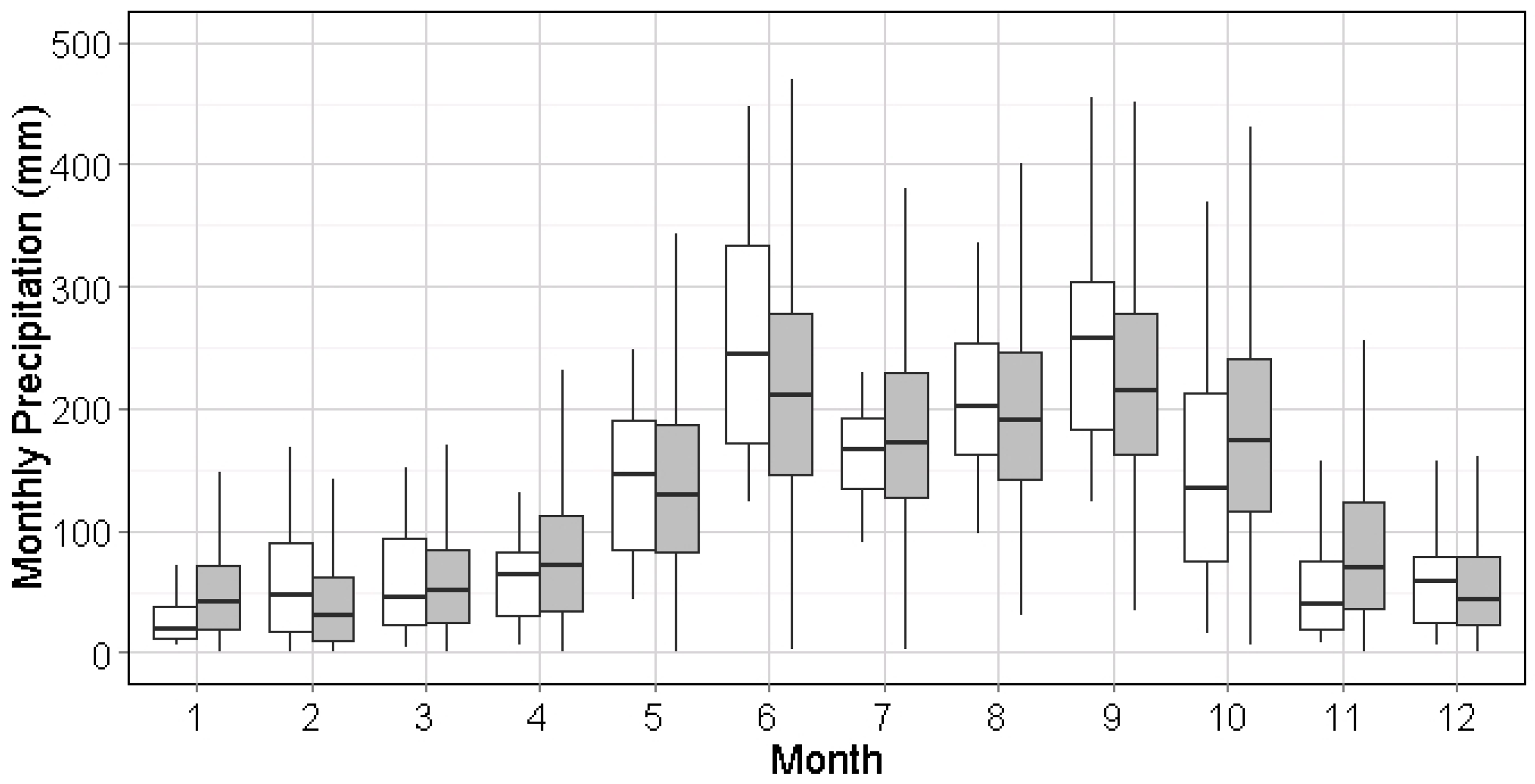
Generally, this algorithm was found to replicate the stationary distribution of precipitation for each month in all cities. Due to the design of the generation process, the moving window method preserves and smooths the seasonality of precipitation with two implications. First, the synthetic precipitation series may have a smoother seasonal shifting period than the historical record, as seen in May in
Figure 6 and
Figure 7. Next, the fluctuation of precipitation in synthetic series for each season (e.g., wet or dry) could be more stable in both mean and variation, i.e., January–March in
Figure 13 and June–September in
Figure 14. This indicates that the seasonal impact on hydrology in further calculations could be mitigated by using the synthetic series, which might be more obvious in the cities with significant seasonal difference, such as Miami, FL.
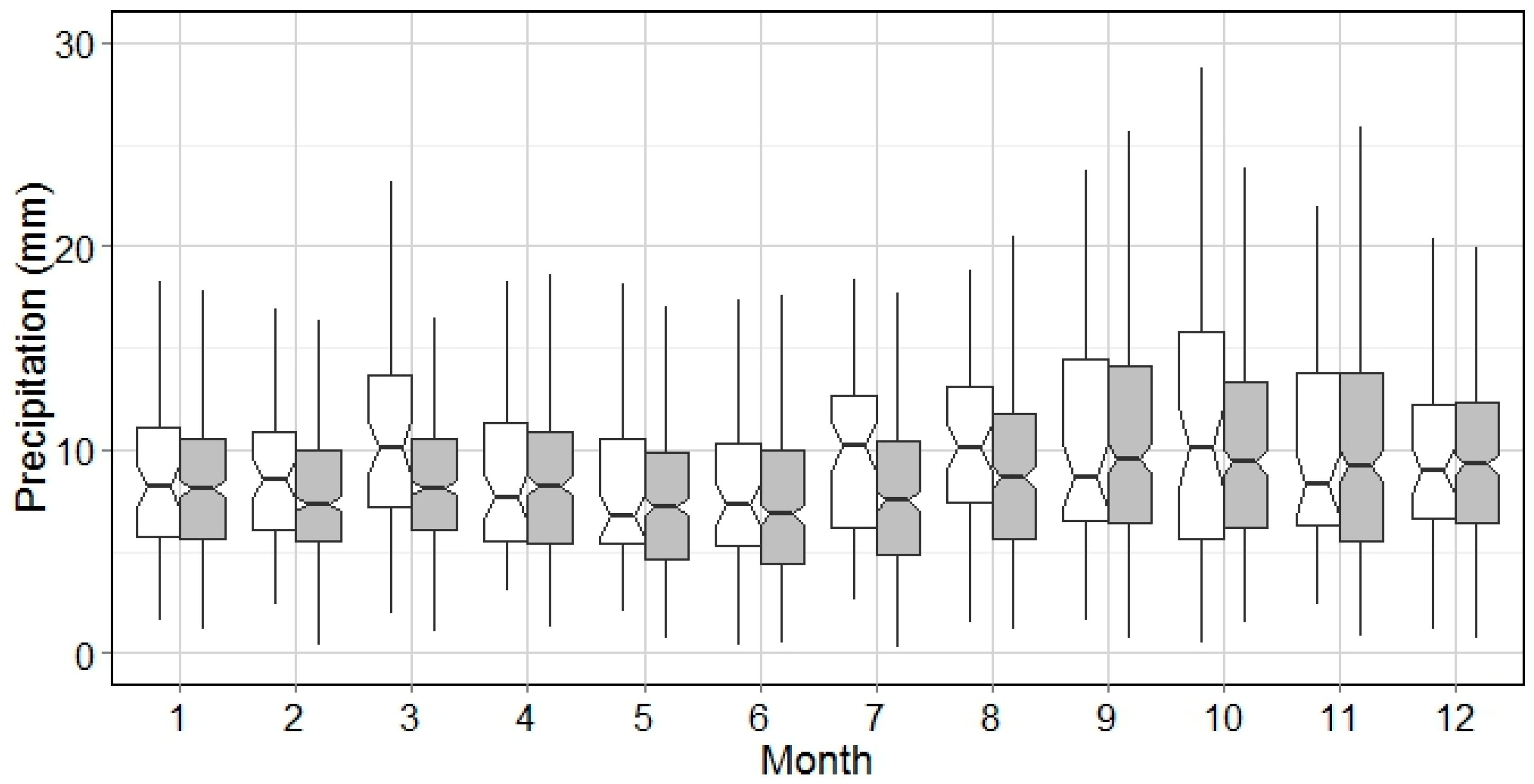
The alignment between the synthetic time series and the historical series in terms of the WEP can be interpreted by local atmospheric circulation patterns. In
Figure 8, the variation of mean WEP in NYC is narrower in winter and spring than in summer and fall. The spring period coincides with when the jet stream moves northward, producing a high frequency of drizzles. By contrast, intensive air convections generating thunderstorms and hurricanes are more popular from July–November.
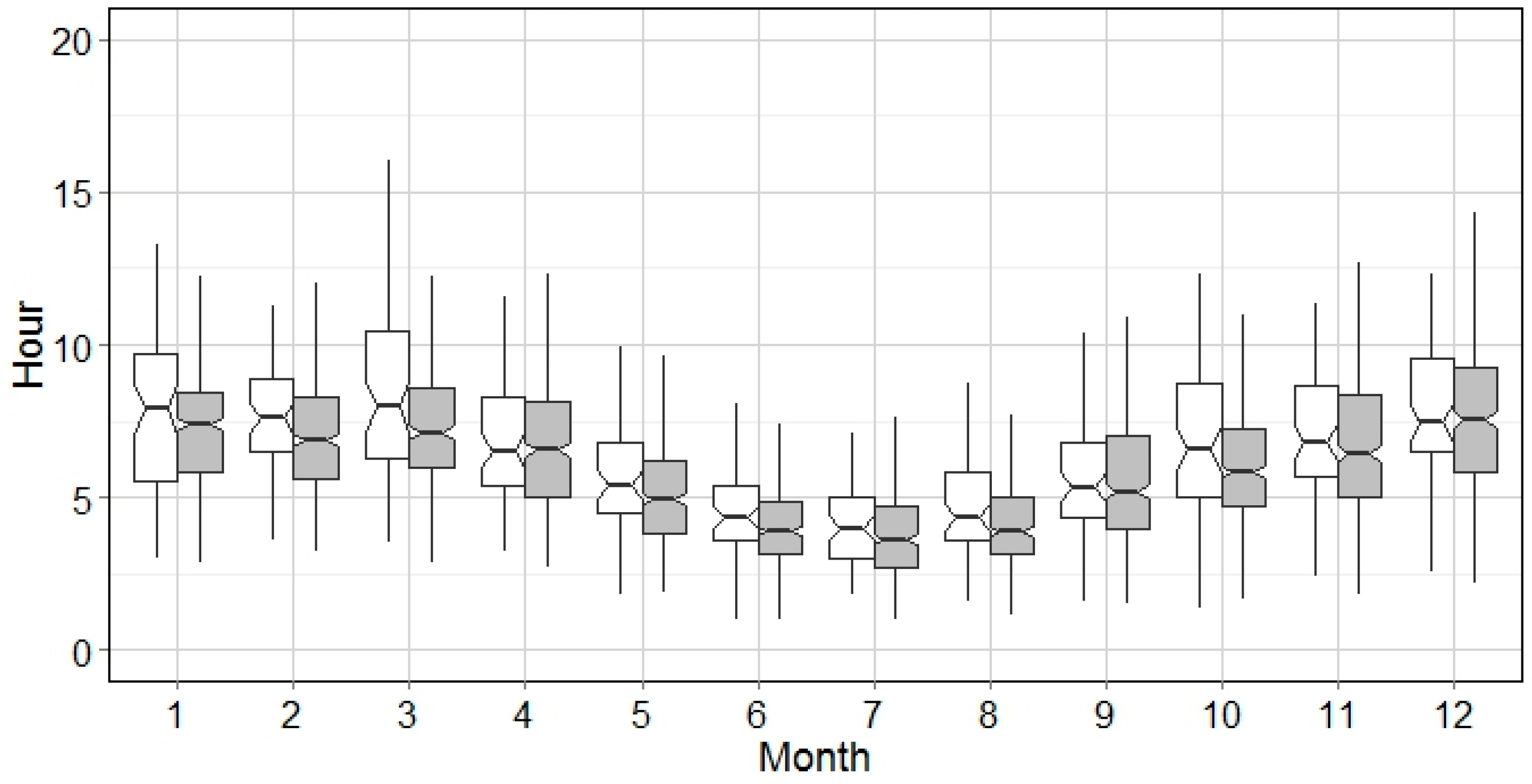
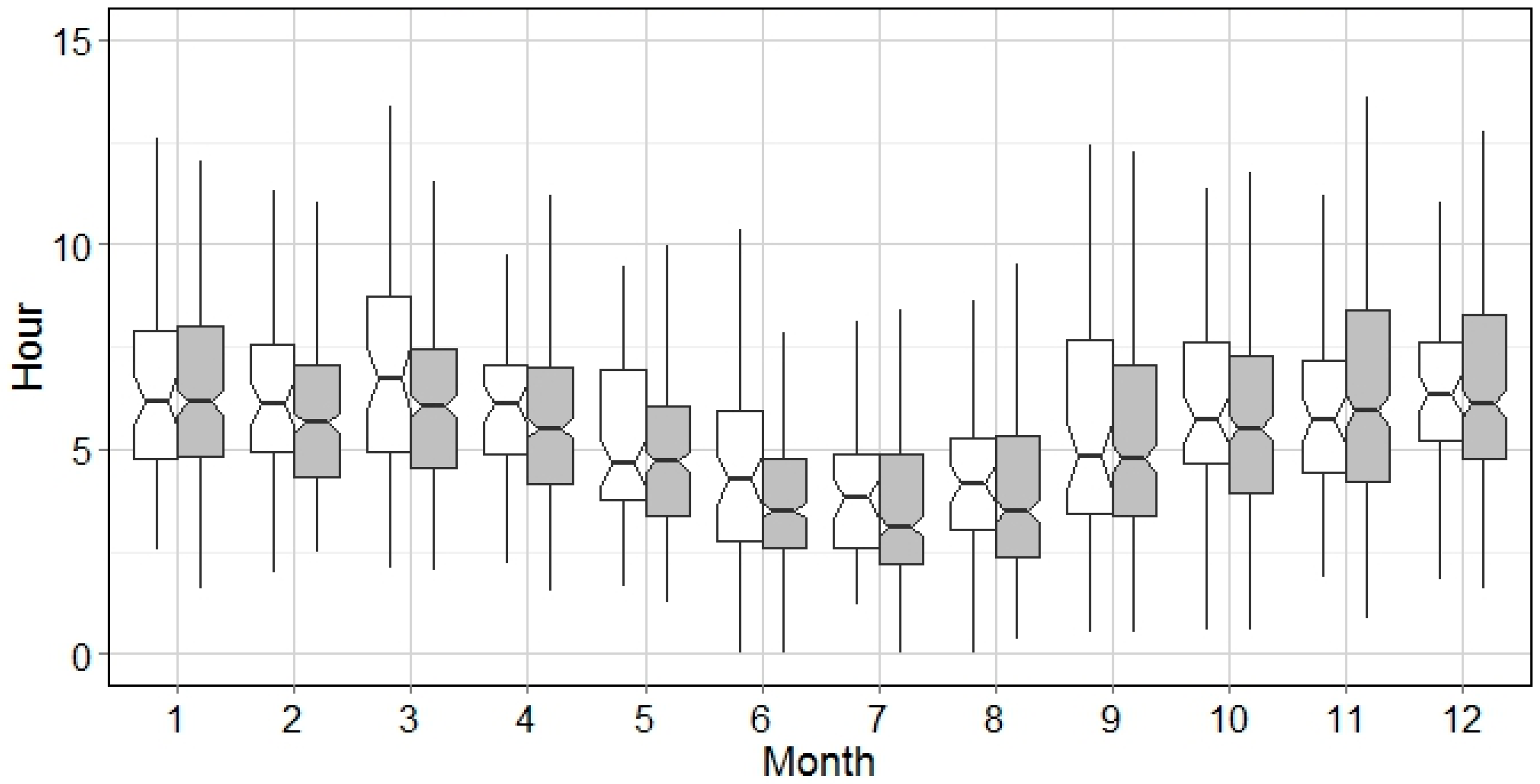
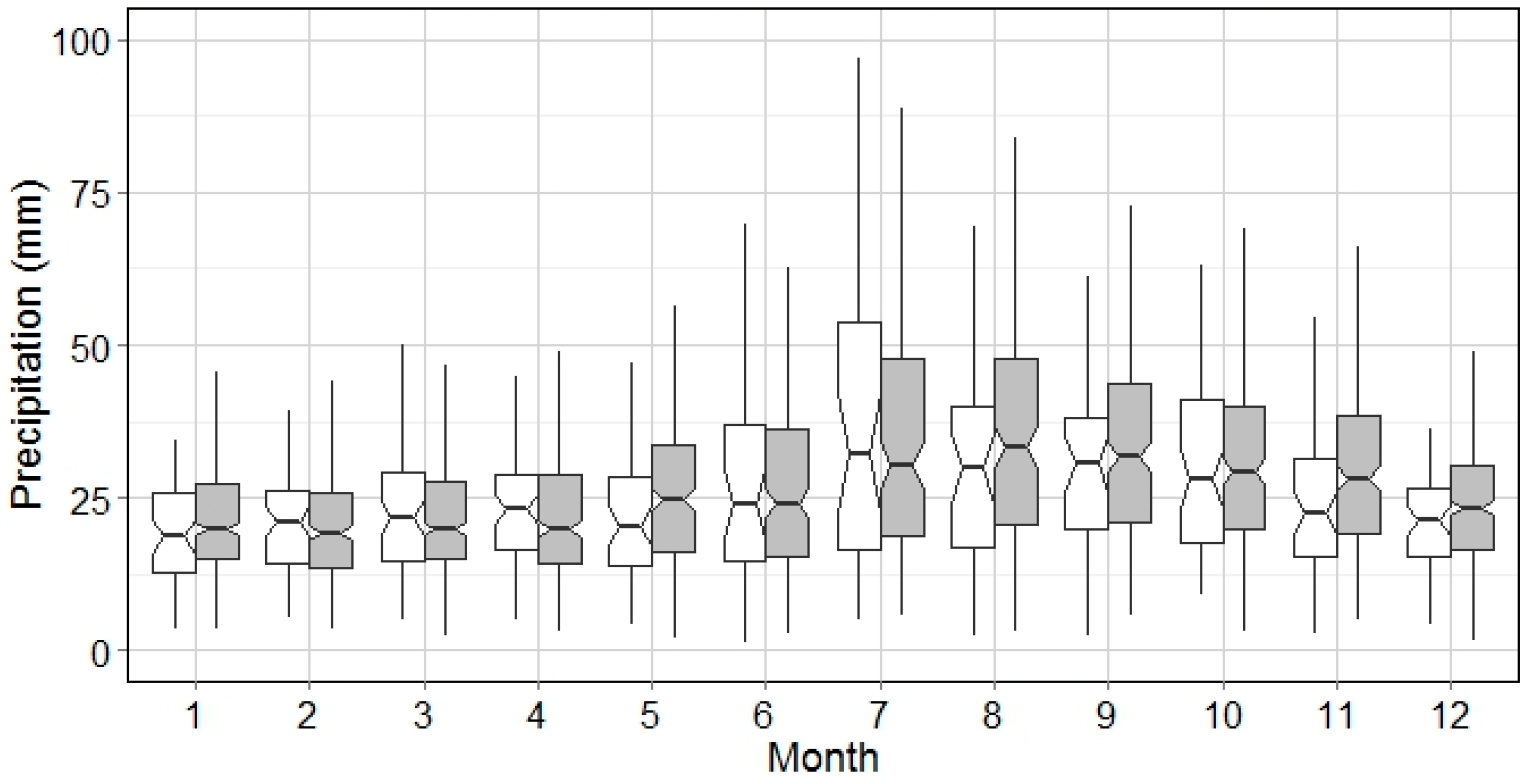
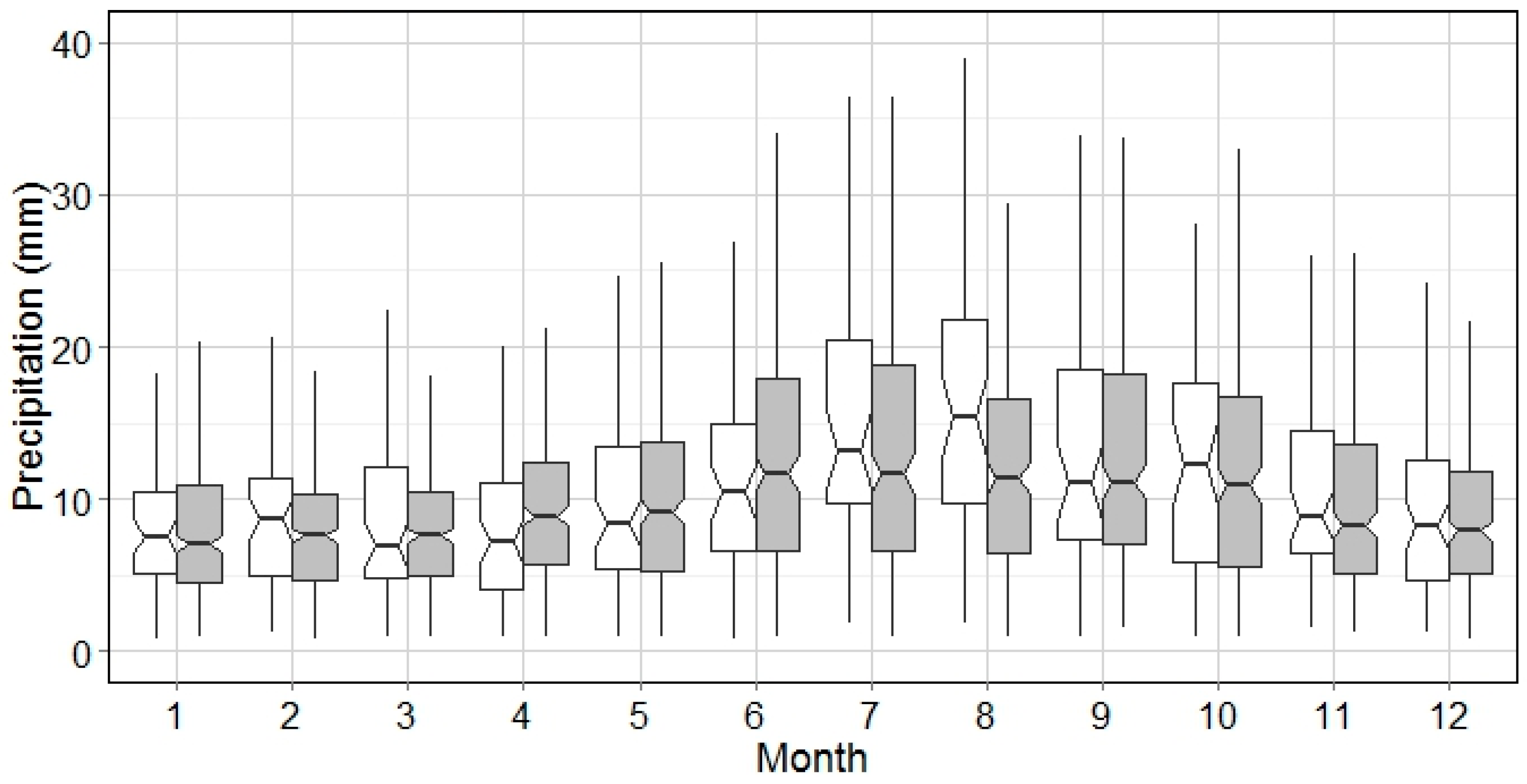
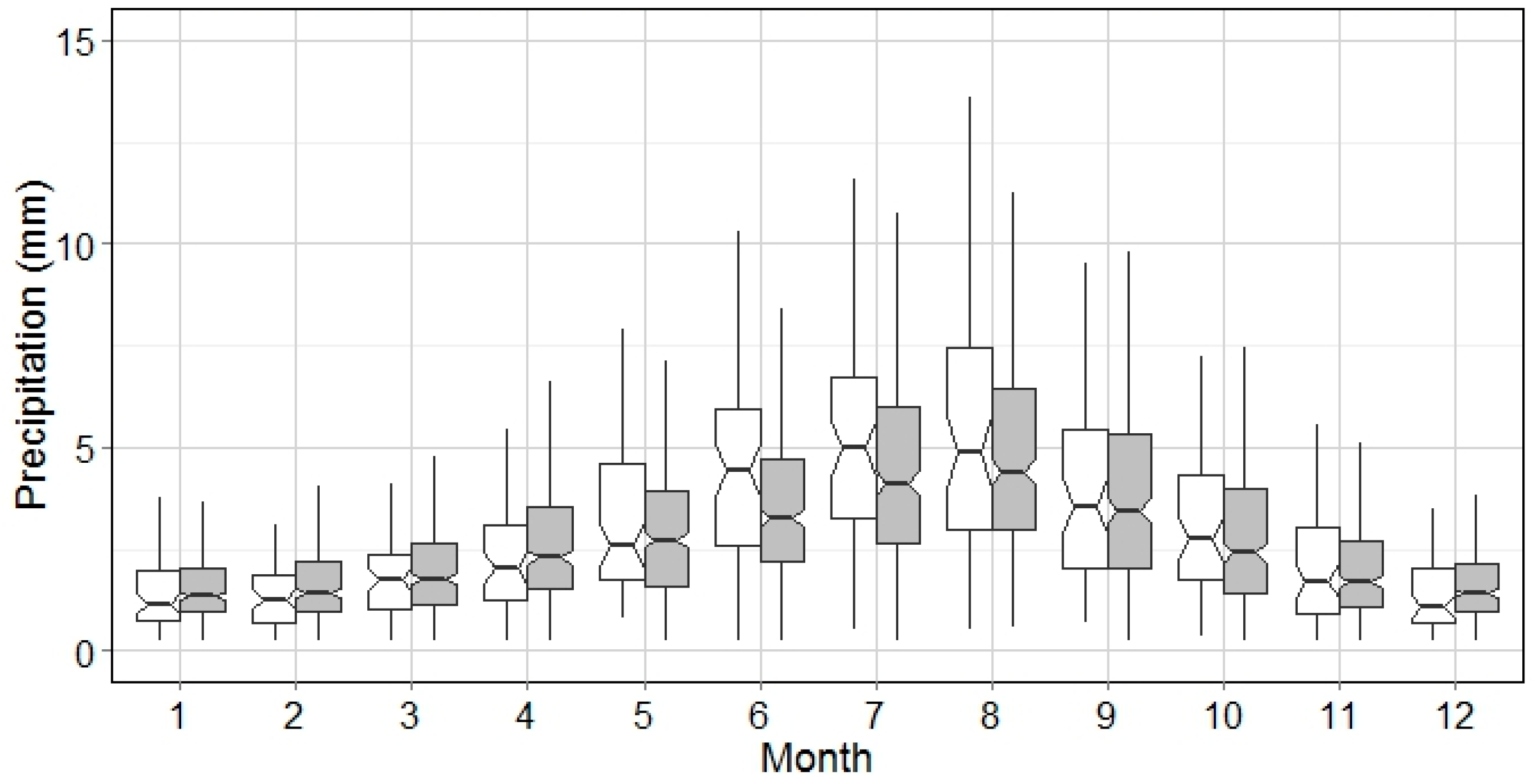
The general pattern of wet events for all months is demonstrated by integrating the analysis of WED and WEP. Based on
Figure 6, the hot season and cold season is divided by the WED of 5 h. This implies that the WEP analysis can be interpreted categorically, e.g., WED > 10 h (
Figure 9), WED between 5 h and 10 h (
Figure 10), and those with WED < 5 h (
Figure 11). It could be seen from
Figure 9,
Figure 10 and
Figure 11 that the WEP range increases as the wet event gets longer. Biggest WEP variations can be observed from July–August, which indicates the precipitation intensity in summer season is much higher. However, this is not seen in
Figure 8 because a big portion of wet events in summer are of short WED (
Figure 4), i.e., thunder storms. Weighted by the portion of each WED category, the variation of WEP in summer season is mainly contributed by events of WED < 5 h with relatively low WEP. In contrast, WED in October is, on average, longer than 5 h, and the WEP variation is largest in October, as shown in
Figure 8.
The potential for bias in runoff calculations may come from dry events. Does the algorithm resample short, dry events more frequently so that the soil moisture drying process isn’t as complete as it should be? For example, in NYC, the variability in DED is relatively large compared to WED. The SD of WED is about 6 h; by contrast the SD for DED is about 75 h. This indicates that, generally, the synthetic dry event would not significantly impact the accuracy of urban runoff simulations as the soil moisture drops most rapidly in the first 24-hours after a wet event, after which the drying process is significantly slowed and has minimum impact on stormwater runoff calculations.
Potential Improvement
This paper is a first from a big project investigating potential climate change uncertainties and their impact on green infrastructure (GI) performance in urban watershed. The focus of this study was to test if non-parametric precipitation generation could preserve the stationarity of precipitation using a single variable. Although that was demonstrated in this paper, there still exists some uncertainty on the future applications of this method in urban hydrology practice. These uncertainties include the need to develop a generalized means of determining IntEDP, assessing the reliability of using non-stationary methods to predict regionalized precipitation from a limited sample record, and the non-stationary impacts of climate change and local and temporal variation in weather patterns. Companion papers and future work on this big project will be used to fill in these gaps.
The IntEDP in this study is defined with qualitative evidence. Ideally, a sensitivity analysis is needed to discover a value that preserves the statistic consistency. However, such a value is highly localized, and the process to develop a generalized value for a wider application is complex. The purpose of showing
Figure 1 is to provide a simple guide for non-expert users to determine a value for their own applications. A companion paper, Yu, Miller [
34], has introduced a generalized method based on Reference [
36].
The representativeness of the precipitation models is highly dependent on the sample size of the historical records, which is an inherent weakness when modeling two common scenarios in urban hydrology: Rare events and short observation records. In different ways, both of these situations have a limited sample size that harms the resampling process. For parametric stochastic methods, Bárdossy [
37] suggested a simulated annealing process to incorporate the regional precipitation properties into a model. Pinault and Allier [
38] extended the stochastic precipitation results into a catchment scale by keeping the spatial distribution consistency. Yet, neither method applies to a non-parametric model, which is highly data driven. One possible solution would be to lump observations from several nearby locations with similar climates to expand the feeding sample. For example, Yu, Miller [
34] investigated the general relationship between precipitation and temperature at an hourly scale by combining the data from NYC, Philadelphia, and Boston. Such a solution would increase the geographic area represented by the synthetic ensembles and allow for more widespread use.
Precipitation dynamics under the effects of climate change and/or general climate variability, including temporally varying basins [
39], may violate the stationarity assumptions of the non-parametric method. However, meteorological dynamics are a complex process that cannot be represented by traditional stochastic-based methods relying on only precipitation data. Unless one digs into the physical basis of the formation of precipitation with other variables, “How does precipitation vary on temperature, time and geography?” is hard to be unfold. This is also an extension topic of this research. Yu, Miller [
34] have associated hourly precipitation and monthly temperature mediated by pressure change, which is the direct cause of cloud and precipitation formation. Another study that applies this finding to a non-stationary precipitation generator for climate change using similar stochastic methods on multi-dimensional data has been completed and will be published soon. In fact, this model may also apply to regionalized precipitation when importing the necessary climate variables from other locations without considering climate change, because the physical concept of precipitation formation holds regardless of location. In addition, this addition paper explores the Clausius–Clapeyron relation, used by many researchers in precipitation change under global warming, which is useful for predicting extreme events.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













