An Improved Genetic Algorithm Coupling a Back-Propagation Neural Network Model (IGA-BPNN) for Water-Level Predictions



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data
2.2. Methods
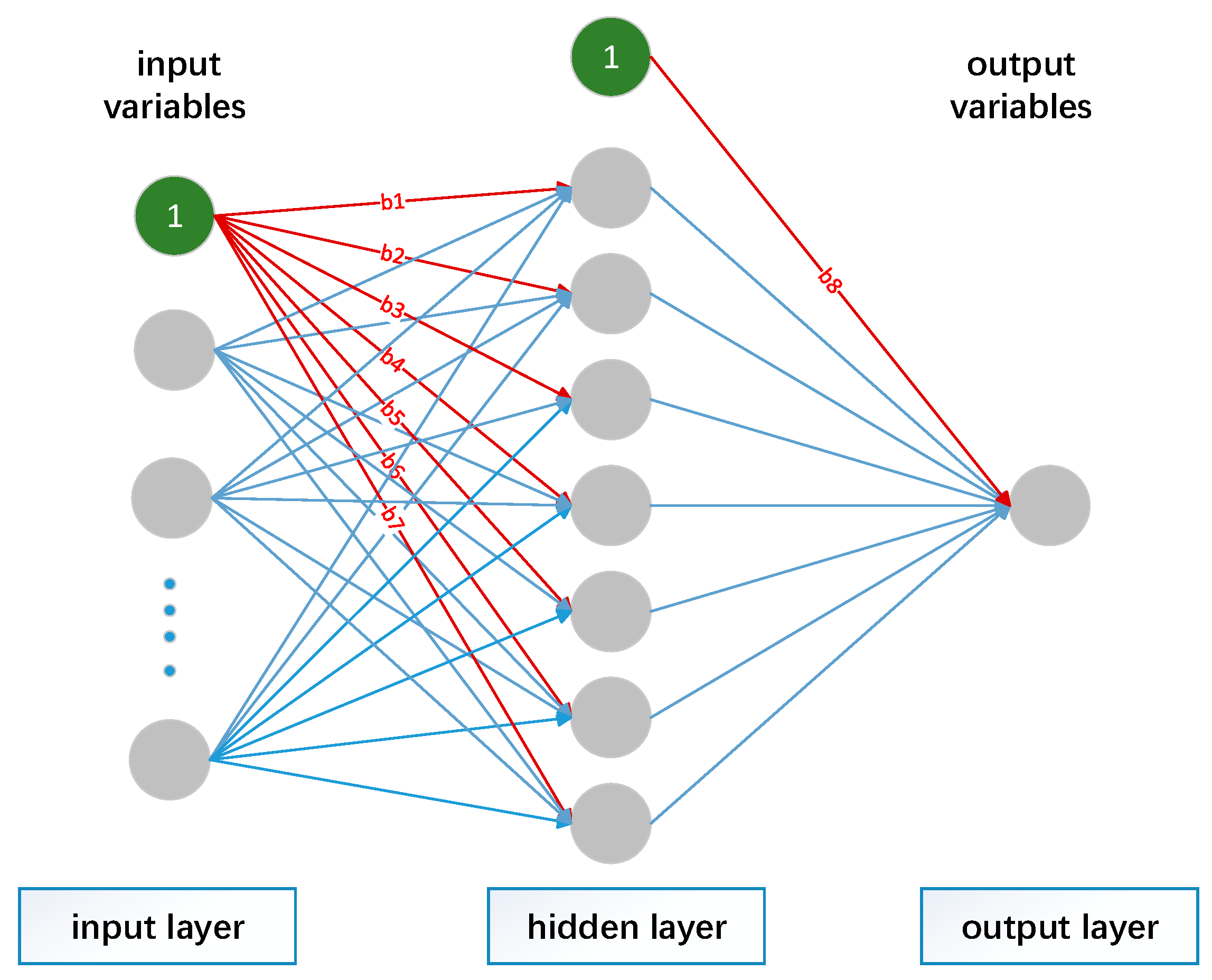
2.2.1. Back-Propagation Neural Network
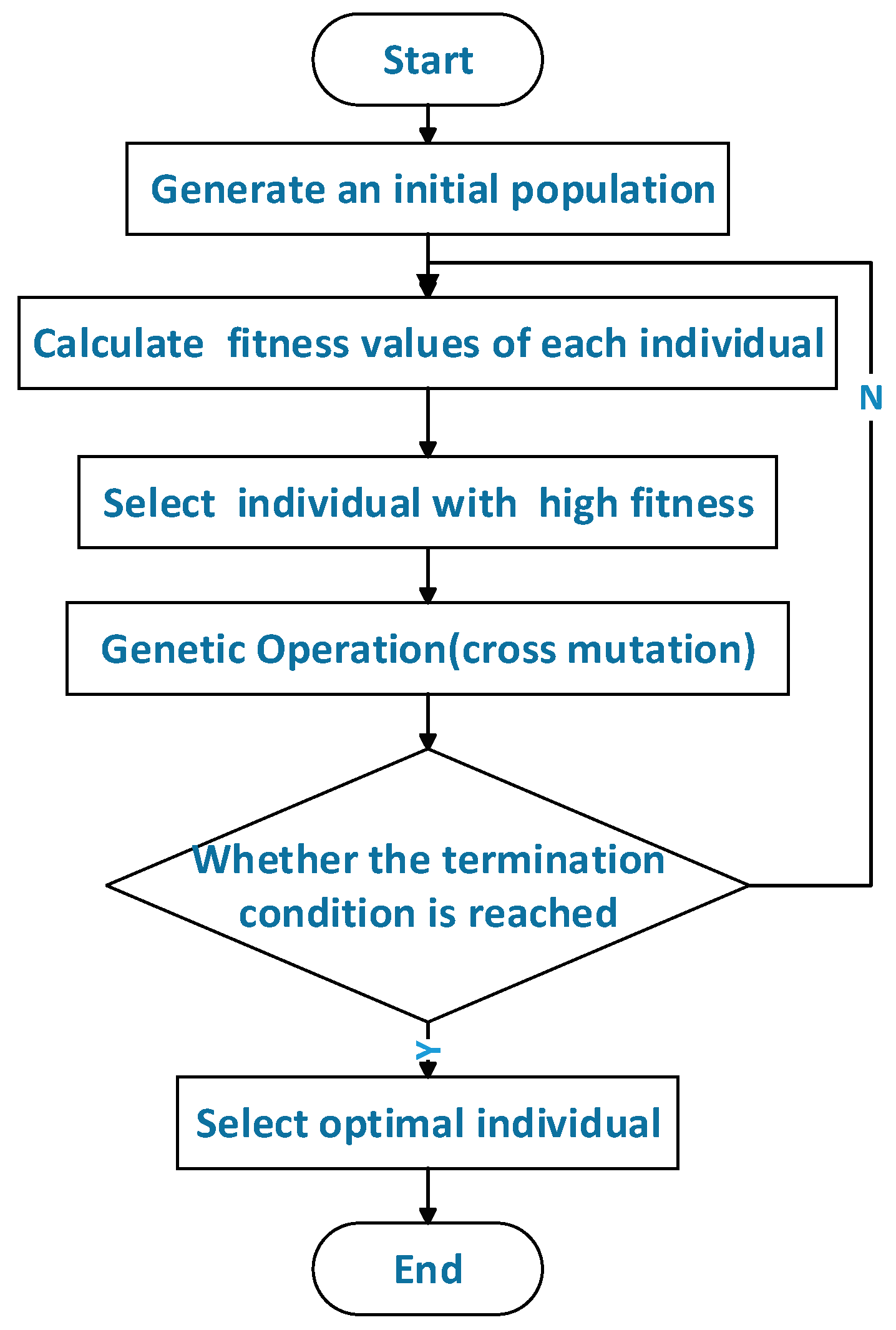
2.2.2. Genetic Algorithm
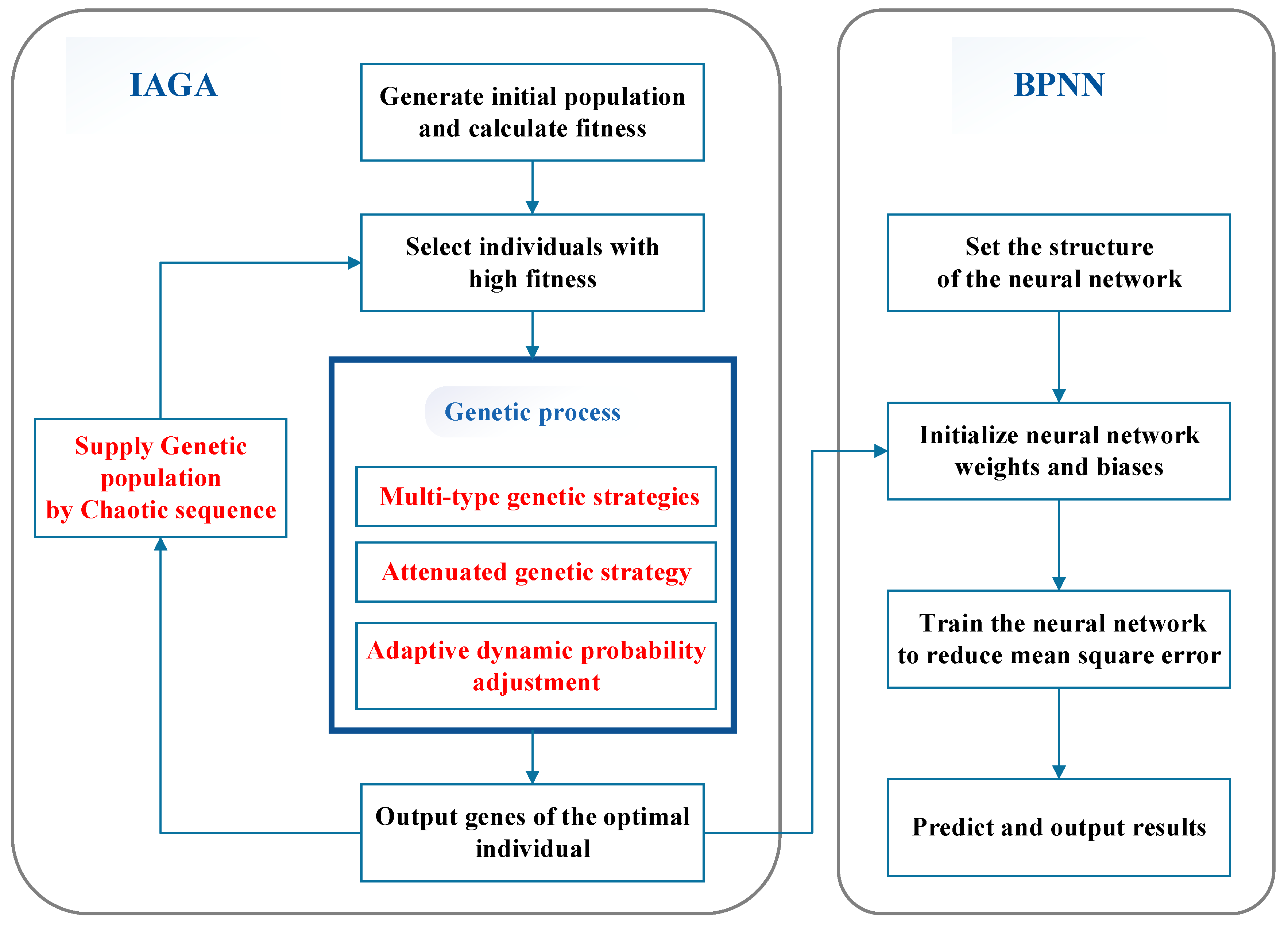
2.2.3. Improved Genetic Algorithm Coupled with Neural Network Model
2.2.4. Improved Genetic Algorithm Coupled with Neural Network Model
3. Results and Discussion
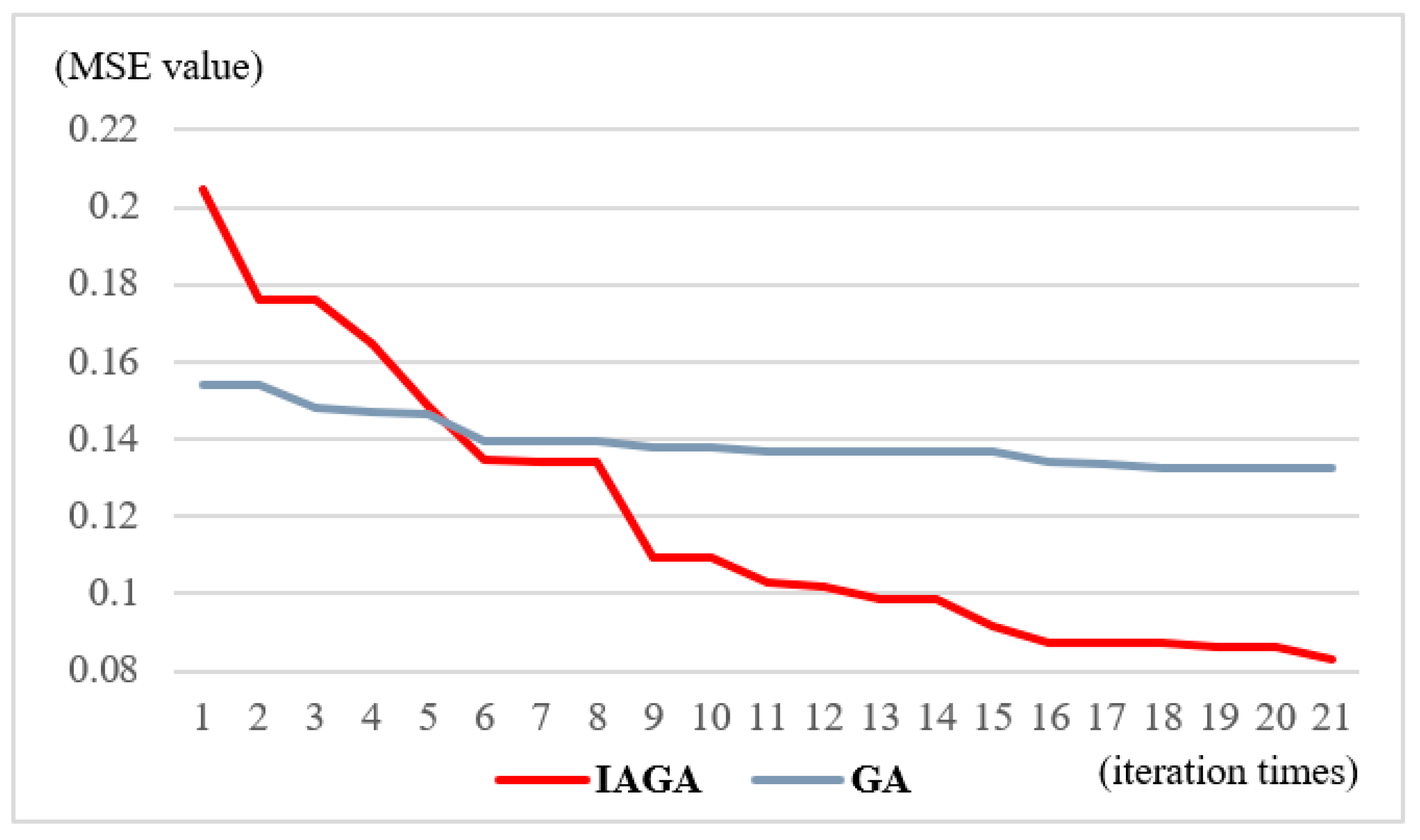
3.1. Model Parameters Setting
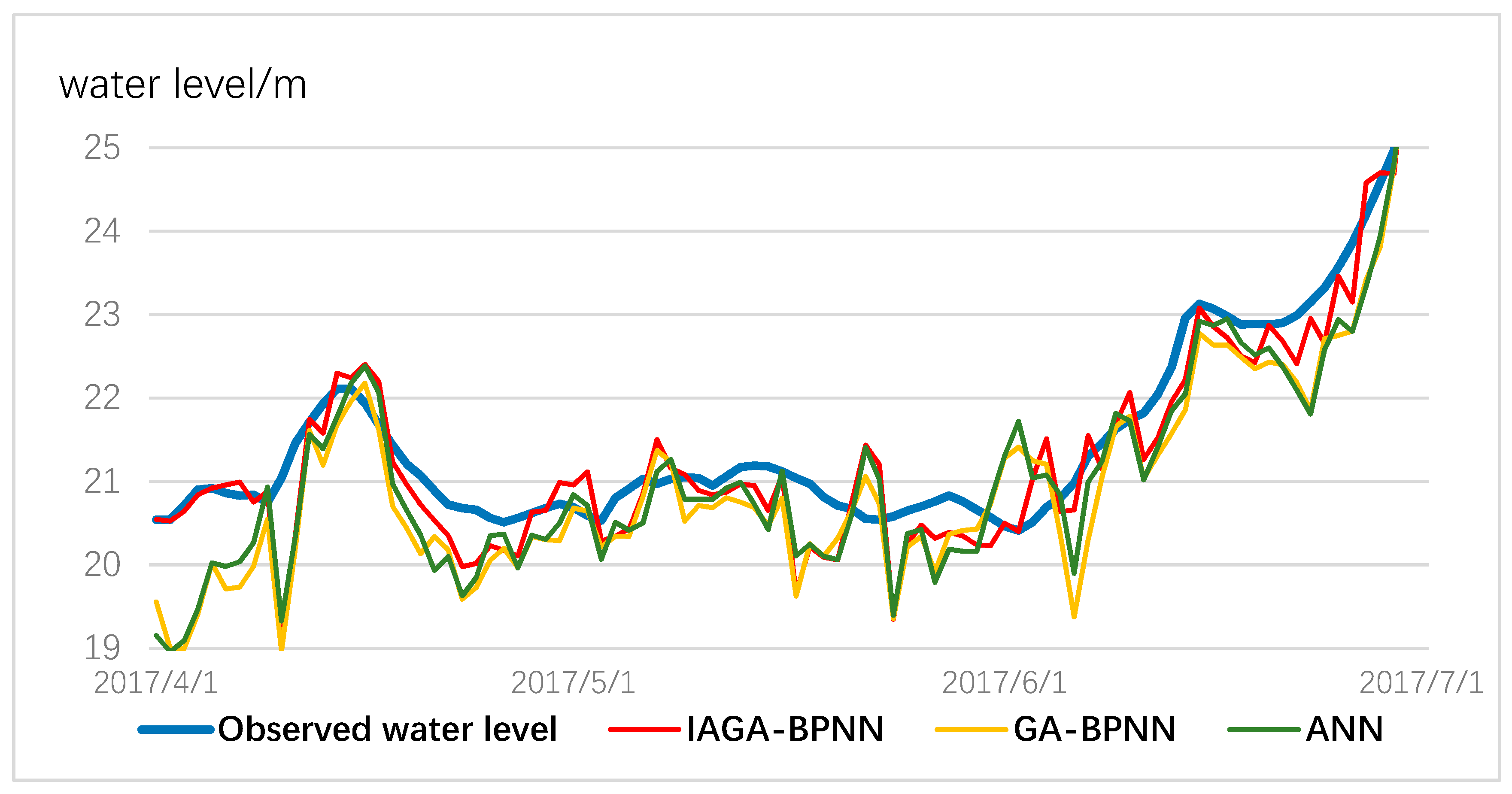
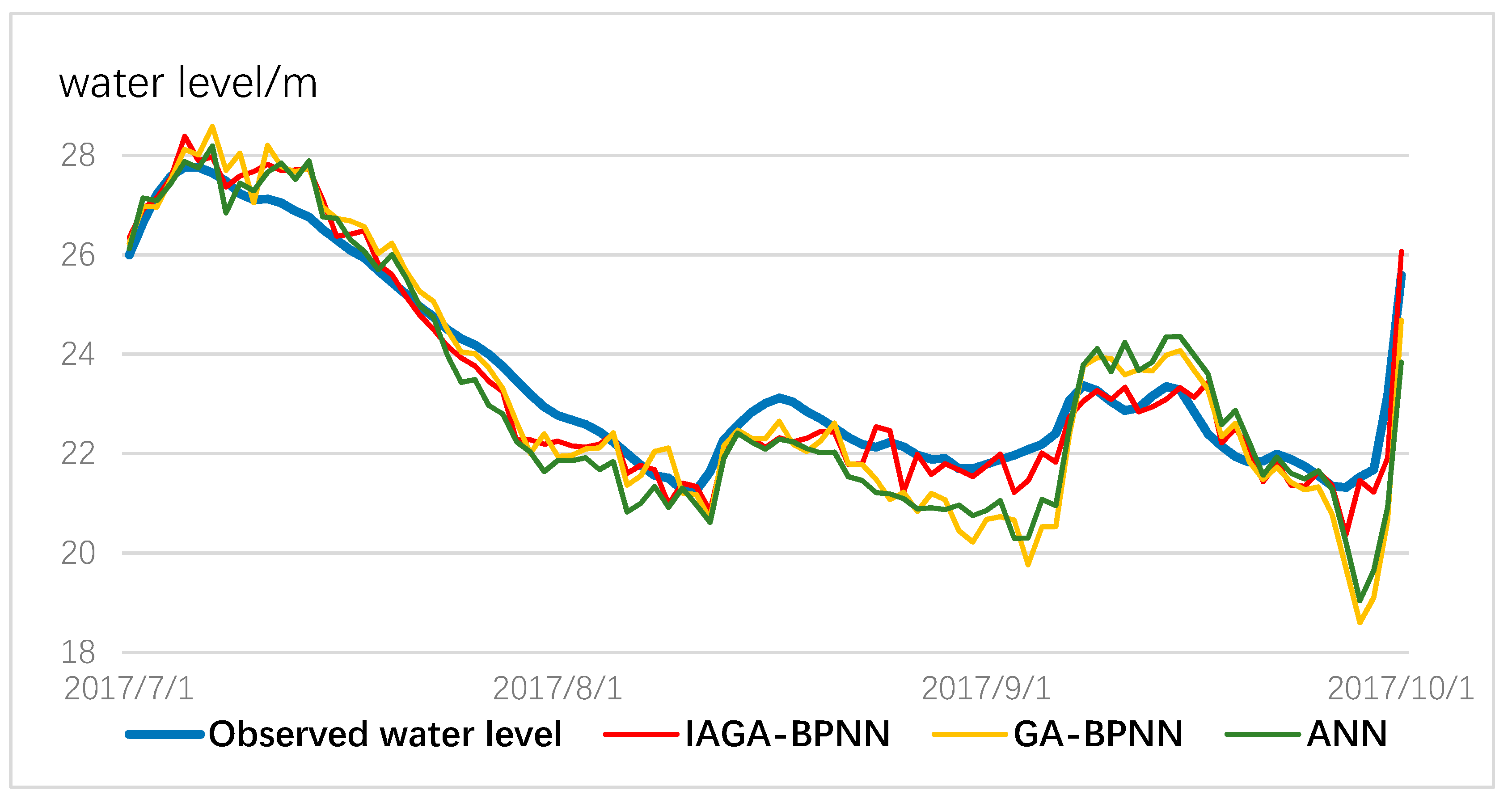
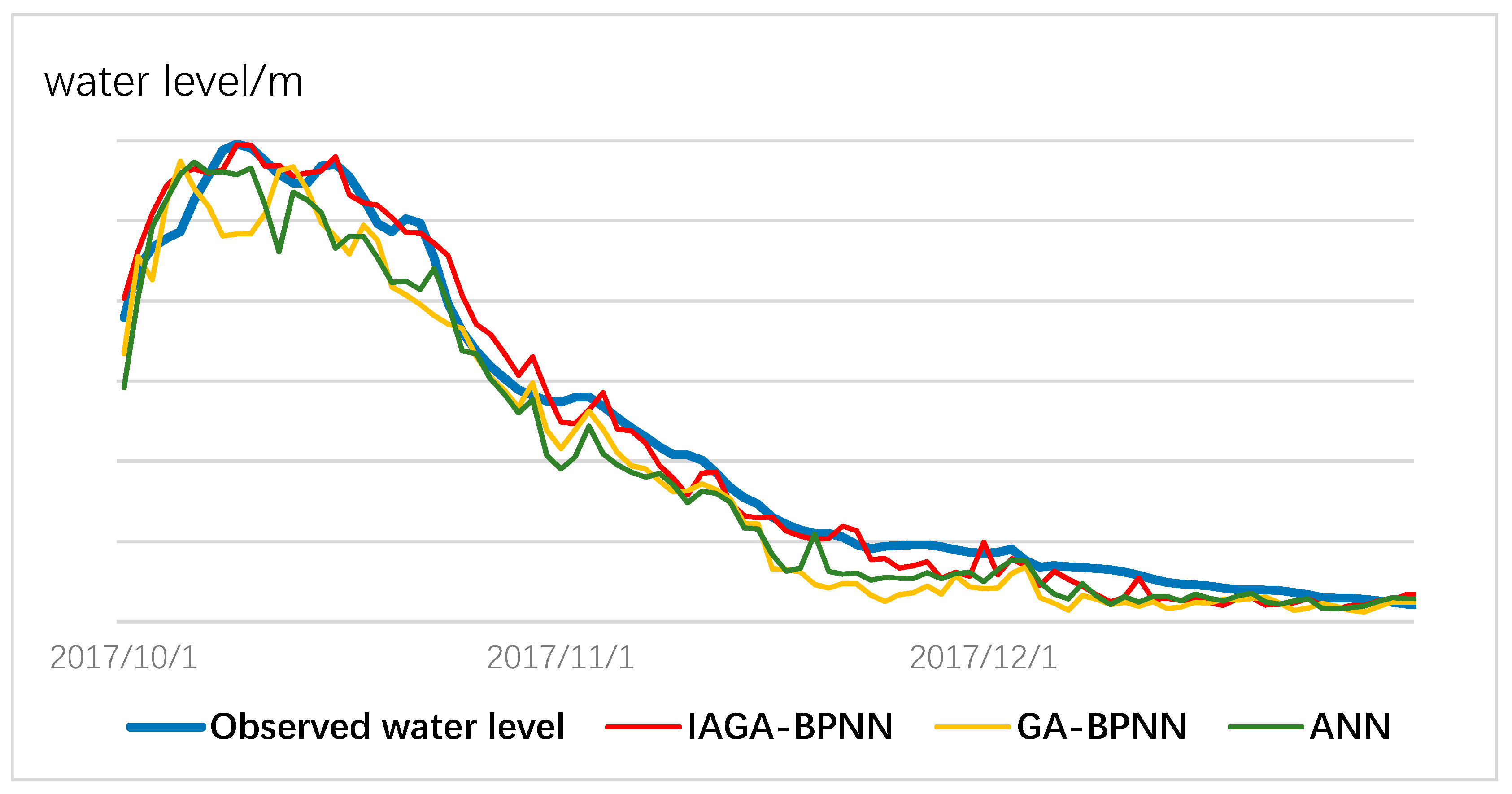
3.2. Prediction Results
3.3. Comparison of Improved Genetic Algorithm Coupling a Back-Propagation Neural Network (IGA-BPNN) with Traditional GA-BPNN and Artificial Neural Network
4. Conclusions
- The IGA-BPNN model proposed uses a variety of genetic strategies to maximize the efficiency of the genetic algorithm for neural network initial weights and biases. It can deal with the limited optimization, and local convergence is often occurring in the algorithm, while facing the complex and multi-node networks.
- Compared with the traditional ANN and GA-BPNN models, the IGA-BPNN can capture the non-linear rainfall; the water-level relationship of the studied area very well and performs better when predicting water level, regardless of frequent rain or the gentle change of water level. The IGA-BPNN model has a suitability for water-level predictions and would provide a better effect of short-term flood forecasting.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Aerts, J.; Botzen, W.; Clarke, K.; Cutter, S.; Hall, J.W.; Merz, B.; Michel-Kerjan, E.; Mysiak, J.; Surminski, S.; Kunreuther, H. Integrating human behaviour dynamics into flood disaster risk assessment. Nat. Clim. Chang. 2018, 8, 193. [Google Scholar] [CrossRef]
- Park, E.; Parker, J. A simple model for water table fluctuations in response to precipitation. J. Hydrol. 2008, 356, 344–349. [Google Scholar] [CrossRef]
- ASCE. Artificial neural networks in hydrology. I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar] [CrossRef]
- Anderson, M.P.; Woessner, W.W.; Hunt, R.J. Applied Groundwater Modeling: Simulation of Flow and Advective Transport; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Yoon, H.; Jun, S.-C.; Hyun, Y.; Bae, G.-O.; Lee, K.-K. A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater level forecasting using artificial neural networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Nayak, P.C.; Rao, Y.S.; Sudheer, K. Groundwater level forecasting in a shallow aquifer using artificial neural network approach. Water Resour. Manag. 2006, 20, 77–90. [Google Scholar] [CrossRef]
- Bustami, R.; Bessaih, N.; Bong, C.; Suhaili, S. Artificial neural network for precipitation and water level predictions of Bedup River. IAENG Int. J. Comput. Sci. 2007, 34, 228–233. [Google Scholar]
- Adamowski, J.; Chan, H.F. A wavelet neural network conjunction model for groundwater level forecasting. J. Hydrol. 2011, 407, 28–40. [Google Scholar] [CrossRef]
- Piasecki, A.; Jurasz, J.; Skowron, R. Forecasting surface water level fluctuations of lake Serwy (Northeastern Poland) by artificial neural networks and multiple linear regression. J. Environ. Eng. Landsc. Manag. 2017, 25, 379–388. [Google Scholar] [CrossRef]
- Zhong, C.; Jiang, Z.; Chu, X.; Guo, T.; Wen, Q. Water level forecasting using a hybrid algorithm of artificial neural networks and local Kalman filtering. J. Eng. Marit. Environ. 2019, 233, 174–185. [Google Scholar] [CrossRef]
- Wang, Y.; Tabari, H.; Xu, Y.; Xu, Y.; Wang, Q. Unraveling the role of human activities and climate variability in water level changes in the Taihu plain using artificial neural network. Water 2019, 11, 720. [Google Scholar] [CrossRef]
- Faruk, D.Ö. A hybrid neural network and ARIMA model for water quality time series prediction. Eng. Appl. Artif. Intell. 2010, 23, 586–594. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Bazartseren, B.; Hildebrandt, G.; Holz, K.-P. Short-term water level prediction using neural networks and neuro-fuzzy approach. Neurocomputing 2003, 55, 439–450. [Google Scholar] [CrossRef]
- Kuremoto, T.; Kimura, S.; Kobayashi, K.; Obayashi, M. Time series forecasting using a deep belief network with restricted Boltzmann machines. Neurocomputing 2014, 137, 47–56. [Google Scholar] [CrossRef]
- Wang, L.; Zeng, Y.; Chen, T. Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Syst. Appl. 2015, 42, 855–863. [Google Scholar] [CrossRef]
- Khan, A.U.; Bandopadhyaya, T.K.; Sharma, S. Genetic algorithm based backpropagation neural network performs better than backpropagation neural network in stock rates prediction. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 162–166. [Google Scholar]
- Kisi, O.; Alizamir, M.; Zounemat-Kermani, M. Modeling groundwater fluctuations by three different evolutionary neural network techniques using hydroclimatic data. Nat. Hazards 2017, 87, 367–381. [Google Scholar] [CrossRef]
- Fonseca, C.M.; Fleming, P.J. An overview of evolutionary algorithms in multiobjective optimization. Evol. Comput. 1995, 3, 1–16. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Sedki, A.; Ouazar, D.; El Mazoudi, E. Evolving neural network using real coded genetic algorithm for daily rainfall–runoff forecasting. Expert Syst. Appl. 2009, 36, 4523–4527. [Google Scholar] [CrossRef]
- Dash, N.B.; Panda, S.N.; Remesan, R.; Sahoo, N. Hybrid neural modeling for groundwater level prediction. Neural Comput. Appl. 2010, 19, 1251–1263. [Google Scholar] [CrossRef]
- Sivanandam, S.; Deepa, S. Genetic algorithm optimization problems. In Introduction to Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2008; pp. 165–209. [Google Scholar]
- Singh, D.; Agrawal, S. Self organizing migrating algorithm with nelder mead crossover and log-logistic mutation for large scale optimization. In Computational Intelligence for Big Data Analysis; Springer International Publishing: Cham, Switzerland, 2015; pp. 143–164. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature. 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Chen, F.-C. Back-propagation neural networks for nonlinear self-tuning adaptive control. IEEE Control Syst. Mag. 1990, 10, 44–48. [Google Scholar] [CrossRef]
- Goh, A.T. Back-propagation neural networks for modeling complex systems. Artif. Intell. Eng. 1995, 9, 143–151. [Google Scholar] [CrossRef]
- Buscema, M. Back propagation neural networks. Subst. Use Misuse 1998, 33, 233–270. [Google Scholar] [CrossRef]
- Holland, J. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Application to Biology; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Hassan, R.; Cohanim, B.; De Weck, O.; Venter, G. A comparison of particle swarm optimization and the genetic algorithm. In Proceedings of the 46th AIAA/ASME/ASCE/AHS/ASC structures, structural dynamics and materials conference, Austin, TX, USA, 18–21 April 2005; p. 1897. [Google Scholar]
- Kuo, J.-T.; Wang, Y.-Y.; Lung, W.-S. A hybrid neural–genetic algorithm for reservoir water quality management. Water Res. 2006, 40, 1367–1376. [Google Scholar] [CrossRef]
- Wang, W.; Ding, J. Wavelet network model and its application to the prediction of hydrology. Nat. Sci. 2003, 1, 67–71. [Google Scholar]
- Niaona, Z.; Dejiang, Z.; Yong, F. The optimal design of terminal sliding controller for flexible manipulators based on chaotic genetic algorithm. Control Theory Appl. 2008, 25, 451–455. [Google Scholar]
- Xian, Z.; Wu, H.; Siqing, S.; Shaoquan, Z. Application of genetic algorithm-neural network for the correction of bad data in power system. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 1894–1897. [Google Scholar]
- Kim, H.-D.; Park, C.-H.; Yang, H.-C.; Sim, K.-B. Genetic algorithm based feature selection method development for pattern recognition. In Proceedings of the 2006 SICE-ICASE International Joint Conference, Busan, Korea, 18–21 October 2006; pp. 1020–1025. [Google Scholar]
- Li, P.; Tan, Z.; Yan, L.; Deng, K. Time series prediction of mining subsidence based on genetic algorithm neural network. In Proceedings of the 2011 International Symposium on Computer Science and Society, London, UK, 26–28 September 2011; pp. 83–86. [Google Scholar]
- Gao, C.; Wang, B.; Zhou, C.J.; Zhang, Q. Multiple sequence alignment based on combining genetic algorithm with chaotic sequences. Genet. Mol. Res. 2016, 15, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.L.; Chau, K.-W. A flood forecasting neural network model with genetic algorithm. Intjenvironpollut 2006, 28, 261–273. [Google Scholar] [CrossRef]
- Michalewicz, Z.; Janikow, C.Z.; Krawczyk, J.B. A modified genetic algorithm for optimal-control problems. Comput. Math. Appl. 1992, 23, 83–94. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Organization | Available Data | DataSet |
|---|---|---|---|
| Meteorological | CMA | 2010–2017 | evapotranspiration, precipitation, ground temperature, humidity, sunshine-hours, wind direction, atmospheric pressure, temperature |
| Station Observation | HHB | 2010–2017 | water level |
| Delay Time | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| The CCF of precipitation | 0.642 | 0.714 | 0.630 | 0.533 | 0.528 |
| The CCF of upstream water level | 0.722 | 0.706 | 0.671 | 0.662 | 0.638 |
| Meteorological Type | Correlation Coefficient |
|---|---|
| evapotranspiration wind direction | 0.54 |
| ground temperature | 0.47 |
| precipitation | 0.77 |
| atmospheric pressure | 0.52 |
| humidity | 0.48 |
| sunshine hours | 0.53 |
| temperature | 0.62 |
| wind direction | 0.54 |
| Parameter Type | IGA Parameter |
|---|---|
| Basic parameter | number of generations = 20 population size = 40 |
| Genetic parameter | crossover probability = [0.9, 0.4] mutation probability = [0.1, 0.01] number of crossover = [50, 1] number of mutation = [20, 1] |
| Parameter Type | BPNN Parameter |
|---|---|
| Study parameter | Learning rate = 0.01 momentum factor = 0.7 transfer function = |
| Structure parameter | Number of input nodes = 48 (5 meteorological stations × 8 types of meteorological information per meteorological station + the water level monitored by 8 stations) number of hidden nodes = 7, number of output nodes = 1 The initial value of weight and bias = genes of best individual in IGA |
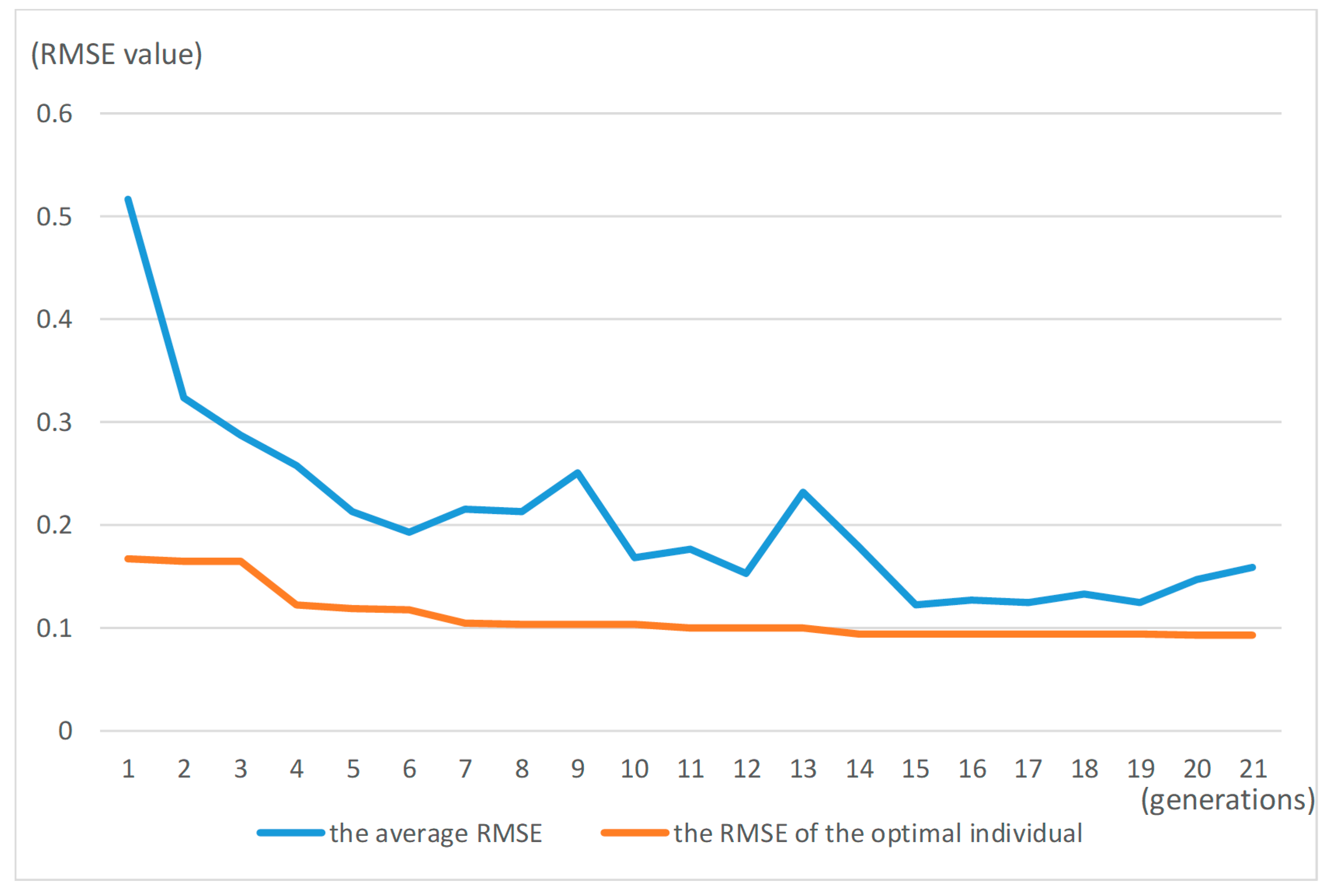
| Number of Generations | 1 | 4 | 7 | 10 | 13 | 16 | 19 | 21 |
|---|---|---|---|---|---|---|---|---|
| The RMSE value of Optimal individual | 0.167 | 0.164 | 0.117 | 0.104 | 0.100 | 0.093 | 0.093 | 0.093 |
| The average RMSE in population | 0.516 | 0.287 | 0.193 | 0.251 | 0.152 | 0.122 | 0.135 | 0.147 |
| Times | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| RMSE | 0.241 | 0.473 | 0.535 | 0.299 | 0.765 | 0.522 | 0.522 | 0.680 | 0.306 | 0.381 |
| Times | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| RMSE | 0.409 | 0.721 | 0.316 | 1.0988 | 0.0519 | 0.399 | 0.8006 | 0.319 | 0.820 | 0.361 |
| IGA-BPNN | GA-BPNN | ANN | ||||
|---|---|---|---|---|---|---|
| Verification | Prediction | Verification | Prediction | Verification | Prediction | |
| RMSE | 0.2123 | 0.4722 | 0.3436 | 0.6258 | 0.3145 | 0.6432 |
| NSE | 0.9792 | 0.9382 | 0.9521 | 0.8233 | 0.9243 | 0.7443 |
| R | 0.9734 | 0.9423 | 0.9642 | 0.9257 | 0.9621 | 0.9015 |
| MSRE | 0.011 | 0.031 | 0.015 | 0.037 | 0.014 | 0.045 |
| MAE | 0.241 | 0.516 | 0.227 | 0.472 | 0.375 | 0.501 |
| MARE | 0.010 | 0.023 | 0.014 | 0.033 | 0.015 | 0.029 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, N.; Xiong, C.; Du, W.; Wang, C.; Lin, X.; Chen, Z. An Improved Genetic Algorithm Coupling a Back-Propagation Neural Network Model (IGA-BPNN) for Water-Level Predictions. Water 2019, 11, 1795. https://doi.org/10.3390/w11091795
Chen N, Xiong C, Du W, Wang C, Lin X, Chen Z. An Improved Genetic Algorithm Coupling a Back-Propagation Neural Network Model (IGA-BPNN) for Water-Level Predictions. Water. 2019; 11(9):1795. https://doi.org/10.3390/w11091795
Chicago/Turabian StyleChen, Nengcheng, Chang Xiong, Wenying Du, Chao Wang, Xin Lin, and Zeqiang Chen. 2019. "An Improved Genetic Algorithm Coupling a Back-Propagation Neural Network Model (IGA-BPNN) for Water-Level Predictions" Water 11, no. 9: 1795. https://doi.org/10.3390/w11091795
APA StyleChen, N., Xiong, C., Du, W., Wang, C., Lin, X., & Chen, Z. (2019). An Improved Genetic Algorithm Coupling a Back-Propagation Neural Network Model (IGA-BPNN) for Water-Level Predictions. Water, 11(9), 1795. https://doi.org/10.3390/w11091795