Uncertainty Analysis of Spatiotemporal Models with Point Estimate Methods (PEMs)—The Case of the ANUGA Hydrodynamic Model



Abstract
:1. Introduction
2. Materials and Methods
2.1. ANUGA
2.2. Monte Carlo Simulation
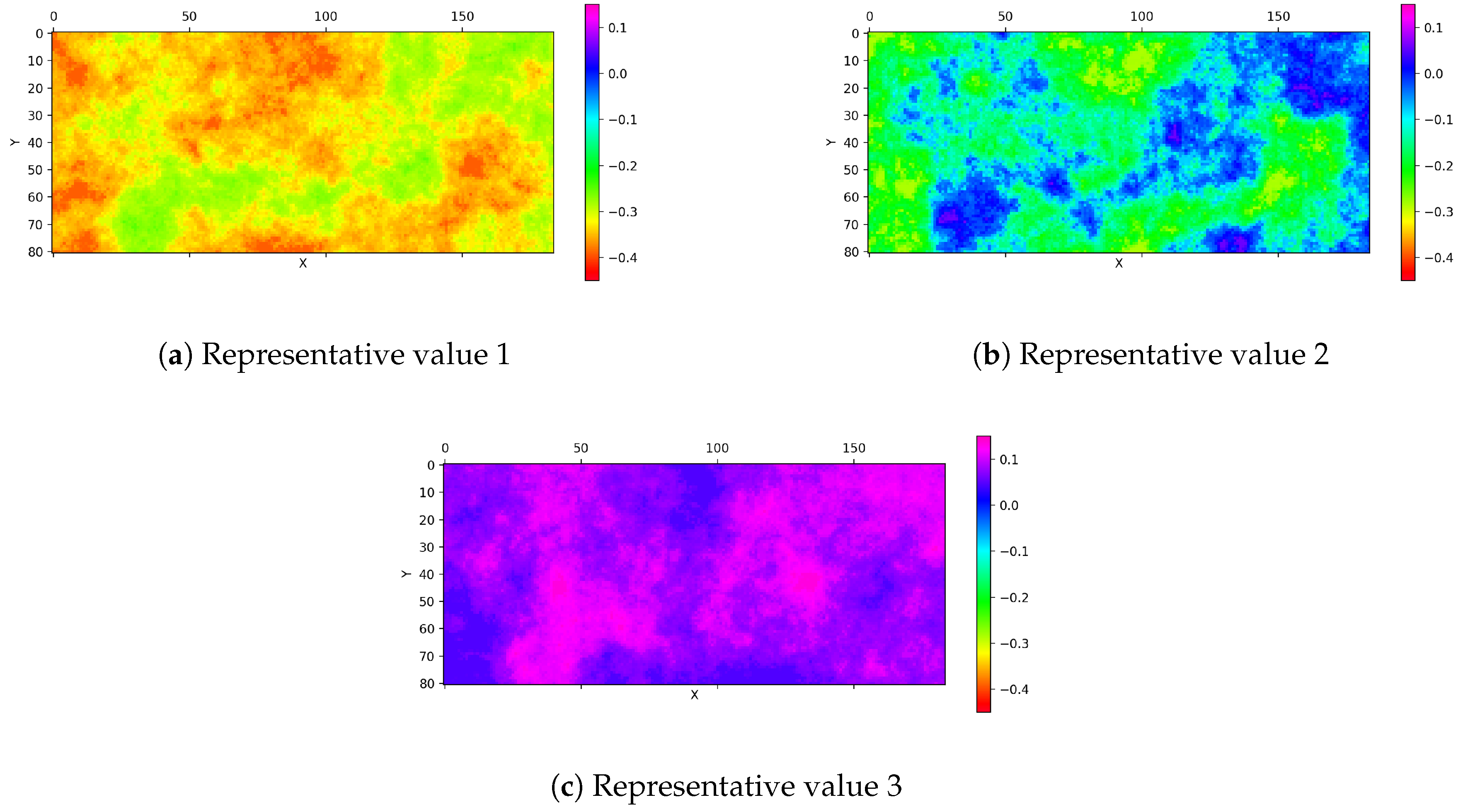
2.3. Hong’s Point Estimate Method
2.3.1. Theory
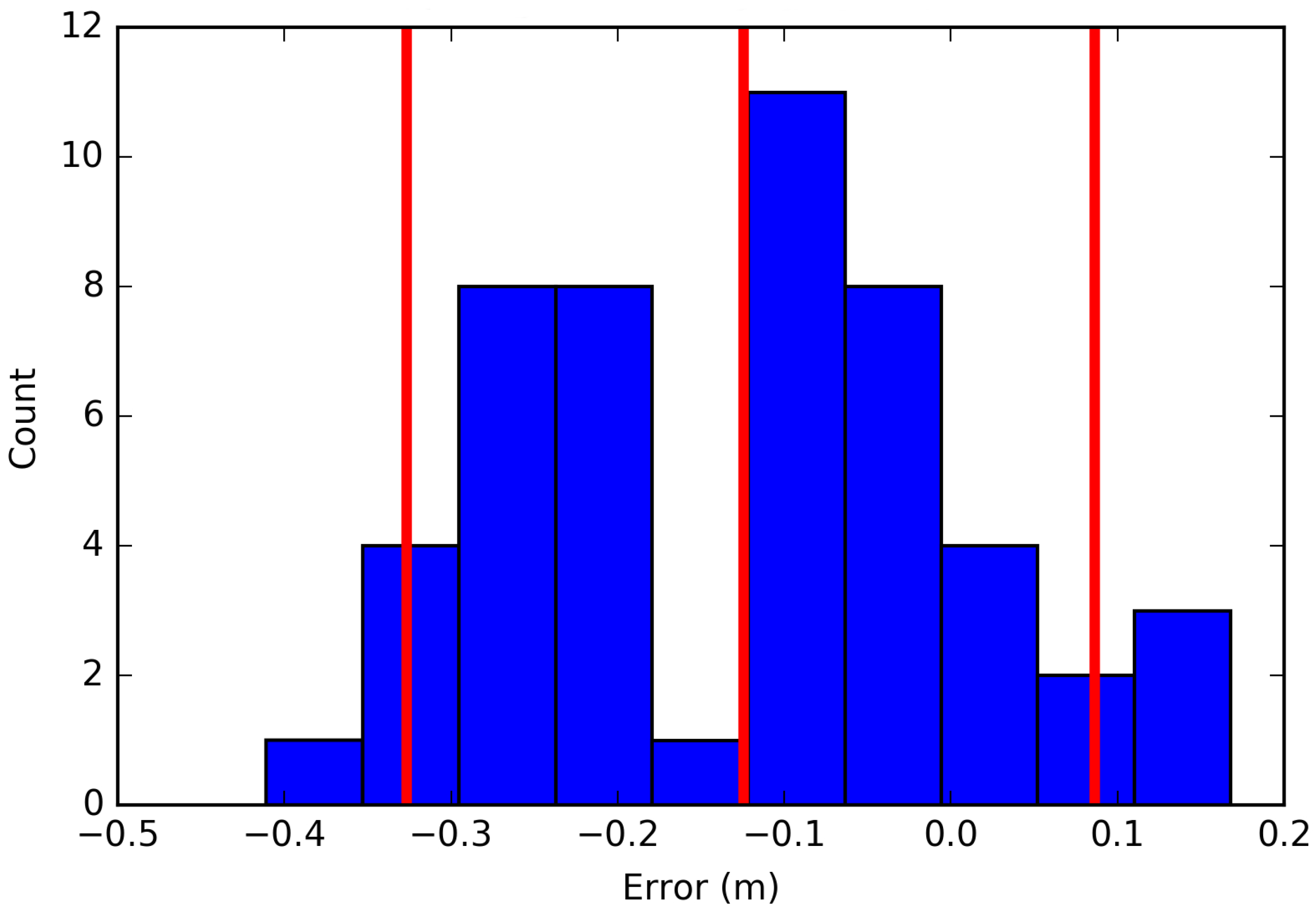
2.3.2. Spatial Implementation of PEM
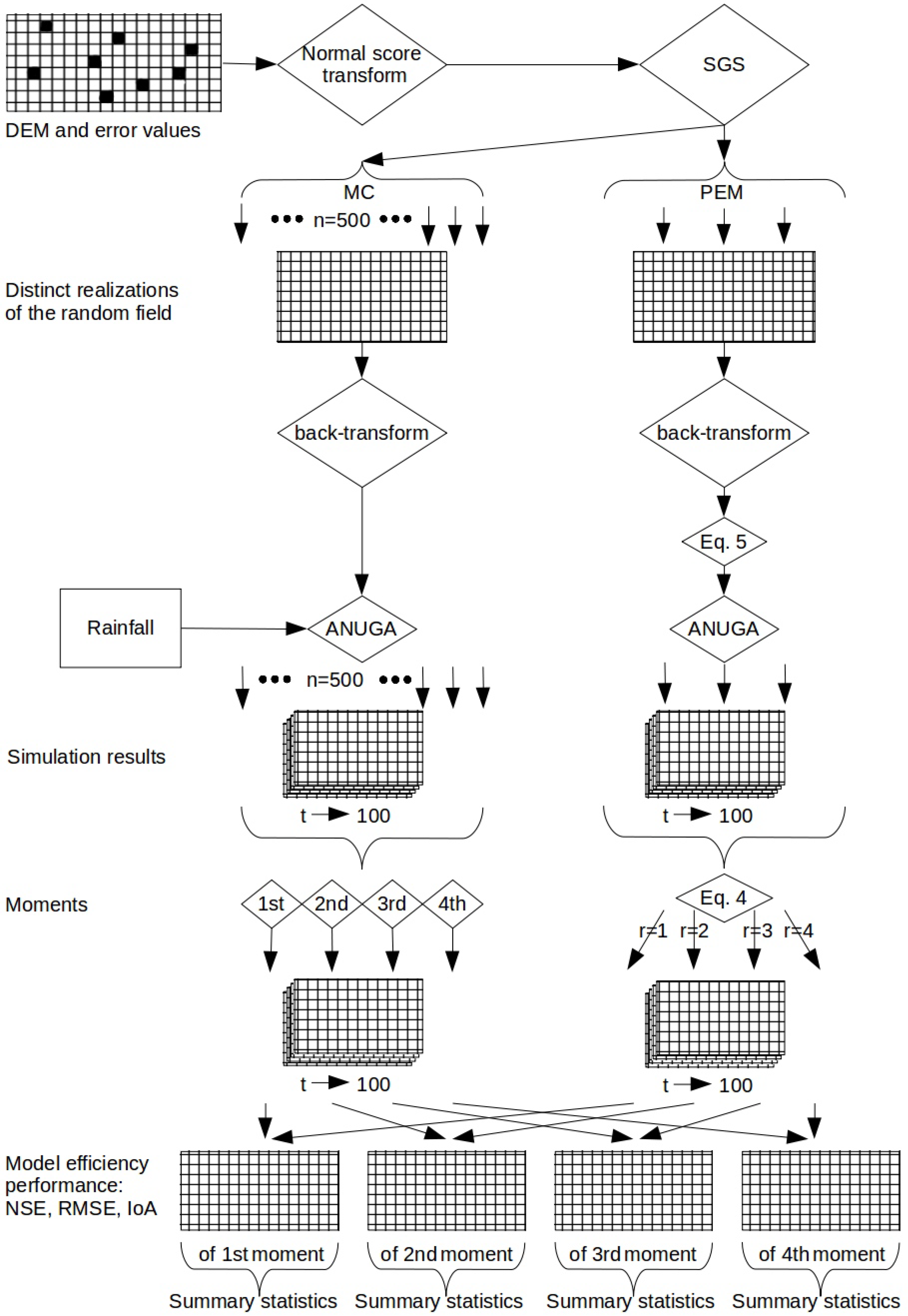
2.4. Workflow
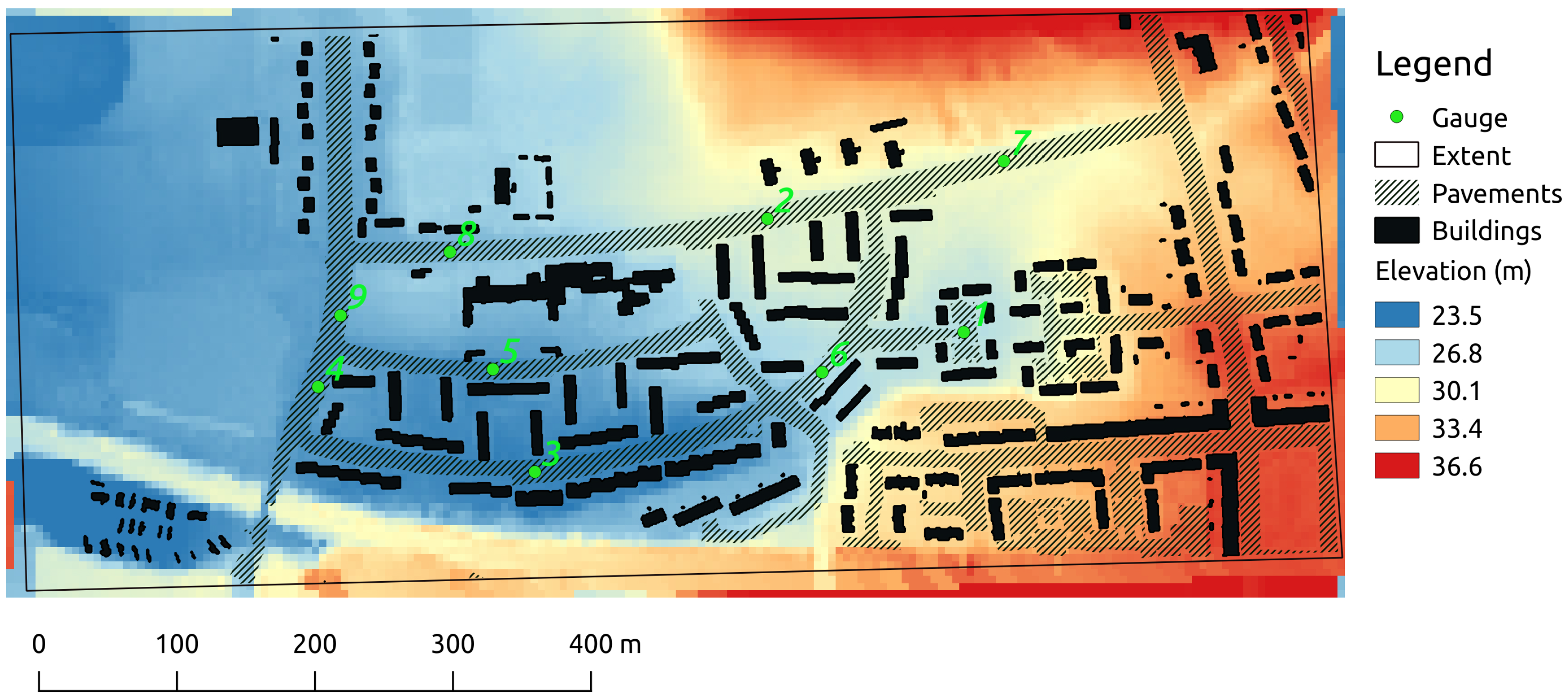
2.5. Case Study
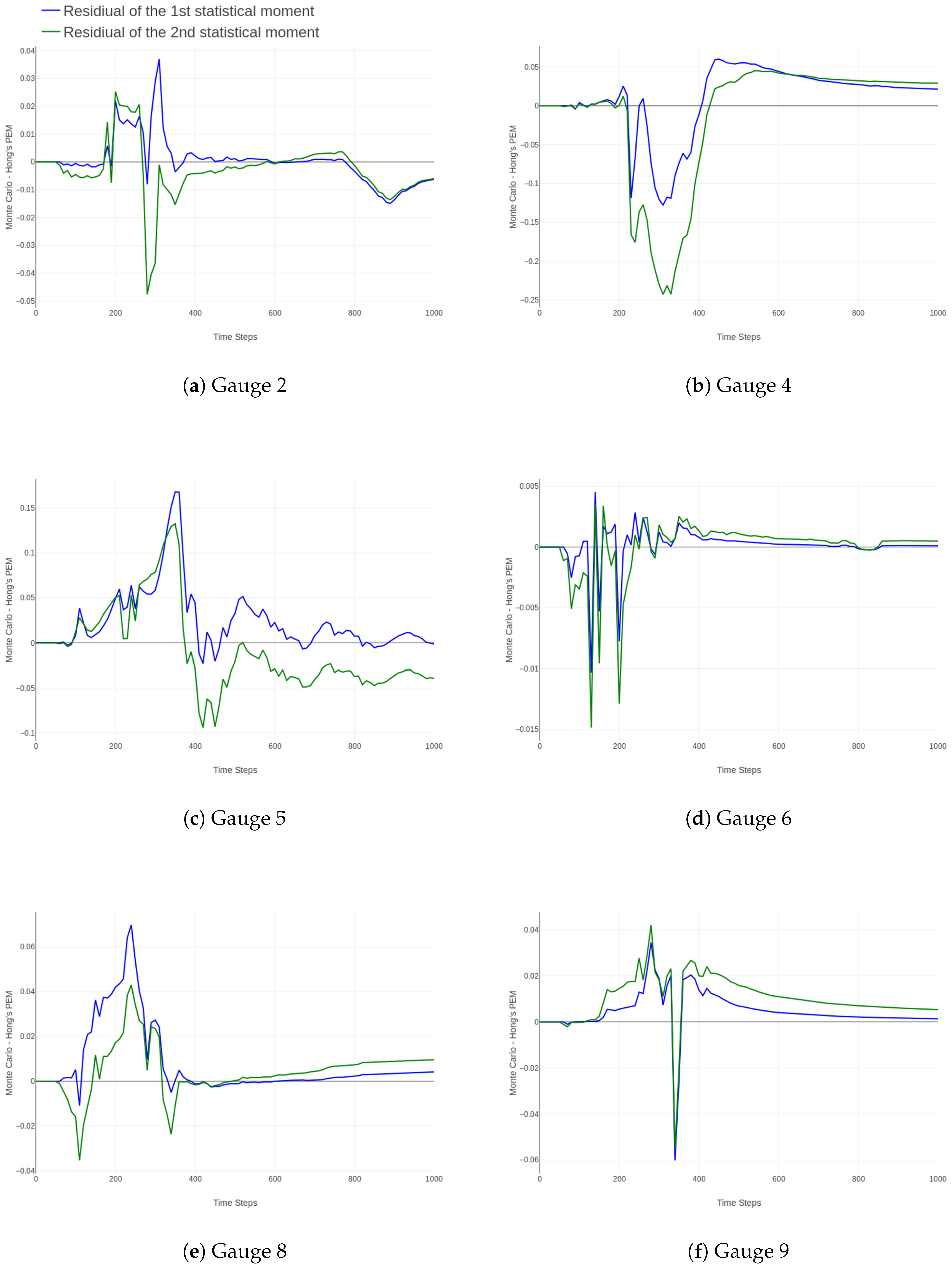
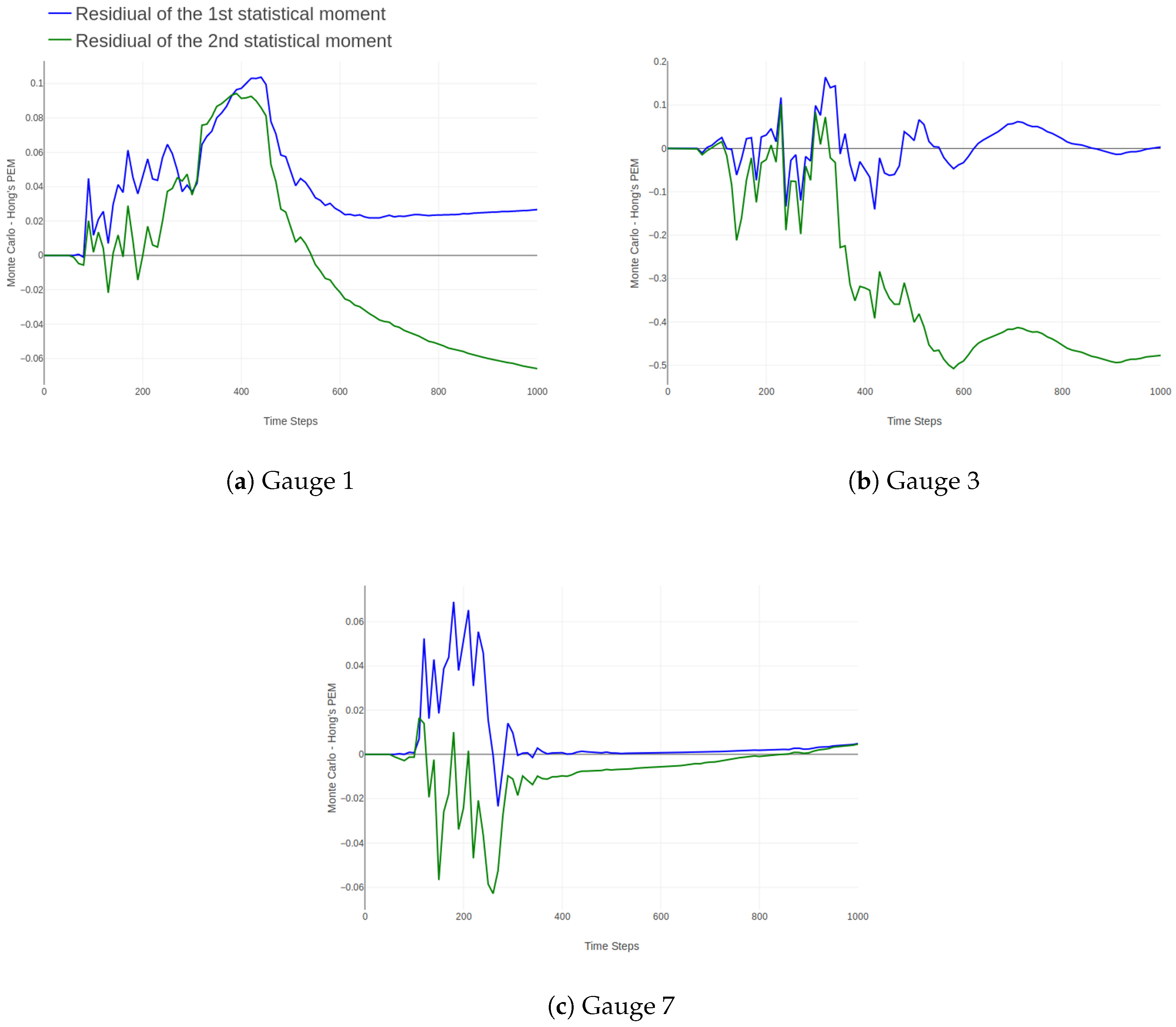
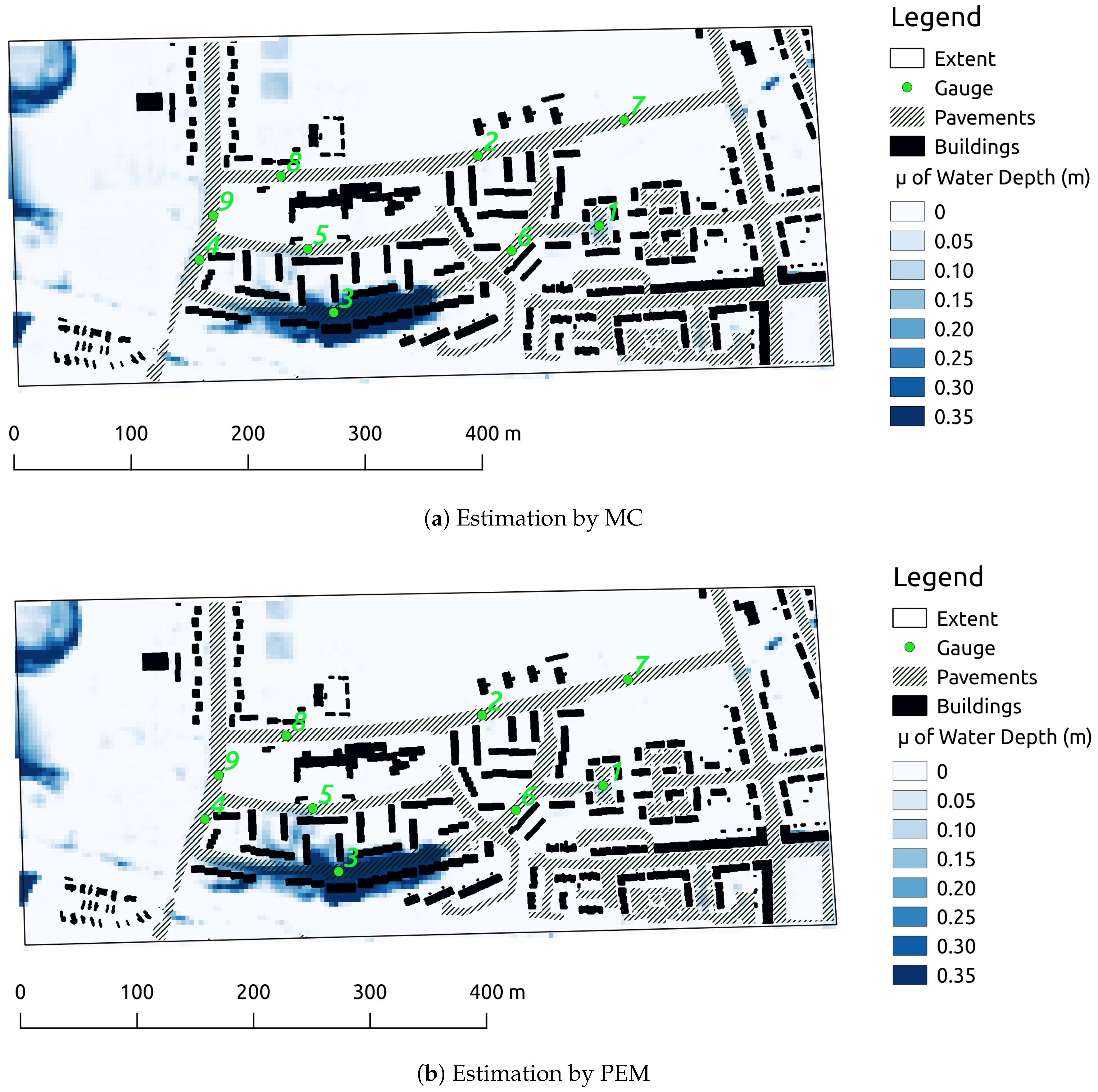
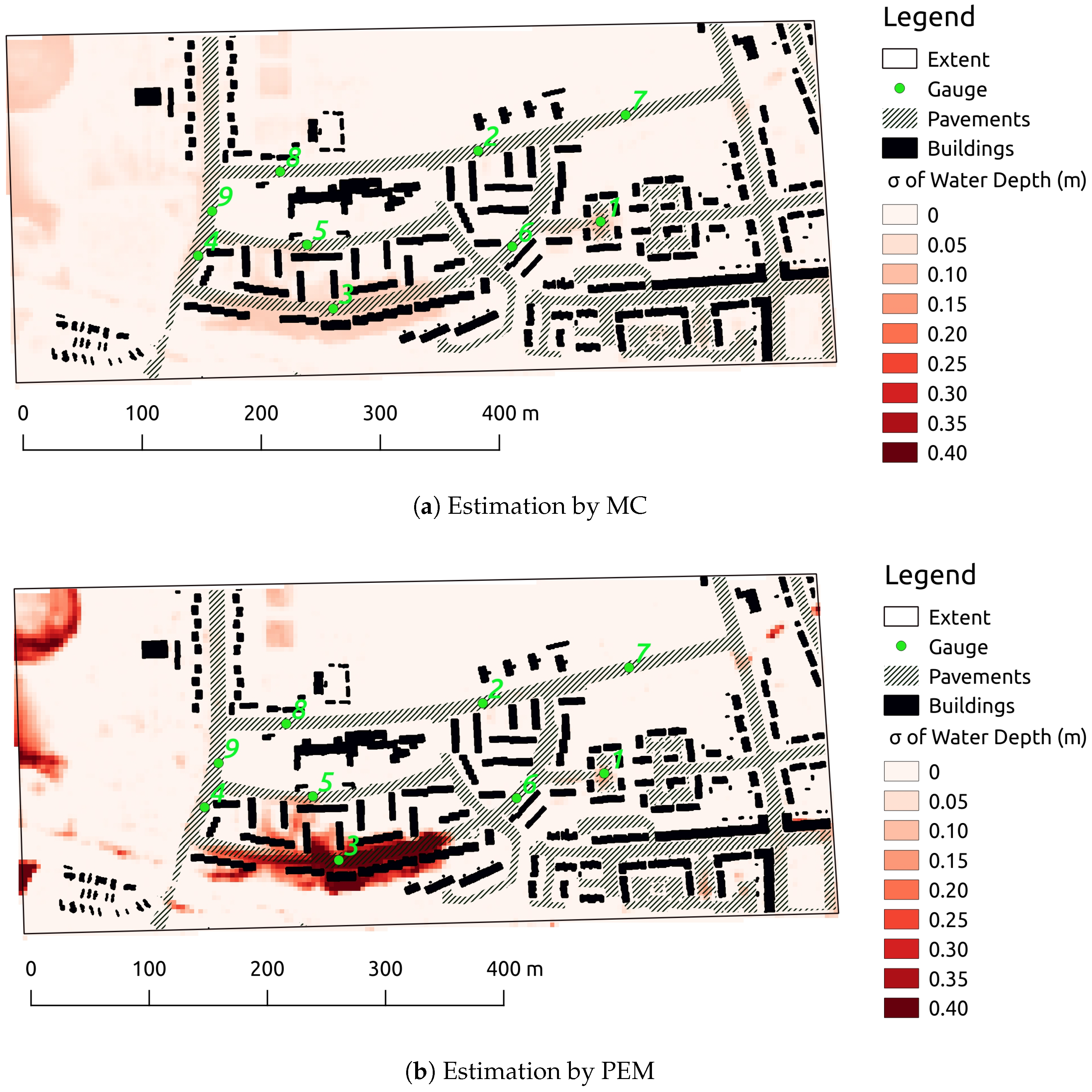
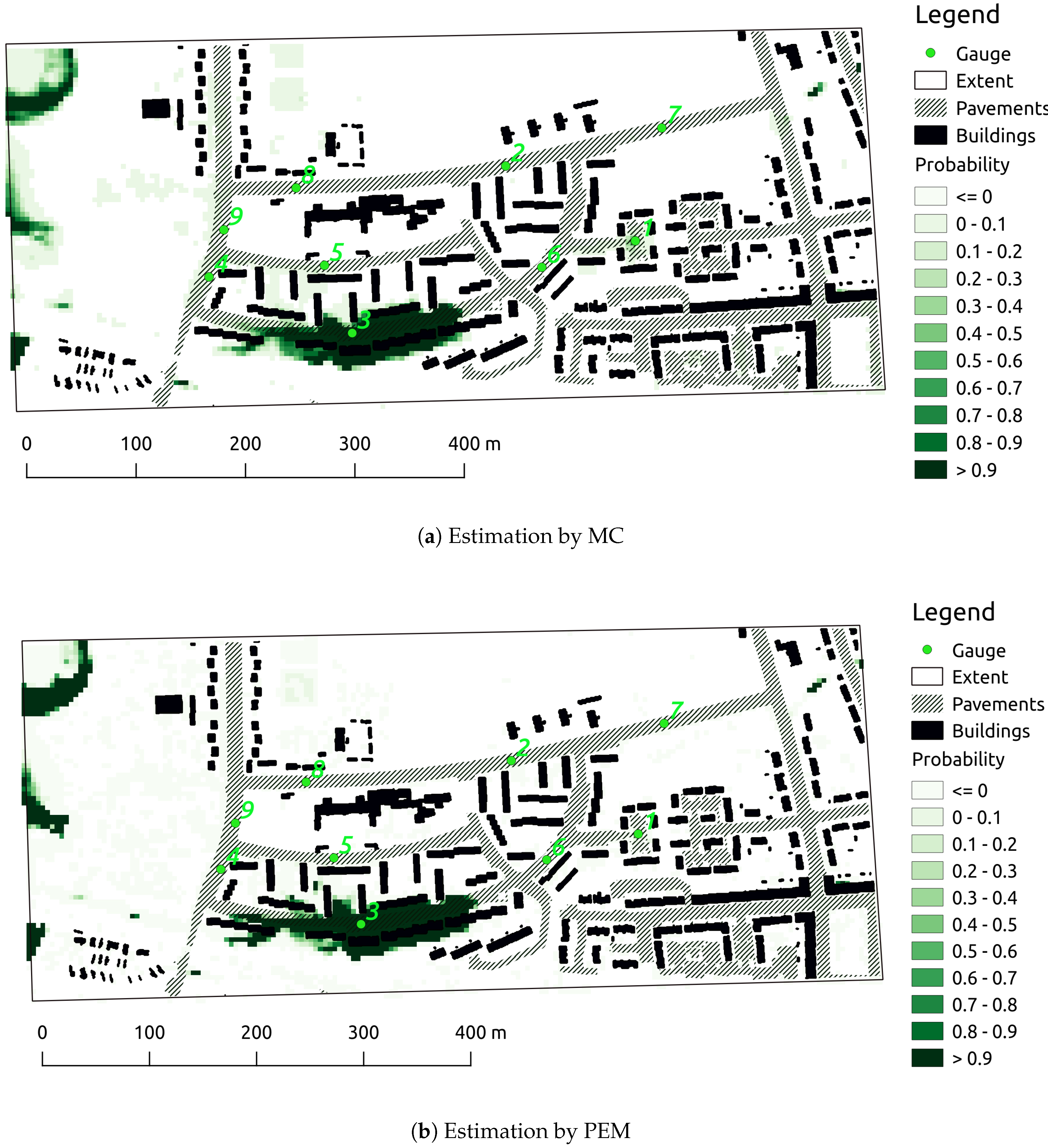
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Di Baldassarre, G.; Schumann, G.; Bates, P.D.; Freer, J.E.; Beven, K.J. Flood-plain mapping: A critical discussion of deterministic and probabilistic approaches. Hydrol. Sci. J. 2010, 55, 364–376. [Google Scholar] [CrossRef]
- Daniell, J.; Wenzel, F.; McLennan, A.; Daniell, K.; Kunz-Plapp, T.; Khazai, B.; Schaefer, A.; Kunz, M.; Girard, T. The global role of natural disaster fatalities in decision-making: statistics, trends and analysis from 116 years of disaster data compared to fatality rates from other causes. In Proceedings of the EGU General Assembly 2016 Conference, Vienna, Austria, 17–22 April 2016; Volume 18, p. 2021. [Google Scholar]
- Bubeck, P.; Kreibich, H.; Penning-Rowsell, E.C.; Botzen, W.; De Moel, H.; Klijn, F. Explaining differences in flood management approaches in Europe and in the USA–a comparative analysis. J. Flood Risk Manag. 2017, 10, 436–445. [Google Scholar] [CrossRef]
- Almeida, G.A.; Bates, P.; Freer, J.E.; Souvignet, M. Improving the stability of a simple formulation of the shallow water equations for 2-D flood modeling. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Bates, P.D. Integrating remote sensing data with flood inundation models: How far have we got? Hydrol. Process. 2012, 26, 2515–2521. [Google Scholar] [CrossRef]
- Hapuarachchi, H.A.P.; Wang, Q.J.; Pagano, T.C. A review of advances in flash flood forecasting. Hydrol. Process. 2011, 25, 2771–2784. [Google Scholar] [CrossRef]
- Merkuryeva, G.; Merkuryev, Y.; Sokolov, B.V.; Potryasaev, S.; Zelentsov, V.A.; Lektauers, A. Advanced river flood monitoring, modelling and forecasting. J. Comput. Sci. 2015, 10, 77–85. [Google Scholar] [CrossRef]
- Neal, J.; Villanueva, I.; Wright, N.; Willis, T.; Fewtrell, T.; Bates, P. How much physical complexity is needed to model flood inundation? Hydrol. Process. 2012, 26, 2264–2282. [Google Scholar] [CrossRef] [Green Version]
- Teng, J.; Jakeman, A.J.; Vaze, J.; Croke, B.F.; Dutta, D.; Kim, S. Flood inundation modelling: A review of methods, recent advances and uncertainty analysis. Environ. Model. Softw. 2017, 90, 201–216. [Google Scholar] [CrossRef]
- Stephens, E.M.; Bates, P.; Freer, J.; Mason, D. The impact of uncertainty in satellite data on the assessment of flood inundation models. J. Hydrol. 2012, 414, 162–173. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.J.; Hsu, K.C. Dynamic interactions of groundwater flow and soil deformation in randomly heterogeneous porous media. J. Hydrol. 2013, 499, 50–60. [Google Scholar] [CrossRef]
- Chang, C.H.; Tung, Y.K.; Yang, J.C. Monte Carlo simulation for correlated variables with marginal distributions. J. Hydraul. Eng. 1994, 120, 313–331. [Google Scholar] [CrossRef]
- Graham, W.; McLaughlin, D. Stochastic analysis of nonstationary subsurface solute transport: 2. Conditional moments. Water Resour. Res. 1989, 25, 2331–2355. [Google Scholar] [CrossRef]
- Li, S.G.; McLaughlin, D. A nonstationary spectral method for solving stochastic groundwater problems: Unconditional analysis. Water Resour. Res. 1991, 27, 1589–1605. [Google Scholar] [CrossRef]
- Gires, A.; Onof, C.; Maksimovic, C.; Schertzer, D.; Tchiguirinskaia, I.; Simoes, N. Quantifying the impact of small scale unmeasured rainfall variability on urban runoff through multifractal downscaling: A case study. J. Hydrol. 2012, 442, 117–128. [Google Scholar] [CrossRef] [Green Version]
- Tung, Y.K. Mellin transform applied to uncertainty analysis in hydrology/hydraulics. J. Hydraul. Eng. 1990, 116, 659–674. [Google Scholar] [CrossRef]
- Che-Hao, C.; Yeou-Koung, T.; Jinn-Chuang, Y. Evaluation of probability point estimate methods. Appl. Math. Model. 1995, 19, 95–105. [Google Scholar] [CrossRef]
- Franceschini, S.; Tsai, C.; Marani, M. Point estimate methods based on Taylor Series Expansion—The perturbance moments method—A more coherent derivation of the second order statistical moment. Appl. Math. Model. 2012, 36, 5445–5454. [Google Scholar] [CrossRef]
- Harr, M.E. Probabilistic estimates for multivariate analyses. Appl. Math. Model. 1989, 13, 313–318. [Google Scholar] [CrossRef]
- Hong, H.P. An efficient point estimate method for probabilistic analysis. Reliab. Eng. Syst. Saf. 1998, 59, 261–267. [Google Scholar] [CrossRef]
- Rosenblueth, E. Point estimates for probability moments. Proc. Natl. Acad. Sci. USA 1975, 72, 3812–3814. [Google Scholar] [CrossRef] [Green Version]
- Rosenblueth, E. Two-point estimates in probabilities. Appl. Math. Model. 1981, 5, 329–335. [Google Scholar] [CrossRef]
- Christakos, G. Random Field Models in Earth Sciences; Courier Corporation: North Chelmsford, MA, USA, 2012. [Google Scholar]
- Aerts, J.C.J.H.; Goodchild, M.F.; Heuvelink, G.B.M. Accounting for Spatial Uncertainty in Optimization with Spatial Decision Support Systems. Trans. GIS 2003, 7, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Ehlers, L.; Refsgaard, J.C.; Sonnenborg, T.O.; He, X.; Jensen, K.H. Using sequential Gaussian simulation to quantify uncertainties in interpolated gauge based precipitation. In Proceedings of the EGU General Assembly 2016 Conference, Vienna, Austria, 17–22 April 2016; Volume 18, p. 15751. [Google Scholar]
- Gonçalvès, J.; Vallet-Coulomb, C.; Petersen, J.; Hamelin, B.; Deschamps, P. Declining water budget in a deep regional aquifer assessed by geostatistical simulations of stable isotopes: Case study of the Saharan “Continental Intercalaire”. J. Hydrol. 2015, 531, 821–829. [Google Scholar] [CrossRef]
- Varouchakis, E.A.; Hristopulos, D.T. Dynamic Modelling of Aquifer Level Using Space-Time Kriging and Sequential Gaussian Simulation. In Proceedings of the EGU General Assembly 2016 Conference, Vienna, Austria, 17–22 April 2016; Volume 18, p. 11694. [Google Scholar]
- Shields, M.D.; Teferra, K.; Hapij, A.; Daddazio, R.P. Refined stratified sampling for efficient Monte Carlo based uncertainty quantification. Reliab. Eng. Syst. Saf. 2015, 142, 310–325. [Google Scholar] [CrossRef] [Green Version]
- Wu, K.; Li, J. A surrogate accelerated multicanonical Monte Carlo method for uncertainty quantification. J. Comput. Phys. 2016, 321, 1098–1109. [Google Scholar] [CrossRef] [Green Version]
- Gurdak, J.J.; Qi, S.L. Vulnerability of Recently Recharged Ground Water in the High Plains Aquifer to Nitrate Contamination; Technical Report; U. S. Geological Survey: Reston, VA, USA, 2006.
- Niemunis, A.; Wichtmann, T.; Petryna, Y.; Triantafyllidis, T. Stochastic modelling of settlements due to cyclic loading for soil-structure interaction. In Proceedings of the International Conference on Structural Damage and Lifetime Assessment, Rome, Italy, 17–18 February 2005; Volume 18. [Google Scholar]
- Tejchman, J.; Górski, J. Deterministic and statistical size effect during shearing of granular layer within a micro-polar hypoplasticity. Int. J. Numer. Anal. Methods Geomech. 2008, 32, 81–107. [Google Scholar] [CrossRef]
- Dodwell, T.J.; Ketelsen, C.; Scheichl, R.; Teckentrup, A.L. A hierarchical multilevel Markov chain Monte Carlo algorithm with applications to uncertainty quantification in subsurface flow. SIAM/ASA J. Uncertain. Quantif. 2015, 3, 1075–1108. [Google Scholar] [CrossRef] [Green Version]
- Moradkhani, H.; DeChant, C.M.; Sorooshian, S. Evolution of ensemble data assimilation for uncertainty quantification using the particle filter-Markov chain Monte Carlo method. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Ter Braak, C.J.; Clark, M.P.; Hyman, J.M.; Robinson, B.A. Treatment of input uncertainty in hydrologic modeling: Doing hydrology backward with Markov chain Monte Carlo simulation. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef] [Green Version]
- Feinberg, J.; Langtangen, H.P. Chaospy: An open source tool for designing methods of uncertainty quantification. J. Comput. Sci. 2015, 11, 46–57. [Google Scholar] [CrossRef] [Green Version]
- Suchomel, R.; Mašı, D. Comparison of different probabilistic methods for predicting stability of a slope in spatially variable c-phi soil. Comput. Geotech. 2010, 37, 132–140. [Google Scholar] [CrossRef]
- Nielsen, O.; Roberts, S.; Gray, D.; McPherson, A.; Hitchman, A. Hydrodynamic modelling of coastal inundation. In Proceedings of the MODSIM 2005 International Congress on Modelling and Simulation, Melbourne, Austrilia, 12–15 December 2005; pp. 518–523. [Google Scholar]
- Roberts, S.; Nielsen, O.; Gray, D.; Sexton, J. ANUGA User Manual; Geoscience Australia and Australian National University: Canberra, Austrilia, 2010. [Google Scholar]
- Mungkasi, S.; Roberts, S. Validation of ANUGA hydraulic model using exact solutions to shallow water wave problems. J. Phys. Conf. Ser. 2013, 423, 012029. [Google Scholar] [CrossRef] [Green Version]
- Néelz, S.; Pender, G. Benchmarking the Latest Generation of 2D Hydraulic Modelling Packages; Technical Report SC120002; UK Environment Agency: Rotherham, UK, 2013.
- Fan, Y.; Huang, W.; Huang, G.; Huang, K.; Zhou, X. A PCM-based stochastic hydrological model for uncertainty quantification in watershed systems. Stoch. Environ. Res. Risk Assess. 2015, 29, 915–927. [Google Scholar] [CrossRef]
- Miller, K.; Berg, S.; Davison, J.; Sudicky, E.; Forsyth, P. Efficient uncertainty quantification in fully-integrated surface and subsurface hydrologic simulations. Adv. Water Resour. 2018, 111, 381–394. [Google Scholar] [CrossRef]
- Deutsch Clayton, V.; Journel André, G. GSLIB Geostatistical Software Library and User’s Guide; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Savichev, V.; Bezrukov, A.; Muharlyamov, A.; Barskiy, K.; Rustam, S. High Performance Geostatistics Library. 2010. Available online: http://hpgl.github.io/hpgl/index.html (accessed on 13 October 2017).
- Bennett, N.D.; Croke, B.F.; Guariso, G.; Guillaume, J.H.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.; Norton, J.P.; Perrin, C. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Biondi, D.; Freni, G.; Iacobellis, V.; Mascaro, G.; Montanari, A. Validation of hydrological models: Conceptual basis, methodological approaches and a proposal for a code of practice. Phys. Chem. Earth Parts A/B/C 2012, 42, 70–76. [Google Scholar] [CrossRef]
- Pav, S. PDQ Functions via Gram Charlier, Edgeworth, and Cornish Fisher Approximations. 2017. Available online: https://cran.r-project.org/web/packages/PDQutils/index.html (accessed on 13 October 2017).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1st Moment | 0.73 | 0.99 | 2.35 | 141.49 | −34.87 |
| 2nd Moment | −1.95 | 0.96 | 38.10 | 2008.66 | −35.86 |
| 3rd Moment | −0.78 | −0.25 | 1.81 | 12.61 | −1.72 |
| 4th Moment | 0.07 | −0.32 | 0.96 | 10.92 | −1.74 |
| 1st Moment | 0.0074 | 0.0007 | 0.0164 | 0.1775 | 3.6896 |
| 2nd Moment | 0.0179 | 0.0014 | 0.054 | 0.9263 | 6.1075 |
| 3rd Moment | 5.092 | 3.6726 | 4.101 | 20.4579 | 1.0632 |
| 4th Moment | 74.6667 | 33.7397 | 85.76 | 443.706 | 1.7032 |
| 1st Moment | 0.96 | 0.99 | 0.09 | 0.96 | −5.28 |
| 2nd Moment | 0.88 | 0.99 | 0.18 | 0.99 | −2.22 |
| 3rd Moment | 0.55 | 0.64 | 0.35 | 0.99 | −0.23 |
| 4th Moment | 0.62 | 0.81 | 0.36 | 0.99 | −0.51 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Issermann, M.; Chang, F.-J. Uncertainty Analysis of Spatiotemporal Models with Point Estimate Methods (PEMs)—The Case of the ANUGA Hydrodynamic Model. Water 2020, 12, 229. https://doi.org/10.3390/w12010229
Issermann M, Chang F-J. Uncertainty Analysis of Spatiotemporal Models with Point Estimate Methods (PEMs)—The Case of the ANUGA Hydrodynamic Model. Water. 2020; 12(1):229. https://doi.org/10.3390/w12010229
Chicago/Turabian StyleIssermann, Maikel, and Fi-John Chang. 2020. "Uncertainty Analysis of Spatiotemporal Models with Point Estimate Methods (PEMs)—The Case of the ANUGA Hydrodynamic Model" Water 12, no. 1: 229. https://doi.org/10.3390/w12010229
APA StyleIssermann, M., & Chang, F. -J. (2020). Uncertainty Analysis of Spatiotemporal Models with Point Estimate Methods (PEMs)—The Case of the ANUGA Hydrodynamic Model. Water, 12(1), 229. https://doi.org/10.3390/w12010229