1. Introduction
Multi-attribute decision-making refers to the process of sorting and selecting among a group of alternatives by using the obtained information [
1]. Multi-attribute decision-making methods include Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS) [
2], set pair analysis (SPA) [
3], grey relation analysis (GRA) [
4], grey target method (GTM) [
5], etc. Under the influence of many factors, the objective things in nature are complex and changeable (e.g., runoff and flood in the hydrological and water resources system), which show great uncertainty like randomness, fuzziness and greyness [
6], in addition to the fuzziness of human thinking. In recent years, the multi-attribute decision-making methods with uncertain decision information, especially uncertain attribute values and attribute weights, have become a hot research issue. In general, the priority and also difficulty in solving this kind of problem is to transform uncertain decision-making into definite decision-making. During this process, on the one hand, we should try to avoid or reduce the loss of decision information. The more information loss, the larger deviation caused in the selection of the optimal scheme, which may fail to achieve the expected objectives in scheme implementation and incur risk events. On the other hand, the cumbersome calculation of interval numbers should be reduced, so that the technique is more operable in a practical application. For instance, when using the methods in references [
7,
8], the comparison of interval numbers only considers their upper and lower boundaries, which loses too much information even though the decision-making efficiency is enhanced. Moreover, the tedious calculation in rough set method [
9] and Vlsekriterijumska Optimizacija I Kompromisno Resenje (VIKOR) method [
10] makes interval number ranking more difficult.
At present, grey analysis, set pair analysis, stochastic analysis and fuzzy analysis are the four main kinds of hydrologic uncertainty analysis methods. In information theory, a system with some known information and also some unknown information is a grey system, such as the hydrologic and water resources system. Grey relation analysis is a multi-factor analysis method in the grey system theories [
11]. Its basic idea is to determine the closeness of relation between a comparison sequence and a reference sequence according to their geometric similarity. Grey relation analysis can overcome the shortcomings of regression analysis, variance analysis and other factor analysis methods in traditional mathematical statistics [
12], and has the advantages of a small sample size and simple calculation procedure. Gao and Zhang [
13] first used grey relation analysis for scheme selection. However, in the relation coefficient series obtained from the alternatives and the reference scheme, the larger relation coefficient often plays a decisive role in determining the relation degree, while the information implied by other relation coefficients tends to be neglected. As an improvement, Zhang [
14] put forward the grey entropy method (GEM) based on the idea that an alternative scheme is better when it is evenly closer to the reference scheme. This method combines the relation degree in grey relation analysis with the balance degree defined in grey entropy by multiplication, and thus, develops the degree of balance and approach for scheme decision-making, which in some way remedies grey relation analysis. The GEM has been widely used in logistics [
15], transportation [
16], tourism [
17] and other industries, with satisfactory results. Grey entropy is a concept that combines grey system theory and information entropy theory. As an effective statistical measurement for information uncertainty [
18], it is consistent with the physical meaning of Shannon entropy. Wang et al. [
19] defined the grey distance entropy of the real grey number and the interval grey number, respectively, took it as the measurement for the proximity degree of the two grey numbers, and discussed the multi-attribute decision-making methods based on grey distance entropy and TOPSIS. Liu et al. [
20] deemed that in the grey entropy method the attribute value is a real number and the attribute weight is not considered, thus they extended the application scope to interval numbers. At present, grey entropy is mainly used to determine the objective weight of indexes in uncertain decision-making, and there are not many in-depth theoretical studies. The comparison of the above decision-making methods is shown in
Table 1.
The combination of the Mahalanobis-Taguchi System (MTS) theory and grey entropy can provide a new idea for uncertain multi-attribute decision-making. The Mahalanobis-Taguchi System [
21,
22], proposed by Japanese engineer Taguchi G. in the 1990s, is a pattern recognition method for unbalanced data. Scholars are becoming gradually more familiar with MTS and constantly try to explore its application or its combination with other theories in different fields. Buenviaje et al. [
23] obtained medical patterns from historical data sets through MTS. Huang et al. [
24] utilized the data mining function of MTS, combined it with the artificial neural network (ANN) and came up with the MTS-ANN algorithm. Zeng et al. [
25] studied how to make the risk decision on power transformer maintenance by using MTS and the grey cumulative prospect theory. Chang et al. [
26] employed the three key tools of MTS, namely, orthogonal table, Mahalanobis distance and signal-to-noise ratio, to tackle the problem of multi-attribute decision-making with interval numbers on the basis of TOPSIS. The orthogonal table [
27] is a direct test method for multi-factor system optimization. It can be expressed in the form of L
a(
bN), where
a is the number of tests,
b the number of levels of each factor and
N the number of factors that can be arranged at most in the orthogonal table. The orthogonal table is a prepared set of standard tables, from which the suitable one is chosen in actual application according to the number of factors and the number of levels of each factor. The orthogonal table designs a small number of tests and obtains comprehensive information, which can effectively reduce the loss of information. The Mahalanobis distance [
28], proposed by Indian statistician Mahalanobis, is a covariance distance that, compared with Euclidean distance, can better reflect the correlation between attributes. The concept of signal-to-noise ratio (SNR) [
29] originates from signal transmission and is defined as the ratio of signal power to noise power. Taguchi G. redefined the SNR, regarding the square (
μ2) and the variance (
σ2) of the expected value of an index (non-negative and continuous) as the signal power and the noise power, respectively. The SNR can be divided into three types: nominal-the-better, smaller-the-better and larger-the-better. The first one means that the closer to the expected value when it is positive, the better; the second one means that the smaller the expected value when it is 0, the better; the third one means that the larger the expected value when it is
, the better. The signal-to-noise ratio can be used to measure the volatility of indexes and thereby ensure the accuracy of decision results.
Like other pattern recognition methods, MTS also uses distance to measure the similarity between samples; however, instead of using Euclidean distance, it uses Mahalanobis distance, which is more suitable to distinguish sample similarity. As the theory of MTS has only been developed for the past 20 years and there are few studies on its integration with grey analysis, more work needs to be done to deepen this field of theoretical research and expand its application.
To address the uncertain multi-attribute decision-making problem in which both attribute weight and attribute value are interval numbers, we improved the grey entropy method based on the treatment of interval numbers in reference [
26], and put forward a multi-dimensional interval number decision model based on the Mahalanobis-Taguchi System with the grey entropy method (MTS-GEM). The model is applied to the selection of the optimal scheme of controlling the Pankou reservoir’s water level in flood season, which can facilitate reservoir operation research.
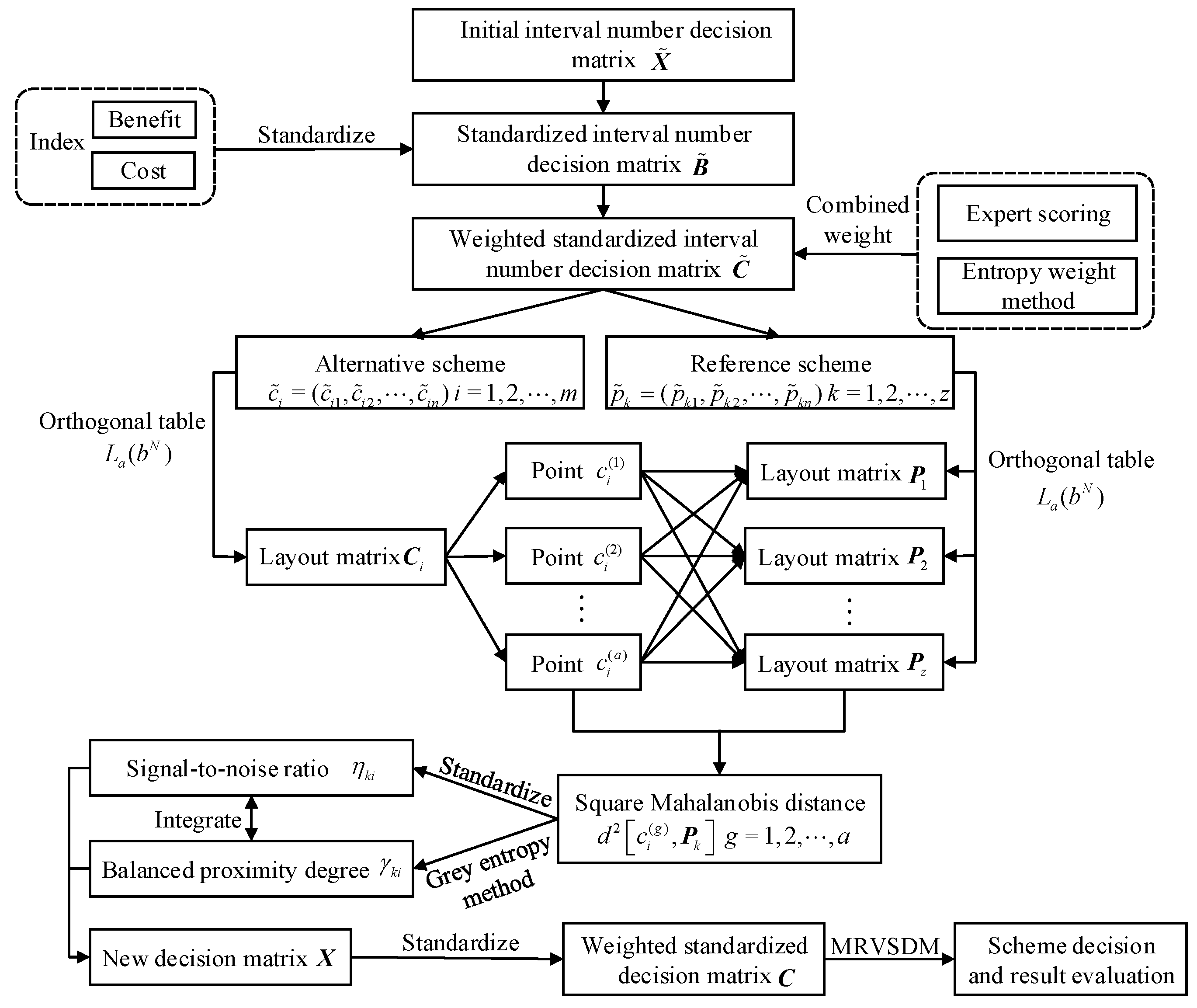
4. Multi-Dimensional Interval Number Decision Model Based on MTS-GEM
4.1. Development of the Weighted Standardized Decision Matrix
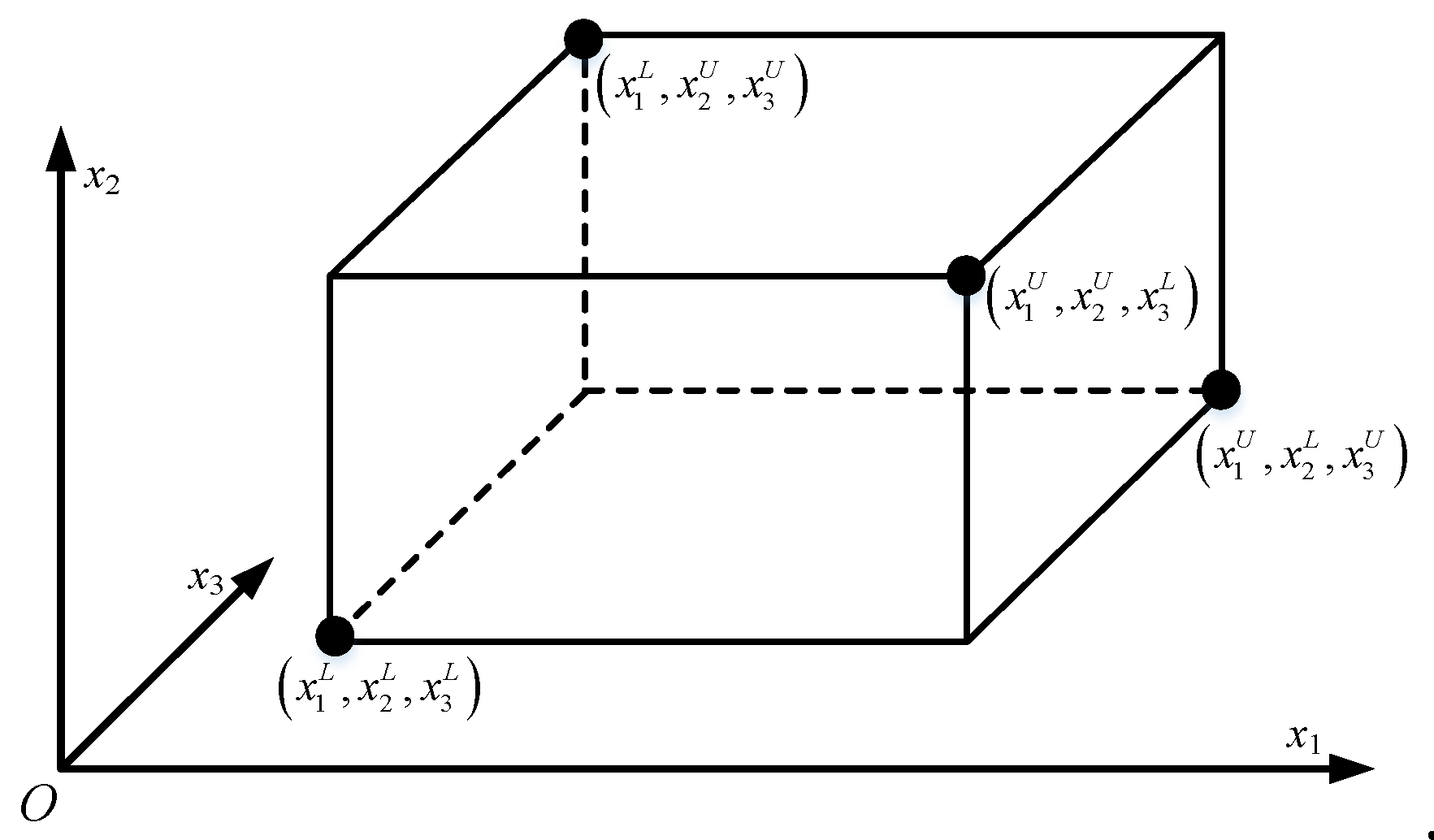
Suppose that there are m alternative schemes and n indexes, and they constitute the initial interval number decision matrix (i=1,2,…,m; j=1,2,…,n) where . As the dimensions of the indexes are often different, we used Equations (11) and (12) to nondimensionalize different types of indexes, and get the standardized interval number decision matrix , where .
For a cost index:
where
and
.
To make the weight distribution of each index reasonable, the integration of expert scoring (subjective weight) and entropy weight method [
35] (objective weight) is used to determine the combined weight of each index.
1 Subjective weight where
Assuming that there are experts who participate in the weight scoring of n indexes, the scoring matrix is (l=1,2,…,; j=1,2,…,n) where , then .
2 Objective weight , where
First, the entropy of the interval number index is calculated based on the standardized interval number decision matrix
:
where
and
are the information entropy of the interval number index’s lower bound and upper bound, respectively; when
or
,
or
.
Then, calculate the objective weight of the interval number index
:
3 Combined weight , where
Considering both the subjective weight
and the objective weight
, we obtained the combined weight of the interval number index
where
and is an empirical factor that reflects the preference of decision makers between subjective experience and objective data [
36].
With the standardized decision matrix
and the indexes’ combined weight
, we used the multiplication algorithm of interval number to obtain the weighted standardized decision matrix
, where
. Additionally, based on TOPSIS, the positive ideal scheme
and the negative ideal scheme
were determined:
4.2. Orthogonal Test of Schemes and Calculation of Derivative Indicators
According to the number of indexes, a two-level orthogonal table with
N≥
n was selected, where
n indexes can be arranged in any
n columns. For the interval number
, take
as level 1 and
as level 2. The layout matrix
of the alternative scheme
(
i=1,2,…,
m) is as follows:
where
(
g=1,2,…,
a) is the distribution point of scheme
and
,
, …,
are the components of
.
Similarly, the layout matrix of the positive ideal scheme and the layout matrix of the negative ideal scheme can be obtained.
Here, we define derivative indicators as the signal-to-noise ratio and the degree of balance and approach based on square Mahalanobis distance obtained by the initial interval number indexes. According to Equation (6), calculate the square Mahalanobis distance between the alternative scheme’s distribution point and the positive/negative ideal scheme, and we obtain and .
1 Signal-to-noise ratio
The SB signal-to-noise of the scheme
i to the positive (negative) ideal scheme is
(
):
where
a is the number of orthogonal tests and
,
is the square Mahalanobis distance standardized by Equation (18):
2 Improved degree of balance and approach
The correlation degree of the alternative scheme
and the positive (negative) ideal scheme is
(
):
where
(
) is the correlation coefficient of the alternative scheme
and the positive (negative) ideal scheme at distribution point
g.
Based on the square Mahalanobis distance, the formula of correlation coefficient is revised as follows:
where the distinguishing coefficient
is set at 0.5.
The balance degree of the alternative scheme
and the positive (negative) ideal scheme is
(
):
where
and
.
The degree of balance and approach of the alternative scheme
and the positive (negative) ideal scheme is
(
):
4.3. Scheme Decision-Making
Based on the signal-to-noise ratio and the improved degree of balance and approach, the decision matrix
Y is constructed as shown in Equation (23), in which the benefit indicator is
and
, while the cost indicator is
and
:
Now, the decision-making problem with multi-dimensional interval numbers is changed into a decision-making problem with multi-dimensional real numbers [
37]. The optimal scheme can be selected with the following multi-dimensional real vector space decision-making method (MRVSDM).
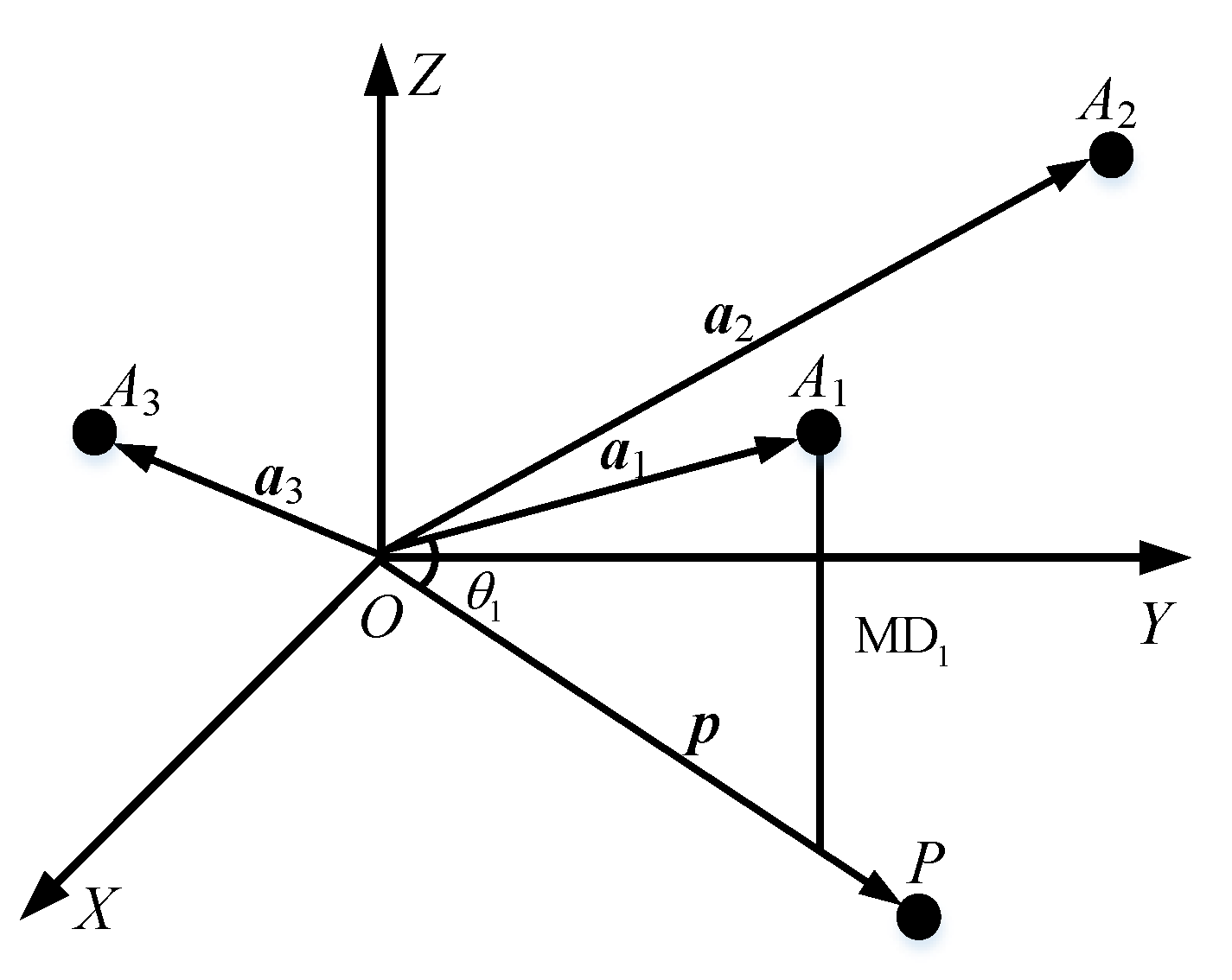
The n-dimensional real numbers are regarded as the points A1,…,Ai,…,Am in an n-dimensional space with O as the origin, and then we can get the vectors ,…,,…,.
Assuming that the reference scheme vector is , and are the modules of vector ai and vector , respectively. Between vectors ai and , calculate their angle (where is their product), as well as their mapping distance .
The set of mapping distance can be obtained. According to the principle that the smaller is, the closer vector ai is to vector , the scheme that satisfies the objective is selected as the optimal scheme.
The diagram of decision-making in a three-dimensional real number vector space is shown in
Figure 2. The input of the MTS-GEM model is the interval number indexes derived from different schemes. After orthogonal tests and calculation of the Mahalanobis distance, the signal-to-noise ratio, the improved degree of balance and approach, the output is the mapping distance from each scheme to the ideal scheme. The flow chart of this study is shown in
Figure 3.
5. Case Study
5.1. Initial Interval Number Decision Matrix and Its Weighted Standardization
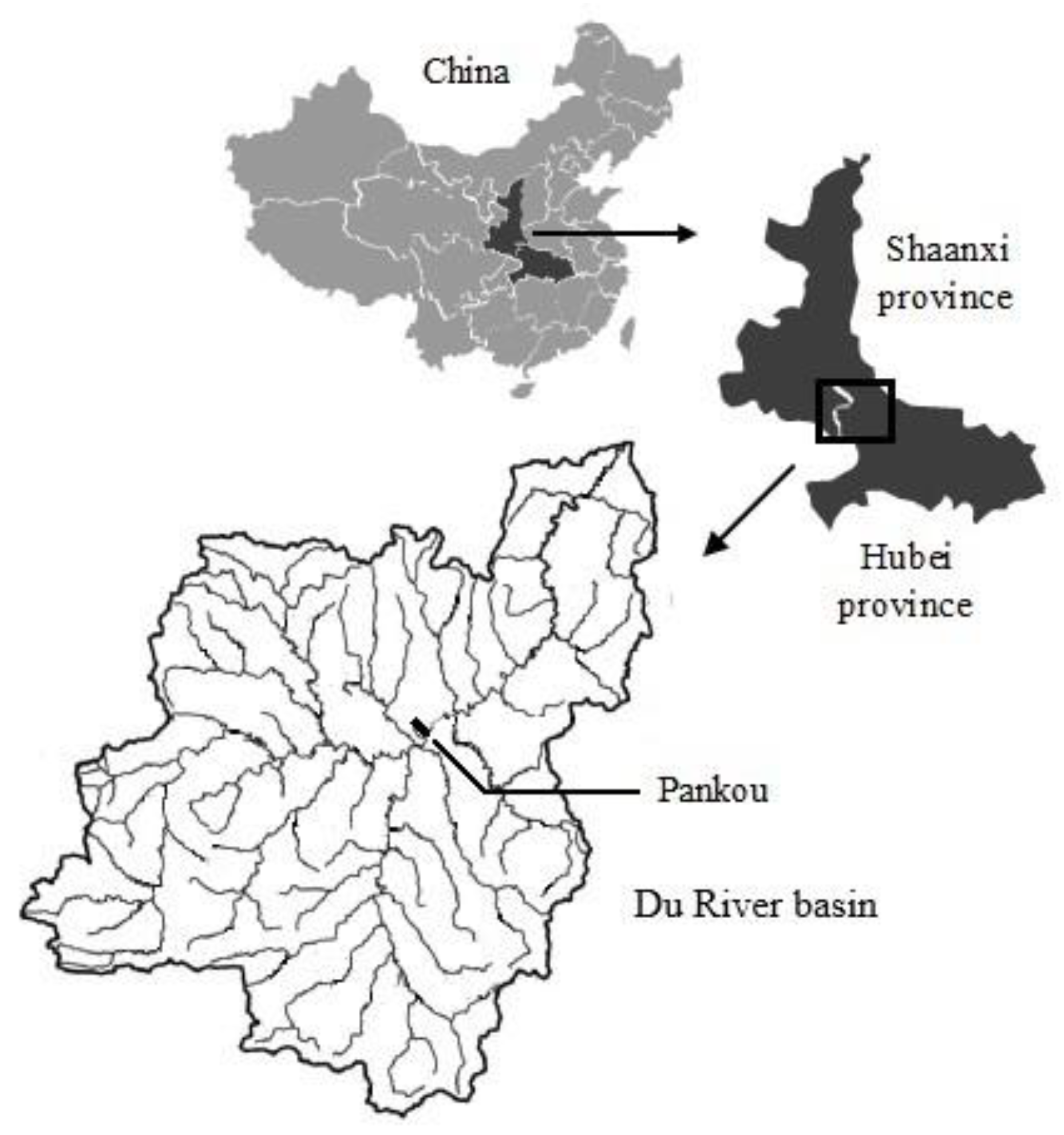
Multi-objective reservoir operation is a multi-dimensional and complicated system engineering issue. Affected by runoff forecast, operation model, solution method and other factors, in the obtained non-inferior solution set, the attribute values are not always a precise real number but an interval number with uncertainty. The Pankou reservoir, located at the upstream of the Du River in China, is an annual-regulating reservoir with comprehensive utilization tasks of power generation, flood control, water supply and so forth. Its basic information is listed in
Table 3, and its location map is shown in
Figure 4.
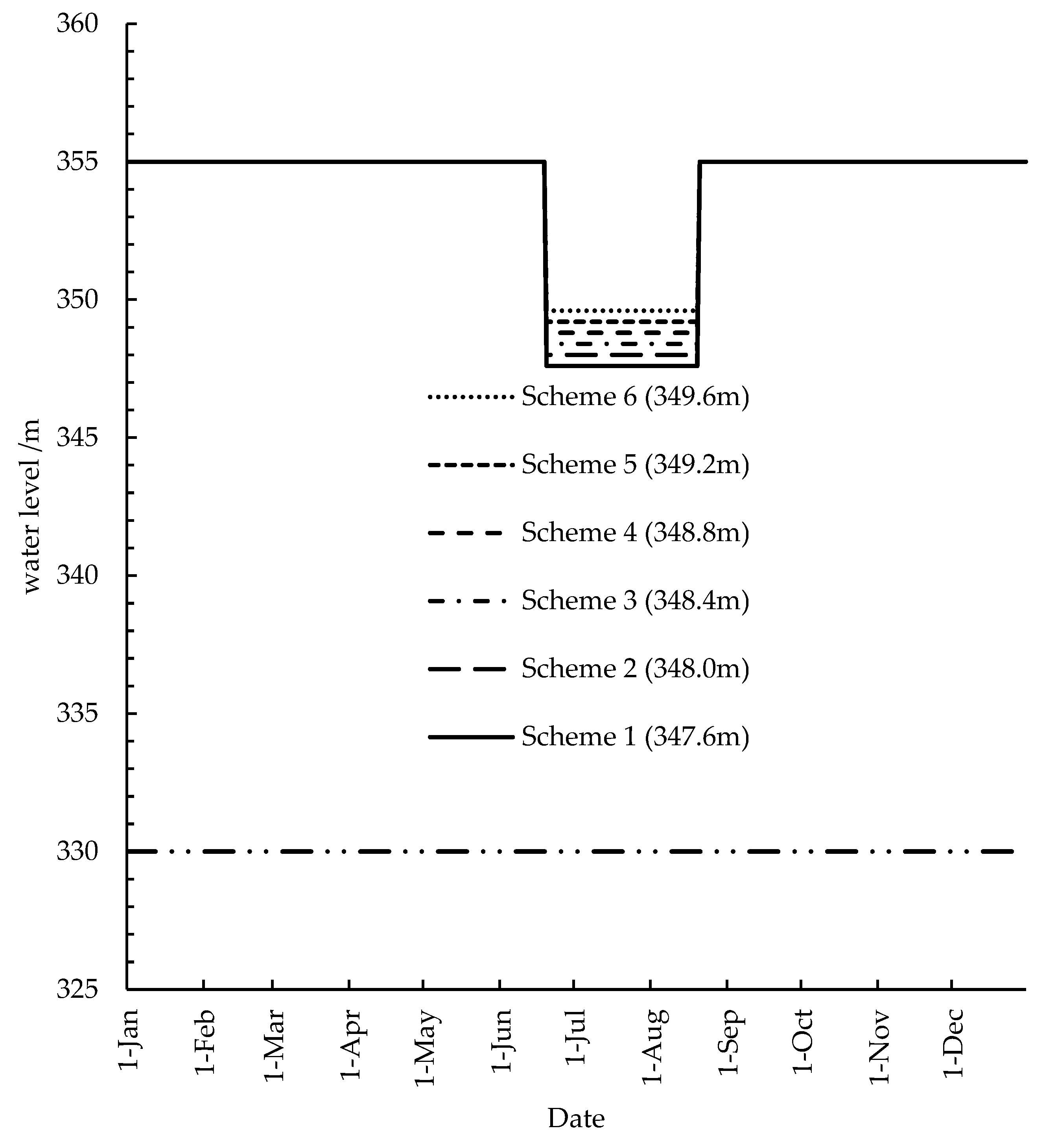
According to the current regulations of the China Yangtze River Flood Control and Drought Relief Headquarters, for the Pankou reservoir, the upper limit of operation water level in flood season (June 20–August 20) is the flood control limit water level (347.6 m), while in other periods it is the normal water level (355 m); the lower limit of operation water level in all periods is the dead water level (330 m), and falling to the lower limit should be avoided during operation.
However, in the actual operation of the Pankou reservoir, it can barely store water to the normal water level in most years, undermining such benefits as power generation and water supply. In order to reasonably adjust the upper limit of water level in flood season and improve the utilization rate of flood resources, in reference [
38] the three indexes of flood control risk rate, annual generated power and water storage at the end of flood season were used as the evaluation indexes for selecting the optimal scheme of water level upper limit in flood season. Flood control risk rate was obtained by means of flood stochastic simulation [
39]. Firstly, the flood stochastic simulation model was used to simulate
n (a large number) pieces of annual maximum flood inflow hydrographs, which can fully reflect the statistical characteristics of the reservoir’s measured flood inflow. Then, a flood operation calculation was conducted to obtain the highest annual water level sequence, and the ratio of times that the water level limit was exceeded to
n was taken as the flood control risk rate, the value of which needs to meet people’s acceptable level of risk. Annual generated power refers to the total electricity generated by the hydropower station within a one-year operation cycle, which represents the power generation benefit of the hydropower station. The more annual generated power, the greater the annual power generation benefit. The water storage at the end of the flood season refers to the water storage between the dead water level and the particular water level at the end of flood season, which represents the water supply benefit of the reservoir. The more water storage at the end of flood season, the greater the water supply benefit.
The scheme setting is shown in
Figure 5. Currently, Scheme 1 is being adopted as the operation strategy of the Pankou reservoir’s upper water level limit in flood season.
For the flood control risk rate, the Monte Carlo method was used to randomly simulate 100 groups of 1000 floods corresponding to the 1000-year return period (0.1%). After flood operation calculation of each flood, the number of times that the design flood water level (357.14m) is exceeded in each group of 1000 floods were counted as
. The flood control risk rate of each group was
, and the flood control risk rate in the form of an interval number was
. Similarly, the annual generated power and water storage at the end of flood season were obtained through reservoir operation calculation by using the monthly inflow data of 41 years from 1971 to 2011. Then, the minimum and maximum values of the 41 results formed the interval numbers. The initial interval number decision matrix
is shown in
Table 4.
According to Equation (11)–(12), the benefit indexes (annual generated power, water storage at the end of flood season) and the cost index (flood control risk rate) in
Table 3 are standardized, resulting in the standardized interval number decision matrix
shown in
Table 5.
According to Lynne [
40] who derives the variance formula of interval number sample matrix based on uniform distribution, for
, its variance
can be expressed as follows:
Based on the definition of the correlation coefficient of two random real number variables in the probability theory and mathematical statistics, the correlation coefficient of two interval variables
(
h,
j=1,2,…,
n) is:
From Equation (24)–(25), the correlation coefficient matrix of
can be obtained, as shown in
Table 6.
It is shown in
Table 5 that there is positive correlation among the three indexes. The correlation between the flood control risk rate and annual generated power or water storage at the end of flood season is slightly weak. The correlation between annual generated power and water storage at the end of flood season is significant in that their correlation coefficient is 0.971. Thus, it is necessary to consider the correlation between the indexes in the decision-making process of the reservoir water level scheme in flood season.
There are five experts to grade the importance of the indexes, and the subjective weight of the interval number indexes obtained from the scoring matrix is
. According to Equation (13), the information entropy weight is
and
. Thus, the objective weight of the interval number indexes is
. Let the empirical factor
be 0.5, then the combined weight is
. From
and
, the weighted standardized decision matrix
is obtained, as shown in
Table 7.
Through the matrix , based on TOPSIS and Equation (15), the positive (negative) ideal scheme () is determined as follows:
.
5.2. Orthogonal Test of the Schemes
Since there are three indexes, the orthogonal table is
. The alternative scheme’s layout matrix
Ci (
i=1,2,…,6), the positive ideal scheme’s layout matrix
and the negative ideal scheme’s layout matrix
are shown in
Table 8.
5.3. Scheme Decision-Making and Result Evaluation
The square Mahalanobis distance from each point in the layout matrix
Ci to the positive ideal scheme’s layout matrix
and the negative ideal scheme’s layout matrix
is worked out, as shown in
Table 9.
The square Mahalanobis distance is standardized by Equation (18) and the SNR indicator is obtained. The indicator of the degree of balance and approach is worked out by Equation (19)–(22). Accordingly, the decision matrix
X is derived, as shown in
Table 10.
In accordance with Equation (11)–(12),
X is standardized and with the weight of each index being 0.25, the weighted standardized decision matrix
C is obtained, as shown in
Table 11.
is taken as the reference scheme to calculate the mapping distance from the alternative scheme to the reference scheme.
To verify the feasibility and effectiveness of the method in this paper, the first comparison method of scheme ranking (method 1) is based on the closeness degree of the SNR defined by Equation (26), according to reference [
40]:
On the basis of TOPSIS, the improved closeness degree of the degree of balance and approach is defined as follows:
When , , the closer scheme i is to the positive ideal scheme, whereas when , , the farther scheme i is to the positive ideal scheme. This ranking criterion is that the larger is, the better the corresponding scheme i is, which is the second method for comparison (method 2).
The schemes are sorted according to the different ranking criteria of method 1, method 2 and the method in this study. The results are shown in
Table 12.
It can be seen from
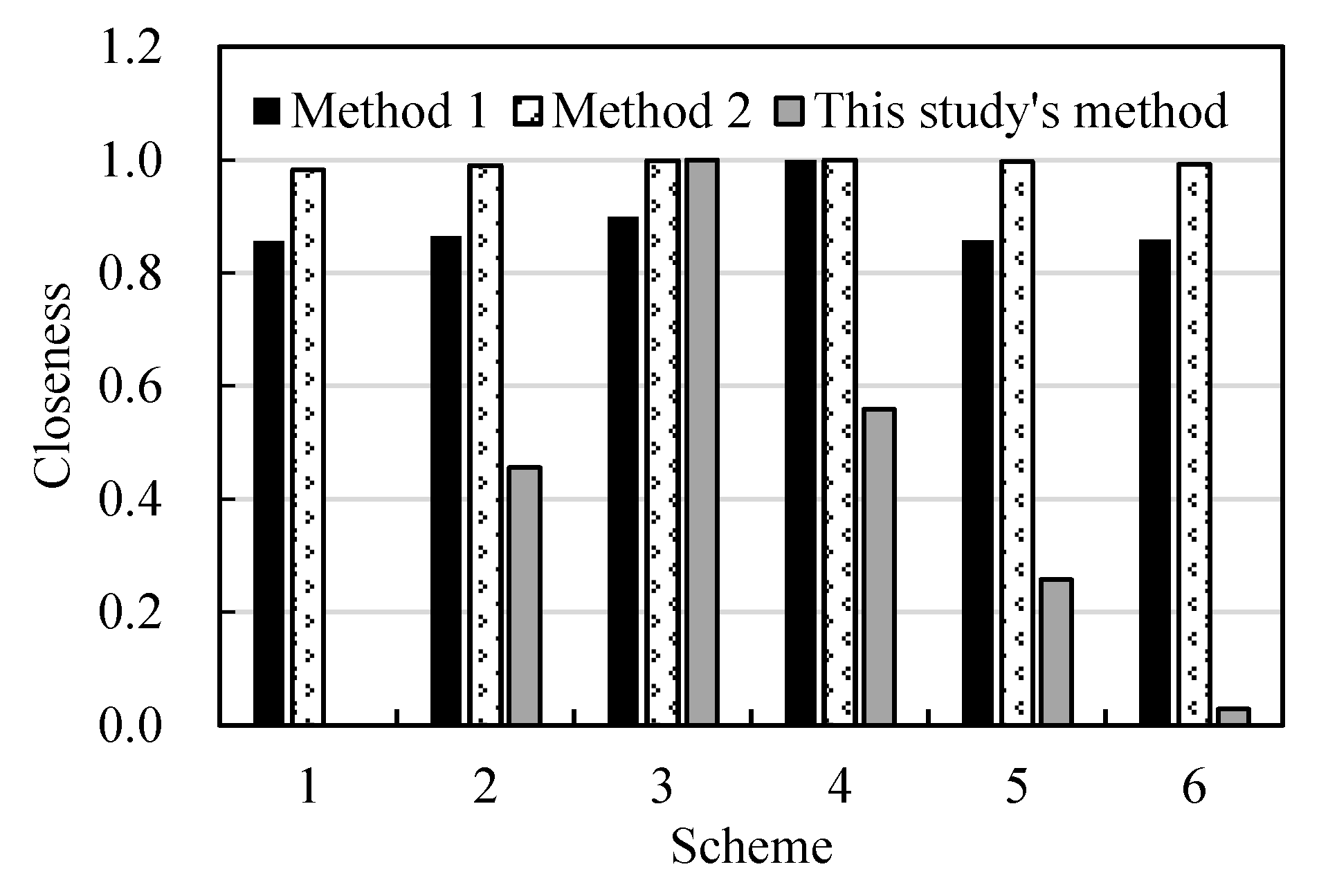
Table 11 that Scheme 1 ranks the last in the decision results of all the three methods, meaning that the currently-adopted strategy is far from decent and other schemes need to be selected, which conforms to the status quo of the Pankou reservoir. This study’s method chooses Scheme 3 as the optimal scheme, which raises the upper water level limit in flood season by 0.8 m compared with Scheme 1.
The reasons for the inconsistent scheme ranking results can be explained by the calculation process of the SNR and the improved degree of balance and approach in
Section 4.2. The two indicators respectively reflect the output strength and the degree of balance and approach of geometric curves in the alternative and the reference schemes. If method 1 or method 2 is used alone, their decision results will be less likely to be adopted. The method proposed in this paper includes the advantages of both method 1 and method 2, and gets closer to the reference scheme by the mapping distance, producing more accurate and reasonable decision results. Therefore, scheme 3 is recommended as the optimal.
In
Table 11, the closeness degree of the SNR and the closeness degree of the balance and approach degree are benefit indicators, whereas the mapping distance is a cost indicator, and therefore converted into a benefit indicator by the range method. After normalizing the three indicators, the decision results of the three methods are illustrated in
Figure 6. It can be seen that compared with method 1 and method 2, this study’s method produces more obviously distinct decision results, which proves that the proposed model can effectively mine the hidden rules in data, especially for the analysis of a system with deficient information.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}