
Optimal Water Quality Sensor Placement by Accounting for Possible Contamination Events in Water Distribution Networks



Abstract
:1. Introduction
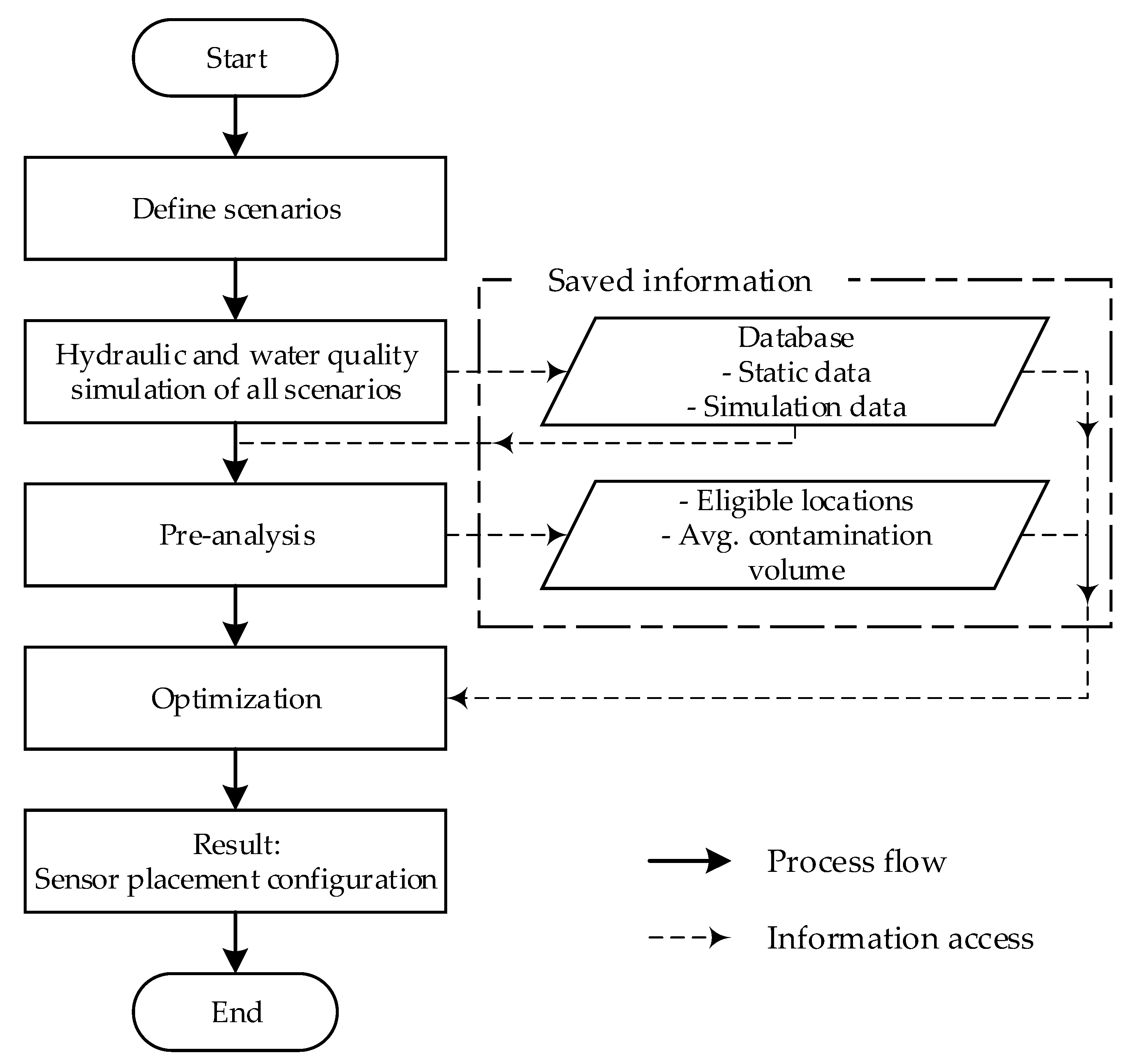
2. Materials and Methods
2.1. Scenario Creation
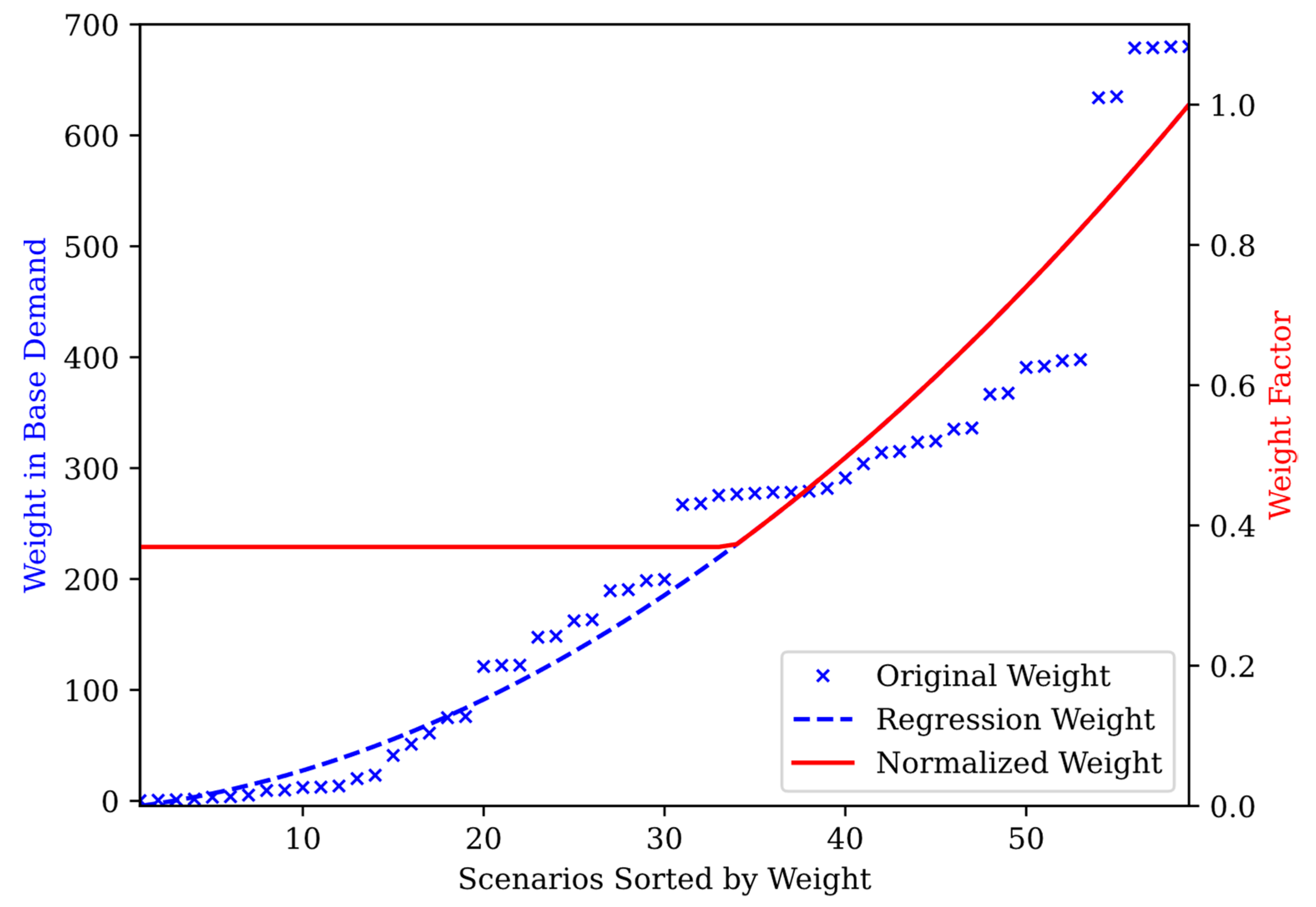
2.2. Databasing
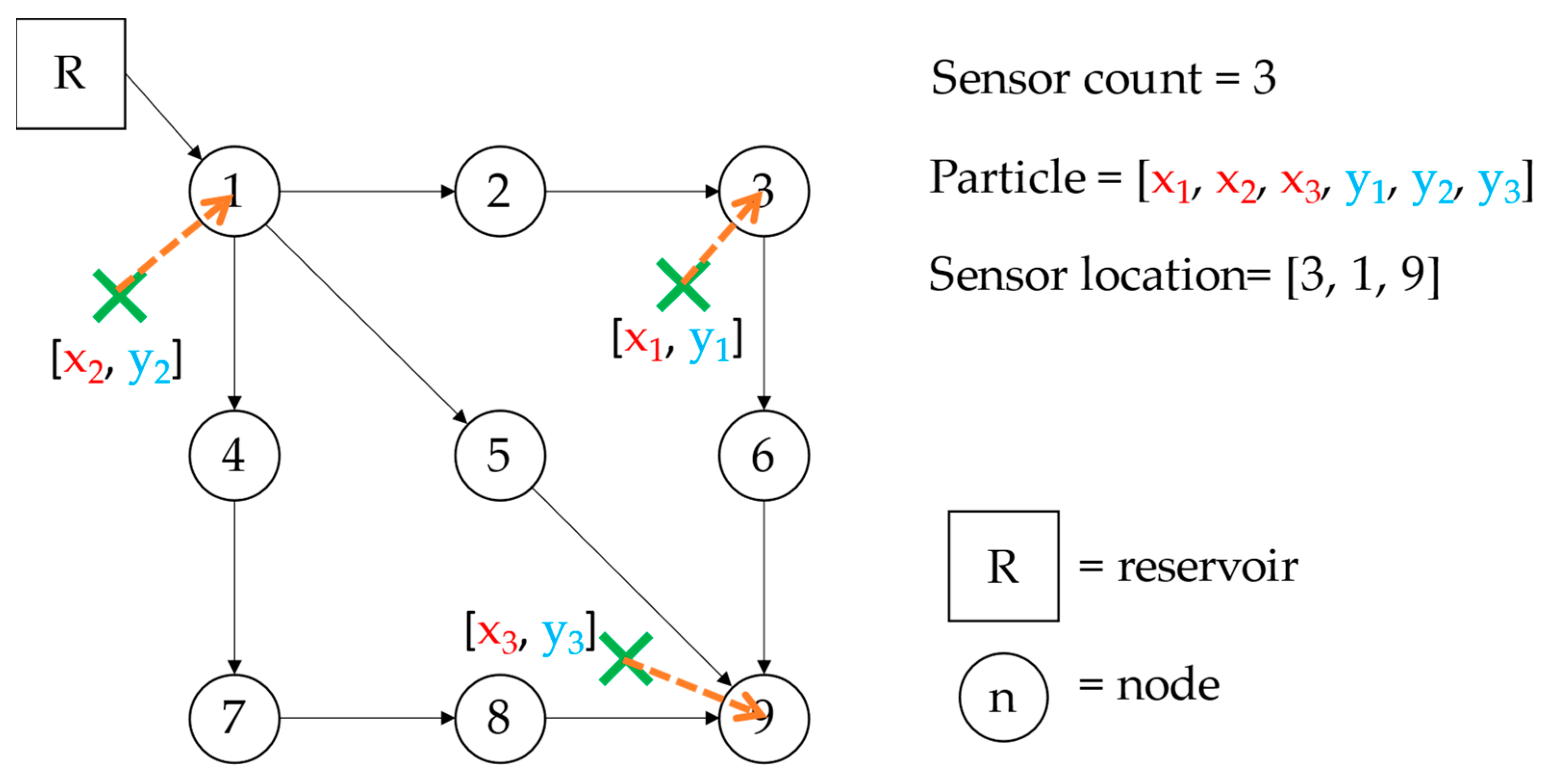
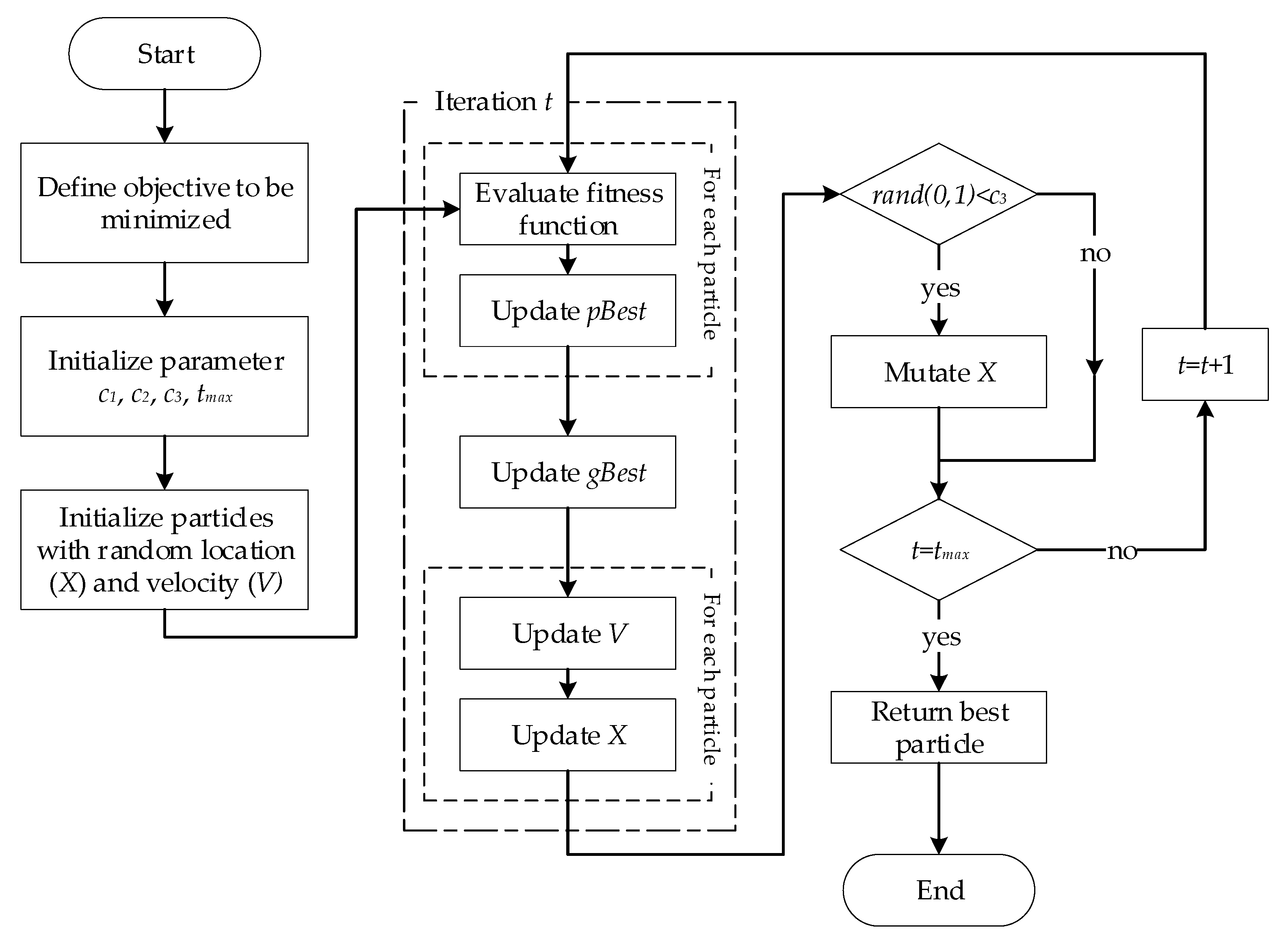
2.3. Optimization
- (1)
- Location
- (2)
- Velocity
- (3)
- Personal best location ()
- (4)
- Global best location ()
3. Objective Functions
3.1. Blindspot (BS)
3.2. Consumed Contamination (CC)
3.3. Localization Efficiency (LE)
4. Application
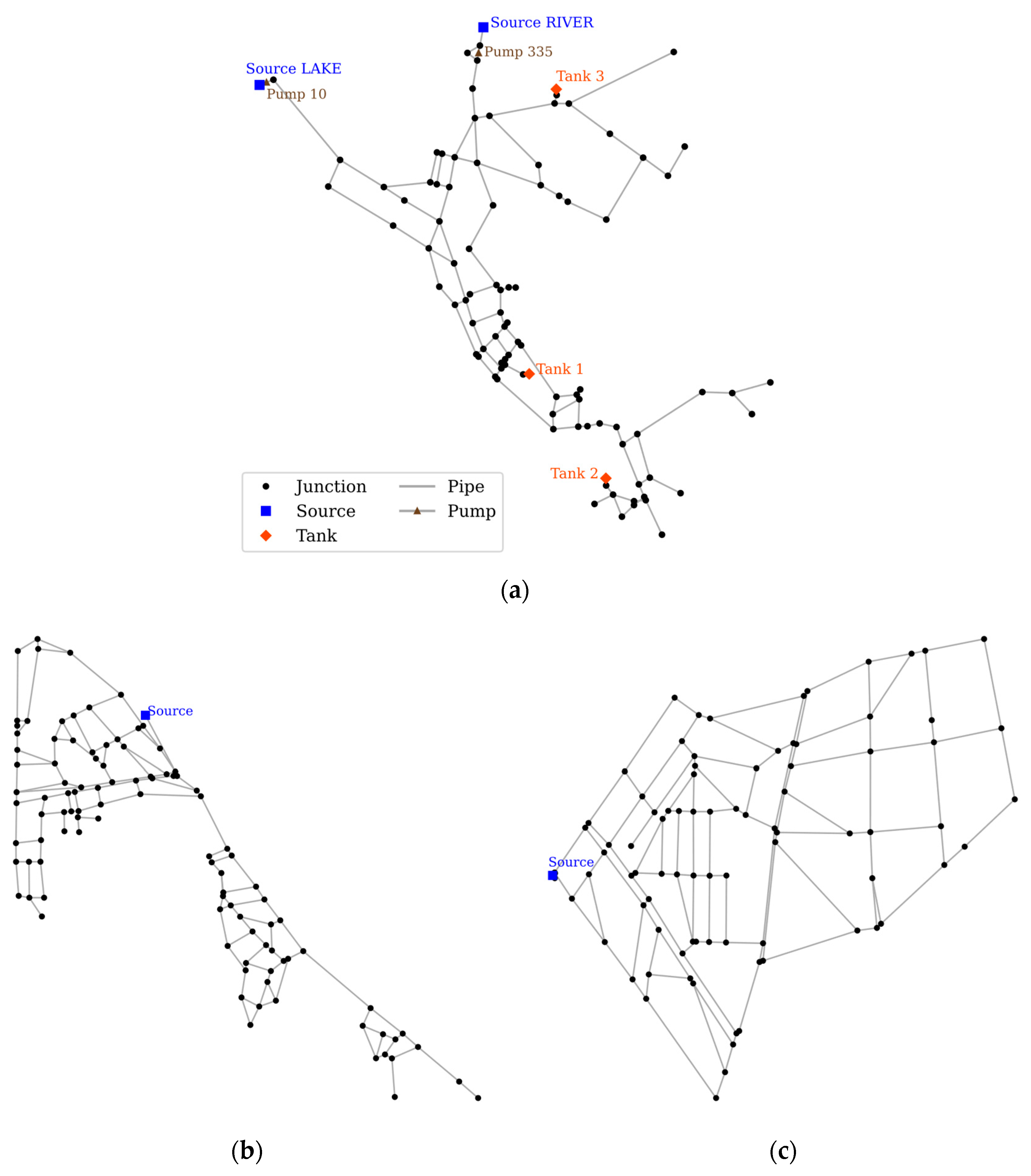
4.1. Study Networks
4.2. Benchmark Comparison (NET3 Network)
4.3. SPSO Performance Evaluation (NET-A and NET-B Networks)
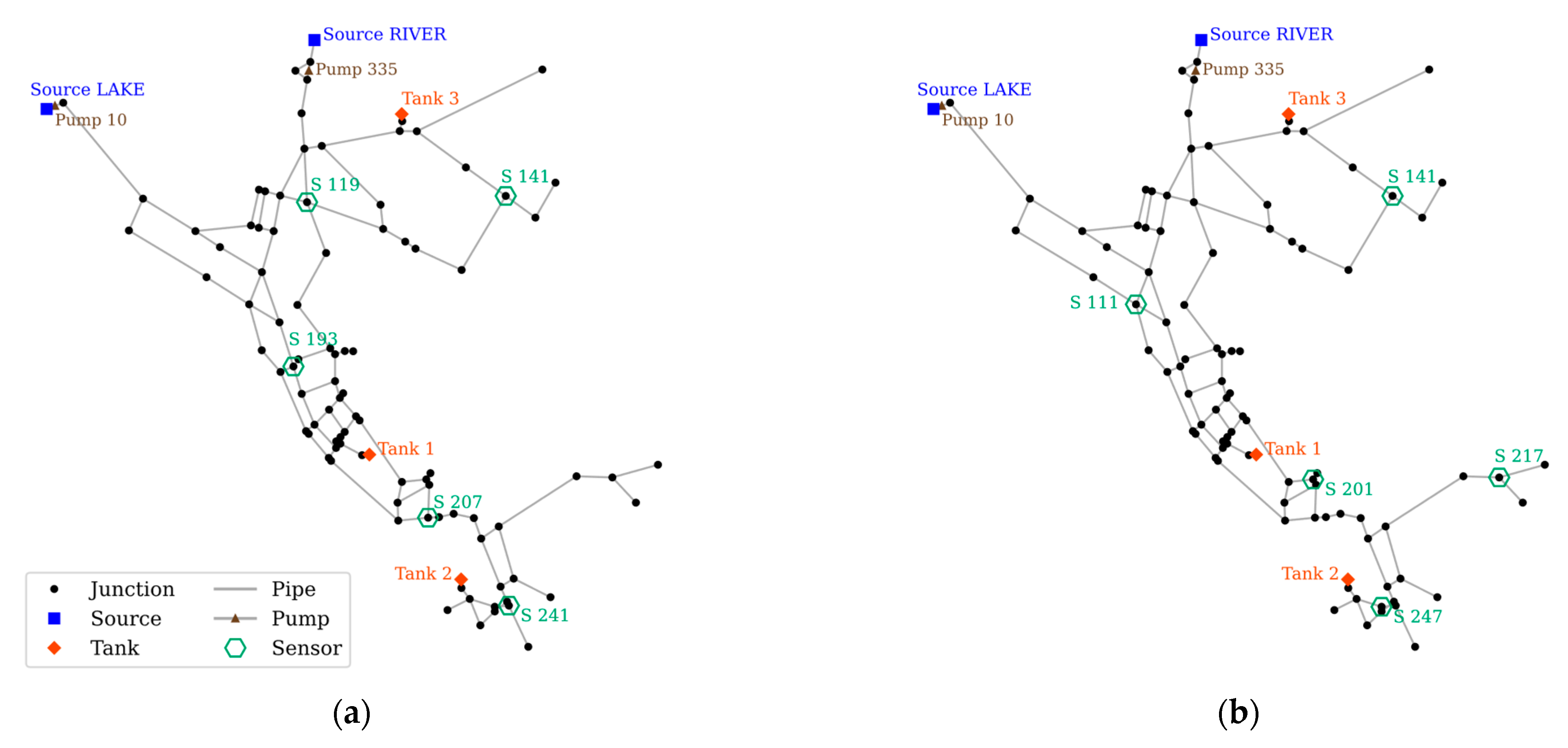
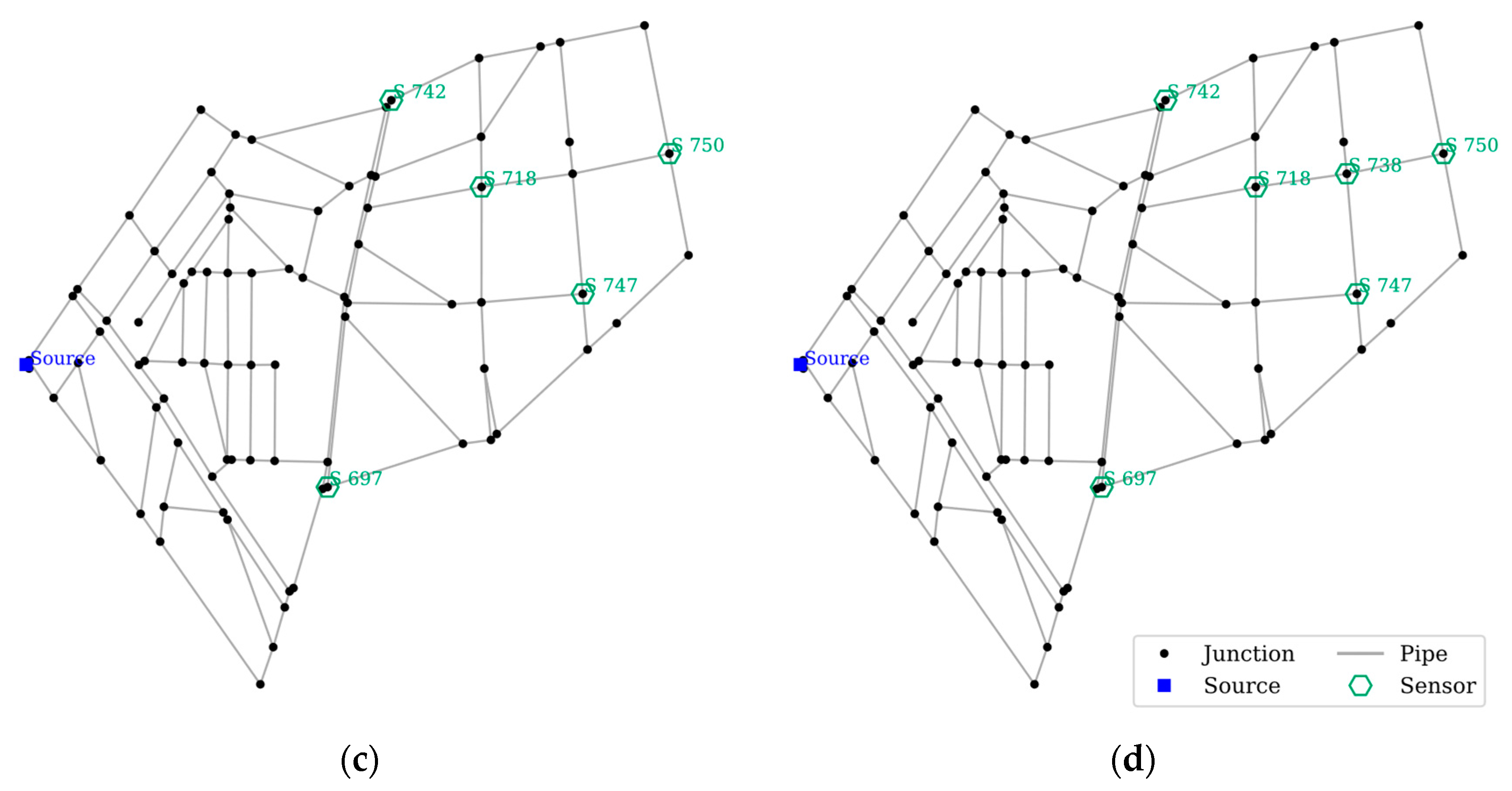
4.3.1. SPSO Performance on NET-A
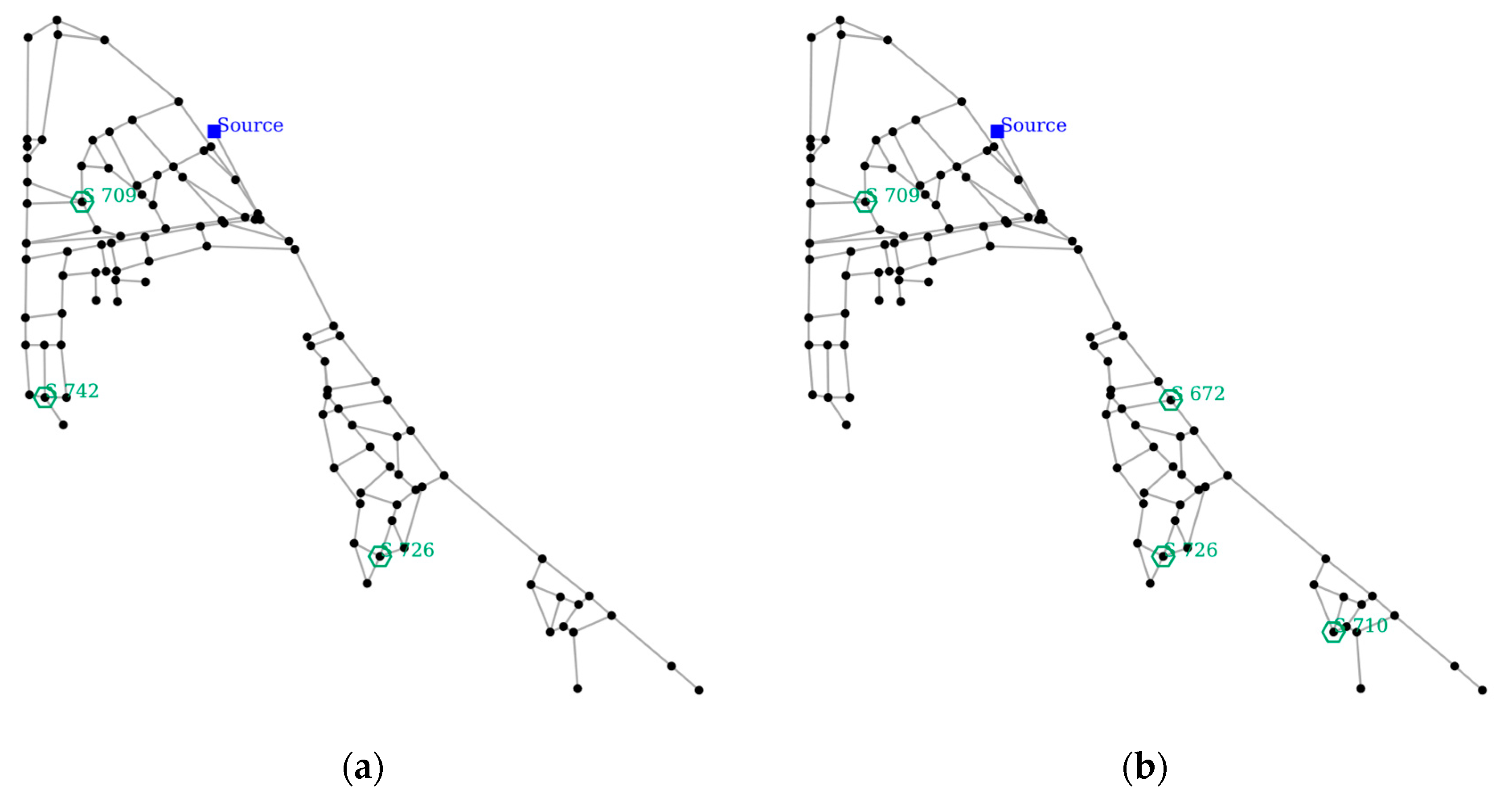
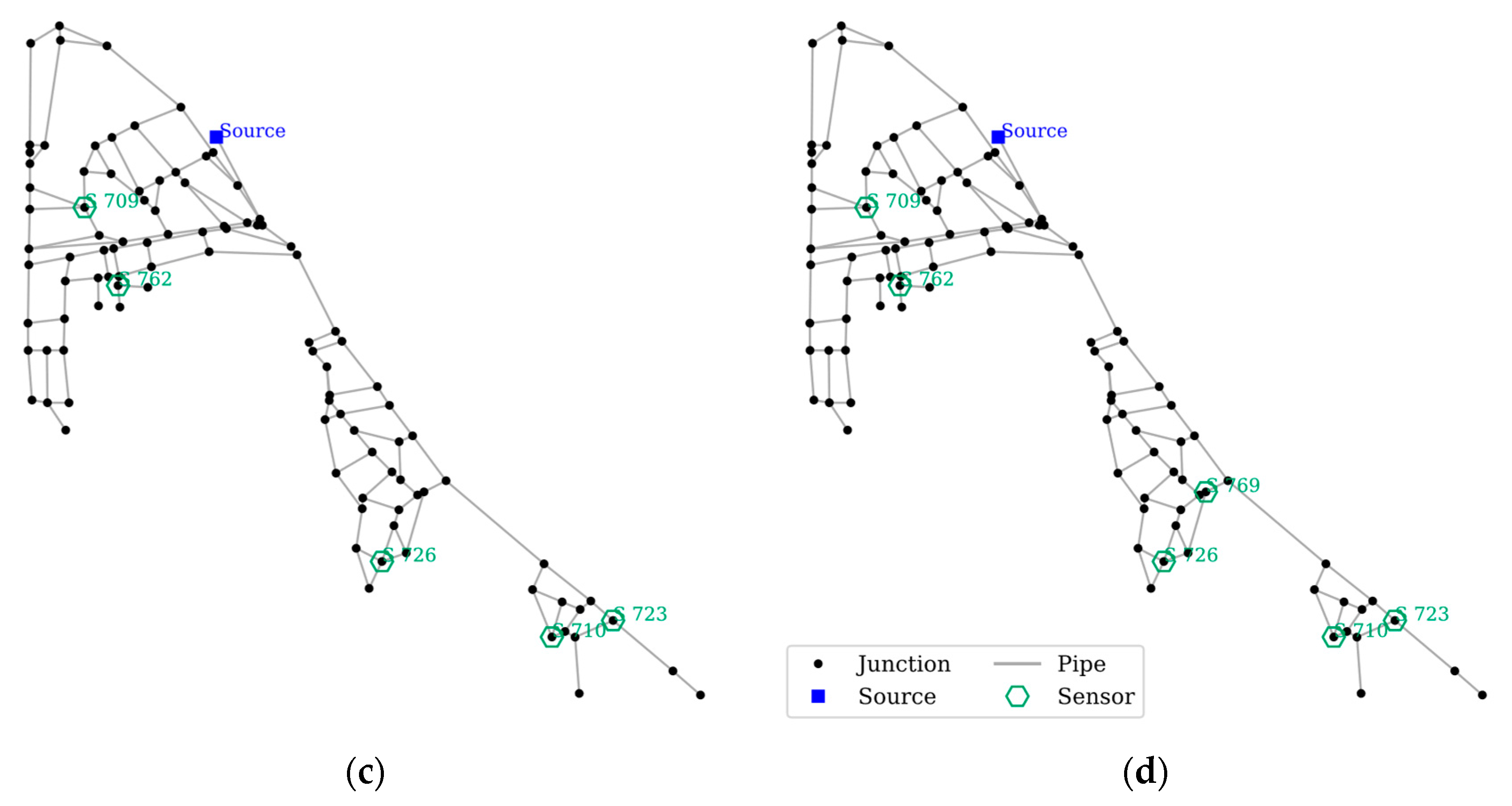
4.3.2. SPSO Performance on NET-B
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kirmeyer, G.J.; Martel, K. Pathogen Intrusion into the Distribution System; American Water Works Association: Denver, CO, USA, 2001. [Google Scholar]
- Rasekh, A.; Hassanzadeh, A.; Mulchandani, S.; Modi, S.; Banks, M.K. Smart Water Networks and Cyber Security. J. Water Resour. Plan. Manag. 2016, 142, 01816004. [Google Scholar] [CrossRef]
- Rathi, S.; Gupta, R.S. Sensor Placement Methods for Contamination Detection in Water Distribution Networks: A Review. Procedia Eng. 2014, 89, 181–188. [Google Scholar] [CrossRef] [Green Version]
- Lee, B.H.; Deininger, R.A. Optimal Locations of Monitoring Stations in Water Distribution System. J. Environ. Eng. 1992, 118, 4–16. [Google Scholar] [CrossRef]
- Kumar, A.; Kansal, M.L.; Arora, G. Identification of Monitoring Stations in Water Distribution System. J. Environ. Eng. 1997, 123, 746–752. [Google Scholar] [CrossRef]
- Al-Zahrani, M.A.; Moeid, K. Locating optimum water quality monitoring stations in water distribution system. In Proceedings of the Bridging the Gap: Meeting the World’s Water and Environmental Resources Challenges, Orlando, FL, USA, 20–24 May 2001; pp. 1–9. [Google Scholar] [CrossRef]
- Kessler, A.; Ostfeld, A.; Sinai, G. Detecting Accidental Contaminations in Municipal Water Networks. J. Water Resour. Plan. Manag. 1998, 124, 192–198. [Google Scholar] [CrossRef]
- Berry, J.W.; Fleischer, L.; Hart, W.E.; Phillips, C.A.; Watson, J.-P. Sensor Placement in Municipal Water Networks. J. Water Resour. Plan. Manag. 2005, 131, 237–243. [Google Scholar] [CrossRef] [Green Version]
- Watson, J.-P.; Greenberg, H.J.; Hart, W.E. A Multiple-Objective Analysis of Sensor Placement Optimization in Water Networks. Crit. Transit. Water Environ. Resour. Manag. 2004, 10, 1–10. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Walski, T. Multi-Objective Optimization of Sensor Placement in Water Distribution Systems. In Proceedings of the 8th Annual Water Distribution Systems Analysis Symposium, Cincinnati, OH, USA, 27–30 August 2006; pp. 1–11. [Google Scholar]
- Ostfeld, A.; Salomons, E. Optimal Layout of Early Warning Detection Stations for Water Distribution Systems Security. J. Water Resour. Plan. Manag. 2004, 130, 377–385. [Google Scholar] [CrossRef]
- Rossman, L.A. EPANET 2: Users Manual; National Risk Management Research Laboratory: Cincinnati, OH, USA, 2000.
- Preis, A.; Ostfeld, A. Multiobjective Contaminant Sensor Network Design for Water Distribution Systems. J. Water Resour. Plan. Manag. 2008, 134, 366–377. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Lu, Y.; Huang, S.; Xiao, Y.; Wang, W. Incremental Sensor Placement Optimization on Water Network. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2013; pp. 467–482. [Google Scholar]
- Montalvo, I.; Izquierdo, J.; Pérez, R.; Tung, M.M. Particle Swarm Optimization applied to the design of water supply systems. Comput. Math. Appl. 2008, 56, 769–776. [Google Scholar] [CrossRef] [Green Version]
- Suribabu, C.R.; Neelakantan, T.R. Design of water distribution networks using particle swarm optimization. Urban Water J. 2006, 3, 111–120. [Google Scholar] [CrossRef]
- Eberhart, R.C.; Shi, Y. Comparison between genetic algorithms and particle swarm optimization. In International Conference on Evolutionary Programming; Springer: Berlin/Heidelberg, Germany, 1998; pp. 611–616. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95 International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360), Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar] [CrossRef]
- Bristow, E.C.; Brumbelow, K. Delay between Sensing and Response in Water Contamination Events. J. Infrastruct. Syst. 2006, 12, 87–95. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Hrudey, S.; French, S.; Bedford, T.; Soane, E.; Pollard, S. A role for human reliability analysis (HRA) in preventing drinking water incidents and securing safe drinking water. Water Res. 2009, 43, 3227–3238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marlim, M.S.; Kang, D. Identifying Contaminant Intrusion in Water Distribution Networks under Water Flow and Sensor Report Time Uncertainties. Water 2020, 12, 3179. [Google Scholar] [CrossRef]
- van Rossum, G.; Drake, F.L., Jr. Python Reference Manual; Centrum voor Wiskunde en Informatica: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Klise, K.A.; Hart, D.; Moriarty, D.; Bynum, M.L.; Murray, R.; Burkhardt, J.; Haxton, T. Water Network Tool for Resilience (WNTR) User Manual; Sandia National Laboratories: Albuquerque, NM, USA, 2017.
- Berry, J.; Booman, E.; Riesen, L.A.; Hart, W.E.; Phillips, C.A.; Watson, J.P.; Murray, R. User’s Manual: TEVA-SPOT Toolkit 2.4; EPA 600/R-08/041B; National Homeland Security Research Center, US EPA: Washington, DC, USA, 2010.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Node 1 | Node 2 | Node 3 | Node 4 | Node 5 |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 |
| 1800 | 1 | 0 | 1 | 0 | 0 |
| 3600 | 1 | 1 | 1 | 0 | 0 |
| 5400 | 1 | 1 | 1 | 0 | 1 |
| 7200 | 1 | 1 | 1 | 0 | 1 |
| 9000 | 1 | 1 | 1 | 0 | 1 |
| No. of Elements | Network | ||
|---|---|---|---|
| NET3 | NET-A | NET-B | |
| Junctions | 91 | 104 | 87 |
| Sources | 2 | 1 | 1 |
| Tanks | 3 | 0 | 0 |
| Pipes | 115 | 151 | 129 |
| Pumps | 2 | 0 | 0 |
| TEVA-SPOT | SPSO | Improvement | |
|---|---|---|---|
| Fitness | 0.2851 | 0.2192 | 23.1% |
| BS | 0.1868 | 0.1648 | 11.8% |
| CC | 0.1984 | 0.1280 | 35.5% |
| LE | 0.4701 | 0.3647 | 22.4% |
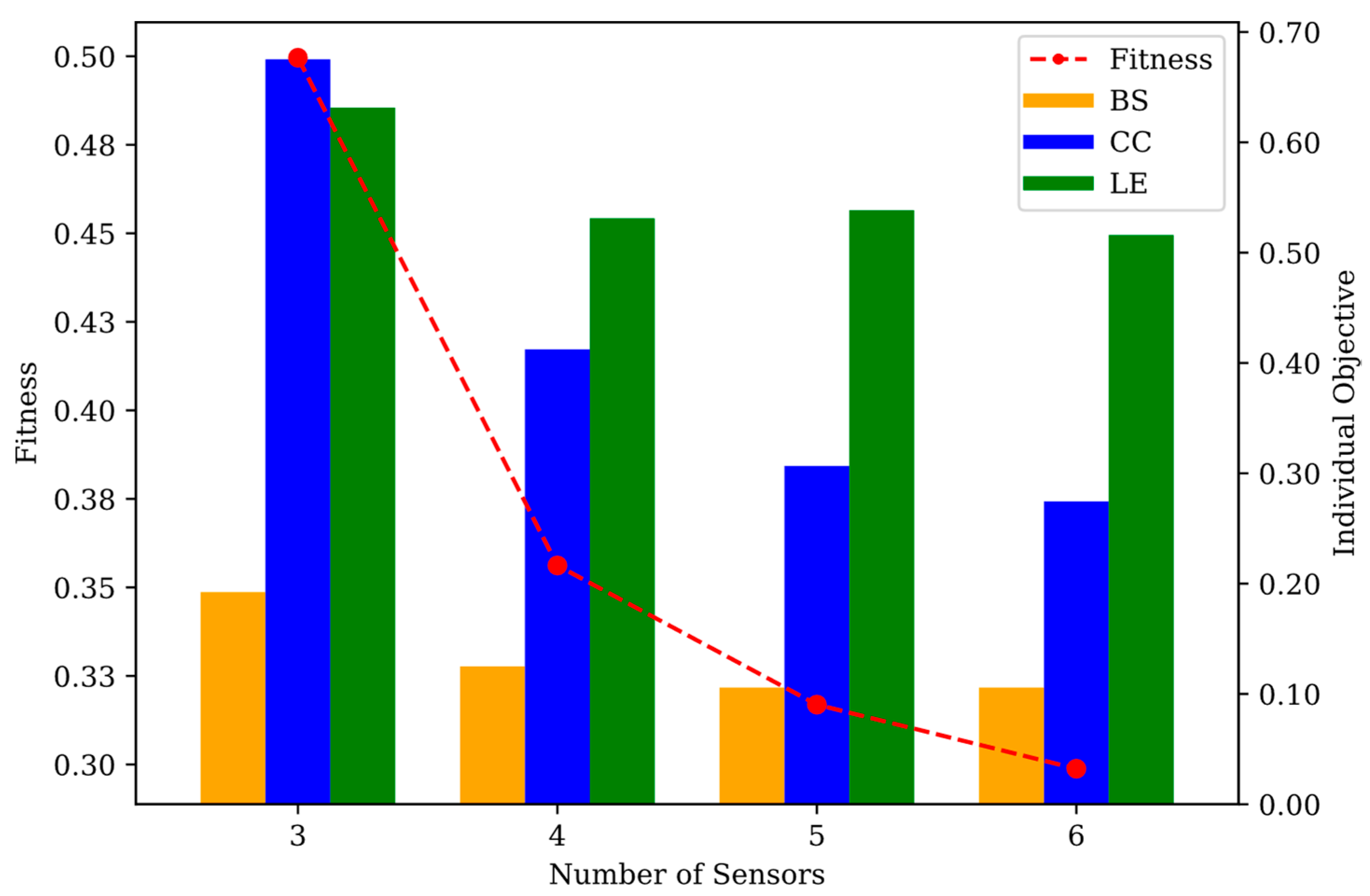
| Objective | Config | Number of Sensors | |||
|---|---|---|---|---|
| A | 3 | B | 4 | C | 5 | D | 6 | |
| Fitness | 0.4996 | 0.3562 | 0.3169 | 0.2988 |
| BS | 0.1923 | 0.1250 | 0.1058 | 0.1058 |
| CC | 0.6752 | 0.4123 | 0.3066 | 0.2745 |
| LE | 0.6314 | 0.5312 | 0.5385 | 0.5160 |
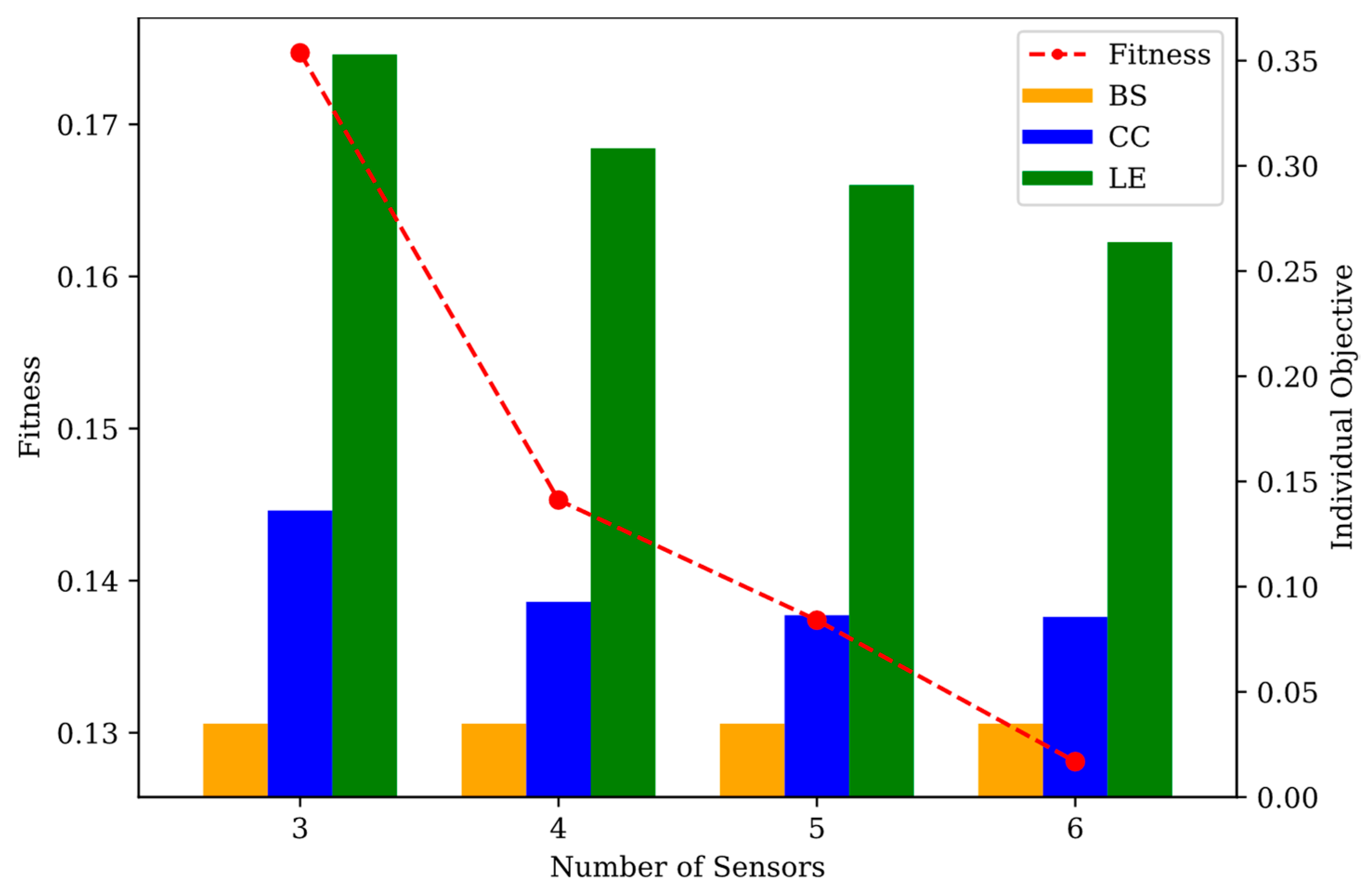
| Objective | Config | Number of Sensors | |||
|---|---|---|---|---|
| A | 3 | B | 4 | C | 5 | D | 6 | |
| Fitness | 0.1747 | 0.1453 | 0.1374 | 0.1281 |
| BS | 0.0349 | 0.0349 | 0.0349 | 0.0349 |
| CC | 0.1362 | 0.0928 | 0.0864 | 0.0856 |
| LE | 0.3529 | 0.3083 | 0.2909 | 0.2637 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marlim, M.S.; Kang, D. Optimal Water Quality Sensor Placement by Accounting for Possible Contamination Events in Water Distribution Networks. Water 2021, 13, 1999. https://doi.org/10.3390/w13151999
Marlim MS, Kang D. Optimal Water Quality Sensor Placement by Accounting for Possible Contamination Events in Water Distribution Networks. Water. 2021; 13(15):1999. https://doi.org/10.3390/w13151999
Chicago/Turabian StyleMarlim, Malvin S., and Doosun Kang. 2021. "Optimal Water Quality Sensor Placement by Accounting for Possible Contamination Events in Water Distribution Networks" Water 13, no. 15: 1999. https://doi.org/10.3390/w13151999
APA StyleMarlim, M. S., & Kang, D. (2021). Optimal Water Quality Sensor Placement by Accounting for Possible Contamination Events in Water Distribution Networks. Water, 13(15), 1999. https://doi.org/10.3390/w13151999