
Stochastic Modeling of Hydroclimatic Processes Using Vine Copulas


Abstract
:1. Introduction
2. Methods
2.1. First-Order Univariate Processes
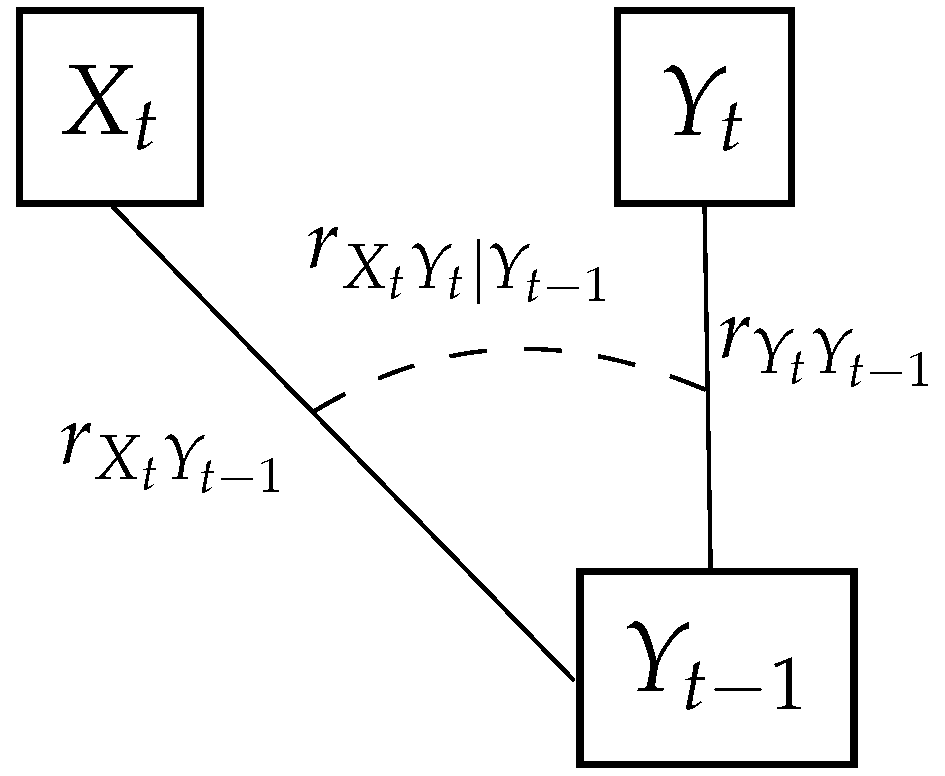
2.2. First-Order Bivariate Processes
- i
- Fit the appropriate marginal distributions characterising the random variables (or use the empirical distribution).
- ii
- Select suitable copulas , , and .
- iii
- Generate the first variable () using the univariate copula model from the previous subsection.
- iv
- Generate the second variable () using Equation (4).
2.3. First-Order Intermittent-Continuous Bivariate Processes
- i
- Fit the appropriate marginal distributions characterizing the RV’s.
- ii
- Select and fit the suitable copulas , , and .
- iii
- Calculate the transition-probability matrix of the Markov chain for the intermittent process . Simulate a desired length of the Markov sequence.
- iv
- Split the time series into dry and wet blocks.
- v
- Generate “blocks” representing using the univariate copula model (Equation (3)).
- vi
- Generate the wet block using the vine model of Equation (4) and the appropriate marginal distribution. Use as seed for the first value of the wet block the last value of the previous dry block.
- vii
- Generate the dry block using the vine model (Equation (3)) and the appropriate marginal distribution. Use as seed for the first value of the dry block the last value of the previous wet block.
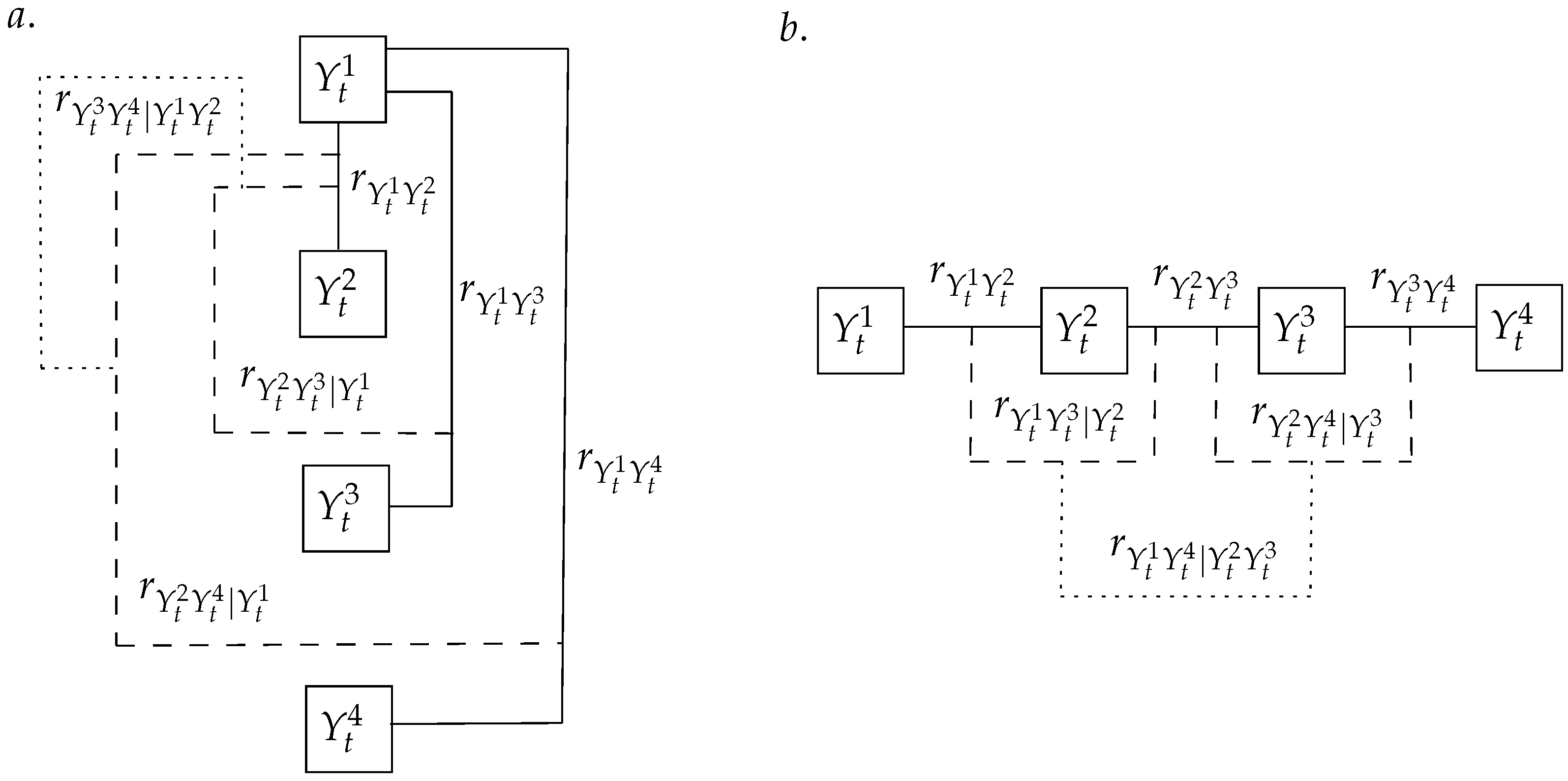
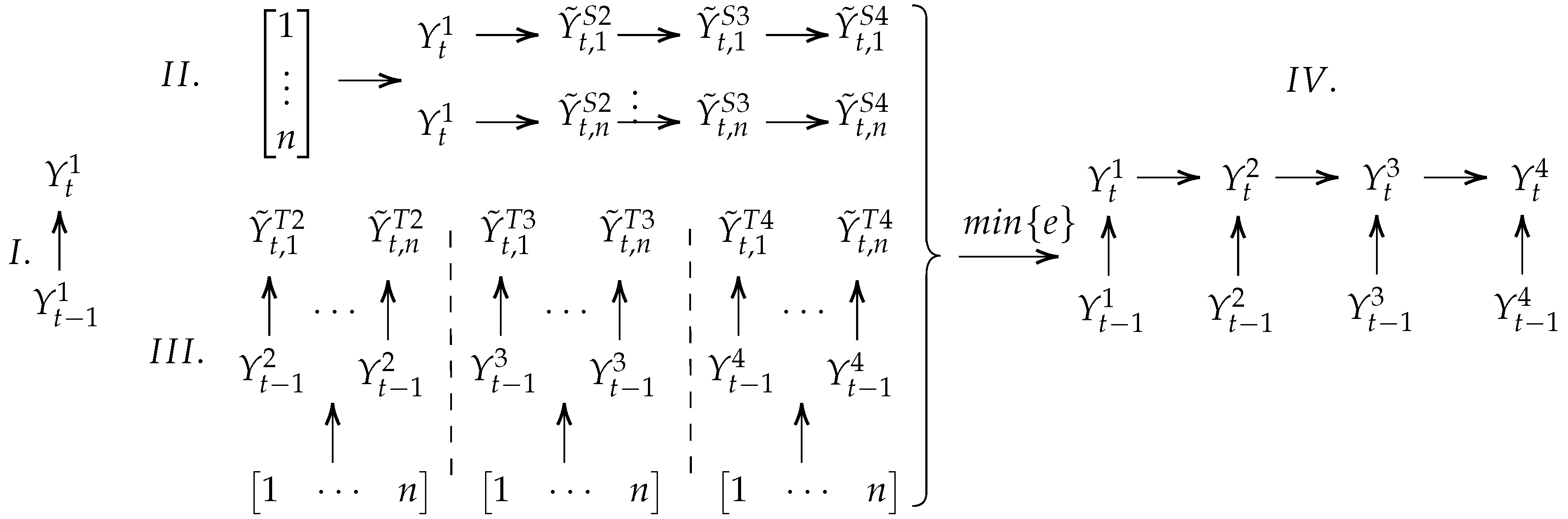
2.4. Multivariate Processes
- i
- Generate one realization of from based on the temporal model.
- ii
- Generate n realizations of based on according to the spatial model. These are denoted with a tilde and the superscript as .
- iii
- Generate n realizations of based on according to the temporal model. These are denoted with a tilde and the superscript as . The spatial and temporal realizations are all plausible realizations of , which implies that a section between the two sets exists.
- iv
- Identify the common space. This is performed by identifying the realizations that minimize the root mean squared error (RMSE).
- i
- Fit the appropriate marginal distributions characterizing the RV’s.
- ii
- Identify suitable models to describe spatial and temporal dependence.
- iii
- Select and fit suitable copulas to model dependencies.
- iv
- Select the number of trials n for the repetitive sampling.
- v
- Generate the first temporal realization according to the sampling order of the selected spatial model.
- vi
- Generate n realizations from the spatial and temporal models independently.
- vii
- Select the realization which minimizes the error (Equation (10)).
2.5. Admissible Marginal Distributions and Copula Fitting
3. Case Study
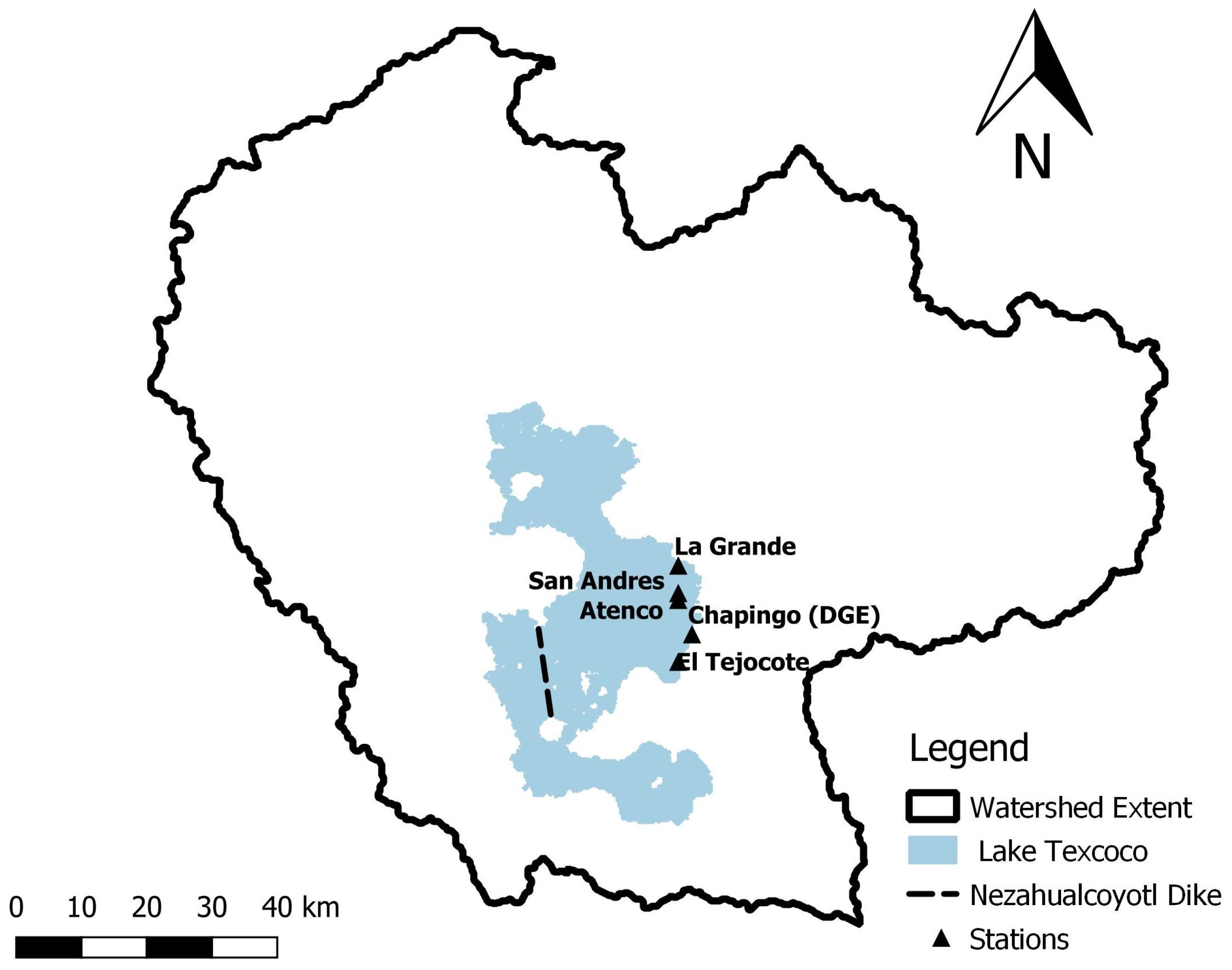
3.1. Area of Study
- is the precipitation at time t (m/day).
- is the evaporation at time t (m/day).
- is the tributary area of the basin (m).
- is the surface area of the lake (m).
- is the daily change in volume (m/day).
3.2. Data
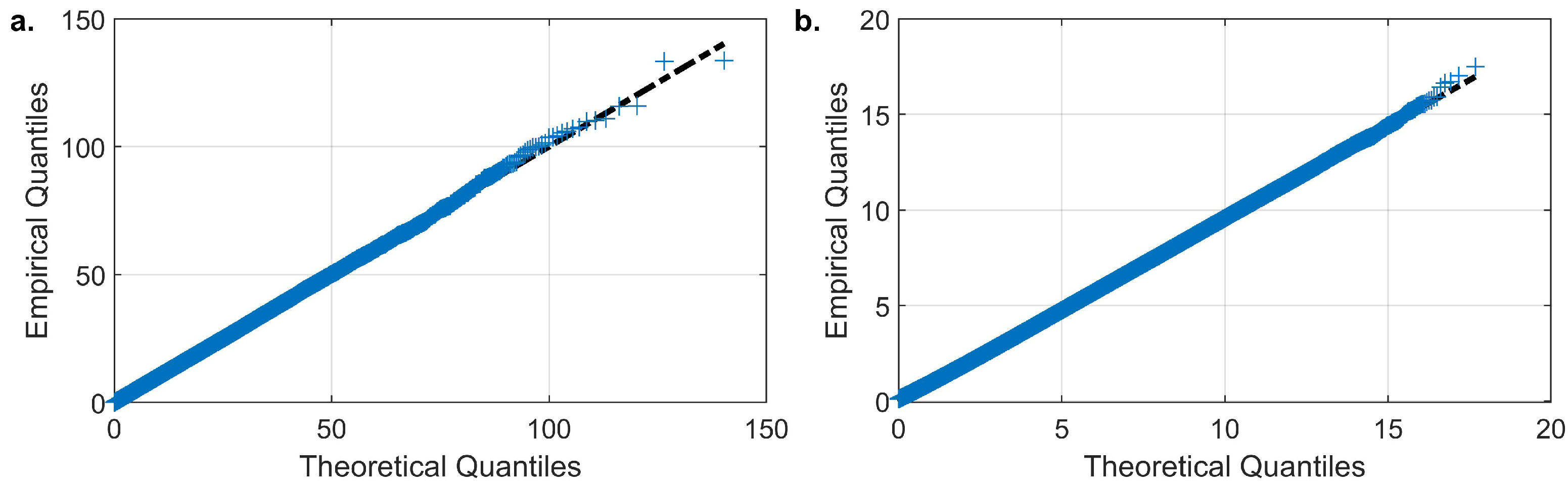
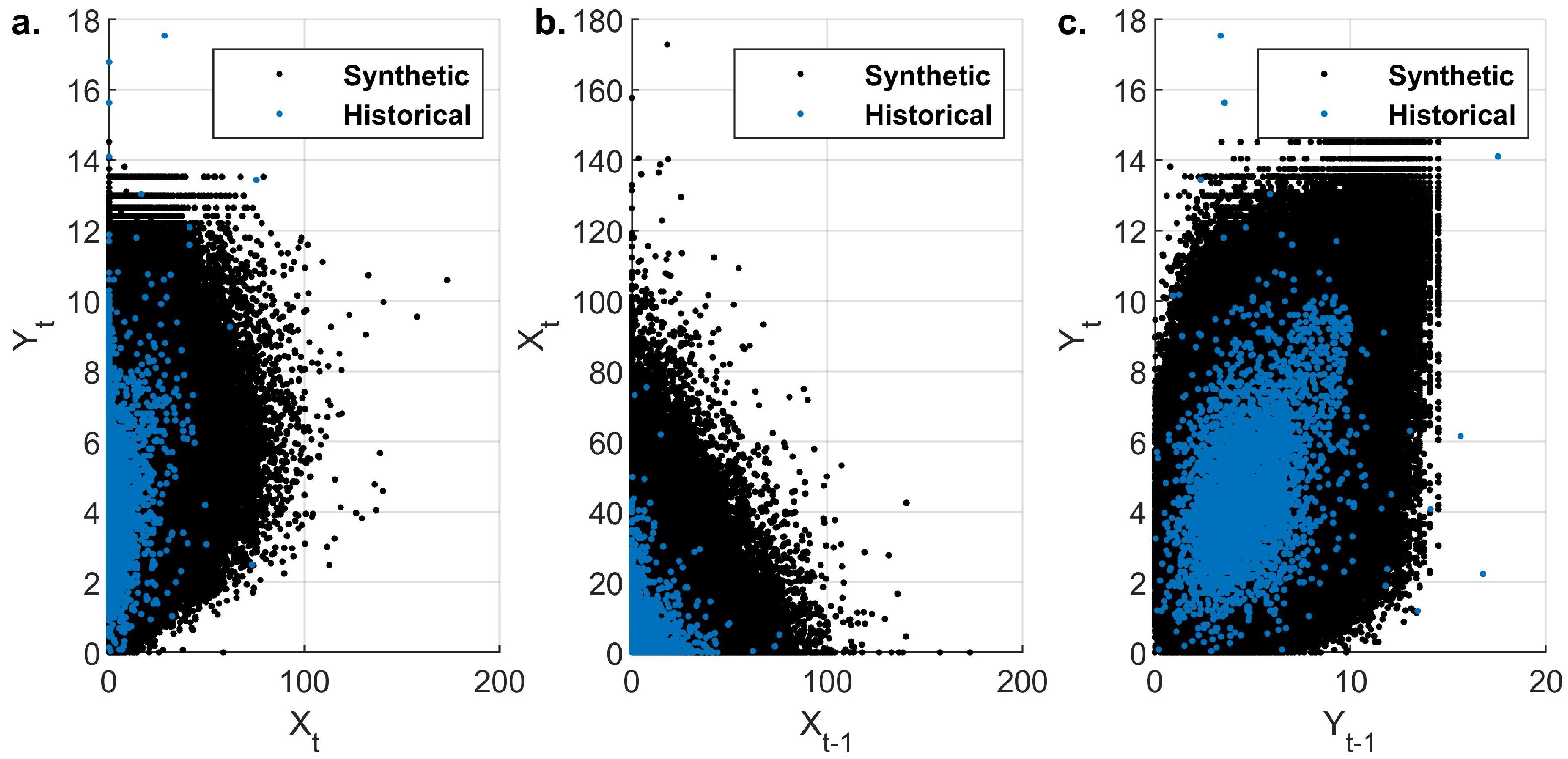
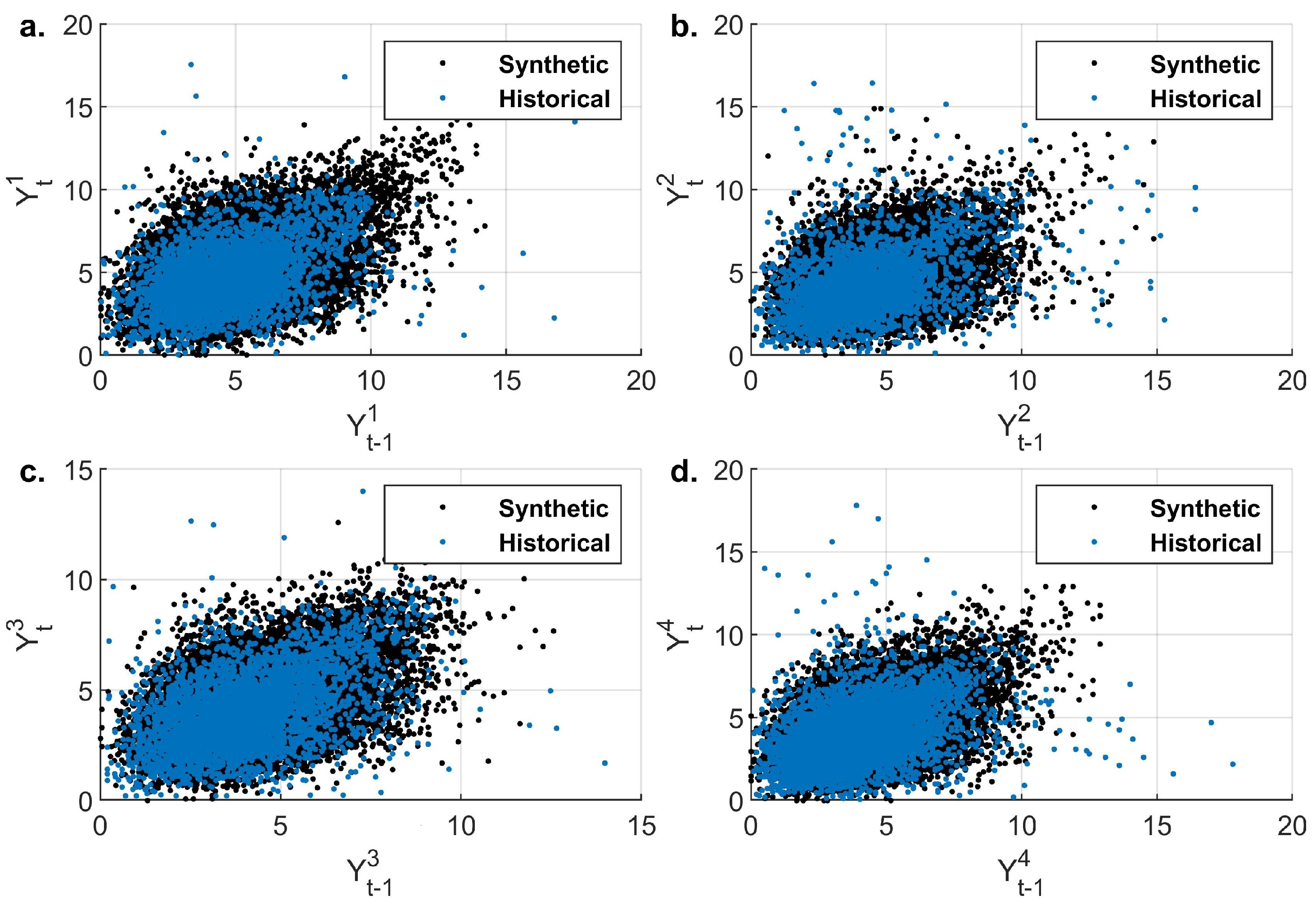
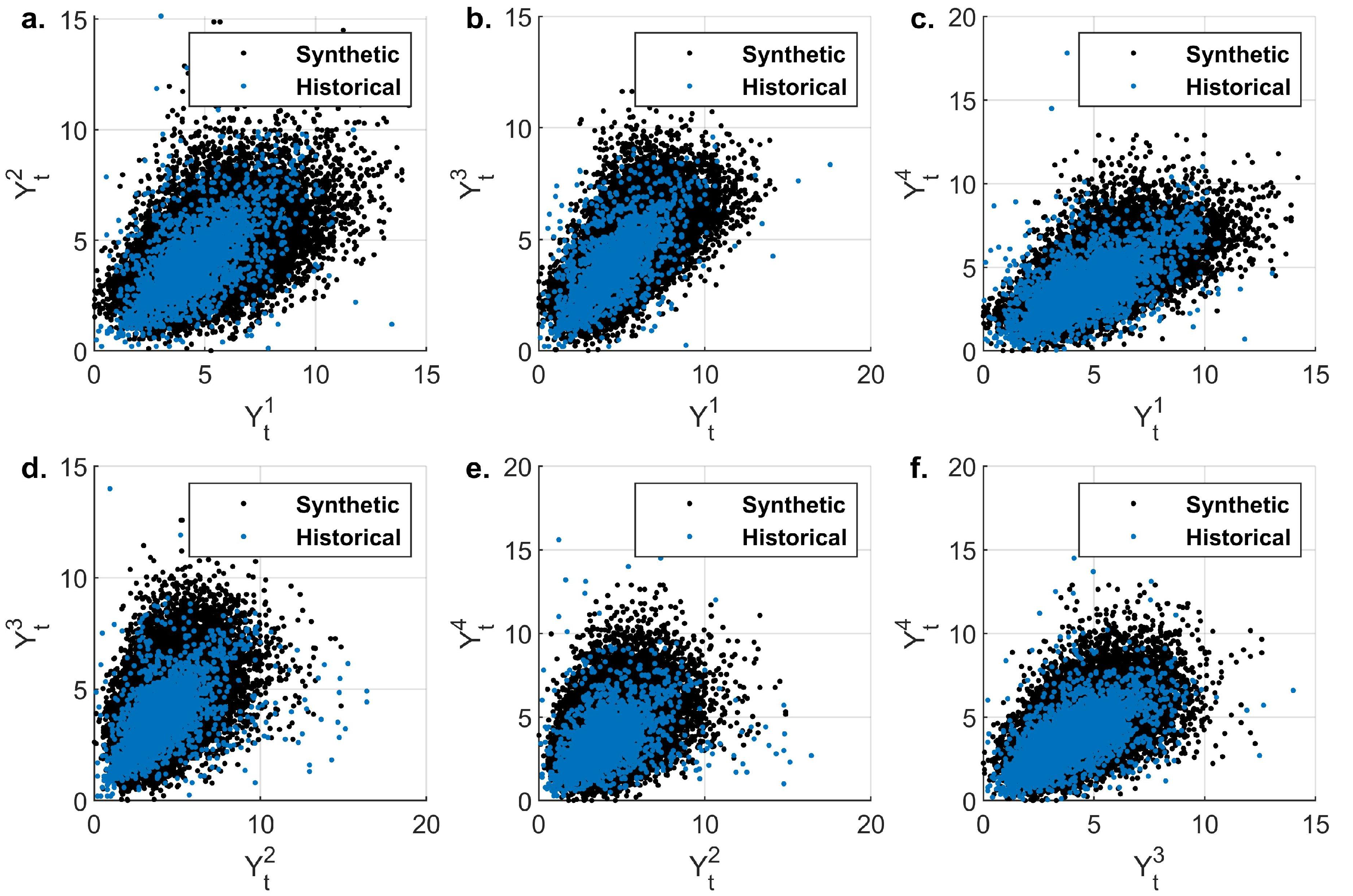
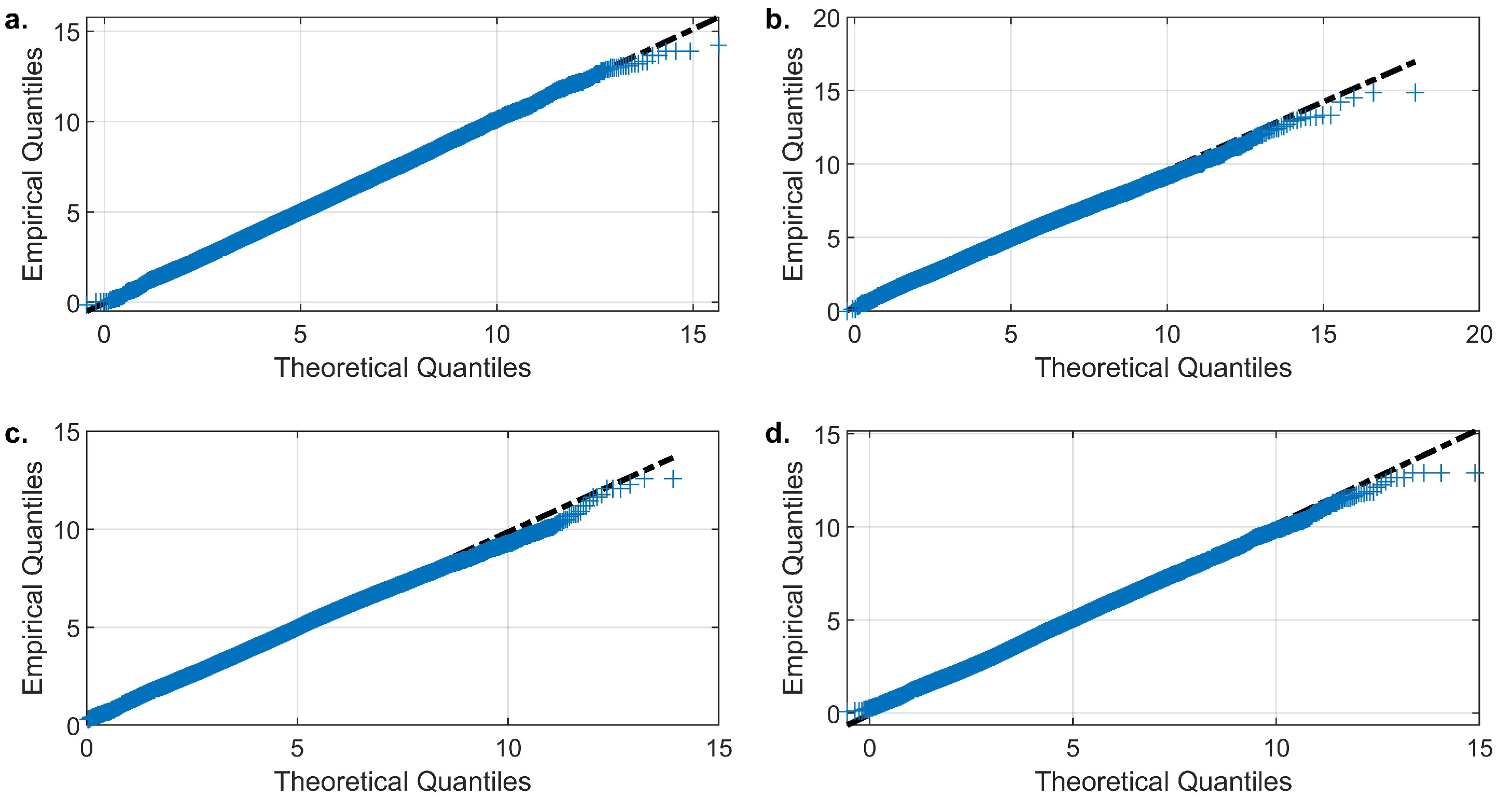
3.3. Simulation of Daily Evaporation and Precipitation
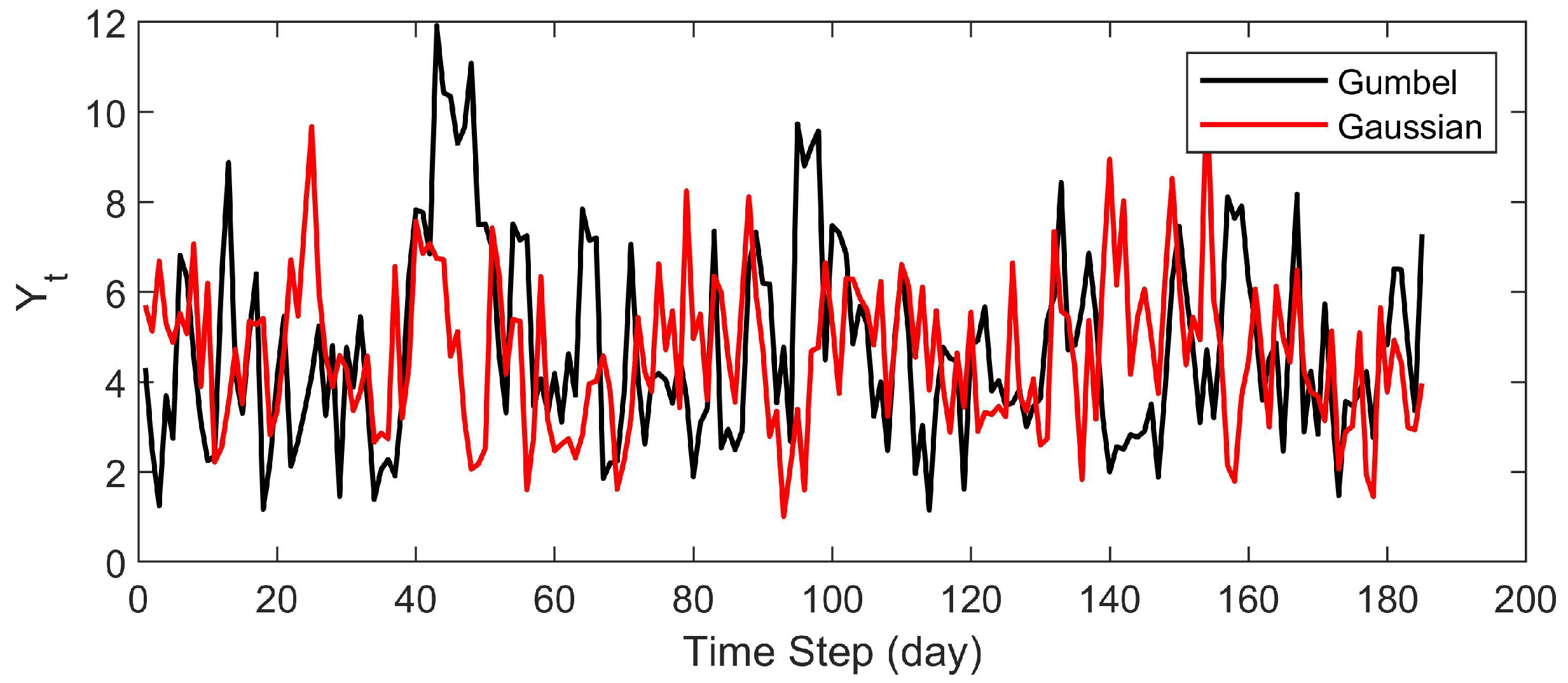
The Effect of the Choice of Copula
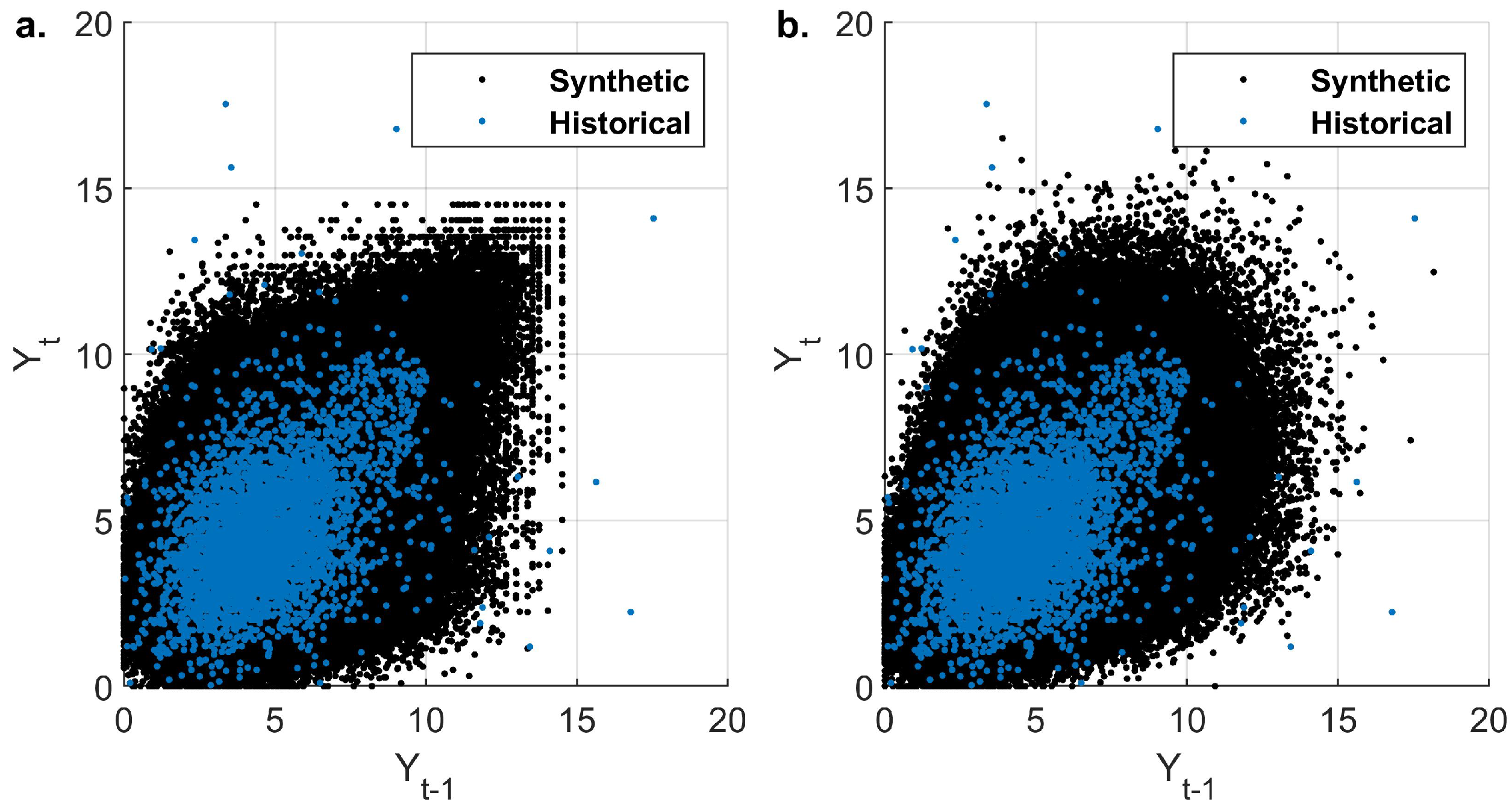
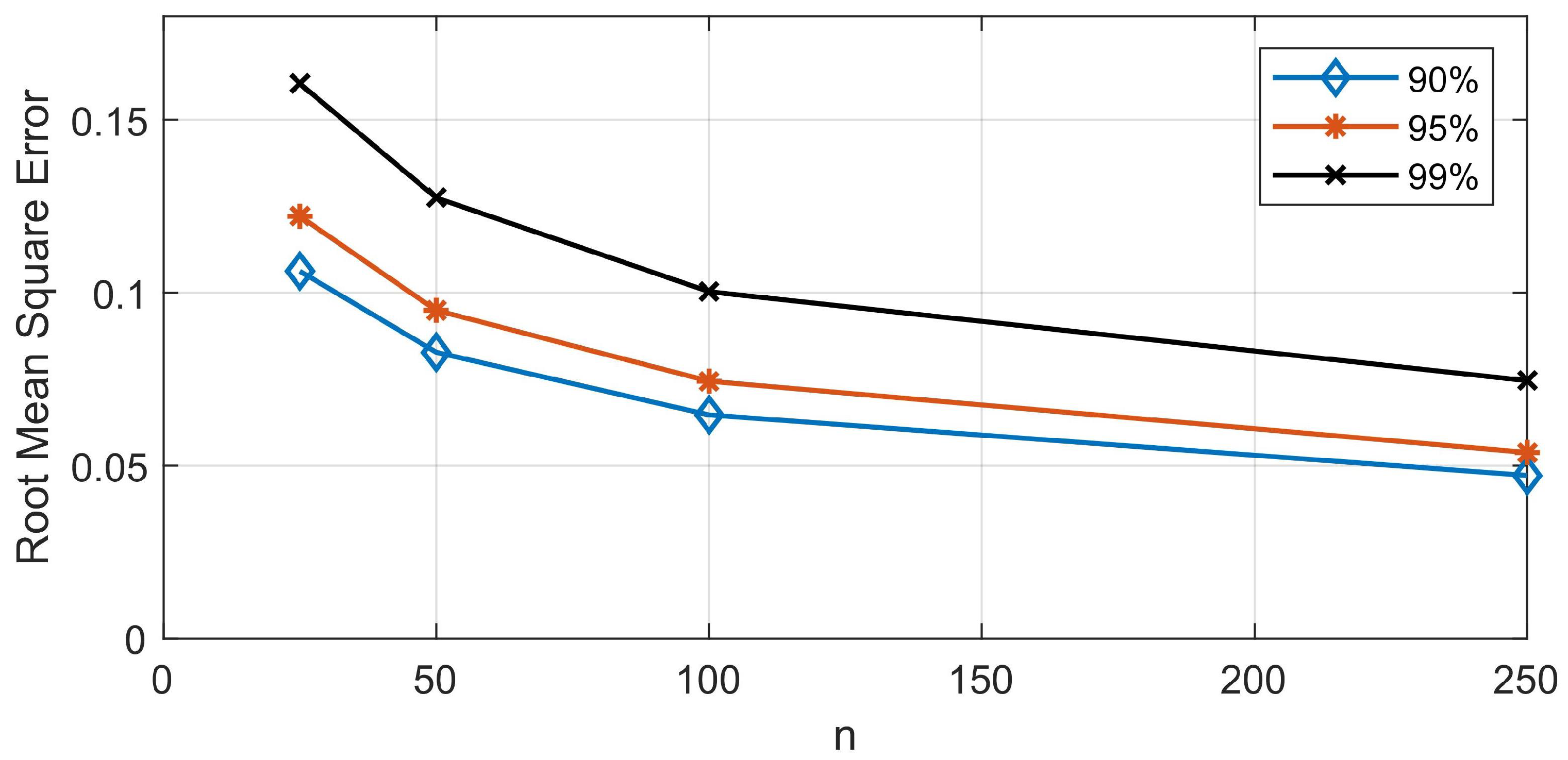
3.4. Simulation of Evaporation across Multiple Stations
Exploration of the Repetitive Sampling Length
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Distribution Functions
Appendix B. Inverse Conditional Copulas
References
- Fiering, M.B. Streamflow Synthesis; Harvard University Press: Cambridge, MA, USA, 1967. [Google Scholar] [CrossRef]
- Klemeš, V.; Srikanthan, R.; McMahon, T.A. Long-memory flow models in reservoir analysis: What is their practical value? Water Resour. Res. 1981, 17, 737–751. [Google Scholar] [CrossRef]
- Vogel, R.M.; Stedinger, J.R. The value of stochastic streamflow models in overyear reservoir design applications. Water Resour. Res. 1988, 24, 1483–1490. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Makropoulos, C. A Surrogate Based Optimization Approach for the Development of Uncertainty-Aware Reservoir Operational Rules: The Case of Nestos Hydrosystem. Water Resour. Manag. 2015, 29, 4719–4734. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Makropoulos, C. Multiobjective optimisation on a budget: Exploring surrogate modelling for robust multi-reservoir rules generation under hydrological uncertainty. Environ. Model. Softw. 2015. [Google Scholar] [CrossRef]
- Papoulakos, K.; Pollakis, G.; Moustakis, Y.; Markopoulos, A.; Iliopoulou, T.; Dimitriadis, P.; Koutsoyiannis, D.; Efstratiadis, A. Simulation of water-energy fluxes through small-scale reservoir systems under limited data availability. Energy Procedia 2017, 125, 405–414. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Economou, A. Evaluation of the parameterization-simulation-optimization approach for the control of reservoir systems. Water Resour. Res. 2003, 39. [Google Scholar] [CrossRef] [Green Version]
- Koskinas, A.; Tegos, A. StEMORS: A Stochastic Eco-Hydrological Model for Optimal Reservoir Sizing. Open Water J. 2020, 6, 1. [Google Scholar]
- Haberlandt, U.; Hundecha, Y.; Pahlow, M.; Schumann, A.H. Rainfall Generators for Application in Flood Studies. In Flood Risk Assessment and Management: How to Specify Hydrological Loads, Their Consequences and Uncertainties; Schumann, A.H., Ed.; Springer: Dordrecht, The Netherlands, 2011; pp. 117–147. [Google Scholar]
- Papalexiou, S.M.; Koutsoyiannis, D. A global survey on the seasonal variation of the marginal distribution of daily precipitation. Adv. Water Resour. 2016, 94, 131–145. [Google Scholar] [CrossRef]
- Kossieris, P. Exploring the Statistical and Distributional Properties of Residential Water Demand at Fine Time Scales. Water 2018, 10, 1481. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.A.; Fiering, M. Mathematical synthesis of streamflow sequences for the analysis of river basins by simulation. In Design of Water Resources-Systems; Harvard University Press: Cambridge, UK, 1962; pp. 459–493. [Google Scholar]
- Lombardo, F.; Volpi, E.; Koutsoyiannis, D.; Papalexiou, S.M. Just two moments! A cautionary note against use of high-order moments in multifractal models in hydrology. Hydrol. Earth Syst. Sci. 2014, 18, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. Knowable moments for high-order stochastic characterization and modelling of hydrological processes. Hydrol. Sci. J. 2019. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D.; Manetas, A. Simple Disaggregation by Accurate Adjusting Procedures. Water Resour. Res. 1996, 32, 2105–2117. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Papalexiou, S.M.; Efstratiadis, A.; Makropoulos, C. A Cautionary Note on the Reproduction of Dependencies through Linear Stochastic Models with Non-Gaussian White Noise. Water 2018, 10, 771. [Google Scholar] [CrossRef] [Green Version]
- Beran, J. Statistics for Long-Memory Processes; Routledge: London, UK, 1994. [Google Scholar] [CrossRef]
- Lloyd, E.H.; Hurst, H.E.; Black, R.P.; Simaika, Y.M. Long-Term Storage: An Experimental Study. J. R. Stat. Society. Ser. A Gen. 1966, 129, 591. [Google Scholar] [CrossRef]
- Mandelbrot, B.B. Une classe de processus stochastiques homothétiques a soi: Application à la loi elimatoloeique de H. E. Hurst. C. R. Aead. Sci. 1965, 260, 3274–3277. [Google Scholar]
- Koutsoyiannis, D. The Hurst phenomenon and fractional Gaussian noise made easy. Hydrol. Sci. J. 2002, 47, 573–595. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D.; Iliopoulou, T.; Papanicolaou, P. A Global-Scale Investigation of Stochastic Similarities in Marginal Distribution and Dependence Structure of Key Hydrological-Cycle Processes. Hydrology 2021, 8, 59. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. A generalized mathematical framework for stochastic simulation and forecast of hydrologic time series. Water Resour. Res. 2000, 36, 1519–1533. [Google Scholar] [CrossRef] [Green Version]
- Efstratiadis, A.; Dialynas, Y.G.; Kozanis, S.; Koutsoyiannis, D. A multivariate stochastic model for the generation of synthetic time series at multiple time scales reproducing long-term persistence. Environ. Model. Softw. 2014, 62, 139–152. [Google Scholar] [CrossRef]
- Dupuis, D.J. Using Copulas in Hydrology: Benefits, Cautions, and Issues. J. Hydrol. Eng. 2007, 12, 381–393. [Google Scholar] [CrossRef]
- Genest, C.; Favre, A.C. Everything You Always Wanted to Know about Copula Modeling but Were Afraid to Ask. J. Hydrol. Eng. 2007, 12, 347–368. [Google Scholar] [CrossRef]
- Salvadori, G.; Michele, C.D. On the Use of Copulas in Hydrology: Theory and Practice. J. Hydrol. Eng. 2007, 12, 369–380. [Google Scholar] [CrossRef]
- Daneshkhah, A.; Remesan, R.; Chatrabgoun, O.; Holman, I.P. Probabilistic modeling of flood characterizations with parametric and minimum information pair-copula model. J. Hydrol. 2016, 540, 469–487. [Google Scholar] [CrossRef] [Green Version]
- Lu Chen, S.G. Copulas and Its Application in Hydrology and Water Resources, 1st ed.; Springer: Singapore, 2019; p. 290. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Copulas and Their Applications in Water Resources Engineering; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.; Salas, J.D. Copula-based stochastic simulation of hydrological data applied to Nile River flows. Hydrol. Res. 2011, 42, 318–330. [Google Scholar] [CrossRef]
- Jeong, C.; Lee, T. Copula-based modeling and stochastic simulation of seasonal intermittent streamflows for arid regions. J. Hydro-Environ. Res. 2015, 9, 604–613. [Google Scholar] [CrossRef]
- Serinaldi, F. A multisite daily rainfall generator driven by bivariate copula-based mixed distributions. J. Geophys. Res. Atmos. 2009. [Google Scholar] [CrossRef] [Green Version]
- Leontaris, G.; Morales-Nápoles, O.; Wolfert, A. Probabilistic scheduling of offshore operations using copula based environmental time series—An application for cable installation management for offshore wind farms. Ocean Eng. 2016, 125, 328–341. [Google Scholar] [CrossRef] [Green Version]
- Bedford, T.; Daneshkhah, A.; Wilson, K.J. Approximate Uncertainty Modeling in Risk Analysis with Vine Copulas. Risk Anal. 2016, 36, 792–815. [Google Scholar] [CrossRef] [Green Version]
- Chatrabgoun, O.; Hosseinian-Far, A.; Chang, V.; Stocks, N.G.; Daneshkhah, A. Approximating non-Gaussian Bayesian networks using minimum information vine model with applications in financial modelling. J. Comput. Sci. 2018, 24, 266–276. [Google Scholar] [CrossRef] [Green Version]
- Cooke, R.M. Markov and entropy properties of tree and vines-dependent variables. In Proceedings of the ASA Section of Bayesian Statistical Science, Istanbul, Turkey, 16–18 August 1997. [Google Scholar]
- Pereira, G.; Veiga, A. PAR(p)-vine copula based model for stochastic streamflow scenario generation. Stoch. Environ. Res. Risk Assess. 2018, 32, 833–842. [Google Scholar] [CrossRef]
- Jäger, W.S.; Nápoles, O.M. A Vine-Copula Model for Time Series of Significant Wave Heights and Mean Zero-Crossing Periods in the North Sea. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part Civ. Eng. 2017. [Google Scholar] [CrossRef] [Green Version]
- Sarmiento, C.; Valencia, C.; Akhavan-Tabatabaei, R. Copula autoregressive methodology for the simulation of wind speed and direction time series. J. Wind. Eng. Ind. Aerodyn. 2018. [Google Scholar] [CrossRef]
- Brechmann, E.C.; Czado, C. COPAR—multivariate time series modeling using the copula autoregressive model. Appl. Stoch. Model. Bus. Ind. 2015, 31, 495–514. [Google Scholar] [CrossRef] [Green Version]
- Torres-Alves, G.A.; Morales-Nápoles, O. Reliability Analysis of Flood Defenses: The Case of the Nezahualcoyotl Dike in the Aztec City of Tenochtitlan. Reliab. Eng. Syst. Saf. 2020, 107057. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de répartition à n dimensions et leurs marges. Publ. L’InstitutDe Stat. L’Université Paris 1959, 8, 229–231. [Google Scholar]
- Joe, H. Dependence Modeling with Copulas; Chapman & Hall/CRC Monographs on Statistics & Applied Probability; Taylor and Francis: Hoboken, NJ, USA, 2014. [Google Scholar]
- Joe, H. Families of m-variate distributions with given margins and m(m − 1)/2bivariate dependence parameters. In Distributions with Fixed Marginals and Related Topics; Rüschendorf, L., Schweizer, B., Taylor, M.D., Eds.; Lecture Notes–Monograph Series; Institute of Mathematical Statistics: Hayward, CA, USA, 1996; Volume 28, pp. 120–141. [Google Scholar] [CrossRef]
- Aas, K.; Czado, C.; Frigessi, A.; Bakken, H. Pair-copula constructions of multiple dependence. Insur. Math. Econ. 2009. [Google Scholar] [CrossRef] [Green Version]
- Morales-Nápoles, O.; Steenbergen, R.D.J.M. Large-Scale Hybrid Bayesian Network for Traffic Load Modeling from Weigh-in-Motion System Data. J. Bridge Eng. 2015, 20, 04014059. [Google Scholar] [CrossRef]
- Morales-Nápoles, O.; Steenbergen, R.D. Analysis of axle and vehicle load properties through Bayesian Networks based on Weigh-in-Motion data. Reliab. Eng. Syst. Saf. 2014, 125, 153–164. [Google Scholar] [CrossRef]
- Bedford, T.; Cooke, R.M. Vines—A new graphical model for dependent random variables. Ann. Statist. 2002, 30, 1031–1068. [Google Scholar] [CrossRef]
- Cooke, R.M.; Joe, H.; Aas, K. Vines arise. In Dependence Modeling: Vine Copula Handbook; World Scientific: Singapure, 2010. [Google Scholar] [CrossRef]
- Papalexiou, S.M. Unified theory for stochastic modelling of hydroclimatic processes: Preserving marginal distributions, correlation structures, and intermittency. Adv. Water Resour. 2018, 115, 234–252. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Makropoulos, C.; Koutsoyiannis, D. Simulation of Stochastic Processes Exhibiting Any-Range Dependence and Arbitrary Marginal Distributions. Water Resour. Res. 2018, 54, 9484–9513. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Coupling stochastic models of different timescales. Water Resour. Res. 2001, 37, 379–391. [Google Scholar] [CrossRef] [Green Version]
- Tsoukalas, I.; Efstratiadis, A.; Makropoulos, C. Building a puzzle to solve a riddle: A multi-scale disaggregation approach for multivariate stochastic processes with any marginal distribution and correlation structure. J. Hydrol. 2019, 575, 354–380. [Google Scholar] [CrossRef]
- Kurowicka, D.; Cooke, R. Sampling algorithms for generating joint uniform distributions using the vine-copula method. Comput. Stat. Data Anal. 2007, 51, 2889–2906. [Google Scholar] [CrossRef]
- Coles, S. An Introduction to Statistical Modeling of Extreme Values; Springer: London, UK, 2001. [Google Scholar]
- Hosking, J.R.M. L-Moments: Analysis and Estimation of Distributions Using Linear Combinations of Order Statistics. (English). J. R. Stat. Soc. Ser. B Methodol. 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Zorzetto, E.; Botter, G.; Marani, M. On the emergence of rainfall extremes from ordinary events. Geophys. Res. Lett. 2016, 43, 8076–8082. [Google Scholar] [CrossRef] [Green Version]
- Genest, C.; Rémillard, B.; Beaudoin, D. Goodness-of-fit tests for copulas: A review and a power study. Insur. Math. Econ. 2009, 44, 199–213. [Google Scholar] [CrossRef]
- Choroś, B.; Ibragimov, R.; Permiakova, E. Copula Estimation. In Copula Theory and Its Applications; Jaworski, P., Durante, F., Härdle, W.K., Rychlik, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 77–91. [Google Scholar]
- CLICOM. CISECE-Centro de Investigacion Cientifica y deEducacion Superior de Ensenada. Available online: http://clicom-mex.cicese.mx/ (accessed on 10 September 2019).
- Savenije, H.H.G. HESS Opinions “Topography driven conceptual modelling (FLEX-Topo)”. Hydrol. Earth Syst. Sci. 2010, 14, 2681–2692. [Google Scholar] [CrossRef] [Green Version]
- Tsoukalas, I.; Efstratiadis, A.; Makropoulos, C. Stochastic Periodic Autoregressive to Anything (SPARTA): Modeling and Simulation of Cyclostationary Processes With Arbitrary Marginal Distributions. Water Resour. Res. 2018, 54, 161–185. [Google Scholar] [CrossRef]
- Ibragimov, R.; Lentzas, G. Copulas and long memory. Probab. Surv. 2017, 14, 289–327. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. HESS Opinions “A random walk on water”. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. Climate change, the Hurst phenomenon, and hydrological statistics. Hydrol. Sci. J. 2003, 48, 3–24. [Google Scholar] [CrossRef]
- Markonis, Y.; Moustakis, Y.; Nasika, C.; Sychova, P.; Dimitriadis, P.; Hanel, M.; Máca, P.; Papalexiou, S. Global estimation of long-term persistence in annual river runoff. Adv. Water Resour. 2018, 113, 1–12. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Name | Coordinates | Time Period | |
|---|---|---|---|---|
| Longitude | Latitude | |||
| 15008 | Atenco | −98.92 | 19.54 | 1 January 1961–22 August 2013 |
| 15044 | La Grande | −98.92 | 19.58 | 1 January 1964–31 August 2014 |
| 15083 | San Andres | −98.92 | 19.53 | 1 May 1967–31 December 2014 |
| 15167 | El Tejocote | −98.92 | 19.44 | 1 December 1957–1 January 2007 |
| 15170 | Chapingo (DGE) | −98.9 | 19.48 | 13 March 1957–1 January 2000 |
| Station | Probability Distribution Function | |
|---|---|---|
| Precipitation | Evaporation | |
| Atenco | Weibull | Generalized Extreme Value |
| La Grande | Weibull | Generalized Extreme Value |
| San Andres | Weibull | Generalized Extreme Value |
| El Tejocote | Weibull | Generalized Extreme Value |
| Chapingo (DGE) | Weibull | Generalized Extreme Value |
| Pairs | Atenco | La Grande | San Andres | El Tejocote | Chapingo (DGE) |
|---|---|---|---|---|---|
| Gauss | Gauss | Gauss | Gauss | Gauss | |
| Gumbel | Gumbel | Gumbel | Gumbel | Gumbel | |
| Gumbel | Gumbel | Gumbel | Gumbel | Gumbel |
| Historical | 0.27 | 0.4 | −0.22 |
| Synthetic | 0.27 | 0.37 | −0.18 |
| Water Level at the Foot of the Dike (m) () | m.a.s.l. | Gaussian Copula | Gumbel Copula | ||
|---|---|---|---|---|---|
| Return Period (Years) | Return Period (Years) | ||||
| 1 | 2231 | 0.00171 | 586 | 0.00099 | 1006 |
| 2 | 2232 | 0.02641 | 38 | 0.02068 | 48 |
| 3 | 2233 | 0.16189 | 6 | 0.14956 | 7 |
| 4 | 2234 | 0.45131 | 2 | 0.44657 | 2 |
| 5 | 2235 | 0.74568 | 1 | 0.75102 | 1 |
| 6 | 2236 | 0.91468 | 1 | 0.92038 | 1 |
| Historical | 0.41 | 0.36 | 0.45 | 0.44 |
| Synthetic | 0.41 | 0.37 | 0.46 | 0.40 |
| Historical | 0.57 | 0.70 | 0.70 | 0.50 | 0.48 | 0.63 |
| Synthetic | 0.60 | 0.70 | 0.62 | 0.56 | 0.50 | 0.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pouliasis, G.; Torres-Alves, G.A.; Morales-Napoles, O. Stochastic Modeling of Hydroclimatic Processes Using Vine Copulas. Water 2021, 13, 2156. https://doi.org/10.3390/w13162156
Pouliasis G, Torres-Alves GA, Morales-Napoles O. Stochastic Modeling of Hydroclimatic Processes Using Vine Copulas. Water. 2021; 13(16):2156. https://doi.org/10.3390/w13162156
Chicago/Turabian StylePouliasis, George, Gina Alexandra Torres-Alves, and Oswaldo Morales-Napoles. 2021. "Stochastic Modeling of Hydroclimatic Processes Using Vine Copulas" Water 13, no. 16: 2156. https://doi.org/10.3390/w13162156
APA StylePouliasis, G., Torres-Alves, G. A., & Morales-Napoles, O. (2021). Stochastic Modeling of Hydroclimatic Processes Using Vine Copulas. Water, 13(16), 2156. https://doi.org/10.3390/w13162156