Deterministic Analysis and Uncertainty Analysis of Ensemble Forecasting Model Based on Variational Mode Decomposition for Estimation of Monthly Groundwater Level


 ,
, 
 ,
,  and
and
Abstract
:1. Introduction
2. Methodologies
2.1. Data Decomposition (VMD)
- Step 1:
- Compute the related analytic signal of by using the Hilbert transform to obtain a unilateral frequency spectrum.
- Step 2:
- Shift frequency spectrum of to the baseband by mixing with an exponent tuned to the respective computed central frequency.
- Step 3:
- Estimate the bandwidth through H1 Gaussian smoothness of the demodulated signal.
2.2. Feature Selection of Input Variables (Boruta)
2.3. Prediction Model (ELM)
2.4. Uncertainty Analysis (Bootstrap)
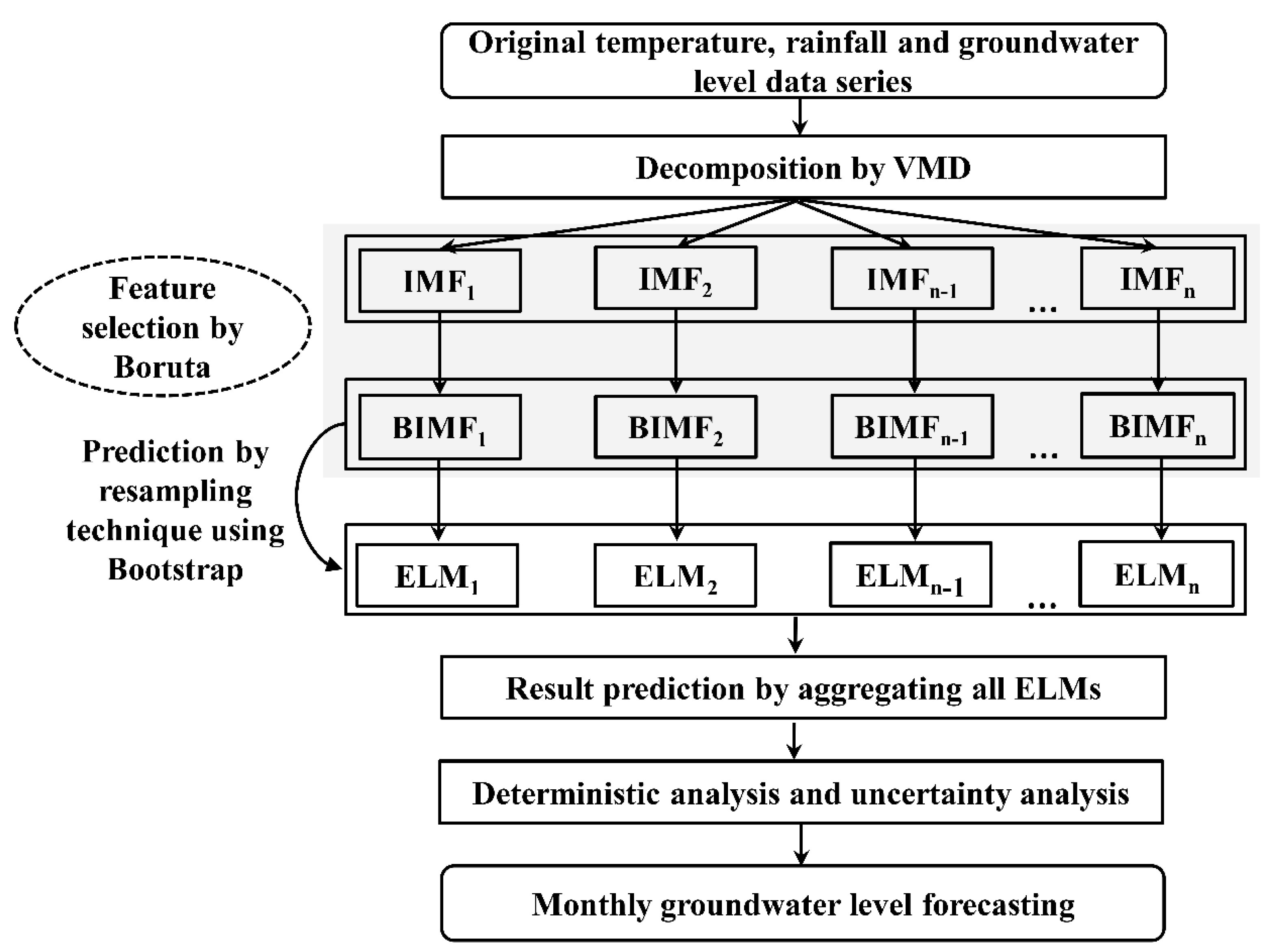
3. Model Development
4. Case Study
4.1. Study Area and Hydrological Data
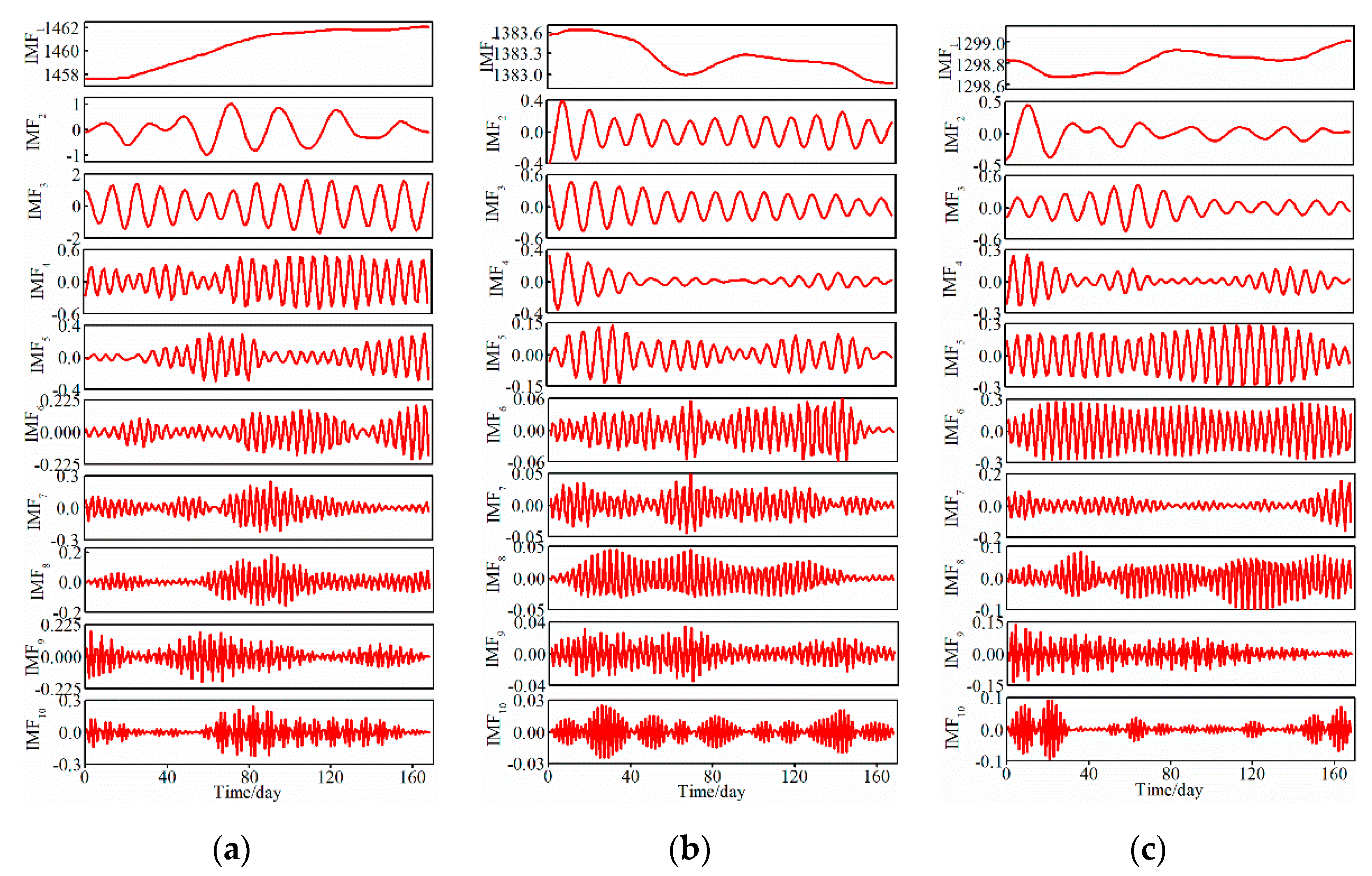
4.2. Decomposition Results
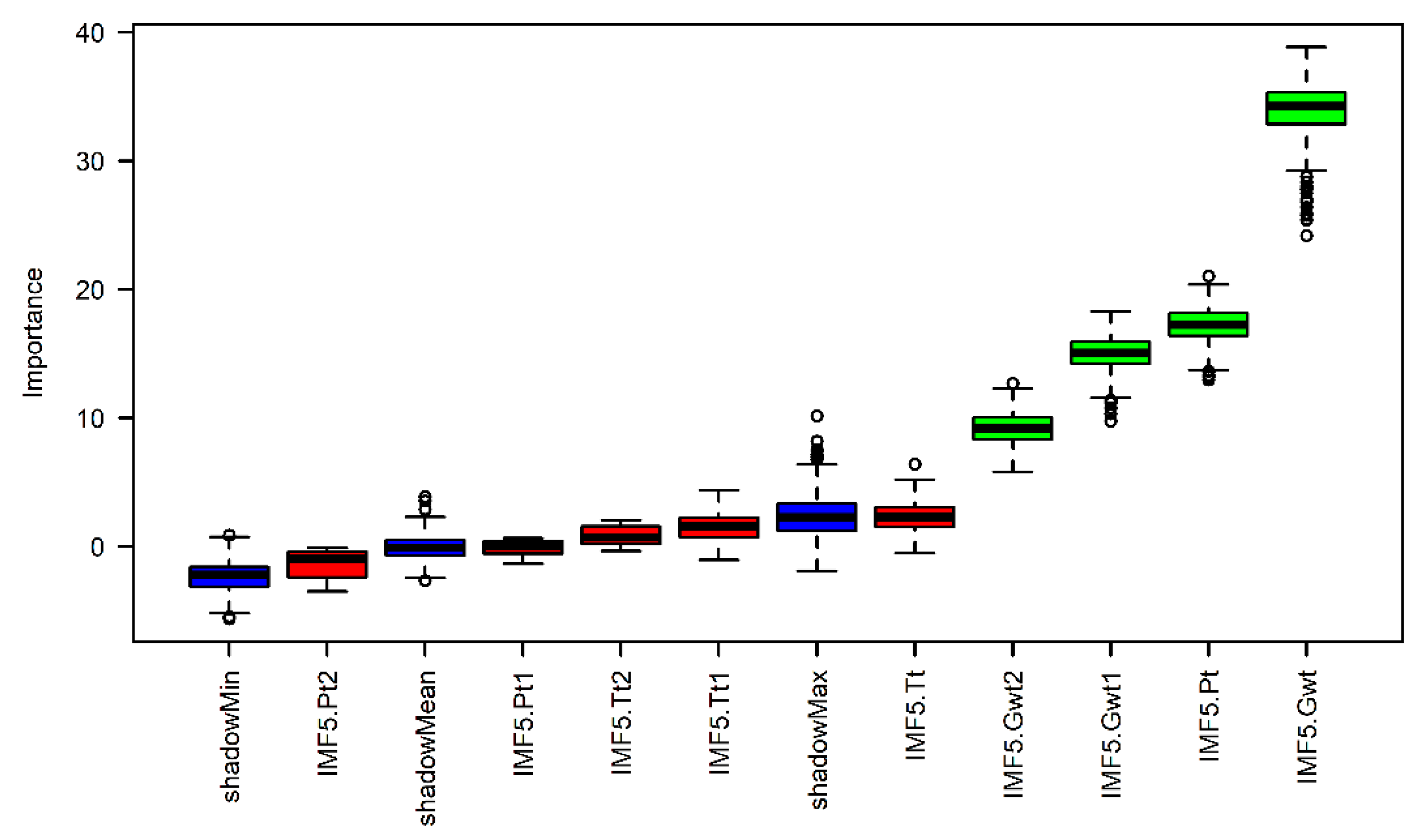
4.3. Determination of Input Variables
4.4. Performance Criteria
5. Results and Discussion
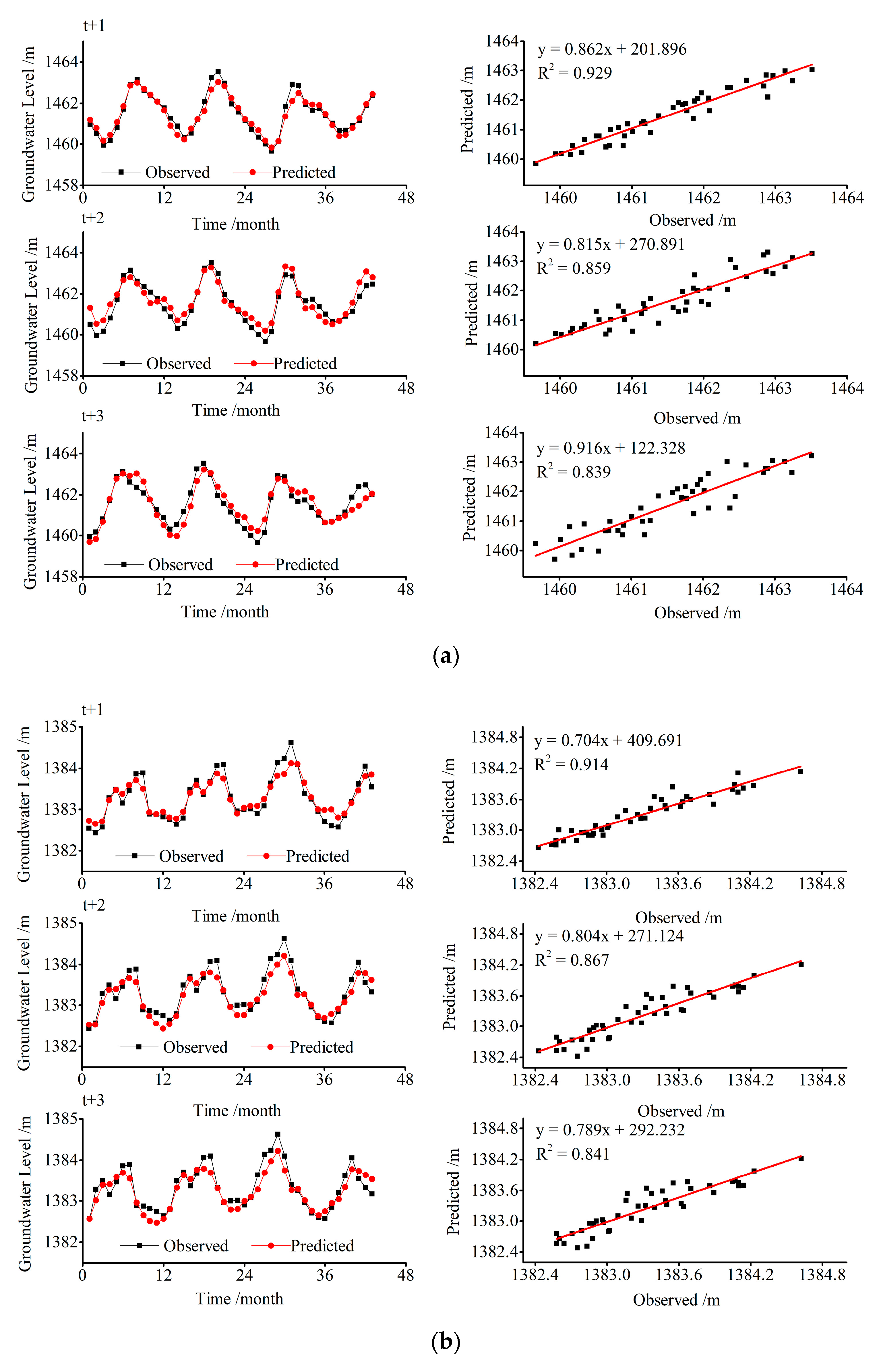
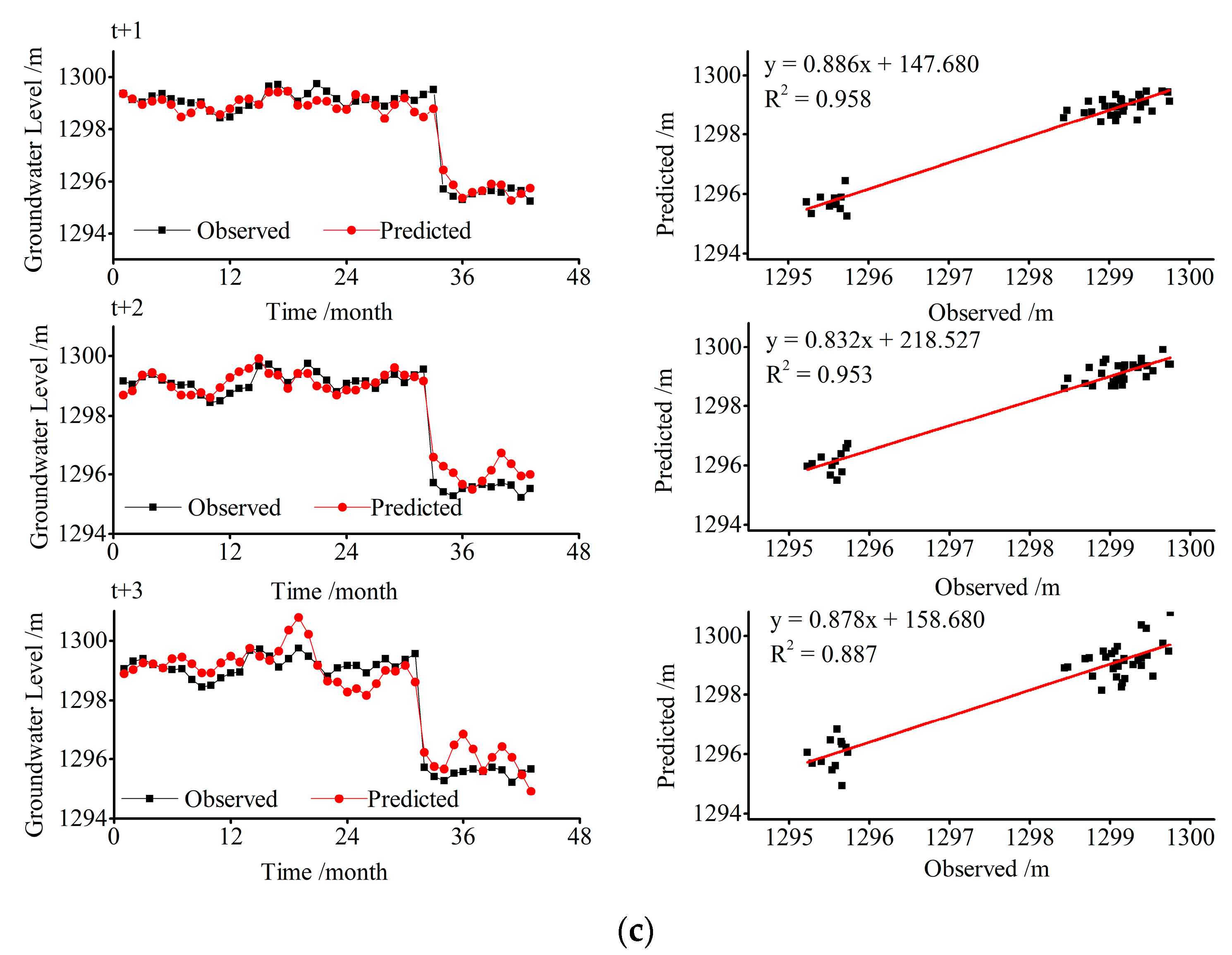
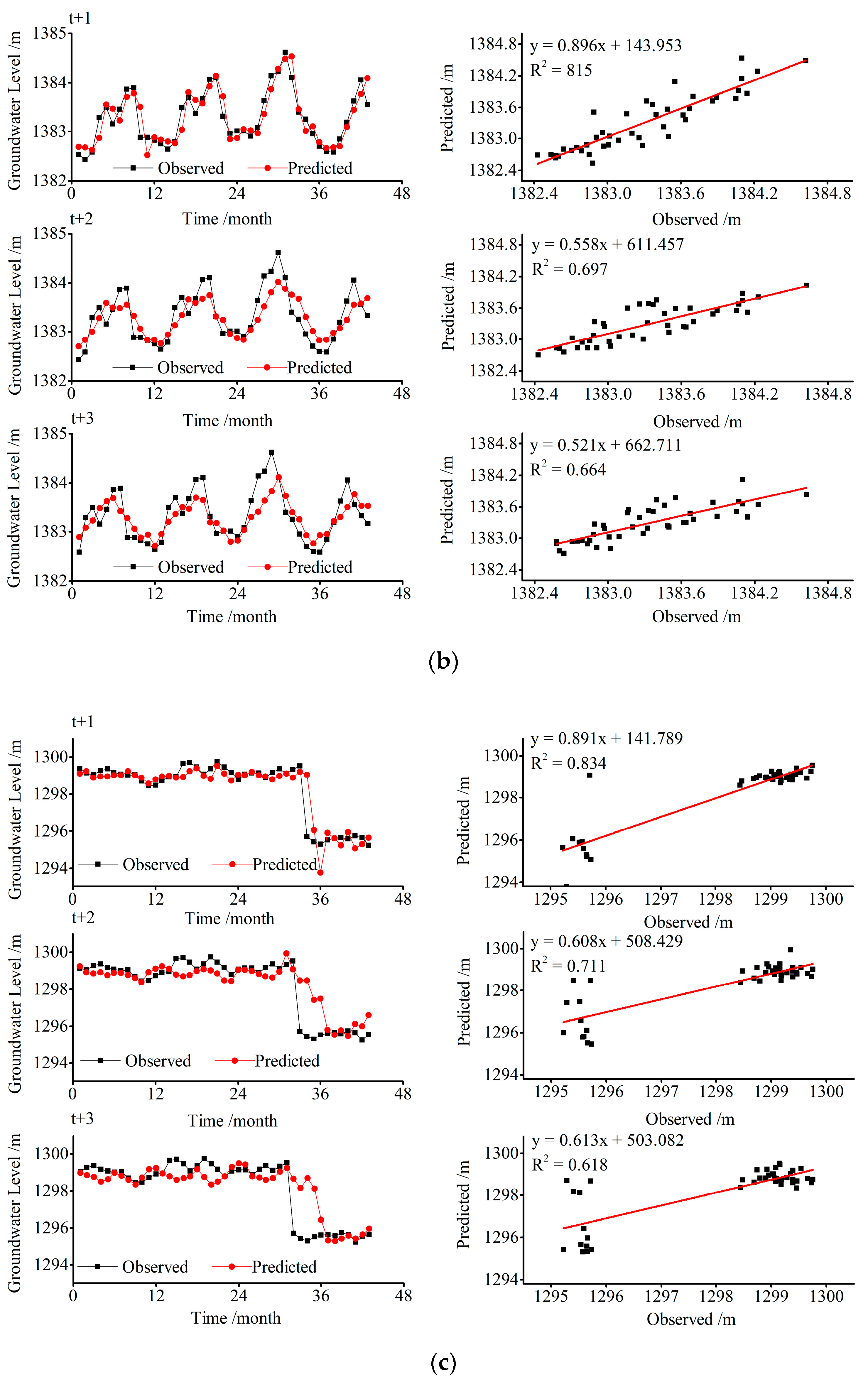
5.1. Model Performance
5.2. Model Comparison
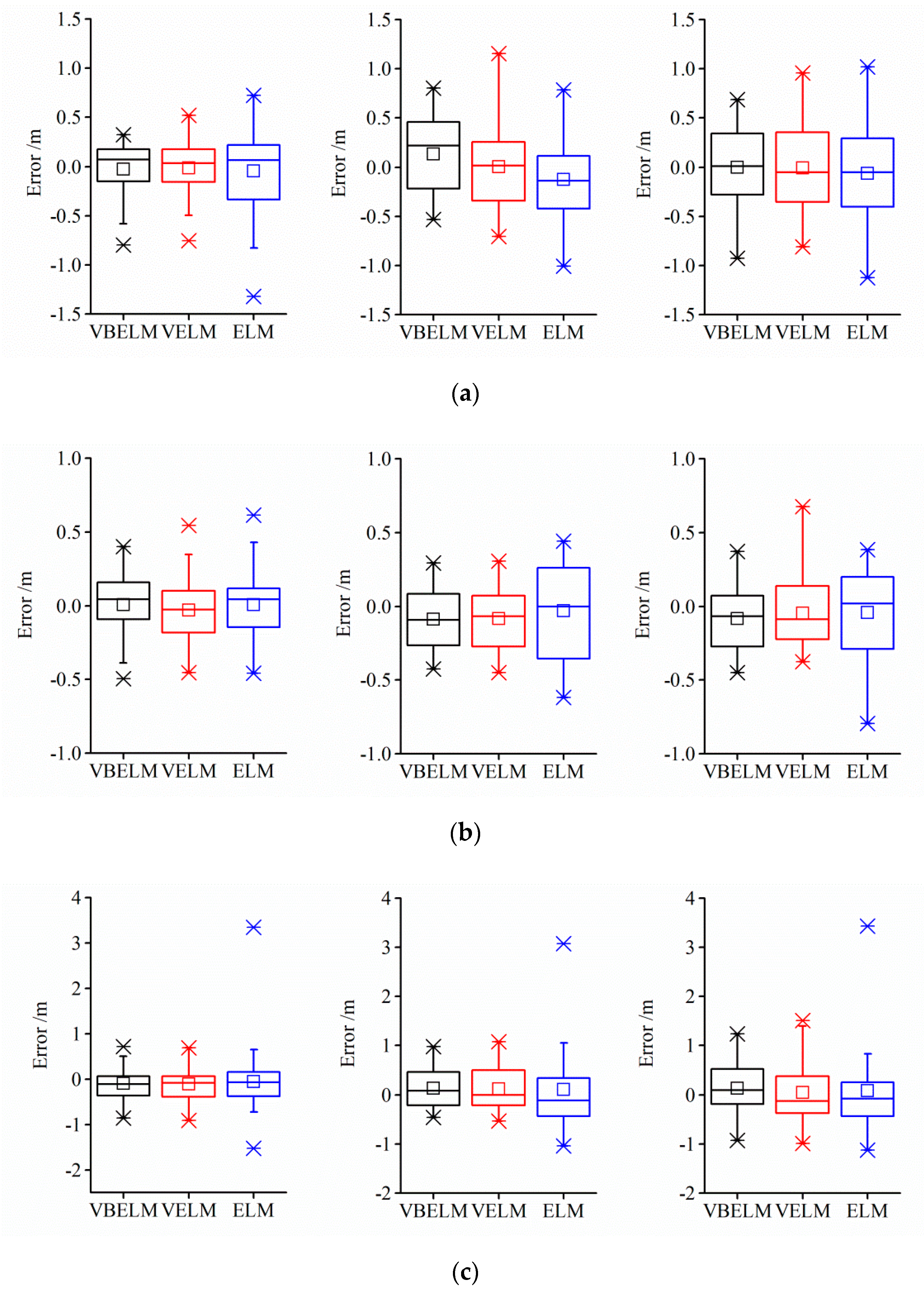
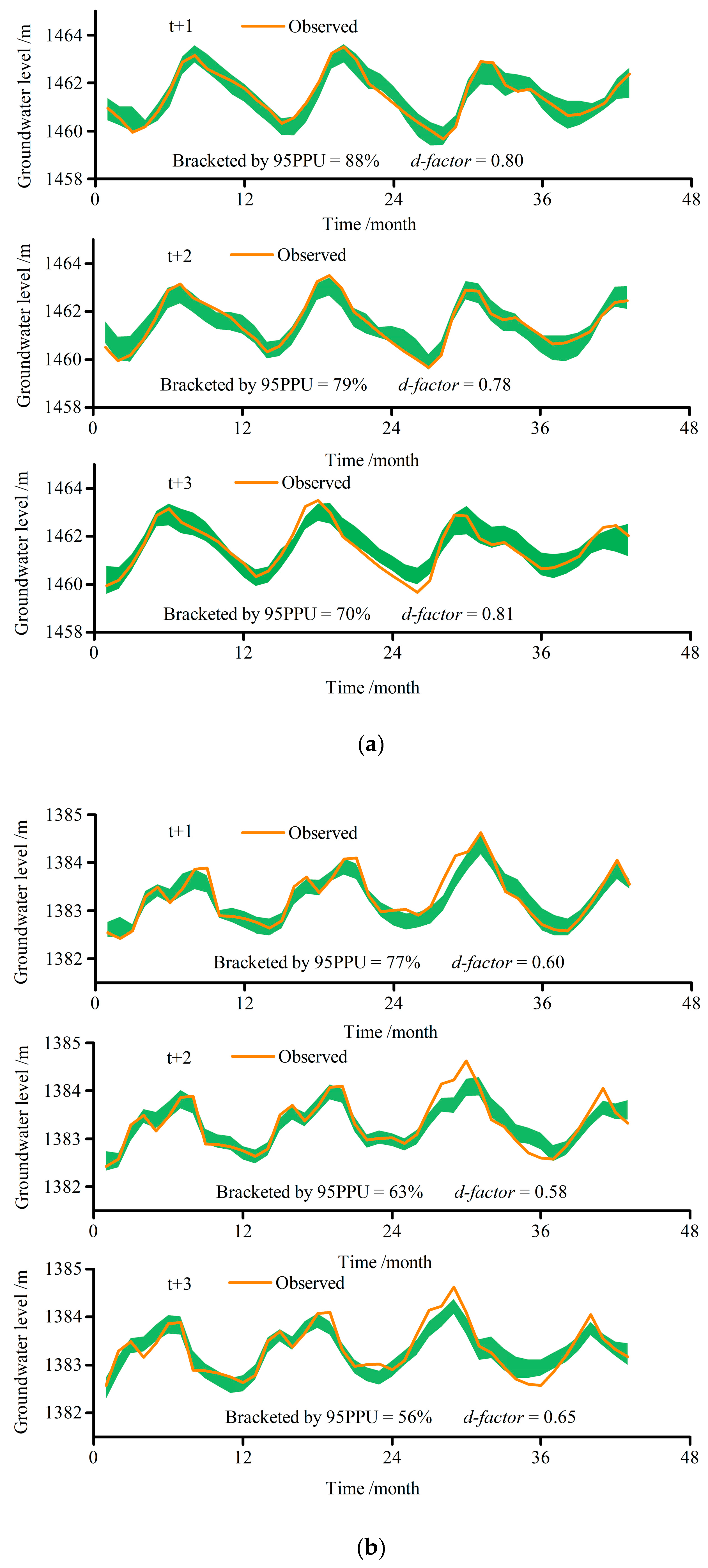
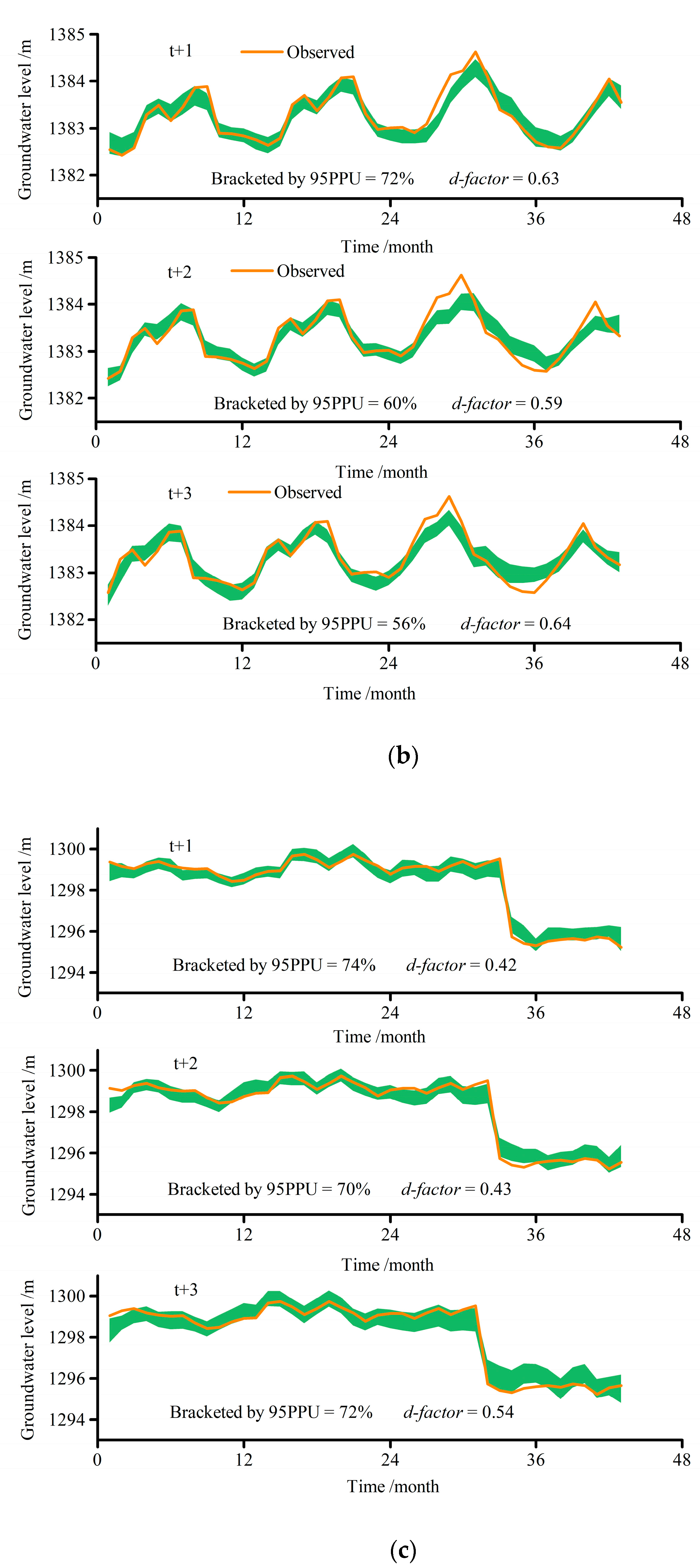
5.3. Uncertainty Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VMD | Variational mode decomposition |
| EMD | Empirical mode decomposition |
| EEMD | Ensemble empirical mode decomposition |
| ELM | Extreme learning machines |
| VELM | Variational mode decomposition with extreme learning machine |
| VBELM | Variational mode decomposition with Boruta and extreme learning machine |
| ANN | Artificial Neural Network |
| SVM | Support Vector Machine |
| WT | Wavelet Transform |
| IMF | Intrinsic mode function |
| R | Coefficient of correlation |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| NS | Nash-Sutcliffe efficiency coefficient |
| Max | Maximum |
| Min | Minimum |
| Std | Standard deviation |
| SK | Skewness |
References
- Cui, Y.; Shao, J. The Role of Ground Water in Arid/Semiarid Ecosystems, Northwest China. Ground Water 2005, 43, 471–477. [Google Scholar] [CrossRef] [PubMed]
- Yadav, B.; Gupta, P.K.; Patidar, N.; Himanshu, S.K. Ensemble modelling framework for groundwater level prediction in urban areas of India. Sci. Total. Environ. 2020, 712, 135539. [Google Scholar] [CrossRef] [PubMed]
- Mohanty, S.; Jha, M.K.; Kumar, A.; Sudheer, K.P. Artificial Neural Network Modeling for Groundwater Level Forecasting in a River Island of Eastern India. Water Resour. Manag. 2010, 24, 1845–1865. [Google Scholar] [CrossRef]
- Wen, X.; Feng, Q.; Deo, R.C.; Wu, M.; Si, J. Wavelet analysis–artificial neural network conjunction models for multi-scale monthly groundwater level predicting in an arid inland river basin, northwestern China. Hydrol. Res. 2016, 48, 1710–1729. [Google Scholar] [CrossRef]
- Wang, W.-C.; Xu, D.-M.; Chau, K.-W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO–SVM model based on EEMD. J. Hydroinformatics 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Wen, X.; Feng, Q.; Yu, H.; Wu, J.; Si, J.; Chang, Z.; Xi, H. Wavelet and adaptive neuro-fuzzy inference system conjunction model for groundwater level predicting in a coastal aquifer. Neural Comput. Appl. 2015, 26, 1203–1215. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.-W.; Sethi, R. Artificial neural network simulation of hourly groundwater levels in a coastal aquifer system of the Venice lagoon. Eng. Appl. Artif. Intell. 2012, 25, 1670–1676. [Google Scholar] [CrossRef] [Green Version]
- Shiri, J.; Kisi, O.; Yoon, H.; Lee, K.-K.; Nazemi, A.H. Predicting groundwater level fluctuations with meteorological effect implications—A comparative study among soft computing techniques. Comput. Geosci. 2013, 56, 32–44. [Google Scholar] [CrossRef]
- Fallah-Mehdipour, E.; Haddad, O.B.; Marin˜o, M.A. Prediction and simulation of monthly groundwater levels by genetic programming. J. Hydro–Environ. Res. 2013, 7, 253–260. [Google Scholar] [CrossRef]
- Patil, A.P.; Deka, P.C. An extreme learning machine approach for modeling evapotranspiration using extrinsic inputs. Comput. Electron. Agric. 2016, 121, 385–392. [Google Scholar] [CrossRef]
- Chen, X.; Li, F.-W.; Feng, P. A new hybrid model for nonlinear and non-stationary runoff prediction at annual and monthly time scales. HydroResearch 2018, 20, 77–92. [Google Scholar] [CrossRef]
- Zhou, Y.; Guo, S.; Chang, F.J. Explore an evolutionary recurrent ANFIS for modelling multi-step-ahead flood forecasts. J. Hydrol. 2019, 570, 343–355. [Google Scholar] [CrossRef]
- Chen, K.; Chen, H.; Zhou, C.; Huang, Y.; Qi, X.; Shen, R.; Liu, F.; Zuo, M.; Zou, X.; Wang, J.; et al. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 2020, 171, 115454. [Google Scholar] [CrossRef] [PubMed]
- Diez-Sierra, J.; Del Jesus, M. Long-term rainfall prediction using atmospheric synoptic patterns in semi-arid climates with statistical and machine learning methods. J. Hydrol. 2020, 586, 124789. [Google Scholar] [CrossRef]
- Tikhamarine, Y.; Souag-Gamane, D.; Ahmed, A.N.; Kisi, O.; El-Shafie, A. Improving artificial intelligence models accuracy for monthly streamflow forecasting using grey Wolf optimization (GWO) algorithm. J. Hydrol. 2020, 582, 124435. [Google Scholar] [CrossRef]
- Rajaee, T.; Ebrahimi, H.; Nourani, V. A review of the artificial intelligence methods in groundwater level modeling. J. Hydrol. 2019, 572, 336–351. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, G.; Hou, J.; Xie, J.; Lv, M.; Liu, F. Hybrid forecasting model for non-stationary daily runoff series: A case study in the Han River Basin, China. J. Hydrol. 2019, 577, 123915. [Google Scholar] [CrossRef]
- Adamowski, J.; Chan, H.F. A wavelet neural network conjunction model for groundwater level forecasting. J. Hydrol. 2011, 407, 28–40. [Google Scholar] [CrossRef]
- Deo, R.C.; Tiwari, M.K.; Adamowski, J.F.; Quilty, J.M. Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stoch. Environ. Res. Risk Assess. 2017, 31, 1211–1240. [Google Scholar] [CrossRef]
- Huang, S.; Chang, J.; Huang, Q.; Chen, Y. Monthly streamflow prediction using modified EMD-based support vector machine. J. Hydrol. 2014, 511, 764–775. [Google Scholar] [CrossRef]
- Wang, W.-C.; Ahmadi, M.H.; Qiu, L.; Chen, Y. Improving forecasting accuracy of medium and long-term runoff using artificial neural network based on EEMD decomposition. Environ. Res. 2015, 139, 46–54. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Peng, Y.; Zhang, C.; Wang, B. Are hybrid models integrated with data preprocessing techniques suitable for monthly streamflow forecasting? Some experiment evidences. J. Hydrol. 2015, 530, 137–152. [Google Scholar] [CrossRef]
- Barzegar, R.; Fijani, E.; Moghaddam, A.A.; Tziritis, E.P. Forecasting of groundwater level fluctuations using ensemble hybrid multi-wavelet neural network-based models. Sci. Total. Environ. 2017, 20–31. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Wang, F.; Yang, Z. Comparative Analysis of ANN and SVM Models Combined with Wavelet Preprocess for Groundwater Depth Prediction. Water 2017, 9, 781. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.-Y.; Qiu, J.; Li, F. Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting. Water 2018, 10, 853. [Google Scholar] [CrossRef] [Green Version]
- Niu, W.-J.; Feng, Z.-K.; Zeng, M.; Feng, B.-F.; Min, Y.-W.; Cheng, C.-T.; Zhou, J.-Z. Forecasting reservoir monthly runoff via ensemble empirical mode decomposition and extreme learning machine optimized by an improved gravitational search algorithm. Appl. Soft Comput. 2019, 82, 105589. [Google Scholar] [CrossRef]
- Daubechies, I. The wavelet transform, time-frequency localization and signal analysis. IEEE Trans. Inf. Theory 1990, 36, 961–1005. [Google Scholar] [CrossRef] [Green Version]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decompostion: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Napolitano, G.; Serinaldi, F.; See, L. Impact of EMD decomposition and random initialisation of weights in ANN hindcasting of daily stream flow series: An empirical examination. J. Hydrol. 2011, 406, 199–214. [Google Scholar] [CrossRef]
- Kisi, O.; Latifoğlu, L.; Latifoğlu, F. Investigation of Empirical Mode Decomposition in Forecasting of Hydrological Time Series. Water Resour. Manag. 2014, 28, 4045–4057. [Google Scholar] [CrossRef]
- Feng, Q.; Wen, X.; Li, J. Wavelet Analysis-Support Vector Machine Coupled Models for Monthly Rainfall Forecasting in Arid Regions. Water Resour. Manag. 2015, 29, 1049–1065. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Naganna, S.R.; Ghaemi, A.; Deka, P.C. Wavelet coupled MARS and M5 Model Tree approaches for groundwater level forecasting. J. Hydrol. 2017, 553, 356–373. [Google Scholar] [CrossRef]
- Hadi, S.J.; Tombul, M. Streamflow Forecasting Using Four Wavelet Transformation Combinations Approaches with Data-Driven Models: A Comparative Study. Water Resour. Manag. 2018, 32, 4661–4679. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, H.; Singh, V.P. Forward Prediction of Runoff Data in Data-Scarce Basins with an Improved Ensemble Empirical Mode Decomposition (EEMD) Model. Water 2018, 10, 388. [Google Scholar] [CrossRef] [Green Version]
- Rezaie-Balf, M.; Kim, S.; Fallah, H.; Alaghmand, S. Daily river flow forecasting using ensemble empirical mode decomposition based heuristic regression models: Application on the perennial rivers in Iran and South Korea. J. Hydrol. 2019, 572, 470–485. [Google Scholar] [CrossRef]
- Nourani, V.; Baghanam, A.H.; Adamowski, J.; Kisi, O. Applications of hybrid wavelet–Artificial Intelligence models in hydrology: A review. J. Hydrol. 2014, 514, 358–377. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Huang, K.; Gui, W. Non-ferrous metals price forecasting based on variational mode decomposition and LSTM network. Knowledge-Based Syst. 2020, 188, 105006. [Google Scholar] [CrossRef]
- Zuo, G.; Luo, J.; Wang, N.; Lian, Y.; He, X. Decomposition ensemble model based on variational mode decomposition and long short-term memory for streamflow forecasting. J. Hydrol. 2020, 585, 124776. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- He, X.; Luo, J.; Zuo, G.; Xie, J. Daily Runoff Forecasting Using a Hybrid Model Based on Variational Mode Decomposition and Deep Neural Networks. Water Resour. Manag. 2019, 33, 1571–1590. [Google Scholar] [CrossRef]
- Sahani, M.; Dash, P.K.; Samal, D. A real-time power quality events recognition using variational mode decomposition and online-sequential extreme learning machine. Measurement 2020, 157, 107597. [Google Scholar] [CrossRef]
- He, F.; Zhou, J.Z.; Feng, Z.-K.; Liu, G.; Yang, Y. A hybrid short-term load forecasting model based on variational mode decomposition and long short-term memory networks considering relevant factors with Bayesian optimization algorithm. Appl. Energy 2019, 237, 103–116. [Google Scholar] [CrossRef]
- Jayakumar, C.; Sangeetha, J. Kernellized support vector regressive machine based variational mode decomposition for time frequency analysis of Mirnov coil. Microprocess. Microsyst. 2020, 75, 103036. [Google Scholar] [CrossRef]
- Bisoi, R.; Dash, P.K.; Parida, A.K. Hybrid Variational Mode Decomposition and evolutionary robust kernel extreme learning machine for stock price and movement prediction on daily basis. Appl. Soft Comput. 2019, 74, 652–678. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, K.; Qin, L.; An, X. Deterministic and probabilistic interval prediction for short-term wind power generation based on variational mode decomposition and machine learning methods. Energy Convers. Manag. 2016, 112, 208–219. [Google Scholar] [CrossRef]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y. Multi-step ahead wind speed forecasting using an improved wavelet neural network combining variational mode decomposition and phase space reconstruction. Renew. Energy 2017, 113, 1345–1358. [Google Scholar] [CrossRef]
- Majumder, I.; Dash, P.; Bisoi, R. Variational mode decomposition based low rank robust kernel extreme learning machine for solar irradiation forecasting. Energy Convers. Manag. 2018, 171, 787–806. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S.; Singh, V.P. Machine Learning Models Coupled with Variational Mode Decomposition: A New Approach for Modeling Daily Rainfall-Runoff. Atmosphere 2018, 9, 251. [Google Scholar] [CrossRef] [Green Version]
- Srivastav, R.K.; Sudheer, K.; Chaubey, I. A simplified approach to quantifying predictive and parametric uncertainty in artificial neural network hydrologic models. Water Resour. Res. 2007, 43, 43. [Google Scholar] [CrossRef] [Green Version]
- Tiwari, M.K.; Chatterjee, C. Uncertainty assessment and ensemble flood forecasting using bootstrap based artificial neural networks (BANNs). J. Hydrol. 2010, 382, 20–33. [Google Scholar] [CrossRef]
- Tiwari, M.K.; Chatterjee, C. A new wavelet–bootstrap–ANN hybrid model for daily discharge forecasting. J. Hydroinformatics 2010, 13, 500–519. [Google Scholar] [CrossRef] [Green Version]
- Gopalan, S.P.; Kawamura, A.; Amaguchi, H.; Takasaki, T.; Azhikodan, G. A bootstrap approach for the parameter uncertainty of an urban-specific rainfall-runoff model. J. Hydrol. 2019, 579, 124195. [Google Scholar] [CrossRef]
- Tiwari, M.K.; Adamowski, J.F. Medium-Term Urban Water Demand Forecasting with Limited Data Using an Ensemble Wavelet–Bootstrap Machine-Learning Approach. J. Water Resour. Plan. Manag. 2015, 141, 04014053. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.-K.; Niu, W.-J.; Tang, Z.-Y.; Jiang, Z.-Q.; Xu, Y.; Liu, Y.; Zhang, H.-R. Monthly runoff time series prediction by variational mode decomposition and support vector machine based on quantum-behaved particle swarm optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar] [CrossRef]
- Sahoo, S.; Russo, T.; Elliott, J.; Foster, I. Machine learning algorithms for modeling groundwater level changes in agricultural regions of the U.S. Water Resour. Res. 2017, 53, 3878–3895. [Google Scholar] [CrossRef]
- Kursa, M.B.; Jankowski, A.; Rudnicki, W.R. Boruta—A system for feature selection. Fundam. Inform. 2010, 101, 271–285. [Google Scholar] [CrossRef]
- Christa, M.; Kempa-Liehrb, A.W.; Feindta, M. Distributed and parallel time series feature extraction for industrial big data applications. arXiv 2016, arXiv:1610.07717. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with theBorutaPackage. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Prasad, R.; Deo, R.C.; Li, Y.; Maraseni, T. Weekly soil moisture forecasting with multivariate sequential, ensemble empirical mode decomposition and Boruta-random forest hybridizer algorithm approach. Catena 2019, 177, 149–166. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the extreme learning machine algorithm for the prediction of monthly Effective Drought Index in eastern Australia. Atmos. Res. 2015, 153, 512–525. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Feng, Y.; Gong, D.; Jiang, S.; Zhao, L.; Cui, N. Hybrid particle swarm optimization with extreme learning machine for daily reference evapotranspiration prediction from limited climatic data. Comput. Electron. Agric. 2020, 173, 105430. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme Learning Machine: A New Learning Scheme of Feedforward Neural Networks. In Proceedings of the 2004 IEEE international joint conference on neural networks, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Efron, B.J.; Tibshirani, R. An Introduction to the Bootstrap; Chapman and Hall: London, UK, 1993. [Google Scholar]
- Twomey, J.M.; Smith, A.E. Bias and variance of validation methods for function approximation neural networks under conditions of sparse data. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 1998, 28, 417–430. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Zadeh, H.A.; Isazadeh, M.; Terzi, O. A comparative study of artificial neural network (MLP, RBF) and support vector machine models for river flow prediction. Environ. Earth Sci. 2016, 75, 1–14. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Yu, Y.; Zhao, W.; Yang, Q.; Liu, J. Evaluation of groundwater sustainability in the arid Hexi Corridor of Northwestern China, using GRACE, GLDAS and measured groundwater data products. Sci. Total. Environ. 2020, 705, 135829. [Google Scholar] [CrossRef]
- Huang, N.; Chen, H.; Cai, G.; Fang, L.; Wang, Y. Mechanical Fault Diagnosis of High Voltage Circuit Breakers Based on Variational Mode Decomposition and Multi-Layer Classifier. Sensors 2016, 16, 1887. [Google Scholar] [CrossRef] [Green Version]
- Citakoglu, H.; Cobaner, M.; Haktanir, T.; Kisi, O. Estimation of Monthly Mean Reference Evapotranspiration in Turkey. Water Resour. Manag. 2014, 28, 99–113. [Google Scholar] [CrossRef]
- Nayak, P.C.; Rao, Y.R.S.; Sudheer, K.P. Groundwater Level Forecasting in a Shallow Aquifer Using Artificial Neural Network Approach. Water Resour. Manag. 2006, 20, 77–90. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Well I | Well II | Well III | Zhangye | Gaotai | ||||
|---|---|---|---|---|---|---|---|---|
| GWL (m) | GWL (m) | GWL (m) | P (mm) | T (°C) | P (mm) | T (°C) | ||
| Max | All | 1464.24 | 1384.72 | 1299.88 | 60.4 | 25.72 | 65.7 | 25.62 |
| Training | 1464.24 | 1384.72 | 1299.99 | 55.7 | 25.72 | 65.7 | 25.62 | |
| Testing | 1463.51 | 1384.62 | 1299.75 | 56.7 | 24.33 | 61.4 | 24.89 | |
| Min | All | 1455.02 | 1382.39 | 1295.23 | 0 | −14.91 | 0 | −14.4 |
| Training | 1455.02 | 1382.39 | 1297.64 | 0 | −14.91 | 0 | −14.4 | |
| Testing | 1459.67 | 1382.43 | 1295.23 | 0 | −11.29 | 0 | −10.36 | |
| Mean | All | 1460.60 | 1383.25 | 1298.69 | 11.433 | 8.472 | 9.688 | 8.795 |
| Training | 1460.38 | 1383.25 | 1298.82 | 11.29 | 8.372 | 9.718 | 8.609 | |
| Testing | 1461.47 | 1383.25 | 1298.23 | 11.974 | 8.863 | 9.583 | 9.444 | |
| Std | All | 1.951 | 0.467 | 0.864 | 14.316 | 11.374 | 12.100 | 11.332 |
| Training | 2.074 | 0.444 | 0.414 | 14.432 | 11.401 | 11.976 | 11.421 | |
| Testing | 0.992 | 0.543 | 1.591 | 14.008 | 11.394 | 12.654 | 11.109 | |
| SK | All | −0.48 | 0.629 | −2.604 | 1.515 | −0.234 | 1.999 | −0.237 |
| Training | −0.273 | 0.674 | −0.313 | 1.554 | −0.229 | 2.022 | −0.241 | |
| Testing | 0.247 | 0.528 | −1.087 | 1.410 | −0.263 | 1.989 | −0.215 | |
| Parameters | Alpha | Tau | K | DC | Init | Tol |
|---|---|---|---|---|---|---|
| Value | 2000 | 0 | 10 | 0 | 1 | 1 × 10−7 |
| Observation Sites | Lead Month | R | Root Mean Square Error (RMSE) (m) | Mean Absolute Error (MAE) (m) | NS |
|---|---|---|---|---|---|
| 1-month ahead | 0.964 | 0.273 | 0.217 | 0.924 | |
| Well I | 2-month ahead | 0.927 | 0.399 | 0.352 | 0.840 |
| 3-month ahead | 0.916 | 0.405 | 0.337 | 0.831 | |
| 1-month ahead | 0.956 | 0.199 | 0.159 | 0.865 | |
| Well II | 2-month ahead | 0.932 | 0.214 | 0.180 | 0.838 |
| 3-month ahead | 0.917 | 0.223 | 0.185 | 0.811 | |
| 1-month ahead | 0.979 | 0.354 | 0.280 | 0.948 | |
| Well III | 2-month ahead | 0.976 | 0.420 | 0.337 | 0.931 |
| 3-month ahead | 0.942 | 0.566 | 0.471 | 0.881 |
| Observation Sites | Lead Month | R | RMSE (m) | MAE (m) | NS |
|---|---|---|---|---|---|
| 1-month ahead | 0.961 | 0.282 | 0.210 | 0.919 | |
| Well I | 2-month ahead | 0.912 | 0.410 | 0.335 | 0.830 |
| 3-month ahead | 0.919 | 0.423 | 0.344 | 0.817 | |
| 1-month ahead | 0.924 | 0.209 | 0.167 | 0.852 | |
| Well II | 2-month ahead | 0.927 | 0.220 | 0.183 | 0.827 |
| 3-month ahead | 0.914 | 0.229 | 0.198 | 0.801 | |
| 1-month ahead | 0.977 | 0.362 | 0.285 | 0.946 | |
| Well III | 2-month ahead | 0.972 | 0.450 | 0.344 | 0.921 |
| 3-month ahead | 0.949 | 0.641 | 0.504 | 0.847 |
| Observation Sites | Lead Month | R | RMSE (m) | MAE (m) | NS |
|---|---|---|---|---|---|
| 1-month ahead | 0.928 | 0.374 | 0.288 | 0.857 | |
| Well I | 2-month ahead | 0.915 | 0.424 | 0.342 | 0.819 |
| 3-month ahead | 0.853 | 0.535 | 0.417 | 0.706 | |
| 1-month ahead | 0.903 | 0.238 | 0.191 | 0.808 | |
| Well II | 2-month ahead | 0.835 | 0.307 | 0.264 | 0.666 |
| 3-month ahead | 0.815 | 0.314 | 0.261 | 0.625 | |
| 1-month ahead | 0.913 | 0.645 | 0.368 | 0.828 | |
| Well III | 2-month ahead | 0.843 | 0.890 | 0.574 | 0.691 |
| 3-month ahead | 0.786 | 1.016 | 0.629 | 0.616 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.; Feng, Q.; Wen, X.; Yin, Z.; Yang, L.; Sheng, D. Deterministic Analysis and Uncertainty Analysis of Ensemble Forecasting Model Based on Variational Mode Decomposition for Estimation of Monthly Groundwater Level. Water 2021, 13, 139. https://doi.org/10.3390/w13020139
Wu M, Feng Q, Wen X, Yin Z, Yang L, Sheng D. Deterministic Analysis and Uncertainty Analysis of Ensemble Forecasting Model Based on Variational Mode Decomposition for Estimation of Monthly Groundwater Level. Water. 2021; 13(2):139. https://doi.org/10.3390/w13020139
Chicago/Turabian StyleWu, Min, Qi Feng, Xiaohu Wen, Zhenliang Yin, Linshan Yang, and Danrui Sheng. 2021. "Deterministic Analysis and Uncertainty Analysis of Ensemble Forecasting Model Based on Variational Mode Decomposition for Estimation of Monthly Groundwater Level" Water 13, no. 2: 139. https://doi.org/10.3390/w13020139
APA StyleWu, M., Feng, Q., Wen, X., Yin, Z., Yang, L., & Sheng, D. (2021). Deterministic Analysis and Uncertainty Analysis of Ensemble Forecasting Model Based on Variational Mode Decomposition for Estimation of Monthly Groundwater Level. Water, 13(2), 139. https://doi.org/10.3390/w13020139