
A Novel Runoff Forecasting Model Based on the Decomposition-Integration-Prediction Framework

 , ,
, ,
Abstract
:1. Introduction
- (1)
- The development of a runoff forecasting framework named Decomposition-Integration-Prediction (DIP) using parallel-input neural network, and proposed a novel runoff forecasting model with VMD, GRU, and Stochastic Fractal Search (SFS) algorithm under this framework;
- (2)
- The application the model to the runoff forecasting of Pingshan and Yichang Hydrological Stations in Upper Yangtze River Basin, China, and then verified the reliability and prediction performance of this forecasting method;
- (3)
- We further highlight the rationality and advantages of the proposed hybrid forecasting model by employing the seven models as comparative forecast models in terms of combinatorial principle and evaluating indicator, including AR, BP, LSTM, GRU, and three decomposition-based hybrid models Variational Mode Decomposition-Long Short-Term Memory (VMD-LSTM), Variational Mode Decomposition-Gated Recurrent Unit (VMD-GRU), Variational Mode Decomposition-Gated Recurrent Unit-Stochastic Fractal Search (VMD-GRU-SFS) based on the DPR framework.
2. Methodologies
2.1. Variational Mode Decomposition
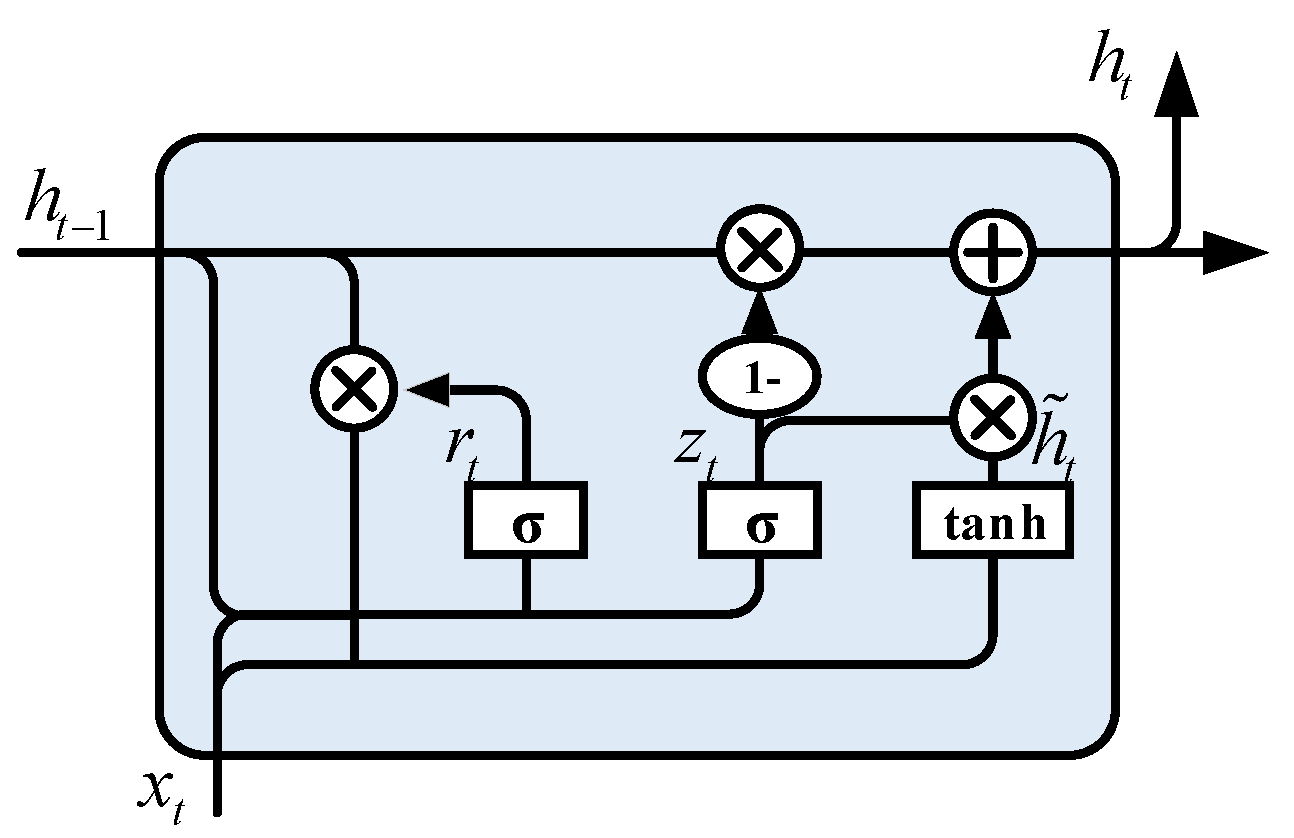
2.2. Gated Recurrent Unit
2.3. Stochastic Fractal Search Optimization
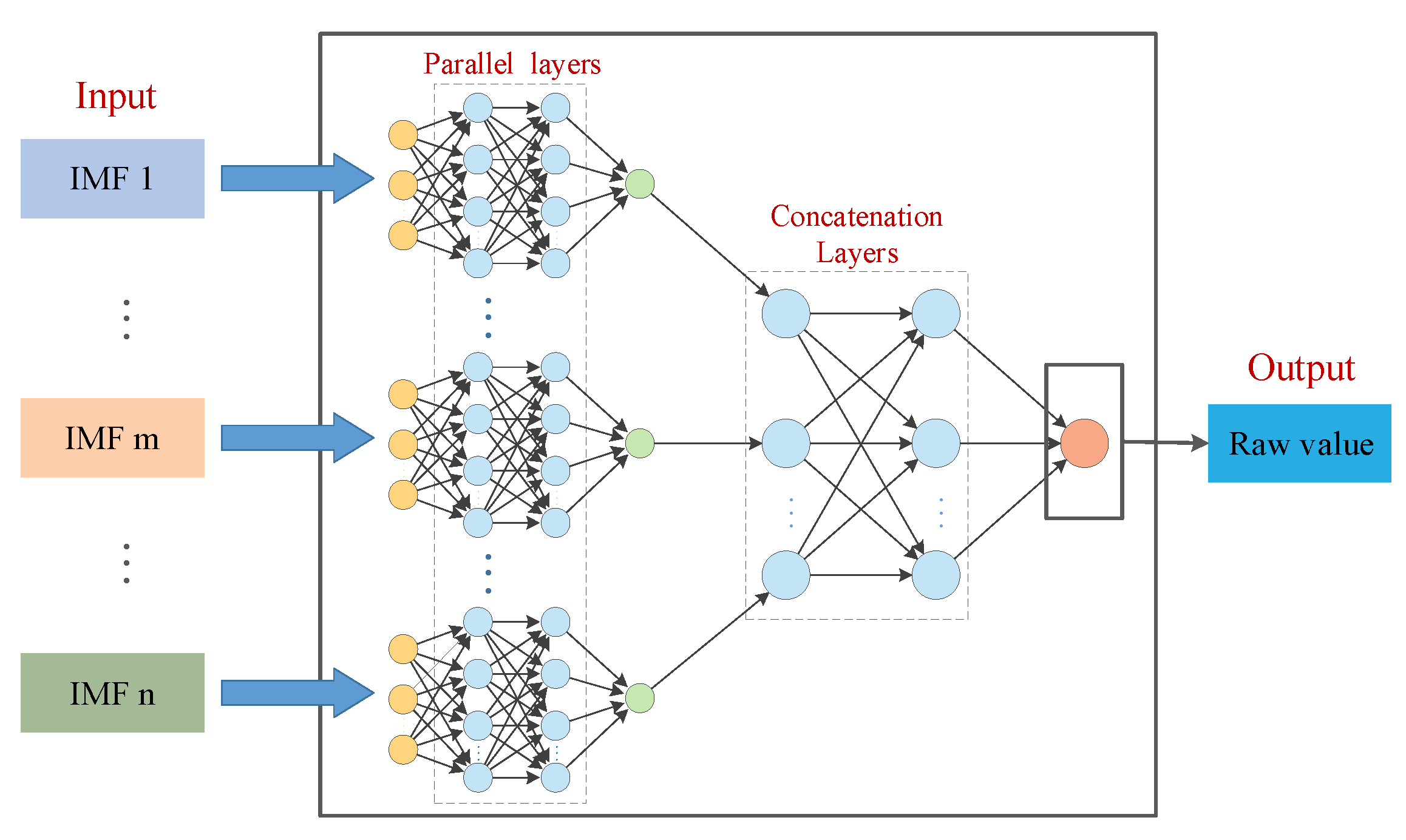
2.4. The Novel Runoff Forecasting Model Based on DIP Framework
- (1)
- Data Pre-processing. Data cleaning is first used to process the runoff time series if the consistency check result is rejected. Next, we use VMD to decompose the runoff data into a set of sub-series with different frequencies. For optimal selection of decomposition level, check whether the last extracted component exhibits central-frequency aliasing. Then, the data in all sub-series are divided into training and testing datasets that are normalized to a range of [0, 1] aswhere and are the normalized and raw value of the ith runoff data sample, respectively. Parameters and are the maximum and minimum of data samples.
- (2)
- Lag period selection. For each sub-series decomposition by VMD, Partial Autocorrelation Function (PACF), is used to select the optimal Lag period for generating modeling samples, where the PACF lag count is set to 36. Assuming is the value to be predicted of the kth runoff component, we select the values which PACF exceeds 95% confidence interval in the 36 delay periods of time t as the input variables for this sub-series.
- (3)
- Model training & Hyper-parameters optimization. Using some open-source software libraries, such as Tensorflow and Keras, to build and training the multi-input neural network. To improve the forecasting performance, SFS is applied to optimize the hyper-parameters of the proposed framework. In this work, we mainly consider the numbers of hidden layers and hidden nodes for parallel layers and concatenation layers in parallel-input neural network. The number of hidden layers is initialized from 1 to 3 and the number of hidden nodes ranging from 5 to 100.
- (4)
- Forecasting application. In the third step, the parallel-input neural network has been trained. In forecasting application, the prediction result of the model should be denormalized to obtain the final predicted value.
3. Model Evaluation
4. Case Studies
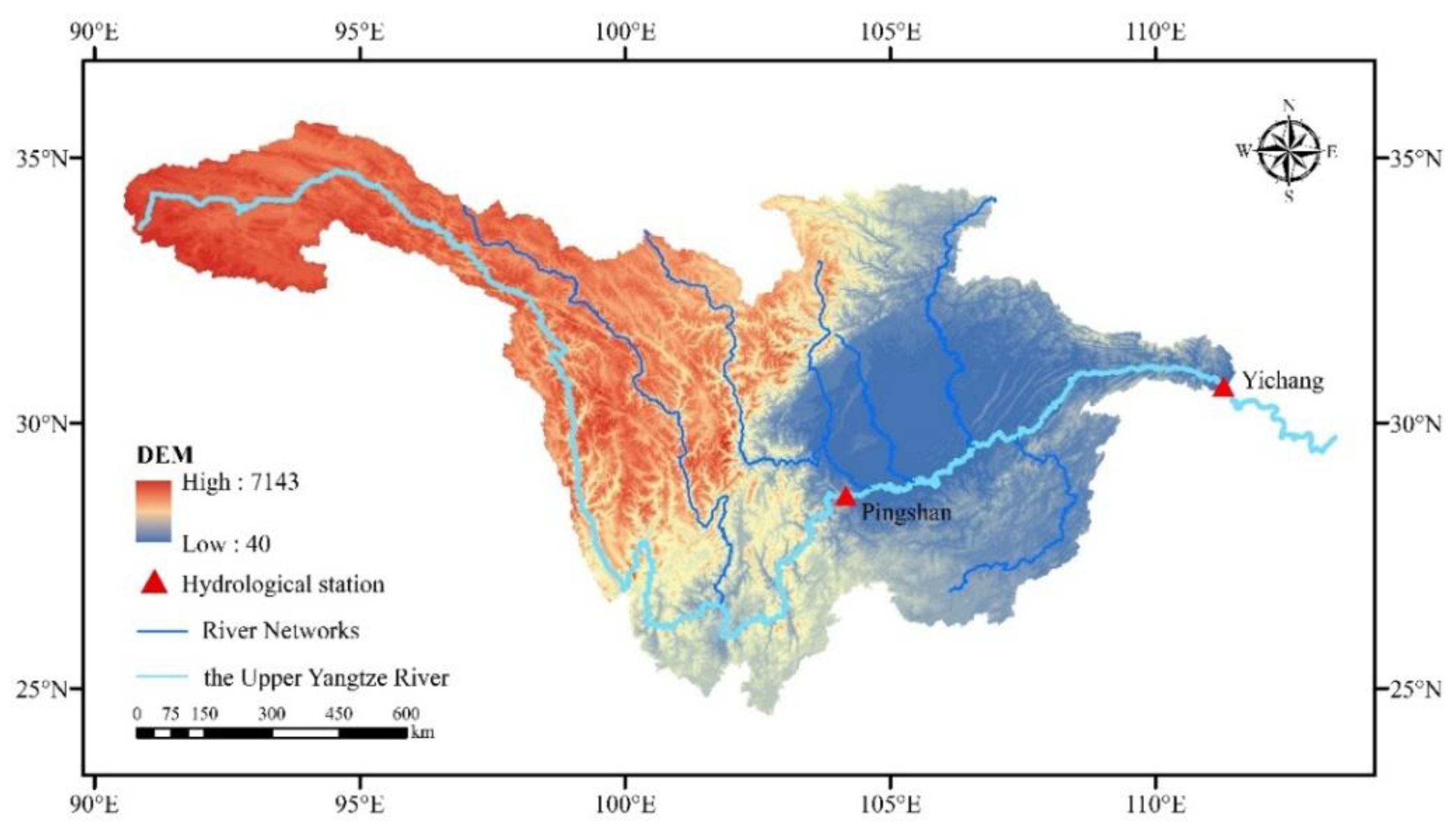
4.1. Study Area and Dataset
4.2. Data Preparation
4.3. Model Parameter
4.4. Comparative Experiment Develop
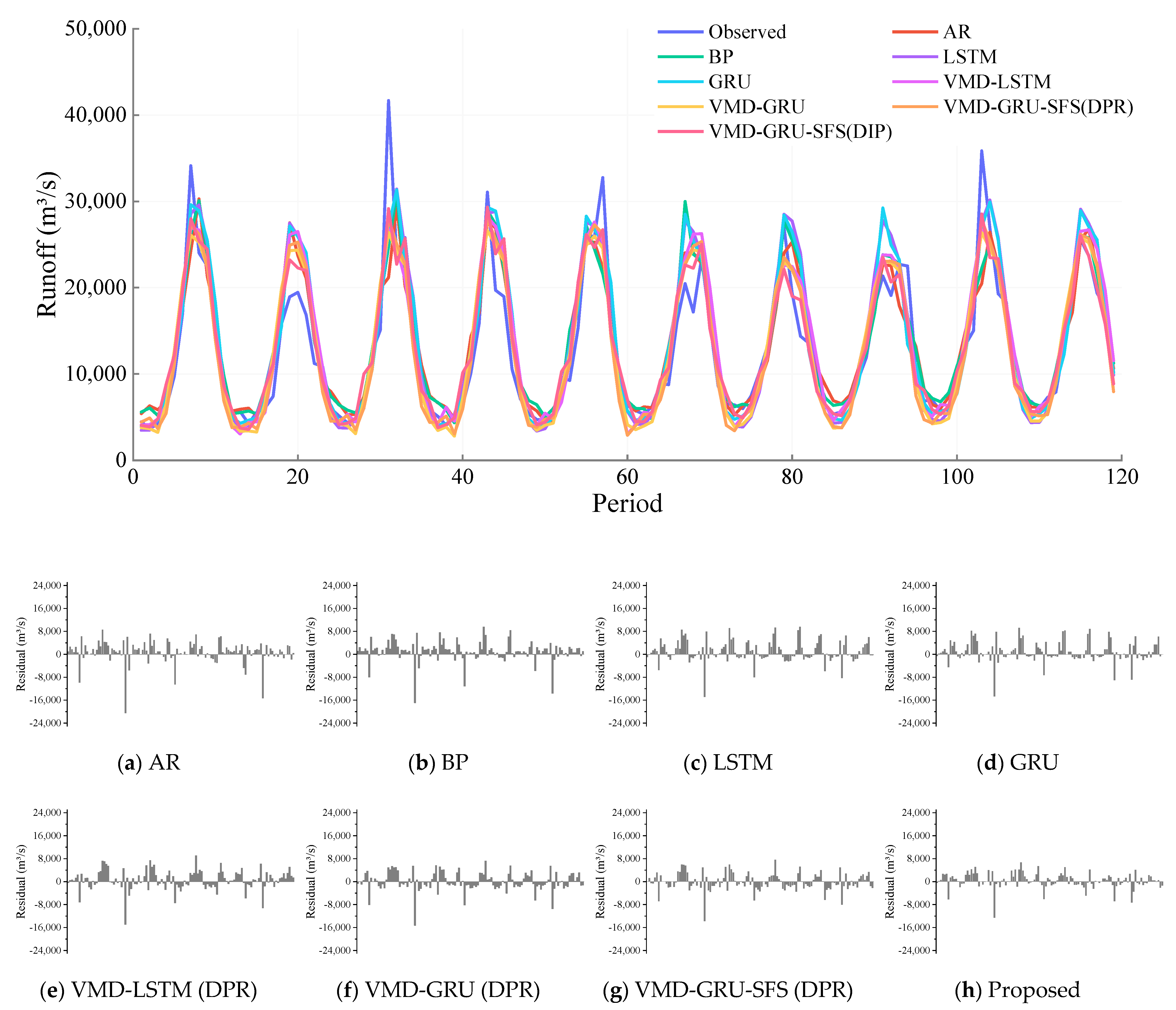
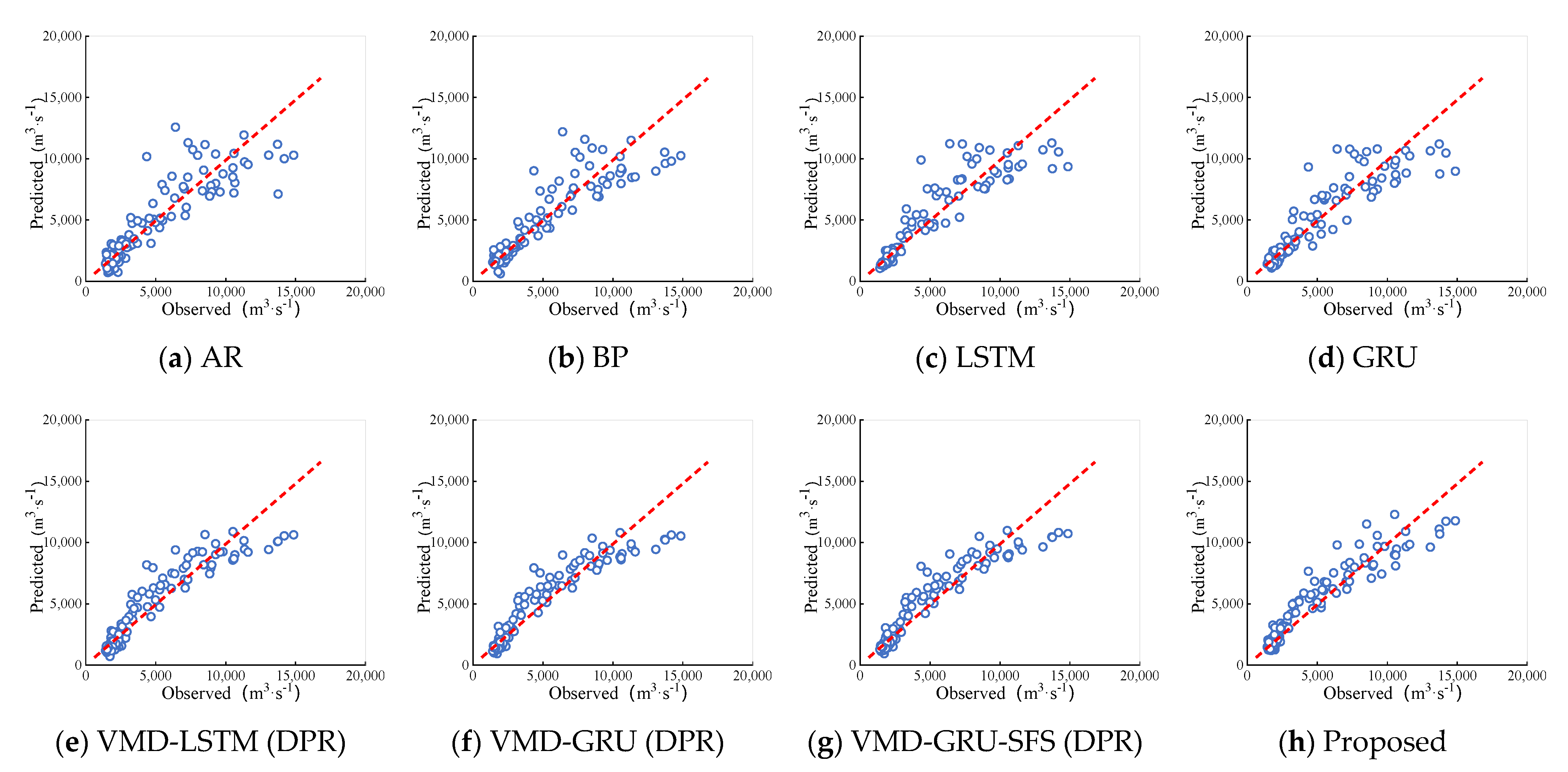
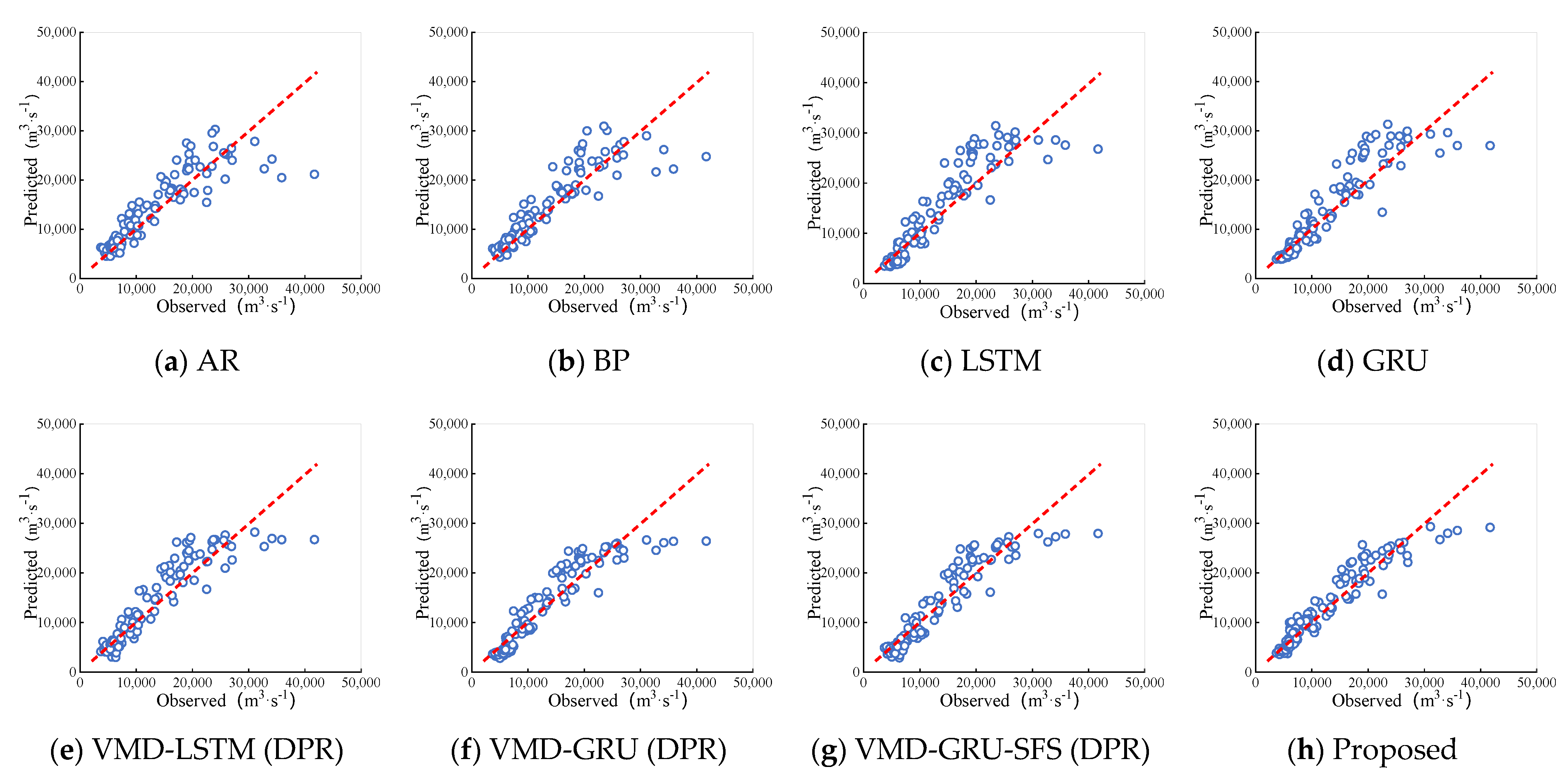
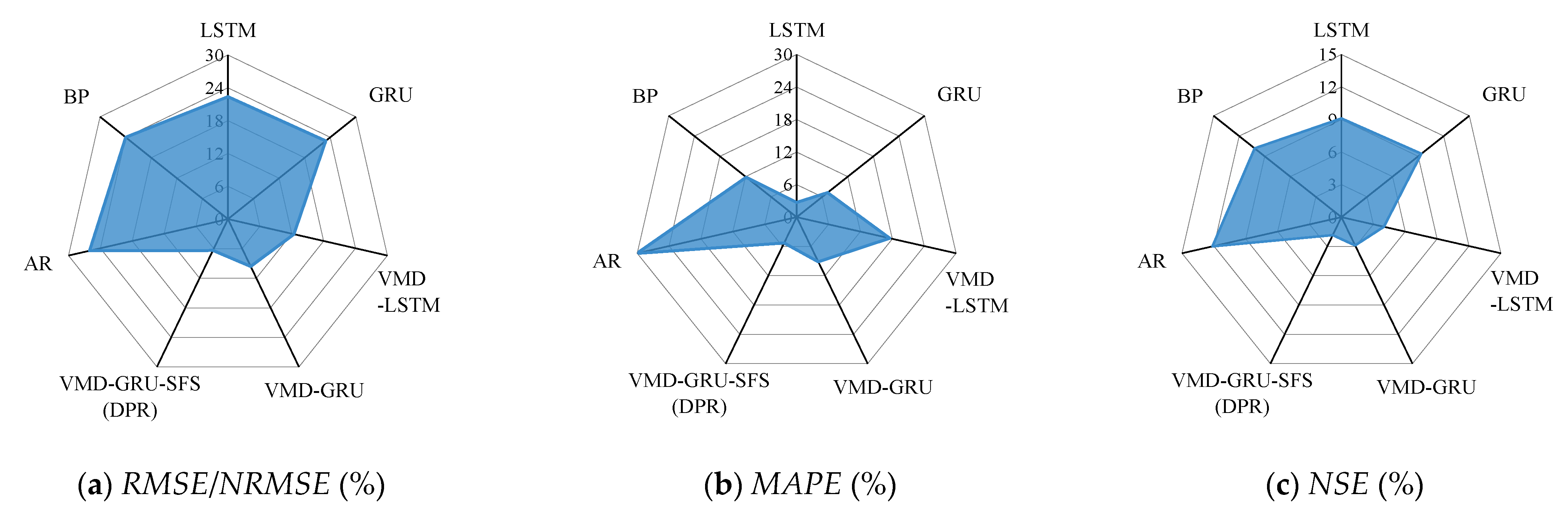
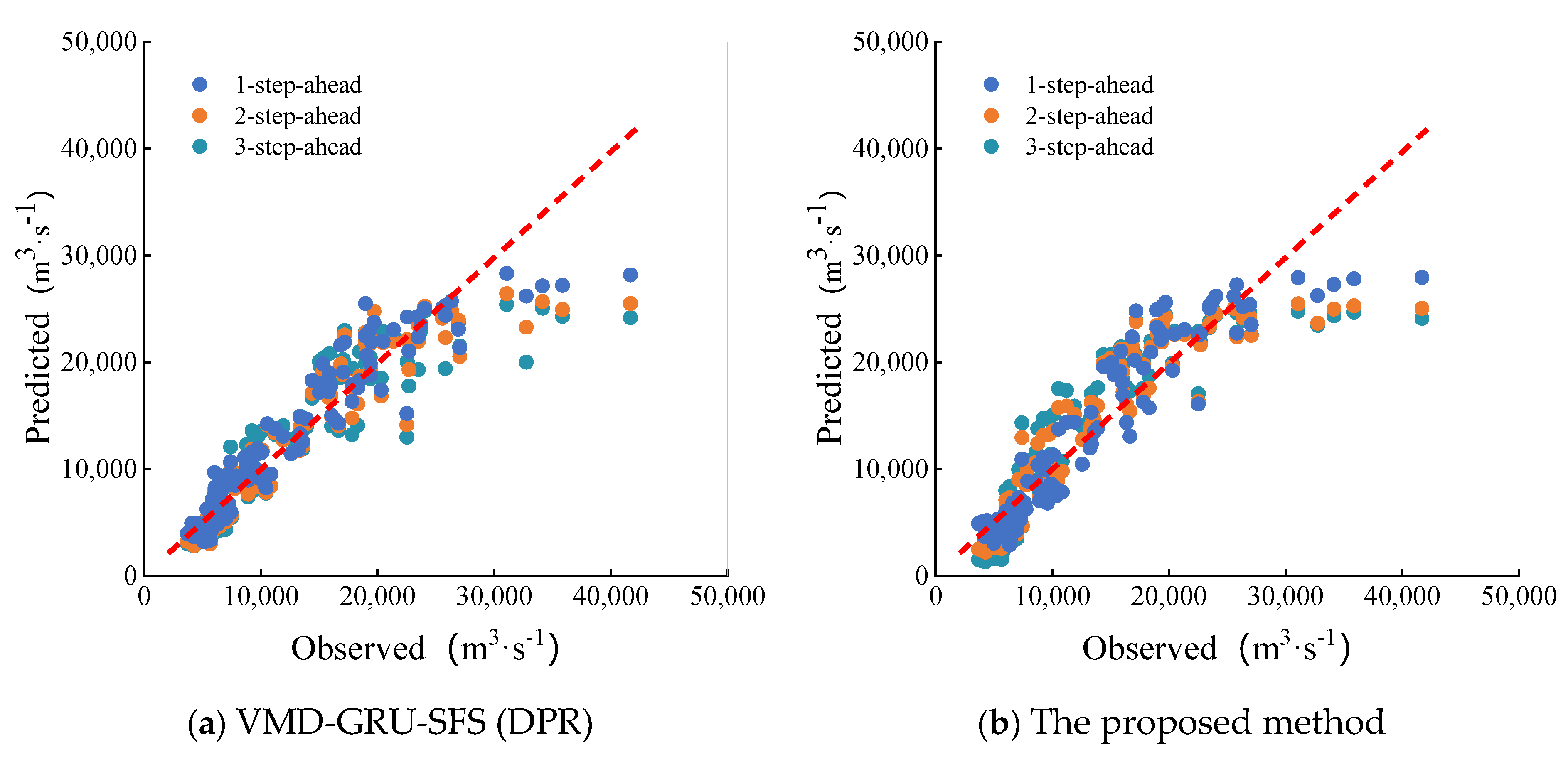
5. Result Analysis and Discussion
6. Conclusions
- (1)
- This method can more effectively identify the internal variation characteristics of runoff series, adaptively aggregate the prediction results of sub-series, and improve the overall prediction accuracy of the model.
- (2)
- Compared with other hybrid runoff forecasting models based on DPR framework, this method can significantly shorten the training time of the model and has better practical value.
- (3)
- Compared with the VMD-GRU-SFS hybrid model based on DPR, the proposed method has better multi-step prediction ability and can effectively extend the prediction period.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Full Name |
|---|---|
| DIP | Decomposition-IntegrationPrediction |
| VMD | Variational Mode Decomposition |
| GRU | Gated Recurrent Unit |
| SFS | Stochastic Fractal Search |
| AR | Autoregressive |
| MA | Moving Average |
| ARMA | Autoregressive Moving Average |
| ARIMA | Autoregressive Integrated Moving Average |
| BP | Back Propagation |
| SVM | Support Vector Machine |
| ELM | Extreme Learning Machine |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| DWT | Discrete Wavelet Transform |
| XWT | Cross Wavelet Transform |
| WCT | Wavelet Coherence Transform |
| LSWA | Least-Squares Wavelet Analysis |
| LSCWA | Least-Squares Cross Wavelet Analysis |
| EMD | Empirical Mode Decomposition |
| DPR | Decomposition-Prediction-Reconstruction |
| VMD-LSTM (DPR) | Variational Mode Decomposition-Long Short-Term Memory based on Decomposition-Prediction-Reconstruction |
| VMD-GRU (DPR) | Variational Mode Decomposition-Gated Recurrent Unit based on Decomposition-Prediction-Reconstruction |
| VMD-GRU-SFS (DPR) | Variational Mode Decomposition-Gated Recurrent Unit-Stochastic Fractal Search based on Decomposition-Prediction-Reconstruction |
| VMD-GRU-SFS (DIP) | Variational Mode Decomposition-Gated Recurrent Unit-Stochastic Fractal Search based on Decomposition-Integration-Prediction |
| PACF | Partial Autocorrelation Function |
| RMSE | Root Mean Square Error |
| NRMSE | Normalized Root Mean Square Error |
| MAPE | Mean Absolute Percentage Error |
| NSE | Nash-Sutcliffe Efficiency |
| UYR | the Upper Yangtze River |
References
- Feng, Z.K.; Niu, W.J.; Tang, Z.Y.; Jiang, Z.Q.; Xu, Y.; Liu, Y.; Zhang, H.R. Monthly runoff time series prediction by variational mode decomposition and support vector machine based on quantum-behaved particle swarm optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Chang, J.; Zhang, H.; Wang, Y.; Zhu, Y. Assessing the impact of climate variability and human activity to streamflow variation. Hydrol. Earth Syst. Sci. Discuss. 2015, 12, 5251–5291. [Google Scholar] [CrossRef] [Green Version]
- Zhang, A.; Zhang, C.; Fu, G.; Wang, B.; Bao, Z.; Zheng, H. Assessments of Impacts of Climate Change and Human Activities on Runoff with SWAT for the Huifa River Basin, Northeast China. Water Resour. Manag. 2012, 26, 2199–2217. [Google Scholar] [CrossRef]
- Woldemeskel, F.; McInerney, D.; Lerat, J.; Thyer, M.; Kavetski, D.; Shin, D.; Tuteja, N.; Kuczera, G. Evaluating post-processing approaches for monthly and seasonal streamflow forecasts. Hydrol. Earth Syst. Sci. 2018, 22, 6257–6278. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Li, F.W.; Feng, P. A new hybrid model for nonlinear and non-stationary runoff prediction at annual and monthly time scales. J. Hydro-Environ. Res. 2018, 20, 77–92. [Google Scholar] [CrossRef]
- Zerouali, B.; Chettih, M.; Alwetaishi, M.; Abda, Z.; Elbeltagi, A.; Santos, C.A.G.; Hussein, E.E. Evaluation of Karst Spring Discharge Response Using Time-Scale-Based Methods for a Mediterranean Basin of Northern Algeria. Water 2021, 13, 2946. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Vujadinovic, T.; Hassan, Q.K. Application of the Least-Squares Wavelet software in hydrology: Athabasca River Basin. J. Hydrol. Reg. Stud. 2021, 36, 100847. [Google Scholar] [CrossRef]
- Roy, B.; Singh, M.P.; Kaloop, M.R.; Kumar, D.; Hu, J.W.; Kumar, R.; Hwang, W.S. Data-Driven Approach for Rainfall-Runoff Modelling Using Equilibrium Optimizer Coupled Extreme Learning Machine and Deep Neural Network. Appl. Sci. 2021, 11, 6238. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, G.; Hou, J.; Xie, J.; Lv, M.; Liu, F. Hybrid forecasting model for non-stationary daily runoff series: A case study in the Han River Basin, China. J. Hydrol. 2019, 577, 123915. [Google Scholar] [CrossRef]
- De Vera, A.; Alfaro, P.; Terra, R. Operational Implementation of Satellite-Rain Gauge Data Merging for Hydrological Modeling. Water 2021, 13, 533. [Google Scholar] [CrossRef]
- He, X.; Luo, J.; Zuo, G.; Xie, J. Daily Runoff Forecasting Using a Hybrid Model Based on Variational Mode Decomposition and Deep Neural Networks. Water Resour. Manag. 2019, 33, 1571–1590. [Google Scholar] [CrossRef]
- He, X.; Luo, J.; Li, P.; Zuo, G.; Xie, J. A Hybrid Model Based on Variational Mode Decomposition and Gradient Boosting Regression Tree for Monthly Runoff Forecasting. Water Resour. Manag. 2020, 34, 865–884. [Google Scholar] [CrossRef]
- Bittelli, M.; Tomei, F.; Pistocchi, A.; Flury, M.; Boll, J.; Brooks, E.S.; Antolini, G. Development and testing of a physically based, three-dimensional model of surface and subsurface hydrology. Adv. Water Resour. 2010, 33, 106–122. [Google Scholar] [CrossRef]
- Partington, D.; Brunner, P.; Simmons, C.T.; Werner, A.D.; Therrien, R.; Maier, H.R.; Dandy, G.C. Evaluation of outputs from automated baseflow separation methods against simulated baseflow from a physically based, surface water-groundwater flow model. J. Hydrol. 2012, 458–459, 28–39. [Google Scholar] [CrossRef] [Green Version]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep learning with a long short-term memory networks approach for rainfall-runoff simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Chang, J.; Huang, Q.; Chen, Y. Monthly streamflow prediction using modified EMD-based support vector machine. J. Hydrol. 2014, 511, 764–775. [Google Scholar] [CrossRef]
- Elshorbagy, A.; Simonovic, S.P.; Panu, U.S. Performance Evaluation of Artificial Neural Networks for Runoff Prediction. J. Hydrol. Eng. 2000, 5, 424–427. [Google Scholar] [CrossRef]
- Mutlu, E.; Chaubey, I.; Hexmoor, H.; Bajwa, S.G. Comparison of artificial neural network models for hydrologic predictions at multiple gauging stations in an agricultural watershed. Hydrol. Process. 2008, 22, 5097–5106. [Google Scholar] [CrossRef]
- Feng, Z.K.; Niu, W.J.; Tang, Z.Y.; Xu, Y.; Zhang, H.R. Evolutionary artificial intelligence model via cooperation search algorithm and extreme learning machine for multiple scales nonstationary hydrological time series prediction. J. Hydrol. 2021, 595, 126062. [Google Scholar] [CrossRef]
- Niu, W.-J.; Feng, Z.-K.; Chen, Y.-B.; Zhang, H.; Cheng, C.-T. Annual Streamflow Time Series Prediction Using Extreme Learning Machine Based on Gravitational Search Algorithm and Variational Mode Decomposition. J. Hydrol. Eng. 2020, 25, 04020008. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Sulaiman, S.O.; Deo, R.C.; Chau, K.W. An enhanced extreme learning machine model for river flow forecasting: State-of-the-art, practical applications in water resource engineering area and future research direction. J. Hydrol. 2019, 569, 387–408. [Google Scholar] [CrossRef]
- Hosseini, S.M.; Mahjouri, N. Integrating Support Vector Regression and a geomorphologic Artificial Neural Network for daily rainfall-runoff modeling. Appl. Soft Comput. 2016, 38, 329–345. [Google Scholar] [CrossRef]
- Shijun, C.; Qin, W.; Yanmei, Z.; Guangwen, M.; Xiaoyan, H.; Liang, W. Medium- and long-term runoff forecasting based on a random forest regression model. Water Supply 2020, 20, 3658–3664. [Google Scholar] [CrossRef]
- Chiang, Y.M.; Chang, F.J. Integrating hydrometeorological information for rainfall-runoff modelling by artificial neural networks. Hydrol. Process. 2009, 23, 1650–1659. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall—runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Wang, W.C.; Xu, D.M.; Chau, K.W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO–SVM model based on EEMD. J. Hydroinformatics 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Venkata Ramana, R.; Krishna, B.; Kumar, S.R.; Pandey, N.G. Monthly Rainfall Prediction Using Wavelet Neural Network Analysis. Water Resour. Manag. 2013, 27, 3697–3711. [Google Scholar] [CrossRef] [Green Version]
- Solgi, A.; Nourani, V.; Pourhaghi, A. Forecasting daily precipitation using hybrid model of wavelet-artificial neural network and comparison with adaptive neurofuzzy inference system (case study: Verayneh station, Nahavand). Adv. Civ. Eng. 2014, 2014, 279368. [Google Scholar] [CrossRef] [Green Version]
- Hadi, S.J.; Tombul, M. Streamflow Forecasting Using Four Wavelet Transformation Combinations Approaches with Data-Driven Models: A Comparative Study. Water Resour. Manag. 2018, 32, 4661–4679. [Google Scholar] [CrossRef]
- Azuara, J.; Sabatier, P.; Lebreton, V.; Jalali, B.; Sicre, M.A.; Dezileau, L.; Bassetti, M.A.; Frigola, J.; Combourieu-Nebout, N. Mid- to Late-Holocene Mediterranean climate variability: Contribution of multi-proxy and multi-sequence comparison using wavelet spectral analysis in the northwestern Mediterranean basin. Earth-Sci. Rev. 2020, 208, 103232. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Qiu, J.; Li, F.F. Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting. Water 2018, 10, 853. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Zhang, H.; Singh, V.P. Forward Prediction of Runoff Data in Data-Scarce Basins with an Improved Ensemble Empirical Mode Decomposition (EEMD) Model. Water 2018, 10, 388. [Google Scholar] [CrossRef] [Green Version]
- Sankaran, A.; Janga Reddy, M. Analyzing the Hydroclimatic Teleconnections of Summer Monsoon Rainfall in Kerala, India, Using Multivariate Empirical Mode Decomposition and Time-Dependent Intrinsic Correlation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1221–1225. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, H.; Zhang, J.; Yan, Y.; Zhang, L.; Wu, C.; Hua, X.; Wang, Y. Wind power prediction based on variational mode decomposition multi-frequency combinations. J. Mod. Power Syst. Clean Energy 2019, 7, 281–288. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. Short-Term Wind Speed Forecasting Based on Hybrid Variational Mode Decomposition and Least Squares Support Vector Machine Optimized by Bat Algorithm Model. Sustainability 2019, 11, 652. [Google Scholar] [CrossRef] [Green Version]
- He, F.; Zhou, J.; Feng, Z.K.; Liu, G.; Yang, Y. A hybrid short-term load forecasting model based on variational mode decomposition and long short-term memory networks considering relevant factors with Bayesian optimization algorithm. Appl. Energy 2019, 237, 103–116. [Google Scholar] [CrossRef]
- He, S.; Guo, S.; Chen, K.; Deng, L.; Liao, Z.; Xiong, F.; Yin, J. Optimal impoundment operation for cascade reservoirs coupling parallel dynamic programming with importance sampling and successive approximation. Adv. Water Resour. 2019, 131. [Google Scholar] [CrossRef]
- Wen, S.; Su, B.; Wang, Y.; Zhai, J.; Sun, H.; Chen, Z.; Huang, J.; Wang, A.; Jiang, T. Comprehensive evaluation of hydrological models for climate change impact assessment in the Upper Yangtze River Basin, China. Clim. Chang. 2020, 163, 1207–1226. [Google Scholar] [CrossRef]
- Pei, S.; Qin, H.; Zhang, Z.; Yao, L.; Wang, Y.; Wang, C.; Liu, Y.; Jiang, Z.; Zhou, J.; Yi, T. Wind speed prediction method based on Empirical Wavelet Transform and New Cell Update Long Short-Term Memory network. Energy Convers. Manag. 2019, 196, 779–792. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Snin, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R Soc. London Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Chrupała, G.; Kádár, A.; Alishahi, A. Learning Language through Pictures. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, July 2015; pp. 112–118. Available online: https://aclanthology.org/P15-2019/ (accessed on 9 November 2021).
- Li, C.; Tang, G.; Xue, X.; Saeed, A.; Hu, X. Short-Term Wind Speed Interval Prediction Based on Ensemble GRU Model. IEEE Trans. Sustain. Energy 2020, 11, 1370–1380. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A Novel CNN-GRU-Based Hybrid Approach for Short-Term Residential Load Forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Salimi, H. Stochastic Fractal Search: A powerful metaheuristic algorithm. Knowl. Based Syst. 2015, 75, 1–18. [Google Scholar] [CrossRef]
- Awad, N.H.; Ali, M.Z.; Suganthan, P.N.; Jaser, E. Differential evolution with stochastic fractal search algorithm for global numerical optimization. In Proceedings of the IEEE Congress on Evolutionary Computation, Vancouver, BC, Canada, 24–29 July 2016; pp. 3154–3161. [Google Scholar]
- Khalilpourazari, S.; Khalilpourazary, S. A Robust Stochastic Fractal Search approach for optimization of the surface grinding process. Swarm Evol. Comput. 2018, 38, 173–186. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, P.; Xie, J.; Li, J.; Li, C. Additive Model for Monthly Reservoir Inflow Forecast. J. Hydrol. Eng. 2014, 20, 04014079. [Google Scholar] [CrossRef]
- Zhong, W.; Guo, J.; Chen, L.; Zhou, J.; Zhang, J.; Wang, D. Future hydropower generation prediction of large-scale reservoirs in the upper Yangtze River basin under climate change. J. Hydrol. 2020, 588, 125013. [Google Scholar] [CrossRef]
- Zuo, G.; Luo, J.; Wang, N.; Lian, Y.; He, X. Two-stage variational mode decomposition and support vector regression for streamflow forecasting. Hydrol. Earth Syst. Sci. 2020, 24, 5491–5518. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, L. On practical challenges of decomposition-based hybrid forecasting algorithms for wind speed and solar irradiation. Energy 2016, 112, 208–220. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]












| IMFs | Input Variables | Numbers of Input |
|---|---|---|
| IMF1 | Xt-1~Xt-11, Xt-14, Xt-15, Xt-17~Xt-19 | 16 |
| IMF2 | Xt-1~Xt-11, Xt-14~Xt-19 | 17 |
| IMF3 | Xt-1~Xt-10, Xt-12, Xt-14, Xt-17~Xt-22 | 18 |
| IMF4 | Xt-1~Xt-10, Xt-14, Xt-15, Xt-17, Xt-20~Xt-23, Xt-27, Xt-29 | 19 |
| IMF5 | Xt-2, Xt-4~Xt-9, Xt-13~Xt-16, Xt-18~Xt-20, Xt-24, Xt-27 | 16 |
| IMF6 | Xt-1~Xt-8, Xt-10~Xt-12, Xt-16, Xt-20, Xt-23, Xt-35 | 15 |
| IMF7 | Xt-1~Xt-12, Xt-16~Xt-20, Xt-23~Xt-28, Xt-30~Xt-32, Xt-36 | 27 |
| IMF8 | Xt-1~Xt-3, Xt-5, Xt-6, Xt-8, Xt-13, Xt-14, Xt-16, Xt-25~Xt-29 | 14 |
| Station | Layers | Hidden Layers | Hidden Nodes | Activation Function | Loss Function | Optimizer | Epochs | Batch Size |
|---|---|---|---|---|---|---|---|---|
| Pingshan | multi-input layers | 2 | 22 | softsign | mse | adam | 20 | 8 |
| 29 | softsign | |||||||
| concatenation layers | 2 | 37 | softsign | |||||
| 12 | linear | |||||||
| Yichang | multi-input layers | 2 | 27 | softsign | mse | adam | 20 | 8 |
| 43 | softsign | |||||||
| concatenation layers | 2 | 34 | softsign | |||||
| 19 | linear |
| Model | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | NRMSE | MAPE | NSE | RMSE | NRMSE | MAPE | NSE | |
| AR | 1464.36 | 10.89 | 24.2 | 0.835 | 1771.89 | 13.18 | 25.6 | 0.791 |
| BP | 1378.41 | 10.26 | 20.9 | 0.854 | 1724.55 | 12.83 | 20.3 | 0.805 |
| LSTM | 1302.25 | 9.69 | 13.7 | 0.869 | 1688.15 | 12.56 | 18.4 | 0.813 |
| GRU | 1282.78 | 9.54 | 15.9 | 0.873 | 1700.87 | 12.65 | 19.3 | 0.811 |
| VMD-LSTM (DPR) | 1228.62 | 9.14 | 21.8 | 0.883 | 1496.11 | 11.13 | 21.7 | 0.853 |
| VMD-GRU (DPR) | 1178.06 | 8.76 | 20.2 | 0.892 | 1449.76 | 10.79 | 19.7 | 0.862 |
| VMD-GRU-SFS (DPR) | 1134.25 | 8.44 | 19.2 | 0.901 | 1399.51 | 10.41 | 18.9 | 0.871 |
| Proposed | 1056.28 | 7.86 | 19.6 | 0.914 | 1310.62 | 9.75 | 17.9 | 0.887 |
| Model | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | NRMSE | MAPE | NSE | RMSE | NRMSE | MAPE | NSE | |
| AR | 3946.35 | 10.38 | 19.9 | 0.852 | 4433.03 | 11.67 | 22.9 | 0.757 |
| BP | 3785.58 | 9.96 | 18.3 | 0.863 | 4343.23 | 11.43 | 22.1 | 0.771 |
| LSTM | 3562.45 | 9.37 | 14.7 | 0.879 | 4204.73 | 11.06 | 20.1 | 0.784 |
| GRU | 3469.44 | 9.13 | 13.9 | 0.885 | 4098.51 | 10.78 | 17.6 | 0.794 |
| VMD-LSTM (DPR) | 3241.23 | 8.53 | 18.2 | 0.899 | 3828.96 | 10.08 | 20.9 | 0.821 |
| VMD-GRU (DPR) | 3202.11 | 8.43 | 15.4 | 0.902 | 3670.41 | 9.66 | 20.1 | 0.834 |
| VMD-GRU-SFS (DPR) | 2917.92 | 7.68 | 16.9 | 0.918 | 3414.16 | 8.98 | 19.1 | 0.856 |
| Proposed | 2943.65 | 7.75 | 16.6 | 0.917 | 3145.08 | 8.28 | 16.2 | 0.878 |
| Steps | VMD-GRU-SFS(DPR) | The Proposed | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | NRMSE | MAPE | NSE | RMSE | NRMSE | MAPE | NSE | |
| 1-step-ahead | 3414.16 | 8.98 | 19.1 | 0.856 | 3145.08 | 8.28 | 16.2 | 0.878 |
| 2-step-ahead | 3913.61 | 10.30 | 23.7 | 0.812 | 3405.01 | 8.96 | 20.9 | 0.857 |
| 3-step-ahead | 4368.91 | 11.50 | 29.9 | 0.765 | 3905.09 | 10.28 | 21.1 | 0.813 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Zhou, J.; Mo, L.; Jia, B.; Yang, Y.; Fang, W.; Qin, Z. A Novel Runoff Forecasting Model Based on the Decomposition-Integration-Prediction Framework. Water 2021, 13, 3390. https://doi.org/10.3390/w13233390
Xu Z, Zhou J, Mo L, Jia B, Yang Y, Fang W, Qin Z. A Novel Runoff Forecasting Model Based on the Decomposition-Integration-Prediction Framework. Water. 2021; 13(23):3390. https://doi.org/10.3390/w13233390
Chicago/Turabian StyleXu, Zhanxing, Jianzhong Zhou, Li Mo, Benjun Jia, Yuqi Yang, Wei Fang, and Zhou Qin. 2021. "A Novel Runoff Forecasting Model Based on the Decomposition-Integration-Prediction Framework" Water 13, no. 23: 3390. https://doi.org/10.3390/w13233390
APA StyleXu, Z., Zhou, J., Mo, L., Jia, B., Yang, Y., Fang, W., & Qin, Z. (2021). A Novel Runoff Forecasting Model Based on the Decomposition-Integration-Prediction Framework. Water, 13(23), 3390. https://doi.org/10.3390/w13233390