
Prediction of Total Nitrogen and Phosphorus in Surface Water by Deep Learning Methods Based on Multi-Scale Feature Extraction


Abstract
:1. Introduction
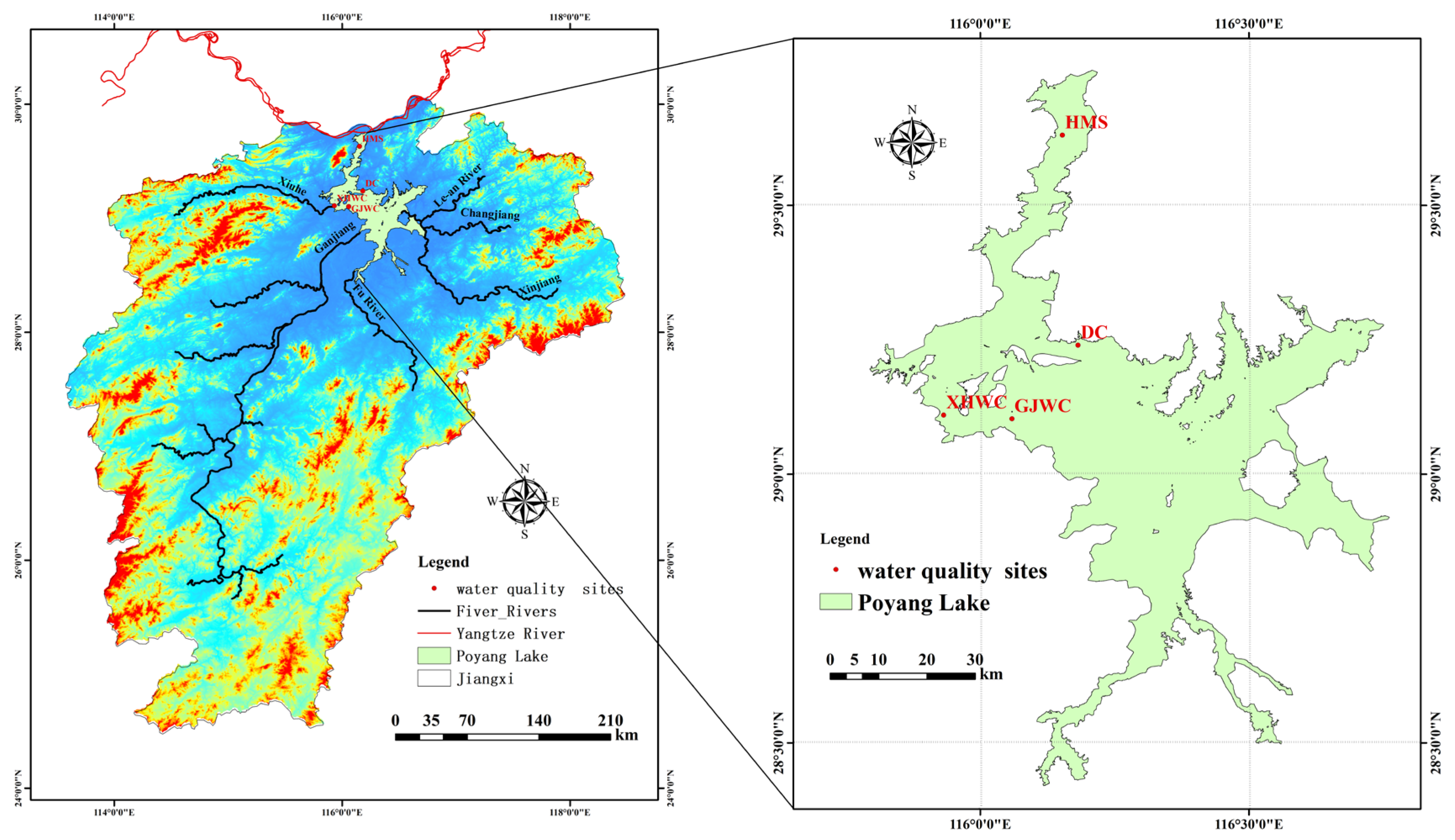
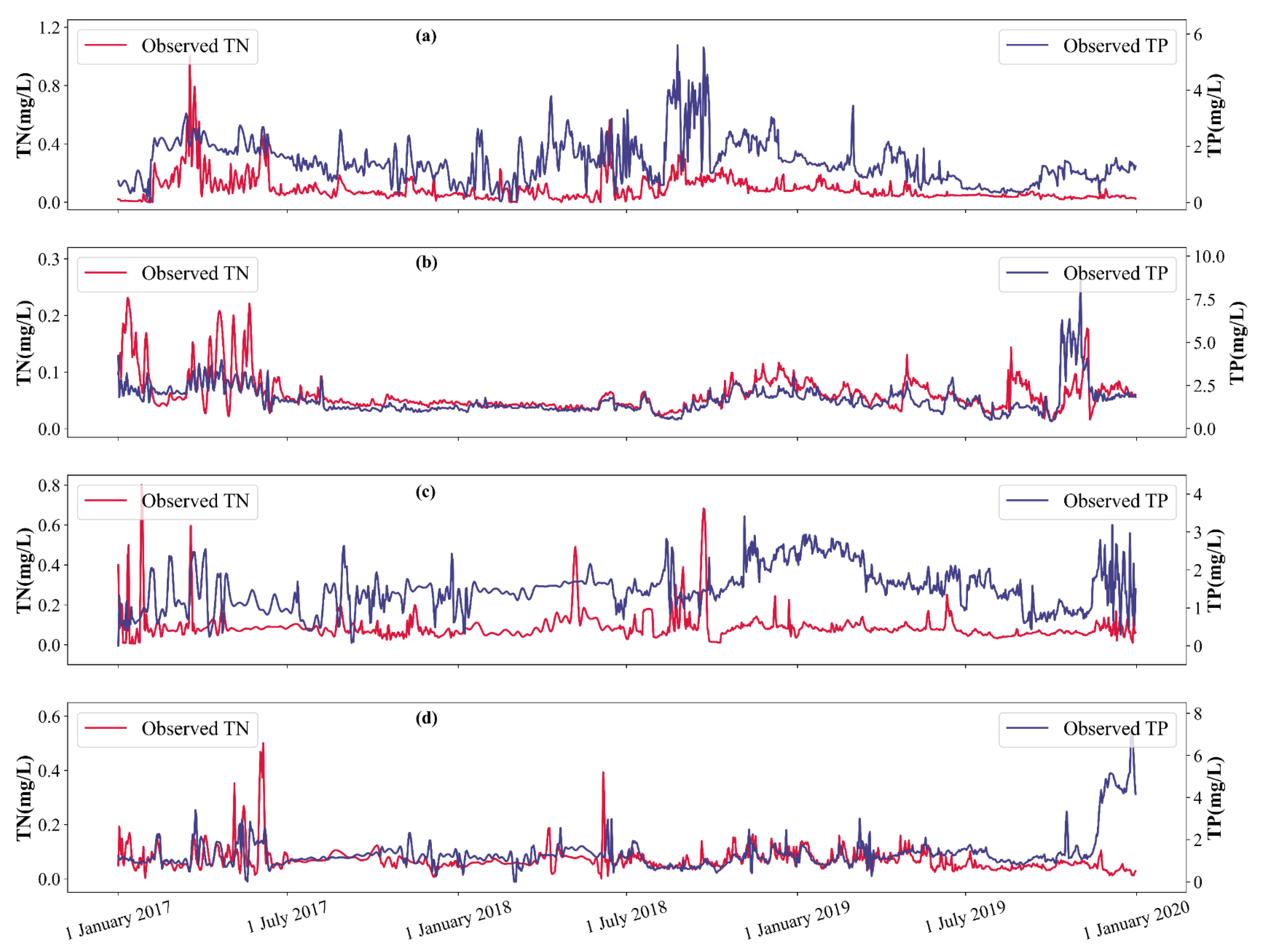
2. Study Area and Data
3. Methodology
3.1. VMD
3.1.1. Theory of VMD
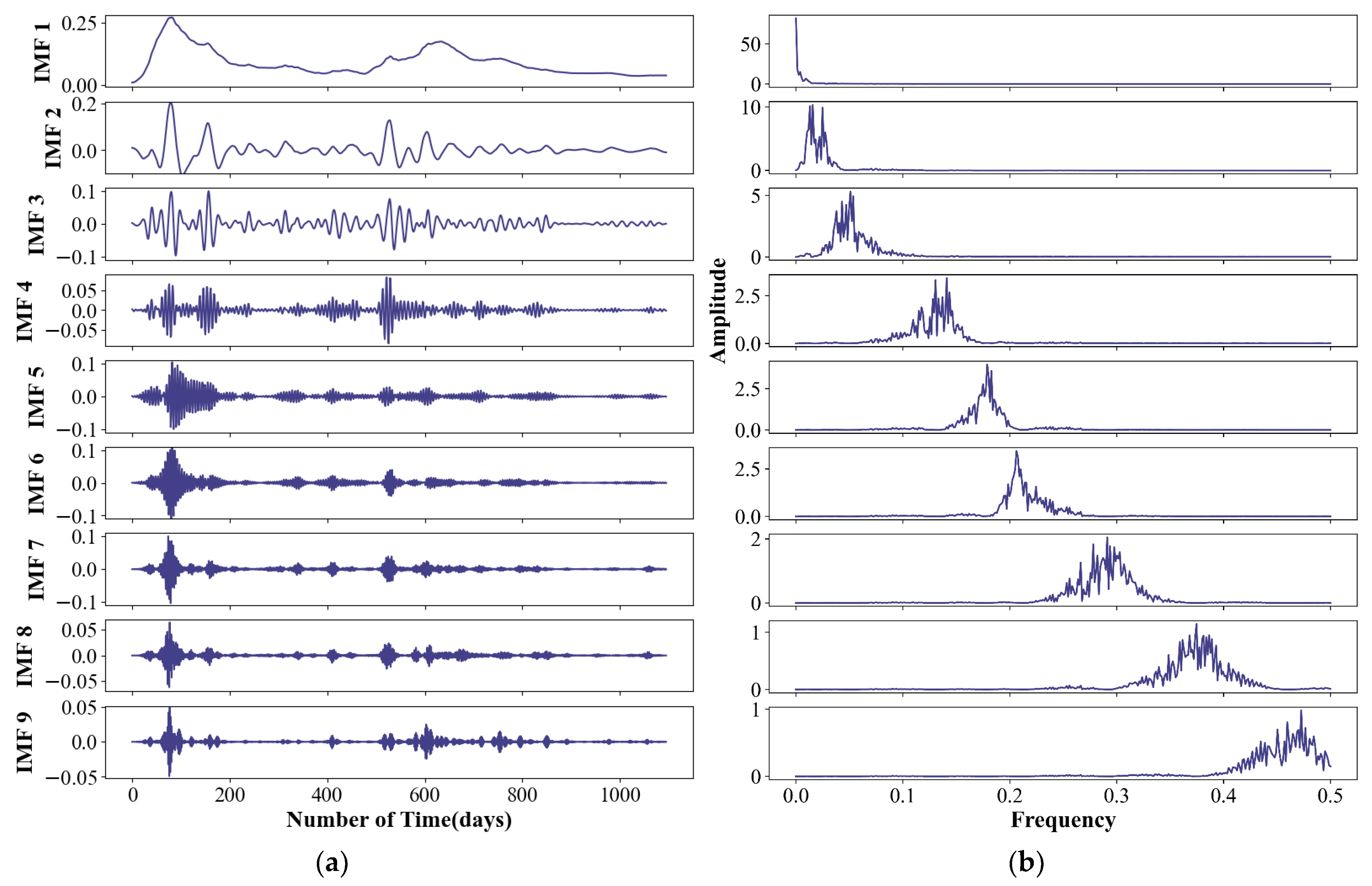
3.1.2. Determination of the Level of Decomposition
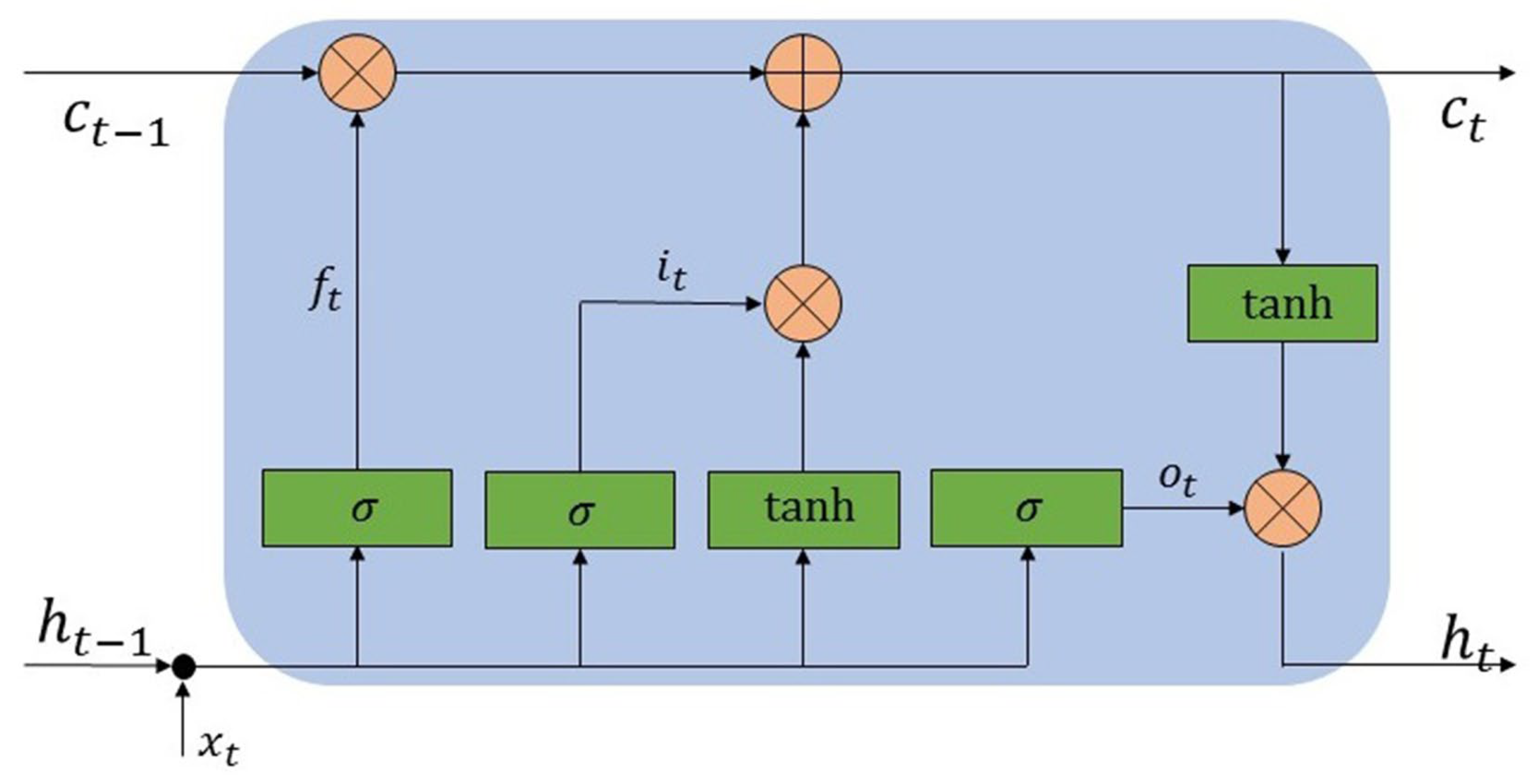
3.2. Long Short-Term Memory
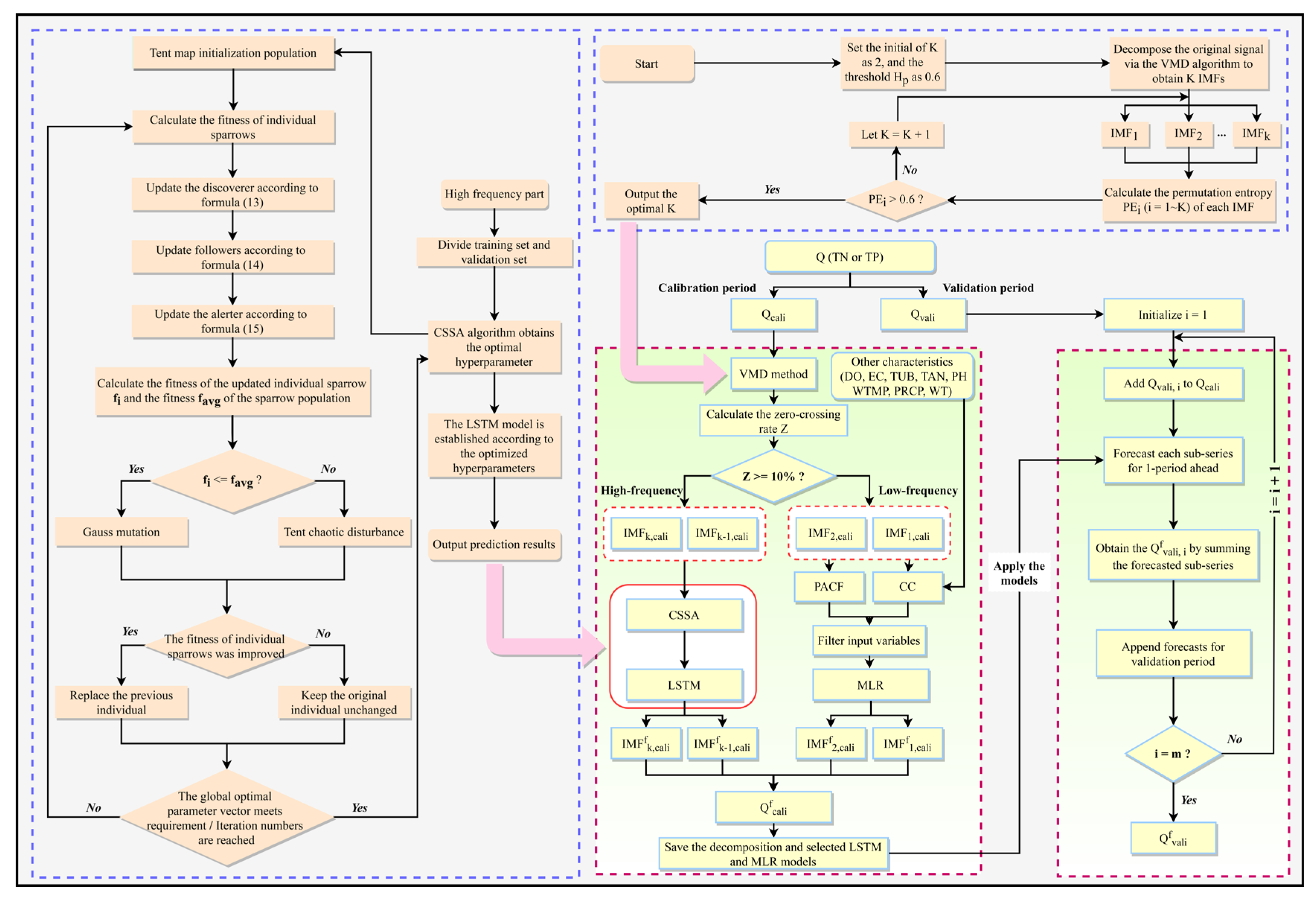
3.3. Chaos Sparrow Search Algorithm
3.3.1. Basic Sparrow Search Algorithm
3.3.2. Improved Sparrow Algorithm
3.4. Multiple Linear Regression
3.5. Water Quality Prediction Based on Hybrid Models
3.6. Model Performance Evaluation
4. Results
4.1. Decomposition Results Using VMD
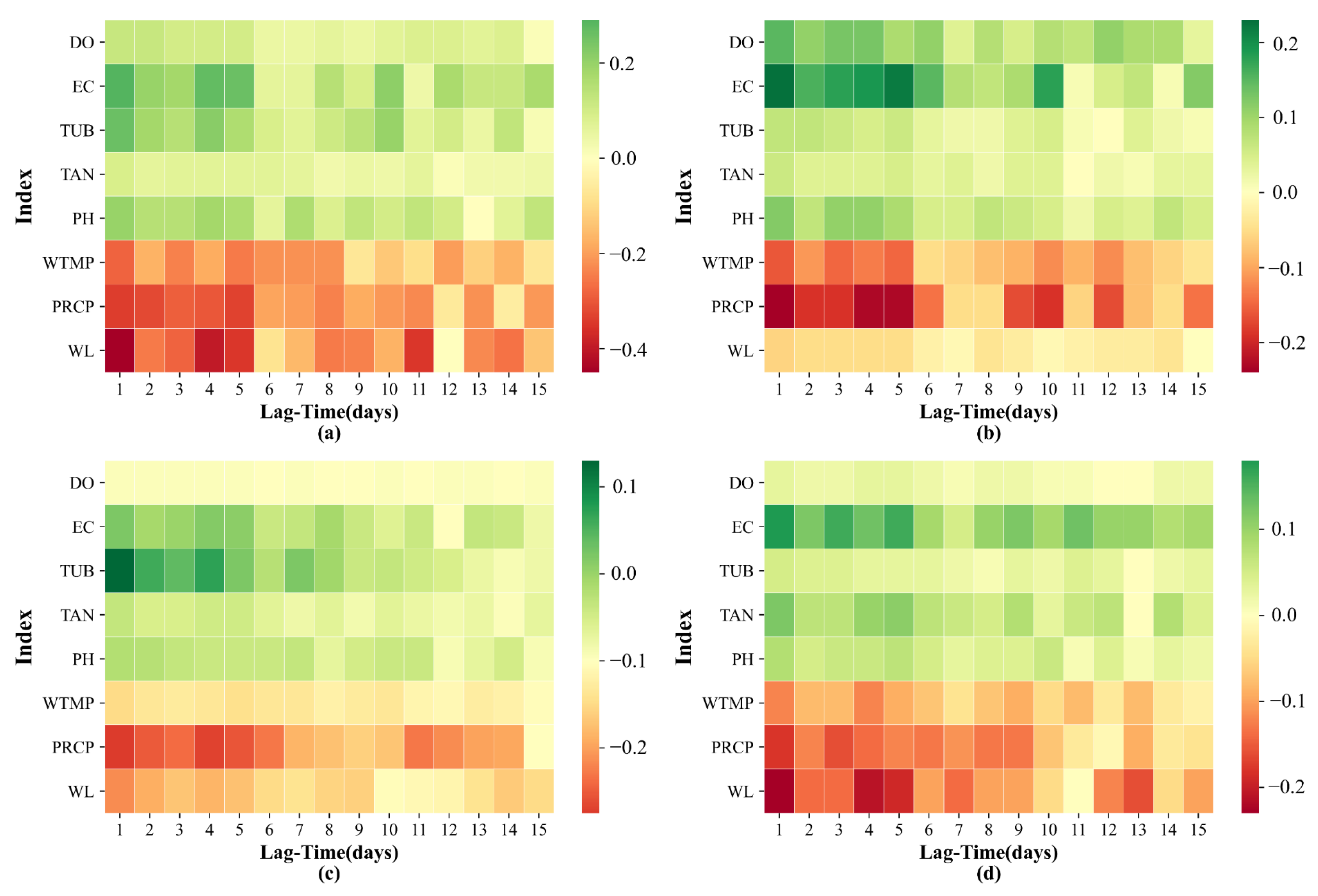
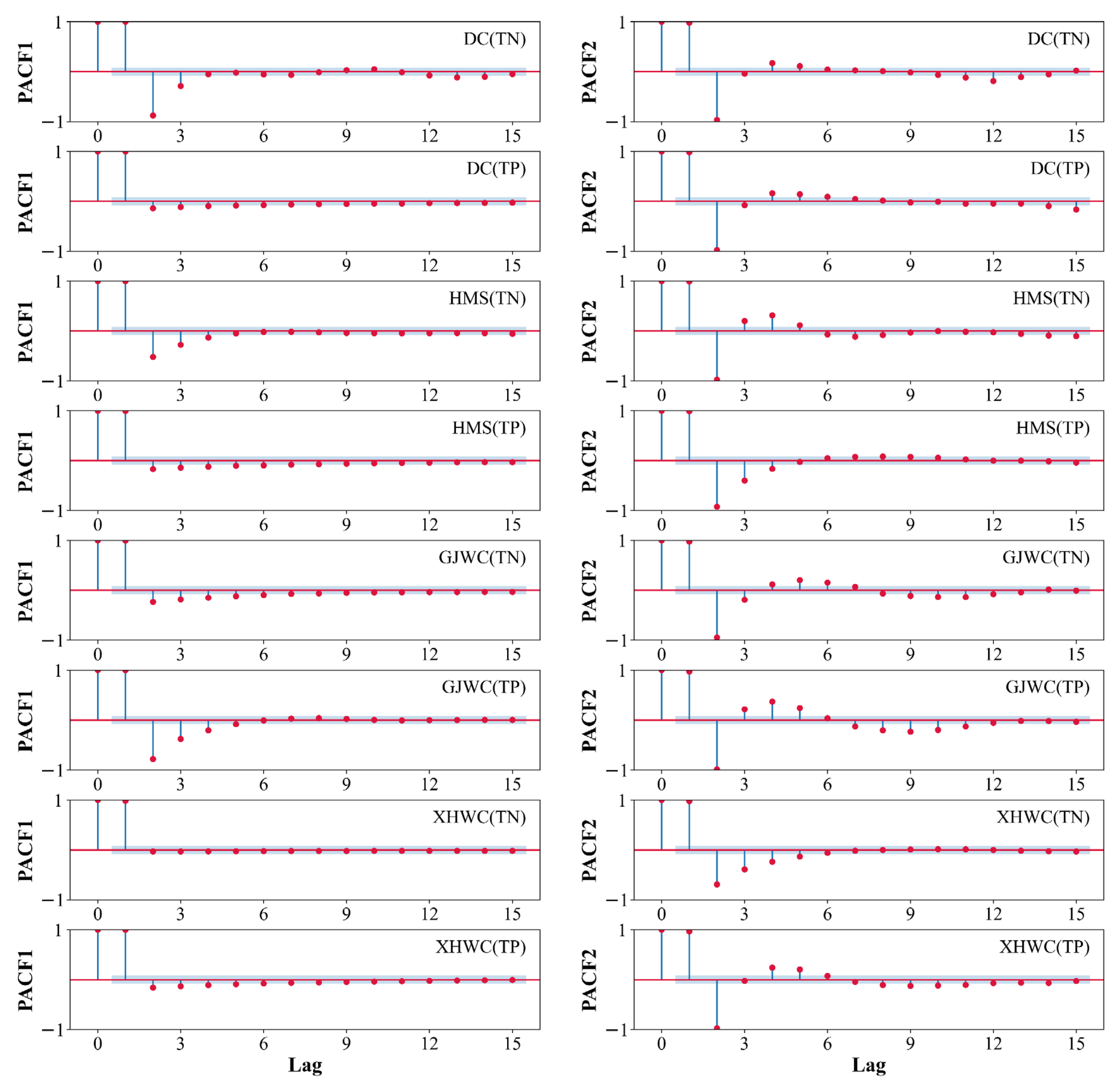
4.2. Model Building and Inputs
4.3. Comparison of Different Metaheuristic Optimization Algorithms
4.3.1. Experimental Settings
4.3.2. Comparison of Results
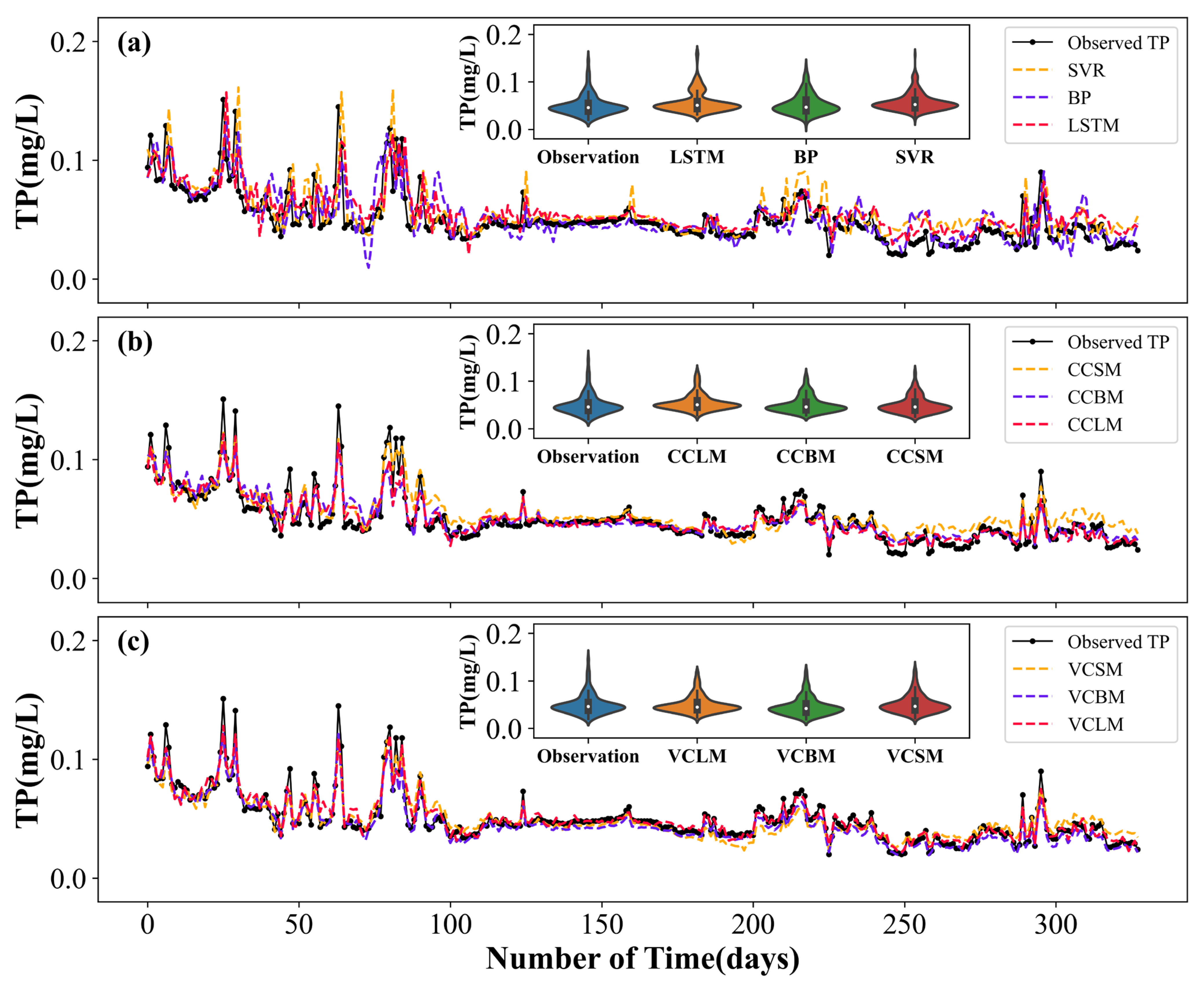
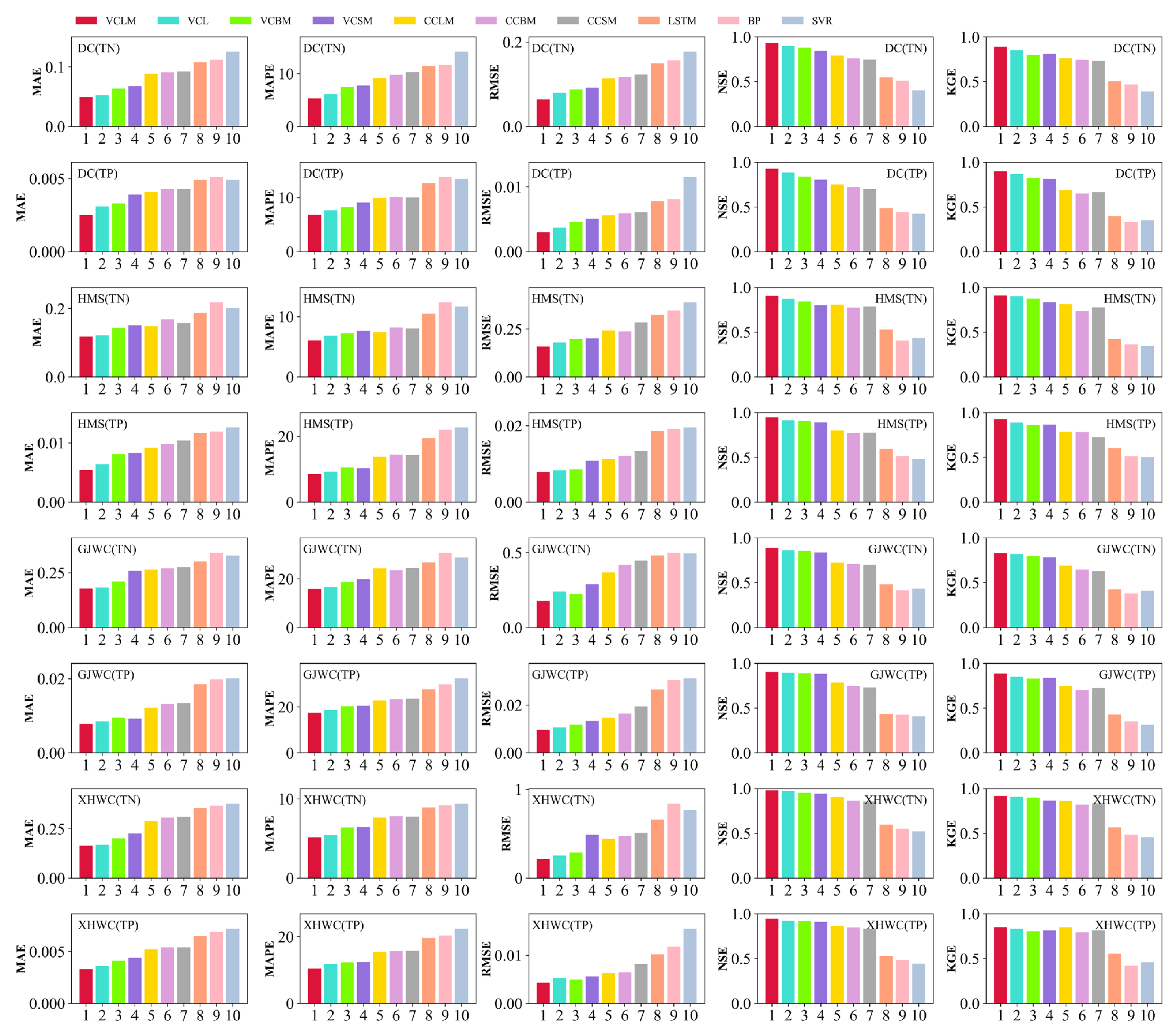
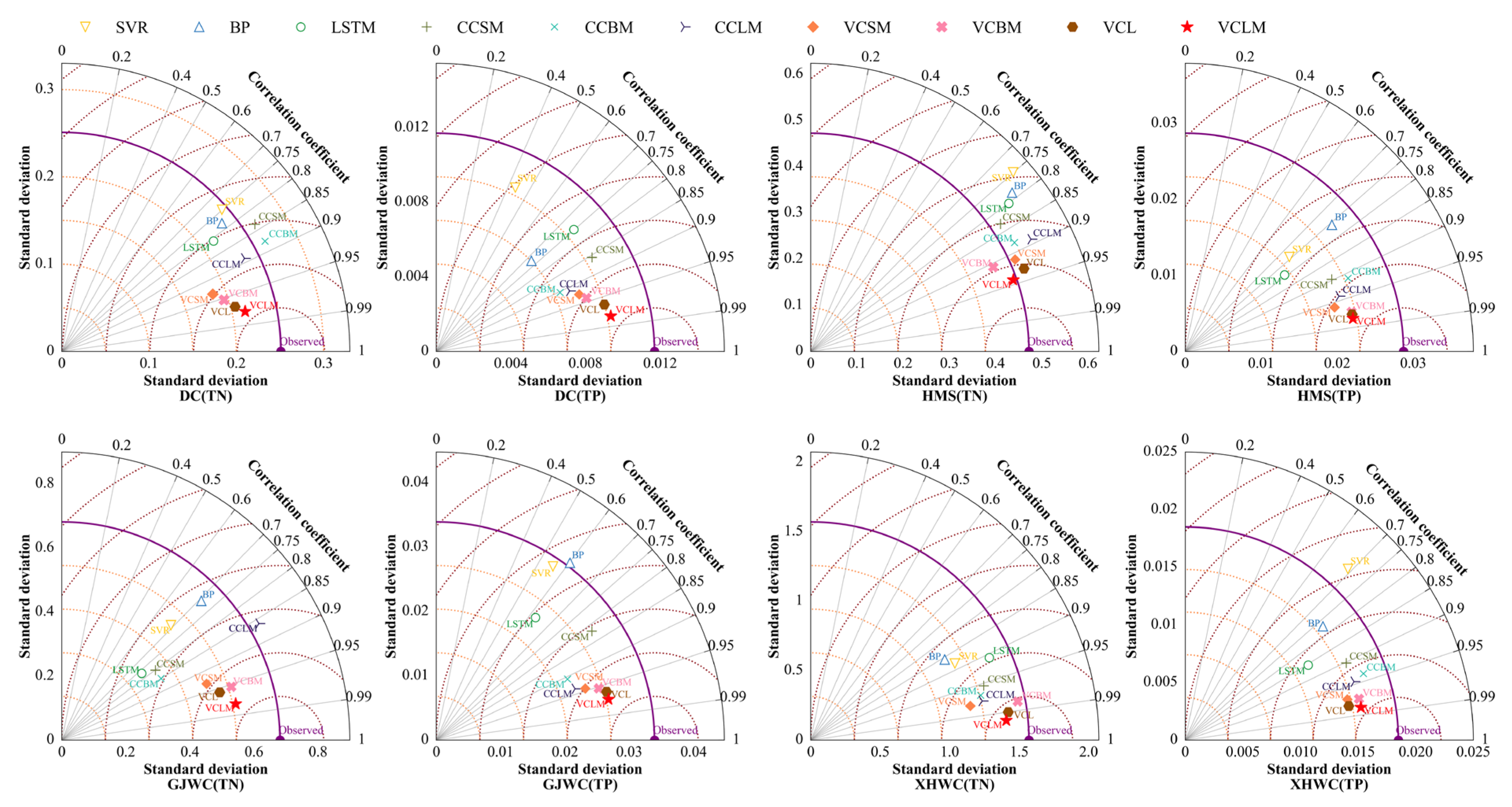
4.4. Comparison of the Results of Various Prediction Models
4.4.1. Water Quality Prediction Performance with Standalone Model
4.4.2. Water Quality Prediction Performance with CEEMDAN Decomposition
4.4.3. Water Quality Prediction Performance with VMD Decomposition
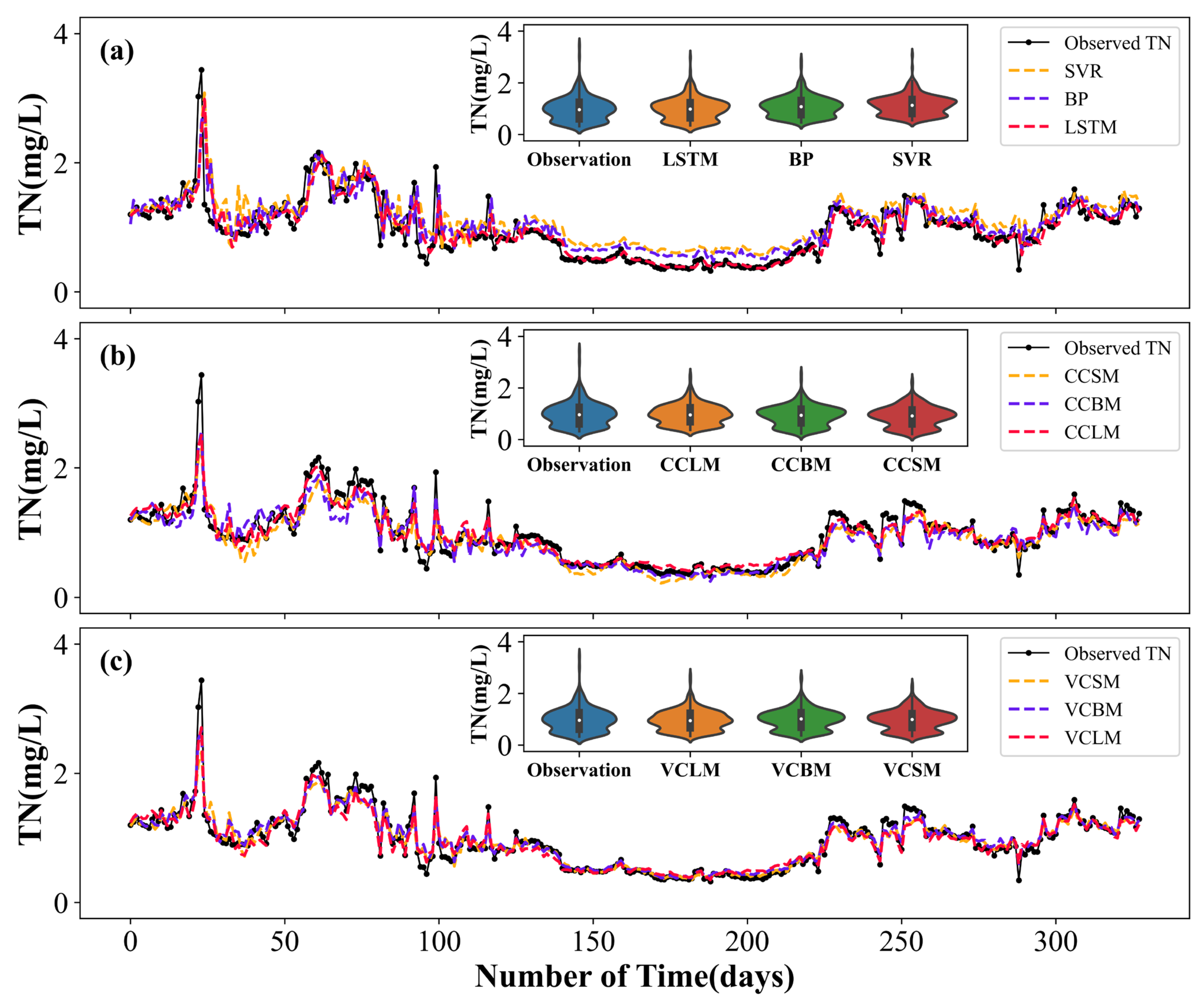
4.4.4. Water Quality Prediction Performance in Different Stations
5. Discussion
5.1. Rationality of Hindcasting and Forecasting Experiments
5.2. Adaptive VMD Decomposition Enhances the Model Performance
5.3. LSTM Guarantees the Hybrid Model Performance
5.4. Spatial Difference of VCLM Model Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| BP | back-propagation neural network |
| CC | correlation coefficient |
| CCBM | CEEMDAN-CSSA-BP-MLR |
| CCLM | CEEMDAN-CSSA-LSTM-MLR |
| CCSM | CEEMDAN-CSSA-SVR-MLR |
| CEEMDAN | complete ensemble empirical mode decomposition with adaptive noise |
| CSSA | chaos sparrow search algorithm |
| DC | Duchang Station |
| DO | dissolved oxygen |
| EC | electrical conductivity |
| EEMD | ensemble empirical mode decomposition |
| ELM | extreme learning machine |
| EMD | empirical mode decomposition |
| GJWC | Ganjiang Wucheng Station |
| HMS | Hamashi Station |
| IMF | intrinsic mode function |
| KGE | Kling–Gupta efficiency |
| LSTM | long short-term memory network |
| MAE | mean absolute error |
| MAPE | mean absolute percentage error |
| MLR | multiple linear regression model |
| NSE | Nash–Sutcliffe efficiency coefficient |
| PACF | partial autocorrelation function |
| PE | permutation entropy |
| PH | potential of hydrogen |
| PRCP | precipitation |
| RMSE | root mean square error |
| SSA | sparrow search algorithm |
| SVR | support vector regression |
| SWAT | soil and water assessment tool |
| TAN | total ammonia nitrogen |
| TN | total nitrogen |
| TP | total phosphorus |
| TUB | turbidity |
| VCBM | VMD-CSSA-BP-MLR |
| VCL | VMD-CSSA-LSTM |
| VCLM | VMD-CSSA-LSTM-MLR |
| VCSM | VMD-CSSA-SVR-MLR |
| VMD | variational mode decomposition |
| WL | water level |
| WTMP | water temperature |
| XHWC | Xiuhe Wucheng Station |
References
- Baek, S.S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399. [Google Scholar] [CrossRef]
- United States Environmental Protection Agency. Available online: https://www.epa.gov/caddis-vol2/caddis-volume-2-sources-stressors-responses-nutrients (accessed on 3 March 2022).
- Amano, Y.; Machida, M.; Tatsumoto, H.; George, D.; Berk, S.; Taki, K. Prediction of Microcystis Blooms Based on TN:TP Ratio and Lake Origin. Sci. World J. 2008, 8, 558–572. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huo, S.; He, Z.; Su, J.; Xi, B.; Zhu, C. Using Artificial Neural Network Models for Eutrophication Prediction. Procedia Environ. Sci. 2013, 18, 310–316. [Google Scholar] [CrossRef] [Green Version]
- Portielje, R.; Molen, D. Relationships between eutrophication variables: From nutrient loading to transparency. In Shallow Lakes ’98; Springer: Dordrecht, The Netherlands, 1999; Volume 143, pp. 375–387. [Google Scholar] [CrossRef]
- Rao, K.; Zhang, X.; Wang, M.; Liu, J.; Guo, W.; Huang, W.; Xu, J. The relative importance of environmental factors in predicting phytoplankton shifting and cyanobacteria abundance in regulated shallow lakes. Environ. Pollut. 2021, 286, 117555. [Google Scholar] [CrossRef]
- Hatvani, I.G.; Kovacs, J.; Markus, L.; Clement, A.; Hoffmann, R.; Korponai, J. Assessing the relationship of background factors governing the water quality of an agricultural watershed with changes in catchment property (W-Hungary). J. Hydrol. 2015, 521, 460–469. [Google Scholar] [CrossRef]
- Kosten, S.; Huszar, V.L.M.; Mazzeo, N.; Scheffer, M.; da Sternberg, L.S.L.; Jeppesen, E. Lake and watershed characteristics rather than climate influence nutrient limitation in shallow lakes. Ecol. Appl. 2009, 19, 1791–1804. [Google Scholar] [CrossRef]
- Varol, M. Temporal and spatial dynamics of nitrogen and phosphorus in surface water and sediments of a transboundary river located in the semi-arid region of Turkey. Catena 2013, 100, 1–9. [Google Scholar] [CrossRef]
- Sinshaw, T.A. Artificial Neural Network for Prediction of Total Nitrogen and Phosphorus in US Lakes. J. Environ. Eng. 2019, 145, 04019032. [Google Scholar] [CrossRef]
- Song, C.; Chen, X. Performance Comparison of Machine Learning Models for Annual Precipitation Prediction Using Different Decomposition Methods. Remote Sens. 2021, 13, 1018. [Google Scholar] [CrossRef]
- Arnold, J.G.; Moriasi, D.N.; Gassman, P.W.; Abbaspour, K.C.; White, M.J.; Srinivasan, R.; Santhi, C.; Harmel, R.D.; Van Griensven, A.; Van Liew, M.W.; et al. SWAT: Model Use, Calibration, and Validation. Trans. ASABE 2012, 55, 1491–1508. [Google Scholar] [CrossRef]
- Huber, W.C.; Heaney, J.P.; Cunningham, B.A.; Barnwell, T.O. Storm Water Management Model (SWMM) Bibliography; Environmental Research Laboratory, Office of Research and Development, US Environmental Protection Agency: Washington, DC, USA, 1985.
- Lin, S.; Jing, C.; Chaplot, V.; Yu, X.; Zhang, Z.; Moore, N.; Wu, J. Effect of DEM resolution on SWAT outputs of runoff, sediment and nutrients. Hydrol. Earth Syst. Sci. Discuss. 2010, 7, 4411–4435. [Google Scholar] [CrossRef]
- Baek, S.S.; Ligaray, M.; Pyo, J.; Park, J.P.; Kang, J.H.; Pachepsky, Y.; Chun, J.A.; Cho, K.H. A novel water quality module of the SWMM model for assessing low impact development (LID) in urban watersheds. J. Hydrol. 2020, 586, 124886. [Google Scholar] [CrossRef]
- Choubin, B.; Borji, M.; Hosseini, F.S.; Mosavi, A.; Dineva, A.A. Mass wasting susceptibility assessment of snow avalanches using machine learning models. Sci. Rep. 2020, 10, 18363. [Google Scholar] [CrossRef] [PubMed]
- Choubin, B.; Hosseini, F.S.; Fried, Z.; Mosavi, A. Application of Bayesian Regularized Neural Networks for Groundwater Level Modeling. In Proceedings of the 2020 IEEE 3rd International Conference and Workshop in Óbuda on Electrical and Power Engineering (CANDO-EPE), Budapest, Hungary, 18–19 November 2020; pp. 209–212. [Google Scholar] [CrossRef]
- Li, X.; Yan, D.; Wang, K.; Weng, B.; Qin, T.; Liu, S. Flood Risk Assessment of Global Watersheds Based on Multiple Machine Learning Models. Water 2019, 11, 1654. [Google Scholar] [CrossRef] [Green Version]
- Mosavi, A.; Golshan, M.; Janizadeh, S.; Choubin, B.; Melesse, A.M.; Dineva, A.A. Ensemble models of GLM, FDA, MARS, and RF for flood and erosion susceptibility mapping: A priority assessment of sub-basins. Geocarto Int. 2020, 35, 1–20. [Google Scholar] [CrossRef]
- Chen, K.; Chen, H.; Zhou, C.; Huang, Y.; Qi, X.; Shen, R.; Liu, F.; Zuo, M.; Zou, X.; Wang, J.; et al. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 2020, 171, 115454. [Google Scholar] [CrossRef]
- Fang, X.; Li, X.; Zhang, Y.; Zhao, Y.; Qian, J.; Hao, C.; Zhou, J.; Wu, Y. Random forest-based understanding and predicting of the impacts of anthropogenic nutrient inputs on the water quality of a tropical lagoon. Environ. Res. Lett. 2021, 16, 055003. [Google Scholar] [CrossRef]
- Liu, S.; Tai, H.; Ding, Q.; Li, D.; Xu, L.; Wei, Y. A hybrid approach of support vector regression with genetic algorithm optimization for aquaculture water quality prediction. Math. Comput. Model. 2013, 58, 458–465. [Google Scholar] [CrossRef]
- Mahmoudi, N.; Orouji, H.; Fallah-Mehdipour, E. Integration of Shuffled Frog Leaping Algorithm and Support Vector Regression for Prediction of Water Quality Parameters. Water Resour. Manag. 2016, 30, 2195–2211. [Google Scholar] [CrossRef]
- Jadhav, M.S.; Khare, K.C.; Warke, A.S. Water Quality Prediction of Gangapur Reservoir (India) Using LS-SVM and Genetic Programming. Lakes Reserv. Sci. Policy Manag. Sustain. Use 2015, 20, 275–284. [Google Scholar] [CrossRef]
- Xiang, Y.; Jiang, L. Water Quality Prediction Using LS-SVM and Particle Swarm Optimization. In Proceedings of the 2009 Second International Workshop on Knowledge Discovery and Data Mining, Moscow, Russia, 23–25 January 2009; pp. 900–904. [Google Scholar] [CrossRef]
- Anmala, J.; Turuganti, V. Comparison of the performance of decision tree (DT) algorithms and extreme learning machine (ELM) model in the prediction of water quality of the Upper Green River watershed. Water Environ. Res. 2021, 93, 2360–2373. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.; Bai, Y. Comparative Study of Optimization Intelligent Models in Wastewater Quality Prediction. In Proceedings of the 2018 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Xi’an, China, 15–17 August 2018; pp. 221–225. [Google Scholar] [CrossRef]
- Azad, A.; Karami, H.; Farzin, S.; Saeedian, A.; Kashi, H.; Sayyahi, F. Prediction of Water Quality Parameters Using ANFIS Optimized by Intelligence Algorithms (Case Study: Gorganrood River). KSCE J. Civ. Eng. 2018, 22, 2206–2213. [Google Scholar] [CrossRef]
- Fu, Z.; Cheng, J.; Yang, M.; Batista, J.; Jiang, Y. Wastewater discharge quality prediction using stratified sampling and wavelet de-noising ANFIS model. Comput. Electr. Eng. 2020, 85, 106701. [Google Scholar] [CrossRef]
- Jin, T.; Cai, S.; Jiang, D.; Liu, J. A data-driven model for real-time water quality prediction and early warning by an integration method. Environ. Sci. Pollut. Res. 2019, 26, 30374–30385. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Wang, X.; Ou, Y. Water Simulation Method Based on BPNN Response and Analytic Geometry. Procedia Environ. Sci. 2010, 2, 446–453. [Google Scholar] [CrossRef] [Green Version]
- Han, H.G.; Chen, Q.L.; Qiao, J.F. An efficient self-organizing RBF neural network for water quality prediction. Neural Netw. 2011, 24, 717–725. [Google Scholar] [CrossRef]
- Weihui, D.; Guoyin, W.; Xuerui, Z.; Yishuai, G.; Guangdi, L. Water quality prediction based on a novel hybrid model of ARIMA and RBF neural network. In Proceedings of the 2014 IEEE 3rd International Conference on Cloud Computing and Intelligence Systems, 27–29 November 2014; pp. 33–40. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Yuan, P.; Wang, L.; Cheng, D. An adaptive daily runoff forecast model using VMD-LSTM-PSO hybrid approach. Hydrol. Sci. J. 2021, 66, 1488–1502. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, J.; Chen, K.; Wang, Y.; Liu, L. Water quality prediction method based on LSTM neural network. In Proceedings of the 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Bai, Y.; Liu, M.D.; Ding, L.; Ma, Y.J. Double-layer staged training echo-state networks for wind speed prediction using variational mode decomposition. Appl. Energy 2021, 301, 117461. [Google Scholar] [CrossRef]
- Zhang, J.; Qiu, H.; Li, X.; Niu, J.; Nevers, M.B.; Hu, X.; Phanikumar, M.S. Real-Time Nowcasting of Microbiological Water Quality at Recreational Beaches: A Wavelet and Artificial Neural Network-Based Hybrid Modeling Approach. Environ. Sci. Technol. 2018, 52, 8446–8455. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Xu, L.; Li, D. Multi-scale prediction of water temperature using empirical mode decomposition with back-propagation neural networks. Comput. Electr. Eng. 2016, 49, 1–8. [Google Scholar] [CrossRef]
- Li, C.; Li, Z.; Wu, J.; Zhu, L.; Yue, J. A hybrid model for dissolved oxygen prediction in aquaculture based on multi-scale features. Inf. Process. Agric. 2018, 5, 11–20. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Seo, Y.; Kim, S.; Ghorbani, M.; Samadianfard, S.; Naghshara, S.; Kim, N.W.; Singh, V.P. Can Decomposition Approaches Always Enhance Soft Computing Models? Predicting the Dissolved Oxygen Concentration in the St. Johns River, Florida. Appl. Sci. 2019, 9, 2534. [Google Scholar] [CrossRef] [Green Version]
- Song, C.; Yao, L.; Hua, C.; Ni, Q. A water quality prediction model based on variational mode decomposition and the least squares support vector machine optimized by the sparrow search algorithm (VMD-SSA-LSSVM) of the Yangtze River, China. Environ. Monit. Assess. 2021, 193, 363. [Google Scholar] [CrossRef]
- Huang, J.; Huang, Y.; Hassan, S.G.; Xu, L.; Liu, S. Dissolved oxygen content interval prediction based on auto regression recurrent neural network. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 1–10. [Google Scholar] [CrossRef]
- Fijani, E.; Barzegar, R.; Deo, R.; Tziritis, E.; Skordas, K. Design and implementation of a hybrid model based on two-layer decomposition method coupled with extreme learning machines to support real-time environmental monitoring of water quality parameters. Sci. Total Environ. 2019, 648, 839–853. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, J. Predicting polycyclic aromatic hydrocarbons in surface water by a multiscale feature extraction-based deep learning approach. Sci. Total Environ. 2021, 799, 149509. [Google Scholar] [CrossRef]
- Li, B.; Yang, G.; Wan, R. Multidecadal water quality deterioration in the largest freshwater lake in China (Poyang Lake): Implications on eutrophication management. Environ. Pollut. 2020, 260, 114033. [Google Scholar] [CrossRef]
- Tang, X.; Li, H.; Xu, X.; Yang, G.; Liu, G.; Li, X.; Chen, D. Changing land use and its impact on the habitat suitability for wintering Anseriformes in China’s Poyang Lake region. Sci. Total Environ. 2016, 557, 296–306. [Google Scholar] [CrossRef] [PubMed]
- Wantzen, K.M.; Rothhaupt, K.O.; Mörtl, M.; Cantonati, M.; Tóth, L.G.; Fischer, P. Ecological effects of water-level fluctuations in lakes: An urgent issue. In Ecological Effects of Water-Level Fluctuations in Lakes; Springer: Berlin/Heidelberg, Germany, 2008; Volume 204, pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Stosic, T.; Stosic, B.; Singh, V.P. Optimizing streamflow monitoring networks using joint permutation entropy. J. Hydrol. 2017, 552, 306–312. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, Y.; Yang, H. Research on Economic Optimization of Microgrid Cluster Based on Chaos Sparrow Search Algorithm. Comput. Intell. Neurosci. 2021, 2021, 5556780. [Google Scholar] [CrossRef]
- Liu, L.; Sun, S.Z.; Yu, H.; Yue, X.; Zhang, D. A modified Fuzzy C-Means (FCM) Clustering algorithm and its application on carbonate fluid identification. J. Appl. Geophys. 2016, 129, 28–35. [Google Scholar] [CrossRef]
- Rudolph, G. Local convergence rates of simple evolutionary algorithms with Cauchy mutations. IEEE Trans. Evol. Comput. 1997, 1, 249–258. [Google Scholar] [CrossRef]
- Li, J.; Deng, D.; Zhao, J.; Cai, D.; Hu, W.; Zhang, M.; Huang, Q. A Novel Hybrid Short-Term Load Forecasting Method of Smart Grid Using MLR and LSTM Neural Network. IEEE Trans. Ind. Inform. 2021, 17, 2443–2452. [Google Scholar] [CrossRef]
- Zhang, X.; Peng, Y.; Zhang, C.; Wang, B. Are hybrid models integrated with data preprocessing techniques suitable for monthly streamflow forecasting? Some experiment evidences. J. Hydrol. 2015, 530, 137–152. [Google Scholar] [CrossRef]
- Zuo, G.; Luo, J.; Wang, N.; Lian, Y.; He, X. Two-stage variational mode decomposition and support vector regression for streamflow forecasting. Hydrol. Earth Syst. Sci. 2020, 24, 5491–5518. [Google Scholar] [CrossRef]
- Pool, S.; Vis, M.; Seibert, J. Evaluating model performance: Towards a non-parametric variant of the Kling-Gupta efficiency. Hydrol. Sci. J. 2018, 63, 1941–1953. [Google Scholar] [CrossRef]
- He, X.; Luo, J.; Li, P.; Zuo, G.; Xie, J. A Hybrid Model Based on Variational Mode Decomposition and Gradient Boosting Regression Tree for Monthly Runoff Forecasting. Water Resour. Manag. 2020, 34, 865–884. [Google Scholar] [CrossRef]
- Feng, Z.; Niu, W.; Tang, Z.; Jiang, Z.; Xu, Y.; Liu, Y.; Zhang, H. Monthly runoff time series prediction by variational mode decomposition and support vector machine based on quantum-behaved particle swarm optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Huang, S.; Chang, J.; Huang, Q.; Chen, Y. Monthly streamflow prediction using modified EMD-based support vector machine. J. Hydrol. 2014, 511, 764–775. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X.; Lei, X.; Wang, H.; Zhang, X.; You, J.; Tan, Q.; Liu, X. Teleconnection analysis of monthly streamflow using ensemble empirical mode decomposition. J. Hydrol. 2019, 582, 124411. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Yang, X.S. Flower pollination algorithm for global optimization. In Proceedings of the International Conference on Unconventional Computing and Natural Computation, Orléan, France, 3–7 September 2012; pp. 240–249. [Google Scholar] [CrossRef] [Green Version]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar] [CrossRef]
- Kargar, K.; Samadianfard, S.; Parsa, J.; Nabipour, N.; Shamshirband, S.; Mosavi, A.; Chau, K.W. Estimating longitudinal dispersion coefficient in natural streams using empirical models and machine learning algorithms. Eng. Appl. Comput. Fluid Mech. 2020, 14, 311–322. [Google Scholar] [CrossRef]
- Sarkar, M.; De Bruyn, A. LSTM Response Models for Direct Marketing Analytics: Replacing Feature Engineering with Deep Learning. J. Interact. Mark. 2021, 53, 80–95. [Google Scholar] [CrossRef]
- Reddy, B.K.; Delen, D. Predicting hospital readmission for lupus patients: An RNN-LSTM-based deep-learning methodology. Comput. Biol. Med. 2018, 101, 199–209. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Decomposed IMFs | No. of Inputs | Input Variables | Output |
|---|---|---|---|---|
| DC(TN) | IMF1 | 9 | ||
| IMF2 | 7 | |||
| DC(TP) | IMF1 | 8 | ||
| IMF2 | 6 | |||
| HMS(TN) | IMF1 | 9 | ||
| IMF2 | 7 | |||
| HMS(TP) | IMF1 | 7 | ||
| IMF2 | 7 | |||
| GJWC(TN) | IMF1 | 9 | ||
| IMF2 | 9 | |||
| GJWC(TP) | IMF1 | 8 | ||
| IMF2 | 5 | |||
| XHWC(TN) | IMF1 | 7 | ||
| IMF2 | 7 | |||
| XHWC(TP) | IMF1 | 6 | ||
| IMF2 | 4 |
| Methods | Parameter Settings |
|---|---|
| CSSA | The proportion of producers is 20%, and the proportion of scouters is 20% |
| SSA | The proportion of producers is 20%, and the proportion of scouters is 20% |
| GWO | Step size , where linearly decreases from 2 to 0, , search parameter |
| PSO | Cognitive component , social component , inertia weight |
| GSA | Initial gravitational constant , search parameter |
| FPA | Switch probability , step size for global pollination drawn from a Levy flight distribution, step size for local pollination drawn from a uniform distribution within |
| Run | CSSA | SSA | GWO | PSO | GSA | FPA |
|---|---|---|---|---|---|---|
| 1 | 0.1116 | 0.1516 | 0.1616 | 0.1624 | 0.1191 | 0.1086 |
| 2 | 0.1024 | 0.1530 | 0.1438 | 0.1052 | 0.1158 | 0.1393 |
| 3 | 0.1339 | 0.1139 | 0.1601 | 0.1566 | 0.1087 | 0.1453 |
| 4 | 0.1203 | 0.1229 | 0.1463 | 0.1309 | 0.1508 | 0.1419 |
| 5 | 0.1464 | 0.1592 | 0.1197 | 0.1240 | 0.1412 | 0.1255 |
| 6 | 0.1056 | 0.1520 | 0.1625 | 0.1322 | 0.1459 | 0.1623 |
| 7 | 0.1387 | 0.1231 | 0.1044 | 0.1608 | 0.1430 | 0.1153 |
| 8 | 0.1428 | 0.1185 | 0.1485 | 0.1527 | 0.1454 | 0.1451 |
| 9 | 0.1381 | 0.1219 | 0.1231 | 0.1208 | 0.1207 | 0.1297 |
| 10 | 0.1174 | 0.1089 | 0.1097 | 0.1317 | 0.1318 | 0.1409 |
| Avg. | 0.1257 | 0.1325 | 0.1380 | 0.1377 | 0.1354 | 0.1325 |
| Run | CSSA | SSA | GWO | PSO | GSA | FPA |
|---|---|---|---|---|---|---|
| 1 | 0.1210 | 0.1203 | 0.1458 | 0.1300 | 0.1399 | 0.1426 |
| 2 | 0.1055 | 0.1488 | 0.1085 | 0.1480 | 0.1245 | 0.1263 |
| 3 | 0.1128 | 0.1451 | 0.1463 | 0.1208 | 0.1040 | 0.1415 |
| 4 | 0.1167 | 0.1080 | 0.1219 | 0.1072 | 0.1255 | 0.1678 |
| 5 | 0.1403 | 0.1341 | 0.1633 | 0.1258 | 0.1481 | 0.1108 |
| 6 | 0.0988 | 0.1323 | 0.1447 | 0.1253 | 0.1297 | 0.1710 |
| 7 | 0.1238 | 0.1482 | 0.1482 | 0.1554 | 0.1392 | 0.1342 |
| 8 | 0.1371 | 0.1103 | 0.1502 | 0.1525 | 0.1203 | 0.1405 |
| 9 | 0.1230 | 0.1484 | 0.1618 | 0.1403 | 0.1304 | 0.1196 |
| 10 | 0.1019 | 0.1267 | 0.1474 | 0.1334 | 0.1135 | 0.1004 |
| Avg. | 0.1181 | 0.1322 | 0.1438 | 0.1339 | 0.1275 | 0.1355 |
| Run | CSSA | SSA | GWO | PSO | GSA | FPA |
|---|---|---|---|---|---|---|
| 1 | 0.1612 | 0.1714 | 0.1900 | 0.1504 | 0.1860 | 0.1882 |
| 2 | 0.1789 | 0.1718 | 0.1781 | 0.1738 | 0.1825 | 0.1809 |
| 3 | 0.1608 | 0.1793 | 0.1650 | 0.2042 | 0.1710 | 0.1607 |
| 4 | 0.1659 | 0.1635 | 0.1918 | 0.1619 | 0.1836 | 0.1692 |
| 5 | 0.1845 | 0.1662 | 0.1908 | 0.1876 | 0.1744 | 0.1959 |
| 6 | 0.1610 | 0.1714 | 0.1765 | 0.1658 | 0.1635 | 0.1647 |
| 7 | 0.1472 | 0.1953 | 0.1829 | 0.1843 | 0.1607 | 0.1664 |
| 8 | 0.1622 | 0.1426 | 0.2187 | 0.1782 | 0.1473 | 0.1577 |
| 9 | 0.1580 | 0.1830 | 0.1931 | 0.1763 | 0.1825 | 0.1591 |
| 10 | 0.1567 | 0.1718 | 0.1963 | 0.1959 | 0.1488 | 0.1724 |
| Avg. | 0.1637 | 0.1716 | 0.1883 | 0.1778 | 0.1702 | 0.1724 |
| Station | Item | VCLM | VCL | VCBM | VCSM | CCLM | CCBM | CCSM | LSTM | BP | SVR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DC (TN) | MAE | 0.0493 | 0.0523 | 0.0637 | 0.0678 | 0.0887 | 0.0909 | 0.0926 | 0.1080 | 0.1120 | 0.1254 |
| MAPE | 5.34% | 6.15% | 7.46% | 7.73% | 9.16% | 9.77% | 10.29% | 11.46% | 11.67% | 14.14% | |
| RMSE | 0.0640 | 0.0795 | 0.0871 | 0.0922 | 0.1136 | 0.1174 | 0.1227 | 0.1489 | 0.1568 | 0.1766 | |
| NSE | 0.9346 | 0.9015 | 0.8790 | 0.8452 | 0.7910 | 0.7614 | 0.7459 | 0.5483 | 0.5106 | 0.4052 | |
| KGE | 0.8909 | 0.8509 | 0.8001 | 0.8127 | 0.7653 | 0.7448 | 0.7352 | 0.5046 | 0.4694 | 0.3899 | |
| DC (TP) | MAE | 0.0025 | 0.0031 | 0.0033 | 0.0039 | 0.0041 | 0.0043 | 0.0043 | 0.0049 | 0.0051 | 0.0049 |
| MAPE | 6.84% | 7.68% | 8.23% | 9.06% | 9.94% | 10.12% | 10.05% | 12.68% | 13.79% | 13.46% | |
| RMSE | 0.0030 | 0.0037 | 0.0046 | 0.0051 | 0.0056 | 0.0059 | 0.0061 | 0.0078 | 0.0081 | 0.0115 | |
| NSE | 0.9247 | 0.8829 | 0.8402 | 0.8034 | 0.7520 | 0.7214 | 0.7015 | 0.4873 | 0.4418 | 0.4219 | |
| KGE | 0.8994 | 0.8673 | 0.8257 | 0.8124 | 0.6881 | 0.6497 | 0.6649 | 0.3986 | 0.3327 | 0.3488 | |
| HMS (TN) | MAE | 0.1175 | 0.1215 | 0.1435 | 0.1507 | 0.1482 | 0.1681 | 0.1571 | 0.1875 | 0.2179 | 0.2008 |
| MAPE | 6.05% | 6.83% | 7.23% | 7.67% | 7.47% | 8.21% | 8.04% | 10.49% | 12.38% | 11.67% | |
| RMSE | 0.1584 | 0.1797 | 0.1979 | 0.2012 | 0.2429 | 0.2376 | 0.2828 | 0.3232 | 0.3457 | 0.3891 | |
| NSE | 0.9058 | 0.8747 | 0.8427 | 0.7995 | 0.8078 | 0.7714 | 0.7864 | 0.5288 | 0.4050 | 0.4331 | |
| KGE | 0.9086 | 0.8994 | 0.8758 | 0.8359 | 0.8140 | 0.7349 | 0.7752 | 0.4230 | 0.3628 | 0.3472 | |
| HMS (TP) | MAE | 0.0054 | 0.0064 | 0.0081 | 0.0083 | 0.0092 | 0.0098 | 0.0104 | 0.0117 | 0.0119 | 0.0126 |
| MAPE | 8.50% | 9.21% | 10.57% | 10.33% | 13.76% | 14.44% | 14.29% | 19.40% | 21.95% | 22.62% | |
| RMSE | 0.0079 | 0.0083 | 0.0086 | 0.0108 | 0.0112 | 0.0121 | 0.0134 | 0.0186 | 0.0191 | 0.0195 | |
| NSE | 0.9185 | 0.9058 | 0.8953 | 0.8943 | 0.8026 | 0.7694 | 0.7768 | 0.5944 | 0.5144 | 0.4843 | |
| KGE | 0.9275 | 0.8901 | 0.8605 | 0.8677 | 0.7844 | 0.7814 | 0.7294 | 0.6012 | 0.5135 | 0.5029 | |
| GJWC (TN) | MAE | 0.1774 | 0.1828 | 0.2093 | 0.2576 | 0.2640 | 0.2694 | 0.2748 | 0.3018 | 0.3409 | 0.3267 |
| MAPE | 15.82% | 16.72% | 18.65% | 19.81% | 24.31% | 23.64% | 24.49% | 26.79% | 30.79% | 28.94% | |
| RMSE | 0.1785 | 0.2406 | 0.2253 | 0.2891 | 0.3696 | 0.4180 | 0.4462 | 0.4798 | 0.4991 | 0.4945 | |
| NSE | 0.8864 | 0.8621 | 0.8545 | 0.8367 | 0.7222 | 0.7068 | 0.6972 | 0.4819 | 0.4131 | 0.4324 | |
| KGE | 0.8266 | 0.8205 | 0.7958 | 0.7864 | 0.6893 | 0.6449 | 0.6257 | 0.4246 | 0.3826 | 0.4091 | |
| GJWC (TP) | MAE | 0.0078 | 0.0085 | 0.0095 | 0.0092 | 0.0121 | 0.0131 | 0.0134 | 0.0185 | 0.0199 | 0.0201 |
| MAPE | 17.47% | 18.69% | 20.34% | 20.49% | 22.84% | 23.35% | 23.61% | 27.63% | 29.83% | 32.47% | |
| RMSE | 0.0096 | 0.0106 | 0.0118 | 0.0134 | 0.0147 | 0.0165 | 0.0195 | 0.0265 | 0.0305 | 0.0312 | |
| NSE | 0.9058 | 0.8932 | 0.8895 | 0.8823 | 0.7853 | 0.7442 | 0.7322 | 0.4334 | 0.4266 | 0.4057 | |
| KGE | 0.8849 | 0.8511 | 0.8301 | 0.8349 | 0.7501 | 0.6981 | 0.7246 | 0.4291 | 0.3537 | 0.3139 | |
| XHWC (TN) | MAE | 0.1647 | 0.1688 | 0.2019 | 0.2278 | 0.2886 | 0.3066 | 0.3115 | 0.3554 | 0.3682 | 0.3788 |
| MAPE | 5.16% | 5.42% | 6.37% | 6.44% | 7.64% | 7.82% | 7.78% | 8.94% | 9.21% | 9.42% | |
| RMSE | 0.2155 | 0.2519 | 0.2898 | 0.4875 | 0.4390 | 0.4738 | 0.5090 | 0.6581 | 0.8389 | 0.7670 | |
| NSE | 0.9510 | 0.9252 | 0.9034 | 0.8826 | 0.8337 | 0.8249 | 0.7977 | 0.5975 | 0.5521 | 0.5228 | |
| KGE | 0.9187 | 0.9081 | 0.8973 | 0.8671 | 0.8218 | 0.8114 | 0.8161 | 0.5664 | 0.4843 | 0.4590 | |
| XHWC (TP) | MAE | 0.0033 | 0.0036 | 0.0041 | 0.0044 | 0.0052 | 0.0054 | 0.0054 | 0.0065 | 0.0069 | 0.0072 |
| MAPE | 10.50% | 11.81% | 12.29% | 12.38% | 15.38% | 15.63% | 15.82% | 19.63% | 20.37% | 22.38% | |
| RMSE | 0.0043 | 0.0052 | 0.0049 | 0.0056 | 0.0063 | 0.0065 | 0.0081 | 0.0102 | 0.0118 | 0.0155 | |
| NSE | 0.9463 | 0.9227 | 0.9192 | 0.9088 | 0.8647 | 0.8497 | 0.8324 | 0.5294 | 0.4864 | 0.4429 | |
| KGE | 0.8536 | 0.8314 | 0.8065 | 0.8143 | 0.8518 | 0.7932 | 0.8146 | 0.5577 | 0.4219 | 0.4597 |
| Item | Hindcast | Forecast | ||
|---|---|---|---|---|
| CEEMDAN-LSTM | VMD-LSTM | CEEMDAN-LSTM | VMD-LSTM | |
| MAE | 0.0327 | 0.0285 | 0.0895 | 0.0523 |
| MAPE | 3.64% | 3.16% | 9.24% | 6.15% |
| RMSE | 0.0289 | 0.0157 | 0.1012 | 0.0795 |
| NSE | 0.9844 | 0.9987 | 0.7841 | 0.9015 |
| KGE | 0.9745 | 0.9824 | 0.7529 | 0.8509 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, M.; Wu, S.; Huang, B.; Kang, C.; Gui, F. Prediction of Total Nitrogen and Phosphorus in Surface Water by Deep Learning Methods Based on Multi-Scale Feature Extraction. Water 2022, 14, 1643. https://doi.org/10.3390/w14101643
He M, Wu S, Huang B, Kang C, Gui F. Prediction of Total Nitrogen and Phosphorus in Surface Water by Deep Learning Methods Based on Multi-Scale Feature Extraction. Water. 2022; 14(10):1643. https://doi.org/10.3390/w14101643
Chicago/Turabian StyleHe, Miao, Shaofei Wu, Binbin Huang, Chuanxiong Kang, and Faliang Gui. 2022. "Prediction of Total Nitrogen and Phosphorus in Surface Water by Deep Learning Methods Based on Multi-Scale Feature Extraction" Water 14, no. 10: 1643. https://doi.org/10.3390/w14101643
APA StyleHe, M., Wu, S., Huang, B., Kang, C., & Gui, F. (2022). Prediction of Total Nitrogen and Phosphorus in Surface Water by Deep Learning Methods Based on Multi-Scale Feature Extraction. Water, 14(10), 1643. https://doi.org/10.3390/w14101643