
Capability and Robustness of Novel Hybridized Artificial Intelligence Technique for Sediment Yield Modeling in Godavari River, India

 , , ,
, , ,  ,
,  and
and 
Abstract
:1. Introduction
2. Proposed Methodology
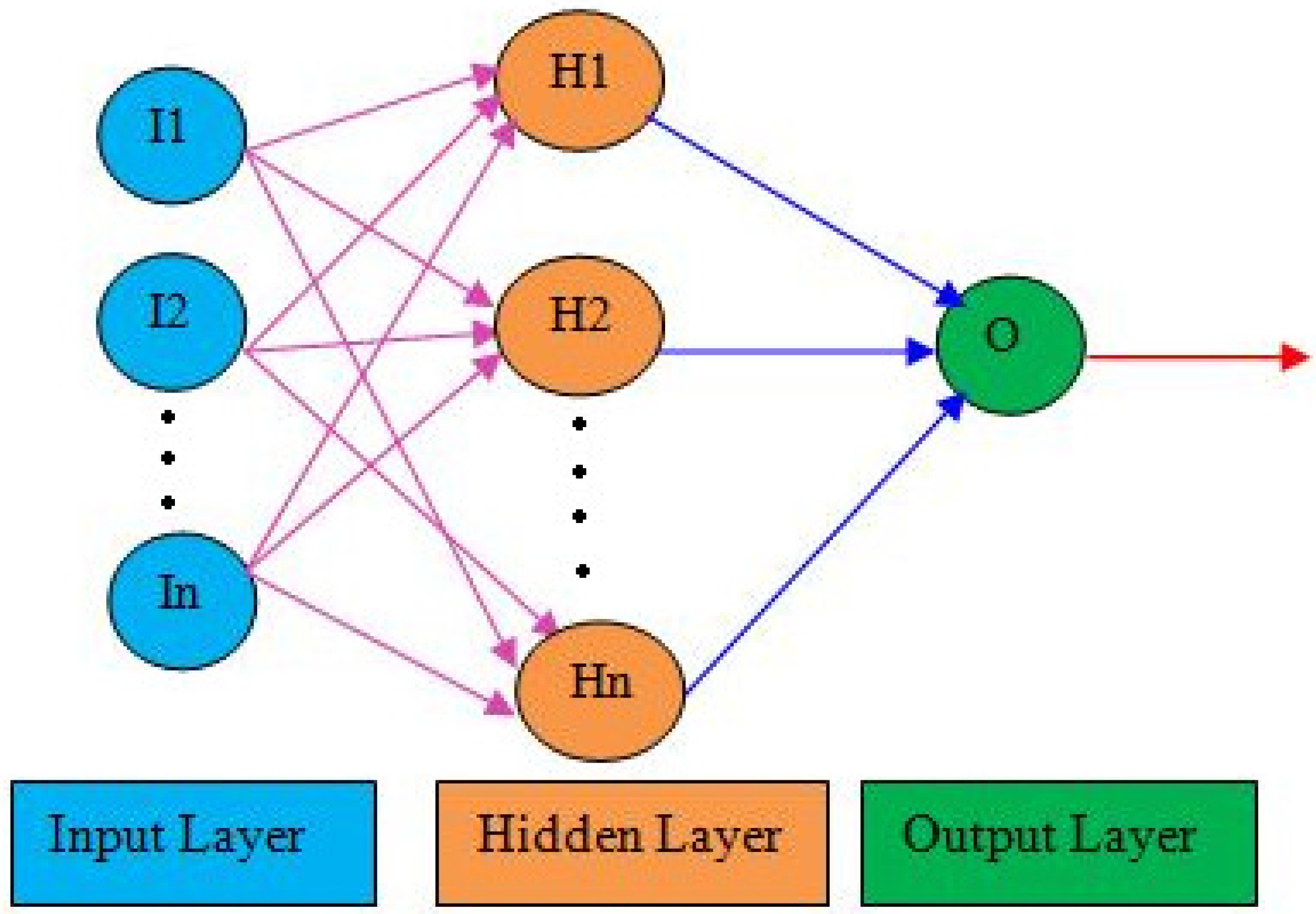
2.1. GA-ANN
2.2. ANN
2.3. MLR Model
2.4. SRC Model
3. Data Analysis of Study Region
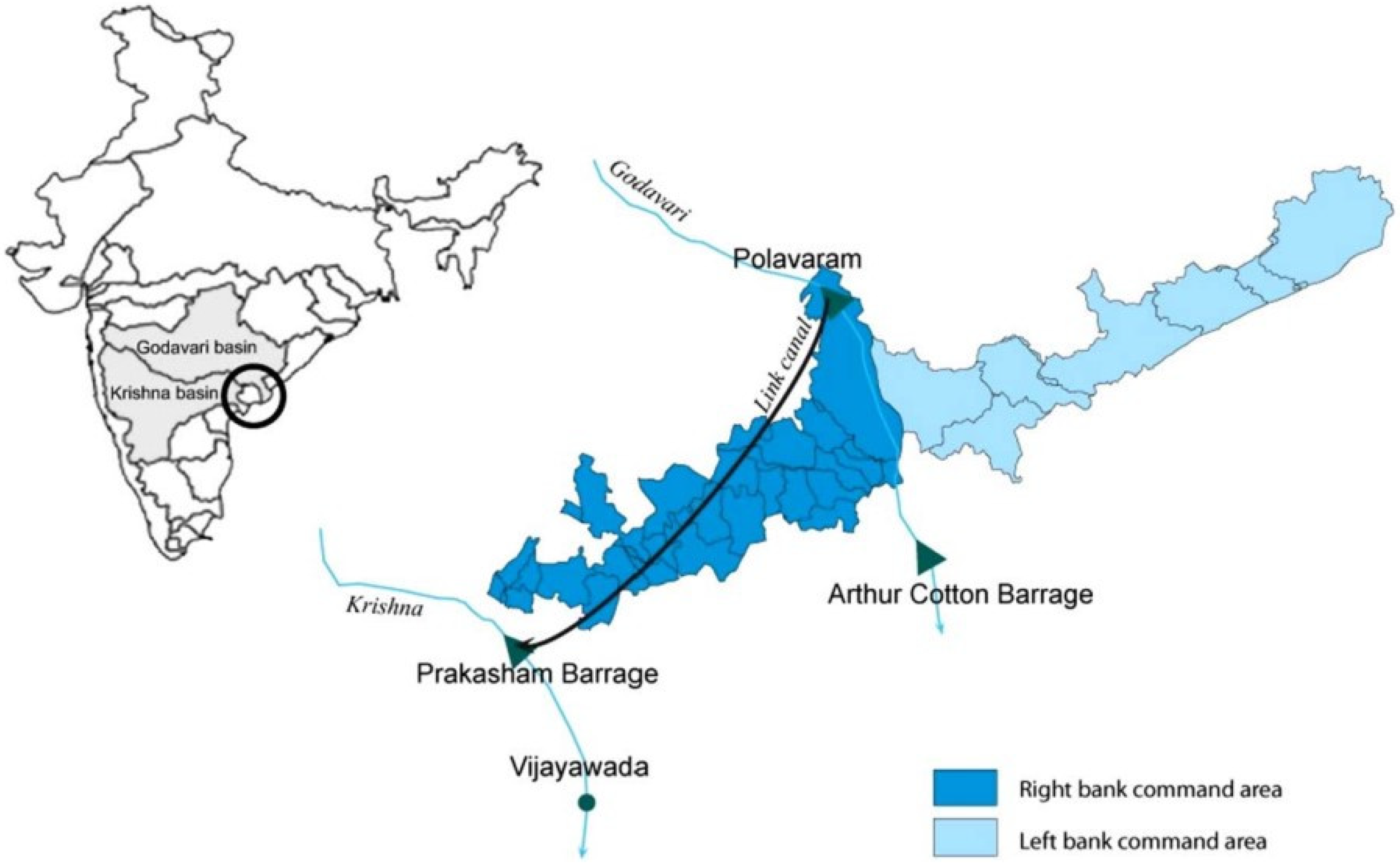
3.1. Study Region
3.2. Statistical Data Analysis
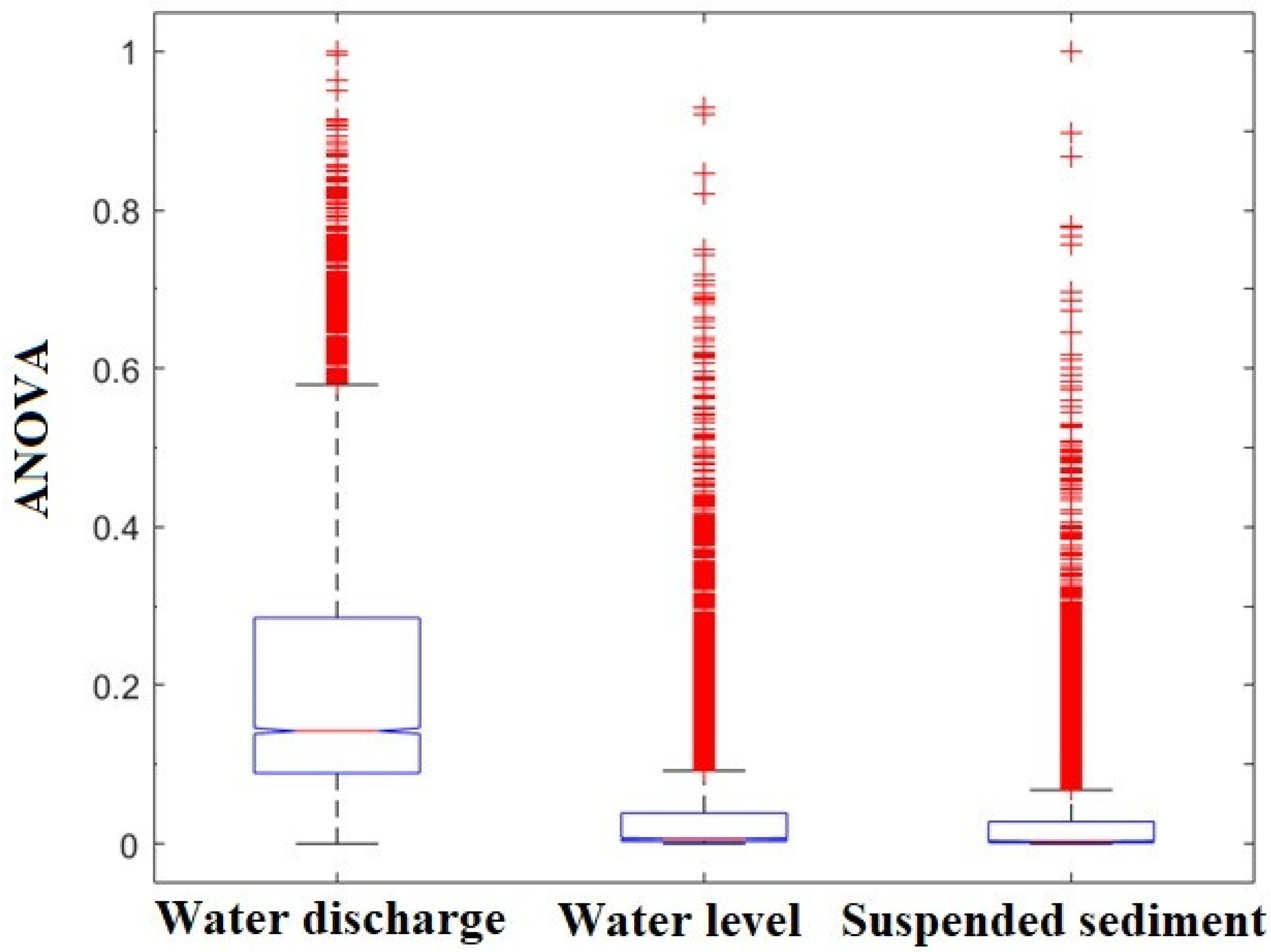
3.3. Data Preparation and Data Processing
4. Results and Discussion
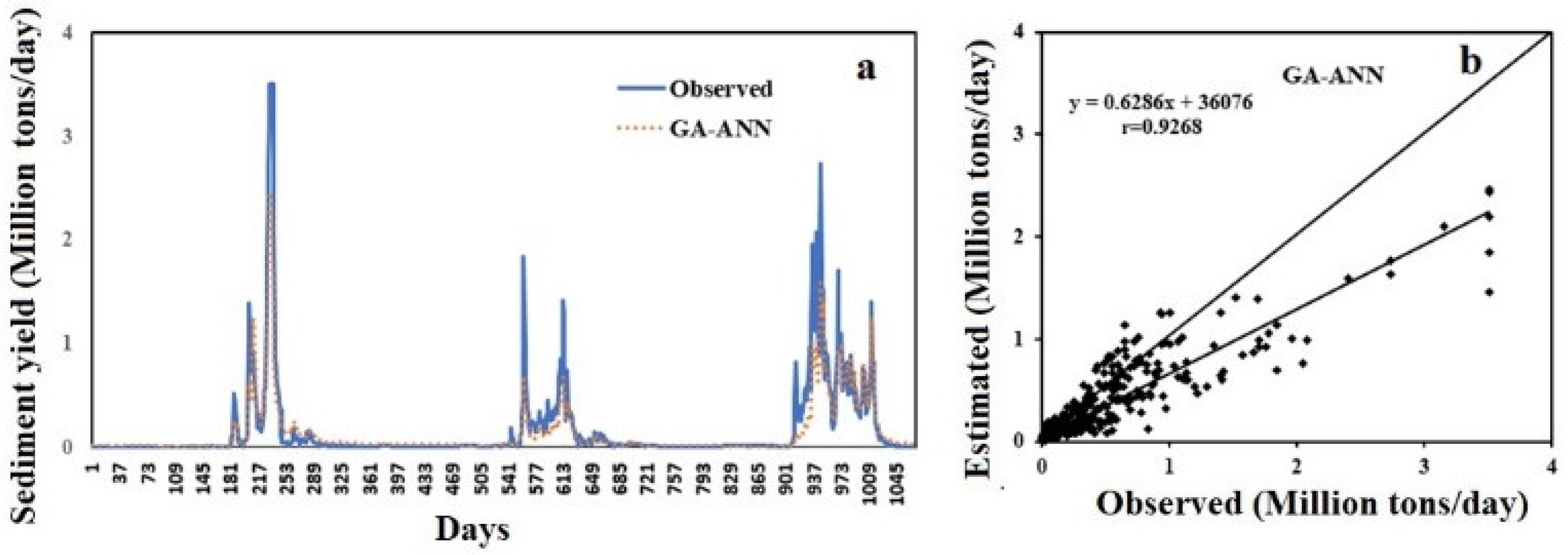
4.1. GA-ANN
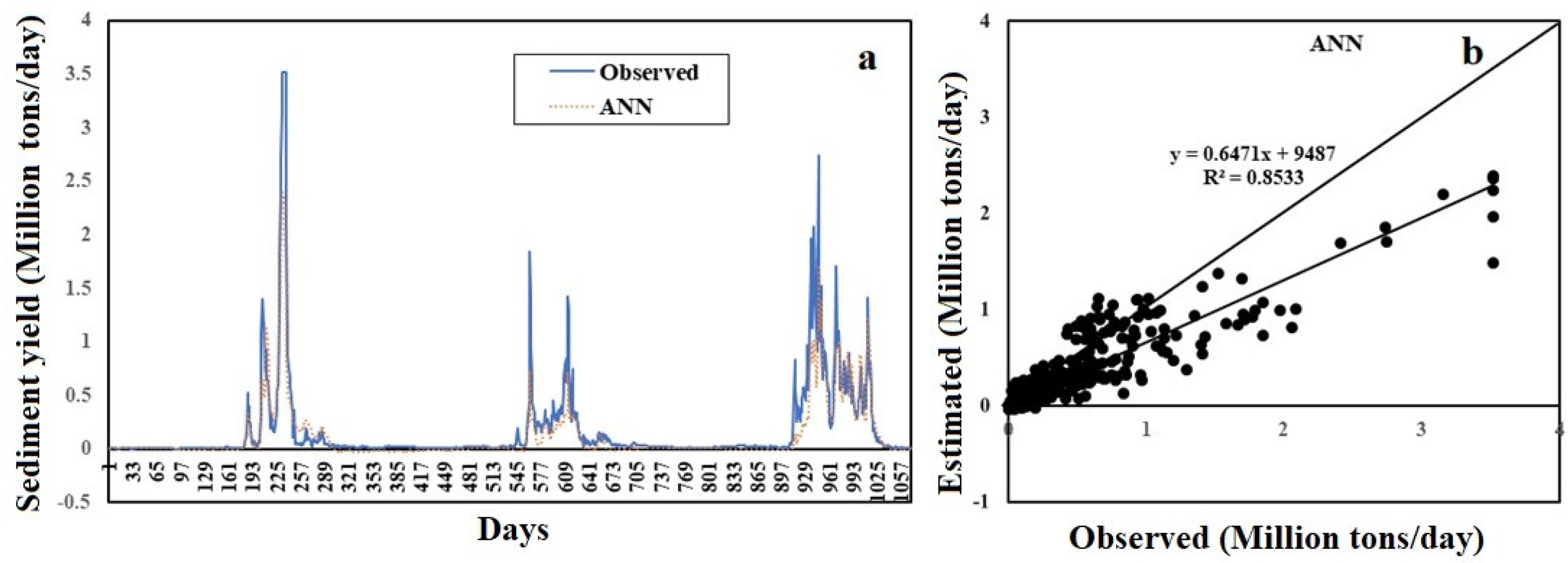
4.2. ANN
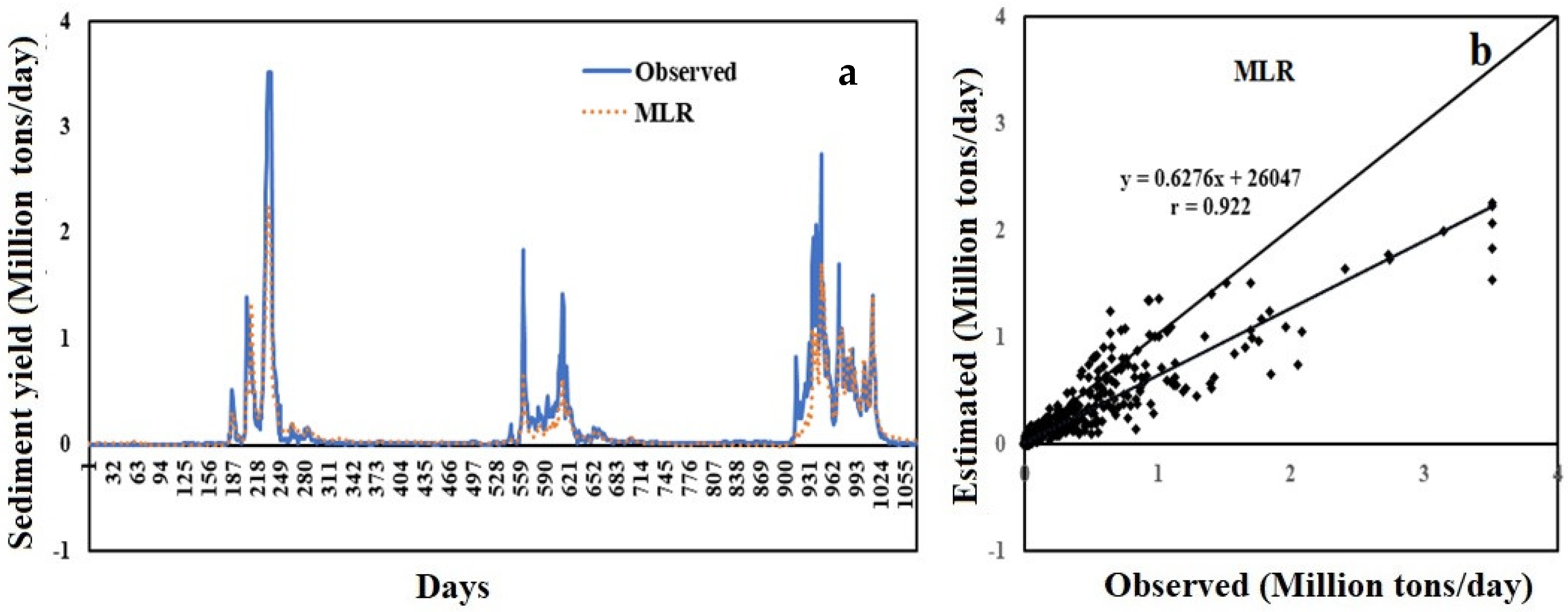
4.3. MLR
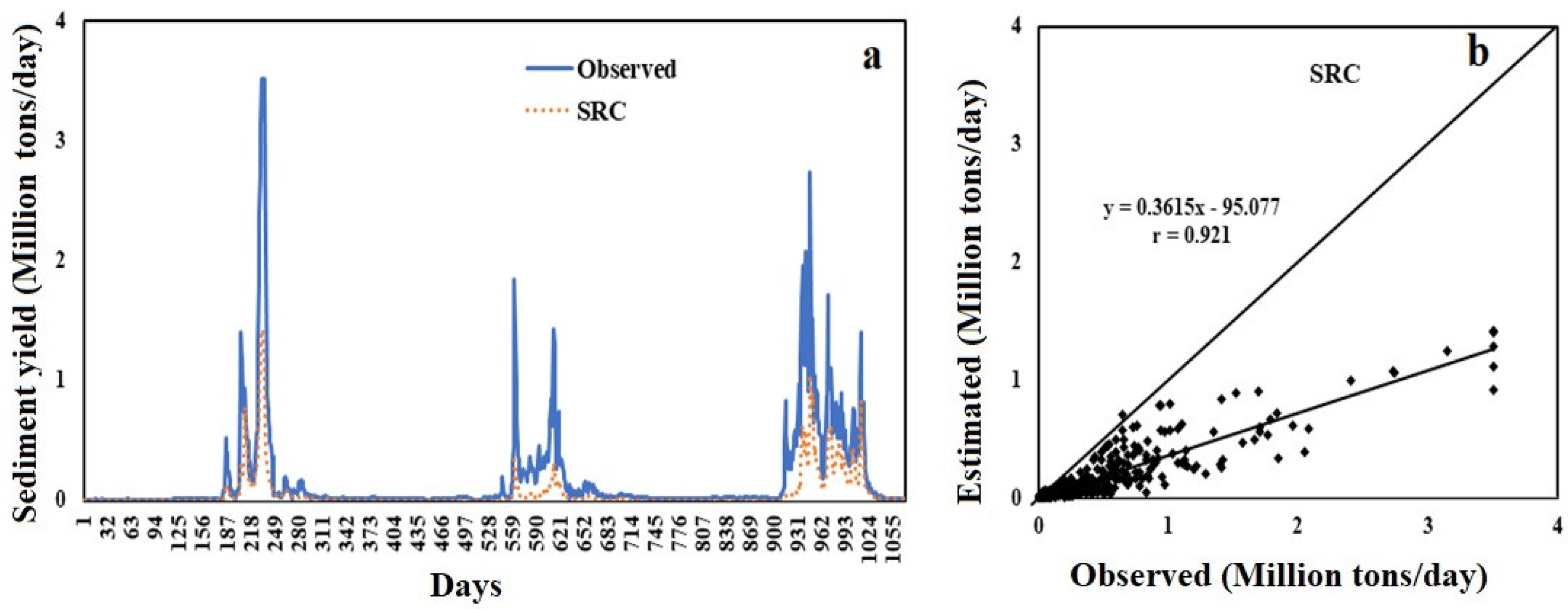
4.4. SRC
4.5. Comparative Assessment of Various Models on the Basis of Testing Data Set
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sivakumar, B. Suspended sediment load estimation and the problem of inadequate data sampling: A fractal view. Earth Surf. Processes Landf. 2005, 31, 414–427. [Google Scholar] [CrossRef]
- Taniguchi, T. Observation of sediment load in the river with the thiltmeter (with the tiltmeter of zöllner suspension). Hydrol. Sci. J. 1958, 3, 22–32. [Google Scholar] [CrossRef] [Green Version]
- Cigizoglu, H.K. Estimation and forecasting of daily suspended sediment data by multi-layer perceptrons. Adv. Water Resour. 2004, 27, 185–195. [Google Scholar] [CrossRef]
- Cobaner, M.; Unal, B.; Kisi, O. Suspended sediment concentration estimation by an adaptive neuro-fuzzy and neural network approaches using hydro-meteorological data. J. Hydrol. 2009, 367, 52–61. [Google Scholar] [CrossRef]
- Mukherjee, S.; Veer, V.; Tyagi, S.K.; Sharma, V. Sedimentation study of Hirakud reservoir through remote sensing techniques. J. Spat. Hydrol. 2007, 7, 122–130. [Google Scholar]
- Hsieh, T.-C.; Ding, Y.; Yeh, K.-C.; Jhong, R.-K. Numerical Investigation of Sediment Flushing and Morphological Changes in Tamsui River Estuary through Monsoons and Typhoons. Water 2022, 14, 1802. [Google Scholar] [CrossRef]
- Lee, F.Z.; Lai, J.S.; Sumi, T. Reservoir Sediment Management and Downstream River Impacts for Sustainable Water Resources—Case Study of Shihmen Reservoir. Water 2022, 14, 479. [Google Scholar] [CrossRef]
- Hsieh, T.C.; Ding, Y.; Yeh, K.C.; Jhong, R.K. Investigation of morphological changes in the tamsui river estuary using an integrated coastal and estuarine processes model. Water 2020, 12, 1084. [Google Scholar] [CrossRef]
- Pektas, A.O.; Cigizoglu, H.K. Long-range forecasting of suspended sediment. Hydrol. Sci. J. 2017, 62, 2415–2425. [Google Scholar] [CrossRef]
- FEMA [Federal Emergency Management Agency]. National Dam Safety Program. 1999. Available online: http://www.fema.gov/mit/ndspweb.htm (accessed on 10 April 2022).
- Evans, J.E.; Mackey, S.D.; Gottgens, J.F.; Gill, W.M. Lessons from a dam failure. Ohio J. Sci. 2000, 100, 121–131. [Google Scholar]
- Duan, W.L.; He, B.; Takara, K.; Luo, P.; Nover, D.; Hu, M.C. Modeling suspended sediment sources and transport in the Ishikari River basin, Japan, using SPARROW. Hydrol. Earth Syst. Sci. 2015, 19, 1293–1306. [Google Scholar] [CrossRef] [Green Version]
- Gaurav, K.; Sinha, R.; Panda, P.K. The Indus flood of 2010 in Pakistan: A perspective analysis using remote sensing data. Nat. Hazards 2011, 59, 1815–1826. [Google Scholar] [CrossRef]
- ZICL. Risk Nexus. In Urgent Case for Recovery: What We Can Learn from the August 2014 Karnali River Foods in Nepal; Zurich Insurance Group Ltd.: Zurich, Switzerland, 2014. [Google Scholar]
- Kisi, O.; Shree, J. River suspended sediment estimation by climatic variables implication: Comparative study among soft computing techniques. Comput. Geosci. 2012, 43, 73–82. [Google Scholar] [CrossRef]
- Melesse, A.M.; Ahmad, S.; McClain, M.E.; Wang, X.; Lim, Y.H. Suspended sediment load prediction of river systems: An artificial neural network approach. Agric. Water Manag. 2011, 98, 855–866. [Google Scholar] [CrossRef]
- Zhu, Y.M.; Lu, X.X.; Zhou, Y. Suspended sediment flux modeling with artificial neural network: An example of the Longchuanjiang River in the Upper Yangtze Catchment, China. Geomorphology 2007, 84, 111–125. [Google Scholar] [CrossRef]
- Yadav, A.; Chatterjee, S.; Equeenuddin, S.M. Prediction of suspended sediment yield by artificial neural network and traditional mathematical model in Mahanadi River basin, India. Sustain. Water Resour. Manag. 2018, 4, 745–759. [Google Scholar] [CrossRef]
- Yadav, A.; Chatterjee, S.; Equeenuddin, S.M. Suspended sediment yield estimation using genetic algorithm-based artificial intelligence models: Case study of Mahanadi River, India. Hydrol. Sci. J. 2018, 63, 1162–1182. [Google Scholar] [CrossRef]
- Oltman, D.O. Statistics for Business and Economics; McGraw-Hill Publishing: New York, NY, USA, 1990; p. 1117. [Google Scholar]
- Jain, S.K. Development of integrated sediment rating curves using ANNs. J. Hydraul. Eng. 2001, 127, 30–37. [Google Scholar] [CrossRef]
- McBean, E.A.; Al-Nassri, S. Uncertainty in suspended sediment transport curves. J. Hydraul. Eng. 1988, 114, 63–74. [Google Scholar] [CrossRef]
- Lenzi, M.A.; Marchi, L. Suspended sediment load during floods in a small stream of the Dolomites (northeastern Italy). Catena 2000, 39, 267–282. [Google Scholar] [CrossRef]
- Khoi, D.N.; Suetsugi, T. The responses of hydrological processes and sediment yield to land-use and climate change in the Be River Catchment, Vietnam. Hydrol. Process 2014, 28, 640–652. [Google Scholar] [CrossRef]
- Buendia, C.; Bussi, G.; Tuset, J.; Vericat, D.; Sabater, S.; Palau, A.; Batalla, R.J. Effects of afforestation on runoff and sediment load in an upland Mediterranean catchment. Sci. Total Environ. 2016, 540, 144–157. [Google Scholar] [CrossRef] [PubMed]
- Kingston, G.B.; Dandy, G.C.; Maier, H.R. Review of artificial intelligence techniques and their applications to hydrological modeling and water resources management Part 2–optimization. Water Resour. Res. 2008, 61, 67–99. [Google Scholar]
- Razia, S.; Narasingarao, M.R.; Bojja, P. Development and analysis of support vector machine techniques for early prediction of breast cancer and thyroid. J. Adv. Res. Dyn. Control Syst. 2017, 9, 869–878. [Google Scholar]
- Chakravorti, T.; Satyanarayana, P. Nonlinear system identification using kernel based exponentially extended random vector functional link network. Appl. Soft Comput. 2020, 89, 106–117. [Google Scholar] [CrossRef]
- Anila, M.; Pradeepini, G. Study of prediction algorithms for selecting appropriate classifier in machine learning. J. Adv. Res. Dyn. Control Syst. 2017, 9, 257–268. [Google Scholar]
- Hussain, M.A.; Jayanthi, A. Novel Approach Certificate Revocation in MANET using Fuzzy Logic. Indones. J. Electr. Eng. Comput. Sci. 2018, 10, 654–663. [Google Scholar] [CrossRef]
- Patel, A.K.; Chatterjee, S.; Gorai, A.K. Development of an expert system for iron ore classification. Arab. J. Geosci. 2018, 11, 401. [Google Scholar] [CrossRef]
- Ramaiah, P.; Kumar, S. Dynamic analysis of soil structure interaction (SSI) using ANFIS model with oba machine learning approach. Int. J. Civ. Eng. Technol. 2018, 9, 496–512. [Google Scholar]
- Patel, A.K.; Chatterjee, S.; Gorai, A.K. Development of a machine vision system using the support vector machine regression (SVR) algorithm for the online prediction of iron ore grades. Earth Sci. Inform. 2019, 12, 197–210. [Google Scholar] [CrossRef]
- Patel, A.K.; Chatterjee, S.; Gorai, A.K. Effect on the performance of a support vector machine-based machine vision system with dry and wet ore sample images in classification and grade prediction. Pattern Recognit. Image Anal. 2019, 29, 309–324. [Google Scholar] [CrossRef]
- Dabbakuti, J.R.K.K.; Bhavya, L.G. Application of singular spectrum analysis using artificial neural networks in TEC predictions for ionospheric space weather. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5101–5107. [Google Scholar] [CrossRef]
- Dabbakuti, J.R.K.K.; Jacob, A.; Veeravalli, V.R.; Kallakunta, R.K. Implementation of IoT analytics ionospheric forecasting system based on machine learning and ThingSpeak. IET Radar Sonar Navig. 2019, 14, 341–347. [Google Scholar] [CrossRef]
- Ranjeeta, B.; Chakravorti, T.; Nayak, N.R. A hybrid Hilbert Huang transform and improved fuzzy decision tree classifier for assessment of power quality disturbances in a grid connected distributed generation system. Int. J. Power Energy Convers. 2020, 11, 60–81. [Google Scholar]
- Bhattacharya, B.; Lobbrecht, A.H.; Solomatine, D.P. Neural networks and reinforcement learning in control of water systems. J. Water Resour. Plan Manag. 2003, 129, 458–465. [Google Scholar] [CrossRef]
- Wang, Y.M.; Traore, S. Time-lagged recurrent network for forecasting episodic event suspended sediment load in typhoon prone area. Int. J. Phys. Sci. 2009, 4, 519–528. [Google Scholar]
- Singh, G.; Panda, R. Daily sediment yield modeling with artificial neural network using 10-fold cross validation method: A small agricultural watershed, Kapgari, India. Int. J. Earth Sci. Eng. 2011, 6, 43–450. [Google Scholar]
- Tayfur, G. Artificial neural networks for sheet sediment transport. Hydrol. Sci. J. 2002, 47, 879–892. [Google Scholar] [CrossRef] [Green Version]
- Kisi, Ö. Multi-layer perceptrons with Levenberg-Marquardt training algorithm for suspended sediment concentration prediction and estimation/Prévision et estimation de la concentration en matières en suspension avec des perceptrons multi-couches et l’algorithme d’apprentissage de Levenberg-Marquardt. Hydrol. Sci. J. 2004, 49, 1025–1040. [Google Scholar]
- Kisi, O. Suspended sediment estimation using neuro-fuzzy and neural network approaches. Hydrol. Sci. J. 2005, 50, 683–696. [Google Scholar] [CrossRef]
- Jothiprakash, V.; Garg, V. Reservoir sedimentation estimation using artificial neural network. J. Hydrol. Eng. 2009, 14, 1035–1040. [Google Scholar] [CrossRef]
- Patil, R.A.; Shetkar, R.V. Prediction of sediment deposition in reservoir using artificial neural networks. Int. J. Civ. Eng. Technol. 2016, 7, 1–12. [Google Scholar]
- Toriman, E.; Jaafar, O.; Maru, R.; Arfan, A.; Ahmar, A.S. Daily Suspended Sediment Discharge Prediction Using Multiple Linear Regression and Artificial Neural Network. J. Phys. Conf. Ser. 2018, 954, 012030. [Google Scholar]
- Kisi, O. Constructing neural network sediment estimation models using a data-driven algorithm. Math. Comput. Simul. 2008, 79, 94–103. [Google Scholar] [CrossRef]
- Bishop, M.C. Neural Networks for Pattern Recognition; Oxford Clarendon Press: Oxford, UK, 1998. [Google Scholar]
- Yadav, A.; Chatterjee, S.; Equeenuddin, S.M. Suspended sediment yield modeling in Mahanadi River, India by multi-objective optimization hybridizing artificial intelligence algorithms. Int. J. Sediment. Res. 2021, 36, 76–91. [Google Scholar] [CrossRef]
- Yadav, A.; Satyannarayana, P. Multi-objective genetic algorithm optimization of artificial neural network for estimating suspended sediment yield in Mahanadi River basin, India. Int. J. River Basin Manag. 2020, 18, 207–215. [Google Scholar] [CrossRef]
- Yadav, A. Estimation and Forecasting of Suspended Sediment Yield in Mahanadi River Basin: Application of Artificial Intelligence Algorithms; NIT Rourkela: Orissa, India, 2020. [Google Scholar]
- Yadav, A.; Prasad, B.B.V.S.V.; Mojjada, R.K.; Kothamasu, K.K.; Joshi, D. Application of Artificial Neural Network and Genetic Algorithm Based Artificial Neural Network Models for River Flow Prediction. Rev. Intell. Artif. 2020, 34, 745–751. [Google Scholar] [CrossRef]
- Zhang, D.; Xiao, J.; Zhou, N.; Zheng, M.; Luo, X.; Jiang, H.; Chen, K. A genetic algorithm based support vector machine model for blood-brain barrier penetration prediction. BioMed Res. Int. 2015, 2015, 292683. [Google Scholar] [CrossRef] [Green Version]
- Chatterjee, S.; Bandopadhyay, S. Goodnews bay platinum resource estimation using least square support vector regression with selection of input space dimension and hyperparameters. Nat. Resour. Res. 2011, 20, 117–129. [Google Scholar] [CrossRef]
- Su, J.; Wang, X.; Liang, Y.; Chen, B. GA-based support vector machine model for the prediction of monthly reservoir storage. J. Hydrol. Eng. 2014, 19, 1430–1437. [Google Scholar] [CrossRef]
- Adib, A.; Mahmoodi, A. Prediction of suspended sediment load using ANN GA conjunction model with markov chain approach at flood conditions. KSCE J. Civ. Eng. 2017, 21, 447–457. [Google Scholar] [CrossRef]
- Altunkaynak, A. Adaptive estimation of wave parameters by Geno-Kalman filtering. Ocean Eng. 2008, 35, 1245–1251. [Google Scholar] [CrossRef]
- Topchy, A.P.; Lebedko, O.A.; Miagkikh, V.V. Fast learning in multilayered neural networks by means of hybrid evolutionary and gradient algorithms. In Proceedings of the IC on Evolutionary Computation and Its Applications, Moscow, Russia, June 1996. [Google Scholar]
- Nasseri, M.; Asghari, K.; Abedini, M.J. Optimized scenario for rainfall forecasting using genetic algorithm coupled with artificial neural network. Expert Syst. Appl. 2008, 35, 1415–1421. [Google Scholar] [CrossRef]
- Gowda, C.C.; Mayya, S.G. Comparison of back propagation neural network and genetic algorithm neural network for stream flow prediction. J. Comput. Environ. Sci. 2014, 2014, 290127. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.R.; Cai, Y.J.; Sun, P.D.; Chen, B. The use of combined neural networks and genetic algorithms for prediction of river water quality. J. Appl. Res. Technol. 2014, 12, 493–499. [Google Scholar] [CrossRef]
- Adib, A.; Jahanbakhshan, H. Stochastic approach to determination of suspended sediment concentration in tidal rivers by artificial neural network and genetic algorithm. Can. J. Civ. Eng. 2013, 40, 299–312. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Piri, J. Daily suspended sediment concentration simulation using hydrological data of Pranhita River Basin, India. Comput. Electron. Agric. 2017, 138, 20–28. [Google Scholar] [CrossRef]
- Paz, E. A Survey of Parallel Genetic Algorithms. 1998. Available online: http://www.www.illigal.ge.uiuc.edu (accessed on 10 April 2022).
- Agrawal, S.; Sarkar, S.; Srivastava, G.; Maddikunta, P.K.R.; Gadekallu, T.R. Genetically optimized prediction of remaining useful life. Sustain. Comput. Inform. Syst. 2021, 31, 100565. [Google Scholar] [CrossRef]
- Agrawal, S.; Sarkar, S.; Alazab, M.; Maddikunta, P.K.R.; Gadekallu, T.R.; Pham, Q.V. Genetic CFL: Hyperparameter Optimization in Clustered Federated Learning. Comput. Intell. Neurosci. 2021, 2021, 7156420. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.; Lakshmanna, K.; Rajput, D.S.; Kaluri, R.; Srivastava, G. Hybrid genetic algorithm and a fuzzy logic classifier for heart disease diagnosis. Evol. Intell. 2020, 13, 185–196. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Deb, K. A comparative analysis of selection schemes used in genetic algorithms. In Foundations of Genetic Algorithms; Rawlins, G.J., Ed.; Morgan Kaufmann: San Mateo, CA, USA, 1991; pp. 69–93. [Google Scholar]
- Beyer, H.G. Evolutionary algorithms in noisy environments: Theoretical issues and guidelines for practice. Comput. Methods Appl. Mech. Eng. 2000, 186, 239–267. [Google Scholar] [CrossRef]
- Wang, Q.J. The genetic algorithm and its application to calibrating conceptual rainfall-runoff models. Water Resour. Res. 1991, 27, 2467–2471. [Google Scholar] [CrossRef]
- Liong, S.Y.; Chan, W.T.; ShreeRam, J. Peak-flow forecasting with genetic algorithm and SWMM. J. Hydraul. Eng. 1995, 121, 613–617. [Google Scholar] [CrossRef]
- Cieniawski, S.E.; Eheart, J.W.; Ranjithan, S. Using genetic algorithms to solve a multiobjective groundwater monitoring problem. Water Resour. Res. 1995, 31, 399–409. [Google Scholar] [CrossRef]
- Jain, A.; Srinivasulu, S. Development of effective and efficient rainfall-runoff models using integration of deterministic, real-coded genetic algorithms, and artificial neural network techniques. Water Resour. Res. 2004, 40, 1–12. [Google Scholar] [CrossRef]
- Tayfur, G.; Moramarco, T. Predicting hourly-based flow discharge hydrographs from level data using genetic algorithms. J. Hydrol. 2008, 352, 77–93. [Google Scholar] [CrossRef] [Green Version]
- Altunkaynak, A. Sediment load prediction by genetic algorithms. Adv. Eng. Softw. 2009, 40, 928–934. [Google Scholar] [CrossRef]
- Sirdari, Z.Z.; Ghani, A.A.; Sirdari, N.Z. Bedload transport predictions based on field measurement data by combination of artificial neural network and genetic programming. Pollution 2015, 1, 85–94. [Google Scholar]
- Chatterjee, S.; Bandopadhyay, S. Reliability estimation using a genetic algorithm-based artificial neural network: An application to a laud-haul-dump machine. Expert Syst. Appl. 2012, 39, 10943–10951. [Google Scholar] [CrossRef]
- Davis, L. Handbook of Genetic Algorithms; Van Nostrand Reinhold: Graham, NC, USA, 1991. [Google Scholar]
- Dejong, K. An Analysis of the Behavior of a Class of Genetic Adaptive Systems. Ph.D. Thesis, Department of Computer and Communication Sciences, University of Michigan, Ann Arbor, MI, USA, 1975. [Google Scholar]
- Haghizade, A.; Shui, L.T.; Goudarzi, E. Estimation of yield sediment using artificial neural network at basin scale. Aust. J. Basic Appl. Sci. 2010, 4, 1668–1675. [Google Scholar]
- Reddy, G.T.; Khare, N. Hybrid firefly-bat optimized fuzzy artificial neural network based classifier for diabetes diagnosis. Int. J. Intell. Eng. Syst. 2017, 10, 18–27. [Google Scholar] [CrossRef]
- Panwar, S.; Khan, M.Y.A.; Chakrapani, G.J. Grain size characteristics and provenance determination of sediment and dissolved load of Alaknanda River, Garhwal Himalaya, India. Environ. Earth Sci. 2016, 75, 91. [Google Scholar] [CrossRef]
- Alp, M.; Cigizoglu, H.K. Suspended sediment estimation by feed forward back propagation method using hydro meteorological data. Environ. Model. Softw. 2007, 22, 2–13. [Google Scholar] [CrossRef]
- Kişi, Ö. Streamflow forecasting using different artificial neural network algorithms. J. Hydrol. Eng. 2007, 12, 532–539. [Google Scholar] [CrossRef]
- Fotovatikhah, F.; Herrera, M.; Shamshirband, S.; Chau, K.W.; Faizollahzadeh Ardabili, S.; Piran, M.J. Survey of computational intelligence as basis to big flood management: Challenges, research directions and future work. Eng. Appl. Comput. Fluid Mech. 2018, 12, 411–437. [Google Scholar] [CrossRef] [Green Version]
- Panagoulia, D. Artificial neural networks and high and low flows in various climate regimes. Hydrol. Sci. J. 2006, 51, 563–587. [Google Scholar] [CrossRef]
- Cigizoglu, H.K.; Kisi, O. Methods to improve the neural network performance in suspended sediment estimation. J. Hydrol. 2006, 317, 221–238. [Google Scholar] [CrossRef]
- Bouzeria, H.; Ghenim, A.N.; Khanchoul, K. Using artificial neural network (ANN) for prediction of sediment loads, application to the Mellah catchment northeast Algeria. J. Water Land Dev. 2017, 33, 47–55. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Tang, Z.; De Almeida, C.; Fishwick, P.A. Time series forecasting using neural networks vs. Box-Jenkins methodology. Simulation 1991, 57, 303–310. [Google Scholar] [CrossRef]
- Demuth, H.B.; Beale, M. Neural Network Toolbox for Use with MATLAB, Users Guide; The Mathworks Inc.: Natick, MA, USA, 1998. [Google Scholar]
- Adeloye, A.; Munari, A.D. Artificial neural network based generalized storage yield-reliability models using the Levenberg–Marquardt algorithm. J. Hydrol. 2006, 362, 215–230. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. Learn Syst. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Pramanik, N.; Panda, R.K. Application of neural network and adaptive neuro-fuzzy inference systems for river flow prediction. Hydrol. Sci. J. 2009, 54, 247–260. [Google Scholar] [CrossRef]
- Cigizoglu, H.K.; Murat, A. Generalized regression neural network in modeling river sediment yield. Adv. Eng. Softw. 2006, 37, 63–68. [Google Scholar] [CrossRef]
- Walling, D.E. Suspended sediment and solute response characteristics of the river Exe, Devon, England. In Research in Fluvial Geomorphology, Proceedings of the 5th Guelph Symposium on Geomorphology; Davidson-Arnott, R., Nickling, W., Eds.; Geo Abstracts: Norwich, UK, 1978; pp. 169–197. [Google Scholar]
- Jansson, M.B. Comparison of sediment rating curves developed load and on concentration. Nord. Hydrol. 1997, 28, 189–200. [Google Scholar] [CrossRef]
- Godavari Basin, Government of India, Ministry of Water Resources. March 2014. Available online: www.india-wris.nrsc.gov.in (accessed on 10 April 2022).
- Altun, H.; Bilgil, A.; Fidan, B.C. Treatment of multidimensional data to enhance neural network estimators in regression problems. Expert Syst. Appl. 2007, 32, 599–605. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of dimensionality reduction techniques on big data. IEEE Access 2020, 8, 54776–54788. [Google Scholar] [CrossRef]
- Sriram, S.; Vinayakumar, R.; Alazab, M.; Soman, K.P. Network flow based IoT botnet attack detection using deep learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 189–194. [Google Scholar]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Mittal, M.; Alenezi, M.; Alazab, M. The use of ensemble models for multiple class and binary class classification for improving intrusion detection systems. Sensors 2020, 20, 2559. [Google Scholar] [CrossRef]
- Boukhrissa, Z.A.; Khanchoul, K.; Le Bissonnais, Y.; Tourki, M. Prediction of sediment load by sediment rating curve and neural network (ANN) in El Kebir catchment, Algeria. J. Earth Syst. Sci. 2013, 122, 1303–1312. [Google Scholar] [CrossRef] [Green Version]
- Sharma, N.; Zakaullah, M.; Tiwari, H.; Kumar, D. Runoff and sediment yield modeling using ANN and support vector machines: A case study from Nepal watershed, Model. Earth Syst. Environ. 2015, 1, 23. [Google Scholar] [CrossRef] [Green Version]
- Rajaee, T.; Mirbagheri, S.A.; Zounemat-Kermani, M.; Nourani, V. Daily suspended sediment concentration simulation using ANN and neuro-fuzzy models. Sci. Total Environ. 2009, 407, 4916–4927. [Google Scholar] [CrossRef] [PubMed]
- Kisi, O.; Guven, A. A machine code based genetic programming for suspended sediment concentration estimation. Adv. Eng. Softw. 2010, 41, 939–945. [Google Scholar] [CrossRef]
- Bharati, L.; Smakhtin, V.U.; Anand, B.K. Modeling water supply and demand scenarios: The Godavari–Krishna inter-basin transfer, India. Water Policy 2009, 11, 140–153. [Google Scholar] [CrossRef] [Green Version]
- Malik, A.; Kumar, A.; Kisi, O. Daily pan evaporation estimation using heuristic methods with gamma test. J. Irrig. Drain Eng. 2018, 144, 4018023. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | WD (m3/s) | WL (m) | SSY (tons/day) |
|---|---|---|---|
| Mean (Xmean) | 4.502 | 2850.6 | 3131 |
| Standard Deviation (SD) | 2.8 | 5830.1 | 7115.9 |
| Maximum (Xmax) | 17.12 | 57,310.57 | 86,400 |
| Minimum (Xmin) | 1.18 | 46.927 | 0 |
| Skewness | 1.4764 | 3.6159 | 4.5379 |
| Coefficient of variation (Cv) | 0.622 | 2.045 | 2.272 |
| Xmax/Xmean | 3.802 | 20.104 | 27.60 |
| WD | WL | SSY | |
|---|---|---|---|
| WD | 1 | ||
| WL | 0.8974 | 1 | |
| SSY | 0.8586 | 0.7942 | 1 |
| WD | WL | SSY | |
|---|---|---|---|
| WD | 1 | ||
| WL | 0.9389 | 1 | |
| SSY | 0.7633 | 0.7967 | 1 |
| SL | Statistics | Training | Testing | Validation |
|---|---|---|---|---|
| 1. | MAE | 0.01678 | 0.020492 | 0.018921 |
| 2. | R | 0.873212 | 0.926835 | 0.79354 |
| 3. | MSE | 0.001492 | 0.002836 | 0.001786 |
| 4. | R2 | 0.7624 | 0.8589 | 0.6288 |
| 5. | RMSE | 0.038627 | 0.053252 | 0.042259 |
| 6. | Error variance | 0.001491 | 0.002779 | 0.00166 |
| SL | Error Statistics | Testing | Validation | Training |
|---|---|---|---|---|
| 1. | RMSE | 0.0538 | 0.04514 | 0.0376 |
| 2. | MAE | 0.237 | 0.0230 | 0.0207 |
| 3. | r | 0.924 | 0.799 | 0.8797 |
| 4. | Error variance | 0.00269 | 0.00195 | 0.00141 |
| 5. | MSE | 0.00289 | 0.002038 | 0.001414 |
| 6. | R2 | 0.853 | 0.638 | 0.7738 |
| SL. | Error Statistics | Training | Testing | Validation |
|---|---|---|---|---|
| 1. | MAE | 0.017119 | 0.020384 | 0.018783 |
| 2. | r | 0.872037 | 0.92169 | 0.791669 |
| 3. | MSE | 0.001499 | 0.002967 | 0.0018 |
| 4. | R2 | 0.7604 | 0.8495 | 0.6267 |
| 5. | RMSE | 0.038723 | 0.054473 | 0.042425 |
| 6. | Error variance | 0.0015 | 0.002857 | 0.001687 |
| SL. | Statistics | Training | Testing | Validation |
|---|---|---|---|---|
| 1. | MAE | 0.028542 | 0.031133 | 0.014297 |
| 2. | R2 | 0.7463 | 0.8489 | 0.5739 |
| 3. | Error variance | 0.003 | 0.005905 | 0.000881 |
| 4. | r | 0.900352 | 0.917363 | 0.99081 |
| 5. | MSE | 0.003814 | 0.00686 | 0.000969 |
| 6. | RMSE | 0.061759 | 0.082824 | 0.031131 |
| Model | RMSE | Input | MAE | Optimum Parameters | Correlation Coefficient (r) |
|---|---|---|---|---|---|
| GA-ANN | 0.0533 | Q, WL | 0.0205 | TF: tan-sigmoid and pure linear, NN: 11; CP: 0.9; CC: 43; HL: 1; G: 50; PS: 50; MP: 0.05 | 0.9268 |
| ANN | 0.0538 | Q, WL | 0.0237 | CC: 0.001; NN: 30; HL: 1; TF: tan-sigmoid and pure linear | 0.9240 |
| MLR | 0.0545 | Q, WL | 0.0204 | a: 0.0076; b: 0.0075; c:0.681 | 0.9217 |
| SRC | 0.0828 | Q | 0.0311 | a: 0.4379; b: 1.0799 | 0.9174 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yadav, A.; Joshi, D.; Kumar, V.; Mohapatra, H.; Iwendi, C.; Gadekallu, T.R. Capability and Robustness of Novel Hybridized Artificial Intelligence Technique for Sediment Yield Modeling in Godavari River, India. Water 2022, 14, 1917. https://doi.org/10.3390/w14121917
Yadav A, Joshi D, Kumar V, Mohapatra H, Iwendi C, Gadekallu TR. Capability and Robustness of Novel Hybridized Artificial Intelligence Technique for Sediment Yield Modeling in Godavari River, India. Water. 2022; 14(12):1917. https://doi.org/10.3390/w14121917
Chicago/Turabian StyleYadav, Arvind, Devendra Joshi, Vinod Kumar, Hitesh Mohapatra, Celestine Iwendi, and Thippa Reddy Gadekallu. 2022. "Capability and Robustness of Novel Hybridized Artificial Intelligence Technique for Sediment Yield Modeling in Godavari River, India" Water 14, no. 12: 1917. https://doi.org/10.3390/w14121917
APA StyleYadav, A., Joshi, D., Kumar, V., Mohapatra, H., Iwendi, C., & Gadekallu, T. R. (2022). Capability and Robustness of Novel Hybridized Artificial Intelligence Technique for Sediment Yield Modeling in Godavari River, India. Water, 14(12), 1917. https://doi.org/10.3390/w14121917