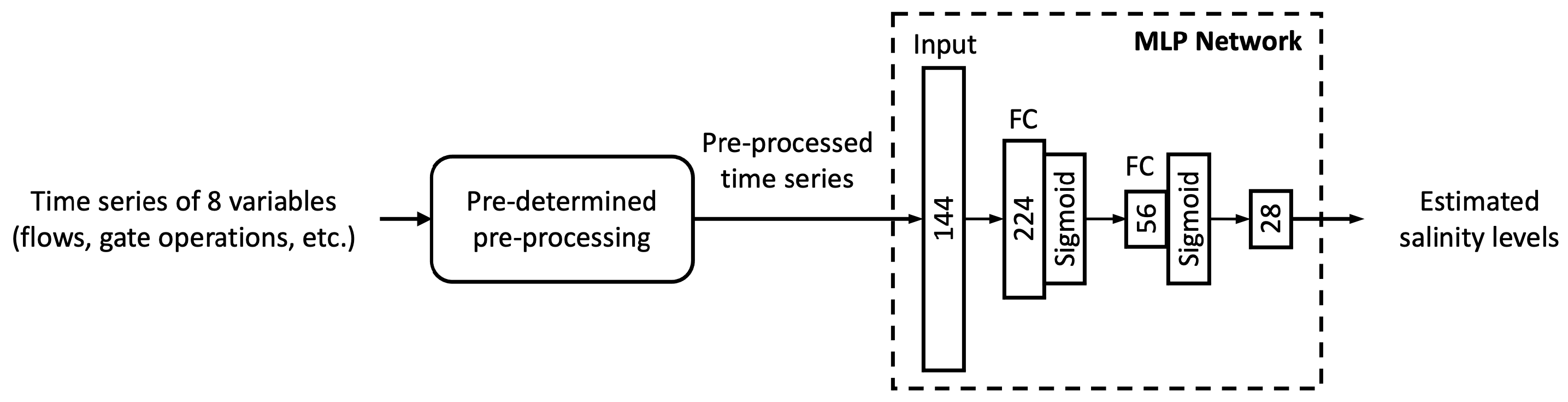
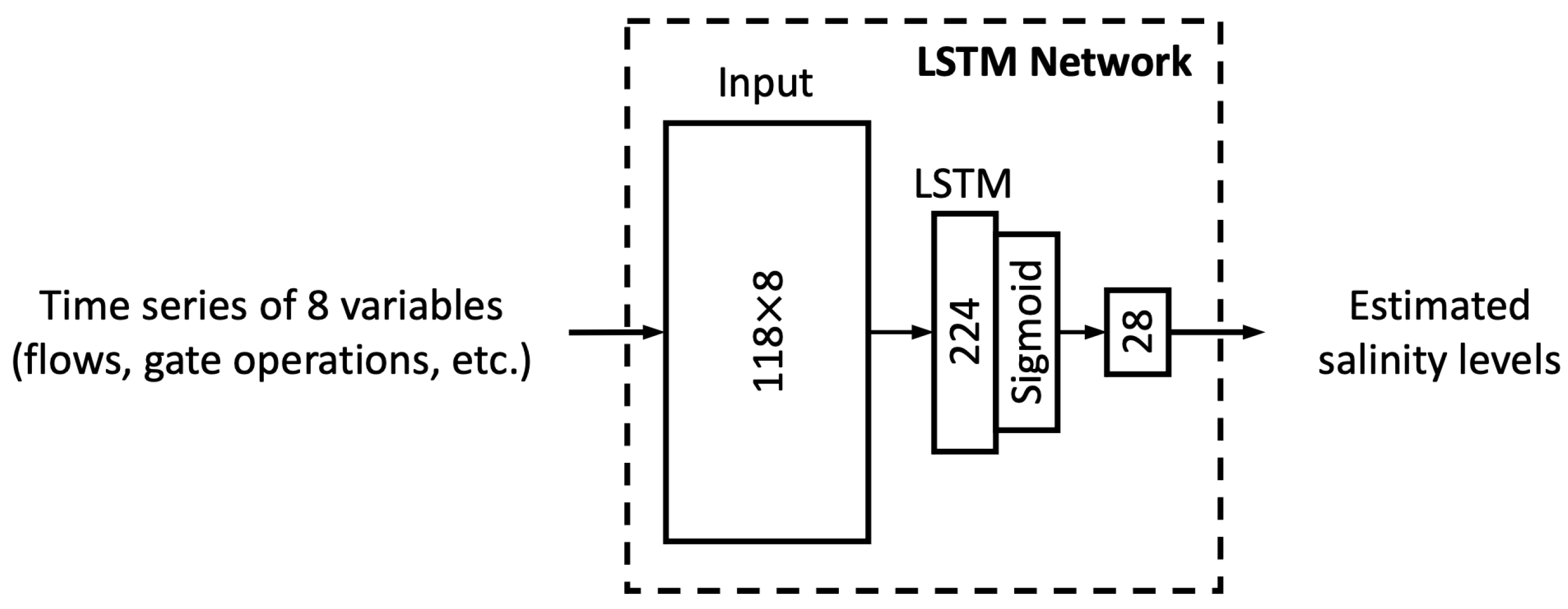
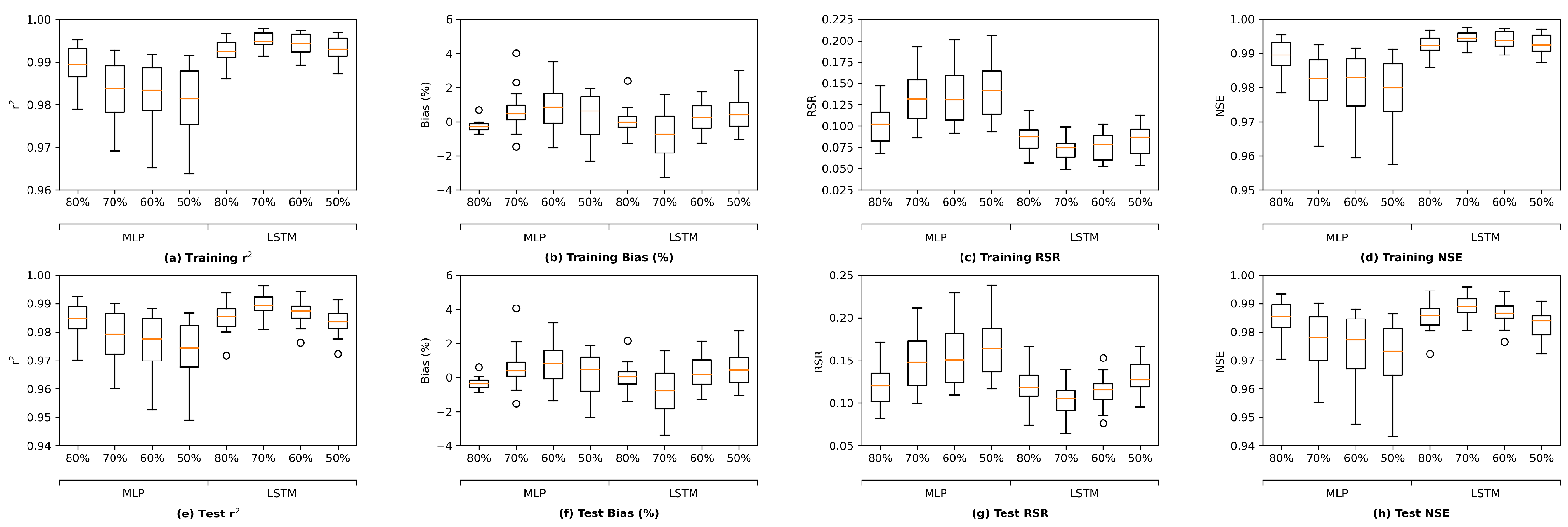
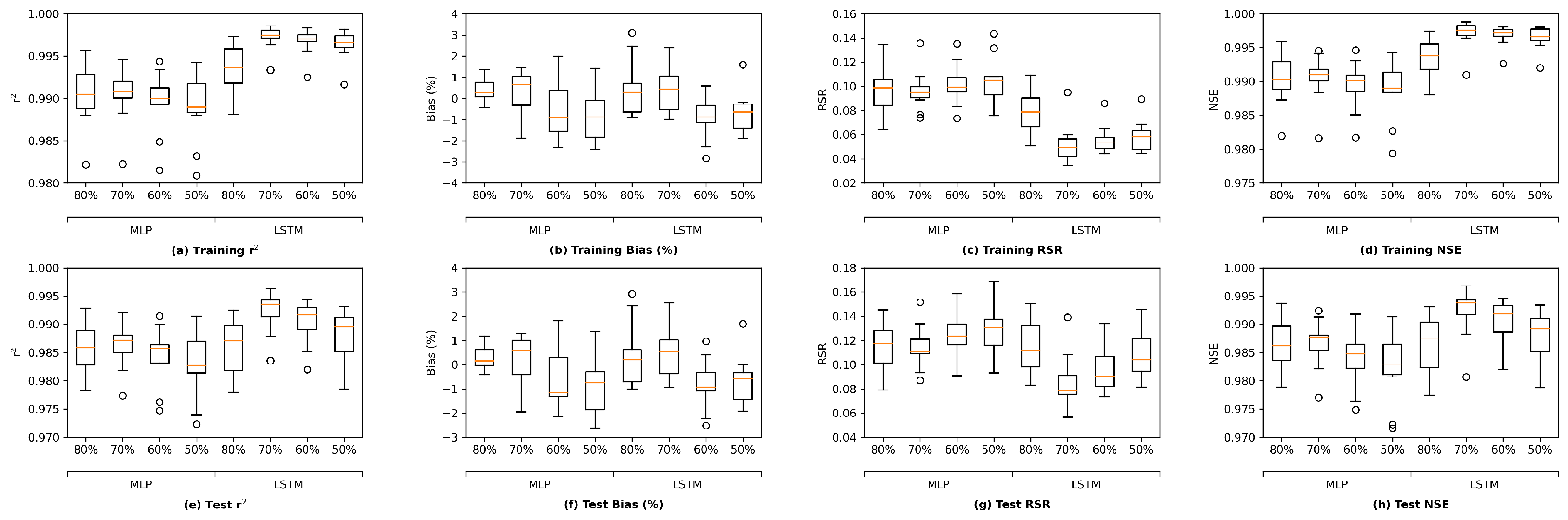
This section presents three types of results consisting of sensitivity analysis results, performance of the MLP and LSTM models proposed, and performance of two additional deep-learning architectures. The sensitivity analysis aims to identify the appropriate portion of the available data for training as well as the appropriate amount of antecedent input information, namely, memory to be used for training. The outcome of sensitivity analysis is utilized to train the proposed MLP and LSTM models of which the results are presented next. Finally, two additional deep-learning models are trained in the same way as the MLP and LSTM models have been trained. Their performance is compared with that of the original MLP and LSTM models developed.
3.2. Salinity Simulation Results
The capability of the proposed MLP and LSTM models in emulating DSM2 in salinity simulation is examined from two aspects. Firstly, their performance quantified via the above-mentioned statistical metrics at different ranges of salinity is scrutinized. Even though it is important to capture the full range of salinity variations, high salinity is typically more of a concern from a water resource management perspective. Relevant water quality standards [
26] normally prescribe a maximum salinity threshold that water operations need to comply with. Additionally, salinity (represented by EC) simulations from the proposed machine-learning models are compared to the target salinity directly. As illustrated in
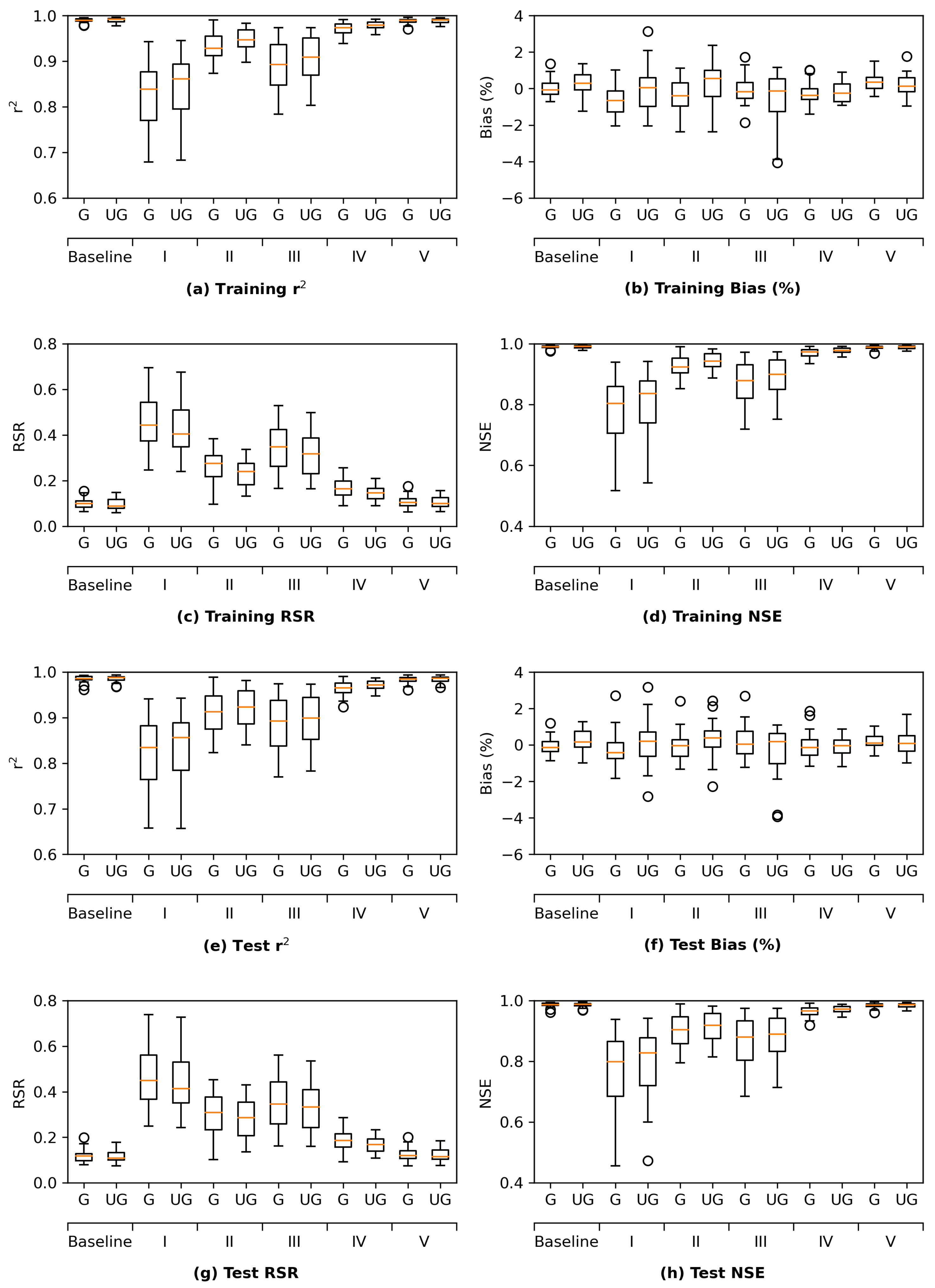
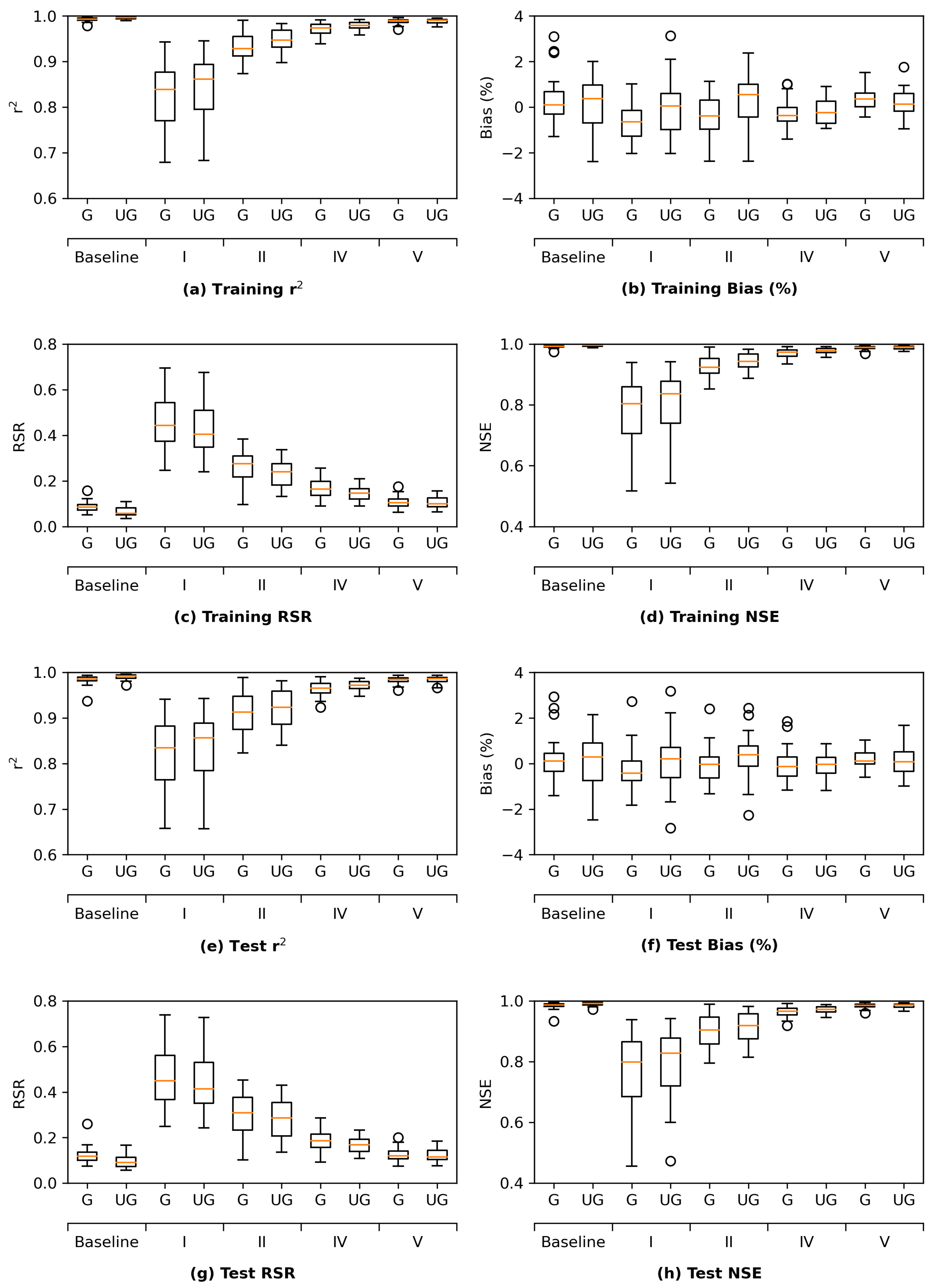
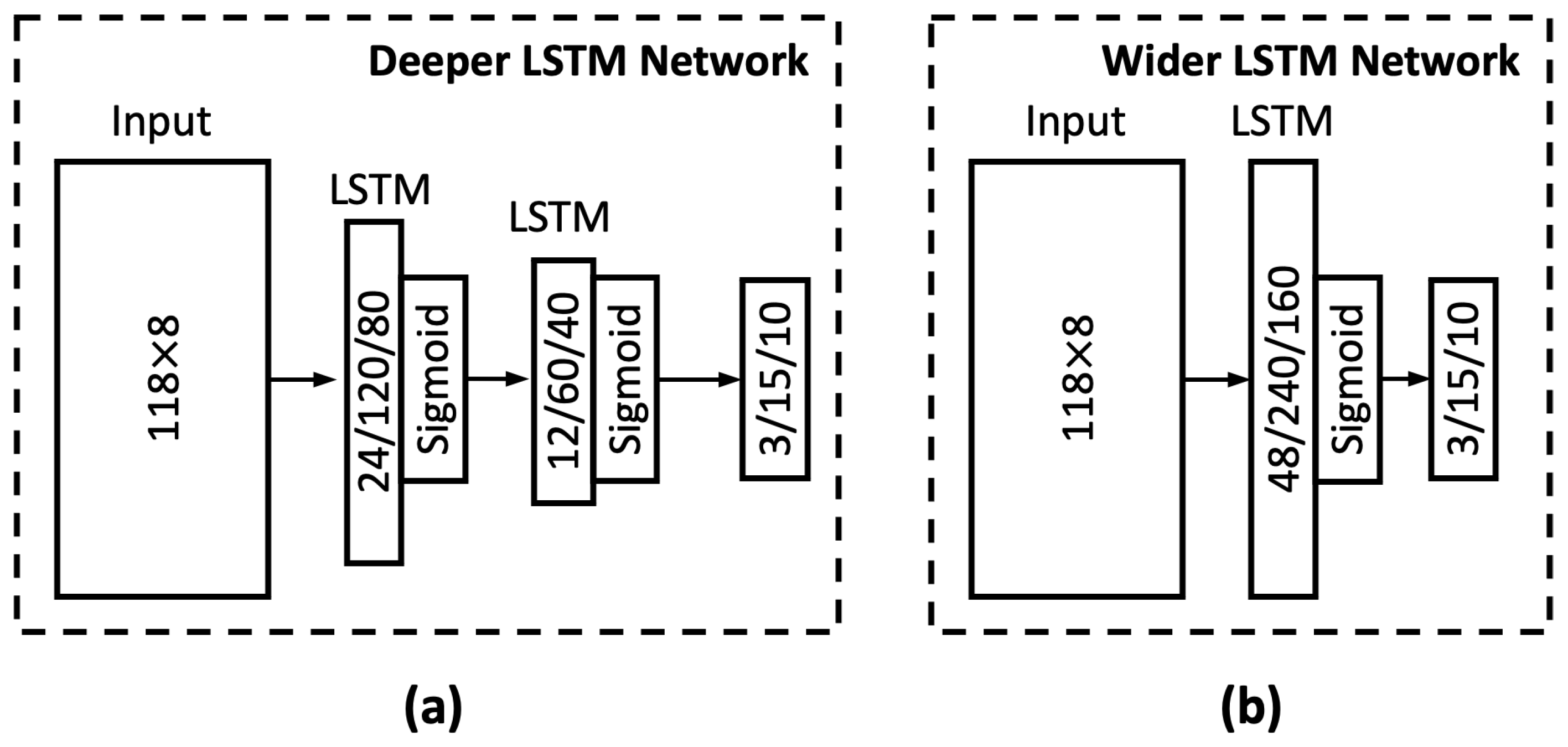
Section 3.1, the grouped LSTM generally outperforms its ungrouped counterpart, while the ungrouped MLP tends to yield better performance than the grouped MLP model. For the sake of simplicity, the current section focuses on the results from the grouped LSTM (LSTM G) model. The corresponding results from the ungrouped MLP model are presented in
Figure A2 and
Figure A3 of
Appendix C.
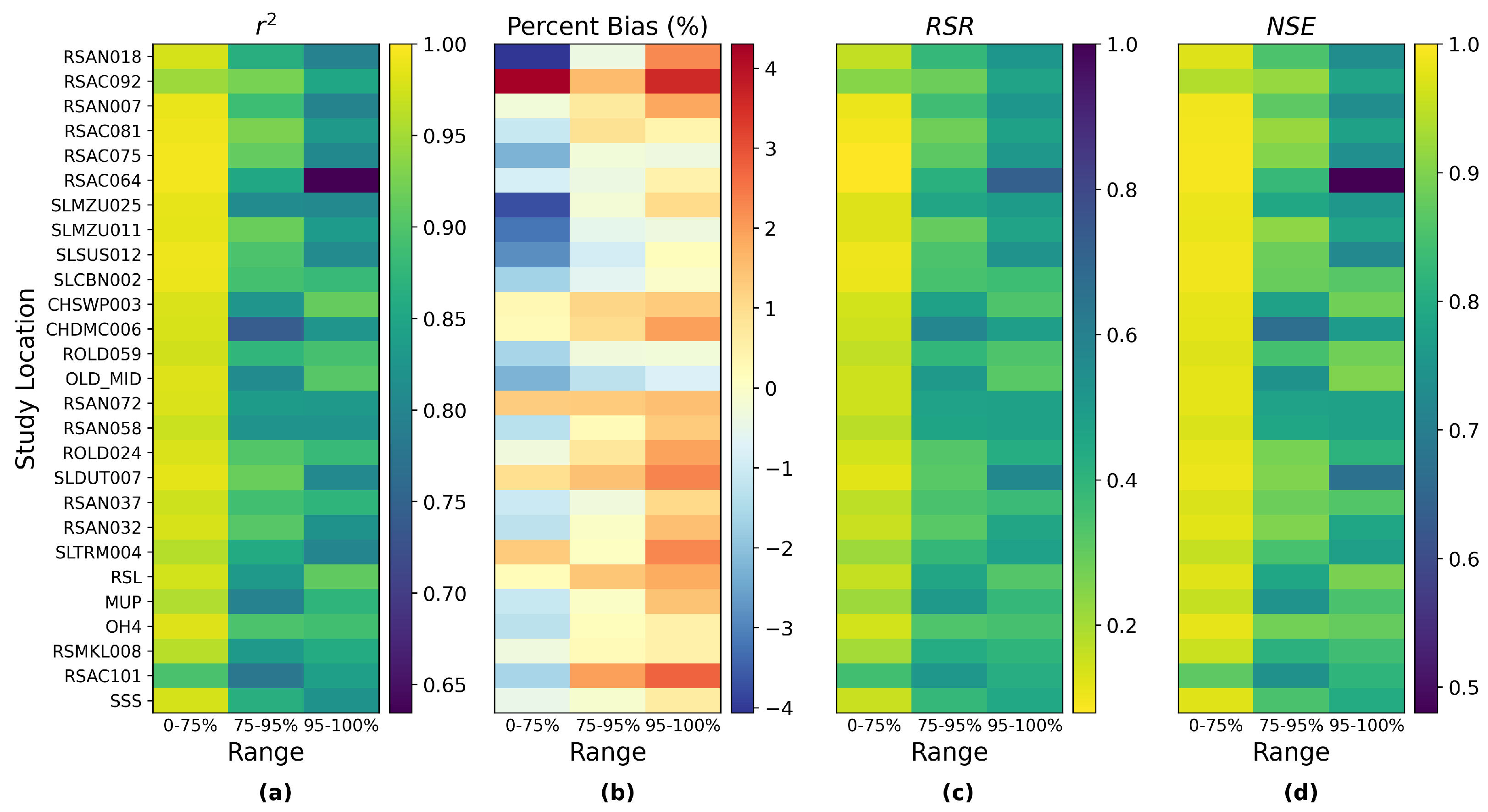
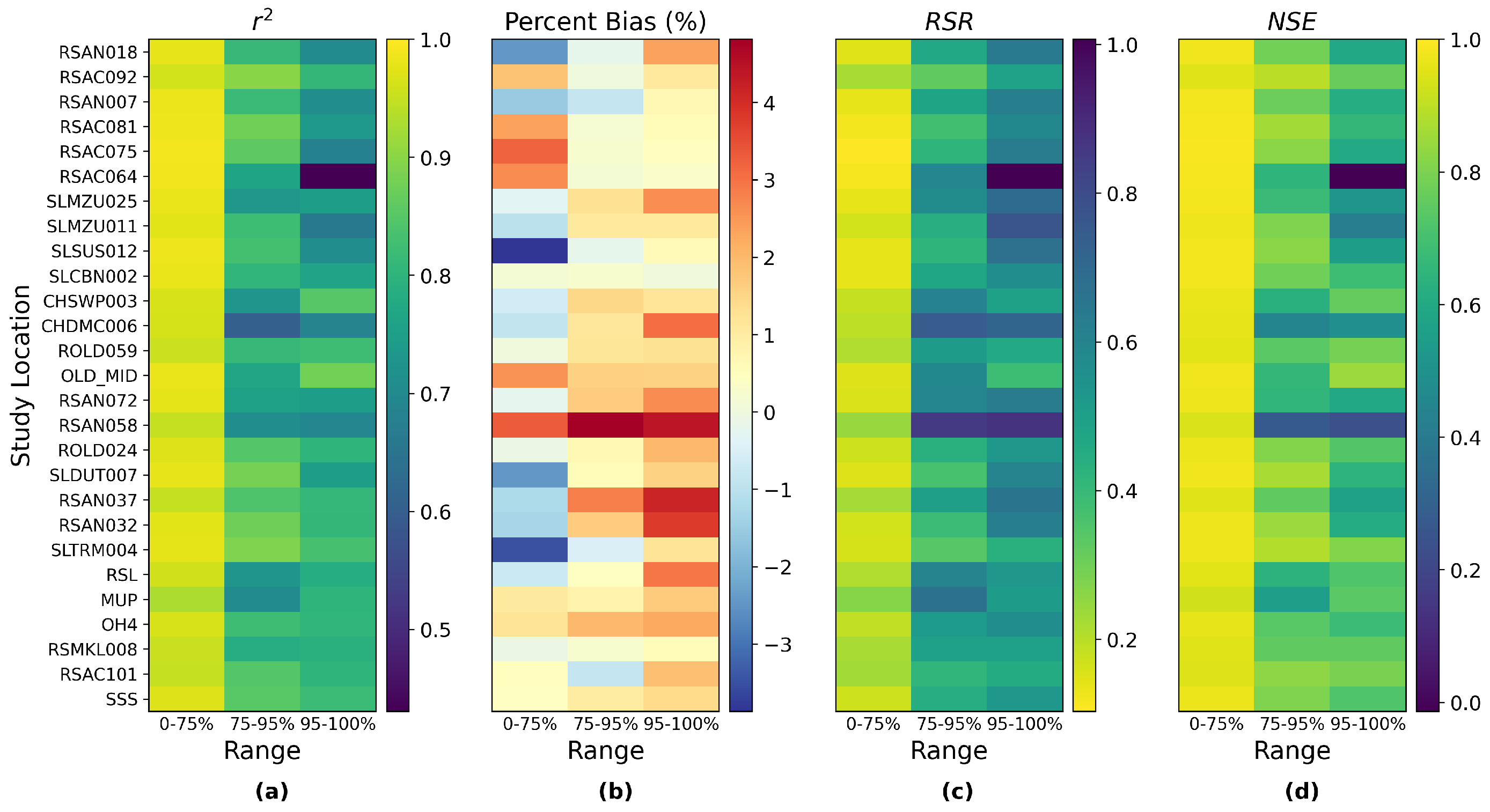
Figure 9 shows the statistical metrics
, percent bias, RSR, and NSE for each study location calculated in three ranges of salinity, low-middle (0–75%), high (75–95%), and extremely high (95–100%) range of EC. A note on the symbology of the figure is that “yellow” for
, NSE, and RSR reflects the satisfactory performance of the simulation models. The dark red and dark blue reflect the positive and negative percent bias, respectively, and the light color shows the near-ideal percent bias. As a general trend, model performance is most satisfactory when the salinity is in the low-middle range and decreases with higher salinity. Despite this trend, the metrics are generally desirable even for the extremely high range of salinity. Most of the metrics of extremely high salinity for location RSAC064 (location #4 in
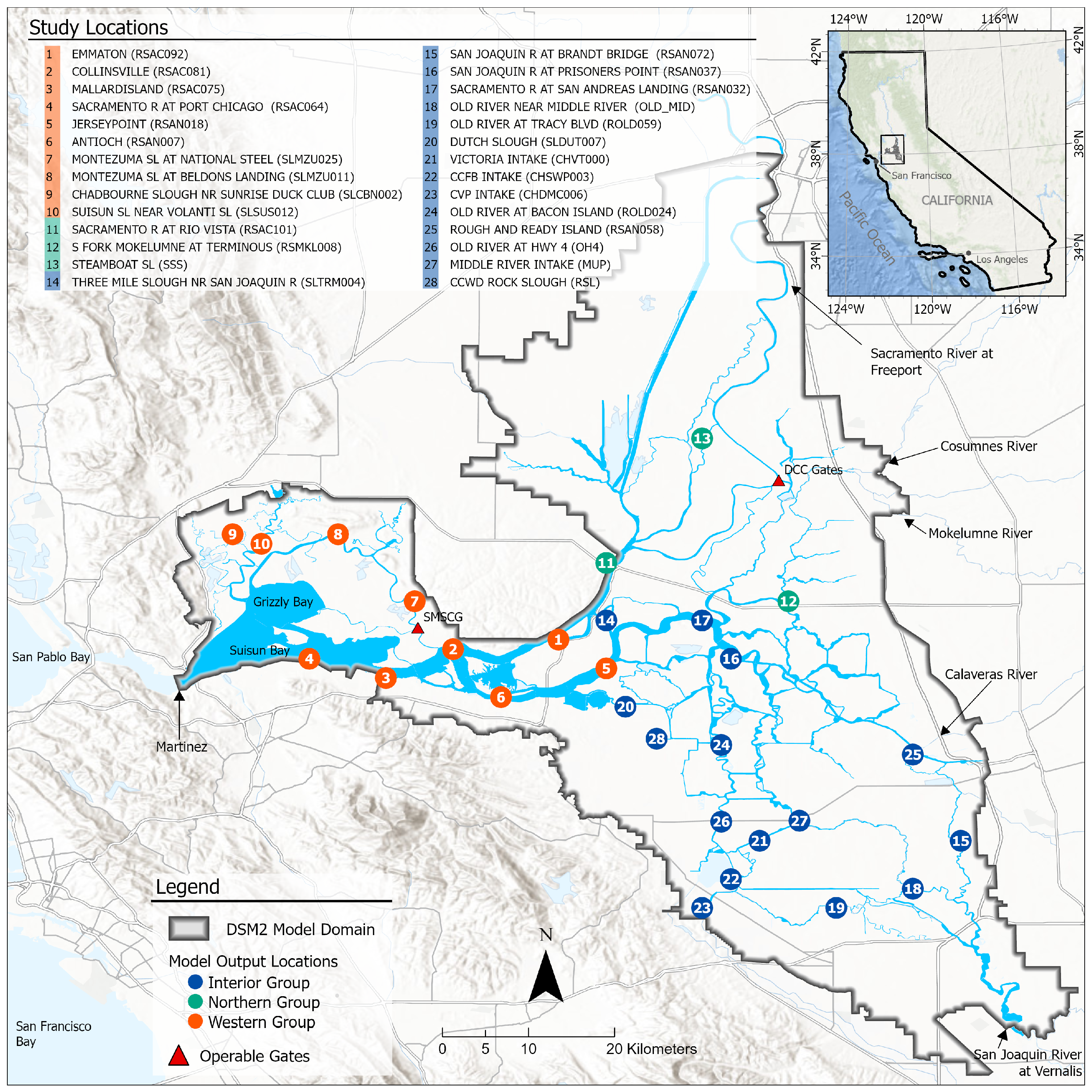
Figure 1) are distinctive from their counterparts of other locations. Its
and NSE are the lowest while its RSR is the highest, even though they are all acceptable. This is further investigated by looking at the numerator and denominator components of the formulas for these metrics (
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6 in
Appendix D). It is evident that, compared to other locations, the high RSR and low NSE of RSAC064 during the extremely high range of salinity are caused by a relatively low variance in salinity at this location, while the low
can be attributed to the relatively low numerator (differences between individual daily salinity and the overall mean value) when calculating this metric. The bias of RSAC064 is actually very small (
Figure 9) and in line with the biases of all other locations. Another notable pattern is that the model generally overestimates low-middle EC range of salinity (referring to the formula for bias calculation in
Table 2), and underestimates high and extremely high ranges of salinity for most locations. The corresponding metrics of the ungrouped MLP model share similar patterns but are slightly inferior (
Figure A2 in
Appendix C).
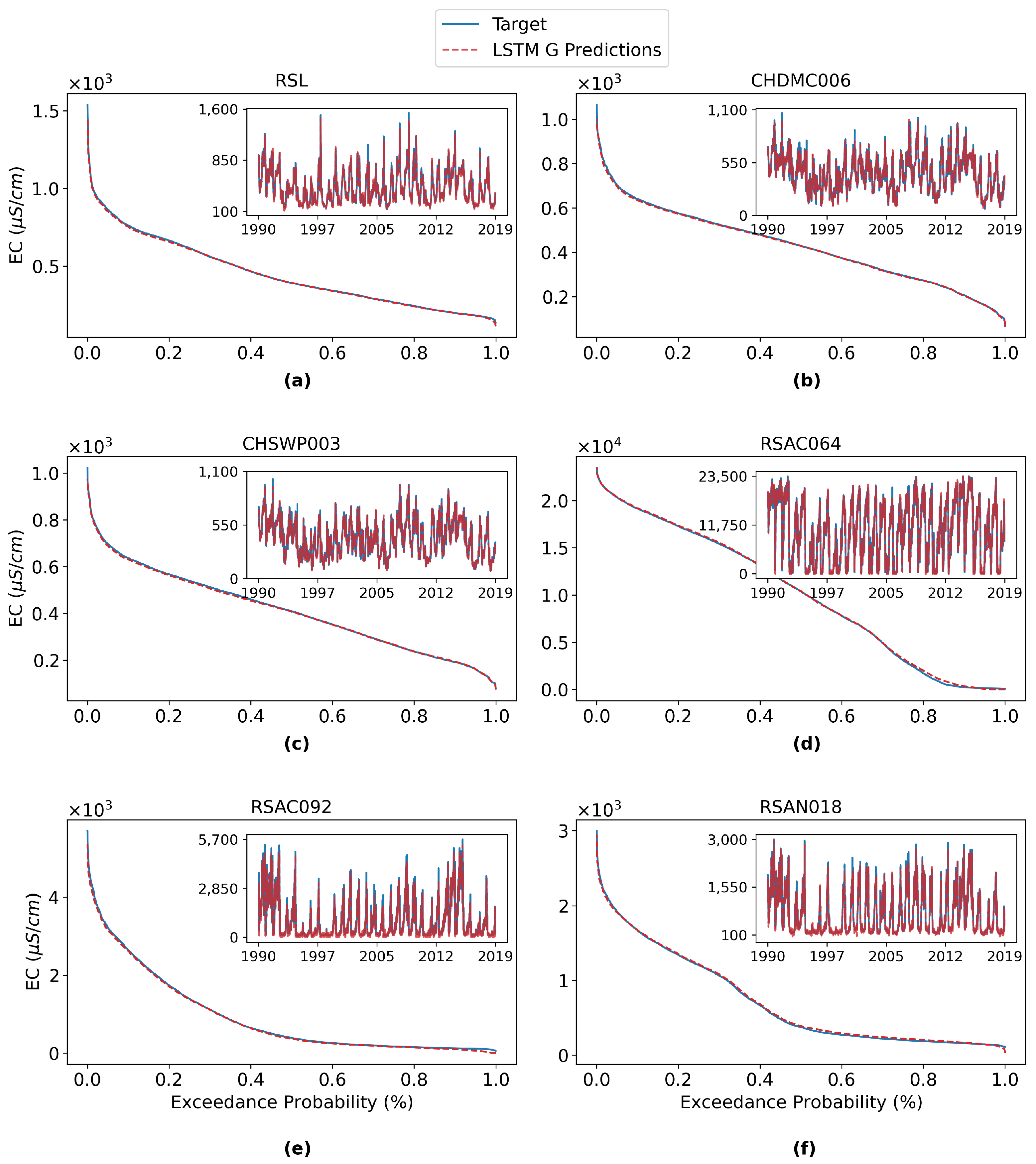
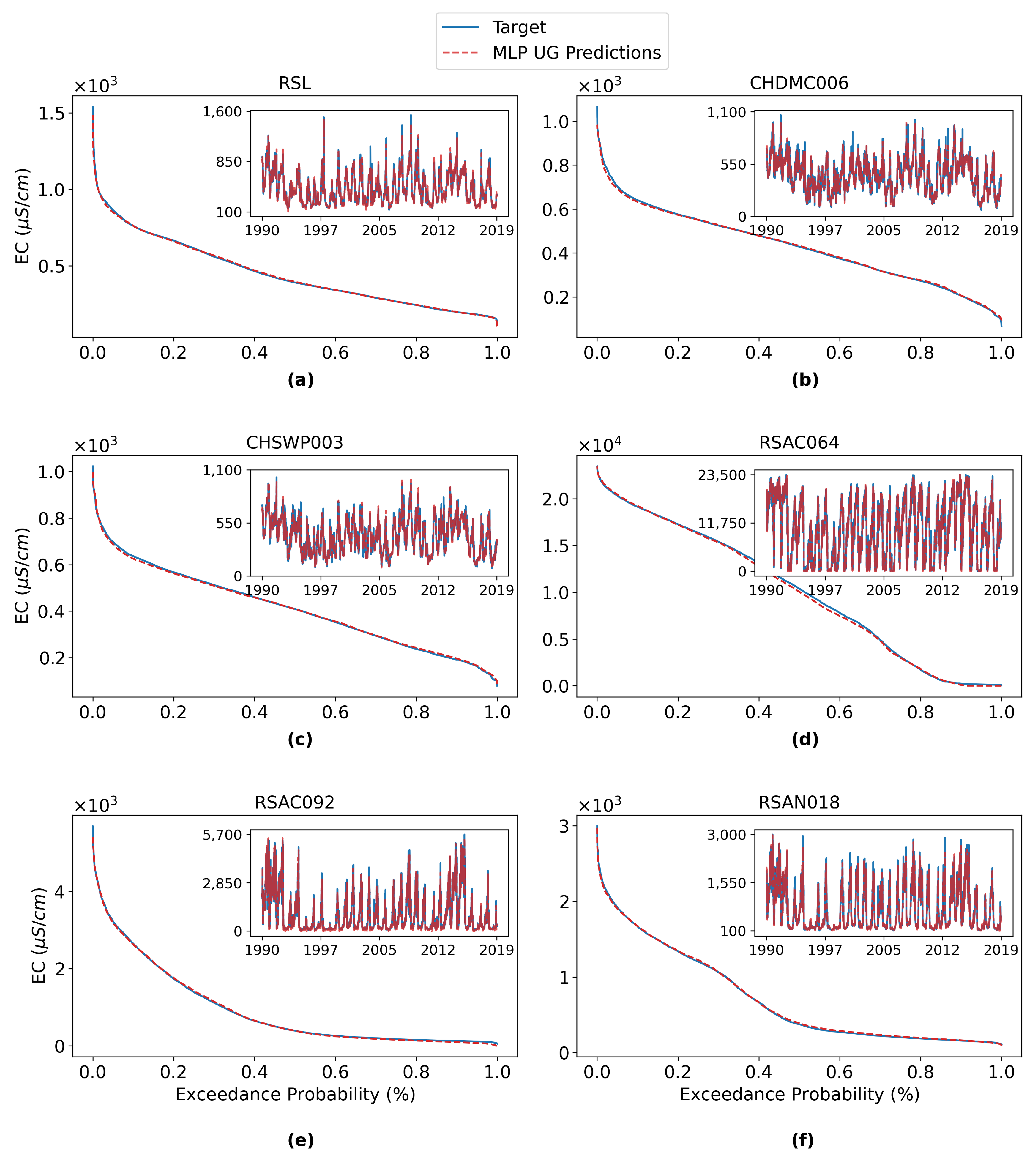
In addition to the statistical metrics, the specific daily salinity simulations from the proposed models are compared to the corresponding target salinity. For demonstration purposes, the results from the grouped LSTM model are presented at six selected locations in the form of exceedance probability curves and time series plots. These locations include three intake locations where water is pumped and transferred to various users to meet different needs: CCWD Rock Slough (RSL; location #28 in
Figure 1), CVP Intake (CHDMC006; location #23), CCFB Intake (CHSWP003; location #22). Two important salinity compliance locations: Emmaton (RSAC092; location #1) and Jersey Point (RSAN018; location #5) are also included. The last location is the Sacramento River at Port Chicago (RSAC064; location #4) of which some of the metrics for an extremely high range of salinity are not as desirable as their counterparts for other locations, as previously noted in
Figure 9.
Figure 10 shows the corresponding exceedance probability curves and daily time series plots comparing DSM2 emulation with process-based DSM2 outputs. The simulations mimic the target salinity very well at all six locations across the full spectrum of exceedance probabilities. There are only marginal discrepancies between them, especially the upper tail (high salinity) at some locations. This is corroborated by the time series plots which show that the simulations generally capture the temporal variations of the target salinity but slightly underestimate the peak values. For RSAC064, though some statistical metrics of it are inferior to those of other locations, visual inspection of the exceedance curve and time series plot reveals that the grouped LSTM model can skillfully apprehend the temporal pattern and magnitude of the reference salinity at this location. The relevant results of the ungrouped MLP model (
Figure A3 in
Appendix C) are highly similar but slightly inferior.
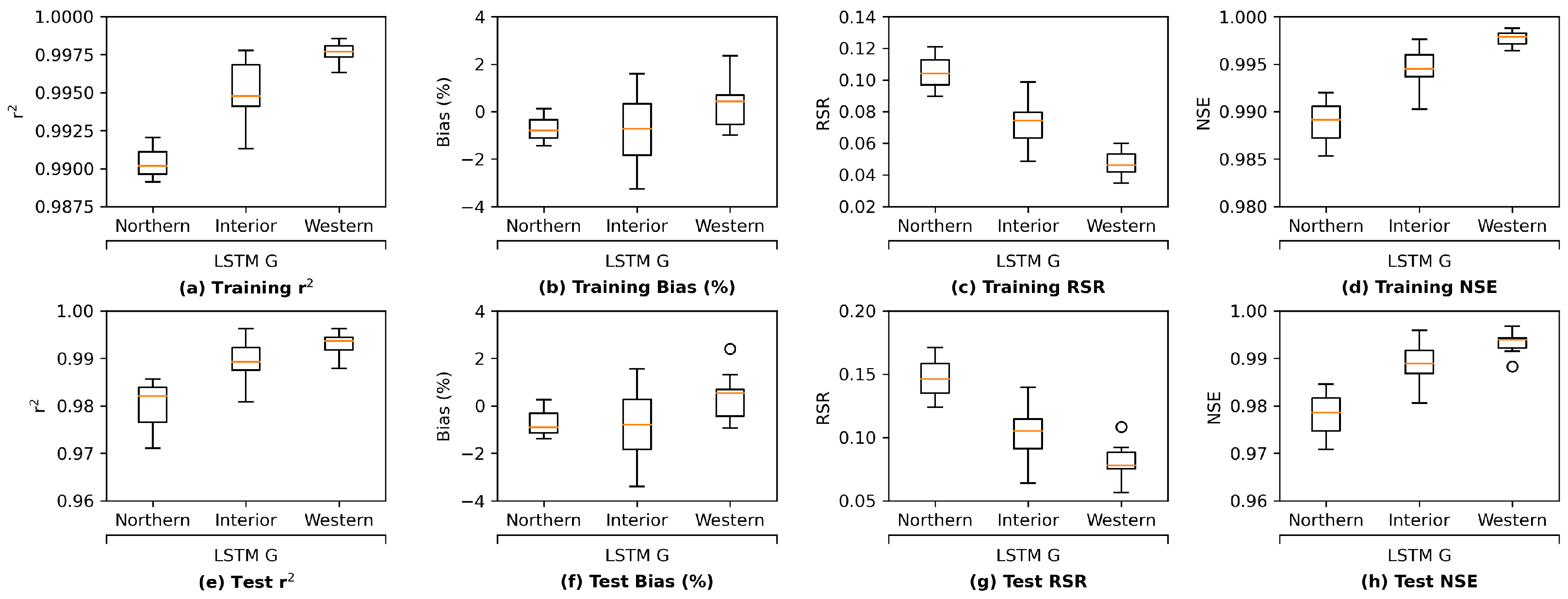
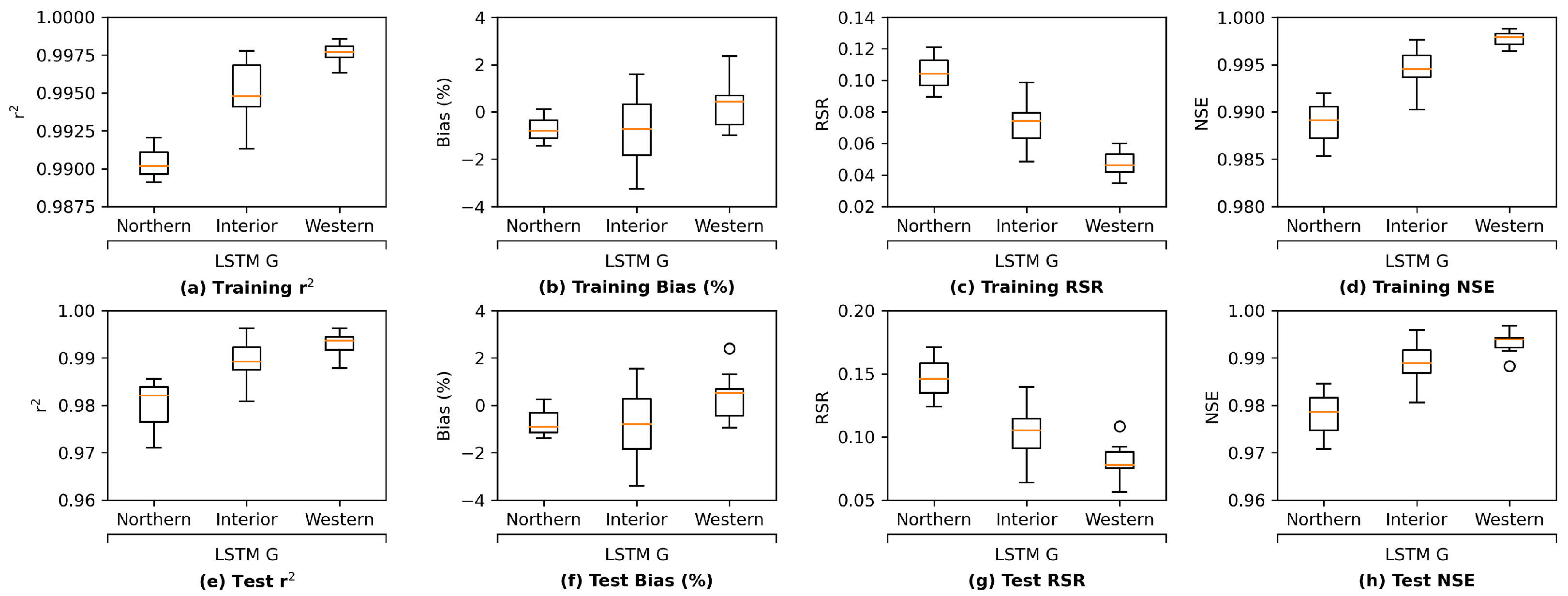
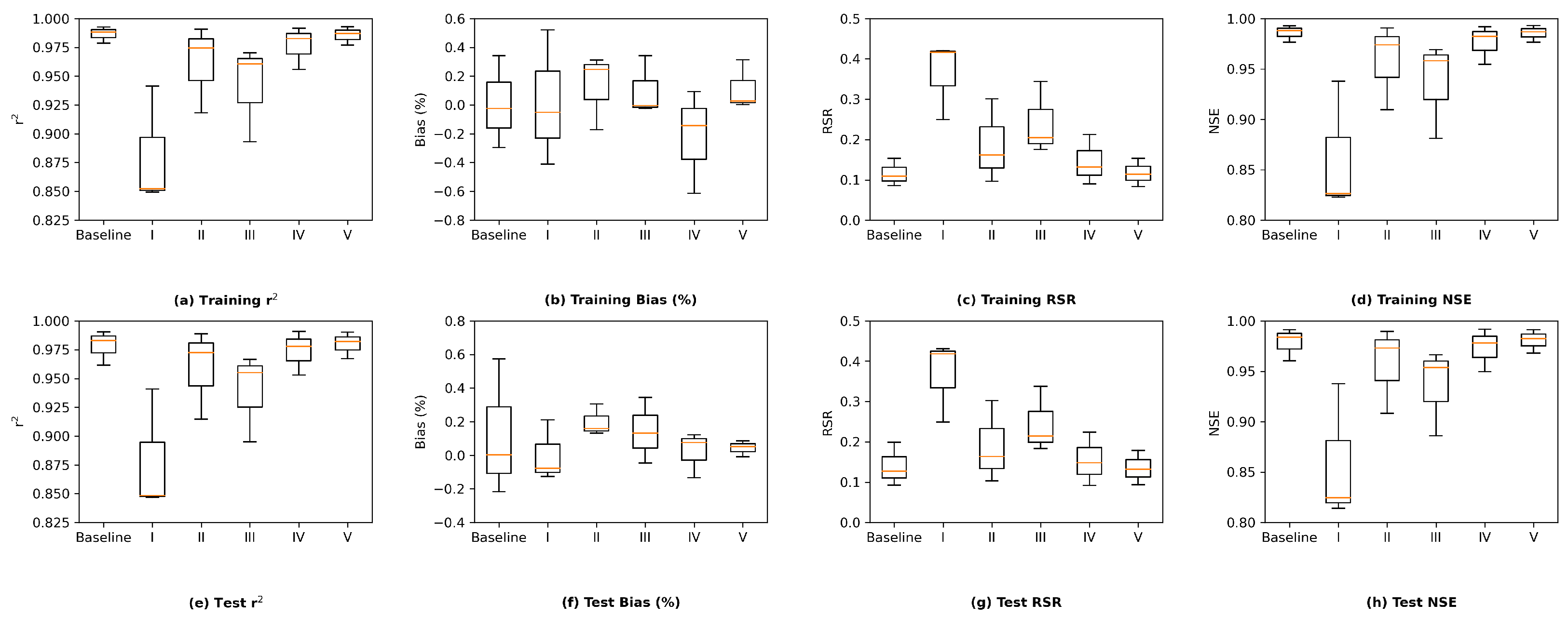
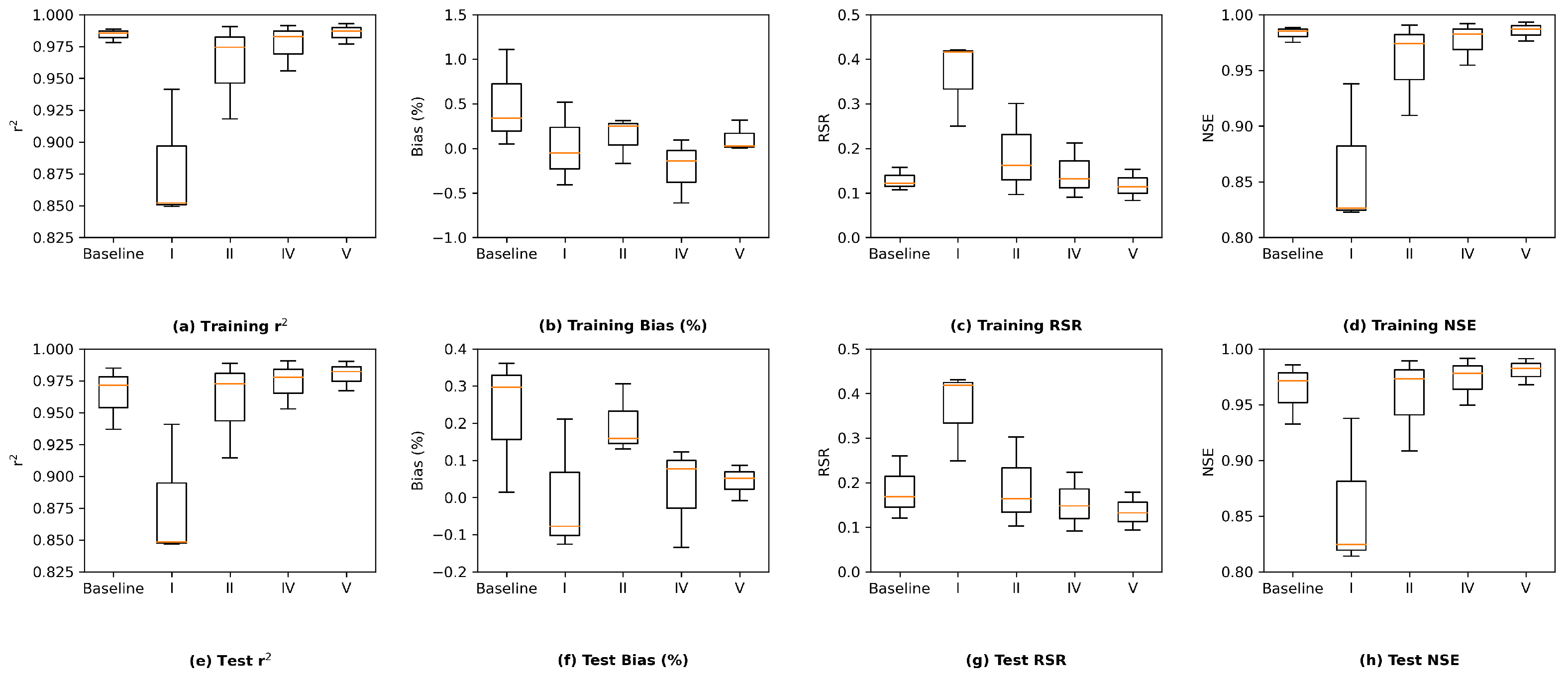
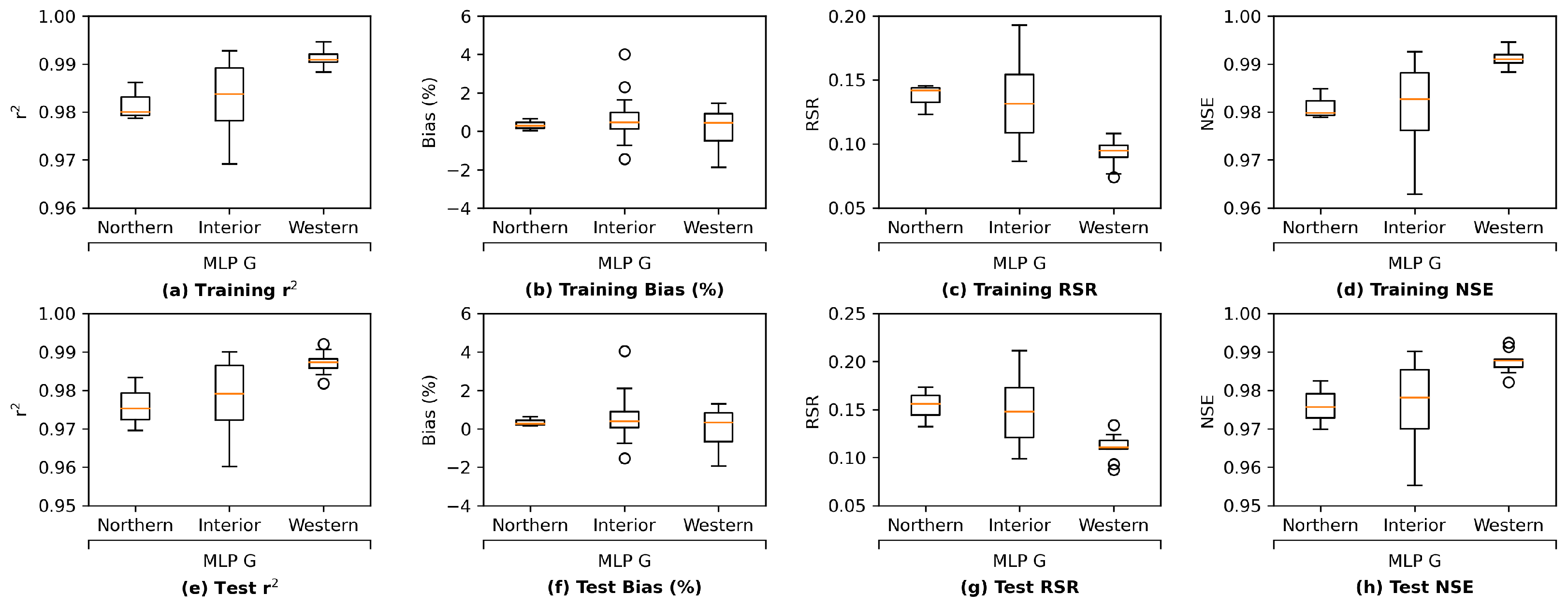
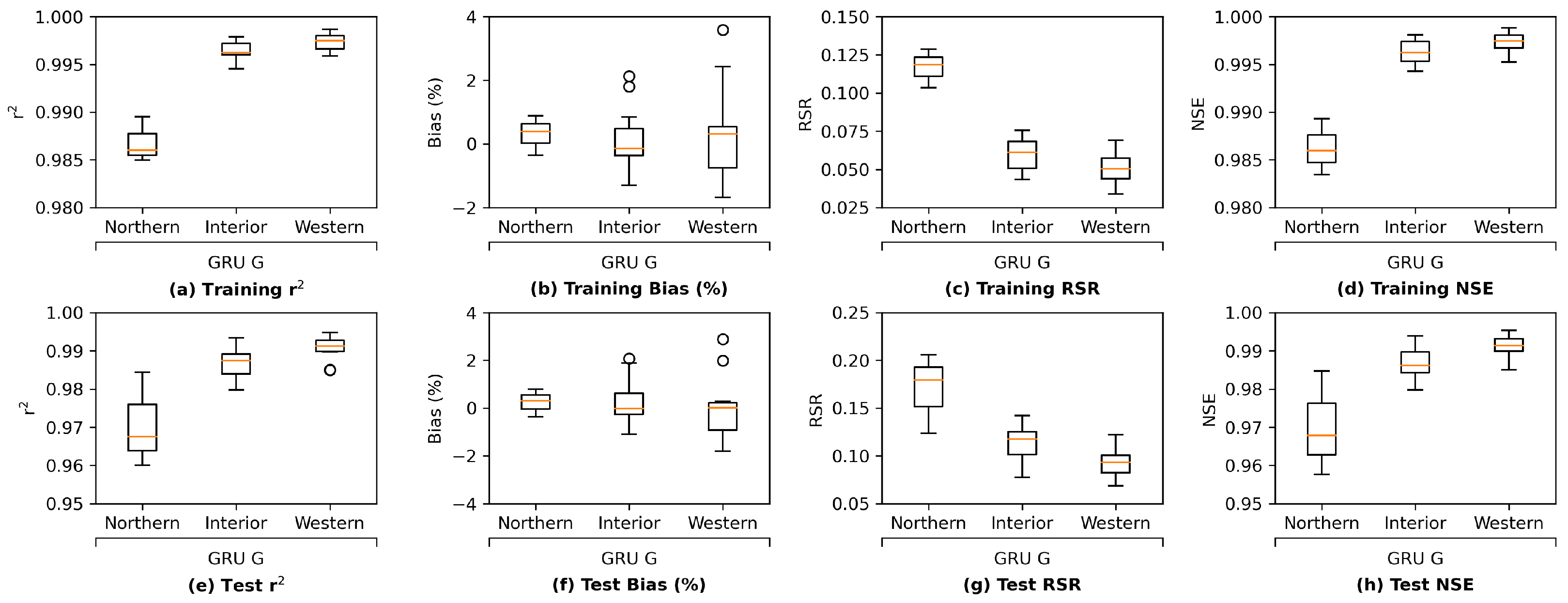
We further investigate the results by comparing the group-wise performance of the grouped LSTM model in
Figure 11. It can be observed that the LSTM model delivers the best test performance in the western Delta group, which is likely due to the fact that this group is located the closest to the ocean and is more affected by seawater. Their salinity level patterns appear to be more regular. In addition, the LSTM model achieves the worse test performance on the northern Delta among the three groups. There are only 3 stations in the northern Delta group, while there are 10 and 15 in the western and interior Delta groups, respectively. As a result, the amount of information provided by the training set for northern Delta is much less than the other two groups, making the task more challenging. Finally, estimating salinity levels for the interior Delta group is known as the most difficult because their salinity levels can be affected by more variables, our LSTM model delivers the worse test performance of the group compared to the western Delta group, as expected. The box and whisker plots of group-wise performance of the other three proposed models, namely, MLP, ResNet, and GRU, can be found in
Figure A15,
Figure A16 and
Figure A17 in
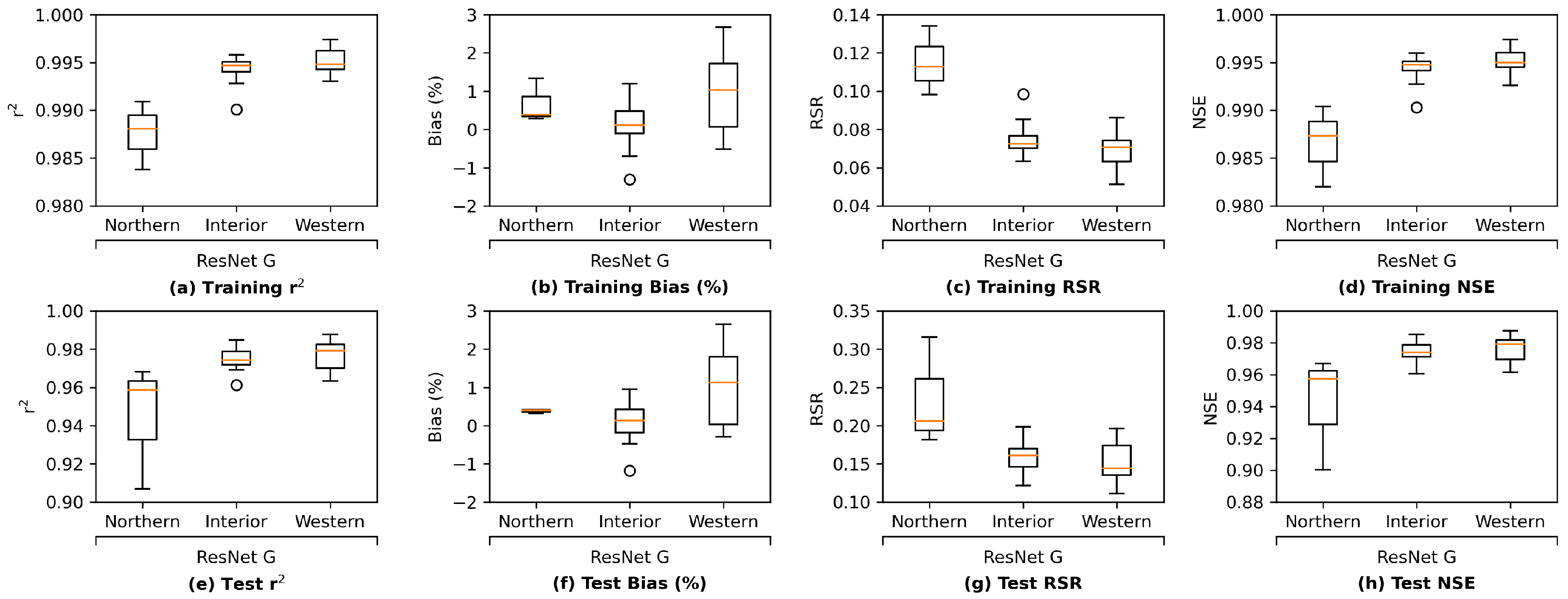
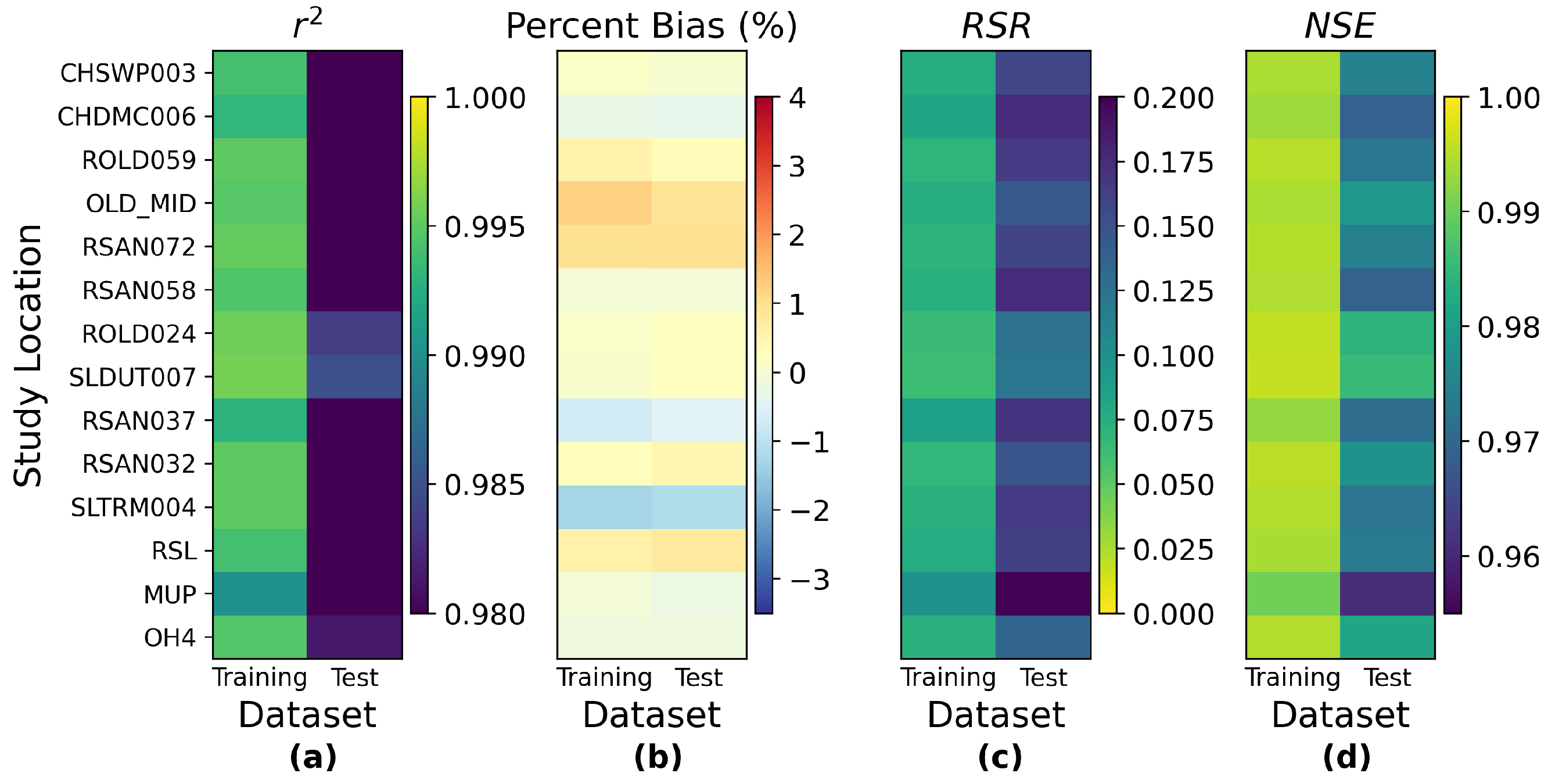
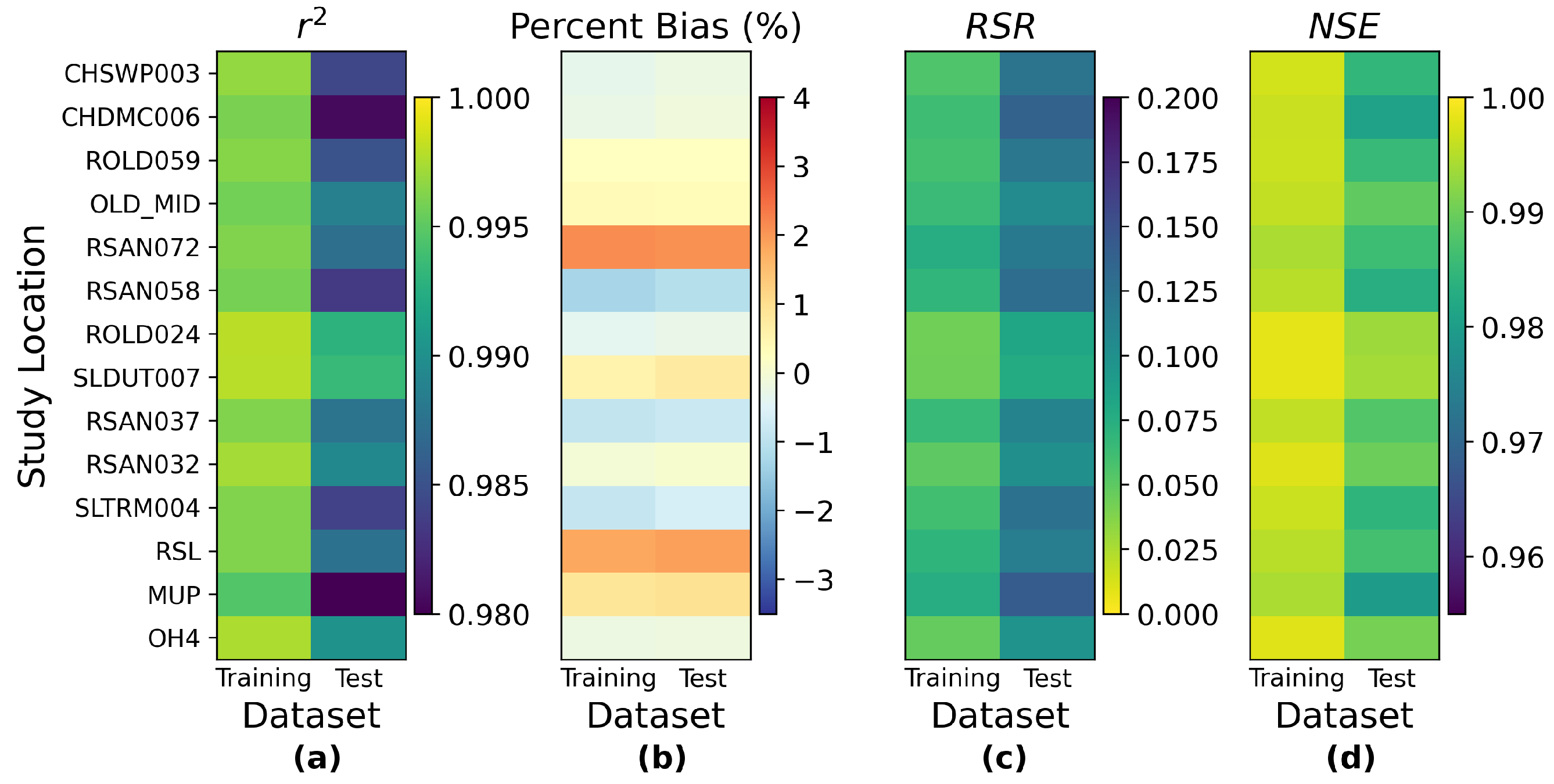
Appendix I. The other three models present a similar pattern, except for ResNet, which estimates the interior Delta group mildly better than the western Delta one, indicating that the interior Delta group benefits more from the additional convolutional path attached to an MLP model to compensate for the potential estimation residuals. These comparisons lead to the conclusion that to accurately estimate the salinity levels for the interior Delta group, relying only on the pre-processed, dimension-reduced input data may not be sufficient and more detailed information from inputs is necessary.
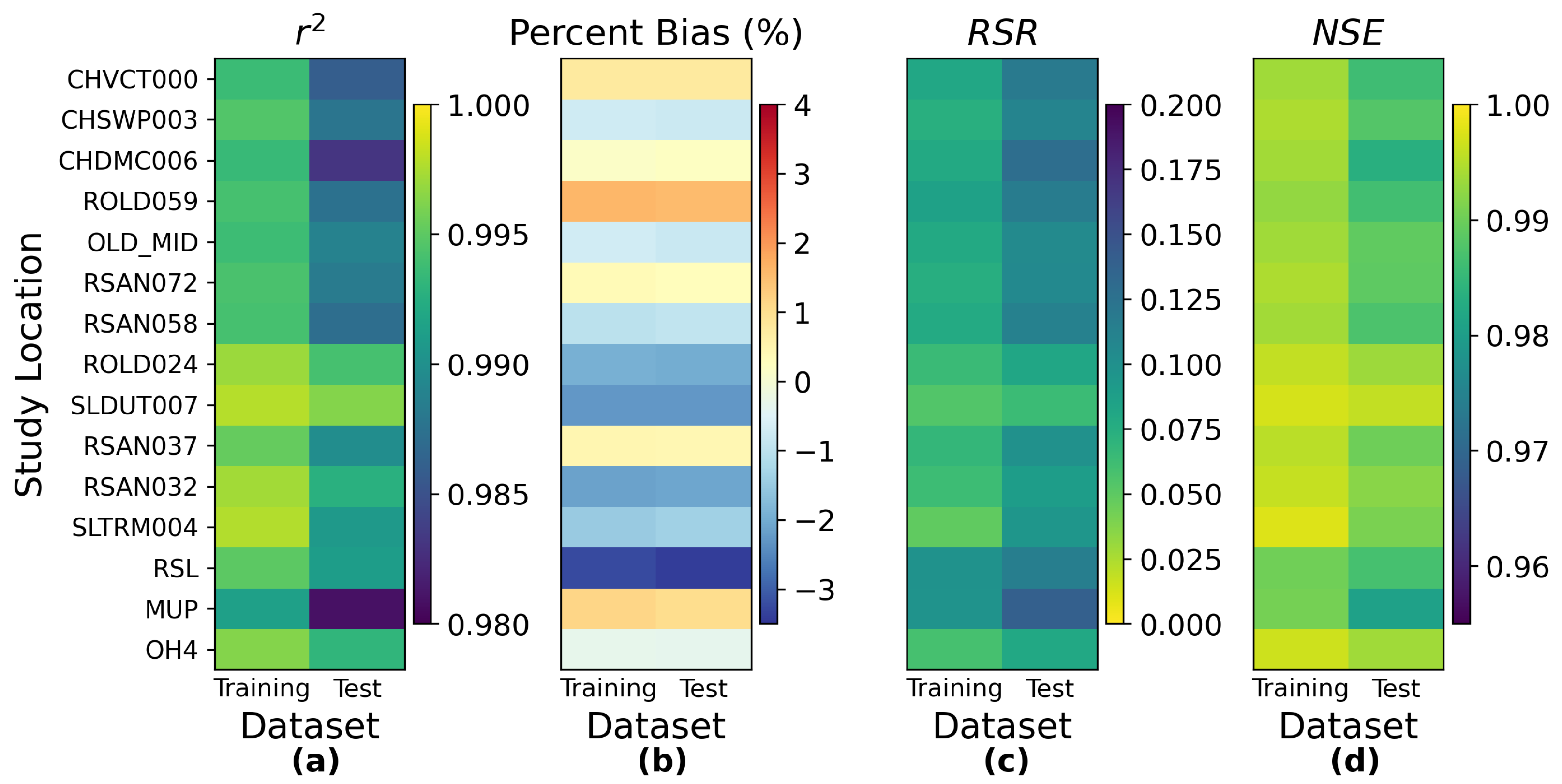
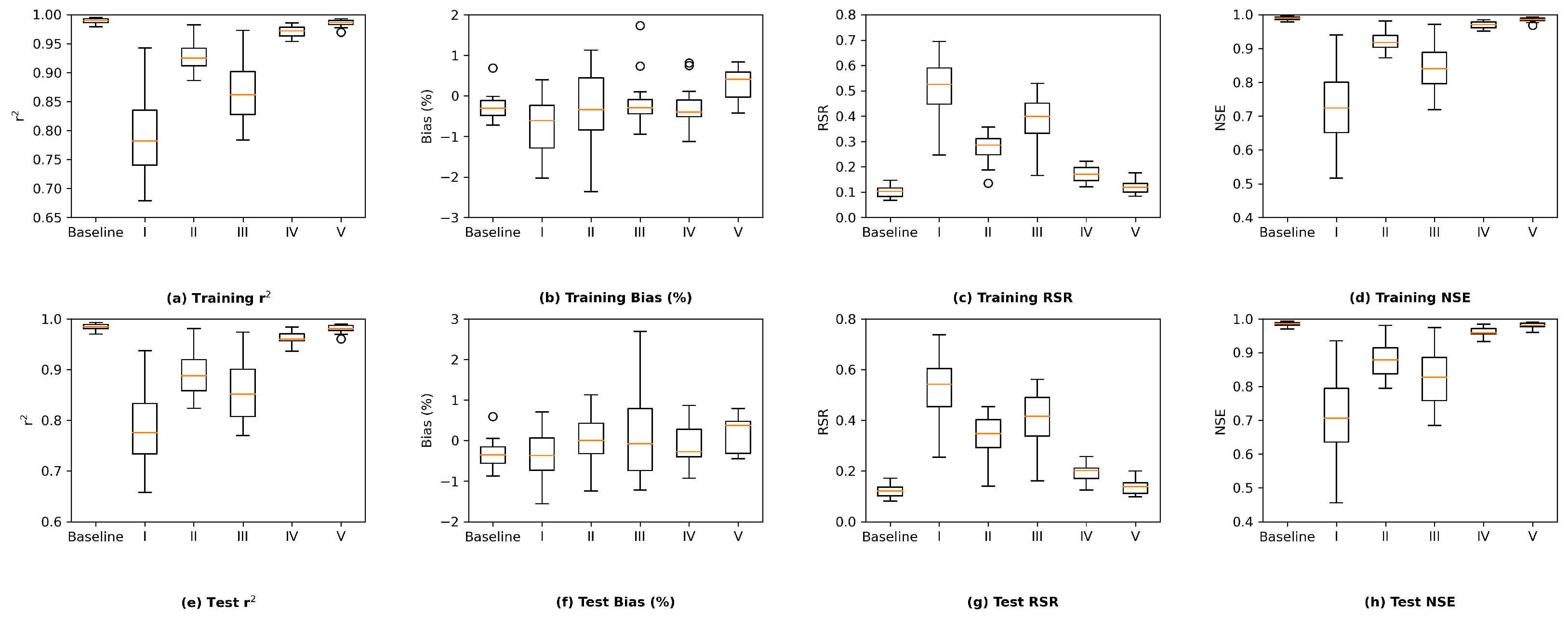
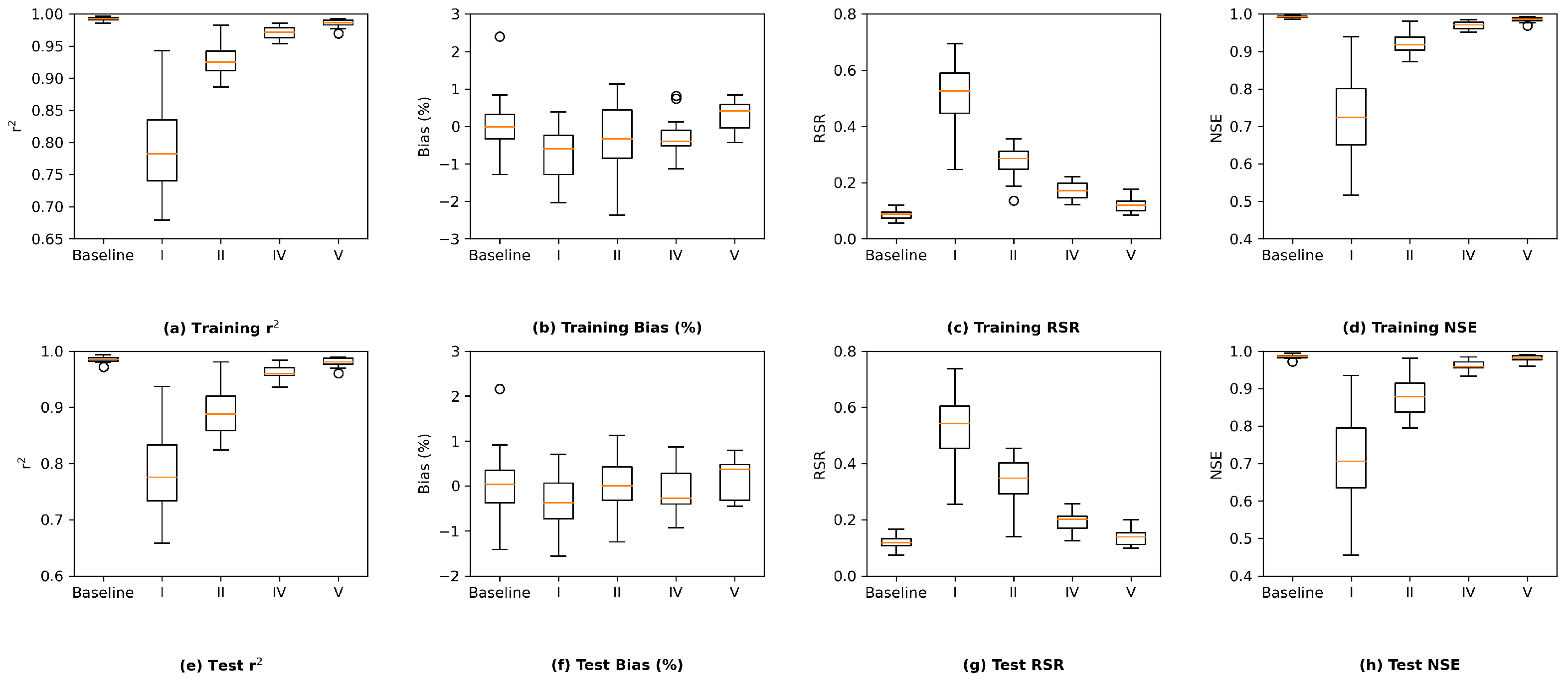
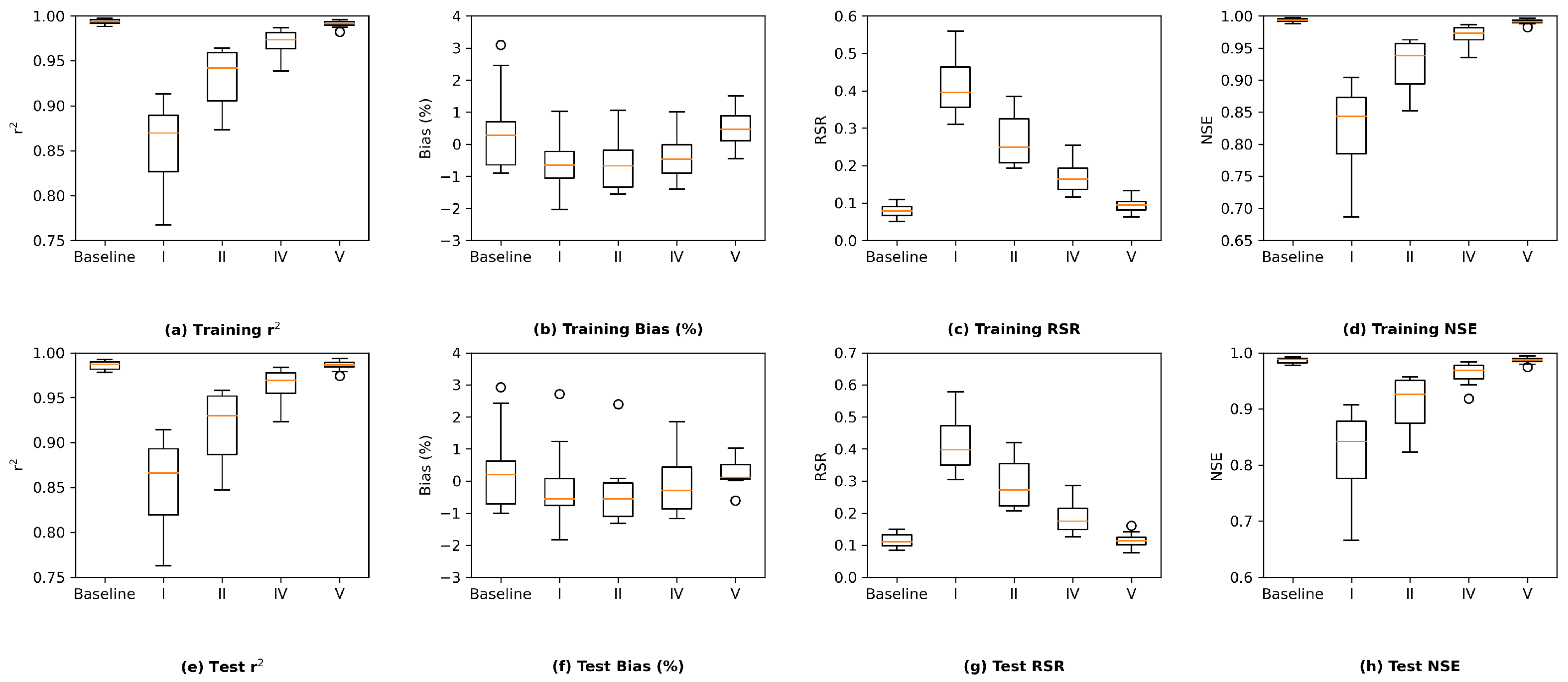
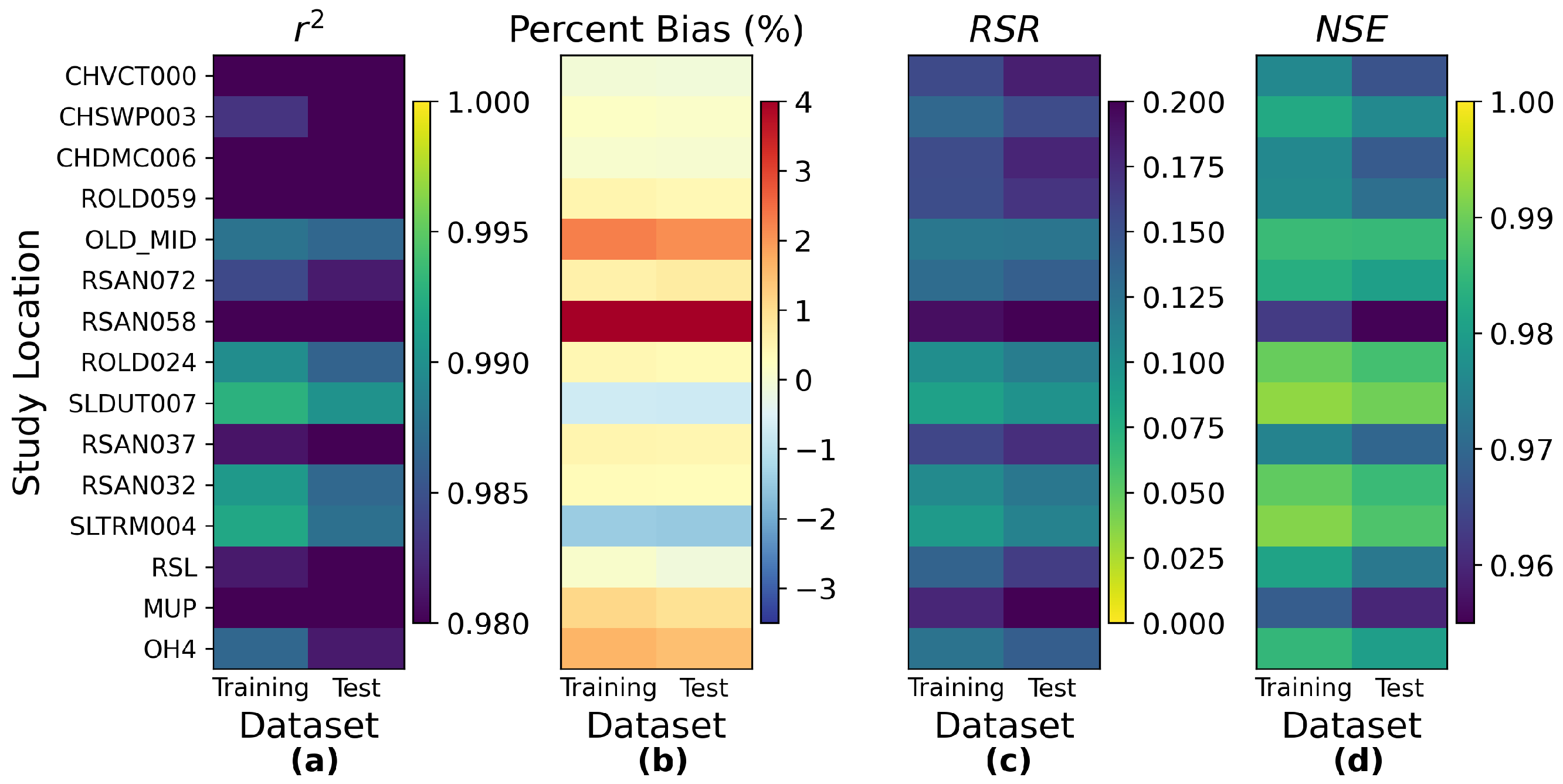
Based on the observations above, we consider the interior Delta group as the key group and visualize the station-wise performance of this group in
Figure 12. In general, among the 14 stations in the interior Delta group, all the four proposed models appear to show a poorer test performance on RSAN037 (location #16 in
Figure 1), ROLD059 (location #19), CHWSP003 (location #22), CHDMC006 (location #23), RSAN058 (location #25), MUP (location #27), and RSL (location #28). According to
Figure 1, all of them are located at the central part of interior Delta, and hence are further away from the locations where input variables are measured. We can observe the same patterns in the station-wise performance comparison plots of proposed MLP, ResNet, and GRU models, which can be found in
Figure A18,
Figure A19 and
Figure A20 in
Appendix J.
In short, the proposed MLP and LSTM models are able to solidly mimic DSM2-simulated daily salinity across the study locations. The models tend to overestimate the low-middle range of salinity but underestimate the high range of salinity. However, the biases are generally small with the absolute amount being less than 4%. The grouped LSTM model has an edge over the ungrouped MLP model.
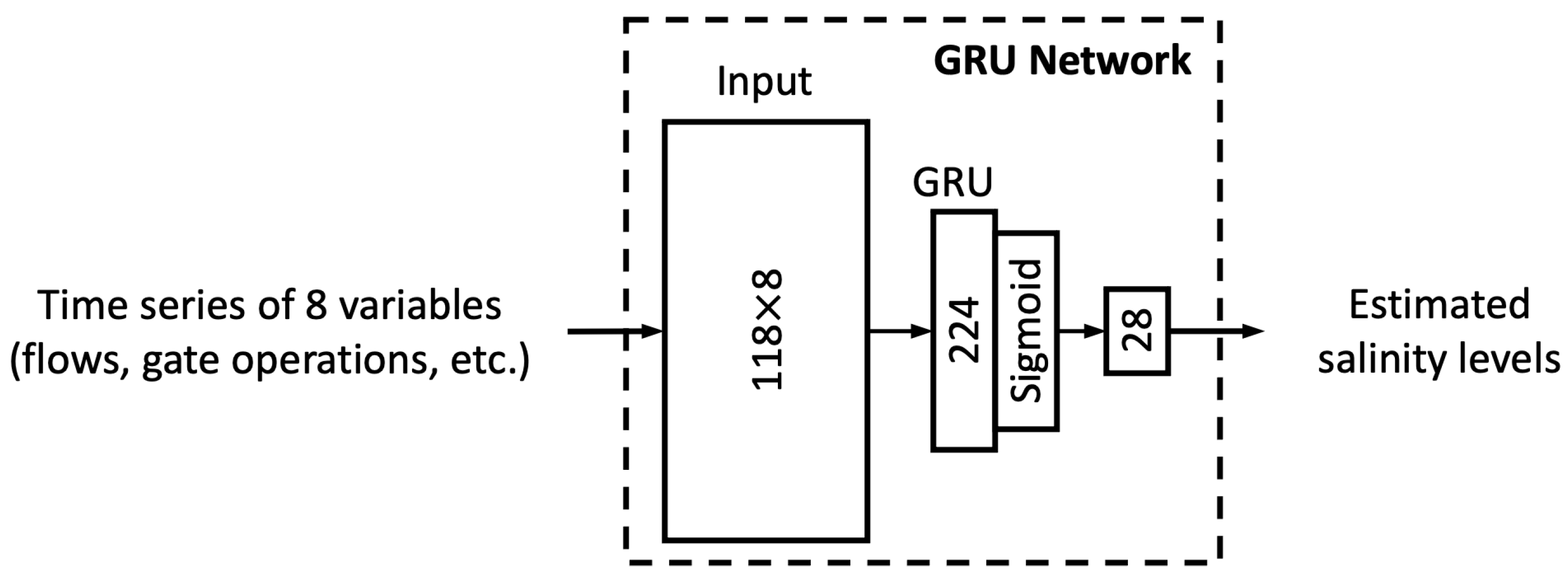
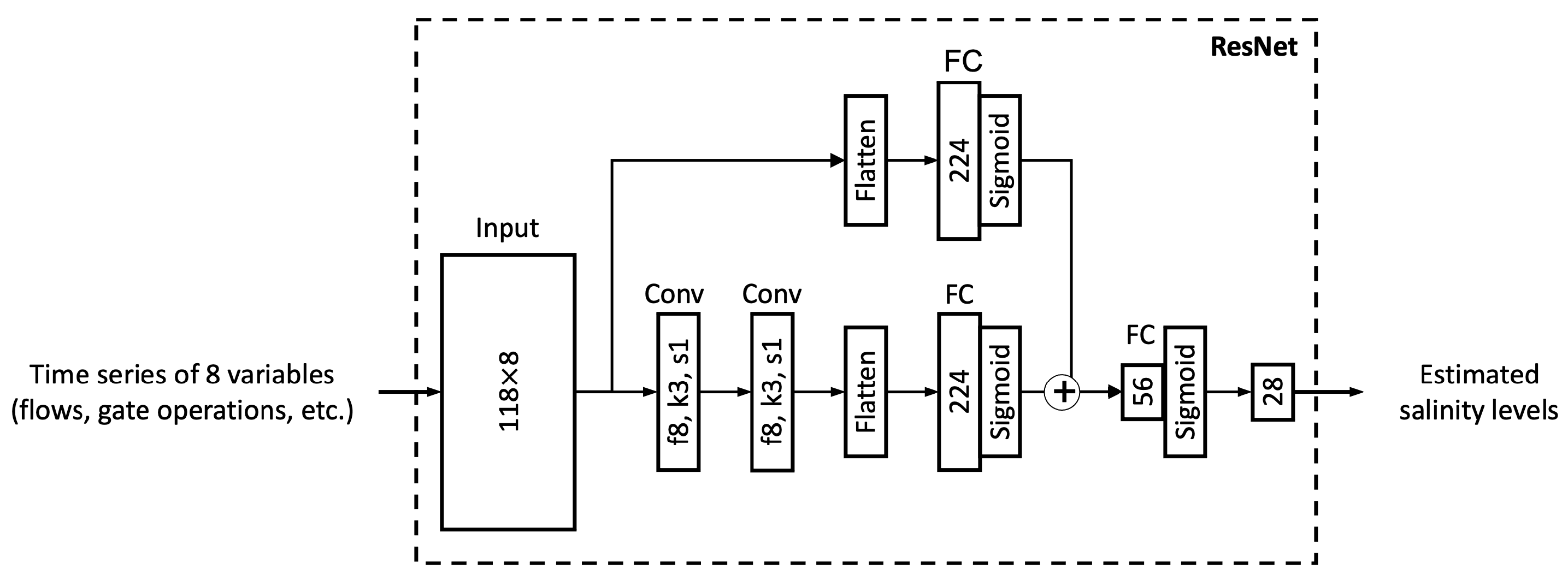
3.3. Performance of Additional Architectures
The simpler MLP and more complex LSTM models are shown to soundly emulate DSM2 in salinity simulation (
Section 3.2). The current sub-section further assesses the two performance exploratory neural networks, GRU and ResNet, whose structural complexities are in between those of the MLP and LSTM models.
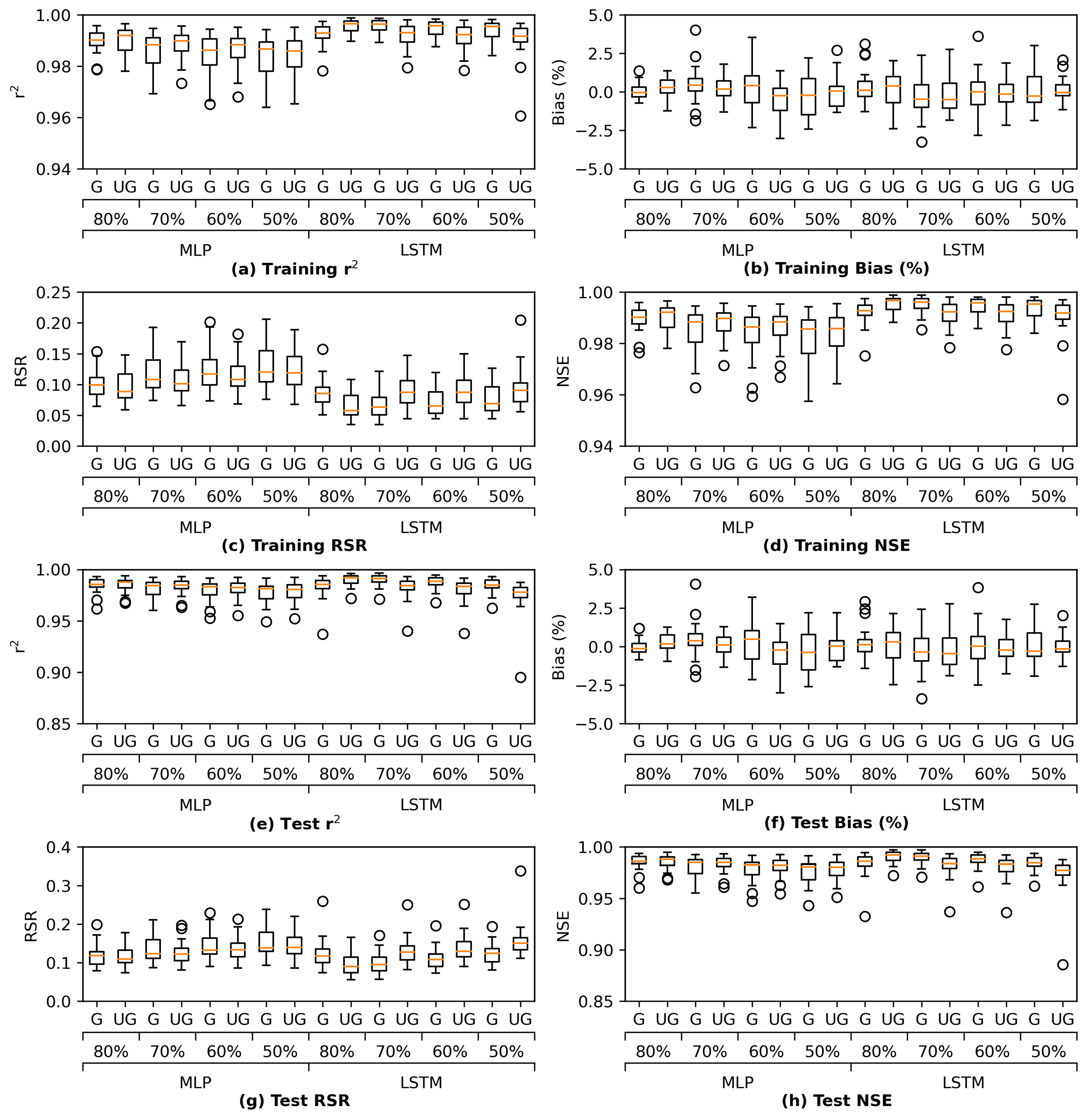
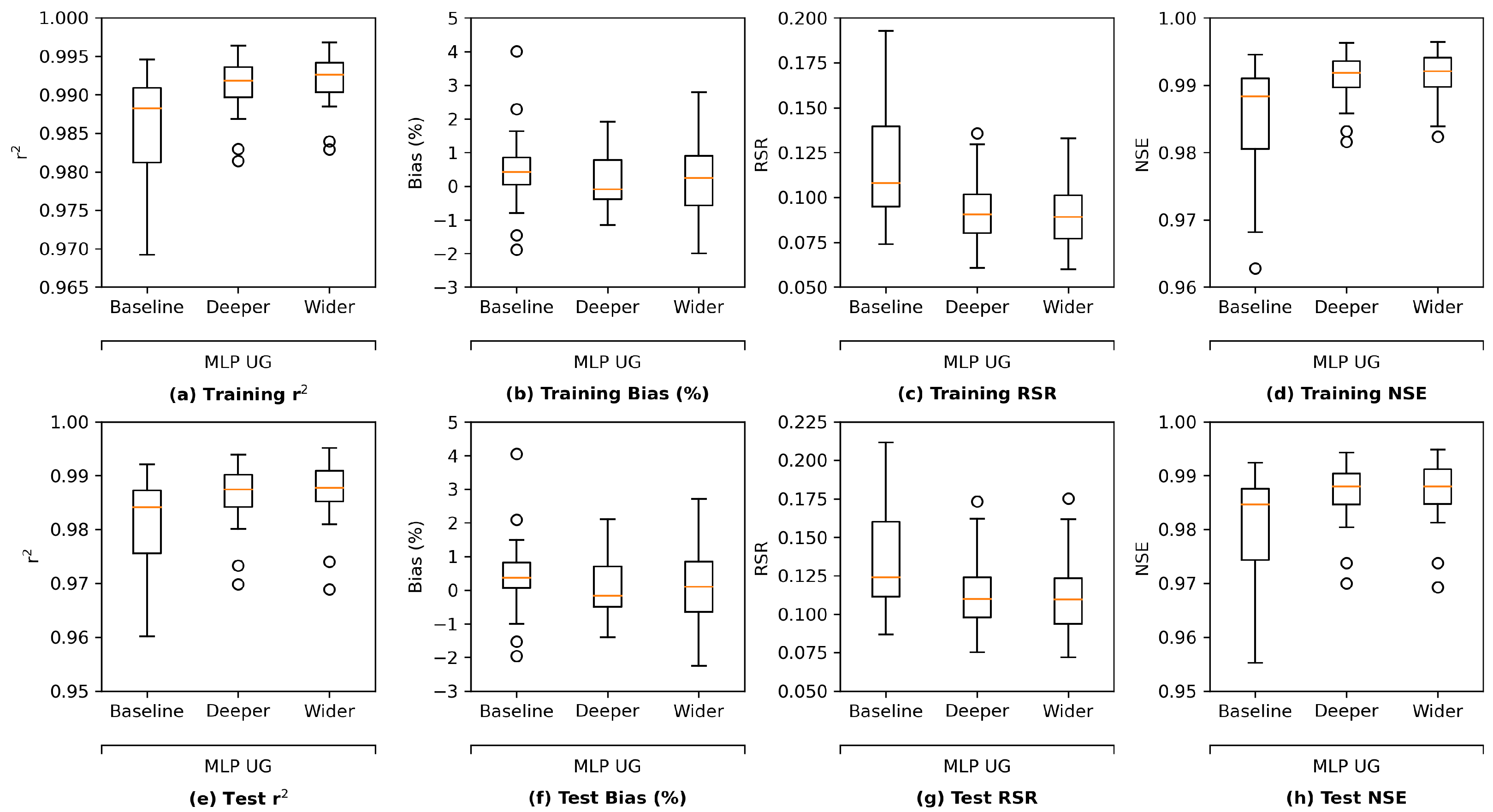
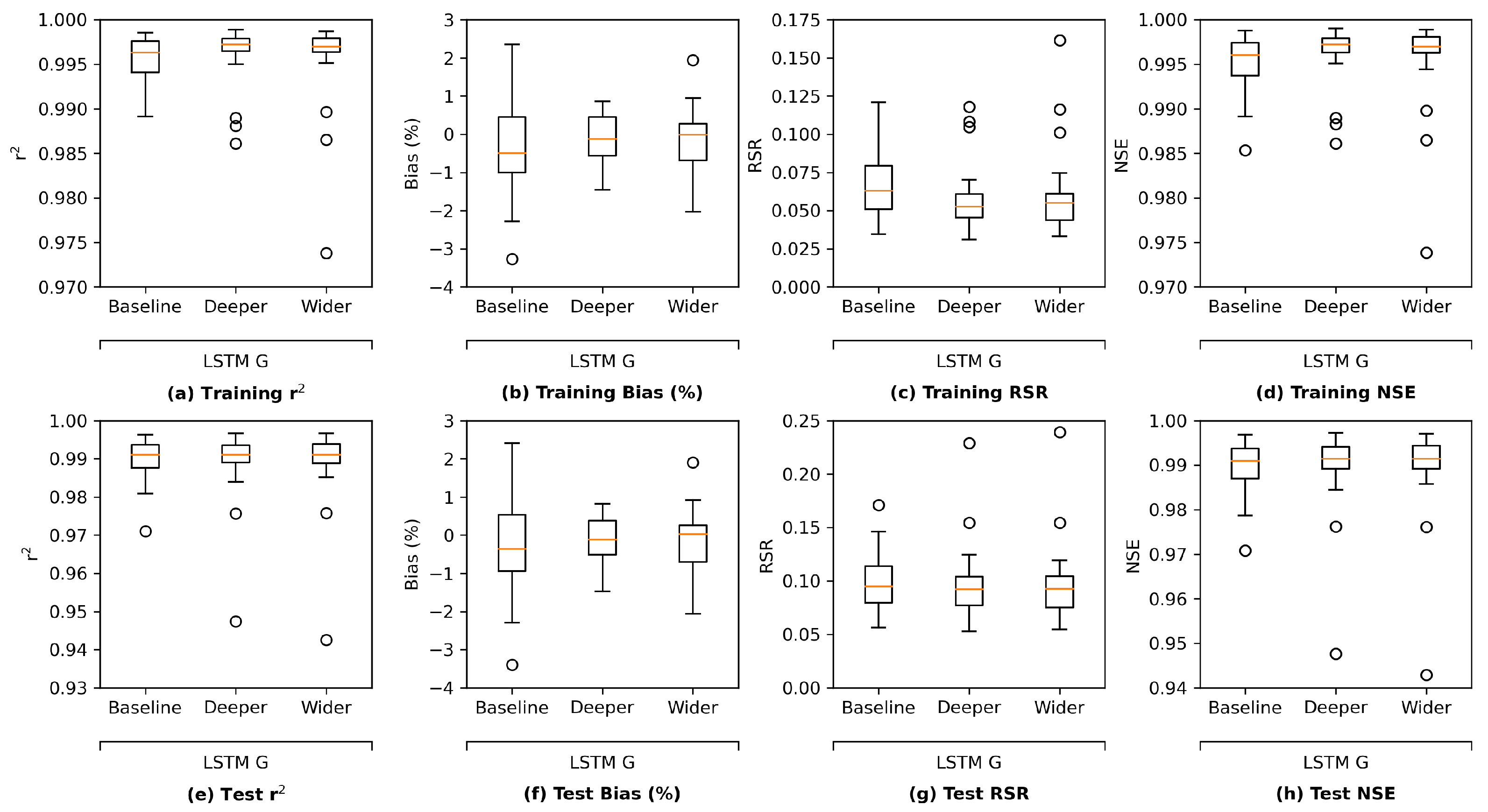
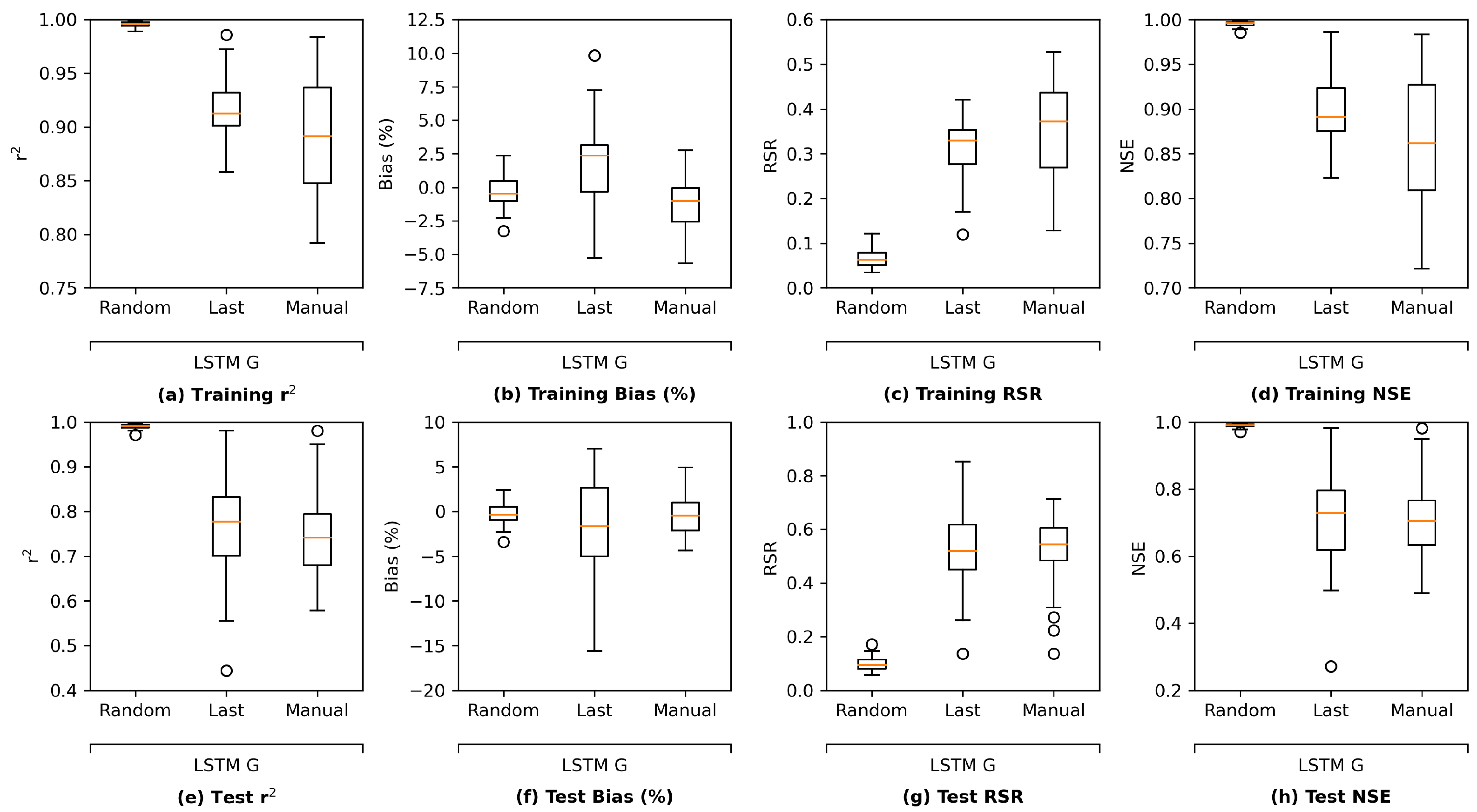
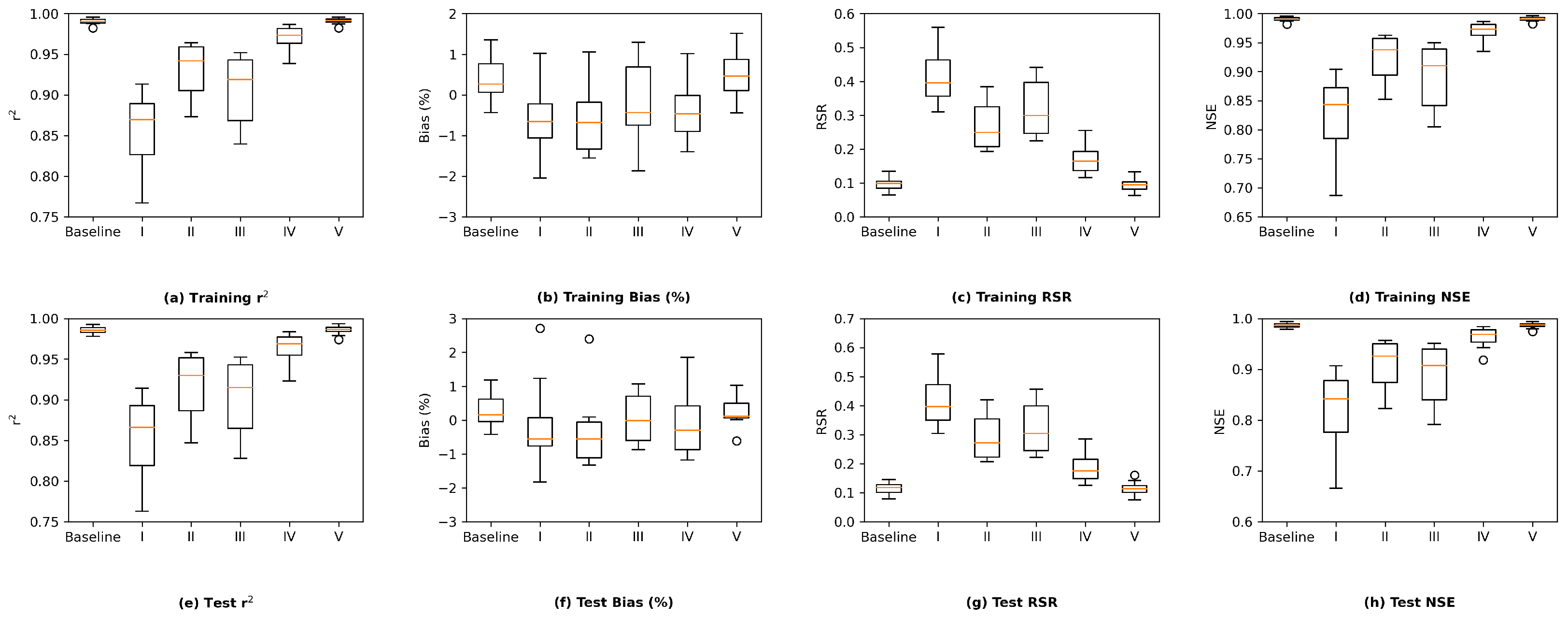
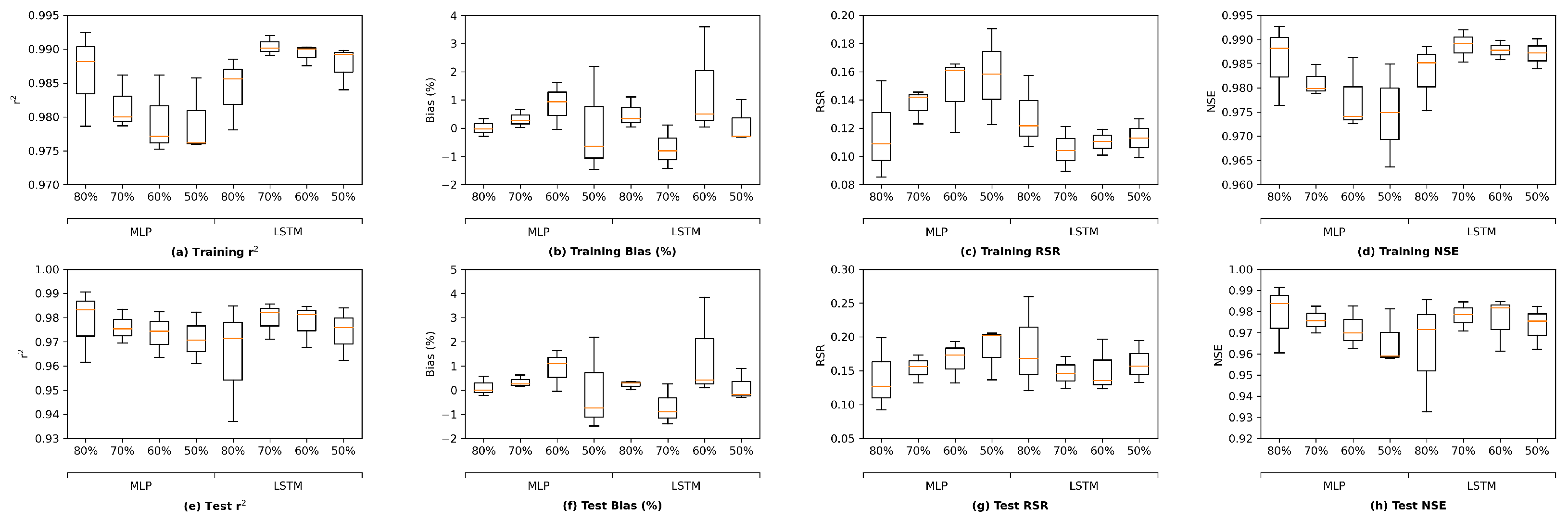
Figure 13 illustrates the comparison of performance in terms of four study metrics. Each model architecture has its grouped (G) and ungrouped (UG) versions. The figure reveals that all the proposed architectures have satisfactory performance in both G and UG scenarios. The training results in
Figure 13a–d indicate that the GRU model performs best while the MLP model is outperformed by the other three architectures, most likely because the MLP model has the simplest complexity and thus the fewest parameters. Meanwhile, the test results in
Figure 13e,f suggest that LSTM and GRU models yield better results than MLP and ResNet models in the corresponding G or UG scenarios, reflecting that recurrent-based architectures are more suitable for the time series estimation task in this study. Moreover, the grouped GRU model appears to overfit more to training data than the grouped LSTM model, which is probably because it does not have an internal cell state to regularize the learned features. In addition, as the proposed ResNet model has more parameters than the MLP model, the ResNet model clearly overfits more as its training performance is better while its test performance is poorer than MLP. Potential model overfitting will be further discussed in the following section.
In addition, for all architectures except for the LSTM model, not grouping (UG) the stations can lead to a slight performance improvement in comparison with grouping. This is likely due to that with more stations (information) available, it is less likely for the models to converge to a “bad” local minimum while the most complex LSTM model is less impacted by the information fed into it.
In brief, the RNN-based architectures (LSTM and GRU) achieve better statistical performance than MLP and ResNet models, which is most likely because the RNN-based models are much more complex in terms of model sizes as well as their internal feature extraction processes (
Table A7 in
Appendix E). The exploratory ResNet and GRU are more prone to overfitting than the originally proposed MLP and LSTM, respectively. Among all the models examined, the grouped LSTM model has the most desirable metrics.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
































