
Performance Assessment of Event-Based Ensemble Landslide Susceptibility Models in Shihmen Watershed, Taiwan


Abstract
:1. Introduction
2. Methods
2.1. Single Landslide Susceptibility Model
2.1.1. Logistic Regression (LR) Model
2.1.2. Random Forest (RF) Model
2.1.3. Support Vector Machine (SVM) and Kernel Logistic Regression (KLR) Models
2.1.4. Gradient-Boosting Decision Tree (GBDT) Model
2.2. Ensemble Landslide Susceptibility Model
2.3. Single Model Establishment Process
2.3.1. Logistic Regression (LR) Model
2.3.2. Nonparametric Models (RF, SVM, KLR, GBDT)
2.4. Model Performance Assessment
2.4.1. Receiver Operating Characteristic (ROC) Curve
2.4.2. Inferential Statistics
2.4.3. Spearman’s Rank Correlation Coefficient
3. Research Area and Materials
3.1. Research Area and Topographic Factor
3.2. Landslide Inventory and Rainfall Factor
4. Results of Analysis
4.1. Results of Single Models
4.1.1. Logistic Regression (LR) Model
4.1.2. Random Forest (RF) Model
4.1.3. Support Vector Machine (SVM) Model
4.1.4. Kernel Logistic Regression (KLR) Model
4.1.5. Gradient-Boosting Decision Tree (GBDT) Model
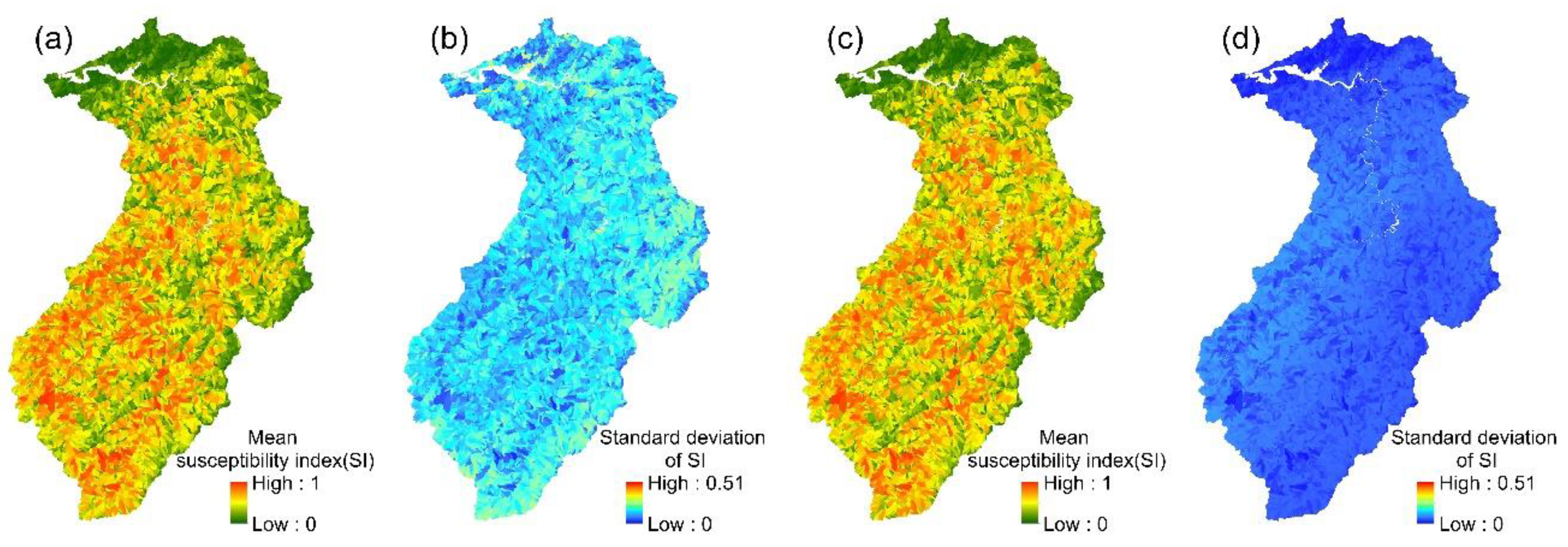
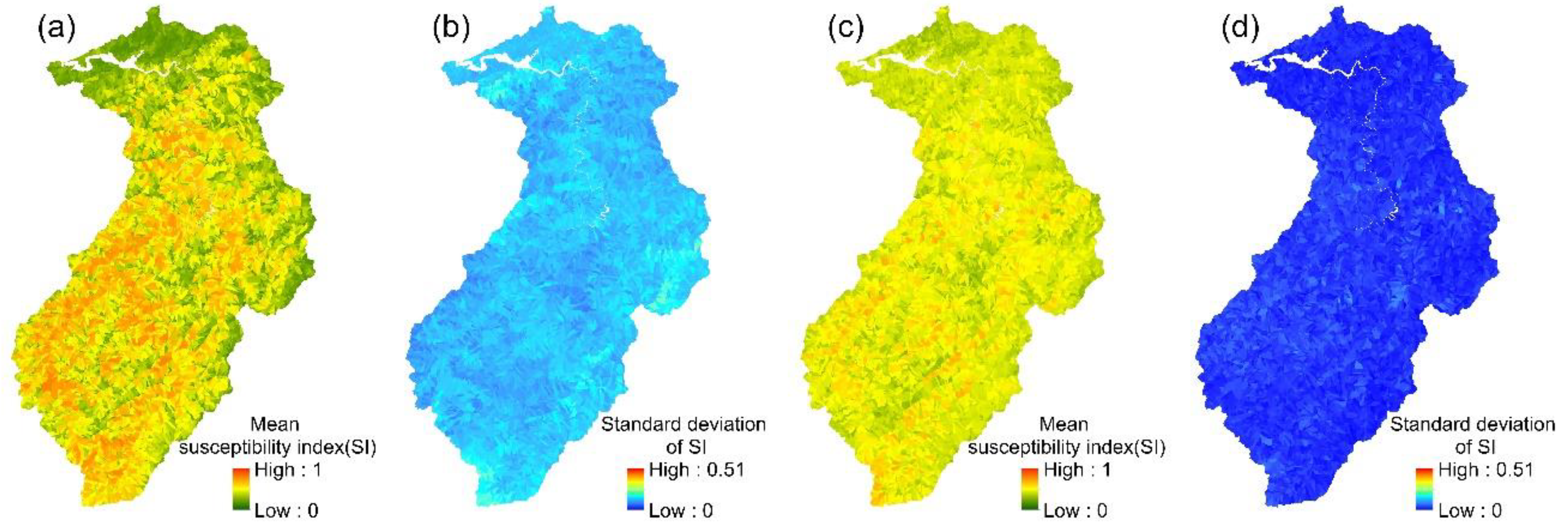
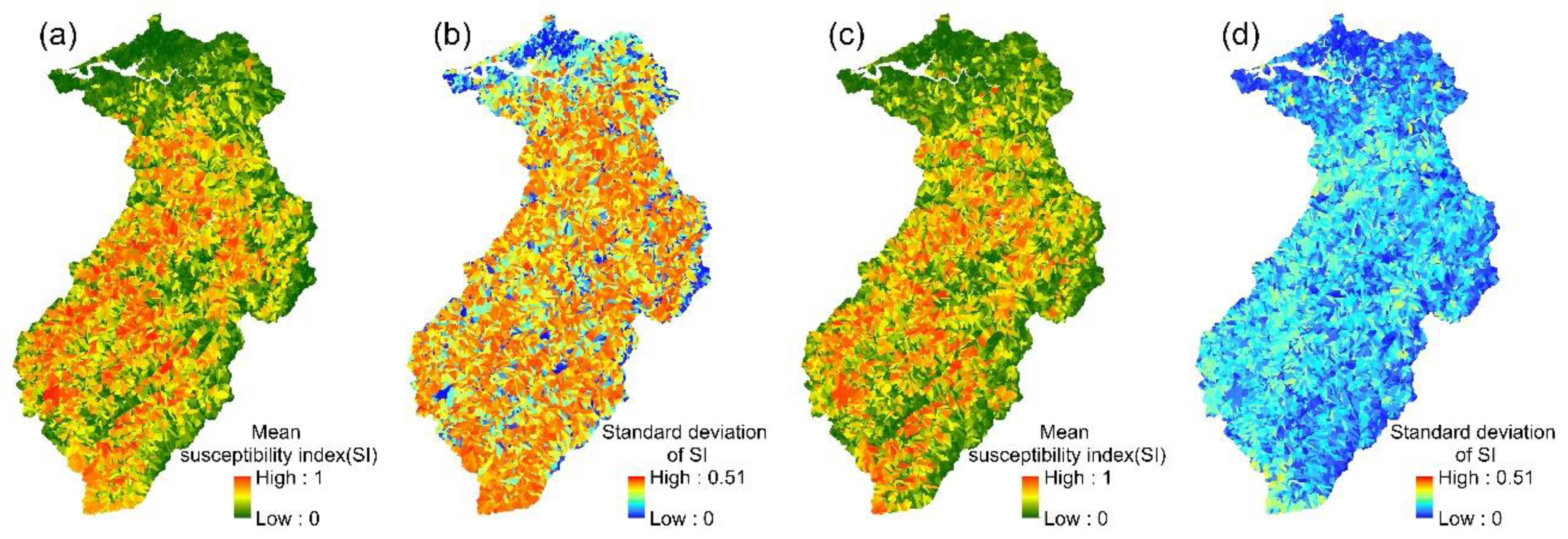
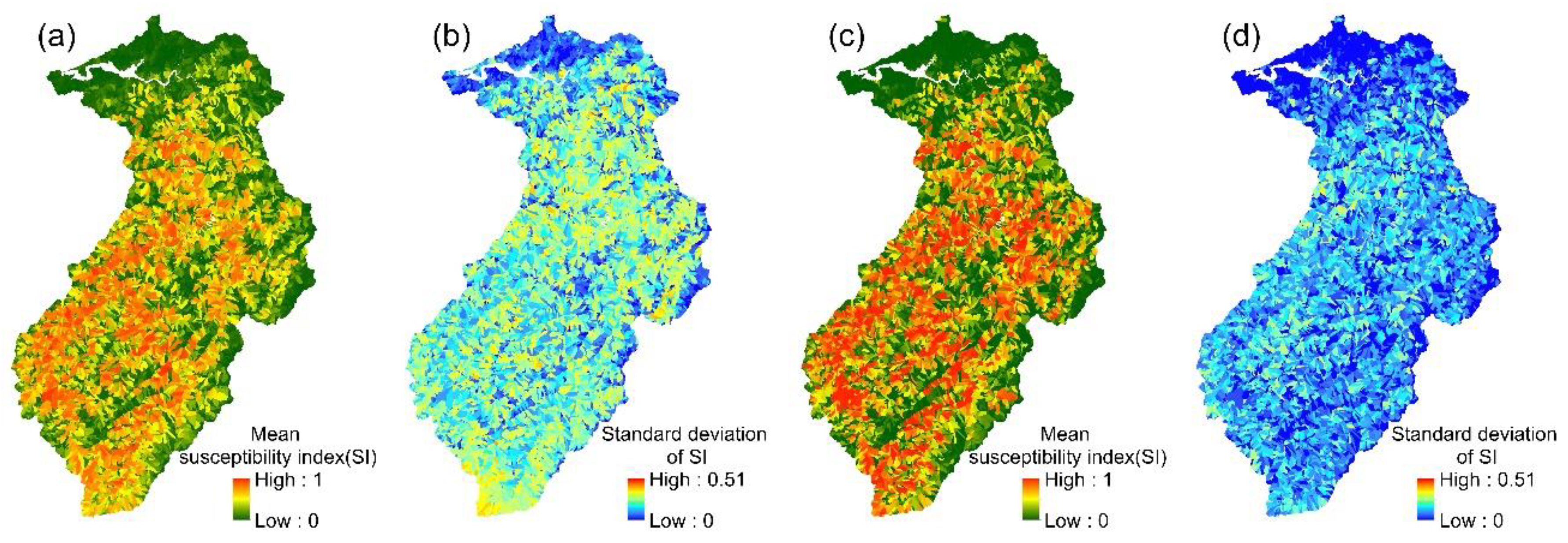
4.2. Results of Ensemble Models
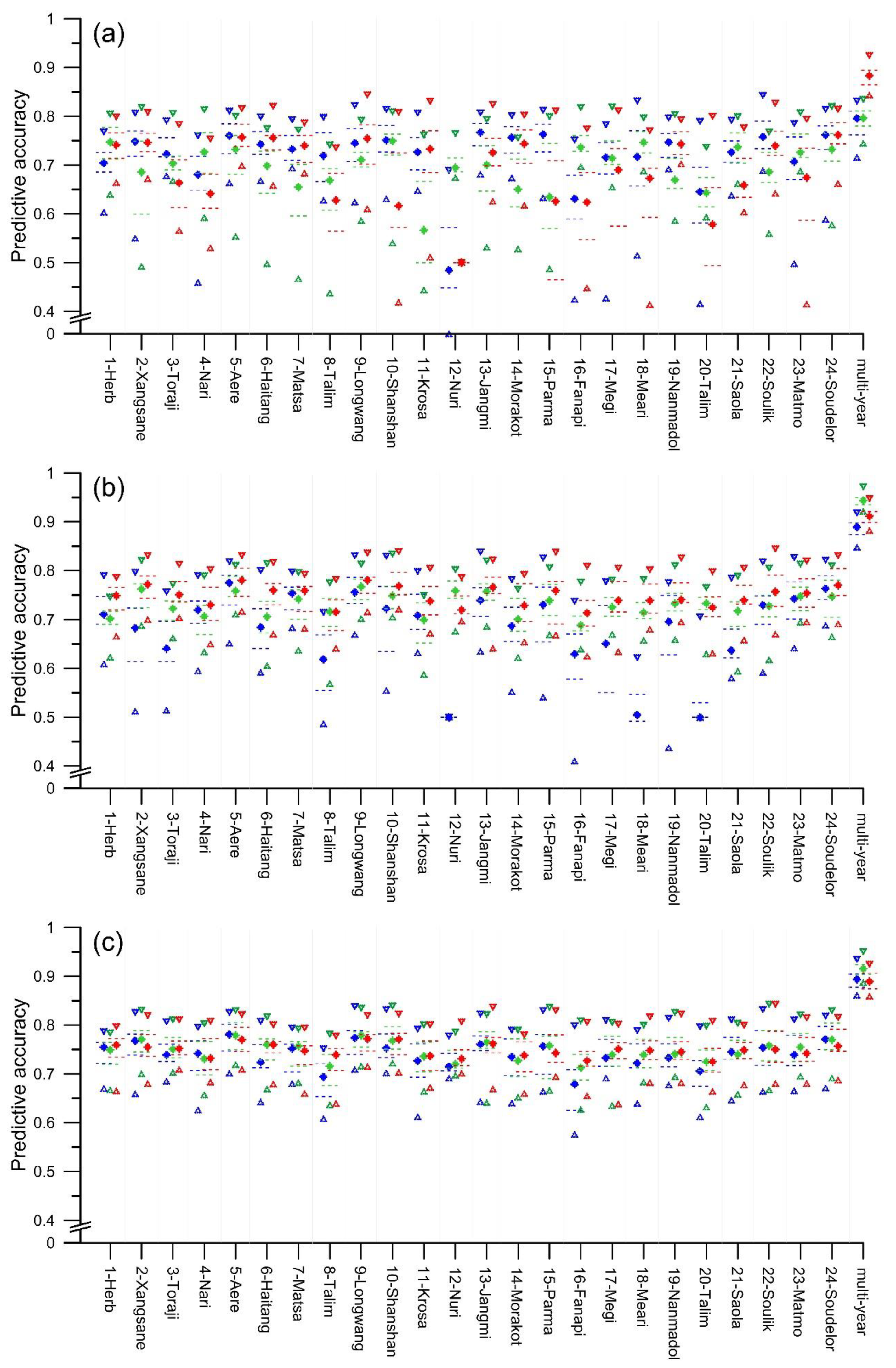
4.3. Assessment of Model Accuracy
5. Discussion
5.1. Comparison of the Performance of Single and Ensemble Models
5.2. Comparison of the Performance of Event-Based and Multi-Year Models
5.3. Correlations between the Susceptibility Maps of the Optimal Model and Other Models
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Van Westen, C.; Van Asch, T.W.; Soeters, R. Landslide hazard and risk zonation—Why is it still so difficult? Bull. Eng. Geol. Environ. 2006, 65, 167–184. [Google Scholar] [CrossRef]
- Brownlee, J. Parametric and Nonparametric Machine Learning Algorithms. Machine Learning Mastery. Available online: https://machinelearningmastery.com/parametric-and-nonparametric-machine-learning-algorithms (accessed on 12 January 2021).
- Lee, C.T.; Huang, C.C.; Lee, J.F.; Pan, K.L.; Lin, M.L.; Dong, J.J. Statistical approach to storm event-induced landslides susceptibility. Nat. Hazards Earth Syst. Sci. 2008, 8, 941–960. [Google Scholar] [CrossRef] [Green Version]
- Lu, A.; Haung, W.K.; Lee, C.F.; Wei, L.W.; Lin, H.H.; Chi, C. Combination of Rainfall Thresholds and Susceptibility Maps for Early Warning Purposes for Shallow Landslides at Regional Scale in Taiwan. In Workshop on World Landslide Forum; Casagli, N., Tofani, V., Sassa, K., Bobrowsky, P.T., Takara, K., Eds.; Springer: Cham, Germany, 2020; pp. 217–225. [Google Scholar]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Wu, C.Y.; Chen, S.C. Integrating spatial, temporal, and size probabilities for the annual landslide hazard maps in the Shihmen watershed, Taiwan. Nat. Hazards Earth Syst. Sci. 2013, 13, 2353–2367. [Google Scholar] [CrossRef] [Green Version]
- Wu, C. Landslide Susceptibility Based on Extreme Rainfall-Induced Landslide Inventories and the Following Landslide Evolution. Water 2019, 11, 2609. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Wu, X.; Niu, R.; Wang, Y.; Zhang, K. Using the rotation and random forest models of ensemble learning to predict landslide susceptibility. Geomat. Nat. Hazards Risk 2020, 11, 1542–1564. [Google Scholar] [CrossRef]
- Brock, J.; Schratz, P.; Petschko, H.; Muenchow, J.; Micu, M.; Brenning, A. The performance of landslide susceptibility models critically depends on the quality of digital elevation models. Geomat. Nat. Hazards Risk 2020, 11, 1075–1092. [Google Scholar] [CrossRef]
- Bui, D.T.; Le, K.T.T.; Nguyen, V.C.; Le, H.D.; Revhaug, I. Tropical forest fire susceptibility mapping at the Cat Ba National Park Area, Hai Phong City, Vietnam, using GIS-based kernel logistic regression. Remote Sens. 2016, 8, 347. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Chang, K.T.; Merghadi, A.; Yunus, A.P.; Pham, B.T.; Dou, J. Evaluating scale effects of topographic variables in landslide susceptibility models using GIS-based machine learning techniques. Sci. Rep. 2019, 9, 12296. [Google Scholar] [CrossRef] [Green Version]
- Mokhtari, M.; Abedian, S. Spatial prediction of landslide susceptibility in Taleghan basin, Iran. Stoch. Environ. Res. Risk Assess. 2019, 33, 1297–1325. [Google Scholar] [CrossRef]
- Oh, H.J.; Kadavi, P.R.; Lee, C.W.; Lee, S. Evaluation of landslide susceptibility mapping by evidential belief function, logistic regression and support vector machine models. Geomat. Nat. Hazards Risk 2018, 9, 1053–1070. [Google Scholar] [CrossRef] [Green Version]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Hyperparameter tuning and performance assessment of statistical and machine-learning algorithms using spatial data. Ecol. Model. 2019, 406, 109–120. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.G.; Lee, D.K.; Park, C.; Ahn, Y.; Kil, S.H.; Sung, S.; Biging, G.S. Estimating landslide susceptibility areas considering the uncertainty inherent in modeling methods. Stoch. Environ. Res. Risk Assess. 2018, 32, 2987–3019. [Google Scholar] [CrossRef]
- Park, S.; Kim, J. Landslide susceptibility mapping based on random forest and boosted regression tree models, and a comparison of their performance. Appl. Sci. 2019, 9, 942. [Google Scholar] [CrossRef] [Green Version]
- Nsengiyumva, J.B.; Valentino, R. Predicting landslide susceptibility and risks using GIS-based machine learning simulations, case of upper Nyabarongo catchment. Geomat. Nat. Hazards Risk 2020, 11, 1250–1277. [Google Scholar] [CrossRef]
- Chen, X.; Chen, W. GIS-based landslide susceptibility assessment using optimized hybrid machine learning methods. Catena 2021, 196, 104833. [Google Scholar] [CrossRef]
- Gassner, C.; Promper, C.; Beguería, S.; Glade, T. Climate change impact for spatial landslide susceptibility. In Engineering Geology for Society and Territory; Christine, G., Catrin, P., Santiago, B., Thomas, G., Eds.; Springer: Cham, Germany, 2015; Volume 1, pp. 429–433. [Google Scholar]
- Lucà, F.; D’Ambrosio, D.; Robustelli, G.; Rongo, R.; Spataro, W. Integrating geomorphology, statistic and numerical simulations for landslide invasion hazard scenarios mapping: An example in the Sorrento Peninsula (Italy). Comput. Geosci. 2014, 67, 163–172. [Google Scholar] [CrossRef]
- Ozturk, U.; Pittore, M.; Behling, R.; Roessner, S.; Andreani, L.; Korup, O. How robust are landslide susceptibility estimates? Landslides 2021, 18, 681–695. [Google Scholar] [CrossRef]
- Knevels, R.; Petschko, H.; Proske, H.; Leopold, P.; Maraun, D.; Brenning, A. Event-Based Landslide Modeling in the Styrian Basin, Austria: Accounting for Time-Varying Rainfall and Land Cover. Geosciences 2020, 10, 217. [Google Scholar] [CrossRef]
- Shou, K.J.; Yang, C.M. Predictive analysis of landslide susceptibility under climate change conditions—A study on the Chingshui River Watershed of Taiwan. Eng. Geol. 2015, 192, 46–62. [Google Scholar] [CrossRef]
- Tanyas, H.; Rossi, M.; Alvioli, M.; van Westen, C.J.; Marchesini, I. A global slope unit-based method for the near real-time prediction of earthquake-induced landslides. Geomorphology 2019, 327, 126–146. [Google Scholar] [CrossRef]
- Moayedi, H.; Khari, M.; Bahiraei, M.; Foong, L.K.; Bui, D.T. Spatial assessment of landslide risk using two novel integrations of neuro-fuzzy system and metaheuristic approaches; Ardabil Province, Iran. Geomat. Nat. Hazards Risk 2020, 11, 230–258. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Li, C.; Peng, J.; Peng, D.; Xu, Q.; Zhang, Q.; Bate, B. GIS-based soil planar slide susceptibility mapping using logistic regression and neural networks: A typical red mudstone area in southwest China. Geomat. Nat. Hazards Risk 2021, 12, 852–879. [Google Scholar] [CrossRef]
- Nachappa, T.G.; Kienberger, S.; Meena, S.R.; Hölbling, D.; Blaschke, T. Comparison and validation of per-pixel and object-based approaches for landslide susceptibility mapping. Geomat. Nat Hazards Risk 2020, 11, 572–600. [Google Scholar] [CrossRef]
- Sur, U.; Singh, P.; Meena, S.R. Landslide susceptibility assessment in a lesser Himalayan road corridor (India) applying fuzzy AHP technique and earth-observation data. Geomat. Nat. Hazards Risk 2020, 11, 2176–2209. [Google Scholar] [CrossRef]
- Luo, L.; Lombardo, L.; van Westen, C.; Pei, X.; Huang, R. From scenario-based seismic hazard to scenario-based landslide hazard: Rewinding to the past via statistical simulations. Stoch. Environ. Res. Risk Assess. 2021. [Google Scholar] [CrossRef]
- Di Napoli, M.; Carotenuto, F.; Cevasco, A.; Confuorto, P.; Di Martire, D.; Firpo, M.; Pepe, G.; Raso, E.; Calcaterra, D. Machine learning ensemble modelling as a tool to improve landslide susceptibility mapping reliability. Landslides 2020, 17, 1897–1914. [Google Scholar] [CrossRef]
- Thuiller, W.; Georges, D.; Engler, R. Biomod2 Package Manual. 2015. Available online: https://CRAN.R-project.org/package=biomod2 (accessed on 12 July 2021).
- Wolpert, D.H. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Lee, M.J.; Choi, J.W.; Oh, H.J.; Won, J.S.; Park, I.; Lee, S. Ensemble-based landslide susceptibility maps in Jinbu area, Korea. Env. Earth Sci. 2012, 67, 23–37. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, H.; Mei, H.; Xiao, D.; Li, Y.; Li, M. Landslide Susceptibility Mapping Using the Stacking Ensemble Machine Learning Method in Lushui, Southwest China. Appl. Sci. 2020, 10, 4016. [Google Scholar] [CrossRef]
- Menard, S.W. Applied Logistic Regression Analysis, 2nd ed.; Sage University Paper Series on Quantitative Application in the Social Sciences, Series no. 106; Sage: Thousand Oaks, CA, USA, 1995. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Olden, J.D.; Kennard, M.J.; Pusey, B.J. Species invasions and the changing biogeography of Australian freshwater fishes. Glob. Ecol. Biogeogr. 2008, 17, 25–37. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory. IEEE Trans. Neural Netw. 1997, 8, 1564. [Google Scholar]
- Foody, G.M.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef] [Green Version]
- Cawley, G.C.; Talbot, N.L. Efficient approximate leave-one-out cross-validation for kernel logistic regression. Mach. Learn. 2008, 71, 243–264. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the Hoa Binh province of Vietnam: A comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 2012, 171, 12–29. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Cheong, Y.L.; Leitão, P.J.; Lakes, T. Assessment of land use factors associated with dengue cases in Malaysia using Boosted Regression Trees. Spat. Spatio-Temporal Epidemiol. 2014, 10, 75–84. [Google Scholar] [CrossRef]
- Green, D.M.; Swets, J.A. Signal Detection Theory and Psychophysics; Wiley: New York, NY, USA, 1966; Volume 1, pp. 1969–2012. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Statist. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Wilcoxon, F. Some uses of statistics in plant pathology. Biometrics Bull. 1945, 1, 41–45. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.A. Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Spearman, C. The Proof and Measurement of Association Between Two Things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Myers, J.L.; Well, A.D. Research Design and Statistical Analysis; Routledge: London, UK, 2003. [Google Scholar]
- Xie, M.; Esaki, T.; Zhou, G. GIS-based probabilistic mapping of landslide hazard using a three-dimensional deterministic model. Nat. Hazards 2004, 33, 265–282. [Google Scholar] [CrossRef]
- Liu, J.K.; Weng, T.C.; Hung, C.H.; Yang, M.T. Remote Sensing Analysis of Heavy Rainfall Induced Landslide. In Proceedings of the 21st Century Civil Engineering Technology and Management Conference, Hsinchu, Taiwan, 28 December 2001; Minghsin University of Science and Technology: Xinfeng Township, Taiwan, 2001; pp. C21–C31. (In Chinese). [Google Scholar]
- Dai, F.; Lee, C. A spatiotemporal probabilistic modelling of storm-induced shallow landsliding using aerial photographs and logistic regression. Earth Surf. Processes Landf. J. Br. Geomorphol. Res. Group 2003, 28, 527–545. [Google Scholar] [CrossRef]
- Lee, C.T.; Chung, C.C. Common patterns among different landslide susceptibility models of the same region. In Proceedings of the Workshop on World Landslide Forum, Ljubljana, Slovenia, 30 May–2 June 2017; Springer: Cham, Germany, 2017; pp. 937–942. [Google Scholar]
- Chien, F.C. The Relationship among Probability of Failure, Landslide Susceptibility and Rainfall. Master’s Thesis, National Central University, Taoyuan City, Taiwan, 2015. [Google Scholar]
- Fu, C.C. Event-Based Landslide Susceptibility and Rainfall-Induced Landslide Probability Prediction Model in the Zengwen Reservoir Catchment. Master’s Thesis, National Central University, Taoyuan City, Taiwan, 2017. [Google Scholar]
- Lai, J.S.; Chiang, S.H.; Tsai, F. Exploring influence of sampling strategies on event-based landslide susceptibility modeling. ISPRS Int. J. Geo-Inf. 2019, 8, 397. [Google Scholar] [CrossRef] [Green Version]
- Xiao, T.; Segoni, S.; Chen, L.; Yin, K.; Casagli, N. A step beyond landslide susceptibility maps: A simple method to investigate and explain the different outcomes obtained by different approaches. Landslides 2020, 17, 627–640. [Google Scholar] [CrossRef] [Green Version]
- Lei, X.; Chen, W.; Pham, B.T. Performance evaluation of GIS-based artificial intelligence approaches for landslide susceptibility modeling and spatial patterns analysis. ISPRS Int. J. Geo-Inf. 2020, 9, 443. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ensemble Methods | Description |
|---|---|
| PM | Mean of susceptibility indexes. The PM ensemble model calculates the mean of the susceptibility indexes for the selected models. |
| PME | Median of susceptibility indexes. The PME ensemble model calculates the median of the susceptibility indexes for the selected models. |
| PMW | Weighted mean of susceptibility indexes. The PMW ensemble model calculates the relative importance of the weights based on the accuracies of the selected models, and then calculates the weighted mean of the susceptibility indexes for the models. |
| CA | Committee averaging. After identifying the threshold value of each selected model and converting the susceptibility index to binary value, the CA ensemble model calculates the average of binary values for the selected models. |
| Model | Hyperparameter | Range |
|---|---|---|
| RF | number of trees (numtree) | 100–1500 |
| number of variables (mtry) | 3–14 | |
| SVM | penalty parameter (C) | 0.001–1000 |
| RBF parameter (γ) | 0.001–1000 | |
| KLR | penalty parameter (C) | 0.001–1000 |
| RBF parameter (γ) | 0.001–1000 | |
| GBDT | number of trees (numtree) | 100–1000 |
| number of variables (mtry) | 5–14 | |
| learning rate | 0.1–1 |
| Assessment Methods | Description | Explanation |
|---|---|---|
| Receiver operating characteristic (ROC) curve | The area under the ROC curve (AUROC) represented the model’s performance and predictive accuracy. | AUROC ranges in value from 0 to 1. An excellent model has an AUROC near 1, and a poor performance model has an AUROC near 0. |
| Mann–Whitney test | The test was used to compare the predictive accuracy of multi-year model to that of event-based models. | A p-value < 0.05 indicates that the null hypothesis is rejected and a statistically significant difference between the predictive accuracy of multi-year model and that of event-based models exists. |
| Kruskal–Wallis test | The test was used to compare the predictive accuracy of different modeling methods. | A p-value < 0.05 indicates that null hypothesis is rejected and a statistically significant difference of the predictive accuracy of 9 modeling methods exists. |
| Spearman’s rank correlation coefficient | The coefficient was used for a quantitative comparison on landslide susceptibility maps. | The value ranges between −1 and 1. A coefficient close to 1 means small differences between the susceptibility map of the optimal model and that of other models. |
| Event | Test Accuracy | Event | Test Accuracy |
|---|---|---|---|
| 1-Herb | 0.825 | 14-Morakot | 0.832 |
| 2-Xangsane | 0.776 | 15-Parma | 0.802 |
| 3-Toraji | 0.740 | 16-Fanapi | 0.815 |
| 4-Nari | 0.760 | 17-Megi | 0.859 |
| 5-Aere | 0.824 | 18-Meari | 0.798 |
| 6-Haitang | 0.789 | 19-Nanmadol | 0.862 |
| 7-Matsa | 0.832 | 20-Talim | 0.812 |
| 8-Talim | 0.806 | 21-Saola | 0.815 |
| 9-Longwang | 0.859 | 22-Soulik | 0.835 |
| 10-Shanshan | 0.826 | 23-Matmo | 0.835 |
| 11-Krosa | 0.850 | 24-Soudelor | 0.823 |
| 12-Nuri | 0.842 | Multi-year | 0.798 |
| 13-Jangmi | 0.849 |
| Event | Hyperparameter Tuned | Test Accuracy | Event | Hyperparameter Tuned | Test Accuracy | ||
|---|---|---|---|---|---|---|---|
| Numtree | Mtry | Numtree | Mtry | ||||
| 1-Herb | 100 | 8 | 0.797 | 14-Morakot | 300 | 13 | 0.815 |
| 2-Xangsane | 500 | 14 | 0.772 | 15-Parma | 1000 | 14 | 0.820 |
| 3-Toraji | 700 | 11 | 0.851 | 16-Fanapi | 600 | 14 | 0.848 |
| 4-Nari | 400 | 13 | 0.821 | 17-Megi | 200 | 11 | 0.872 |
| 5-Aere | 1000 | 12 | 0.820 | 18-Meari | 500 | 7 | 0.849 |
| 6-Haitang | 700 | 11 | 0.792 | 19-Nanmadol | 600 | 14 | 0.913 |
| 7-Matsa | 700 | 12 | 0.845 | 20-Talim | 600 | 13 | 0.824 |
| 8-Talim | 300 | 11 | 0.808 | 21-Saola | 700 | 13 | 0.944 |
| 9-Longwang | 600 | 13 | 0.843 | 22-Soulik | 500 | 11 | 0.846 |
| 10-Shanshan | 500 | 14 | 0.819 | 23-Matmo | 900 | 13 | 0.883 |
| 11-Krosa | 700 | 12 | 0.855 | 24-Soudelor | 400 | 13 | 0.827 |
| 12-Nuri | 1000 | 14 | 0.881 | Multi-year | 400 | 14 | 0.789 |
| 13-Jangmi | 900 | 13 | 0.855 | ||||
| Event | Hyperparameter Tuned | Test Accuracy | Event | Hyperparameter Tuned | Test Accuracy | ||
|---|---|---|---|---|---|---|---|
| C | γ | C | γ | ||||
| 1-Herb | 2.683 | 0.017 | 0.721 | 14-Morakot | 0.029 | 0.029 | 0.768 |
| 2-Xangsane | 79.060 | 0.007 | 0.717 | 15-Parma | 2.024 | 0.052 | 0.766 |
| 3-Toraji | 0.494 | 0.091 | 0.759 | 16-Fanapi | 3.556 | 0.029 | 0.772 |
| 4-Nari | 0.655 | 0.029 | 0.755 | 17-Megi | 0.121 | 0.017 | 0.786 |
| 5-Aere | 4.715 | 0.013 | 0.732 | 18-Meari | 2.024 | 0.029 | 0.787 |
| 6-Haitang | 33.932 | 0.001 | 0.729 | 19-Nanmadol | 1.151 | 0.017 | 0.797 |
| 7-Matsa | 754.312 | 0.001 | 0.757 | 20-Talim | 4.715 | 0.002 | 0.674 |
| 8-Talim | 2.024 | 0.069 | 0.758 | 21-Saola | 10.985 | 0.091 | 0.861 |
| 9-Longwang | 14.563 | 0.005 | 0.754 | 22-Soulik | 19.307 | 0.002 | 0.712 |
| 10-Shanshan | 138.950 | 0.002 | 0.741 | 23-Matmo | 1.151 | 0.017 | 0.739 |
| 11-Krosa | 2.024 | 0.007 | 0.758 | 24-Soudelor | 0.373 | 0.007 | 0.728 |
| 12-Nuri | 3.556 | 0.022 | 0.754 | Multi-year | 0.1 | 0.774 | 0.806 |
| 13-Jangmi | 184.207 | 0.001 | 0.769 | ||||
| Event | Hyperparameter Tuned | Test Accuracy | Event | Hyperparameter Tuned | Test Accuracy | ||
|---|---|---|---|---|---|---|---|
| C | γ | C | γ | ||||
| 1-Herb | 244.205 | 0.005 | 0.712 | 14-Morakot | 0.017 | 0.039 | 0.729 |
| 2-Xangsane | 59.636 | 0.005 | 0.712 | 15-Parma | 2.683 | 0.017 | 0.771 |
| 3-Toraji | 1.151 | 0.052 | 0.781 | 16-Fanapi | 33.932 | 0.013 | 0.784 |
| 4-Nari | 10.985 | 0.017 | 0.775 | 17-Megi | 2.024 | 0.069 | 0.815 |
| 5-Aere | 1.151 | 0.022 | 0.760 | 18-Meari | 33.932 | 0.007 | 0.725 |
| 6-Haitang | 1.526 | 0.029 | 0.717 | 19-Nanmadol | 8.286 | 0.003 | 0.829 |
| 7-Matsa | 244.205 | 0.002 | 0.747 | 20-Talim | 1.151 | 0.069 | 0.712 |
| 8-Talim | 1.526 | 0.069 | 0.744 | 21-Saola | 14.563 | 0.281 | 0.833 |
| 9-Longwang | 3.556 | 0.039 | 0.765 | 22-Soulik | 244.205 | 0.001 | 0.730 |
| 10-Shanshan | 0.494 | 0.029 | 0.745 | 23-Matmo | 1.526 | 0.039 | 0.737 |
| 11-Krosa | 33.932 | 0.004 | 0.746 | 24-Soudelor | 8.286 | 0.005 | 0.737 |
| 12-Nuri | 59.636 | 0.029 | 0.723 | Multi-year | 1.0 | 0.1 | 0.812 |
| 13-Jangmi | 3.556 | 0.029 | 0.767 | ||||
| Event | Hyperparameter Tuned | Test Accuracy | Event | Hyperparameter Tuned | Test Accuracy | ||||
|---|---|---|---|---|---|---|---|---|---|
| Numtree | Mtry | Learning Rate | Numtree | Mtry | Learning Rate | ||||
| 1-Herb | 100 | 8 | 0.1 | 0.800 | 14-Morakot | 200 | 8 | 0.1 | 0.833 |
| 2-Xangsane | 700 | 13 | 0.9 | 0.772 | 15-Parma | 300 | 13 | 0.5 | 0.823 |
| 3-Toraji | 100 | 8 | 0.1 | 0.777 | 16-Fanapi | 100 | 13 | 0.5 | 0.815 |
| 4-Nari | 300 | 11 | 0.6 | 0.807 | 17-Megi | 1000 | 13 | 0.8 | 0.848 |
| 5-Aere | 600 | 14 | 0.3 | 0.821 | 18-Meari | 1000 | 14 | 0.4 | 0.788 |
| 6-Haitang | 200 | 11 | 0.7 | 0.772 | 19-Nanmadol | 1000 | 10 | 0.7 | 0.852 |
| 7-Matsa | 100 | 12 | 1.0 | 0.837 | 20-Talim | 100 | 13 | 0.7 | 0.807 |
| 8-Talim | 100 | 9 | 0.3 | 0.817 | 21-Saola | 100 | 7 | 0.3 | 0.832 |
| 9-Longwang | 200 | 6 | 0.1 | 0.845 | 22-Soulik | 200 | 6 | 0.2 | 0.839 |
| 10-Shanshan | 200 | 6 | 0.9 | 0.815 | 23-Matmo | 100 | 6 | 1.0 | 0.843 |
| 11-Krosa | 200 | 11 | 0.5 | 0.841 | 24-Soudelor | 100 | 6 | 0.1 | 0.811 |
| 12-Nuri | 1000 | 9 | 0.3 | 0.827 | Multi-year | 900 | 7 | 0.1 | 0.804 |
| 13-Jangmi | 100 | 12 | 0.1 | 0.861 | |||||
| Event for Calibration or Prediction | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | ||
| Model trained by event | 1 | 90 | 71 | 70 | 67 | 79 | 67 | 75 | 74 | 76 | 77 | 75 | 77 | 78 | 75 | 76 | 75 | 78 | 76 | 78 | 73 | 74 | 69 | 76 | 67 |
| 2 | 74 | 90 | 75 | 78 | 71 | 74 | 70 | 76 | 81 | 79 | 78 | 78 | 75 | 73 | 79 | 79 | 83 | 76 | 81 | 75 | 80 | 73 | 78 | 77 | |
| 3 | 70 | 75 | 92 | 75 | 71 | 74 | 73 | 74 | 78 | 78 | 76 | 74 | 79 | 75 | 77 | 77 | 81 | 74 | 81 | 72 | 78 | 76 | 78 | 74 | |
| 4 | 71 | 75 | 72 | 92 | 65 | 71 | 67 | 70 | 77 | 76 | 78 | 75 | 77 | 69 | 77 | 76 | 79 | 68 | 79 | 70 | 80 | 69 | 73 | 72 | |
| 5 | 80 | 77 | 74 | 74 | 91 | 74 | 81 | 78 | 81 | 82 | 78 | 79 | 83 | 79 | 77 | 78 | 83 | 78 | 82 | 74 | 73 | 75 | 80 | 72 | |
| 6 | 67 | 73 | 69 | 74 | 70 | 90 | 76 | 82 | 75 | 77 | 78 | 78 | 78 | 76 | 76 | 72 | 79 | 76 | 77 | 74 | 79 | 76 | 75 | 72 | |
| 7 | 72 | 73 | 68 | 69 | 79 | 76 | 91 | 78 | 77 | 76 | 79 | 77 | 78 | 77 | 76 | 72 | 76 | 72 | 77 | 70 | 76 | 72 | 72 | 70 | |
| 8 | 64 | 70 | 65 | 65 | 73 | 74 | 72 | 91 | 75 | 74 | 76 | 78 | 70 | 73 | 72 | 67 | 68 | 75 | 77 | 72 | 65 | 72 | 72 | 68 | |
| 9 | 76 | 75 | 72 | 75 | 78 | 75 | 76 | 78 | 93 | 79 | 82 | 80 | 78 | 74 | 78 | 77 | 78 | 78 | 84 | 75 | 79 | 78 | 80 | 79 | |
| 10 | 76 | 75 | 74 | 75 | 80 | 72 | 76 | 75 | 82 | 90 | 80 | 80 | 81 | 77 | 79 | 77 | 84 | 77 | 79 | 73 | 77 | 76 | 79 | 73 | |
| 11 | 74 | 74 | 67 | 74 | 74 | 74 | 76 | 77 | 81 | 79 | 92 | 74 | 79 | 77 | 78 | 71 | 79 | 73 | 69 | 68 | 75 | 67 | 69 | 71 | |
| 12 | 71 | 70 | 70 | 71 | 72 | 70 | 72 | 72 | 75 | 73 | 73 | 90 | 74 | 71 | 74 | 77 | 79 | 73 | 76 | 70 | 77 | 72 | 76 | 72 | |
| 13 | 77 | 77 | 74 | 76 | 78 | 75 | 80 | 79 | 78 | 79 | 82 | 75 | 92 | 79 | 77 | 75 | 75 | 74 | 76 | 71 | 82 | 79 | 77 | 64 | |
| 14 | 72 | 70 | 66 | 68 | 78 | 72 | 79 | 78 | 76 | 78 | 78 | 78 | 77 | 90 | 74 | 69 | 76 | 77 | 70 | 71 | 69 | 68 | 73 | 65 | |
| 15 | 69 | 76 | 72 | 77 | 69 | 69 | 68 | 68 | 80 | 81 | 78 | 82 | 74 | 69 | 91 | 77 | 84 | 73 | 82 | 75 | 77 | 67 | 77 | 77 | |
| 16 | 67 | 71 | 71 | 69 | 74 | 66 | 72 | 63 | 71 | 74 | 74 | 72 | 70 | 69 | 73 | 93 | 81 | 69 | 69 | 67 | 77 | 63 | 76 | 74 | |
| 17 | 72 | 73 | 73 | 74 | 76 | 63 | 71 | 69 | 79 | 79 | 72 | 79 | 71 | 75 | 78 | 78 | 93 | 74 | 81 | 73 | 70 | 73 | 76 | 78 | |
| 18 | 72 | 71 | 69 | 69 | 68 | 72 | 70 | 74 | 79 | 77 | 71 | 78 | 73 | 71 | 76 | 72 | 74 | 89 | 80 | 75 | 79 | 77 | 79 | 78 | |
| 19 | 72 | 72 | 70 | 74 | 74 | 74 | 76 | 74 | 78 | 77 | 72 | 79 | 74 | 72 | 78 | 74 | 81 | 73 | 93 | 74 | 83 | 79 | 80 | 77 | |
| 20 | 69 | 70 | 63 | 68 | 71 | 73 | 72 | 73 | 76 | 73 | 71 | 79 | 72 | 70 | 70 | 72 | 75 | 75 | 79 | 89 | 80 | 74 | 76 | 74 | |
| 21 | 66 | 74 | 70 | 72 | 69 | 74 | 73 | 75 | 76 | 77 | 74 | 79 | 80 | 73 | 76 | 74 | 80 | 73 | 81 | 73 | 91 | 79 | 77 | 75 | |
| 22 | 72 | 72 | 67 | 72 | 75 | 73 | 74 | 76 | 77 | 77 | 71 | 80 | 80 | 76 | 74 | 72 | 78 | 80 | 85 | 75 | 83 | 92 | 81 | 79 | |
| 23 | 72 | 73 | 70 | 71 | 76 | 71 | 72 | 73 | 79 | 78 | 73 | 79 | 76 | 75 | 75 | 76 | 80 | 77 | 82 | 74 | 75 | 80 | 92 | 81 | |
| 24 | 74 | 74 | 69 | 72 | 75 | 75 | 75 | 77 | 82 | 80 | 77 | 81 | 77 | 77 | 78 | 76 | 83 | 80 | 82 | 76 | 80 | 81 | 82 | 89 | |
| 25 | 90 | 88 | 89 | 90 | 92 | 89 | 92 | 90 | 92 | 91 | 91 | 94 | 93 | 90 | 91 | 89 | 94 | 91 | 95 | 91 | 92 | 93 | 92 | 89 | |
| Inventory Type | Metric | LR(1) | RF(2) | SVM(3) | KLR(4) | GBDT(5) | PM(6) | PME(7) | PMW(8) | CA(9) |
|---|---|---|---|---|---|---|---|---|---|---|
| Event-based | Mean training accuracy | 0.813 | 0.878 | 0.833 | 0.856 | 0.977 | 0.909 | 0.883 | 0.912 | 0.923 |
| CV of training accuracy | 0.038 | 0.028 | 0.054 | 0.037 | 0.011 | 0.013 | 0.017 | 0.013 | 0.019 | |
| Mean predictive accuracy | 0.712 | 0.695 | 0.681 | 0.674 | 0.728 | 0.748 | 0.738 | 0.747 | 0.748 | |
| CV of predictive accuracy | 0.118 | 0.104 | 0.146 | 0.142 | 0.059 | 0.055 | 0.063 | 0.055 | 0.047 | |
| Multi-year | Mean predictive accuracy | 0.788 | 0.795 | 0.880 | 0.886 | 0.943 | 0.911 | 0.892 | 0.916 | 0.890 |
| CV of predictive accuracy | 0.040 | 0.029 | 0.026 | 0.021 | 0.014 | 0.019 | 0.022 | 0.018 | 0.022 |
| N | Mean Rank | d.f. | H | p | Post Hoc Test | |
|---|---|---|---|---|---|---|
| LR(1) | 576 | 2481.79 | 8 | 514.142 | 0.000 | >2–4 |
| RF(2) | 576 | 2013.05 | - | |||
| SVM(3) | 576 | 2080.67 | - | |||
| KLR(4) | 576 | 1924.60 | - | |||
| GBDT(5) | 576 | 2571.61 | >2–4 | |||
| PM(6) | 576 | 3134.95 | >1–5 | |||
| PME(7) | 576 | 2873.52 | >1–5 | |||
| PMW(8) | 576 | 3120.86 | >1–5 | |||
| CA(9) | 576 | 3131.45 | >1–5 |
| Modeling Method | Inventory Type | N | Mean Rank | Sum of | U | p |
|---|---|---|---|---|---|---|
| LR (1) | Event-based | 552 | 279.95 | 154,531.00 | 1903.000 | 0.000 |
| Multi-year | 24 | 485.21 | 11,645.00 | |||
| RF (2) | Event-based | 552 | 277.78 | 153,332.00 | 704.000 | 0.000 |
| Multi-year | 24 | 535.17 | 12,844.00 | |||
| SVM (3) | Event-based | 552 | 276.50 | 152,629.00 | 1.000 | 0.000 |
| Multi-year | 24 | 564.46 | 13,547.00 | |||
| KLR (4) | Event-based | 552 | 276.50 | 152,628.00 | 0.000 | 0.000 |
| Multi-year | 24 | 564.50 | 13,548.00 | |||
| GBDT (5) | Event-based | 552 | 276.50 | 152,628.00 | 0.000 | 0.000 |
| Multi-year | 24 | 564.50 | 135,48.00 | |||
| PM (6) | Event-based | 552 | 276.50 | 152,628.00 | 0.000 | 0.000 |
| Multi-year | 24 | 564.50 | 13,548.00 | |||
| PME (7) | Event-based | 552 | 276.50 | 152,628.00 | 0.000 | 0.000 |
| Multi-year | 24 | 564.50 | 13,548.00 | |||
| PMW (8) | Event-based | 552 | 276.50 | 152,628.00 | 0.000 | 0.000 |
| Multi-year | 24 | 564.50 | 13,548.00 | |||
| CA (9) | Event-based | 552 | 276.50 | 152,628.00 | 0.000 | 0.000 |
| Multi-year | 24 | 564.50 | 13,548.00 |
| Susceptibility Map | Spearman’s Rank Correlation Coefficient | Susceptibility Map | Spearman’s Rank Correlation Coefficient |
|---|---|---|---|
| Event-based LR model | 0.924 | Multi-year LR model | 0.928 |
| Event-based RF model | 0.917 | Multi-year RF model | 0.913 |
| Event-based SVM model | 0.938 | Multi-year SVM model | 0.811 |
| Event-based KLR model | 0.946 | Multi-year KLR model | 0.864 |
| Event-based GBDT model | 0.938 | Multi-year GBDT model | 0.936 |
| Event-based PM ensemble model | 0.962 | Multi-year PM ensemble model | 1.000 |
| Event-based PME ensemble model | 0.954 | Multi-year PME ensemble model | 0.990 |
| Event-based PMW ensemble model | 0.963 | Multi-year PMW ensemble model | 1.000 |
| Event-based CA ensemble model | 0.940 | Multi-year CA ensemble model | 0.950 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.-Y.; Lin, S.-Y. Performance Assessment of Event-Based Ensemble Landslide Susceptibility Models in Shihmen Watershed, Taiwan. Water 2022, 14, 717. https://doi.org/10.3390/w14050717
Wu C-Y, Lin S-Y. Performance Assessment of Event-Based Ensemble Landslide Susceptibility Models in Shihmen Watershed, Taiwan. Water. 2022; 14(5):717. https://doi.org/10.3390/w14050717
Chicago/Turabian StyleWu, Chun-Yi, and Sheng-Yu Lin. 2022. "Performance Assessment of Event-Based Ensemble Landslide Susceptibility Models in Shihmen Watershed, Taiwan" Water 14, no. 5: 717. https://doi.org/10.3390/w14050717
APA StyleWu, C. -Y., & Lin, S. -Y. (2022). Performance Assessment of Event-Based Ensemble Landslide Susceptibility Models in Shihmen Watershed, Taiwan. Water, 14(5), 717. https://doi.org/10.3390/w14050717