
Investigation of Data-Driven Rating Curve (DDRC) Approach

 , , ,
, , ,
Abstract
:1. Introduction
2. Material and Methods
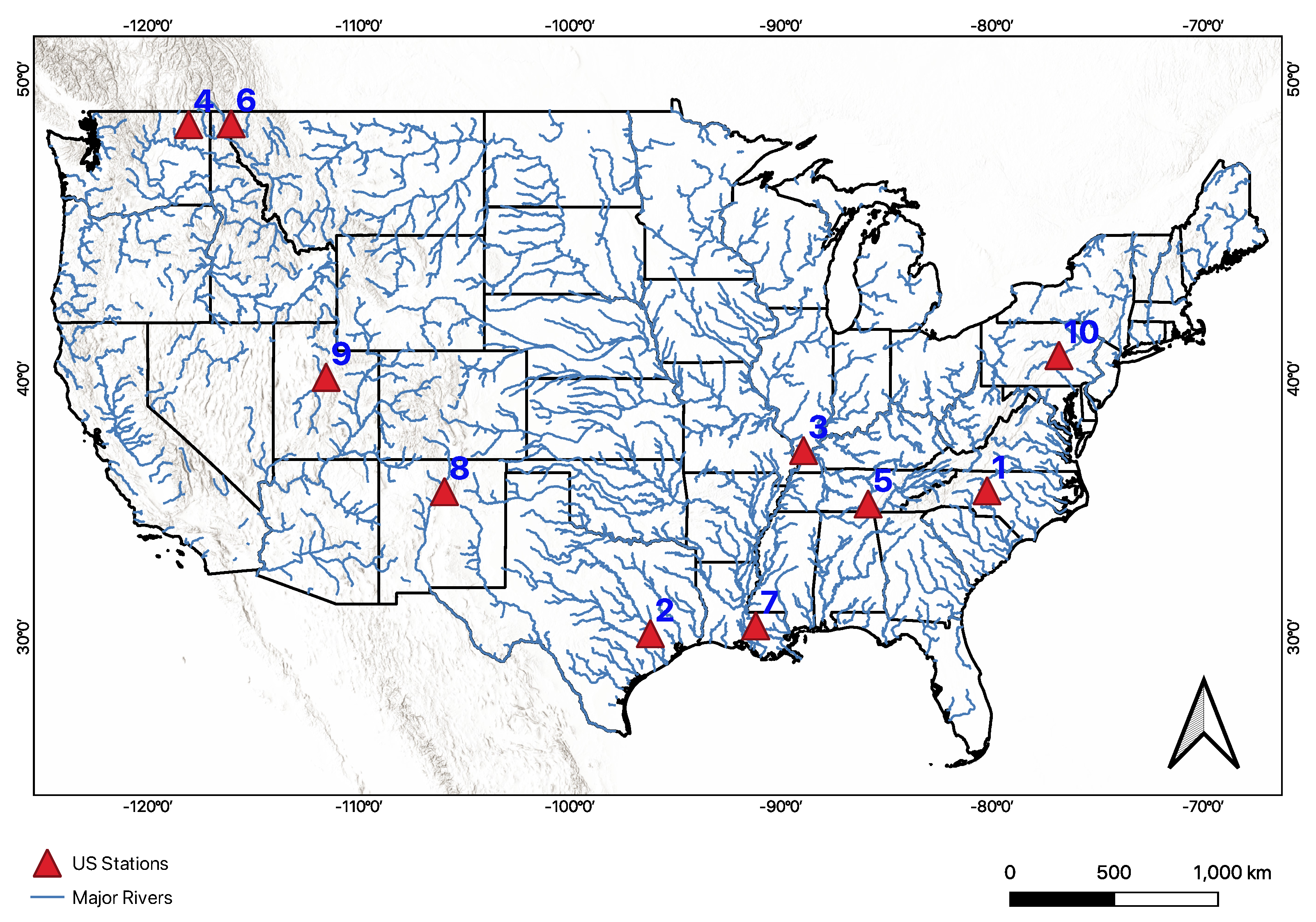
2.1. Study Area
2.2. Observation Dataset
2.3. Data Preparation
2.4. Methods
2.4.1. Prediction Interval
2.4.2. Clustering
2.4.3. Sampling
2.4.4. Outlier Detection
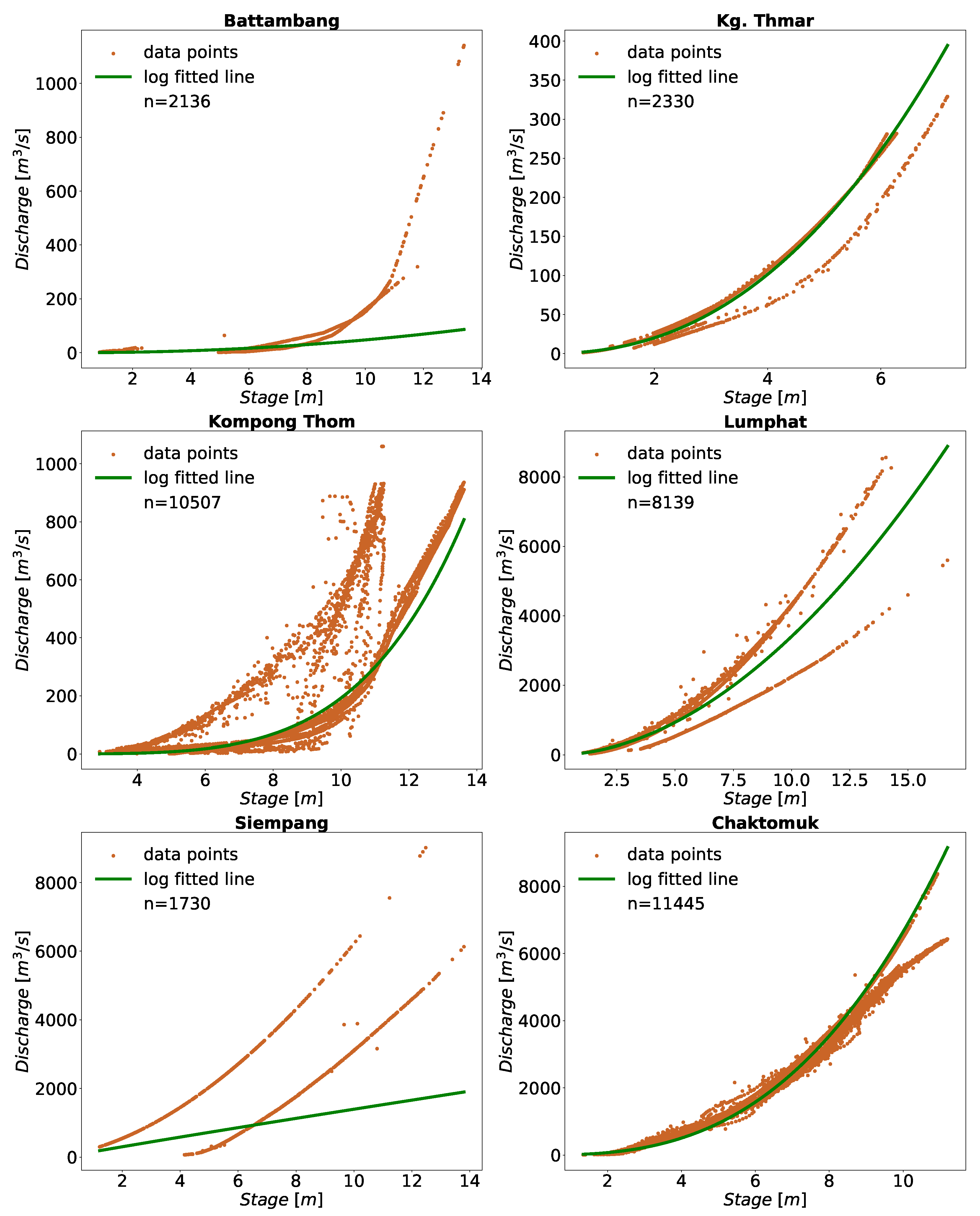
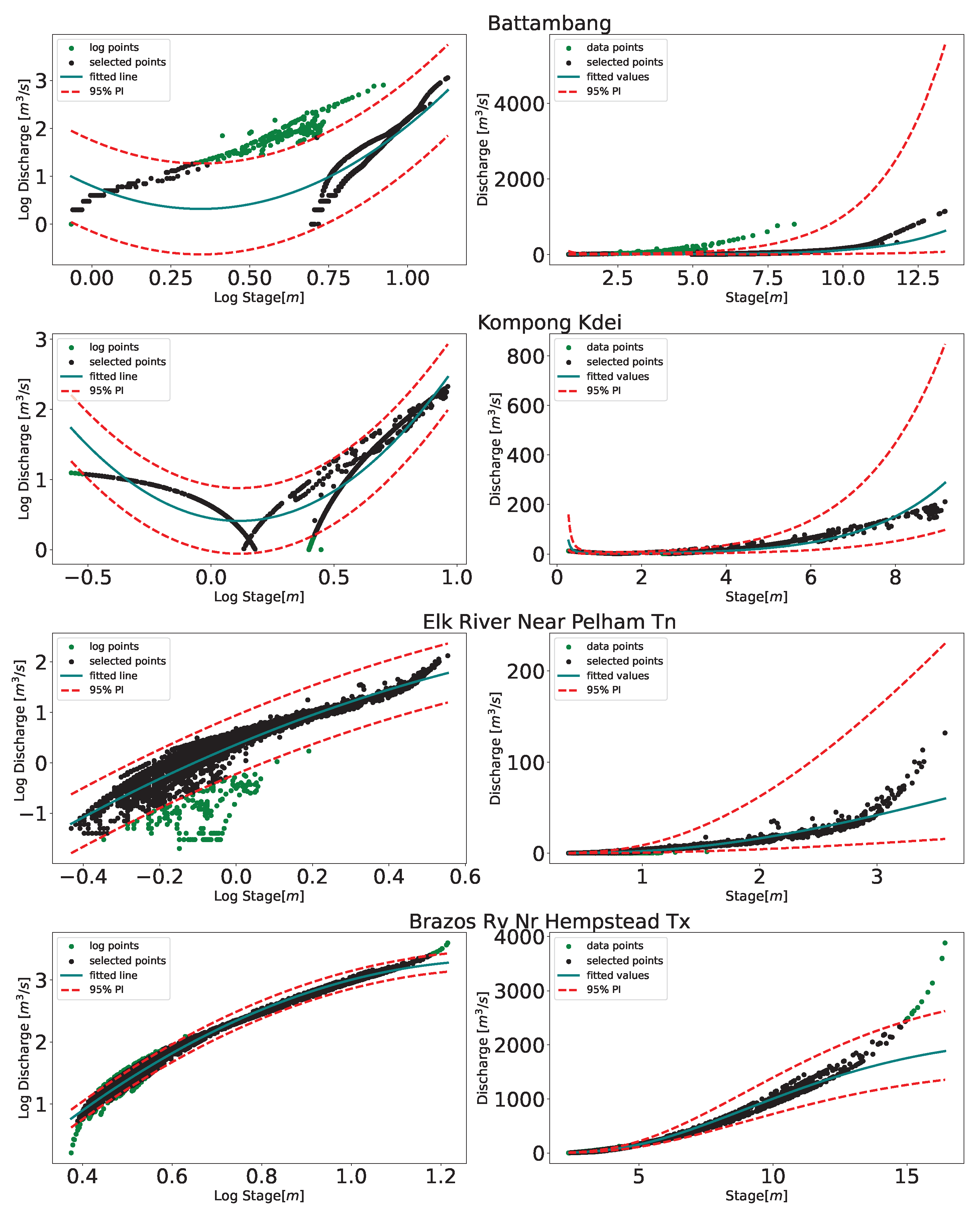
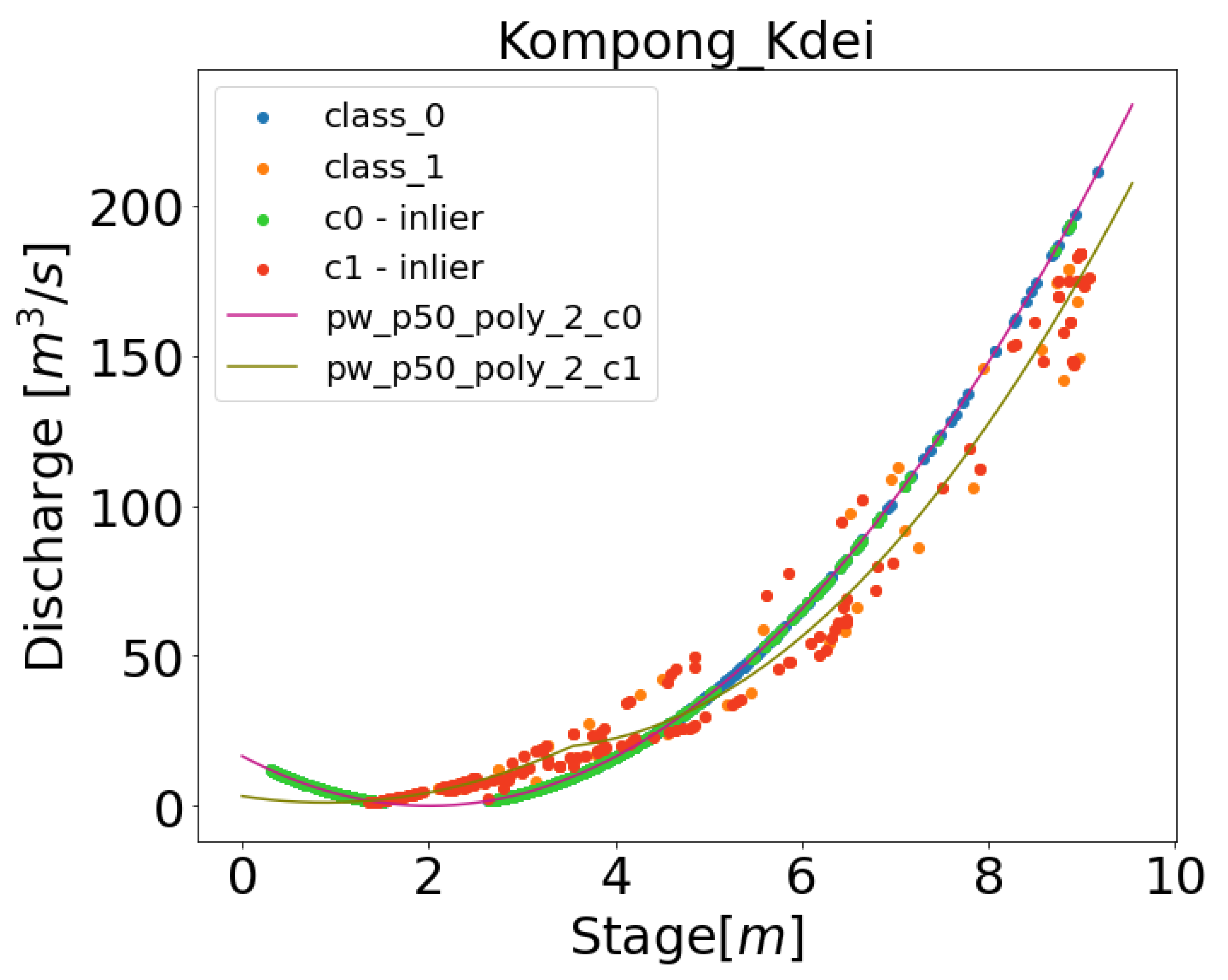
2.4.5. Piecewise Curve Fitting
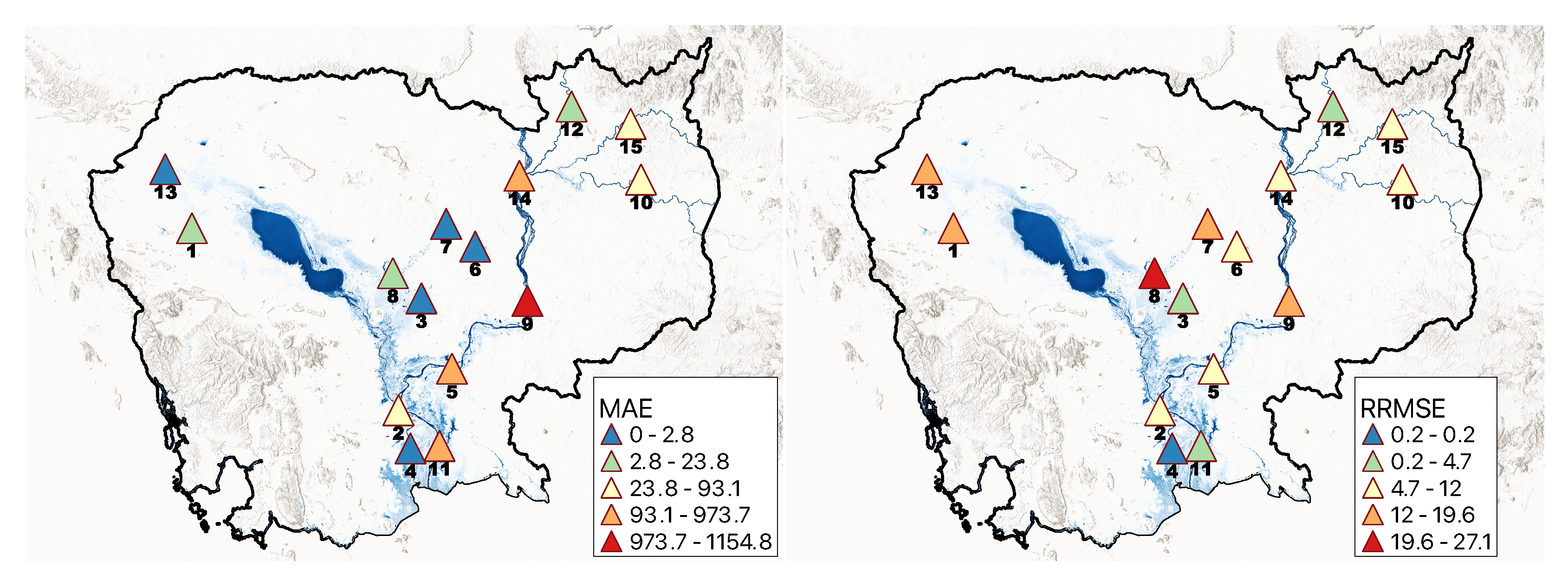
2.4.6. Accuracy Assessment
3. Results & Discussions
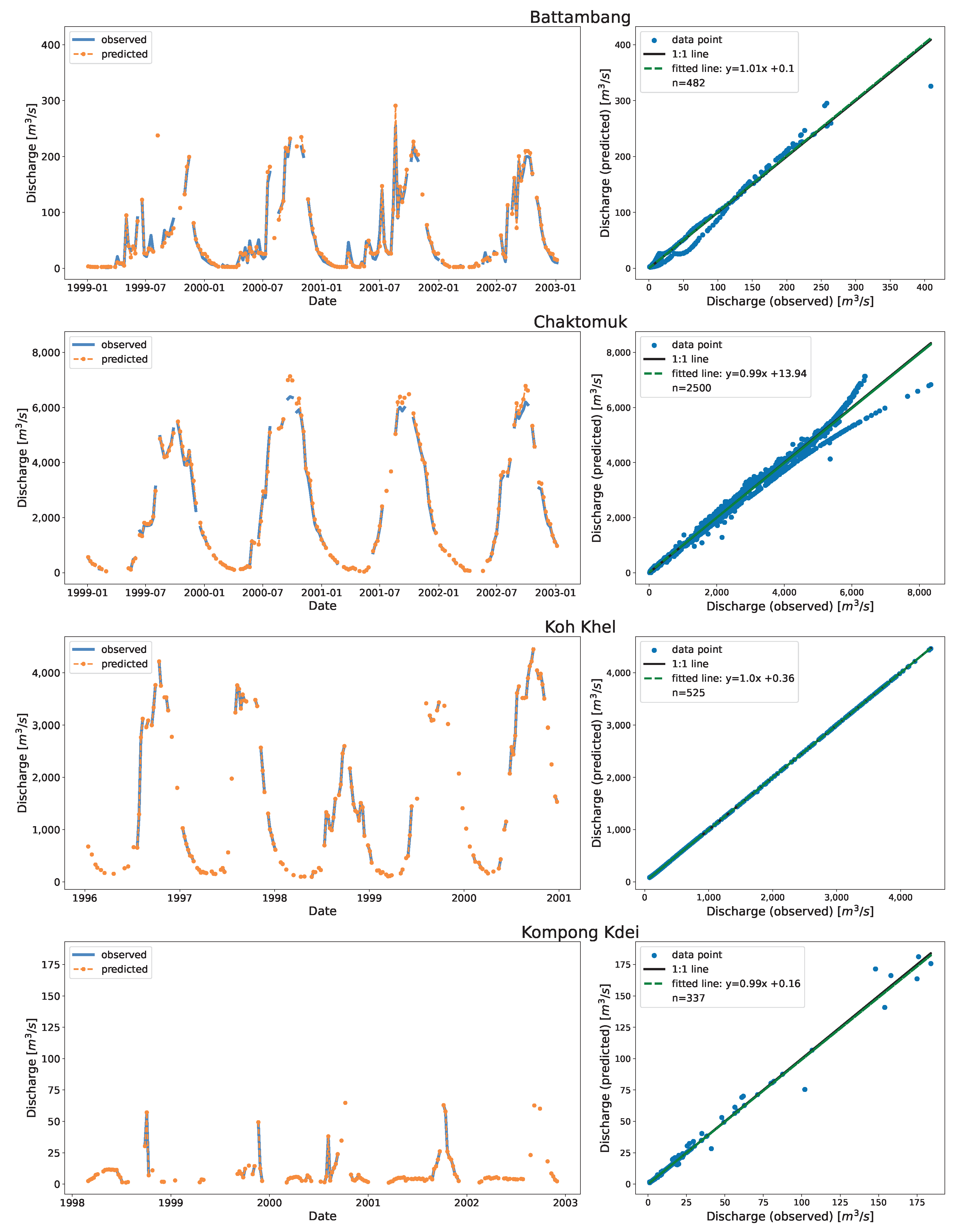
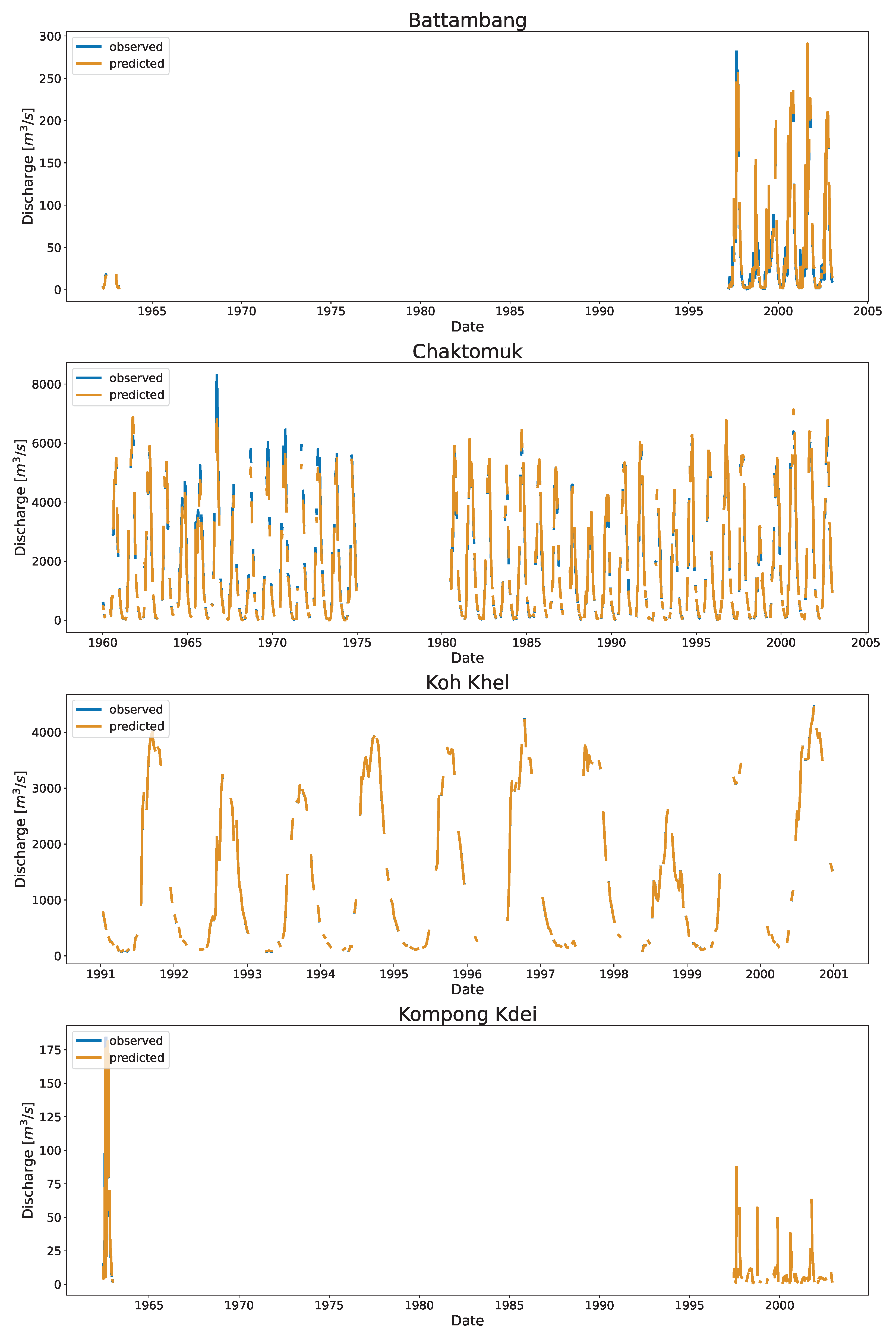
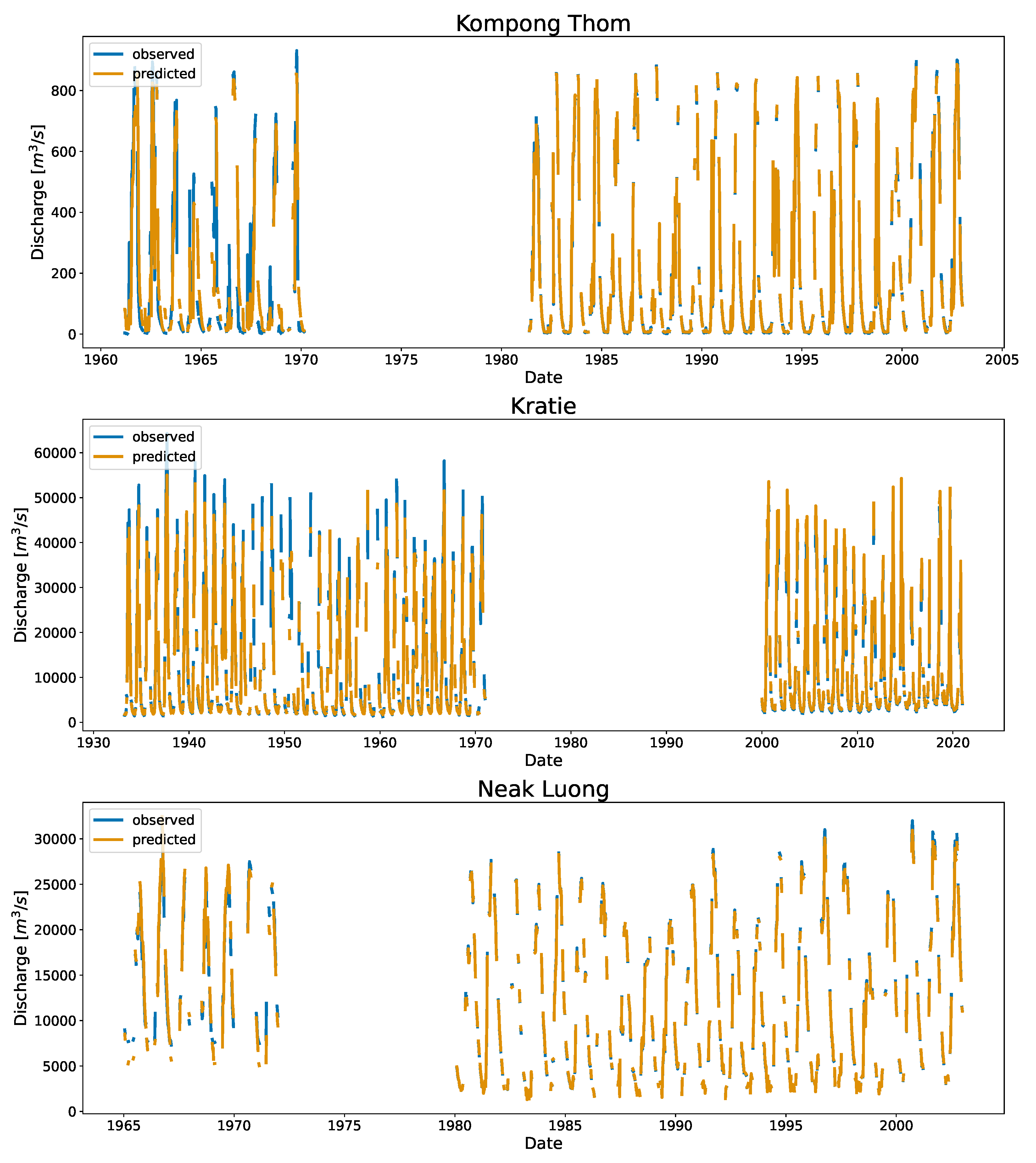
3.1. Application in Cambodia
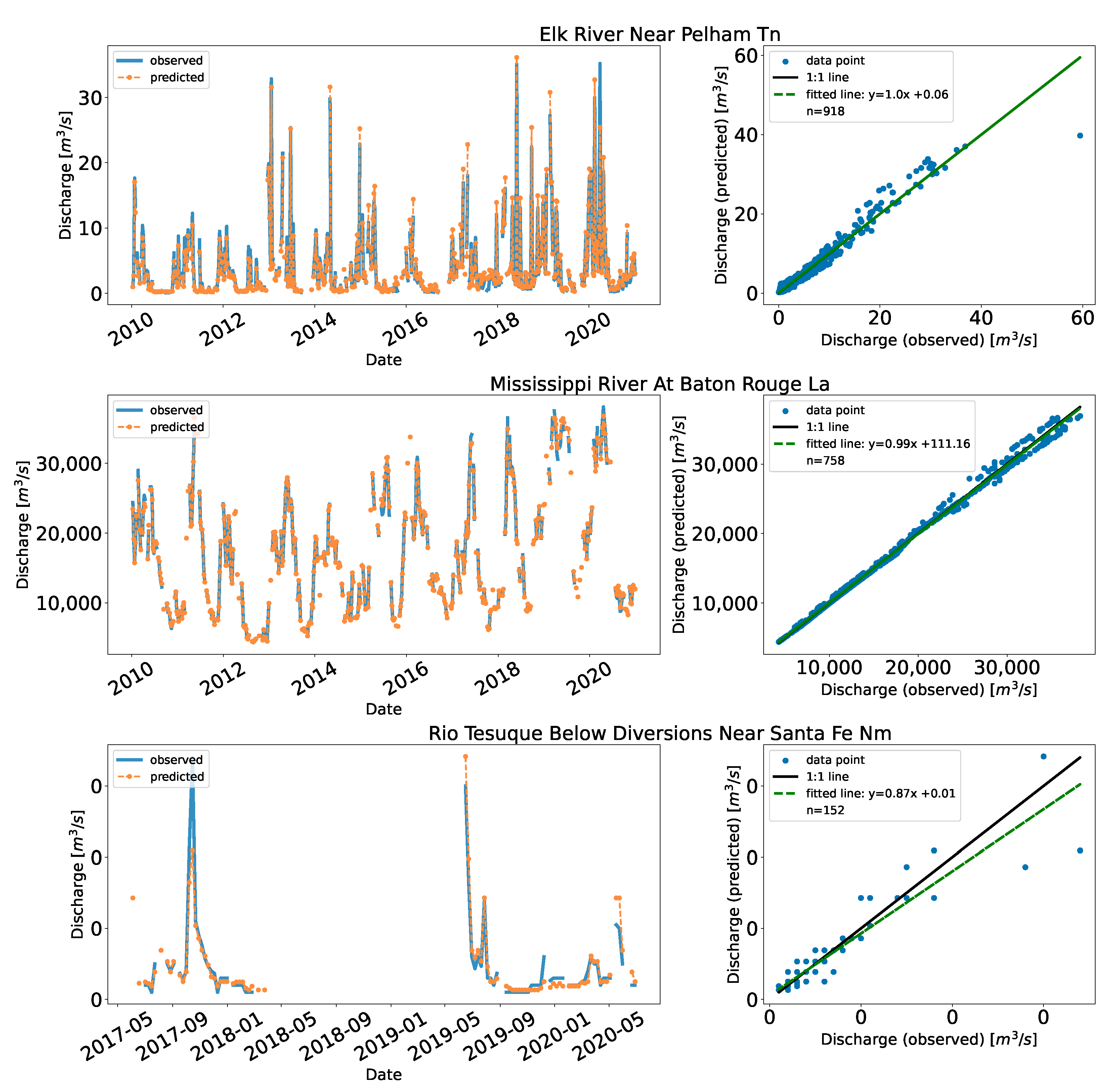
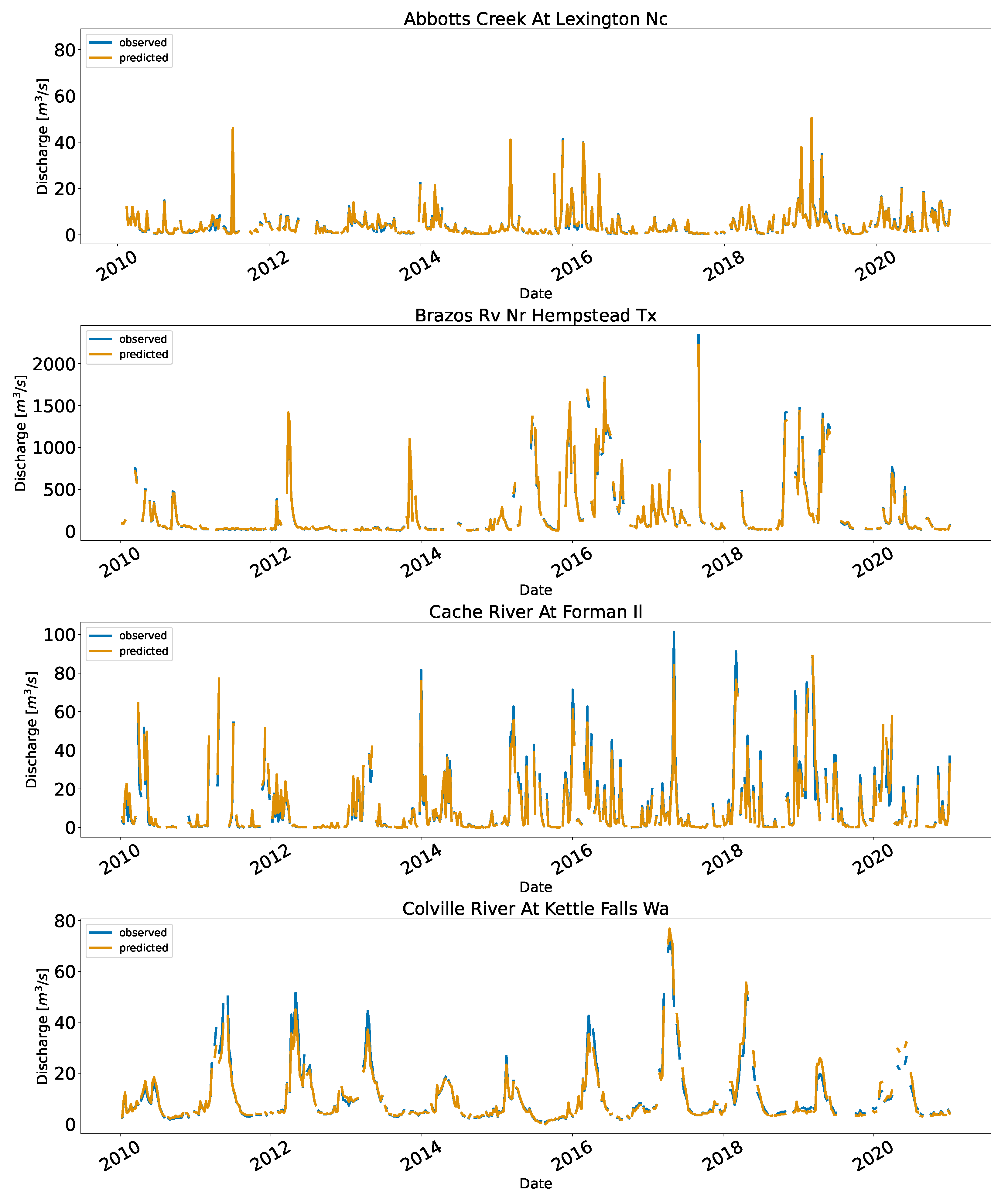
3.2. Application in the US
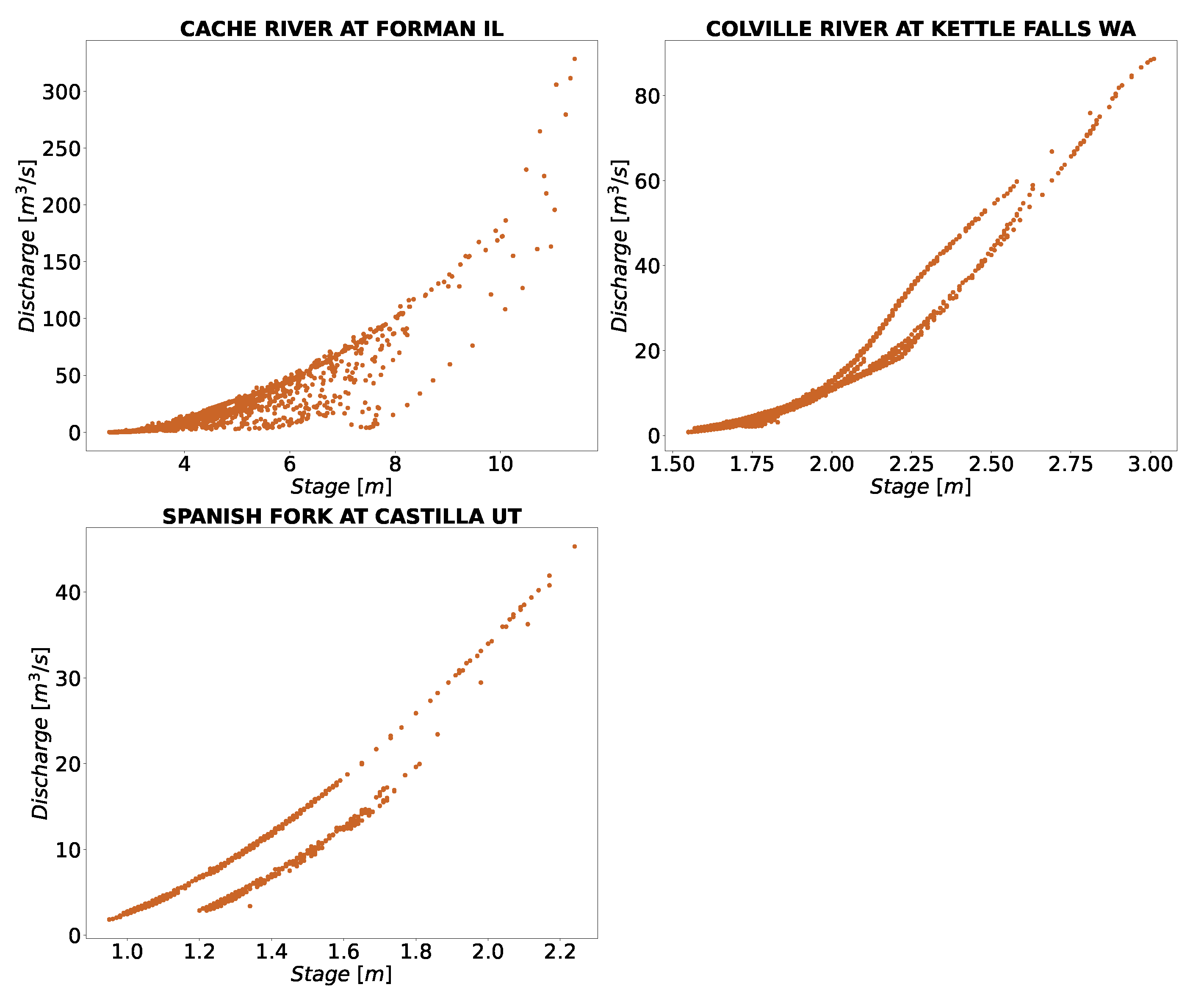
3.3. Discussion
- (1)
- Threshold, controlling the absolute percent difference between the auto and percentile breakpoint, took numerical values.
- (2)
- The Euclidean distance between the centers of the clusters: this parameter determined whether the cluster was necessary for the station and took numerical values.
- (3)
- The outlier detection contained various parameters in the algorithm. For example, sklearn’s OneClassSVM, which was used in the study, has parameters like the upper bound on the fraction of training error (also called nu), choice of kernel, and kernel coefficient.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Result of 95% Prediction Intervals

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | # Points Before PI | # Points After PI | % Change |
|---|---|---|---|
| Battambang | 2344 | 2136 | 8.9 |
| Chaktomuk | 11,941 | 11,445 | 4.2 |
| Kg. Thmar | 2462 | 2330 | 5.4 |
| Koh Khel | 3653 | 3626 | 0.7 |
| Kompong Cham | 15706 | 15331 | 2.4 |
| Kompong Chen | 1807 | 1693 | 6.3 |
| Kompong Kdei | 1592 | 1487 | 6.6 |
| Kompong Thom | 11,302 | 10,507 | 7.0 |
| Kratie | 21,331 | 20,112 | 5.7 |
| Lumphat | 8679 | 8139 | 6.2 |
| Neak Luong | 10,449 | 9850 | 5.7 |
| Siempang | 1730 | 1730 | 0.0 |
| Sisophon | 1384 | 1311 | 5.3 |
| Stung Treng | 40,543 | 39,114 | 3.5 |
| Voeun Sai | 8375 | 7722 | 7.8 |
| Average Change (%) | 5.0 | ||
Appendix B. Full Time Series Plot of Cambodia


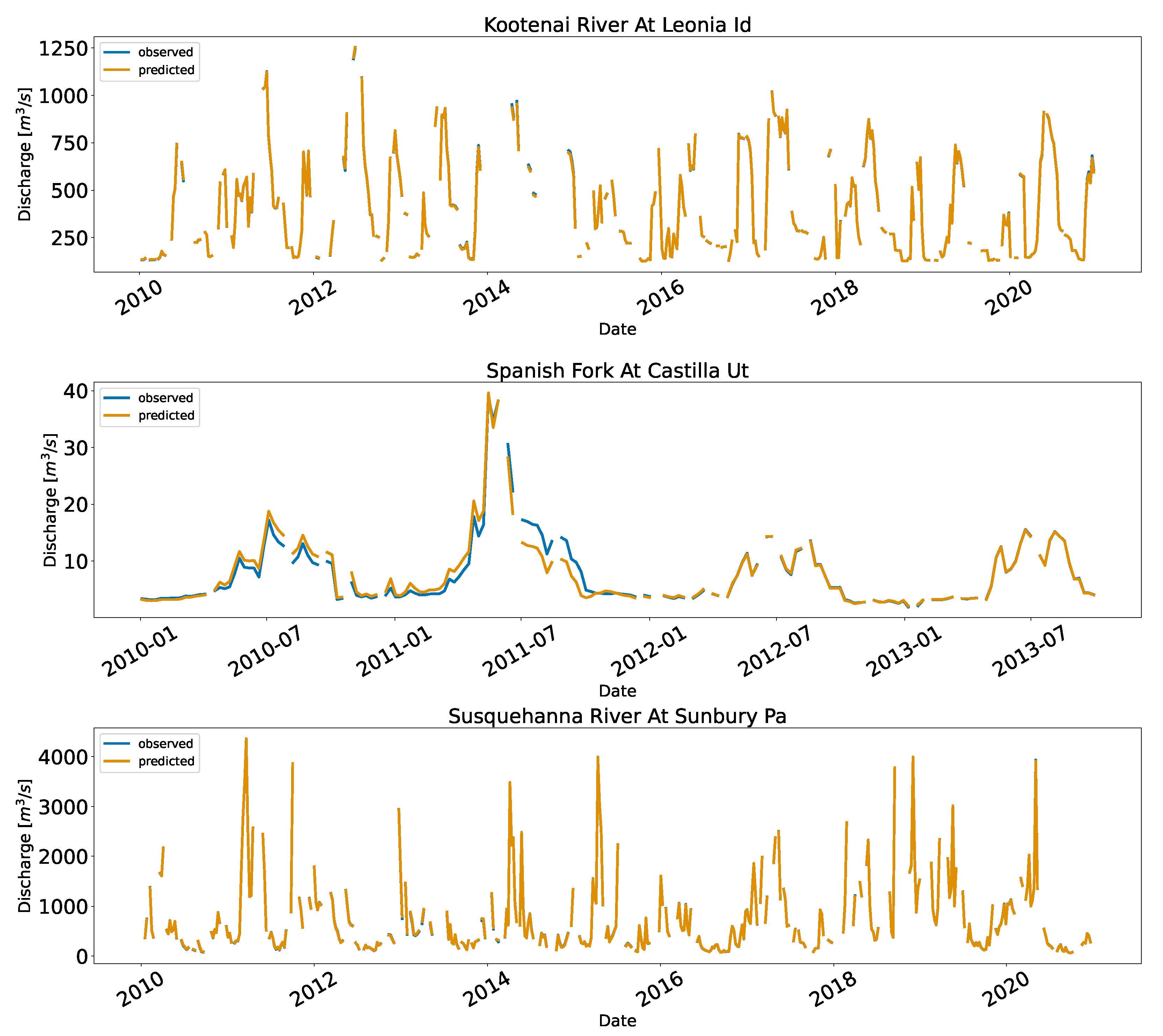
Appendix C. Full Time Series Plot of the US


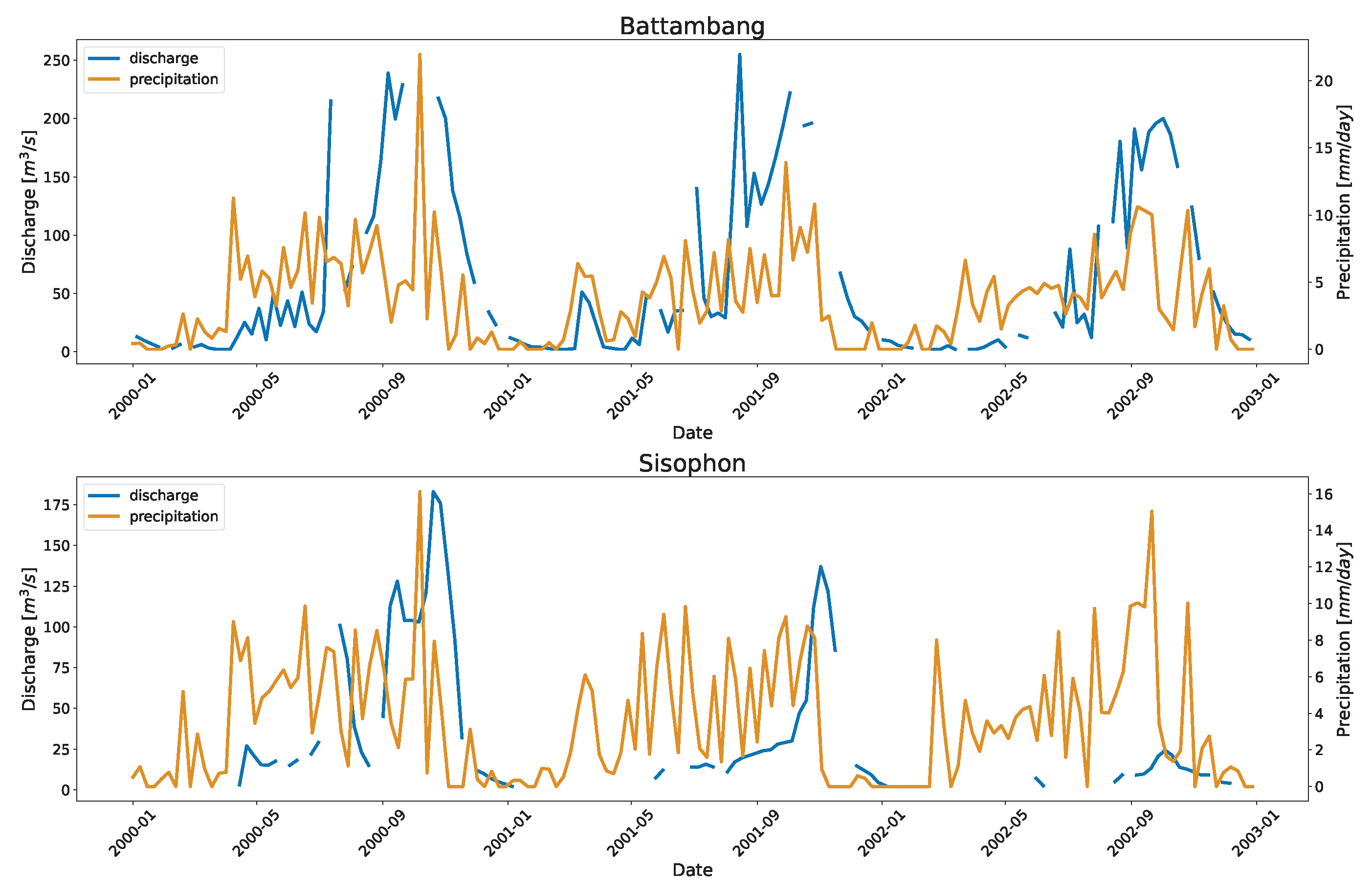
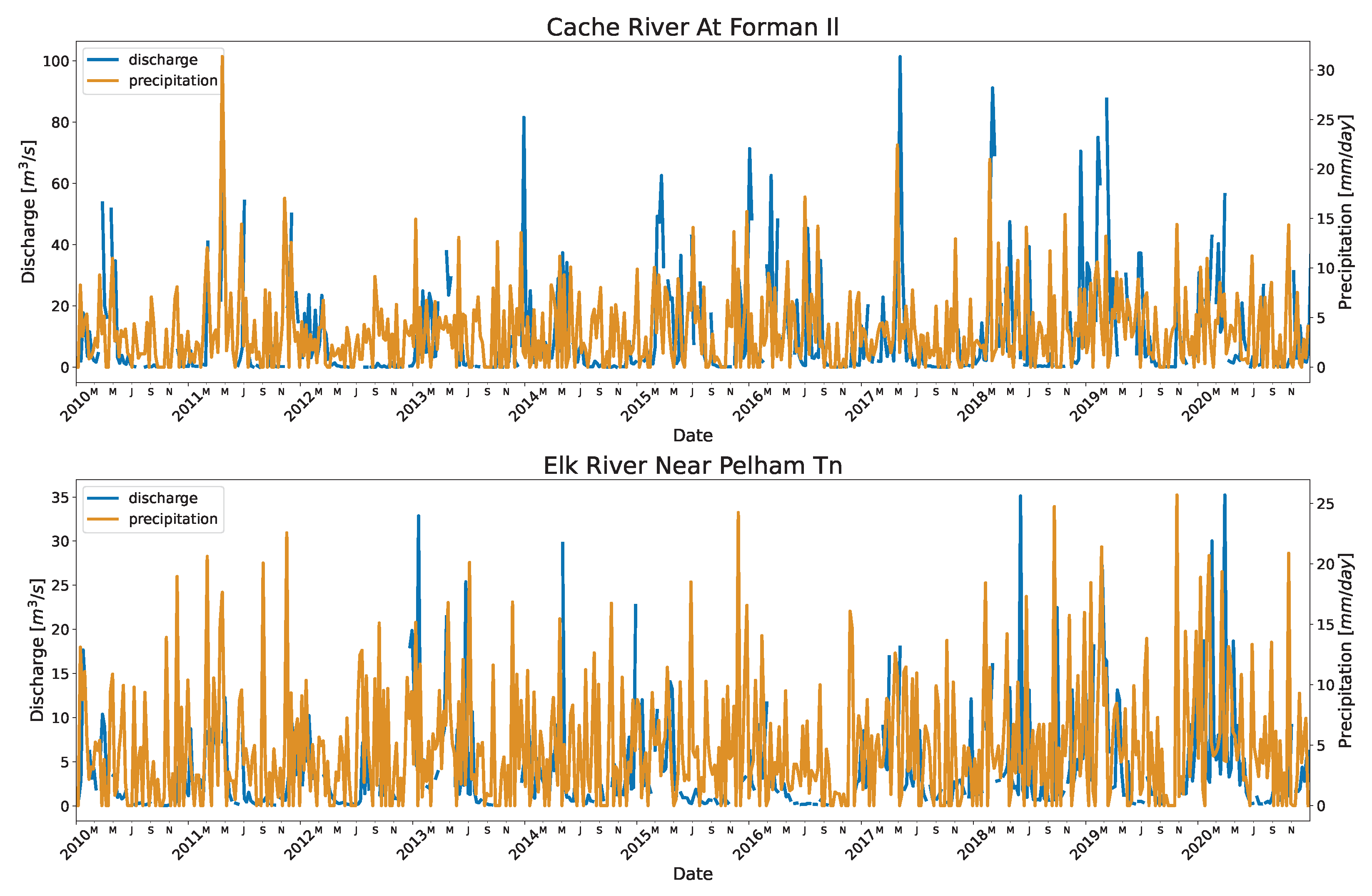
Appendix D. Plot of Precipitation and Discharge


References
- Tellman, B.; Sullivan, J.A.; Kuhn, C.; Kettner, A.J.; Doyle, C.S.; Brakenridge, G.R.; Erickson, T.A.; Slayback, D.A. Satellite imaging reveals increased proportion of population exposed to floods. Nature 2021, 596, 80–86. [Google Scholar] [CrossRef]
- Tospornsampan, J.; Malone, T.; Katry, P.; Pengel, B.; An, P.H. Short and Medium-term Flood Forecasting at the Regional Flood Management and Mitigation Centre. In Integrated Flood Risk Management in the Mekong River Basin Proceedings; Mekong River Commission: Bangkok, Thailand, 2009; pp. 155–164. [Google Scholar]
- Werner, M.; Schellekens, J.; Gijsbers, P.; van Dijk, M.; van den Akker, O.; Heynert, K. The Delft-FEWS flow forecasting system. Environ. Model. Softw. 2013, 40, 65–77. [Google Scholar] [CrossRef]
- Pagano, T.C. Evaluation of Mekong River commission operational flood forecasts, 2000–2012. Hydrol. Earth Syst. Sci. 2014, 18, 2645–2656. [Google Scholar] [CrossRef]
- WMO. First Steering Committee Meeting (SCM 1) on the Mekong River Commission Flash Flood Guidance (MRCFFG) System; Technical Report; World Meteorological Organization (WMO): Pnom Penh, Cambodia, 2017. [Google Scholar]
- Azad, W.H.; Hassan, M.H.; Ghazali, N.H.; Weisgerber, A.; Ahmad, F. National Flood Forecasting and Warning System of Malaysia: An Overview. In Water Resources Development and Management; Springer: Singapore, 2020; pp. 264–273. [Google Scholar] [CrossRef]
- WMO. Coastal Flooding Forecast Strengthened in Indonesia; World Meteorological Organization: Geneva, Switzerland, 2019; Available online: https://public.wmo.int/en/media/news/coastal-flooding-forecast-strengthened-indonesia (accessed on 8 February 2019).
- Snow, A.D.; Christensen, S.D.; Swain, N.R.; Nelson, E.J.; Ames, D.P.; Jones, N.L.; Ding, D.; Noman, N.S.; David, C.H.; Pappenberger, F.; et al. A High-Resolution National-Scale Hydrologic Forecast System from a Global Ensemble Land Surface Model. JAWRA J. Am. Water Resour. Assoc. 2016, 52, 950–964. [Google Scholar] [CrossRef] [PubMed]
- Qiao, X.; Nelson, E.J.; Ames, D.P.; Li, Z.; David, C.H.; Williams, G.P.; Roberts, W.; Sánchez Lozano, J.L.; Edwards, C.; Souffront, M.; et al. A systems approach to routing global gridded runoff through local high-resolution stream networks for flood early warning systems. Environ. Model. Softw. 2019, 120, 104501. [Google Scholar] [CrossRef]
- Alfieri, L.; Burek, P.; Dutra, E.; Krzeminski, B.; Muraro, D.; Thielen, J.; Pappenberger, F. GloFAS-global ensemble streamflow forecasting and flood early warning. Hydrol. Earth Syst. Sci. 2013, 17, 1161–1175. [Google Scholar] [CrossRef]
- Hirpa, F.A.; Salamon, P.; Beck, H.E.; Lorini, V.; Alfieri, L.; Zsoter, E.; Dadson, S.J. Calibration of the Global Flood Awareness System (GloFAS) using daily streamflow data. J. Hydrol. 2018, 566, 595–606. [Google Scholar] [CrossRef] [PubMed]
- De Perez, E.C.; Van Den Hurk, B.; Van Aalst, M.K.; Amuron, I.; Bamanya, D.; Hauser, T.; Jongma, B.; Lopez, A.; Mason, S.; De Suarez, J.M.; et al. Action-based flood forecasting for triggering humanitarian action. Hydrol. Earth Syst. Sci. 2016, 20, 3549–3560. [Google Scholar] [CrossRef]
- Nauman, C.; Anderson, E.; de Perez, E.C.; Kruczkiewicz, A.; McClain, S.; Markert, A.; Griffin, R.; Suarez, P. Perspectives on flood forecast-based early action and opportunities for Earth observations. J. Appl. Remote Sens. 2021, 15, 032002. [Google Scholar] [CrossRef]
- Fenton, J.; Keller, R.J. The Calculation of Streamflow from Measurements of Stage: Technical Report. September, 2001. Available online: https://www.ewater.org.au/archive/crcch/archive/pubs/pdfs/technical200106.pdf (accessed on 23 December 2022).
- ISO 18320; Hydrometry—Measurement of Liquid Flow in Open Channels—Determination of the Stage–Discharge Relationship. ISO: Geneve, Switzerland, 2020. Available online: https://www.iso.org/standard/62154.html (accessed on 23 December 2022).
- Lambie, J.C. Measurement of flow-velocity-area methods. In Hydrometry: Principles and Practices; John Wiley: New York, NY, USA, 1978; pp. 1–52. [Google Scholar]
- Herschy, R.W. Hydrometry: Principles and Practices, 2nd ed.; John Wiley: New York, NY, USA, 1999; p. 376. [Google Scholar]
- Turnipseed, D.P.; Sauer, B.V. Discharge Measurements at Gaging Stations. In U.S. Geological Survey Techniques and Methods 3–A8; US Geological Survey: Reston, VA, USA, 2010. Available online: https://pubs.er.usgs.gov/publication/tm3A8 (accessed on 23 December 2022).
- Singh, V.P.; Cui, H.; Byrd, A.R. Derivation of rating curve by the Tsallis entropy. J. Hydrol. 2014, 513, 342–352. [Google Scholar] [CrossRef]
- Rojas, M.; Quintero, F.; Young, N. Analysis of Stage–Discharge Relationship Stability Based on Historical Ratings. Hydrology 2020, 7, 31. [Google Scholar] [CrossRef]
- Rantz, S.E. Measurement and Computation of Streamflow; Technical Report; US Government Publishing Office: Washington, DC, USA, 1982. [Google Scholar] [CrossRef]
- Leonard, J.; Mietton, M.; Najib, H.; Gourbesville, P. Rating curve modelling with Manning’s equation to manage instability and improve extrapolation. Hydrol. Sci. J. 2009, 45, 739–750. [Google Scholar] [CrossRef]
- Domeneghetti, A.; Castellarin, A.; Brath, A. Assessing rating-curve uncertainty and its effects on hydraulic model calibration. Hydrol. Earth Syst. Sci. 2012, 16, 1191–1202. [Google Scholar] [CrossRef]
- Sefe, F.T. A study of the stage-discharge relationship of the Okavaiigo River at Mohembo, Botswana. Hydrol. Sci. J. 1996, 41, 97–116. [Google Scholar] [CrossRef]
- Kennedy, E. Discharge ratings at gaging stations. In Techniques of Water-Resources Investigations; US Geological Survey: New York, NY, USA, 1984. [Google Scholar] [CrossRef]
- Schmidt, A.R.; Yen, B.C. Stage-Discharge Rating Curves Revisited. In Hydraulic Measurements and Experimental Methods; ASCE: Reston, VA, USA, 2002; pp. 1–10. [Google Scholar] [CrossRef]
- Fenton, J.D. Rating Curves: Part 2—Representation and Approximation. In Proceedings of the Conference on Hydraulics in Civil Engineering, Barton, AIC, Australia, 5–8 November 2001; Institution of Engineers, Australia: Barton, AIC, Australia, 2001; pp. 319–328. [Google Scholar]
- Petersen-Øverleir, A. Modelling stage—Discharge relationships affected by hysteresis using the Jones formula and nonlinear regression. Hydrol. Sci. J. 2010, 51, 365–388. [Google Scholar] [CrossRef]
- Yoo, C.; Park, J. A mixture-density-network based approach for finding rating curves: Facing multi-modality and unbalanced data distribution. KSCE J. Civ. Eng. 2010, 14, 243–250. [Google Scholar] [CrossRef]
- Fenton, J.D. On the generation of stream rating curves. J. Hydrol. 2018, 564, 748–757. [Google Scholar] [CrossRef]
- Morgenschweis, G. Hydrometrie; VDI-Buch, Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Chaplot, B.; Birbal, P. Development of stage-discharge rating curve using ANN. Int. J. Hydrol. Sci. Technol. 2022, 14, 75. [Google Scholar] [CrossRef]
- Mayer, T.; Poortinga, A.; Bhandari, B.; Nicolau, A.; Markert, K.; Thwal, N.; Markert, A.; Haag, A.; Kilbride, J.; Chishtie, F. Others Deep learning approach for Sentinel-1 surface water mapping leveraging Google Earth Engine. ISPRS Open J. Photogramm. Remote Sens. 2021, 2, 100005. [Google Scholar] [CrossRef]
- Rozos, E.; Leandro, J.; Koutsoyiannis, D. Development of Rating Curves: Machine Learning vs. Statistical Methods. Hydrology 2022, 9, 166. [Google Scholar] [CrossRef]
- Lyon, S.; Nathanson, M.; Lam, N.; Dahlke, H.; Rutzinger, M.; Kean, J.; Laudon, H. Can low-resolution airborne laser scanning data be used to model stream rating curves? Water 2015, 7, 1324–1339. [Google Scholar] [CrossRef]
- MRC. Mekong River Commission Annual Mekong Hydrology, Flood, and Drought Report 2018; Technical Report; Mekong River Commission: Vientiane, Laos, 2020. [Google Scholar]
- Hughes, D.A.; Heal, K.V.; Leduc, C. Improving the visibility of hydrological sciences from developing countries. Hydrol. Sci. J. 2014, 59, 1627–1635. [Google Scholar] [CrossRef]
- MRC. Overview of the Hydrology of the Mekong Basin; Technical Report; Mekong River Commission: Vientiane, Laos, 2005. [Google Scholar]
- Pearce, F. When the Rivers Run Dry: Water, the Defining Crisis of the Twenty-First Century; Beacon Press: Boston, MA, USA, 2006. [Google Scholar]
- MRC. Discharge and Sediment Monitoring Project (DSMP). Available online: https://portal.mrcmekong.org/dsmp/dsmp-description (accessed on 29 August 2022).
- Tetzlaff, D.; Carey, S.K.; McNamara, J.P.; Laudon, H.; Soulsby, C. The essential value of long-term experimental data for hydrology and water management. Water Resour. Res. 2017, 53, 2598–2604. [Google Scholar] [CrossRef]
- Campbell, I.C.; Say, S.; Beardall, J. Tonle Sap Lake, the Heart of the Lower Mekong. Mekong 2009, 251–272. [Google Scholar] [CrossRef]
- Kummu, M.; Tes, S.; Yin, S.; Adamson, P.; Józsa, J.; Koponen, J.; Richey, J.; Sarkkula, J. Water balance analysis for the Tonle Sap Lake–floodplain system. Hydrol. Process. 2014, 28, 1722–1733. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-based outliers: Algorithms and applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. Adv. Neural Inf. Process. Syst. 1999, 12. Available online: https://papers.nips.cc/paper/1999/hash/8725fb777f25776ffa9076e44fcfd776-Abstract.html (accessed on 23 December 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Jekel, C.F.; Venter, G. pwlf: A Python Library for Fitting 1D Continuous Piecewise Linear Functions; Manual; Github 2019. Available online: https://github.com/cjekel/piecewise_linear_fit_py (accessed on 23 December 2022).
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Kling, H.; Fuchs, M.; Paulin, M. Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios. J. Hydrol. 2012, 424–425, 264–277. [Google Scholar] [CrossRef]
- Fowler, K.; Peel, M.; Western, A.; Zhang, L. Improved Rainfall-Runoff Calibration for Drying Climate: Choice of Objective Function. Water Resour. Res. 2018, 54, 3392–3408. [Google Scholar] [CrossRef]
- Usman, M.; Ndehedehe, C.E.; Ahmad, B.; Manzanas, R.; Adeyeri, O.E. Modeling streamflow using multiple precipitation products in a topographically complex catchment. Model. Earth Syst. Environ. 2021, 8, 1875–1885. [Google Scholar] [CrossRef]
- Knoben, W.J.; Freer, J.E.; Woods, R.A. Technical note: Inherent benchmark or not? Comparing Nash-Sutcliffe and Kling-Gupta efficiency scores. Hydrol. Earth Syst. Sci. 2019, 23, 4323–4331. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Yang, T.; Gao, S.; Zhang, L.; Ding, Z.; Wen, X.; Gourley, J.J.; Hong, Y. Can artificial intelligence and data-driven machine learning models match or even replace process-driven hydrologic models for streamflow simulation?: A case study of four watersheds with different hydro-climatic regions across the CONUS. J. Hydrol. 2021, 598, 126423. [Google Scholar] [CrossRef]
- Mazrooei, A.; Sankarasubramanian, A. Improving monthly streamflow forecasts through assimilation of observed streamflow for rainfall-dominated basins across the CONUS. J. Hydrol. 2019, 575, 704–715. [Google Scholar] [CrossRef]
- Lee, J.W. Insurgency: The Cambodian Civil War, 1970–1975; Technical Report; US Army School for Advanced Military Studies Fort Leavenworth United States: Fort Leavenworth, KS, USA, 2019. [Google Scholar]
- MRC. Mekong River Commission-History; MRC: Vientiane, Laos, 2021; Available online: https://www.mrcmekong.org/about/mrc/history/ (accessed on 1 August 2022).
- MRC. MRC (2009) Annual Mekong Flood Report 2008; Technical Report; Mekong River Commission: Vientiane, Laos, 2009. [Google Scholar]
- Azamathulla, H.M.; Ghani, A.A.; Leow, C.S.; Chang, C.K.; Zakaria, N.A. Gene-Expression Programming for the Development of a Stage-Discharge Curve of the Pahang River. Water Resour. Manag. 2011, 25, 2901–2916. [Google Scholar] [CrossRef]
- Ferreira, C. Gene Expression Programming: A New Adaptive Algorithm for Solving Problems. arXiv 2001, arXiv:cs/0102027. [Google Scholar] [CrossRef]
- Inomata, H.; Fukami, K. Restoration of historical hydrological data of Tonle Sap Lake and its surrounding areas. Hydrol. Process. 2008, 22, 1337–1350. [Google Scholar] [CrossRef]
- MRC-RFMMC. Regional Flood Management and Mitigation Centre. Available online: http://ffw.mrcmekong.org/ (accessed on 23 December 2022).
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Kdd; AAAI: Portland, OR, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited. ACM Trans. Database Syst. (TODS) 2017, 42. [Google Scholar] [CrossRef]
- Williams, C.; Rasmussen, C. Gaussian processes for regression. Adv. Neural Inf. Process. Syst. 1995, 8. Available online: https://papers.nips.cc/paper/1995/hash/7cce53cf90577442771720a370c3c723-Abstract.html (accessed on 23 December 2022).
- Birkinshaw, S.J.; O’Donnell, G.M.; Moore, P.; Kilsby, C.G.; Fowler, H.J.; Berry, P.A. Using satellite altimetry data to augment flow estimation techniques on the Mekong River. Hydrol. Process. 2010, 24, 3811–3825. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Di Baldassarre, G.; Montanari, A. Uncertainty in river discharge observations: A quantitative analysis. Hydrol. Earth Syst. Sci. 2009, 13, 913–921. [Google Scholar] [CrossRef]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A survey on neural network interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Funk, C.; Peterson, P.; Landsfeld, M.; Pedreros, D.; Verdin, J.; Shukla, S.; Husak, G.; Rowland, J.; Harrison, L.; Hoell, A.; et al. The climate hazards infrared precipitation with stations—A new environmental record for monitoring extremes. Sci. Data 2015, 2, 1–21. [Google Scholar] [CrossRef] [Green Version]











| ID | Station Name | Latitude | Longitude | Discharge Reported | Drainage Area (km) | Min Date | Max Date |
|---|---|---|---|---|---|---|---|
| 1 | Battambang | 13.092 | 103.200 | No | 3110 | 1962-04-03 | 2002-12-31 |
| 2 | Chaktomuk | 11.563 | 104.935 | No | 86,510 | 1960-01-01 | 2002-12-31 |
| 3 | Kg. Thmar | 12.503 | 105.127 | No | 3960 | 1962-04-23 | 2002-12-31 |
| 4 | Koh Khel | 11.242 | 105.036 | No | 6400 | 1991-01-01 | 2000-12-31 |
| 5 | Kompong Cham | 11.911 | 105.384 | No | 666,000 | 1960-01-01 | 2002-12-31 |
| 6 | Kompong Chen | 12.939 | 105.579 | No | 1350 | 1962-04-24 | 2002-12-31 |
| 7 | Kompong Kdei | 13.129 | 105.335 | No | 11,500 | 1962-05-21 | 2002-12-10 |
| 8 | Kompong Thom | 12.715 | 104.888 | No | 13,850 | 1961-03-04 | 2002-12-31 |
| 9 | Kratie | 12.481 | 106.018 | Yes | 646,000 | 1933-03-14 | 2020-12-31 |
| 10 | Lumphat | 13.501 | 106.971 | Yes | 27,600 | 1965-01-01 | 2020-12-31 |
| 11 | Neak Luong | 11.263 | 105.280 | No | 750,000 | 1965-01-01 | 2002-12-31 |
| 12 | Siempang | 14.115 | 106.388 | No | 25,240 | 1965-01-01 | 2012-12-31 |
| 13 | Sisophon | 13.587 | 102.977 | No | 4240 | 1962-04-02 | 2002-12-15 |
| 14 | Stung Treng | 13.533 | 105.950 | Yes | 635,000 | 1910-01-01 | 2020-12-31 |
| 15 | Voeun Sai | 13.968 | 106.884 | Yes | 15,720 | 1965-01-01 | 2020-12-31 |
| ID | Station Name | USGS Code | Latitude | Longitude | Drainage Area (km) | Min Date | Max Date |
|---|---|---|---|---|---|---|---|
| 1 | Abbotts Creek At Lexington, NC | 02121500 | 35.807 | −80.235 | 450 | 2010-01-01 | 2020-12-31 |
| 2 | Brazos River Near Hempstead, TX | 08111500 | 30.129 | −96.188 | 88,870 | 2010-01-01 | 2020-12-31 |
| 3 | Cache River at Forman, IL | 03612000 | 37.336 | −88.924 | 632 | 2010-01-01 | 2020-12-31 |
| 4 | Colville River At Kettle Falls, WA | 12409000 | 48.594 | −118.061 | 2608 | 2010-01-01 | 2020-12-31 |
| 5 | Elk River Near Pelham, TN | 03578000 | 35.297 | −85.870 | 170 | 2010-01-01 | 2020-12-31 |
| 6 | Kootenai River At Leonia, ID | 12305000 | 48.618 | −116.046 | 30,406 | 2010-01-01 | 2020-12-31 |
| 7 | Mississippi River At Baton Rouge, LA | 07374000 | 30.446 | −91.192 | 2,915,834 | 2010-01-01 | 2020-12-31 |
| 8 | Rio Tesuque Below Diversions Near Santa Fe, NM | 08308050 | 35.772 | −105.941 | 78 | 2017-05-27 | 2020-06-27 |
| 9 | Spanish Fork at Castilla, UT | 10150500 | 40.050 | −111.547 | 1688 | 2010-01-01 | 2020-12-31 |
| 10 | Susquehanna River At Sunbury, PA | 01554000 | 40.834 | −76.827 | 47,396 | 2010-01-01 | 2020-12-31 |
| Station | ||||||
|---|---|---|---|---|---|---|
| Battambang | 1.00 | 1141.00 | 59.38 | 3.00 | 19.00 | 103.00 |
| Chaktomuk | 6.20 | 8370.00 | 2111.51 | 295.00 | 1390.00 | 4217.60 |
| Kg. Thmar | 1.37 | 329.00 | 73.33 | 9.53 | 37.75 | 142.41 |
| Koh Khel | 73.06 | 4501.65 | 1374.47 | 163.53 | 794.81 | 2948.13 |
| Kompong Cham | 1947.00 | 69,025.00 | 14,320.82 | 2949.00 | 6506.00 | 28,433.00 |
| Kompong Chen | 1.04 | 539.78 | 37.40 | 3.80 | 8.79 | 77.64 |
| Kompong Kdei | 1.02 | 211.13 | 20.56 | 3.54 | 5.85 | 24.54 |
| Kompong Thom | 1.00 | 1060.00 | 235.15 | 9.00 | 84.20 | 546.00 |
| Kratie | 1250.00 | 66,700.00 | 13,482.16 | 2750.00 | 6275.00 | 26,500.00 |
| Lumphat | 28.71 | 8562.00 | 832.22 | 193.48 | 429.53 | 1257.35 |
| Neak Luong | 1374.00 | 32,188.00 | 12,237.90 | 3924.40 | 10,444.00 | 20,809.20 |
| Siempang | 67.50 | 9015.95 | 1234.07 | 237.00 | 534.33 | 2410.00 |
| Sisophon | 2.00 | 300.00 | 38.72 | 6.00 | 19.00 | 62.00 |
| Stung Treng | 1007.00 | 78,093.00 | 13,556.94 | 2718.00 | 6800.00 | 25,500.00 |
| Voeun Sai | 117.00 | 17,950.67 | 940.83 | 394.30 | 659.51 | 1414.00 |
| Station | ||||||
|---|---|---|---|---|---|---|
| Abbotts Creek At Lexington, NC | 0.27 | 109.02 | 5.34 | 0.84 | 2.21 | 6.08 |
| Brazos River Near Hempstead, TX | 5.32 | 2432.41 | 228.15 | 21.78 | 63.71 | 319.98 |
| Cache River At Forman, IL | 0.03 | 125.44 | 10.08 | 0.27 | 2.3 | 16.82 |
| Colville River At Kettle Falls, WA | 0.78 | 88.63 | 10.59 | 3.62 | 5.97 | 14.53 |
| Elk River Near Pelham, TN | 0.04 | 131.96 | 4.85 | 0.49 | 2.02 | 6.24 |
| Kootenai River At Leonia, ID | 124.03 | 1509.29 | 406.81 | 168.77 | 302.99 | 659.78 |
| Mississippi River At Baton Rouge, LA | 4247.52 | 38,510.85 | 16,870.23 | 9118.01 | 15,574.24 | 24,040.96 |
| Rio Tesuque Below Diversions Near Santa Fe, NM | 0.00 | 0.45 | 0.04 | 0.01 | 0.02 | 0.05 |
| Spanish Fork At Castilla, UT | 1.82 | 45.31 | 7.95 | 3.45 | 4.79 | 12.52 |
| Susquehanna River At Sunbury, PA | 60.31 | 6711.08 | 844.95 | 225.68 | 569.17 | 1302.57 |
| ID | Station | KGE | MAE | RRMSE |
|---|---|---|---|---|
| 1 | Battambang | 0.986 | 5.023 | 18.722 |
| 2 | Chaktomuk | 0.995 | 93.051 | 8.342 |
| 3 | Kg. Thmar | 0.998 | 0.907 | 2.733 |
| 4 | Koh Khel | 1.000 | 2.534 | 0.208 |
| 5 | Kompong Cham | 0.991 | 973.741 | 11.970 |
| 6 | Kompong Chen | 0.995 | 1.126 | 8.340 |
| 7 | Kompong Kdei | 0.992 | 0.603 | 17.515 |
| 8 | Kompong Thom | 0.972 | 23.834 | 27.107 |
| 9 | Kratie | 0.984 | 1154.824 | 16.782 |
| 10 | Lumphat | 0.996 | 36.883 | 7.997 |
| 11 | Neak Luong | 0.997 | 351.567 | 4.689 |
| 12 | Siempang | 0.999 | 9.157 | 2.707 |
| 13 | Sisophon | 0.967 | 2.798 | 19.557 |
| 14 | Stung Treng | 0.998 | 299.945 | 6.420 |
| 15 | Voeun Sai | 0.995 | 40.345 | 8.401 |
| Mean | 0.991 | 199.756 | 10.766 | |
| Standard Deviation | 0.010 | 369.281 | 7.619 |
| Station | ||||||
|---|---|---|---|---|---|---|
| MAE | RRMSE | MAE | RRMSE | MAE | RRMSE | |
| Battambang | 7.653 | 7.777 | 5.917 | 27.326 | 0.459 | 31.519 |
| Chaktomuk | 207.806 | 6.115 | 85.477 | 17.681 | 16.786 | 7.203 |
| Kg. Thmar | 2.215 | 1.643 | 0.906 | 1.417 | 0.054 | 2.860 |
| Koh Khel | 1.978 | 0.074 | 2.766 | 2.733 | 2.564 | 0.335 |
| Kompong Cham | 2179.283 | 6.431 | 980.935 | 2.748 | 56.442 | 16.626 |
| Kompong Chen | 0.900 | 1.792 | 1.402 | 38.641 | 0.549 | 16.804 |
| Kompong Kdei | 3.907 | 10.24 | 0.163 | 5.282 | 0.035 | 7.741 |
| Kompong Thom | 28.137 | 7.502 | 29.144 | 307.327 | 6.721 | 50.005 |
| Kratie | 3204.292 | 11.557 | 883.934 | 12.223 | 217.841 | 15.445 |
| Lumphat | 53.854 | 4.112 | 31.328 | 34.634 | 38.992 | 9.505 |
| Neak Luong | 577.349 | 3.149 | 364.371 | 2.615 | 41.487 | 5.363 |
| Siempang | 21.334 | 1.913 | 6.208 | 2.757 | 3.656 | 1.305 |
| Sisophon | 6.927 | 9.544 | 2.286 | 73.672 | 1.044 | 26.922 |
| Stung Treng | 1084.199 | 4.726 | 173.109 | 4.799 | 57.756 | 3.822 |
| Voeun Sai | 67.900 | 4.954 | 32.099 | 33.277 | 39.574 | 7.579 |
| Mean | 496.516 | 5.435 | 173.336 | 37.809 | 32.264 | 13.536 |
| Standard Deviation | 959.157 | 3.435 | 323.583 | 77.241 | 55.753 | 13.577 |
| ID | Station | KGE | MAE | RRMSE |
|---|---|---|---|---|
| 1 | Abbotts Creek At Lexington, NC | 0.996 | 0.344 | 12.287 |
| 2 | Brazos River Near Hempstead, TX | 0.997 | 10.504 | 10.938 |
| 3 | Cache River At Forman, IL | 0.962 | 1.494 | 36.487 |
| 4 | Colville River At Kettle Falls, WA | 0.974 | 1.141 | 20.703 |
| 5 | Elk River Near Pelham, TN | 0.977 | 0.604 | 28.122 |
| 6 | Kootenai River At Leonia, ID | 0.999 | 2.304 | 0.978 |
| 7 | Mississippi River At Baton Rouge, LA | 0.995 | 296.219 | 2.801 |
| 8 | Rio Tesuque Below Diversions Near Santa Fe, NM | 0.909 | 0.009 | 39.107 |
| 9 | Spanish Fork At Castilla, UT | 0.963 | 0.751 | 16.164 |
| 10 | Susquehanna River At Sunbury, PA | 0.999 | 6.804 | 1.328 |
| Mean | 0.977 | 32.017 | 16.892 | |
| Standard Deviation | 0.028 | 92.892 | 14.021 |
| Station | ||||||
|---|---|---|---|---|---|---|
| MAE | RRMSE | MAE | RRMSE | MAE | RRMSE | |
| Abbotts Creek At Lexington, NC | 0.661 | 6.048 | 0.332 | 22.225 | 0.097 | 18.547 |
| Brazos River Near Hempstead, TX | 42.538 | 6.026 | 4.622 | 19.728 | 2.570 | 7.545 |
| Cache River At Forman, IL | 5.412 | 19.947 | 0.720 | 106.264 | 0.079 | 41.223 |
| Colville River At Kettle Falls, WA | 3.674 | 15.944 | 0.645 | 13.458 | 0.311 | 13.936 |
| Elk River Near Pelham, TN | 1.560 | 17.542 | 0.459 | 142.081 | 0.217 | 23.826 |
| Kootenai River At Leonia, ID | 4.679 | 0.782 | 2.173 | 0.827 | 0.760 | 0.961 |
| Mississippi River At Baton Rouge, LA | 784.163 | 3.080 | 194.461 | 2.238 | 116.091 | 1.802 |
| Rio Tesuque Below Diversions Near Santa Fe, NM | 0.018 | 31.625 | 0.006 | 58.531 | 0.005 | 27.537 |
| Spanish Fork At Castilla, UT | 1.850 | 13.038 | 0.600 | 4.245 | 0.107 | 15.179 |
| Susquehanna River At Sunbury, PA | 6.247 | 0.430 | 7.690 | 3.830 | 4.655 | 1.903 |
| Mean | 85.080 | 11.446 | 21.171 | 37.343 | 12.489 | 15.246 |
| Standard Deviation | 245.955 | 10.017 | 60.937 | 49.512 | 36.433 | 13.056 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhandari, B.; Markert, K.; Mishra, V.; Markert, A.; Griffin, R. Investigation of Data-Driven Rating Curve (DDRC) Approach. Water 2023, 15, 604. https://doi.org/10.3390/w15030604
Bhandari B, Markert K, Mishra V, Markert A, Griffin R. Investigation of Data-Driven Rating Curve (DDRC) Approach. Water. 2023; 15(3):604. https://doi.org/10.3390/w15030604
Chicago/Turabian StyleBhandari, Biplov, Kel Markert, Vikalp Mishra, Amanda Markert, and Robert Griffin. 2023. "Investigation of Data-Driven Rating Curve (DDRC) Approach" Water 15, no. 3: 604. https://doi.org/10.3390/w15030604
APA StyleBhandari, B., Markert, K., Mishra, V., Markert, A., & Griffin, R. (2023). Investigation of Data-Driven Rating Curve (DDRC) Approach. Water, 15(3), 604. https://doi.org/10.3390/w15030604