1. Introduction
Flood frequency analysis plays a key role and is a constant topic in hydrology and water resources, especially for hydraulic design and flood hazard mitigation and management (e.g., [
1,
2]). Adequate estimations of extreme annual maximum daily flow are very important for flood control in which the upper-tail behavior of the flood frequency distribution is the key [
3,
4]. The frequency analysis of hydrological extremes requires a fit of a probability distribution to the observed data in order to suitably represent the frequency of occurrence of rare events [
5]. More than 20 statistical distributions have been used as the flood frequency distributions [
3]. Statistical criteria must be used to determine the suitable distribution for flood frequency analysis [
6]. However, for a given region, different model selection methods often result in different optimal distributions, especially when the focus is on the upper tail of flood frequency distribution [
7]. The flood estimation vary widely for different distributions. Therefore, the most suitable distribution must be chosen.
There are mainly two kinds of model selection techniques: hypothesis tests based on goodness-of-fit and information-based criteria [
5]. The commonly used hypothesis tests are the Kolmogorov–Smirnov (KS) test, Anderson–Darling (AD) test, probability plot correlation coefficient (PPCC), chi-squared test and log-likelihood ratio tests (t-test and F-test). Information-based criteria include the Akaike Information Criterion [
8], Akaike Information Criterion–second order variant (AICc) and Bayesian Information Criterion (BIC).
There have been some studies in the past on the comparison of various model selection methods. The choice of a distribution for flood frequency should be based on features reflecting the upper tail shape [
9]. However, there are rare studies about the comparison of model selection criteria with emphasis on the upper tail of flood frequency distribution. Cicioni et al. (1973) considered the two-parameter lognormal (LN2), three-parameter log-normal (LN3), Pearson type III distribution (P3) and Generalized Extreme Value (GEV) distributions for the flood data from 108 stations in Italy with record length of more than 27 years, and used Chi-squared, KS, Cramer–Von Mises and AD tests for distribution selection, giving the result that the Chi-squared test selected LN2 but other tests selected GEV [
7]. Haktanir and Horlacher (1993) applied a statistical model comprising nine different probability distributions for flood frequency analysis of annual flood peak series for 11 unregulated streams [
10]. The distributions were compared by classical goodness-of-fit tests (GOFT) on the observed series. However, different classical goodness-of-fit tests often result in different distributions for a specific region. Haddad et al. (2012) presented a case study with flood data from Tasmania in Australia in order to select the best fit flood frequency distribution by examining four model selection criteria: AIC, AICc, BIC and a modified Anderson–Darling (AD) Criterion [
11]. It was found from the Monte Carlo simulation that AD is more successful in correctly recognizing the parent distribution than AIC and BIC when the parent is a three-parameter distribution. On the other hand, AIC and BIC are better at correctly recognizing the parent distribution when the parent is a two-parameter distribution. Baldassarre (2009) demonstrated that model selection criteria such as AIC, BIC and AD which are seldom used in hydrological applications, can help to identify the best probability model [
12]. These three methods were compared through an extensive numerical analysis by using synthetic data samples. The model selection criteria based on AIC, BIC and AD were also adopted by Laio et al. (2009) and Calenda et al. (2009) [
5,
13], with further investigation to verify which of the selection criteria is more efficient, especially in the case of small samples and heavy tailed distributions, as these are commonly encountered in flood frequency analysis. The studies were carried out by a Monte Carlo simulation to investigate the robustness of the model selection criteria in recognizing the real parent distributions. Overall, none of the classical hypothesis tests and information-based criteria can be used as a universal indicator to select the suitable distributions for different stations around the world. Burnham and Anderson (2002) indicated that the hypothesis test and information-based approaches have different selection frequencies [
14]. Even if the same parameter estimation method is used, different model selection criteria result in different optimal distributions. This is perhaps because each type of model selection criteria has its own characteristics and applicable scope [
15]. Therefore, it is not surprising that the results of these tests are not always in agreement.
Estimating the magnitude and frequency of large floods is difficult and involves a large degree of uncertainty, especially when the flow record is of limited length. The Monte Carlo method and Paleohydrologic techniques offer a way to lengthen a short-term data record and, to reduce the uncertainty in hydrologic analysis [
16,
17,
18].
The basic assumption of traditional frequency analysis methods is that the hydrological data used are stationary, independent and identically distributed over time. However, in the past decades this stationarity assumption has been severely challenged because global climate change [
19] and/or large-scale human activities [
20] have altered the statistical characteristics of hydrological processes [
21]. Some hydrologists have declared that “stationarity is dead” [
22], and suggest that nonstationary probabilistic models need to be identified and possibly used in some practical cases when the characteristics of hydrological processes have been significantly changed [
23,
24,
25].
Selection of a flood frequency distribution is a necessary step in flood frequency analysis. However, selection of the best fit distribution from a large number of candidate distributions available in the literature is a difficult task. There are two reasons behind having no unique probability distributions for a given region. (1) Flood characteristics are different in different rivers; (2) there is a lack of an effective model selection criterion to be used to determine the suitable distribution for flood frequency analysis.
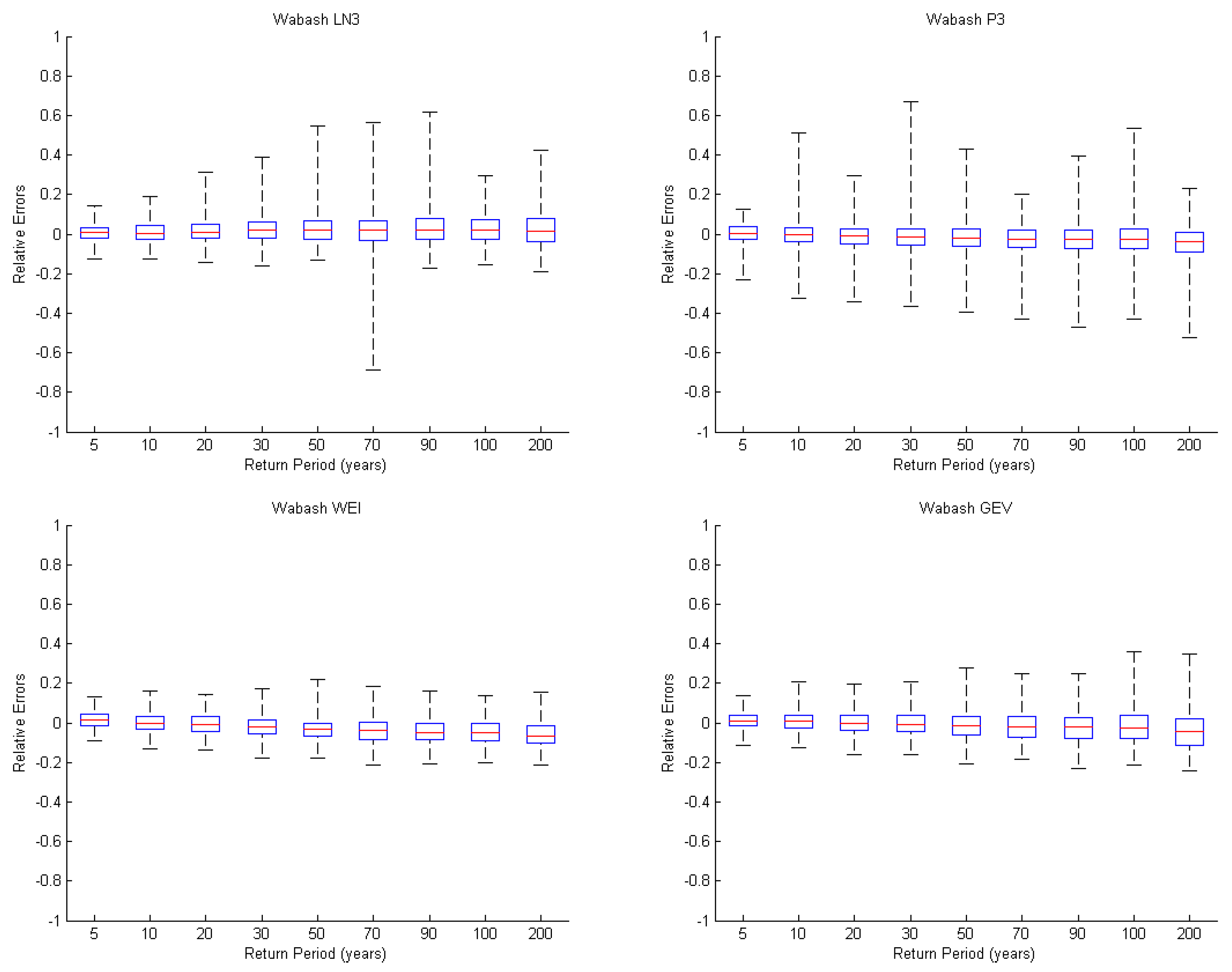
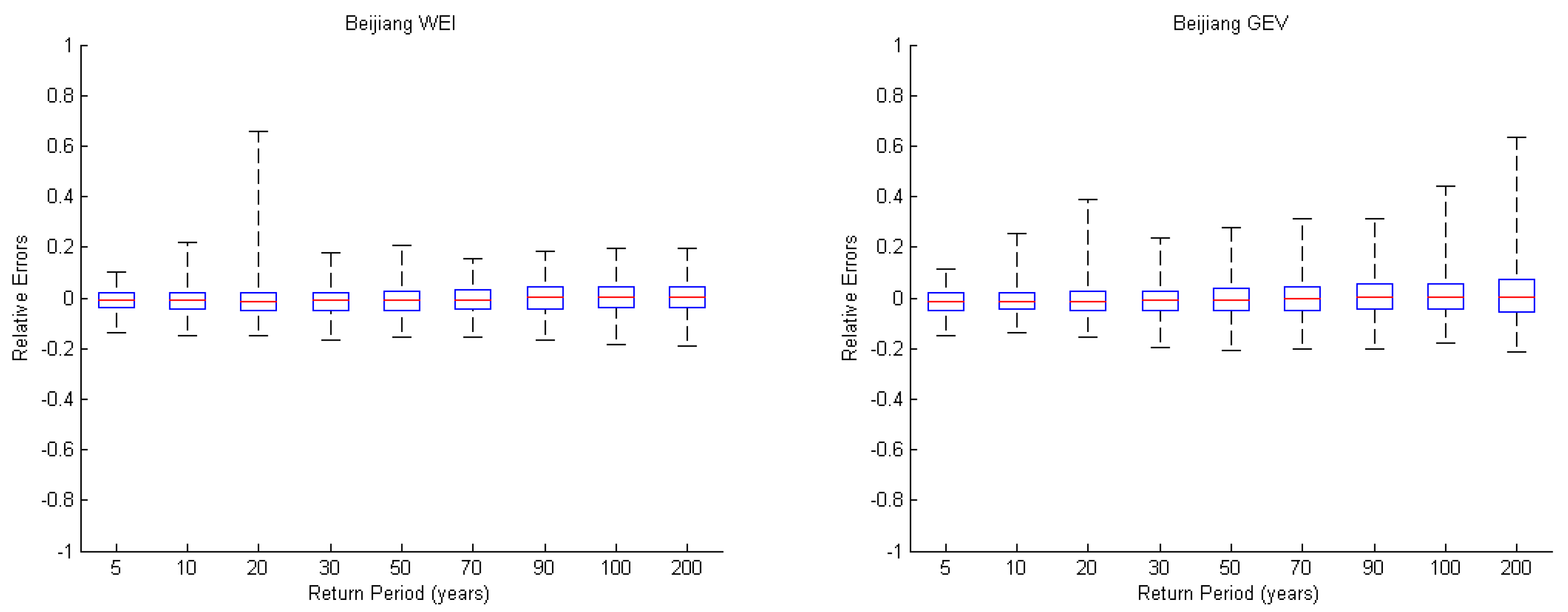
Flood frequency curves of different distributions show differences mainly at the tails of the distributions, especially at the high flow part which generally shows big differences for different distributions [
10]. Hosking and Wallis (1986) argued that the choice of a distribution for flood frequency should be based on features reflecting the upper tail shape [
9]. The observed flow data at the high flow part play an important role in the flood frequency analysis and should be addressed in the goodness-of-fit. The question is which model selection criterion can be a good indicator of the goodness of prediction for the extreme upper tail quantiles such as return periods of 100 years or more. In order to determine the more efficient model selection criterion which focuses on the upper-tail behaviour and reduces the influence of the lower tail end, a new composite criterion method to identify the optimal distribution is proposed in this study. The composite criterion can evaluate the goodness of predictions of the extreme upper-tail events carried out using synthetic samples of data by Monte Carlo simulation with Kappa distribution as the parent distribution. Stochastic simulation is widely applied for estimating the design flood of various hydrological systems.
In order to reveal the best fitted distribution for different regions in the flood frequency analysis with emphasis on the upper-tail behavior, the study aims at clarifying how the model selection methods work in different situations in the flood frequency analysis by (1) verifying whether hypothesis tests or information-based criteria methods are more efficient at the high flow part by clarifying the characteristic of model selection methods, and (2) trying to establish a composite of model selection criteria methods which can meet the demand of the engineering design. The findings from this study will benefit hazard mitigation and water resources management.
3. Study Area and Data
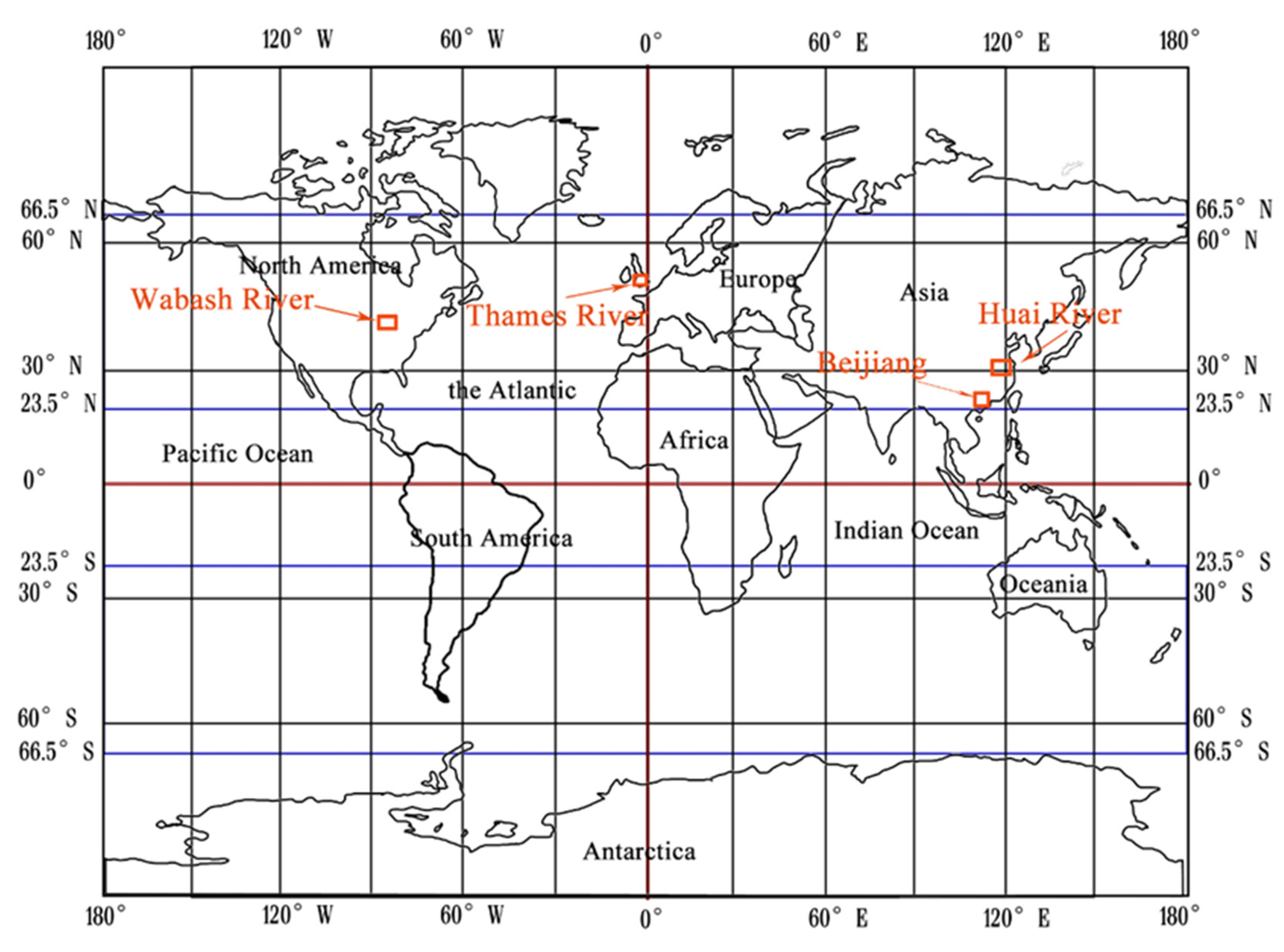
In order to verify the applicability of the methodology in different regions around the world, four hydrological stations with long historical data are used as case studies, including Kingston at Thames River, Lafayette at Wabash River, Shijiao at Beijiang River and Lutaizi at Huai River. These four stations are located in different areas in 23.5–66.5 degrees north of latitude in China, the UK and the US respectively (see
Figure 1 and
Table 2) with long-term data ranging from 48 to 127 years.
Figure 1 gives their geographical locations and
Table 2 summarizes the geographical and data information. The stations cover a wide range of climate conditions. Annual maximum daily flows are used in the analysis.
Thames River is the biggest river in the UK with the length of 338 km and drainage area of 9948 km2. It is located at a temperate climate zone with high humidity and relatively stable temperature. Kingston station, located at the lower reach of Thames River, is used in the study. The skewness coefficient Cs of the flood series at Kingston station is large with the value of 1.181, which implies a steep upper tail of the optimal frequency distribution.
With a length of 810 km, Wabash River is the largest and most important river in Indiana, USA. Wabash basin, mostly in Indiana, is dominated by a humid continental climate with cold winters, and warm and wet summers. Lafayette station, which is located at the middle reach of Wabash River and controls a drainage area of 18,821 km2, is used in the study. The small Cs value of 0.280 for the flood series at Lafayette station indicates that the upper tail of the optimal frequency distributions is gentle at this station.
Beijiang River, located at the subtropical monsoon climate zone of China, has an annual average temperature between 14 and 22 °C, and an annual mean rainfall of 1700 mm. Shijiao station, the main controlling station (controlling a drainage area of 38,363 km2) located at the lower reach of the Beijiang River, is used in this study. The small Cs value of 0.230 for the flood series at Shijiao station shows a gentle upper tail frequency distribution at this station.
Huai River, located between Changjiang River (Yangtze River) and Huanghe River (Yellow River), covers a large area. Its north part is in a warm temperate zone, while the south part is in a monsoon climate zone with an annual average temperature between 11 and 16 °C. Lutaizi station, the control station in the middle river reach with a drainage area of 91,620 km2, is selected as a case study in this paper. For Lutaizi Station, the large Cs value of 1.198 infers a steep upper tail frequency distribution.
The record lengths of the data are given in
Table 2 in descending order. The observed flood discharge series at each station is visually investigated to see if there are apparent trends or jumps. Statistical tests including the Spearman test for trend and the R/S analysis method for change point are conducted formally and summarized in
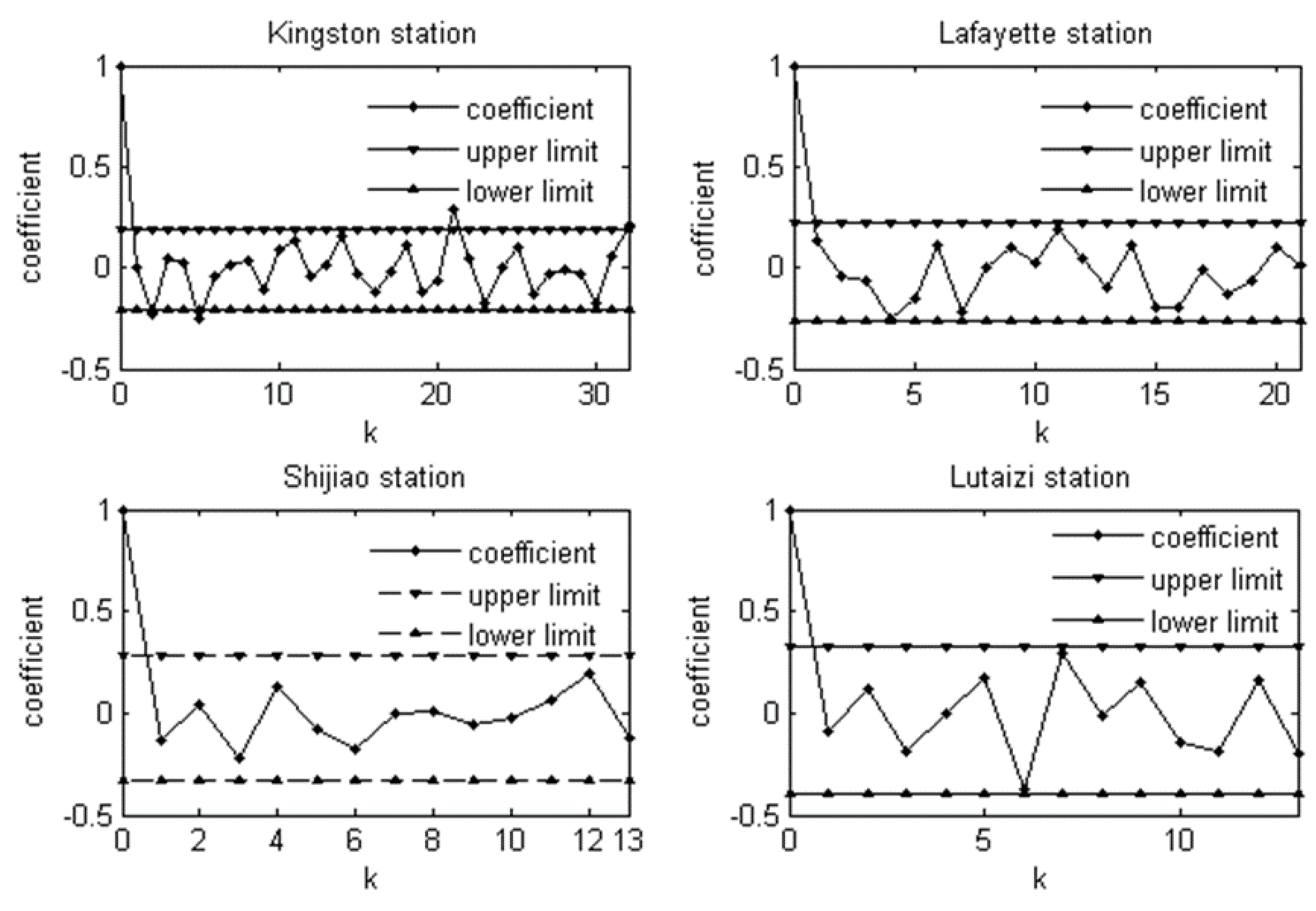
Table 3, from which it can be seen that there are no statistically significant trends and change point for annual maximum daily discharges. The fluctuation change of annual maximum flow is the biggest at Lafayette station and is the lowest at Kingston station. The autocorrelation coefficient and randomness test indicate that hydrological sequences satisfy the independent assumption (
Figure 2). Therefore, the flood series data of the studied rivers fulfil the basic assumptions of traditional frequency analysis methods, i.e., stationary, independent and identically distributed over time.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}