Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making


Abstract
:1. Introduction
2. Preliminaries
2.1. Hesitant Fuzzy Linguistic Term Set
- (i)
- ; and
- (ii)
- ; and
2.2. Hesitant Intuitionistic Fuzzy Linguistic Term Set
- (i)
- +
- (ii)
- +
2.3. Probabilistic Linguistic Term Sets
- (1)
- If the values of are different for all elements in PLTS, then arrange all the elements according to the values of directly.
- (2)
- If all the values of become equal for two or more elements, then
- (a)
- When the lower indices are unequal, arrange according to the values of in descending order.
- (b)
- When the lower indices are incomparable, arrange according to the values of in descending order.
- (1)
- If , then is calculated according to Definition 7.
- (2)
- If , then according to Definition 8, add some linguistic terms to the one with the smaller number of elements.
3. Probabilistic Hesitant Intuitionistic Linguistic Term Set
- (i)
- (ii)
- .
3.1. The Normalization of PHILTEs
3.2. The Comparison between PHILTEs
- (1)
- if , then ;
- (2)
- if and
- (a)
- , then ;
- (b)
- , then ;
- (c)
- , then is indifferent to and is denoted as .
- (I)
- If then >.
- (II)
- If then .
- (III)
- If then in this case we are unable to decide which one is superior. Thus, in this case, we do the comparison of PHILTEs on the bases of the deviation degree of normalized PHILTEs as follows.
- (1)
- If then .
- (2)
- If then .
- (3)
- If in such case we say that is indifferent to and is denoted by .
3.3. Basic Operations of PHILTEs
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
- (7)
- (8)
4. Aggregation Operators and Attribute Weights
4.1. The Aggregation Operators for PHILTEs
4.2. Maximizing Deviation Method for Calculating the Attribute Weights
5. MAGDM with Probabilistic Hesitant Intuitionistic Linguistic Information
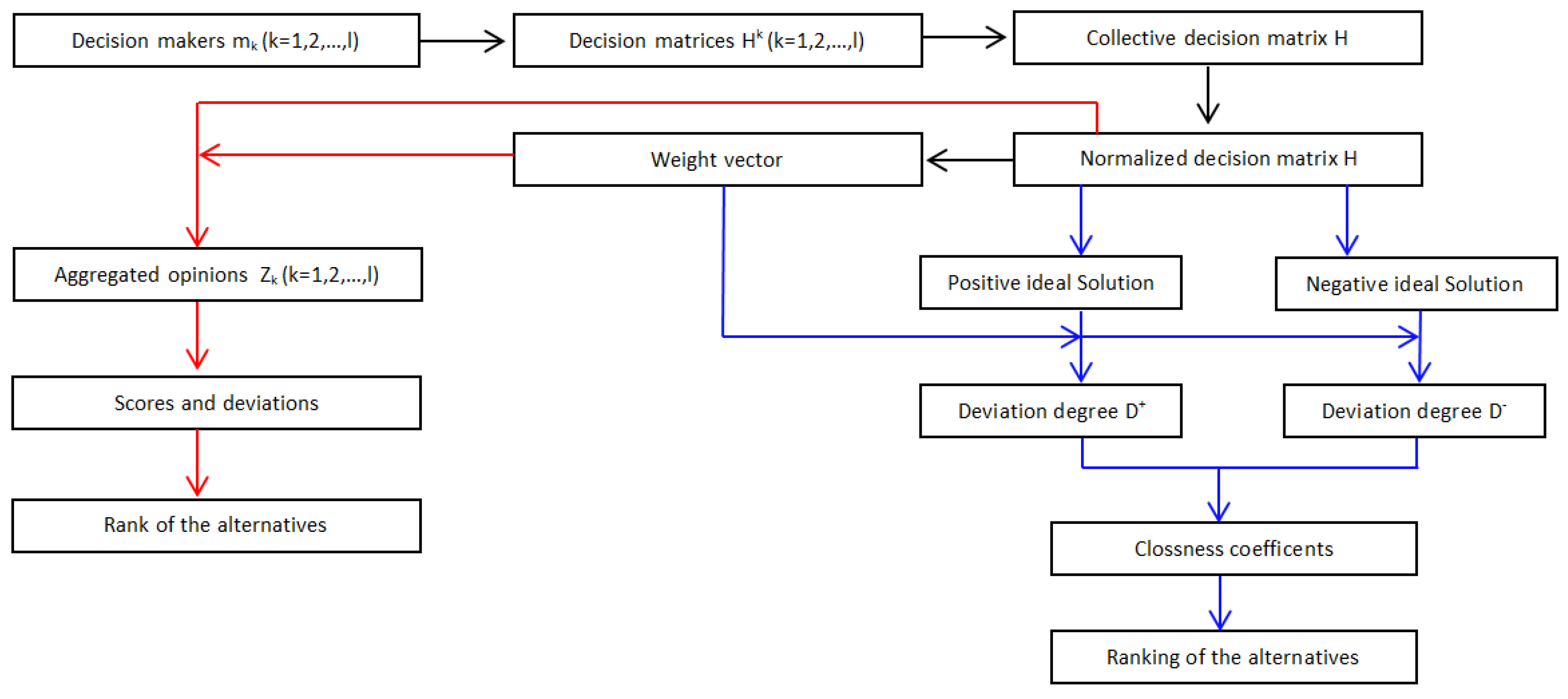
5.1. Extended TOPSIS Method for MAGDM with Probabilistic Hesitant Intuitionistic Linguistic Information
5.2. The Aggregation-Based Method for MAGDM with Probabilistic Hesitant Intuitionistic Linguistic Information
6. A Case Study
6.1. The Extended TOPSIS Method for the Considered Case
6.2. The Aggregation-Based Method for the Considered Case
7. Discussions and Comparison
- In Table 9, the disadvantages of HIFLTS are apparent because in HIFLTS the probabilities of the linguistic terms is not considered which means that all possible linguistic terms in HIFLTS have same occurrence possibility which is unrealistic, whereas the inspection of Table 7 shows that PHILTS not only contains the linguistic terms, but also considers the probabilities of linguistic terms, and, thus, PHILTS constitutes an extension of HIFLTS.
- The inspection of Table 10 reveals that the extended TOPSIS method and the aggregation-based method give the same best alternative . The TOPSIS method with the traditional HIFLTSs gives as the best alternative.
- This difference of best alternative in Table 10 is due to the effect of probabilities of membership and non-membership linguistic terms, which highlight the critical role of probabilities. Thus, our methods are more rational to get the ranking of alternatives and further to find the best alternative.
- Extended TOPSIS method and aggregation-based method for MAGDM with PLTS information explained in [19] are more promising and better than extended TOPSIS method and aggregation-based method for MAGDM with HFLTS information. However, a clear superiority of PHILTS is that it assigns to each element the degree of belongingness and also the degree of non-belongingness along with probability. PLTS only assigns to each element a belongingness degree along with probability. Using PLTSs, various frameworks have been developed by DMs [19,29] but they are still intolerant, since there is no mean of attributing reliability or confidence information to the degree of belongingness.
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Xu, Z.; Zhou, W. Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment. Fuzzy Optim. Decis. Mak. 2017, 16, 481–503. [Google Scholar] [CrossRef]
- Bashir, Z.; Rashid, T.; Wątróbski, J.; Sałabun, W.; Malik, A. Hesitant Probabilistic Multiplicative Preference Relations in Group Decision Making. Appl. Sci. 2018, 8, 398. [Google Scholar] [CrossRef]
- Alcantud, J.C.R.; Giarlotta, A. Necessary and possible hesitant fuzzy sets: A novel model for group decision making. Inf. Fusion 2019, 46, 63–76. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its applications to approximate reasoning. Inf. Sci. Part I II III 1975, 8–9, 43–80, 199–249, 301–357. [Google Scholar]
- Ju, Y.B.; Yang, S.H. Approaches for multi-attribute group decision making based on intuitionistic trapezoid fuzzy linguistic power aggregation operators. J. Intell. Fuzzy Syst. 2014, 27, 987–1000. [Google Scholar]
- Merigó, J.M.; Casanovas, M.; Martínez, L. Linguistic aggregation operators for linguistic decision making based on the Dempster–Shafer theory of evidence. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2010, 18, 287–304. [Google Scholar]
- Zhu, H.; Zhao, J.B.; Xu, Y. 2-Dimension linguistic computational model with 2-tuples for multi-attribute group decision making. Knowl. Based Syst. 2016, 103, 132–142. [Google Scholar] [CrossRef]
- Meng, F.Y.; Tang, J. Extended 2-tuple linguistic hybrid aggregation operators and their application to multi-attribute group decision making. Int. J. Comput. Intell. Syst. 2014, 7, 771–784. [Google Scholar] [CrossRef]
- Li, C.C.; Dong, Y. Multi-attribute group decision making methods with proportional 2-tuple linguistic assessments and weights. Int. J. Comput. Intell. Syst. 2014, 7, 758–770. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.S. Multi-period multi-attribute group decision-making under linguistic assessments. Int. J. Gen. Syst. 2009, 38, 823–850. [Google Scholar] [CrossRef]
- Li, D.F. Multiattribute group decision making method using extended linguistic variables. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2009, 17, 793–806. [Google Scholar] [CrossRef]
- Agell, N.; Sánchez, M.; Prats, F.; Roselló, L. Ranking multi-attribute alternatives on the basis of linguistic labels in group decisions. Inf. Sci. 2012, 209, 49–60. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar]
- Zhu, J.; Li, Y. Hesitant Fuzzy Linguistic Aggregation Operators Based on the Hamacher t-norm and t-conorm. Symmetry 2018, 10, 189. [Google Scholar] [CrossRef]
- Cui, W.; Ye, J. Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality. Symmetry 2018, 10, 330. [Google Scholar] [CrossRef]
- Liu, D.; Liu, Y.; Chen, X. The New Similarity Measure and Distance Measure of a Hesitant Fuzzy Linguistic Term Set Based on a Linguistic Scale Function. Symmetry 2018, 10, 367. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Lin, M.; Xu, Z.; Zhai, Y.; Zhai, T. Multi-attribute group decision-making under probabilistic uncertain linguistic environment. J. Oper. Res. Soc. 2017. [Google Scholar] [CrossRef]
- Atanassov, K. Intuitionistic Fuzzy Sets; Springer: Heidelberg, Germany, 1999. [Google Scholar]
- Bashir, Z.; Rashid, T.; Wątróbski, J.; Sałabun, W.; Ali, J. Intuitionistic-fuzzy goals in zero-sum multi criteria matrix games. Symmetry 2017, 9, 158. [Google Scholar] [CrossRef]
- Beg, I.; Rashid, T. Group Decision making Using Intuitionistic Hesitant Fuzzy Sets. Int. J. Fuzzy Logic Intell. Syst. 2014, 14, 181–187. [Google Scholar] [CrossRef]
- Boran, F.E.; Gen, S.; Kurt, M.; Akay, D. A multi-criteria intuitionistic fuzzy group decision making for supplier selection with TOPSIS method. Expert Syst. Appl. 2009, 36, 11363–11368. [Google Scholar] [CrossRef]
- De, S.K.; Biswas, R.; Roy, A.R. An application of intuitionistic fuzzy sets in medical diagnosis. Fuzzy Sets Syst. 2001, 117, 209–213. [Google Scholar] [CrossRef]
- Li, D.F. Multiattribute decision making models and methods using intuitionistic fuzzy sets. J. Comput. Syst. Sci. 2005, 70, 73–85. [Google Scholar] [CrossRef]
- Liu, P.; Mahmood, T.; Khan, Q. Multi-Attribute Decision-Making Based on Prioritized Aggregation Operator under Hesitant Intuitionistic Fuzzy Linguistic Environment. Symmetry 2017, 9, 270. [Google Scholar] [CrossRef]
- Beg, I.; Rashid, T. Hesitant intuitionistic fuzzy linguistic term sets. Notes Intuit. Fuzzy Sets 2014, 20, 53–64. [Google Scholar]
- Zhang, Y.; Xu, Z.; Wang, H.; Liao, H. Consistency-based risk assessment with probablistic linguistic prefrence relation. Appl. Soft Comput. 2016, 49, 817–833. [Google Scholar] [CrossRef]
- Xu, Z.S.; Xia, M.M. On distance and correlation measures of hesitant fuzzy information. Int. J. Intell. Syst. 2011, 26, 410–425. [Google Scholar] [CrossRef]
- Kim, S.H.; Ahn, B.S. Interactive group decision making procedure under incomplete information. Eur. J. Oper. Res. 1999, 116, 498–507. [Google Scholar] [CrossRef]
- Kim, S.H.; Choi, S.H.; Kim, J.K. An interactive procedure for multiple attribute group decision making with incomplete information: Range-based approach. Eur. J. Oper. Res. 1999, 118, 139–152. [Google Scholar] [CrossRef]
- Park, K.S. Mathematical programming models for characterizing dominance and potential optimality when multicriteria alternative values and weights are simultaneously incomplete. IEEE Trans. Syst. Man Cybern. 2004, 34, 601–614. [Google Scholar] [CrossRef]
- Xu, Z.S. An interactive procedure for linguistic multiple attribute decision making with incomplete weight information. Fuzzy Optim. Decis. Mak. 2007, 6, 17–27. [Google Scholar] [CrossRef]


{kind=link}
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
| c | c | |
|---|---|---|
| x | ||
| x | ||
| x | ||
| x | ||
| x | ||
| c | c | |
| x | ||
| x | ||
| x | ||
| x | ||
| x |
| c | |
|---|---|
| x | |
| x | |
| x | |
| x | |
| x | |
| c | |
| x | |
| x | |
| x | |
| x | |
| x | |
| c | |
| x | |
| x | |
| x | |
| x | |
| x | |
| c | |
| x | |
| x | |
| x | |
| x | |
| x |
| c | c | c | c | |
|---|---|---|---|---|
| x | ||||
| x | ||||
| x | ||||
| x | ||||
| x |
| TOPSIS [28] | |
| Proposed extend TOPSIS | |
| Proposed aggregation model |
| Advantages | Limitations |
|---|---|
| 1. PHILTS generalize the existing PLTS models | 1. It is essential to take membership as |
| since PHILTS take more information from the DMs | well as non-membership probabilistic |
| into account. | data. |
| 2. PHILTS is not affected by partial vagueness. | 2. Its computational index is |
| 3. PHILTS is more in line with people’s language, | high. |
| leading to much more fruitful decisions. | |
| 4. The attribute weights are calculated with | |
| objectivity (without favor). |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malik, M.G.A.; Bashir, Z.; Rashid, T.; Ali, J. Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Symmetry 2018, 10, 392. https://doi.org/10.3390/sym10090392
Malik MGA, Bashir Z, Rashid T, Ali J. Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Symmetry. 2018; 10(9):392. https://doi.org/10.3390/sym10090392
Chicago/Turabian StyleMalik, M. G. Abbas, Zia Bashir, Tabasam Rashid, and Jawad Ali. 2018. "Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making" Symmetry 10, no. 9: 392. https://doi.org/10.3390/sym10090392
APA StyleMalik, M. G. A., Bashir, Z., Rashid, T., & Ali, J. (2018). Probabilistic Hesitant Intuitionistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Symmetry, 10(9), 392. https://doi.org/10.3390/sym10090392