Information Security Methods—Modern Research Directions


 , , ,
, , ,
Abstract
:1. Introduction
2. Research in Engineering of Information Security Systems
- an ISS is seen as a complex of security tools designed to ensure the security of the information system and the information processed in it;
- each information security tool is a complex of security mechanisms implemented in the tool;
- security mechanisms must be applied to each possible object-subject and subject-subject information flow;
- each security mechanism is designed to neutralize a specific threat to the specific information flow.
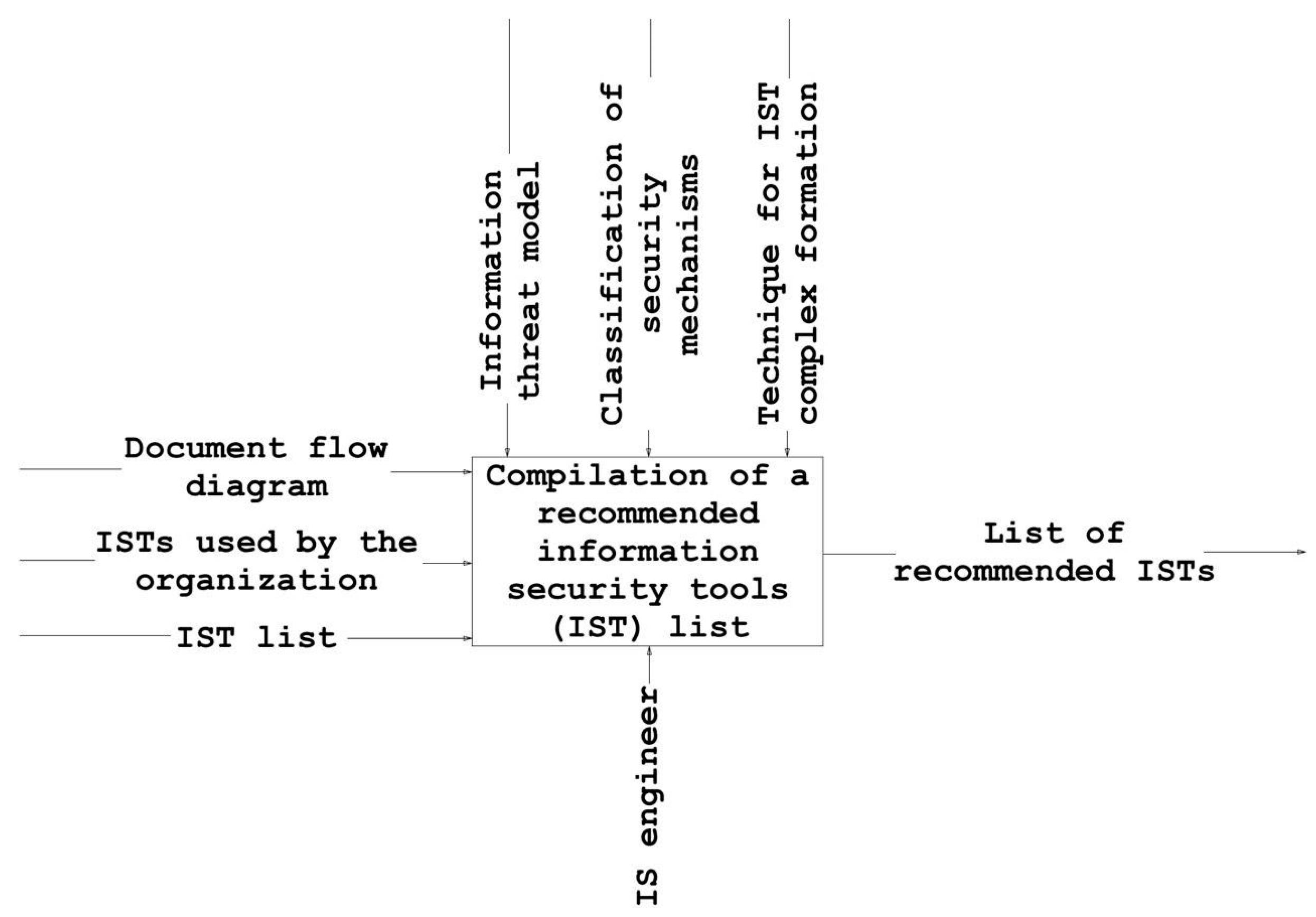
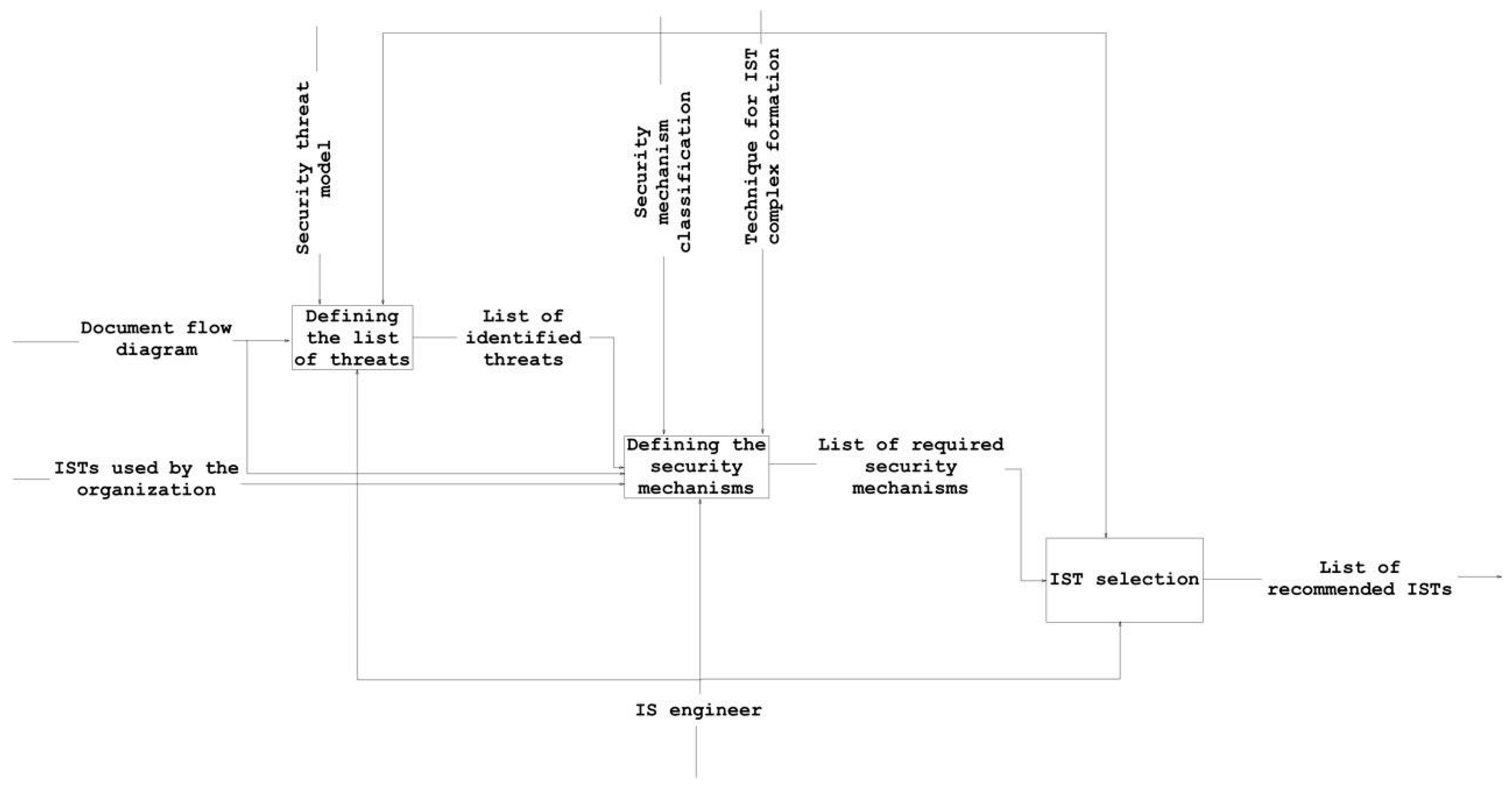
- construct a diagram of the information flows that need to be secured (document flow diagram);
- compile a list of active information security tools (IST) for each information flow;
- compile a list of information threats for each information flow.
- identify a list of threats for each information flow in the organization;
- for each information flow, identify the security mechanisms employed in the organization and determine if they are sufficient;
- for each information flow, determine the recommended ISTs that make it possible to neutralize threats that are not currently covered.
2.1. Document Flow Model
- visual environment, exposed to a threat of visual access to information, i.e., information can be obtained from a document without any additional transformations;
- physical environment, exposed to a threat of access to the information carrier;
- acoustic/vibroacoustic environment, exposed to a threat of verbal information leakage;
- signal environment, exposed to a threat of access to information by means of stray electromagnetic radiation from information carriers and transmission facilities;
- virtual environment, exposed to a threat of access to information directly in Random Access Memory (RAM).
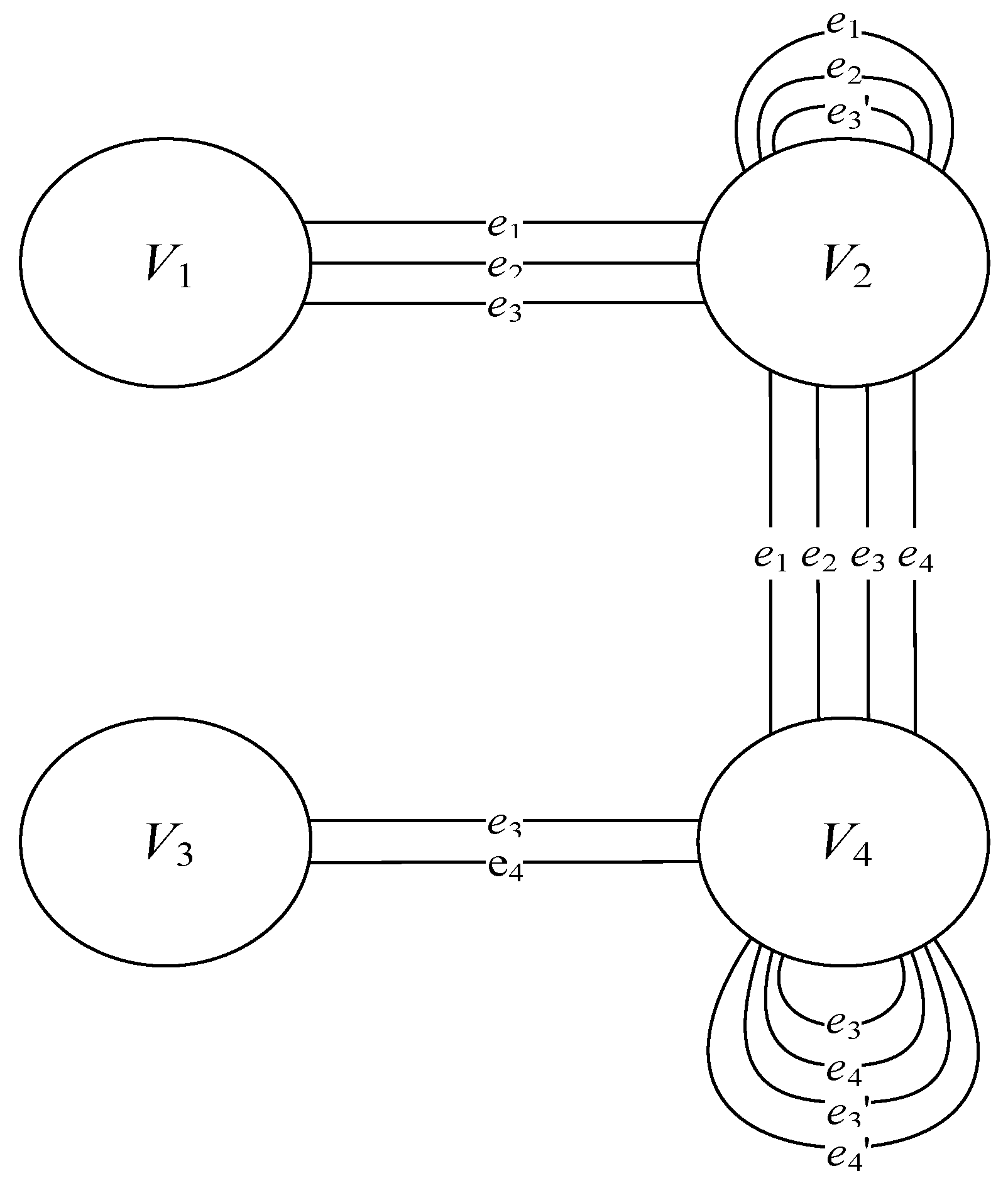
- V1—an object that contains analog data, including hard copies of documents;
- V2—a person;
- V3—an object that contains digital data;
- V4—a process.
- e1—in a visual environment;
- e2—in an acoustic environment;
- e3—in an electromagnetic environment;
- e4—in a virtual environment.
- e3’—in an electromagnetic environment;
- e4’—in a virtual environment.
2.2. Information Threat Model
- impersonation of the recipient Vi;
- impersonation of the recipient Vj;
- use of an unauthorized channel ez;
- channel control by an intruder ez.
- transmission of secured information to a decoy in the network (due to a spoofed IP address, a URL, an email address for document flow type {V4, e4’, V4}), or recording of restricted information in an unprotected file (for the document flow type {V3, e4’, V4});
- unauthorized information reading from a file that is being secured (for document flow type {V3, e4’, V4});
- use of network protocols that do not support encryption (for document flow type {V4, e4’, V4});
- network packet capture by means of network traffic analysis (for document flow type {V4, e4’, V4}).
2.3. Information Security Model
- identification and authentication (IA);
- access control (AC);
- memory clearing (MC);
- event logging (EL);
- encryption (EN).
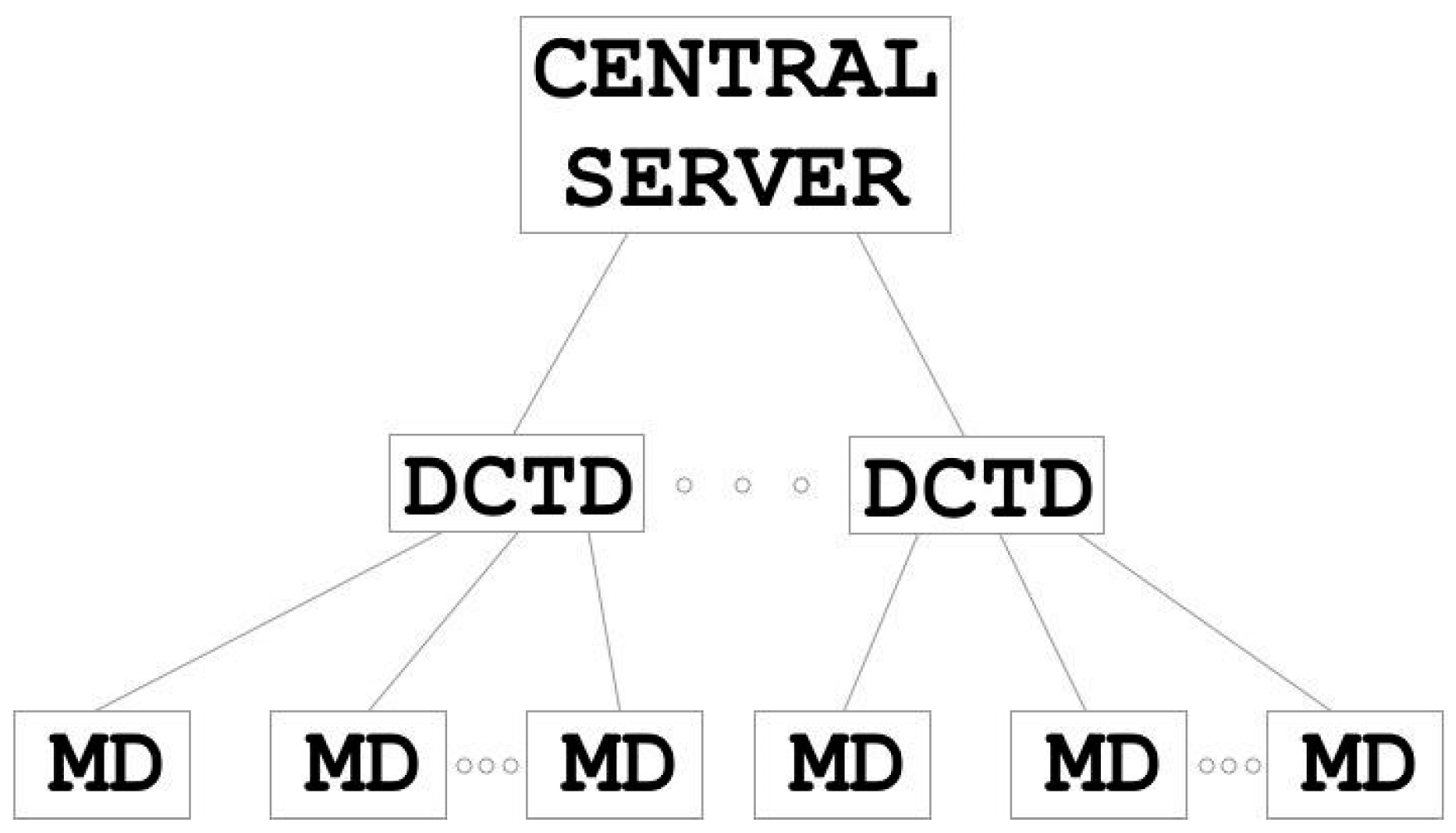
2.4. Computer Network Model
3. Research in Implementation of Information Security Mechanisms
- biometric user authentication using neural networks integrated with standard techniques;
- encryption mechanisms, by improving primality algorithms;
- mechanisms for secure transfer and authentication of digital objects through the development of steganographic data transformation methods;
- mechanisms of element authentication in process control systems (PCS) and creation of secure links for data transfer between these objects, by adapting typical network protocols to the specific aspects of the PCS operation.
3.1. Authentication Research
- a password can easily be disclosed to another person, and such disclosure can be both accidental and intentional (and further, done voluntarily or under duress or threats);
- after such disclosure occurs, it remains completely non-evident and, until any damage follows as a result of the disclosure, it is unnoticed in most cases, thus not directly causing the user to change the password;
- the user can simply forget the password, which could potentially lose access to their information;
- the password can be guessed through the application of exhaustive methods;
- the Login-Password storage responsible for the comparison during authentication can be attacked [81].
3.1.1. Static Biometric User Characteristics
3.1.2. Dynamic Biometric User Characteristics
3.1.3. Keystroke Dynamics in a Fixed Passphrase
3.1.4. Keystroke Dynamics in an Arbitrary Text
3.1.5. Signature Dynamics-Based Authentication
3.1.6. Integration of Several Authentication Methods with Guarantee of No Loss of Properties of the Best Method
- the output values of the neural network and the naive Bayes classifier are convoluted with the use of a monotonic function. The function includes several additional coefficients-convolution parameters. The application of this function guarantees that such a set of coefficients is available in degenerating the convolution into a separate classifier with its quality parameters;
- the resultant convolution is optimized to select the optimal convolution parameters and the decision thresholds for classification purposes. The classification thresholds are selected individually for each user and may vary among themselves. Given that individual classifiers are fragments of convolution, after optimization they guarantee a result that is at least as high as their individual quality values based on error probability, regardless of any specific type of criteria.
3.1.7. Further Research
3.2. Methods for Generating Prime Numbers for Data
- probabilistic primality tests are currently enjoying extensive use, e.g. the Miller–Rabin combined algorithm is applied extensively in public-key cryptosystems for the development of simple 512-, 1024-, and 2048-bit keys;
- Fermat’s little theorem underlies (as a primality criterion) the majority of the primality tests that are currently used in practice [110]. A primality criterion is understood as a necessary condition in which prime numbers must be satisfied.
Results of New Primality Criteria-Finding Research
3.3. Digital Steganography Research
3.3.1. Spatial Embedding of Information in Uncompressed Digital Images
3.3.2. Frequency Embedding of Information in Uncompressed Digital Images
3.3.3. Information Embedding in JPEG Compressed Images
3.3.4. Further Research
3.4. Research in Secure Data Transmission
- -
- secure data exchange between devices;
- -
- authorization of devices in the network;
- -
- remote software update on devices;
- -
- access control to information;
- -
- anonymization of received information.
- AES-CTR—AES stream encryption mode;
- AES-CBC—algorithm for calculating the message authentication code.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. List of Primality Criteria
| Primality Criteria | ||
| −3 | −2 | |
| 1 | 2 | |
| 3 | −2 | |
| 4 | −4 | |
| 5 | −4 | |
| −3 | −1 | |
| 1 | 3 | |
| 1 | 4 | |
| 1 | 5 | |
| 2 | 1 | |
| 2 | 2 | |
| 2 | 3 | |
| 2 | 4 |
| Primality criteria | ||
| 1 | 1 | |
| 4 | 1 | |
| 2 | 2 | |
| 3 | 2 | |
| 2 | 3 | |
| 1 | 4 | |
| 2 | 4 | |
| 4 | 2 | |
| −2 | 2 | |
| 1 | 1 | |
| 2 | 1 | |
| 3 | 1 | |
| 4 | 1 | |
| 3 | 2 | |
| 2 | 2 | |
| 1 | 2 | |
| −1 | 3 | |
| 1 | 3 | |
| 2 | 3 | |
| 3 | 3 | |
| 5 | 3 | |
| 1 | 4 | |
| −1 | 4 | |
| −1 | 5 |
References
- Sabanov, A.G.; Shelupanov, A.A.; Mesheryakov, R.V. Requirements for authentication systems according to severity levels. Polzunovsky Vestn. 2012, 2, 61–67. [Google Scholar]
- Rososhek, S.K.; Mesheryakov, R.V.; Shelupanov, A.A.; Bondarchuk, S.S. Embedding cryptographic functions in a communication system with limited resources. Inf. Secur. Issues 2004, 2, 22–25. [Google Scholar]
- Mesheryakov, R.V.; Shelupanov, A.A.; Zyryanova, T.Y. Reliability characteristics of distributed cryptographic information-telecommunication systems with limited resources. Comput. Technol. 2007, 12, 62–67. [Google Scholar]
- Mesheryakov, R.V.; Shelupanov, A.A. Conceptual Issues of Information Security in the Region and Training of Staff. Spiiras Proc. 2014, 3, 136–159. [Google Scholar] [CrossRef]
- Smolina, A.R.; Shelupanov, A.A. Classification of techniques for the production of computer-technical expertise using the graph theory approach. IT Secur. 2016, 2, 73–77. [Google Scholar]
- Smolina, A.R.; Shelupanov, A.A. Technique of carrying out the preparatory stage of the research in the production of computer-technical expertise. Rep. Tusur 2016, 19, 31–34. [Google Scholar]
- Prishep, S.V.; Timchenko, S.V.; Shelupanov, A.A. Approaches and criteria for assessing information security risks. IT Secur. 2007, 4, 15–21. [Google Scholar]
- Mironova, V.G.; Shelupanov, A.A. Methodology of formation of threats to the security of confidential information in uncertain conditions of their occurrence. Izv. Sfedutechnical Sci. 2012, 12, 39–45. [Google Scholar]
- Agarwal, A. Threat Modeling—Data Flow Diagram vs. Process Flow Diagram. 2016. Available online: https://www.peerlyst.com/posts/threat-modeling-data-flow-diagram-vs-process-flow-diagram-anurag-agarwal (accessed on 24 October 2018).
- Frydman, M.; Ruiz, G.; Heymann, E.; César, E.; Miller, B.P. Automating Risk Analysis of Software Design Models. Sci. World J. 2014, 2014, 805856. [Google Scholar] [CrossRef]
- Pan, J.; Zhuang, Y. PMCAP: A Threat Model of Process Memory Data on the Windows Operating System. Secur. Commun. Netw. 2017, 2017, 4621587. [Google Scholar] [CrossRef]
- Liu, F.; Li, T. A Clustering K-Anonymity Privacy-Preserving Method for Wearable IoT Devices. Secur. Commun. Netw. 2018, 2018, 4945152. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L.A.; Janicke, H.; Jiang, J.; Shu, L. Authentication Protocols for Internet of Things: A Comprehensive Survey. Secur. Commun. Netw. 2017, 2017, 6562953. [Google Scholar] [CrossRef]
- Wagner, T.D.; Palomar, E.; Mahbub, K.; Abdallah, A.E. Relevance Filtering for Shared Cyber Threat Intelligence (Short Paper). In Information Security Practice and Experience; Springer: Cham, Switzerland, 2017; pp. 576–586. [Google Scholar]
- Lakhno, V. Creation of the adaptive cyber threat detection system on the basis of fuzzy feature clustering. East. Eur. J. Enterp. Technol. 2016, 2, 18–25. [Google Scholar] [CrossRef]
- Bodeau, D.J.; McCollum, C.D. System-of-Systems Threat Model; The Homeland Security Systems Engineering and Development Institute (HSSEDI) MITRE: Bedford, MA, USA, 2018.
- Darwisha, S.; Nouretdinova, I.; Wolthusen, S.D. Towards Composable Threat Assessment for Medical IoT (MIoT). Procedia Comput. Sci. 2017, 113, 627–632. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Wei, Q. Quantitative Analysis of the Security of Software-Defined Network Controller Using Threat/Effort Model. Math. Probl. Eng. 2017, 2017, 8740217. [Google Scholar] [CrossRef]
- Luh, R.; Temper, M.; Tjoa, S.; Schrittwieser, S. APT RPG: Design of a Gamified Attacker/Defender Meta Model. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Madeira, Portugal, 22–24 January 2018; pp. 526–537. [Google Scholar]
- Aydin, M.M. Engineering Threat Modelling Tools for Cloud Computing; University of York Computer Science: Heslington, York, UK, 2016; 138p. [Google Scholar]
- Alhebaishi, N.; Wang, L.; Jajodia, S.; Singhal, A. Threat Modeling for Cloud Data Center Infrastructures. In International Symposium on Foundations and Practice of Security; Springer: Cham, Switzerland, 2016; pp. 302–319. [Google Scholar]
- Johnson, P.; Vernotte, A.; Ekstedt, M.; Lagerström, R. pwnPr3d: An Attack-Graph-Driven Probabilistic Threat-Modeling Approach. In Proceedings of the 2016 11th International Conference on Availability, Reliability and Security (ARES), Salzburg, Austria, 31 August–2 September 2016; pp. 278–283. [Google Scholar]
- Boukhtouta, A.; Mouheb, D.; Debbabi, M.; Alfandi, O.; Iqbal, F.; El Barachi, M. Graph-theoretic characterization of cyber-threat infrastructures. Digit. Investig. 2015, 14, S3–S15. [Google Scholar] [CrossRef] [Green Version]
- Konev, A.A.; Davidova, E.M. Approach to the description of the structure of the information security system. Rep. Tusur 2013, 2, 107–111. [Google Scholar]
- Boiko, A.; Shendryk, V. System Integration and Security of Information Systems. Procedia Comput. Sci. 2017, 104, 35–42. [Google Scholar] [CrossRef]
- Xuezhong, L.; Zengliang, L. Evaluating Method of Security Threat Based on Attacking-Path Graph Model. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Hubei, China, 12–14 December 2008; pp. 1127–1132. [Google Scholar]
- Solic, K.; Ocevcic, H.; Golub, M. The information systems’ security level assessment model based on an ontology and evidential reasoning approach. Comput. Secur. 2015, 55, 100–112. [Google Scholar] [CrossRef]
- Jouini, M.; Rabai, L. A Scalable Threats Classification Model in Information Systems. In Proceedings of the 9th International Conference on Security of Information and Networks (SIN’16), Newark, NJ, USA, 20–22 July 2016; pp. 141–144. [Google Scholar]
- Konev, A.; Shelupanov, A.; Egoshin, N. Functional Scheme of the Process of Access Contro. In Proceedings of the 3rd Russian-Pacific Conference on Computer Technology and Applications (RPC), Vladivostok, Russia, 18–25 August 2018; pp. 1–7. [Google Scholar]
- Konev, A.A. Approach to building a model of threats to protected information. Rep. Tusur 2012, 1, 34–39. [Google Scholar]
- Novokhrestov, A.; Konev, A. Mathematical model of threats to information systems. AIP Conf. Proc. 2016, 1772, 060015. [Google Scholar] [Green Version]
- Hettiarachchi, S.; Wickramasinghe, S. Study to Identify Threats to Information Systems in Organizations and Possible Countermeasures through Policy Decisions and Awareness Programs to Ensure the Information Security. Available online: http://www.academia.edu/28512865/Study_to_identify_threats_to_Information_Systems_in_organizations_and_possible_countermeasures_through_policy_decisions_and_awareness_programs_to_ensure_the_information_security (accessed on 20 October 2018).
- Chaula, J.A.; Yngström, L.; Kowalski, S. Security Metrics and Evaluation of Information Systems Security. Available online: https://pdfs.semanticscholar.org/f2bb/401cb3544f4ddeb12161cd4dfcd8ef99613f.pdf (accessed on 14 October 2018).
- Basu, A.; Blanning, R. Metagraphs and Their Applications; Springer: Cham, Switzerland, 2007; 174p. [Google Scholar]
- Jouini, M.; Rabai, L.; Aissa, A. Classification of security threats in information systems. Procedia Comput. Sci. 2014, 32, 489–496. [Google Scholar] [CrossRef]
- Prasad, P.S.; Sunitha Devi, B.; Janga Reddy, M.; Gunjan, V.K. A survey of fingerprint recognition systems and their applications. Lect. Notes Electr. Eng. 2019, 500, 513–520. [Google Scholar]
- Prasad, P.S.; Sunitha Devi, B.; Preetam, R. Image enhancement for fingerprint recognition using Otsu’s method. Lect. Notes Electr. Eng. 2019, 500, 269–277. [Google Scholar]
- El Beqqal, M.; Azizi, M.; Lanet, J.L. Polyvalent fingerprint biometric system for authentication. Smart Innovation. Syst. Technol. 2019, 111, 361–366. [Google Scholar]
- Shaheed, K.; Liu, H.; Yang, G.; Qureshi, I.; Gou, J.; Yin, Y. A Systematic Review of Finger Vein Recognition Techniques. Information 2018, 9, 213. [Google Scholar] [CrossRef]
- Uçan, O.N.; Bayat, O.; Çoşkun, M.B. Development and evaluation of the authentication systems by using phase-only correlation palm print identificaton methods. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–4. [Google Scholar]
- Shelton, J.; Rice, C.; Singh, J.; Jenkins, J.; Dave, R.; Roy, K.; Chakraborty, S. Palm Print Authentication on a Cloud Platform. In Proceedings of the 2018 International Conference on Advances in Big Data, Computing and Data Communication Systems, icABCD 2018, Durban, South Africa, 6–7 August 2018; pp. 1–6. [Google Scholar]
- Ali, M.M.H.; Gaikwad, A.T.; Yannawar, P.L. Palmprint identification and verification system based on euclidean distance and 2d locality preserving projection method. Adv. Intell. Syst. Comput. 2019, 707, 205–216. [Google Scholar]
- Rajagopal, G.; Manoharan, S.K. Personal Authentication Using Multifeatures Multispectral Palm Print Traits. Sci. World J. 2015, 2015, 861629. [Google Scholar] [CrossRef]
- Mathivanan, B.; Palanisamy, V.; Selvarajan, S. A hybrid model for human recognition system using hand dorsum geometry and finger-knuckle-print. J. Comput. Sci. 2012, 8, 1814–1821. [Google Scholar]
- Gupta, P.; Srivastava, S.; Gupta, P. An accurate infrared hand geometry and vein pattern based authentication system. Knowl. Based Syst. 2016, 103, 143–155. [Google Scholar] [CrossRef]
- Burgues, J.; Fierrez, J.; Ramos, D.; Ortega-Garcia, J. Comparison of distance-based features for hand geometry authentication. In European Workshop on Biometrics and Identity Management; Springer: Berlin/Heidelberg, Germany, 2009; pp. 325–332. [Google Scholar]
- Tsapatsoulis, N.; Pattichis, C. Palm geometry biometrics: A score-based fusion approach. In Proceedings of the AIAI-2009 Workshops, Thessaloniki, Greece, 23–25 April 2009; pp. 158–167. [Google Scholar]
- Klonowski, M.; Plata, M.; Syga, P. User authorization based on hand geometry without special equipment. Pattern Recognit. 2018, 73, 189–201. [Google Scholar] [CrossRef]
- Yuan, X.; Gu, L.; Chen, T.; Elhoseny, M.; Wang, W. A fast and accurate retina image verification method based on structure similarity. In Proceedings of the 2018 IEEE Fourth International Conference on Big Data Computing Service and Applications (BigDataService), Bamberg, Germany, 26–29 March 2018; pp. 181–185. [Google Scholar]
- Rani, B.M.S.; Jhansi Rani, A.; Divya sree, M. A powerful artificial intelligence-based authentication mechanism of retina template using sparse matrix representation with high security. Adv. Intell. Syst. Comput. 2019, 815, 679–688. [Google Scholar]
- Poosarala, A.; Jayashree, R. Uniform classifier for biometric ear and retina authentication using smartphone application. In Proceedings of the 2nd International Conference on Vision, Image and Signal Processing, Las Vegas, NV, USA, 27–29 July 2018; p. 58. [Google Scholar]
- Boriev, Z.; Nyrkov, A.; Sokolov, S.; Chernyi, S. Software and hardware user authentication methods in the information and control systems based on biometrics. IOP Conf. Ser. Mater. Sci. Eng. 2016, 124, 012006. [Google Scholar] [CrossRef] [Green Version]
- Prasad, P.S.; Baswaraj, D. Iris recognition systems: A review. Lect. Notes Electr. Eng. 2019, 500, 521–527. [Google Scholar]
- Ghali, A.A.; Jamel, S.; Pindar, Z.A.; Disina, A.H.; Daris, M.M. Reducing Error Rates for Iris Image using higher Contrast in Normalization process. IOP Conf. Ser. Mater. Sci. Eng. 2017, 226, 1–10. [Google Scholar] [CrossRef]
- Haware, S.; Barhatte, A. Retina Based Biometric Identification Using SURF and ORB Feature Descriptors; IEEE: New York, NY, USA, 2017; ISBN 978-1-5386-1716-8. [Google Scholar]
- Yaman, M.A.; Subasi, A.; Rattay, F. Comparison of Random Subspace and Voting Ensemble Machine Learning Methods for Face Recognition. Symmetry 2018, 10, 651. [Google Scholar] [CrossRef]
- Galterio, M.G.; Shavit, S.A.; Hayajneh, T. A Review of Facial Biometrics Security for Smart Devices. Computers 2018, 7, 37. [Google Scholar] [CrossRef]
- Omieljanowicz, M.; Popławski, M.; Omieljanowicz, A. A Method of Feature Vector Modification in Keystroke Dynamics. Adv. Intell. Syst. Comput. 2019, 889, 458–468. [Google Scholar]
- Smriti, P.; Srivastava, S.; Singh, S. Keyboard Invariant Biometric Authentication. In Proceedings of the 2018 4th International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad Uttar Pradesh, India, 9–10 February 2018; pp. 1–6. [Google Scholar]
- Kochegurova, E.; Luneva, E.; Gorokhova, E. On continuous user authentication via hidden free-text based monitoring. Adv. Intell. Syst. Comput. 2019, 875, 66–75. [Google Scholar]
- Muliono, Y.; Ham, H.; Darmawan, D. Keystroke Dynamic Classification using Machine Learning for Password Authorization. Procedia Comput. Sci. 2018, 135, 564–569. [Google Scholar] [CrossRef]
- Khalifa, A.A.; Hassan, M.A.; Khalid, T.A.; Hamdoun, H. Comparison between mixed binary classification and voting technique for active user authentication using mouse dynamics. In Proceedings of the 2015 International Conference on Computing, Control, Networking, Electronics and Embedded Systems Engineering (ICCNEEE), Khartoum, Sudan, 7–9 September 2015; pp. 281–286. [Google Scholar]
- Lozhnikov, P.S.; Sulavko, A.E. Usage of quadratic form networks for users’ recognition by dynamic biometrie images. In Dynamics of Systems, Mechanisms and Machines (Dynamics); IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Yang, L.; Cheng, Y.; Wang, X.; Liu, Q. Online handwritten signature verification using feature weighting algorithm relief. Soft Comput. 2018, 22, 7811–7823. [Google Scholar] [CrossRef]
- Jimenez, A.; Raj, B. A two factor transformation for speaker verification through ℓ1 comparison. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2018; pp. 1–6. [Google Scholar]
- Rahulamathavan, Y.; Sutharsini, K.R.; Ray, I.G.; Lu, R.; Rajarajan, M. Privacy-preserving ivector-based speaker verification. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 496–506. [Google Scholar] [CrossRef]
- Todkar, S.P.; Babar, S.S.; Ambike, R.U.; Suryakar, P.B.; Prasad, J.R. Speaker Recognition Techniques: A Review. In Proceedings of the 2018 3rd International Conference for Convergence in Technology, I2CT 2018, Pune, India, 6–7 April 2018. [Google Scholar]
- Tovarek, J.; Ilk, G.H.; Partila, P.; Voznak, M. Human Abnormal Behavior Impact on Speaker Verification Systems. IEEE Access 2018, 6, 40120–40127. [Google Scholar] [CrossRef]
- Sharifi, O.; Eskandari, M. Optimal Face-Iris Multimodal Fusion Scheme. Symmetry 2016, 8, 48. [Google Scholar] [CrossRef]
- Chee, K.; Jin, Z.; Yap, W.; Goi, B. Two-dimensional winner-takes-all hashing in template protection based on fingerprint and voice feature level fusion. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1411–1419. [Google Scholar]
- Jaswal, G.; Kaul, A.; Nath, R. Multimodal Biometric Authentication System Using Hand Shape, Palm Print, and Hand Geometry. Adv. Intell. Syst. Comput. 2019, 799, 557–570. [Google Scholar]
- Gupta, P.; Gupta, P. Multibiometric authentication system using slap fingerprints, palm dorsal vein, and hand geometry. IEEE Trans. Ind. Electron. 2018, 65, 9777–9784. [Google Scholar] [CrossRef]
- Alam, B.; Jin, Z.; Yap, W.-S.; Goi, B.-M. An alignment-free cancelable fingerprint template for bio-cryptosystems. J. Netw. Comput. Appl. 2018, 115, 20–32. [Google Scholar] [CrossRef]
- Yang, J.; Sun, W.; Liu, N.; Chen, Y.; Wang, Y.; Han, S. A Novel Multimodal Biometrics Recognition Model Based on Stacked ELM and CCA Methods. Symmetry 2018, 10, 96. [Google Scholar] [CrossRef]
- Kaur, T.; Kaur, M. Cryptographic key generation from multimodal template using fuzzy extractor. In Proceedings of the 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, India, 10–12 August 2017; pp. 1–6. [Google Scholar]
- Murugan, C.A.; KarthigaiKumar, P. Survey on Image Encryption Schemes, Bio cryptography and Efficient Encryption Algorithms. Mob. Netw. Appl. 2018. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Hu, J.; Zheng, G.; Chaudhry, J.; Adi, E.; Valli, C. Securing Mobile Healthcare Data: A Smart Card Based Cancelable Finger-Vein Bio-Cryptosystem. IEEE Access 2018, 6, 36939–36947. [Google Scholar] [CrossRef]
- Lai, Y.-L.; Jin, Z.; Jin Teoh, A.B.; Goi, B.-M.; Yap, W.-S.; Chai, T.-Y.; Rathgeb, C. Cancellable iris template generation based on Indexing-First-One hashing. Pattern Recognit. 2017, 64, 105–117. [Google Scholar] [CrossRef]
- Chee, K.-Y.; Jin, Z.; Cai, D.; Li, M.; Yap, W.-S.; Lai, Y.-L.; Goi, B.-M. Cancellable speech template via random binary orthogonal matrices projection hashing. Pattern Recognit. 2018, 76, 273–287. [Google Scholar] [CrossRef]
- Afanasiev, A.A.; Vedeniev, L.T.; Voronsov, A.A. Authentication. Theory and practice of providing secure access to information resources. In Textbook for High Schools, 2nd ed.; Shelupanov, A.A., Gruzdev, S.L., Nahaev, Y.S., Eds.; Hot Line-Telecom: Moscow, Russia, 2012; 550p. [Google Scholar]
- Bezmaliy, V. Password protection: Past, present, future. Comput. Press 2008, 9, 37–45. [Google Scholar]
- Popov, M. Biometric Security Systems; BDI, Institute of Economic Security: Moscow, Russia, 2002; Volume 41. [Google Scholar]
- Ross, A.; Dass, S.; Jain, A.K. A deformable model for fingerprint matching. J. Pattern Recognit. 2005, 38, 95–103. [Google Scholar] [CrossRef]
- Matsumoto, T.; Hoshino, H.; Yamada, K.; Hasino, S. Impact of artificial gummy fingers on fingerprint systems. In Proceedings of the Optical Security and Counterfeit Deterrence Techniques IV, San Jose, CA, USA, 23–25 January 2002; Volume 4677, pp. 275–289. [Google Scholar]
- Jain, A.K.; Ross, A.; Pankanti, S. Biometric: A Tool for Information Security. IEEE Trans. Inf. Forensics Secur. 2006, 1, 125–144. [Google Scholar] [CrossRef]
- Kukula, E.; Elliott, S. Implementation of Hand Geometry at Purdue University’s Recreational Center: An Analysis of User Perspectives and System Performance. In Proceedings of the 35th Annual International Carnahan Conference on Security Technology, Las Palmas, Spain, 11–14 October 2001; pp. 83–88. [Google Scholar]
- Kumar, A.; Wong, D.C.; Shen, H.C.; Jain, A.K. Personal Verification using Palmprint and Hand Geometry Biometric. In Proceedings of the 4th International Conference on Audio- and Video-based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; pp. 668–678. [Google Scholar]
- The distributed System of Recognition of Persons on the Basis of Geometrical Characteristics. Available online: http://masters.donntu.org/2010/fknt/kolesnik/library/tez1.htm (accessed on 29 December 2017).
- Ganorkar, S.R.; Ghatol, A.A. Iris Recognition: An Emerging Biometric Technology. In Proceedings of the 6th WSEAS International Conference on Signal Processing, Robotics and Automation, Elounda, Corfu, Greece, 16–19 February 2007; pp. 91–96. [Google Scholar]
- Marino, C.; Penedo, M.G.; Penas, M.; Carreira, M.J.; Gonzalez, F. Personal authentication using digital retinal images. J. Pattern Anal. Appl. 2006, 9, 21–33. [Google Scholar] [CrossRef]
- Favata, J.T.; Srikantan, G.; Srihari, S.N. Handprinted character digit recognition using a multiple resolution. In Proceedings of the IWFHR-1994, Taipei, Taiwan, 7–9 December 1994; pp. 57–66. [Google Scholar]
- Doroshenko, T.Y.; Kostyuchenko, E.Y. Authentication system based on the dynamics of the handwritten signature. Rep. Tusur 2014, 2, 219–223. [Google Scholar]
- Rakhmanenko, I.A. Study formants and chalk-cepstral coefficients as a vector of signs for the task of identification by voice. In Proceedings of the Electronic means and control systems, Tomsk, Russia, 25–27 November 2015; pp. 188–192. [Google Scholar]
- Banerjee, S.P.; Woodard, D.L. Biometric Authentication and Identification Using Keystroke Dynamics: A Survey. J. Pattern Recognit. Res. 2012, 7, 116–139. [Google Scholar] [CrossRef]
- Shirochin, V.P.; Kulik, A.V.; Marchenko, V.V. Dynamic authentication based on the analysis of the keyboard handwriting. Visnyk Ntuu “Kpi” Inform. Oper. Comput. Sci. 1999, 32, 1–16. [Google Scholar]
- Kostyuchenko, E.Y.; Mesheryakov, R.V. Identification by biometric parameters when using the apparatus of neural networks. Neurocomput. Dev. Appl. 2007, 7, 39–50. [Google Scholar]
- Gorbunov, I.V. Algorithms and Software for Identification of Pareto-Optimal Fuzzy Systems Based on Meta-Heuristic Methods; TUSUR: Tomsk, Russia, 2014; 192p. [Google Scholar]
- Kostyuchenko, E.; Krivonosov, E.; Shelupanov, A. Integrated approach to user authentication based on handwritten signature. In Proceedings of the CEUR, Delmenhorst, Germany, 20–21 July 2017; Volume 2081, pp. 66–69. [Google Scholar]
- Gurakov, M.A.; Krivonosov, E.O.; Tomyshev, M.D.; Mescheryakov, R.V.; Hodashinskiy, I.A. Integration of the Bayesian classifier and perceptron for problem identification on dynamics, using a genetic algorithm for the identification threshold selection. Lect. Notes Comput. Sci. 2016, 9719, 620–627. [Google Scholar]
- Rivest, R.; Shamir, A.; Adleman, L. A Method for Obtaining Digital Signatures and Public-Key Cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Benhamouda, F.; Ferradi, H.; Géraud, R.; Naccache, D. Non-interactive provably secure attestations for arbitrary RSA prime generation algorithms. Lect. Notes Comput. Sci. 2017, 10492, 206–223. [Google Scholar]
- Padmaja, C.J.L.; Bhagavan, V.S.; Srinivas, B. RSA encryption using three Mersenne primes. Int. J. Chem. Sci. 2016, 14, 2273–2278. [Google Scholar]
- Vaskouski, M.; Kondratyonok, N.; Prochorov, N. Primes in quadratic unique factorization domains. J. Number Theory 2016, 168, 101–116. [Google Scholar] [CrossRef]
- Jo, H.; Park, H. Fast prime number generation algorithms on smart mobile devices. Clust. Comput. 2017, 20, 2167–2175. [Google Scholar] [CrossRef]
- Iswari, N.M.S. Key generation algorithm design combination of RSA and ElGamal algorithm. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering: Empowering Technology for Better Future, ICITEE, Yogyakarta, Indonesia, 5–6 October 2016; p. 7863255. [Google Scholar]
- Raghunandan, K.R.; Shetty, R.; Aithal, G. Key generation and security analysis of text cryptography using cubic power of Pell’s equation. In Proceedings of the 2017 International Conference on Intelligent Computing, Instrumentation and Control Technologies, ICICICT, Kerala, India, 6–7 July 2017; pp. 1496–1500. [Google Scholar]
- Balabanov, A.A.; Agafonov, A.F.; Ryku, V.A. Algorithm for rapid key generation in the RSA cryptographic system. Bull. Sci. Tech. Dev. 2009, 7, 11–17. [Google Scholar]
- Vasilenko, O.N. Numerical-Numerical Algorithms in Cryptography; MNCMO: Moscow, Russia, 2003; 326p. [Google Scholar]
- Cheremushkin, A.V. Lectures on Arithmetic Algorithms in Cryptography; MNCMO: Moscow, Russia, 2002; 104p. [Google Scholar]
- Ribenboim, P. The Little Book of Bigger Primes; Springer-Verlag: New York, NY, USA, 2004; 356p. [Google Scholar]
- Kruchinin, D.V.; Kruchinin, V.V. Method for constructing algorithms for verifying the simplicity of natural numbers for the protection of information. Rep. Tusur 2011, 2, 247–251. [Google Scholar]
- Kruchinin, D.V.; Kruchinin, V.V. A Method for Obtaining Generating Function for Central Coefficients of Triangles. J. Integer Seq. 2012, 15, 3. [Google Scholar]
- Shablya, Y.V.; Kruchinin, D.V.; Shelupanov, A.A. A generator of criteria for the simplicity of the natural number. Rep. Tusur 2015, 4, 97–101. [Google Scholar]
- Melman, V.S.; Shablya, Y.V.; Kruchinin, D.V. Methods of analyzing the simplicity tests of numbers. In Proceedings of the XII International Scientific and Practical Conference “Electronic Tools and Control Systems”, Tomsk, Russia, 16–18 November 2016; pp. 54–55. [Google Scholar]
- Kruchinin, D.V.; Shablya, Y.V. Software for the analysis of tests for the simplicity of the natural number. Rep. Tusur 2014, 4, 95–99. [Google Scholar]
- Fridrich, J. Steganography in Digital Media: Principles, Algorithms, and Applications; Cambridge University Press: Cambridge, UK, 2010; 437p. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference, 4th ed.; Springer-Verlag: London, UK, 2007; 1111p. [Google Scholar]
- Xu, W.-L.; Chang, C.-C.; Chen, T.-S.; Wang, L.-M. An improved least-significant-bit substitution method using the modulo three strategy. Displays 2016, 42, 36–42. [Google Scholar] [CrossRef]
- Kim, C.; Yang, C.-N. Data hiding based on overlapped pixels using hamming code. Multimed. Tools Appl. 2016, 75, 15651–15663. [Google Scholar] [CrossRef]
- Yang, C.-N.; Hsu, S.-C.; Kim, C. Improving stego image quality in image interpolation based data hiding. Comput. Stand. Interfaces 2017, 50, 209–215. [Google Scholar] [CrossRef]
- Chen, H.; Ni, J.; Hong, W.; Chen, T.-S. High-Fidelity Reversible Data Hiding Using Directionally Enclosed Prediction. IEEE Signal Process. Lett. 2017, 24, 574–578. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.-S.; Chen, J. Reversible data hiding using Delaunay triangulation and selective embedment. Inf. Sci. 2015, 308, 140–154. [Google Scholar] [CrossRef]
- Chen, W.-Y. Color image steganography scheme using DFT, SPIHT codec, and modified differential phase-shift keying techniques. Appl. Math. Comput. 2008, 196, 40–54. [Google Scholar] [CrossRef]
- Rabie, T.; Kamel, I. High-capacity steganography: A global-adaptive-region discrete cosine transform approach. Multimed. Tools Appl. 2017, 76, 6473–6493. [Google Scholar] [CrossRef]
- Rabie, T.; Kamel, I. Toward optimal embedding capacity for transform domain steganography: A quad-tree adaptive-region approach. Multimed. Tools Appl. 2017, 76, 8627–8650. [Google Scholar] [CrossRef]
- Chen, S.-T.; Huang, H.-N.; Kung, W.-M.; Hsu, C.-Y. Optimization-based image watermarking with integrated quantization embedding in the wavelet-domain. Multimed. Tools Appl. 2016, 75, 5493–5511. [Google Scholar] [CrossRef]
- Yu, L.; Zhao, Y.; Ni, R.; Zhu, Z. PM1 steganography in JPEG images using genetic algorithm. Soft Comput. 2009, 13, 393–400. [Google Scholar] [CrossRef]
- Nikolaidis, A. Low overhead reversible data hiding for color JPEG images. Multimed. Tools Appl. 2016, 75, 1869–1881. [Google Scholar] [CrossRef]
- Wang, K.; Lu, Z.-M.; Hu, Y.-J. A high capacity lossless data hiding scheme for JPEG images. J. Syst. Softw. 2013, 86, 1965–1975. [Google Scholar] [CrossRef]
- Yang, C.-N.; Kim, C.; Lo, Y.-H. Adaptive real-time reversible data hiding for JPEG images. J. Real-Time Image Process. 2018, 14, 147–157. [Google Scholar] [CrossRef]
- Hong, W. Efficient data hiding based on block truncation coding using pixel pair matching technique. Symmetry 2018, 10, 2. [Google Scholar] [CrossRef]
- Hong, W.; Zhou, X.; Lou, D.-C.; Chen, T.-S.; Li, Y. Joint image coding and lossless data hiding in VQ indices using adaptive coding techniques. Inf. Sci. 2018, 463–464, 245–260. [Google Scholar] [CrossRef]
- Evsutin, O.O. Modification of steganographic LSB method based on the usage of modular cellular automata. Inf. Sci. Control Syst. 2014, 1, 15–22. [Google Scholar]
- Evsutin, O.O. Research of the discrete orthogonal transformation received with use the dynamics of cellular automata. Comput. Opt. 2014, 38, 314–321. [Google Scholar] [CrossRef]
- Evsutin, O.O.; Kokurina, A.S.; Meshcheryakov, R.V. Algorithms for data hiding in digital images using interpolation. Rep. Tusur 2015, 1, 108–112. [Google Scholar]
- Evsutin, O.; Kokurina, A.; Meshcheryakov, R.; Shumskaya, O. The adaptive algorithm of information unmistakable embedding into digital images based on the discrete Fourier transformation. Multimed. Tools Appl. 2018, 77, 28567–28599. [Google Scholar] [CrossRef]
- Evsutin, O.O.; Kokurina, A.S.; Shelupanov, A.A.; Shepelev, I.I. An improved algorithm for data hiding in compressed digital images based on PM1 method. Comput. Opt. 2015, 39, 572–581. [Google Scholar] [CrossRef]
- Evsutin, O.O.; Shelupanov, A.A.; Meshcheryakov, R.V.; Bondarenko, D.O. An algorithm for information embedding into compressed digital images based on replacement procedures with use of optimization. Comput. Opt. 2017, 41, 412–421. [Google Scholar] [CrossRef] [Green Version]
- Choo, K.-K.R.; Gritzalis, S.; Park, J.H. Cryptographic Solutions for Industrial Internet-of-Things: Research Challenges and Opportunities. IEEE Trans. Ind. Inform. 2018, 14, 3567–3569. [Google Scholar] [CrossRef]
- Keke, G.; Meikang, Q. Blend Arithmetic Operations on Tensor-Based Fully Homomorphic Encryption Over Real Numbers. IEEE Trans. Ind. Inform. 2018, 14, 3590–3598. [Google Scholar]
- He, D.; Ma, M.; Zeadally, S.; Kumar, N.; Liang, K. Certificateless Public Key Authenticated Encryption with Keyword Search for Industrial Internet of Things. IEEE Trans. Ind. Inform. 2018, 14, 3618–3627. [Google Scholar] [CrossRef]
- Xu, P.; He, S.; Wang, W.; Susilo, W.; Jin, H. Lightweight Searchable Public-Key Encryption for Cloud-Assisted Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2018, 14, 3712–3723. [Google Scholar] [CrossRef]
- Zhou, R.; Zhang, X.; Du, X.; Wang, X.; Yang, G.; Guizani, M. File-Centric Multi-Key Aggregate Keyword Searchable Encryption for Industrial Internet of Things. IEEE Trans. Ind. Inform. 2018, 14, 3648–3658. [Google Scholar] [CrossRef]
- Li, X.; Niu, J.; Bhuiyan, M.Z.A.; Wu, F.; Karuppiah, M.; Kumari, S. A Robust ECC-Based Provable Secure Authentication Protocol with Privacy Preserving for Industrial Internet of Things. IEEE Trans. Ind. Inform. 2018, 14, 3599–3609. [Google Scholar] [CrossRef]
- Karati, A.; Islam, S.K.H.; Karuppiah, M. Provably Secure and Lightweight Certificateless Signature Scheme for IIoT Environment. IEEE Trans. Ind. Inform. 2018, 14, 3701–3711. [Google Scholar] [CrossRef]
- Shen, J.; Zhou, T.; Liu, X.; Chang, Y.-C. A Novel Latin-Square-Based Secret Sharing for M2M Communications. IEEE Trans. Ind. Inform. 2018, 14, 3659–3668. [Google Scholar] [CrossRef]
- Sharma, P.K.; Singh, S.; Jeong, Y.-S.; Park, J.H. DistBlockNet: A Distributed Blockchains-Based Secure SDN Architecture for IoT Networks. IEEE Commun. Mag. 2017, 55, 78–85. [Google Scholar] [CrossRef]
- Sharma, P.K.; Rathore, S.; Park, J.H. DistArch-SCNet: Blockchain-Based Distributed Architecture with Li-Fi Communication for a Scalable Smart City Network. IEEE Consum. Electron. Mag. 2018, 7, 55–64. [Google Scholar] [CrossRef]
- Kim, D.-Y.; Kim, S.; Park, J.H. Remote Software Update in Trusted Connection of Long Range IoT Networking Integrated with Mobile Edge Cloud. IEEE Access 2017. [Google Scholar] [CrossRef]
- Patel, H. Non-parametric feature generation for RF-fingerprinting on ZigBee devices. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Verona, NY, USA, 27 November–1 December 2017; pp. 1–5. [Google Scholar]
- Bojinov, H.; Michalevsky, Y.; Nakibly, G.; Boneh, D. Mobile device identification via sensor fingerprinting. arXiv, 2014; arXiv:1408.1416. [Google Scholar]
- Ferdowsi, A.; Saad, W. Deep Learning for Signal Authentication and Security in Massive Internet of Things Systems. arXiv, 2018; arXiv:1803.00916. [Google Scholar]
- Novokhrestov, A.K.; Nikiforov, D.S.; Konev, A.A.; Shelupanov, A.A. Model of Security Threats to the Automated System for Commercial Accounting of Energy Resources. Rep. Tusur 2016, 19, 111–114. [Google Scholar] [CrossRef]
- Gong, L.; Zheng, J. Research on Evaluation Method of Hierarchical Network Security Threat. Revista de la Facultad de Ingeniería U.C.V. 2016, 31, 49–58. [Google Scholar]
- Antonov, M.M.; Konev, A.A.; Nikiforov, D.S.; Cherepanov, S.A. Organization of a Protected Heterogeneous Network in Automated Systems for Commercial Accounting of Energy Resources. Rep. Tusur 2016, 19, 107–110. [Google Scholar] [CrossRef]
- Usmonov, B.; Evsutin, O.; Iskhakov, A.; Shelupanov, A.; Iskhakova, A.; Meshcheryakov, R. The cybersecurity in development of IoT embedded technologies. In Proceedings of the 2017 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 2–4 November 2017; pp. 1–4. [Google Scholar]
- Iskhakov, S.; Shelupanov, A.; Mitsel, A. Internet of Things: Security of Embedded Devices. In Proceedings of the 2018 3rd Russian-Pacific Conference on Computer Technology and Applications (RPC), Vladivostok, Russia, 18–25 August 2018; pp. 1–4. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
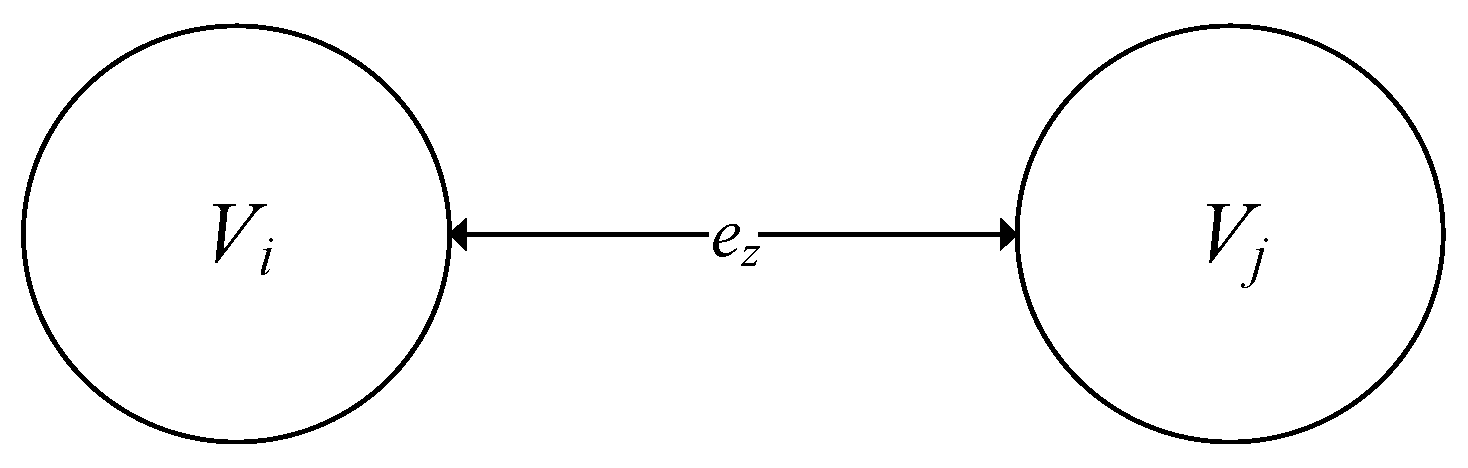{kind=link}
{kind=link}
| Types of Threats | Types of Security Mechanisms | ||
|---|---|---|---|
| Document Flow Types | |||
| Human—Process {V2, e4, V4} | Digital Storage Medium—Process {V3, e4, V4} | Process—Process {V4, e4, V4} | |
| Type 1 | IA AC EL EN | IA AC EL EN | IA AC EL EN |
| Type 2 | IA AC EL EN | IA AC EL EN | IA AC EL EN |
| Type 3 | IA AC EL | IA AC EL | IA AC EL |
| Type 4 | MC EL | MC EL | MC EL |
| Threat | Security Mechanisms |
|---|---|
| Unauthorized user access to data being processed by an application process | IA-user authentication at program launch AC-control of user access to program launch EL-log of user activity with the program EN-display of encrypted information only for the user |
| Input of secured information to unauthorized software | IA-authentication of the program file AC-closed software environment implementation EL-log of user activity with the program EN-input of only encrypted information by the user |
| Use of an unauthorized (incorrect) device driver during data input/output | IA-diver authentication at launch AC-control of user access to input/output devices in the operating system EL-log of driver events |
| Readout of the information being processed from RAM buffers associated with the input/output device | MC-clearing RAM buffers EL-log of memory clearing events |
| Set Elements | Attributes |
|---|---|
| Element of set X1 (set of software) | Software name Software version Number of the port used by the software |
| Element of set X2 (set of operating systems) | OS name OS version IP-address used by the OS |
| Element of set X3 (set of local area networks) | Network name Protocols in the network (OSI model network layer) Routing table IP-address and network mask |
| Element of set E1 (set of links between software) | OSI model application layer (session, presentation) |
| Element of set E2 (set of links between operating systems) | Protocols of the OSI model transport layer |
| Element of set E3 (set of links between local area networks) | Protocols of the OSI model network layer |
| Biometric Characteristic | Papers | Results |
|---|---|---|
| Finger print | [36,37,38] | Classification accuracy up to 99%. Best EER = 0.0038 [39]. |
| Palm print | [40,41,42] | Classification accuracy up to 99%. EER = 0.0054 [43]. |
| Palm geometry | [44,45,46,47] | Classification accuracy up to 99%. FAR = 0.0%, FRR = 1.19% and ERR = 0.59% [48] |
| Iris | [49,50,51] | Classification accuracy higher than 99.9%. FAR = 0,00001%, FRR = 0.1% [52] |
| Retina | [53,54] | The true acceptance rate 98.148% [55] |
| Face | [56,57] | FAR = 0,1%, FRR = 7% [52] |
| Keystroke dynamics | [58,59,60] | Classification accuracy 92.60% [61] |
| Signature dynamics | [62,63] | Average FAR = 5.125%, FRR = 5.5%, AER = 5.31% [64] |
| Speech | [65,66,67] | Classification accuracy up to 99%. EER = 1% [68] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shelupanov, A.; Evsyutin, O.; Konev, A.; Kostyuchenko, E.; Kruchinin, D.; Nikiforov, D. Information Security Methods—Modern Research Directions. Symmetry 2019, 11, 150. https://doi.org/10.3390/sym11020150
Shelupanov A, Evsyutin O, Konev A, Kostyuchenko E, Kruchinin D, Nikiforov D. Information Security Methods—Modern Research Directions. Symmetry. 2019; 11(2):150. https://doi.org/10.3390/sym11020150
Chicago/Turabian StyleShelupanov, Alexander, Oleg Evsyutin, Anton Konev, Evgeniy Kostyuchenko, Dmitry Kruchinin, and Dmitry Nikiforov. 2019. "Information Security Methods—Modern Research Directions" Symmetry 11, no. 2: 150. https://doi.org/10.3390/sym11020150
APA StyleShelupanov, A., Evsyutin, O., Konev, A., Kostyuchenko, E., Kruchinin, D., & Nikiforov, D. (2019). Information Security Methods—Modern Research Directions. Symmetry, 11(2), 150. https://doi.org/10.3390/sym11020150