1. Introduction
The communication of the decision-making process is a very complex problem when we are receiving information about attributes. One the most powerful theories is that of the multi attribute decision making (MADM), which handles problems that extensively impact the human real-life problems. The basic methodology is that a decision maker is presented with his evaluation in a set of many attributes and alternatives to find the best ranking order alternative in MADM approaches. Zadeh [
1] introduced a fuzzy set with the generalization of a classical set to solve ambiguous and vague information. Fuzzy set is used in many practical situations and has grown as an independent theory that interests researchers in many fields. After the success, fuzzy set was generalized to intuitionistic fuzzy set (IFS) by Atanassov [
2] under the restriction that the membership and non-membership function sum was less than or equal to one. In [
2] proposed a different mathematical operation under the IFS environment and studied the important properties. Uncertainty in human real problems is one of the continuous research areas and produces many new theories. Fuzzy decision-making (FDM) problems and their extension are presented in different ways to solve real life problems and have more attractive research to obtain the best results. Many decision making (DM) techniques have been proposed to explain the multi attribute decision-making process. Ramon et al. [
3] presented the 2-tuple model and customer segmentation and their algorithms, k-means, which are more effective methods in the calculation of frequency and monetary exploitation.
Revanasiddappa and Harish [
4] presented a new feature selection technique based on intuitionistic fuzzy entropy (IFE) for text classification. Firstly, intuitionistic fuzzy C-means (IFCM) clustering technique is employed to compute the intuitionistic membership values. The computed intuitionistic membership values are then used to estimate intuitionistic fuzzy entropy via match degree. Additionally, features with lower entropy values are selected to categorize the text documents. Juan Antonio Morente-Molinera et al. [
5] focused on solving the problem by carrying out multi-criteria group decision making approaches using different new methods. Concretely, fuzzy ontologies reasoning procedures are used in order to reduce, at the very least, the experts needed to participate in the preference providing step. In this new advanced technique, the logic of alternative comparison relies on the ontology reasoning process, allowing experts to focus on how important the criteria are to them. Albadan et al. [
6] proposed the procedures of selection of personnel delimited only to the making of non-programmed decisions through the implementation of game mechanics. In order to model this selection, the purpose of the following study is to carry out the formulation of inference rules based on fuzzy logic in order to capture the tacit transfer of certain types of information in personnel selection processes and to determine the aspects that allow the shaping of aspirants. In [
7], the author defined generalized operation for intuitionistic fuzzy numbers.
Morente-Molinera proposed the technique of fuzzy ontologies in order to allow the experts to focus on determining the importance that should be given to different criteria. Thus, they deal directly with a high number of alternatives. Experts decide the importance of each criterion, and the alternatives ranking is calculated automatically using the fuzzy ontology. Liang et al. [
8] presented the partial estimations, which determined that the introduced estimator is more capable and trusted to evaluate, consequently improving the overall results. There are many methodologies that evaluate the overall information that converges in different suppositions. If an ordinary collection of information is not considered in this environment, there is other information that can be considered by linguistic variables (LV) related to FNs, which are related to the membership function to one and the non-membership function to zero—more precisely, “good” and “bad”. Wang et al. [
9] proposed ILS, and their MADM approach of using the IL aggregation information achieved some great consideration. Liu et al. [
10] presented a new power aggregation operator, while Su et al. [
11] generalized the concept to ordered weighted averaging (OWA) and intuitionistic linguistic ordered weighted averaging (ILOWA) operator. Xiao et al. [
12] studied the ILOWA operator and applied it in the financial DM process. Liu and Jin [
13] extended the intuitionistic uncertain linguistic values (IULVs) by using LV in intuitionistic linguistic variables (ILV) and studying their important properties. We observed that LVs are special facets of IULVs, which are more general and have more information. Liu et al. [
14] presented and extended the linguistic (LF) aggregation operators. Yager [
15] introduced a new Pythagorean fuzzy (PFS) set that is a generalization of IFS by membership and non-membership functions under the condition that the square sum of these functions is less than or equal to one. To motivate this idea, Yager [
16] explained this shortcoming with an example—a decision maker makes a decision in the form of MD as
, a N-MD is
. Under IFS, the value does not satisfy the condition of a sum greater than 1, while in PFS, it satisfies the condition that the square sum is less than or equal to 1. After the successful implementation, Peng and Yang [
17] presented the different aggregation operators, namely, the Pythagorean fuzzy weighted averaging (PFWA), the Pythagorean fuzzy weighted power averaging (PFWPA), and the Pythagorean fuzzy weighted power geometric (PFWPG) operator. Garg [
18] introduced a new generalized Pythagorean fuzzy aggregation operator using Einstein operational laws and used them in the decision- making process.
Shakeel et al. [
19] presented some aggregation operators to use the decision information represented by PTFNS, including the Pythagorean trapezoidal fuzzy weighted averaging (PTFWA) operator, the Pythagorean trapezoidal fuzzy ordered weighted averaging (PTFOWA) operator, and the Pythagorean trapezoidal fuzzy hybrid averaging (PTFHA) operator. Shakeel et al. [
20] extended the work of aggregation operators into the interval-valued Pythagorean trapezoidal fuzzy weighted averaging (IVPTFWA) operator, the ordered weighted (IVPTFOWA), and the hybrid averaging (IVPTFHA) operators. Shakeel et al. [
20] used Einstein operational laws and proposed a new concept of the Pythagorean trapezoidal fuzzy Einstein ordered weighted geometric (I-IVPTFEOWG) operator, the induced interval-valued Pythagorean trapezoidal fuzzy Einstein hybrid geometric (I-IVPTFEHG) operator, and their applications in decision making problems. Shakeel et al. [
21] further extended the work to interval-valued Pythagorean trapezoidal fuzzy aggregation operators, the interval-valued Pythagorean trapezoidal fuzzy Einstein weighted geometric, (IVPTFEWG) operator, the interval-valued Pythagorean trapezoidal fuzzy Einstein ordered weighted geometric (IVPTFEOWG) operator, the interval-valued Pythagorean trapezoidal fuzzy Einstein hybrid geometric (IVPTFEHG), and their applications in decision making. The detail literature survey of aggregation operators and their applications in decision making problems discussed in [
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32].
In this paper, we introduce a new aggregation operator using Einstein operations under trapezoidal uncertain linguistic fuzzy sets and their applications in decision making. The motivations for the study are listed below.
- (1)
Our anticipated aggregation information is more general and precise compared to the existing information.
- (2)
The objectives of the study include proposing a PTULF Einstein aggregation operator and its operational laws, score, and accuracy function, establishing the MADM program approach based on the PTULF Einstein aggregation operators, and providing illustrative examples of the MADM program.
- (3)
The comparative analysis is a strong testament to the new approach, as it shows that the proposed study is consistent.
To solve a MADM process, the weight of the attributes plays an important role in making decisions under the aggregation approaches.
The rest of the paper is arranged is follows.
Section 2 consists of the background materials.
Section 3 presents a new PTULF aggregation operator under Einstein operations, the Pythagorean trapezoidal uncertain linguistic fuzzy Einstein weighted averaging (PTULFEWA) operator, the Pythagorean trapezoidal uncertain linguistic fuzzy Einstein ordered weighted averaging (PTULFEOWA), and the Pythagorean trapezoidal uncertain linguistic fuzzy Einstein hybrid averaging (PTULFEHA) operator.
Section 4 describes the MADM technique under the PTFL environment. In
Section 5, a numerical example is given to demonstrate the importance of the methodologies.
Section 6 shows a comparative study of the proposed and existing approaches. The conclusion is given in
Section 7.
5. Illustrative Example Surface Irrigation Problem
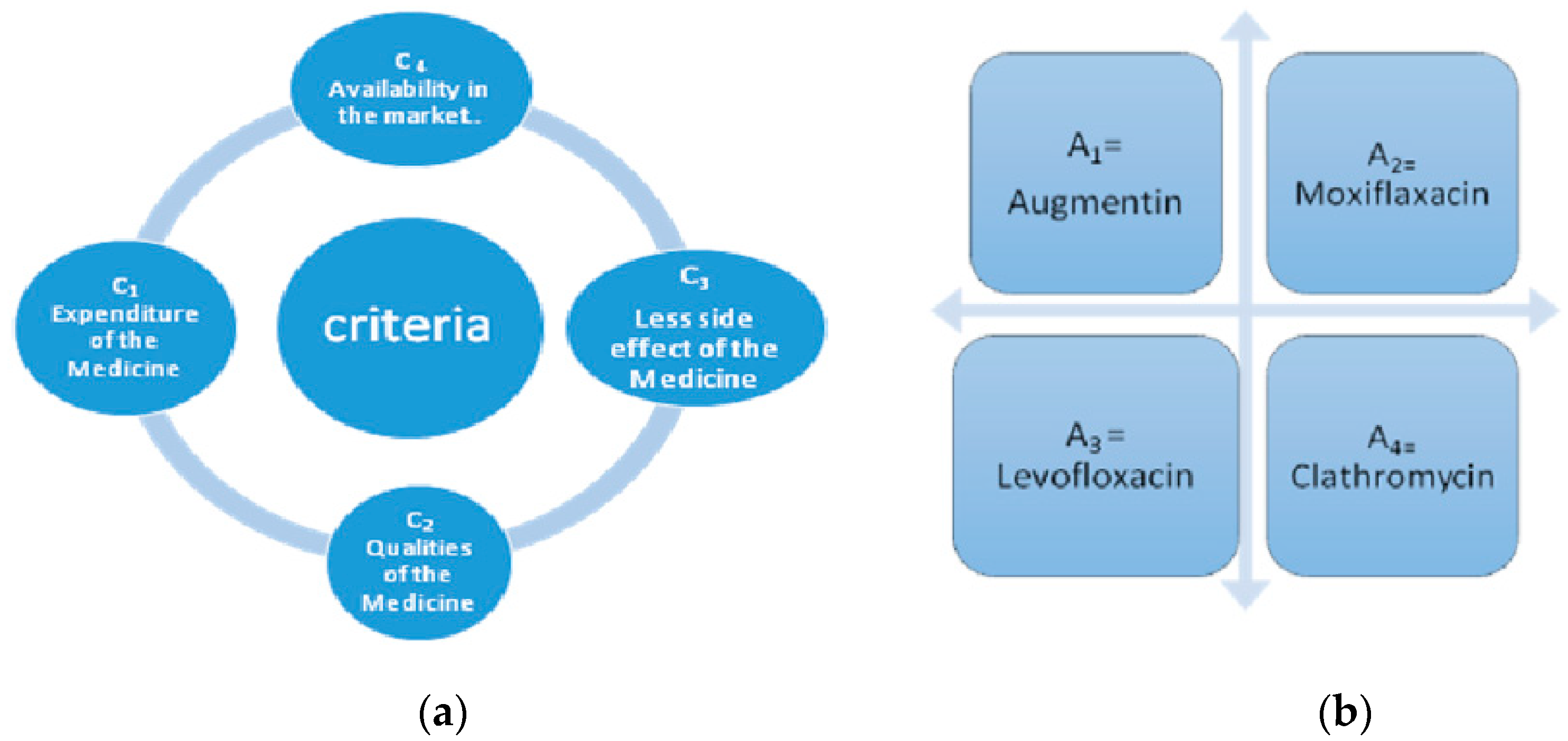
An illustrative example was considered to demonstrate the suggested technique in DM. The ratio of upper respiratory tract infection (URTI) was increasing day-by-day in Pakistan; consequently, we wanted to control the ratio of this disease. For this, we considered four possible alternatives, such as,
A1: Augmentin,
A2: Moxiflaxacin,
A3: Levofloxacin,
A4: Clathromycin.
A group of decision makers was invited to assess the best one under the following four attributes, Cj (j = 1, 2, 3, 4). Suppose w = (0.40, 0.30, 0.20, 0.10) is a weight vector of Cj
C1: Spending of the Medicine,
C2: Potentials of the Medicine,
C3: Less side effects of the Medicine,
C4: Accessibility in the market.
The detail description of criteria and alternative are given in
Figure 2a,b, respectively.
The decision makers gave their decisions and considered the weights λ = (0.10, 0.20, 0.30, 0.40).
Table 1,
Table 2,
Table 3 and
Table 4 show the decisions of the exports under the PTLUF,
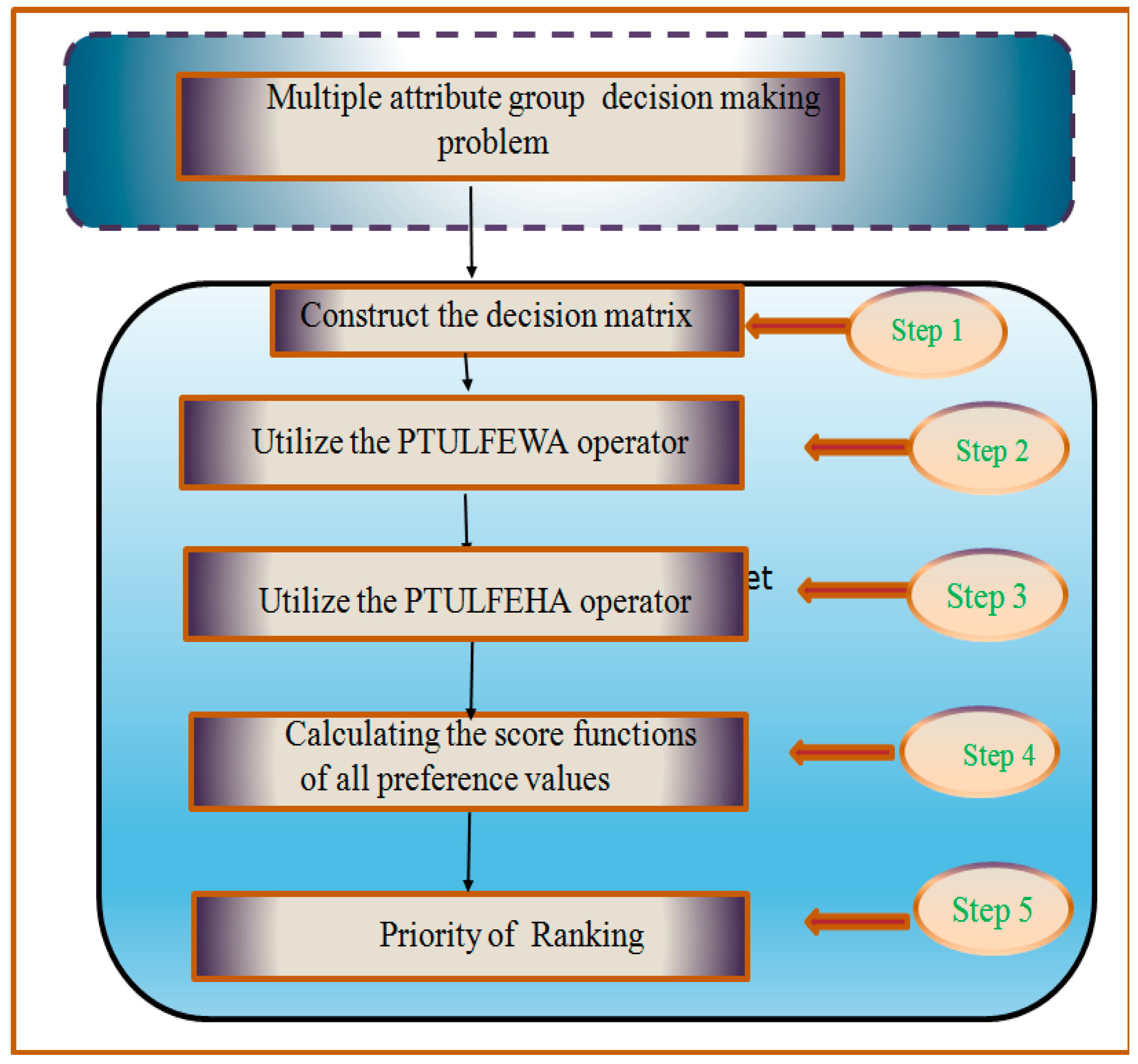
Step 1. The decision makers’ decisions are presented in the following Tables.
Step 2. Use the PTULF matrix,
, and the
operator to collect the different overall preference PTL values
of the alternative
(in
Table 5)
Step 3. Apply the
operator to collect the overall values see in
Table 6.
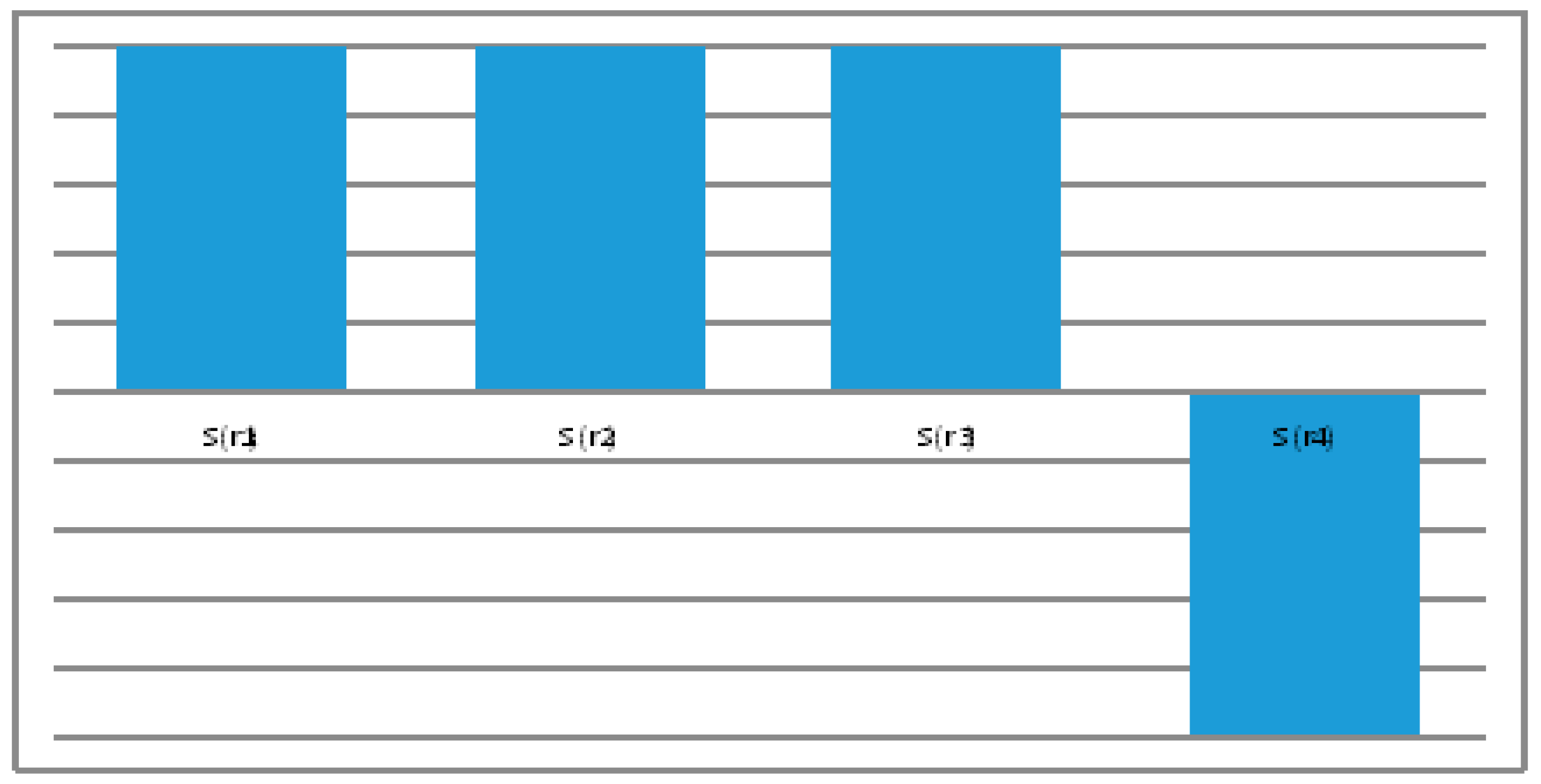
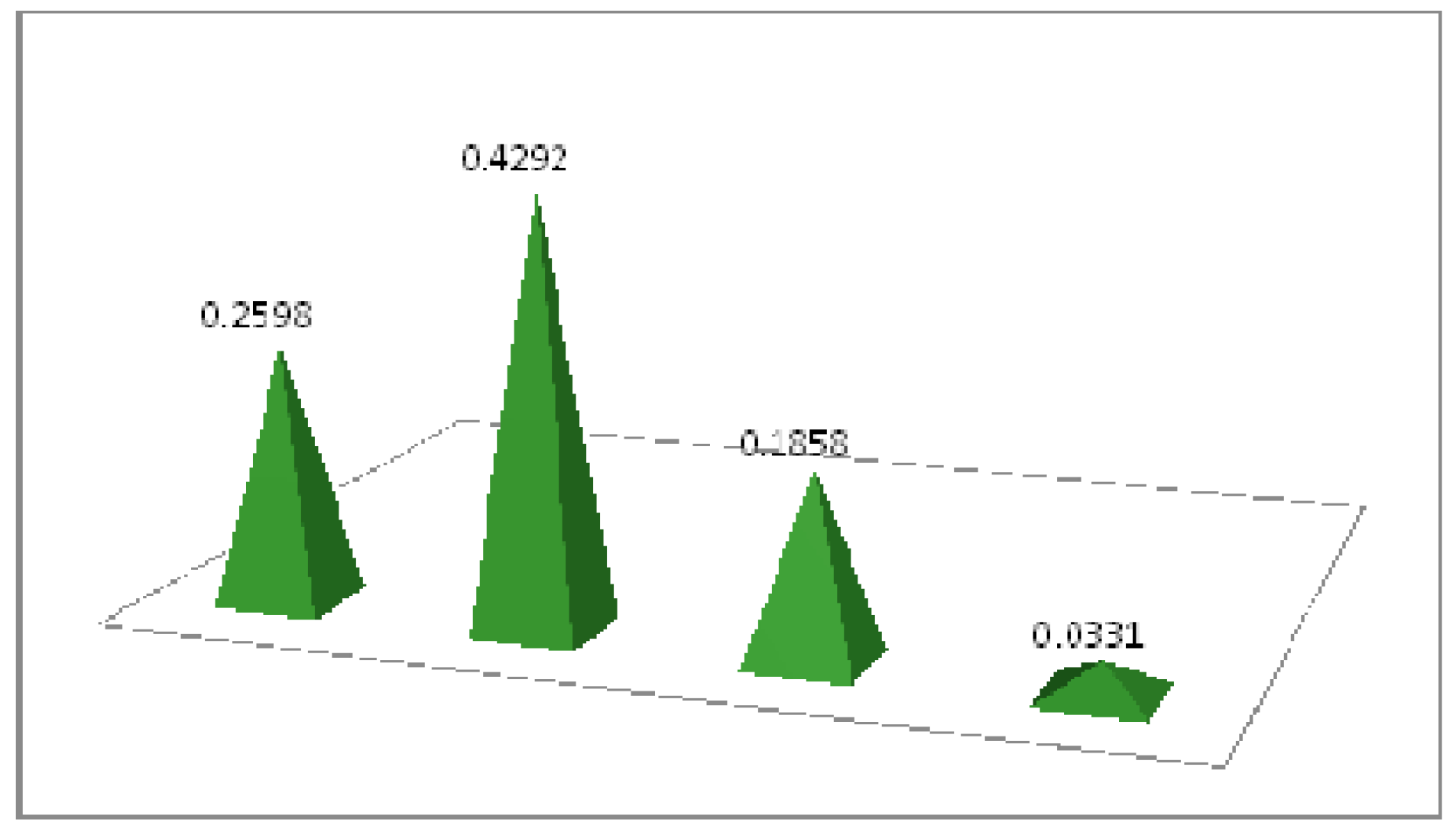
Step 4. Find the scores and ranking of
are given in
Figure 3.
Step 5. Arrange the scores, The best one is

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}