In this section, we explain our proposed complexity reduction methods in detail. In
Section 5.1, initially, the proposed ECS method is explained step by step. Then, it is compared with the reference encoder in terms of percentage reduction in the selected operations. In
Section 5.2, first, the proposed ERPS method is discussed followed by a comparison with the reference encoder. In all of our observations, analysis, and implementation, we used the standard test sequences as shown in
Table 2. In places where the QP value is not mentioned, averaged values for different QP values (25, 30, 35, 40) are used.
5.1. Proposed ECS Approach
The selection of the best CU size is a time-consuming process because the encoder has to go through all possible combinations of sizes and available reference pictures for the selection of the best match on the basis of the minimum RD cost. If the CU size selection process can be reduced, the overall encoding time can be reduced considerably. Therefore, we target the early termination of CU splitting, based on the inter-view and temporal information available. The immediate question that arises is: is there any room for further optimization of the CU size selection process, i.e., if we can predict the maximum CU size early, would we be able to reduce the encoding time? In order to find an answer to this question, we want to know about the percentage relation between CTU depth levels.
Table 3 shows the percentage relation between the depth levels (
).
As it is evident in
Table 3, a high percentage of CUs are best matched at the
level, which is due to the fact that the major portion of a picture is similar.
Table 3 gives us an answer to our question that, yes, there is a very small percentage (1.5%) of CUs that are best matched at Depth Level 3, and on average, 76.3% of CUs are matched at Depth Level 0, which means that if the maximum depth level of the majority of the CUs is predicted correctly, then the time-consuming splitting and matching process for higher depth levels can be saved.
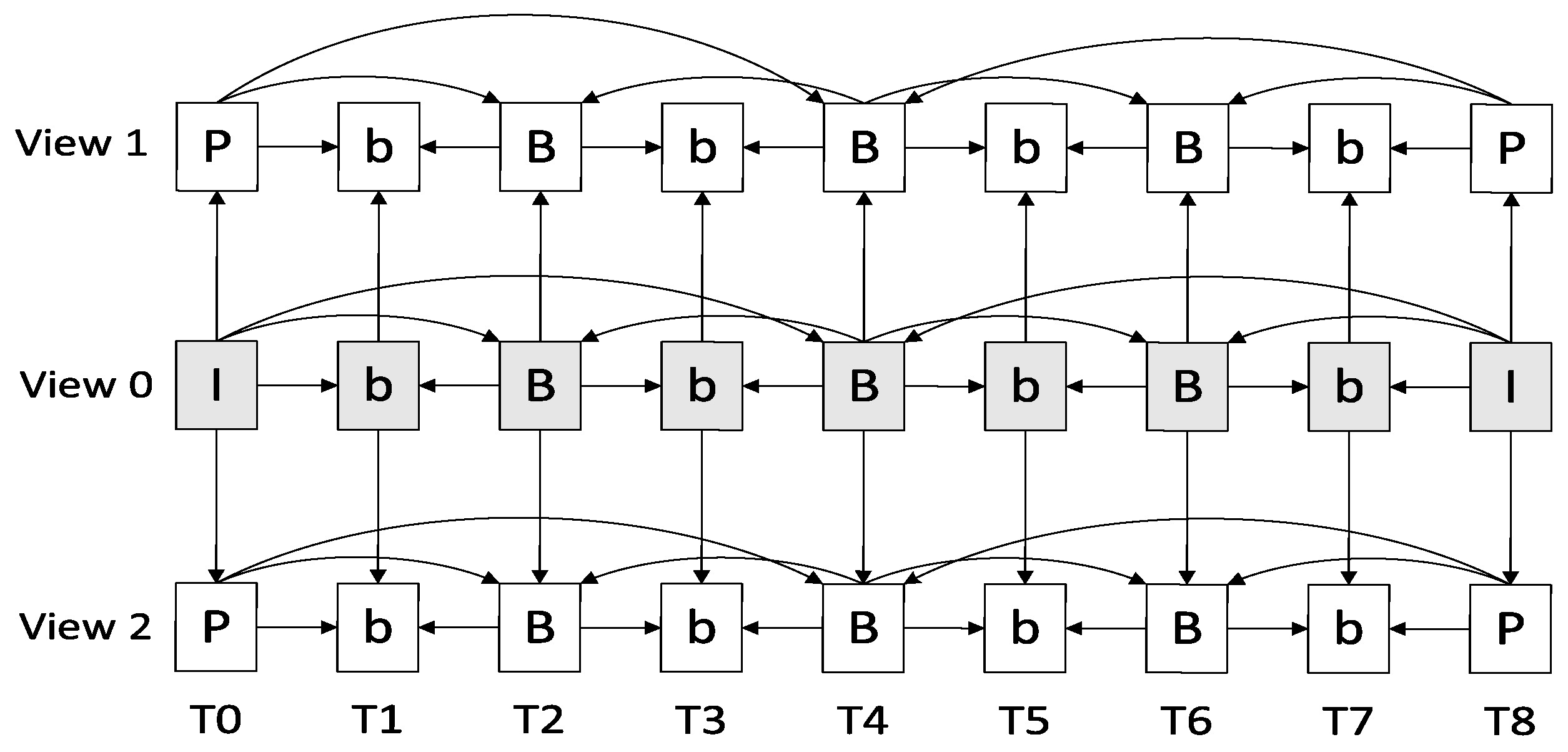
In multi-view video coding, different cameras capture the same scene, which means that the content of the videos is almost the same. The slight difference is due to the change in angle of capturing between the scene and the cameras. In other words, the decisions made by the encoder for multiple video streams of multiple cameras should also be very similar. This can also be observed from the CU splitting decisions shown in
Figure 5. The CU splitting decisions in the same region between the pictures are very similar. This implies that much correlation exists between the views and corresponding regions of the picture. This is our motivation to use the CU splitting decisions of the same region of the base view to predict the CU depth threshold of the dependent views. By the same region in the base view, we mean a square area/window, centered onthe co-located CU of the dependent view. Adding this with the observations in
Table 3, we build our ECS method.
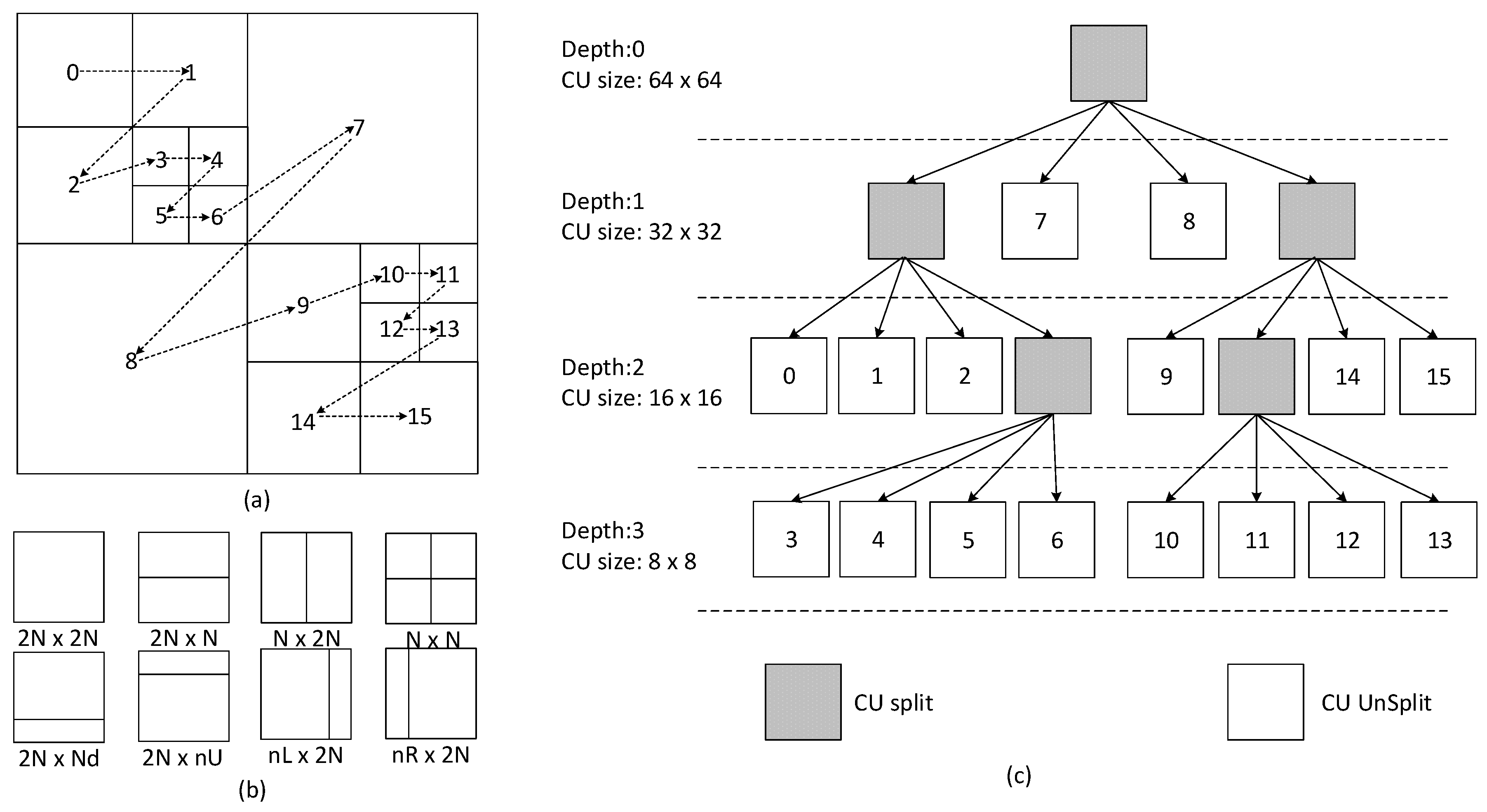
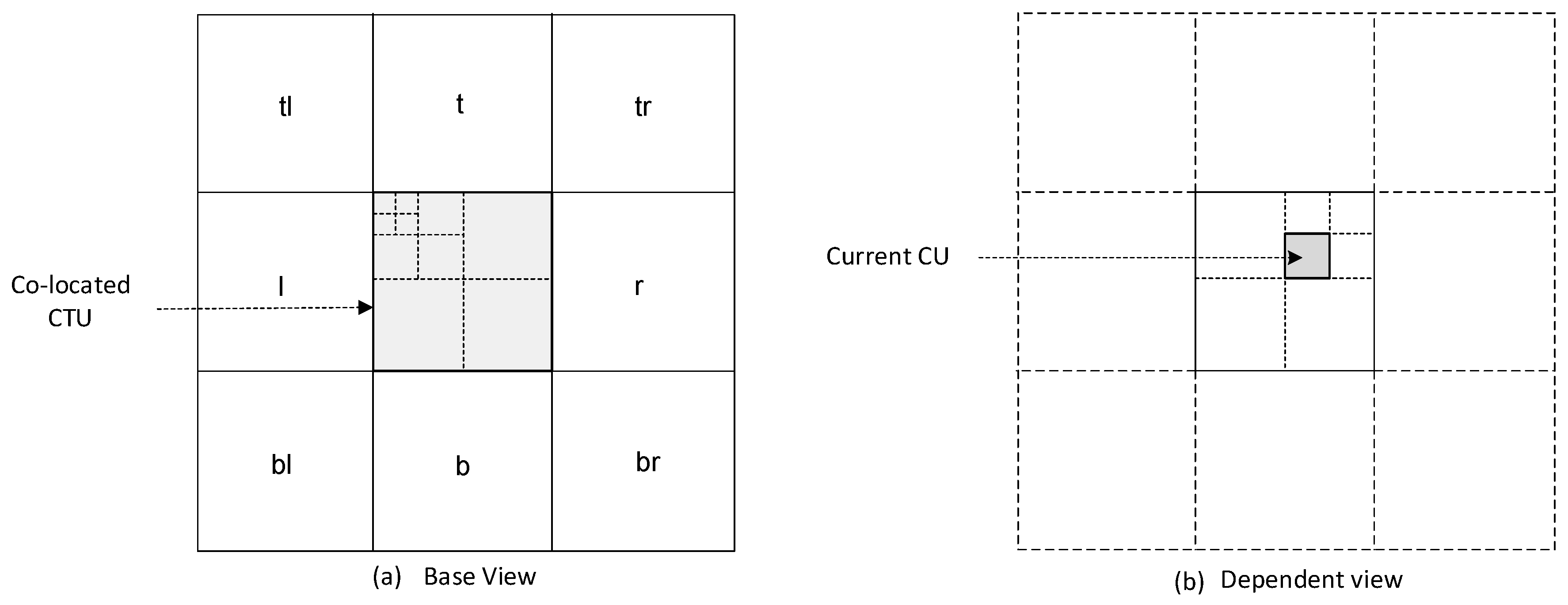
To get the depth threshold value for the CU being encoded in the dependent view, we used a window of 3 × 3 CTUs around the co-located CU in the base view. This is graphically shown in
Figure 6. The CU, which is currently encoded as shown in
Figure 6a, and its co-located CTU along with its neighborhood are depicted in
Figure 6b. To get a broader observation area, the co-located CTU and its eight surrounding CTUs were considered in our analysis. CTUs of the base view were assigned the highest depth level of the CUs they contained after encoder decisions. As an example, the co-located CTU of the base view in
Figure 6a contains 3 CUs of Depth Level 1, 3 CUs of Depth Level 2, and 4 CUs of Depth Level 3. As the highest depth level contained by this CTU was three, the depth level assigned to this CTU was three, i.e.,
. We define the depth threshold for the CU of dependent view based on the depth levels of the CTUs located in its co-located CUs neighborhood in the base view as
shown in Equation (
9).
where,
,
,
,
,
,
,
,
, and
are the maximum CU depths of the CTUs of the base view, as shown in
Figure 6a.
Table 4 gives us an idea of how accurately we can predict the depth threshold, in terms of “
hit” and “
miss”. If the depth of the current CU is higher than our assumed depth, then we call it a “
miss”, otherwise it is called a “
hit”. It can be seen from the results that the hit percentage is very high, which means that the predicted depth threshold
is highly accurate.
Table 5 summarizes the percentages of depths of CUs in the case of a hit. If the CU depth is predicted at
, then the chance to reduce complexity is highest, because the matching process for higher depths is avoided.
Similarly, if a depth level is predicted for a CU, then it does not reduce the encoding complexity because the encoder has to go through all the depth levels.
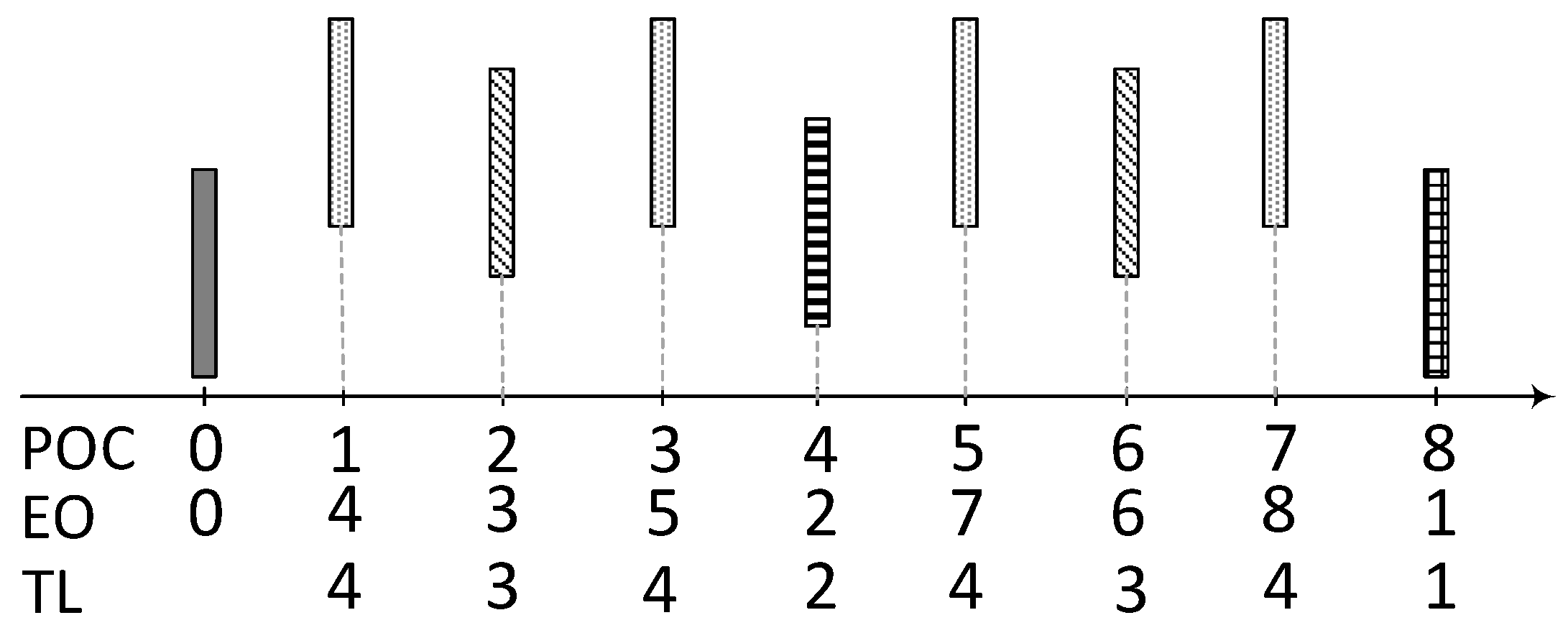
After utilizing the inter-view correlation, now we move on to the temporal domain. It can be seen in
Figure 4, at TL–4, that the adjacent pictures are available as reference pictures. Therefore, in this case, there is a very high probability that the scene has not changed and that the best match can be found at lower depth levels as compared with lower TL pictures.
Table 6 summarizes the relation between depth levels of CTUs and TLs. Here, CTUs are considered instead of CUs because CTUs are of the same size and have a constant number in each picture. Therefore, a CTU is considered at depth level
when it contains at least one CU of depth level
, and a CTU is considered to be at depth level
when it has at least one CU having depth
and no CU with depth
. It can also be seen that at TL–4, above 95% of CTUs are at depth level
and 98.1% of CTUs are at depth levels
and
. Only 1.87% of CTUs have depth level
and
. Therefore, for TL–4, we used
as the depth threshold, shown in Equation (
10).
Table 7 shows the average CU depth relation with TLs in the case of the hit scenario. Here, we can see that a high percentage of CUs are at depth level
. These results are very attractive, but when we go through the details of the encoding process, the possible reduction in encoding complexity is not that much, as can be seen from these results. At TL–4, we find that most of the lower depth CUs are encoded in skip mode, which means that these CUs do not go through the time-consuming splitting and matching process for depth levels. Therefore, detecting these lower depths earlier does not play a significant role in the complexity reduction as the percentages of
Table 7 are suggesting.
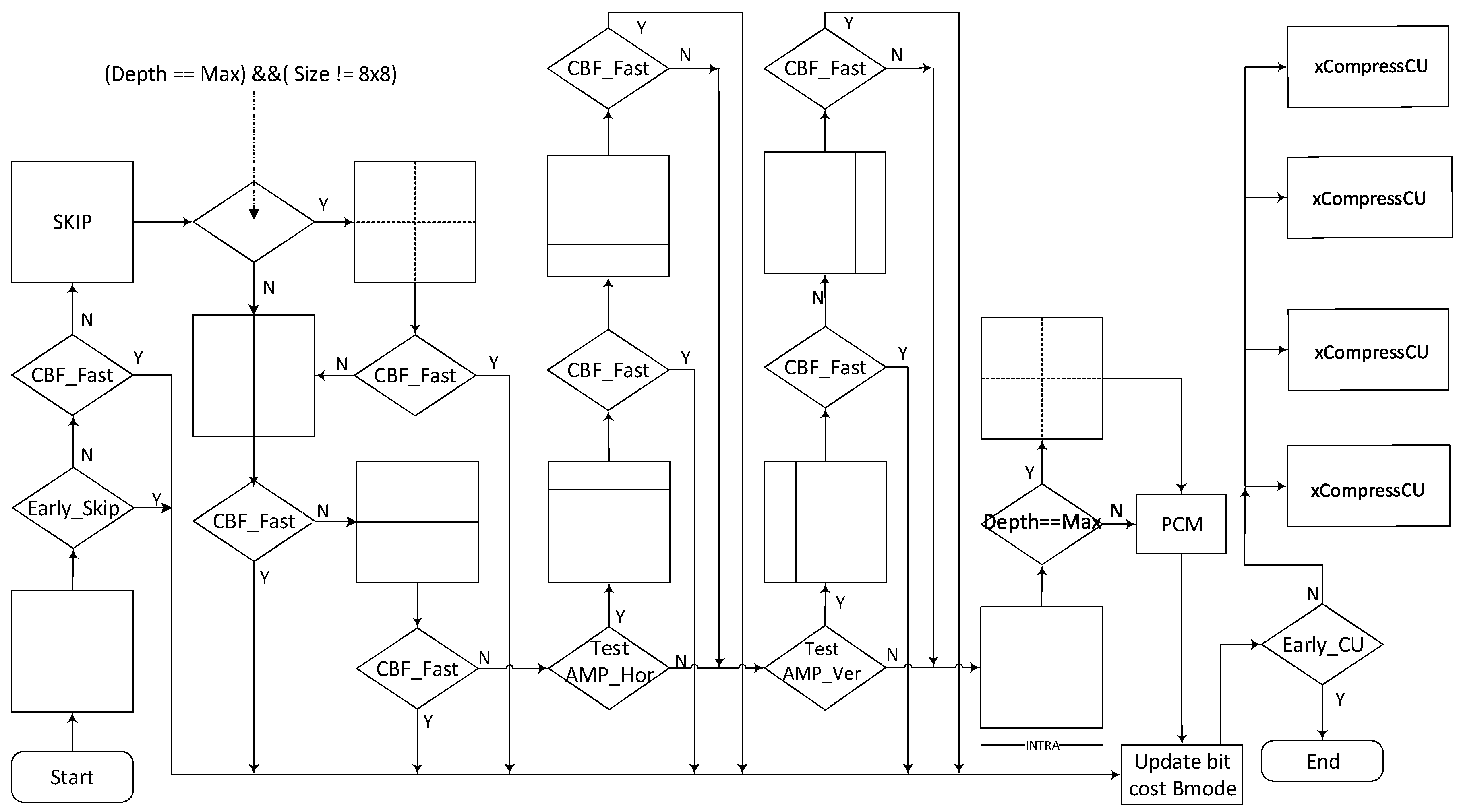
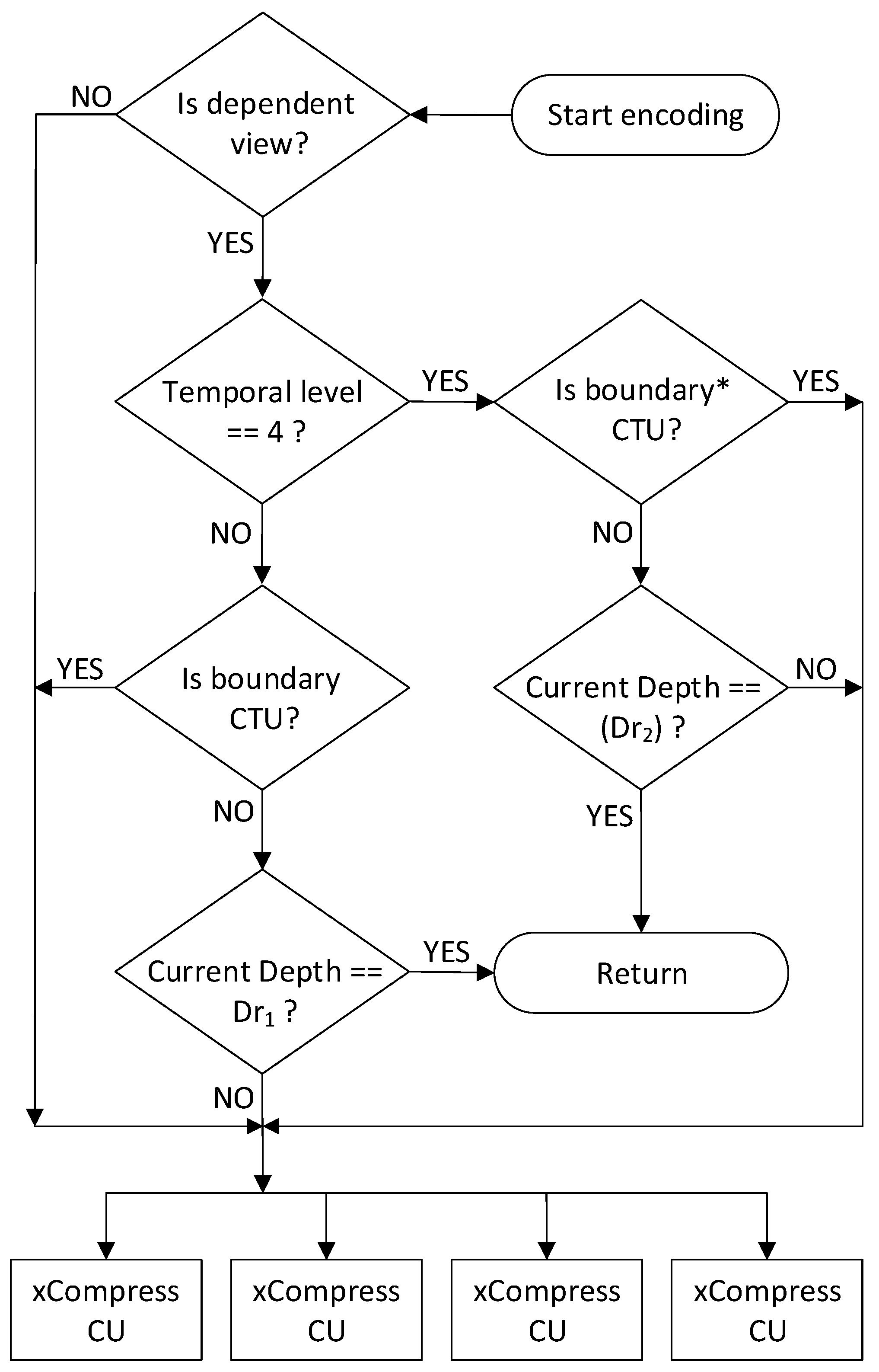
We propose an algorithm for early splitting of the CU. We call this new method ECS. Our algorithm is based on CU splitting information of the base view and CU splitting information related to the TLs of the pictures. The flow of the proposed ECS algorithm is shown in
Figure 7. In our proposed method, we aim to reduce the complexity of dependent view encoding, where the base view is used for gathering information. Our proposed ECS method can be divided into two main parts. In the first part, we only deal with pictures that do not belong to TL–4. When the encoding for the dependent view starts, we first check whether the current CU belongs to a boundary CTU. If it belongs to a boundary CTU, then the normal encoding process is used. If it is a part of non-boundary CTU, then we compare it with the maximum depth threshold
, as shown in Equation (
9), which we have calculated for this CU from the base view. If the current CU depth is equal to the calculated depth threshold, then further splitting to higher depth levels of the CU is not done. In the second part, we deal with pictures that belong to TL–4. As shown in
Table 6, at TL–4, the percentage of depth level
is very high as compared with lower TLs. On the basis of this observation, we modified our method for TL–4. Therefore, we used depth threshold
Equation (
10) for TL–4.
Operations with respect to sizes of the blocks are used as a comparison tool. It can be seen in
Table 8 that there is a significant decrease in the number of SSE, SAD, and HAD operations. To show the effect of resolution, average values of
and
pixels sequences are separately calculated. It can be seen that in the case of the SAD64 and SSE64 operations, the percentage reduction in operations is very low, which means that the CUs at depth level
are not reduced. The highest percentage decrease in SAD operations can be observed at SAD4 and SAD8, which is on average 76.2% and 75.6%, respectively. These are followed by SAD16 and SAD32, which on average are 70.8% and 56.8%, respectively. The percentage reduction in operations SAD12 and SAD24 is comparatively low. A similar pattern can be observed in the percentage reduction of SSE and HAD operations, where the percentage reduction in operations decreases with the increase in the size of the block. This happens because we are trying to reduce the splitting process, and in comparison with the original encoder, the lower depth levels of CUs are mostly avoided in our proposed method. We get the higher percentage reduction in operations, which are related to higher depth levels. It can also be seen that this phenomenon is independent of the video content. These results give us a general view of the complexity reduction of the encoder, as we can see for the percentage reduction of the operations. The size of the operation block is directly proportional to the amount of time the operation takes. Therefore, the high percentage reduction in smaller block size operations might not be reflected as much in the overall encoding time.
5.2. Proposed ERPS Approach
Since video is a sequence of pictures captured in discrete time intervals, these pictures contain many similar contents. The encoder uses this aspect to compress the video data. The encoder maintains a set of encoded frames/pictures as reference pictures for the picture being encoded. This set of reference pictures is selected on the basis of EO and temporal distances. Some pictures in reference lists may be temporally near and some may be far from the picture being encoded. As video is a sequence of discrete pictures in the time domain, the content similarity between the pictures of the video is inversely proportional to the temporal distance between the pictures. Based on this characteristic of video and the video encoder, we built our reference picture selection method. At TL–4 for a picture being encoded, the immediate previous and next pictures are available in the reference picture list. There is a very high probability that these adjacent pictures might be selected as reference pictures rather than a picture, which is at some temporal distance from the picture being encoded.
To further strengthen our argument, the correlation among these pictures, the reference picture selection in terms of the reference indices of both reference lists is analyzed. Moreover, we want to know which pictures are referenced mostly for encoding each picture, so that we can avoid the matching process for the reference pictures that are least expected to be selected as the reference picture. We performed the analysis for both the reference picture lists. We divided our analysis result on the basis of TLs, as shown in
Figure 4.
Table 9 illustrates our analysis of reference indices in terms of the percentage for List–0 and List–1 for various temporal levels. It can be observed from these results that for List–1, at TL–4, the selection of both reference Index–1 and Index–2 is less than 2.5%, while Index–0 is selected 97.5%. Now, our logical argument is also backed up by practical results. Reference picture selection is dependent on the temporal relation between the picture being encoded and the picture being referenced for prediction. Now, using the observations in
Table 9, we can reduce the computation complexity by avoiding the search and matching process for reference Index–1 and Index–2 in List–1. During the encoding process when the TL of the picture being encoded is 4, then we do not use the reference pictures indexed as 1 and 2 in reference picture List–1, only the reference picture, which is indexed as 0 in List–1, used as the reference picture option. For pictures that do not belong to TL–4, normal encoding process is followed.
Algorithm 1 shows the pseudo-code of the proposed ERPS method in the encoding process, which processes the TL of the picture being encoded and outputs List–1, which contains Index–0, Index–1, and Index–2, as shown in Algorithm 1.
| Algorithm 1 Proposed ERPS algorithm |
![Symmetry 11 00454 i001]() |
Table 10 shows the results’ comparisons obtained by our proposed ERPS algorithm with HTM
. We compare both on the basis of the number of SAD, SSE, and HAD operations done in each configuration of the encoder. The results in
Table 10 show the percentage reduction in the number of these operations by our proposed ERPS method with respect to the HTM
encoder configuration using Equation (
7). In the case of the SAD operation, the percentage reduction for sizes 8, 16, 32, and 64 generally shows a similar trend. This means that reference picture selection does not affect a particular size operation, as was observed in the case of the ECS. The percentage reduction for these sizes is also observed to be independent of the video content. It can be seen that the percentage decrease in the SAD and the HAD operations is somewhat similar, but the percentage decrease in the SSE operations is very low. From Equations (
4) and (
5), we see that the SAD operation is called in the cost function for the prediction parameter decision, and the SSE operation is called in the cost function for the mode decision. The prediction parameter decision process is simplified due to our proposed ERPS method. Therefore, the effect can be seen in the percentage reduction in the SAD and the HAD operations; whereas a slight percentage decrease can be observed in the SSE operation because it is used to calculate the cost function for the mode decision. We can see that there is a noticeable reduction in these operations due to our proposed algorithm, but it is not as much as one would have expected. The reason for that is that at TL–4, a huge majority of the CUs are encoded in skip mode.
Table 11 shows the results for the case when both the ECS and ERPS algorithms are applied to the encoder. These results only show the percentage reduction of operations. A general trend similar to the results shown in
Table 8 can be observed. Since ERPS is only applied on TL–4 pictures, it does not play the dominant role in operation reduction of the overall proposed method. One main contribution when compared with ECS results can be observed in the percentage reduction of the HAD64 operation. The complexity of the encoder has definitely decreased, but at this point, we do not know how much complexity has decreased because the results do not show the comparison in terms of encoding time. Apart from encoding time, we also need to check other parameters like bitrate, the PSNR, and the Bjøntegaard Delta Bit Rate (BDBR) [
40]. On the basis of these standard comparison parameters, both methods are compared in the next section.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}