Fractional-Order Fusion Model for Low-Light Image Enhancement



Abstract
:1. Introduction
- As compared to integer-order, we apply fractional calculus to process the original images without logarithmic transformation. Remarkable results have been achieved in preserving the natural character of images.
- A novel fusion framework is introduced to extract more contents in the dark areas while preserving the visual appearance of images.
- The experimental results compared with other image enhancement algorithms show that the proposed model can reveal more hidden contents in dark regions of the images.
2. Background
2.1. Fractional Calculus
2.2. Retinex Theory
3. Fractional-Order Fusion Model Based On Retinex
3.1. Reflectance and Illumination Based On Fractional-Order
3.1.1. Reflectance
3.1.2. Illumination
3.1.3. The Energy Function
3.1.4. Adjust Illumination
3.2. Fusion Framework
4. Implementation of FFM
4.1. Optimization of the Energy Function
4.1.1. R Sub-Problem
4.1.2. L Sub-Problem
4.2. Implementation of the Fusion Process
5. Experiments and Analysis
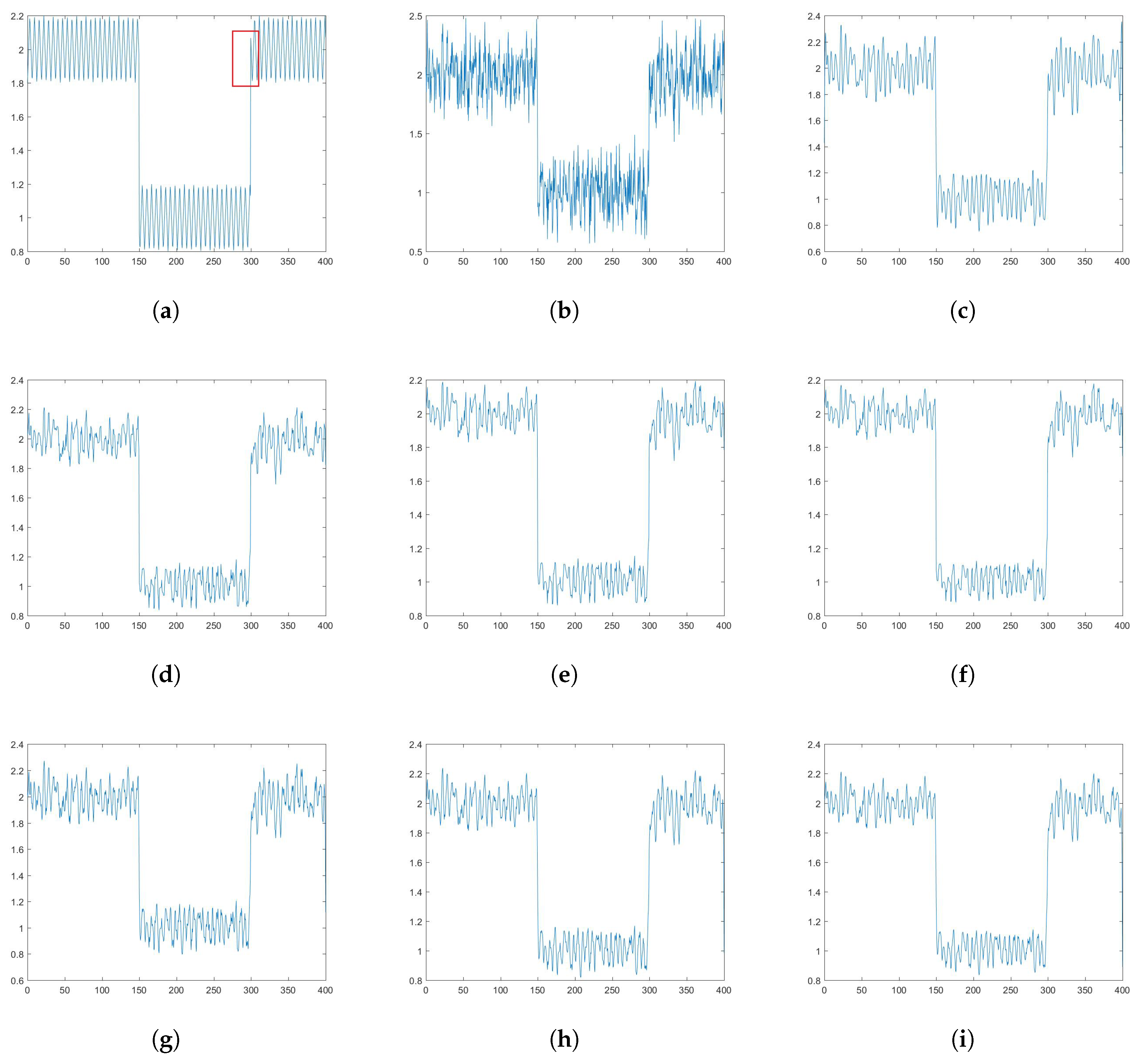
5.1. Fractional Order Impact
5.2. Comparison with Other Algorithms
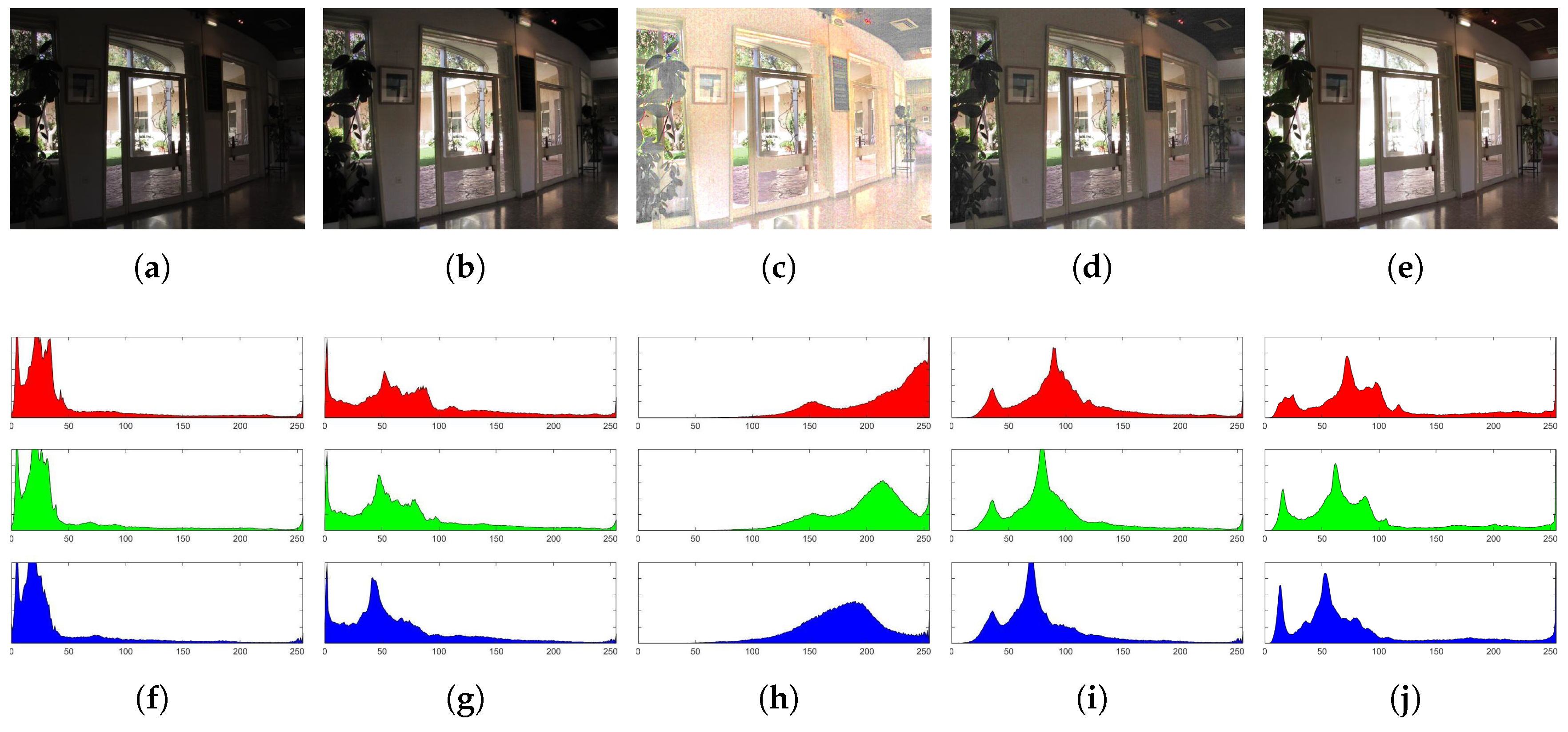
5.2.1. Visual Contrast
5.2.2. Lightness Order Error
5.2.3. Images Quality Assessment
5.2.4. Images Similarity Assessment
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple object tracking using k-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. Comput. Vis. Pattern Recognit. 2016, 779–788. [Google Scholar]
- Wang, R.; Wang, G. Medical X-ray image enhancement method based on tv-homomorphic filter. In Proceedings of the International Conference on Image, Vision and Computing, Chengdu, China, 2–4 June 2017; pp. 315–318. [Google Scholar]
- Cheng, H.D.; Shi, X.J. A simple and effective histogram equalization approach to image enhancement. Digit. Signal Process. 2004, 14, 158–170. [Google Scholar] [CrossRef]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Dong, X.; Wang, G.; Pang, Y.; Li, W.; Wen, J.; Meng, W.; Lu, Y. Fast efficient algorithm for enhancement of low lighting video. In Proceedings of the IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Li, L.; Wang, R.; Wang, W.; Gao, W. A low-light image enhancement method for both denoising and contrast enlarging. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 3730–3734. [Google Scholar]
- Land, E.H.; Mccann, J.J. Lightness and retinex theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.; Xu, X.; Guo, K.; Jia, K.; Hu, B.; Tao, D. A joint intrinsic-extrinsic prior model for retinex. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4020–4029. [Google Scholar]
- Kimmel, R.; Elad, M.; Shaked, D.; Keshet, R.; Sobel, I. A variational framework for retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new low-light image enhancement algorithm using camera response model. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 22–29 October 2017; pp. 3015–3022. [Google Scholar]
- Wang, S.; Zhang, J.; Hu, H.-M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Yue, H.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. Llnet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Gharbi, M.; Chen, J.; Barron, J.T.; Hasinoff, S.W.; Durand, F. Deep bilateral learning for real-time image enhancement. ACM Trans. Graph. 2017, 36, 118. [Google Scholar] [CrossRef]
- Cai, J.; Gu, S.; Lei, Z. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Chongyi, L.; Guo, J.; Porikli, F.; Pang, Y. Lightennet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar]
- Pu, Y.-F.; Zhang, N.; Zhang, Y.; Zhou, J.L. A texture image denoising approach based on fractional developmental mathematics. Pattern Anal. Appl. 2016, 19, 427–445. [Google Scholar] [CrossRef]
- Pu, Y.-F. Fractional calculus approach to texture of digital image. In Proceedings of the International Conference on Signal Processing, Beijing, China, 16–20 November 2006; pp. 1002–1006. [Google Scholar]
- Aygören, A. Fractional Derivative and Integral; Gordon and Breach Science Publishers: Philadelphia, PA, USA, 1993. [Google Scholar]
- Koeller, R.C. Applications of fractional calculus to the theory of Viscoelasticity. Trans. ASME J. Appl. Mech. 1984, 51, 299–307. [Google Scholar] [CrossRef]
- Rossikhin, Y.A.; Shitikova, M.V. Applications of Fractional Calculus to Dynamic Problems of Linear and Nonlinear Hereditary Mechanics of Solids; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Oldham, K.; Spanier, J. The Fractional Calculus Theory and Applications of Differentiation and Integration to Arbitrary Order; Elsevier: Amsterdam, The Netherlands, 1974. [Google Scholar]
- Lee, S. An efficient content-based image enhancement in the compressed domain using retinex theory. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 199–213. [Google Scholar] [CrossRef]
- Pu, Y.-F.; Siarry, P.; Chatterjee, A.; Wang, Z.N.; Zhang, Y.I.; Liu, Y.G.; Zhou, J.L.; Wang, Y. A fractional-order variational framework for retinex: Fractional-order partial differential equation based formulation for multi-scale nonlocal contrast enhancement with texture preserving. IEEE Trans. Image Process. 2018, 27, 1214–1229. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. Lime: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Tseng, P. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 2001, 109, 475–494. [Google Scholar] [CrossRef]
- Candès, E.J.; Wakin, M.B.; Boyd, S.P. Enhancing sparsity by reweighted lsb1 minimization. J. Fourier Anal. Appl. 2007, 14, 877–905. [Google Scholar] [CrossRef]
- Xu, L.; Yan, Q.; Xia, Y.; Jia, J. Structure extraction from texture via relative total variation. ACM Trans. Graph. 2012, 31, 139. [Google Scholar] [CrossRef]
- Farbman, Z.; Fattal, R.; Lischinski, D.; Szeliski, R. Edge-preserving decompositions for multi-scale tone and detail manipulation. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar] [CrossRef]
- Burt, P.J.; Adelson, E.H. The laplacian pyramid as a compact image Code. Read. Comput. Vis. 1987, 31, 671–679. [Google Scholar]
- Chakrabarti, A.; Scharstein, D.; Zickler, T.E. An empirical camera model for internet color vision. BMVC 2009, 1, 4. [Google Scholar]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. No-reference image sharpness assessment in autoregressive parameter space. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 2015, 24, 3218–3231. [Google Scholar]
- Gu, K.; Li, L.; Lu, H.; Min, X.; Lin, W. A fast reliable image quality predictor by fusing micro- and macro-structures. IEEE Trans. Ind. Electron. 2017, 64, 3903–3912. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. Fsim: A feature similarity index for image quality assessment. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 2011, 20, 2378. [Google Scholar] [CrossRef]
- Pu, Y.-F.; Zhou, J.L.; Yuan, X. Fractional differential mask: A fractional differential-based approach for multiscale texture enhancement. IEEE Trans. Image Process. 2010, 19, 491–511. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | NPE [12] | CRM [11] | JIEP [9] | MF [13] | LightenNet [17] | FFM(1) | FFM(2) |
|---|---|---|---|---|---|---|---|
| Middlebury | 359 | 240 | 260 | 207 | 919 | 124 | 224 |
| MF-data | 316 | 402 | 241 | 289 | 807 | 135 | 215 |
| NPEpart1 | 220 | 575 | 337 | 342 | 720 | 182 | 216 |
| NPEpart2 | 210 | 504 | 264 | 272 | 747 | 167 | 205 |
| NPEpart3 | 259 | 568 | 354 | 311 | 785 | 211 | 246 |
| Dataset | Assessment | NPE [12] | CRM [11] | JIEP [9] | MF [13] | LightenNet [17] | FFM(1) | FFM(2) |
|---|---|---|---|---|---|---|---|---|
| Middlebury | ARISM1 | 3.1909 | 2.9654 | 2.8468 | 2.952 | 3.0898 | 2.821 | 2.7284 |
| ARISM2 | 3.4643 | 3.2278 | 3.1103 | 3.2258 | 3.3712 | 3.0866 | 3.0351 | |
| MF-data | ARISM1 | 2.7961 | 2.7584 | 2.6982 | 2.7286 | 2.7624 | 2.6858 | 2.6421 |
| ARISM2 | 3.0527 | 3.0445 | 2.9511 | 2.987 | 3.0127 | 2.9418 | 2.9083 | |
| NPEpart1 | ARISM1 | 2.7833 | 2.7521 | 2.758 | 2.7356 | 2.7396 | 2.7404 | 2.7064 |
| ARISM2 | 3.0252 | 3.0219 | 3.0001 | 2.979 | 2.9819 | 2.9801 | 2.9519 | |
| NPEpart2 | ARISM1 | 2.7278 | 2.6827 | 2.6877 | 2.6723 | 2.6991 | 2.6688 | 2.6403 |
| ARISM2 | 2.991 | 2.9676 | 2.9458 | 2.9373 | 2.9573 | 2.9306 | 2.9118 | |
| NPEpart3 | ARISM1 | 2.9495 | 2.8561 | 2.8417 | 2.8468 | 2.9352 | 2.8031 | 2.7727 |
| ARISM2 | 3.1976 | 3.1346 | 3.0886 | 3.0976 | 3.1785 | 3.0516 | 3.0299 |
| Dataset | Assessment | NPE [12] | CRM [11] | JIEP [9] | MF [13] | LightenNet [17] | FFM(1) | FFM(2) |
|---|---|---|---|---|---|---|---|---|
| Middlebury | FSIM1 | 0.7696 | 0.8117 | 0.8659 | 0.8019 | 0.7427 | 0.9085 | 0.8906 |
| FSIM2 | 0.7589 | 0.8054 | 0.8605 | 0.7924 | 0.7325 | 0.9034 | 0.8832 | |
| PSIM | 0.9954 | 0.9967 | 0.9976 | 0.9960 | 0.9952 | 0.9982 | 0.9976 | |
| MF-data | FSIM1 | 0.8072 | 0.8127 | 0.8648 | 0.8084 | 0.8179 | 0.9123 | 0.8957 |
| FSIM2 | 0.8012 | 0.8078 | 0.8609 | 0.8024 | 0.8122 | 0.9086 | 0.8905 | |
| PSIM | 0.9964 | 0.9966 | 0.9977 | 0.9966 | 0.9967 | 0.9984 | 0.9979 | |
| NPEpart1 | FSIM1 | 0.8911 | 0.8834 | 0.9125 | 0.8869 | 0.8915 | 0.9492 | 0.9457 |
| FSIM2 | 0.8883 | 0.8806 | 0.9105 | 0.8839 | 0.8893 | 0.9474 | 0.9433 | |
| PSIM | 0.9980 | 0.9978 | 0.9985 | 0.9979 | 0.9982 | 0.9989 | 0.9987 | |
| NPEpart2 | FSIM1 | 0.8813 | 0.8553 | 0.9096 | 0.8808 | 0.8708 | 0.9421 | 0.9376 |
| FSIM2 | 0.8779 | 0.8520 | 0.9073 | 0.8774 | 0.8675 | 0.9398 | 0.9344 | |
| PSIM | 0.9977 | 0.9973 | 0.9983 | 0.9977 | 0.9976 | 0.9988 | 0.9986 | |
| NPEpart3 | FSIM1 | 0.8955 | 0.8752 | 0.9225 | 0.8865 | 0.9038 | 0.9522 | 0.9480 |
| FSIM2 | 0.8915 | 0.8710 | 0.9202 | 0.8821 | 0.9006 | 0.9499 | 0.9449 | |
| PSIM | 0.9976 | 0.9974 | 0.9985 | 0.9976 | 0.9980 | 0.9989 | 0.9987 |
| Dataset | NPE [12] | CRM [11] | JIEP [9] | MF [13] | LightenNet [17] | FFM |
|---|---|---|---|---|---|---|
| Middlebury | 20.01 | 0.67 | 14.24 | 0.73 | 15.91 | 24.50 |
| MF-data | 13.47 | 0.42 | 8.58 | 0.47 | 10.32 | 15.70 |
| NPEpart1 | 10.44 | 0.37 | 7.58 | 0.49 | 8.09 | 11.41 |
| NPEpart2 | 12.66 | 0.41 | 11.16 | 0.45 | 10.07 | 14.27 |
| NPEpart3 | 10.15 | 0.30 | 7.01 | 0.35 | 7.87 | 11.82 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Q.; Pu, Y.-F.; Rahman, Z.; Aamir, M. Fractional-Order Fusion Model for Low-Light Image Enhancement. Symmetry 2019, 11, 574. https://doi.org/10.3390/sym11040574
Dai Q, Pu Y-F, Rahman Z, Aamir M. Fractional-Order Fusion Model for Low-Light Image Enhancement. Symmetry. 2019; 11(4):574. https://doi.org/10.3390/sym11040574
Chicago/Turabian StyleDai, Qiang, Yi-Fei Pu, Ziaur Rahman, and Muhammad Aamir. 2019. "Fractional-Order Fusion Model for Low-Light Image Enhancement" Symmetry 11, no. 4: 574. https://doi.org/10.3390/sym11040574
APA StyleDai, Q., Pu, Y. -F., Rahman, Z., & Aamir, M. (2019). Fractional-Order Fusion Model for Low-Light Image Enhancement. Symmetry, 11(4), 574. https://doi.org/10.3390/sym11040574