The Asymmetric Alpha-Power Skew-t Distribution


Abstract
:1. Introduction
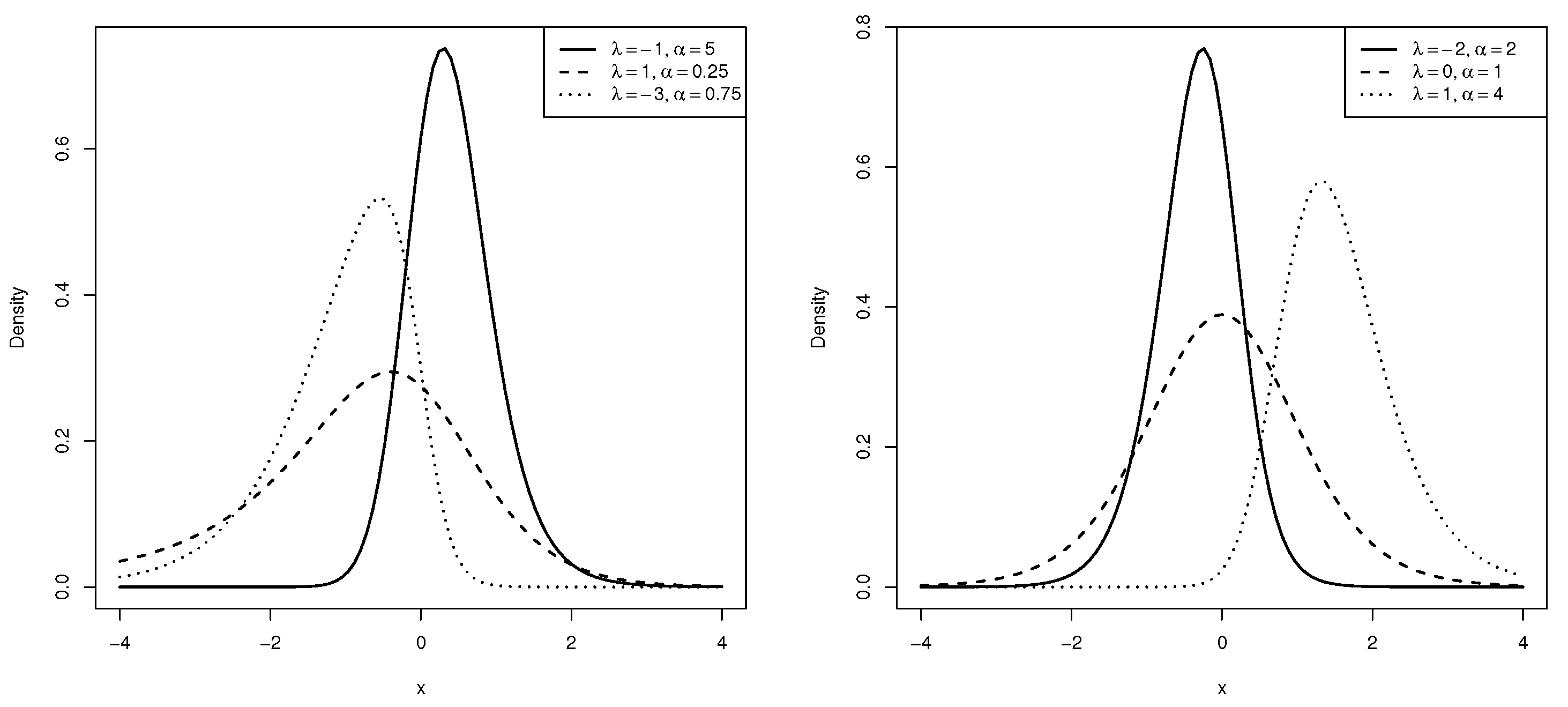
2. The Alpha-Power Skew-t Distribution
- (i)
- if , then ,
- (ii)
- if , then ,
- (iii)
- if and , then , where denotes the Student-t disribution with ν degree of freedom.
- (iv)
- if , then ,
- (v)
- if and , then ,
- (vi)
- if and , then ,
- (vii)
- if , and , then ,
2.1. Moments
2.2. Distribution Function
2.3. Location and Scale Extension
3. Statistical Inference for APST Distribution
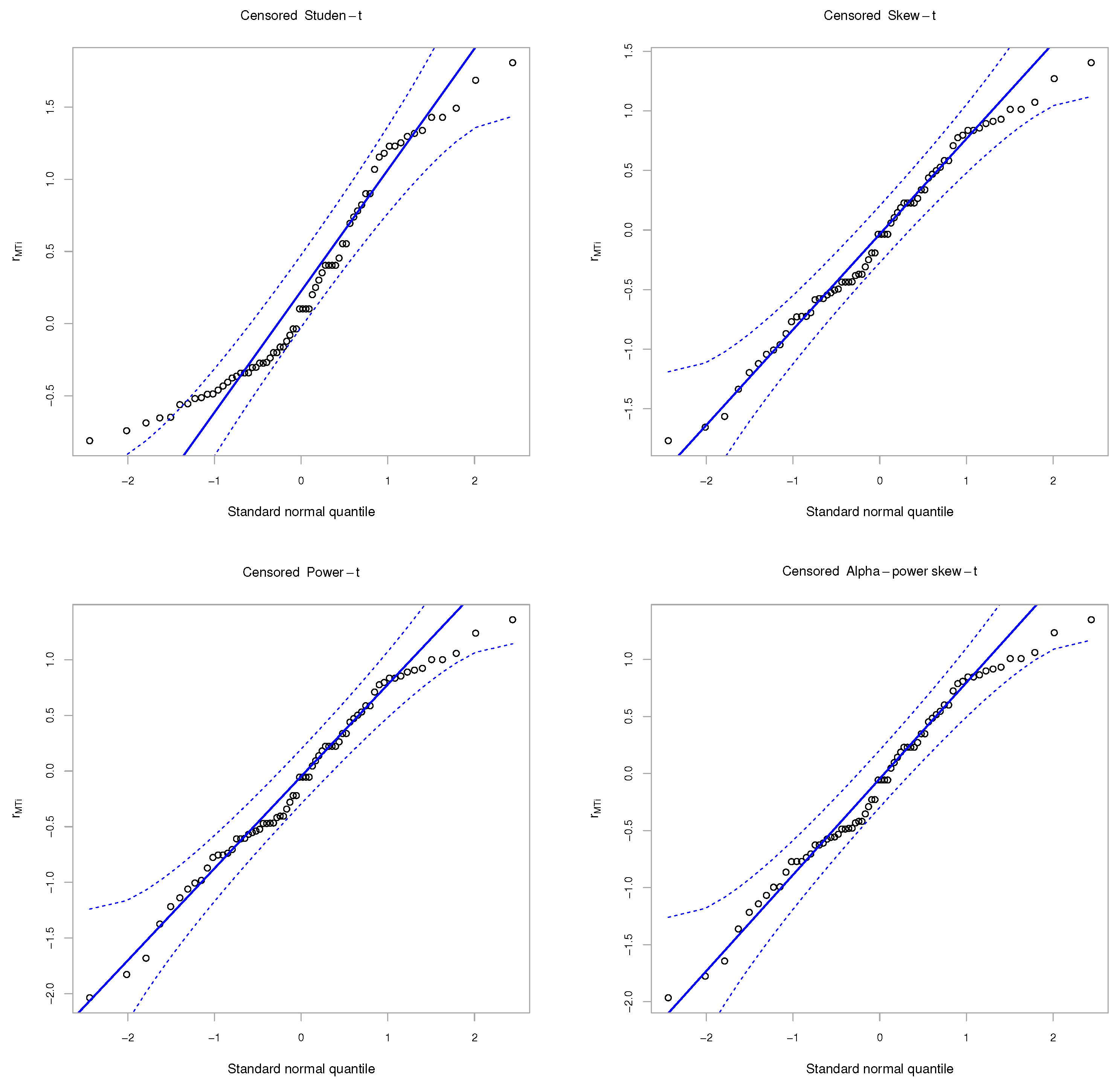
3.1. Extension to Censored Data
3.2. Properties of the CAPST Model
- If , then , where CST indicates the censored skew-t model.
- If , then , where CPT indicates the censored power-t model.
- If and , then , that is, the censored Student-t model follows.
- If , then , where CAPSN indicates the censored alpha-power skew-normal model.
- If and , then , that is, the censored skew-normal model follows.
- If and , then , that is, the censored power-normal model follows.
- If , and , then , that is, the censored normal model follows.
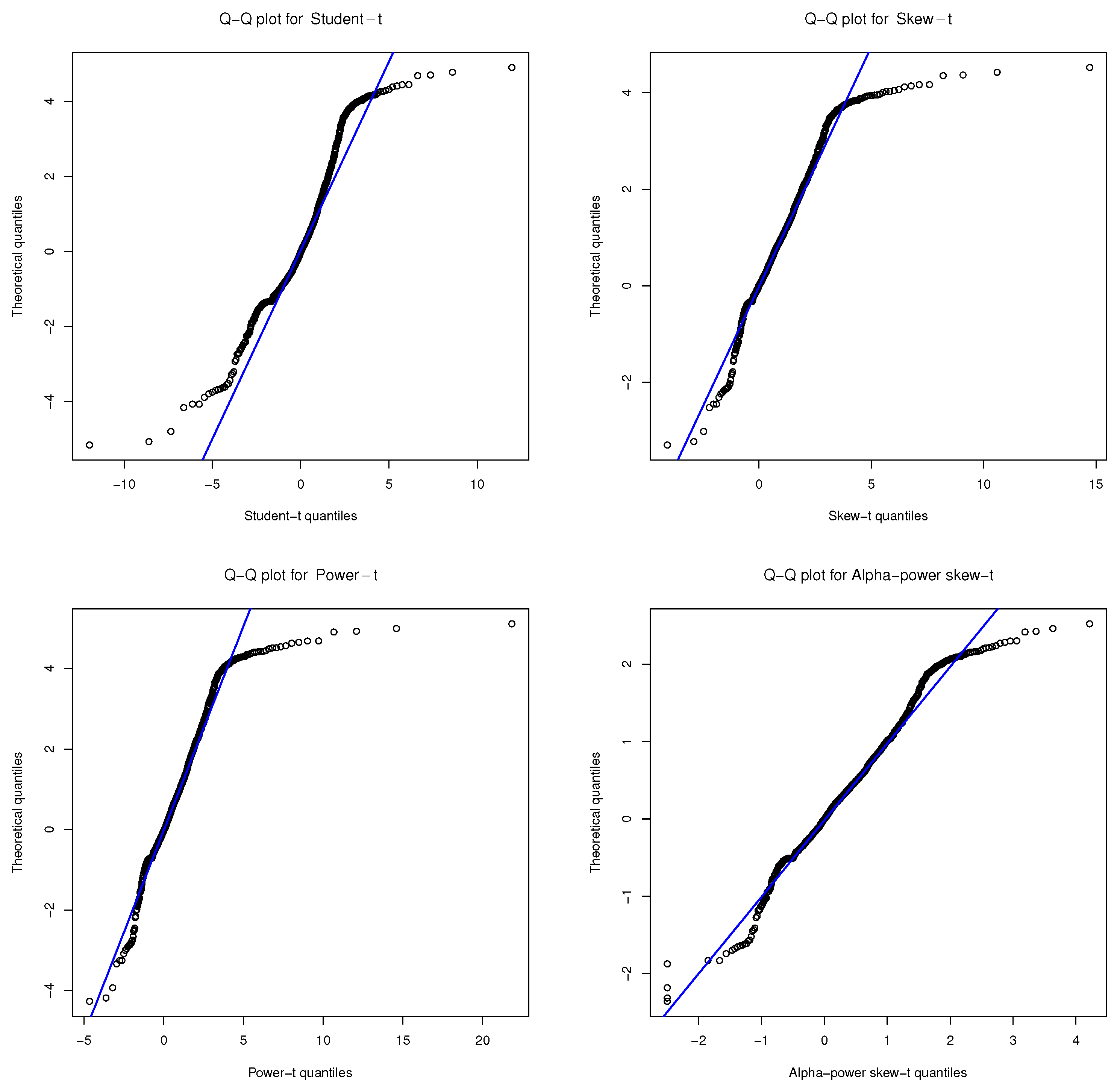
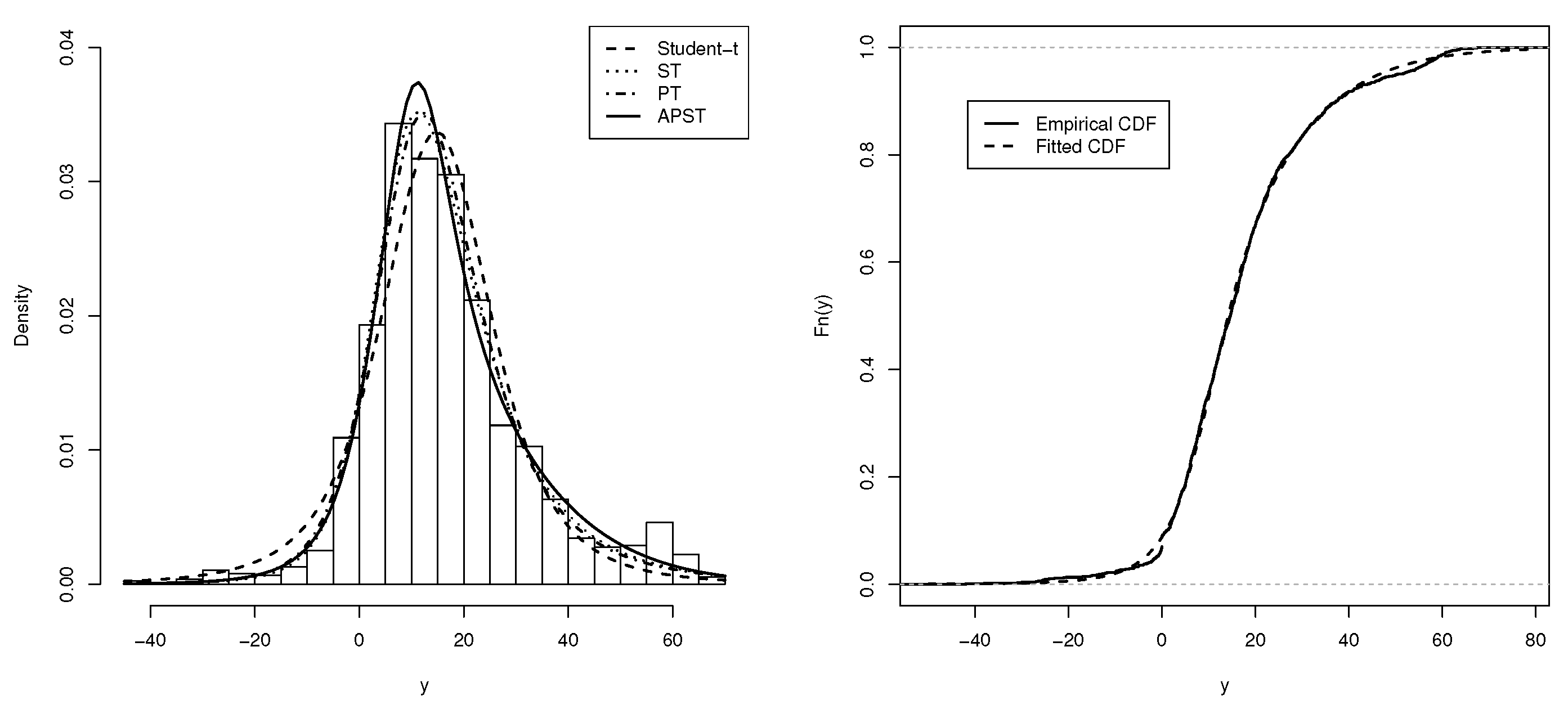
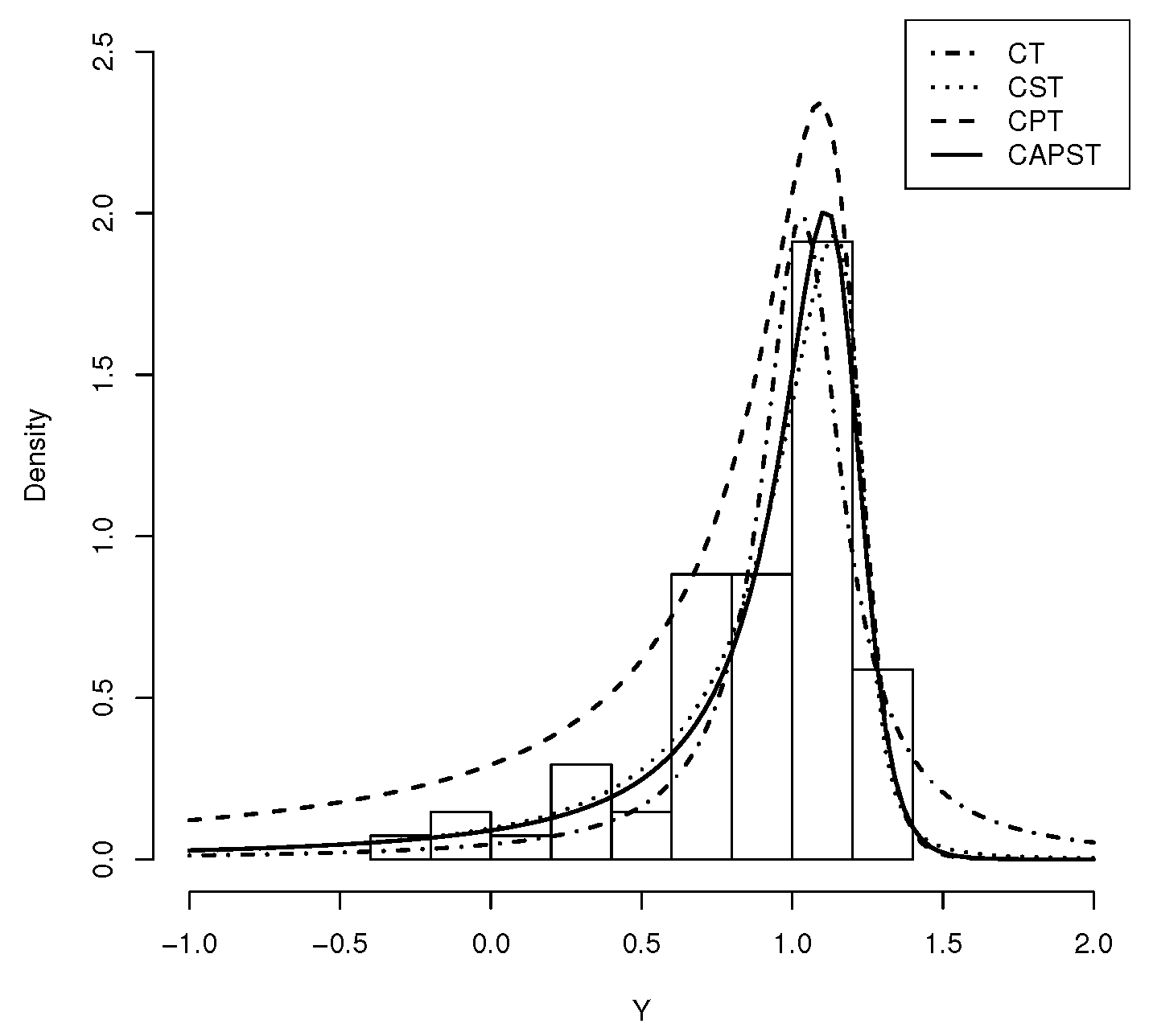
4. Real Data Applications
4.1. Application 1: Volcano Heights Data
4.2. Application 2: Stellar Abundances Data
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Durrans, S.R. Distributions of fractional order statistics in hydrology. Water Resour. Res. 1992, 28, 1649–1655. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. The alpha–power tobit model. Commun. Stat. Theory Methods 2013, 42, 633–643. [Google Scholar] [CrossRef]
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. An alpha-power extension for the Birnbaum-Saunders distribution. Statistics 2014, 48, 896–912. [Google Scholar] [CrossRef]
- Gupta, R.D.; Gupta, R.C. Analyzing skewed data by power-normal model. Test 2008, 17, 197–210. [Google Scholar] [CrossRef]
- Pewsey, A.; Gómez, H.W.; Bolfarine, H. Likelihood–based inference for power distributions. Test 2012, 21, 775–789. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Skew-normal alpha-power model. Stat. J. Theor. Appl. Stat. 2014, 48, 1414–1428. [Google Scholar] [CrossRef]
- Azzalini, A.; Capitanio, A. Distributions generated by perturbation of symmetry with emphasis on a multivariate skew-t distribution. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2003, 65, 367–389. [Google Scholar] [CrossRef]
- Branco, M.D.; Dey, D.K. General class of multivariate skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar] [CrossRef] [Green Version]
- Durrans, S.R. Multivariate skew t-distribution. Stat. J. Theor. Appl. Stat. 2003, 37, 359–363. [Google Scholar]
- Sahu, S.K.; Dey, D.K.; Branco, M.D. A new class of multivariate skew distributions with applications to Bayesian regression models. Can. J. Stat. 2003, 31, 129–150. [Google Scholar] [CrossRef] [Green Version]
- Jones, M.C.; Faddy, M.J. A skew extension of the t-distribution, with Applications. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2003, 65, 159–174. [Google Scholar] [CrossRef]
- Zhao, J.; Kim, H.M. Power t distributions. Commun. Stat. Appl. Methods 2016, 23, 321–334. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: http://www.R-project.org (accessed on 10 October 2019).
- Lehman, E.L.; Casella, G. Theory of Point Estimation, 2nd ed.; Springer: New York, NY, USA, 1998. [Google Scholar]
- Frieden, B.R. Science from Fisher Information: A Unification; Cambridge Univerisity Press: Cambridge, UK, 2004. [Google Scholar]
- Arellano-Valle, R.B.; Azzalini, A. The centered parameterization and related quantities of the skew–t distribution. J. Multivar. Anal. 2013, 113, 73–90. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Azzalini, A. The centered parametrization for the multivariate skew-normal distribution. J. Multivar. Anal. 2008, 99, 1362–1382. [Google Scholar] [CrossRef]
- Akaike, H. A new look at statistical model identification. IEEE Trans. Autom. Contr. 1974, 19, 716–722. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Bozdogan, H. Model selection and akaike’s information criterion (AIC): The general theory and its analytical extensions. Psychometrika 2010, 52, 345–370. [Google Scholar] [CrossRef]
- Siebert, L.; Simkin, T.; Kimberly, P. Global Volcanism Program. In Volcanoes of the World; v. 4.6.0.; Venzke, E., Ed.; Smithsonian Institution: Washington, DC, USA, 2013; Available online: https://doi.org/10.5479/si.GVP.VOTW4-2013 (accessed on 10 October 2019).
- Feigelson, E.D. astrodatR: Astronomical Data. R Package v. 0.1. Available online: http://CRAN.R-project.org/package=astrodatR (accessed on 10 October 2019).
- Mattos, T.; Garay, A.M.; Lachos, V.H. Likelihood-based inference for censored linear regression models with scale mixtures of skew-normal distributions. J. Appl. Stat. 2018, 45, 2019–2066. [Google Scholar] [CrossRef]
- Barros, M.; Galea, M.; González, M.; Leiva, V. Influence diagnostics in the tobit censored response model. Stat. Methods Appl. 2010, 19, 379–397. [Google Scholar] [CrossRef]
- Ortega, E.M.; Bolfarine, H.; Paula, G.A. Influence diagnostics in generalized log-gamma regression models. Comput. Stat. Data Anal. 2003, 42, 165–186. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Skew | Power | Alpha—Power Skew | ||||
|---|---|---|---|---|---|---|
| Skewness | Kurtosis | Skewness | Kurtosis | Skewness | Kurtosis | |
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| n | Mean | Variance | ||
|---|---|---|---|---|
| 1520 | 16.7760 | 15.6682 | 0.6461 | 4.3809 |
| Distribution | ||||
|---|---|---|---|---|
| Estimates | Student-t | ST | PT | APST |
| 14.7835(0.3615 ) | 4.7469(0.6892) | 8.4027(0.7923) | 11.5509(0.1337) | |
| 11.0045(0.3975) | 14.1532(0.7237) | 11.8146(0.4707) | 22.6885(0.0792) | |
| – | 1.5673(0.1838) | – | 5.2347(0.2870) | |
| – | – | 1.7912(0.1147) | 0.3205(0.0347) | |
| 3.4156(0.3601) | 3.4075(0.3454) | 2.7473(0.2566) | 12.8734(2.9729) | |
| −6273.35 | −6219.25 | −6228.77 | −6205.94 | |
| AIC | 12,552.70 | 12,446.49 | 12,465.53 | 12,421.87 |
| BIC | 12,568.68 | 12,467.79 | 12,486.53 | 12,448.50 |
| CAIC | 12,571.68 | 12,471.79 | 12,490.83 | 12,453.50 |
| Distribution | ||||
|---|---|---|---|---|
| Estimates | CT | CST | CPT | CAPST |
| 1.0314(0.0010) | 1.2306(0.0018) | 1.2098(0.0052) | 1.1761(0.0054) | |
| 0.1596(0.0012) | 0.2712(0.0058) | 0.0818(0.0008) | 0.0905(0.0020) | |
| – | −3.5655(3.7748) | – | 0.6580(0.5031) | |
| – | – | 0.1705(0.0208) | 0.1518(0.0251) | |
| 0.9974(0.0884) | 1.2501(0.1774) | 6.0927(0.7501) | 6.0999(0.7326) | |
| −29.50743 | −18.87016 | −17.67113 | −14.80241 | |
| AIC | 65.01487 | 45.74033 | 43.34227 | 39.60482 |
| BIC | 71.67339 | 54.61836 | 52.22030 | 50.70236 |
| CAIC | 59.38987 | 38.37525 | 35.97719 | 30.57256 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tovar-Falón, R.; Bolfarine, H.; Martínez-Flórez, G. The Asymmetric Alpha-Power Skew-t Distribution. Symmetry 2020, 12, 82. https://doi.org/10.3390/sym12010082
Tovar-Falón R, Bolfarine H, Martínez-Flórez G. The Asymmetric Alpha-Power Skew-t Distribution. Symmetry. 2020; 12(1):82. https://doi.org/10.3390/sym12010082
Chicago/Turabian StyleTovar-Falón, Roger, Heleno Bolfarine, and Guillermo Martínez-Flórez. 2020. "The Asymmetric Alpha-Power Skew-t Distribution" Symmetry 12, no. 1: 82. https://doi.org/10.3390/sym12010082
APA StyleTovar-Falón, R., Bolfarine, H., & Martínez-Flórez, G. (2020). The Asymmetric Alpha-Power Skew-t Distribution. Symmetry, 12(1), 82. https://doi.org/10.3390/sym12010082