The Application of a Hybrid Model Using Mathematical Optimization and Intelligent Algorithms for Improving the Talc Pellet Manufacturing Process



Abstract
:1. Introduction
2. Materials and Methods
2.1. Talc Pellet Forming Process
2.2. Method
2.2.1. Self-Organizing Map
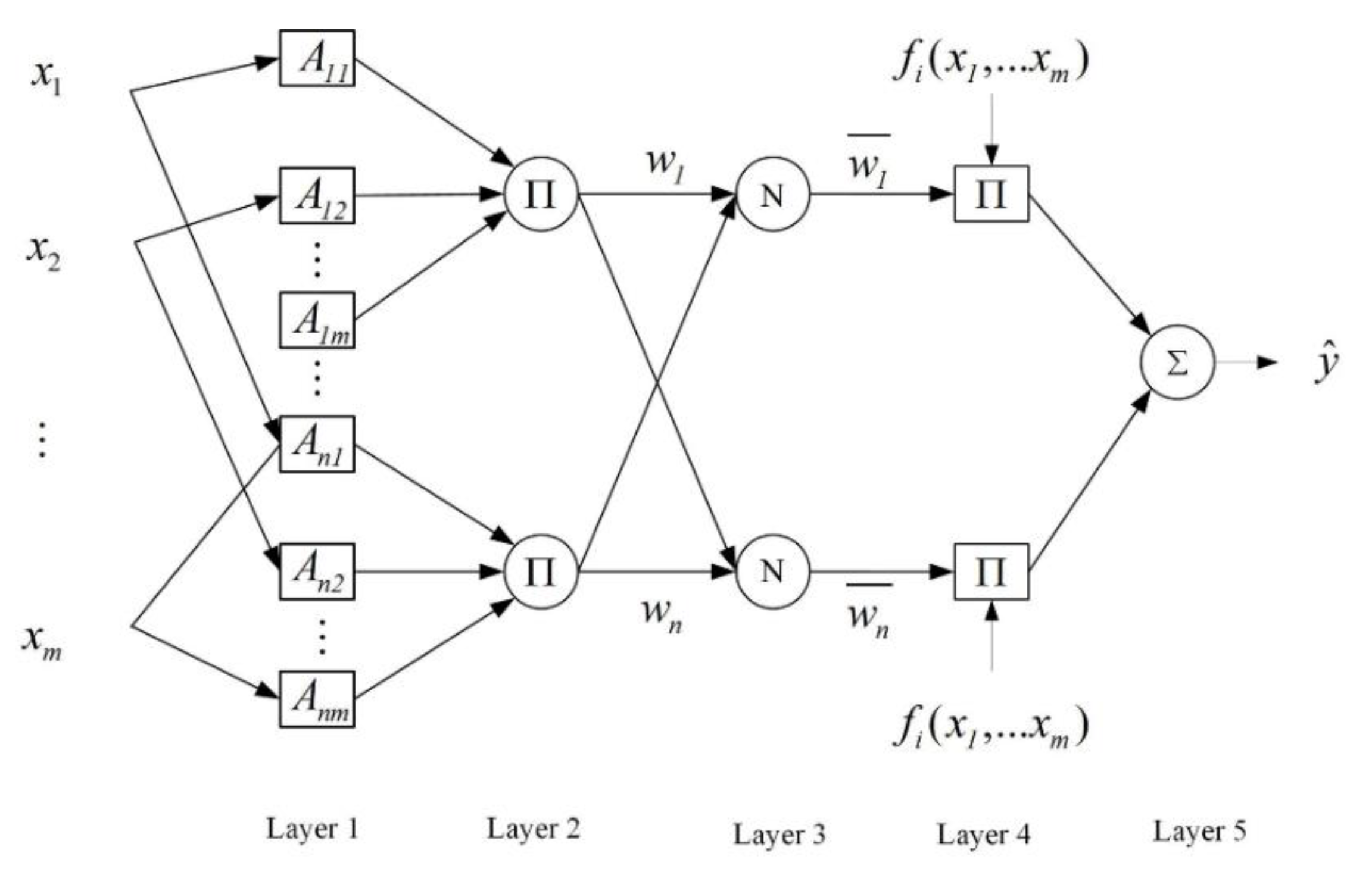
2.2.2. Adaptive Neuro-Fuzzy Inference System
- Layer 1: Adjust every node by using Equation (9):
- Layer 2: Calculate each node by multiplying the fuzzy value. The output is calculated as:
- Layer 3: Sum the fuzzy value of every node to one value by:
- Layer 4: Normalize the fuzzy value of every node by:where are the consequent parameters from Takag–Sugeno–Kang’s pattern.
- Layer 5: Sum all output from layer four to obtain the final output by:
2.2.3. The ANFIS Training Algorithm
Genetic Algorithm
- Chromosome encodes: Design the chromosomes as the system-represented solution by using any encoding method on the solving condition.
- Population initialization: Initialize the prototype population at the beginning of GA. The first population group is randomly created by matching with the defined population size.
- The fitness function: Define the score of each possible solution. Every chromosome implies the fitness of the inheritance consideration for themselves in order to create the next-generation chromosome.
- Selection: Select the genetic operator that supports the worthy member to transfer into the next generation. The process of selecting the best chromosome among the whole population is normally selected by good origin for good species according to the natural selection concept.
- Crossover: The copying of the new chromosome is pasted at a random position of the father and behind the random position of the mother to become the first offspring chromosome. The second offspring chromosome occurs by the same process as the first offspring while switching the position of the father and mother.
- Mutation: Mutate the value of the chromosome. The mutation process randomly mutates the position under the mutation possibility by changing some genes on the chromosome.
- Replacement: Replace the previous generation chromosomes with mutated chromosomes.
- Termination condition: Terminate the procedure when the condition is satisfied.
Particle Swarm Optimization
2.2.4. Performance Evaluation
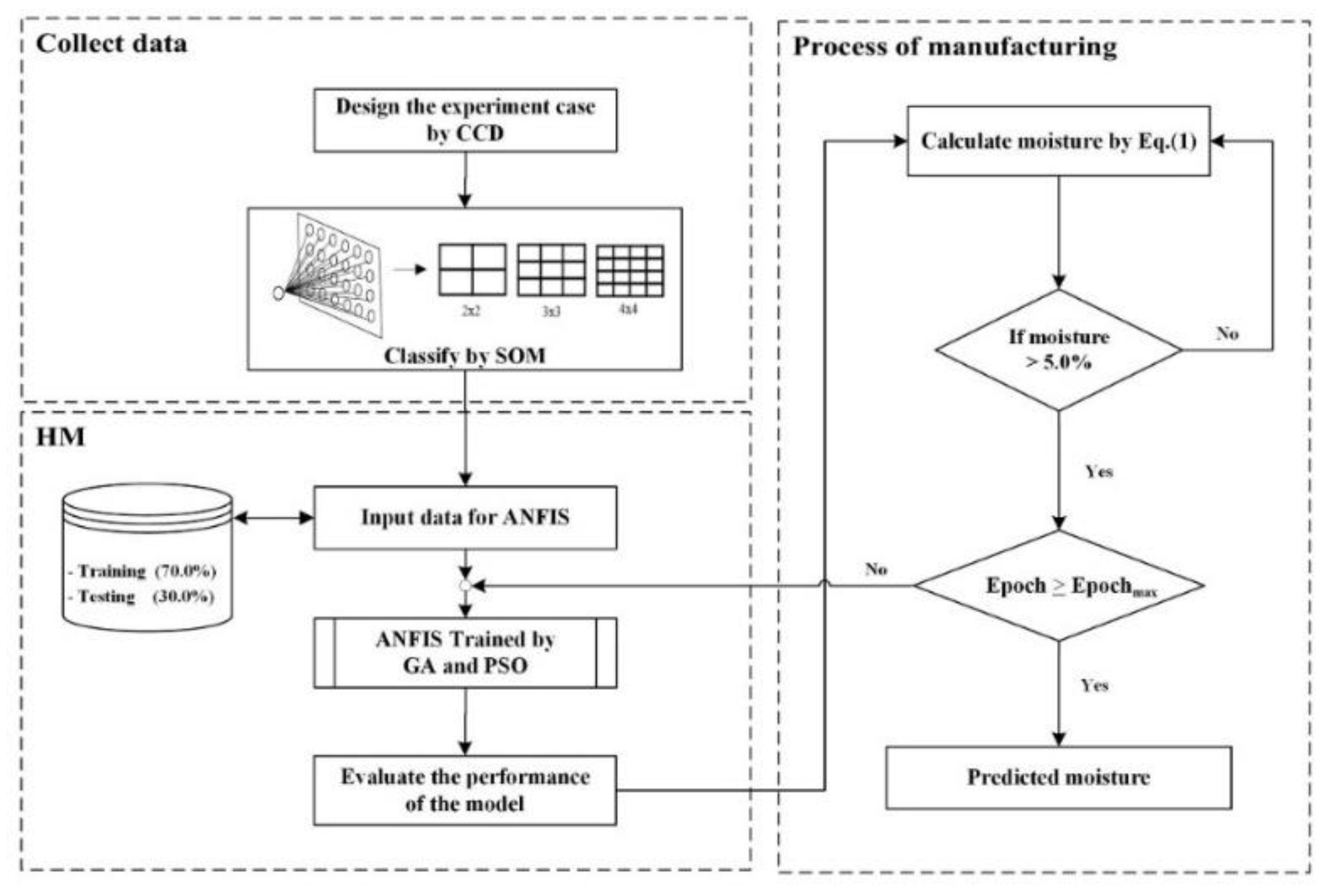
3. The Proposed Model
3.1. The Experimental Design
3.2. A Hybrid Model
3.3. The Experimental Setting
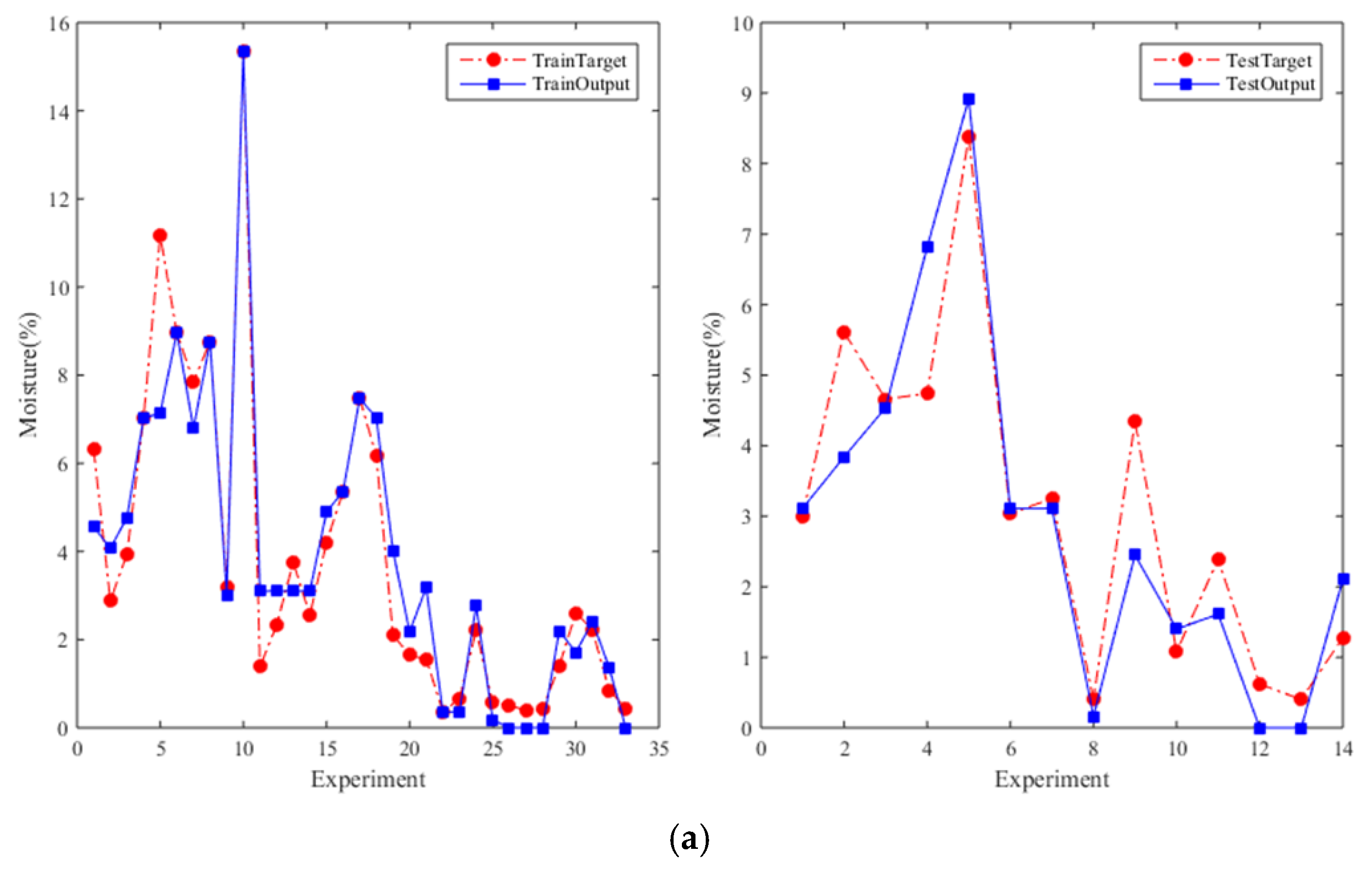
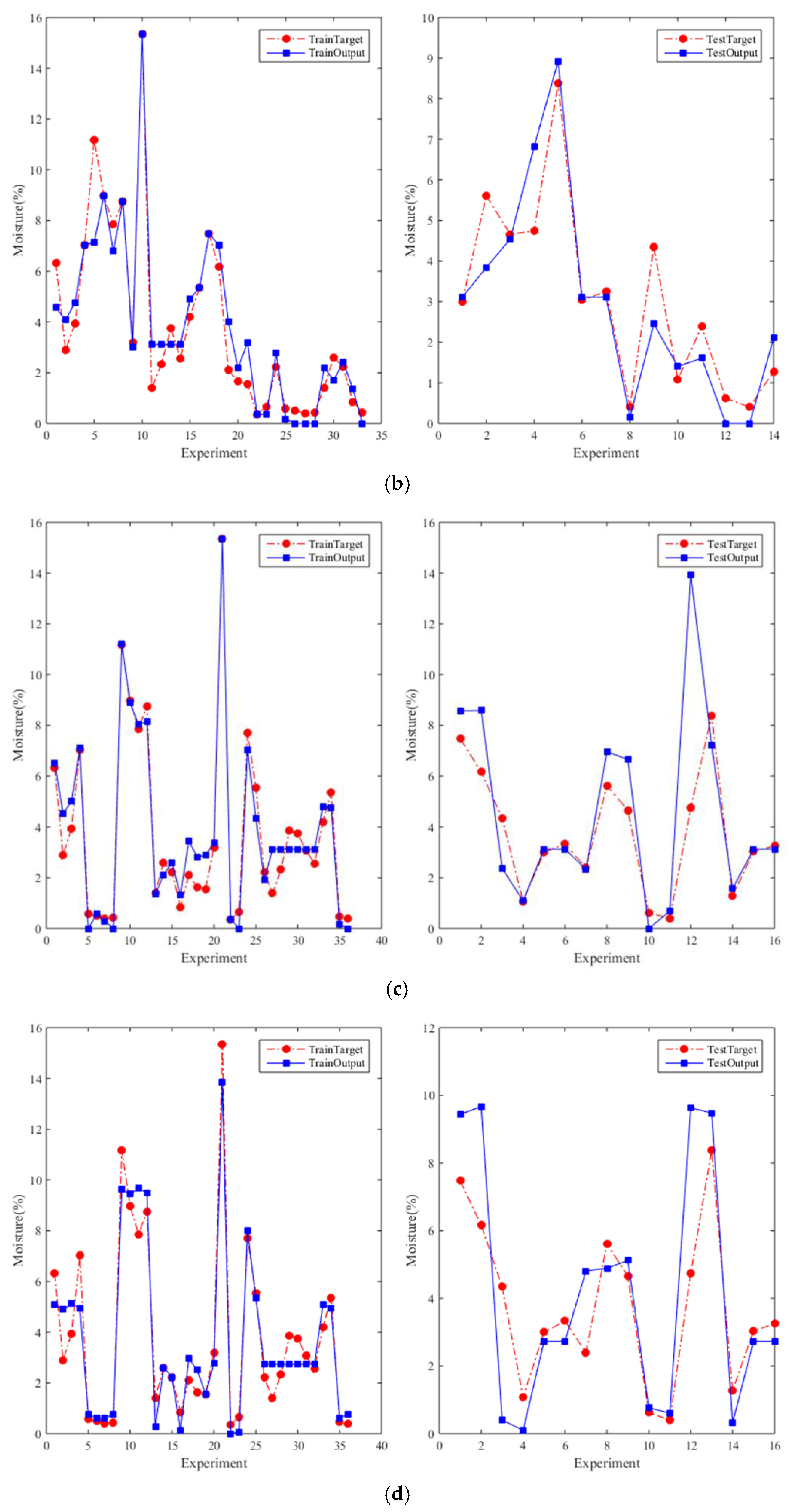
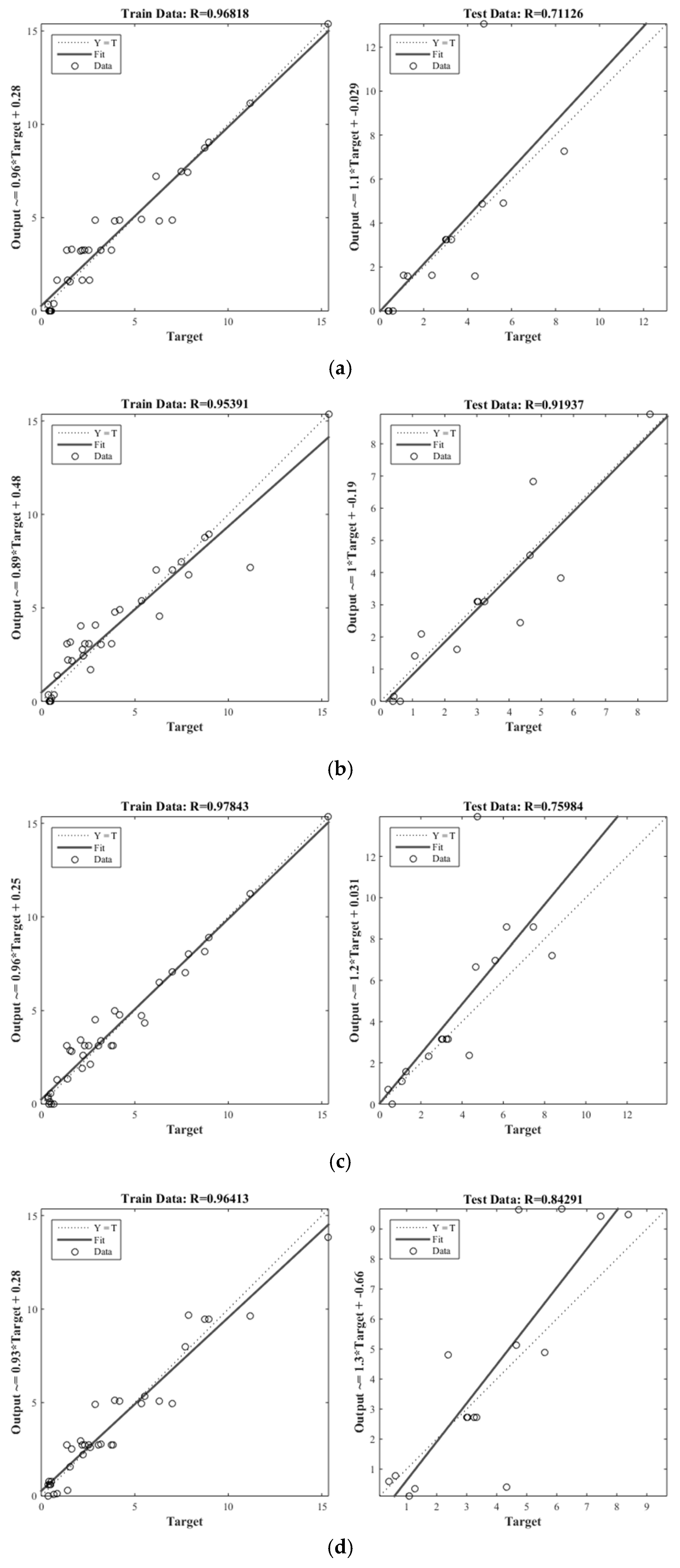
4. Result and Discussion
4.1. The Results of the SOM Algorithm
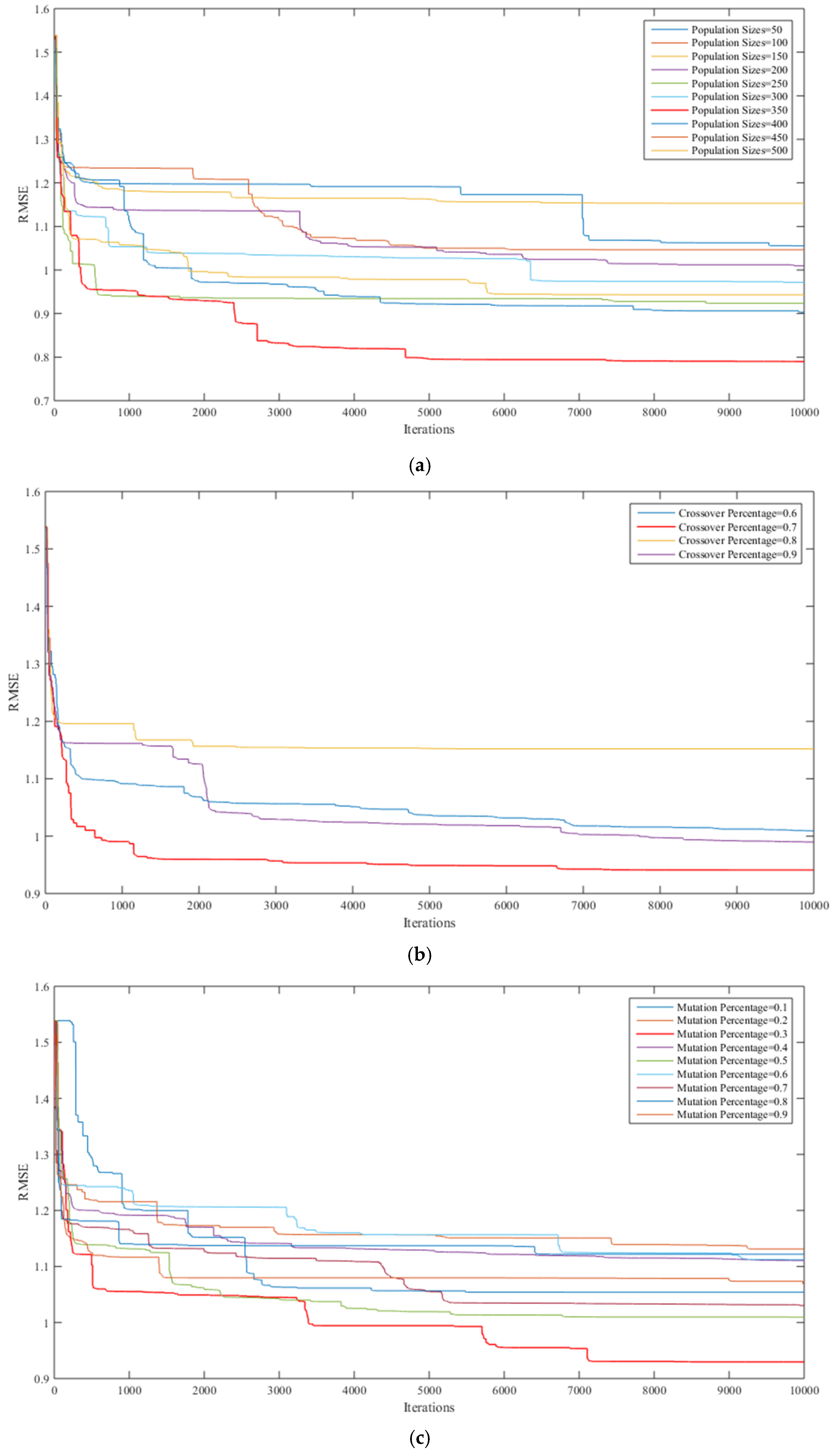
4.2. The Optimal Parameter of HM-GA
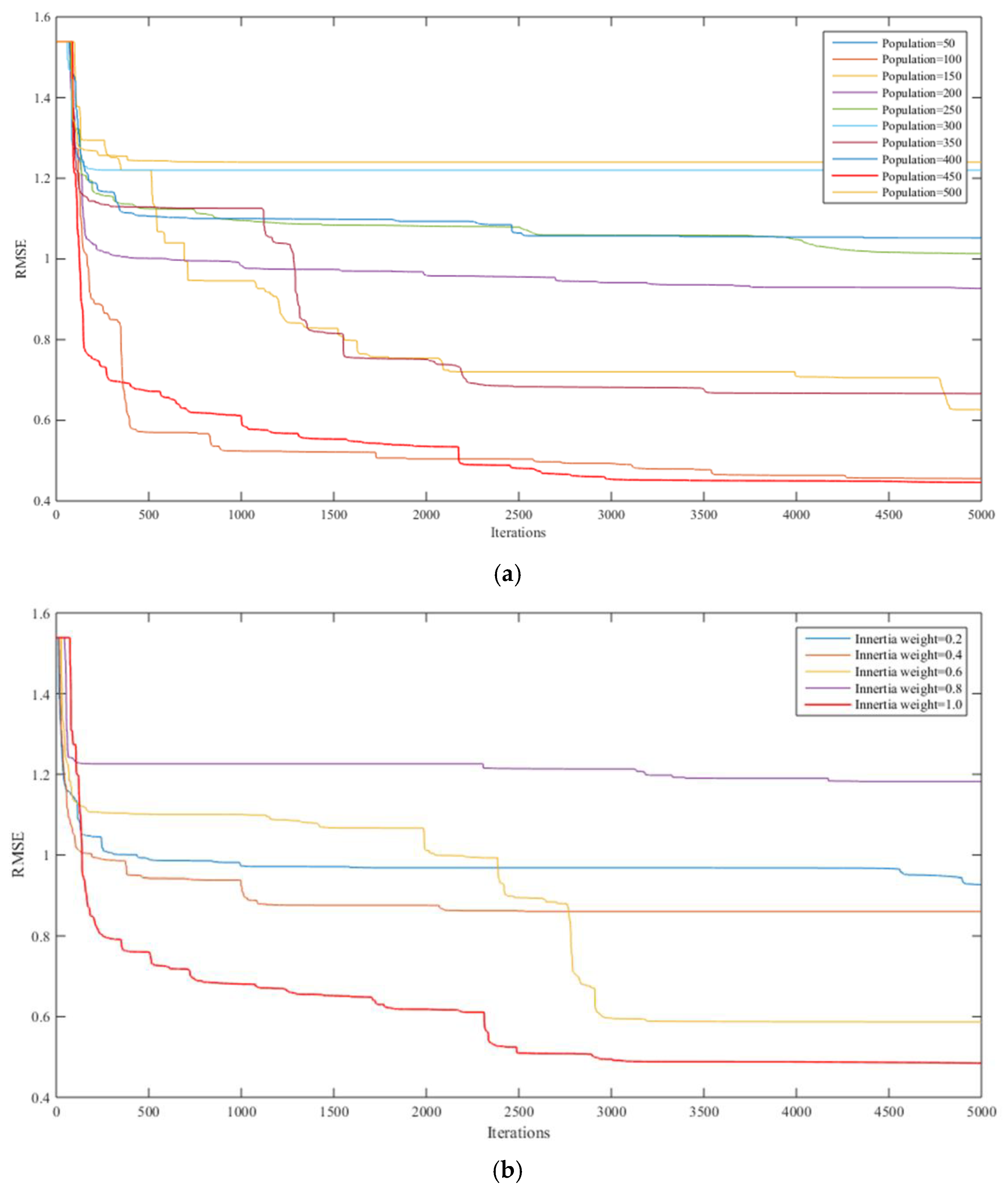
4.3. The Optimal Parameter of HM-PSO
4.4. The Comparison Results Approach from HM-GA and HM-PSO
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Driscoll, M. The structure of the Talc supply market. In Proceedings of the 3rd China Liaoning International Magnesia Materials Exposition, Shenyang, China, 22–24 September 2008; pp. 1–7. [Google Scholar]
- Loveday, A.U.; Nwanya, S.C.; Amaechi, O.P. Artificial neural network application to a process time planning problem for palm oil production. Eng. Appl. Sci. Res. 2020, 47, 161–169. [Google Scholar]
- Talpur, N.; Salleh, M.N.; Hussain, K.; Ali, H. Modified ANFIS with Less model complexity for classification problems. In Proceedings of the Computational Intelligence in Information Systems Conference (CIIS 2018), Phuket, Thailand, 17–19 November 2018; pp. 36–47. [Google Scholar]
- Buragohain, M. Adaptive Network Based Fuzzy Inference System (ANFIS) as a Tool for System Identification with Special Emphasis on Training Data Minimization. Ph.D. Thesis, Indian Institute of Technology Guwahati, Guwahati, India, July 2008. [Google Scholar]
- Caydas, U.; Hascalik, A.; Ekici, S. An Adaptive Neuro-Fuzzy Inference System (ANFIS) model for wire-EDM. Expert Syst. Appl. 2009, 36, 6135–6139. [Google Scholar]
- Zhange, Y.; Lei, J. Prediction of laser cutting roughness in intelligent manufacturing mode based on ANFIS. Procedia Eng. 2017, 174, 82–89. [Google Scholar] [CrossRef]
- Sen, B.; Mandal, U.K.; PrasadMondal, S. Advancement of an intelligent system based on ANFIS for predicting machining performance parameters of inconel 690—A perspective of metaheuristic approach. Measurement 2017, 109, 9–17. [Google Scholar] [CrossRef]
- Abdollahi, H. An Adaptive Neuro-Based Fuzzy Inference System (ANFIS) for the prediction of option price: The case of the Australian option market. Int. J. Appl. Math. Comput. 2020, 11, 99–117. [Google Scholar] [CrossRef]
- Bui, D.T.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W.; et al. New hybrids of ANFIS with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar]
- Yaseen, Z.M.; Ebtehaj, I.; Bonakdari, H.; Deo, R.; Mehr, A.D.; Mohtar, W.M.; Diop, L.; Ei-shafie, A.; Singh, V. Novel approach for streamflow forecasting using a hybrid ANFIS-FFA model. J. Hydrol. 2017, 554, 263–276. [Google Scholar] [CrossRef]
- Gocken, M.; Boru, A. Integrating metaheuristics and ANFIS for daily mean temperature forecasting. Int. J. Glob. Warm. 2016, 9, 110–128. [Google Scholar] [CrossRef]
- Oliverira, M.V.; Schirru, R. Applying particle swarm optimization algorithm for tuning a neuro-fuzzy inference system for sensor monitoring. Prog. Nucl. Energy 2009, 51, 177–183. [Google Scholar]
- Alarifi, I.M.; Nguyen, H.M.; Bakhtiyari, A.N.; Asadi, A. Feasibility of ANFIS-PSO and ANFIS-GA models in predicting thermophysical properties of Al2O3-MWCNT/Oil hybrid nanofluid. Materials 2019, 12, 3628. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Hynes, N.R. Prediction and optimization of surface roughness in thermal drilling using integrated ANFIS and GA approach. Eng. Sci. Technol. Int. J. 2020, 23, 30–41. [Google Scholar] [CrossRef]
- Rezakazemi, M.; Dashti, A.; Asghari, M.; Shirazian, S. H2-selective mixed matrix membranes modeling using ANFIS, PSO-ANFIS, GA-ANFIS. Int. J. Hydrogen Energy 2017, 42, 15211–15225. [Google Scholar] [CrossRef]
- Sabeti, M.; Deevband, M.R. Hybrid evolutionary algorithms based on PSO-GA for training ANFIS structure. Int. J. Comput. Sci. 2015, 12, 78–86. [Google Scholar]
- Dariane, A.B.; Azimi, S. Forecasting streamflow by combination of genetic input selection algorithm and wavelet transform using ANFIS model. Hydrol. Sci. J. 2016, 61, 585–600. [Google Scholar] [CrossRef]
- Jeong, C.; Shin, J.-Y.; Kim, T.; Heo, J.-H. Monthly precipitation forecasting with a neuro-fuzzy model. Water Resour. Manag. 2012, 26, 4467–4483. [Google Scholar] [CrossRef]
- Kohonen, T.; Simula, O.; Visa, A.; Kangas, J. Engineering applications of the self-organizing map. Proc. IEEE 1996, 84, 1358–1384. [Google Scholar] [CrossRef]
- Khanzadeh, M.; Rao, P.; Jafari-Marandi, R.; Smith, B.K.; Tschopp, M.A.; Bian, L. Quantifying geometric accuracy with unsupervised machine learning: Using self-organizing map on fused filament fabrication additive manufacturing parts. J. Manuf. Sci. Eng. 2018, 140, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Jha, R.; Dulikravich, G.S.; Chakraborti, N.; Fan, M.; Schwartz, J.; Koch, C.C.; Marcelo, J.; Colaco, M.J.; Poloni, C.; Egorov, I.N. Self-organizing maps for pattern recognition in design of alloys. Mater. Manuf. Processes 2017, 32, 1067–1074. [Google Scholar] [CrossRef]
- Nourani, V.; Alami, M.T.; Vousoughi, F.D. Hybrid of SOM-clustering method and wavelet-ANFIS approach to model and infill missing groundwater level data. J. Hydrol. Eng. 2016, 21, 1–19. [Google Scholar] [CrossRef]
- Amiryousefi, M.R.; Mohebbi, M.; Khodaiyan, F.; Asadic, S. An empowered adaptive neuro-fuzzy inference system using self-organizing map clustering to predict mass transfer kinetics in deep-fat frying of ostrich meat plates. Comput. Electron. Agric. 2011, 76, 89–95. [Google Scholar] [CrossRef]
- Nasir, V.; Cool, J. Intelligent wood machining monitoring using vibration signals combined with self-organizing maps for automatic feature selection. Int. J. Adv. Manuf. Technol. 2020, 108, 1811–1825. [Google Scholar]
- Standard Test Method for Laboratory Determination of Water (Moisture) Content of Soil and Rock by Mass; ASTM D 2216–98; ASTM International: Washington, DC, USA, 28 March 2004.
- Asan, U.; Ercan, S. An Introduction to Self-Organizing Maps; Atlantis Press: Istanbul, Turkey, 2012; pp. 299–319. [Google Scholar]
- Wangsoh, N.; Watthayu, W.; Sukawat, D. Appropriate learning rate and neighborhood function of Self-Organizing Map (SOM) for specific humidity pattern classification over Southern Thailand. Int. J. Model. Optim. 2016, 6, 61–65. [Google Scholar]
- Stefanovic, P.; Kurasova, O. Visual analysis of Self-Organizing Maps. Nonlinear Anal. 2011, 16, 488–504. [Google Scholar] [CrossRef] [Green Version]
- Jang, J.-S.R. ANFIS: Adaptive-Network-Based Fuzzy. IEEE Trans. Syst. Man Cybern. Syst. Hum. 1993, 23, 665–685. [Google Scholar]
- Holland, J. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1979. [Google Scholar]
- Goldberg, D.E. Genetic Algorithm in Search Optimization and Machine Learning; Addison Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A new optimizer using particle swarm theory. In Proceedings of the Sixth International Symposium on Micromachine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Talukder, S. Mathematical Modelling and Applications of Particle Swarm Optimization. Master’s Thesis, Blekinge Institute of Technology, Karlskrona, Sweden, February 2011. [Google Scholar]
- Ohale, P.E.; Uzoh, C.F.; Onukwuli, O.D. Optimal factor evaluation for the dissolution of alumina from azaraegbelu clay in acid solution using RSM and ANN comparative analysis. S. Afr. J. Chem. Eng. 2017, 24, 43–54. [Google Scholar] [CrossRef]
- Montogomery, D.C. Design and Analysis of Experiments; John Wiley & Sons Inc.: New York, NY, USA, 2001. [Google Scholar]
- Pham, H. Springer Handbook of Engineering Statistics; Springer: London, UK, 2006. [Google Scholar]
- Moayedi, H.; Raftari, M.; Sharifi, A.; Jus, W.W.; Safuan, A.; Rashid, A. Optimization of ANFIS with GA and PSO estimating α ratio in driven. Eng. Comput. 2019, 36, 227–238. [Google Scholar] [CrossRef]
- Wu, D.; Chen, H.; Huang, Y.; He, Y. Monitoring of weld joint penetration during variable polarity plasma arc welding based on the keyhole characteristics and PSO-ANFIS. J. Mater. Process. Technol. 2017, 239, 113–124. [Google Scholar] [CrossRef]
- Lei, S.; Zhan, H.; Wang, K.; Su, Z. How training data affect the accuracy and robustness of neural networks for image classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–14. [Google Scholar]
- Ismail, S.; Shabri, A.; Samsudin, R. A hybrid model of Self Organizing Maps and least square support vector machine for river flow forecasting. Hydrol. Earth Syst. Sci. 2012, 16, 4417–4433. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Symbol | The Value of α | Unit | ||||
|---|---|---|---|---|---|---|---|
| 1.682 | 1.0 | 0 | −1.0 | −1.682 | |||
| Talc | Ta | 18.6892 | 18 | 17.5 | 17 | 16.3107 | kg |
| Water | W | 4.3446 | 4 | 3.75 | 3.5 | 3.1553 | kg |
| Temperature | Temp | 191.35 | 150 | 120 | 90 | 48.65 | °C |
| Feed Speed | FS | 0.56 | 0.43 | 0.34 | 0.24 | 0.11 | m/min |
| Air Flow | AF | 8.40 | 7.21 | 6.35 | 5.48 | 4.29 | m/sec |
| No. | Ta | W | Temp | FS | AF | MC | No. | Ta | W | Temp | FS | AF | MC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 17 | 3.5 | 90 | 0.24 | 7.21 | 6.31 | 27 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 1.38 |
| 2 | 18 | 3.5 | 90 | 0.24 | 5.48 | 2.89 | 28 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 2.33 |
| 3 | 17 | 4 | 90 | 0.24 | 5.48 | 3.94 | 29 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3.85 |
| 4 | 18 | 4 | 90 | 0.24 | 7.21 | 7.02 | 30 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3.75 |
| 5 | 17 | 3.5 | 150 | 0.24 | 5.48 | 0.56 | 31 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3.07 |
| 6 | 18 | 3.5 | 150 | 0.24 | 7.21 | 0.51 | 32 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 2.56 |
| 7 | 17 | 4 | 150 | 0.24 | 7.21 | 0.39 | 33 | 17 | 3.5 | 90 | 0.24 | 5.48 | 4.19 |
| 8 | 18 | 4 | 150 | 0.24 | 5.48 | 0.42 | 34 | 18 | 4 | 90 | 0.24 | 5.48 | 5.37 |
| 9 | 17 | 3.5 | 90 | 0.43 | 5.48 | 11.17 | 35 | 17 | 3.5 | 150 | 0.24 | 7.21 | 0.45 |
| 10 | 18 | 3.5 | 90 | 0.43 | 7.21 | 8.96 | 36 | 17 | 4 | 150 | 0.24 | 5.48 | 0.41 |
| 11 | 17 | 4 | 90 | 0.43 | 7.21 | 7.86 | 37 | 18 | 3.5 | 90 | 0.43 | 5.48 | 7.47 |
| 12 | 18 | 4 | 90 | 0.43 | 5.48 | 8.76 | 38 | 17 | 4 | 90 | 0.43 | 5.48 | 6.16 |
| 13 | 17 | 3.5 | 150 | 0.43 | 7.21 | 1.41 | 39 | 17 | 3.5 | 150 | 0.43 | 5.48 | 4.34 |
| 14 | 18 | 3.5 | 150 | 0.43 | 5.48 | 2.61 | 40 | 18 | 3.5 | 150 | 0.43 | 7.21 | 1.08 |
| 15 | 17 | 4 | 150 | 0.43 | 5.48 | 2.22 | 41 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3 |
| 16 | 18 | 4 | 150 | 0.43 | 7.21 | 0.85 | 42 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3.33 |
| 17 | 16.31 | 3.75 | 120 | 0.34 | 6.35 | 2.11 | 43 | 18 | 4 | 150 | 0.43 | 5.48 | 2.39 |
| 18 | 18.69 | 3.75 | 120 | 0.34 | 6.35 | 1.64 | 44 | 18 | 3.5 | 90 | 0.24 | 7.21 | 5.61 |
| 19 | 17.5 | 3.16 | 120 | 0.34 | 6.35 | 1.56 | 45 | 17 | 4 | 90 | 0.24 | 7.21 | 4.66 |
| 20 | 17.5 | 4.34 | 120 | 0.34 | 6.35 | 3.19 | 46 | 18 | 3.5 | 150 | 0.24 | 5.48 | 0.62 |
| 21 | 17.5 | 3.75 | 49 | 0.34 | 6.35 | 15.36 | 47 | 18 | 4 | 150 | 0.24 | 7.21 | 0.4 |
| 22 | 17.5 | 3.75 | 191 | 0.34 | 6.35 | 0.36 | 48 | 17 | 3.5 | 90 | 0.43 | 7.21 | 4.74 |
| 23 | 17.5 | 3.75 | 120 | 0.11 | 6.35 | 0.66 | 49 | 18 | 4 | 90 | 0.43 | 7.21 | 8.38 |
| 24 | 17.5 | 3.75 | 120 | 0.56 | 6.35 | 7.7 | 50 | 17 | 4 | 150 | 0.43 | 7.21 | 1.28 |
| 25 | 17.5 | 3.75 | 120 | 0.34 | 4.29 | 5.54 | 51 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3.04 |
| 26 | 17.5 | 3.75 | 120 | 0.34 | 8.4 | 2.21 | 52 | 17.5 | 3.75 | 120 | 0.34 | 6.35 | 3.25 |
| SOM | Value | ANFIS | Value |
|---|---|---|---|
| Initial learning rate | 0.85 | Fuzzy type | Sugeno |
| Initial weight vector | Random | Input/outputs | 5/1 |
| Max. radius of neighbourhood | Size 10 | Input MF type | Gaussian |
| Max. number of iterations | 5000 | Output MF type | Linear |
| SOM array size | 2 × 2, 3 × 3, 4 × 4 | Training algorithm | GA, PSO |
| No. of MFs for each input | 10 | ||
| Fuzzy rules | 10 |
| GA | Value | PSO | Value |
|---|---|---|---|
| Population Size | 350 | Population size | 450 |
| Iteration | 10,000 | Iteration | 5000 |
| Crossover percentage | [0.6,0.9] | Inertia weight | 1.0 |
| Mutation percentage | (0,1) | Damping ratio | 0.99 |
| Mutation ratio | 0.1 | Personal learning coefficient | 1.0 |
| Selection pressure | 8 | Global learning coefficient | 2.0 |
| Gamma | 0.2 |
| Cluster | 1 | 2 |
|---|---|---|
| 1 | 48.07 | 7.69 |
| 2 | 1.92 | 42.31 |
| Model | Train Data | Test Data | ||||
|---|---|---|---|---|---|---|
| R | RMSE | AAD | R | RMSE | AAD | |
| HM-GA | 0.9682 | 0.8984 | 0.401 | 0.7113 | 2.3959 | 0.493 |
| HM-PSO | 0.9539 | 1.0693 | 0.393 | 0.9192 | 0.9785 | 0.376 |
| ANFIS-GA | 0.9784 | 0.7203 | 0.314 | 0.7598 | 2.5396 | 0.416 |
| ANFIS-PSO | 0.9641 | 0.9137 | 0.333 | 0.8431 | 2.0327 | 0.485 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buntam, D.; Permpoonsinsup, W.; Surin, P. The Application of a Hybrid Model Using Mathematical Optimization and Intelligent Algorithms for Improving the Talc Pellet Manufacturing Process. Symmetry 2020, 12, 1602. https://doi.org/10.3390/sym12101602
Buntam D, Permpoonsinsup W, Surin P. The Application of a Hybrid Model Using Mathematical Optimization and Intelligent Algorithms for Improving the Talc Pellet Manufacturing Process. Symmetry. 2020; 12(10):1602. https://doi.org/10.3390/sym12101602
Chicago/Turabian StyleBuntam, Dussadee, Wachirapond Permpoonsinsup, and Prayoon Surin. 2020. "The Application of a Hybrid Model Using Mathematical Optimization and Intelligent Algorithms for Improving the Talc Pellet Manufacturing Process" Symmetry 12, no. 10: 1602. https://doi.org/10.3390/sym12101602
APA StyleBuntam, D., Permpoonsinsup, W., & Surin, P. (2020). The Application of a Hybrid Model Using Mathematical Optimization and Intelligent Algorithms for Improving the Talc Pellet Manufacturing Process. Symmetry, 12(10), 1602. https://doi.org/10.3390/sym12101602