This section introduces the related methods and materials used in this study to address the applied financial application issues related to EPS to reach meaningful empirical research with a rich treasure trove of knowledge, as follows.
3.1. Background of the Applied Study Framework
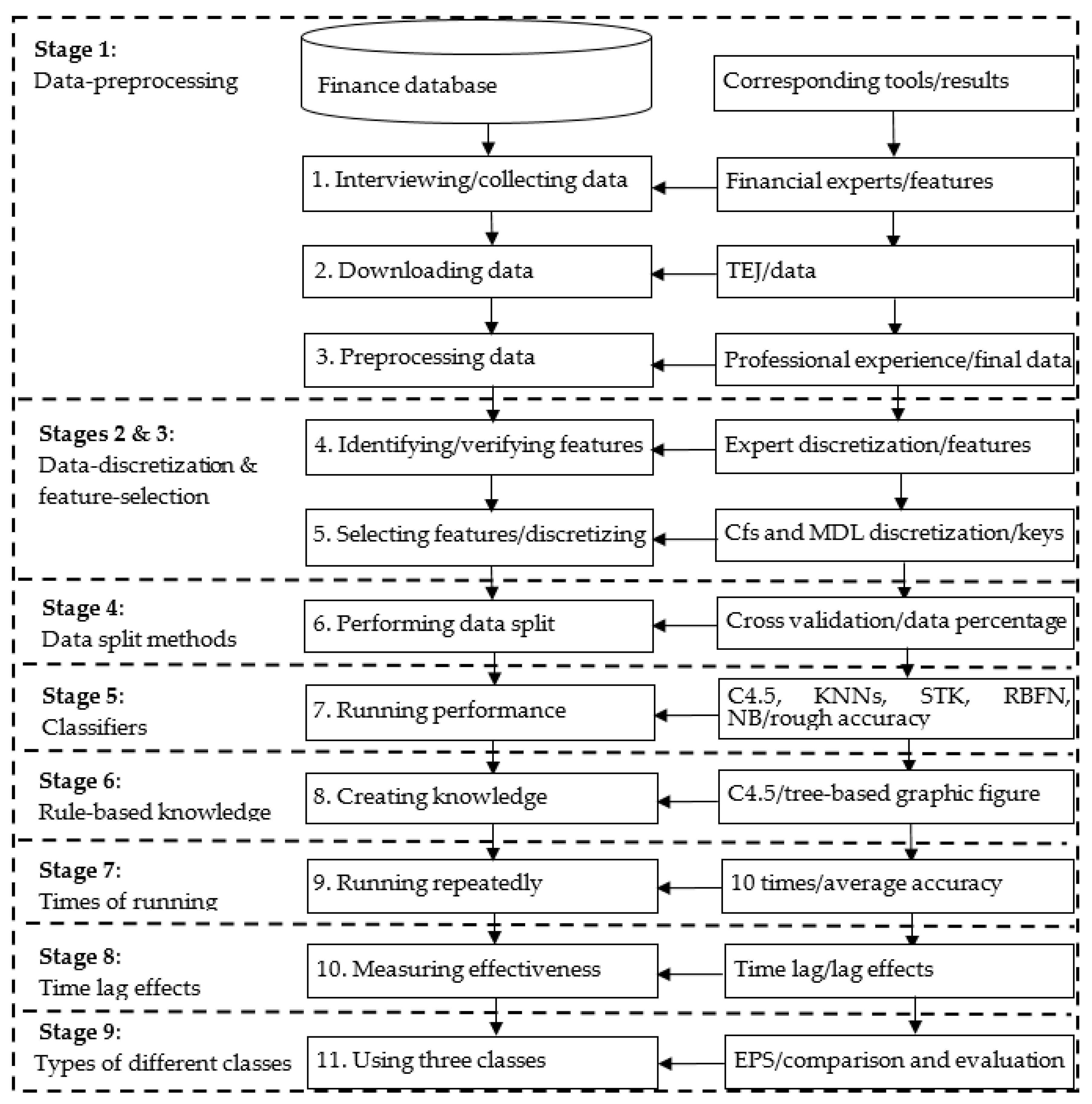
In practice, benefiting the consideration of financial stock investment settled in the big data framework of the complicated stock market for interesting financial truths and options, accurately classifying the EPS of listed companies is an interesting issue attracting investors; however, unscientific decisions are unfortunately involved in the profit-making development, which may never be successful for the investing plan. Highly skilled investors have searched for an intelligent model to properly identify the potential positive/negative target from the vast sea of stocks for escaping possible losses and, conversely, maximizing profits. To keep making the right investor decisions, this study uses the advantages of past reviews of literature and the managerial experience of experts on financial ratios to propose a hybrid multicomponential discretization model with ML techniques to develop effective early-warning rules for the identification of positive/negative EPS. This study proposes a map of advanced multicomponential discretization models for identifying financial diagnoses and has the purpose of using 2009–2014 financial statements to research the EPS of companies on TWSE from six different industry online financial databases to assess the componential performance of the models, with effective comparative studies for getting rich features. The varied components of the models in the study test the performance measurements of differently organized data-preprocessing, data-discretization, feature-selection, two data split methods, machine learners, rule-based DT knowledge, time-lag effects, different times of running experiments, and two types of different classes.
Recently, a varied function of emerged linear and nonlinear ML techniques [
55,
56] in advanced soft computing algorithms such as DT-C4.5, the KNN algorithm, ensemble STK, RBFN, and NB, other than the nonlinear support vector machine, multilayer perceptron, and the linear logistic regression, has been used as an important research approach for both academicians and practitioners due to their superior past performance and has been well studied, with a wide application field with beneficial effects. Therefore, past prominent capability is very worthy of being a starting point to a study and overview of the linear or nonlinear comparative studies for further research work. In view of these interesting facts for modeling classification works [
57,
58], they are used as the basis for the complete construction of the study framework. There are nine components (stages), with 11 detailed steps for raising the advantages and rationalities of this study. (1) Data-preprocessing: This component is used to build a tangible benefit from the reviews of literature and experts from a specific database. (2) Data-discretization: The discretization facilitates the use of data from the view of natural language and improves classification accuracy. (3) Feature-selection: This core technique is used to lower data dimension and complexity to speed the benefits of operating experiments. (4) Two data-split methods: The different data-split methods are used for comparison of the review of practical datasets in the same environment. (5) Machine learners: Different classifiers are assessed and compared to discover the best suitable tool for EPS financial diagnosis. (6) Rule-based DT knowledge: The decisional rules generated by the DT-C4.5 algorithm are used for constructing the instructions of the “IF…THEN…” form used to help define a better choice to achieve a specific goal. (7) Different times of running experiments: It has the advantage of determining the performance of various classifiers with the same given data. (8) Time lag effects: The lag effects of different time periods are measured to understand whether the financial data consider a substantial time-lag effect demonstrated by the given data as well as to identify the right time lag. (9) Types of different classes: The merit of measuring different classes is used to define the performance difference of various classifiers. Mainly, the nine major stages systematically detail the computing processes to support a further clear definition, which is described in
Figure 1, to present a flowchart of the applied hybrid models proposed to represent data relativity, with the corresponding tools and steps for experiencing the empirical outcomes (results) of EPS.
These abovementioned components are selected based on the following three reasons. First, they had a high level of evaluation in past studies. Second, no one has tried to use them in predicting EPS of financial fields and then created rule-based decisional knowledge for the stock market to address this practical problem. Third, it is worthwhile to explore the interesting issue of multicomponential discretization models, and its application areas of research and its application advantage are accordingly expected and studied here.
From the restricted review, the study has a valuable contribution and directions in which the multicomponential discretization models are very limited and rarely seen for such an industry setting. Thus, the applied hybrid models proposed are of interest, with the uses of the above nine stages with 11 detailed steps. The proposed hybrid models are implemented and executed in a step-by-step mode; some steps (e.g., five classifiers: DT-C4.5, KNNs, STK, RBFN, and NB) are respectively run for each model from a software package tool, and some other steps are coded or stored in the CSV format of Excel software (e.g., data-preprocessing is implemented in Microsoft Excel).
3.2. Algorithm of the Applied Hybrid Models Proposed
In the subsection, this study applies five main hybrid classification models, with nine stages, to address financial application issues related to EPS to find a meaningful empirical research method. To improve the readability of this study, the concepts and structures of these models are addressed in a tableau list report. The main stages of these proposed hybrid models (referred to as Models A–E) are data-preprocessing, data-discretization, feature-selection, data split methods, various classifiers, time-lag effects, and the measurement of two types of classes.
Table 1 lists their information in detail below. Interestingly, the order performance for executing data-discretization and feature-selection is evaluated in this study.
The algorithm for the above five hybrid models, with the experience of an empirical case study application extracted from a real financial database in Taiwan, is detailed and implemented in 11 steps systematically, as follows.
Stage 1. Data-preprocessing:
Table 1 shows that this component is used in all the applied hybrid models proposed, Models A–E.
Step 1. Consulting field experts and gathering data: In this step, we first interviewed field experts interested in financial analysis and investment management and studied the online financial database of the noted Taiwan Economic Journal (TEJ) [
59], which is targeted as the object of the experiments in order to identify and confirm essential features. The 25 essential features, including 24 condition features encoded as X1–X24 and one decision feature (X25) encoded as Class, were first defined with the help of financial experts and literature reviews. Financial experts added the first four extra features (X1–X4; Year, Season, Industrial Classification, and Total Capital) to the list of the 20 features (renamed, in order, as X5–X24) that were seen in
Section 2.1. The classes of EPS were suggested by experts.
Step 2. Downloading the data used from the TEJ database: Accordingly, raw data for these features were downloaded as an experimental dataset, with 4702 instances from the TEJ database for a six-year period. For ease of presentation, the dataset is named the TEJ dataset.
Step 3. Preprocessing the data: In further analysis, this step filtered six industries. The six industries are electrical machinery, biotechnology and medical, semiconductor, optoelectronics, electronic components, and shipping industries, which are well-known and of high trading volume among Taiwanese investors. As this was the first attempt to find rules in the Taiwanese stock market, the study chose these industries to begin. To facilitate the operation of the experiment, this step cleared irrelevant columns with incomplete or inaccurate data, added and computed some new columns that were not present in the TEJ dataset (such as times interest earned), joined columns of special stock and common stock as the feature of total capital, reconfirmed the information of the TEJ dataset with official reports reviewed from TWSE, and stored the dataset in Excel software format.
Table 2 lists all the feature information with descriptive statistics from the TEJ dataset.
Stages 2 and 3. Data-discretization and feature-selection:
Table 1 makes it is clear that the component of data-discretization is only used in Models B, D, and E, and the component of feature-selection is for Models C–E.
Step 4. Identifying and verifying and discretizing features: The decisional feature of this study is defined as EPS, which is divided into two types of two and three classes, and the conditional features are 20 financial ratios plus the related four financial variables of Year, Season, Industrial Classification, and Total Capital, which are listed in
Table 2. In two classes, the decisional feature of EPS named as Class is firstly classified into P (>0 in NTD, i.e., positive profit) and N (≦0, negative profit), according to the opinion and selection of three experts.
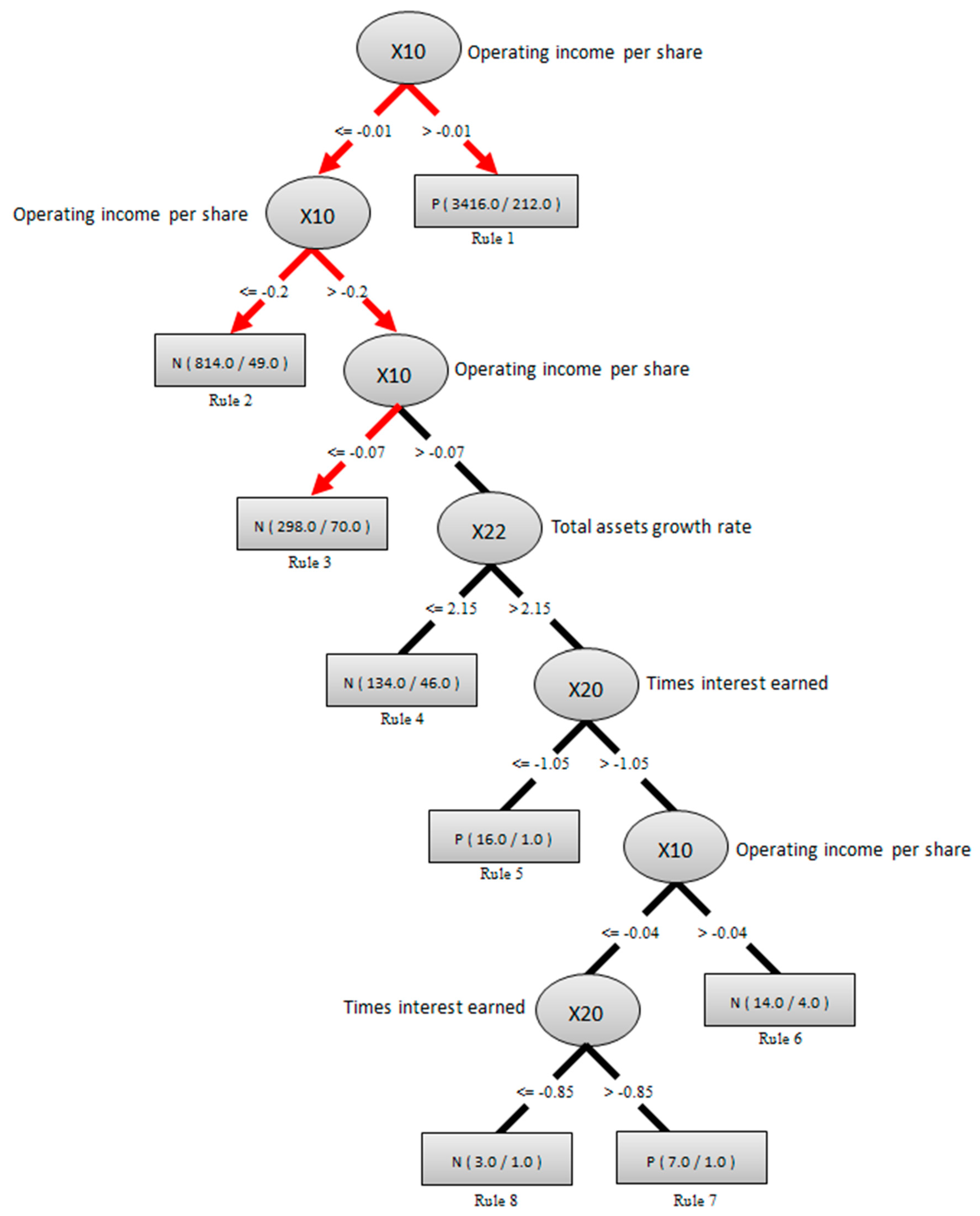
Step 5. Selecting the features and/or discretizing the data: Subsequently, test five organized ways of data-mining the models using various components of data-preprocessing, data-discretization, and feature-selection for performance comparison, including (1) with data-preprocessing but without data-discretization and feature-selection, (2) with data-preprocessing and data-discretization but without feature-selection, (3) with data-preprocessing and feature-selection but without data-discretization, (4) conducting data-preprocessing and data-discretization before feature-selection, and (5) conducting data-preprocessing and feature-selection before data-discretization. The above five ways are mainly measured for component performances by using a Cfs subset evaluation algorithm of search method for feature-selection and a filter function of discretizing tool with minimum description length (MDL) of automatic data-discretization in professional software for data mining techniques from software-defined networks, followed by different classifiers that are executed by employing professional package services. As a result, there are a total of three core determinators, including times interest earned, operating income per share, and total assets growth rate, that are identified in the feature-selection processes for influencing EPS in the type of two classes, which is significantly improved and associated with the stock price of a specific listed stock.
Stage 4. Data-split methods: This component is used for Models A–E.
Step 6. Performing cross-validation and percentage data-split: Furthermore, it is interesting to find out an appropriate model to overcome problems faced in real life by assessing the function of various components of models and then selecting a suitable model. It is desirable to avoid spending a long-time on training a model that is poor. Thus, this step uses two model-selection methods, cross-validation and percentage data-split, when training/testing the processing of the target dataset to make the right selection. On the one hand, based on a study by Džeroski and Zenko [
60], the cross-validation method, a general approach for model-selection, is allocated and synthesized with “testing the models with the entire training dataset, and choosing the one that works best” when various models are used with a large set of real problems. In the reviews of model-selection, a basic form of cross-validation divides the dataset into two sets, with the bigger set used for training and the other smaller set used for testing if data are not scarce and are substantial enough to enable input–output measurements. On the contrary, another model-selection approach is to use percentage-split data; it is a popular approach in ML application algorithms from numerous studies [
61,
62]. The percentage-split for the dataset partitions the original set into different groups of training/testing sub-datasets, such as 90%/10% and 80%/20%. In practice, the training/testing sub-dataset is usually at a 2/1 ratio to achieve a good and reasonable result. To reverify their selection performance, the above two methods are adopted into all the proposed hybrid models, and, from past successful examples, the 10-fold cross-validation and 67%/33% percentage-split of data are commonly used in this step.
Stage 5. Classifiers: This component is used in Models A–E.
Step 7. Applying classifiers and making performance comparisons: Accordingly, run five classifiers (DT-C4.5, KNNs, STK, RBFN, and NB) for each model from the software package tool, with no changes predesigned on these learning classifiers; the five classifiers are selected from performance assessments based on their past high satisfactory results, and their classification performance in accuracy rate due to common use under the two classes of EPS is compared to see and judge their differences that may have some implied information for stock investors. The accuracy rate in one run for these classifiers is then achieved.
Stage 6. Rule-based knowledge: This component is used for Models A–E.
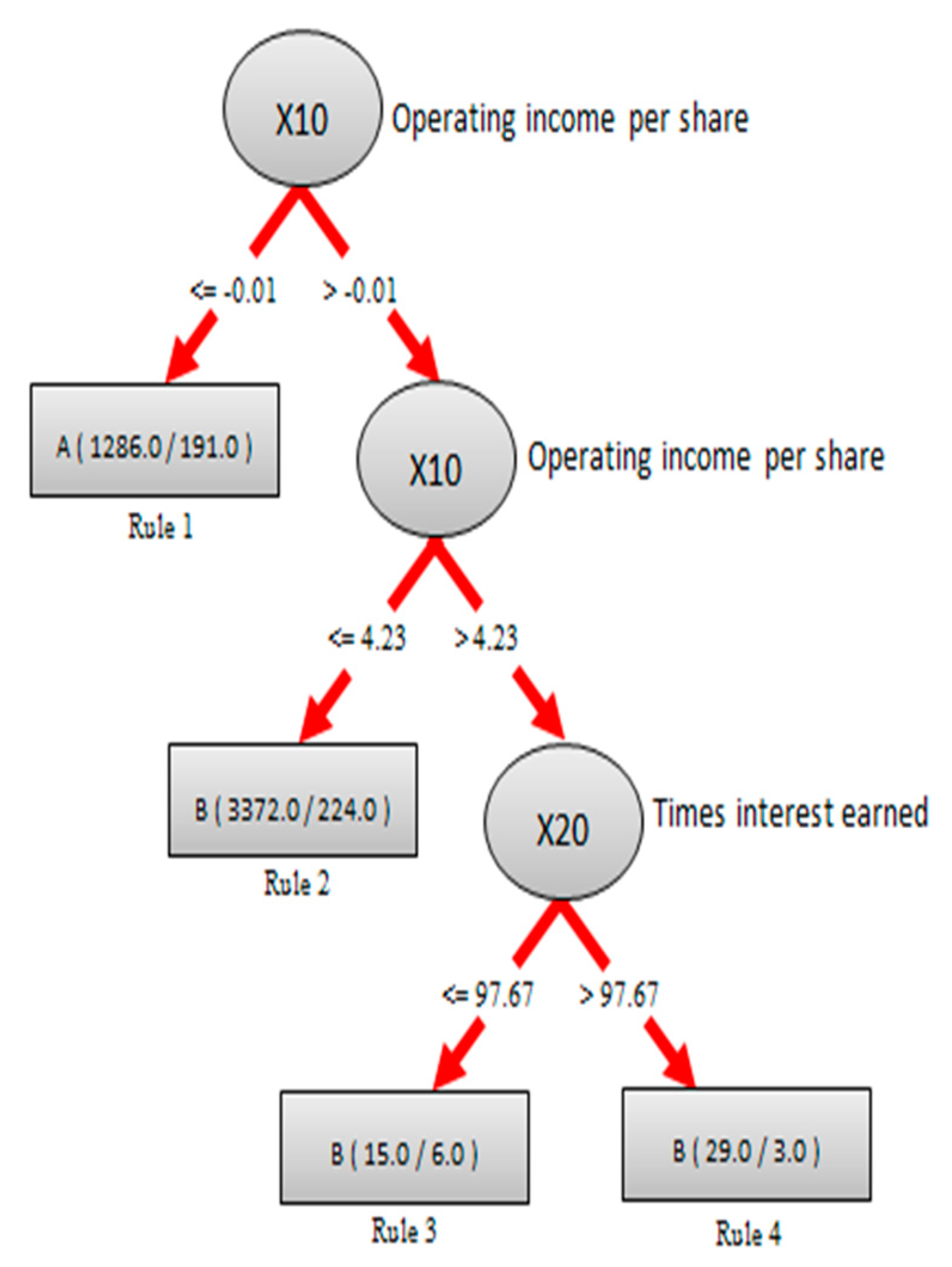
Step 8. Creating rule-based knowledge for interested parties: To generate and understand the hidden information of forming “IF…THEN…” in rule-based knowledge, this step employs a fundamental step of the DT-C4.5 algorithm to create a decisional-tree-based structure (in a graphic figure) to represent the formatted knowledge of the target TEJ dataset. The knowledge in the figure is crucial to a varied topic of EPS in financial investment. For easy presentation and reading, the created tree-based structure (in a graphic figure) and its explanations will be uniformly displayed in the next section.
Stage 7. Times of running experiments: This component is used in Models A–E.
Step 9. Running the experiments repeatedly: To further validate and test the classification accuracy of the five classifiers, the experiment is repeatedly run 10 times for the TEJ dataset, and the average accuracy is obtained for the difference analysis.
Stage 8. Time-lag effects: This component is used for Models A–E.
Step 10. Measuring the effectiveness of time lag: To consider whether time lag has an influence on the prediction of EPS, divide the dataset by seasons, and use the EPS of the current season (T+0), the next season (T+1), the third season (T+2), and the fourth season (T+3) as the decisional feature to test and find the best performing models, which are using the DT-C4.5 and RBFN classifiers and dividing EPS into two classes due to their suitability.
Stage 9. Types of different classes: Finally, this component is used for Models A–E.
Step 11. Using three classes of EPS: To further differentiate and create the class difference, use three classes (i.e., A (<0), B (0~3.75), and C (>3.75)) of EPS based on the automatic discretization recommendation instead of two classes in all the applied hybrid models proposed, and the experiments from Steps 1–10 are run again.








{kind=link}
{kind=link}
{kind=link}