1. Introduction
Dynamics of nonlinear systems is a central concern in science, engineering, and mechanical problems. In order to analyze them, test prototypes represent a powerful strategy [
1]. This is because their nonlinear dynamics allow getting a better grasp of the phenomena and physical behavior of several industries and equipment applications including: robotic systems, aerospace systems, marine vehicles [
2,
3]. There exist multiple versions of the classic models of the pendulum, among which the most known are the reaction wheel pendulum (RWP), the pendulum on a cart with linear displacement, the Furuta pendulum with a rotating base, and also these with two and three bars, among others. This study considers the well-know educative RWP dynamical system.
The RWP is an inverted pendulum balanced by a flywheel, i.e., an actuated rotating reaction wheel. It exhibits important challenges in the field of control theory including robustness, stabilization, and nonlinearities. These features combined make it an attractive and adequate system for performing research and high-level education. Various engineering problems can be modeled similarly as inverted pendulum, including rocket launch and human-powered vehicles.
In the literature, the problem of control in RWP has been addressed with both linear and non-linear techniques as well as artificial intelligent methods. These can be found mainly as: control Lyapunov functions [
4], passivity-based control [
5], proportional-integral controllers [
6], fuzzy logic [
7], feedback linearization [
8], and deep neural networks [
9].
The below-mentioned items represent the key aspects that make this approach different from similar works:
- ✓
Global stabilization of the discrete version of the RWP dynamic model system via control Lyapunov functions with global exponential convergence and optimality properties.
- ✓
Robustness performance against parametric uncertainties while preserving asymptotic convergence properties.
- ✓
The comparison of the proposed discrete-inverse optimal controllers via control Lyapunov functions with the discrete versions of the passivity-based and Lyapunov-based controllers (from the continuous domain) demonstrating superior performances regarding stabilization of the RWP system with minimum settling times.
After a thorough literature review regarding the different approaches to the RWP dynamical system modeling and control, we identified a niche to occupy. Despite the wide variety of methods presented to date, strategies based on discrete-inverse optimal control are scarcely applied to model this sort of system [
10,
11,
12]. Therefore, it stands for the research gap this article tries to occupy.
To design a discrete inverse optimal controller via a CLF, it is required to obtain a discrete version of the dynamic model of the RWP system [
13]. Here, we use the forward difference method to obtain this discrete equivalent. In addition, it is worth mentioning that the proposed controller is based on the discrete control theory presented in [
11]. It is mandatory to have the discrete version of the studied plant for developing any simulation using the approach here proposed.
Regarding the design of the discrete inverse optimal controller, it is important to highlight that: (i) it is based on the discrete version of the classical optimal control theory that works with the discrete-time Hamilton–Jacobi–Bellman (DT-HJB) equivalent [
12], and (ii) the solution of this partial differential equation is referenced in the literature as the function value associated with a functional cost for some discrete dynamic system [
14]. Here, we use the DT-HJB solutions, which implies that this control law is optimal for the reaction wheel pendulum [
11].
The remainder of this study is organized as follows:
Section 2 presents the continuous dynamical formulation of the RWP and its discrete version using the backward difference method with discretization time
.
Section 3 presents the general theory about discrete-inverse optimal control designs via control Lyapunov functions; also, it is presented the proof of the exponential stabilization capabilities and optimality properties.
Section 4 presents all the numerical validations including parametric uncertainties, variations in the control gains, and comparisons with nonlinear classical methodologies developed in the continuous domain.
Section 5 presents the main conclusions derived from this research and some guidelines for possible future works.
2. Dynamical Modeling of the Reaction Wheel Pendulum
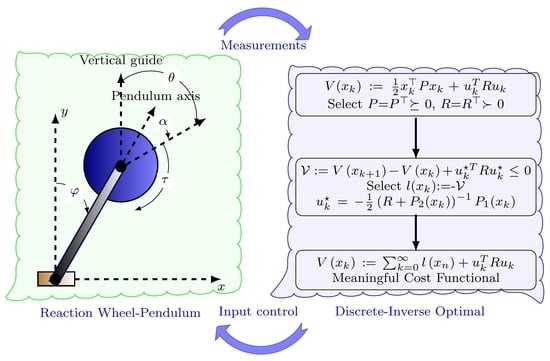
One of the most classical dynamical systems used in education is the RWP, since it allows verifying multiple linear and nonlinear control strategies that deal with nonlinearities caused by trigonometric relationships between the system variables [
10]. The dynamical structure of the RWP system emerges in different applications such as transportation systems, bridge crane models, synchronous machines used in power systems, among others. A schematic bi-dimensional representation of the RWP system is depicted in
Figure 1, where the main physical variables have been reported [
4,
15].
In the physical representation of the RWP system presented in
Figure 1, we can observe the following variables: the pendulum angle
(from the vertical axis) and the angle
between the pendulum and wheel, which are measured with sensors located at each of the axes of rotation. In addition, this system has a motor coupled to the opposite end of the pivot, acting on an inertia wheel, which allows controlling oscillations on it to the reaction torque
. The dynamic model of this system is derived as follows in the continuous-time domain.
2.1. Dynamical Model in the Continuous Domain
The first step in obtaining a discrete dynamical formulation of the RWP system corresponds to define its continuous formulation. For doing so, let us define an auxiliary variable named
. With this definition, the dynamical model of the RWP system is defined by (
1) as recommended in [
15].
where
a,
b, and
c represent positive constants related to the physical parameters of the system,
defines the angular position of the pendulum measured from the vertical axis, and
is the relative angle of the reaction wheel measured from the same vertical axis.
The control input
u couple the electric DC motor variables with the reaction wheel movement variables. Note that the control input represents the amount of voltage applied to the DC motor, which is traduced by the current flow into it to a mechanical torque applied directly to the reaction wheel [
8]. This torque moves the wheel, which in turn makes the pendulum bar moves from the initial point to the desired upright position [
13]. In addition, due to the structure of the nonlinear dynamical model (
1) the behavior of the variable
is wholly defined as the double integral of the control input
u. In addition, this variable does not affect the angular position of the pendulum directly since both Equations in (
1) are uncoupled. This situation allows ensuring that the dynamics of the angular speed
and the angular position of the reaction wheel, i.e.,
can be wholly known as follows:
Observe that if the control input is of class one, i.e., , and it is upper and lower bounded, then the angular speed of the reaction wheel, i.e., , will tend to zero when the angular position of the pendulum and its angular speed reach the equilibrium point.
Remark 1. Note when the angular speed of the reaction wheel goes to zero, this implies that the angular position of this wheel, i.e., θ, reaches a constant value, which corresponds to its equilibrium point, since from (1), we know that for , and , being k a real constant. It is worth mentioning that must be understood as the equilibrium point of the state variable x. From the transformation of the dynamical system (
1) to a state-space representation, we define the following state variables:
and
. Now, if these are substituted in (
1), then, the following second-order dynamical model yields:
Remark 2. The RWP system defined in (2) has two main equilibrium points, which have infinite repetitions. These two main points are P P and P P; which are cyclical each , being k a integer number. However, the main interest of controlling an RWP is to maintain its upright position from any initial position, i.e., to regulate all the state variables over P. 2.2. Dynamical Model in the Discrete Domain
The representation of the RWP system in the discrete domain is reached by using the classical forward difference, which allows knowing the next step, i.e.,
, as a function of the current information of the system [
16], i.e.,
. This forward difference takes the following form [
17,
18]:
where
represent the discretization time.
Note that if we apply the discretization defined in (
3) on (
2), then, we reach the following discrete model for the RWP system:
For the sake of compactness, the discrete dynamical model of the RWP model defined in (
4) is rewritten as follows:
where
corresponds to a vector of nonlinear functions of the state variables and
is known as the input matrix,
is the vector of all the state variables, and
in an
m-dimensional vector that contains all the control inputs. It is worth mentioning that in the case of the RWP system
and
, which implies that functions in (
5) take the following form:
To develop a discrete-inverse optimal controller via control Lyapunov functions, the compact structure of the RWP system defined in (
5) is considered as it will presented in the next section.
3. Discrete-Inverse Optimal Formulation via CLF
Using Lyapunov functions in control theory allows developing robust methodologies for controlling physical systems in continuous or discrete representations. The main advantage of using this approach is the global asymptotic stability performance under well-defined operative conditions of the system [
11]. Here, we employ the discrete-inverse optimal control theory to develop a nonlinear controller applicable to the RWP system with optimal and asymptotic properties [
19].
Definition 1. (Inverse optimal control law (taken from [
11])).
The following control lawwhere is a square matrix associated with the number of control inputs, and is the transpose operation applied on the input matrix is said inverse optimal if:- (i)
it allows achieving the global exponential stability of the equilibrium point for the discrete system (5), and - (ii)
it minimizes a cost functional defined as (8) with , being
Note that Definition 1 is based on the complete knowledge of the function
. Here, we employ a classical hyperparaboloid CLF with the structure presented in (
10).
where
P is a symmetric positive definite matrix with appropriate dimensions.
To obtain a general inverse optimal control law as defined in (
7), we can substitute (
10) into it, which yields:
where
I is an identity matrix with appropriate dimensions.
Now, if we define
and
, then, Equation (
11) generates the following inverse optimal control law:
where both parts of (
11) have been pre-multiplied by
R.
Remark 3. The existence of the inverse optimal control law is ensured due to the positive definite and symmetry properties of the matrix, which ensures the existence of the inverse in (12) [11]. 3.1. Global Stability Test
The inverse optimal control law (
12) guarantees the global stability behavior in the discrete-affine dynamic system (
5) if the following inequality constraint is held [
11]
for some
,
, being
, and
.
To verify that the condition (
13) is required, let us to recur to the definition of
in (
9) where we substitute
, which produces:
Note that if
P is selected such that
, then, the asymptotic stability is ensured around the equilibrium point
. Furthermore, through
P, we can achieve a desired negativity amount for the closed-loop function
in Expression (
14). Note that this desired negativity can be satisfied by defining a positive definite matrix
Q such that:
where
corresponds to any norm, for simplicity it could be Euclidean norm; and
defines the minimum eigenvalue of the matrix
Q; which implies that (
15) maintains the condition (
13).
Now, if we compare (
14) and (
15), then,
Remark 4. Due to being a radially unbounded function, then, the solution of the discrete-affine system (5) with (12) is global exponentially stable according to [19,20]. 3.2. Optimality Test
To demonstrate that the discrete-inverse control law
defined in (
7) is optimal, let us consider the function
as follows:
where
is the solution of the DT-HJB equation, i.e.,
To obtain the optimal value for the cost functional defined in (
8), let us substitute (
17) on it as follows:
To simplify Expression (
18), we recur to an identity matrix with the form
, which allows rewriting it as presented below.
Now, from (
12) we know that
, which implies that (
19) can take the following form:
Remembering the definitions of
,
, and
, we can simplify (
20) as presented below.
Note that if the upper bound of the sum is defined as
N, then, we obtain from (
22) the following result:
where we can observe that
when
due the global exponential convergence presented in the previous section; this implies that Expression (
22) can be written as follows:
Remark 5. From (23), it is possible to conclude that the maximum value is reached when , which implies that the control law (12) is indeed optimal, since it minimizes the cost functional (8), where the optimal solution is:for all . 4. Numerical Validations
To demonstrate the effectiveness and robustness of the proposed discrete-inverse optimal control design via control Lyapunov functions, we consider that the dynamical model (
5) has the following constants:
and
, these values were taken from [
7]. It is important to mention that as recommended in [
21], the magnitude of the control function, i.e.,
, can be at most 10. Note that the control gains inside of the
P matrix have been defined using a heuristic search based on multiple simulations as follows:
4.1. Evaluation of the Controller for Different Values of the R Gain
The effectiveness of the proposed controller is tested considering the aforementioned parameters; also, the simulation was run for some values of gain
R in the interval between
and
in steps of
(this interval is selected based on heuristic evaluations using multiple intervals of analysis. However, these values enclosed most of the possible behaviors reached by the proposed controller when applied to the RWP system.). In this case the initial conditions are
. Note that these initial guesses have been selected based on the physical recommendations for the RWP system provided in reference [
21], where these can avoid over-saturation events in the control input.
Figure 2 reports the behavior of the angular position of the pendulum bar, its velocity, and the control input. From these results, we can observe that:
- ✓
The gain
R highly influences the behavior of the angular position of the RWP system depicted in
Figure 2a, since small values of this allows reaching the desired operational point about in 375 samples, (i.e., 375 ms) (see curves for
and
); however, when this parameter increases then the system exhibits oscillations around the desired point and the settling time is between 400 ms and 700 ms.
- ✓
The angular speed of the pendulum bar depicted in
Figure 2b presents a negative acceleration between the interval from 0 ms to 300 ms. However, when the concave form of the angular position changes to a convex one, this velocity is reduced from its negative maximum to zero. In addition, the figure shows the overpass in the angular position due to the effects produced on this by the
R gain.
- ✓
For small values of the
R gain, it is possible to observe two main saturations of the control gain about 10 and
(see
Figure 2). These saturations imply that the motor, coupled with the reaction wheel, is accelerated to its maximum values to reach the desired operative point in minimum settling times. When the
R gain increases, it is possible to observe that the second saturation disappears which enlarge the settling times of the state variables, due to the acceleration of the motor is not at its maximums.
Figure 3 presents the phase-portrait of the state variables and the evaluation of the Lyapunov function, which have been normalized with the maximum of the cost functional given by
. From
Figure 3, we can observe that: (i) the phase portrait of the state variables show that for all the tested values of the
R gain, the system is global exponentially stabilized via discrete-inverse optimal control based on a CLF design (see
Figure 3a); and (ii) the Lyapunov function presented in
Figure 3b confirms that the selected gains in the control matrix
P generate a positive definite matrix, which makes that the Lyapunov function is always positive or zero. Additionally, it is confirmed that for
samples, the final value of this function is zero, which implies that the cost functional is maximum as demonstrated in (
23).
4.2. Performance under Parametric Variations
To demonstrate that the proposed discrete-inverse optimal controller via CLF design is efficient under parametric variations, we evaluate variations in the a and b parameters from to of its rate values in steps of . In this simulation is assumed that the R gain is settled as 1. Note that in this simulation case, the controller has been settling with the parameters a and b at their nominal values, i.e., of these.
Results in
Figure 4 confirm that the proposed discrete-inverse optimal controller allows reaching global asymptotic stability in the angular position of the pendulum bar independent on the parametric variations of the constants
a and
b. However, for values lower than the
of these, the settling time increases, while for values larger than this bound, this time is reduced. This situation is attributable to the multiplication effect that has the gain
b regarding the control input, as can be seen in the discrete model (
4), which can attenuate or increment the effect of the control input in the closed-loop dynamics of the RWP system.
4.3. Comparison with Nonlinear Controllers
Here, the proposed inverse optimal control via CLF is compared with a nonlinear controller based on a direct Lyapunov control proposed in [
4], the structure of this control law is presented below
being
and
defined as 3500 and 135, respectively. In addition, the proposed inverse optimal control is also compared with a nonlinear passivity-based controller proposed in [
5], which has the following control law
being
,
and
, which are selected to make it comparative with the Lyapunov-based design.
It is important to mention that all the three controllers defined in (
12), (
24), and (
25) are based on Lyapunov stability theory, which implies that all of them have global asymptotic stability properties for the closed-loop operation. In addition, it is possible to observe that all of them have a very similar control law, which is composed of linear feedback of the states
and
and the nonlinear effect of the sinusoidal function weighted by a constant [
22].
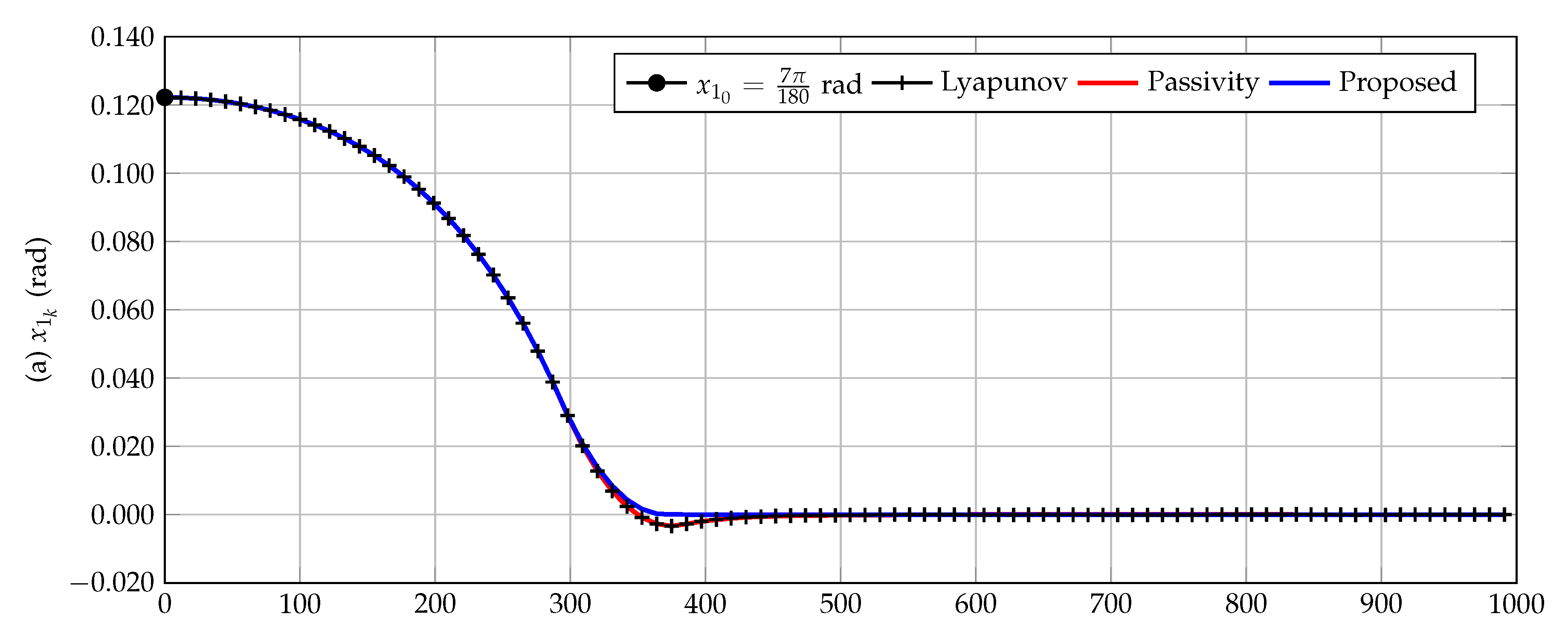
In
Figure 5 is presented the comparison between the proposed inverse optimal controller and the Lyapunov-based design and the passivity-based approach reported in [
4,
5], respectively.
From
Figure 5, we can state that the Lyapunov-based and the passivity-based approaches have the same numerical performances since the angular position are overlapped for both controllers. Furthermore, these controllers take about 470 ms to establish around the reference. In comparison, the proposed inverse optimal control approach outperforms all its counterparts reaching the reference signal in about 370 ms. It is worthy to mention that the comparative approaches present an overpass to the reference signal. This implies that some oscillations in the vertical position are experienced. Simultaneously, the proposed method does not present this behavior, which confirms its efficiency in contrast to powerful and well-known nonlinear approaches.
5. Conclusions and Future Works
This research addressed the global stabilization of a reaction wheel pendulum using the discrete-affine dynamical model with two state variables via control Lyapunov functions. The main advantages of the proposed control design are the following:
The feedback control law guarantees an exponential an asymptotically stable behavior with capabilities of working under parametric uncertainties without compromising the convergence to the equilibrium point in settling times lower than 700 ms.
The control function is is indeed an optimal signal since it minimizes the cost function and make it to reach the global optimum value of the cost functional at with settling times between 370 ms and 700 ms.
Comparing the proposed controller with classical nonlinear controllers has demonstrated that the studied discrete inverse optimal controller via control Lyapunov functions can achieve global stabilization of the RWP system with exponential convergence. This is an advantage regarding classical passivity-based and Lyapunov-based depending on selecting the R gains and the values of the P matrix. Hence, it is possible to reach the equilibrium point with lower settling times.
As future works, the following developments could be considered: (i) to extend the formulation of the discrete-inverse optimal control via control Lyapunov functions to power electronic converters to integrate renewables and battery energy storage systems, and (ii) to apply the proposed controller to reduce frequency oscillations in power systems by improving controllers in synchronous machines.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




