3.1. Network Storage Data Acquisition
The network crawler is applied to the network storage data crawling, and thus to provide support for the data integrity detection. As a complete automatic image annotation system, it is necessary to use the crawler technology to automatically obtain the network image and build an image annotation database. On this basis, the web crawler technology is used to capture the image and related text information.
Web crawler design:
The main function of web crawler is to obtain the network data. It mainly uses the hypertext link in web page to roam, find, and collect information in the Internet, so as to provide the data source for the next stage of information extraction, organization, and management. Generally, the crawler starts from an initial URL set and uses some search strategy to traverse the web page and download various data resources along the URL of hypertext link, such as breadth-first strategy, depth-first strategy.
The web crawler system will maintain a URL table, including some original URLs. Based on these URLs, Robot downloads the corresponding pages and extracts new URLs from them and then adds them to the URL table. After that, Robot repeats the above process until the URL queue is empty.
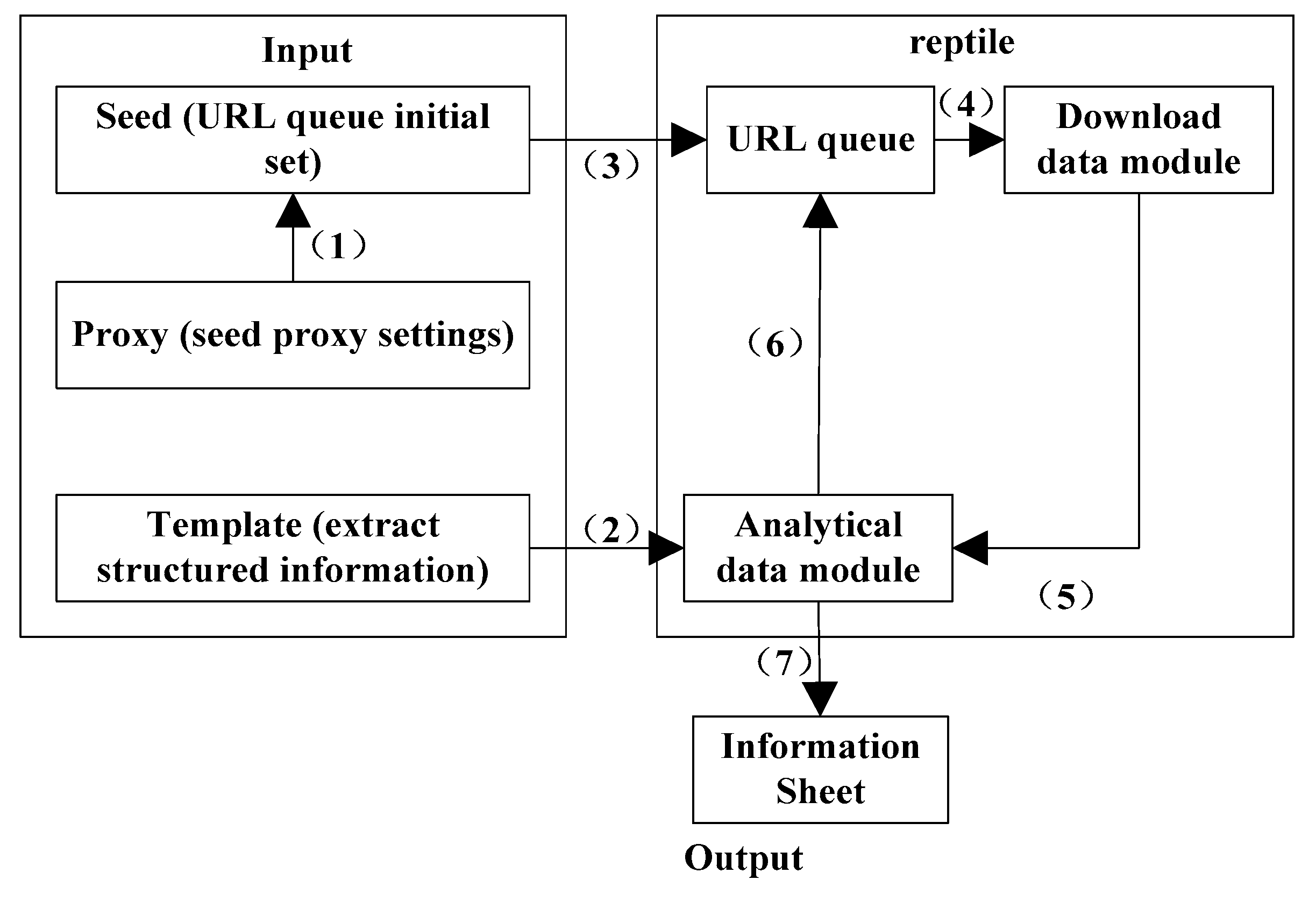
On this basis, the basic framework of web crawler is shown in
Figure 1 (source: author own conception, adapted from Wu Libing):
The working process of crawler is as follows:
Import the seed (the initial URL list) and import the agent. Import templates (regular expressions constructed by different web features). The agent is corresponded to the seed URL, and the seed is put into the crawling queue as the initial set of URL queue. Take the waiting URL from the queue, and then enter the crawling state. After that, the web source file corresponding to the URL is downloaded. Transfer the regular expression in the template object array and the downloaded web page source file into the web page analysis module for matching, so that the structured information can be obtained. The important links contained in the structured information, such as URL of the next page of post list and URL of the post, which continues to be put into the URL queue and waits for crawling. Information required by other users in structured information, such as post name, post sender, reply number, and reply content are stored in the information table.
Extraction of image and related text:
Through the research on the page, the text information related to the image mainly includes:
(1) The texts around the image in page, most of them are too long, including a lot of semantic information. During the page analysis, they are mostly related to the page structure, such as the adjacent texts in the same row or column of the table. When an image exists as an illustration, the surrounding words have limited contribution to the annotation on the image.
(2) File name, title, or description information of image are usually concise phrases or words, which have strong generalization ability.
(3) The title of the image link page. The content of image web page is highly relative to image, and some titles which are used to generalize the content of hyperlink web page. Meanwhile, they also have something to do with image semantics.
The image semantics mainly comes from the analysis of related text. Firstly, Chinese characters and English existing in related text are translated into Chinese, and then the automatic word segmentation and the part of speech tagging are carried out.
When the system receives a large amount of text information through the crawler program, the following problem is how to extract the keywords from documents. One of the obvious differences between Chinese and English is that in Chinese text, there is no obvious natural separator between Chinese characters or vocabularies. Meanwhile, the number of Chinese words is uncertain, and the collocation is flexible, and the semantics is diverse. Most of them are composed of two or more Chinese characters, and the writing is continuous, which brings more difficulties for Chinese understanding and keyword extraction.
Generally, users may retrieve in the form of words or single character when querying, so the system should label images with shorter words or single character as much as possible. When the annotation platform receives various long texts, it is necessary to divide the whole sentence into smaller vocabulary units at first, and then process them through the keyword selection module [
8].
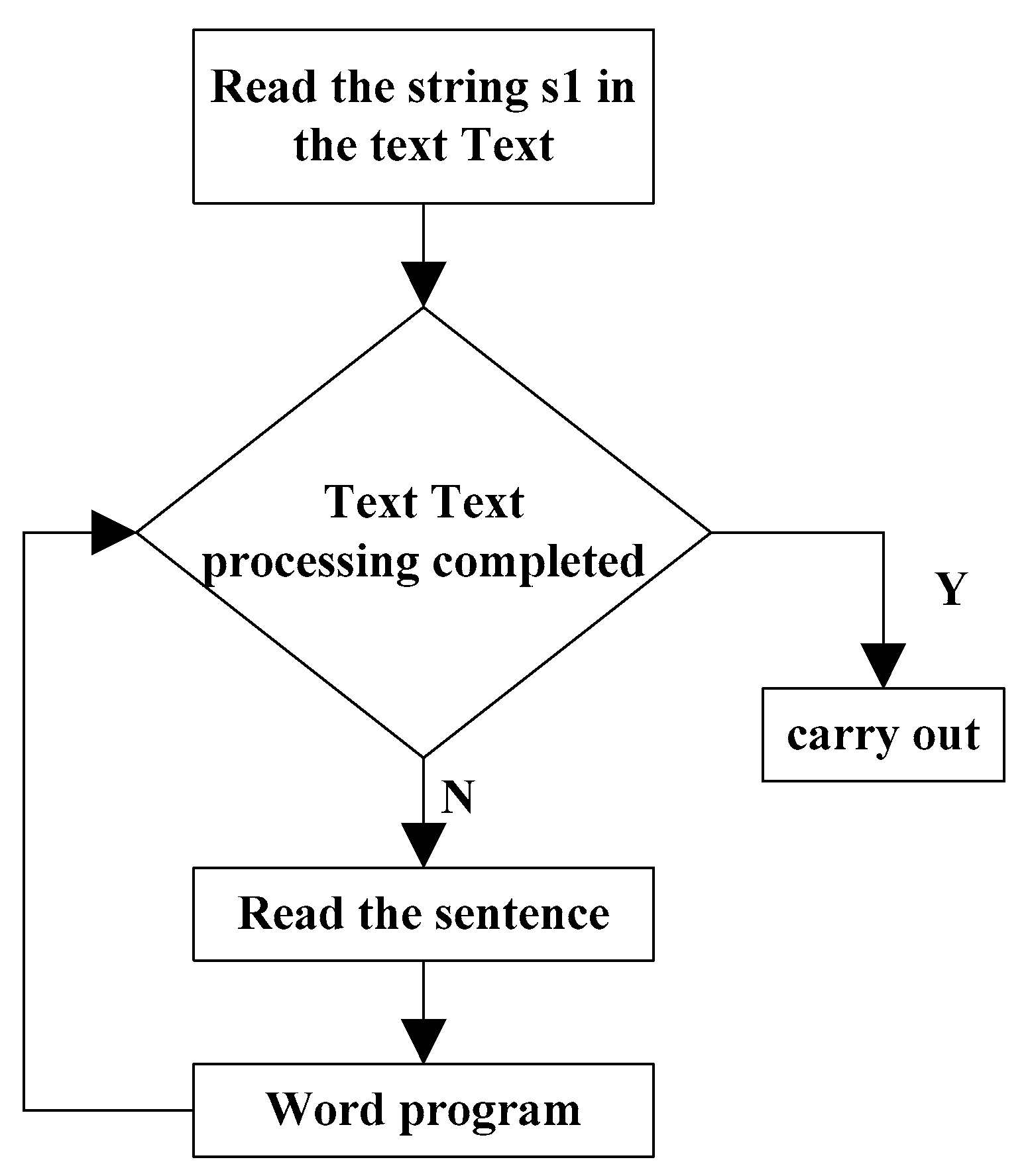
In Chinese word segmentation, it is necessary to consider the complexity of time on the premise of accuracy [
9]. A simple way is the maximum matching method of positive word subtraction. The basic thought is to build a dictionary in advance, and then extract a preset length word string from the long sentences of natural language, and compare it with the dictionary. If the string belongs to the dictionary, it will be regarded as a meaningful word string. Then, the separator is used to split it and output it. Otherwise, it is necessary to shorten the word string and search again in the dictionary. Finally, we should move backward and repeat the above steps. The basic description of this algorithm is shown in
Figure 2 (source: author own conception, adapted from Wang Ruilei).
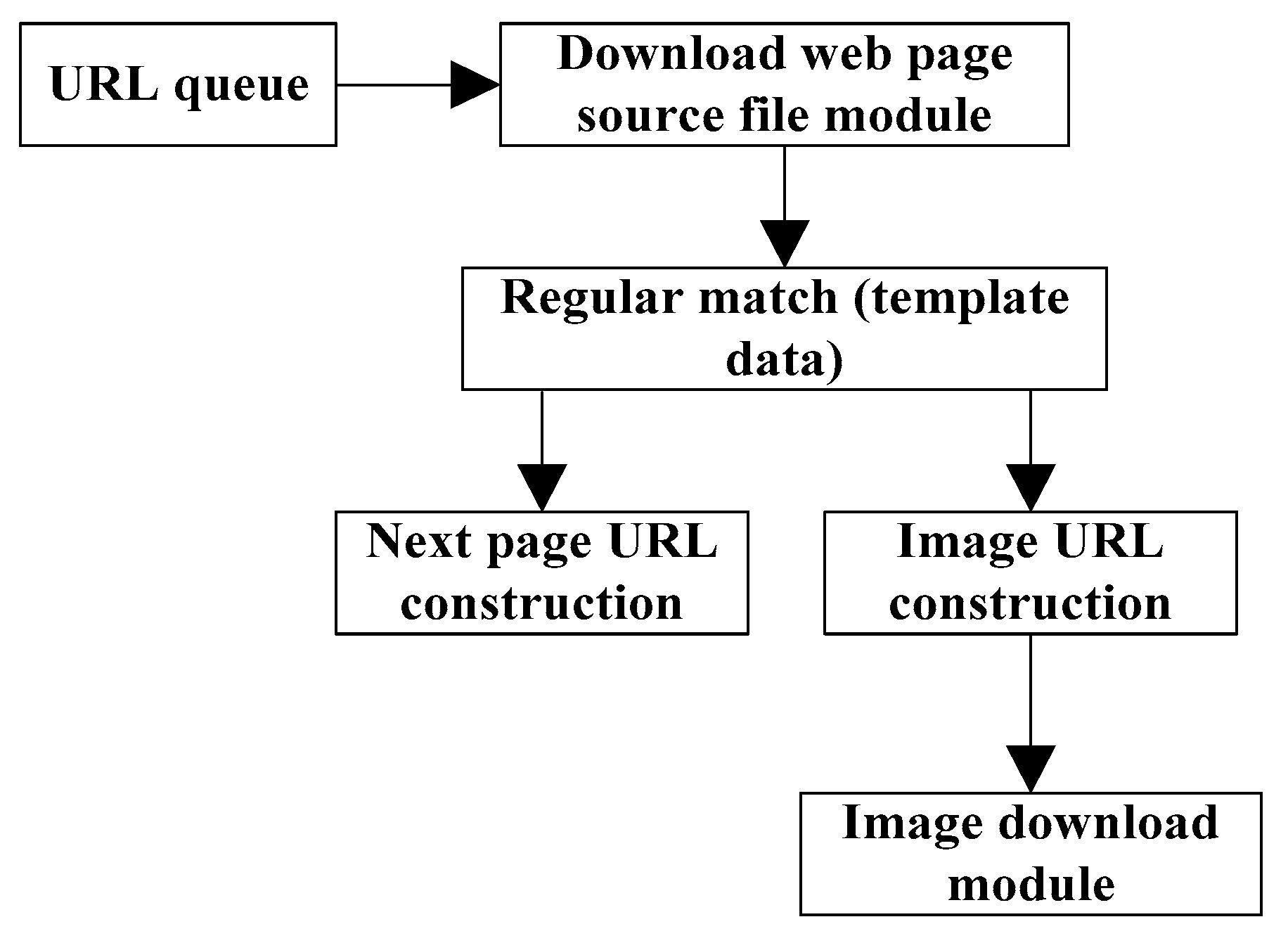
With the distributed crawler as the core, an automatic image download program is implemented, and the main flow chart is shown in
Figure 3. It mainly includes the web source file downloading module, regular matching module, next page URL construction and image URL construction module, and image download module whose entry parameter is image URL.
3.2. Data Feature Extraction Based on Symmetrical Difference
In the above process of data acquisition, the automatic word segmentation and pos tagging, Chinese word segmentation are used to achieve the feature analysis of the text data. Then, the symmetrical difference algorithm is taken as the main method and background subtraction is taken as the auxiliary method, so that the image data feature extraction and preliminary recognition of data integrity are achieved. Thus, the precision rate of data integrity detection is improved.
The symmetrical difference algorithm can remove the influence of the background revealed by the motion and draw the contour of the moving object accurately [
10,
11]. The basic algorithm is as follows: the source images of three consecutive frames in video sequence are
,
and
. The absolute difference gray-scale images of two adjacent source images are calculated respectively, namely
and
.
where,
is a window function to suppress noise. Because the mean filtering will blur the image, leading to the loss of edge information, the median filtering function with 3 × 3 window is chosen to suppress the noise.
The binary images
and
are obtained by calculating threshold values of
and
respectively. The binary image
of symmetrical difference result is obtained by logic operation of
and
at each pixel position. The formula is
The basic idea of background subtraction is to subtract the current image from the background image stored in advance or real-time background image. The pixel point whose difference is greater than a certain threshold value is regarded as the point on the moving target. Otherwise, it is considered as the background point, which is very suitable for detecting the moving target when the background image changes less with time. By comparing the difference of gray values between the current source image
and background image
, the foreground image
can be obtained. The formula is
where,
denotes the threshold value.
The ideal background is obtained on the basis of the given frame image, in which denotes the image splice operator and denotes the common background of frame and frame .
Formula (4) is used to judge the attribution of sub block
,
The moving object detection algorithm based on background subtraction and symmetrical difference can accurately extract and update the background model when the image has several moving targets.
3.3. Data Integrity Detection and Accountability Mechanism
Based on the data collection and feature extraction above, the random sentry data segment is introduced to achieve the final data integrity detection. Combined with the accountability scheme of data security of the trusted third party, the trusted third party was taken as the core. The online state judgment was made for each user operation. Meanwhile, credentials that cannot be denied by both parties were generated, so as to ensure the reliability of audit and accountability of trusted third party when the cloud is not trusted. In addition, it is able to prevent the verifier from providing the false verification results.
This scheme randomly selects the sentry data segment to detect the data integrity. Because the sentry data segment contains the selected sentry information, the effective data and other sentry data, this scheme can support the detector to carry out infinite detection, and thus to improve the data integrity detection and recall rate. It is not necessary to worry about the sentry leakage caused by multiple tests.
Next, the scheme flow is introduced according to the data preprocessing stage, the challenge initiation stage and the detection and verification stage.
3.3.1. Data Preprocessing Stage
The original data blocking: firstly, the network storage user runs the key generation formula: . Secondly, the public key and private key held by the user are generated, and the private key is saved as a secret pair. After that, the user uses the public key to encrypt the original data file: . Then, the file block algorithm is carried out, . is divided into blocks. The sizes of blocks are the same. Finally, each data block in set is divided into blocks: . Finally, the data block matrix consisting of vectors is obtained: .
Erasure code: the network storage user performs the erasure code on the obtained data matrix,
. The vandermonde matrix
of erasure correction code is a matrix with
rows and
columns,
. Its model is shown in Formula (5)
In fact, data matrix
is obtained by
matrix multiplications, that is to say, each data block set
is multiplied by the vandermonde matrix
of erasure correction code in the form of vector, and then these products constitute the data matrix.
According to the vandermonde matrix with rows and columns, we can see that there are redundant data blocks in this error correction code. In other words, for data vector , when the maximum loss is data blocks, the entire data vector can be recovered completely.
Sentry position generation: after the data matrix is generated, the network storage user sets the number of sentries which need to be placed in each data block, . Meanwhile, the user uses the sentry insertion position generation algorithm to calculate the position array. denotes the position of the th sentry which needs to be inserted into the data block. denotes the data block after inserting the sentry data. represents the bit length of after inserting the sentry data. represents the bit length of each sentry. Thus, the proportion of the actual effective data in data block to the total storage data is .
The generation algorithm
of sentry insertion position is to select the random number to hash the bit length of
, namely
. The function
denotes the random number generated by
.
denotes the unique ID of network storage user.
is the hash function, and
. Because
is generated by random number, it is necessary to reorder the set of sentry positions from big to small. Finally, the orderly sequence of sentry insertion positions can be obtained [
12,
13].
Sentry data generation: network storage user uses the array of orderly sentry insertion position and preset length of sentry to calculate sentry at position :.
The sentry generation algorithm is defined as the binary 0/1 string -bit data with the result . At this stage, network storage user needs to take and as secrets and then save them locally. In addition, they are not disclosed to any other party in the data preprocessing stage.
Sentry insertion: after the network storage user generates the sentry, the sentry insertion algorithm is used to insert the sentry set
into the data block
:
When calculating the position of sentry , we do not consider that the insertion of previous will affect the change of sentry position behind. When is implemented, it is necessary to move the original position back positions of . After transformation, we will insert into the data block matrix to generate the final confusion data matrix , and then upload the data matrix to the network server.
Upload parameter to trusted third party: the network cloud storage user uses the public key of trusted third party to encrypt the parameters which are used in the data pre-processing stage, . After that, we can store them in the trusted third party. In the subsequent data integrity detection, the network storage user authorization can directly use the private key to decrypt . According to the calculated parameters, the challenge can be sent to the cloud.
3.3.2. Start Challenge
Cloud storage users put forward detection request. When cloud storage users need to detect the integrity of data files stored in cloud server, they will send a detection request to the trusted third party, and then the trusted third party will perform the data integrity detection instead of users.
Detection parameter analysis: after receiving the detection request from the user, the trusted third party checks the user rights at first, so as to judge whether the user has the read permission for the data file. If the applicant has the read permission, the trusted third party uses
to decrypt the pre-processing parameter set
to get
. The random generation algorithm
is performed. Where,
is the number of rows and
is the number of columns of matrix
.
denotes the number of data blocks
that the trusted third-party plans to detect. According to the detection intensity and detection environment,
can be determined by the trusted third party. If the trusted third party wants to conduct comprehensive data integrity detection,
can be bigger at this time. If the trusted third party wants to conduct periodic data integrity detection, the value of
can be moderate at this time. If the current network fluctuates greatly or the soft and hard environment is lack, the value of
can be reduced [
14,
15].
The output of algorithm denotes the subscript of the selected detection data block. Then, the trusted third party uses the array and algorithm to generate sentry positions of data blocks . Finally, the algorithm is used to calculate the real positions of sentries in data block .
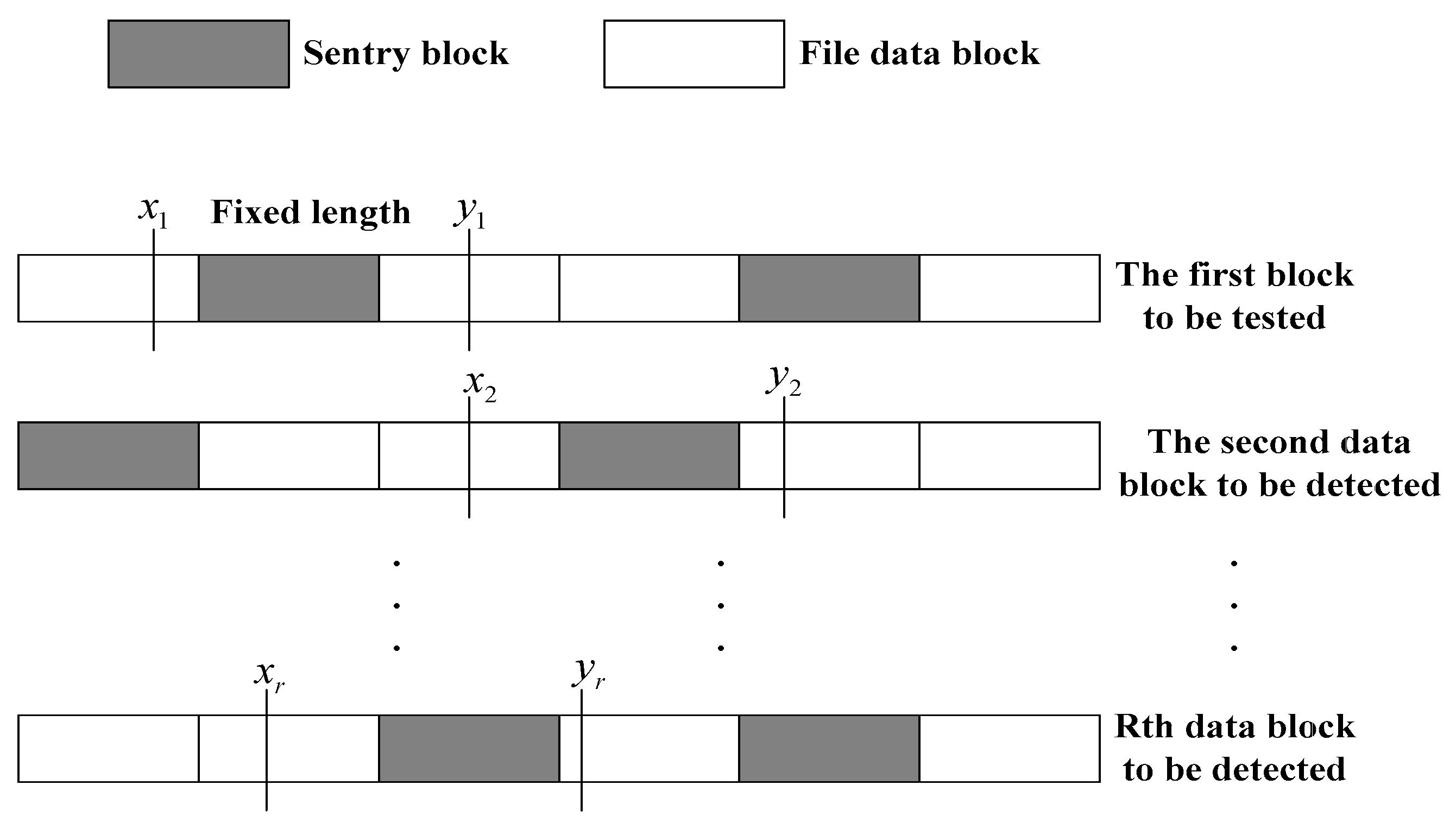
The generation of detection interval: the trusted third party uses the form of selecting data interval to determine the data range. That is to say, the data interval
is selected from data block
for final detection of data integrity. The data block
corresponds to an interval, and the lengths of
intervals
are the same, but their positions are different in corresponding
(see
Figure 4).
The selection of interval length
is similar to the selection condition of the number
of detection data block
, which can be determined by the trusted third party through the detection intensity and detection environment. Meanwhile, the minimum length of interval
should be bigger than the length of
. Because
,
must be bigger than the position length
of sentry. That is to say, the detection interval range must be bigger than the length of sentry, so that the reliability of data integrity detection can be guaranteed, and thus avoiding the sentry leakage caused by multiple detection [
16,
17,
18].
In order to ensure that the data interval
contains the sentry information, the trusted third party randomly selects
random numbers
from the integer interval
, and then extracts the sentry position
of corresponding random number
from the sentry position set
of data block
corresponding to
. That is the aggregation
. See
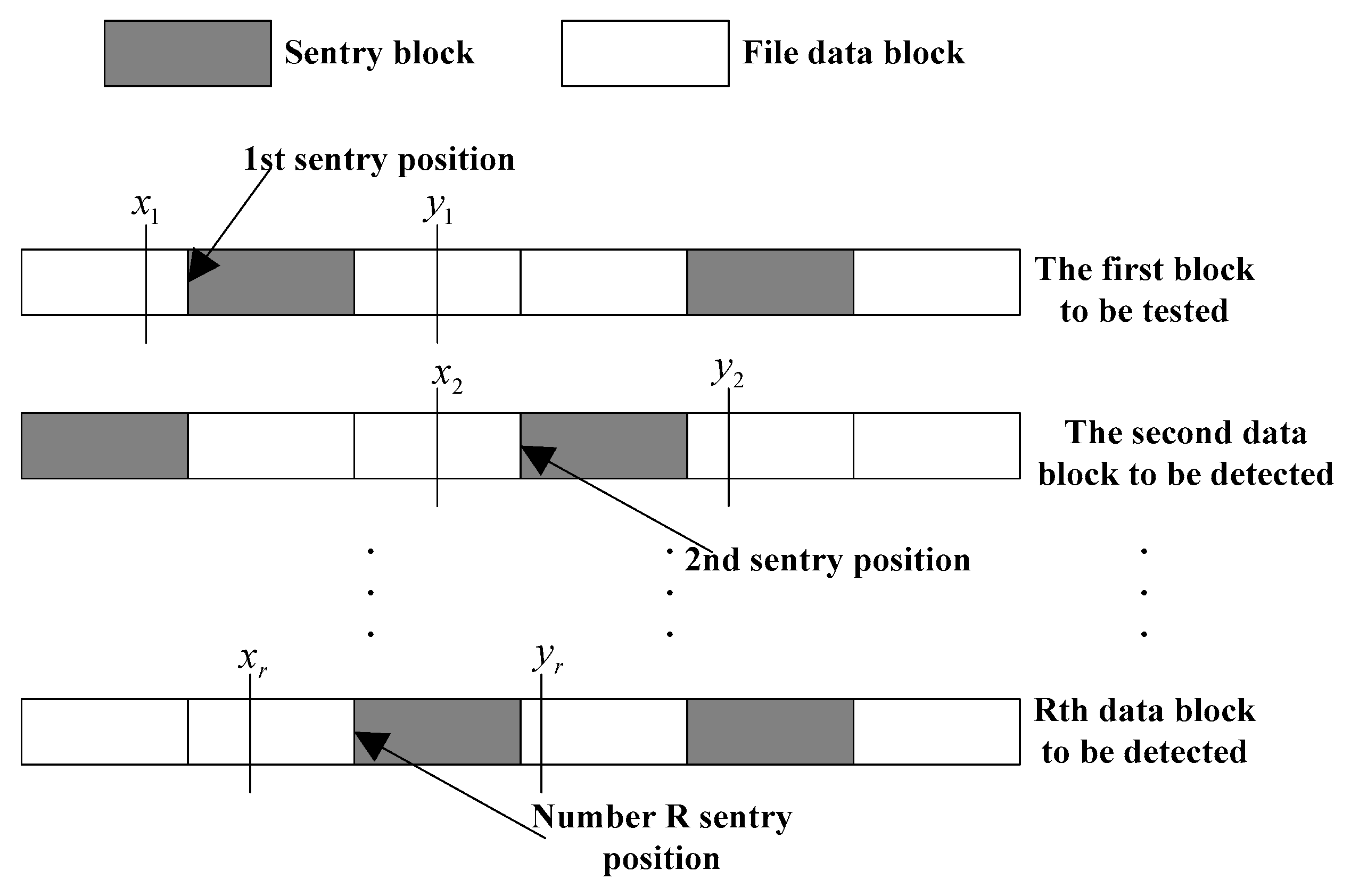
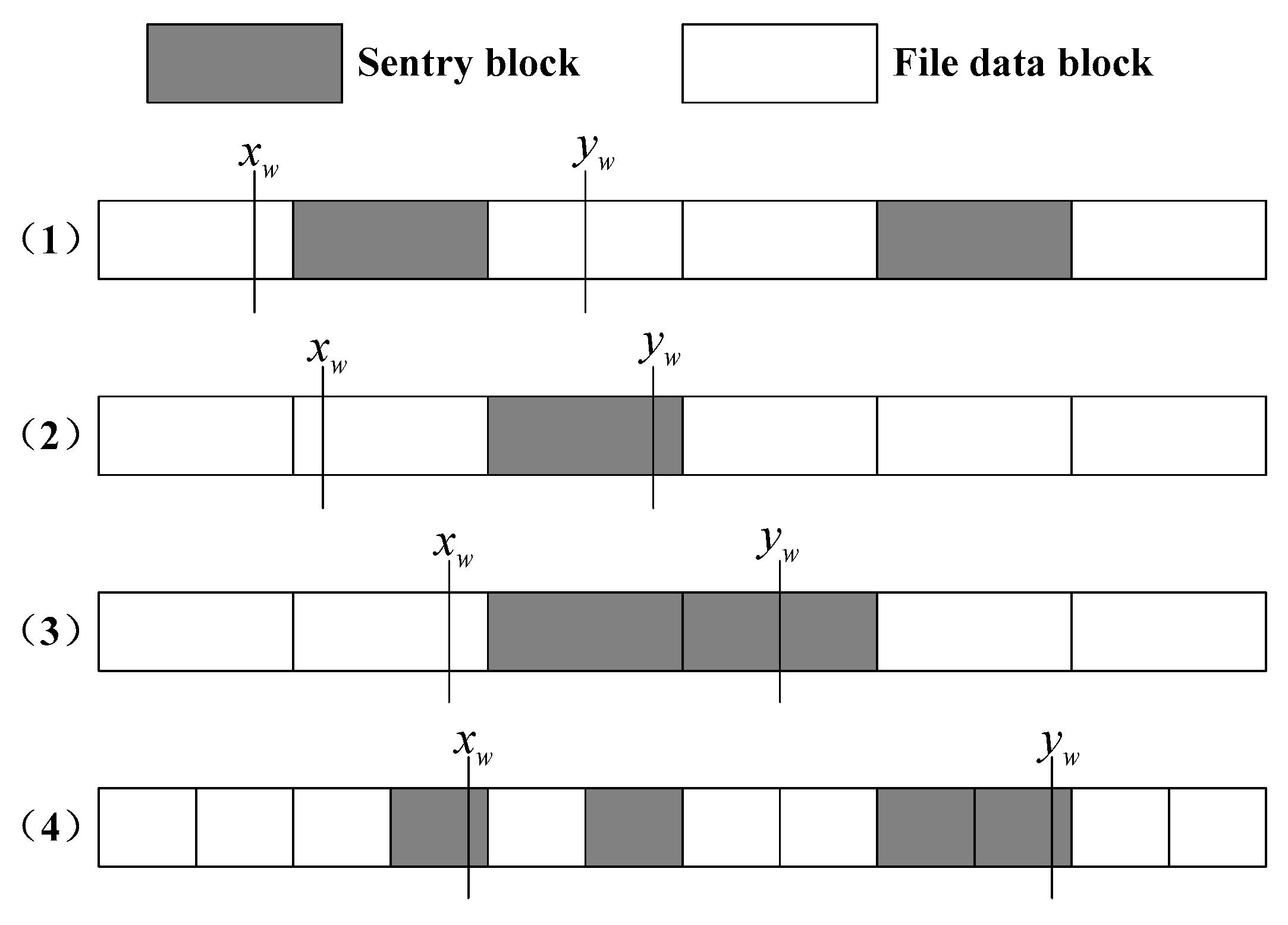
Figure 5:
The length of detection interval the trusted third party is set as . In order to put the sentry corresponding to the set in the detection interval , the distance between and the left vertex of interval is defined. denotes the basic threshold which is randomly generated at . If is close to 1, the probability that the length of is close to . is far away from the left vertex of interval with the increase of , and the probability that sentry in the interval is incomplete.
In the detection interval
of data block
, the sentry
is uncertain, so the number of sentries in an interval may be uncertain. A small number of sentries may only be included in some information [
19,
20]. The situation of sentry in interval is shown in
Figure 6. (1) shows that sentry
is located in the interval
completely, namely
. (2) shows that only partial data of sentry
is located in the interval
, namely
. Due to the uncertainty of the length
of interval, this interval may include several sentries of position
in addition to sentry
, which is shown in (3) and (4) of
Figure 6.
Start challenge request: the trusted third party encrypts the array of the serial number of detected data block and the array which is composed of detection interval corresponding to serial number through the cloud public key and then sends them to the remote server as the challenge request .
3.3.3. Detection and Verification Stage
Evidence generation: after receiving the challenge request , the server uses the private key to decrypt , then uses the decrypted and to perform the evidence generation algorithm , so as to output the credentials which is used to submit the trusted third party for data integrity detection. Finally, the public key of trusted third party is used to encrypt and return it to the trusted third party.
Evidence verification: after receiving the detection credentials sent from the cloud, the trusted third party uses the evidence validation algorithm to judge whether the data file is complete. The detailed process is as follows: the trusted third party locates the sentry positions included in the detection interval according to the sentry position array of data block , namely . Then, the trusted third party calculates the detailed information of sentry by the sentry generation algorithm . By comparing with the corresponding position in detection evidence , we can see that only partial data appears in the sentry of detection area. If data segments in are compared, it means that the data has not been modified or damaged in this time. Otherwise, it means that the data stored in remote server is incomplete. Finally, the trusted third party submits the data integrity detection result to cloud storage user.
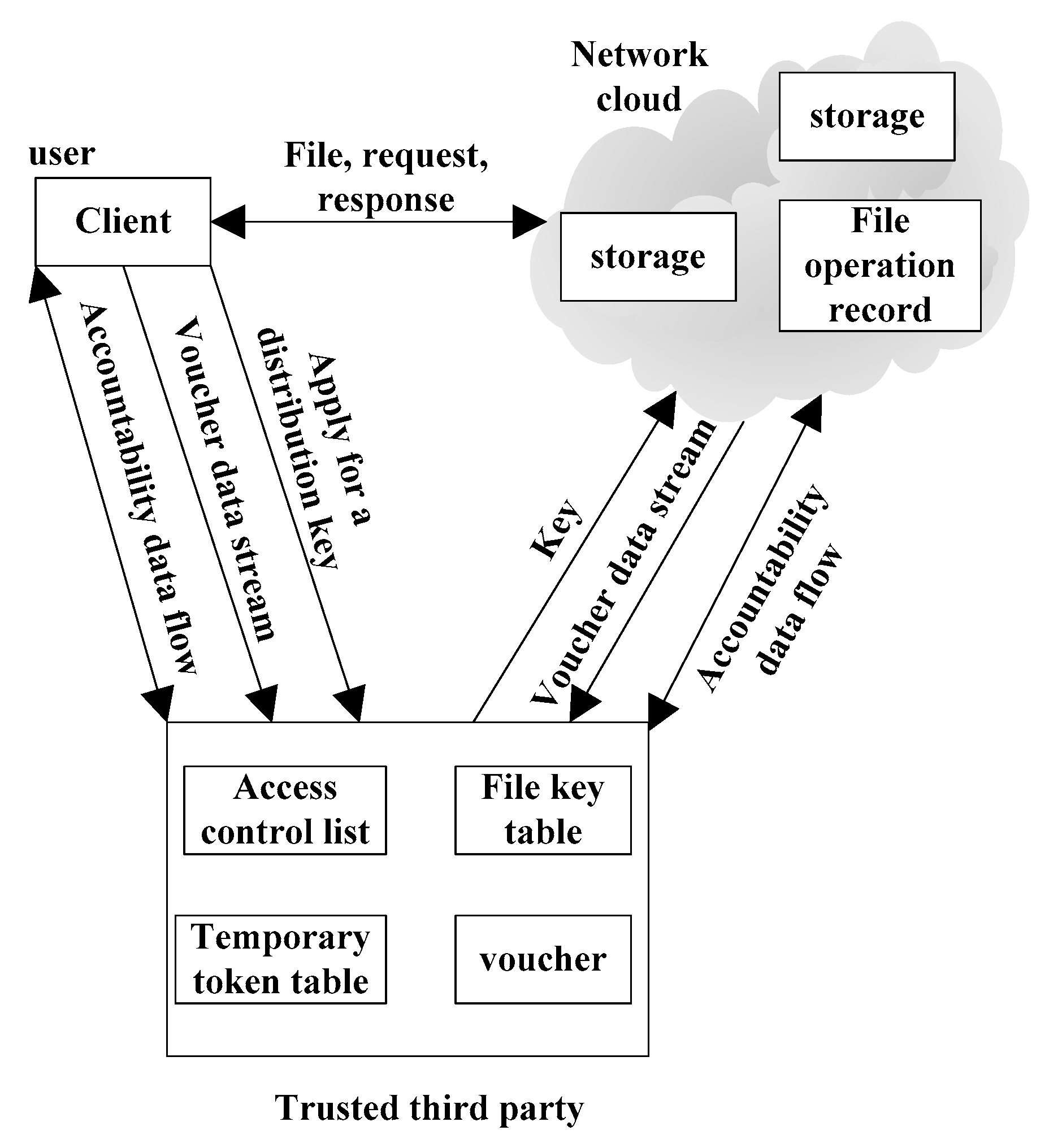
(4) Data security accountability based on trusted third party
With the popularization and development of cloud storage, people pay more and more attention to the security of cloud data. When the data stored in the cloud is illegally modified, neither the user nor the cloud can provide cogent credentials to divide the responsibility. Therefore, a data security accountability scheme based on trusted third party. This scheme takes the trusted third party as the core and carries out the online status judgment in each user operation, and then the credentials that cannot be denied by both parties are generated, so as to ensure the reliability of the audit and accountability of trusted third party when the cloud is not trusted.
A credible third-party accountability system needs to provide the following functions:
Any operation on cloud data is recorded in trusted third party and cloud;
When disputes occur, the trusted third party can accurately find the responsible party and determine the responsibility;
The certificate that is used to judge the responsible party has non repudiation.
Figure 7 is the framework of data security accountability based on trusted third party
In
Figure 7, the user operates the cloud files through the browser or other clients. When the users log in to the cloud through the browser or other clients in each time, they can get a temporary token from the trusted third party. The file key version is formed after each user operation. When the user and the cloud operate the data, the accountability voucher will be generated and saved in the table of trusted third-party voucher. When the accountability is proposed or some disputes between the two parties occur, the trusted third party can judge the responsibility based on the clouding file operation records and local vouchers.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










