Designing a Supermarket Service Robot Based on Deep Convolutional Neural Networks


Abstract
:1. Introduction
- (1)
- We develop a supermarket service robot on the basis of DCNNs, in which hardware and software systems are designed. In order to verify the working stability of the robot, a supermarket simulation environment is built, and two working modes of automatic commodity procurement and replenishment are verified.
- (2)
- We develop a small-scale image dataset containing 12 supermarket commodities, and compare three different methods for commodities detection and recognition with the designed supermarket service robot. Experiment results demonstrate the effectiveness of the proposed method.
2. Our Method
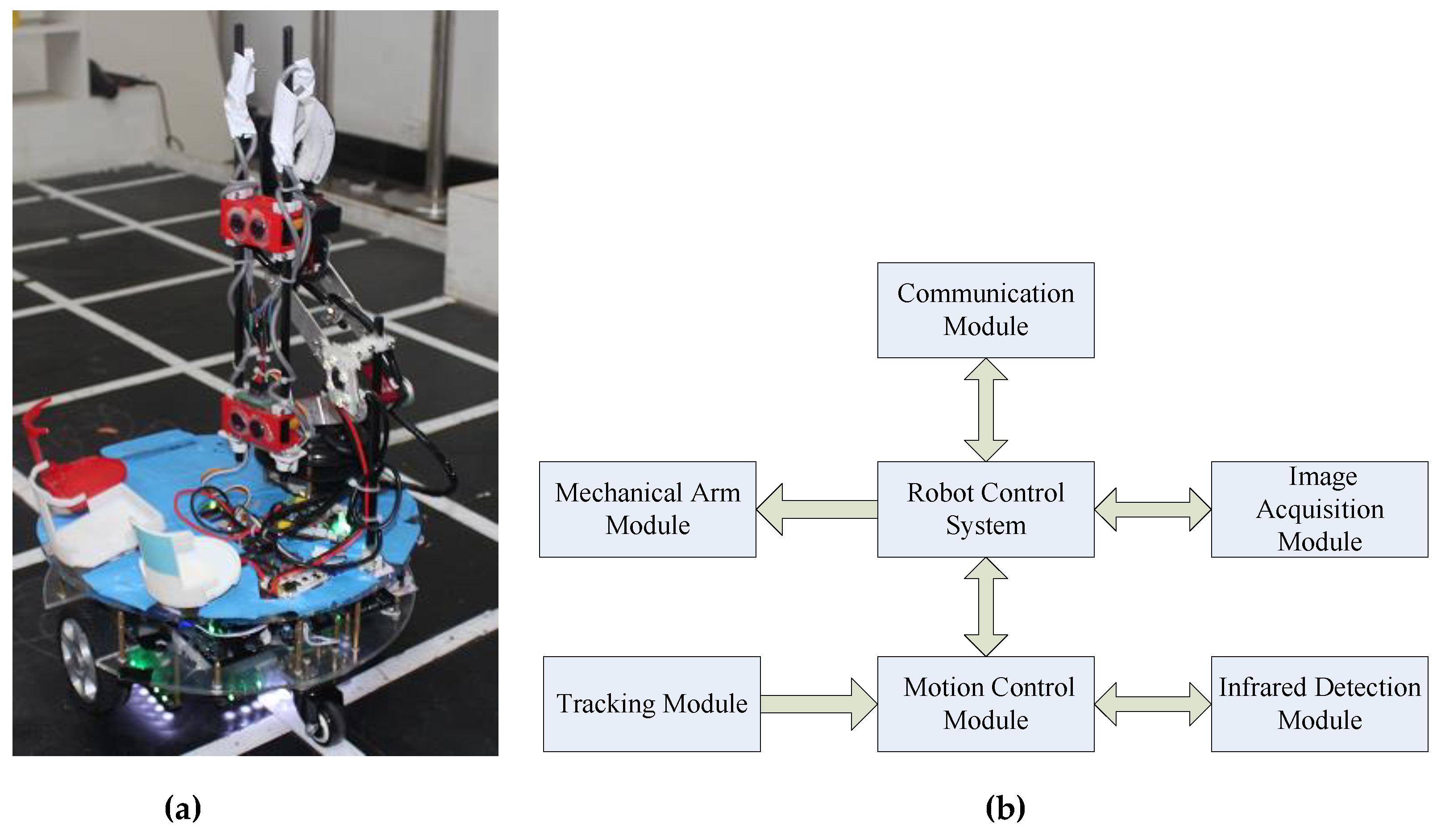
2.1. Robot Hardware System
2.1.1. The Hardware Framework
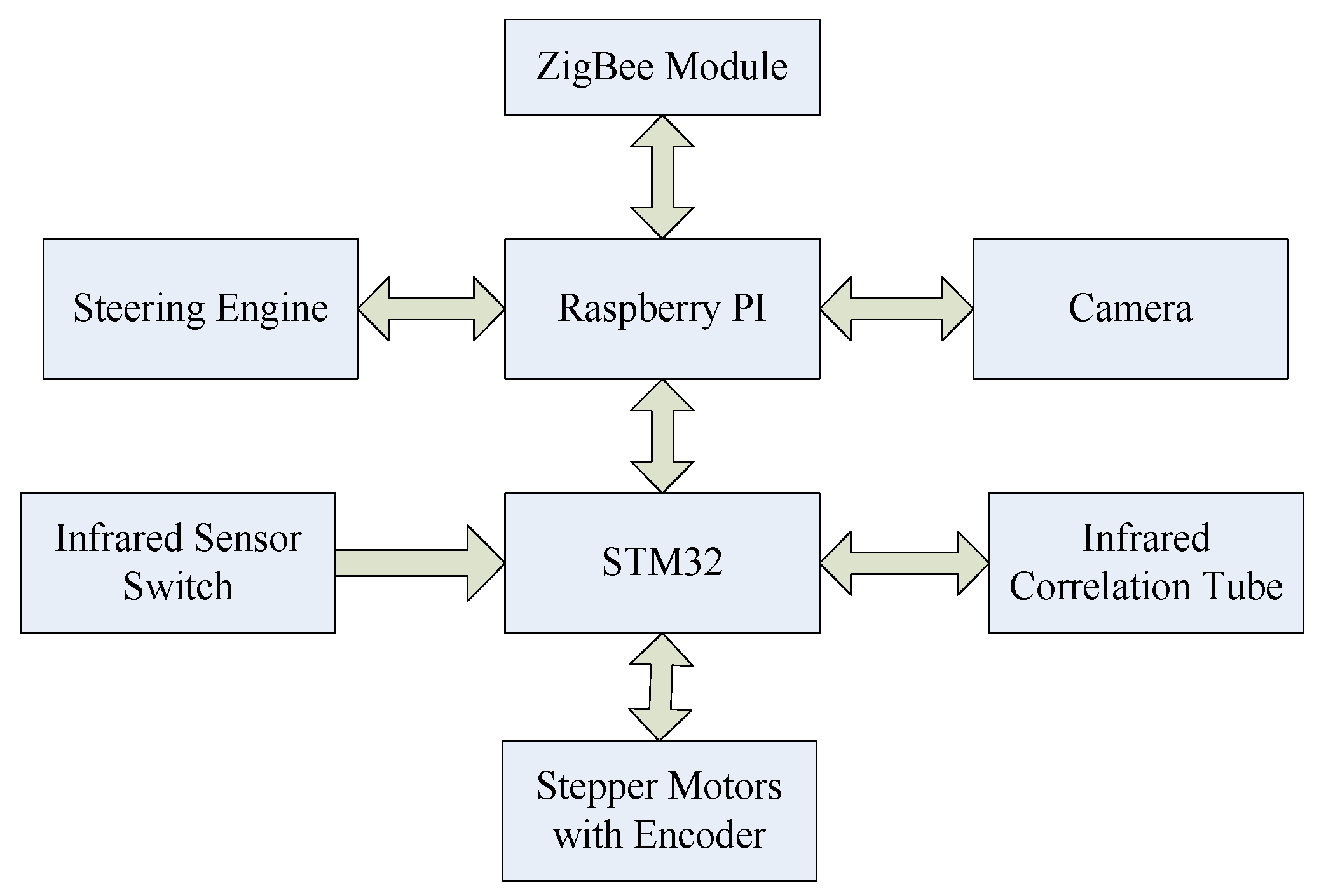
2.1.2. Robot Hardware Components
2.2. Robot Software System
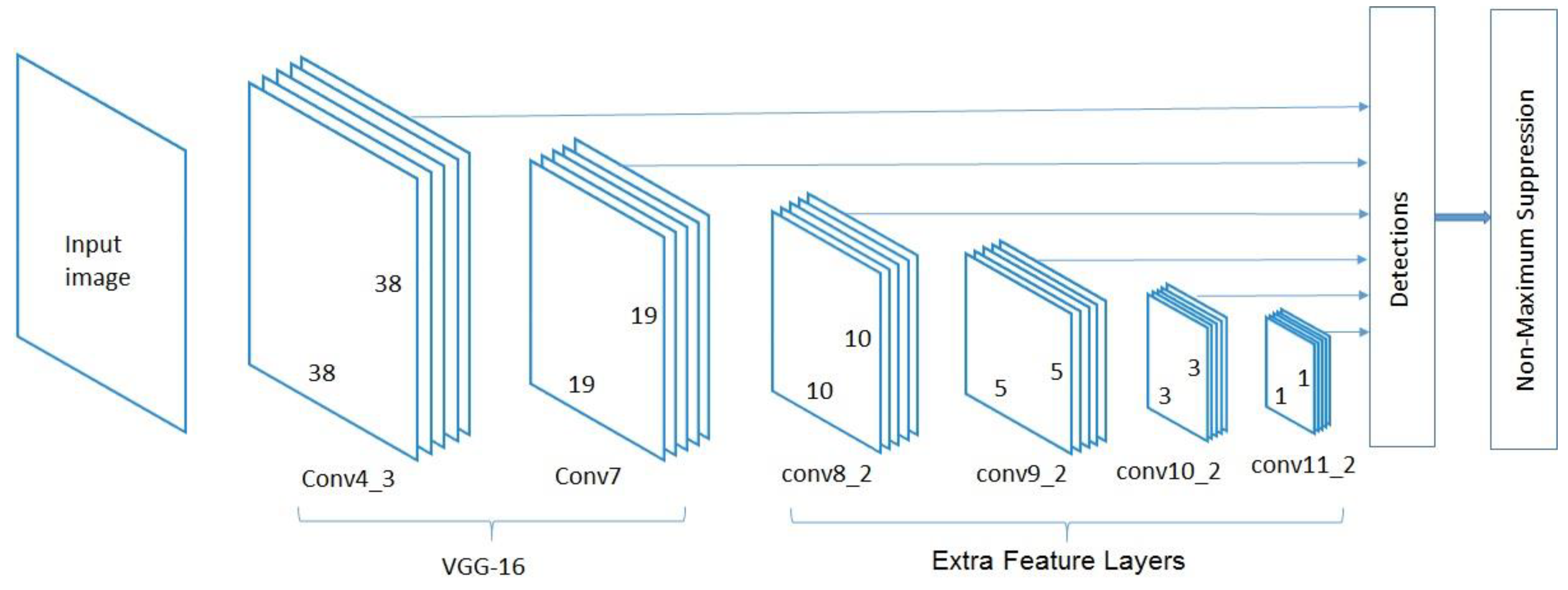
2.2.1. The Principle of SSD
2.2.2. ROS
3. Experiments
3.1. Experimental Setup
3.2. Experimental Results and Analysis
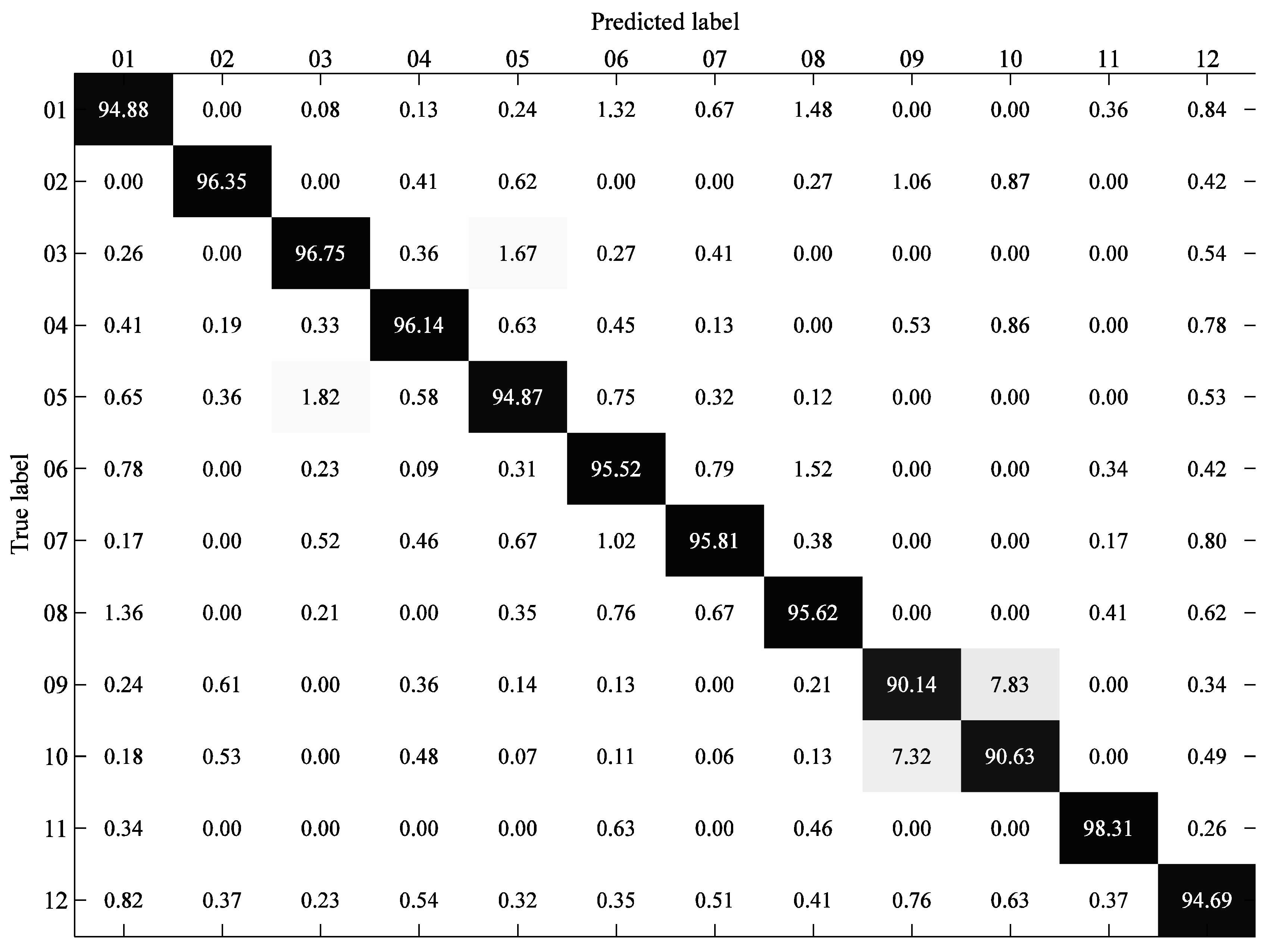
3.2.1. Performance Analysis of SSD
3.2.2. Comparisons between Hand-Crafted Features and SSD
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, H.; Fang, T.; Zhou, T.; Wang, Y.; Wang, L. Deep learning-based multimodal control interface for human-robot collaboration. Procedia CIRP 2018, 72, 3–8. [Google Scholar] [CrossRef]
- Fang, Z.; Weng, W.; Wang, W.; Zhang, C.; Yang, G. A Vision-Based Robotic Laser Welding System for Insulated Mugs with Fuzzy Seam Tracking Control. Symmetry 2019, 11, 1385. [Google Scholar] [CrossRef] [Green Version]
- Kounalakis, T.; Triantafyllidis, G.A.; Nalpantidis, L. Deep learning-based visual recognition of rumex for robotic precision farming. Comput. Electron. Agric. 2019, 165, 104973. [Google Scholar] [CrossRef]
- Li, X.; Cao, L.; Tiong, A.M.H.; Phan, P.T.; Phee, S.J. Distal-end force prediction of tendon-sheath mechanisms for flexible endoscopic surgical robots using deep learning. Mech. Mach. Theory 2019, 134, 323–337. [Google Scholar] [CrossRef]
- Paulius, D.; Sun, Y. A Survey of Knowledge Representation in Service Robotics. Robot. Auton. Syst. 2019, 118, 13–30. [Google Scholar] [CrossRef] [Green Version]
- Bertacchini, F.; Bilotta, E.; Pantano, P. Shopping with a robotic companion. Comput. Hum. Behav. 2017, 77, 382–395. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Chen, C.-Y.; Liang, J.-J.; Tsai, T.-N.; Liu, C.-Y.; Li, T.-H.S. Design and implementation of prototype service robot for shopping in a supermarket. In Proceedings of the 2017 International Conference on Advanced Robotics and Intelligent Systems (ARIS), Taipei, Taiwan, 6–8 September 2017; pp. 46–51. [Google Scholar]
- Pasquale, G.; Ciliberto, C.; Odone, F.; Rosasco, L.; Natale, L. Are we done with object recognition? The iCub robot’s perspective. Robot. Auton. Syst. 2019, 112, 260–281. [Google Scholar] [CrossRef] [Green Version]
- Cartucho, J.; Ventura, R.; Veloso, M. Robust Object Recognition Through Symbiotic Deep Learning In Mobile Robots. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2336–2341. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale invariant key points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 4, pp. 506–513. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3−8 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning affective features with a hybrid deep model for audio–visual emotion recognition. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3030–3043. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Li, Y.; Dai, S.; Zhao, L.; Yan, X.; Shi, Y. Topological Design Methods for Mecanum Wheel Configurations of an Omnidirectional Mobile Robot. Symmetry 2019, 11, 1268. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.-H.; Chung, P.-L.; Lin, H.-W. Deep learning for object identification in ROS-based mobile robots. In Proceedings of the 2018 IEEE International Conference on Applied System Invention (ICASI), Chiba, Japan, 13–17 April 2018; pp. 66–69. [Google Scholar]
- Bayar, V.; Akar, B.; Yayan, U.; Yavuz, H.S.; Yazici, A. Fuzzy logic based design of classical behaviors for mobile robots in ROS middleware. In Proceedings of the IEEE International Symposium on Innovations in Intelligent Systems and Applications (INISTA) Proceedings, Alberobello, Italy, 23–25 June 2014; pp. 162–169. [Google Scholar]
- Sikeridis, D.; Tsiropoulou, E.E.; Devetsikiotis, M.; Papavassiliou, S. Context-Aware Wireless-Protocol Selection in Heterogeneous Public Safety Networks. IEEE Trans. Veh. Technol. 2018, 68, 2009–2013. [Google Scholar] [CrossRef]
- Butt, T.A.; Phillips, I.; Guan, L.; Oikonomou, G. Adaptive and context-aware service discovery for the internet of things. In Proceedings of the 13th International Conference, NEW2AN 2013 and 6th Conference, ruSMART 2013, Petersburg, Russia, 28–30 August 2013; pp. 36–47. [Google Scholar]
- Tsiropoulou, E.E.; Baras, J.S.; Papavassiliou, S.; Qu, G. On the mitigation of interference imposed by intruders in passive RFID networks. In Proceedings of the International Conference on Decision and Game Theory for Security, New York, NY, USA, 2–4 November 2016; pp. 62–80. [Google Scholar]
- Zhang, K.; Liang, X.; Lu, R.; Shen, X. Sybil attacks and their defenses in the internet of things. IEEE Internet Things J. 2014, 1, 372–383. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | mAP | FPS |
|---|---|---|
| YOLO | 67.3 | 16 |
| Faster RCNN | 78.1 | 3 |
| SSD | 77.6 | 17 |
| Method | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SIFT | 84.14 | 85.83 | 91.37 | 87.48 | 85.75 | 88.26 | 89.54 | 85.27 | 80.53 | 81.41 | 93.86 | 87.27 | 86.72 |
| HOG | 83.65 | 85.86 | 90.76 | 86.85 | 84.36 | 86.63 | 86.78 | 84.64 | 82.36 | 80.87 | 92.17 | 85.86 | 85.90 |
| SSD | 94.88 | 96.35 | 96.75 | 96.14 | 94.87 | 95.52 | 95.81 | 95.62 | 90.14 | 90.63 | 98.31 | 94.69 | 94.98 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.; Yang, B.; Cui, Y.; Chen, Y.; Zhang, S.; Zhao, X. Designing a Supermarket Service Robot Based on Deep Convolutional Neural Networks. Symmetry 2020, 12, 360. https://doi.org/10.3390/sym12030360
Chen A, Yang B, Cui Y, Chen Y, Zhang S, Zhao X. Designing a Supermarket Service Robot Based on Deep Convolutional Neural Networks. Symmetry. 2020; 12(3):360. https://doi.org/10.3390/sym12030360
Chicago/Turabian StyleChen, Aihua, Benquan Yang, Yueli Cui, Yuefen Chen, Shiqing Zhang, and Xiaoming Zhao. 2020. "Designing a Supermarket Service Robot Based on Deep Convolutional Neural Networks" Symmetry 12, no. 3: 360. https://doi.org/10.3390/sym12030360
APA StyleChen, A., Yang, B., Cui, Y., Chen, Y., Zhang, S., & Zhao, X. (2020). Designing a Supermarket Service Robot Based on Deep Convolutional Neural Networks. Symmetry, 12(3), 360. https://doi.org/10.3390/sym12030360