1. Introduction
Hohle [
1] used the convolution between two random variables, exponential and Gaussian, to model simple reaction times (RTs) elicited via psychological experiments. The distributions resulting from such convolutions are known as exponential-Gaussian distributions or, simply, Ex-Gaussian (EG) distributions. Other distributions, though, have been proposed to model RT data. For example, it has been shown that the shifted Wald, shifted Birnbaum–Saunders [
2] and shifted Gamma distributions [
3] provide good fits to RT data (the Birnbaum–Saunders distribution has also been used to model neural activity [
4], and a flexible version of it was proposed recently [
5]. The slashed quasi-Gamma distribution (an extension of the generalised Gamma distribution) has been proposed to model data with varying skewness and high kurtosis [
6]. To our knowledge, neither the flexible Birnbaum–Saunders nor the slashed quasi-Gamma distributions have been tested in the modelling of RT data; hence, this is a task for future research). Nonetheless, distributions of RTs resulting from psychological experiments are commonly adjusted with the EG distribution model.
EG distributions were first introduced in an RT analysis carried out by McGill [
7], who, when studying the RT cumulative distribution function as a result of different intensities of auditory stimuli, found that they had an exponential form with similar constant times. This led to the assumption that, at least, one component of the total RT had an exponential distribution, and since the time constants that the curves implied seemed to be almost independent of stimulus intensity, McGill [
7] hypothesised that this component was the necessary time for the required motor response. Moreover, as the resulting distributions changed according to stimulus intensity, RTs are assumed to contain a non-exponential component that represents the decision time.
As part of a model designed to represent the disjunctive structure of RTs, Christie and Luce [
8] assumed that the observed response time consisted of an exponentially distributed decision time plus a variable time or motor response time whose distribution was not specified. Hence, these two studies, by McGill [
7] and Christie and Luce [
8], offer opposite interpretations of the component with the exponential distribution.
Hohle [
1] proposed a very simple hypothesis: the observed RT results from the sum or convolution of two independent random variables: (a) an exponentially distributed dominant variable with parameter
, as proposed by McGill [
7] and Christie and Luce [
8], and (b) another variable with a normal distribution,
which may be the sum of a number of component variables with similar variations.
Therefore, under this assumption, for
and
, where
and
are independent, it follows that the probability density function (PDF) of the random variable
resulting from the convolution of
and
is given by:
This will be denoted by
. The cumulative distribution
, survival
, relative risk
and hazard functions
are given by:
where
is the survival function of the normal distribution. Additionally,
and the asymmetry and kurtosis coefficients are given by:
It can be then concluded that the EG model has positive asymmetry. Furthermore, when
, then
, which entails that:
Although the EG distribution can be useful in modelling positively skewed data (e.g., RTs), in practice, it is not unlikely that data take other shapes (e.g., normal or negatively skewed). Hence, having more flexible distributions is key to model data appropriately. This article proposes a modified EG distribution in which the Gaussian component is replaced by a skew-normal (SN) distribution. Doing so gives origin to the exponential skew-normal distribution; a distribution capable of adapting to various data shapes. First, the statistical properties of this distribution are presented. Given singularity issues associated with the skew-normal distribution, a centred version of this distribution is then described. Next, the performance of the proposed distribution is illustrated via two published datasets. Finally, this distribution is considered in the bigger picture of data analyses and modelling.
2. Exponential Skew-Normal Distribution
The EG model exhibits positive asymmetry, because the exponential model is positive asymmetric since the second component of the convolution is symmetric around
In his proposal, Hohle [
1] assumed that the second component of the convolution, from which the EG model results, follows a normal distribution that is located at
and has a constant variation that represents the sum of a number of variables with similar variations that represents the necessary time for the required motor response, according to McGill’s hypothesis [
7], or the variable motor response time, according to Christie and Luce’s [
8].
It is assumed herein that the variable motor response time, or the necessary time for the motor response, follows a skew-normal distribution (see [
9]) whose PDF is given by:
where
and
denote the standard normal density and cumulative distribution functions, respectively. The asymmetry is controlled by the parameter
, and the notation
is used herein; for
, it is the normal model. The asymmetry and kurtosis ranges of this distribution are
and
, respectively (these values are extracted from [
10]). The PDF of the location-scale model can be written as:
with
and
as the location-scale parameters. The notation
is used herein.
Then, for
and
, where
and
are independent, the PDF of the random variable
resulting from the convolution of
and
is given by:
where
and:
This distribution is denoted as
It can be observed that, if
, then:
that is, the EG distribution is obtained. Therefore, the exponential skew-normal (ESN) model contains the EG model as a special case, which entails that the ESN distribution is more flexible in terms of asymmetry than the EG model.
The ESN convolution model can be written in terms of the cumulative distribution function of the extended skew-normal model (here E; see [
10], p. 40) and setting
:
where
is given by
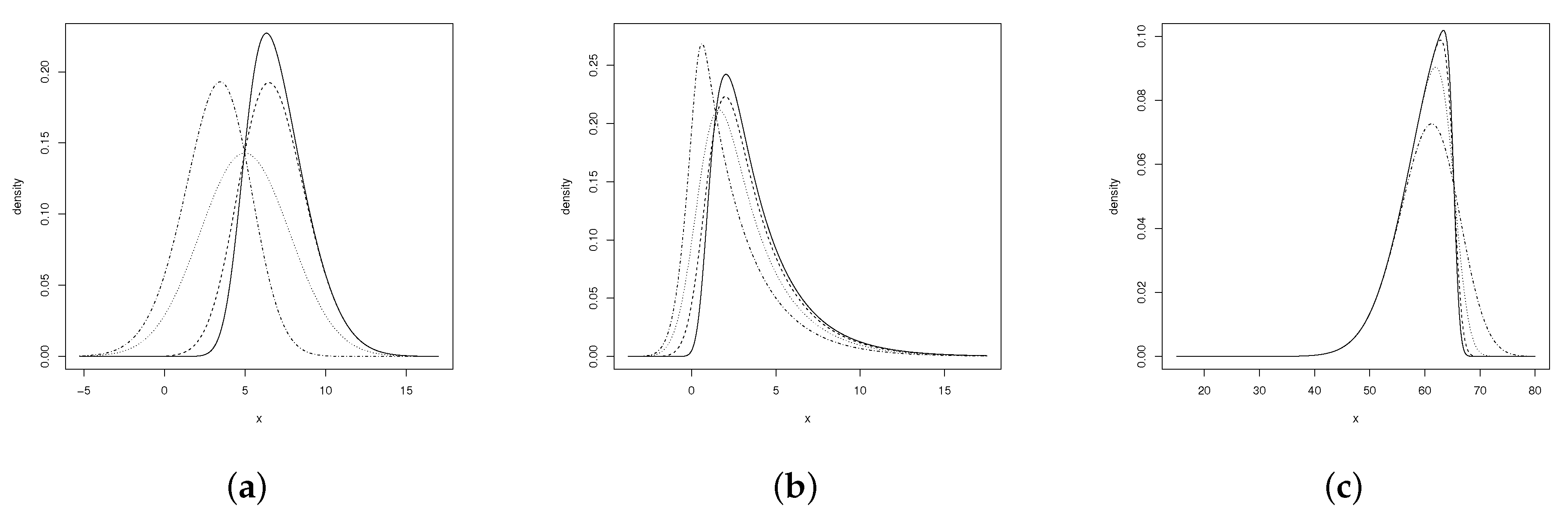
Figure 1 shows the ESN’s density behaviour for certain parameter values; (a) and (b) present a comparison between the ESN and EG distributions (the EG ensues when ESN has
); (c) illustrates the case of negatively skewed ESN distributions.
The cumulative distribution function (CDF) of a random variable with an ESN distribution does not have a closed-form expression and should be calculated using a numerical approximation algorithm. It is given by:
where:
Moreover, the survival, hazard, and inverse risk functions are given by:
2.1. Moments
The moments of the ESN distribution can be obtained directly from the stochastic representation of the random variable
where
and
are independent random variables. Thus, the r
th moment of the random variable
is given by:
Given that
, the even moments of the SN distribution match those of the normal distribution and by expressing the odd moments of the SN distribution (see [
11]), it results that:
where:
Hence, from the central moments given by
, the expected value and variance of the ESN random variable are:
Grushka [
12] found that the asymmetry and kurtosis coefficients of the EG random variable depended on the scale parameters of the convolution distributions, i.e.,
and
As for the ESN model, the asymmetry (
) and kurtosis (
) coefficients are given by the following expressions:
and:
where
and
denotes the sign function. Therefore, in line with Grushka’s findings [
12], (
) and (
)depend on
and the asymmetry parameter
A
grid is constructed for
and
values and
values within
; these values are obtained numerically using
R statistical software. Doing so indicated that if
, then
; while if
, then
Moreover, if
, then
; and if
, then
Therefore, the range of asymmetry of the ESN model is (−0.9953, 2], which makes it more flexible than the EG model and other asymmetric models such as the SN model [
9] and the power-normal model [
13,
14].
Similarly, for the same range of
and
values, the kurtosis coefficient is within the
range (these values were obtained numerically using the
R statistical software). Moreover, if
, then
; while if
, then
, and if
, then
Therefore, the kurtosis range of the ESN model makes the ESN more flexible than asymmetric models, including the SN model [
9], the power-normal model [
13,
14] and the SN Alpha-power model [
15].
The moment- and characteristic-generating functions of the ESN model are given by:
and:
Note that, for
and
which means that
In other words, the ESN distribution is closed for the linear combination of the form
2.2. Exponential-Centred Sn Distribution
The skew-normal model is a suitable alternative for datasets with a significant degree of asymmetry; however, its drawback is that it has a singular information matrix if its asymmetry parameter equals zero, i.e.,
[
9]. Regarding this case (in which
is in the proximity of zero), some authors have proposed a reparameterization [
16]. Another option is to use the so-called centred skew-normal distribution [
9], which is obtained as shown below.
For
with
and
where
and
, let the
Y random variable be defined as:
For this random variable, it follows that:
Given that the random variable
Y is a linear combination of
,
Y also follows an SN distribution, and after some calculations, it results that:
where:
with
and
(these values are provided in [
9]).
This is known as the centred SN (CSN) distribution and is denoted by
Ref. [
9] showed that the information matrix of the CSN model can be written as:
where
is the information matrix of the SN model;
D the matrix of the derivatives of the parameter vector
with respect to the parameter vector
[
9] showed that
is a non-singular matrix.
Hence, based on this very reparameterization, the exponential-centred SN model is given by:
with
and
as defined in Equation (
12). This model will be denoted by
When
, the
model is then obtained.
Note that this centred representation of the SN model reduces the space range of the asymmetry parameter since
(see [
17]).
3. Estimation
For a random sample
where
it is possible to estimate the parameters of the
model by maximising the log-likelihood function:
Another alternative could be to maximise the log-likelihood function of the parameter vector
which is given by:
and then use the relationships defined in Equation (
12) to find the estimates of vector
The elements of the score function
, i.e., the derivative of the log-likelihood function with respect to the parameters, are given in
Appendix A.
The score equations are estimated by equating the scores to zero (). Then, the maximum likelihood estimators of the parameter vector are calculated by solving the system of equations by means of Newton–Raphson or quasi-Newton numerical methods, among others.
The observed information matrix of the parameter vector
is defined as
, i.e., minus the second derivative of the log-likelihood function with respect to the parameters, provided in
Appendix B.
The elements of the Fisher information matrix of vector are given by and should be calculated numerically.
The information matrix of the ECSN model can be obtained as the relationship in Equation (
13) using an appropriate matrix
Furthermore, the observed information matrix
and Fisher information matrix
of this model, for the parameter vector
can be written in terms of the observed and expected information matrices of the ESN model, of the parameter vector
in the form:
where:
The elements of this matrix
can be found in their general form in Azzalini and Capitanio ([
17], p. 68). Note that when
, the inferior sub-matrix of size
is nonsingular and converges to a diagonal matrix
. This event entails that the matrix
is nonsingular for
.
Therefore, in regular conditions and by applying the asymptotic theory to the maximum likelihood estimator vector of the parameter vector
Then, using the same stochastic convergence argument, it follows that
converges to a normal distribution; that is:
Hence, for the ECSN convolution model, the elements in the diagonal of
represent the estimates of the variances of
and
. The
confidence intervals can be estimated in the conventional
form, where
represents the standard error of the parameter
.
3.1. Illustrations
3.1.1. Reaction Times
Ref. [
18] investigated the sensorimotor processing of words by using a masked priming (MP) task. The MP is a task commonly used in experimental psychology and in which a prime word (e.g., below) is “sandwiched” for a short time (e.g., 35 ms) between a preceding masking pattern (or forward mask, e.g., LKPFH; shown for, say, 200 ms) and a proceeding target word (e.g., above; shown until a response is made). In some variations, there can be a masking pattern between the prime and the target word (called backward mask), and this was the case in Ansorge et al.’s study (such a pattern was shown for approximately 35 ms). Traditionally, there are congruent and incongruent trials; in the former case, there is a match between the response of the participant and a correct or expected response, while in the latter, there is a mismatch between those responses. The time the participant takes in responding is known as the reaction time (RT) and is measured in milliseconds.
Twelve females and 12 males participated in an MP task, and their RTs were collected for both congruent and incongruent trials (see Experiment 2a). The descriptive statistics for the distribution of mean RTs during incongruent trials were as follows:
,
,
, and
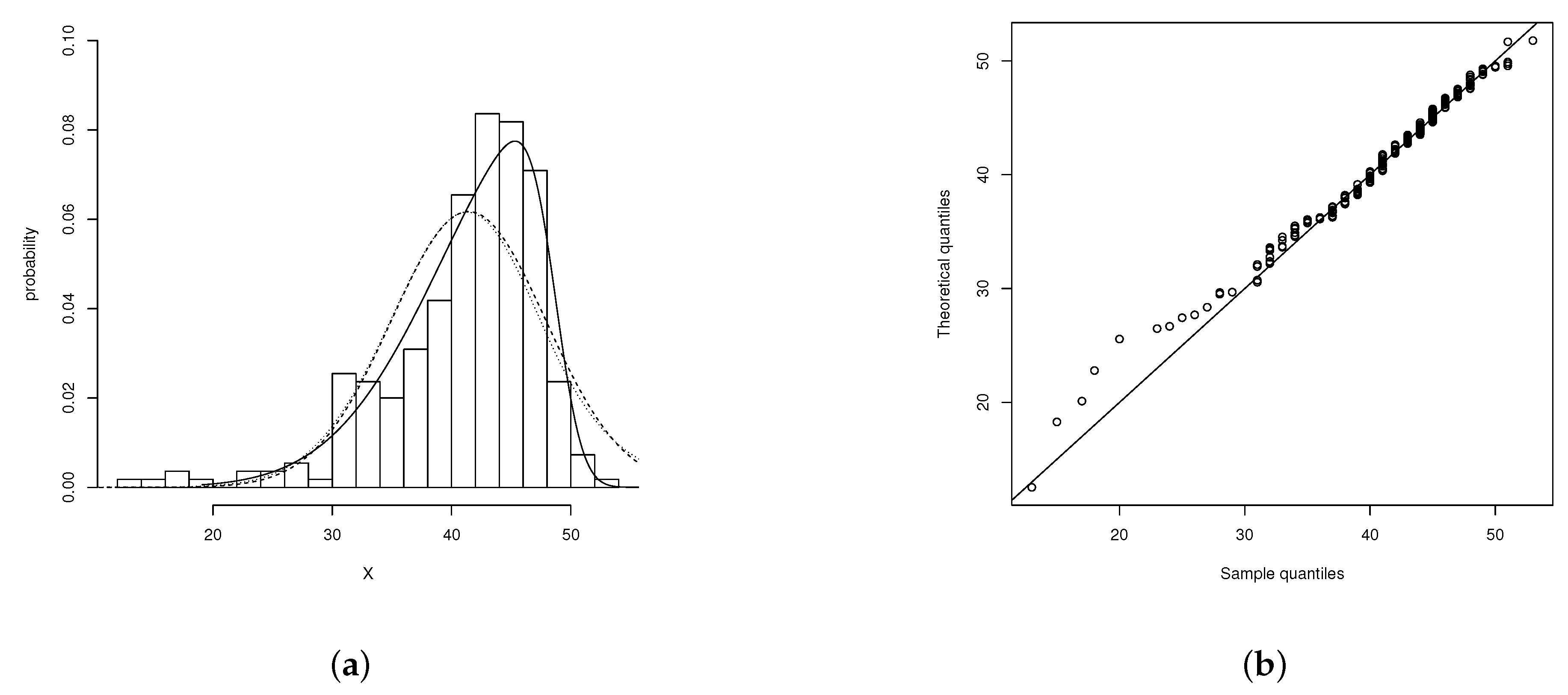
. These statistics indicated that the distribution of RTs was negatively skewed; hence, an EG distribution would not provide an appropriate fit as its asymmetry is always positive. When the data were fitted with the ECSN, the following estimates were obtained:
and
. Considering the centred representation of the ECSN model, the estimated parameters were as follows:
and
. Therefore, the ECSN gave an optimal fit, and it was further corroborated via the Kolmogorov–Smirnov (
D) test;
,
(in this work, the
D test is used to assess the suitability of a given statistical distribution to a dataset. However, other tests exist; e.g., Cramér–von Mises, Anderson–Darling, Shapiro–Wilk,
, Hosmer–Lemeshow, Kuiper, Kernelized Stein discrepancy, Moran, and Zhang’s
,
and
tests).
Figure 2 displays the distribution of mean RTs and the ECSN distribution’s fits.
The following example is provided to illustrate that negatively skewed data can emerge in situations other than RTs. For example, in psychometrics, some rating scales can show a negative skew.
3.1.2. The Flourishing Scale
Ref. [
19] validated the Flourishing Scale (FS) in a sample of adults (
) with low and moderate levels of well-being. The FS rating scale is an eight item measure of social-psychological functioning that tackles aspects such as relationships, self-esteem, purpose and optimism.
The authors aimed to understand the distribution of the total Flourishing scores (X = TFS, ); a global measure of the core aspects of individuals’ optimal social and psychological functioning. The descriptive statistics of the TFS showed an average of a standard deviation of a skewness of and a kurtosis of . The negative skewness suggested that the EG model was not the most suitable option because its range of asymmetry was positive. In addition, the high kurtosis left little room for models such as the SN, whose ranges of kurtosis and asymmetry were [3, 3.86) and (−0.9953, 0.9953), respectively.
The EG, the skew-normal Alpha-power (SNAP) and the ECSN models were fitted to the data. The exponential representation
was used for those models. The four parameter model
, studied by [
15], is more flexible than its SN and power-normal (PN) counterparts because when
, the SN distribution was obtained, and when
, the PN distribution was obtained; a normal distribution ensues when
and
. The SNAP’s ranges of asymmetry and kurtosis were
and
respectively [
15], which made it a good fit to the TFS data.
These models were compared using the Akaike information criterion (AIC) [
20] and the Bayesian information criterion (BIC) of Schwarz [
21], defined as:
where
p is the number of parameters of the vector
of the specific model. Based on the results of the AIC and the BIC, the most suitable model for the TFS data was the ECSN model (see
Table 1).
Figure 3 further shows the good fit of the ECSN model.
Figure 4 shows the low degree of fit of the EG (a) and the SNAP (b) models; but it is evident that the EG gave a better fit than SNAP (see also the AIC and BIC values in
Table 1).
A null hypothesis test of no difference between the ECSN model and the EG model can be expressed as,
By using the likelihood-ratio test (models are nested),
it is found that:
This was a value larger than the critical 5% chi-squared value, i.e.,
Therefore, the null hypothesis was rejected, and it could be concluded that the ECSN model—which involved one extra parameter, making it more flexible in terms of asymmetry—fit the data better than the EG model (compare
Figure 3b and
Figure 4a).
Furthermore, the D test was used to determine the best fit for the TFS data. The results were as follows: for the EG model, D = 0.200 (p-value = 0.000); for the SNAP model, D = 0.2290 (p-value = 0.000); and for the ECSN model, D = 0.0981 (p-value = 0.1411). The results thus corroborated that the ECSN model was suitable for the TFS data.
4. Discussion
Data can take different distributional shapes, but some shapes are more common in certain research fields (for more information about other distributions and their applications, see the Special Issues in Volume 11 Issue 11 (year 2019) and Volume 12 Issue 5 (year 2020) in this journal). RTs, for example, are a ubiquitous metric in experimental psychology, and it is well known that their distribution is positively skewed. However, that is not necessarily always the case, and normally or negatively shaped RTs can ensue. In those cases, the EG distribution, a distribution traditionally used to model RT data, is not able to fit the data well. In this article, a distribution capable of fitting traditional RT data and RT data that deviate from a positive skew was proposed.
It is important, however, to frame the proposed distribution within the larger field of data analysis and modelling. While most research across scientific fields tends to focus on average differences, not much attention is paid to investigate group differences in variation. Indeed, tests designed to account for both location and scale (e.g., the Cucconi test) are rarely used. Adopting a distributional modelling approach enables tackling data differently by considering, at a minimum, the data’s location (e.g., mean) and scale (e.g., SD). To our knowledge, the only existing statistical approach able to model data in a proper distributional manner is the generalised additive models for location, scale and shape (GAMLSS).
To conclude, the ECSN distribution was proposed as a new statistical distribution suitable to adjust the shape of RT data. As the ECSN was a four parameter distribution, it could be used to model RT data’s location, scale and shape. It is our hope to see this distribution implemented in the GAMLSS R package so that it is put to the test in research contexts. The necessary Rcodes and datasets to reproduce the estimations and plots reported here can be found at
https://figshare.com/projects/Two_new_distributions_for_the_modelling_of_RT_data/81743.









{kind=link}
{kind=link}
{kind=link}
{kind=link}