1. Introduction
With the increasing complexity of social issues, decision-making is influenced by both subjective and objective factors. Generally, it is difficult for a small number of experts to comprehensively judge all decision-making objects due to the limitation of their knowledge structure and cognitive level. The rapid development of information technology has made the collection of decision-making opinions of expert groups more modern and systematic; moreover, huge group decision-making has become the optimal solution to solve complex decision-making problems. The opinions of decision-makers could be more accurately expressed by using linguistic variables, because it is usually hard for decision-makers to provide accurate quantitative judgments in the decision-making process of some complex problems [
1]. However, it is also a challenge for a single-linguistic term to accurately describe such complex situations when the decision-making object is between two linguistic levels, or when the decision-makers in the group decision-making process have multiple uncertain linguistic judgments. Based on this, a decision-making framework for hesitant fuzzy linguistics has been proposed [
2]. At present, the research on hesitant fuzzy linguistic decision-making mainly focuses on the representation of linguistic terms, arithmetic rules, set-ups, and related decision-making methods. Liao et al. [
3] redefined hesitant fuzzy linguistics term set (HFLTS) and gave its mathematical form, because there are some abnormal results in the calculation process of asymmetric evaluation scales. Furthermore, Liao et al. [
4] proposed a new score function for HFLTS based on hesitancy and linguistic scaling functions. In terms of decision-making methods, Chen and K. S. Chin [
5] transformed hesitant fuzzy linguistic information into probabilistic linguistic information for information collection. Additionally, Zafeiris and Koman [
6] presented a quantitative aggregation algorithm considering the ability of decision-makers for different decision scenarios. Wang et al.’s [
7] system reviews the research progress of HFLTS decision-making. In particular, hesitant fuzzy linguistic multi-attribute consensus decision-making has attracted the attention of many scholars. Wu and Xu [
8] proposed the consensus measure and the consensus model of hesitant fuzzy decision matrices from the perspective of the unification of expert opinions. Wu and Xu [
9] defined a new degree of group consensus based on the possible distribution of HFLTS, and established a consensus model with non-consensus opinion recognition and feedback adjustment rules. Zhang et al. [
10] defined the distance measure of HFLTS considering the width and center of the HFLTS envelope. Wei and Ma [
11] defined the consensus level among hesitant fuzzy decision matrices based on the envelope of HFLTS.
These methods are just simple staging expert decision or consensus adjustment information to solve the complex problem of group decision-making, to a certain extent, which is a difficult to achieve consensus among all decision-making experts. It is necessary to repeatedly modify the expert decision information, which will inevitably lead to a big difference between the expert consensus decision-making information and the original expert decision information. In addition, for a group decision-making method that directly integrates all expert decision information, it is necessary to determine the weight assigned by experts and the method of information aggregation in the assembly process. It is difficult to avoid the loss of expert decision information caused by subjective factors in the decision-making process. The main reason for these shortcomings is that these decision-making methods do not consider expert group classification problems under hesitant fuzzy linguistic information. Therefore, according to the similarity classification method [
12], a hesitant fuzzy linguistic huge group expert classification and decision information aggregation method based on cluster-consensus information integration is proposed by combining it with the class-center distance-based classification accuracy test index [
13]. Through this method, the information loss in the process of expert decision information aggregation can be minimized; moreover, scientific and accurate decision results can be obtained.
In
Section 2, the theoretical basis of the hesitant fuzzy linguistic group decision-making model is introduced on the basis of relevant literature. In
Section 3, the proposed hesitant fuzzy linguistic group decision-making method is presented in two parts.
Section 3.1 mainly introduces the classification method of expert groups, and
Section 3.2 shows the aggregation process of expert evaluation information. Then, the detailed steps of the group decision-making model based on hesitant fuzzy linguistics are summarized. In
Section 4, the effectiveness of the decision-making method is verified through its application to urban water resources sustainability evaluation. In
Section 5, the decision-making method of this paper is compared with other methods to further discuss its advantages in the decision-making process of a large group of experts, and to show the innovation of this research. In
Section 6, the research content of the paper is summarized and the research conclusion of the paper is discussed.
2. Basic Concepts
2.1. Hesitant Fuzzy Linguistic Terms
Let denote an ordered set of odd language terms, where denotes the term in set ; , is the granularity of the linguistic term in set . Set satisfies the following conditions: (1) ; and (2) has the inverse negative operator: If , .
Based on the concept of a set of linguistic terms, the following set of hesitant fuzzy linguistic terms were defined.
Definition 1 ([
14])
. Let be a set of linguistic terms; then, a hesitant fuzzy linguistic term set in S can be defined as a set of a finite number of consecutive linguistic terms in S, that is, .
In the process of decision analysis using the hesitant fuzzy linguistic term set, the relevant literature expands the representation of the hesitant fuzzy linguistic term set in Definition 1, enriches the arithmetic rules of the hesitant fuzzy linguistic term set, and avoids the actual information loss caused by the aggregation of evaluation results during the application process. By setting the subscript of the term to an odd number of consecutive integers with 0 as the center of symmetry, an asymmetric hesitant fuzzy linguistic term set is proposed [
3].
Definition 2 ([
3])
. Let be a set of odd language terms, where is a positive integer; is the granularity of the set of linguistic terms. The set of symmetric language terms S satisfies the following conditions: (1) order or ;
and (2) there is a negative operator: ,
where .
If is a set of a finite number of consecutive linguistic terms ordered in S,
is a set of hesitant fuzzy linguistic terms in S; .
In addition, in order to retain the given linguistic information as much as possible and to avoid the loss of linguistic information, a continuous linguistic term set is proposed, , where is a sufficiently large positive integer. The extended language term set is called a virtual linguistic term set, which is only used in calculation processes; expert decision-making processes still use linguistic term set .
For any two language terms in the extended linguistic term set , , in the calculation process, the following rules are met:
Definition 3 ([
3])
. Let ,
,
and be the set of three hesitant fuzzy linguistic terms in S. The algorithm is defined as follows:andtake the big operator as;
andtake the small operator as;
The upper boundaryand the lower boundary of are and , respectively;
The envelope set ofis.
2.2. Huge Group Decision-Making
Based on the fuzzy linguistic approach, decision plans or a certain indicator in a single language term can be evaluated by experts. However, experts are limited by their level of knowledge and the decision-making conditions in the actual decision-making process. They often hesitate between multiple language terms when choosing such terms for evaluation. It is difficult for the background knowledge of individual decision-makers to meet the requirements of decision-making judgments due to complex decision-making problems; moreover, huge group decision-making has become a new direction in the application of hesitant fuzzy linguistics.
Let be a set of hesitant fuzzy linguistic terms in ; then, is a continuously ordered subset of S, that is, . Let the expert decision set be , the decision object attribute set be , and the corresponding attribute weight vector be . Let be the set of hesitant fuzzy linguistic terms given by the expert; , where denotes the modulus of ; the larger the modulus of , the greater the degree of hesitation of the expert; denotes the decision information of the expert on the attribute for the decision object . In view of the above-mentioned decision-making problem, it is necessary to effectively gather the decision information of all experts and to rank the decision objects .
4. Example Analysis
In this paper, the water resource sustainability evaluation of three cities
was taken as an example. The three aspects of resource endowment, social economy, and environment were comprehensively are evaluated. The attribute of the evaluation index is represented by
, and the weight of the index given by experts is 0.35, 0.35, and 0.3. The predetermined set of evaluation language terms is
, where
to
represent extreme bad, bad, slightly bad, general, slightly good, good, and excellent, respectively. Experts can judge the evaluation indicators through language information during the sustainable assessment of water resources in the three cities according to the above language set. In this case, 30 experts from relevant fields were selected to participate in the evaluation process. The expert language information was converted into hesitant fuzzy terms by a conversion function. The expert decision hesitant fuzzy linguistic term set information is illustrated in
Table 1. Then, the water resource sustainability conditions of the three cities were sorted according to the hesitant fuzzy linguistic information of the corresponding attributes of the three cities given by the experts in
Table 1.
The specific evaluation process is described as follows.
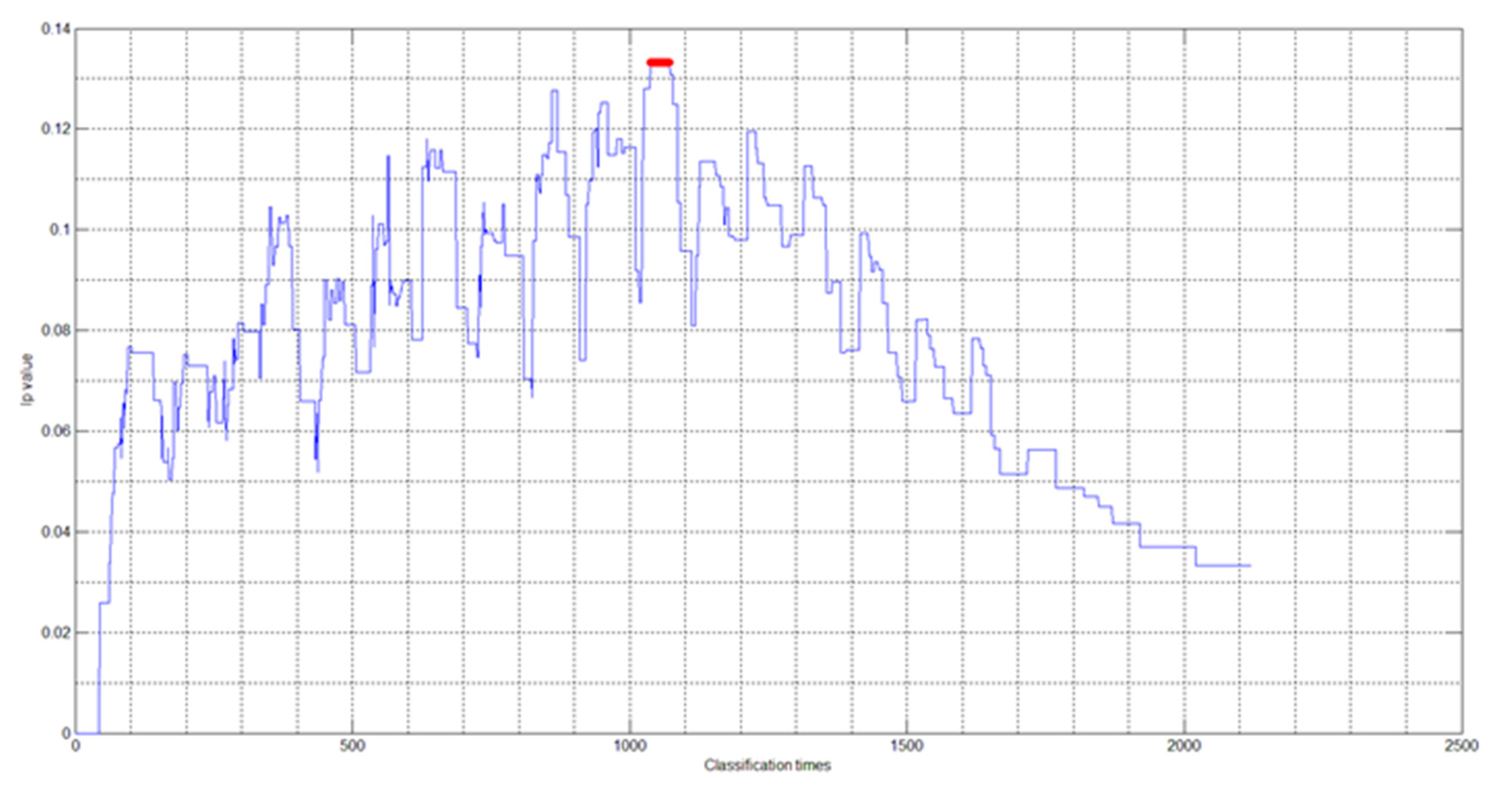
Step 1: Generate a classification based on expert decision information. The similarity
between experts is calculated according to Formulas (1) and (2), where
. On this basis, the expert groups were classified according to the clustering algorithm based on the breadth-first search neighbors. The values of the classification parameters
r and
were adjusted and the classification effect test index
under the obtained classification results was calculated. Classification is meaningless when
; thus, it should not be considered. Therefore, the effective value ranges of parameters
r and
are [0.8,1] and [0,1]. In the decision-making process, to traverse all possible values of parameters
r and
, 0.01 was taken as the step for numerical changes in order to visually analyze the correspondence between the value of the classification parameter
r and the parameter
and
. Next, the parameter values were selected in turn within the parameter change range
,
and the
was calculated under each classification result, as shown in
Figure 1.
The red marked point in
Figure 1 is the maximum value of index
. When
,
,
takes the maximum value of 0.1332. At this time, the experts were divided into four categories, and the classification results were:
Step 2: Assembly of expert decision information within the class.
① Calculate the degree of consensus of the four types of experts: . Set the group consensus level to . Due to , the decision information of the four types of experts needs to be adjusted.
② Let , ; the decision information needs to be adjusted through the calculation of the degree of consensus; set expert ’s hesitant fuzzy term for the attribute of the decision object .
③ Set the adjustment parameter . The information of the fourth type of expert’s hesitant fuzzy term set for the attribute of the decision object is is gathered by the arithmetic average operator, while the modified hesitant fuzzy term set is ; thus, the fourth type of information is modified. The group consensus of the experts is , that is, the four types of expert groups reached intra-class consensus.
④ Keep the other decision information unchanged; replace the hesitant fuzzy term set of expert . with respect to the attribute of decision object in the expert decision matrix by the revised hesitant fuzzy term set to form a new expert decision matrix. Then, classify each type of expert hesitant fuzzy language decision information matrix into the probabilistic language combination , .
Step 3: Assembly of expert decision information between classes. Set the preference coefficient
; the class weights of the expert classes
,
,
, and
are 0.2598, 0.2768, 0.2328, and 0.2306, respectively, according to the calculation method of the expert class weight in the paper. On this basis, the inter-class information was assembled; the final decision results of the three cities are:
Step 4: Sort the decision objects. According to Formula (12), the expected values of the three cities were calculated , and . The final ranking result was , that is, the sustainable development levels of water resources in the three cities were ranked as , , and . Thus, again, the best alternative is .
5. Discussion and Comparison
In order to further verify the effectiveness of the proposed method, the consensus model [
11] and the classification aggregation model [
19] were used to deal with the decision-making problem in the example. The final decision results of the three methods are as follows in
Table 2.
It is necessary for the 30 experts to reach a consensus at the same time when using the consensus model to make a direct decision. The decision-making process needs to adjust the difference information of experts repeatedly to ensure the level of the group consensus. Compared with the decision-making method in which the expert classification is carried out first and then the experts are promoted to reach a consensus, the amount of expert information that needs to be adjusted by using the consensus model for decision-making is significantly increased. The difference between the expert decision information after consensus adjustment and the original information is large, which changes the decision-making opinions of the expert group.
Table 2 shows that the ranking results of the consensus model are slightly different from the other two methods, because the consensus model needs to repeatedly modify the expert decision information during the decision-making process, and there is a certain error in the final decision results.
In the process of example decision-making by the classification aggregation model, although the difference between experts is reduced by the expert classification, the weight assigned by all experts still needs to be calculated first in the process of expert decision information aggregation, and this weight has a great impact on the final decision-making results. In addition, when the size of the expert group is large, problems associated with the average weight assigned by experts easily appear. We used the consensus model so as to reduce the amount of adjustment of the expert decision information, so that the classified expert group could reach a consensus within the class. In the actual decision-making process, we do not need to consider the weight difference of experts in the same class, which improves the efficiency of group decision-making.
Table 2 shows that the ranking results of the classification aggregation method are same as that of the method in this paper, but the method in this paper does not need to pre-specify the weight assigned by experts, which avoids the human error caused by subjectively assigning a weight.
Therefore, the decision-making method proposed in this paper not only avoids the errors that may occur during the integration of decision information, but also has better applicability.




{kind=link}