1. Introduction
Grid-based pathfinding has been the subject of considerable interest in a number of fields such as video games and robotics navigation.
[
1] is a simple, best-first search algorithm that relies on a heuristic function to guide the search towards finding the optimal path between a source node and a goal node in a grid map. To reduce the execution time of the
algorithm, researchers typically focus on finding new heuristic functions that reduce the number of visited nodes (i.e., search space) during pathfinding.
is optimal if the used heuristic function is admissible, i.e., never overestimates when predicting the distance to reach the goal [
2].
Weighted (
) [
3] relaxes the admissibility rule and multiplies the heuristic function by a factor
. While doing so might lead to finding sub-optimal paths, inflating the heuristic forces the search algorithm to prioritize exploring more promising paths rather than exploring every possible path to guarantee optimality. For example,
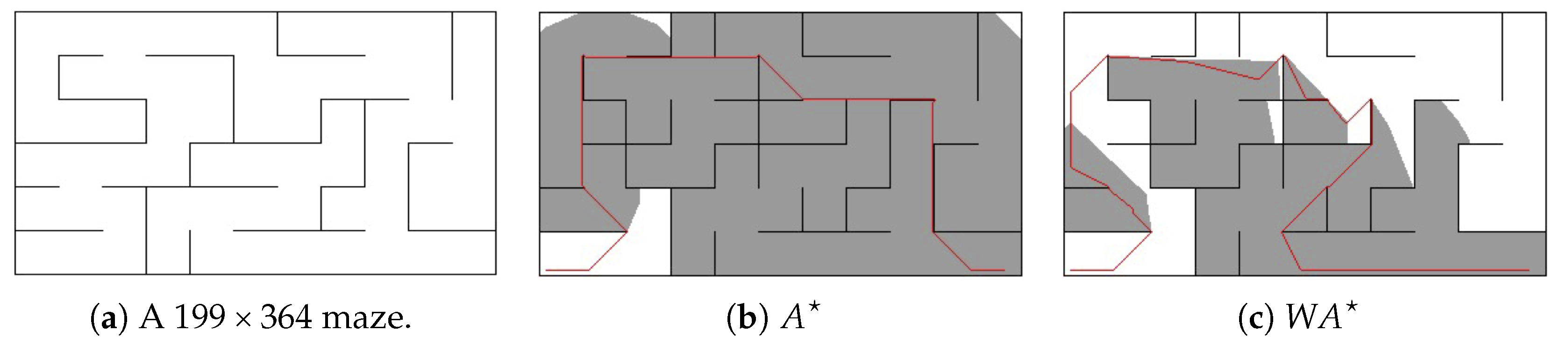
Figure 1 compares the number of visited nodes in both
and
(with
) when trying to find the same path in an 8-neighbor grid map of a
maze. Both algorithms use the octile-distance heuristic, which is a commonly-used admissible heuristic function that allows both straight and diagonal movements. As shown by
Figure 1c, the greedy nature of
led it to prioritizing the exploration of the closer nodes to the goal, which resulted in finding a different, sup-optimal path. By contrast,
slowly explores all similar nodes, i.e., nodes with the same cost, to guarantee optimality (as shown by
Figure 1b).
is a simple yet effective extension of
and is still in wide use to this day [
4,
5]. However,
, as well as
, has no knowledge about the geometry of obstacles in a grid map, which could mislead the search into exploring paths with blocked ends. For example,
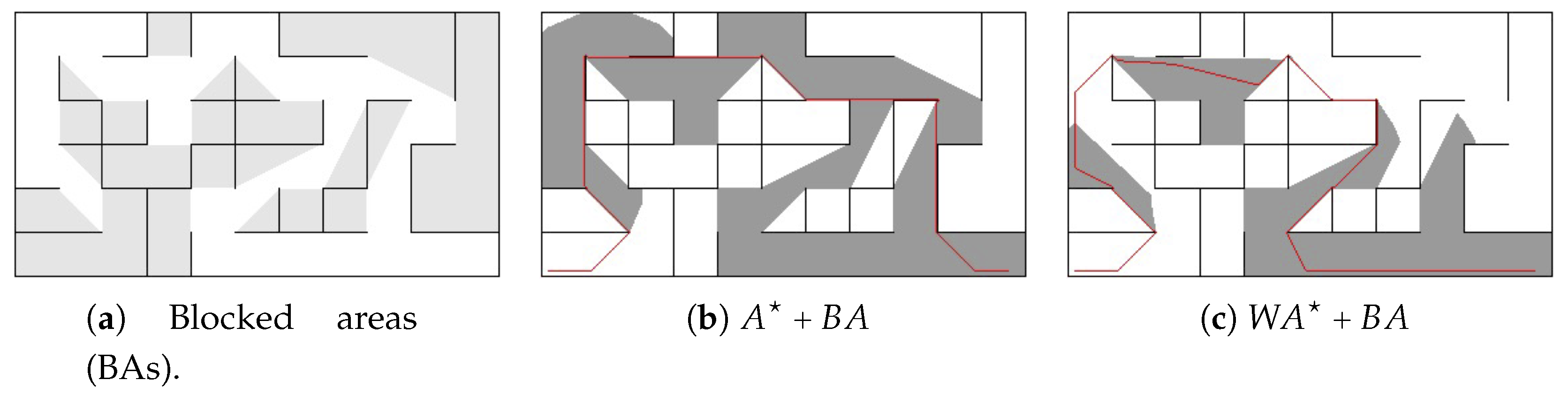
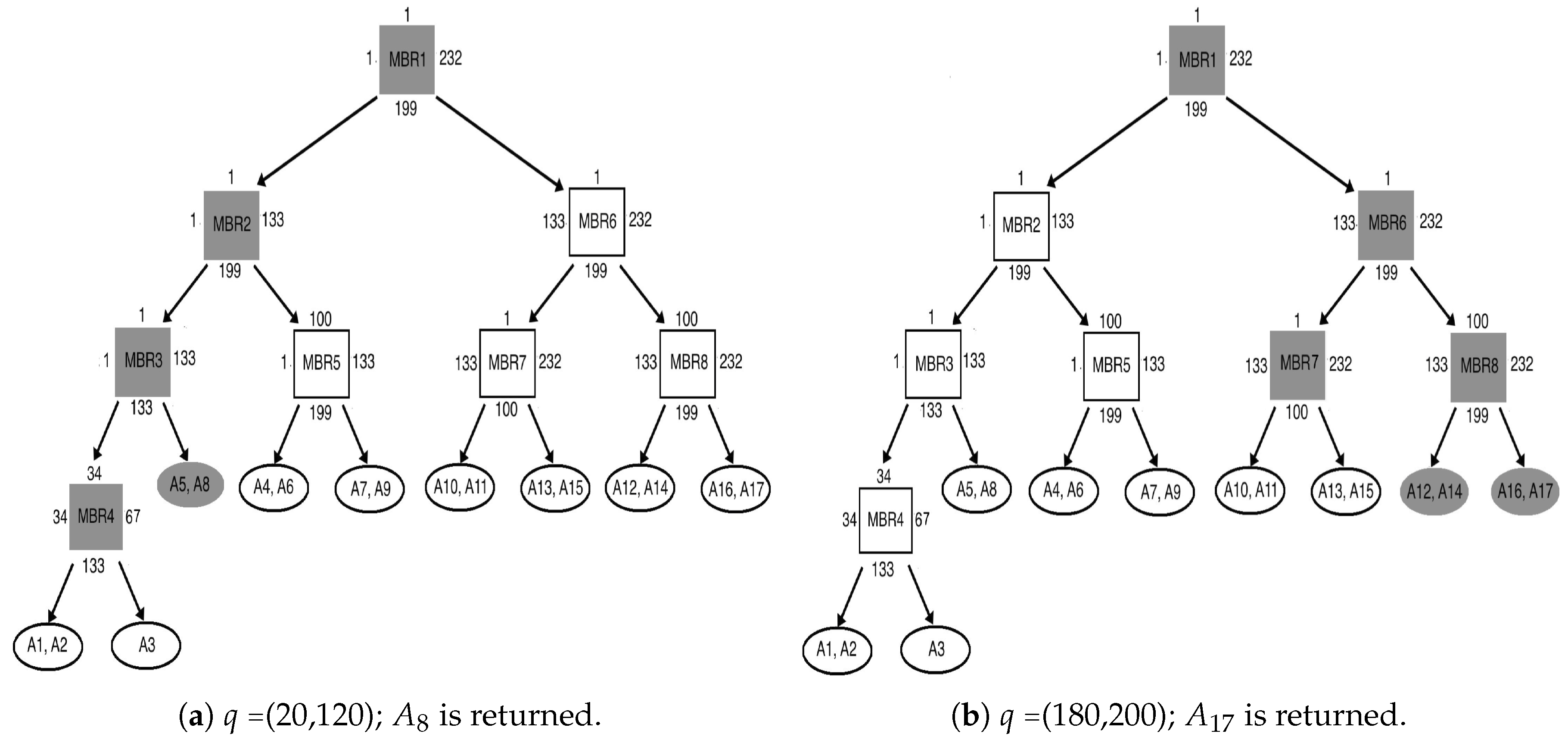
Figure 2a shows twenty two polygon-shaped areas with blocked ends in the maze of
Figure 1a. We refer to such shapes as blocked areas (BAs) because they are bound by obstacles from all directions, except for the one direction where the search may enter this area. This paper aims to make knowledge about blocked areas in a grid map available during pathfinding. By doing so, a search algorithm can avoid exploring useless paths inside blocked areas, which in turn reduces search time. For example,
Figure 1 shows that both
and
have wastefully explored most of the blocked areas identified in
Figure 2a. By comparison,
Figure 2b,c show the potential of using the blocked areas’ knowledge into guiding both search algorithms to avoid exploring blocked areas and thus significantly reducing the number of visited nodes while performing pathfinding.
To make use of the blocked areas’ knowledge, we propose the following approach. First, a preprocessing algorithm investigates the geometry of obstacles in a grid map and identifies blocked areas. Next, information about blocked areas is stored in a memory-efficient balanced binary search tree, referred to as the BA-tree. During actual pathfinding, a search algorithm accesses the BA-tree to determine if a particular node is inside a blocked area. If so, then this node is not explored, i.e., eliminated from the search space.
An important property of our proposed method is that it does not depend on any specific heuristic function. Instead, it utilizes the geometry of obstacles to eliminate irrelevant parts to the search, i.e., in a sense, it reduces a map to a new (more concise) map that a heuristic search algorithm can investigate at a faster speed using its original heuristic function. Therefore, our method is orthogonal to the search algorithm itself, and hence can be combined with many heuristic search algorithms in the literature. As a proof of concept, in this paper, we present and evaluate our proposed method using
and
search algorithms combined with the octile-distance heuristic. Another important property of our approach is that it preserves the optimality of a search algorithm. We present mathematical proofs of this claim in
Section 4.
In addition, our approach has a small memory overhead because nodes in a grid map need not store any information about blocked areas, which would scale poorly for large maps. Instead, during pathfinding, a search algorithm retrieves this information from the BA-tree, where the memory requirements are bound by a small fraction of nodes in a grid map, as will be explained by
Section 5.
While the concept of blocked areas can be generalized to any obstacle shape, in this paper, we consider maps where obstacles are represented as vertical and horizontal line-segments, which in turn form blocked areas that are polygons. Such cases are commonly found in maps of mazes, buildings and transportation maps.
We evaluate the impact of using the blocked areas’ knowledge for
and
using a publicly available benchmark set that includes sixty maps of mazes and rooms [
6]. Our evaluation shows that the search space (i.e., the number of visited nodes during pathfinding) of
is reduced by 34%, on average, for both mazes and rooms. This results in a significant reduction in search time for both
and
. Specifically, in mazes, the execution times of both
and
were reduced by 10–35% (the average is
). In rooms, the execution times of both
and
were reduced by 5–
(the average is
). Our evaluation also demonstrated that the memory overhead associated with storing blocked areas’ information in memory during preprocessing and the time associated with accessing this information during pathfinding are both small.
The remainder of this paper is organized as follows:
Section 2 surveys related work.
Section 3 provides background information about
and
search algorithms.
Section 4 presents the definition of blocked areas.
Section 5 describes the proposed preprocessing algorithm for finding blocked areas in a grid map.
Section 6 describes the proposed algorithms for constructing and accessing the BA-tree.
Section 7 evaluates the impact of using the blocked areas’s knowledge in reducing execution time for both
and
.
Section 8 concludes the paper.
2. Related Work
Several heuristic search algorithms in the literature, such as and , assume no prior knowledge about maps. However, in many grid-based pathfinding domains, maps have static nature, i.e., their territories remain mostly the same. Examples of such domains are video games and city maps. Therefore, preprocessing approaches where prior knowledge about grid maps are utilized for the purpose of speeding up pathfinding has attracted many researchers due to the amortized runtime overhead (preprocessing needs to be executed only once).
In general, the efficiency of preprocessing approaches for pathfinding depends on the following: (i) the type of knowledge collected; (ii) the runtime overhead of accessing this knowledge during actual pathfinding; and (iii) the memory overhead of storing this knowledge. Below, we survey previously proposed preprocessing methods and describe their difference to our work.
Some researchers proposed preprocessing approaches where optimal paths between all or some nodes are pre-calculated and stored in a database, which is looked up during actual pathfinding [
7,
8,
9,
10]. While pathfinding in these approaches is fast and optimal, in general (despite using compression techniques) memory requirements are huge because memory is proportional to the number of nodes in a map. By contrast, the memory requirement in our work is bounded by the number of blocked areas, which is, in practice, a small fraction compared to the total number of nodes in a grid map.
Other researchers suggested using preprocessing to create an abstraction layer (or multiple layers) for each group of nodes in the map with pre-calculated local paths. During actual pathfinding, a path is found first using the abstract map. This path is then refined in a subsequent step for the original map. The returned path is, however, not guaranteed to be optimal. Examples of such works are [
11,
12,
13].
A related approach to the abstraction method is introduced by [
14], where all shortest paths between all pairs of nodes are abstracted (instead of abstracting each group of nodes in a grid map). This is done using a preprocessing step that identifies all subgoals in a map. A subgoal is a sequence of nodes such that a path between any pair of nodes inside a subgoal is optimal only if it is a part of the optimal path to the next subgoal. During actual pathfinding, an optimal high-level path between subgoals is found first. This path is then refined to an optimal low-level path.
Compared to abstraction-based approaches, our approach does not require any additional refinement steps when performing pathfinding. In addition, it needs not store in memory any knowledge about pre-computed local distances between nodes.
A similar work to ours is the dead-end heuristic [
15], which describes areas that are irrelevant to the current search. During the preprocessing phase, the map is decomposed into smaller areas and a high-level abstract graph with nodes representing those small areas is created. During actual pathfinding, the search is split into two phases. The first phase identifies all nodes in the high-level graph that are relevant to the shortest path (the other nodes are called the dead-end areas). The second phase performs actual pathfinding while avoiding dead areas. Due to using an abstract graph, dead-end heuristic requires an extra step during pathfinding; a step that is not needed in our work.
Another similar work to ours is [
16], which uses preprocessing to identify swamps, a collection of nodes that can be skipped during optimal pathfinding. Conceptually, swamps and blocked areas have the same definition. In addition, similar to our work, swamps require no additional refinement steps during search time. However, unlike our work, each node in a map is required to store an identifier that tells which swamp this node belongs to so that, during pathfinding, search for nodes inside swamps is blocked. Our approach also blocks search inside the blocked areas, however, without requiring nodes to store blocked areas’ identifiers (which would be memory-inefficient in large maps). Instead, this information is retrieved from a memory-efficient binary search tree data structure during pathfinding.
Similar to
and
, there are also other heuristic search algorithms in the literature that assume no prior knowledge about maps, such as the Explicit Estimation Search [
17] and Jump Point Search [
18] algorithms. Our work is complementary to those algorithms, i.e., pre-computed knowledge about blocked areas can be combined with those algorithms to reduce search time. As a proof of concept, this paper evaluates the impact of blocked areas’ knowledge on reducing search time for the
and
algorithms.
The Grid-Based Path Planning Competition (GPPC) [
19] was introduced in 2012 to facilitate comparing different search algorithms using a standard set of maps, some of which were created artificially and others were taken from commercial video games [
6]. We use sixty available maps of mazes and rooms from the same set to evaluate the proposed approach in this work. Details of the competing algorithms in the GCCP are summarized by [
20].
A noticeable related field to our work is route planning in transportation networks, in which preprocessing techniques have been proposed to find the shortest paths in road networks [
21]. Some of these techniques have also been used in the context of grid-based pathfinding. For example, in the GCCP’15 contest, a route planning approach based on the contraction hierarchies (CH) algorithm [
22] achieved competitive performance. During a preprocessing phase, the CH algorithm uses a node contraction method to augment the shortest paths between each pair of nodes in a graph with shortcuts. During actual pathfinding, the search makes use of these shortcuts to reduce the execution time.
3. Background
In this paper, a grid map is represented as a 2D array of points (or nodes), where each node is identified by
x and
y coordinates. In addition, each node has a flag to indicate if it is either an obstacle or a non-obstacle node. For a given node
n,
is the set of non-obstacle nodes that are reachable from
n via a single movement, which can be vertical, horizontal or diagonal. Consider node
, the movement cost from
n to
m is represented by the function
c(
n,
m):
Algorithm 1 shows the pseudo code for the classical algorithm, which finds the shortest path between a source node s and a goal node g in a grid map G. is a best-first search algorithm that gradually expands nodes along the way from s to g while prioritizing exploring node with better heuristic scores. When expanding a node q, the algorithm defines the following four values: gscore(q), which is the distance from the source node s to q; hscore(q), which is the algorithm’s “guess" of the distance from q to the goal node g; fscore(q) = gscore(q) + hscore(q), which represents the priority of q in the search; and (q), which is a pointer to the parent of q in the path from s to g.
The algorithm maintains two lists: open and closed. When expanding a node, it is put in the open list. Nodes in the open list are then iteratively explored by their increasing order of fscore. A node that has been explored is removed from the open list and is put in the closed list so that it is not explored again. When the goal node is found, the search terminates and the path is constructed by recursively following the parent pointers from the goal node to the source node.
The optimality of
is only guaranteed if the heuristic function is admissible, i.e., estimated distance by
hscore(
q) is always less than or equal to the actual distance from
q to the goal node
g [
2]. One simple way of never overestimating
hscore(
q) is always assuming a straight line movement from
q to
g. An example of such a heuristic function is the octile-distance function, which is popularly used in 8-connected grid maps where horizontal, vertical and diagonal movements are allowed. Specifically, the octile-distance from node
q to a goal node
g is equal to the minimum number of diagonal steps, plus the minimum number of either vertical or horizontal steps needed to go from
q to
g. The octile-distance is given by the equation
where
is the number of horizontal steps and
is the number of vertical steps from
q to
g. Note that minimum(
,
) represents the number of diagonal steps from
q to
g.
| Algorithm 1 pathfinding |
- Input:
Grid map G with a source node s and a goal node g - Output:
The shortest path between s and g in G
⇐ list ⇐ list add s into with gscore(s), fscore(s) = hscore(s), (s) while is not empty do get and remove node with minimum fscore from if then return path from s to g end if add n into for each node and do gscore ⇐ gscore(n) + c(q,n) if then add q into with gscore(q) = gscore, fscore(q) = gscore(q) + hscore(q), (q) else if gscore < gscore(q) then update q in with gscore(q) = gscore, fscore(q) = gscore(q) + hscore(q), (q) end if end for end while return
|
has the same pseudo code in Algorithm 1 with only one modification: it calculates
fscore(
q) =
gscore(
q) +
×
hscore(
q),
. As previously explained, this simple yet elegant modification adds a stronger greedy nature of the search algorithm that leads it to finding a path more quickly, albeit being a sub-optimal path. It is proven that the cost of the sub-optimal path found by
is bounded by
× the cost of the optimal path [
2].
The speed at which the algorithm, as well as the algorithm, finds a path is affected by the quality of its heuristic function. For example, if the heuristic function computes an inaccurate estimate of the to-go-distance to the goal node, then the search algorithm will waste time exploring uninteresting nodes, i.e., nodes that are not pertaining to the shortest path. As previously mentioned, in many grid maps, a heuristic function may compute inaccurate distance estimates due to their unawareness of blocked ends created by the geometry of obstacles. To this end, this paper aims to identify areas in a grid map with blocked ends and make use of this knowledge to enable search algorithms to avoid wasting time exploring nodes in such areas.
4. Blocked Area Definition
For a given undirected 2D grid map, a blocked area (BA) is a connected subgraph of adjacent non-obstacle nodes that is bound by a continuous but non-enclosing chain of obstacle nodes. A blocked area’s entrance is the imaginary straight line that connects the two end points of the obstacles’ chain. Intuitively, any path that connects a node inside a blocked area with a node outside the blocked area passes by its entrance.
Given a blocked area A, we define (A) to be the set of all nodes that lie on the imaginary straight line of A’s entrance. As a result that nodes in a grid map are discrete, the imaginary line may not cross the nodes themselves, and instead, cross the squares that are formed by the nodes. Therefore, a more precise definition of (A) is the set of all nodes that lie on the corners of the intersecting squares with the entrance’s imaginary straight line. The remaining set of nodes inside the blocked area are defined as (A). Both of these sets are mutually exclusive, i.e., if node (A), then (A), and vice versa. We also define (A) to be the set of all nodes n such that (A) and (A).
Given the aforementioned definition of a blocked area, all nodes in (A) and (A) must be non-obstacle nodes. Otherwise, A is not a blocked area. Furthermore, due to not having obstacles inside or along the entrance of a blocked area A, the following two properties hold:
- Property 1
There is always a path between a node (A) and a node (A).
- Property 2
There is always a shortest path between two nodes and (A) such that this path does not pass by any node (A).
The main claim of this paper is that blocked areas can be ignored during pathfinding without affecting the correctness and the optimality of a heuristic search algorithm. In below, Lemma 1 proves the correctness claim by showing that there is always an alternative path to any path that passes by a blocked area in a grid map. Lemma 2 proves the optimality claim by showing that there is an alternative path that is also optimal.
Lemma 1. Consider a blocked area A and a pair of nodes s and g that are outside A. If there is a path between s and g that passes by an internal node inside A, then there is also another path between s and g that does not pass by an internal node inside A.
Proof. Let (s,g) denote a path between s and g, where s, g∈(A). Additionally, let us assume this path passes by a node (A). In order to prove Lemma 1, we need to show that there is another path, i.e., (s,g), such that n ∉ (s,g).
First, because n ∈ (s,g), we can rewrite (s,g) = (s,n) + (n,g). Next, because (A), both (s,n) and (n,g) cross A’s entrance. Therefore, we can rewrite (s,g) = (s,x) + (x,n) + (n,y) + (y,g), where nodes x and (A). Note that (x,n) and (n,y) exist (Property 1). Next, because x and (A), (x,y) exists such that (x,y) (Property 2). Therefore, we can construct a new path (s,g) such that (s,g) = (s,x) + (x,y) + (y,g), where all nodes in (s,x), (x,y) and (y,g) (A). □
Lemma 2. Consider a blocked area A and a pair of nodes s and g that are outside A. If there is an optimal path between s and g that passes by an internal node inside A, then there is also another optimal path between s and g that does not pass by an internal node inside A.
Proof. Let (s,g) denote a path between s and g (s, g∈(A)) such that it passes by a node (A). Additionally, let (s,g) be an optimal path with cost c. From Lemma 1, there is at least one path between s and g, denoted (s,g), such that (s,g). Let be the cost of (s,g). In order to prove Lemma 2, we need to show that = c.
As we showed earlier, we can write (s,g) = (s,x) + (x,n) + (n,y) + (y,g) and (s,g) = (s,x) + (x,y) + (y,g), where nodes x and (A). Let , and be the cost of (x,n), (n,y) and (x,y), respectively. Thus, . To show that = c, we need to show .
First, because c is optimal, . Thus, . Second, due to Property 2, (x,y) is optimal, i.e., it has a less or equal length to (x,n) + (n,y). Therefore, , which leads to . Combining both inequalities, the only possible solution is . □
5. Blocked Area Detection
In this paper, we consider grid maps where obstacle nodes are adjacent to each other such that they form vertical or horizontal line-segments. In such grid maps, blocked areas have polygon shapes with internal non-obstacle nodes and a non-enclosing perimeter of obstacle nodes. The open side of the blocked area’s perimeter represents its entrance.
In a grid map, each line-segment obstacle is represented by two distinct nodes, i.e., = (,) and = (,), which are its end points. A horizontal line-segment obstacle has the same x-coordinate in both of its end points. A vertical line-segment obstacle has the same y-coordinate in both of its end points. We use the notation to refer to a line-segment obstacle.
A vertical and a horizontal line-segment obstacles may intersect in a grid map. To identify such a scenario, we introduce a data structure called corner, which is represented by three distinct nodes v, t and h, where t is the intersection point, v is the end point of the vertical side and h is the end point of the horizontal side. We use the notation to refer to a corner. Note that when a horizontal and a vertical line-segment obstacle intersect, up to four corners with different geometrical shapes can be generated. For example, the intersection + has a single intersection point and four corners with the following shapes: ┌, └, ┐ and ┘.
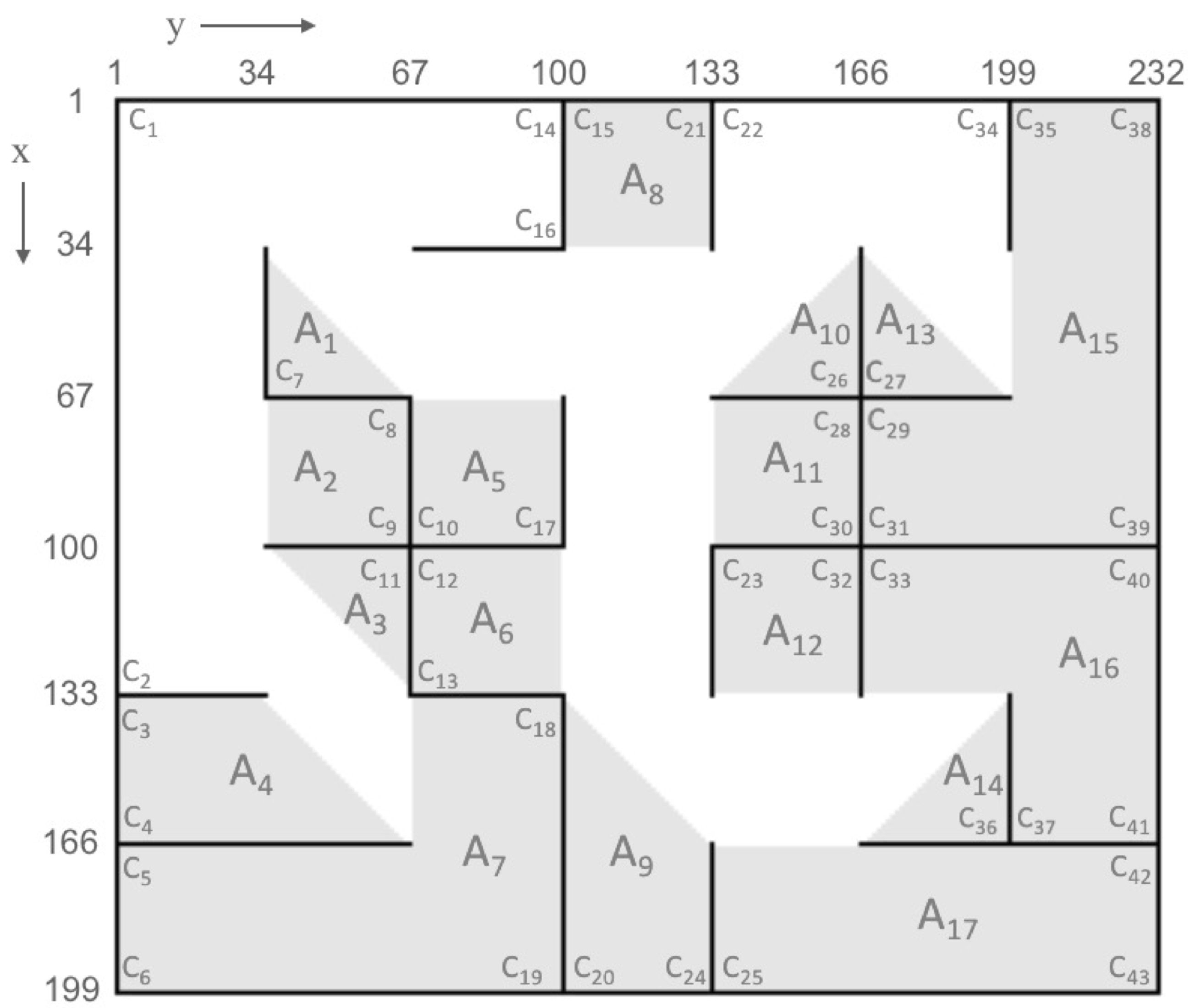
Figure 3 shows an example of a maze with 11 and 13 horizontal and vertical line-segment obstacles, respectively. Those obstacles intersect in 24 different intersection points such that 43 corners are generated. For example, the vertical line-segment (67,67)→(133,67) intersects with the horizontal line-segment (100,34)→(100,100). As a result, the four corners
,
,
and
are generated, where
is represented by (67,67)→(100,67)→(100,34),
is represented by (67,67)→(100,67)→(100,100),
is represented by (133,67)→(100,67)→(100,34) and
is represented by (133,67)→(100,67)→(100,100).
In a grid map, a polygon-shaped blocked area is formed when one or more corners are connected together such that a subset of non-obstacle nodes are bound within a continuous (but non-enclosing) chain of vertical and horizontal line-segment obstacles. For example, in
Figure 3, blocked area
is bound by the continuously connected corners (written in counterclockwise order):
,
,
and
. Similarly, blocked area
is bound by the continuously connected corners:
,
,
,
and
. An interesting case is
, which is a triangular-shaped blocked area that was formed by the single corner
.
A polygon-shaped blocked area is represented by its perimeter joint points, which can be extracted from its corners. For example, consider blocked area
in
Figure 3, which is formed by the corners
,
and
(sorted in counterclockwise order). This blocked area is represented by the five points (166,133)→(199,133)→(199,232)→(166,232)→(166,166). The middle three points are the intersection points of
,
and
, respectively. The first and the last points are the free points in
and
. The entrance is represented by the straight line (166,166)→(166,133).
In general, a polygon-shaped blocked area with s corners (sorted in counterclockwise order): , , …, can be represented by joint points: , , , …, , , where is the intersection point of corner and and are the free points of the two corners and , respectively. The entrance is represented by the straight line between and .
A simple and key observation is the following: a corner can only be in one unique blocked area. In other words, different blocked areas in a grid map have disjoin sets of connected corners. Therefore, to identify blocked areas in a grid map, we propose the following approach. First, identify all corners that result from the intersections between vertical and horizontal line-segment obstacles in a grid map. Then, identify each disjoint subset of corners that belong to the same blocked area. Finally, extract joint points from these disjoint sets to represent each blocked area.
Algorithm 2 presents the pseudo code for a preprocessing algorithm that performs the aforementioned approach. Firstly, in lines 1–2, Algorithm 2 uses the sweep line algorithm [
23] to identify all intersection points between vertical and horizontal line-segments obstacles. The sweep line algorithm is a widely-used method for finding line-line intersections in Euclidean spaces due to its linearithmic performance [
24]. Subsequently, Algorithm 2 extracts all corners from all intersections. Extracting corners from an intersection is straightforward (For brevity, pseudo codes of straightforward functions are not shown.).
Secondly, in lines 3–10, Algorithm 2 identifies which corners are connected. To do so, we propose the Partition and Sort method, which identifies all pairs of connected corners for every horizontal and vertical line-segment obstacle in a grid map. To explain, consider the horizontal line-segment obstacle (100,133)→(100,232), where the intersection points of the corners
,
,
,
,
,
and
are located. Our method first partitions the corners into two sublists: upward corners and downward corners. Upward corners are the corners with their vertical side located upward from the horizontal line-segment obstacle, which include corners
,
and
. Downward corners are the corners with their vertical side located downward from the horizontal line-segment obstacle, which include
,
,
and
. Next, our method sorts the corners in each sublist according to the y-coordinates of their vertical sides so that adjacent corners are next to each other. In the sorted order, each adjacent pair of corners with distinct intersection points are connected. For example, sorting the upward corners will give
,
and
. The first adjacent pair (
,
) are not connected because they have the same intersection point, while the second adjacent pair (
,
) are connected due to having distinct intersection points. Similarly, sorting the downward corners will give
,
,
and
, where only two adjacent pairs are connected: (
,
) and (
,
). Algorithm 3 presents the pseudo code for our proposed Partition and Sort method. Similar to horizontal line-segment obstacles, the Partition and Sort method is applied to vertical line-segment obstacles but while partitioning to left and right (instead of up and down) and sorting by
x-coordinates (instead of sorting by
y-coordinates).
| Algorithm 2 Blocked Area Detection Algorithm |
- Input:
Grid map G with a set of vertical line-segment obstacles V and a set of horizontal line-segment obstacles H. The number of intersections is R and the number of corners is N. - Output:
List of all blocked areas in G
- 1:
, , …, ⇐ SweepLineAlgorithm(V, H) - 2:
, , …, ⇐ extractCorners(, , …, ) - 3:
a union-find data structure with initially N disjoint corners: , , …, - 4:
for each line L in do - 5:
⇐ subset of corners with intersection points in L - 6:
⇐ PartitionAndSort(,L) - 7:
for each pair of corners and in do - 8:
.union( , ) - 9:
end for - 10:
end for - 11:
an initially empty list of blocked areas - 12:
for each disjoint set S in do - 13:
, , …, ⇐ get corners in S - 14:
sort , , …, counterclockwise - 15:
, , , …, , ⇐ extractJoints(, , …, ) - 16:
createBlockedArea(, , , …, , ) - 17:
add A to - 18:
end for - 19:
for each blocked area A in do - 20:
if (A) has obstacle nodes or (A) has obstacle nodes then - 21:
remove A from - 22:
end if - 23:
end for - 24:
return
|
The Partition and Sort method identifies connected corners in pairs. However, a blocked area can have multiple connected corners. To find all connected corners, we propose using a union-find data structure, which is a commonly-used data structure for keeping track of connected components in graphs (Sedgewick and Wayne, 2011). A union-find data structure starts by initially assuming all corners are disjoint and put into separate sets. Then, every time a pair of corners are found to be connected by the Partition and Sort method, union-find data structure unions their sets. By doing so for all pairs of connected corners in a grid map, the union-find data structure will have all connected corners put in the same set. Furthermore, all sets in the union-find data structure are disjoint.
| Algorithm 3 Partition and Sort method |
- Input:
Set of l corners: , , …, with intersection points located on line-segment obstacle L. - Output:
All pairs of connected corners on L
- 1:
⇐ an initially empty list - 2:
ifL is horizontal then - 3:
⇐ an initially empty list - 4:
⇐ an initially empty list - 5:
⇐x-coordinate of L - 6:
for each corner in , , …, do - 7:
⇐ x-coordinate of the vertical end point of - 8:
if then - 9:
add to - 10:
else - 11:
add to - 12:
end if - 13:
end for - 14:
sort corners in and by the y-coordinate of their intersection points - 15:
for each adjacent pairs of corners and in and do - 16:
if and have distinct intersection points then - 17:
add (,) to - 18:
end if - 19:
end for - 20:
else ifL is vertical then - 21:
⇐ an initially empty list - 22:
⇐ an initially empty list - 23:
⇐ y-coordinate of L - 24:
for each corner in , , …, do - 25:
⇐ y-coordinate of the horizontal end point of - 26:
if then - 27:
add to - 28:
else - 29:
add to - 30:
end if - 31:
end for - 32:
sort corners in and by the x-coordinate of their intersection points - 33:
for each adjacent pairs of corners and in and do - 34:
if and have distinct intersection points then - 35:
add (,) to - 36:
end if - 37:
end for - 38:
end if - 39:
return
|
Thirdly, in lines 11–18, Algorithm 2 creates polygon-shaped blocked areas by extracting their perimeter’s joint points from every disjoint set of corners in the union-find data structure.
Finally, in lines 19–23, Algorithm 2 removes all blocked areas that do not satisfy our definition in
Section 4, which stated that all internal and entrance nodes must be non-obstacle nodes. For example, in
Figure 3,
and
form a blocked area. However, this blocked area is discarded because its entrance intersects with the vertical line-segment obstacle (34,166)→(133,166)), i.e., it has obstacle nodes in its entrance. Another example are corners
,
,
and
, which form a blocked area that was discarded because it has internal obstacle nodes.
The detailed description of how Algorithm 2 determines which blocked areas have obstacles in their or sets is not shown but can be explained as follows. As a result that a blocked area’s entrance is a straight line, the sweep line algorithm is used to determine if there is any horizontal or vertical line-segment obstacle that intersects with the entrance of a blocked area A. If so, A is discarded. Additionally, we modify the sweep line algorithm so that it can be used to identify all blocked areas with internal vertical or horizontal line-segment obstacles. Those blocked areas are also discarded.
Lemma 3. The generated set of polygon-shaped blocked areas by Algorithm 2 satisfy the definition given in Section 4, i.e., each polygon-shaped blocked area is a connected subgraph of adjacent non-obstacle nodes that is bound by a continuous but non-enclosing chain of obstacle nodes. Proof. As previously explained, in lines 1–18, Algorithm 2 identifies all non-enclosing polygon shapes of obstacles that represent blocked areas in a map. Then, in lines 19–23, Algorithm 2 determines which non-enclosing polygon shapes have obstacles in their or sets and ensures that they are removed, i.e., not recognized as blocked area. Thus, Algorithm 2 guarantees that each polygon-shaped blocked area in the final output is a connected subgraph of adjacent non-obstacle nodes that are bound by a continuous but non-enclosing chain of vertical and horizontal line-segment obstacles (i.e., obstacle nodes). □
We now present a complexity analysis of Algorithm 2’s execution time. For convenience, let us assume, in a grid map, that is the number of vertical line-segment obstacles, is the number of horizontal line-segment obstacles, R is the number of intersections, N is the number of corners and P is the number of blocked areas. The following inequalities hold:
The maximum number of possible intersections occurs when every vertical line-segment obstacle intersects with every horizontal line-segment obstacle.
Each intersection generates anywhere between one to four corners.
The maximum number of blocked areas occurs when each corner, alone, forms a triangular-shaped blocked area.
Table 1 describes an execution time complexity analysis for Algorithm 2. Authors in [
24] have shown that, for a given Cartesian space with
n line-segments and
k intersections, the sweep line algorithm is bound by
. This explains the upper bounds shown for lines 1 and 19–23 in
Table 1. In addition, note that we use the weighted union-find data structure (Sedgewick and Wayne, 2011), which guarantees that union operations are executed in logarithmic-time. Therefore, in lines 4–10, the most expensive operation inside the loop is the Partition and Sort method. Specifically, let us assume that the number of corners in
is
, the Partition and Sort needs linear time (i.e.,
) to partition the corners and linearithmic time (i.e.,
) to sort the corners. Due to having a loop, the overall execution of the Partition and Sort method is bound by
. Finally, in lines 11-18, the most expensive operation in the loop is the sort operation in line 14. Hence, the overall loop’s execution is bound by
.
By taking into account the above three inequalities, the entire execution of Algorithm 2 is bound by () +N. This shows that the preprocessing time of Algorithm 2 has an efficient linearithmic growth.
By the end of its execution, Algorithm 2 will identify all polygon-shaped blocked areas in a grid map. Each polygon-shaped blocked area is represented by its perimeter joint points, i.e., each blocked area is stored in memory using pointers that point to the nodes located at these joints. Assuming
is the number of joints in blocked area
, the total number of extra pointers needed to store all blocked areas is
. In practice, even for large maps,
J represents a small fraction compared to the total number of nodes in a map. For example, in all of our benchmark set in
Section 7,
J is less than 5.4% of the total number of nodes in the map.
7. Experimental Results
We evaluate the performance by showing the reduction in execution time for both
and
algorithms after combining the knowledge of blocked areas in their search. We perform pathfinding for sixty maps of mazes and rooms taken from the public pathfinding benchmarks library [
6]. The modified algorithms are denoted by
and
. All four search algorithms:
,
,
and
are implemented and compiled using Java SE 8 and all experiments were executed on a Red Hat Enterprise Linux 6 machine with a 2.2 GHz Intel Xeon-E5 processor and a 64 GB DDR3 memory with a speed of 1333 MHz.
Below, we describe, in detail, the implementation of the modified search algorithms and the tested benchmark set. Then, we present the evaluation results.
7.1. Search Implementation
Algorithm 6 shows the pseudo code for the implementation of algorithm. Compared to the standard implementation of (shown in Algorithm 1), Algorithm 6 has two modifications. First, before adding node q into the , the algorithm accesses the BA-tree (in line 14) using the search function presented in Algorithm 5 to determine the blocked area A where q is located. Second, in line 15–17, the algorithm inserts q into the (i.e., included in the search) only if one of the following three conditions are satisfied:
q is not inside a blocked area.
q is inside a blocked area; however, this blocked area also contains the goal node g. This condition ensures that the search never ignores a blocked area where the goal node is located.
q is inside a blocked area; however, this blocked area also contains the parent node of q. This condition is needed in the case that the source node s happens to be inside a blocked area. If so, this blocked area is included in the search.
The aforementioned conditions are checked in the order shown, i.e., condition 2 is only checked if condition 1 is not satisfied and condition 3 is only checked if both conditions 1 and 2 are not satisfied. If none of the three conditions is satisfied, then
q is not inserted into the
list and therefore discarded from the search space.
and
have the same implementations as
and
, respectively, except that they calculate
fscore(
q) =
gscore(
q) +
×
hscore(
q), where
is a real number that controls the inflation of the heuristic function
hscore(
q). In this paper, we set
.
| Algorithm 6 pathfinding |
- Input:
Grid map G with a source node s and a goal node g - Output:
The shortest path between s and g in G
- 1:
⇐ list - 2:
⇐ list - 3:
⇐ the root node of the -tree - 4:
add s into with gscore(s), fscore(s) = hscore(s), (s) - 5:
while is not empty do - 6:
get and remove node with minimum fscore from - 7:
if then - 8:
return path from s to g - 9:
end if - 10:
add n into - 11:
for each node and do - 12:
gscore ⇐ gscore(n) + c(q,n) - 13:
if then - 14:
A ⇐ searchBAtree (q, ) - 15:
if or or searchBAtree ((q), ) then - 16:
add q into with gscore(q) = gscore, fscore(q) = gscore(q) + hscore(q), (q) - 17:
end if - 18:
else if gscore < gscore(q) then - 19:
update q in with gscore(q) = gscore, fscore(q) = gscore(q) + hscore(q), (q) - 20:
end if - 21:
end for - 22:
end while - 23:
return
|
An important note is that a tie may occur when extracting the node with the minimum
f-score in the open list, i.e., there might be multiple nodes that have the same minimum
f-score (line 6). In such a case, ties are broken in favor of the node with the largest
g-score. Such tie-breaking strategy is common in the literature [
29,
30]. We use this strategy in the implementation of all four tested algorithms.
In all four algorithms, the list is implemented using a binary min heap data structure, while the closed list is implemented using a hash table data structure that uses chaining to resolve collisions.
7.2. Benchmark Set
Thirty grid maps of mazes and thirty grid maps of rooms were selected form the public pathfinding benchmarks library to evaluate performance in this paper. A maze’s map consists of corridors with fixed sizes that are randomly scattered. A room’s map consists of squares with fixed sizes that are uniformly distributed with randomly generated doors between every two adjacent rooms (squares). All sixty maps of mazes and rooms have 512 × 512 resolution, i.e., the number of nodes in each row and in each column is 512.
The thirty mazes are divided into three types, each of which has ten maps, which are: maze-8, maze-16 and maze-32, where 8, 16 and 32 are the sizes of the corridors in each type, respectively. Similarly, the thirty rooms are divided into three types, each of which has ten maps, which are: room-8, room-16 and room-32, where 8, 16 and 32 are the sizes of the squares in each type, respectively. The pathfinding benchmarks library also provides, for each grid map, hundreds of test cases with randomly generated source and goal points (called scenarios) for performing pathfinding. We use all of these scenarios in our evaluation (however, we discard invalid scenarios where either the source or the goal node is an obstacle).
Table 2 summarizes the evaluated benchmarks set. In all sixty maps, obstacles are represented as vertical and horizontal line-segments. Therefore, in
Table 2, we also include information about the number of horizontal and vertical line-segment obstacles, as well as the number of intersections and corners in every map. All of these measurements are relevant to the blocked area detection algorithm presented in
Section 5.
7.3. Preprocessing Evaluation
Prior to performing pathfinding, in all sixty maps, a preprocessing step is executed to identify all blocked areas (using Algorithm 2), and then construct the BA-tree (using Algorithm 4). In some maps, some of the identified triangular-shaped blocked areas are small, i.e., they have one side with short length. As an optimization, such blocked areas were discarded because they are not useful during actual pathfinding. In all maps, preprocessing time was less than 300 milliseconds.
Table 3 presents an evaluation of the preprocessing step by showing the following measurements: (i) the number of blocked areas (
); (ii) the percentage of nodes covered by those blocked areas (
insideBA%); (iii) the percentage of nodes stored in memory due to blocked areas (
joints%); (iv) the size of the BA-tree, i.e., the total number of tree nodes used to construct the BA-tree (
); and (v) the worst-case number of searched nodes when accessing the BA-tree (
).
In a grid map, the percentage of nodes covered by blocked areas represents an upper bound on the number of nodes that can be eliminated during pathfinding. On average, the percentages of covered nodes in maze-8, maze-16 and maze-32 are , and , respectively. On average, the percentages of covered nodes in room-8, room-16 and room-32 are , and , respectively.
As was previously mentioned in
Section 5, blocked areas are stored in memory using pointers that point to nodes located at the joints of blocked areas.
Table 3 shows that, in the worst-case, the total number of joints in blocked areas is less than
of the total number of nodes in mazes and is less than
in rooms. This demonstrates the memory efficiency of our approach.
While accessing the BA-tree is not part of preprocessing, in
Table 3, we also measure the worst-case scenario of accessing the BA-tree. Specifically, we use the search function in Algorithm 5 to access the BA-tree using every node in a grid map as a search query, and then we report in
Table 3 the worst-case number of how many nodes in the BA-tree were searched. In all sixty grid maps, the worst-case search needed was no more than
nodes in the BA-tree, where
n is the total number of nodes in the BA-tree. This shows that, in practice, the access time of the BA-tree is logarithmic.
7.4. Pathfinding Evaluation
We demonstrate the impact of the blocked areas’ knowledge in pathfinding using two comparisons: (i) versus ; and (ii) versus . We do so by computing the relative execution time, which is a intuitive measurement of the reduction in execution time. For example, let us assume that the execution time of when performing pathfinding for a particular map is 500 milliseconds, while the execution time for when performing the same pathfinding is 300 milliseconds. In this case, the relative execution time is , which demonstrates that the execution time of was reduced by when using the blocked areas’ knowledge in its pathfinding. We also evaluate the reduction in search space, i.e., the reduction in the number of visited nodes during pathfinding, by computing the relative search space.
As shown by
Table 2, our benchmarks set consists of six types of maps, each of which has ten instances. Furthermore, each map instance has hundreds of scenarios. Therefore, we measure performance for each one of the six map types by computing the average relative execution time and the average relative search space for all ten instances combined. Specifically, we use the following formula:
where
is the number of scenarios in map instance
i;
is the execution time when performing pathfinding using
for scenario
j in map instance
i; and
is the execution time when performing pathfinding using
for scenario
j in map instance
i. A similar formula is used for computing the relative search space. Furthermore, the average relative execution time and search space of
over
are computed in the same manner.
Table 4 shows the average relative execution time and search space for the two aforementioned comparisons. In all three types of mazes, on average, the search spaces of both
and
were reduced by
, which translated into a reduction in execution time by
, on average. In room maps, the search spaces of
were reduced by
,
and
, on average, for room-8, room-16 and room-32, respectively. As a result, the execution times were reduced by
,
and
, respectively. In the case of
, on average, the search spaces for room-8, room-16 and room-32 were reduced by
,
and
, respectively. This caused the execution time to be reduced by
,
and
, respectively.
The performance results in
Table 4 can be explained by
in
Table 3, which is the percentage of how many nodes are covered by blocked areas in a map. For example, all three types of mazes have approximately the same coverage percentage (around
, on average). Thus, they have a similar performance in
Table 4. On the other hand, room maps have different
values, which explains their varying performance. For example, room-32, where the coverage percentage is the highest (
, on average), the execution time was reduced by
, on average. However, in the case of room-8, where the coverage is the lowest (
, on average), the execution time was reduced by
, on average.
Appendix A shows absolute execution times for all maps.
The performance results in
Table 4 demonstrates that using blocked areas’ knowledge during pathfinding has significant impact on reducing search time in both
and
. However,
Table 4 hides some of the interesting details about how the benefit of blocked areas’ knowledge compares between short-distance pathfinding versus long-distance pathfinding. For example, in mazes, there are thousands of pathfinding scenarios available from the pathfinding benchmarks library, in which some scenarios have short paths (i.e., path cost is less than 100), whereas some scenarios have long paths with cost up to 2000.
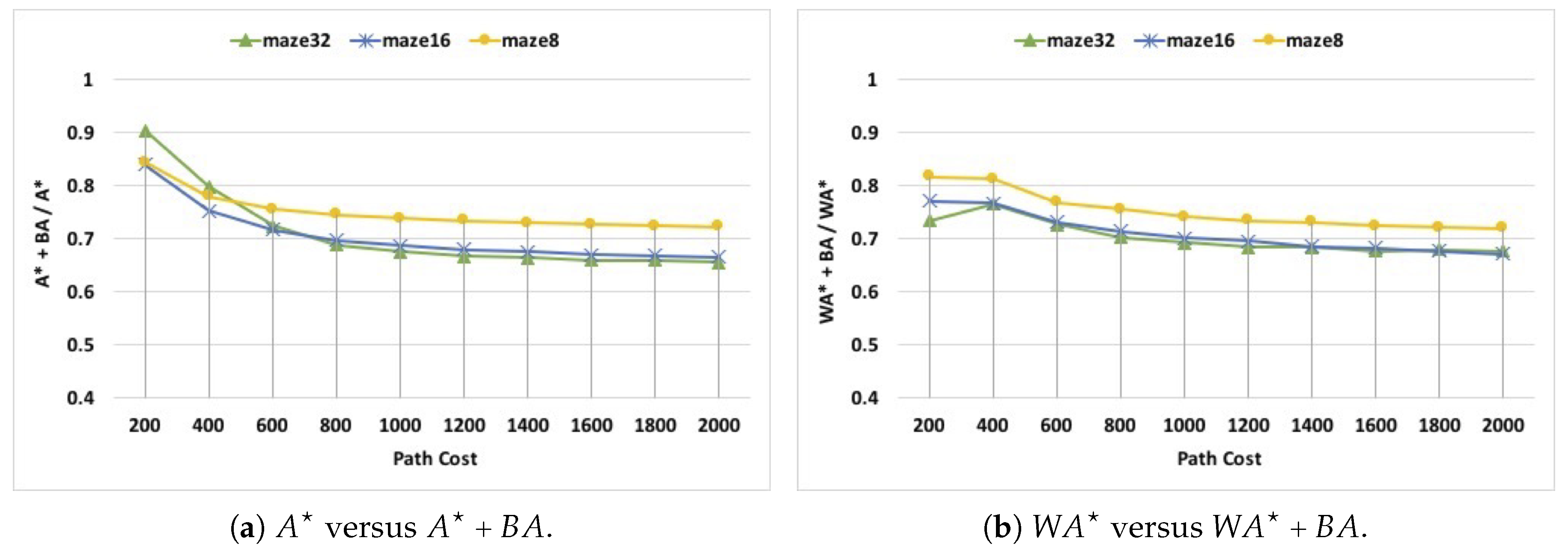
Figure 6 demonstrates the impact of blocked areas’ knowledge on different path costs in mazes. Specifically, in
Figure 6, we divide all scenarios into ten groups, where scenarios in the first group have path costs from 0 to 200, scenarios in the second group have path costs from 200 to 400, scenarios in the third group have path costs from 400 to 600 and so on. Similarly,
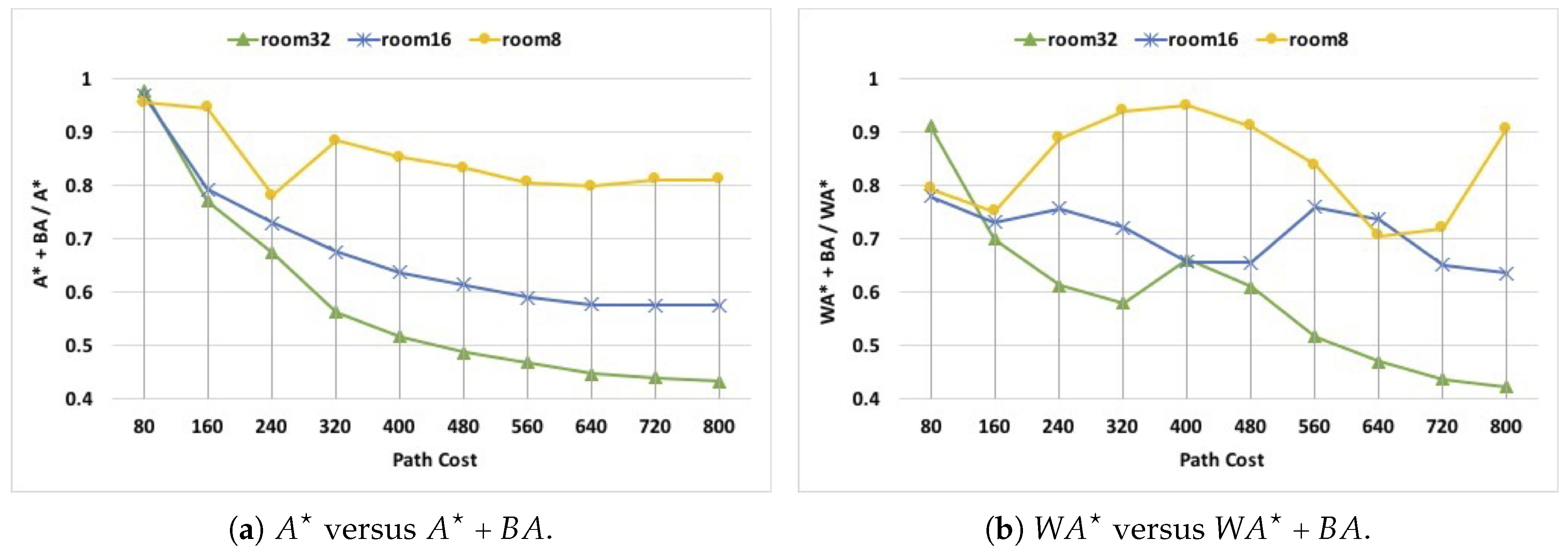
Figure 7 depicts the impact of blocked areas’ knowledge on different path costs in rooms. Note that, unlike mazes, scenarios in room maps have path costs that are between 0 and 800. Therefore, these scenarios are divided into ten groups, where scenarios in the first group have path costs between 0 and 80, scenarios in the second group have path costs between 80 and 160, scenarios in the third group have path costs between 160 and 240 and so on.
Figure 6 shows that, in all three types of mazes, blocked area’s knowledge has significant but different performance impacts on both short-distance and long-distance pathfinding. Specifically, in
, the execution time is reduced by
for low path costs, and then this reduction steadily improves as the path cost increases, to reach around 35%, for high path costs. In
, the reduction in execution time varies from
in low path costs to
in high path costs.
Figure 7 shows that, in all three types of rooms, the impact of blocked area’s knowledge on performance is mostly significant in both short-distance and long-distance pathfinding. However, this impact differs across different room types. In
, in the case of room-32, the reduction in execution time starts from a moderate
, and then sharply improves as the path cost increases to reach
for paths with high costs. In room-16, the reduction in execution time starts from
in low path costs and quickly increases to reach
in high path costs. In room-8, the reduction in execution time gradually increases from
in low path costs to
in high path costs. In
, the performance behavior is less deterministic, i.e., in some cases the reduction in execution time decreases as the path cost increases. However, this nondeterminism varies in degree between different types of rooms. In room-32, the reduction in execution time starts form
for low path costs and then sharply improves to reach
in high path costs (with the exception of one case). In room-16, the reduction in execution time varies between
and
while having less consistent behavior. In room-8, the reduction in execution time varies between
and
while also having no consistent trend in performance.
We summarize the results of our evaluation of pathfinding in mazes and rooms as follows. In all three types of mazes, in general, the execution times of both and were reduced by 10– (the average reduction is ). In all three types of rooms, in general, the execution times of both and were reduced by 5– (the average reduction is ). Unlike mazes, different room map types have significantly different degrees of how many nodes are covered by blocked areas, which led to having different performance behaviors.
Finally, it is worthwhile to mention that eliminating nodes inside blocked areas during pathfinding often led
to find a different path from the one found by
. However, in all maps and in all scenarios, both paths had the same optimal cost (as was also proven in
Section 4). In the case of
and
, both algorithms found sub-optimal paths. In most cases, the two paths obtained by both algorithms have the same cost. However, interestingly, in some cases, we observed that
found paths with lower costs than
. This is because the exploration of blocked areas led
in some cases to find a longer path. On average,
reduces the path cost of
by
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






