GRID: GRID Resample by Information Distribution


Abstract
:1. Introduction
1.1. Graph-Based Superpixel Segmentation
1.2. Gradient-Based Superpixel Segmentation
1.3. Background of Seed-Demand Superpixels
2. Grid Sampling-Based Superpixel Segmentation
2.1. Simple Linear Iterative Clustering
- For a CIELAB color image with pixels, its element can be described as a 5-dimensional feature vector . Specifically, it is fused by a Lab color feature and a coordinate of 2-dimensional Euclidean space ;
- A set of evenly distributed seeds are sampled on the image plane , where is a user-specified parameter to expect the number of superpixels. Thus, is initially partitioned to a series of regular cells on the image gird with an interval of .
- In the assignment step, each pixel is assigned a label in accordance with the nearest cluster center based on a normalized Euclidean distance measured bywhere is the quotient of maximal and within this cluster to normalize color and spatial proximity, and represents the Euclidean metric;
- During the updating step, a local k-means approach is adopted in a search region based on . This is done to re-compute the cluster center with the feature vectorwhere represents the cluster centered at , is the number of pixels in . This procedure is performed on all cluster regions and are then adjusted to . As a result, all pixels are associated with new labels, and the new centers of all search regions in the next loop are obtained. This step is iterated until it reaches a predefined global termination;
- All disjoint components are merged to their neighboring superpixels by a region growing method, so that the connectivity among superpixels can be enforced heuristically.
2.2. SLIC-like Superpixel Segmentation
- It adopts a grid sampling strategy to distribute the incipient seeds during the initialization step. Therefore, the joint color–spatial space distance measurement in Equation (1) could both control the size and compactness of superpixels;
- It firstly avoids performing redundant distance calculations by localizing the search region in the assignment step, which reduces the time complexity of k-means from to ;
- It yields desirable adherence to image boundaries, and is faster and more memory efficient than existing methods.
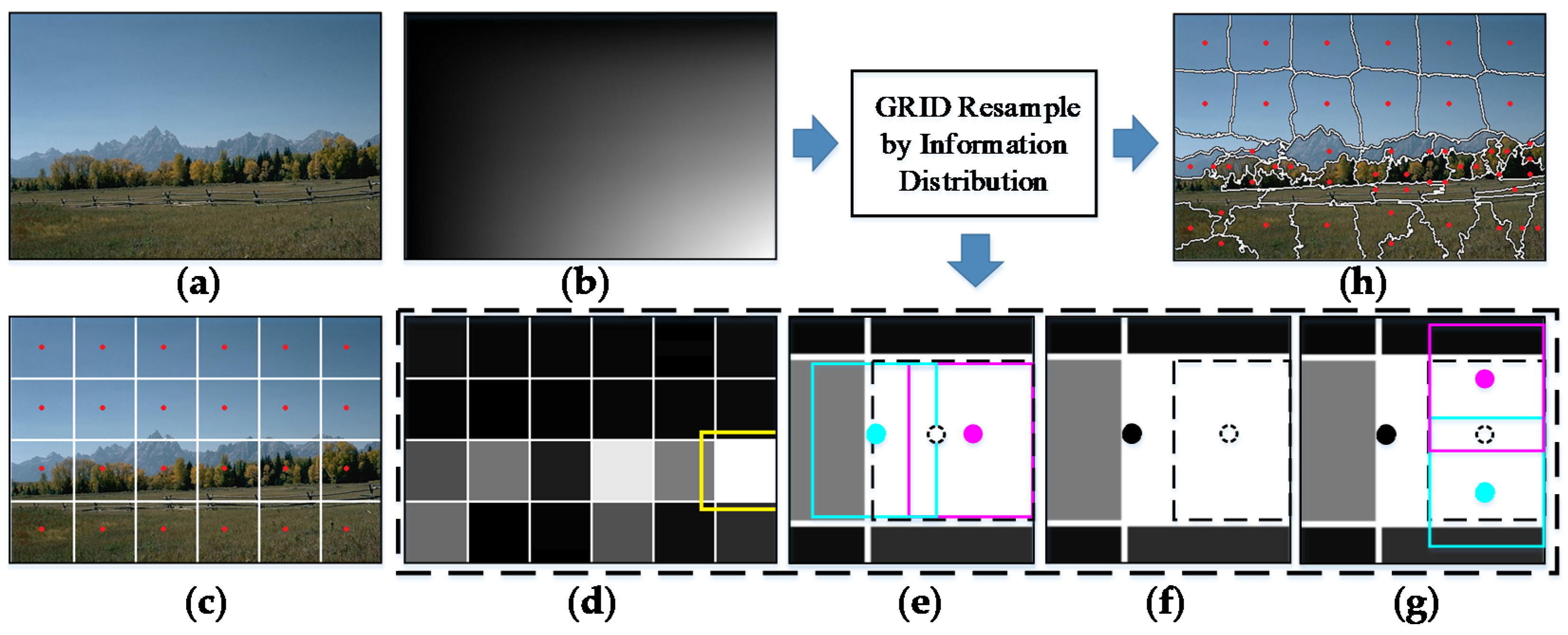
3. Proposed GRID Superpixel Initialization
3.1. Analysis of Grid Sampling-Based Initialization
3.2. Coarse-to-fine Seeds Modification by GRID
- The conventional grid sampling initialization with half the expected number of seeds is performed on the image plane. A set of evenly distributed seeds are sampled as the initial center of clusters.
- The accumulation of lightness difference of all pixels in a region from the center is calculated for simply representing the amount of color information in cellCompared with color dimensions a and b, the lightness L changes strongly in CIELAB color space, which also plays a major role in the color distance in Equation (1). Therefore, it is more efficient than accumulating the 3-channel color difference in Equation (7).
- A priority queue with decreasing order is introduced to hold all , which always returns the maximum element that contains the greatest color information while it is not empty. These three steps are done to roughly establish an ordered distribution of color information for all rectangular cells on a larger scale.
- Followed by recursive modifications on the positions and number of at a more precise level, is acquired by popping the top-most element from , and the corresponding seed is divided into two new seeds and to balance the color information. Specifically, two new sub-regions and are delimited in with 2/3 the area centered at and , respectively, which are also symmetric in the center of . The positions of the two new seeds are collinear with the original seed that minimizes the sum of and .
- The new two seeds are pushed on for balancing the region containing global maximum information in the next loop. These last two steps are repeated till increases to the exact number specified by the user.
| Algorithm 1: GRID resample by information distribution framework |
| Input: the Lab image , the expected superpixel number |
| Output: the seeds set that number of elements is identical to /* Coarse Initialization */ calculate the summed area table of lightness in . initialize the seeds set similar to the conventional grid sampling method. initialize a priority queue with decreasing order. for each seed do calculate the amount of lightness information of the corresponding cell by Equation (9). create a vector node . push the node on . end for /* Recursive Modifications */ while the length of is not equal to do pop the top-most node corresponding to from . divide into two new seeds and that contain the minimal . create two vector nodes and , then push on . end while return the seeds set |
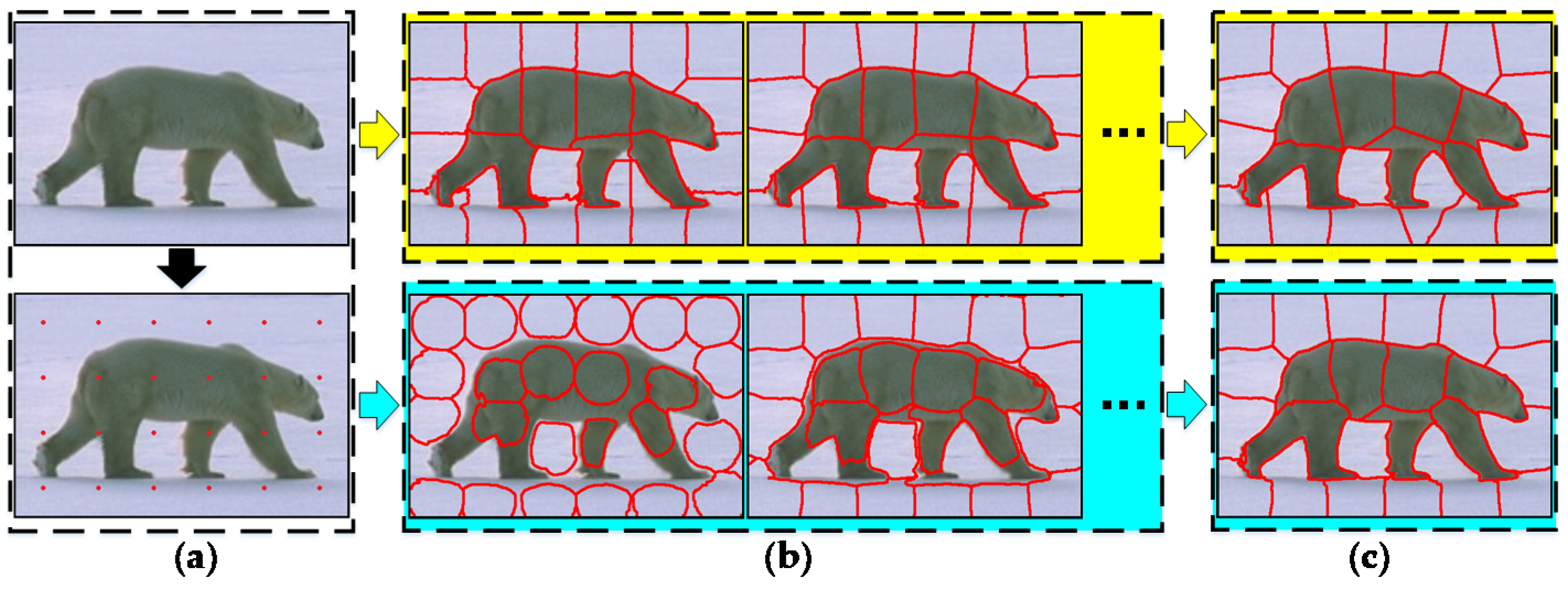
4. Experiment and Analysis
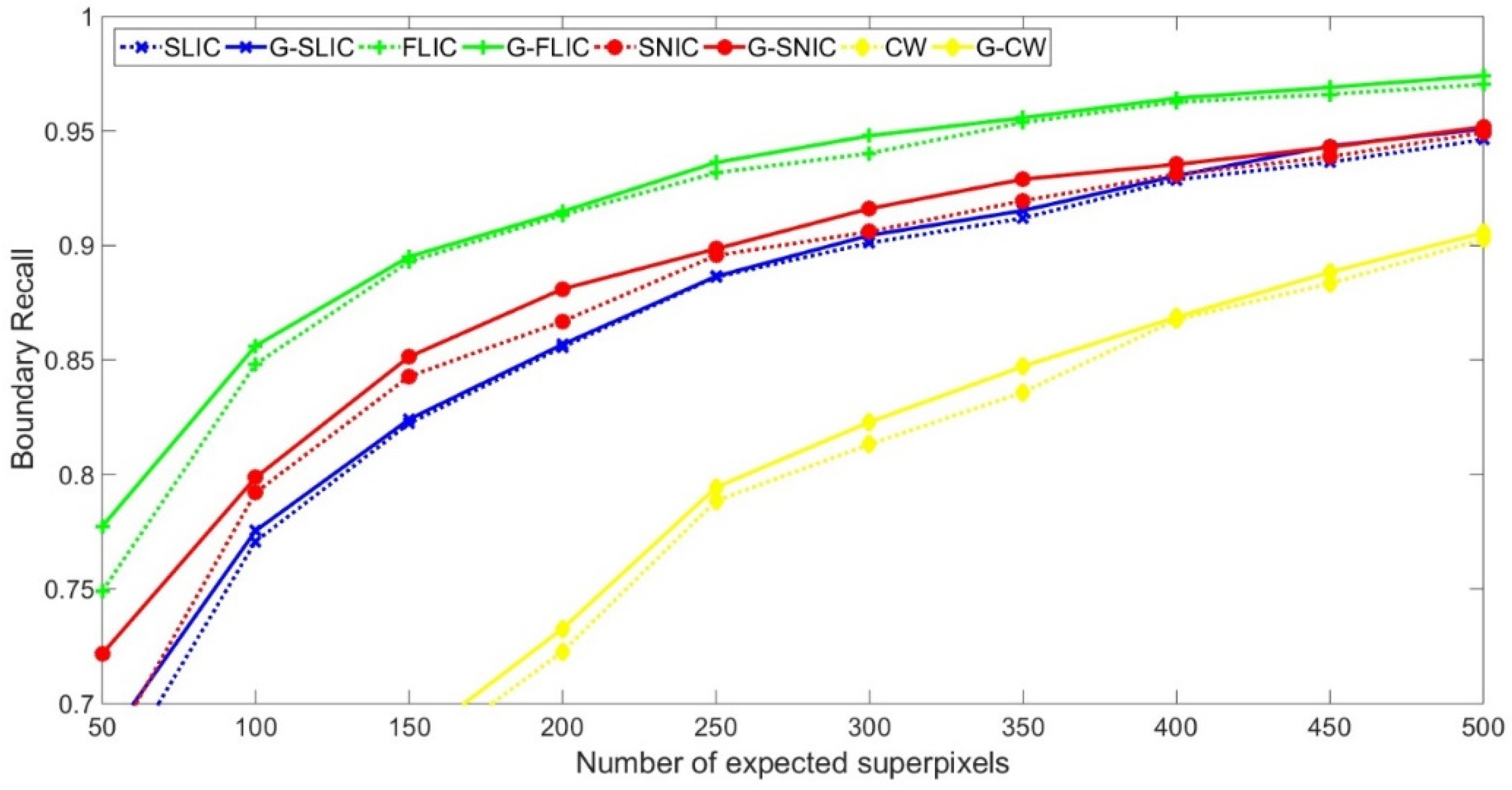
4.1. Quantitative Evaluation by Metrics
4.2. Visual Comparisons of Superpixel Results
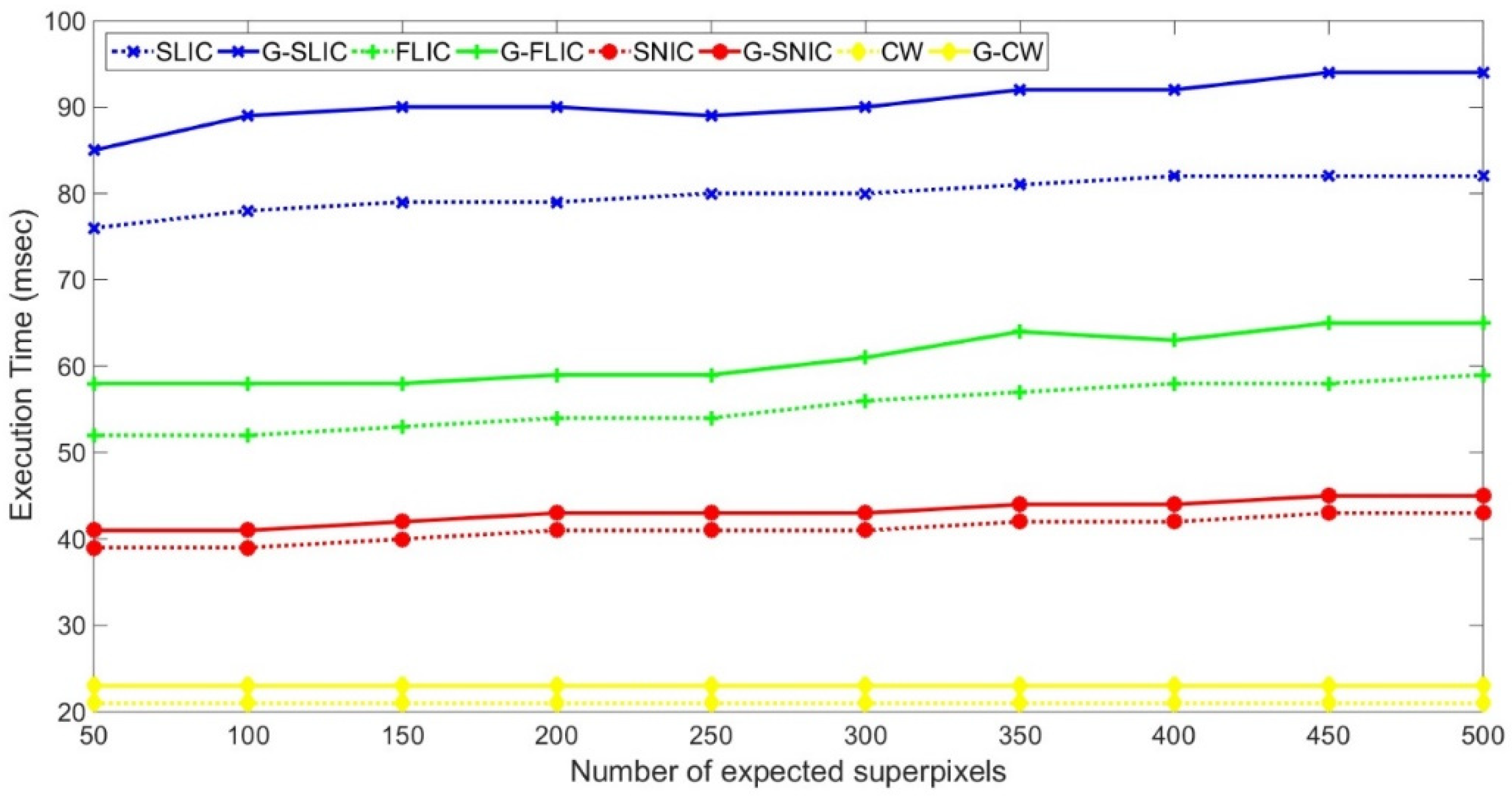
4.3. Analysis of Computational Efficiency
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 10–17. [Google Scholar]
- Lee, K.; Sim, J. Warping Residual Based Image Stitching for Large Parallax. Proceedings of the Computer Vision and Pattern Recognition (CVPR). Available online: http://cvpr20.com/ (accessed on 25 July 2020).
- Yeo, D.; Son, J.; Han, B.; Han, J. Superpixel-based tracking-by-segmentation using Markov chains. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 511–520. [Google Scholar]
- Spampinato, C.; Palazzo, S.; Giordano, D. Gamifying video object segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1942–1958. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, H.; Li, X.; Zhang, L.; Ruan, X.; Yang, M. Dense and sparse reconstruction error based saliency descriptor. IEEE Trans. Image Process. 2016, 25, 1592–1603. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Hou, J.; Ni, Y.; Chau, L. Accurate light field depth estimation with superpixel regularization over partially occluded regions. IEEE Trans. Image Process. 2018, 27, 4889–4900. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Grady, L. Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]
- Shen, J.; Du, Y.; Wang, W.; Li, X. Lazy random walks for superpixel segmentation. IEEE Trans. Image Process. 2014, 23, 1451–1462. [Google Scholar] [CrossRef]
- Kang, X.; Zhu, L.; Ming, A. Dynamic random walk for superpixel segmentation. IEEE Trans. Image Process. 2020, 29, 3871–3884. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef] [Green Version]
- Giraud, R.; Ta, V.; Papadakis, N. Robust superpixels using color and contour features along linear path. Comput. Vis. Image Underst. 2018, 170, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Yu, M.; Li, B.; He, Y. Intrinsic manifold SLIC: A simple and efficient method for computing content-sensitive superpixels. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 653–666. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Hou, Q.; Ren, B.; Cheng, M.; Rosin, P. FLIC: Fast linear iterative clustering with active search. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; pp. 7574–7581. [Google Scholar]
- Achanta, R.; Susstrunk, S. Superpixels and polygons using simple non-iterative clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4895–4904. [Google Scholar]
- Huang, C.; Wang, W.; Wang, W.; Lin, S.; Lin, Y. USEAQ: Ultra-fast superpixel extraction via adaptive sampling from quantized regions. IEEE Trans. Image Process. 2018, 27, 4916–4931. [Google Scholar] [CrossRef] [PubMed]
- Hu, Z.; Zou, Q.; Li, Q. Watershed superpixel. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 349–353. [Google Scholar]
- Neubert, P.; Protzel, P. Compact Watershed and Preemptive SLIC: On improving trade-offs of superpixel segmentation algorithms. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 996–1001. [Google Scholar]
- Machairas, V.; Faessel, M.; Cardenas, D.; Chabardes, T.; Walter, T.; Decencière, E. Waterpixels. IEEE Trans. Image Process. 2015, 24, 3707–3716. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.; Zhou, Y.; Gong, Y. Content-adaptive superpixel segmentation. IEEE Trans. Image Process. 2018, 27, 2883–2896. [Google Scholar] [CrossRef]
- Xu, L.; Luo, B.; Pei, Z.; Qin, K. PFS: Particle-filter-based superpixel segmentation. Symmetry 2018, 10, 143. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Du, Q.; Faber, V.; Gunzburger, M. Centroidal Voronoi tessellations: Applications and algorithms. SIAM Rev. 1999, 41, 637–676. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Guo, B.; Wang, G.; Zheng, Y.; Liu, Y.; He, W. NICE: Superpixel segmentation using non-iterative clustering with efficiency. Appl. Sci. 2020, 10, 4415. [Google Scholar] [CrossRef]
- Meyer, F. Color image segmentation. In Proceedings of the International Conference on Image Processing (ICIP), Singapore, 7–11 September 1992; pp. 303–306. [Google Scholar]
- Achanta, R.; Marquez, P.; Fua, P.; Susstrunk, S. Scale-adaptive superpixels. In Proceedings of the IS&T Color and Imaging Conference (CIC), Vancouver, BC, Canada, 12–16 November 2018; pp. 1–6. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Liu, X.; Gao, Y.; Ma, X.; Soomro, N. Superpixel segmentation: A benchmark. Signal Process. Image Commun. 2017, 56, 28–39. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| The 5-dimensional Feature vector of the element in an image | |
| The Color vector of in a 3-channel CIELAB image space consisting l, a and b | |
| The Position vector of in a 2-dimensional Euclidean space consisting x and y | |
| The priority of pixel in a watershed-based algorithm | |
| The set of excepted seeds in image | |
| The updated set of excepted seeds | |
| The Step size of regular cells in the image grid | |
| A joint spatial–color Euclidean Distance between and in a image plane | |
| The final Label assigned to by a superpixel algorithm | |
| The probability function of color in a multivariate double exponential distribution | |
| The Total information contained in a superpixel region | |
| The Amount of color information in cell | |
| The value of an element in a Summed Area Table |
| User-Expected Superpixel Number | Number of Superpixels Generated by Algorithms without GRID Initialization (SLIC/FLIC/SNIC/CW) | GRID-Based Superpixel Number | ||
|---|---|---|---|---|
| Min Number | Mean Number | Max Number | ||
| 50 | 28/33/40/40 | 41/45/40/40 | 50/67/40/40 | 50/50/50/50 |
| 100 | 69/78/96/96 | 92/101/96/96 | 114/131/96/96 | 100/100/100/100 |
| 150 | 107/119/150/150 | 143/156/150/150 | 168/204/150/150 | 150/150/150/150 |
| 200 | 145/156/187/187 | 185/198/187/187 | 223/257/187/187 | 200/200/200/200 |
| 250 | 198/190/260/260 | 252/243/260/260 | 300/309/260/260 | 250/250/250/250 |
| 300 | 235/221/294/294 | 289/280/294/294 | 354/349/294/294 | 300/300/300/300 |
| 350 | 259/272/330/330 | 324/347/330/330 | 379/425/330/330 | 350/350/350/350 |
| 400 | 323/310/400/400 | 394/401/400/400 | 452/493/400/400 | 400/400/400/400 |
| 450 | 367/331/442/442 | 436/426/442/442 | 487/539/442/442 | 450/450/450/450 |
| 500 | 408/363/504/504 | 496/472/504/504 | 554/595/504/504 | 500/500/500/500 |
| Algorithm | Initialization | Assignment and Updating | Post-Processing | Total Execution Time |
|---|---|---|---|---|
| SLIC | - | 77 | 2 | 79 |
| G-SLIC | 2 | 84 | 4 | 90 |
| FLIC | - | 48 | 5 | 53 |
| G-FLIC | 2 | 50 | 6 | 58 |
| SNIC | - | 41 | - | 41 |
| G-SNIC | 2 | 41 | - | 43 |
| CW | - | 21 | - | 21 |
| G-CW | 2 | 21 | - | 23 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Guo, B.; Huang, Z.; Gong, J.; Han, X.; He, W. GRID: GRID Resample by Information Distribution. Symmetry 2020, 12, 1417. https://doi.org/10.3390/sym12091417
Li C, Guo B, Huang Z, Gong J, Han X, He W. GRID: GRID Resample by Information Distribution. Symmetry. 2020; 12(9):1417. https://doi.org/10.3390/sym12091417
Chicago/Turabian StyleLi, Cheng, Baolong Guo, Zhe Huang, Jianglei Gong, Xiaodong Han, and Wangpeng He. 2020. "GRID: GRID Resample by Information Distribution" Symmetry 12, no. 9: 1417. https://doi.org/10.3390/sym12091417
APA StyleLi, C., Guo, B., Huang, Z., Gong, J., Han, X., & He, W. (2020). GRID: GRID Resample by Information Distribution. Symmetry, 12(9), 1417. https://doi.org/10.3390/sym12091417