
Hyperspectral Image Classification Based on Cross-Scene Adaptive Learning




Abstract
:1. Introduction
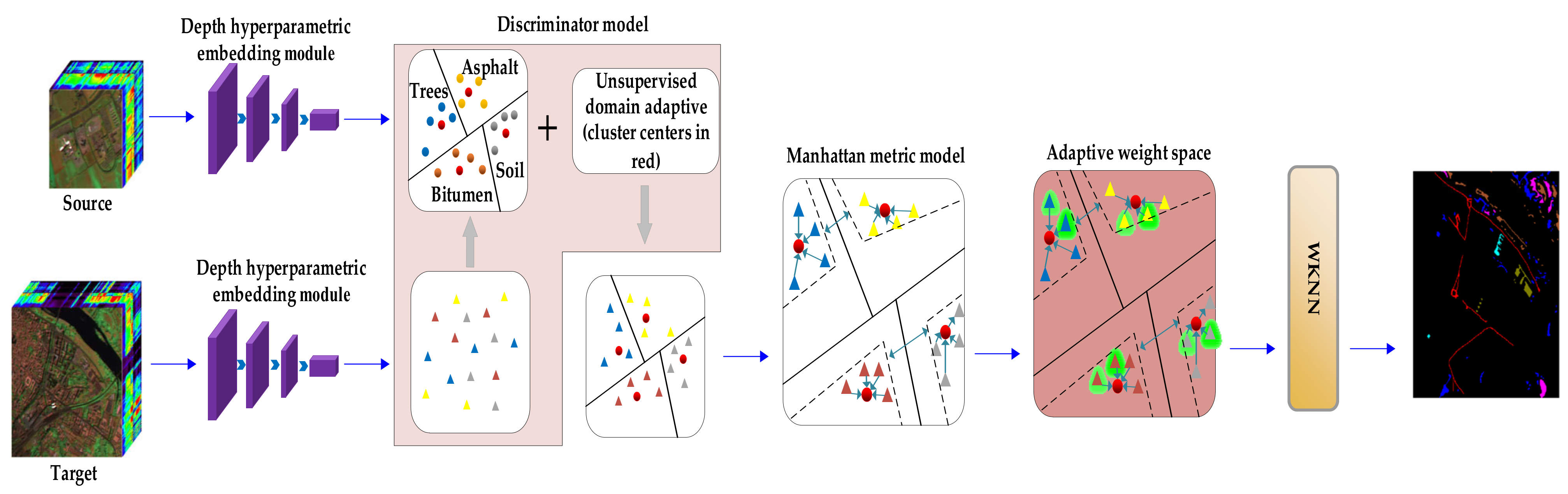
2. The Proposed Methods
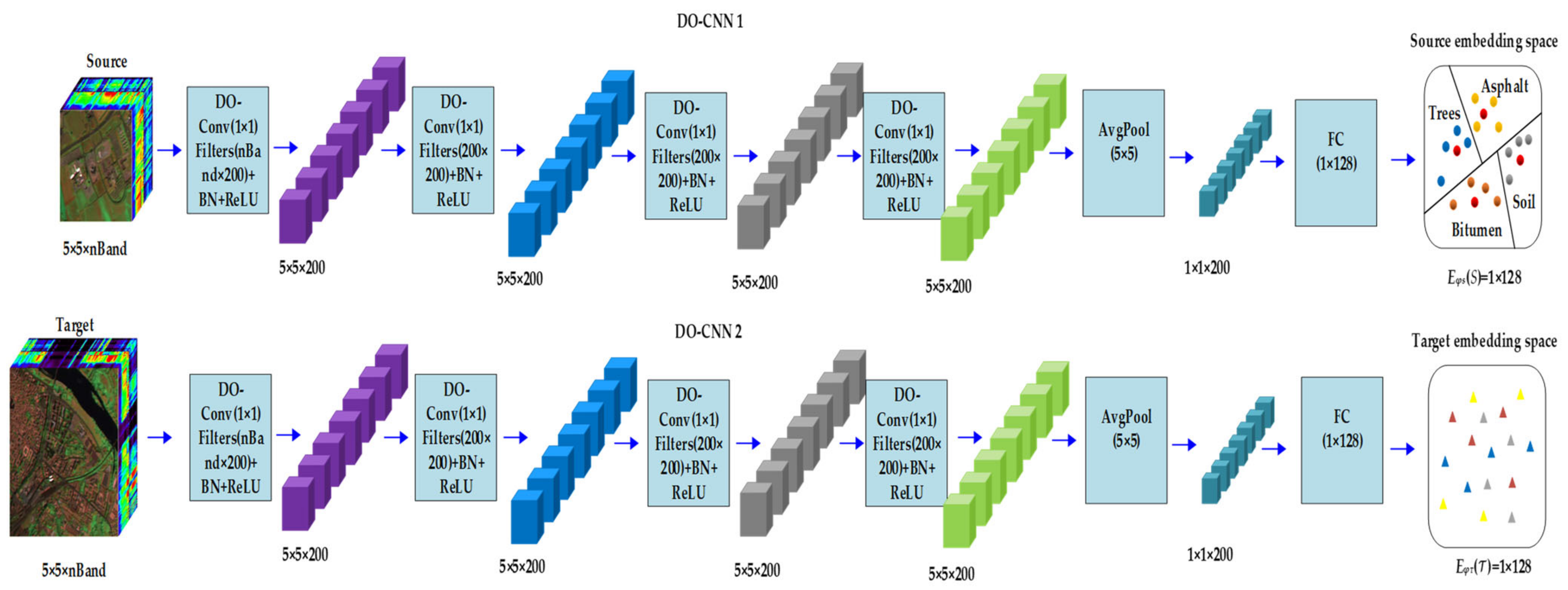
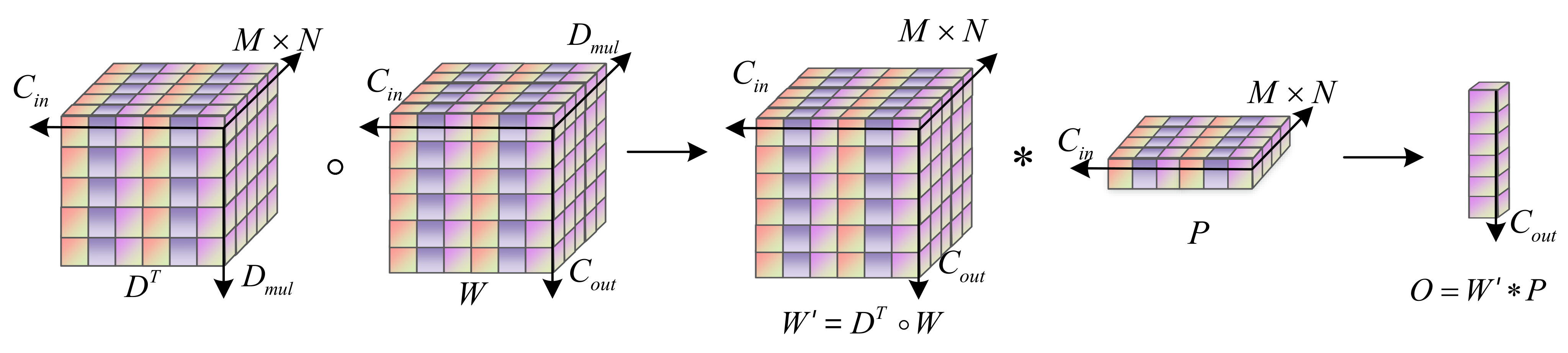
2.1. The Deep Hyperparametric Embedding Model
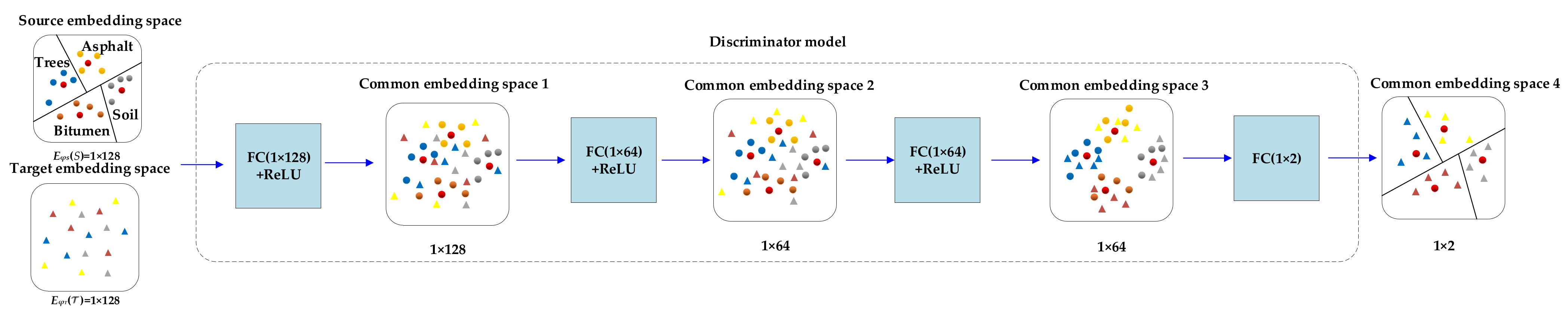
2.2. The Discriminator Model
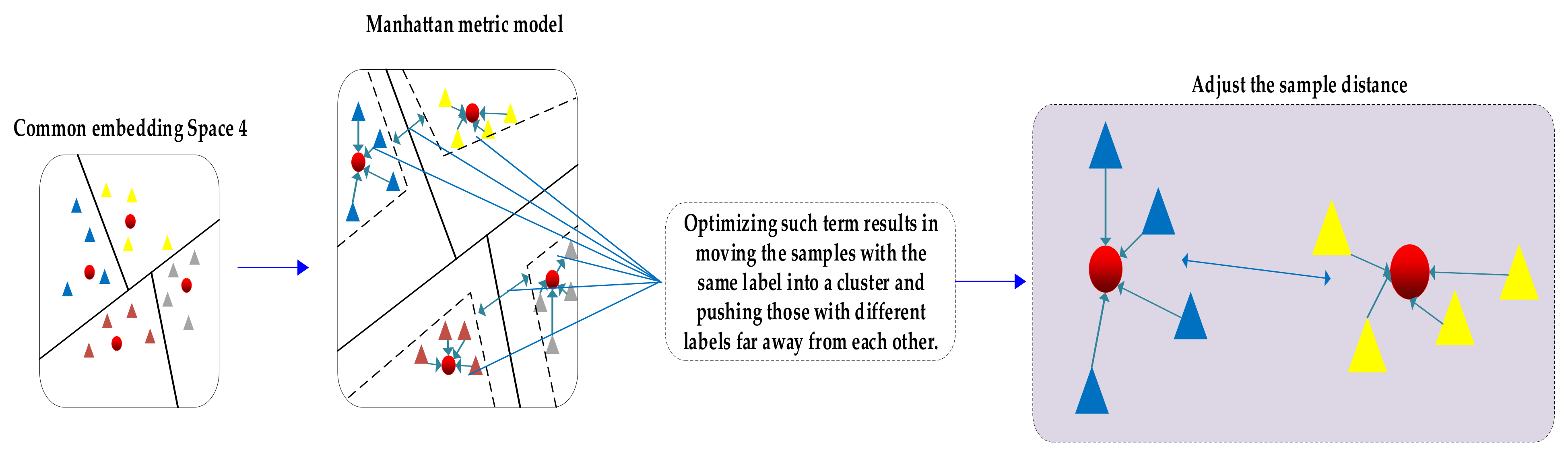
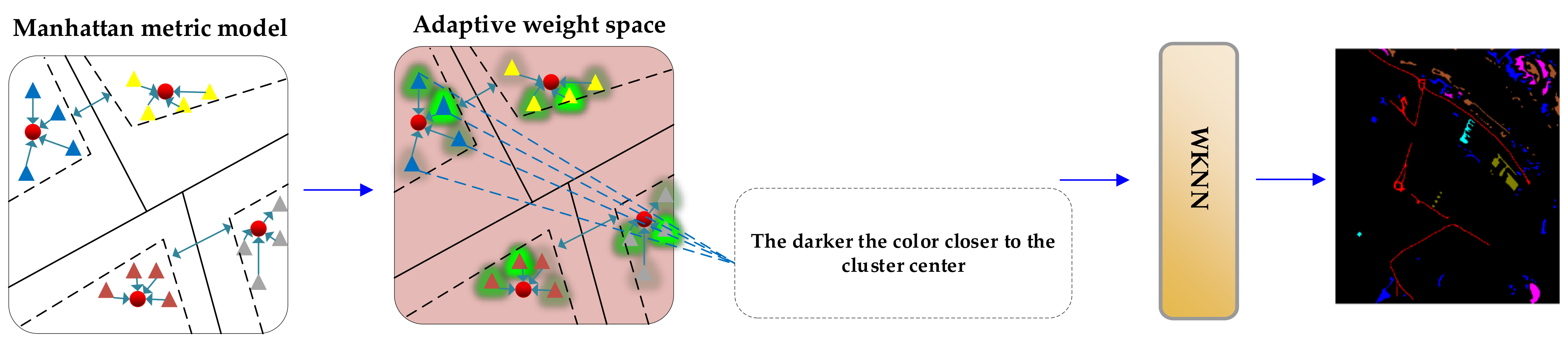
2.3. Manhattan Metric Model
2.4. The Weighted K-Nearest Neighbor
3. Experimental Results and Analysis
3.1. Experimental Datasets Description
3.2. Experimental Platform Parameters Setting
3.3. Comparison Experiments and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bo, C.; Lu, H.; Wang, D. Weighted Generalized Nearest Neighbor for Hyperspectral Image Classification. IEEE Access 2017, 5, 1496–1509. [Google Scholar] [CrossRef]
- Huo, L.; Feng, X. Denoising of Hyperspectral remote sensing image based on principal component analysis and dictionary learning. J. Electron. Inf. Technol. 2014, 36, 2723–2729. [Google Scholar]
- Paul, S.; Poliyapram, V.; İmamoğlu, N.; Uto, K.; Nakamura, R.; Kumar, D.N. Canopy Averaged Chlorophyll Content Prediction of Pear Trees Using Convolutional Autoencoder on Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 1426–1437. [Google Scholar] [CrossRef]
- Jia, Y.; Feng, Y.; Wang, Z. Hyperspectral compressive sensing recovery via spectrum structure similarity. J. Electron. Inf. Technol. 2014, 36, 1406–1412. [Google Scholar]
- Lacar, F.M.; Lewis, M.M.; Grierson, I.T. Use of hyperspectral imagery for mapping grape varieties in the Barossa Valley, South Australia. In Proceedings of the IGARSS 2001. Scanning the Present and Resolving the Future. Proceedings IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No.01CH37217), Sydney, NSW, Australia, 9–13 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 6, pp. 2875–2877. [Google Scholar]
- Gowen, A.A. Hyperspectral imaging—An emerging process analytical tool for food quality and safety control. Trends Food Sci.Technol. 2007, 18, 590–598. [Google Scholar] [CrossRef]
- Rubtsova, N.M.; Vinogradovb, A.N.; Kalininc, P.A. Study of Combustion of Hydrogen—Air and Hydrogen-Methane-Air Mixtures over the Palladium Metal Surface Using a Hyperspectral Sensor and High-Speed Color Filming. Russ. J. Phys. Chem. B 2019, 13, 305–312. [Google Scholar] [CrossRef]
- Voloshin, A.E.; Egorov, V.V.; Kalinin, A.P.; Manomenova, V.L. Cluster Control System in Crystallization Setups for Crystal Growth from Low-Temperature Solutions. Crystallogr. Rep. 2019, 64, 363–365. [Google Scholar] [CrossRef]
- Malthus, T.J.; Mumby, P.J. Remote sensing of the coastal zone: An overview and priorities for future research. Int. J. Remote Sens. 2003, 24, 2805–2815. [Google Scholar] [CrossRef]
- Nepobedimyœ, S.P.; Rodionov, I.D.; Vorontsov, D.V. Hyperspectral remote sounding of the ground. Dokl. Phys. 2004, 49, 411–414. [Google Scholar] [CrossRef]
- Tang, H.; Li, Y.; Han, X.; Huang, Q.; Xie, W. A Spatial–Spectral Prototypical Network for Hyperspectral Remote Sensing Image. IEEE Geosci. Remote. Sens. Lett. 2020, 17, 167–171. [Google Scholar] [CrossRef]
- Bo, C.J.; Lu, H.C.; Wang, D. Spectral-spatial K-Nearest Neighbor approach for hyperspectral image classification. Multimed. Tools Appl. 2018, 77, 10419–10436. [Google Scholar] [CrossRef]
- Li, M.; Zhang, N.; Pan, B.; Xie, S.; Wu, X.; Shi, Z. Hyperspectral Image Classification Based on Deep Forest and Spectral-Spatial Cooperative Feature. Proc. ICIG 2017, 10668, 325–336. [Google Scholar]
- LI, W.; PRASAD, S.; FOWLER J., E. Locality-preserving dimensionality reduction and classification for hyperspectral image analysis. IEEE Trans. Geosci. Remote. Sens. 2012, 50, 1185–1198. [Google Scholar] [CrossRef] [Green Version]
- Samadzadegan, F.; Hasani, H.; Schenk, T. Simultaneous feature selection and SVM parameter determination in classification of hyperspectral imagery using Ant Colony Optimization. Remote Sens. 2012, 38, 139–156. [Google Scholar] [CrossRef]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Cao, H.L.X. Deep Fully Convolutional Network-Based Spatial Distribution Prediction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Rodionova, I.D.; Rodionova, A.I.; Rodionovaa, I.P. Passage of UV-C, Visible, and Near-Infrared Radiation through the Atmosphere. Russ. J. Phys. Chem. B Focus Phys. 2019, 13, 667–673. [Google Scholar] [CrossRef]
- Liu, X.; Yin, X.; Cai, Y.; Wang, M.; Huang, Z.C.B. Visual Saliency-Based Extended Morphological Profiles for Unsupervised Feature Learning of Hyperspectral Images. IEEE Geosci. Remote. Sens. Lett. 2020, 17, 1963–1967. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, K.; Zhu, L.; He, X.; Ghamisi, P.; Benediktsson, J.A. Automatic Design of Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 7048–7066. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Guo, A.J.X.; Zhu, F. A CNN-Based Spatial Feature Fusion Algorithm for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 7170–7181. [Google Scholar] [CrossRef] [Green Version]
- Ge, Z.; Cao, G.; Li, X.; Fu, P. Hyperspectral Image Classification Method Based on 2D–3D CNN and Multibranch Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 5776–5788. [Google Scholar] [CrossRef]
- Zhu, J.; Fang, L.; Ghamisi, P. Deformable Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 1254–1258. [Google Scholar] [CrossRef]
- Yu, C. Hyperspectral Image Classification Method Based on CNN Architecture Embedding with Hashing Semantic Feature. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2019, 12, 1866–1881. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Hou, J.; Li, X.; Du, Q. Learning Sensor-Specific Spatial-Spectral Features of Hyperspectral Images via Convolutional Neural Networks. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 4520–4533. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogramm. Remote. Sening 2018, 145, 108–119. [Google Scholar] [CrossRef]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 3232–3245. [Google Scholar] [CrossRef]
- He, X.; Chen, Y.; Ghamisi, P. Heterogeneous Transfer Learning for Hyperspectral Image Classification Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 3246–3263. [Google Scholar] [CrossRef]
- Yang, F.S.Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar] [CrossRef] [Green Version]
- Rao, M.; Tang, P.; Zhang, Z. Spatial–Spectral Relation Network for Hyperspectral Image Classification with Limited Training Samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2019, 12, 5086–5100. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, J.; Qin, Q. Global Prototypical Network for Few-Shot Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 4748–4759. [Google Scholar] [CrossRef]
- Ye, M.; Xu, Y.; Lu, H.; Yan, K.; Qian, Y. Cross-scene feature selection for hyperspectral images based on cross-domain information gain. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4764–4767. [Google Scholar] [CrossRef]
- Ye, M.; Qian, Y.; Zhou, J.; Tang, Y.Y. Dictionary Learning-Based Feature-Level Domain Adaptation for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 1544–1562. [Google Scholar] [CrossRef] [Green Version]
- Kemker, R.; Kanan, C. Self-taught feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens 2017, 55, 2693–2705. [Google Scholar] [CrossRef]
- Du, B.; Zhang, L.; Tao, D.; Zhang, D. Unsupervised transfer learning for target detection from hyperspectral images. Neurocomputing 2013, 120, 72–82. [Google Scholar] [CrossRef]
- Deng, B.; Jia, S.; Shi, D. Deep Metric Learning-Based Feature Embedding for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 1422–1435. [Google Scholar] [CrossRef]
- Praveen, B.; Menon, V. Study of Spatial–Spectral Feature Extraction Frameworks With 3D Convolutional Neural Network for Robust Hyperspectral Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 1717–1727. [Google Scholar] [CrossRef]
- Ji, S.; Ma, X.; Wang, W.; Yu, L.; Geng, J.; Wang, H. Hyperspectral Image Classification by Parameters Prediction Networks. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3309–3312. [Google Scholar] [CrossRef]
- Cao, J.; Li, Y.; Sun, M. DO-Conv: Depthwise over-parameterized convolutional layer. arXiv 2020, arXiv:2006.12030. [Google Scholar]
- Song, H.O.; Xiang, Y.; Jegelka, S.; Savarese, S. Deep Metric Learning via Lifted Structured Feature Embedding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4004–4012. [Google Scholar] [CrossRef] [Green Version]
- Malkauthekar, M.D. Analysis of euclidean distance and Manhattan Distance measure in face recognition. In Proceedings of the Third International Conference on Computational Intelligence and Information Technology (CIIT 2013), Mumbai, India, 18–19 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 503–507. [Google Scholar] [CrossRef]
- Ma, H.; Gou, J.; Wang, X.; Ke, J.; Zeng, S. Sparse Coefficient-Based k-Nearest Neighbor Classification. IEEE Access 2017, 5, 16618–16634. [Google Scholar] [CrossRef]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 AVIRIS Image North-South Flightline. 2015. Available online: https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html (accessed on 30 September 2015).
- Wang, J.; Ye, M.; Xiong, F.; Qian, Y. Cross-Scene Hyperspectral Feature Selection via Hybrid Whale Optimization Algorithm with Simulated Annealing. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 2473–2483. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indiana Scene | Pavia Scene | |||
|---|---|---|---|---|
| Category | Target Scene | Category | Target Scene | |
| C1 | Concrete/Asphalt | 8.24% | Trees | 30.97% |
| C2 | Corn cleanTill | 16.89% | Asphalt | 21.77% |
| C3 | Corn cleanTill EW | 22.41% | Parking lot | 3.67% |
| C4 | Orchard | 4.38% | Bitumen | 8.75% |
| C5 | Soybeans cleanTill | 13.42% | Meadow | 15.99% |
| C6 | Soybeans cleanTill EW | 4.59% | Soil | 18.85% |
| C7 | Wheat | 30.08% | ||
| Indiana Dataset | Pavia Dataset | |||||
|---|---|---|---|---|---|---|
| Category | Source Scene | Target Scene | Category | Source Scene | Target Scene | |
| C1 | Concrete/Asphalt | 4867 | 2942 | Trees | 266 | 2424 |
| C2 | Corn cleanTill | 9822 | 6029 | Asphalt | 266 | 1704 |
| C3 | Corn cleanTill EW | 11414 | 7999 | Parking lot | 265 | 287 |
| C4 | Orchard | 5106 | 1562 | Bitumen | 206 | 685 |
| C5 | Soybeans cleanTill | 4731 | 4792 | Meadow | 273 | 1251 |
| C6 | Soybeans cleanTill EW | 2996 | 1638 | Soil | 213 | 1475 |
| C7 | Wheat | 3223 | 10739 | |||
| Model | Input | DO-Conv | BN | ReLU | AvgPool | FC Output |
|---|---|---|---|---|---|---|
| Output | Output | |||||
| Parameter | 5 × 5 × nBand | 1 × 1 | Yes | Yes | No | No |
| 5 × 5 × 200 | ||||||
| de | 5 × 5 × 200 | 1 × 1 | Yes | Yes | No | No |
| 5 × 5 × 200 | ||||||
| 5 × 5 × 200 | 1 × 1 | Yes | Yes | No | No | |
| 5 × 5 × 200 | ||||||
| 5 × 5 × 200 | 1 × 1 | Yes | Yes | 5 × 5 | 1 × 128 | |
| 5 × 5 × 200 | 1 × 1 × 200 |
| Class | RBF-SVM | EMP-SVM | DCNN | ED-DMM-UDA | MDDUK | MDUWK | MDDUWK |
|---|---|---|---|---|---|---|---|
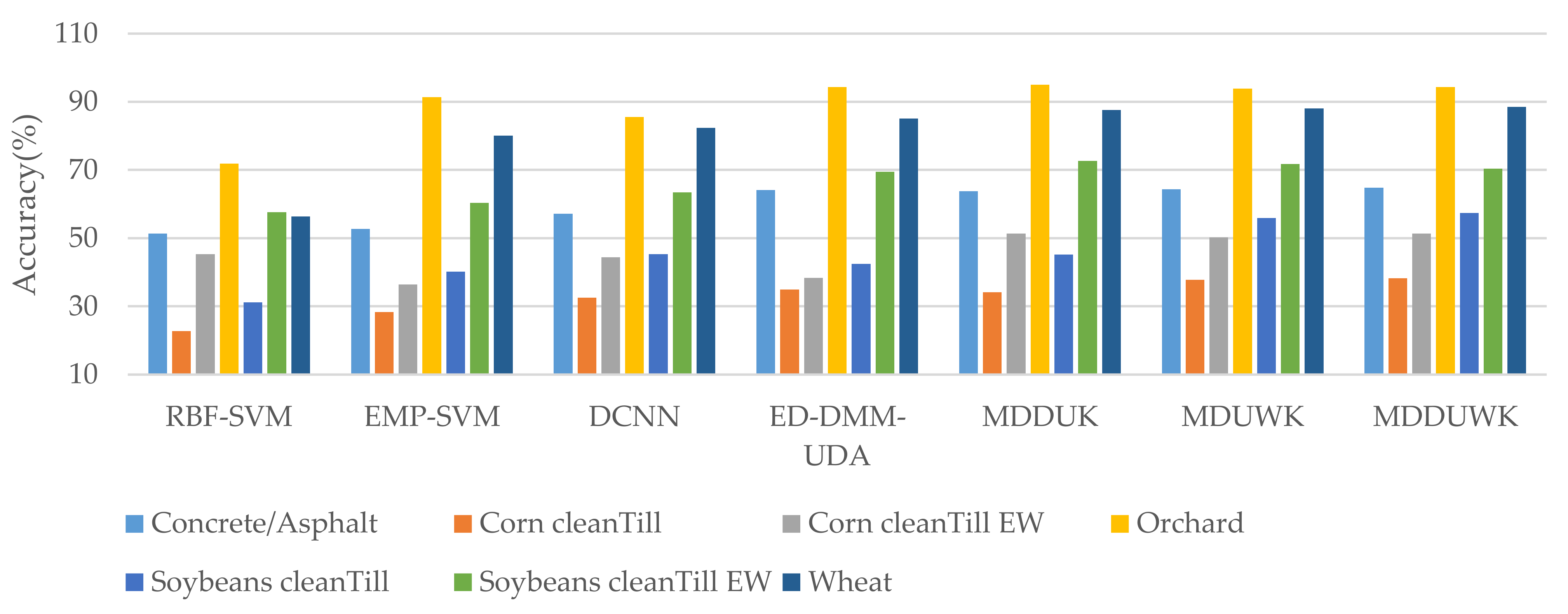
| C1 C2 C3 C4 C5 C6 C7 | 51.34 22.74 45.32 71.85 31.24 57.62 56.43 | 52.73 28.32 36.43 91.32 40.15 60.42 80.14 | 57.13 32.56 44.39 85.51 45.32 63.47 82.36 | 64.13 34.90 38.41 94.36 42.52 69.47 85.09 | 63.83 34.12 51.36 95.07 45.18 72.68 87.65 | 64.31 37.84 50.26 93.82 55.96 71.77 88.09 | 64.77 38.29 51.33 94.31 57.42 70.43 88.57 |
| OA(%) AA(%) K × 100 time(s) | 45.18 48.08 37.42 70.12 | 53.55 55.64 44.73 215.37 | 57.67 58.68 47.92 149.36 | 58.39 61.27 49.76 86.34 | 62.45 64.27 54.17 84.57 | 64.35 66.01 56.64 84.95 | 65.01 66.45 57.38 84.65 |
| Class | RBF-SVM | EMP-SVM | DCNN | ED-DMM-UDA | MDDUK | MDUWK | MDDUWK |
|---|---|---|---|---|---|---|---|
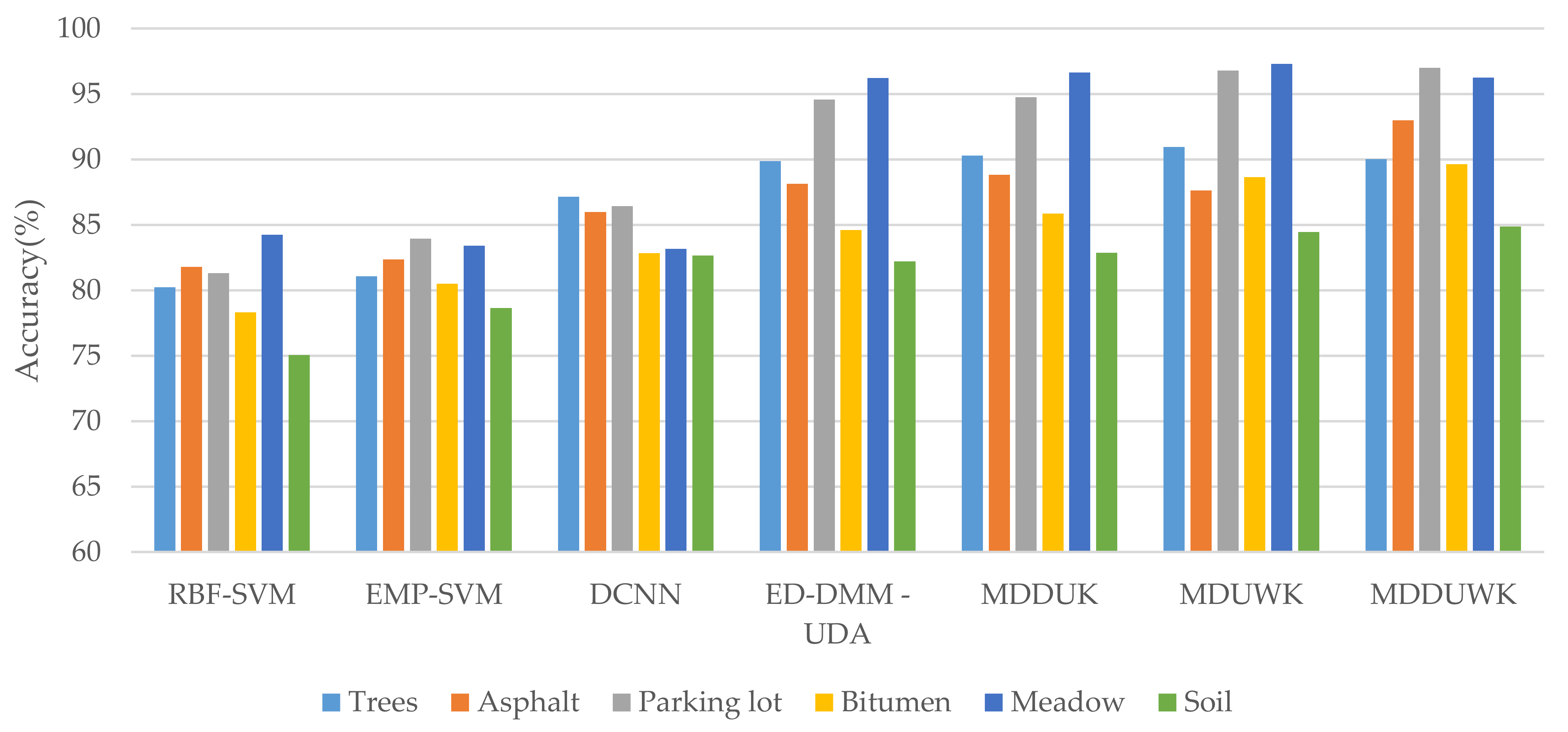
| C1 | 80.24 | 81.06 | 87.13 | 89.86 | 90.30 | 90.95 | 90.02 |
| C2 | 81.78 | 82.34 | 85.99 | 88.14 | 88.82 | 87.62 | 92.99 |
| C3 | 81.32 | 83.94 | 86.43 | 94.57 | 94.76 | 96.78 | 97.00 |
| C4 | 78.31 | 80.51 | 82.84 | 84.59 | 85.85 | 88.63 | 89.62 |
| C5 | 84.24 | 83.41 | 83.16 | 96.21 | 96.65 | 97.29 | 96.26 |
| C6 | 75.06 | 78.65 | 82.65 | 82.21 | 82.85 | 84.45 | 84.88 |
| OA(%) | 80.10 | 81.31 | 84.98 | 88.76 | 89.35 | 90.01 | 90.90 |
| AA(%) | 80.16 | 81.65 | 84.70 | 89.26 | 89.87 | 90.97 | 91.79 |
| K × 100 | 78.32 | 79.13 | 82.15 | 85.83 | 86.58 | 87.41 | 88.52 |
| time(s) | 36.42 | 180.32 | 151.36 | 21.42 | 20.36 | 20.89 | 20.62 |
| Time(s) | RBF SVM | EMP- SVM | DCNN | ED-DMM- UDA | MDDUK | MDUWK | MDDUWK |
|---|---|---|---|---|---|---|---|
| Indiana | 70.12 | 215.37 | 149.36 | 86.34 | 84.57 | 84.95 | 84.65 |
| Pavia | 36.42 | 180.32 | 151.36 | 21.42 | 20.36 | 20.89 | 20.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, A.; Liu, C.; Xue, D.; Wu, H.; Zhang, Y.; Liu, M. Hyperspectral Image Classification Based on Cross-Scene Adaptive Learning. Symmetry 2021, 13, 1878. https://doi.org/10.3390/sym13101878
Wang A, Liu C, Xue D, Wu H, Zhang Y, Liu M. Hyperspectral Image Classification Based on Cross-Scene Adaptive Learning. Symmetry. 2021; 13(10):1878. https://doi.org/10.3390/sym13101878
Chicago/Turabian StyleWang, Aili, Chengyang Liu, Dong Xue, Haibin Wu, Yuxiao Zhang, and Meihong Liu. 2021. "Hyperspectral Image Classification Based on Cross-Scene Adaptive Learning" Symmetry 13, no. 10: 1878. https://doi.org/10.3390/sym13101878
APA StyleWang, A., Liu, C., Xue, D., Wu, H., Zhang, Y., & Liu, M. (2021). Hyperspectral Image Classification Based on Cross-Scene Adaptive Learning. Symmetry, 13(10), 1878. https://doi.org/10.3390/sym13101878