1. Introduction
Diagnostic and Statistical Manual of Mental Disorders 5th ed. (DSM-5) [
1,
2] defined autism spectrum disorder (ASD) as persistent deficits in two areas of development, namely social communication as well as restricted and repetitive behaviors. Children with ASD have a distinct set of deficits but with different levels of severity. Because of this, DSM-5 has divided ASD into three levels of severity based on the support required by children with ASD in their daily lives. These severity levels range from level one to level three, and are known as requiring support, requiring substantial support, and requiring very substantial support, respectively. Children with ASD demonstrate poor social communication skills, as they have deficits in verbal communication, non-verbal communication, and social-emotional reciprocity. Deficits in verbal communication cause children with ASD to exhibit difficulties in understanding spoken language and the use of inappropriate tone of voice during conversation.
In comparison, deficits in non-verbal communication lead to difficulties in understanding the meaning of body gestures, avoidance of eye contact, and inappropriate facial expressions. Furthermore, children with ASD have difficulty deciding when and how to use these nonverbal communication cues. Deficits in social-emotional reciprocity are manifested by difficulties in recognizing their own emotions, expressing their own emotions, recognizing others’ emotions, easily feeling overwhelmed when they are in social situations, and difficulty taking turns during a conversation. Children with ASD also demonstrate restricted and repetitive patterns of behavior, interest, or activities. Deficits in this area are characterized by repetitive body movements and motions, ritualistic behaviors, restricted or extreme interest in specific activities or objects, and obsession with their routine. In this work, information security, a critical aspect of the symmetry concept, has been emphasized because it is very important to protect data for children with ASD. Information security refers to a set of procedures and techniques designed and implemented to prevent unauthorized access, disruption, abuse, or the alteration of private, confidential, and sensitive information or data [
3]. It is an urgent desire in healthcare data [
4]. A sanitizing technique has been implemented in the domain of autism data for information security.
However, the crucial issue in the transmission of autism data is security, privacy, and accuracy, which are more essential for a model or a framework, because many medical data are gathered daily [
5,
6]. Security and privacy are not the same issues at all. Defensive digital security precautions are employed to halt unlawful access to databases, which are known as data security. It includes integrity and availability and emphasizes defending data from malicious attacks or stealing data to make a profit. Moreover, data privacy implies dealing with the capability of a person or an organization to control which types of data through the transmission line should be exchanged, among others. Therefore, it is considered an important issue related to information sharing. Security is vital for protecting data, but it is inadequate to address without privacy.
There are different categories of data related to autism: clinical and screening [
7]. Broadly, these data are medical data (clinical data) involved in health-related information consisting of regular patient care or a clinical trial program partly. An electronic health record is the best form of clinical data, the digital version of a patient’s medical information and history. In addition, electronic versions of record-keeping can ensure the efficiency of coordination and sharing information between sectors such as health, education, and social care [
8,
9]. For example, physiological data on ASD conditions include historical information, specific characteristics, degrees of severity, and associated medical and mental health conditions [
10]. They can also include information about the age at diagnosis, timely monitoring results, and the status of medication prescriptions. Other forms of data are on related intervention and support received by children with ASD. These data consist of speech therapy, occupational therapy, applied behavior analysis (ABA), early intervention, and educational programs.
Moreover, these data can also include details on the frequency and cost of therapy, an Individual Education Plan (IEP), and an Individualized Family Service Program (IFSP). Healthcare data are sensitive data that require additional protection because they come from within a person’s most intimate sphere. Unauthorized disclosure may lead to discrimination and violations of fundamental rights [
11,
12]. For example, these data could be exploited, misused, or misinterpreted for a certain purpose [
10,
13]. Security or authentication systems are often required for an individual that processes and stores medical records [
14,
15]. In addition, many countries have developed standards for a doctor–patient relationship that preserve confidentiality [
16]. These standards protect patients’ dignity and ensure that patients provide accurate information to receive the correct treatment.
There is a growing trend of hacking into healthcare data, because they are an attractive target. Healthcare systems are an easy target for hackers due to their interconnectedness, easily accessible access points, outdated systems, and a lack of emphasis on cybersecurity [
13]. Hackers steal health information because they can make money from it [
15]. A single patient file can be sold for a hundred USD [
17], and a complete set of medical credentials can be sold for over a thousand USD [
13,
18]. Personal information stated in healthcare records can be used for opening bank accounts, securing loans, or getting a passport [
19]. Deficits in social communication and behavior, as stated in medical information, mean that the buyers of information can easily act as a person with ASD. They can also use this disability issue to escape from inconvenient situations, and it is hard for authorities to detect them. Due to this circumstance, healthcare data security is a crucial issue.
Various frameworks or models use different techniques, methods, or algorithms that attain accuracy, data security, and privacy issues, such as cost-effective and model-driven application-level frameworks for e-health data transmission using different encrypted and decrypted algorithms, namely, DES, 3DES or TripleDES, AES, Blowfish, IDEA, and RC4. Some researchers utilize various meta-heuristics algorithms such as artificial bee colony (ABC) [
5], particle swarm optimization (PSO) [
20], crow search algorithm (CSA) [
21], glowworm swarm optimization (GSO) [
22], grey wolf optimizer (GWO) [
23], and others. To address the security and privacy problems, some of these investigations use k-anonymity and query. Such approaches need a large amount of time and computer resources. In addition, some of these traditional meta-heuristics algorithms also possess lower solving precision, slower convergence, and worse local searching ability. Moreover, we identified certain critical issues in the existing studies [
5,
6,
24,
25,
26] which we addressed, thus forming the focus of our research contributions. Such critical issues, put in question form, include, but are not limited to, the following:
For how long will the key value be updated during the key generation stage?
The key length will be allocated based on which value?
How are the values of the parameters defined?
What is the key range value?
In addressing the above issues, we applied data sanitization for autism data security for better accuracy, security, and privacy. Data sanitization is a process that disguises sensitive information in order to facilitate database testing and development [
27]. This can be done by overwriting it with similar types of false data while looking realistic. It is essential to protect vulnerable information, and there is an ethical obligation to do that in many countries. There are various data sanitization techniques, such as encryption/decryption, gibberish generation, number variance, shuffling records, substitution, masking data, and NULL’ing Out. We applied an optimal key that is utilized in the data sanitization technique.
However, the objectives of this study can be summarized as below:
First, to propose a data sanitization process.
Secondly, to enhance an optimal key by considering the above issues, which is used in the data sanitization procedure for the security and privacy of ASD datasets.
Finally, to compare the accuracy achieved by our optimal key with the accuracy of other existing security and privacy frameworks.
The paper is structured as follows:
Section 2 analyzes the relevant works on the application of various encryption and decryption algorithms and techniques. In
Section 3, we describe the methodology.
Section 4 and
Section 5 demonstrate the experiments, results, and discussions, respectively, for ASD datasets, including possible solutions. Finally, we conclude this work in
Section 6, along with the future direction.
3. Methodology and Architecture
The goal of this study was to come up with a potential solution or remedy to an issue. Regarding this, the problem addressed was that of yielding optimal keys using the characteristics of meta-heuristics algorithms. We compared many cutting-edge solutions to the problem in order to establish the ideal solution. Accordingly, we identified a research gap regarding the formation of optimal key in those state-of-the-art solutions. We pointed out some significant issues in the introductory section, wherein existing technologies have no definite resolution to the challenges in terms of security and privacy. Consequently, we addressed these critical issues by forming the optimal key in the proper way.
To provide the solution of the problem, the following framework was utilized.
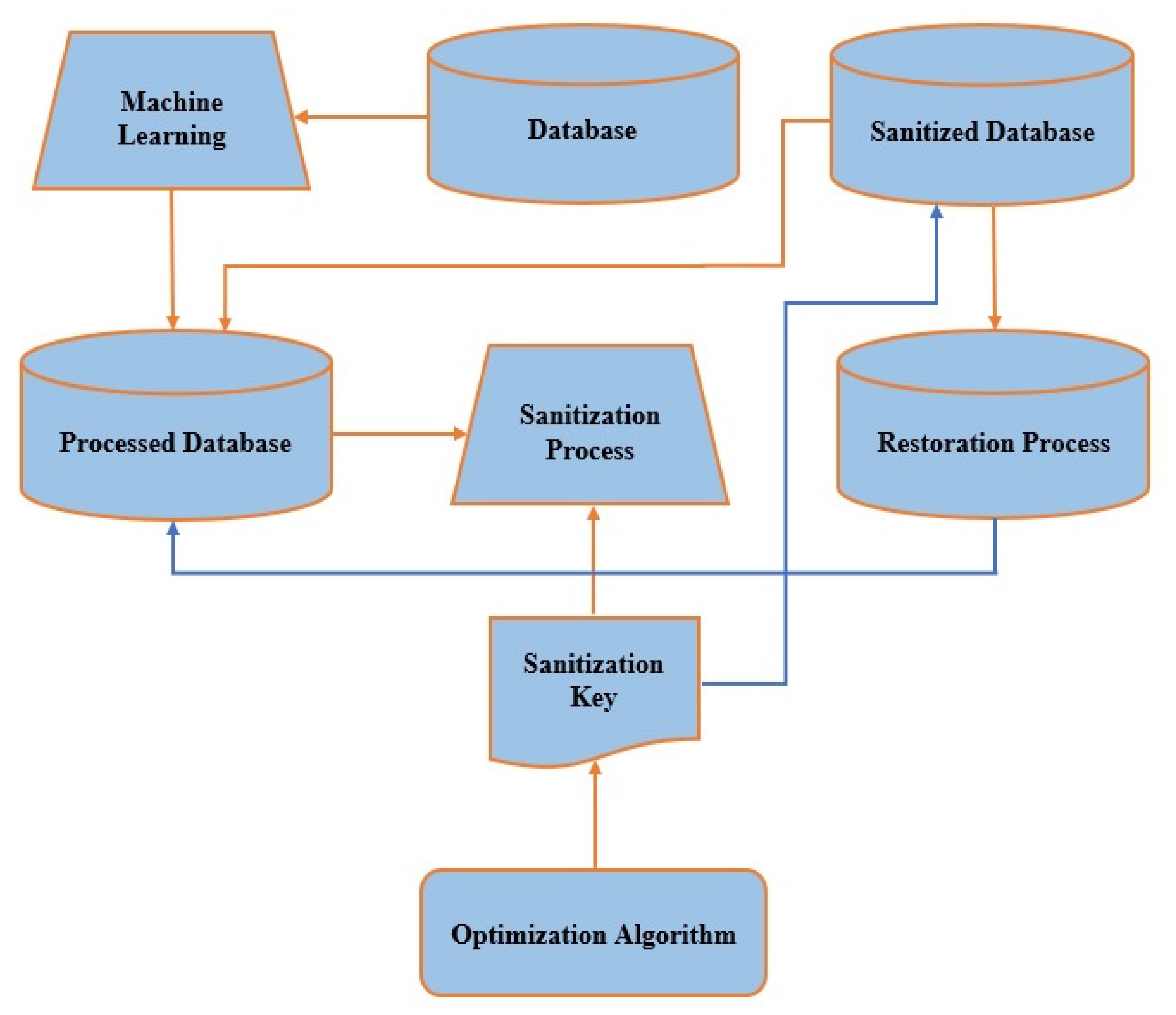
Figure 1 presents the overall architecture of our proposed model, which ensures the security and privacy of autism data and maintains our expected performances.
The different components of the architecture are as follows:
Original Database;
Machine Learning;
Processed Database;
Optimization Algorithms;
Sanitization Key;
Sanitization Process;
Sanitized Database;
Restoration Process.
In this framework, the dark orange arrows represent the sanitization process, which is the focus of this study, and the blue arrows denote the restoration process.
As a security and privacy concern, autism-related sensitive data protection was considered and implemented by means of a data sanitization technique. The major different components of the overall architecture related to the sanitizing purposes have been illustrated below, for concealing the sensitive data related to autism.
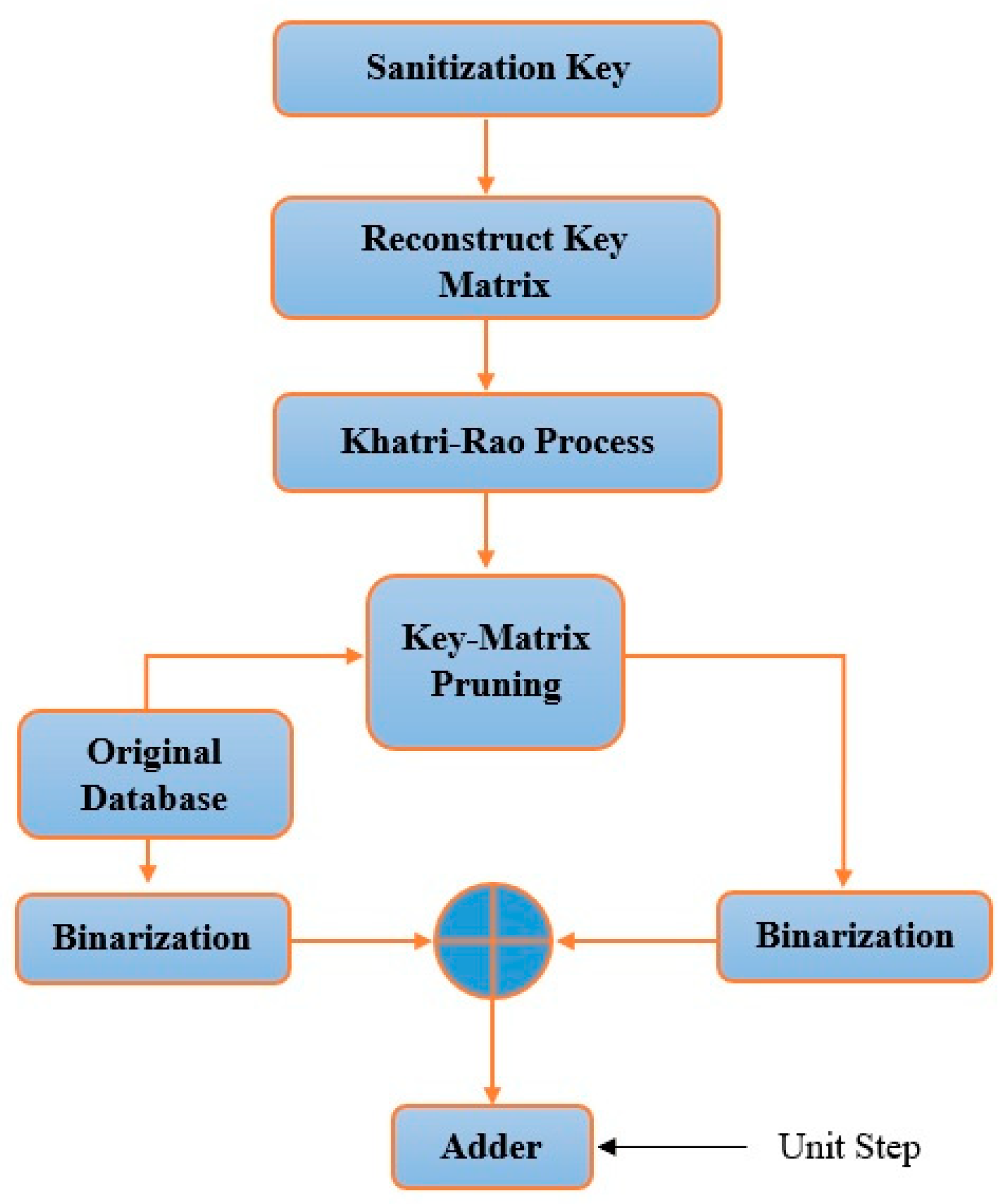
3.1. Sanitization Process
The procedure of the sanitization technique is illustrated in
Figure 2. Here,
D′, a sanitization database, is obtained accompanied by the sanitizing key generated from the processed database during the key generation process. The resulting key matrix,
K2, and
D indicate the pruned key matrix and processed database, respectively, which are binarized to fulfil the XOR function. Processed data
D are obtained from the original database by using machine learning algorithms, so that no blank data, missing data, anonymous data, false data may exist. Following this binary XOR operation, the chance of having ‘0’ is high. Getting such zero values yields insignificant data elements. So, to avoid such zero values, a unit value (one) is added where the + (plus) sign refers to the binary summation. Then, a unit step input is summed up consequently, while
D′ is obtained, as shown in Equation (1).
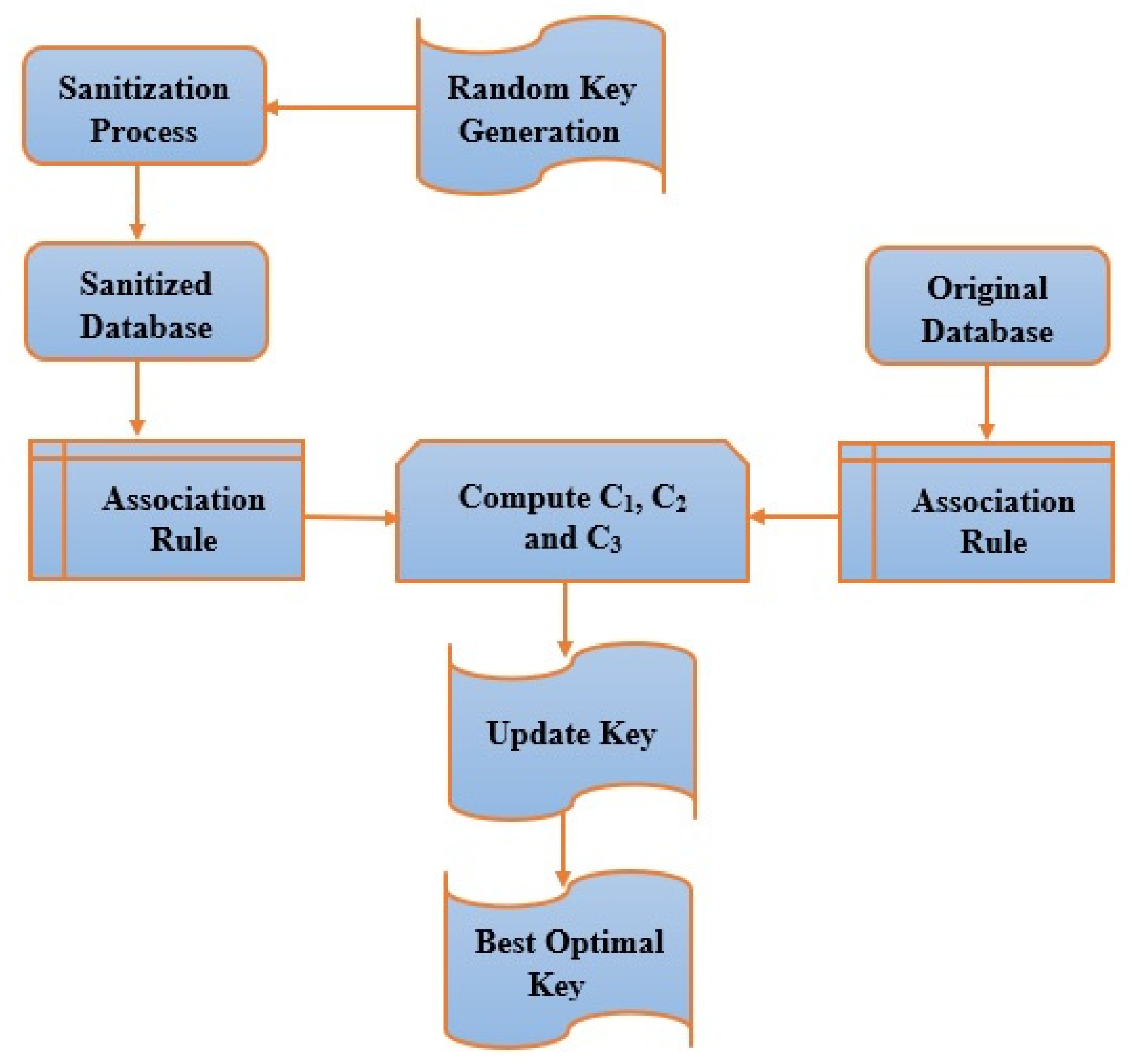
3.2. Sanitization Key Generation
Figure 3 demonstrates the key generation process for sanitization purposes. The optimal key is created with the help of the proposed Enhanced Combined PSO-GWO framework by setting the population of various keys indiscriminately. It is followed by the sanitization process step, through which a sanitized database is obtained. Specifically,
Figure 3 illustrates the key generation process for data sanitization and the restoration process. The proposed Enhanced Combined PSO-GWO algorithm is used at the key update step for obtaining the better key and is performed depending on an iterative loop to obtain the better solution in the process. In the interim, the sanitized database is obtained through the sanitization process. Again, the processed database acquires an association rule and measures the objective functions,
C1, C2, and
C3, respectively. Finally, the key value is updated continuously during this process until the highest termination measure is achieved and the best-desired solution is generated. For this data sanitization process, a key is created optimally by the proposed Enhanced Combined PSO-GWO. The dimension of the chromosome is allotted depending on the value of
. The value fixes the elements, ⌊ 0,
⌋, whereas
D refers to the processed initial database.
3.3. Both Traditional PSO and GWO Algorithms
3.3.1. Traditional PSO Algorithm
In the PSO algorithm, there are three vectors. These are x-vector, p-vector, and v-vector. The x-vector keeps track of the present location for the particle in the searching area, whereas the p-vector (pbest) identifies the position of where the particle has discovered the best solution so far. Moreover, the v-vector incorporates particle velocity, indicating where every other particle will move through the following iteration. At the outset, the particles are randomly shifted in specified directions. The particle’s orientation might be adjusted gradually, and as a result, it began to move in the direction of the prior best location on its own. After that, it explores the surrounding area for the best locations for some fitness functions, fit =
Sm −S. Here, the location of the particle is provided as
∈ Sm, while its velocity is provided as
. Initially, these two variables are picked at random and then updated repeatedly according to two formulae shown in Equation (9)
In this case,
ω, a user-defined behavioral parameter is the inertia weight, which regulates the amount of recurrence in particle velocity. The particle’s previous best position (pbest position) is
, and the particle’s previous best position in the swarm (gbest position) is
; in that way, the particles implicitly interact with each other. This is weighted using stochastic variables
r1,
r2 ∼ U (0, 1), while the acceleration constants are
c1, c2. Regardless of fitness gains, the velocity is added to the particle’s present position to propel it to the next place in the searching area, as shown in Equation (10)
3.3.2. Traditional GWO Algorithm
In the GWO algorithm, there are hierarchical search agents such as level 1 (Alpha), level 2 (Beta), level 3 (Delta), and level 4 (Omega). When the grey wolves hunt their prey, then the characteristic of encircling is expressed mathematically in Equations (11) and (12).
where
u is given the current iteration
and
are referred to as the coefficient vectors. Grey wolves possess a unique skill for detecting the position of prey and encircling it. These grey wolf hunting actions are mathematically reproduced utilizing alpha, beta, and delta wolves’ enhanced awareness of probable prey locations. The first three best solutions are considered, regardless of whether the remainder is required. The mathematical Equations (13)–(15) are provided below:
3.4. The Proposed Enhanced Combined PSO-GWO Algorithm
Despite having good performance, enhancements can be made to traditional algorithms to address the limitations and improve performance. The traditional PSO algorithm demonstrates a few weaknesses, such as lower performance over a wide range of fields. The GWO algorithm also has a few drawbacks: poorer local searching capability, slower convergence, and lower solving precision. Consequently, further analysis is required to improve robustness and integration.
This study implements a new hybrid algorithm for solving those issues. The proposed Enhanced Combined PSO-GWO is elaborated as follows: in this regard, the criteria of the PSO algorithm are implemented in the GWO algorithm. The enclosure of the prey mathematical model, in the suggested method, is provided in Equations (11) and (12), while the mathematical model of the hunting method is shown in Equations (13)–(15). The updating of the location is the main reformation in the suggested model. So, the updating of the location in our Enhanced Combined PSO-GWO model is shown in Equation (16), where
refers to the velocity for the updating of the location of PSO—this is demonstrated in Equations (9) and (10).
Again, c1 and c2 are considered acceleration constants in the traditional PSO algorithm, whereas c1 and c2 fluctuate according to the values 0.1, 0.3, 0.5, 0.7, and 1 in the suggested Enhanced Combined PSO-GWO model. The optimal key selection based on PSO-GWO is presented in Algorithm 1.
| Algorithm 1: Optimal Key Selection through Enhanced Combined PSO-GWO. |
| M j is the Grey Wolf population where j = 1, 2, N. Here, Mα, Mβ, and Mδ denote the best searching agent, 2nd best searching agent, and 3rd best searching agent, respectively. Moreover, e is the components, and H, E are coefficients. The goal of this algorithm is to output the best searching agent, Mα. |
| { |
| Set initial values to the M j |
| Set initial values to e, H, and E also |
| Measure the fitness values of each searching agent, Mα, Mβ, and Mδ. |
| while (u < max) do |
| { |
| for each searching agent, do |
| { |
| Revise the present location of the searching agents using Equation (16) |
| } |
| Revise e, H, and E |
| Assess fitness values for all searching agents |
| Revise Mα, Mβ, and Mδ |
| u: = u + 1 |
| } |
| returnMα |
| } |
5. Results and Discussions
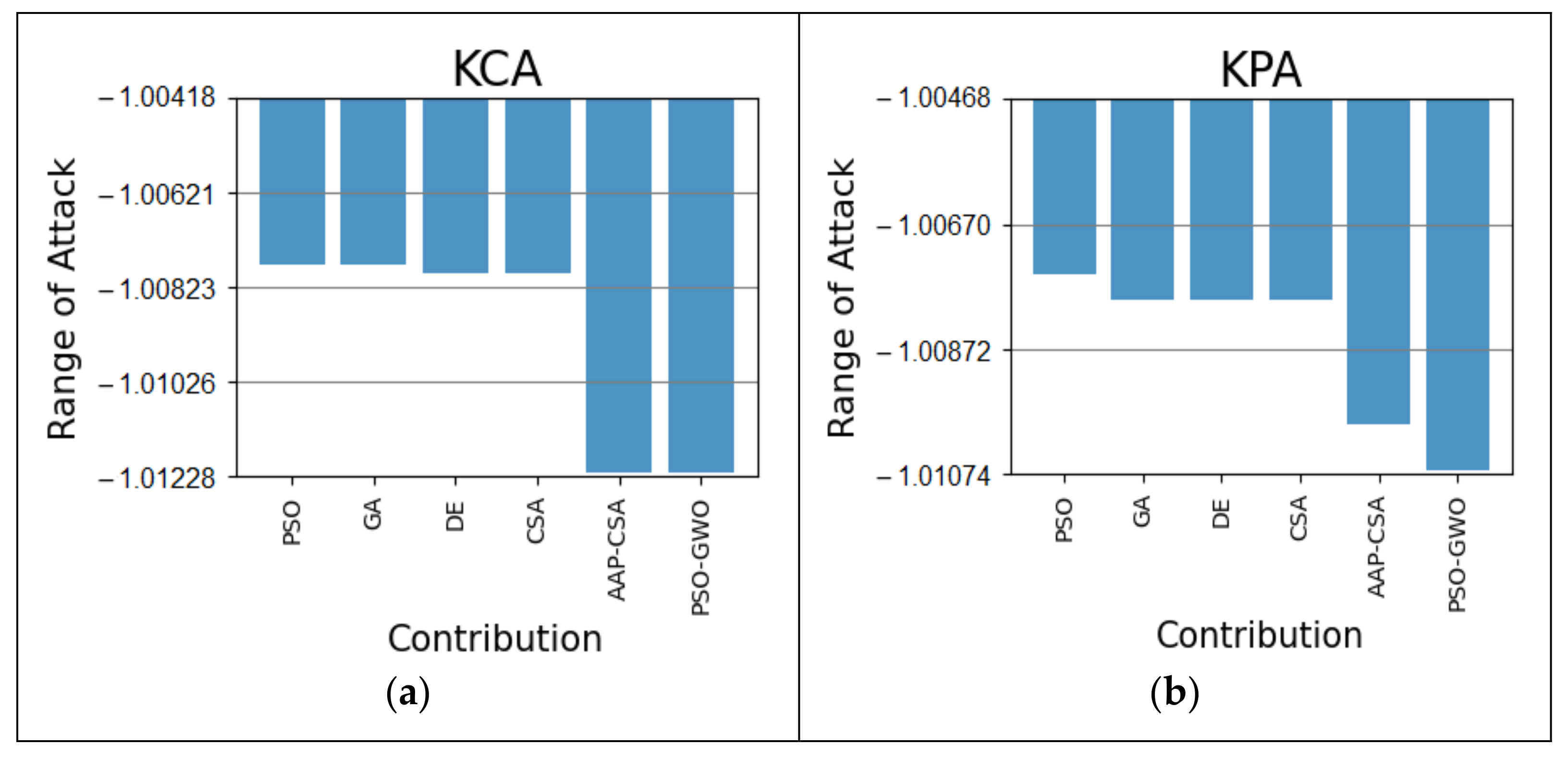
Among the different sorts of attacks, KCA and KPA were investigated initially and compared with other traditional algorithms revealed in
Figure 4. From the simulation, the KCA attack over the proposed method is 0.44% superior to the PSO and GA and 0.43% more beneficial than DE and CSA in
Figure 4a. Again, the KPA attack on the proposed method is 0.36 and 0.01% improved from PSO and AAP-CSA, as well as 0.31% enhanced in comparison with the remaining GA, DE, and CSA algorithms in
Figure 4b. The overall results are shown in
Table 3.
On the other hand, our four types of autism datasets for the CCA and CPA attacks are demonstrated in
Figure 5,
Figure 6,
Figure 7 and
Figure 8.
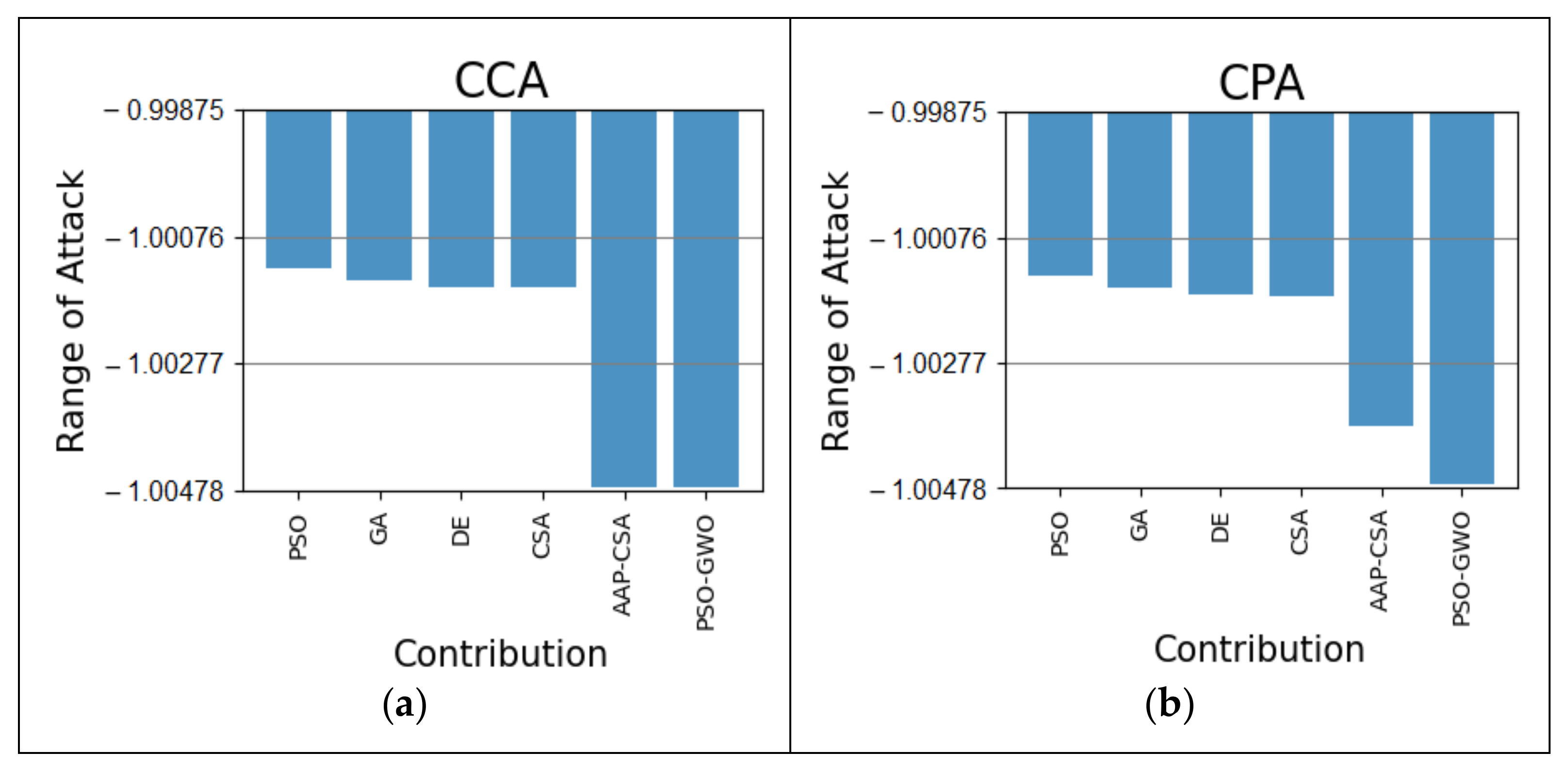
Figure 5a shows that the proposed approach shows an improvement of 0.37% and 0.33% compared to PSO and GA, respectively, and is 0.32% more beneficial than the DE and CSA algorithm, respectively, using the autism at 24 months dataset in terms of a CCA attack. For CPA analysis, our proposed scheme is 0.34%, 0.32%, 0.31%, 0.30%, and 0.10% more effective than the PSO, GA, DE, CSA, and AAP-CSA, respectively, as shown in
Figure 5b. The total outcomes are summarized in
Table 4.
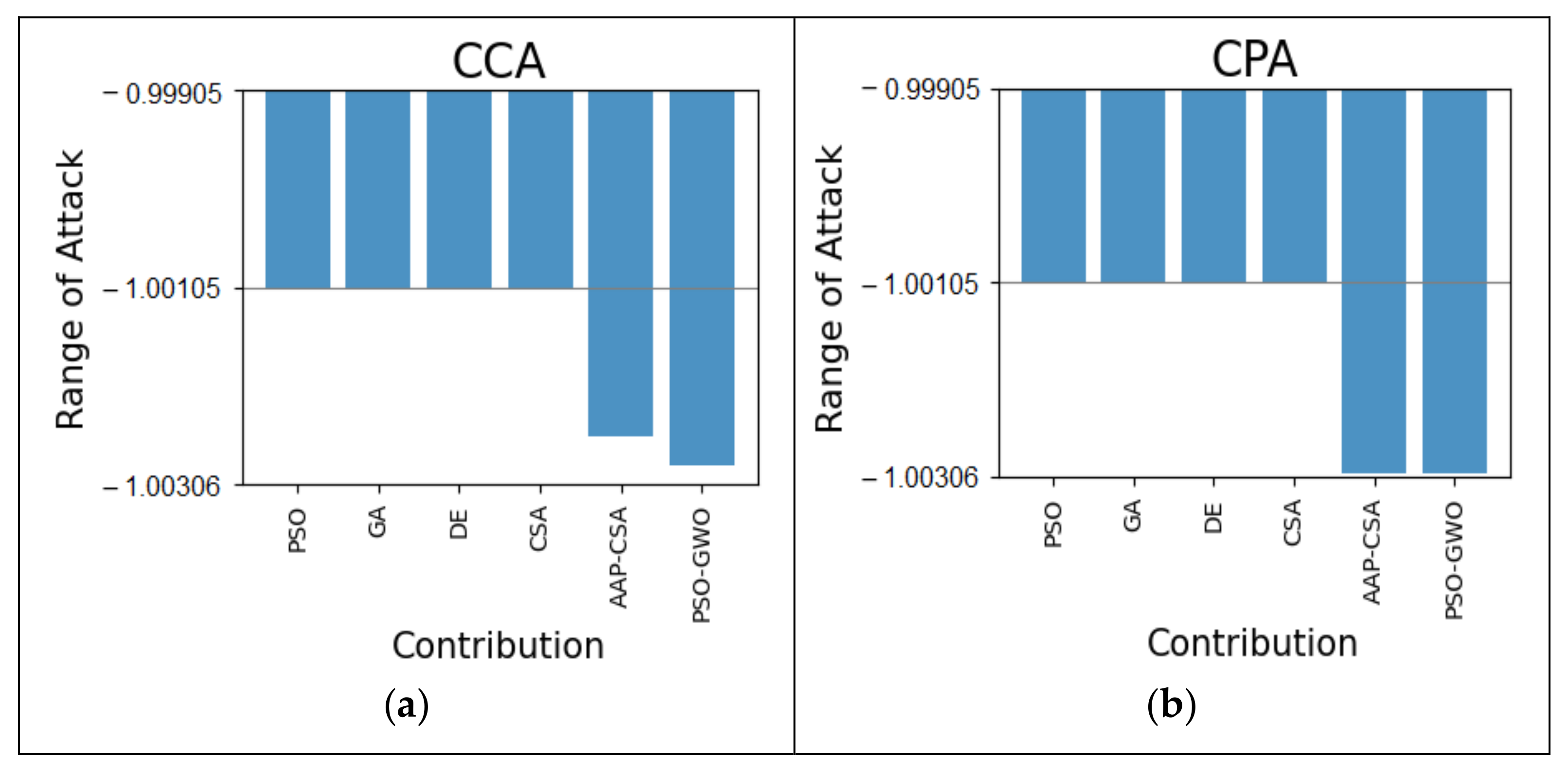
For the autism at 30 months dataset, our method, in terms of the CCA attack, is 0.03% better than AAP-CSA and 0.18% superior to all other typical algorithms, as shown in
Figure 6a. Similarly, the CPA attack is also 0.20% superior to PSO, GA, DE, and CSA, as shown in
Figure 6b.
Table 5 displays the results discussed above.
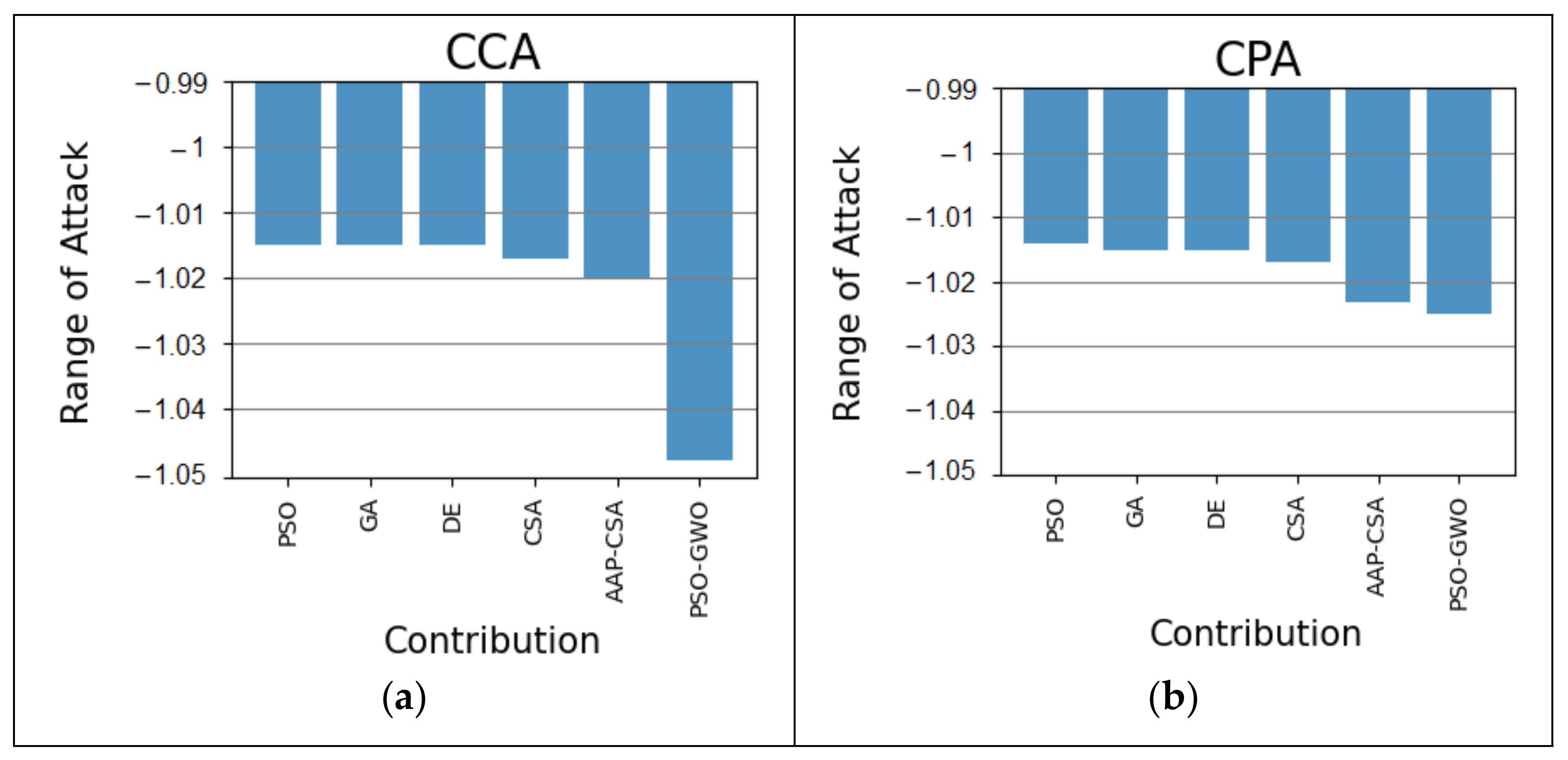
The CCA attack on the autism at 36 months dataset is 3.30% better than PSO, GA, DE, 3.10% superior to CSA, and 2.80% better than AAP-CSA, which is illustrated in
Figure 7a. In addition, our method for the CPA analysis on the 36 months autism dataset is 1.10% more improved than PSO, 1% better than GA and DE, 0.80% superior to CSA algorithms, and 0.20% better than AAP-CSA, as shown in
Figure 7b. The performances are depicted in
Table 6.
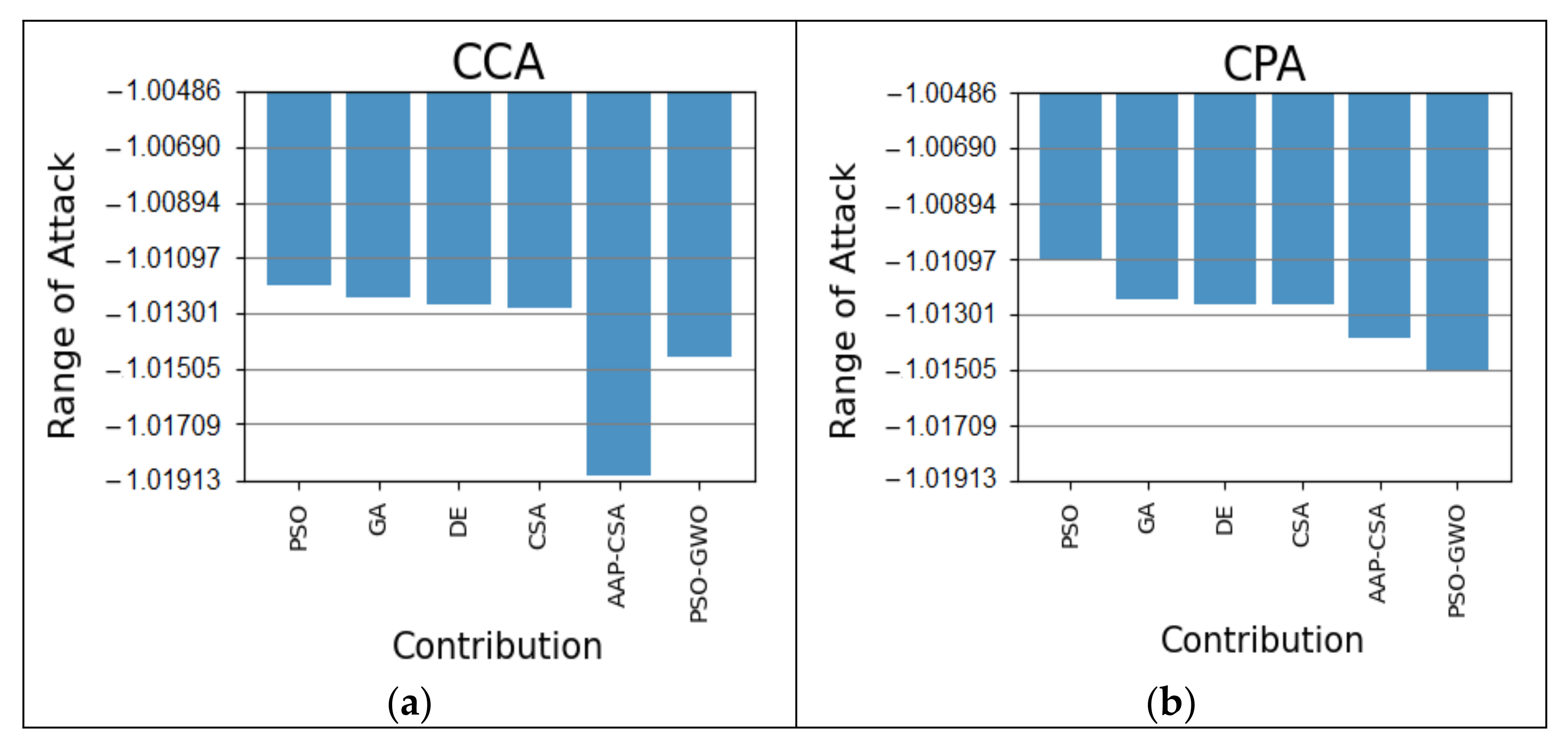
In the case of the autism at 48 months dataset, the CCA simulation for our scheme is 0.26%, 0.23%, 0.22%, and 0.18% better than the PSO, GA, DE, and CSA algorithms, accordingly, as illustrated in
Figure 8a. In
Figure 8b, the CPA attack on the autism at 48 months dataset is 0.40% better than PSO, 0.29% superior to GA, 0.28% higher than DE and CSA, and 0.10% better than AAP-CSA. In this regard, the overall results are shown in
Table 7.
Thus, the simulation demonstrates that our proposed information security technique performed better than the existing conventional algorithms based on some attacks. Therefore, it is revealed from the simulation outcomes that our sanitizing approach performs more effectively and efficiently compared to other existing traditional algorithms.
Due to the fact that sensitive diagnostic data of autism are critical for determining whether an individual is autistic or not, protecting this type of data is critical, which has greater applicability in the healthcare sector. Evidence produced by this study showed that our proposed sanitizing approach protects these data better than existing algorithms against certain attacks. It is, however, suggested that our recommended approach can be widely applied to the healthcare sector for data security and privacy.
6. Conclusions
The security and privacy of the autism dataset through the sanitizing technique were investigated in this study. The emphasis of this method was to conceal the sensitive data of patients. Specifically, an optimal key was produced for concealing the sensitive data, which was selected by the proposed Enhanced Combined PSO-GWO framework and resolved the problems mentioned in introduction. Furthermore, the results obtained by our recommended model were compared with existing traditional algorithms for justification. Mainly, our suggested technique was tested in terms of the different attacks and compared with existing traditional algorithms, and the expected outcomes were achieved, according to the experimental review. Our proposed technique, for the autism at 24 months dataset in terms of the CCA attack, is 0.37% and 0.33% better than the algorithms of PSO and GA, respectively, and 0.32% better than DE and CSA individually. Additionally, the suggested approach, in the case of the CPA attack, shows 0.20% more improvement compared to the PSO, GA, DE, and CSA algorithms, for the autism at 30 months dataset. For the autism at 36 months dataset, the simulation result of the proposed technique with CCA attacks is 3.30% more improved than PSO, GA, and DE, 3.10% better enhanced from CSA, and 2.80% superior to the AAP-CSA algorithms. Finally, in terms of the CPA attack on the autism at 48 months dataset, our technique is 0.40%, 0.29%, 0.28%, and 0.28% superior to PSO, GA, DE, and CSA, and 0.10% better than AAP-CSA, respectively.
Therefore, it is revealed from the analyzed results that our proposed enhanced technique is more effective and efficient compared with the present conventional algorithms.
In contrast, our future research will focus on improving a restoration technique in which the optimal key will be used in information security, specifically for the security and privacy of autism data.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}