
Identification Method of Wheat Cultivars by Using a Convolutional Neural Network Combined with Images of Multiple Growth Periods of Wheat

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Wheat Images Data Analysis
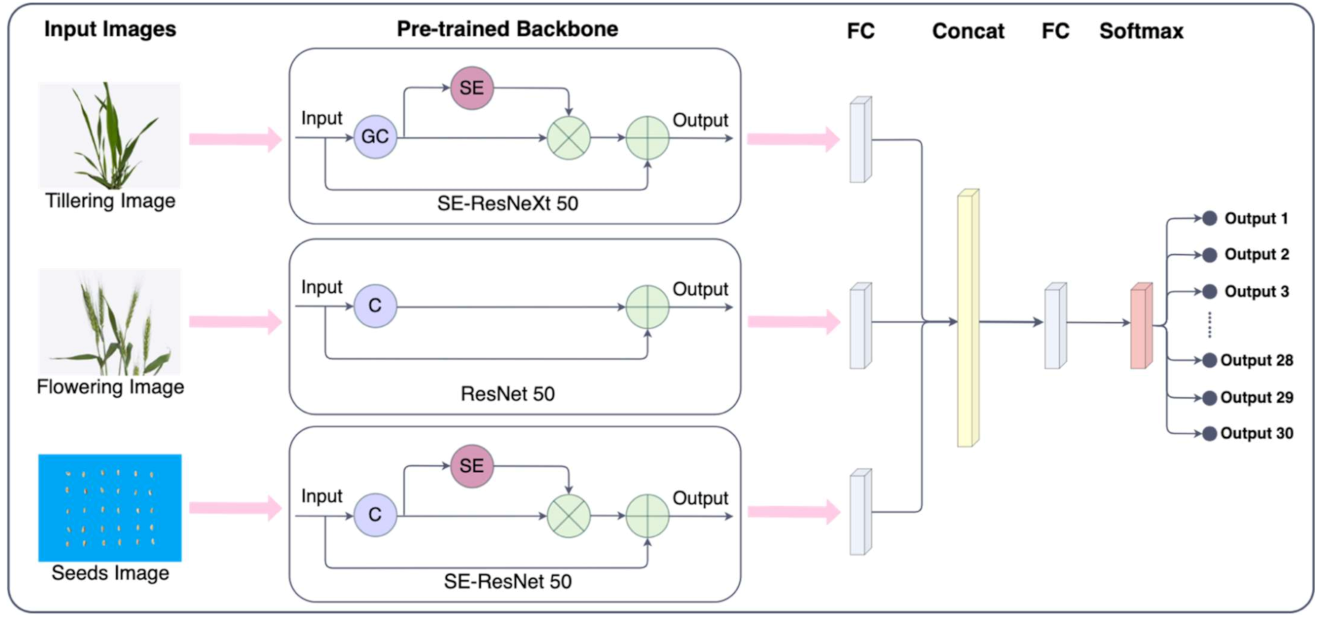
2.2. Wheat Images Deep Learning Model
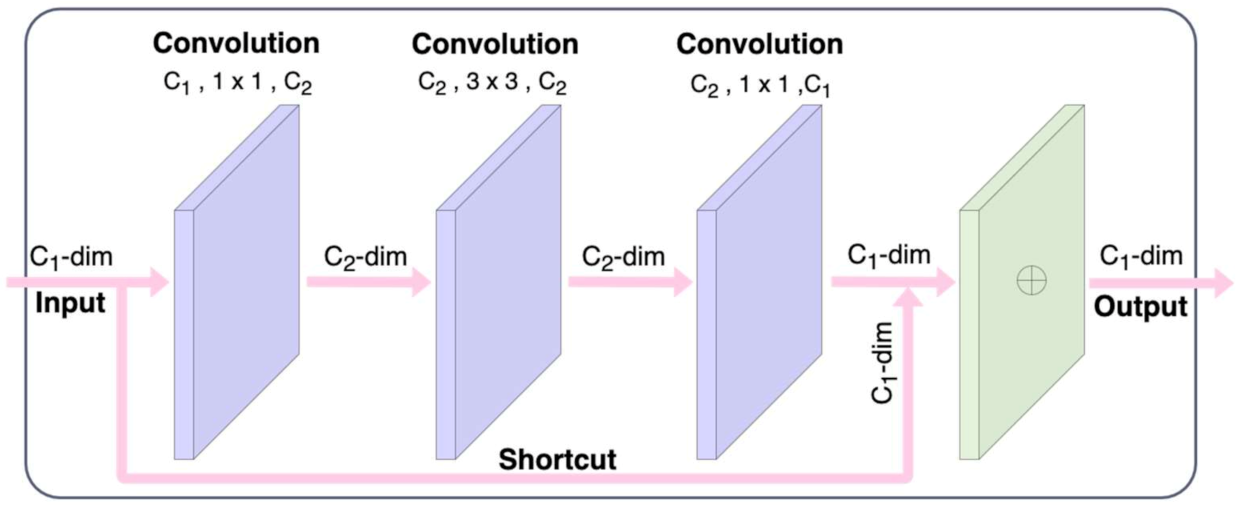
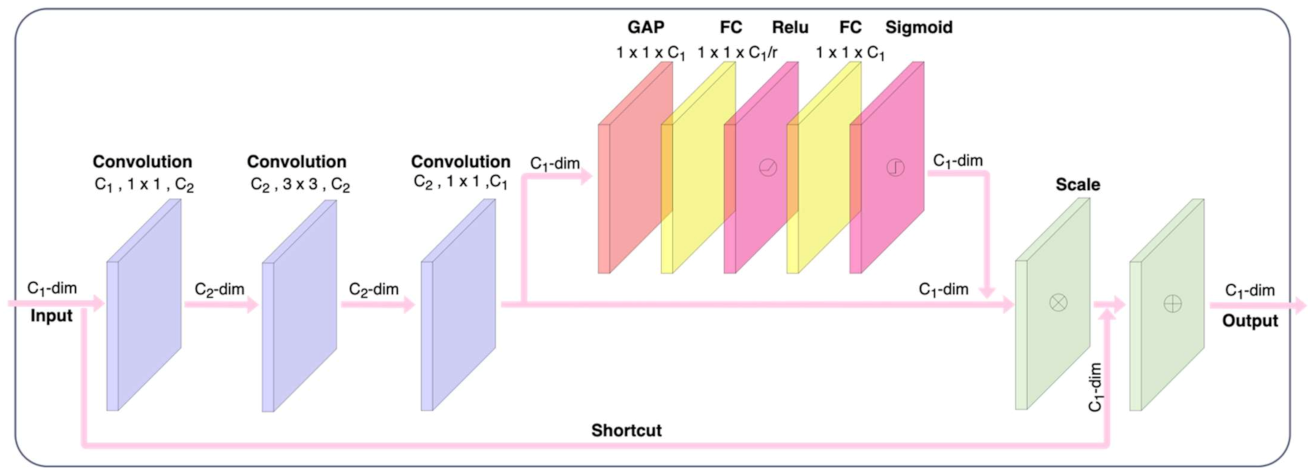
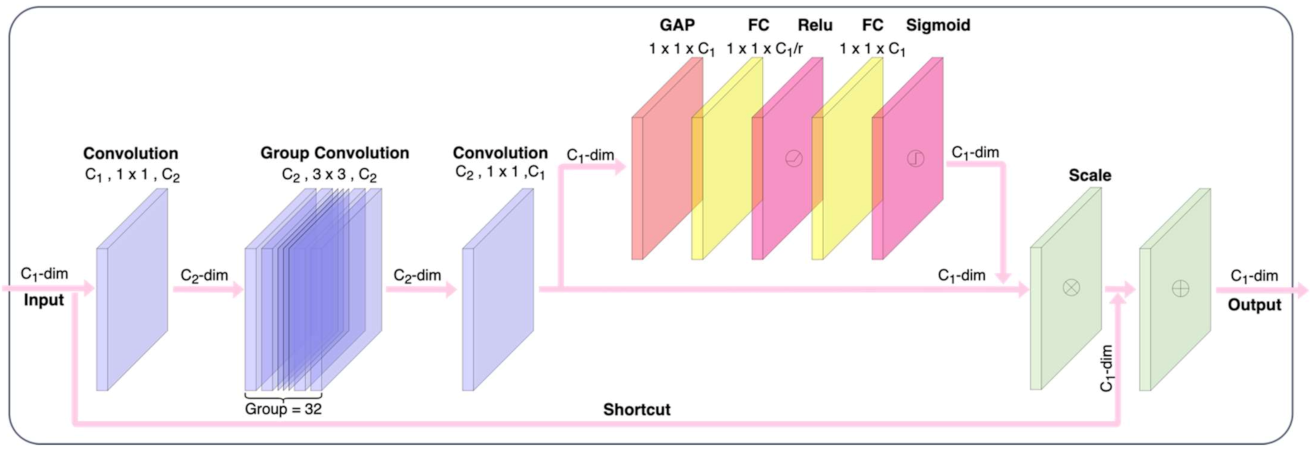
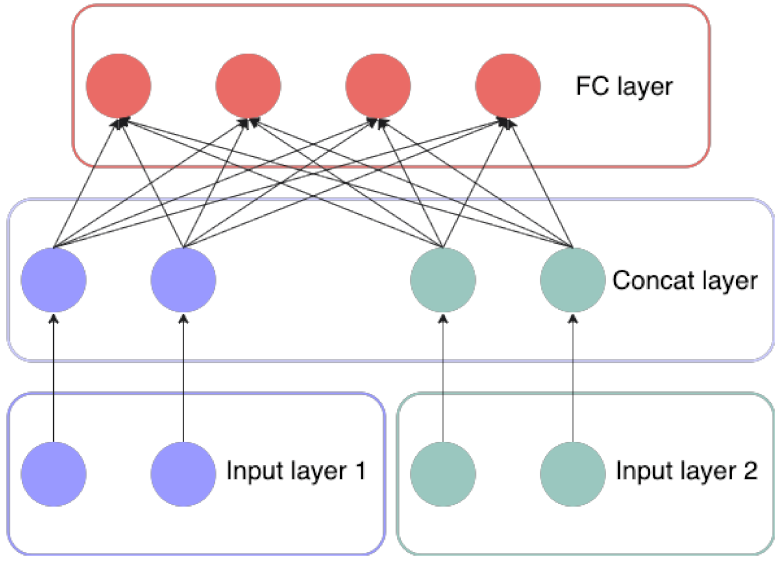
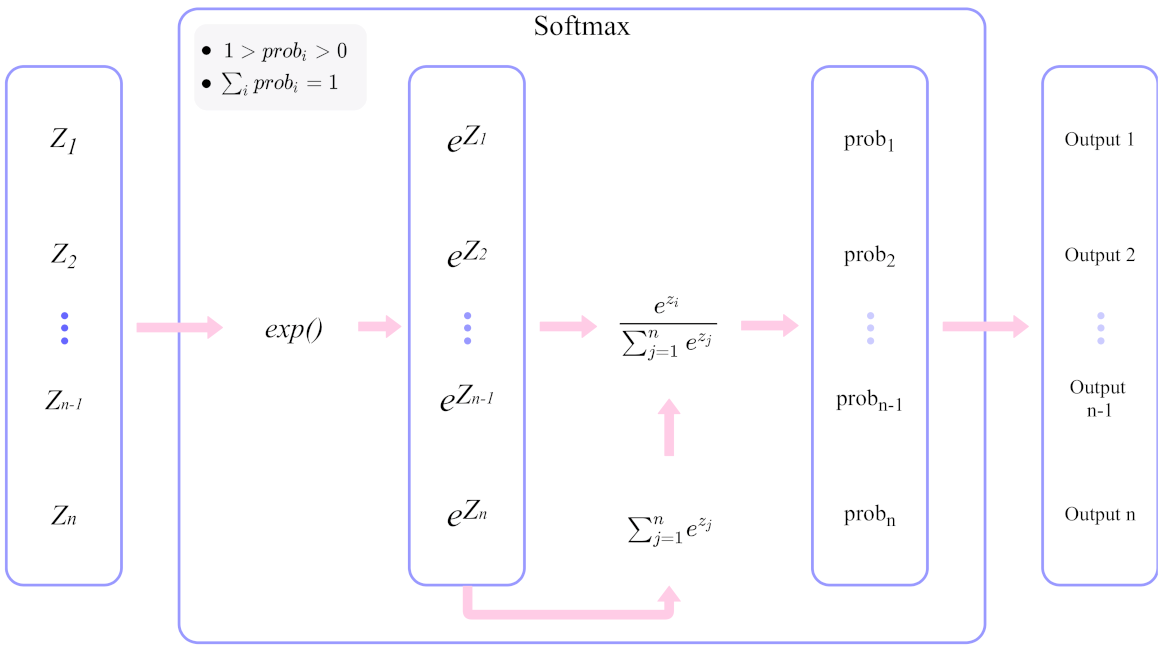
2.3. Network Structure Design
2.4. Data Preprocessing and Enhancement
3. Results and Discussion
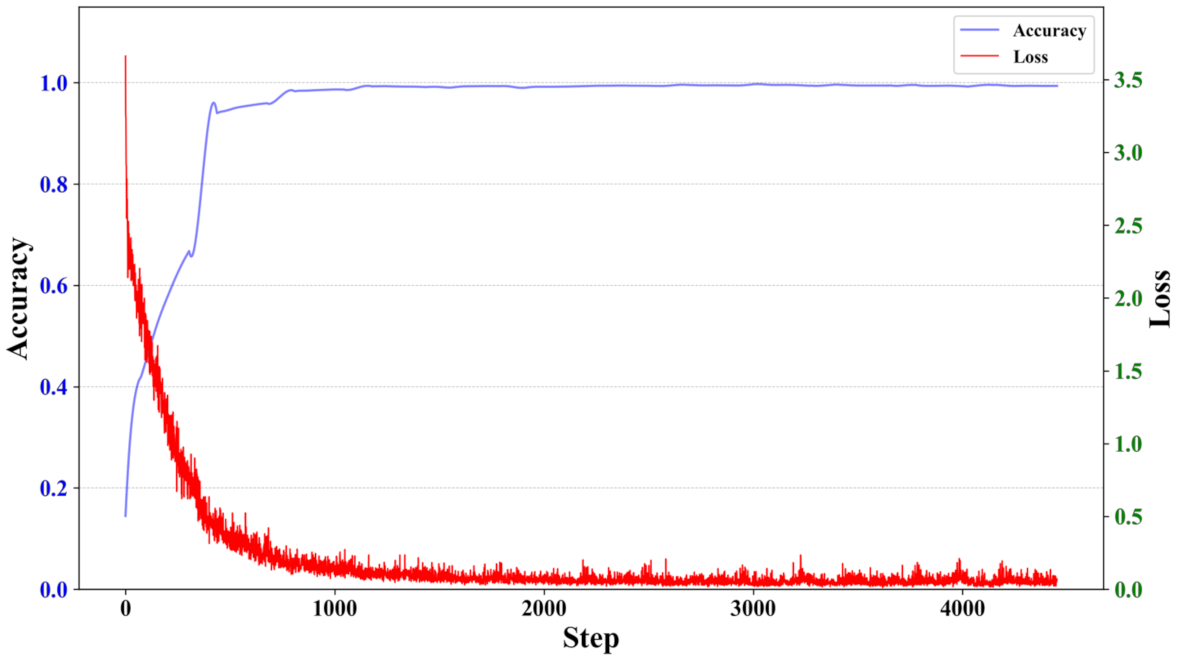
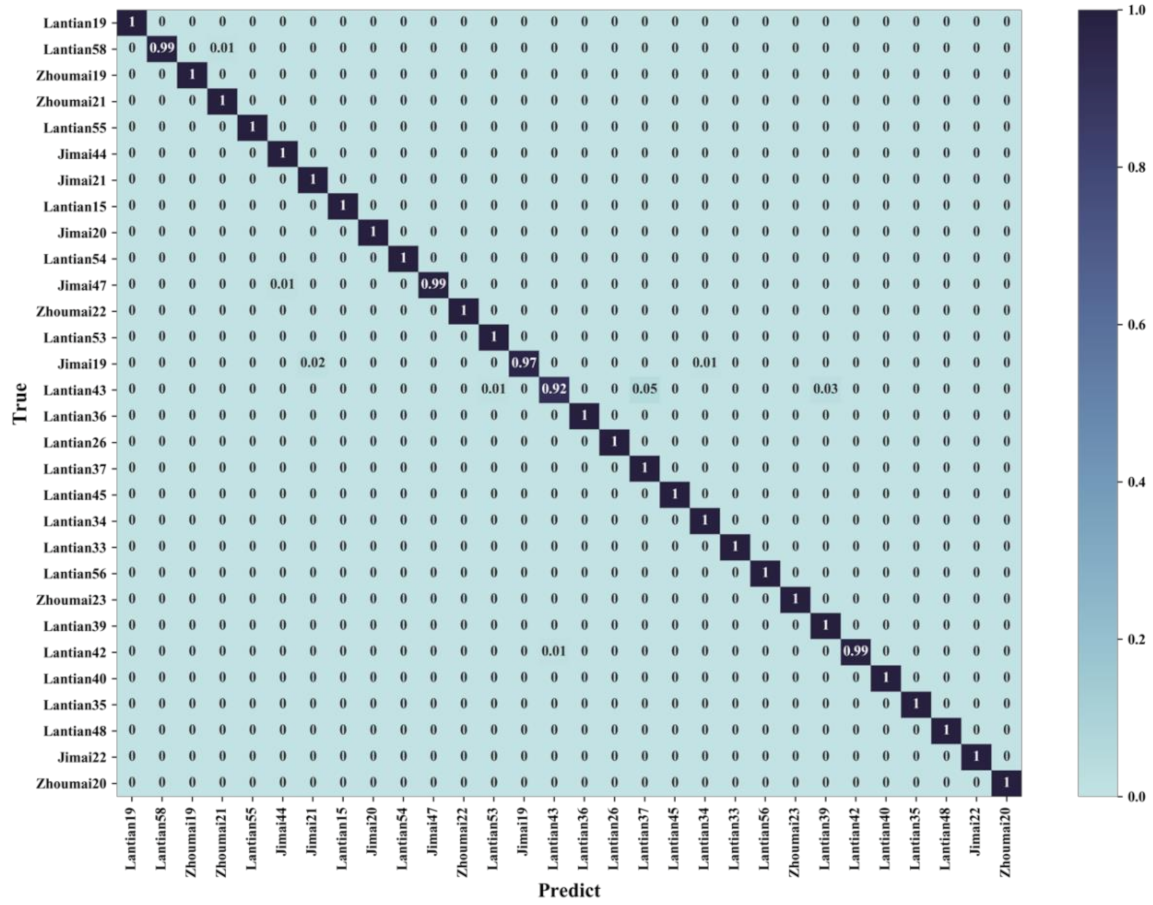
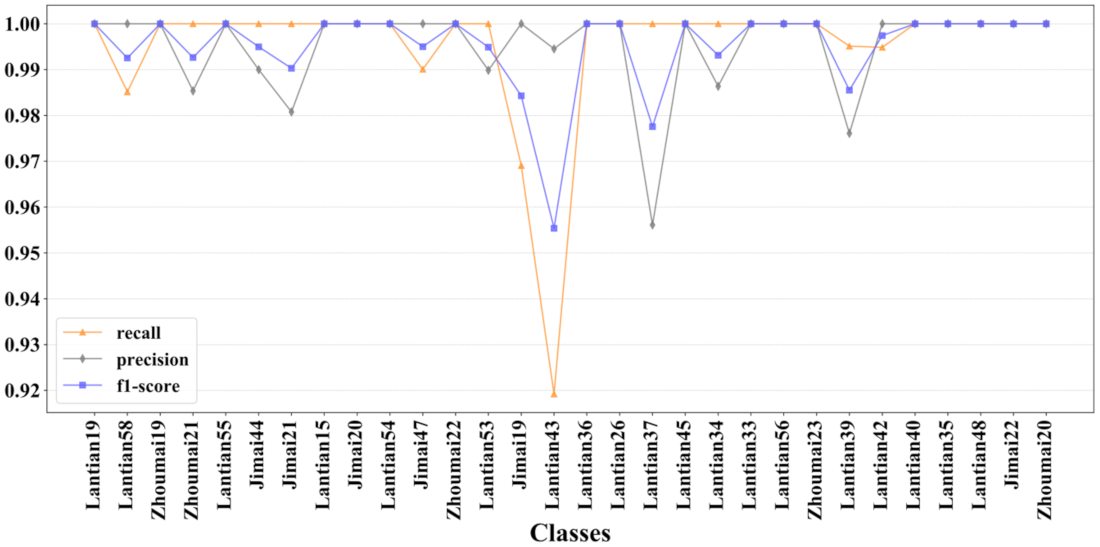
3.1. Result Analysis
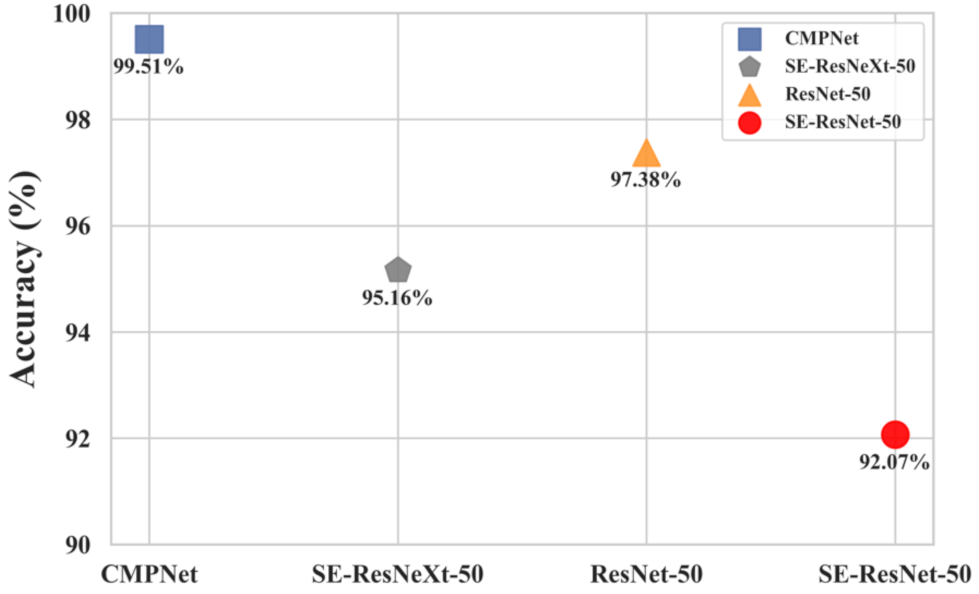
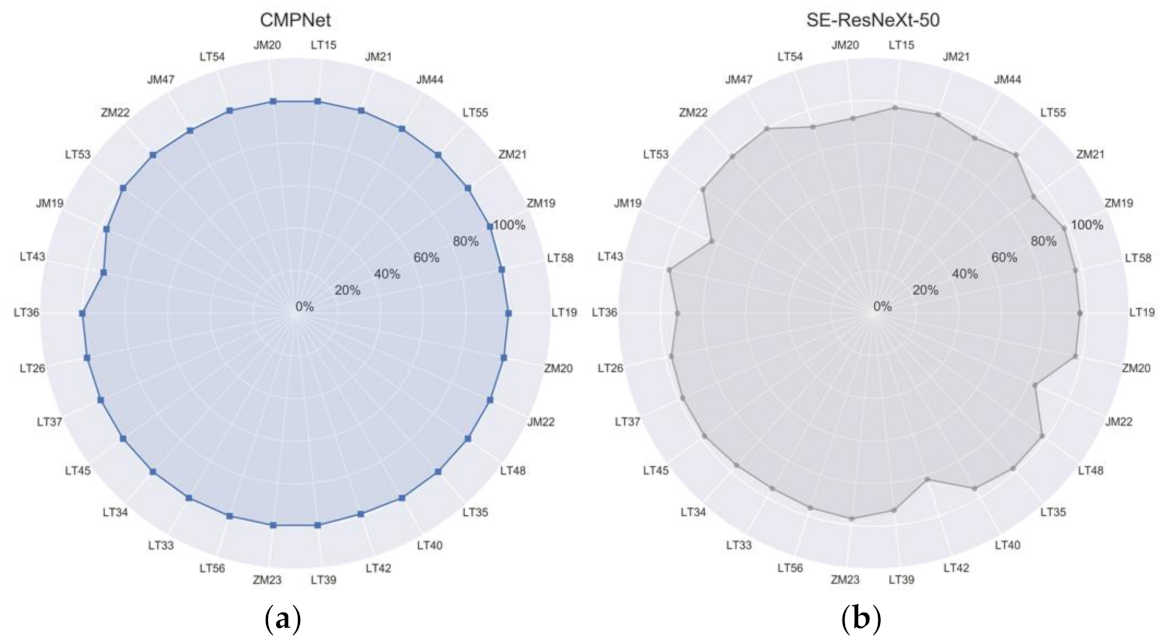
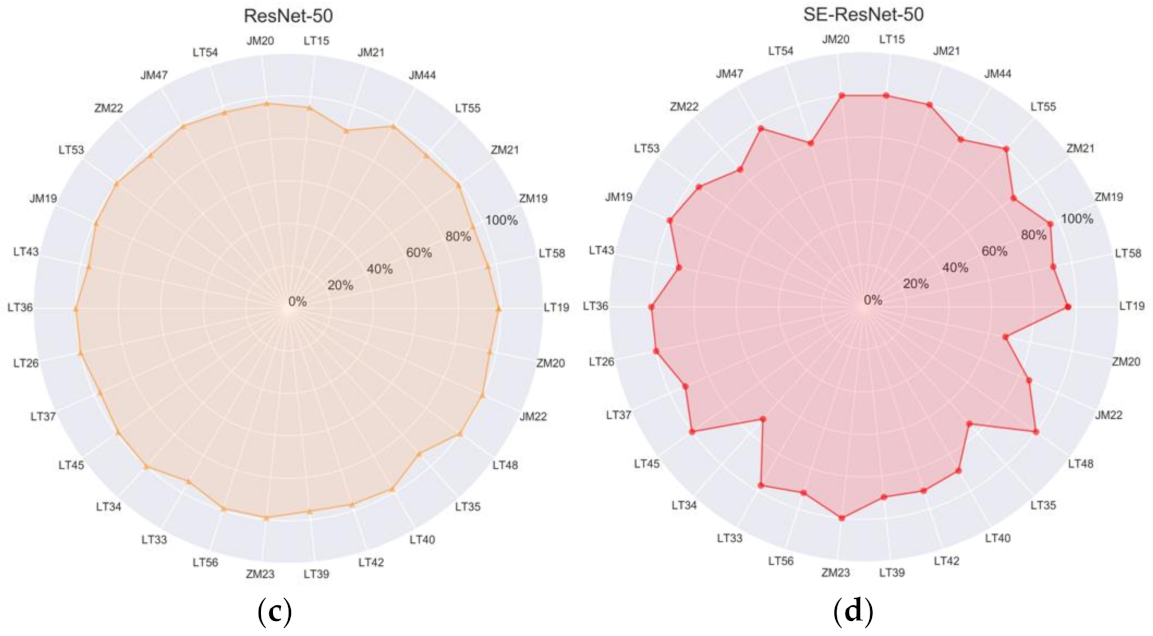
3.2. Comparison with Single Models
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Charmet, G. Wheat domestication: Lessons for the future. Comptes Rendus Biol. 2011, 334, 212–220. [Google Scholar] [CrossRef] [PubMed]
- OECD. Crop Production; OECD: Paris, France, 2018. [Google Scholar]
- Peng, J.; Sun, D.; Nevo, E. Wild emmer wheat, Triticum dicoccoides, occupies a pivotal position in wheat domestication process. Aust. J. Crop. Sci. 2011, 5, 1127–1143. [Google Scholar]
- Salsman, E.; Liu, Y.; Hosseinirad, S.A.; Kumar, A.; Manthey, F.; Elias, E.; Li, X. Assessment of genetic diversity and agronomic traits of durum wheat germplasm under drought environment of the northern Great Plains. Crop. Sci. 2021, 61, 1194–1206. [Google Scholar] [CrossRef]
- Drywa, A.; Poćwierz-Kotus, A.; Dobosz, S.; Kent, M.P.; Lien, S.; Wenne, R. Identification of multiple diagnostic SNP loci for differentiation of three salmonid species using SNP-arrays. Mar. Genom. 2014, 15, 5–6. [Google Scholar] [CrossRef] [PubMed]
- Priya, C.A.; Balasaravanan, T.; Thanamani, A.S. An efficient leaf recognition algorithm for plant classification using support vector machine. In Proceedings of the 21st International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012; pp. 428–432. [Google Scholar] [CrossRef]
- Wang, Z.; Sun, X.; Zhang, Y.; Ying, Z.; Ma, Y. Leaf recognition based on PCNN. Neural Comput. Appl. 2016, 27, 899–908. [Google Scholar] [CrossRef]
- Liu, C.; Han, J.; Chen, B.; Mao, J.; Xue, Z.; Li, S. A novel identification method for apple (Malus domestica Borkh.) cultivars based on a deep convolutional neural network with leaf image input. Symmetry 2020, 12, 217. [Google Scholar] [CrossRef] [Green Version]
- Sabadin, F.; Galli, G.; Borsato, R.; Gevartosky, R.; Campos, G.R.; Fritsche-Neto, R. Improving the identification of haploid maize seeds using convolutional neural networks. Crop. Sci. 2021. [Google Scholar] [CrossRef]
- Ahmed, E.; Moustafa, M. House price estimation from visual and textual features. In Proceedings of the NCTA 8th International Conference on Neural Computation Theory and Applications, Porto, Portugal, 9–11 November 2016. [Google Scholar]
- Quan, S.; Bernhard, P. Bagging ensemble selection for regression. In Proceedings of the Australasian Joint Conference on Advances in Artificial Intelligence, Sydney, NSW, Australia, 4–7 December 2012. [Google Scholar]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Zhang, W.; Lu, Q.; Bai, Y.; Wang, H.; Zhang, Y.; Zhang, L. Analysis and Evaluation on Quality of Winter Wheat Varieties from Gansu Province. J. Triticeae Crop. 2019, 39, 46–51. [Google Scholar]
- Yoo, H.J. Deep convolution neural networks in computer vision. IEIE Trans. Smart Process. Comput. 2015, 4, 35–43. [Google Scholar] [CrossRef]
- Nikhil, K. Deep Learning with Python; Apress: Barkeley, CA, USA, 2017. [Google Scholar]
- Youm, G.Y.; Bae, S.H.; Kim, M. Image super-resolution based on convolution neural networks using multi-channel input. In Proceedings of the 2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Bordeaux, France, 11–12 July 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ma, H.; Han, G.; Peng, L.; Zhu, L.; Shu, J. Rock thin sections identification based on improved squeeze-and-Excitation Networks model. Comput. Geosci. 2021, 152, 104780. [Google Scholar] [CrossRef]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2018, 110, 232–242. [Google Scholar] [CrossRef] [PubMed]
- Jie, H.; Zeng, X. An Efficient Activation Function for BP Neural Network. In Proceedings of the International Workshop on Intelligent Systems and Applications ISA, Wuhan, China, 23–24 May 2009. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Pridmore, R.W. Complementary colors theory of color vision: Physiology, color mixture, color constancy and color perception. Color Res. Appl. 2011, 36, 394–412. [Google Scholar] [CrossRef]
- Bouchard, G. Clustering and Classification Employing Softmax Function Including Efficient Bounds. U.S. Patent 8,065,246, 22 November 2011. [Google Scholar]
- Gao, Z.; Xue, H.; Wan, S. Multiple discrimination and pairwise CNN for view-based 3D object retrieval. Neural Netw. 2020, 125, 290–302. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, P.; Yeung, C.H.; Liu, W.; Jin, C.; Zhang, Y.-C. Time-aware collaborative filtering with the piecewise decay function. arXiv 2010, arXiv:1010.3988v1. [Google Scholar]
- Wen, J.; Lai, Z.; Wong, W.K.; Cui, J.; Wan, M. Optimal feature selection for robust classification via l2,1-norms regularization. IEEE Comput. Soc. 2014, 517–521. [Google Scholar] [CrossRef]
- Li, M.; Fu, J.; Zhang, Y.; Liu, C. Intelligent recognition and analysis method of rock lithology classification based on coupled rock images and hammering audios. Chin. J. Rock Mech. Eng. 2020, 39, 137–145. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030v2. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514v1. [Google Scholar]
- Srinivas, A.; Lin, T.-Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. arXiv 2021, arXiv:2101.11605v2. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cultivar (Lines) | Variety | ||
|---|---|---|---|
| Lantian | Lantian15 | Lantian36 | Lantian45 |
| Lantian19 | Lantian37 | Lantian48 | |
| Lantian26 | Lantian39 | Lantian53 | |
| Lantian33 | Lantian40 | Lantian54 | |
| Lantian34 | Lantian42 | Lantian55 | |
| Lantian35 | Lantian43 | Lantian56 | |
| Lantian58 | |||
| Jimai | Jimai19 | Jimai21 | Jimai44 |
| Jimai20 | Jimai22 | Jimai47 | |
| Zhoumai | Zhoumai19 | Zhoumai21 | Zhoumai23 |
| Zhoumai20 | Zhoumai22 | ||
| Learning Rate | Step Interval |
|---|---|
| 0.0005 | [1, 5] |
| 0.0001 | (5, 10] |
| 0.00002 | (10, 15] |
| 0.00001 | (15, 4452] |
| Configuration Information | |
|---|---|
| OS | Ubuntu Linux |
| CPU | 4 Cores |
| RAM | 32 GB |
| Disk | 100 GB |
| GPU | Tesla V100 |
| Video Memory | 32 GB |
| Training Dataset Accuracy (%) | Test Dataset Accuracy (%) | |
|---|---|---|
| Top-1 Accuracy | 100 | 99.51 |
| Top-2 Accuracy | 100 | 99.83 |
| Model Index | Formula |
|---|---|
| Precision | |
| Recall | |
| F1-score | , |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Liu, C.; Han, J.; Lu, Q.; Wang, H.; Zhang, J.; Bai, X.; Luo, J. Identification Method of Wheat Cultivars by Using a Convolutional Neural Network Combined with Images of Multiple Growth Periods of Wheat. Symmetry 2021, 13, 2012. https://doi.org/10.3390/sym13112012
Gao J, Liu C, Han J, Lu Q, Wang H, Zhang J, Bai X, Luo J. Identification Method of Wheat Cultivars by Using a Convolutional Neural Network Combined with Images of Multiple Growth Periods of Wheat. Symmetry. 2021; 13(11):2012. https://doi.org/10.3390/sym13112012
Chicago/Turabian StyleGao, Jiameng, Chengzhong Liu, Junying Han, Qinglin Lu, Hengxing Wang, Jianhua Zhang, Xuguang Bai, and Jiake Luo. 2021. "Identification Method of Wheat Cultivars by Using a Convolutional Neural Network Combined with Images of Multiple Growth Periods of Wheat" Symmetry 13, no. 11: 2012. https://doi.org/10.3390/sym13112012
APA StyleGao, J., Liu, C., Han, J., Lu, Q., Wang, H., Zhang, J., Bai, X., & Luo, J. (2021). Identification Method of Wheat Cultivars by Using a Convolutional Neural Network Combined with Images of Multiple Growth Periods of Wheat. Symmetry, 13(11), 2012. https://doi.org/10.3390/sym13112012